1. Introduction
Remote sensing is important for monitoring and modeling vegetation dynamics and distribution in large-scale ecological studies. Most of the studies applying these techniques use multispectral indices that are based on a ratio (or some other simple mathematical relation) of the reflectance at two or more wavelengths [
1,
2]. These indices allow for complex data analyses, such as better detecting and visualizing specific targets, like vegetation vigour [
3,
4], water bodies [
5], and deforestation patterns [
6], since they make explicit complex interactions between the bands that cannot be evidenced individually.
The most commonly used indices, such as the Normalized Difference Vegetation Index (NDVI), give a broad and general view of many observable phenomena. Although these traditional measures are still widely used, they present limitations, among which we may point out the saturation of the NDVI for closed canopies, preventing the identification of vegetation heterogeneity. As pointed by Verstraete & Pinty [
7], spectral indices are very sensitive to the desired information and unresponsive to perturbing factors (such as soil color changes, relief, and atmospheric effects). Thus, they argue that more suitable indices should be designed for specific applications and particular instruments, as both the desired signal and the perturbing factors vary spectrally, and the instruments themselves only provide data for certain spectral bands. In this sense, most of the studies have focused on very specific applications or situations [
8], i.e., most of them are very sensitive to new data and, thus, are not easily adaptable to different and possibly new applications or new datasets that are produced from diverse sensors.
Additionally, if the specific bands that are used for computing some indices are not available, they simply cannot be processed (e.g., the NDVI cannot be calculated from RGB images). Finally, most of the existing indices ignore available bands in multispectral images. In particular, land cover analysis is highly dependent on the sensor used for data acquisition [
9]. The ever growing variety of sensors with different technical specifications, such as spatial/spectral resolutions or acquisition protocols, may lead to low performance of traditional spectral indices, as they may not accurately reflect the same properties related to data obtained from different sources [
2]. In all of those situations, the use of techniques that can learn existing patterns of interest from data can lead to more effective indices that are tailored to specific classification-dependent applications.
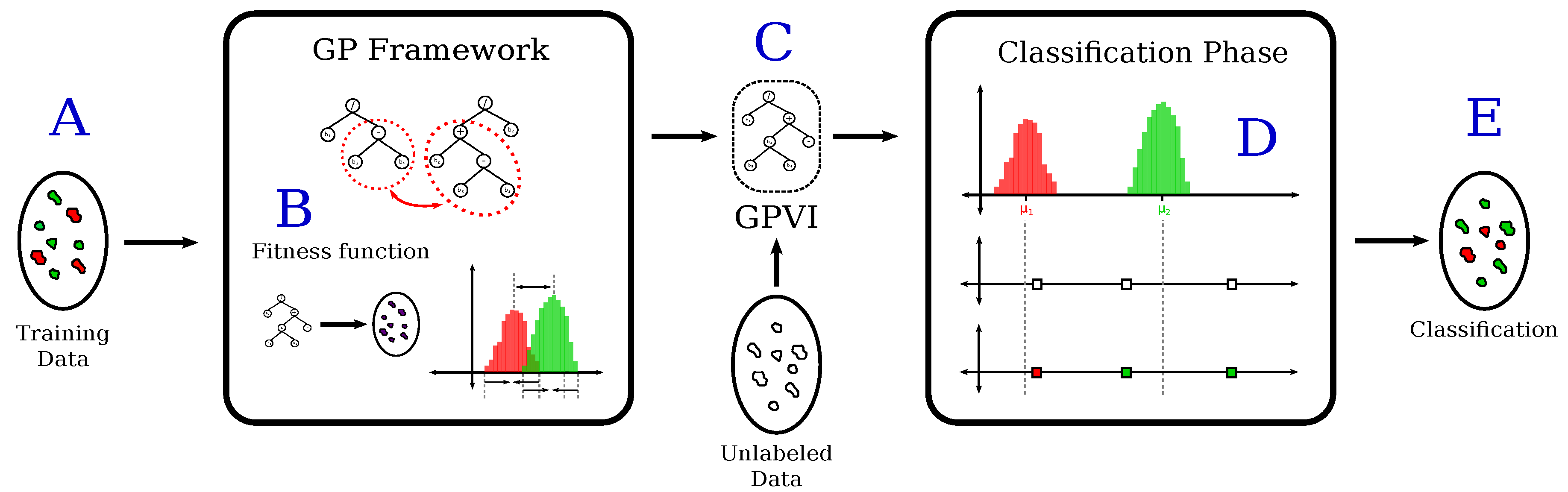
In this paper, we address those shortcomings by proposing a methodology that employs a Genetic-Programming (GP)-based framework for learning spectral indices that are specialized in discriminating pixels that belong to different classes. GP [
10] is an evolution-based method that models candidate solutions for a problem as individuals of a population, and makes them evolve through generations. The objective is to find the best solutions for the target problem as the best individuals of the evolved population.
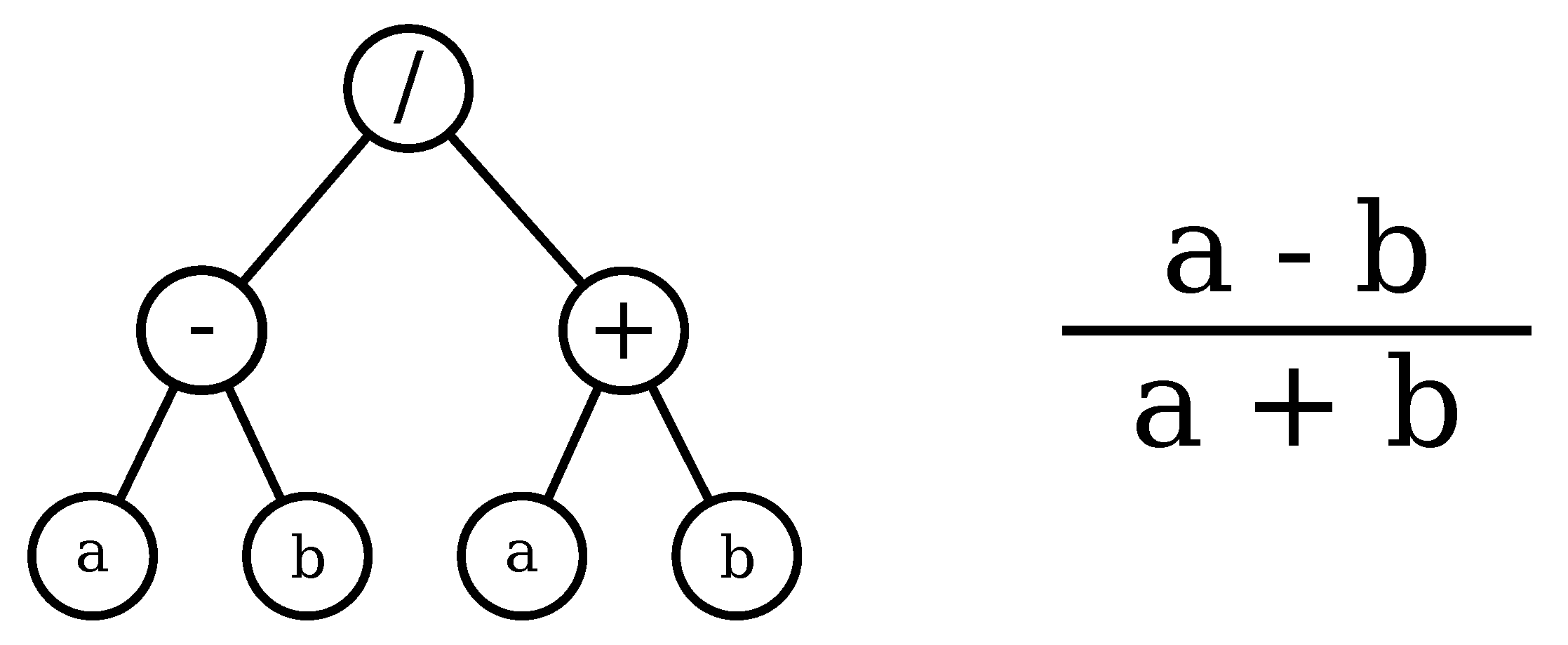
GP is widely known because of its capacity of effectively finding complex solutions to a great variety of problems, and because of its straightforward ability for parallel search [
10]. Perhaps, the most important property of GP is the interpretability of the solutions that are learned trough it, since it provides either math formulas or algorithms in a language that is predefined by the user. This property makes GP more suitable for spectral index learning than other evolutionary algorithms, because it can be designed to output formulas whose terms are spectral bands, combined through a set of operations that are defined by the user. The structure of the formula learned with GP can be further analyzed to determine the contribution of the spectral bands, and then induce high-level knowledge about the objects of study. The capacity of GP in solving a wide variety of complex problems is evidenced in a large volume of works that has successfully applied GP in uncountable domains [
11,
12,
13,
14].
Band selection and combination methods are important in multispectral scenery classification due to the well-known problem of the curse of dimensionality. The GP algorithm naturally selects and combines bands in a simultaneous fashion, as individuals in the population evolve. Hence, our method can be framed as a feature selection and extraction pipeline (rather than a merely band selection protocol) that projects multispectral images into a one-band feature space, yielded by the learned vegetation index. Even in the multispectral scenario, in which the few quantity of spectral bands suggests a lower risk of poor performance due to the curse of dimensionality, the selection of bands prevents classification flaws due to noisy bands.
We performed experiments to confirm our hypothesis related to the ability of Genetic-Programming-based vegetation indices (GPVI) for representing the canopy structural gradient between regions that can be either forests or savannas biomes, and the power of such index in extrapolating the classification of forest and savanna areas on a pixel basis for tropical South America, over time. We collected data from four multispectral sensors: Landsat 5 TM, Landsat 7 ETM+, MODIS MOD09A1.006 (Terra), and MODIS MYD09A1.006 (Aqua), forming monthly temporal series of the period between 2000 and 2016. Biomes are recognized as vegetation units of a particular physiognomy, which is the characteristic spatial arrangement and dominance of plant life forms that explain the vegetation general appearance [
15,
16]. In summary, we target four research questions:
- Q1.
Are GP-based indices more effective than traditional indices in biome type classification tasks?
- Q2.
