1. Introduction
With the rapid development of remote sensing satellite technology, satellite images are increasingly being used in daily lives. An increasing amount of remote sensing data is being used in environmental protection, agricultural engineering, and others [
1]. In daily life, people use remote sensing satellite maps for geological mapping, urban heat island monitoring, environmental monitoring, as well as for fire detection in forests from remote sensing images [
2,
3,
4,
5]. However, more than 66% of the world’s surface is covered by clouds [
6]. Therefore, cloud-covered areas will inevitably appear in remote sensing satellite images. Because of the natural environment and the angles at which the remote sensing images are taken, different types of clouds are captured in such images, including thin clouds, thick clouds, etc. Thick clouds sometimes cover the ground completely, and this affects the subsequent ground recognition and environmental monitoring. The thin cloud is generally semi-transparent and translucent. Although the ground features are not completely blocked, the ground features and the thin cloud information are mixed together, which results in blurred or missing ground feature information. This greatly reduces the quality of the remote sensing images and affects their subsequent recognition. Therefore, cloud detection is a hot topic in the preprocessing of remote sensing images.
The traditional cloud detection methods are mainly divided into threshold-based methods and methods that are based on spatial texture characteristics. The former utilizes the difference in the brightness of the cloud and the ground objects in order to obtain the physical threshold for dividing the cloud and non-cloud areas [
7,
8]. Zhu et al. [
9,
10] proposed cloud detection methods for the Landsat imagery by setting multiple thresholds, derived from unique physical attributes, in order to extract the cloud areas. Luo et al. [
11] utilized a specific scene-dependent decision matrix to identify clouds in the MODIS imagery. Jedlovec and Haines [
12] synthesized several images of the same area at different times into clear sky images and classified them using the synthetic clear sky image data as the threshold. Although the threshold method is simple and effective for specific sensor data, it depends on the selection of spectral bands and physical parameters [
13]. Therefore, the threshold-based methods are only applicable to specific sensors and specific scenarios and lack universal adaptability. In addition, these methods always misidentify the highly reflective non-cloud areas as cloud areas. Therefore, some cloud methods combine geometric and texture features with the spectral features in order to improve the cloud detection accuracy [
14,
15]. The traditional cloud detection methods used in remote sensing images, such as the threshold-based and rule-based cloud detection methods, use hand-crafted features and the special threshold to identify the cloud and non-cloud regions in the remote sensing images, which do not utilize semantic-level information [
16]. Multi-temporal cloud detection methods make use of the time-series imagery in order to reduce further misidentification of the non-cloud areas [
17,
18,
19]. However, these methods require multiple sets of images with and without clouds from the same location, which are difficult to collect. In recent years, a large number of remote sensing image processing algorithms that are based on deep learning have performed well in terms of object recognition [
20,
21] and semantic segmentation [
22,
23].
Cloud detection algorithms can be designed on the basis of the idea of semantic image segmentation algorithm that is based on deep learning. The deep convolutional neural network can extract various features, such as spatial features and spectral features. Long et al. [
24] proposed Fully Convolutional Networks (FCN), which realized end-to-end semantic segmentation and it is the pioneering work in semantic segmentation. Ronneberger et al. [
25] proposed a classic semantic segmentation algorithm, named U-Net, which is based on the encoder-decoder structure. Chen et al. [
26] also designed a semantic segmentation neural network, called Deeplabv3+, based on the encoder-decoder structure, which exhibits excellent performance. Xie et al. [
27] proposed a cloud detection method that combines a super-pixel algorithm and a convolutional neural network. Zi et al. [
28] proposed a cloud detection method that is based on PCANet. Jacob et al. [
29] proposed the Remote Sensing Network (RS-Net) with encoder-decoder convolutional neural network structure, which performs well in detecting clouds in the remote sensing images. Li et al. [
30] proposed a framework that can train deep networks with only block-level binary labels. Yu et al. [
31] proposed the MFGNet, which employs three different modules in order to implement a better fusion of features from different depths and scales.
