Coarse-to-Fine Deep Metric Learning for Remote Sensing Image Retrieval


Abstract
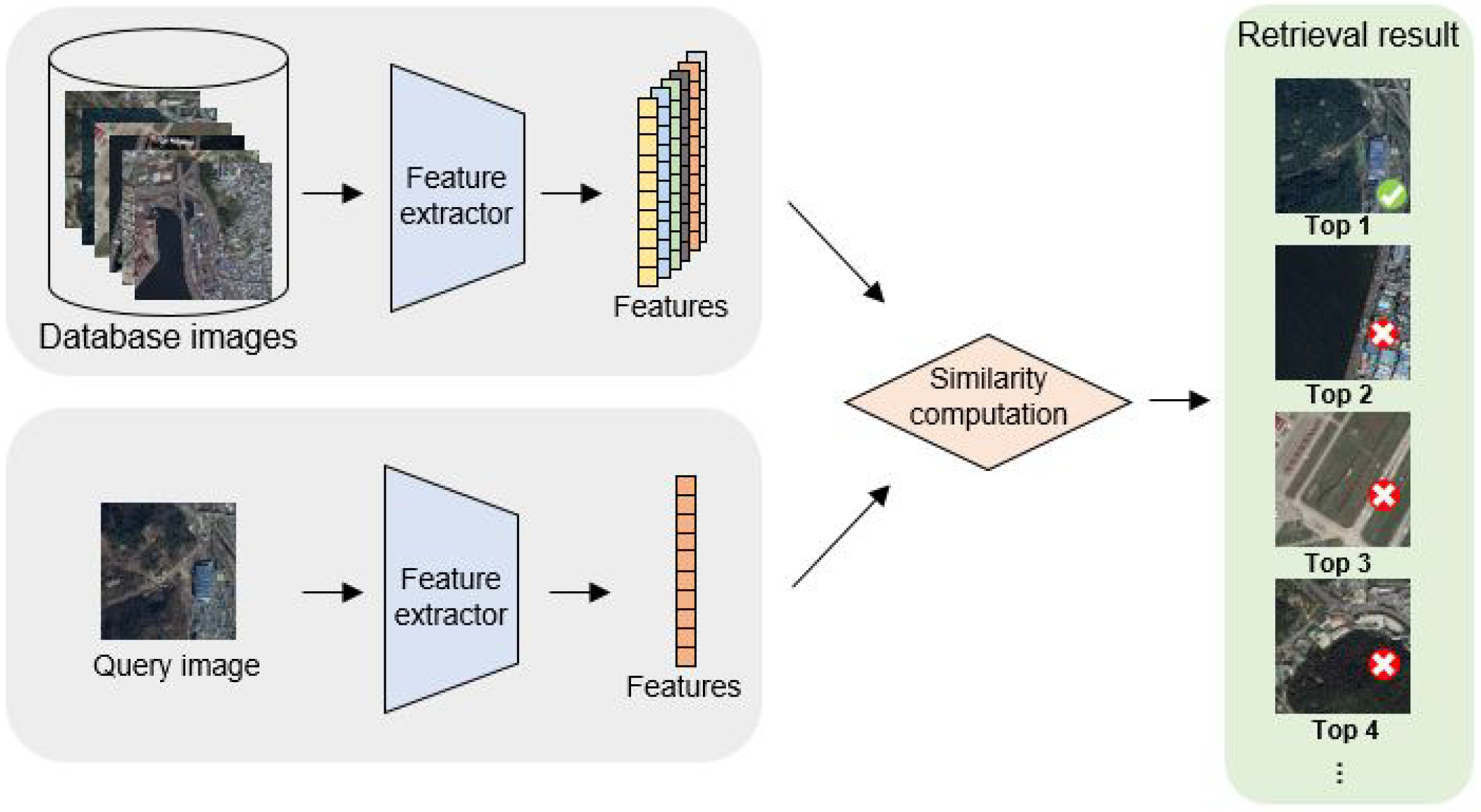
1. Introduction
- We propose a coarse-to-fine deep metric learning method for RSIR. In the first step, the network learns the binary relationship and is then retrained to learn the continuous relationship in the second step. The proposed method is end-to-end trainable using the similarity between images.