Would GP-based indices yield effective results when used in more complex classification problems such as those related to the discrimination of different vegetation types within the same biome?
- Q3.
Are GP-based indices suitable for time-series-based classification tasks?
- Q4.
What are the most frequently selected bands by using the GP-based discovery process?
It is important to state that this framework is not proposed to be a new land cover classification scheme. It is intended as a generic framework for guiding the identification of suitable combinations of spectral bands in remote sensing imagery, which may be used later in classification systems. To answer Q1, we compare classification performance on multispectral pixels projected by GPVI with respect to the ones projected by the widely used Normalized Difference Vegetation Index (NDVI) and Enhanced Vegetation Index (EVI). Furthermore, we handled two finer-scale classification problems, based on the discrimination of subcategories of savannas and forests with respect to its physiognomical structure and, thus providing an answer to Q2. Biomes are often subdivided into structural, compositional and/or functional subcategories (hereafter called “vegetation types”), according to plant phenological patterns (canopy leaf production and loss) or tree cover variation (canopy height and closure), among others. Analysis by vegetation type yields two sub-classes for forest (evergreen forests vs. semi-deciduous forests) and savannas (typical savannas vs. forested savannas). (In the context of this paper, we use the term forested savanna to refer to a tropical savanna biome which structurally resembles forests [
17].) To address Q3, taking advantage of the available temporal data, we perform experiments for whole-time-series classification and analysis, yielded by GPVI and the traditional indices. To address Q4, we analyze the structure of the learned spectral indices to determine the contribution of each band for classification.
2. Related Work
GP and other bio-inspired strategies have been used to develop spectral indices in a wide range of applications [
18,
19,
20]. Chion et al. [
21] proposed the genetic programming-spectral vegetation index (GP-SVI), a method that evolves a regression model to describe the nitrogen level in vegetation. A very similar work by Puente et al. [
22] introduced the Genetic Programming vegetation index (GPSVI) to estimate the vegetation cover factor in soils to assess erosion. Ceccato et al. proposed a new methodology to create a spectral index to retrieve vegetation water content from visible data [
3]. Gerstmann et al. [
23], in turn, introduced a method to find a general-form normalized difference index to separate cereal crops, through an exhaustive search in a set of possible permutations of bands and constants used in a general formula and measures effect size to determine class separability.
Spectral indices have demonstrated an ability to separate different classes of woody vegetation [
24]. However, efforts that apply spectral indices for classification purposes normally rely on time series [
25,
26,
27]. A single value in time of the indices about an object of interest is not enough to discriminate it. This is particularly true in vegetation analysis since an object of interest can change its configuration seasonally. The possibility of novel indices that encode discriminative information invariant through time is open and could be achieved with our proposed technique. Balzarolo et al. [
28] showed that, while using the NDVI index, there is a high correlation between the starting day of the growing season observed with MODIS data, and in-situ observations. Wang et al. [
29] developed a three-band vegetation index to minimize the snow-melt effect in monitoring spring phenology.
GP has also been used for classification. Ross et al. presented a method for mineral classification using three classes [
30]. Rauss et al. [
31] proposed evolving an index that returns values greater than 0 when there is grass in the image, and values smaller than 0, otherwise. In general, approaches for classification are applied in very close configurations like few classes or isolated binary cases. Regarding function learning for general purposes, GP has also been used to learn formulas to combine time series similarity functions [
32,
33], or formulas that extract relevant information from similarity measures obtained throughout the user relevance feedback iterations [
34], or textual sources [
35].
Different from the previous attempts, we propose a method that relies on how data are distributed in the space yielded by candidate indices, instead of driving the learning process exclusively to find indices that satisfy specific purposes (e.g., regression, classification). Albarracín et al. [
36] explored the idea of learning spectral indices for classification tasks. Different from that work, here we conduct a comprehensive formal description of the GP-based index discovery framework. The objective is to guide researchers and developers in the creation of novel realizations and extensions of the proposed approach for managing multispectral data for different applications. To the best of our knowledge, this is one of the first works to describe experiments while using GP-based indices in such problems. We also add further analysis about the relevance of bands found in the learned vegetation indices. This may provide insights about the most important environmental processes that characterize each biome evaluated here. Finally, we introduce an optimized fitness function that is designed for a binary classification problem.
4. Experiments and Results
In this section, we separately address the research questions, stated in
Section 1. Therefore, each question is addressed in a specific subsection, which presents the adopted experimental protocol, used datasets (when necessary), and achieved results.
Additionally, we provide a set of experiments that are orthogonal to the ones that involve the data from Tropical South America (Q1, Q2, Q3, and Q4). In these experiments, we test sensor invariance in GPVI, i.e., how robust is our method when tested on different sensors. Therefore, all experiments presented in
Section 4.1,
Section 4.2,
Section 4.3 and
Section 4.4 consider results that are related to the use of two families of sensors: Landsat and MODIS.
4.1. Gpvi for Broad-Scale Biome Classification
In this section, we address Q1 by performing experiments for the forest/savanna discrimination problem on raw (non-temporarily ordered) pixels, in which traditional vegetation indices (e.g., NDVI, EVI, and EVI2) are widely used.
4.1.1. Data Acquisition and Pre-Processing
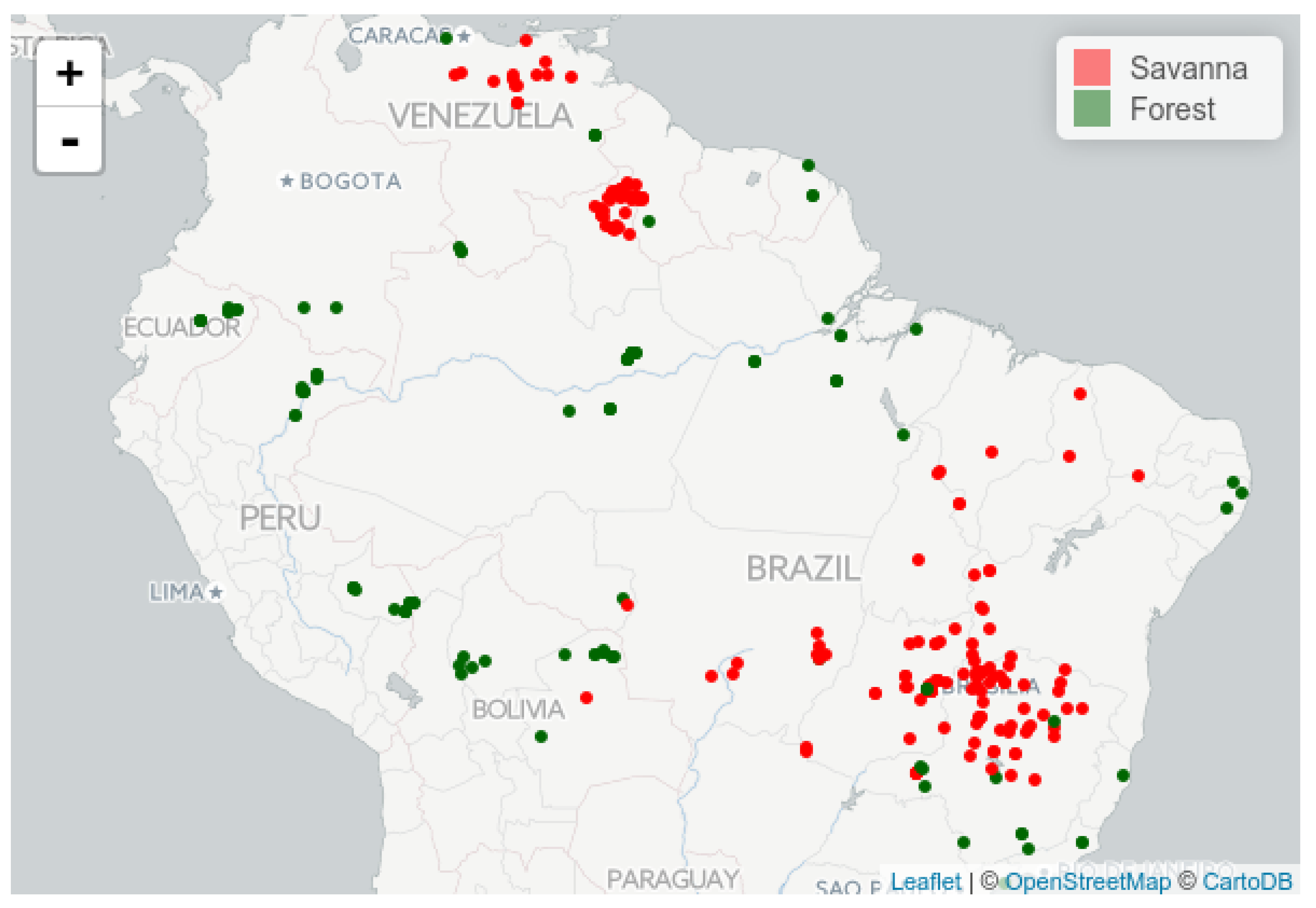
The selected study sites are distributed across the region, comprising South American tropical savannas and forests (
Figure 5). These locations correspond to 250 m × 250 m areas with the centroids imported from a subset of the inventory data used by Dantas et al. [
38]. Each of these points is visually assessed using Google Earth (GE) images from 2016, superimposed with MODIS grid cells of the same size while using Series Views [
39]. The geographical coordinates used as ground truth are defined in terms of whether the MODIS pixel at which the points fall into are completely filled with the vegetation type consistent with the corresponding labeled biome (i.e., savanna or forest) and vegetation types, as determined during the field work campaigns. Pixels that are not entirely filled with the corresponding biome type (e.g., due to deforestation and conversion to other land uses) are either replaced by a neighboring pixel fulfilling these criteria or discarded (when a nearby suitable pixel could not be found).
The data were acquired using the Google Earth Engine (GEE) API to download the scenes containing the study areas along the time. Two different data products from different sensors were downloaded:
Landsat Surface Reflectance sensors(Landsat) (
https://www.usgs.gov/products/data-and-tools/gis-data (As of 3rd March 2020)): we merged data from Landsat 5 Thematic Mapper (TM), and Landsat 7 Enhanced Thematic Mapper Plus (ETM+), as suggested by Kovalskyy and Roy [
40], in order to alleviate the lack of data availability due to the Landsat 7 ETM+ scan line failure in 2003. The GGE API retrieves the data form the United States Geological Survey (USGS), which provides Level-1 terrain-corrected (L1T) products, and already pre-processes the scenes regarding cloud detection (with the
fmask algorithm [
41]), geo-referencing, and atmospheric correction.