Texture and color features are not only important information for the segmentation of cloud regions by the rule-based remote sensing image cloud detection algorithm, but also important information for the neural network detection algorithm to segment the cloud region [
32].
A neural network model within the deep learning framework can extract a variety of image features. However, there is no distinction between the importance of the different types of features, and there will also always be some redundant information. Scientists have discovered the attention mechanism from the study of the human visual system. In cognitive science, humans selectively focus on the part of the total available information and ignore the other visible information due to the bottleneck of information processing [
33]. Such a mechanism is usually called attention mechanism and is divided into the hard attention mechanism and the soft attention mechanism. The soft attention mechanism in a convolutional neural network model is used for locating the most salient features, such that redundancy is removed for the vision tasks [
34]. This mechanism is widely used in image captioning, object detection, and others [
35]. Therefore, filtering the information extracted from the neural network model can help in improving the performance of the neural network model, depending on the characteristics of cloud detection.
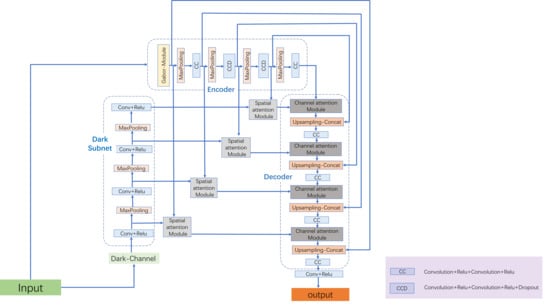
We have proposed a network for cloud detection in remote sensing images, based on Gabor transform and spatial and channel attention mechanism, named NGAD, which is built on the encoder-decoder structure. We have designed a Gabor feature extraction module based on Gabor transform and added it into the encoder in order to enhance the encoder to pay attention to the image texture in the low-level feature map. There is some redundancy in the decoder when interpreting information. Thus, we have introduced a channel attention module to improve the abstract information at the decoder. From the perspective of color characteristics, we have created a new subnet, named Dark channel subnet, and used it as an auxiliary input of the spatial attention module to further eliminate the redundant information in the low-level feature map that assists the decoder. Cloud detection in GF-1 WFV imagery is a challenging task because of the unfixed radiometric calibration parameters and insufficient spectral information [
36,
37,
38]. Therefore, we have evaluated the proposed algorithm by applying it to the GF-1 WFV data set [
39].
The main innovation of this paper can be summarized, as follows. First, we designed a Gabor module that uses the texture features that were extracted by the Gabor filter to help the network perform feature learning. Second, we have introduced attention modules that provide enhanced key information to the cloud detection network based on its network structure and the characteristics of cloud detection. Third, we have proposed the Dark channel subnet in order to generate the auxiliary feature map that is required by the spatial attention module.
2. Methods
The NGAD is based on the encoder-decoder structure with Dark channel subnet. It is an end-to-end convolutional neural network. The width and height of the output are equal to that of the input of the encoder. The evaluation of the network model is divided into two stages, training and testing. In the training stage, the input of the encoder is a multi-spectral image,
. The cloud mask corresponding to the input image is
. The input of Dark channel subnet is generated from
. The output of the NGAD is a probability map
. Next, we use a fixed threshold
t to perform a binary division on the output image in order to obtain the final binary segmentation map. For balancing the commission and omission errors in the cloud mask, the value of
t is taken to be 0.5. The loss function that is used by the network in the training stage is binary cross entropy loss function, and it is expressed as:
During the training phase, the parameters in the network are continuously updated using the back-propagation algorithm [
40] that is based on the loss function. We have also used the Adam optimization gradient algorithm [
41] that enables convergence at high-performing local minima. The implementation of NGAD is based on Python 3.6 and employing Keras 2.2.4 and TensorFlow 1.12 deep learning framework. All of the experiments were carried out using the NVIDIA GEFORCE RTX 2080 Ti card.
In this section, we introduce our proposed network, NGAD, in detail. First, we describe the overall network architecture of NGAD. Subsequently, we analyzed the Gabor feature extraction module for texture feature enhancement, Channel attention module based on the larger scale features, and spatial attention module based on Dark channel subnet, respectively.
