Super-Resolution of Sentinel-2 Imagery Using Generative Adversarial Networks



Abstract
1. Introduction
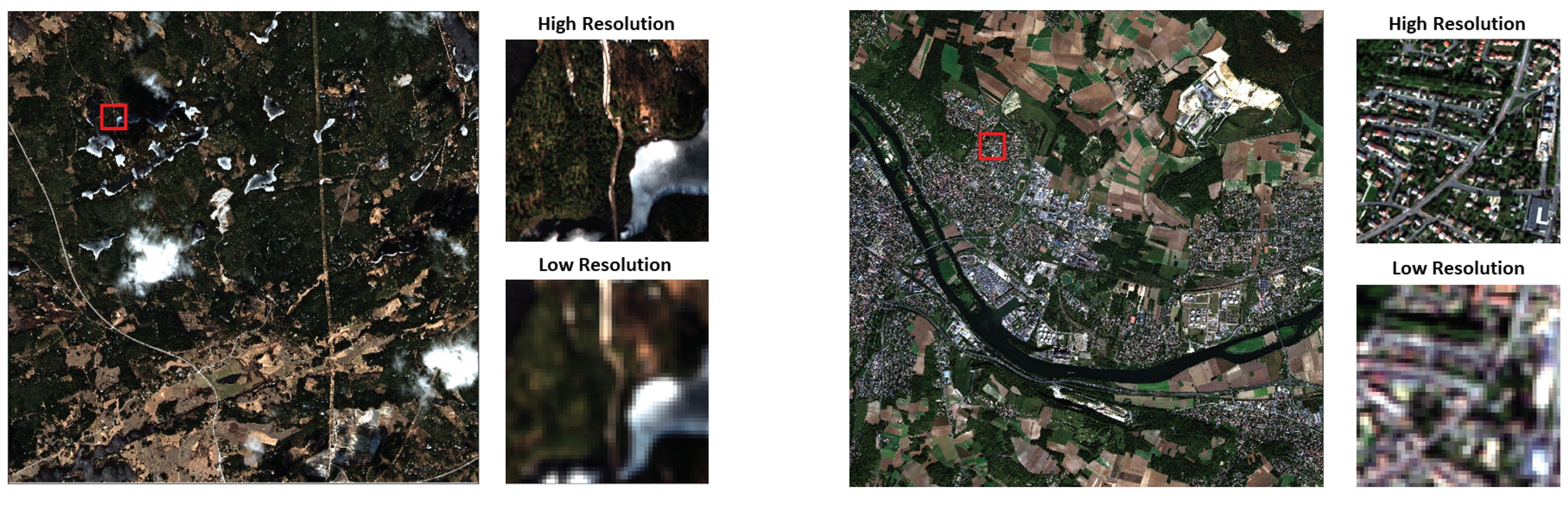
2. Satellite Images
3. Materials and Methods
3.1. Datasets
3.2. Image Pre-Processing
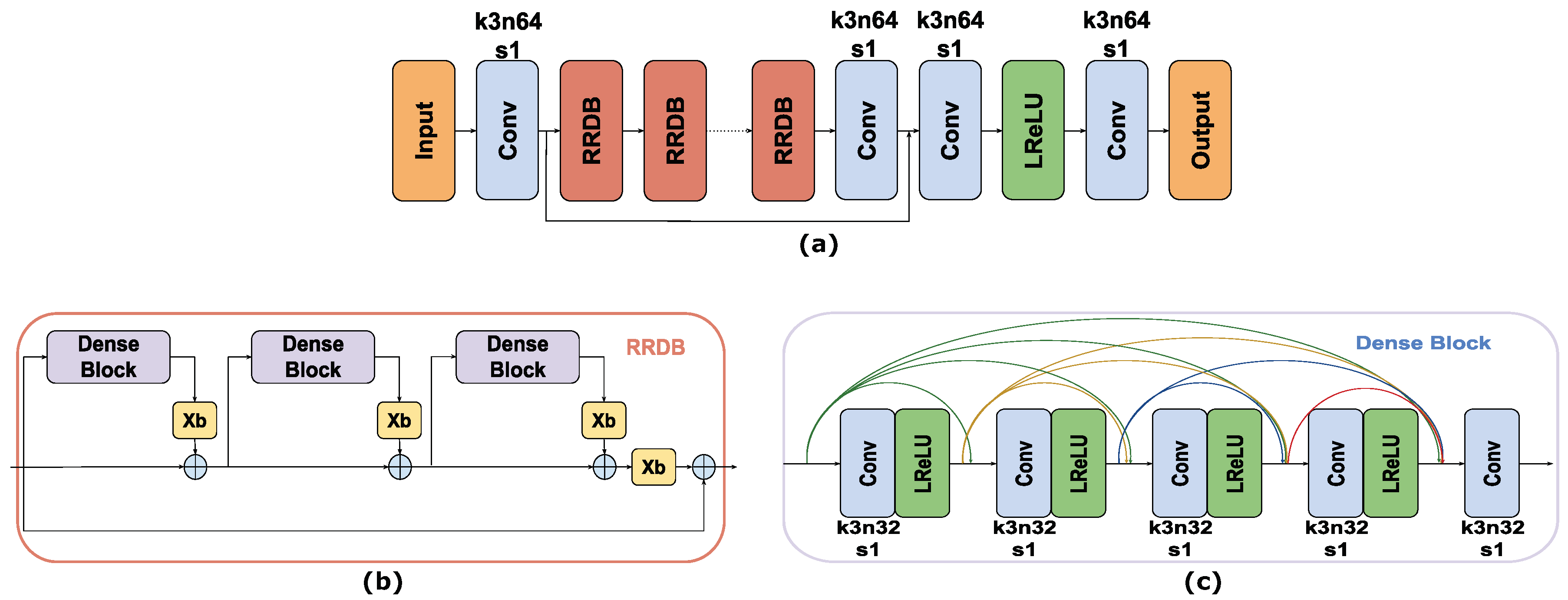
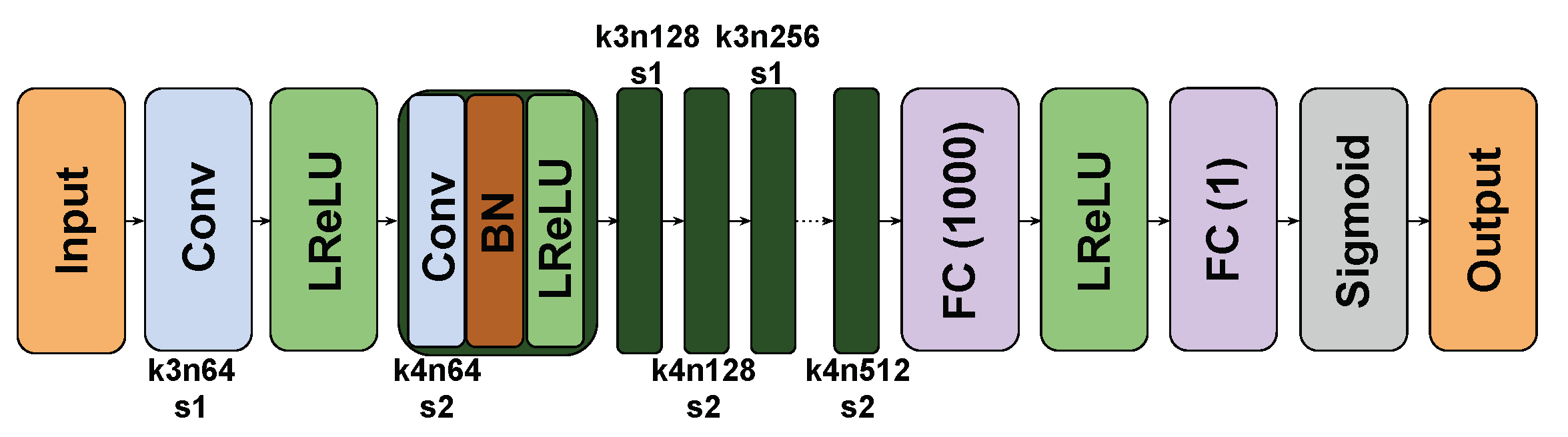
3.3. Network Architecture
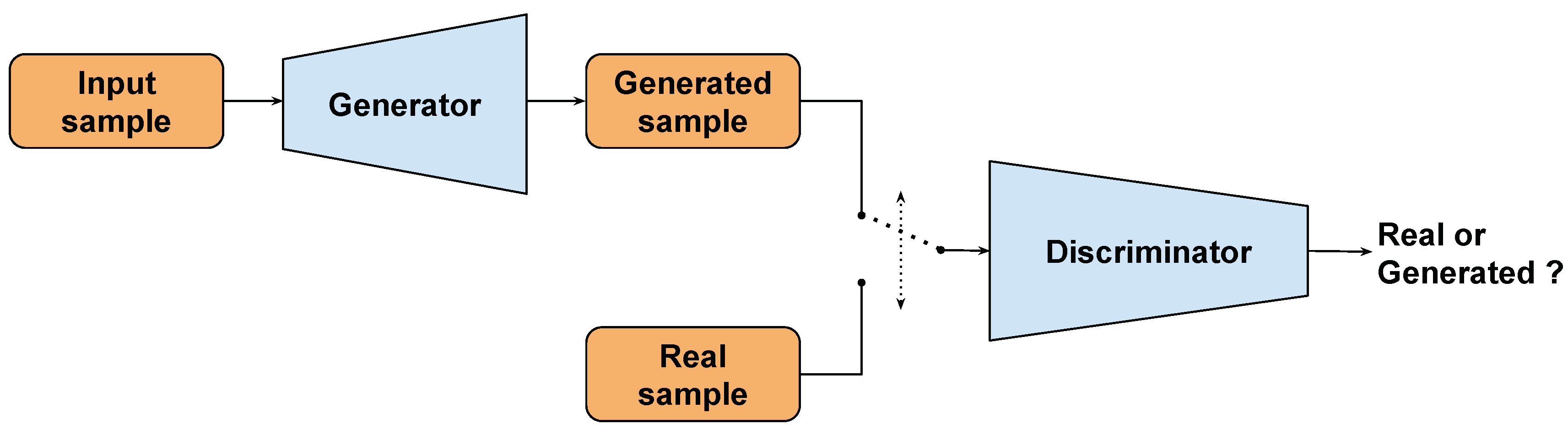
3.4. Methodology and Loss Functions
3.5. Training Details and Network Interpolation
3.6. Quality Assessment
- Peak Signal to Noise Ratio (PSNR): it is one of the standard metrics used to evaluate the quality of a reconstructed image. Here, MaxVal is the maximum value of the HR image (Y). Higher PSNR generally indicates higher image quality.
- Structural Similarity (SSIM) [61]: it is a metric that measures the similarity between two images taking into account three aspects: luminance, contrast and structure. It is in the range , where a SSIM equal to 1 corresponds to identical images. Constants and are values that depends on the dynamic range (L) of the pixels values, with and by default.
- Erreur relative globale adimensionnelle de systhese (ERGAS) [62]: it measures the quality of the output image by taking into consideration the scaling factor (S) as well as the normalized error per channel, considering the mean of each band. Contrary to the PSNR and SSIM metrics for this index a lower value implies higher quality.
