1. Introduction
Numerous studies have demonstrated the utility of terrestrial laser scanning (TLS) for automated segmentation of individual trees in high-density point clouds [
1,
2,
3]. Because these data can be acquired and processed rapidly in comparison to the time required for traditional field inventories, they have the potential to increase the accuracy and frequency of stand-level forest assessment. However, scaling these methods to landscapes larger than a few hectares has been challenging [
1,
2].
Drone remote sensing may be able to overcome this challenge [
4,
5]. Lidar sensors on low-altitude drones can produce measurement densities in the thousands of points per square meter from wide scan angles that clearly resolve individual stem and branch structure [
6]. Previous work has demonstrated that tree stems can be manually extracted from a high-resolution point cloud acquired by a low-altitude drone in a European temperate broadleaf forest [
7,
8]. Diameter at breast height (DBH) estimates using these data are strongly correlated with DBH of the same trees quantified using TLS [
7], and a study in eucalypt forest in Australia showed that tree DBH from TLS data are unbiased with respect to field measurements [
6]. In fact, because high-density lidar data can model wood volume by segmenting individual trees [
3,
9], lidar data provide better estimates of tree-level aboveground biomass (AGB) and wood volume than manual methods using diameter at breast height (DBH) and allometric scaling equations [
6,
10].
However, data from drone lidar differ from TLS measurements in important ways that create challenges to individual tree segmentation [
5]. In general terms, data from drone lidar are about one order of magnitude less dense than TLS measurements, contain about one order of magnitude more noise from random and systematic components, and are acquired using footprints that are about one order of magnitude larger than TLS data. A recent analysis showed that manually identified individual trees could be segmented and their AGB quantified using drone lidar in a temperate broadleaf forest [
4]. It remains unclear whether uncertainties in drone lidar data undermine our ability to apply individual tree segmentation to data sets large enough to support the calibration and validation activities of current and forthcoming space missions [
11], including the NASA Global Ecosystem Dynamics Investigation [
12], ESA BIOMASS [
13], and the NASA-ISRO Synthetic Aperture Radar (NISAR; [
14]).
The challenge is consistent application of segmentation algorithms to large data sets. Individual tree segmentation algorithms developed for TLS data require optimization to local structural conditions [
9,
15]. Because applications to date have been applied to relatively small areas up to a few hectares in size, it is not clear whether these algorithms can be generally applied to forests with varying structural conditions, or if they need to be adjusted to deal with local environments. Moreover, automated tree segmentation algorithms for airborne lidar data are usually based on top-down approaches, such as watershed segmentation [
16,
17]. Here we test bottom-up segmentation typically applied to TLS data that has greater ability to deal with complex stand structure. This test is facilitated by recent advances in ultra-high-density drone lidar technology [
5].
We apply a new individual tree segmentation algorithm called 3D Forest [
15] to ultra-high-density drone lidar and coincident TLS measurements in an old-growth temperate mountain forest in the south Bohemia region of the Czech Republic. The data were acquired using the Brown Platform for Autonomous Remote Sensing (BPAR; [
5]). By generating a mean measurement density that exceeds 4000 points per square meter from scan angles out to 60 degrees, these data provide observations of stem and branch structure that are suitable for individual tree segmentation [
5]. We compared stem diameter and height from automatically segmented tree objects to field measurements and data extracted from TLS scans that we acquired within two days of drone lidar acquisition. Here we use these data to ask what fraction of trees can be automatically segmented and measured using drone lidar in a 25 ha permanent inventory plot, and we develop a Random Forest classifier to identify tree segments as broadleaf or needleleaf trees. We then apply allometric scaling equations to all segmented tree objects to produce a stand-level AGB estimate.