2.1. The Framework of NGAD
Figure 1 shows a block diagram of the proposed NGAD, which is based on the encoder–decoder structure and incorporated with Dark channel subnet. We first use the modified Unet network as our basic framework. The backbone of the network consists of a encoding path and an decoding path. The encodeing path consists the repeated application of CC block or CCD block (CC block with a dropout layer), and a
max pooling operation with stride 2 of downsampling. Similar to Unet, each downsampling step we double the number of the feature channels. Every step in the decoding path consists of an upsampling of the feature map, a concatentation with the correspondingly croped feature map from the encoding path, and CC block same with the encoding path to halves the number of feature channels. The number of convolution kernels of the CC block at the encoding end are 64, 128, 256, and 512, respectively. The decoding end is 256, 128, 64, and 32 respectively. At the final layer, a
convolution is used to map each 32 component feature vector in order to generate semantic score maps for cloud aeras and non-cloud aeras.
The CC block contains two layers of convolution with a rectified linear unit (ReLU) as the activation function, which is expressed as:
The CCD block consists of two convolutional layers with the activation function ReLU and a dropout layer, and the dropout ration was set to 0.2. The convolutional layer in the CC block and CCD block both use the filter size of
. In the training stage, the dropout layer randomly produces certain neurons in the network output 0. This layer is only used in the encoder. In fact, the network structure will be slightly different in each training epoch, and the inactivation of some neurons in the encoder does not affect the feature extraction process. This can effectively prevent overfitting [
42].
The traditional cloud detection methods tend to extract multiple textures and color features to enhance the performance of cloud detection. Deng et al. [
32] used the Gabor transform for extracting the texture features in cloud detection to improve the ability of the algorithm to distinguish between cloud regions and highlighted snow regions. Chethan et al. [
43] also used Gabor transform to extract texture features for cloud detection primarily. Because Gabor transform can extract various texture features that are important for cloud detection, we have introduced the Gabor feature extraction module into the network in order to enhance the learning ability of the network for texture features. The network continuously down samples the feature map using the Max pooling layer to enhance the receptive field of the network, but, at the same time, the detailed information, such as the texture information, is lost, as depicted in
Figure 1. Therefore, the Gabor feature extraction module is added before the first Max pooling layer in order to efficiently enhance the ability of the network to extract the texture information.
In the encoder–decoder structure, the encoder is primarily used for feature extraction and the decoder interprets the information to obtain the final result of the network recognition. The efficient interpretation capability of the decoder will greatly affect the final output of the network. Thus, inspired by the attention mechanism, we have introduced a spatial attention module that is based on Dark channel subnet and Channel attention module based on the higher-level features of the encoder to assist the decoder to enhance the key information, thereby improving the recognition ability of the decoder.
2.2. Gabor Feature Extraction Module
The kernel function of the Gabor wavelet is very similar to the stimulus-response of the receptive field cells in the primary visual cortex of mammals [
44]. Features that were extracted using the Gabor wavelets can overcome the effects of illumination, scale, angle, etc. [
45]. The Gabor transform has good local characteristics in both spatial and frequency domains [
46]. A 2D-Gabor transform kernel function is expressed as:
where
represents the wavelength,
represents the directionality of wavelet,
is the phase offset,
is the standard deviation of the Gaussian envelope, and
is the spatial aspect ratio, and it specifies the ellipticity of the support of the Gabor function. This function consists of real and imaginary parts. The real part of this function is expressed as:
whereas the imaginary part is expressed as:
The real part predominantly extracts the texture features in the image, while the imaginary part predominantly extracts the edge information. Because the texture information extracted from the image is the main requirement, we only use the real part of this kernel function for filtering. In the function,
determines the direction of the filter and, thus, the feature information in different directions can be extracted, depending on the different values taken by
. The range of the
values is
and the interval is
in order to obtain the texture features in multiple directions as uniformly as possible. The value of
is usually greater than 2. Therefore, the range of values is
, and the interval is 1. The size of the Gabor filters is
. Deng et al. [
32] and Chethan et al. [
43] both used Gabor transform to extract texture features for cloud detection primarily, and improve the ability of the algorithm in order to distinguish between cloud regions and highlighted snow regions. They both use eight different orientations. We have also selected eight different orientations. We have selected four wavelengths in order to obtain more multi-scale information. In the parameter selection of the Gabor filter, a total of 32 features are obtained for each superpixel, using eight different orientations and four different wavelengths. The filters of the different wavelength or different directions have been shown, and the filters in each row have the same wavelength, while the filters in each column have the same direction, as shown in
Figure 2. These parameters have been able to extract most of the texture features [
47]. A finer range division will extract more detailed features, but this will also make the network structure more complex.