- We introduce a new loss function to learn continuous information. The triangular ratio loss function considers all the detailed relationships within the tuples, and, therefore, it is appropriate for highly complex RS images that contain many objects.
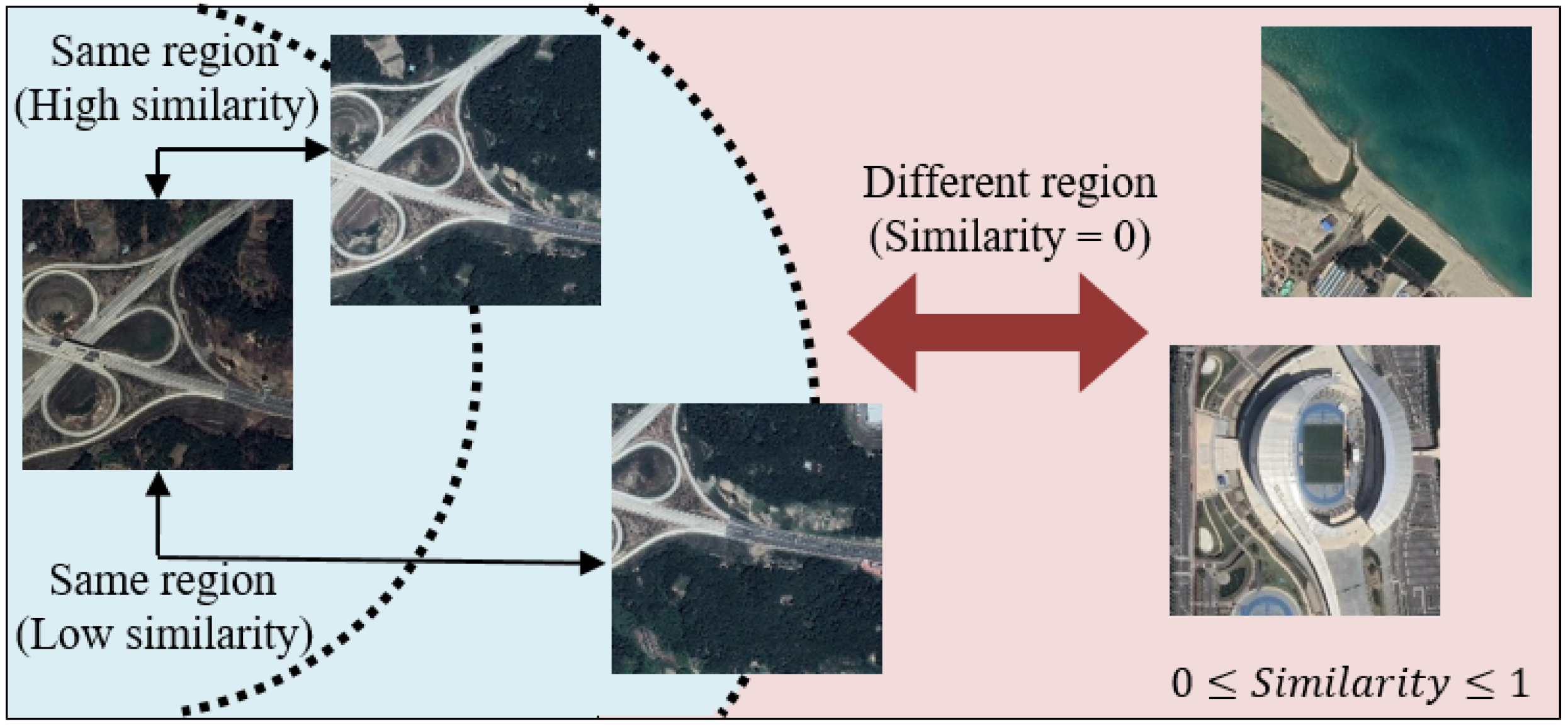
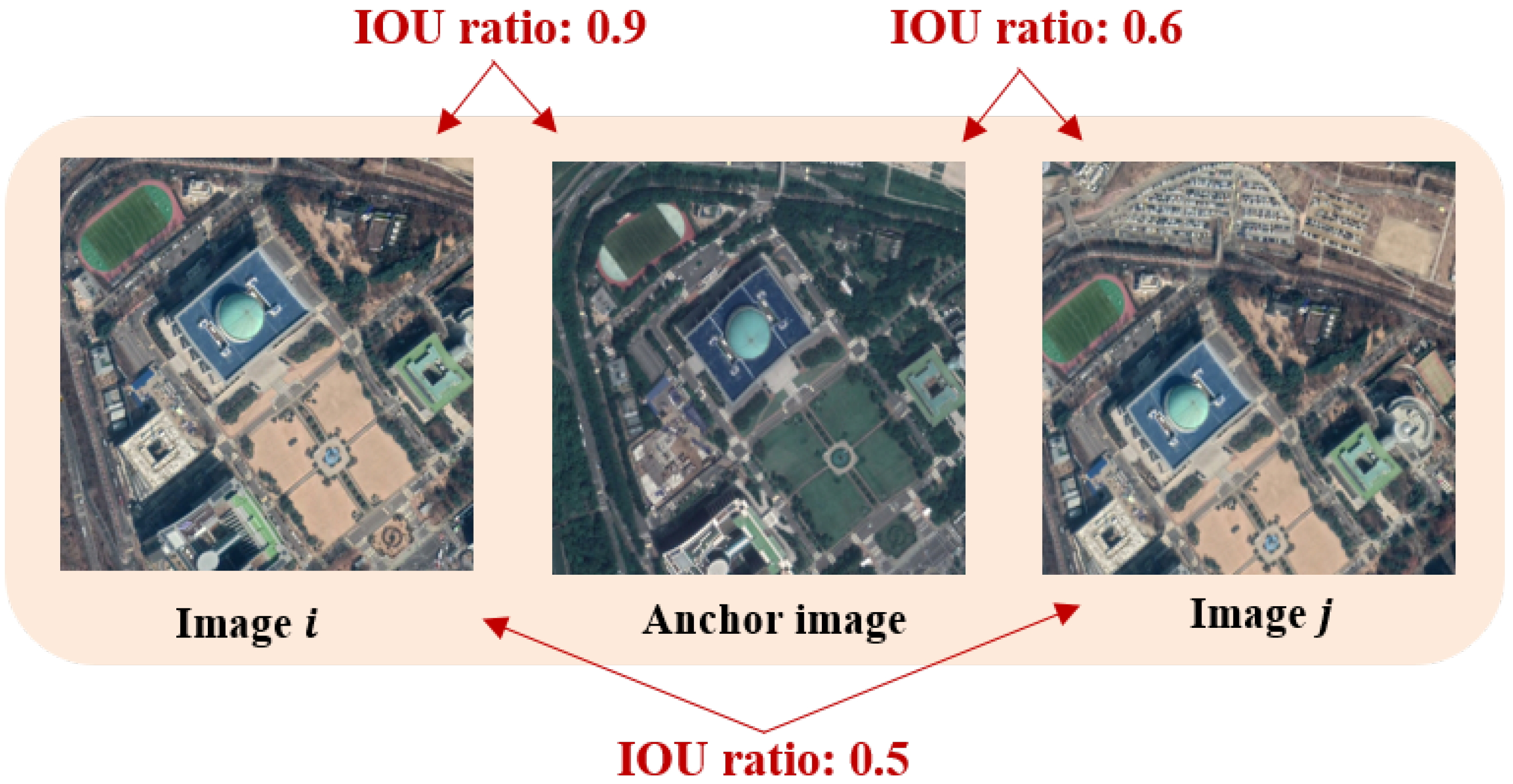
- Using the intersection-over-union (IOU) ratio between images, we confirmed that it is effective to define a continuous similarity between images.