2. Methods
2.1. Study Site and Data Collection
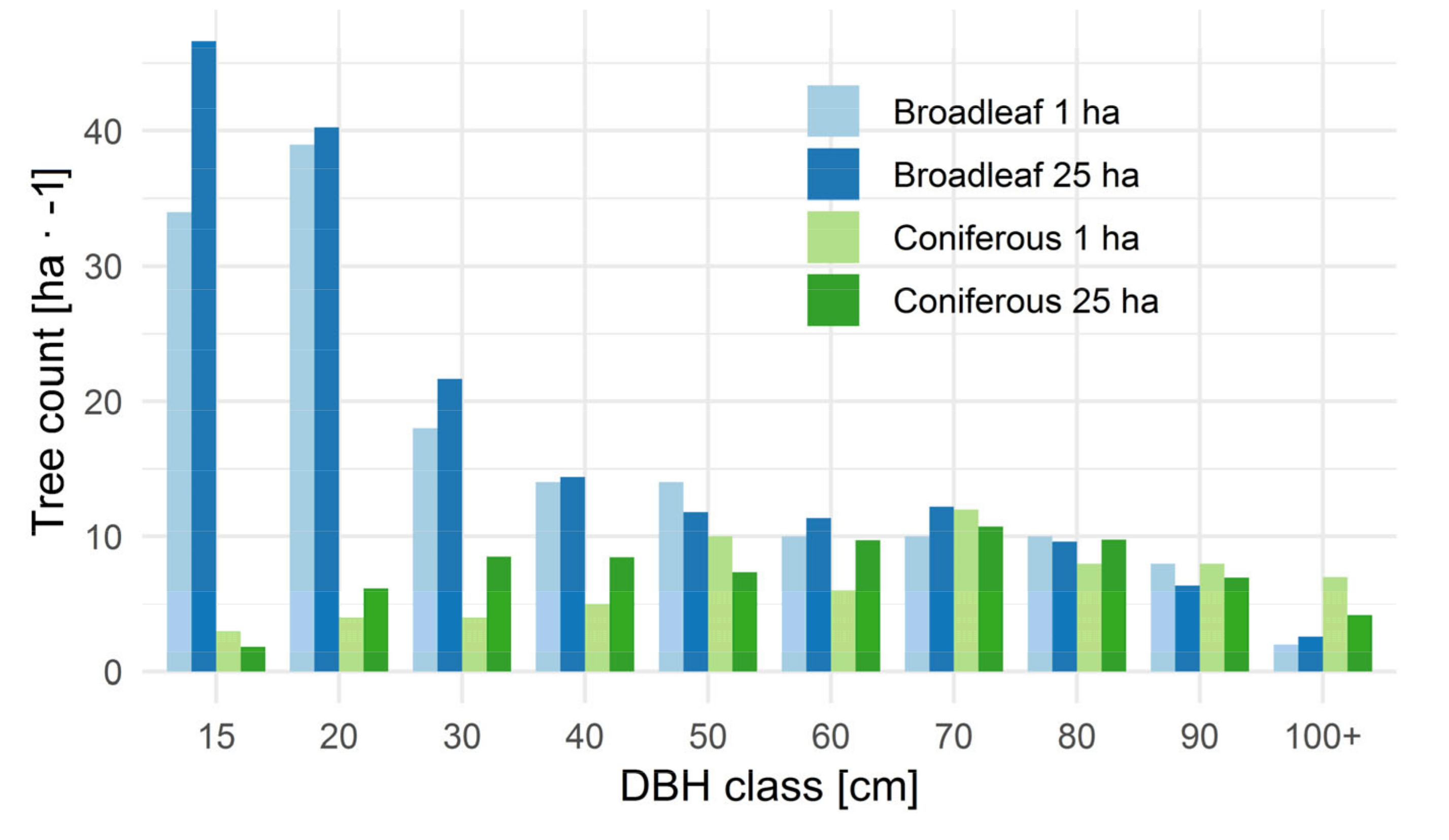
Our analysis is based on supervised segmentation of high-density point clouds from TLS and drone lidar collected within two days of each other under leaf-off conditions (16–18 April 2018) in a temperate mountain forest in the south Bohemia region of the Czech Republic (48°40′N 14°42′E; [
18]). The site contains the 25 ha Žofín Forest Dynamics Plot (ZFDP). The ZFDP lies within the strictly protected (since 1838) forest national nature reserve and represents dense, structurally complex and variable old-growth forest dominated by European beech (
Fagus sylvatica), with Norway spruce (
Picea abies) and individuals of silver fir (
Abies alba), and several other rare species [
19]. At the ZFDP all free-standing woody plants with DBH > 1 cm have been mapped (X, Y, and Z coordinates of stem bases), measured (DBH) and identified to the species level using the ForestGEO protocol [
19,
20,
21] in 2017 (see also
Figure A2). The mean live stem density is >3000 individuals · ha
−1. TLS data were collected from 22 scanning positions within a 1 ha subplot in the ZFDP using a Lecia P20 ScanStation. The species composition and size distribution within the 1 ha subplot closely matched the composition of the 25 ha ZFDP (
Figure 1). These data were co-registered using reflective targets, georeferenced and thinned using a 5 mm voxel grid. Mean absolute error on the target for the co-registration of single scans was 1 mm. Georeferencing of the TLS and field data is based on a permanent network of reference points with geodetically measured coordinates (total station). Ground and vegetation points in TLS data were classified in 3D Forest using the terrain-from-octree algorithm [
15]. A further detailed description of TLS processing is in [
15].
2.2. Drone Lidar
We collected high-density drone lidar using the BPAR [
5]. BPAR is a suite of sensors carried by a heavy-lift Aeroscout B100 helicopter drone. The airborne laser scanner was a RIEGL VUX-1 coupled to an Oxford Technical Solutions (OXTS) Survey +2 GPS and inertial motion unit (IMU). In the configuration used here, the GPS-IMU data stream was recorded at 250 Hz, and the instrument had access to the GPS and GLONASS constellations. During flight operations we collected an independent global navigation satellite system (GNSS) data stream on the ground using a Novel FlexPak 6 Triple Frequency + L-band GNSS receiver, and we used this data stream to differentially correct the OXTS GPS-IMU measurements in post-processing.
Nominal flight altitude was 110 m and the forward flight speed was 6 m · s
−1. The data were collected in six flights over two consecutive days during about 5 h of total flight time over a 1.72 km
2 area that included the ZFDP. There were 45 flight lines in the NE-SW direction and 45 flight lines in the NW-SE direction. We designed this flight plan to produce dense point coverage of stem and branch structure from a wide range of scan angles (−60° to 60°). Previous work has demonstrated that measurements of stem and branch structure require scan angles >30 degrees [
5,
7]. Measurement density in this point cloud is 4387 points · m
−2 within the ZFDP (
Figure 2).
2.3. Sources of Uncertainty in Drone-Lidar Point Clouds
Previous studies have demonstrated the utility of TLS for individual tree segmentation. Measurements from low-altitude drone flight differ from TLS data in ways that require additional processing before segmentation algorithms can be applied. The most important differences are point density, footprint size, and random error in point locations. Point densities from airborne applications decrease from the canopy top to the ground, because most laser energy is reflected by upper-canopy vegetation. Although measurement densities from drone lidar are enormous in comparison to traditional airborne laser scanning [
22], they are about one order of magnitude less dense than typical TLS campaigns. Coupled with a decrease in sampling density from the canopy top to the ground, measurement frequency at breast height is less than typically encountered by algorithms developed for TLS applications.