The Gabor feature extraction module is divided into an upper and a lower branch, as shown in
Figure 3. The upper branch is the texture extraction branch based on the Gabor transform, while the lower branch is a convolution information extraction branch. In general, we cannot know the type of specific features that are extracted by the convolutional layer with the activation function. However, in the upper branch, we can certainly know the specific texture features that are extracted from the feature map in multiple directions.
The information output from the Gabor transform in the upper branch passes through a convolutional layer with the activation function once again in order to increase the variety of the texture features. The difference between the features that were obtained from the upper and the lower branch is then extracted by carrying out a subtraction between the feature maps. After passing through a convolutional layer with the activation function, the difference information is added back to the output feature map of the lower branch. In fact, the upper branch information can produce a local supervision effect on the lower branch information and guide the lower branch to learn and pay more attention to the texture information. In Gabor feature extraction module, the sizes of the convolutional filters are all . The output feature maps of the convolutional layer have the same size as the input feature maps.
2.3. Channel Attention Module Based on the Larger Scale Features
Within the framework of the original encoder-decoder structure, feature maps of different scales at the encoder are introduced to the decoder in order to assist it in interpreting abstract information. However, the feature maps contain not only a large number of low-level features, but also a large amount of redundant information. Although the important low-level information can improve the performance of the decoder, the redundant information contained in it will interfere with the ability of the decoder to interpret the information. To reduce this, it is necessary for the information that is introduced into the decoder to be filtered properly. At the same time, there also is redundant information existing in the feature maps of the decoder.
In image processing that is based on deep learning, the attention mechanism is used to locate the salient features in the deep neural networks model. The attention mechanism is widely used in object detection [
48] and image caption [
49]. Thus, inspired by attention mechanism, we have proposed Channel attention module that is based on the larger scale features.
Figure 4 shows a block diagram of the channel attention module.
There are two inputs of this module.
is the auxiliary feature map which is used for generating the weight map.
is the feature map that needs to be reconstructed. The channel attention module is computed, as follows:
where
R denotes the ReLU function,
D denotes the fully connected layer,
and
,
and
denote the average pooling and max pooling operations, respectively. In the upper branch, the number of channels of
is adjusted to be the same as
using a convolution layer with an activation function. Subsequently, two sets of vectors are obtained by performing a global maximum pooling and global average pooling of the channel dimension. After that, the resulting two sets of vectors obtained via two fully connected layers are then added, and finally the weight map is obtained using the Sigmoid function as:
The weight map and are multiplied to obtain the final reconstructed feature map. The information from the different channels of has different importance. In the channel attention module, each channel of can be associated with a weight to measure the importance of the information contained in it. The important information in is emphasized in and the redundant information is weakened.
The Channel attention module is used at the decoder to reconstruct the feature maps. Thus, the auxiliary feature map of Channel attention module always comes from the information extracted from themselves or the encoder, which contains features on the same scale. On the other hand, the larger scale features of the encoder are used as the auxiliary feature map in order to make better use of the low-level information.