2. Related Work
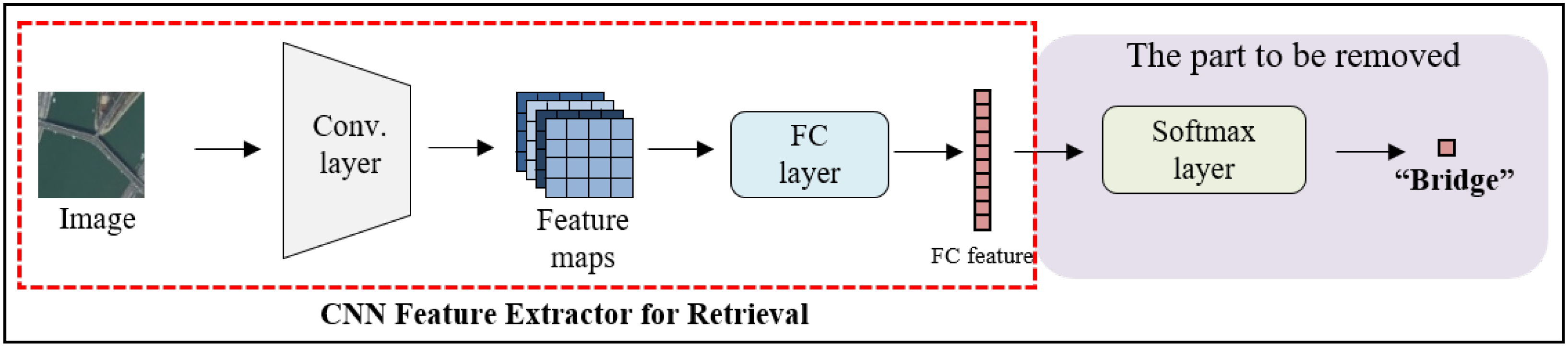
2.1. Image Retrieval for the Conventional CNN Method
2.2. Image Retrieval for the Deep Metric Learning Method
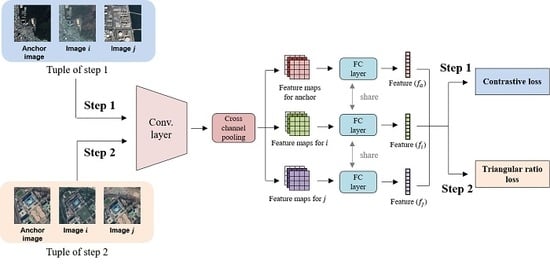
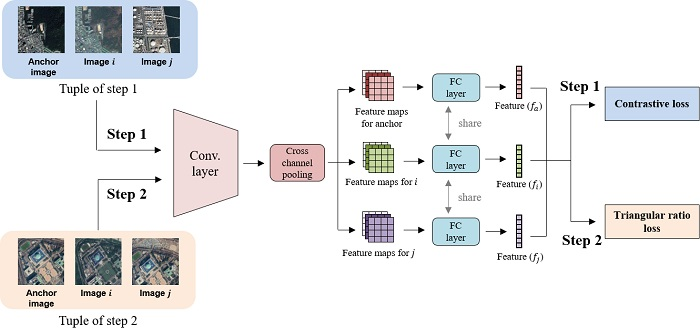
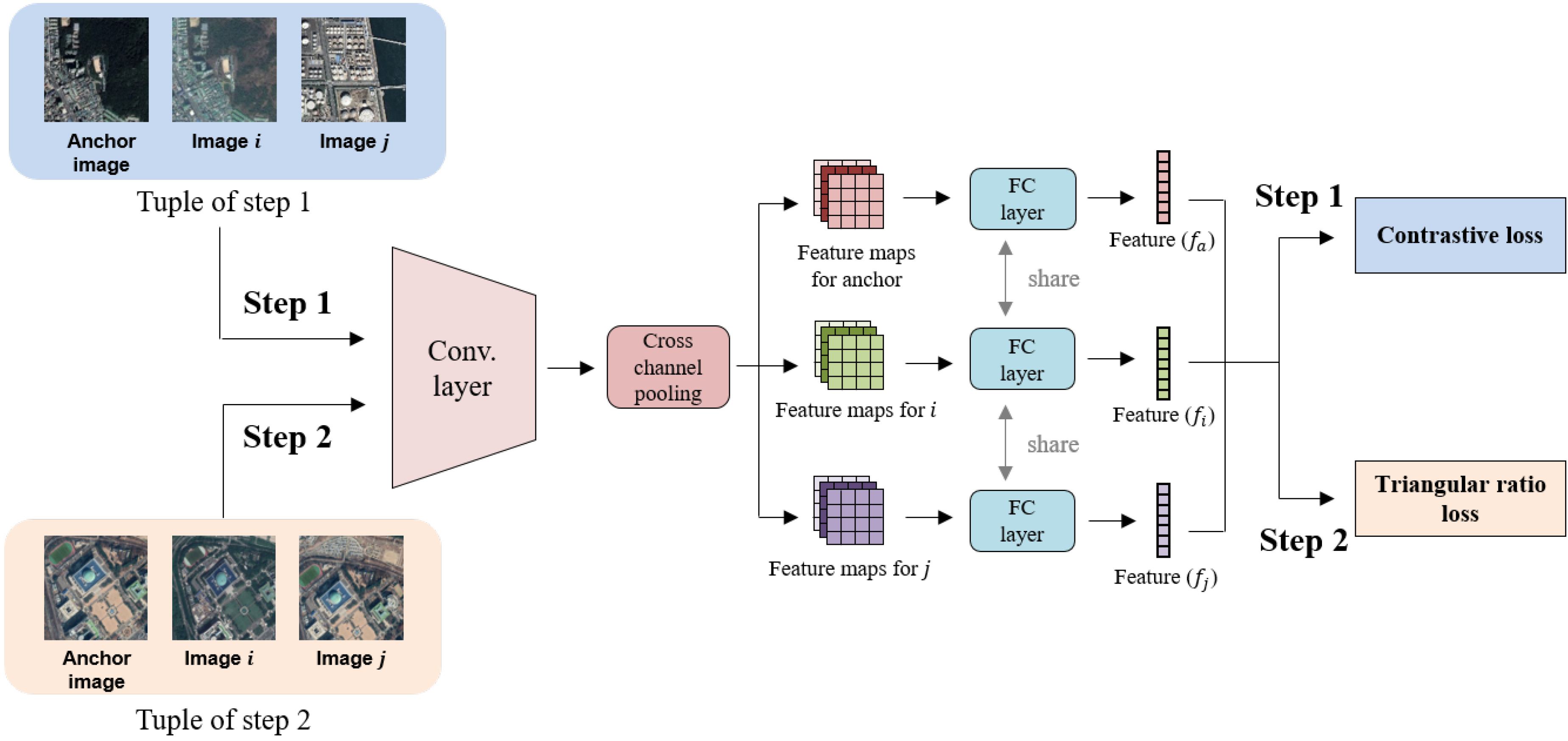
3. Coarse-to-Fine Deep Metric Learning
3.1. Step 1: Coarse Deep Metric Learning
Contrastive Loss
3.2. Step 2: Fine Deep Metric Learning
Triangular Loss
4. Experiments
4.1. Implementation Details
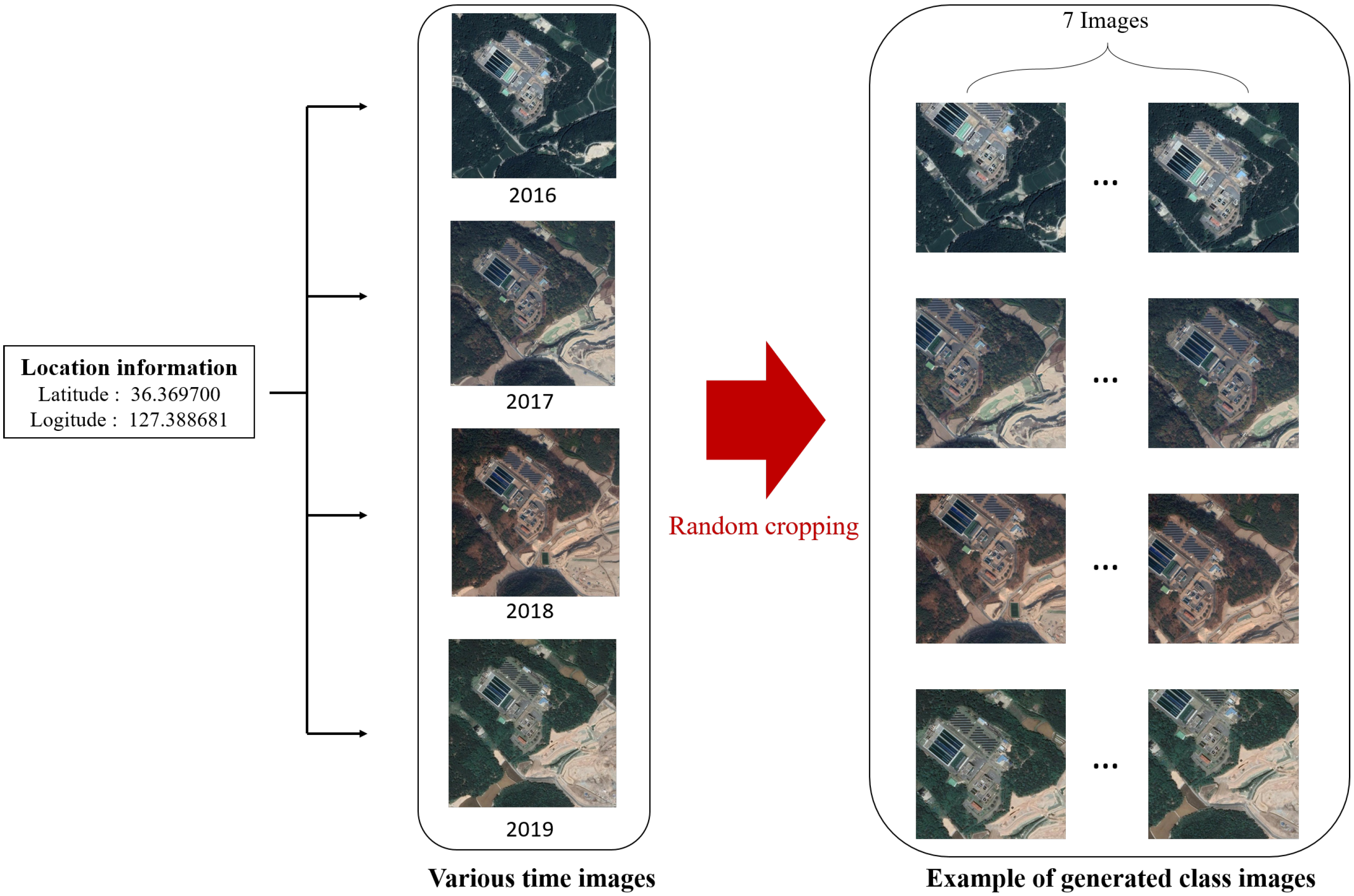
4.2. Google Earth South Korea Dataset
4.3. Experimental Results
Quantitative Experiments
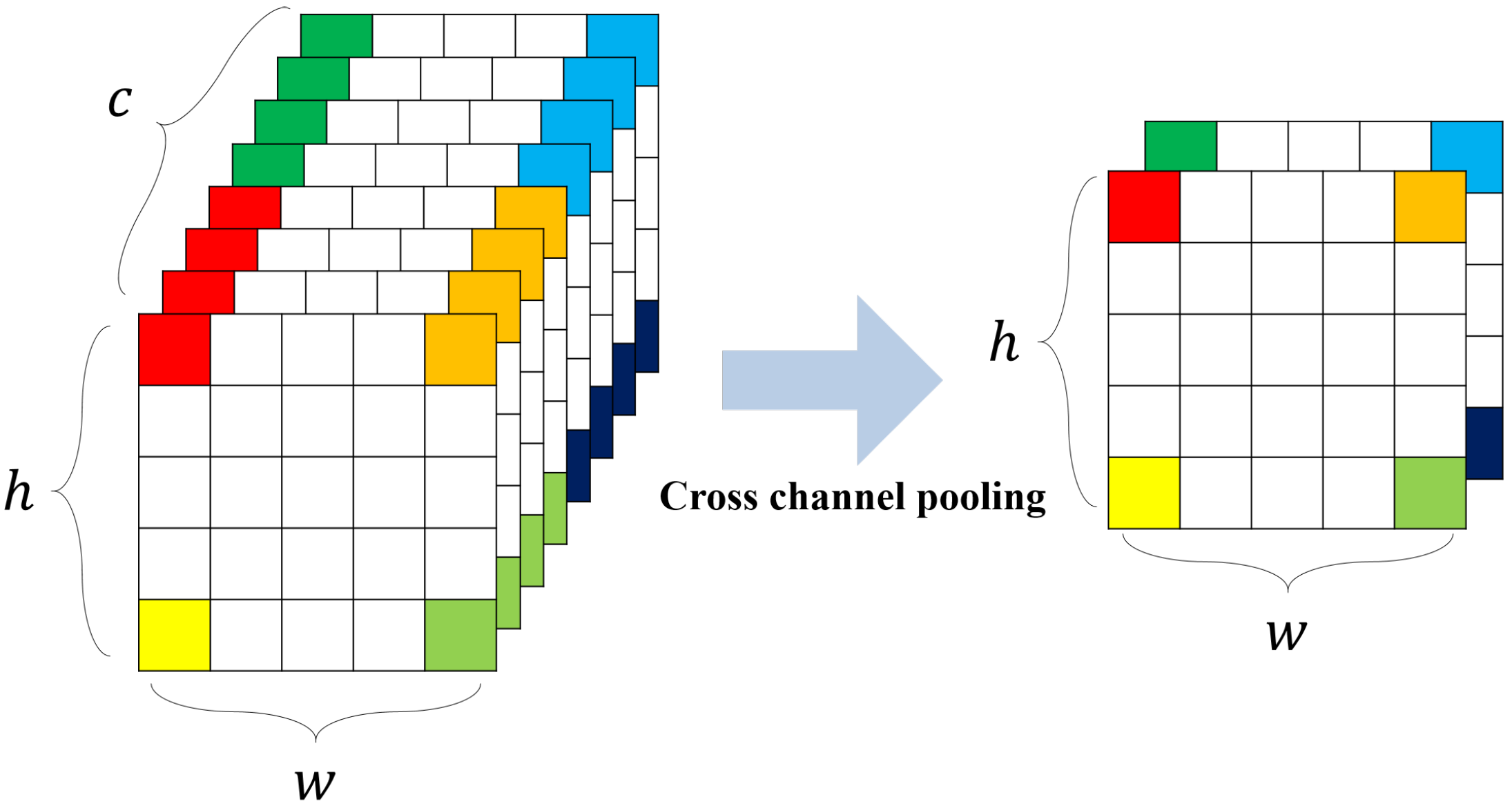
- The Conventional Learning MethodsTo add objectivity to our experiments, we used two types of tuples in the conventional methods. Training was done in each of the loss functions. The first type consisted of an anchor image, a positive image with an at least IOU overlap with the anchor image, and a negative image in a different region from that of the anchor image. The first type of tuple was marked with “†” in the Table 1. The second type consisted of an anchor image, a positive image in an exactly identical region as that of the anchor image, and a negative image in a different region from that of the anchor image. We used the transformed triplet loss of Fan et al. [54] for the evaluation of the comparison results, because the basic form has performance degradation problems.The results for the first tuple type showed that the overall performance improved for both triplet loss and contrastive losses compared with that of the baseline model. In the detailed comparison of the two loss functions, triplet loss scored for r@1, performing better than contrastive loss, which scored . However, triplet loss scored only for r@100, performing worse than contrastive loss, which scored . For the second tuple type, the overall improvement in performance was greater for contrastive loss than that