1. Introduction
Remote sensing images have become the main data source for obtaining land-use information at broad spatial scales. The most common method first assigns each pixel to a category using image segmentation and subsequently generates land-use information according to the pixel-by-pixel classification result [
1,
2]. Since the accuracy of the final extraction is determined by the accuracy of the pixel-by-pixel classification, improving the segmentation accuracy is a common research focus [
3]. The pixel feature extraction method and the classifier performance both have a decisive influence on segmentation results [
4,
5].
Researchers have proposed a variety of methods to extract ideal features. For example, spectral indexes have been widely applied in the classification of low- and medium-spatial-resolution remote sensing images, as they can accurately reflect statistical information regarding pixel spectral values. Commonly used indexes include the vegetation index [
6,
7,
8,
9,
10,
11,
12,
13], water index [
14], normalized difference building index [
15], ecological index [
16], normalized difference vegetation index (NDVI) [
10,
13], and derivative indexes such as the re-normalized difference vegetation index [
12] or the growing season normalized difference vegetation index [
13]. Taking account of the advantage of the short time period of low- and medium-spatial-resolution remote sensing images, some researchers have applied spectral indexes to time-series images [
17,
18]. However, such indexes are mainly used to express common information within the same land-use type through simple band calculations. When these are applied to remote sensing images with rich detail and high spatial resolution, it becomes difficult to extract features with good discrimination, limiting the application of spectral indexes to the classification of such images.
For high-spatial-resolution remote sensing images with a high level of detail, researchers initially proposed the use of texture features with the gray matrix method [
19]. Subsequently, other researchers have proposed a series of methods for extracting more abundant texture features, including the Gabor filter [
20], the Markov random field model [
21], the Gibbs random field model [
22], and the wavelet transform [
23]. Compared with spectral index features, texture features can better express the spatial correlation between pixels, improve the ability to distinguish between features, and effectively improve the accuracy of pixel classification.
Although the combination of spectral and texture features has greatly promoted the development of remote sensing image segmentation technology and significantly improved the accuracy of pixel classification results, the ongoing improvement in remote sensing technology has resulted in increasing image resolutions and higher levels of detail. Traditional texture feature extraction techniques now struggle with high-resolution images, such that new methods are needed to obtain effective feature information from such images [
24,
25].
The developing field of machine learning is currently being applied to pixel feature extraction, with early applications to image processing, including neural networks [
26,
27], support vector machines [
28,
29], decision trees [
30,
31], and random forests [
32,
33]. These methods use pixel spectral information as inputs and achieve the desired feature results through complex calculations. Although these methods can fully explore the relationship between channels and obtain some effective feature information, these features only express the information of a single pixel rather than the spatial relationship between pixels, limiting these methods’ application in the processing of remote sensing images.
Convolutional neural networks (CNNs) use pixel blocks as inputs and compute them with a set of convolution kernels to obtain more features with a stronger distinguishing ability [
34,
35,
36,
37]. The biggest advantage of CNNs lies in their ability to simultaneously extract specific pixel features as well as spatial features of pixel blocks. This approach can reasonably set the structure of the convolutional layer according to the characteristics of the image and the extraction target, so as to extract features that meet the requirements, achieving good results in image processing [
34,
36]. The most widely used CNNs in the field of camera image processing include fully convolutional networks (FCNs) [
38], SegNet [
39], DeepLab [
40], RefineNet [
41], and U-NET [
42]. DeepLab expands the convolution for rich features in camera images, enabling the model to effectively expand the receptive field without increasing the calculations required. SegNet and UNET can establish a symmetrical network structure and segment camera images, resulting in an efficient utilization of high-level semantic features. RefineNet uses a multipath structure to combine coarse high-level semantic features and relatively fine low-level semantic features by equal-weight fusion.
As CNNs have outstanding advantages in feature extraction, they have been widely used in other fields, such as real-time traffic sign recognition [
43], pedestrian recognition [
44], apple target recognition [
45], plant disease detection [
46], and pest monitoring [
47]. Researchers have established a method to extract coordinate information of an object from street view imagery [
48] using CNNs.
Compared to camera images, remote sensing images have fewer details and more mixed pixels. When using a CNN to extract information from remote sensing images, the influence of the convolution structure on feature extraction must be considered [
49]. Existing CNN structures are mainly designed for camera images with a high level of detail; therefore, a more ideal result can be obtained through adjustments that consider the specific characteristics of remote sensing images [
50,
51]. Researchers have proposed a series of such adjustments for applying CNNs to remote sensing image processing [
3] and some classic CNNs have been widely applied in this field [
52,
53]. Based on the characteristic analysis of target objects and specific remote sensing imagery, researchers have established a series of CNNs such as two-branch CNN [
49], WFS-NET [
54], patch-based CNN [
55], and hybrid MLP-CNN [
56]. Researchers have also used remote sensing images to create many benchmark datasets, such as EuroSAT [
57] or the Inria Aerial Image dataset [
58], to test the performance of CNNs.
