Single-Stage Rotation-Decoupled Detector for Oriented Object



Abstract
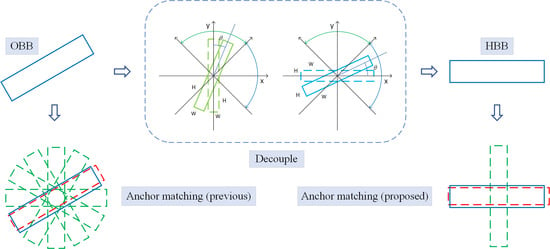
1. Introduction
2. Related Work
2.1. Horizontal Object Detection
2.2. Oriented Object Detection
3. Proposed Method
3.1. Network Architecture
3.2. Rotated Bounding Box Representation
3.3. Anchor Setting
3.4. Rotation-Decoupled Anchor Matching Strategy
3.5. Positive and Negative Sample Balance Strategy
4. Experiments
4.1. Datasets and Settings
4.2. Experimental Results
5. Discussion
6. Conclusions
Author Contributions
Funding
Conflicts of Interest
References
- Liu, W.; Anguelov, D.; Erhan, D.; Szegedy, C.; Fu, C.; Berg, A.C. SSD: Single Shot Multibox Detector. In Proceedings of the European Conference on Computer Vision, Amsterdam, The Netherlands, 8–16 October 2016; pp. 21–37. [Google Scholar]
- Lin, T.-Y.; Goyal, P.; Girshick, R.; He, K.; Dollár, P. Focal loss for dense object detection. In Proceedings of the IEEE International Conference on Computer Vision, Venice, Italy, 22–29 October 2017; pp. 2980–2988. [Google Scholar]
- Zhang, S.; Wen, L.; Bian, X.; Lei, Z.; Li, S.Z. Single-shot refinement neural network for object detection. In Proceedings of the 2018 IEEE Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 19–21 July 2018; pp. 4203–4212. [Google Scholar]
- Tan, M.; Pang, R.; Le, Q.V. Efficientdet: Scalable and efficient object detection. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Nashville, TN, USA, 19–25 June 2020; pp. 10781–10790. [Google Scholar]
- Lin, T.Y.; Maire, M.; Belongie, S.; Hays, J.; Perona, P.; Ramanan, D.; Dollar, P.; Zitnick, C.L. Microsoft coco: Common objects in context. In Proceedings of the 2014 European Conference on Computer Vision (ECCV), Zurich, Switzerland, 6–12 September 2014; pp. 740–755. [Google Scholar]
- Everingham, M.; Van Gool, L.; Williams, C.K.; Winn, J.; Zisserman, A. The pascal visual object classes (voc) challenge. Int. J. Comput. Vision 2010, 88, 303–338. [Google Scholar] [CrossRef]
- Liu, Z.; Hu, J.; Weng, L.; Yang, Y. Rotated region based CNN for ship detection. In Proceedings of the 24th IEEE International Conference on Image Processing (ICIP 2017), Beijing, China, 17–20 September 2017; pp. 900–904. [Google Scholar]
- Liu, W.; Ma, L.; Chen, H. Arbitrary-oriented ship detection framework in optical remote-sensing images. IEEE Geosci. Remote Sens. Lett. 2018, 15, 937–941. [Google Scholar] [CrossRef]
- Yang, X.; Sun, H.; Fu, K.; Yang, J.; Sun, X.; Yan, M.; Guo, Z. Automatic ship detection in remote sensing images from google earth of complex scenes based on multiscale rotation dense feature pyramid networks. Remote Sens. 2018, 10, 132. [Google Scholar] [CrossRef]
- Tang, T.; Zhou, S.; Deng, Z.; Lei, L.; Zou, H. Arbitrary-oriented vehicle detection in aerial imagery with single convolutional neural networks. Remote Sens. 2017, 9, 1170. [Google Scholar] [CrossRef]
- Li, Q.; Mou, L.; Xu, Q.; Zhang, Y.; Zhu, X.X. R3-Net: A deep network for multi-oriented vehicle detection in aerial images and videos. arXiv 2018, arXiv:1808.05560. [Google Scholar]
- Liao, M.; Zhu, Z.; Shi, B.; Xia, G.S.; Bai, X. Rotation-Sensitive Regression for Oriented Scene Text Detection. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, San Francisco, CA, USA, 13–18 June 2018; pp. 5909–5918. [Google Scholar]