The data are available at 250 m/pixel for all the bands in the LANDSAT sensors, and only in bands 1 and 2 of the MODIS ones, while, for bands 3 to 7, the spatial resolutions is of 500 m/pixel. As GEE lets the users define the spatial resolution of the data to be acquired, each area was covered exactly by one pixel in LANDSAT. In MODIS, bands 3–7 contain information of the surrounding region of each one of the areas. For each area, we downloaded a time series, corresponding to the period covered from January, 2000 to August, 2016. In order to fill gaps (principally due to the Landsat 7 failure in 2003), the data were composite into monthly time series and is subsequently linearly interpolated.
Table 1 presents information about the bands downloaded for both sensors, Landsat (
https://www.usgs.gov/faqs/what-are-best-landsat-spectral-bands-use-my-research (As of 3rd March 2020)) and MODIS, associating the channel name with the band code and specifying the wavelength range covered by the band. We selected the channels blue, green, red, near infrared (NIR) 1 and 2, and short-wave infrared (SWIR) 1 and 2. Landsat TM products also normally provide information for the thermal infrared spectral region (LWIR), corresponding to band number 6. However, these specific SR products do not include this information.
4.1.2. Baselines
The indices learned through the proposed method (GPVI) are compared to three of the most widely used vegetation indices to characterize forests and savannas [
42]. Hereafter we will refer to these three methods as our baselines:
Normalized difference vegetation index (NDVI): normalized difference between the red and near infrared channels to measure vegetation greenness [
43].
Enhanced vegetation index (EVI): enhancement of sensitivity adding the blue channel [
44]. Proposed to improve saturation problems occurring in NDVI, when representing forest heterogeneity.
Two-band enhanced vegetation index (EVI2): calibration of EVI so it must not depend on the blue band, particularly because the blue band is not included in products of old sensors and normally presents noise problems [
45].
4.1.3. GP Configuration
Table 2 shows a summary of the configuration of the GP algorithm. The parameters of the formulas (i.e., leaves of the trees) are random real numbers between 0 and
, and the variables are spectral bands. The possible operators of the formula (i.e., internal nodes) are addition (+), subtraction (−), multiplication (*), protected division (%), protected square root (
), and protected natural logarithm (
), as suggested by Koza [
10] in order to avoid division by zero, imaginary roots, and logarithm of negative numbers.
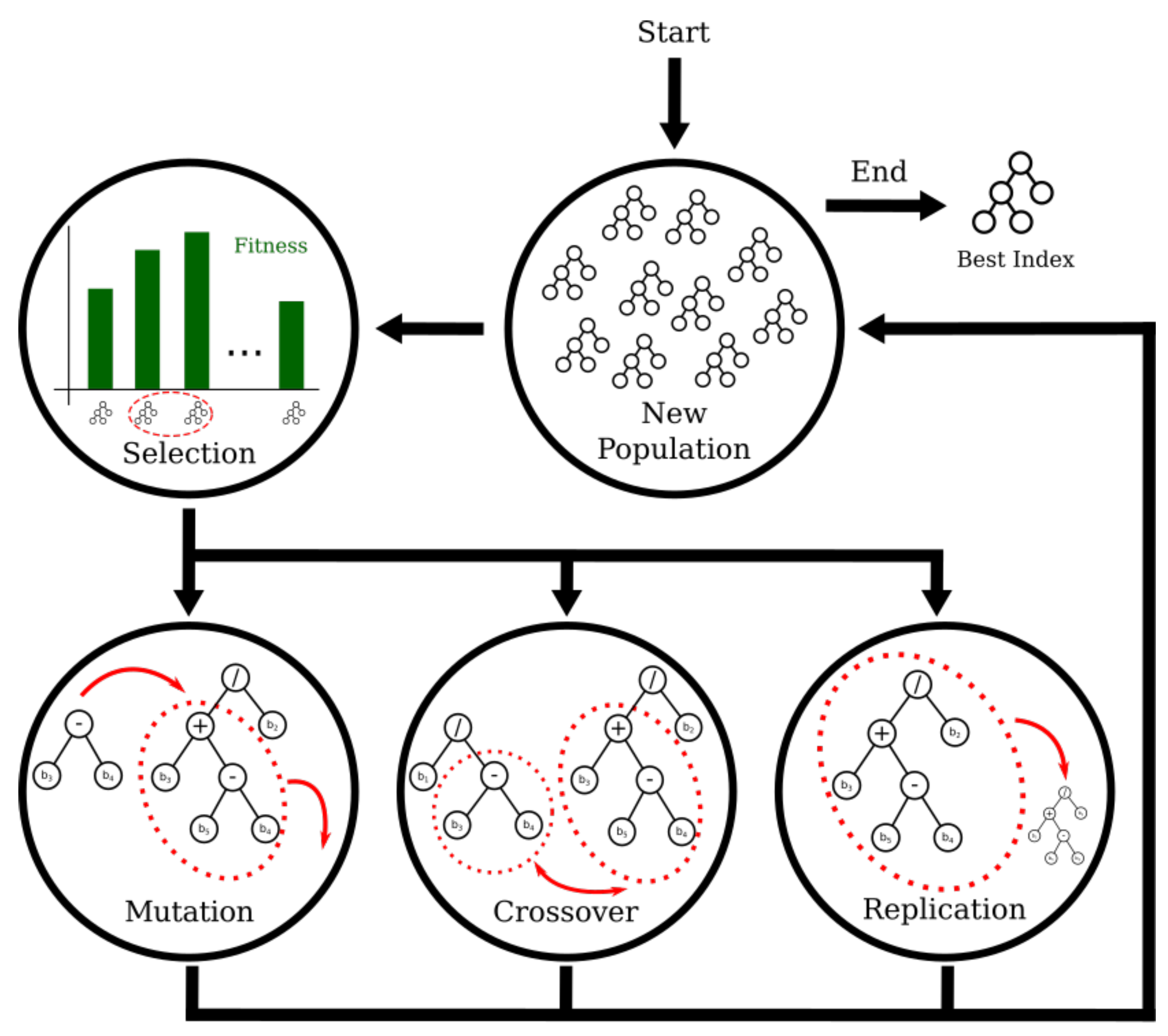
The experiments were performed with 100 individuals and 200 generations. New randomly generated trees will not have a depth greater than 6. The selection method is tournament with three individuals. It consists of randomly selecting three individuals from the population and allowing the best one to go to crossover, as many times as a new population is completed. Once two individuals are chosen, they have a probability of to cross their genetic information and create new individuals. Every new individual in the population has a probability of to mutate. The algorithm must stop when 200 generations are reached. The learning process for all classification problems using this configuration converged correctly, so more complex configurations, e.g., more iterations or a higher number of generations were not likely to improve performance.
4.1.4. Evaluation Protocol
GPVI is optimized to discriminate raw pixels, rather than whole time series. We considered the pixels only corresponding to the first five years (from 2000 to 2004) of the collected time series as training set for the GP framework, without preserving their temporal relation, since GPVI is intended to be time-independent. Thus, each pixel in each location (281 in total) and time stamp (12 months × five years) is a sample. Once obtained, the GPVI is used to classify the rest of the data, used as test set. The classification performance on the test set (from 2005 to 2016) is reported in the following section.
4.1.5. Results
The performance of GPVI and the indices used as baselines are summarized in
Table 3. The columns marked with
Prod.,
User, and
Acc. correspond to the producer’s, user’s, and normalized accuracies, respectively. The producer’s accuracy for each class is the rate of correctly classified samples that belong to that class, while the user’s accuracy is the rate of correctly classified samples that are classified by the system as such. The normalized accuracy is the average of the producer’s accuracy of all the classes, which is a total accuracy (rate of correctly classified samples) giving all of the classes the same weight, regardless of the number of samples that belong to each one. The results obtained for Landsat and MODIS sensors can be contrasted.
The baselines presented similar performances and were clearly outperformed by GPVI ( better as compared to Landsat and to MODIS). In general, the performance for Landsat was better than the one for MODIS, and the rate of correctly classified savannas was higher than the rate of correctly classified forests. Regarding user’s accuracy, a clear superiority of GPVI over the baselines was observed.
It is important to remark that a lower performance of GPVI and the baselines is expected for MODIS, as bands 3 to 7 have lower spatial resolution, which forced the data collection process to include information of the surrounding of the areas, which can be considered as noise.