for triplet loss. Looking into the results for each type of tuples, we observed that the second type showed significantly better performance, because exactly identical regions were matched between images by training with deep metric learning.We also conducted an ablation study to see the effects of cross-channel pooling. Table 2 above shows the performance evaluation results of excluding cross-channel pooling from the method used in Table 1. As a result, most of the loss functions had a noticeable drop in performance. This shows that cross-channel pooling effectively preserves the spatial information, and has a positive effect on the improvement in aerial image retrieval performance.
- Coarse-to-Fine Learning MethodWe conducted an experiment by additional learning with the first coarse deep metric learning model. As a result of the coarse deep metric learning, we observed that using the second type of tuple that defined the positive image as an image in the exact same region as that of the anchor image led to better performance.The Table 3 shows the retrieval result using the coarse-to-fine method. We can confirm the effectiveness of the coarse-to-fine training. Performance improved in the triplet-loss-based model and in the contrastive-loss-based model.The performance improved more for the former model than that for the latter model. Triplet loss forces the distance between the anchor and the positive to be smaller than that between the anchor and the negative. Contrastive loss maximizes the distance between the anchor and the negative, while minimizing the distance between the anchor and the positive. Therefore, contrastive loss identifies the distance between features more strictly than the triplet loss. In addition, it was shown that coarse-to-fine learning resulted in better performance when trained with strictly defined features. Moreover, the overall performance showed greater improvement when using triangular loss