- Spectral Angle Mapper (SAM) [63]: it calculates the angle between two images by computing the dot product divided by the 2-norm of each image. This index indicates higher similarity between images as it approaches zero.
- Correlation Coefficient (CC): it computes the linear correlation between the images. It is in the range , where 1 is total positive linear correlation and n is the number of pixel in each channel.
4. Experiments and Results
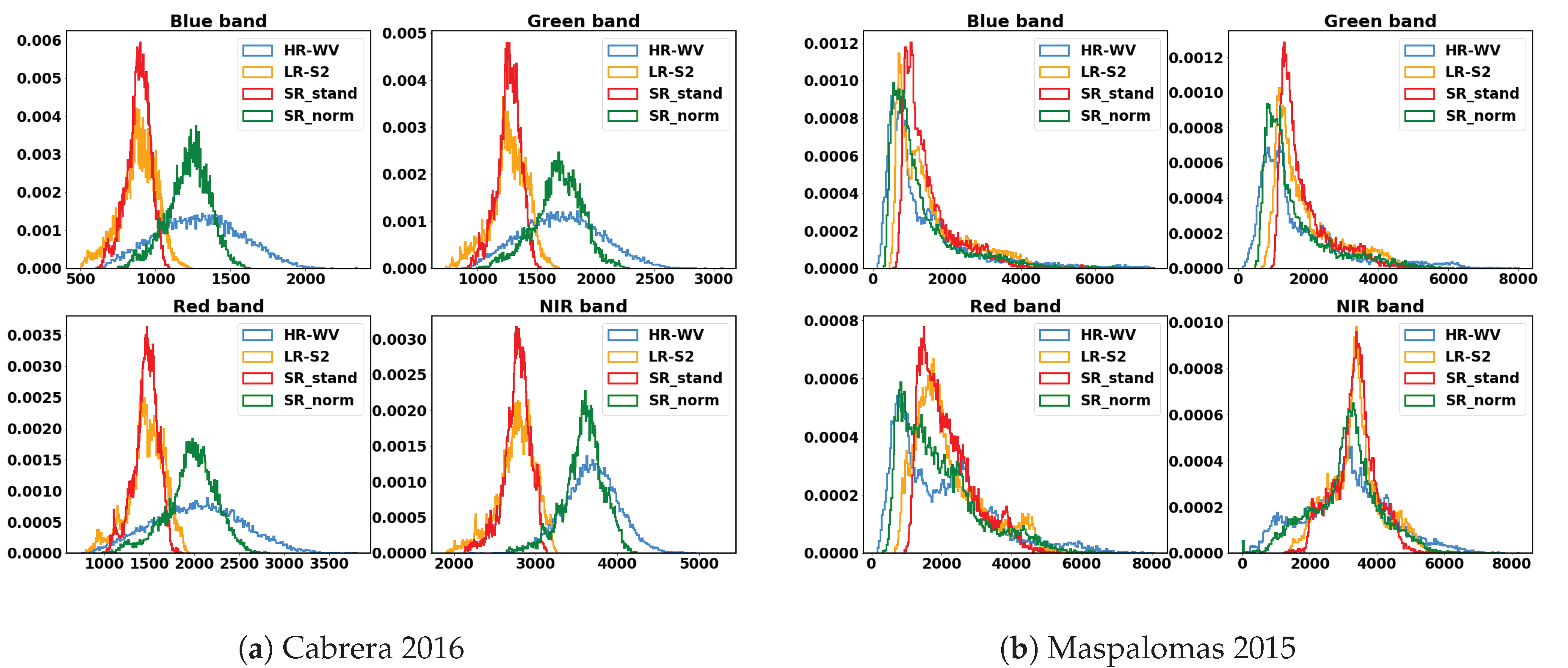
4.1. Data Standardization
4.2. Performance on the W-S Set1
4.3. Performance on the W-S Set2
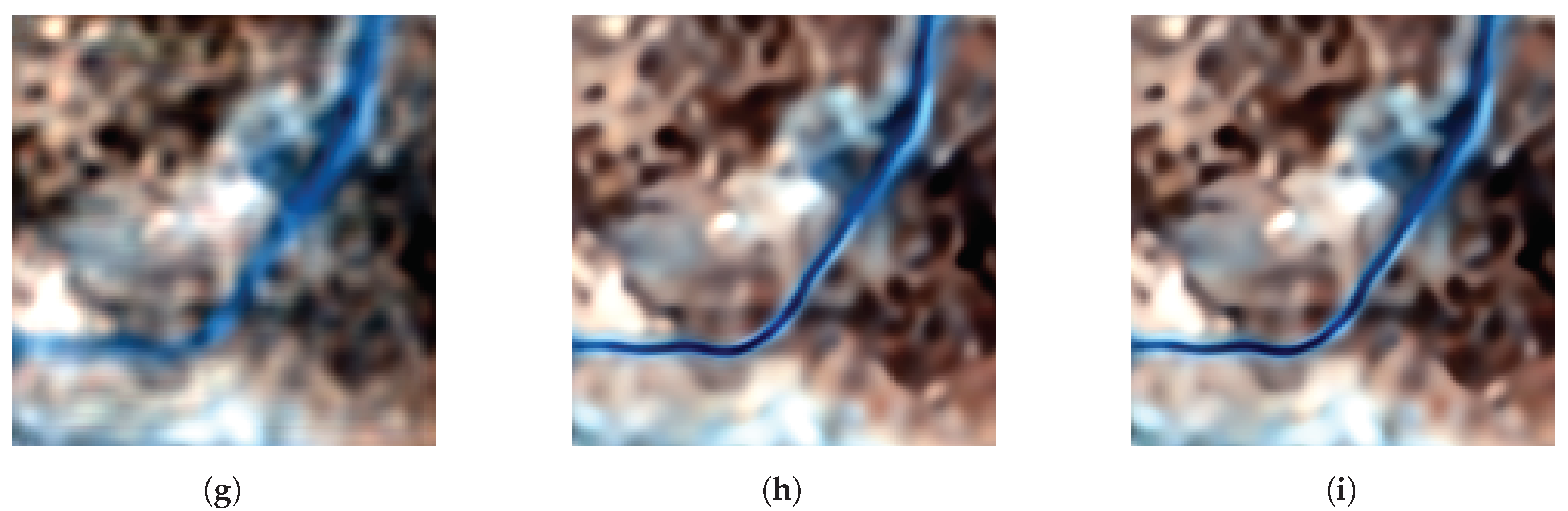
4.4. Comparison with Other SR Models
5. Discussion
6. Conclusions
Author Contributions
Funding
Conflicts of Interest
Abbreviations
| Bic | Bicubic interpolation |
| BOA | Bottom Of Atmosphere |
| CC | Correlation Coefficient |
| CNN | Convolutional Neural Network |
| D | Discriminator network |
| DL | Deep Learning |
| ERGAS | Erreur Relative Globale Adimensionelle de Systhèsis |
| ESA | European Space Agency |
| FC | False Color |
| FLAASH | Fast Line-of-sight Atmospheric Analysis of Hypercubes |
| G | Generator Network |
| GAN | Generative Adversarial Network |
| GCP | Ground Control Points |
| GSD | Ground Sampling Distance |
| HS | Hyperspectral |
| HR | High-resolution image |
| LR | Low-resolution image |
| MS | Multispectral |
| MSE | Multi Spectral Instrument |
| NIR | Near Infrared |
| NN | nearest neighbour |
| PAN | Panchromatic band |
| PSNR | Peak Signal to Noise Ratio |
| RGB | Red-Green-Blue |
| RMSE | Root Mean Square Error |
| RRDB | Residual-in-Residual Dense Blocks |
| SAM | Spectral Angle Mapper |
| SR | Super-resolution image |
| SSIM | Structural Similarity |
| std | Standard Deviation |
| TOA | Top Of Atmosphere |
| VISNIR | Visible and Near Infrared |
| VHSR | Very high spatial resolution |
References
- WorldView-3 Datasheet. Digital Globe. Available online: http://content.satimagingcorp.com.s3.amazonaws.com/media/pdf/WorldView-3-PDF-Download.pdf. (accessed on 26 June 2020).
- Sentinel-2 User Handbook, ESA Standard Document, Issue I, Rev. 2. Available online: https://earth.esa.int/documents/247904/685211/Sentinel-2_User_Handbook (accessed on 11 December 2019).
- Kpalma, K.; Chikr El-Mezouar, M.; Taleb, N. Recent Trends in Satellite Image Pan-sharpening techniques. In Proceedings of the 1st International Conference on Electrical, Electronic and Computing Engineering, Vrnjacka Banja, Serbia, 2–5 June 2014. [Google Scholar]
- Vivone, G.; Alparone, L.; Chanussot, J.; Dalla Mura, M.; Garzelli, A.; Licciardi, G.A.; Restaino, R.; Wald, L. A critical comparison among pansharpening algorithms. IEEE Trans. Geosci. Remote Sens. 2014, 53, 2565–2586. [Google Scholar] [CrossRef]
- Loncan, L.; De Almeida, L.B.; Bioucas-Dias, J.M.; Briottet, X.; Chanussot, J.; Dobigeon, N.; Fabre, S.; Liao, W.; Licciardi, G.A.; Simoes, M.; et al. Hyperspectral pansharpening: A review. IEEE Geosci. Remote Sens. Magaz. 2015, 3, 27–46. [Google Scholar] [CrossRef]
- Mookambiga, A.; Gomathi, V. Comprehensive review on fusion techniques for spatial information enhancement in hyperspectral imagery. Multidimens. Syst. Signal Proces. 2016, 27, 863–889. [Google Scholar] [CrossRef]
- Yokoya, N.; Grohnfeldt, C.; Chanussot, J. Hyperspectral and multispectral data fusion: A comparative review of the recent literature. IEEE Geosci. Remote Sens. Magaz. 2017, 5, 29–56. [Google Scholar] [CrossRef]