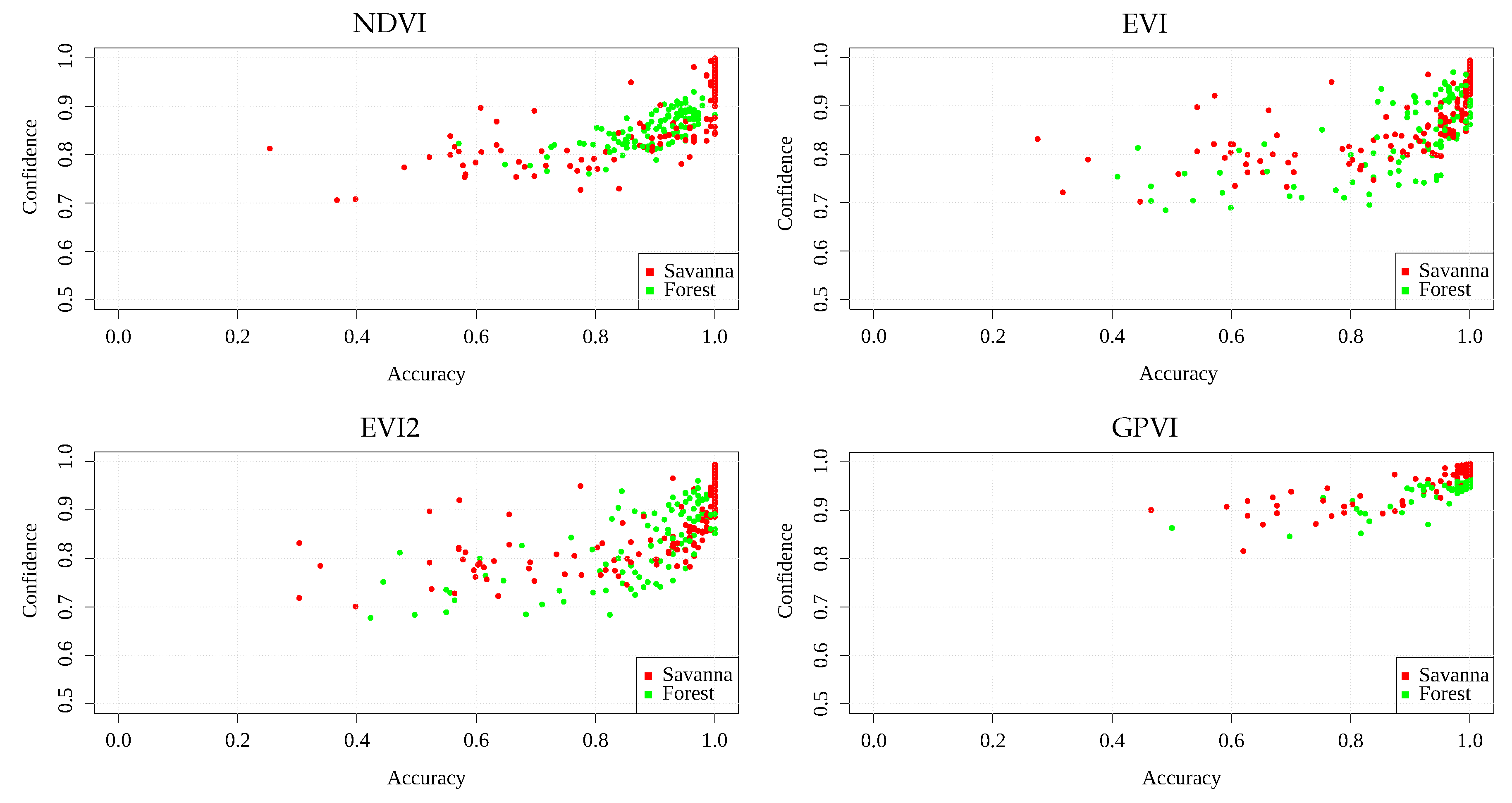
An additional experiment tests the confidence of the classification of the spectral indices. For this, we took the one-band pixel values, yielded by each spectral index, for all of the locations, trained a Logistic Regression classification algorithm with them [
46] ([Ch. 4]), and used its predicted class probability given a data point as a confidence score, since the class that is assigned to the areas depends on whether this value is under or over
. Thus, scores that are close to this value are more likely to be classified incorrectly, since the algorithm is totally uncertain of the class that it assigns to the sample.
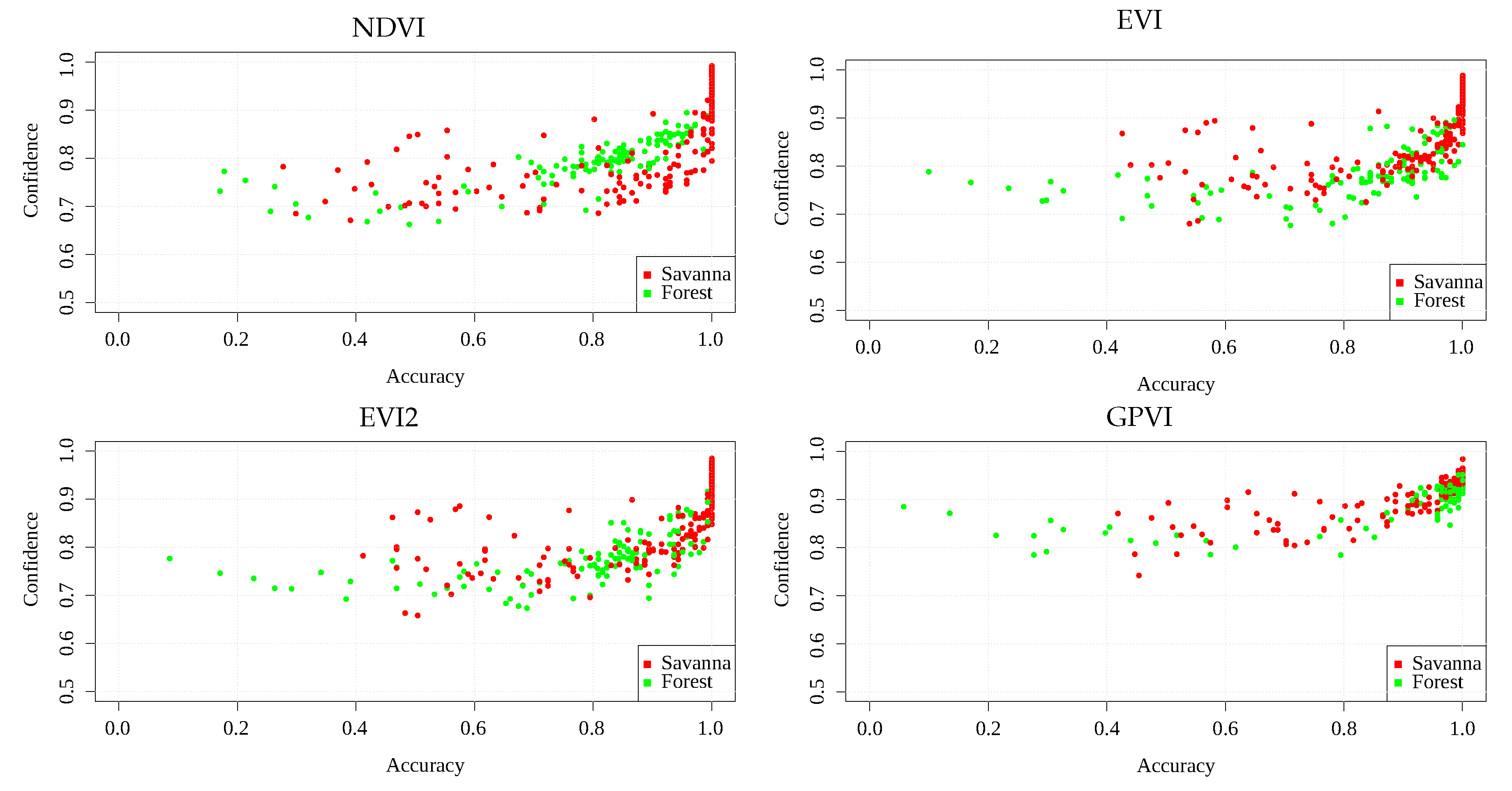
Figure 6 and
Figure 7 show scatterplots of mean accuracy vs. mean confidence score obtained in each area, for Landsat and MODIS, respectively. It can be seen that GPVI presented, on average, higher confidence values than the baselines, which means less confusion at classification time. The fact that savannas and forest can transit into each other’s states [
38], can explain those areas that, in general, obtained low confidence and low accuracy, since a transitional location presents features of both biomes, leading to a higher confusion in the classification algorithm. Those areas presenting low accuracy and high confidence in various experiments could also result from mislabeled samples.
4.2. Gpvi for Finer-Scale Vegetation Type Classification
To address Q2, we consider two separate classification problems that are harder than forest/savanna discrimination, as they deal with the discrimination of vegetation types (subcategories of savannas and forests with respect to their physiognomy): evergreen vs. semi-deciduous forests, and typical vs. forested savannas. In this setting, traditional indices often saturate and, normally, are not even considered in analyses, because they lack representation of within-biome differences (i.e., they consider the whole biome as an homogeneous landscape) [
2,
6,
42].
The data used for this set of experiments, as well as the baselines, the parameters used in the GP framework, and the evaluation protocol, are exactly the same as the ones that are used for the forest/savanna classification problem (
Section 4.1).
The performance of GPVI and the indices used as baselines are summarized in
Table 4 and
Table 5. The results obtained for Landsat and MODIS sensors can be contrasted.
For the evergreen forest/semi-deciduous forest discrimination (
Table 4), the baselines presented similar performances when compared to GPVI, except for NDVI from Landsat, which presented a much inferior performance than the other baselines. In general, the baselines behaved similarly for both sensors, and they were outperformed by GPVI by about
for Landsat, and by approximately
for MODIS. The performance of GPVI using MODIS data was much higher than Landsat, and evergreen forest was classified with a higher rate of correctly classified areas. The user’s accuracy shows an evident bias towards the class evergreen forest for all of the indices. However, this bias is slightly lower for GPVI.
For the typical savanna/forested savanna discrimination (
Table 5), the baselines presented similar performances for both sensors, and they were outperformed by GPVI by about
for Landsat, and by about
for MODIS. The performance of GPVI using Landsat data was superior than using MODIS, and forested savanna obtained a higher rate of correctly classified areas only for Landsat; for MODIS, both classes obtained similar rates. The user’s accuracy shows an evident bias towards typical savannas for all of the indices. However, this bias is slightly lower for GPVI.
4.3. Gpvi for Time-Series Analysis And Classification
To address Q3, we apply GPVI, along with the baselines, to the data collected, but now maintaining its temporal relation. Therefore, we are now not working with raw pixels, but with whole time series. For this set of experiments, there was no index-learning (i.e., training) stage, since we took the same indices that were learned in the experiments for raw-pixel-based forest/savanna classification (
Section 4.1), and evergreen forest/semi-deciduous forest and typical savanna/forested savanna classification (
Section 4.2). The only difference now is that they will be applied to the multispectral time series in order to yield one-dimensional time series.
The data used for this set of experiments, as well as the baselines, are exactly the same as the ones used for the raw-pixelwise forest/savanna classification problem (
Section 4.1).
4.3.1. Experimental Protocol
We use a slightly different protocol from the raw-pixel classification experiments, due to the amount of data available. For pixel classification, each pixel (281 in total) in each location at each time stamp (12 months × 5 years) is a sample, so there are enough data ( 16,860) to provide a reliable comparison between GPVI and other indices. For time series classification, on the other hand, the number of samples is substantially smaller, 25 areas had to be discarded due to a large amount of gaps, preventing a reliable linear interpolation to fill them. This yields 256 areas, which means a sample of 256 sites and, thus, a cross validation protocol is used.