than when using log ratio loss. Figure 9. shows examples of the coarse model and coarse-to-fine model retrieval results based on contrastive loss with the best performance.We integrated the steps of the method proposed in Table 4 and evaluated the performance after training. The overall recall performance degradation occurred when the training was conducted in integration. This shows that the proposed two-step approach is more effective than the integrated approach.
- Comparison with State-Of-The-ArtAs shown in the Table 5, we compared various SOTA methods in the field of image retrieval with our coarse to fine method. The models used for comparison were LDCNN [7], R-MAC Descriptor [45], NetVlad [51], triplet loss, and contrastive loss. These methods are widely used in image retrieval. LDCNN is a method of using low-level features of CNN through the mlpconv layers. R-MAC method identifies the activations of the convolutional feature maps, and uses the features of the parts determined to be important. LDCNN and R-MAC are classification-oriented methods, and therefore, a classification-labeled dataset is needed to train these two models. We used the AID dataset with features (altitude, picture quality, etc.) most similar to the Google Earth South Korea dataset. NetVlad method is primarily used in a smartphone environment for GPS location image retrieval. The method is robust to light changes and obscuring objects. NetVlad method was used with the same conditions as those used for coarse learning, and dense triplet mining was used for the sampling method. The backbone network used for the comparison methods was ResNet-34, except for LDCNN, which used the VGG-16 [34] network because of the number of parameters. As a result, the LDCNN used 490 dimensional feature vectors and the other models used 512 dimensional feature vectors. We confirm that the coarse to fine method has a noticeable difference compared to other SOTA methods.