- Ding, J.; Xue, N.; Long, Y.; Xia, G.S.; Lu, Q. Learning RoI Transformer for Detecting Oriented Objects in Aerial Images. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Los Angeles, CA, USA, 16–19 June 2019. [Google Scholar]
- Yang, X.; Yang, J.; Yan, J.; Zhang, Y.; Zhang, T.; Guo, Z.; Sun, X.; Fu, K. SCRDet: Towards More Robust Detection for Small, Cluttered and Rotated Objects. In Proceedings of the IEEE International Conference on Computer Vision, Seoul, Korea, 27 October–2 November 2019; pp. 8232–8241. [Google Scholar]
- Li, C.; Xu, C.; Cui, Z.; Wang, D.; Jie, Z.; Zhang, T.; Yang, J. Learning Object-Wise Semantic Representation for Detection in Remote Sensing Imagery. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition Workshops, Long Beach, CA, USA, 16–20 June 2019; pp. 20–27. [Google Scholar]
- Xu, Y.; Fu, M.; Wang, Q.; Wang, Y.; Chen, K.; Xia, G.S.; Bai, X. Gliding vertex on the horizontal bounding box for multi-oriented object detection. IEEE Trans. Patt. Anal. Mach. Intell. 2020. [Google Scholar] [CrossRef] [PubMed]
- Pan, X.; Ren, Y.; Sheng, K.; Dong, W.; Yuan, H.; Guo, X.; Ma, C.; Xu, C. Dynamic Refinement Network for Oriented and Densely Packed Object Detection. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Nashville, TN, USA, 19–25 June 2020; pp. 11207–11216. [Google Scholar]
- Zhu, Y.; Du, J.; Wu, X. Adaptive period embedding for representing oriented objects in aerial images. IEEE Trans. Geosci. Remote Sens. 2020, 58, 7247–7257. [Google Scholar] [CrossRef]
- Xia, G.S.; Bai, X.; Ding, J.; Zhu, Z.; Belongie, S.; Luo, J.; Datcu, M.; Pelillo, M.; Zhang, L. DOTA: A Large-Scale Dataset for Object Detection in Aerial Images. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–23 June 2018; pp. 3974–3983. [Google Scholar]
- Liu, Z.; Liu, Y.; Weng, L.; Yang, Y. A high resolution optical satellite image dataset for ship recognition and some new baselines. In Proceedings of the International Conference on Pattern Recognition Applications and Methods, Porto, Portugal, 24–26 February 2017; pp. 324–331. [Google Scholar]
- Zhu, H.; Chen, X.; Dai, W.; Fu, K.; Ye, Q.; Jiao, J. Orientation robust object detection in aerial images using deep convolutional neural network. In Proceedings of the IEEE International Conference on Image Processing, Quebec City, QC, Canada, 27–30 September 2015; pp. 3735–3739. [Google Scholar]
- Girshick, R.; Donahue, J.; Darrell, T.; Malik, J. Rich feature hierarchies for accurate object detection and semantic segmentation. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Nashville, TN, USA, 19–25 June 2014; pp. 580–587. [Google Scholar]
- Girshick, R. Fast R-CNN. In Proceedings of the IEEE International Conference on Computer Vision, Boston, MA, USA, 8–10 June 2015; pp. 1440–1448. [Google Scholar]
- Ren, S.; He, K.; Girshick, R.; Sun, J. Faster r-cnn: Towards real-time object detection with region proposal networks. In Proceedings of the Advances in Neural Information Processing Systems, Montreal, QC, Canada, 7–12 December 2015; pp. 91–99. [Google Scholar]
- He, K.; Gkioxari, G.; Dollar, P.; Girshick, R. Mask R-CNN. In Proceedings of the 16th IEEE International Conference on Computer Vision (ICCV 2017), Venice, Italy, 22–29 October 2017; pp. 2980–2988. [Google Scholar]