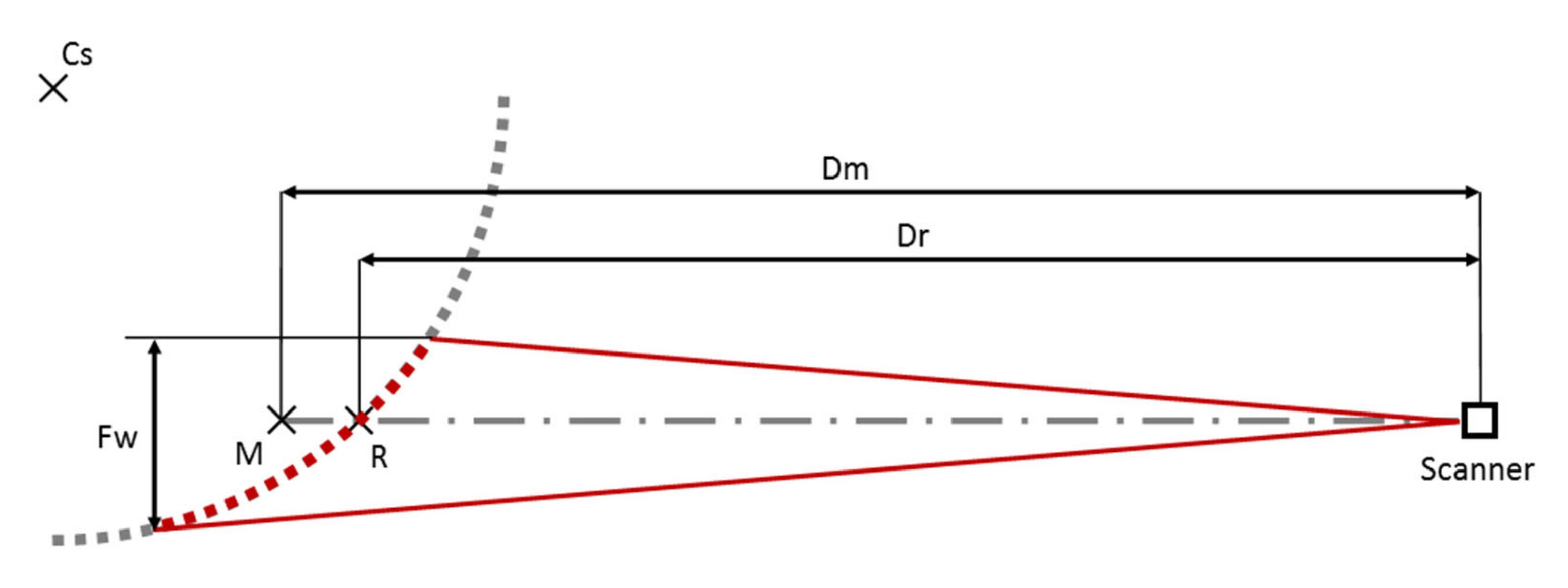
Footprint size in laser scanners is controlled by beam divergence and distance to the reflective target. The VUX-1 produces a 5 cm circular footprint at a distance of 100 m on a target that is perpendicular to the beam path. For the TLS instrument used here, the corresponding number is 2 cm. In practice the difference in footprint size between TLS and airborne applications is larger, because TLS measurements are reflected by objects closer to the sensor. For example, our nominal flight altitude was 110 m. This indicates that no returns were recorded <70 m from the scanner (given a 40 m maximum canopy height). This corresponds to footprint sizes in the 3.5–5.5 cm range at nadir. Beams emitted at wider scan angles can travel farther, and the corresponding footprint size is bigger. For example, a beam traveling along a 60 degree scan angle from 110 m altitude would be reflected by ground at a distance of 190.5 m from the scanner, at which the footprint size would be about 9.5 cm on a target perpendicular to the beam path. For TLS measurements in the 10–20 m range, footprint sizes are 2–4 mm. Thus, the difference in footprint size is about one order or magnitude.
Systematic and random error in the location of recorded laser returns is greater for airborne applications than terrestrial ones. This is because TLS data are acquired from a stationary position and the distance to reflective targets is shorter. Reported ranging accuracies for TLS instruments are <a few mm at distances of 100 m [
23]. Fundamental range accuracy for the VUX-1 is 1 cm. In practice, the realized range accuracy within a given point cloud is probably in the 5–15 cm range. Multiple sources of uncertainty influence this value, including geolocation and altitude knowledge of the sensor at the time of laser firing, and dynamic offsets among flight lines. Footprint size and scan angle can introduce uncertainty into the location of discrete reflective surfaces within the beam path.