- Garzelli, A.; Aiazzi, B.; Baronti, S.; Selva, M.; Alparone, L. Hyperspectral image fusion. In Proceedings of the Hyperspectral Workshop, Frascati, Italy, 17–19 March 2010. [Google Scholar]
- Dian, R.; Li, S.; Fang, L.; Wei, Q. Multispectral and hyperspectral image fusion with spatial-spectral sparse representation. Inform. Fusion 2019, 49, 262–270. [Google Scholar] [CrossRef]
- Marcello, J.; Ibarrola-Ulzurrun, E.; Gonzalo-Martín, C.; Chanussot, J.; Vivone, G. Assessment of Hyperspectral Sharpening Methods for the Monitoring of Natural Areas Using Multiplatform Remote Sensing Imagery. IEEE Trans. Geosci. Remote Sens. 2019, 57, 8208–8222. [Google Scholar] [CrossRef]
- Huang, W.; Xiao, L.; Wei, Z.; Liu, H.; Tang, S. A new pan-sharpening method with deep neural networks. IEEE Geosci. Remote Sens. Lett. 2015, 12, 1037–1041. [Google Scholar] [CrossRef]
- Masi, G.; Cozzolino, D.; Verdoliva, L.; Scarpa, G. Pansharpening by convolutional neural networks. Remote Sens. 2016, 8, 594. [Google Scholar] [CrossRef]
- Palsson, F.; Sveinsson, J.R.; Ulfarsson, M.O. Multispectral and hyperspectral image fusion using a 3-D-convolutional neural network. IEEE Geosci. Remote Sens. Lett. 2017, 14, 639–643. [Google Scholar] [CrossRef]
- Yang, J.; Fu, X.; Hu, Y.; Huang, Y.; Ding, X.; Paisley, J. PanNet: A deep network architecture for pan-sharpening. In Proceedings of the IEEE International Conference on Computer Vision, Venice, Italy, 22–29 October 2017; pp. 5449–5457. [Google Scholar]
- Yang, J.; Zhao, Y.Q.; Chan, J. Hyperspectral and multispectral image fusion via deep two-branches convolutional neural network. Remote Sens. 2018, 10, 800. [Google Scholar] [CrossRef]
- Scarpa, G.; Vitale, S.; Cozzolino, D. Target-adaptive CNN-based pansharpening. IEEE Trans. Geosci. Remote Sens. 2018, 56, 5443–5457. [Google Scholar] [CrossRef]
- Garzelli, A. A review of image fusion algorithms based on the super-resolution paradigm. Remote Sens. 2016, 8, 797. [Google Scholar] [CrossRef]
- Molini, A.B.; Valsesia, D.; Fracastoro, G.; Magli, E. DeepSUM: Deep neural network for Super-resolution of Unregistered Multitemporal images. IEEE Trans. Geosci. Remote Sens. 2019. [Google Scholar] [CrossRef]
- Haut, J.M.; Fernandez-Beltran, R.; Paoletti, M.E.; Plaza, J.; Plaza, A.; Pla, F. A new deep generative network for unsupervised remote sensing single-image super-resolution. IEEE Trans. Geosci. Remote. Sens. 2018, 56, 6792–6810. [Google Scholar] [CrossRef]
- Wang, P.; Zhang, H.; Zhou, F.; Jiang, Z. Unsupervised remote sensing image super-resolution using cycle CNN. In Proceedings of the IGARSS 2019 IEEE International Geoscience and Remote Sensing Symposium, Yokohama, Japan, 28 July–2 August 2019; pp. 3117–3120. [Google Scholar]
- Yang, J.; Wright, J.; Huang, T.; Ma, Y. Image super-resolution as sparse representation of raw image patches. In Proceedings of the 2008 IEEE Conference on Computer Vision and Pattern Recognition, Anchorage, AK, USA, 23–28 June 2008; pp. 1–8. [Google Scholar]
- Yang, J.; Wright, J.; Huang, T.S.; Ma, Y. Image super-resolution via sparse representation. IEEE Trans. Image Proces. 2010, 19, 2861–2873. [Google Scholar] [CrossRef]