2.4. Spatial Attention Module Based on Dark Channel Subnet
We filter the information by adding Dark channel subnet and Spatial attention module in order to further remove the redundant information from the feature map at the encoder and highlight the important information. The Spatial attention module can perform spatial information screening of the feature map in each channel. The importance of the information that is contained in the different regions in a feature map is different [
50]. A block diagram of the Spatial attention module is shown in
Figure 5. In the figure,
is the auxiliary feature map. On the one hand, it is used to generate a weight map. On the other hand, it directly supplements information in the lower branch. After a global maximum pooling and a global average pooling of the spatial dimensions,
obtains two groups of feature maps with only a single channel. Two sets of feature maps with a single channel are obtained after performing a global maximum pooling of the spatial dimensions and a global average pooling process on
. These are concatenated in the channel dimensions and attain a weight map after a convolution layer with an activation function ReLU. The weight map and the feature maps that are generated by
and
are multiplied to obtain the final spatial-dimensionally reconstructed
. The detail processing of Spatial attention module is expressed by Equation(
8). Equation(
8) is expressed as:
where
R denotes the ReLU function.
denotes the convolutional layer with the filter size of
.
and
, respectively, denotes the average pooling and max pooling across the channel. The auxiliary feature map in Spatial attention module should have the ability to characterize the importance of feature maps from the encoder in the spatial dimensions. Therefore, it is necessary to introduce data from outside the encoder-decoder structure for effective information filtering.
Spatial information screening is mainly related to color features. In a few rule-based cloud detection methods, a few color features are often extracted via operations between the different spectrum bands [
15,
51,
52]. In the traditional cloud detection methods, it is generally preferred to convert the original image to a color space, in which the contrast between the cloud and non-cloud regions is more obvious. The color space transformation to the hue, saturation, and intensity (HSI) is always used in cloud detection [
27,
52,
53]. However, we found that the Dark channel image is very similar to the cloud mask, as shown in
Figure 6.
Thus, we have proposed the Dark channel subnet to generate the auxiliary feature map that is required by the spatial attention module. The input of Dark channel subnet is Dark channel image obtained from the three visible bands, red, blue, and green. The processing method is identified as:
Here,
is the Dark channel image.
is the original remote sensing image that has at least three visible bands. The spatial attention module requires that the width and height of the auxiliary feature map need to be the same as the reconstructed map. In Equation (
9),
has the same width and height as the original remote sensing image. We use the same maximum pooling layer and convolutional layer with ReLU as the activation function in the Dark channel subnet in order to adjust the size of the auxiliary feature map. In the Dark channel subnet that is depicted in
Figure 1, the size of the convolutional filters is
and the kernel size of Max pooling layer is
. In the Dark subnet, we adopted the same strategy as the encoder, and the number of channels doubled after each downsampling. Therefore, the number of convolution kernels in the convolutional layer in the Dark subnet are two, four, eight, and 16, respectively.
4. Results and Analysis
4.1. Evaluation of Gabor Feature Extraction Module
The Gabor feature extraction module was primarily designed for guiding the encoder in order to learn the texture features. We removed the channel attention module and Dark channel subnet with Spatial attention module in NGAD and only kept Gabor feature extraction module. This network containing only the Gabor feature extraction module has been named NG. The feature maps directly obtained from the encoder are concatenated with the output of the up-sampling layer in the decoder. The structure of NG is very similar to that of U-Net [
25], but there is an additional Gabor feature extraction module as compared to U-Net. Therefore, we compared the performance of NG with U-Net, which is a kind of a classic image segmentation network having an encoder-decoder structure.
The subjective results of U- Net and NG have been compared, as shown in
Figure 8. The remote sensing image in the first row contains the snow-covered area, which has been marked by the red circles. Generally, a cloud-covered area has high brightness, and, in the figure, the snow-covered area also has high brightness. Thus, the two types of areas are hard to distinguish by the naked eye. However, the snow-covered area is relatively rougher than the cloud-covered area due to its rich texture feature.
It can be seen from the detection results presented in
Figure 8 that NG has relatively few false detections because the texture information is much more efficiently utilized in NG than in U- Net. In the remote sensing image in the second row, a part of the area inside the red circle is barren. The brightness of some areas is relatively high, and this can interfere with the detection of clouds in the image. In terms of the cloud detection results, U-Net has a larger number of false detection areas when compared to NG. Therefore, it can be seen from the detection results of the two remote sensing images that Gabor feature extraction module guides the network to pay attention to the texture information, which is beneficial for the model to correctly identify the non-cloud regions that have high brightness and rich texture information.