2.4. Processing Workflow of the Drone-Lidar Point Cloud
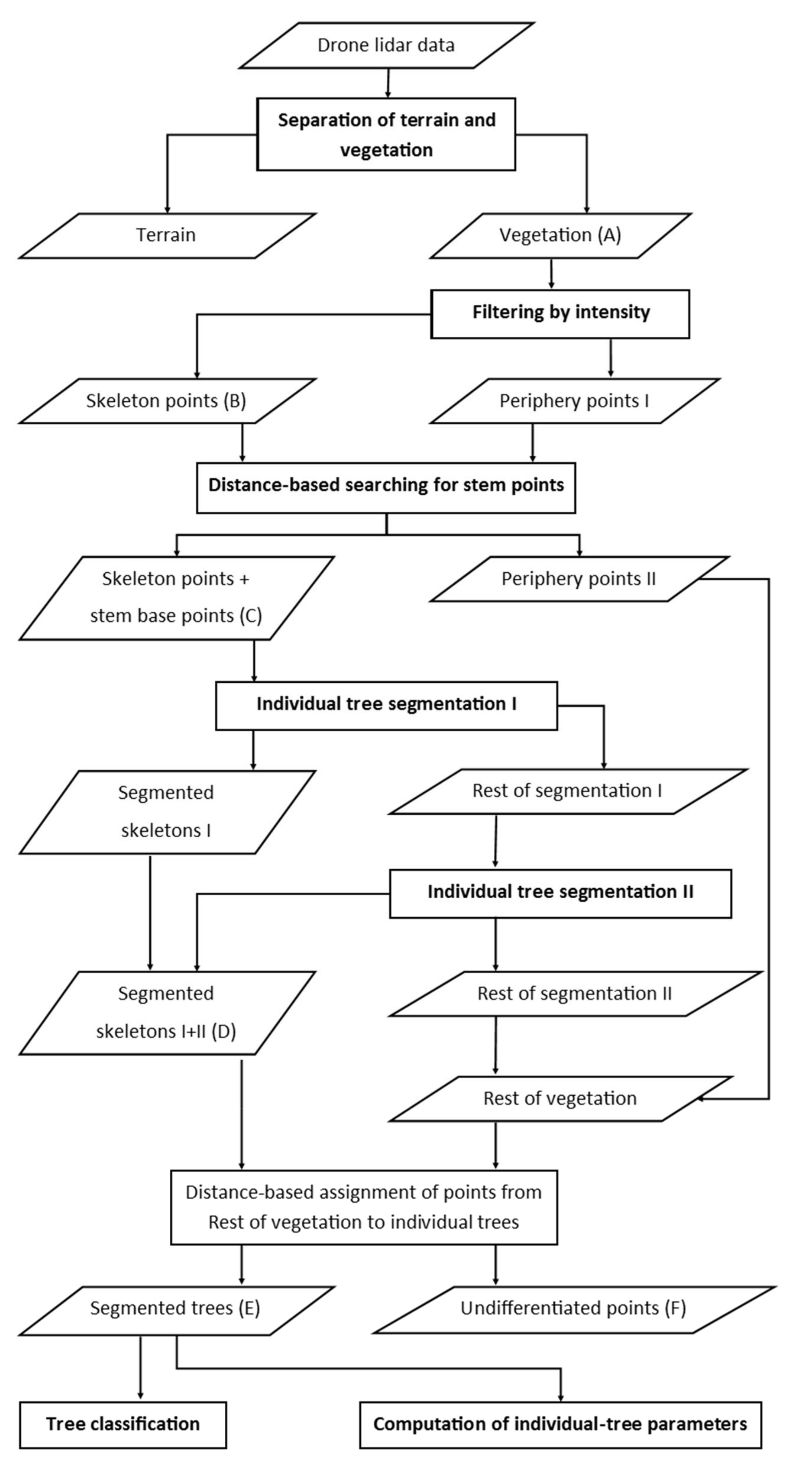
First, we separated the terrain points and vegetation points in FUSION/LDV software (
Figure 3). Then we applied a return-intensity filter to the points classified as vegetation to distinguish reflections from larger stems and branches (hereafter called skeleton points) from partial reflections of small stems, branches and twigs that did not completely fill the laser footprint (hereafter called periphery points I,
Figure 2B and
Figure 3). The intensity filter discarded all returns with 16-bit scaled reflectance intensity <55,000. This threshold was determined by visual inspection of the point cloud. We then searched within periphery points I to identify points that were ≤5 m aboveground and ≤5 cm from the nearest stem point. We assumed that these points were partial stem returns that were removed by intensity filtering and therefore labeled them as stem base points (
Figure 2C and
Figure 3). Next, we applied the segmentation algorithm newly implemented in 3D Forest v. 0.5 [
24] to the skeleton and stem base points in two iterations (
Figure 2D and
Figure 3). In the first iteration the voxel size was set to 10 cm. The second iteration was applied to unsegmented points from the first iteration with a voxel size of 20 cm. Finally, we assigned unsegmented points (labeled rest of vegetation in
Figure 3) to segmented tree objects iteratively (
Figure 2E and
Figure 3) based on point proximity: when the nearest segmented tree was within a specified distance, the unlabeled point was assigned to that segmented tree. We repeated this process 20 times with the following settings, 10 times with a maximum distance of 10 cm, 5 times with a maximum distance of 15 cm and 5 times with a maximum distance of 20 cm.