4.4. Feature Analysis
4.4.1. Visualization of the Feature Descriptor
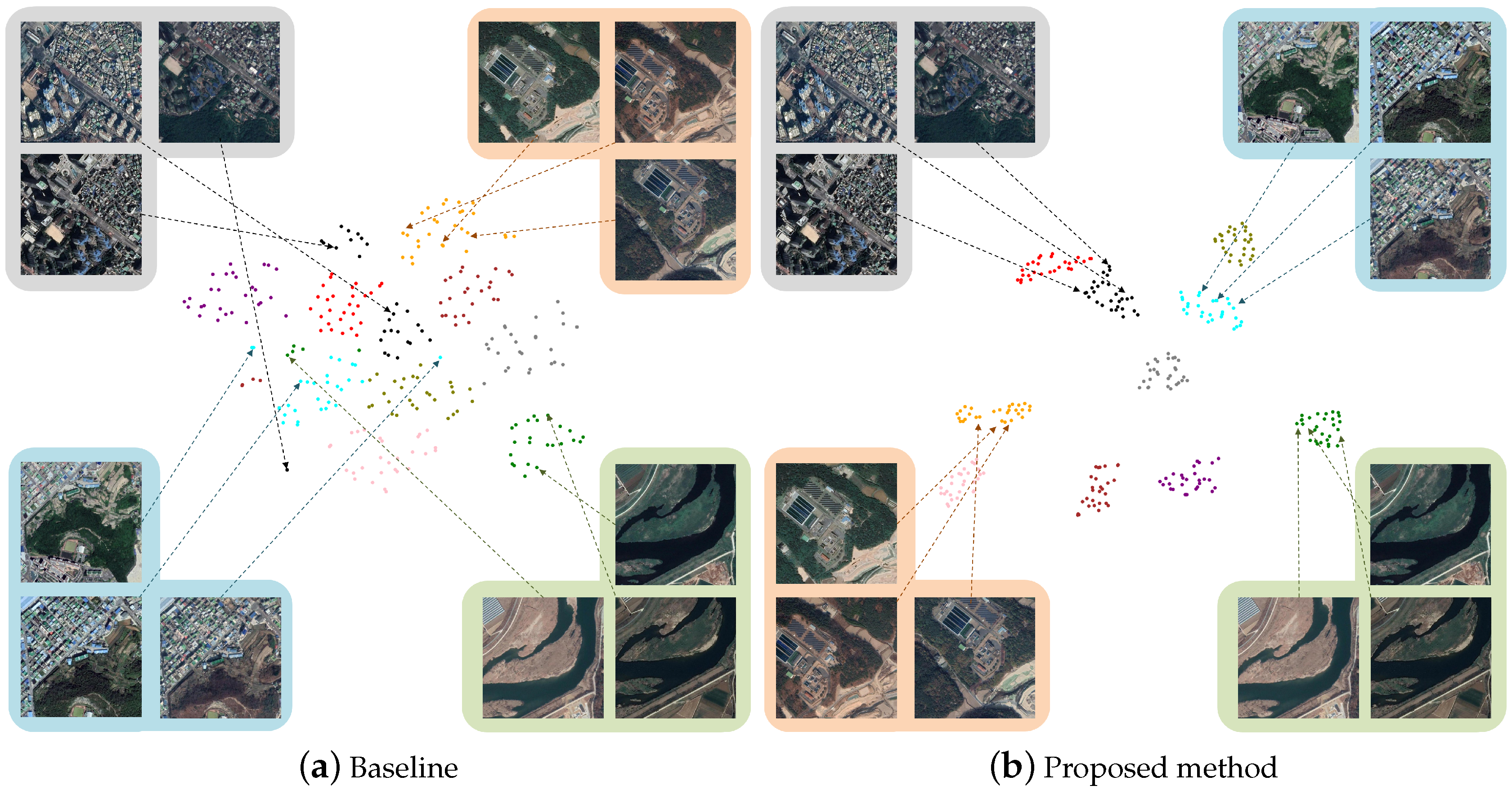
4.4.2. Location Wise t-SNE
4.4.3. Recognition of Differences Between Images
5. Discussion
6. Conclusions
Author Contributions
Acknowledgments
Conflicts of Interest
References
- Cheng, G.; Yang, C.; Yao, X.; Guo, L.; Han, J. When deep learning meets metric learning: Remote sensing image scene classification via learning discriminative CNNs. IEEE Trans. Geosci. Remote. Sens. 2018, 56, 2811–2821. [Google Scholar] [CrossRef]
- Mahdianpari, M.; Salehi, B.; Rezaee, M.; Mohammadimanesh, F.; Zhang, Y. Very deep convolutional neural networks for complex land cover mapping using multispectral remote sensing imagery. Remote. Sens. 2018, 10, 1119. [Google Scholar] [CrossRef]
- Zhu, X.X.; Tuia, D.; Mou, L.; Xia, G.-S.; Zhang, L.; Xu, F.; Fraundorfer, F. Deep learning in remote sensing: A comprehensive review and list of resources. IEEE Geosci. Remote. Sens. Mag. 2017, 5, 8–36. [Google Scholar] [CrossRef]
- Xiong, W.; Lv, Y.; Cui, Y.; Zhang, X.; Gu, X. A discriminative feature learning approach for remote sensing image retrieval. Remote. Sens. 2019, 11, 281. [Google Scholar] [CrossRef]
- Cao, R.; Zhang, Q.; Zhu, J.; Li, Q.; Li, Q.; Liu, B.; Qiu, G. Enhancing remote sensing image retrieval with triplet deep metric learning network. arXiv 2019, arXiv:1902.05818. [Google Scholar] [CrossRef]
- Zhou, W.; Deng, X.; Shao, Z. Region convolutional features for multi-label remote sensing image retrieval. arXiv 2018, arXiv:1807.08634. [Google Scholar]
- Zhou, W.; Newsam, S.; Li, C.; Shao, Z. Learning low dimensional convolutional neural networks for high-resolution remote sensing image retrieval. Remote. Sens. 2017, 9, 489. [Google Scholar] [CrossRef]
- Yue-Hei Ng, J.; Yang, F.; Davis, L.S. Exploiting local features from deep networks for image retrieval. In Proceedings of the IEEE Conference on Computer vision and Pattern Recognition Workshops, Santiago, Chile, 7–13 December 2015; pp. 53–61. [Google Scholar]
- Sattler, T.; Weyand, T.; Leibe, B.; Kobbelt, L. Image retrieval for image-based localization revisited. In Proceedings of the British Machine Vision Conference, Surrey, UK, 3–7 September 2012; p. 4. [Google Scholar]
- Wan, J.; Wang, D.; Hoi, S.C.H.; Wu, P.; Zhu, J.; Zhang, Y.; Li, J. Deep learning for content-based image retrieval: A comprehensive study. In Proceedings of the 22nd ACM International Conference on Multimedia, Orlando, FL, USA, 3–7 November 2014; pp. 157–166. [Google Scholar]
- Maeng, H.; Liao, S.; Kang, D.; Lee, S.-W.; Jain, A.K. Nighttime face recognition at long distance: Cross-distance and cross-spectral matching. In Proceedings of the 11th Asian Conference on Computer Vision, Daejeon, Korea, 5–9 November 2012; pp. 708–721. [Google Scholar]
- Park, S.-C.; Lim, S.-H.; Sin, B.-K.; Lee, S.-W. Tracking non-rigid objects using probabilistic Hausdorff distance matching. Pattern Recognit. 2005, 38, 2373–2384. [Google Scholar] [CrossRef]
- Park, S.-C.; Lee, H.-S.; Lee, S.-W. Qualitative estimation of camera motion parameters from the linear composition of optical flow. Pattern Recognit. 2004, 37, 767–779. [Google Scholar] [CrossRef]
- Roh, H.-K.; Lee, S.-W. Multiple people tracking using an appearance model based on temporal color. In Proceedings of the International Workshop on Biologically Motivated Computer Vision, Seoul, Korea, 15–17 May 2000; pp. 369–378. [Google Scholar]
- Park, J.; Kim, H.-Y.; Park, Y.; Lee, S.-W. A synthesis procedure for associative memories based on space-varying cellular neural networks. Neural Netw. 2001, 14, 107–113. [Google Scholar] [CrossRef]
- Roh, M.-C.; Kim, T.-Y.; Park, J.; Lee, S.-W. Accurate object contour tracking based on boundary edge selection. Pattern Recognit. 2007, 40, 931–943. [Google Scholar] [CrossRef]
- Xi, D.; Podolak, I.T.; Lee, S.-W. Facial component extraction and face recognition with support vector machines. In Proceedings of the Fifth IEEE International Conference on Automatic Face Gesture Recognition, Guildford, UK, 9–11 June 2003; pp. 83–88. [Google Scholar]
- Suk, H.-I.; Sin, B.-K.; Lee, S.-W. Recognizing hand gestures using dynamic bayesian network. In Proceedings of the 2008 8th IEEE International Conference on Automatic Face & Gesture Recognit, Amsterdam, The Netherlands, 17–19 September 2008; pp. 1–6. [Google Scholar]
- Roh, M.-C.; Shin, H.-K.; Lee, S.-W. View-independent human action recognition with volume motion template on single stereo camera. Pattern Recognit. Lett. 2010, 31, 639–647. [Google Scholar] [CrossRef]
- Park, U.; Choi, H.-C.; Jain, A.K.; Lee, S.-W. Face tracking and recognition at a distance: A coaxial and concentric PTZ camera system. IEEE Trans. Inf. Forensics Secur. 2013, 8, 1665–1677. [Google Scholar] [CrossRef]