- Dong, W.; Zhang, L.; Shi, G.; Wu, X. Image deblurring and super-resolution by adaptive sparse domain selection and adaptive regularization. IEEE Trans. Image Proces. 2011, 20, 1838–1857. [Google Scholar] [CrossRef]
- Gou, S.; Liu, S.; Yang, S.; Jiao, L. Remote sensing image super-resolution reconstruction based on nonlocal pairwise dictionaries and double regularization. IEEE J. Sel. Top. Appl. Earth Observ. Remote Sens. 2014, 7, 4784–4792. [Google Scholar] [CrossRef]
- Pan, Z.; Yu, J.; Huang, H.; Hu, S.; Zhang, A.; Ma, H.; Sun, W. Super-resolution based on compressive sensing and structural self-similarity for remote sensing images. IEEE Trans. Geosci. Remote Sens. 2013, 51, 4864–4876. [Google Scholar] [CrossRef]
- Zhang, Y.; Du, Y.; Ling, F.; Fang, S.; Li, X. Example-based super-resolution land cover mapping using support vector regression. IEEE J. Sel. Top. Appl. Earth Observ. Remote Sens. 2014, 7, 1271–1283. [Google Scholar] [CrossRef]
- Li, J.; Yuan, Q.; Shen, H.; Meng, X.; Zhang, L. Hyperspectral image super-resolution by spectral mixture analysis and spatial–spectral group sparsity. IEEE Geosci. Remote Sens. Lett. 2016, 13, 1250–1254. [Google Scholar] [CrossRef]
- Wang, Z.; Chen, J.; Hoi, S.C. Deep learning for image super-resolution: A survey. arXiv 2019, arXiv:1902.06068. [Google Scholar] [CrossRef] [PubMed]
- Dong, C.; Loy, C.C.; He, K.; Tang, X. Learning a deep convolutional network for image super-resolution. In European Conference on Computer Vision; Springer: Berlin/Heidelberg, Germany, 2014; pp. 184–199. [Google Scholar]
- Kim, J.; Kwon Lee, J.; Mu Lee, K. Accurate image super-resolution using very deep convolutional networks. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 27–30 June 2016; pp. 1646–1654. [Google Scholar]
- Kim, J.; Kwon Lee, J.; Mu Lee, K. Deeply-recursive convolutional network for image super-resolution. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 27–30 June 2016; pp. 1637–1645. [Google Scholar]
- Dong, C.; Loy, C.C.; Tang, X. Accelerating the super-resolution convolutional neural network. In European Conference on Computer Vision; Springer: Berlin/Heidelberg, Germany, 2016; pp. 391–407. [Google Scholar]
- Dong, C.; Loy, C.C.; He, K.; Tang, X. Image super-resolution using deep convolutional networks. In IEEE Transactions on Pattern Analysis and Machine Intelligence; IEEE: Piscataway, NJ, USA, 1 February 2016; Volume 38, pp. 295–307. [Google Scholar]
- Goodfellow, I.; Pouget-Abadie, J.; Mirza, M.; Xu, B.; Warde-Farley, D.; Ozair, S.; Courville, A.; Bengio, Y. Generative adversarial nets. Adv. Neural Inform. Proces. Syst. 2014, 2672–2680. [Google Scholar]
- Ledig, C.; Theis, L.; Huszár, F.; Caballero, J.; Cunningham, A.; Acosta, A.; Aitken, A.; Tejani, A.; Totz, J.; Wang, Z.; et al. Photo-realistic single image super-resolution using a generative adversarial network. In Proceedings of the IEEE Conference on Computer Vision and pattern Recognition, Honolulu, HI, USA, 21–26 July 2017; pp. 4681–4690. [Google Scholar]
- Johnson, J.; Alahi, A.; Fei-Fei, L. Perceptual losses for real-time style transfer and super-resolution. In European Conference on Computer Vision; Springer: Berlin/Heidelberg, Germany, 2016; pp. 694–711. [Google Scholar]
- Wang, X.; Yu, K.; Wu, S.; Gu, J.; Liu, Y.; Dong, C.; Qiao, Y.; Change Loy, C. Esrgan: Enhanced super-resolution generative adversarial networks. In Proceedings of the European Conference on Computer Vision (ECCV), Munich, Germany, 8–14 September 2018. [Google Scholar]