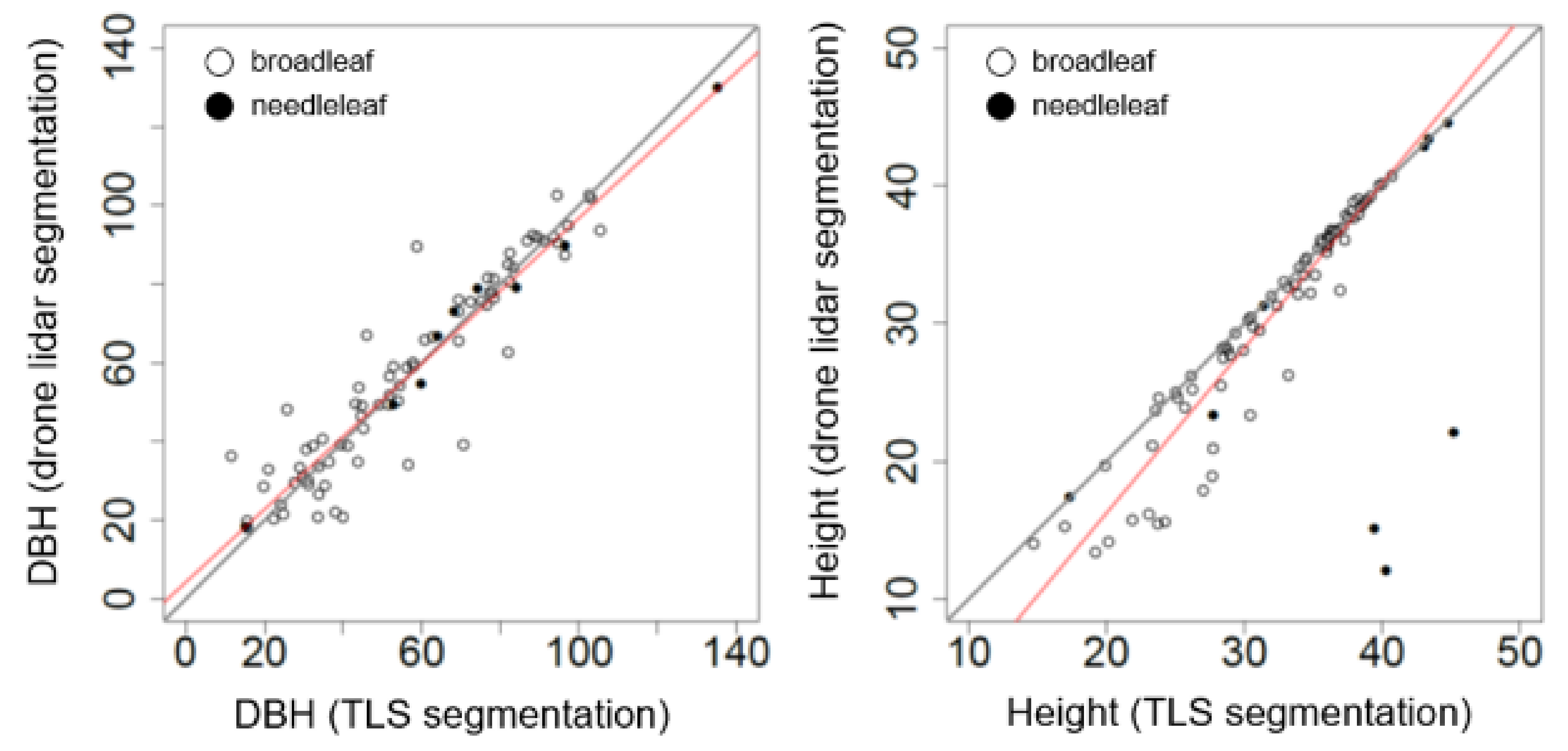
Based on the resulting segmentation (
Figure 2E) we then computed the stem base position, tree height and DBH for each segmented tree object. Stem base position is derived using the median XY algorithm described in [
15]. DBH is the median of 20 estimates obtained using 20 cm vertical slices of each tree object starting at 1.1 m aboveground in 5 cm increments (i.e., the first vertical slice was 1.1–1.3 m, the second was 1.15–1.35 m, etc.). The DBH estimate is based on a randomized Hough transformation of the points within each 20 cm horizontal slice [
15]. Tree height is the maximum Z coordinate among the points within the segmented tree object [
15].
2.5. Random Forest Classification and AGB of Trees
We developed a Random Forest classifier to assign broadleaf or needleleaf labels to segmented tree objects [
25]. We used four Random Forest parameters: the number of trees (n-estimators) was 1000, the criterion was Gini, the maximum depth and the maximum number of features were determined automatically. To train the Random Forest classifier, we used 125 randomly selected broadleaf trees and 125 randomly selected needleleaf trees. Because tree height varies by a factor of 2–3 in this forest, we expressed the height of each point relative to the maximum height within its associated tree object using,
where,
is the scaled value for point
i,
and
are the minimum and maximum height within segmented object
j, and
is the unscaled value for point
i.