- Jung, H.-C.; Hwang, B.-W.; Lee, S.-W. Authenticating corrupted face image based on noise model. In Proceedings of the Sixth IEEE International Conference on Automatic Face and Gesture Recognition, Hong Kong, China, 15–17 July 2004; pp. 272–277. [Google Scholar]
- Hwang, B.-W.; Blanz, V.; Vetter, T.; Lee, S.-W. Face reconstruction from a small number of feature points. In Proceedings of the 15th International Conference on Pattern Recognition, Seoul, Korea, 15–17 May 2000; pp. 838–841. [Google Scholar]
- Song, H.-H.; Lee, S.-W. LVQ combined with simulated annealing for optimal design of large-set reference models. Neural Netw. 1996, 9, 329–336. [Google Scholar] [CrossRef]
- Suk, H.-I.; Jain, A.K.; Lee, S.-W. A network of dynamic probabilistic models for human interaction analysis. IEEE Trans. Circuits Syst. Video Technol. 2011, 21, 932–945. [Google Scholar]
- Thrun, S.; Zlot, R. Reduced sift features for image retrieval and indoor localization. In Proceedings of the Australian Conference on Robotics and Automation, Canberra, Australia, 6–8 December 2004; pp. 1–8. [Google Scholar]
- Lowe, D.G. Distinctive image features from scale-invariant keypoints. Int. J. Comput. Vis. 2004, 60, 91–110. [Google Scholar] [CrossRef]
- Pass, G.; Zabih, R. Histogram refinement for content-based image retrieval. In Proceedings of the Third IEEE Workshop on Applications of Computer Vision, Sarasota, FL, USA, 2–4 December 1996; pp. 96–102. [Google Scholar]
- Aptoula, E. Remote sensing image retrieval with global morphological texture descriptors. IEEE Trans. Geosci. Remote. Sens. 2013, 52, 3023–3034. [Google Scholar] [CrossRef]
- He, K.; Gkioxari, G.; Dollár, P.; Girshick, R. Mask r-cnn. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Honolulu, HI, USA, 21–26 July 2017; pp. 5620–5629. [Google Scholar]
- He, K.; Zhang, X.; Ren, S.; Sun, J. Deep residual learning for image recognition. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 26 June–1 July 2016; pp. 770–778. [Google Scholar]
- Ren, S.; He, K.; Girshick, R.; Sun, J. Faster r-cnn: Towards real-time object detection with region proposal networks. In Proceedings of the Advances in Neural Information Processing Systems, Montreal, QC, Canada, 7–12 December 2015; pp. 91–99. [Google Scholar]
- Son, J.; Baek, M.; Cho, M.; Han, B. Multi-object tracking with quadruplet convolutional neural networks. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Honolulu, HI, USA, 21–26 July 2017; pp. 5620–5629. [Google Scholar]
- Zheng, L.; Yang, Y.; Tian, Q. SIFT meets CNN: A decade survey of instance retrieval. IEEE Trans. Pattern Anal. Mach. Intell. 2017, 40, 1224–1244. [Google Scholar] [CrossRef]
- Simonyan, K.; Zisserman, A. Very deep convolutional networks for large-scale image recognition. arXiv 2014, arXiv:1409.1556. [Google Scholar]
- Yang, Y.; Newsam, S. Bag-of-visual-words and spatial extensions for land-use classification. In Proceedings of the 18th SIGSPATIAL International Conference on Advances in Geographic Information Systems, San Jose, CA, USA, 2–5 November 2010; pp. 270–279. [Google Scholar]
- Xia, G.-S.; Hu, J.; Hu, F.; Shi, B.; Bai, X.; Zhong, Y.; Zhang, L.; Lu, X. AID: A benchmark data set for performance evaluation of aerial scene classification. IEEE Trans. Geosci. Remote. Sens. 2017, 55, 3965–3981. [Google Scholar] [CrossRef]
- Sun, B.; Chen, C.; Zhu, Y.; Jiang, J. GeoCapsNet: Aerial to Ground view Image Geo-localization using Capsule Network. arXiv 2019, arXiv:1904.06281. [Google Scholar]
- Chopra, S.; Hadsell, R.; LeCun, Y. Learning a similarity metric discriminatively, with application to face verification. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, San Diego, CA, USA, 20–26 June 2005; pp. 907–914. [Google Scholar]
- Sun, Y.; Chen, Y.; Wang, X.; Tang, X. Deep learning face representation by joint identification-verification. In Proceedings of the Advances in Neural Information Processing Systems, Montreal, QC, Canada, 8–13 December 2014; pp. 1988–1996. [Google Scholar]
- Kumar, B.; Carneiro, G.; Reid, I. Learning local image descriptors with deep siamese and triplet convolutional networks by minimising global loss functions. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 26 June–1 July 2016; pp. 5385–5394. [Google Scholar]
- Schroff, F.; Kalenichenko, D.; Philbin, J. Facenet: A unified embedding for face recognition and clustering. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Santiago, Chile, 7–13 December 2015; pp. 815–823. [Google Scholar]
- Hoffer, E.; Ailon, N. Deep metric learning using triplet network. In Proceedings of the International Workshop on Similarity-Based Pattern Recognition, Copenhagen, Denmark, 12–14 October 2015; pp. 84–92. [Google Scholar]