U-Net and NG were, respectively, tested by applying them to the test set consisting of multiple scenes.
Table 1 shows the average values of the different objective indicators. Under the condition that the precision of NG is higher than that of U-Net, the false detection rate of NG is lower than that of U-Net, as depicted in the table The kappa coefficient of NG is also higher than U-Net, which indicates that the cloud detection ability of NG consisting of the Gabor feature extraction module is better than that of U-Net. It can be seen from both the subjective and objective detection results that NG enhances the network’s attention to texture information through the Gabor feature extraction module, which effectively improves the accuracy of the cloud detection model.
4.2. Evaluation of the Attention Mechanism Module and Dark Channel Subnet
In the decoder, we proposed a Channel attention module based on the larger scale features. We have introduced the Dark channel subnet with Spatial attention module in order to further enhance the screening ability of the network and its attention to key information that are beneficial for cloud detection in space. We remove Gabor feature extraction module and Dark channel subnet with Spatial attention module within NGAD to obtain a network containing only the channel attention module (NC) in order to evaluate the effect of Channel attention module and Dark channel subnet with the Spatial attention module. Similarly, we remove Gabor feature extraction module from NGAD to obtain the network with Channel attention module and Dark channel subnet with Spatial attention module (NDSC).
For the sake of comparison, U-Net was used once again. The cloud detection results of the three models are basically close to the ground truth, as shown in
Figure 9. However, the shape of the cloud region is irregular and complex, and it is difficult in many regions to judge with the naked eye whether the detection results of each model are consistent with the ground truth. A comparison of the Kappa coefficients obtained for each model indicates that both NC and NDSC perform better than U-Net, and NDSC is observed to be superior to NC. U-Net, NC, and NDSC were, respectively, tested by applying these networks to the test set that included multiple scenes.
Table 2 shows the average values of the different objective indicators. From these, it can be seen that the overall accuracy of NC and NDSC is higher than that of U-Net. The recall rate of NC is slightly lower than U-Net, but its false detection rate is significantly reduced. This shows that the stability of NC is better than U-Net. Each objective indicator of NDSC has higher values than NC and U-Net, and the Kappa coefficient is higher by 1.96% when compared to that of NC. This shows that NDSC exhibits a significantly improved cloud detection ability as compared to NC. Thus, from these experimental results, it is clear that the key information in the network has been effectively enhanced by incorporating Channel attention module in it. On the basis of this module, the ability of the network to filter information is further improved after combining the Dark channel subnet with Spatial attention module.
4.3. Evaluation of NGAD
Our proposed NGAD is composed of the Gabor feature extraction module, Channel attention module, and Dark channel subnet with Spatial attention module. The Gabor feature extraction module is used to guide the attention of the network to the texture information of an image. The channel attention module uses large-scale shallow information on the encoding side in order to reconstruct the information on the decoding side. The Dark channel subnet with Spatial attention module further improves the ability to filter information at the decoding end by introducing additional spatial auxiliary information.
We choose the SegNet [
54], DeepLabv3+ [
26], and RS-Net [
29] comparison in order to evaluate the performance of the proposed cloud detection network, NGAD.
Figure 10 shows the results that were obtained by applying the four models of cloud detection to remote sensing images containing five different types of land-cover.
In the first row, there is no object covering the ground, and some ground areas have high reflectivity similar to the cloud area. In the area that is marked by the red circle, the false alarm detections by the DeepLabv3+ and RS-Net are observed to be significantly higher than NGAD. Although these areas have high brightness, they have more texture information than the cloud areas in the figure. There are no false alarm detections in this area from the SegNet, while many cloud areas are missed from the overall view of the image. Therefore, it can be seen from the Kappa coefficient that the cloud detection ability of SegNet is poor. Similarly, results that correspond to RS-Net show obvious false alarm detections as well as obviously missed cloud detections. Thus, its overall detection ability is worse than SegNet. The results corresponding to NGAD show relatively few false alarm detections and missed detections in the cloud area and, thus, its overall detection ability is better than the other three models.