- Jolicoeur-Martineau, A. The relativistic discriminator: a key element missing from standard GAN. arXiv 2018, arXiv:1807.00734. [Google Scholar]
- Ma, W.; Pan, Z.; Guo, J.; Lei, B. Super-resolution of remote sensing images based on transferred generative adversarial network. In Proceedings of the IGARSS 2018-2018 IEEE International Geoscience and Remote Sensing Symposium, Valencia, Spain, 22–27 July 2018; pp. 1148–1151. [Google Scholar]
- Haut, J.M.; Paoletti, M.E.; Fernandez-Beltran, R.; Plaza, J.; Plaza, A.; Li, J. Remote Sensing Single-Image Superresolution Based on a Deep Compendium Model. IEEE Geosci. Remote Sens. Lett. 2019, 16, 1432–1436. [Google Scholar] [CrossRef]
- Haut, J.M.; Fernandez-Beltran, R.; Paoletti, M.E.; Plaza, J.; Plaza, A. Remote Sensing Image Superresolution Using Deep Residual Channel Attention. IEEE Trans. Geosci. Remote Sens. 2019, 57, 9277–9289. [Google Scholar] [CrossRef]
- Lei, S.; Shi, Z.; Zou, Z. Super-resolution for remote sensing images via local–global combined network. IEEE Geosci. Remote Sens. Lett. 2017, 14, 1243–1247. [Google Scholar] [CrossRef]
- Bulat, A.; Yang, J.; Tzimiropoulos, G. To learn image super-resolution, use a gan to learn how to do image degradation first. In Proceedings of the European Conference on Computer Vision (ECCV), Munich, Germany, 8–14 September 2018; pp. 185–200. [Google Scholar]
- Ma, W.; Pan, Z.; Yuan, F.; Lei, B. Super-Resolution of Remote Sensing Images via a Dense Residual Generative Adversarial Network. Remote Sens. 2019, 11, 2578. [Google Scholar] [CrossRef]
- Pouliot, D.; Latifovic, R.; Pasher, J.; Duffe, J. Landsat super-resolution enhancement using convolution neural networks and Sentinel-2 for training. Remote Sens. 2018, 10, 394. [Google Scholar] [CrossRef]
- Beaulieu, M.; Foucher, S.; Haberman, D.; Stewart, C. Deep Image-To-Image Transfer Applied to Resolution Enhancement of Sentinel-2 Images. In Proceedings of the IGARSS 2018-2018 IEEE International Geoscience and Remote Sensing Symposium, Valencia, Spain, 22–27 July 2018; pp. 2611–2614. [Google Scholar]
- Salgueiro, L.; Marcello, J.; Vilaplana, V. Comparative study of upsampling methods for super-resolution in remote sensing. In Proceedings of the International Conference on Machine Vision, Amsterdam, The Netherlands, 16–18 November 2019. [Google Scholar]
- Chen, H.; Zhang, X.; Liu, Y.; Zeng, Q. Generative Adversarial Networks Capabilities for Super-Resolution Reconstruction of Weather Radar Echo Images. Atmosphere 2019, 10, 555. [Google Scholar] [CrossRef]
- Copernicus Open Access Hub. European Space Agency. Available online: https://scihub.copernicus.eu/dhus/#/home. (accessed on 29 June 29 2020).
- Digital Globe Core Imagery Products Guide. Available online: https://www.geosoluciones.cl/documentos/worldview/DigitalGlobe-Core-Imagery-Products-Guide.pdf (accessed on 11 December 2019).
- WorldView-2 European Cities. European Space Agency (ESA). Available online: https://earth.esa.int/web/guest/-/worldview-2-european-cities-dataset (accessed on 22 July 2019).
- Marcello, J. Procesado Avanzado de Datos de Teledetección para la Monitorización y Gestión Sostenible de Recursos Marinos y Terrestres en Ecosistemas Vulnerables—Artemisat2. Available online: http://artemisat2.ulpgc.es/?page_id=35 (accessed on 11 December 2019).