We apply the GPVIs learned in the raw-pixel-classification phase on the time series of multispectral pixels to yield a one-dimensional time series per pixel. We do the same with the baseline indices. The resulting series are used as an input of a time-series classification scheme.
The time series classification set-up considers the entire time series of each area as a sample, and splits the datasets to settle a -fold cross validation protocol. In this protocol, we randomly sample half of the series, preserving class distribution, and use this half to train our classification algorithm; the other half is used for validation. The subsets are then swapped (the one used for training was now used for validation and vice-versa). This process is repeated five times, which results in a total of ten classification experiments.
We use the well-known 1-NN with Dynamic Time Wrapping (DTW) distance [
47] time-series classification algorithm to perform the experiments. We performed a series of statistical tests in order to compare GPVI with each one of the baselines, as suggested by the literature on classification algorithms [
48,
49]. First, we performed a Friedman test, a non-parametric test across multiple measures, which, in this case, are each one of the
-fold accuracies from GPVI and the three baselines. We complemented our analysis with Wilcoxon Signed Rank tests among every pair of methods. This test can only be done between two sets of experiments, while assuming that each experiment in a population is paired to another experiment of the other population, and it is also non-parametric. For the Friedman and Wilcoxon tests, we considered a significance level of
. Finally, to not underestimate the
p-values yielded by the Wilcoxon tests, we applied Bonferroni post hoc adjustment on the obtained
p-values.
Up to this point, we have shown the effectiveness of GPVI for pixelwise discrimination, without considering temporal information. However, in this section, we show how it behaves using time series, first with a visual comparison of GPVI with the other indices and then with the time-series classification set-up described above.
4.3.2. Time Series Analysis by Visual Assessment
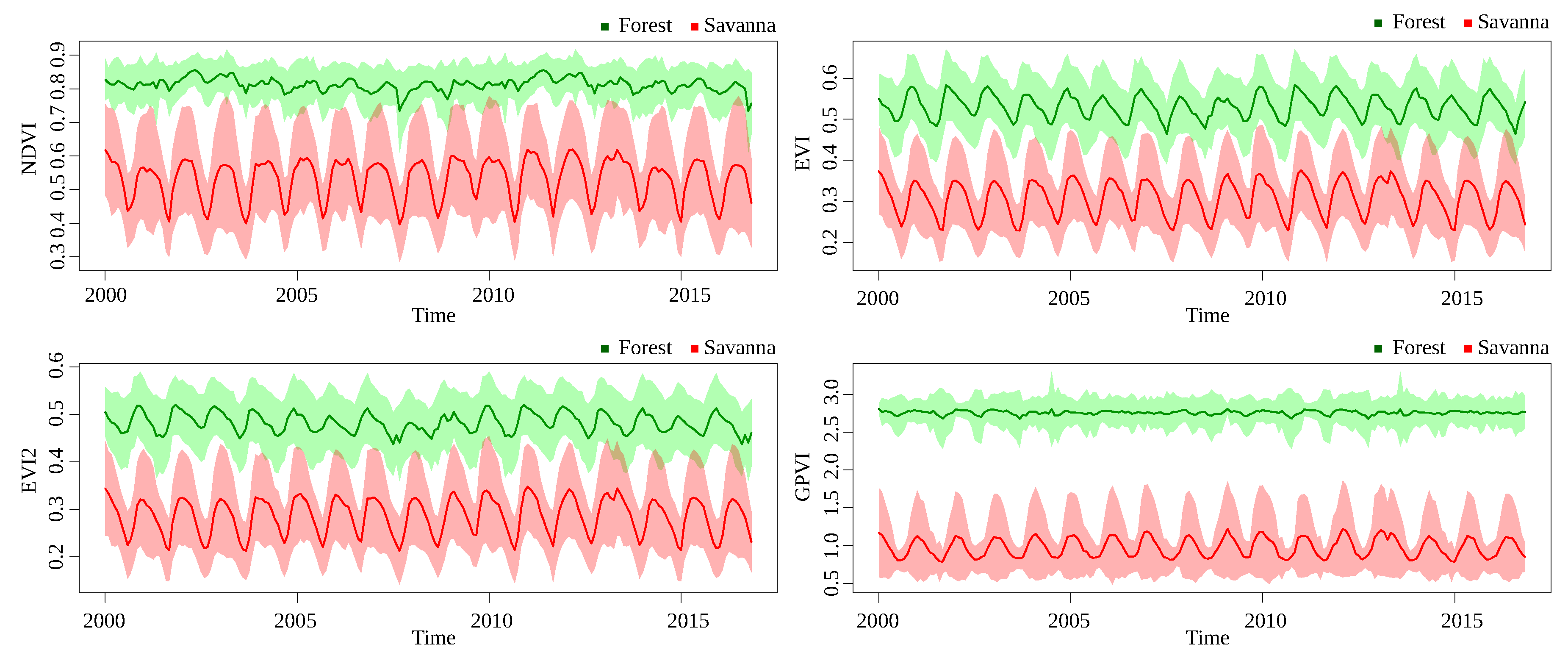
The time series for GPVI and the baselines are graphically represented, taking the mean of the pixel values of all areas from the same class in each time stamp, so it is desirable that the curves corresponding to different classes are far away from each other. The instantaneous standard deviation of each class are also shown around the corresponding curve, only for the forest-savanna discrimination, for visualization purposes, since the other classification problems presented less separability. It is important to point that, since GPVI is learned with many degrees of freedom, the values are not necessarily bounded like NDVI, for example, comprising values between −1 and 1.
Figure 8 and
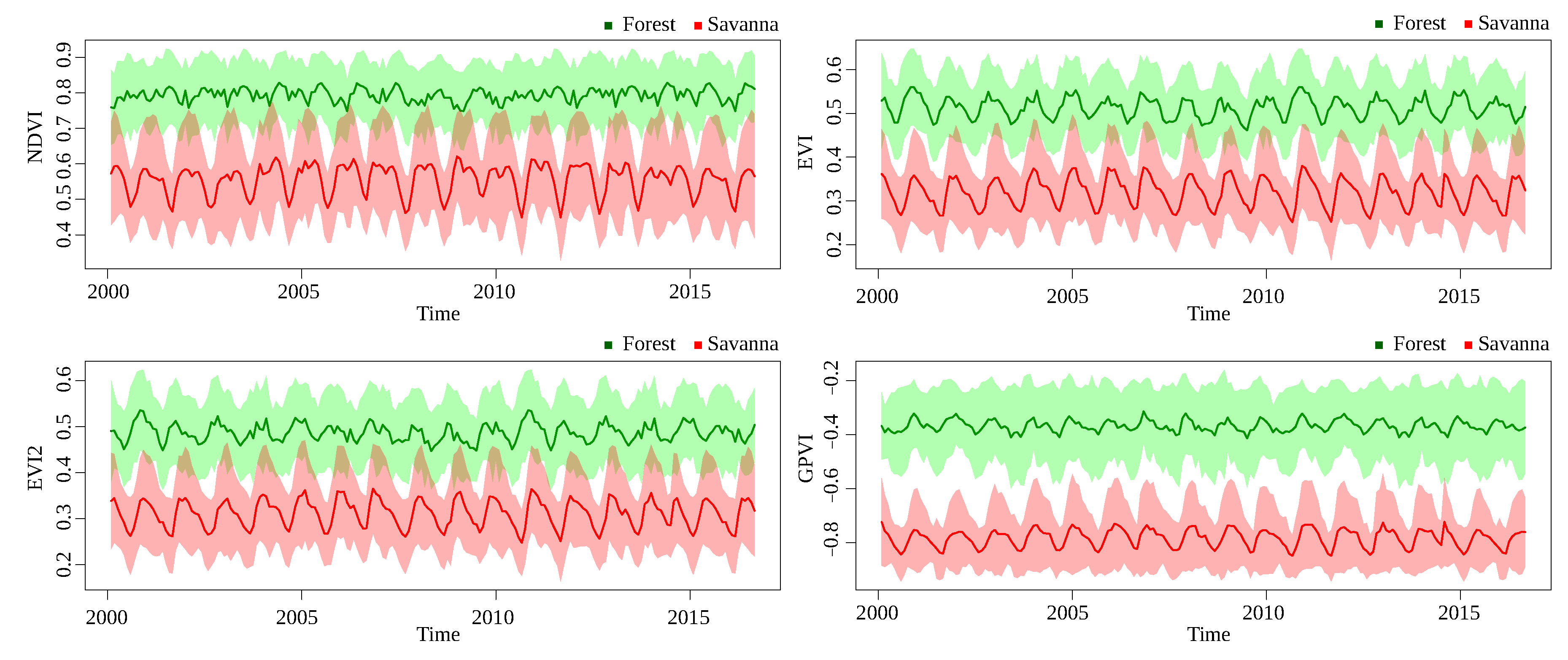
Figure 9 show the time series for Landsat and MODIS, respectively, in the forest/savanna classification problem. Landsat data present a greater separation between the series than MODIS, for GPVI and the baselines. It is clear how GPVI makes it easier to discriminate the values of pixels for the two classes, regardless of the time stamp.
The next classification problem corresponds to evergreen forest/semi-deciduous forest.