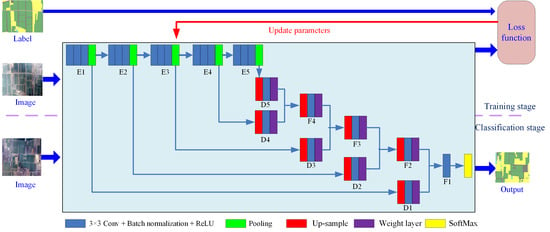
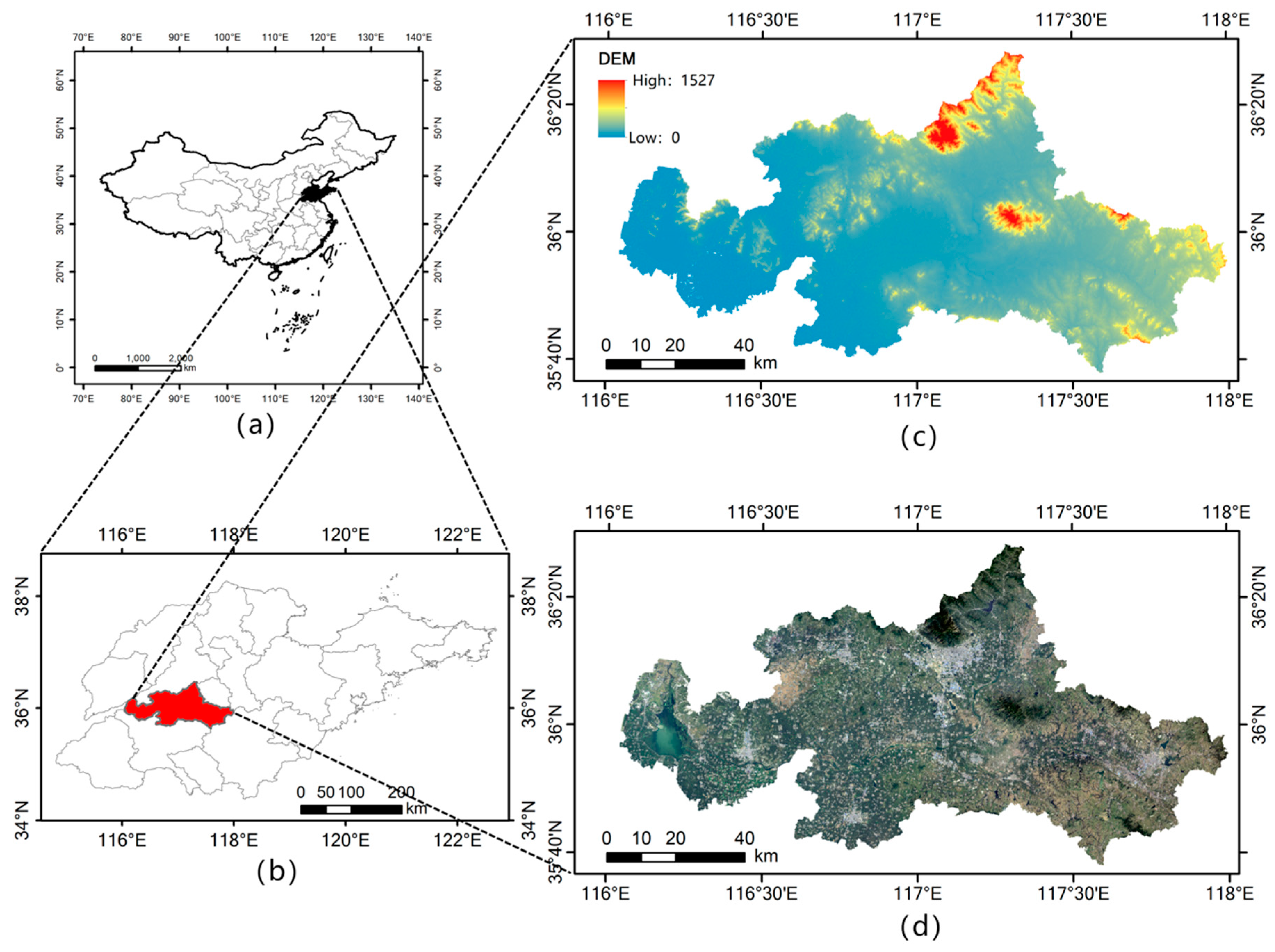
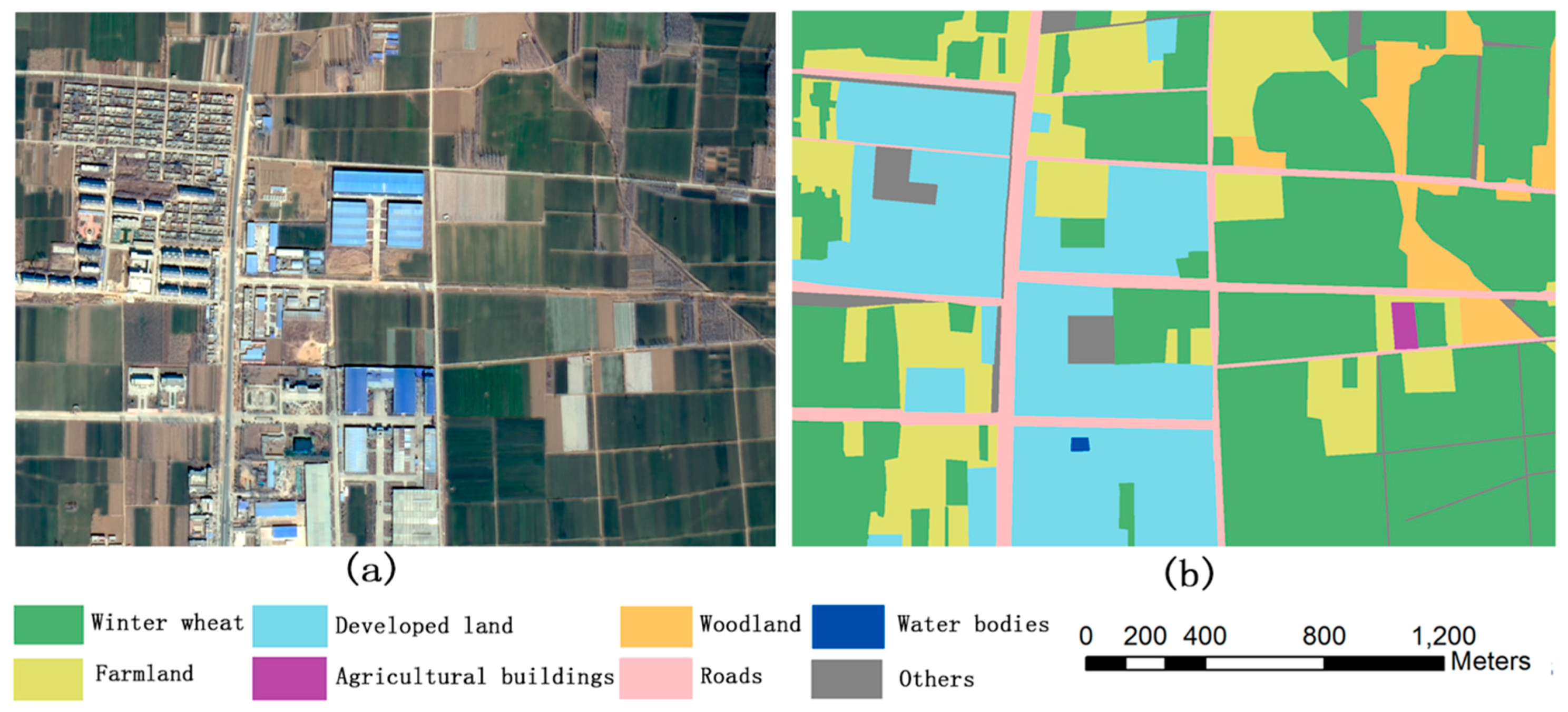
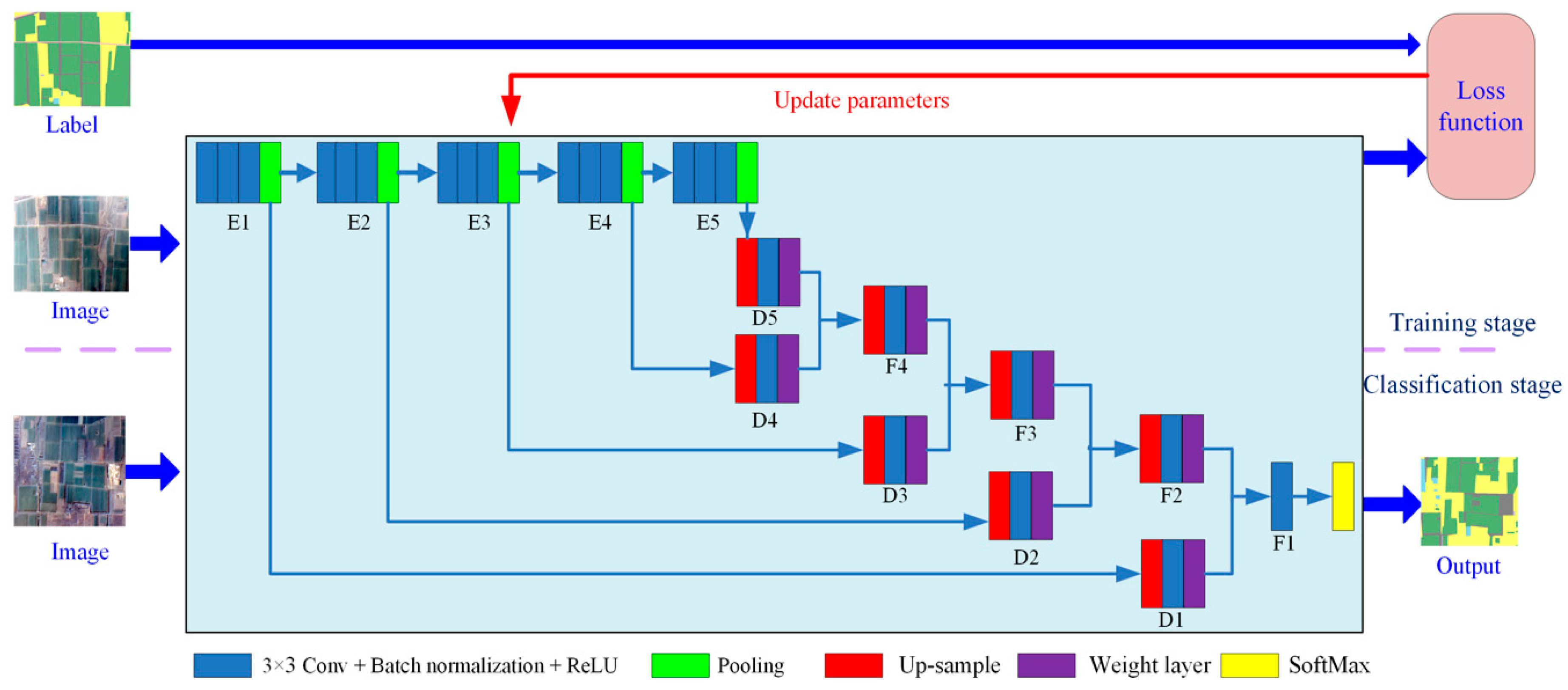
In this study, we established a CNN structure based on variable weight fusion, the weight feature value convolutional neural network (WFCNN), and experimentally assessed its performance. The main contributions of this work are as follows.
Based on the analysis of the data characteristics of remote sensing images, fully considering the impact of image spatial resolution on feature extraction, we establish a suitable network convolution structure;
The proposed approach can effectively fuse low-level semantic features with high-level semantic features and fully considers the data characteristics of adjacent areas around objects on remote sensing images. Compared with the strategies adopted by other models, our approach is more conducive to effective features.