To quantitatively describe each segmented tree object, we divided every tree into 40 vertical layers and calculated the following three features for each layer: (i) diameter (cm), (ii) the standard deviation of Euclidean distances between points and the point-cloud mean for each layer in three dimensions, and (iii) the fraction of dense voxels. Each voxel was 10 cm on a side, and dense voxels were defined as those with >36 points. We used the diameter of each layer based on the assumption that broadleaf and coniferous species in this forest have different silhouettes when point clouds are projected along the sagittal plane. The second and third features were chosen based on the assumption that the distribution of returned laser energy will systematically vary between needleleaf and broadleaf trees in leaf-off condition (i.e., point density of needleleaf trees is greatest on the crown surface and decreases toward the crown center, and the opposite pattern occurs for broadleaf trees in leaf-off condition). We quantified aboveground biomass (AGB) for each segmented tree using the allometric scaling equations for European temperate forests in [
26]. For all trees with the broadleaf classification we used the beech equation. For all trees with the needleleaf classification we used the spruce equation. For AGB computations we excluded segmented trees with a maximum height <10 m because visual examination indicates that many segmented objects <10 m in height were segmentation errors. We also excluded tree objects with DBH > 1.5 m. This value exceeds the size of the largest measured tree in the ZFDP. Segments of this size are therefore very likely to be commission errors (see example commission error in
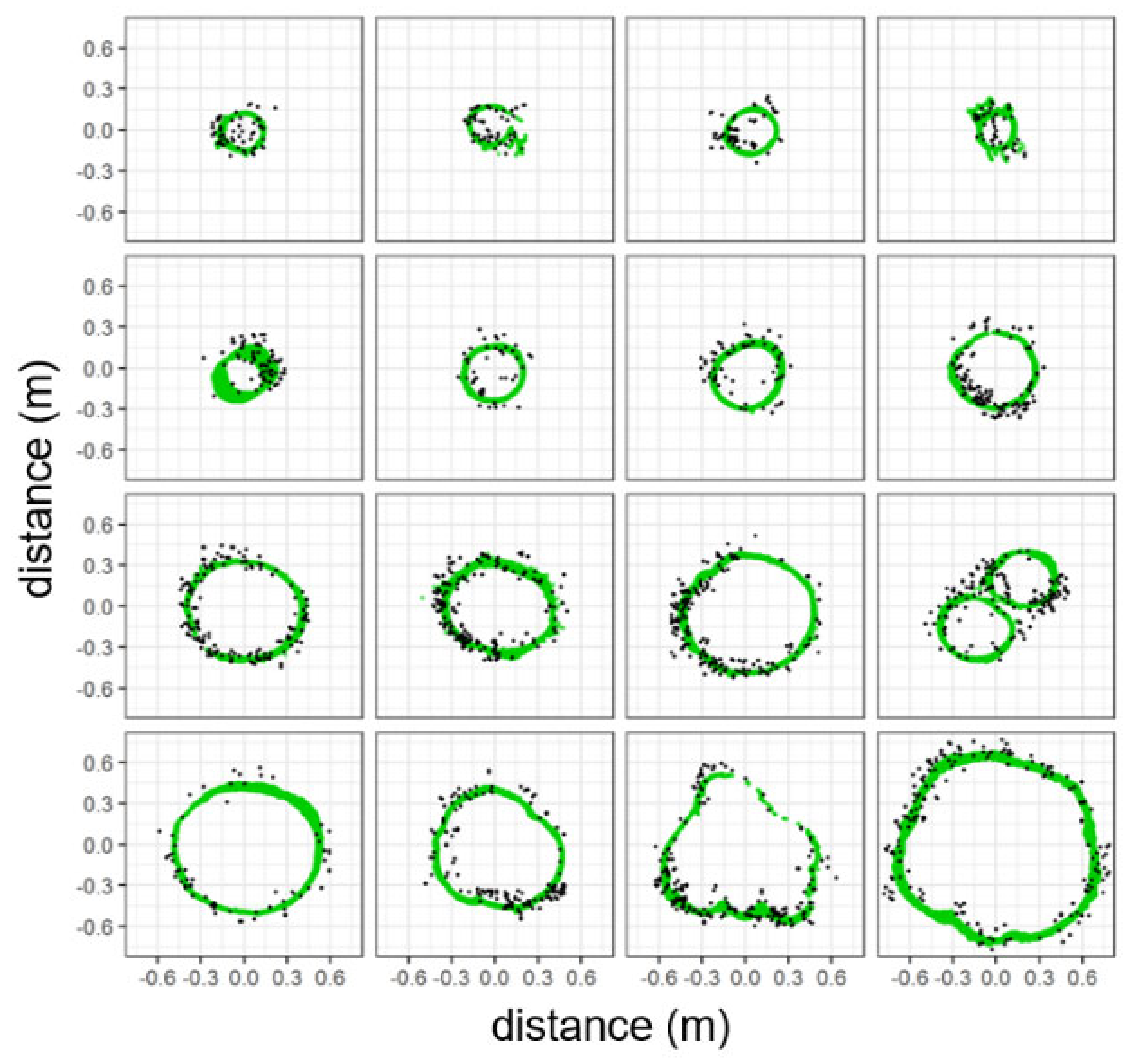
Figure 4, column four, row three). Therefore, our estimate of stand-level AGB is net of all errors in drone-lidar segmentations and classification of tree objects into needleleaf and broadleaf types.
2.6. Evaluating the Impact of Footprint Size and Noise on DBH Estimates
We quantified the impact of random error and footprint size on estimates of tree diameter using a data simulation. To quantify the impact of noise we generated circles over the range of 10–200 cm in diameter with 180 points that were regularly spaced along the circumference of each circle. We then randomized point locations by adding independent, normally distributed random error to each point in the X and Y dimensions with a mean equal to 0 and a standard deviation equal to 1, 2.5, 5 or 10 cm. We estimated the diameters of these circles using the randomized Hough transformation with 400 iterations, and compared the estimated diameters to the true values. We repeated this process 500 times for each diameter and measurement error scenario.
To quantify the impact of footprint size, we generated circles over the range of 10–200 cm in diameter using 3600 points regularly spaced along the circumference. We performed a convolution operation on these points using a binary filter whose length corresponds to a footprint size of 5, 10 or 15 cm (
Appendix A,
Figure A1). The filter proceeded along the circumference of each circle in increments of 2 cm, this was replicated for the four principal directions (which corresponds to the direction of airborne flight lines). At each increment, we estimated the distance measured by laser as mean distance of all points within the extent of the 5, 10 or 15 cm simulated footprint and evaluated the effect of the difference between the estimated and real distance on the DBH estimation. Our analysis ignores some of the complexity of recorded footprints, such as variation in the across-beam laser intensity [
27], and variation in footprint size as a function of scan angle on individual stems. As a point of reference, the VUX-1 produces a 5 cm footprint on an orthogonal surface at a distance of 100 m. At a scan angle of 60 degrees the laser beam path is likely to be longer and the expected footprint size is bigger. Most stem returns from high-density drone lidar are produced by wide scan angles [
5,
7]. The simulated footprint size range of 5–15 cm is therefore likely to encompass the range of footprint sizes on individual trees in our data.