Figure 10 and
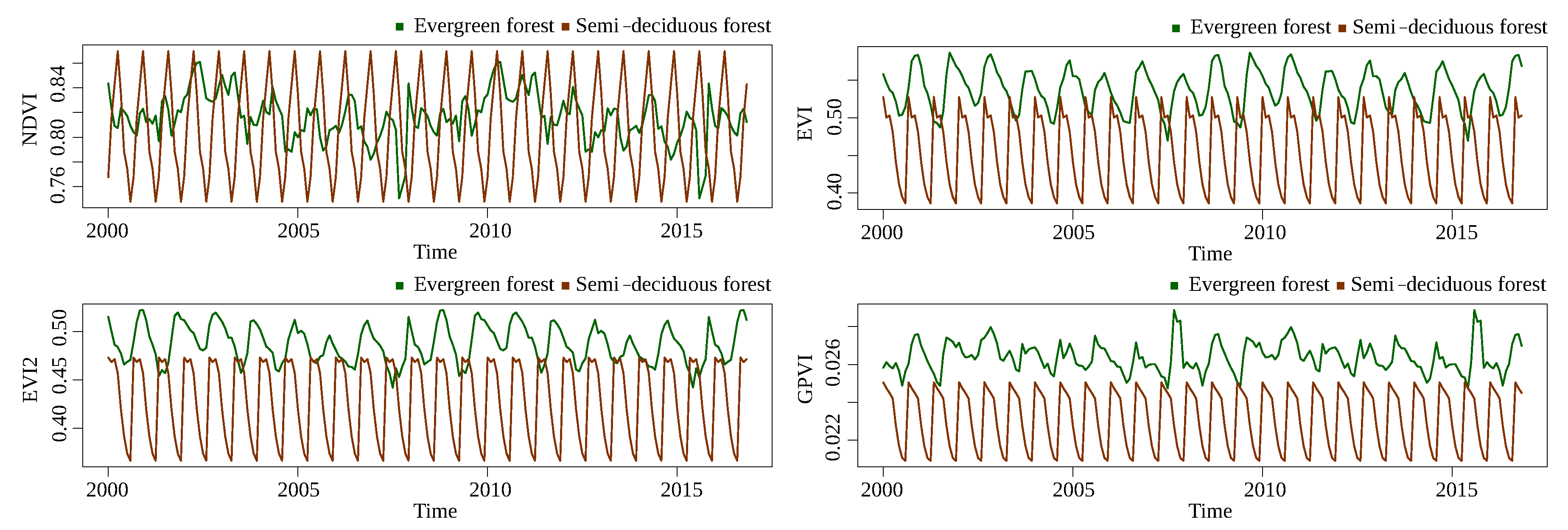
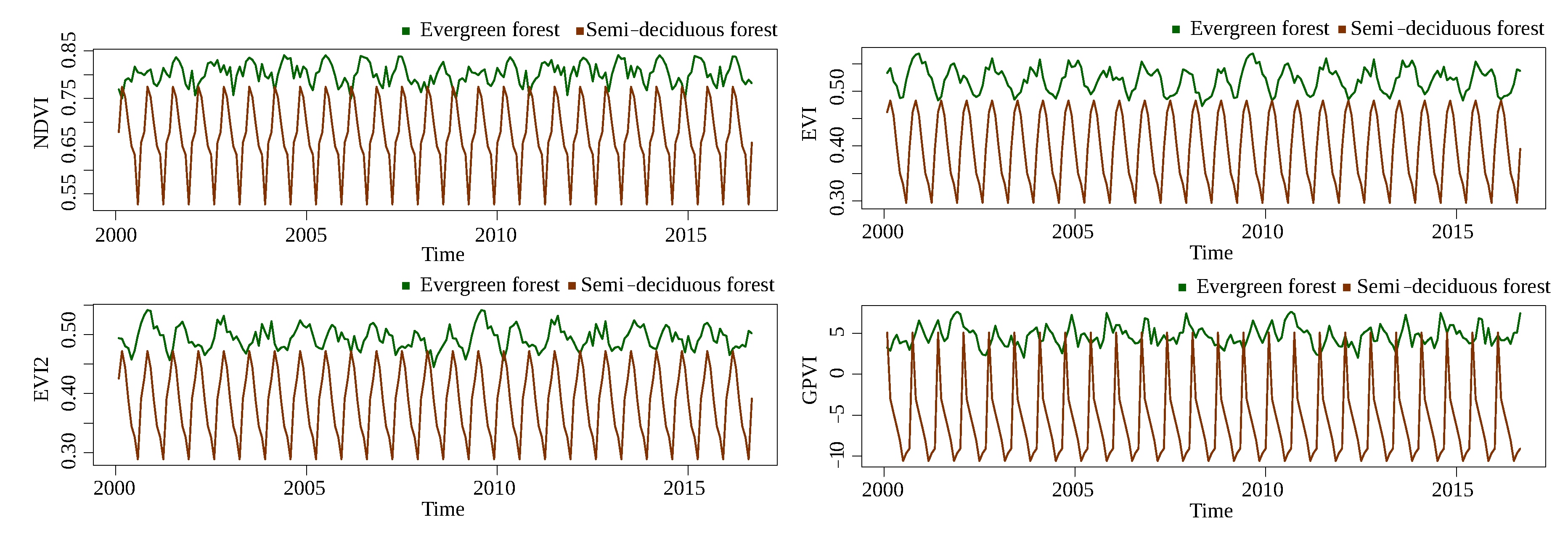
Figure 11 show the time series for Landsat and MODIS, respectively. Although the separation of GPVI is not as good as it was in the forest/savanna problem, it is still better than the baselines. Moreover, the difference between sensors is also not as evident.
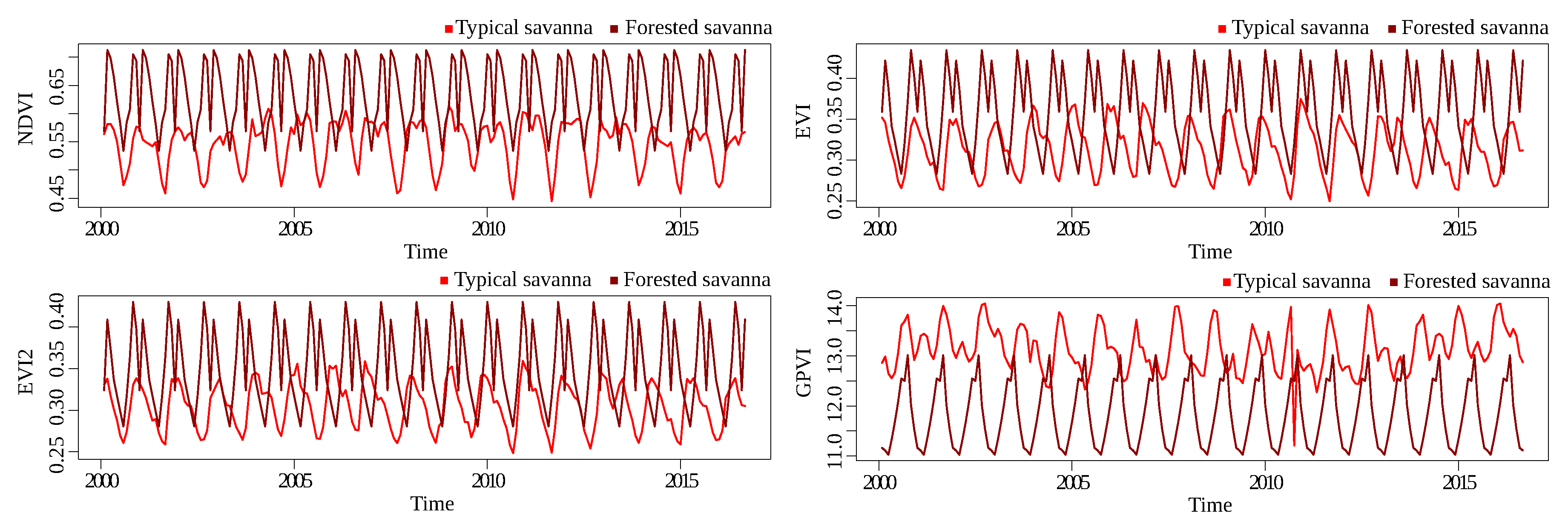
Figure 12 and
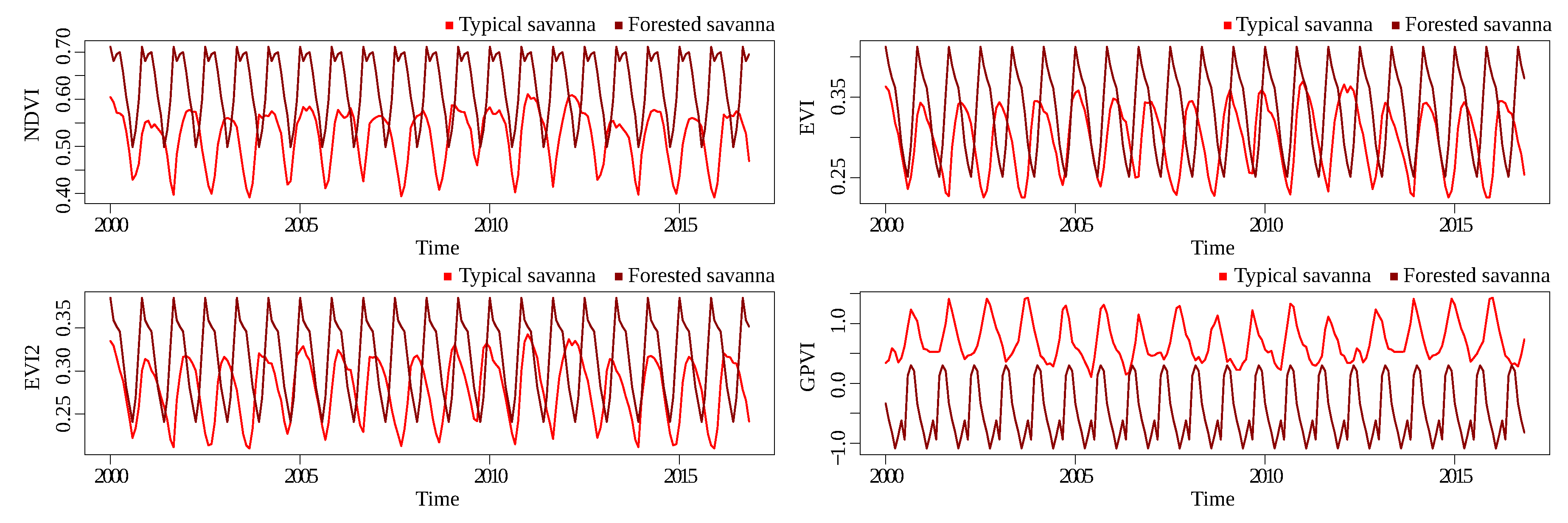
Figure 13 show the time series for Landsat and MODIS, respectively, for the typical savanna/forested savanna savanna classification problem. The separation of the classes for all indices was worse than the other classification problems, showing that discriminating between these two classes is a hard problem—at least with the available spectral information.
4.3.3. Time Series Classification Performance
Table 6 shows the normalized accuracy values that were obtained in the experiment corresponding to the forest/savanna time series discrimination for both sensors, as well as the user’s and producer’s accuracy. The Friedman test p-value associated with Landsat is
, and with MODIS was
, showing that, for both sensors, there was a significant statistical difference. However, the corrected pairwise tests show that there is no significant difference between GPVI and NDVI for Landsat. For MODIS, the tests show no significant difference between GPVI and EVI/EVI2.