4. Results
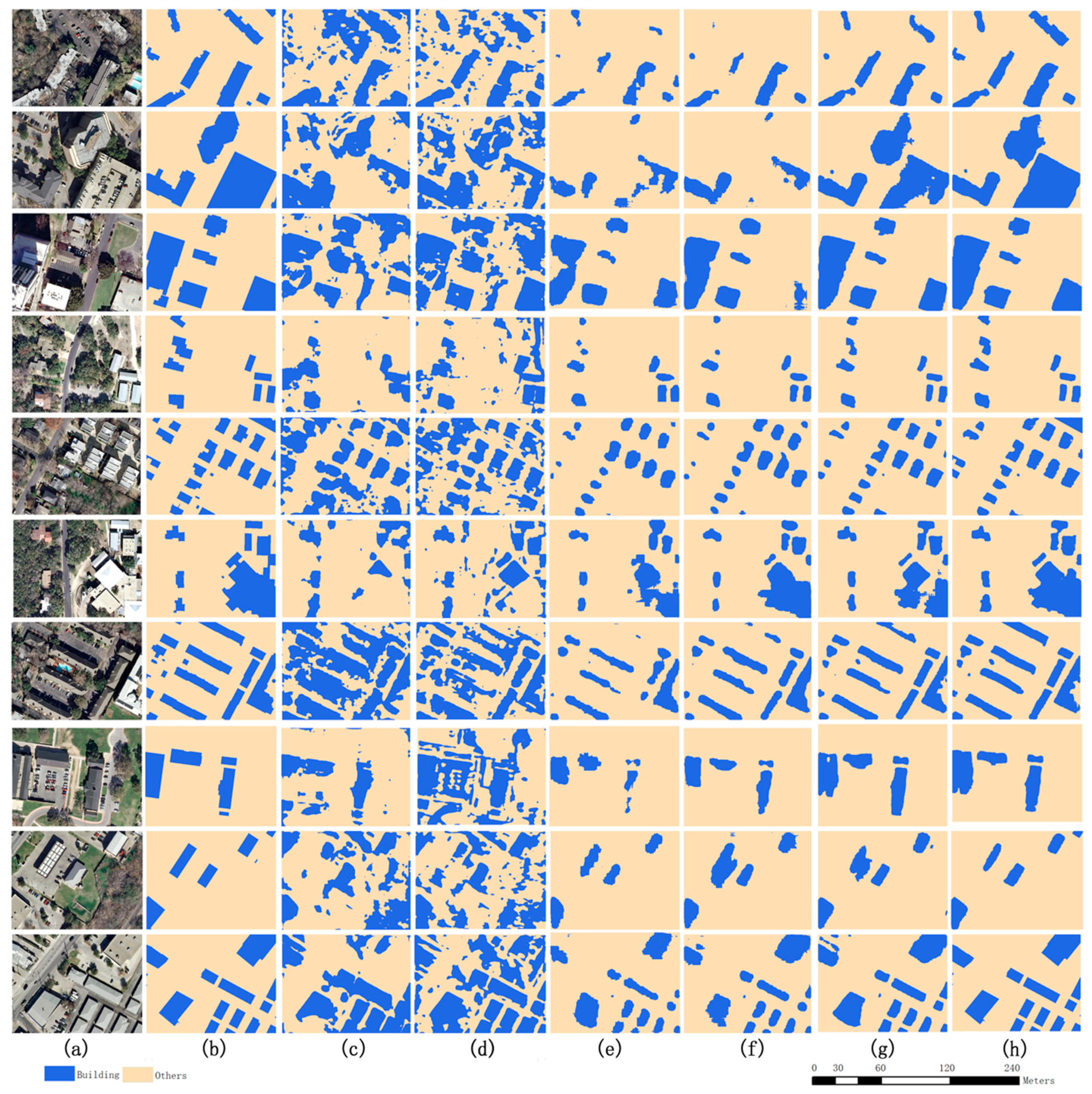
Overall, 10 results tested on the GF-6 images dataset were randomly selected from all models (
Figure 6), and 10 results were tested on the aerial image labeling dataset (
Figure 7). As can be seen from
Figure 6 and
Figure 7, WFCNN performed best in all cases.
SegNet exhibited most errors and the distribution was relatively scattered, with more misclassified pixels in both the edge and inner areas. This shows that it is more reasonable to combine high semantic features with low semantic features than to use only high semantic features.
The number of misclassified pixels produced by all three variants of WFCNN was lower for RefineNet and U-net. The excellent performance of RefineNet and U-Net in the camera image indicates that the network structure should be determined in accordance with the spatial resolution of the image.
WFCNN performed better than WFCNN-1. This excellent performance indicates that the feature vector dimension was too high and is not conducive to improving the accuracy of the classifier. The result that WFCNN performed better than WFCNN-2 shows that the weight layer played a role.
By comparing the performance of U-Net, RefineNet, WFCNN-1, WFCNN-2, and WFCNN, it indicates that different feature fusion methods differ in their contributions to improving accuracy, so it is necessary to choose an appropriate feature fusion method for a given situation.