2.7. Statistical Analysis
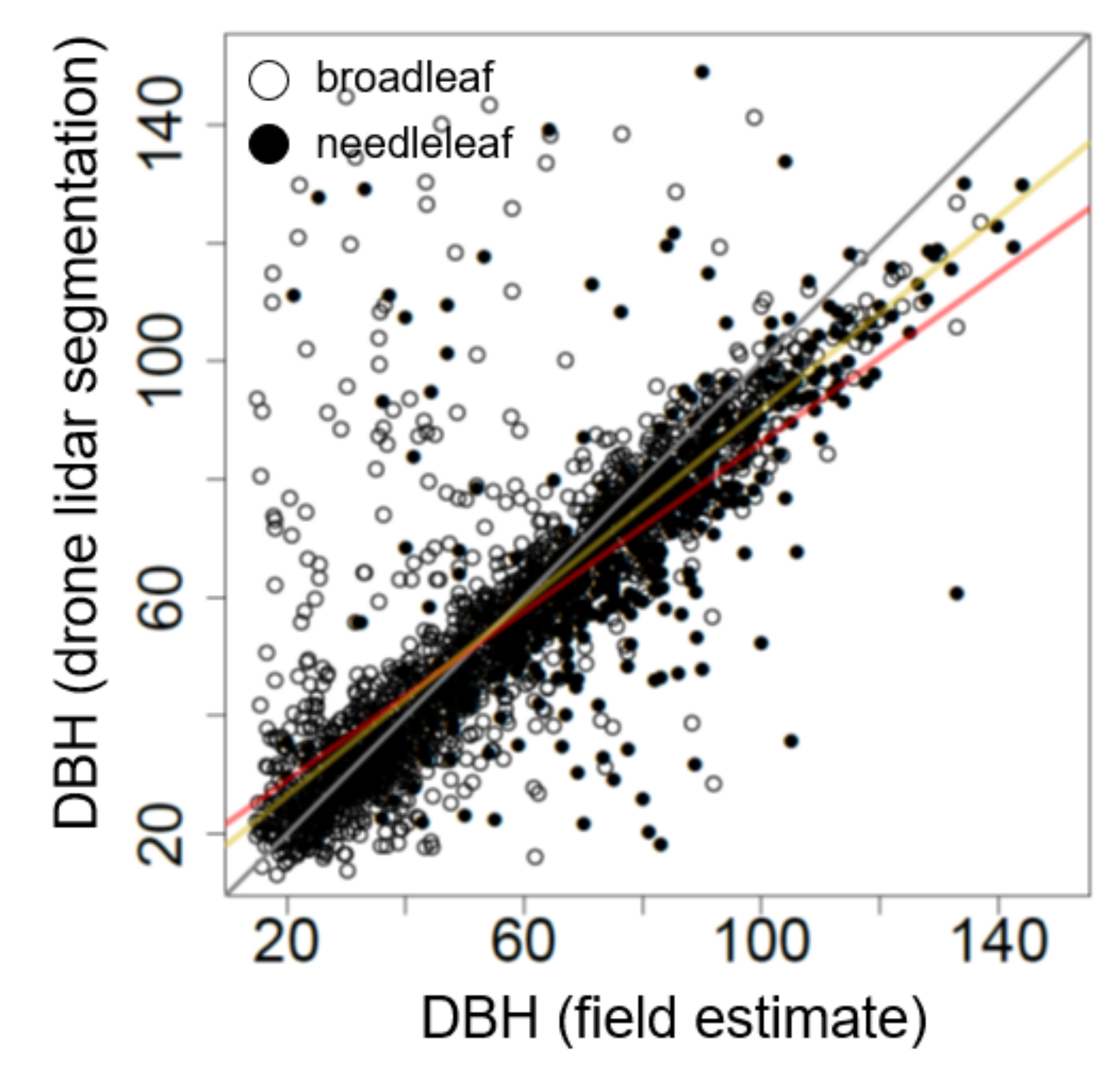
First, we matched the field measurements and TLS segmented trees with trees segmented from drone lidar. The pairing was based on the Euclidean distance between segmented and known tree bases, and was visually examined for errors (
Appendix A,
Figure A2). We compared DBH and height from supervised segmentations of drone lidar to those obtained from TLS measurements and field data using ordinary linear regression. To determine whether there was a difference in the intercept or slope of the relationship between broadleaf and needleleaf trees we used dummy-variables regression [
28,
29]. The regression model was:
where the response variable is DBH or height from drone-lidar segmentations, and
is DBH or height from segmentations using TLS data, or DBH from field measurements. The variable
is a binary indicator variable that takes the value of 0 if the segmented object was a needleleaf tree and a value of 1 if it was a broadleaf tree. The term
denotes a normally distributed random error. The labels used here are from field records, not the Random Forest classifier described above. Consider the relationship when
= 0, which denotes needleleaf trees. When this occurs,
and
are 0, and the model simplifies to:
For broadleaf trees
= 1, and the model is:
Thus, the term is a test of the hypothesis of no difference in the intercept between needleleaf and broadleaf trees, with the value of indicating the change in intercept for broadleaf trees. Similarly, the term tests the hypothesis of no difference in the slopes of the relationships, with the value of indicating the change in slope for broadleaf trees.