Table 7 shows the normalized accuracy values that were obtained in the experiment corresponding to the evergreen forest/semi-deciduous forest time-series discrimination for both sensors, as well as the user’s and producer’s accuracy. The Friedman test p-value for Landsat was
and, for MODIS, was
, showing that there is no significant difference among all of the indices in general. The corrected pairwise tests show the same result. Unlike the forest/savanna problem, results using MODIS dataset shows better results than results with Landsat.
Table 8 shows the normalized accuracy values that were obtained in the experiment corresponding to the typical savanna/forested savanna time series discrimination for both sensors, as well as the user’s and producer’s accuracy. The Friedman test p-value for Landsat is
and, for MODIS, is
, showing that only for Landsat there was a significant difference. The corrected pairwise tests evidence the superiority of GPVI as compared to EVI2 only for Landsat. For this classification problem, both sensors obtained a similar performance.
4.4. Study on the Structure of the GPVIs
To address Q4, we analyze the relevance that GPVI assigns to the bands and operators to attain a good classification, by counting the most frequent formula elements in the top 10-indices obtained in the last population of the GP framework, for the raw-pixel classification experiments (
Section 4.1 and
Section 4.2). We compare the structure of the indices learned in Landsat and MODIS, and the relevance of the associated bands for both sensors in order to check whetherthey match or not.
4.4.1. Experimental Protocol
As mentioned before, we considered the results of the raw-pixel classification experiments and, for each classification problem, we extracted the 10 indices with the best performance that our GP framework found. While using the tree representation of the indices, we extracted all of the possible subtrees (one per inner node), corresponding to the subexpressions of a given formula. We then count and rank the subexpressions, and perform two analyses on this data: in the first one, we build frequency histograms of all of the bands and compare the histograms yielded on the Landsat experiments, with respect to the MODIS ones. In the second analysis, we count how many times each subexpression is present in each experiment and show the 10 most frequent ones, when comparing both sensors.
4.4.2. Results
We present the analysis on the structure of the GPVIs by analyzing the band and subexpression relevance.
Band Relevance
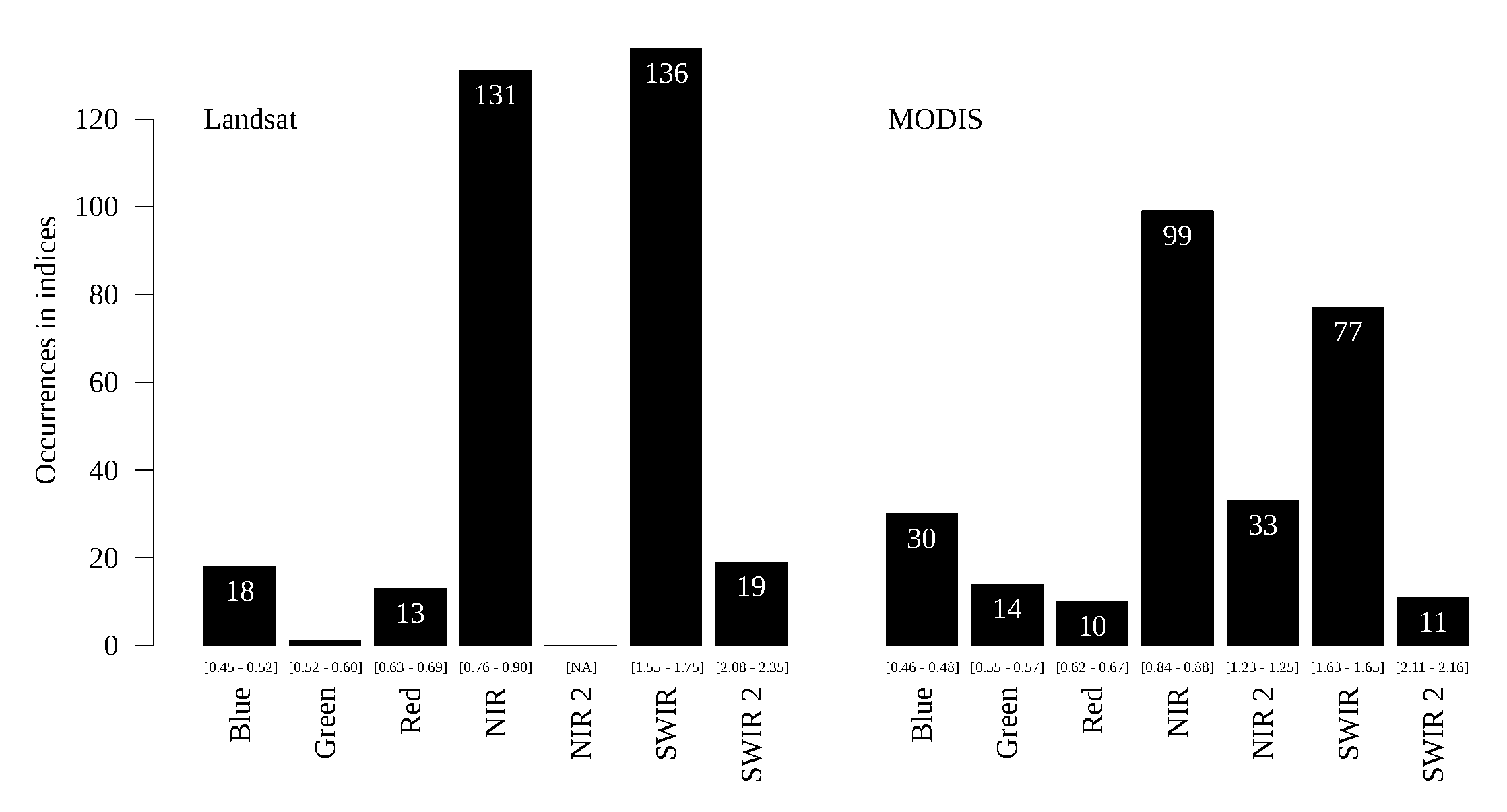
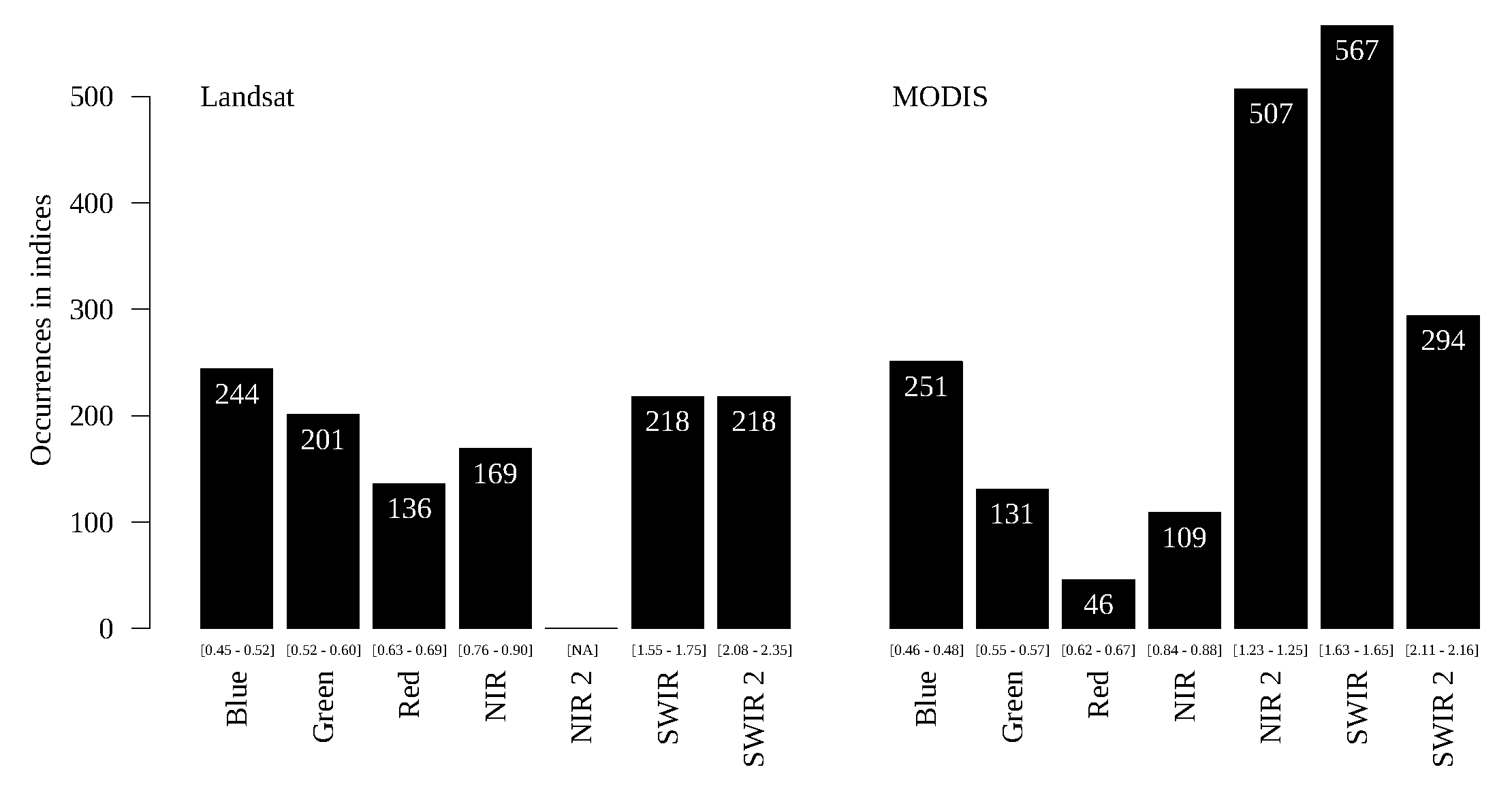
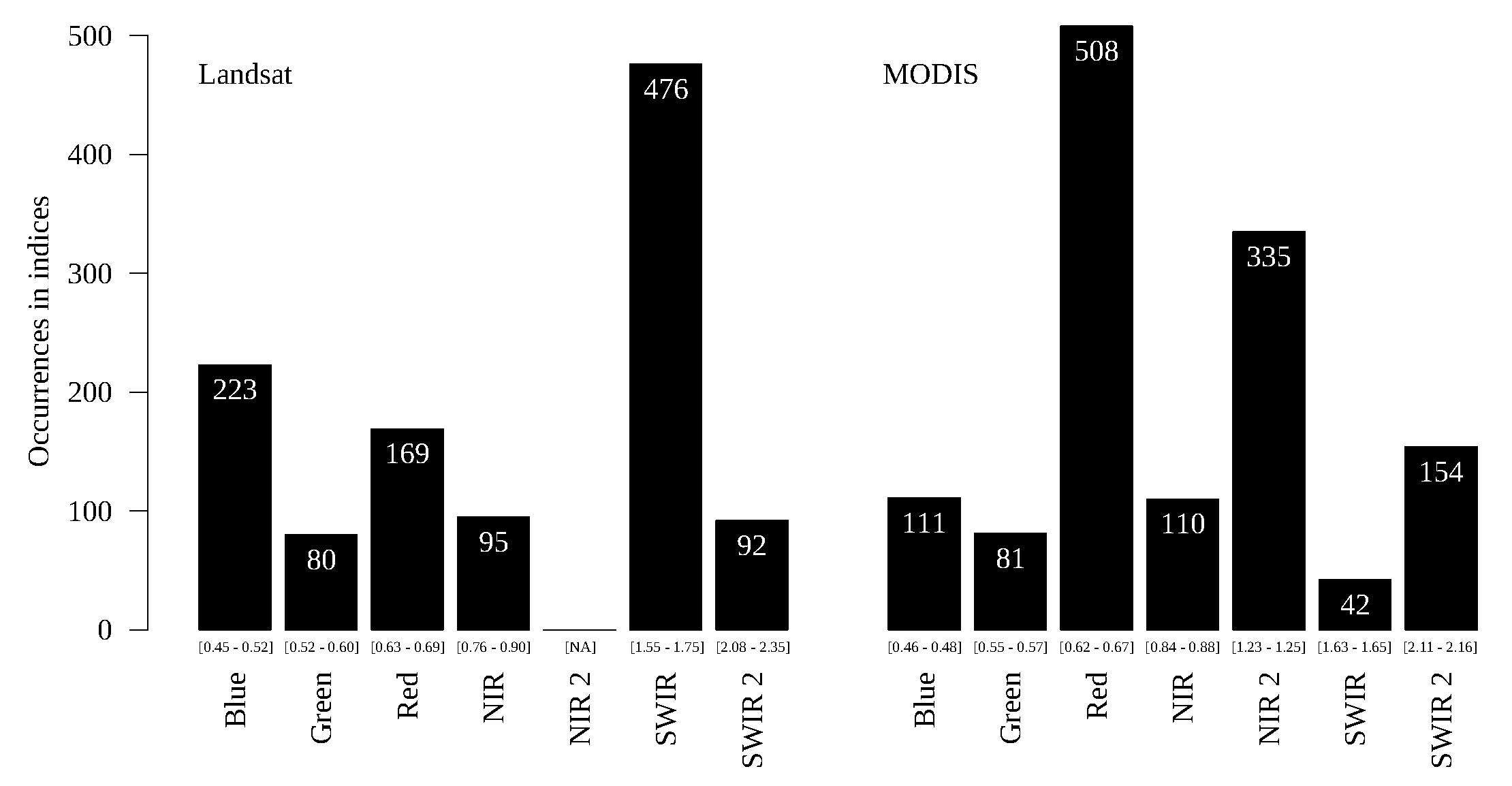
Figure 14,
Figure 15 and
Figure 16 show the number of occurrences of the bands with both sensors for, respectively, the forest/savanna, evergreen forest/semi-deciduous forest, and typical savanna/forested savanna classification problems.