- Marcello, J.; Eugenio, F.; Perdomo, U.; Medina, A. Assessment of atmospheric algorithms to retrieve vegetation in natural protected areas using multispectral high resolution imagery. Sensors 2016, 16, 1624. [Google Scholar] [CrossRef]
- Cooley, T.; Anderson, G.P.; Felde, G.W.; Hoke, M.L.; Ratkowski, A.J.; Chetwynd, J.H.; Gardner, J.A.; Adler-Golden, S.M.; Matthew, M.W.; Berk, A.; et al. FLAASH, a MODTRAN4-based atmospheric correction algorithm, its application and validation. In Proceedings of the IEEE International Geoscience and Remote Sensing Symposium, Toronto, ON, Canada, 24–28 June 2002; Volume 3, pp. 1414–1418. [Google Scholar] [CrossRef]
- Main-Knorn, M.; Pflug, B.; Louis, J.; Debaecker, V.; Müller-Wilm, U.; Gascon, F. Sen2Cor for Sentinel-2. Image and Signal Processing for Remote Sensing XXIII. Int. Soc. Optics Photon. 2017, 10427, 1042704. [Google Scholar]
- Harris Geospatial Solutions. Image Registration. Available online: http://harrisgeospatial.com/docs/ImageRegistration.html (accessed on 13 December 2019).
- Creswell, A.; White, T.; Dumoulin, V.; Arulkumaran, K.; Sengupta, B.; Bharath, A.A. Generative adversarial networks: An overview. IEEE Signal Process. Mag. 2018, 35, 53–65. [Google Scholar] [CrossRef]
- Szegedy, C.; Ioffe, S.; Vanhoucke, V.; Alemi, A.A. Inception-v4, inception-resnet and the impact of residual connections on learning. In Proceedings of the Thirty-First AAAI Conference on Artificial Intelligence, San Francisco, CA, USA, 4–10 February 2017. [Google Scholar]
- Simonyan, K.; Zisserman, A. Very deep convolutional networks for large-scale image recognition. arXiv 2014, arXiv:1409.1556. [Google Scholar]
- Kingma, D.P.; Ba, J. Adam: A method for stochastic optimization. arXiv 2014, arXiv:1412.6980. [Google Scholar]
- Wang, Z.; Bovik, A.C.; Sheikh, H.R.; Simoncelli, E.P. Image quality assessment: from error visibility to structural similarity. IEEE Trans. Image Process. 2004, 13, 600–612. [Google Scholar] [CrossRef]
- Veganzones, M.A.; Simoes, M.; Licciardi, G.; Yokoya, N.; Bioucas-Dias, J.M.; Chanussot, J. Hyperspectral super-resolution of locally low rank images from complementary multisource data. IEEE Trans. Image Process. 2015, 25, 274–288. [Google Scholar] [CrossRef] [PubMed]
- Yuhas, R.H.; Goetz, A.F.; Boardman, J.W. Discrimination among semi-arid landscape endmembers using the spectral angle mapper (SAM) algorithm. In Proceedings of the Summaries of the Third Annual JPL Airborne Geoscience Workshop, Pasadena, CA, USA, 1–5 June 1992; pp. 147–149. [Google Scholar]
- Dong, C.; Loy, C.C.; He, K.; Tang, X. Image super-resolution using deep convolutional networks. IEEE Trans. Pattern Anal. Mach. Intell. 2015, 38, 295–307. [Google Scholar] [CrossRef]
- Lim, B.; Son, S.; Kim, H.; Nah, S.; Mu Lee, K. Enhanced deep residual networks for single image super-resolution. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition Workshops, Honolulu, HI, USA, 21–26 July 2017; pp. 136–144. [Google Scholar]
- Zhang, Y.; Li, K.; Li, K.; Wang, L.; Zhong, B.; Fu, Y. Image super-resolution using very deep residual channel attention networks. In Proceedings of the European Conference on Computer Vision (ECCV), Munich, Germany, 8–14 September 2018; pp. 286–301. [Google Scholar]



















{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Satellite | Spectral Band | Central Wavelenght (nm) | Bandwidth (nm) | Spatial Resolution-GSD (m) |
|---|---|---|---|---|
| B1: Coastal Aerosol | 443 | 20 | 60 | |
| B2: Blue | 490 | 65 | 10 | |
| B3: Green | 560 | 35 | 10 | |
| B4: Red | 665 | 30 | 10 | |
| Sentinel-2 | B5: Red-edge 1 | 705 | 15 | 20 |
| B6: Red-edge 2 | 740 | 15 | 20 | |
| B7: Red-edge 3 | 783 | 20 | 20 | |
| B8: Near-IR | 842 | 115 | 10 | |
| B8A: Near-IR narrow | 865 | 20 | 20 | |
| B9: Water Vapor | 945 | 20 | 60 | |
| B1: Coastal Blue | 425 | 47.3 | Nadir | |
| B2: Blue | 480 | 54.3 | WV-2: 1.84 m | |
| B3: Green | 545 | 63.0 | WV-3: 1.24 m | |
| WorldView-2/3 | B4: Yellow | 605 | 37.4 | |
| B5: Red | 660 | 57.4 | 20° off Nadir | |
| B6: Red-edge | 725 | 39.3 | WV-2: 2.40 m | |
| B7: Near-IR 1 | 833 | 98.9 | WV-3: 1.38 m | |