In the second row, the area inside the red circle is covered by snow, and such regions have high brightness, similar to the cloud area. However, the snow-covered ground is rougher. Because the texture information in NGAD is enhanced by Gabor feature extraction module, it helps to identify these highlighted non-cloud areas correctly. In the other areas in the image, there are thin as well as thick clouds, which makes cloud detection quite difficult. It can be seen from the Kappa coefficient that the detection ability of NGAD is better than the other three models.
In the third row, the image contains highlights of artificial buildings that can easily be erroneously recognized as clouds. There are a large number of scattered point cloud regions below the image, and all four models have been able to detect clouds in these regions. Based on the value of the Kappa, the overall detection performance of NGAD is observed to be better than the other three models.
In the fourth row, most of the vegetation area that is present in the image did not interfere with cloud detection. However, some smooth water-covered areas have been easily misidentified as clouds. In the circled area, the detection results of DeepLabv3+ and RS-Net have all false detections, whereas the results of SegNet and NGAD show fewer false detections. On the basis of the Kappa coefficient, NGAD is observed to be significantly better than SegNet in the overall cloud detection performance.
In the fifth row, a large number of the thick as well as thin clouds cover the water body, and some areas are difficult to distinguish by the naked eye. In the detection results of SegNet and DeepLabv3+, it can be seen that some cloud areas have been mistakenly identified as non-cloud areas. On the basis of the Kappa, the detection performance of NGAD is observed to be relatively stable and still better than the other three models.
The DeepLabv3+, RS-Net, and NGAD networks were tested by applying them to a test set that included multiple scenes.
Table 3 sjows the average values of the objective indicators. It can be seen from the table that the false detections by the NGAD and SegNet are relatively low, which indicates that it is possible to effectively avoid interference with areas similar to clouds, such as ice and snow areas, bare ground highlight areas, etc. It can be seen from the values of OA and precision that the detection accuracy of NGAD is higher. By comparing the recall rates, it can be seen that NGAD can correctly identify a larger number of cloud areas efficiently. In terms of a lower false detection rate, the detection accuracy of NGAD is still higher, which indicates that NGAD is the most robust among the four tested models. From the comparison of the Kappa coefficient, the overall cloud detection performance of NGAD is observed to the best as compared to the other three models. Thus, this comparative study in terms of the subjective as well as objective aspects shows that NGAD exhibits excellent cloud detection performance.
6. Conclusions
Cloud detection methods for remote sensing images that are based deep learning use convolutional neural networks to extract a variety of image features at different scales. However, this feature information contains both information that is conducive to cloud detection as well as a large amount of redundant information. Therefore, it is necessary to further enhance the attention of the network to important information in order to reduce the impact of useless information on the cloud detection performance of the network. Traditional cloud detection methods often perform segmentation of cloud regions in remotely sensed images using the differences in the specific textures and color features between the cloud and the non-cloud regions. Therefore, the traditional feature extraction methods can be introduced into the network in order to guide it to learn important features. At the same time, according to the characteristics of the network and the characteristics of cloud detection, an information screening module can be added to the network to effectively use the characteristic information extracted by it to further improve the network performance.
This paper proposes a cloud detection network for remote sensing images, called NGAD, which is based on Gabor transform, attention mechanism, and Dark channel subnet. The NGAD exhibits enhanced learning of the texture features, which is boosted due to the Gabor feature extraction module. The Channel attention module that is based on the larger scale features uses shallow feature maps with rich information to guide the network to interpret the abstract information, and screens the information from the channel dimension.
On the basis of the characteristics of cloud detection, the Spatial attention module based on Dark channel subnet, by establishing the Dark channel subnet and introducing the Dark channel image, is able to provide screening of feature information from the spatial dimension. The spatial attention module that is based on Dark channel subnet has been combined with the Channel attention module to filter the information in the network efficiently and comprehensively. The overall accuracy rate of NGAD is 97.42% and the false detection rate is 2.22%. The experimental results also show that NGAD improved cloud detection performance effectively.

 ,
, 












{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}