- Kim, S.; Seo, M.; Laptev, I.; Cho, M.; Kwak, S. Deep Metric Learning Beyond Binary Supervision. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Long Beach, CA, USA, 16–20 June 2019; pp. 2288–2297. [Google Scholar]
- Babenko, A.; Lempitsky, V. Aggregating local deep features for image retrieval. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Santiago, Chile, 7–13 December 2015; pp. 1269–1277. [Google Scholar]
- Tolias, G.; Sicre, R.; Jégou, H. Particular object retrieval with integral max-pooling of CNN activations. arXiv 2015, arXiv:1511.05879. [Google Scholar]
- Chen, W.; Chen, X.; Zhang, J.; Huang, K. Beyond triplet loss: a deep quadruplet network for person re-identification. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Honolulu, HI, USA, 21–26 July 2017; pp. 403–412. [Google Scholar]
- Sohn, K. Improved deep metric learning with multi-class n-pair loss objective. In Proceedings of the Advances in Neural Information Processing Systems, Barcelona, Spain, 5–10 December 2016; pp. 1857–1865. [Google Scholar]
- Liu, L.; Shen, C.; Van Den Hengel, A. Cross-convolutional-layer pooling for image recognition. IEEE Trans. Geosci. Remote. Sens. 2016, 39, 2305–2313. [Google Scholar] [CrossRef] [PubMed]
- Deng, J.; Dong, W.; Socher, R.; Li, L.-J.; Li, K.; Fei-Fei, L. Imagenet: A large-scale hierarchical image database. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Miami, FL, USA, 20–25 June 2009; pp. 248–255. [Google Scholar]
- Gorelick, N.; Hancher, M.; Dixon, M.; Ilyushchenko, S.; Thau, D.; Moore, R. Google Earth Engine: Planetary-scale geospatial analysis for everyone. Remote. Sens. Environ. 2017, 202, 18–27. [Google Scholar] [CrossRef]
- Arandjelovic, R.; Gronat, P.; Torii, A.; Pajdla, T.; Sivic, J. NetVLAD: CNN architecture for weakly supervised place recognition. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 26 June–1 July 2016; pp. 5297–5307. [Google Scholar]
- Torii, A.; Sivic, J.; Pajdla, T.; Okutomi, M. Visual place recognition with repetitive structures. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Portland, OR, USA, 25–27 June 2013; pp. 883–890. [Google Scholar]
- Gronat, P.; Obozinski, G.; Sivic, J.; Pajdla, T. Learning and calibrating per-location classifiers for visual place recognition. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Portland, OR, USA, 23–28 June 2013; pp. 907–914. [Google Scholar]
- Fan, C.; Lee, J.; Xu, M.; Kumar Singh, K.; Jae Lee, Y.; Crandall, D.J.; Ryoo, M.S. Identifying first-person camera wearers in third-person videos. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Honolulu, HI, USA, 21–26 July 2017; pp. 5125–5133. [Google Scholar]














{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Methods | ||||
|---|---|---|---|---|
| Triplet loss † | 18.3 | 23.4 | 24.7 | 40.1 |
| Contrastive loss † | 8.7 | 19.5 | 25.2 | 64.5 |
| Triplet loss | 37.8 | 53.5 | 59.1 | 78.4 |
| Contrastive loss | 38.9 | 55.8 | 62.7 | 81.5 |
| Methods | ||||
|---|---|---|---|---|
| Baseline network | 5.7 | 11.6 | 13.9 | 32.6 |
| Triplet loss † | 4.1 | 10.5 | 12.9 | 25.2 |
| Contrastive loss † | 17.2 | 35.2 | 43.7 | 79.9 |
| Triplet loss | 6.4 | 10.3 | 14.4 | 28.3 |
| Contrastive loss | 30.3 | 44.2 | 53.0 | 81.7 |
| Methods | |||||
|---|---|---|---|---|---|
| Step 1 | Step 2 | ||||
| Triplet loss | Log ratio loss | 44.2 | 57.8 | 2.0 | 78.7 |
| Triplet loss | Triangular loss | 46.8 | 59.4 | 65.8 | 82.5 |
| Contrastive loss | Log ratio loss | 47.6 | 61.4 | 66.8 | 86.7 |
| Contrastive loss | Triangular loss | 49.1 | 62.5 | 67.1 | 87.1 |
| Methods | ||||
|---|---|---|---|---|
| Integrated method | 33.6 | 44.7 | 49.4 | 70.4 |
| Coarse-to-Fine method | 49.1 | 62.5 | 67.1 | 87.1 |
| Methods | ||||
|---|---|---|---|---|
| LDCNN | 8.2 | 15.6 | 19.2 | 39.3 |
| R-MAC descriptor | 15.9 | 24.7 | 30.6 | 48.8 |
| NetVlad | 16.2 | 27.8 | 33.7 | 55.0 |
| Triplet loss | 37.8 | 53.5 | 59.1 | 78.4 |
| Constrastive loss | 38.9 | 55.8 | 62.7 | 81.5 |
| Coarse-to-Fine method | 49.1 | 62.5 | 67.1 | 87.1 |
© 2020 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Yun, M.-S.; Nam, W.-J.; Lee, S.-W. Coarse-to-Fine Deep Metric Learning for Remote Sensing Image Retrieval. Remote Sens. 2020, 12, 219. https://doi.org/10.3390/rs12020219
Yun M-S, Nam W-J, Lee S-W. Coarse-to-Fine Deep Metric Learning for Remote Sensing Image Retrieval. Remote Sensing. 2020; 12(2):219. https://doi.org/10.3390/rs12020219
Chicago/Turabian StyleYun, Min-Sub, Woo-Jeoung Nam, and Seong-Whan Lee. 2020. "Coarse-to-Fine Deep Metric Learning for Remote Sensing Image Retrieval" Remote Sensing 12, no. 2: 219. https://doi.org/10.3390/rs12020219
APA StyleYun, M.-S., Nam, W.-J., & Lee, S.-W. (2020). Coarse-to-Fine Deep Metric Learning for Remote Sensing Image Retrieval. Remote Sensing, 12(2), 219. https://doi.org/10.3390/rs12020219