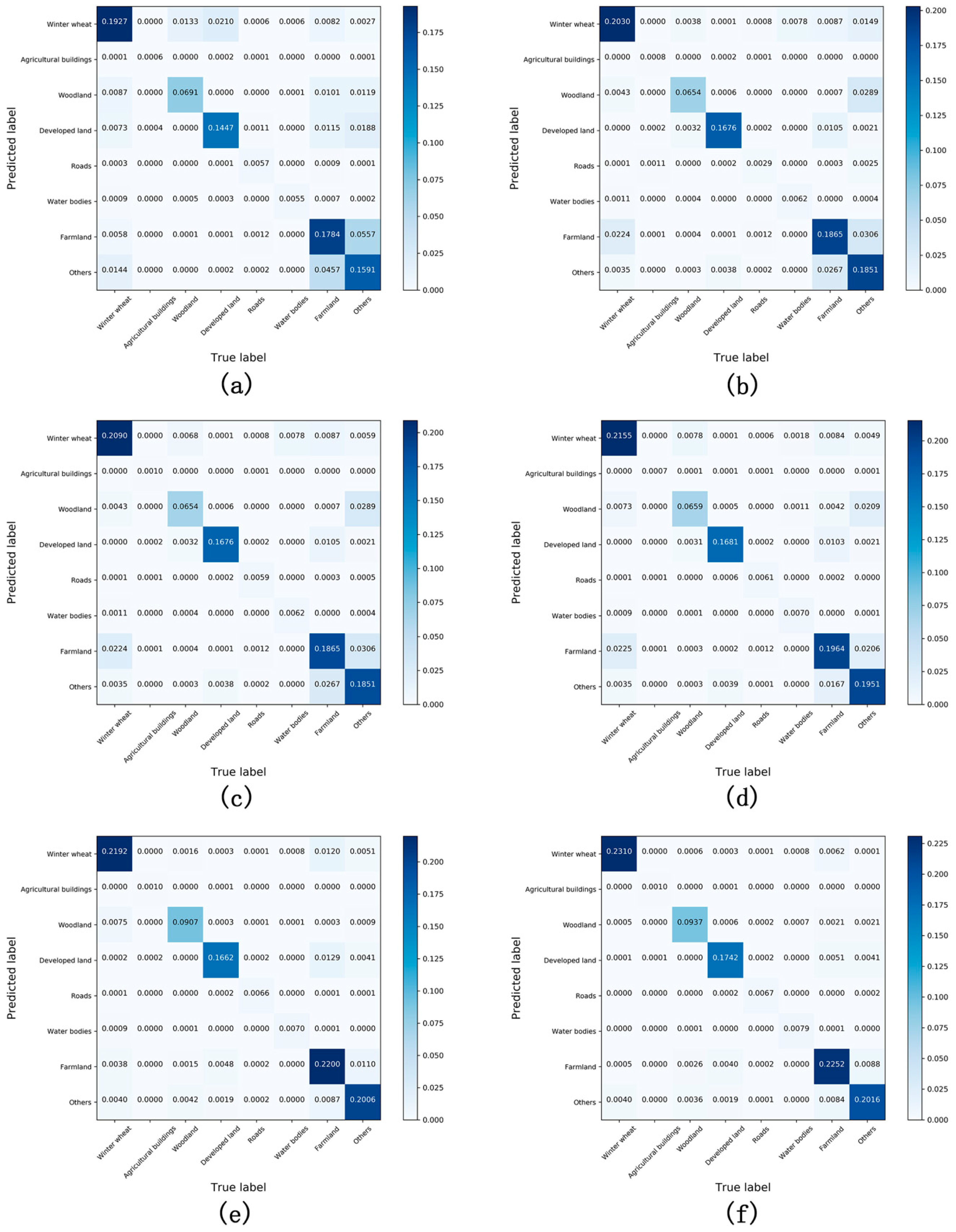
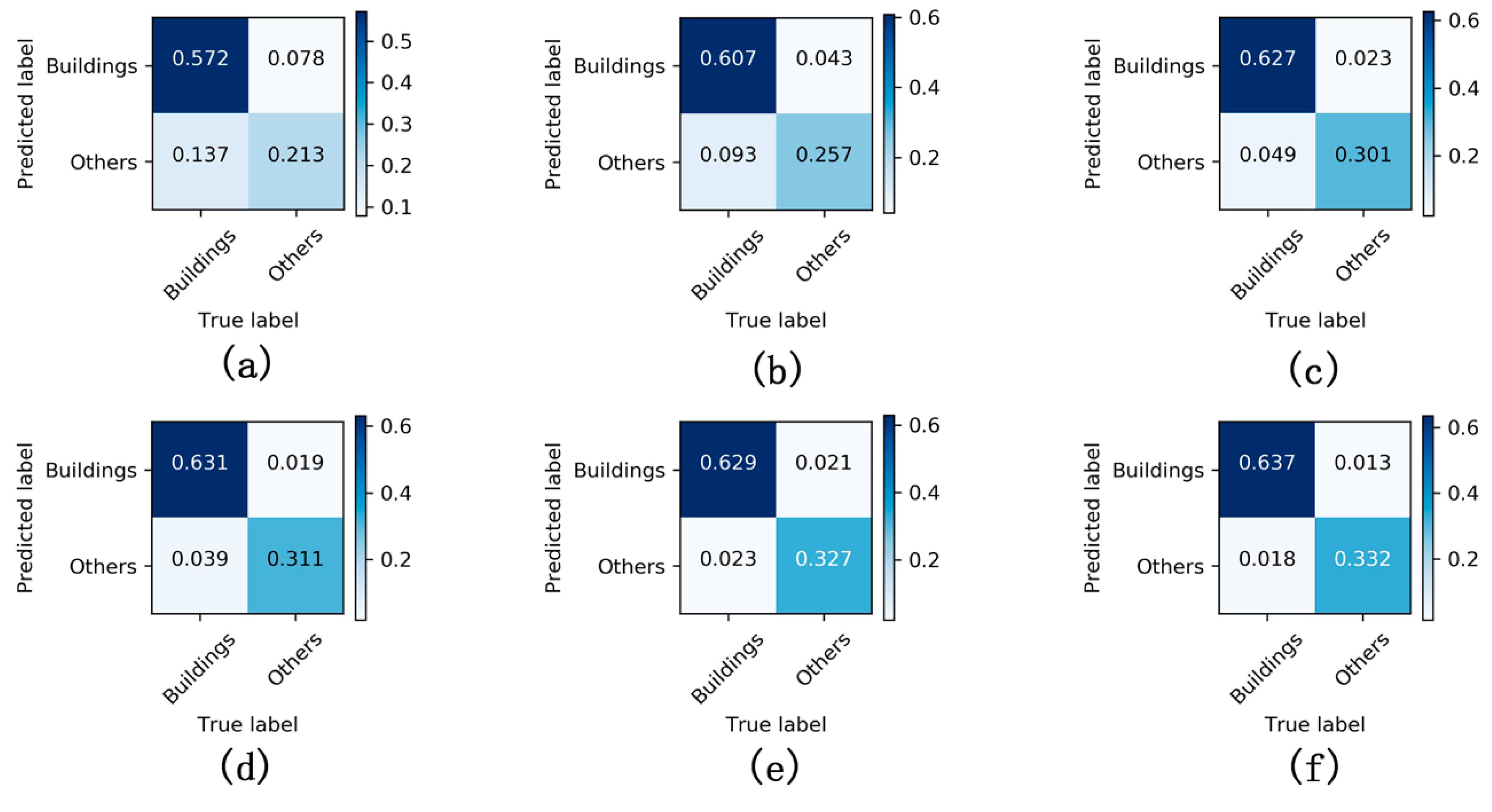
Figure 8 and
Figure 9 present confusion matrices for the different models, which again demonstrate that WFCNN had the best segmentation results. Comparing
Figure 8 and
Figure 9, it can be found that the performance of each model on the aerial image labeling dataset is better than that on the GF-6 images dataset, indicating that the spatial resolution has a certain impact on the performance of the model.
We used accuracy, precision, recall, F1-Score, intersection over union (IoU), and Kappa coefficient as indicators to further evaluate the segmentation results for each model (
Table 7 and
Table 8). The F1-Score is defined as the harmonic mean of precision and recall. IoU is defined as the number of pixels labeled as the same class in both the prediction and the reference, divided by the number of pixels labeled as the class in the prediction or the reference.
The average accuracy of WFCNN was 18.48 % higher than SegNet, 11.44% higher than U-Net, 7.78% higher than RefineNet, 6.68% higher than WFCNN-1, and 2.15% higher than WFCNN-2.
5. Discussion
5.1. Effect of Features on Accuracy
At present, remote sensing image classification mainly relies on three feature types: spectral features mainly express information for individual pixels, textural features mainly express the spatial correlation between adjacent pixels, and semantic features mainly express the relationship between pixels in a specific region in a more abstract way.
CNNs can simultaneously extract these three feature types by reasonably organizing the convolution kernel. For example, the features extracted by using a 1 × 1 convolution kernel are equivalent to spectral features, those obtained by shallow convolutional layers can be regarded as textural features, and those obtained by convolutional layers of different depths can be regarded as semantic. Therefore, advanced semantic features can be considered as including all three feature types. However, in CNNs, advanced semantic features are obtained by deepening the network structure and expanding the receptive field. The spatial resolution of the image, the number of pixels covered by the object area, and other factors will affect the feature extraction results.
In a high-resolution and detailed camera image, an object tends to occupy a larger area, and it is advantageous to use advanced features. When SegNet only uses high-level semantic features to process an image with a high level of detail, a certain number of misclassified pixels occur at the edge, but few occur inside the object.