- Redmon, J.; Divvala, S.; Girshick, R.; Farhadi, A. You only look once: Unified, real-time object detection. In Proceedings of the 2016 IEEE Conference on Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 26 June–1 July 2016; pp. 779–788. [Google Scholar]
- Law, H.; Deng, J. CornerNet: Detecting Objects as Paired Keypoints. In Proceedings of the European Conference on Computer Vision, Munich, Germany, 8–14 September 2018; pp. 765–781. [Google Scholar]
- Zhou, X.; Wang, D.; Krähenbühl, P. Objects as points. arXiv 2019, arXiv:1904.07850. [Google Scholar]
- Tian, Z.; Shen, C.; Chen, H.; He, T. Fcos: Fully convolutional one-stage object detection. In Proceedings of the IEEE International Conference on Computer Vision, Seoul, Korea, 27 October–2 November 2019; pp. 9627–9636. [Google Scholar]
- Yang, X.; Liu, Q.; Yan, J.; Li, A.; Zhang, Z.; Yu, G. R3det: Refined single-stage detector with feature refinement for rotating object. arXiv 2019, arXiv:1908.05612. [Google Scholar]
- Yang, X.; Yan, J.; Yang, X.; Tang, J.; Liao, W.; He, T. SCRDet++: Detecting Small, Cluttered and Rotated Objects via Instance-Level Feature Denoising and Rotation Loss Smoothing. arXiv 2020, arXiv:2004.13316. [Google Scholar]
- Lin, T.Y.; Dollár, P.; Girshick, R.; He, K.; Hariharan, B.; Belongie, S. Feature Pyramid Networks for Object Detection. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Honolulu, HI, USA, 21–26 July 2017; pp. 936–944. [Google Scholar]
- He, K.; Zhang, X.; Ren, S.; Sun, J. Deep residual learning for image recognition. In Proceedings of the 2016 IEEE Conference on Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 27–30 June 2016; pp. 770–778. [Google Scholar]
- Oksuz, K.; Cam, B.C.; Kalkan, S.; Akbas, E. Imbalance problems in object detection: A review. IEEE Trans. Pattern Anal. Mach. Intell. 2020. [Google Scholar] [CrossRef] [PubMed]
- Azimi, S.M.; Vig, E.; Bahmanyar, R.; Körner, M.; Reinartz, P. Towards multi-class object detection in unconstrained remote sensing imagery. In Proceedings of the IEEE Asian Conference on Computer Vision, Perth, Australia, 4–6 December 2018; pp. 150–165. [Google Scholar]
- Howard, A.G. Some improvements on deep convolutional neural network based image classification. arXiv 2013, arXiv:1312.5402. [Google Scholar]
- Jiang, Y.; Zhu, X.; Wang, X.; Yang, S.; Li, W.; Wang, H.; Fu, P.; Luo, Z. R2CNN: Rotational Region CNN for Orientation Robust Scene Text Detection. arXiv 2017, arXiv:1706.09579. [Google Scholar]
- Jian, M.; Wei, S.; Hao, Y.; Li, W.; Hong, W.; Ying, Z.; Xiang, X. Arbitrary-oriented scene text detection via rotation proposals. IEEE Trans. Multimed. 2018, 20, 3111–3122. [Google Scholar]
- Liu, L.; Pan, Z.; Lei, B. Learning a rotation invariant detector with rotatable bounding box. arXiv 2017, arXiv:1711.09405. [Google Scholar]
- Bao, S.; Zhong, X.; Zhu, R.; Zhang, X.; Li, M. Single Shot Anchor Refinement Network for Oriented Object Detection in Optical Remote Sensing Imagery. IEEE Access 2019, 99, 1. [Google Scholar] [CrossRef]
- Li, C.; Xu, C.; Cui, Z.; Wang, D.; Zhang, T.; Yang, J. Feature-Attentioned Object Detection in Remote Sensing Imagery. In Proceedings of the IEEE International Conference on Image Processing, Taipei, Taiwan, 22–25 September 2019; pp. 3886–3890. [Google Scholar]