4. Conclusions and Recommendations
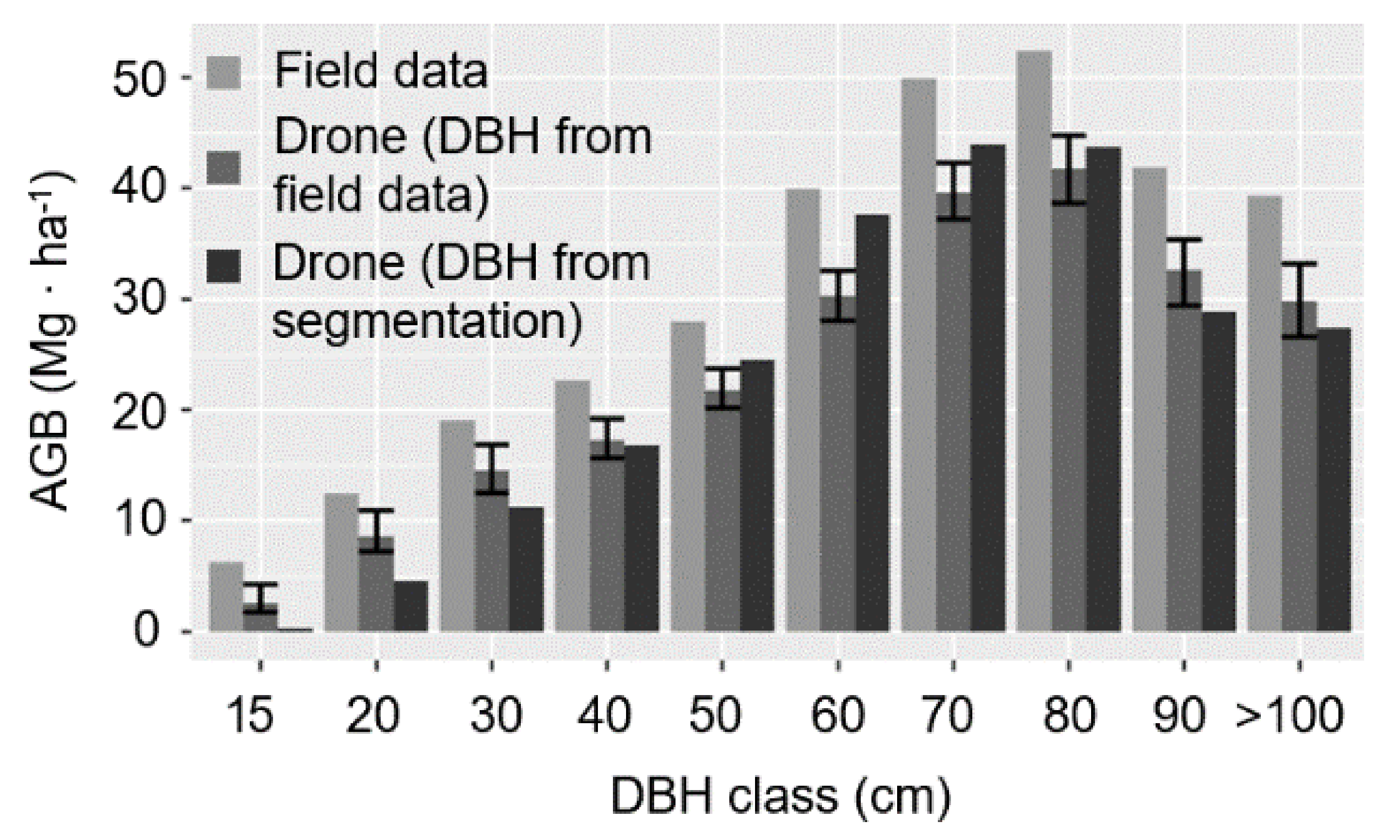
The largest source of uncertainty in our estimate of stand-level AGB is omission errors in tree segmentation. Using supervised segmentation applied to high-density drone lidar, we detected 51% of the individuals and 76% of the AGB within individuals >15 cm DBH. This number is net of all segmentation and Random Forest classification errors necessary to apply allometric scaling equations to segmented trees. We showed that 73.3% of the bias (17.6 percentage points) was due to omission errors, and the remaining 6.4 percentage points were due to DBH estimation errors, variation in footprint size and other sources of uncertainty. Visual examination of high-density point clouds demonstrated that most omitted trees were present with sufficient point densities for automated segmentation. These trees are being removed by intensity filtering prior to deploying the segmentation algorithm. Changes to airborne data collection and pre-processing could therefore reduce errors of omission. For example, reducing the flight altitude and increasing the number of flight lines will reduce laser ranges, footprint size and random error in point locations. It will also increase the mean intensity of recorded laser returns. More sophisticated filtering of points using geometrical and intensity characteristics [
31] and other information, including scan angle and the number of returns per emitted laser pulse, will retain more points for automated segmentation.
Our analysis demonstrates that high-density measurements from low-altitude drone flight can produce information about segmented individual trees that is in some aspects comparable to TLS, despite much lower point densities, attenuation of laser energy within the canopy volume, larger errors in point locations, and larger footprint size. These data can be collected rapidly throughout areas large enough to produce landscape-scale estimates that could augment or replace manual field inventories, and become suitable for calibration and validation of current and forthcoming space missions [
11,
12]. Our analysis does not address whether large-area estimates of AGB from individual tree segmentation are more precise or less biased than area-based extrapolations using traditional methods, and does not address the propagation of sources of uncertainty through area-based summaries [
32,
33,
34].














{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}