In the experiments of this study, the results of SegNet contained more misclassified pixels both at the edge and the inner area. Comparing objects of different sizes showed that smaller objects had more other types of objects adjacent to them and more pixels filled in. This is because the receptive field of high-level semantic features is generally large, and when the type distribution of objects in the receptive field is messy, the extracted feature values will deviate greatly from those of other pixels of the same kind, thus, affecting the accuracy of the segmentation results.
Unlike SegNet, the other models tested here combined low-level semantic features with high-level semantic features, with more accurate results. When segmenting remote sensing images with high spatial resolution, such as GF-6, the different levels of semantic features should be fused and used for classification, which is more reasonable than using advanced semantic features alone.
5.2. Effect of Up-Sampling on Accuracy
The purpose of up-sampling is to encrypt the rough high-level semantic feature graph to generate a feature vector for each pixel. In this study, WFCNN, U-Net, and RefineNet generated feature maps with the same size as compared to the input image through multi-step sampling. However, WFCNN used deconvolution to complete up-sampling, while RefineNet and U-Net used deconvolution to perform up-sampling first and chose linear interpolation for the final up-sampling. The segmentation results for these three models had few mis-segmented pixels within the object, but at the edges, WFCNN’s results were significantly better. When RefineNet and U-Net processed camera images, the edges of the object were very fine. We believe that the reason for this phenomenon is that the structure of a remote sensing image is considerably different from that of a camera image, such that bilinear interpolation does not achieve good results when processing the former. Since the resolution of a camera image is generally high, when two objects are adjacent to each other, the pixel changes across the boundary are usually gentle and the difference between adjacent pixels is small, such that up-sampling using bilinear interpolation is more effective. In contrast, the pixel changes in a remote sensing image are usually sharp across the boundary between two objects and the difference between adjacent pixels is large, resulting in a poor bilinear interpolation effect. Unlike RefineNet and U-Net, WFCNN uses deconvolution for up-picking and correction and all parameters are obtained through learning samples, allowing the model to adapt to the unique characteristics of remote sensing images and achieve good results.
5.3. Effect of Feature Fusion on Accuracy
WFCNN, WFCNN-1, and WFCNN-2 all used feature fusion methods to generate feature vectors for each pixel. Since the convolution kernels used in different convolutional layer levels may be different, potentially causing differences in the feature map depths, it is necessary to adjust the latter before fusion. Choosing an appropriate fusion strategy can help improve the accuracy of the results.
WFCNN used a dimensional reduction strategy while WFCNN-1 used a dimensional increase. Although both can achieve consistent depth adjustments of the feature graph, our results showed that WFCNN performed better, indicating that dimensional reduction is more effective. Our analysis suggests that the effect of the classifier may be influenced by a high dimensionality. In a future study, we intend to test additional fusion strategies to further improve the accuracy of the segmentation results.
Like WFCNN, WFCNN-2 used dimensional reduction, but the former adjusted the characteristics of the participation fusion by using the weight layer beforehand, while the latter directly used dimensional reduction. Once the resulting feature map was fused, it was clear that the weight layer used by WFCNN improved the accuracy of the segmentation results.
6. Conclusions
This study tested a new approach to obtain high-precision land-use information from remote sensing images, using a new CNN-based model (WFCNN) to obtain multi-scale image features. Experimental comparisons with the currently used SegNet and RefineNet models, along with two variants on the original WFCNN model, demonstrated the advantages of this approach. This paper discusses the influence of classification feature selection, up-sampling method, and fusion strategy on segmentation accuracy, indicating that WFCNN can also be applied to other high spatial resolution remote sensing images.
Analyzing the data characteristics of high-resolution remote sensing images allowed the effects of spatial resolution on feature extraction to be fully considered, leading to the adoption of a hierarchical pooling strategy. In the initial stage of feature extraction, a large cell length step was used in WFCNN because the feature values were relatively scattered, allowing the pooling operation to accentuate the advantages of feature aggregation. In the subsequent stage, a smaller pooling step size was adopted due to the large difference between the current resolution and the original image. The experimental results showed that this strategy was more conducive to generating features with good discrimination.
The data characteristics of adjacent regions within remote sensing images were fully considered to effectively combine low-level and high-level semantic features. The proposed WFCNN model uses a variable-weight fusion strategy that adjusts features using a weight adjustment layer to ensure their stability. This strategy is more conducive to extracting effective features than those adopted by other models.
Our method requires training images to be marked pixel-by-pixel, creating a large workload. In subsequent research, we intend to introduce a semi-supervised training method to reduce this requirement and make the model more applicable to real-world situations.

 ,
, 










{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}