| B8: Near-IR 2 | 950 | 99.6 |
| Location | Year | Sentinel-2 | WorldView-2 | WorldView-3 | Resolution |
|---|---|---|---|---|---|
| 2015 | 29 September | 4 June | - | 2.0 m | |
| Maspalomas | 2017 | 10 June | 10 June | - | 1.6 m |
| 2017 | 31 May | - | 31 May | 1.6 m | |
| Cabrera | 2016 | 5 September | 1 September | - | 2.0 m |
| Teide | 2017 | 10 June | - | 13 June | 1.2 m |
| 2018 | 31 May | 1 June | - | 2.0 m |
| Location | Year | Sentinel-2 | WorldView-2 | WorldView-3 | Resolution |
|---|---|---|---|---|---|
| Cabrera | 2019 | 10 May | 10 May | - | 2.0 m |
| Maspalomas | 2018 | 31 May | - | 22 May | 1.2 m |
| LR_nn | LR_cub | SR_0 | SR_0.1 | SR_0.2 | SR_0.5 | SR_0.7 | SR_1 | ||
|---|---|---|---|---|---|---|---|---|---|
| PSNR | mean | 26.048 | 26.049 | 28.099 | 28.036 | 27.893 | 27.476 | 27.160 | 26.099 |
| std | 2.368 | 2.368 | 2.249 | 2.287 | 2.326 | 2.369 | 2.357 | 2.323 | |
| SSIM | mean | 0.527 | 0.527 | 0.622 | 0.624 | 0.621 | 0.605 | 0.585 | 0.514 |
| std | 0.103 | 0.103 | 0.093 | 0.092 | 0.093 | 0.093 | 0.094 | 0.096 | |
| ERGAS | mean | 26.504 | 26.502 | 25.389 | 25.386 | 25.463 | 25.75 | 25.943 | 26.440 |
| std | 9.072 | 9.071 | 8.359 | 8.319 | 8.327 | 8.435 | 8.496 | 8.847 | |
| SAM | mean | 0.121 | 0.121 | 0.095 | 0.096 | 0.098 | 0.103 | 0.107 | 0.121 |
| std | 0.054 | 0.054 | 0.041 | 0.042 | 0.043 | 0.047 | 0.049 | 0.055 | |
| CC | mean | 0.934 | 0.934 | 0.959 | 0.958 | 0.956 | 0.951 | 0.948 | 0.934 |
| std | 0.053 | 0.053 | 0.032 | 0.033 | 0.035 | 0.04 | 0.042 | 0.052 |
| LR_nn | LR_cub | SR_0 | SR_0.1 | SR_0.2 | SR_0.5 | SR_0.7 | SR_1 | ||
|---|---|---|---|---|---|---|---|---|---|
| PSNR | mean | 26.280 | 26.30 | 27.851 | 27.912 | 27.848 | 27.455 | 27.085 | 26.019 |
| std | 1.617 | 1.657 | 1.498 | 1.530 | 1.572 | 1.612 | 1.616 | 1.605 | |
| SSIM | mean | 0.588 | 0.589 | 0.673 | 0.676 | 0.675 | 0.661 | 0.644 | 0.579 |
| std | 0.075 | 0.077 | 0.062 | 0.061 | 0.061 | 0.063 | 0.065 | 0.070 | |
| ERGAS | mean | 29.773 | 29.795 | 29.909 | 29.810 | 29.830 | 29.726 | 29.673 | 29.301 |
| std | 9.072 | 9.071 | 8.359 | 8.319 | 8.327 | 8.435 | 8.496 | 8.847 | |
| SAM | mean | 0.176 | 0.175 | 0.147 | 0.146 | 0.147 | 0.154 | 0.161 | 0.183 |
| std | 0.041 | 0.040 | 0.033 | 0.034 | 0.036 | 0.039 | 0.041 | 0.047 | |
| CC | mean | 0.929 | 0.929 | 0.950 | 0.951 | 0.950 | 0.945 | 0.939 | 0.922 |
| std | 0.053 | 0.052 | 0.036 | 0.036 | 0.037 | 0.042 | 0.046 | 0.059 |
| LR_cub | SRCNN [64] | EDSR [65] | RCAN [66] | SRGAN [35] | RS-ESRGAN (α = 0) | RS-ESRGAN (α = 0.5) | ||
|---|---|---|---|---|---|---|---|---|
| PSNR | mean | 26.049 | 26.528 | 26.481 | 27.029 | 26.898 | 28.099 | 27.476 |
| std | 2.368 | 2.315 | 2.337 | 2.269 | 2.248 | 2.249 | 2.369 | |
| SSIM | mean | 0.527 | 0.586 | 0.600 | 0.617 | 0.602 | 0.622 | 0.605 |
| std | 0.102 | 0.092 | 0.094 | 0.092 | 0.091 | 0.093 | 0.093 | |
| ERGAS | mean | 26.503 | 26.746 | 26.421 | 26.401 | 26.717 | 25.389 | 25.750 |
| std | 9.072 | 9.070 | 8.758 | 8.579 | 9.021 | 8.359 | 8.435 | |
| SAM | mean | 0.121 | 0.115 | 0.115 | 0.107 | 0.110 | 0.0954 | 0.103 |
| std | 0.053 | 0.051 | 0.045 | 0.042 | 0.046 | 0.040 | 0.047 | |
| CC | mean | 0.934 | 0.942 | 0.942 | 0.949 | 0.947 | 0.958 | 0.951 |
| std | 0.053 | 0.046 | 0.039 | 0.034 | 0.039 | 0.031 | 0.040 |
© 2020 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Salgueiro Romero, L.; Marcello, J.; Vilaplana, V. Super-Resolution of Sentinel-2 Imagery Using Generative Adversarial Networks. Remote Sens. 2020, 12, 2424. https://doi.org/10.3390/rs12152424
Salgueiro Romero L, Marcello J, Vilaplana V. Super-Resolution of Sentinel-2 Imagery Using Generative Adversarial Networks. Remote Sensing. 2020; 12(15):2424. https://doi.org/10.3390/rs12152424
Chicago/Turabian StyleSalgueiro Romero, Luis, Javier Marcello, and Verónica Vilaplana. 2020. "Super-Resolution of Sentinel-2 Imagery Using Generative Adversarial Networks" Remote Sensing 12, no. 15: 2424. https://doi.org/10.3390/rs12152424
APA StyleSalgueiro Romero, L., Marcello, J., & Vilaplana, V. (2020). Super-Resolution of Sentinel-2 Imagery Using Generative Adversarial Networks. Remote Sensing, 12(15), 2424. https://doi.org/10.3390/rs12152424