{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Method | MS | PL | BD | BR | GTF | SV | LV | SH | TC | BC | ST | SBF | RA | HA | SP | HC | mAP |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| Two-stage method | |||||||||||||||||
| R-DFPN [37] | ✘ | 80.92 | 65.82 | 33.77 | 58.94 | 55.77 | 50.94 | 54.78 | 90.33 | 66.34 | 68.66 | 48.73 | 51.76 | 55.1 | 51.32 | 35.88 | 57.94 |
| R2CNN [38] | ✘ | 80.94 | 65.67 | 35.34 | 67.44 | 59.92 | 50.91 | 55.81 | 90.67 | 66.92 | 72.39 | 55.06 | 52.23 | 55.14 | 53.35 | 48.22 | 60.67 |
| RRPN [39] | ✘ | 88.52 | 71.2 | 31.66 | 59.3 | 51.85 | 56.19 | 57.25 | 90.81 | 72.84 | 67.38 | 56.69 | 52.84 | 53.08 | 51.94 | 53.58 | 61.01 |
| RoI-Transformer [13] | ✓ | 88.64 | 78.52 | 43.44 | 75.92 | 68.81 | 73.68 | 83.59 | 90.74 | 77.27 | 81.46 | 58.39 | 53.54 | 62.83 | 58.93 | 47.67 | 69.56 |
| SCRDet [14] | ✘ | 89.41 | 78.83 | 50.02 | 65.59 | 69.96 | 57.63 | 72.26 | 90.73 | 81.41 | 84.39 | 52.76 | 63.62 | 62.01 | 67.62 | 61.16 | 69.83 |
| SCRDet [14] | ✓ | 89.98 | 80.65 | 52.09 | 68.36 | 68.36 | 60.32 | 72.41 | 90.85 | 87.94 | 86.86 | 65.02 | 66.68 | 66.25 | 68.24 | 65.21 | 72.61 |
| APE [18] | ✘ | 89.96 | 83.62 | 53.42 | 76.03 | 74.01 | 77.16 | 79.45 | 90.83 | 87.15 | 84.51 | 67.72 | 60.33 | 74.61 | 71.84 | 65.55 | 75.75 |
| One-stage method | |||||||||||||||||
| DRN+Hourglass-104 [17] | ✘ | 88.91 | 80.22 | 43.52 | 63.35 | 73.48 | 70.69 | 84.94 | 90.14 | 83.85 | 84.11 | 50.12 | 58.41 | 67.62 | 68.6 | 52.5 | 70.7 |
| DRN+Hourglass-104 [17] | ✓ | 89.45 | 83.16 | 48.98 | 62.24 | 70.63 | 74.25 | 83.99 | 90.73 | 84.60 | 85.35 | 55.76 | 60.79 | 71.56 | 68.82 | 63.92 | 72.95 |
| R3Det+ResNet101 [30] | ✘ | 89.54 | 81.99 | 48.46 | 62.52 | 70.48 | 74.29 | 77.54 | 90.80 | 81.39 | 83.54 | 61.97 | 59.82 | 65.44 | 67.46 | 60.05 | 71.69 |
| R3Det+ResNet152 [30] | ✘ | 89.24 | 80.81 | 51.11 | 65.62 | 70.67 | 76.03 | 78.32 | 90.83 | 84.89 | 84.42 | 65.10 | 57.18 | 68.1 | 68.98 | 60.88 | 72.81 |
| Ours+ResNet101 | ✘ | 89.70 | 84.33 | 46.35 | 68.62 | 73.89 | 73.19 | 86.92 | 90.41 | 86.46 | 84.30 | 64.22 | 64.95 | 73.55 | 72.59 | 73.31 | 75.52 |
| Ours+ResNet101 | ✓ | 89.15 | 83.92 | 52.51 | 73.06 | 77.81 | 79.00 | 87.08 | 90.62 | 86.72 | 87.15 | 63.96 | 70.29 | 76.98 | 75.79 | 72.15 | 77.75 |
| Method | Backbone | Input Size | mAP | FPS |
|---|---|---|---|---|
| RRD [12] | VGG16 | 384 × 384 | 84.3 | - |
| RoI-Transformer [13] | ResNet101 | 512 × 800 | 86.2 | - |
| R3Det [30] | ResNet101 | 800 × 800 | 89.26 | 12 |
| R3Det [30] | ResNet152 | 800 × 800 | 89.33 | 10 |
| DRN [17] | Hourglass-104 | 768 × 768 | 92.7 | - |
| Ours | ResNet101 | 768 × 768 | 94.29 | 40 |
| Ours | ResNet152 | 768 × 768 | 94.61 | 31 |
© 2020 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Zhong, B.; Ao, K. Single-Stage Rotation-Decoupled Detector for Oriented Object. Remote Sens. 2020, 12, 3262. https://doi.org/10.3390/rs12193262
Zhong B, Ao K. Single-Stage Rotation-Decoupled Detector for Oriented Object. Remote Sensing. 2020; 12(19):3262. https://doi.org/10.3390/rs12193262
Chicago/Turabian StyleZhong, Bo, and Kai Ao. 2020. "Single-Stage Rotation-Decoupled Detector for Oriented Object" Remote Sensing 12, no. 19: 3262. https://doi.org/10.3390/rs12193262
APA StyleZhong, B., & Ao, K. (2020). Single-Stage Rotation-Decoupled Detector for Oriented Object. Remote Sensing, 12(19), 3262. https://doi.org/10.3390/rs12193262