We analyzed the histograms of band frequencies for the learned indices of both sensor families (Landsat and MODIS) in order to identify similarities and differences regarding the use of specific bands in the GP-based indices. To discriminate forests from savannas, there was an agreement between the two sensors, in that the most frequent bands were NIR and SWIR. This differs from the baselines, which consider the Red channel instead of the SWIR one. In fact, even the Blue channel (also used in EVI) was more frequently selected than the red one for both sensors. The NIR2 channel was selected as frequently as the Blue for MODIS. Apparently, the lack of this band did not give any disadvantage to the Landsat sensor to discriminate correctly.
The classification problems by vegetation type did not attain a satisfactory agreement for band frequency between the sensors. The separation by physiognomy between the same biome is clearly a harder problem.
The NIR2 and SWIR bands for the MODIS sensor have clear relevance in the evergreen forest/semi-deciduous forest problem, while, for Landsat, it is not prominent (
Figure 15). The only agreement between the sensors is that the Red and NIR bands, which are used in the baselines, are the least frequent. The performance of GPVI for MODIS is about
superior to Landsat (
Table 4), which suggests that the NIR2 band has high relevance in characterizing these classes.
The typical savanna/forested savanna problem presented no agreement between the sensors (
Figure 16). For example, the SWIR band is the most frequent for Landsat and the least frequent for MODIS, and the Red band, the most frequent for MODIS, is not so frequent for Landsat. This was also the most difficult pair of classes to discriminate in previous analyses.
Subexpression Relevance
Table 9 shows the top-ten most frequent formula elements found in the indices for the three classification problems.
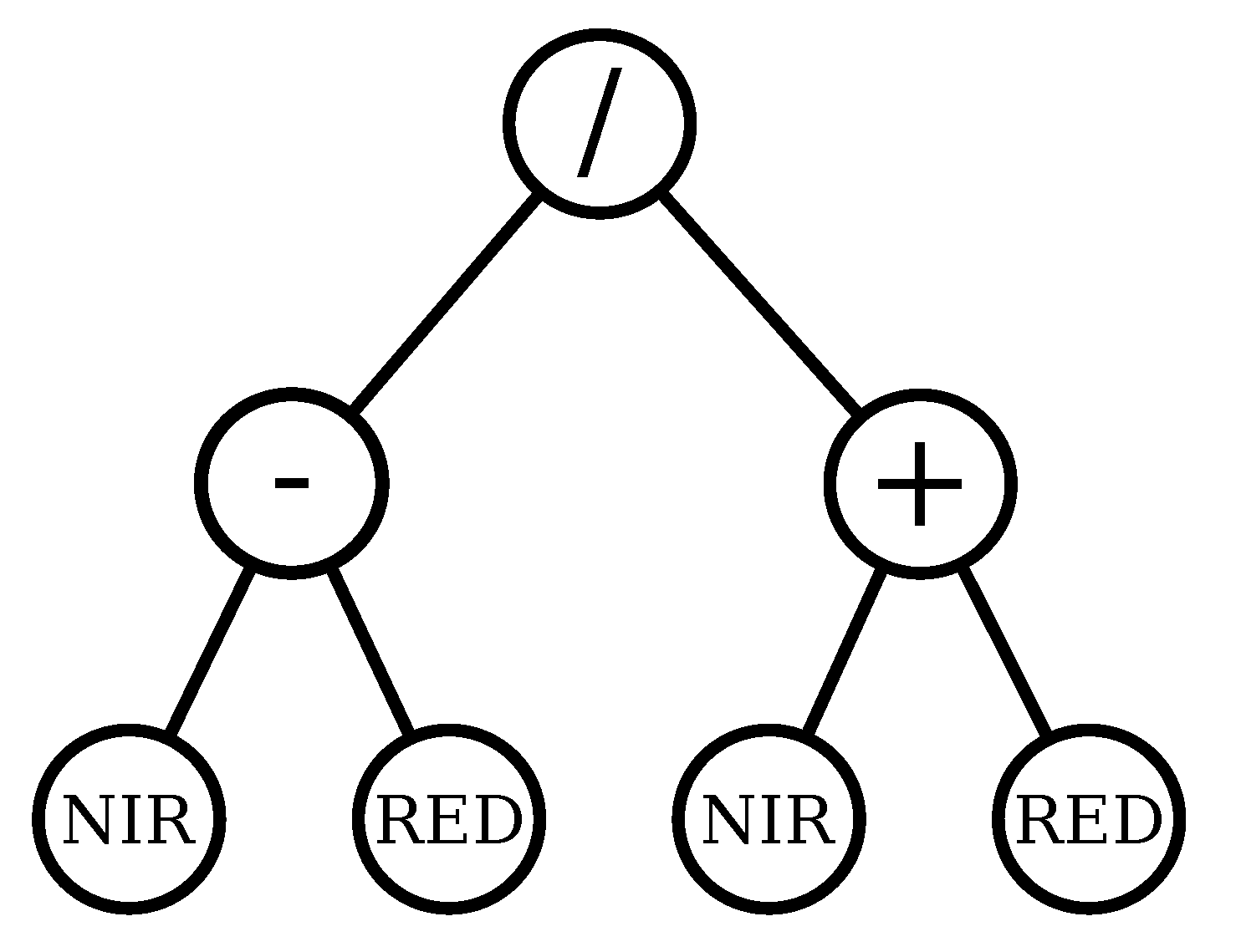
Regarding the Landsat data, it can be seen that the most recurrent bands are NIR and SWIR, and that the operations SWIR–NIR and SWIR2 % NIR appear various times. The following is an example of a GPVI learned in the forest/savanna classification problem for Landsat.
For MODIS, the NIR and SWIR bands are also the most recurrent, and the operations NIR2 % NIR and NIR % SWIR appear various times. The following is an example of a GPVI learned in the forest/savanna classification problem for MODIS.
For the classification of different physiognomies within the same biome, the complexity of the learned indices increases significantly, and a greater quantity of operations and constants appear in the formulas.
5. Discussion
The discussion about the results presented in
Section 4 is guided by the research questions defined in
Section 1. The performance of GPVI on the non-temporal-pixelwise forest/savanna classification problem (Q1) show a clear superiority of GPVI over NDVI, EVI, and EVI2. This suggests that there exist complex interactions between the bands that characterize the class of a sample, regardless of its behavior through time. In the baselines, savannas sometimes took high values that could be interpreted by the classification routine as forests, and vice versa (
Figure 8 and
Figure 9). Thus, it is not possible to point out one area in a specific timestamp, measure its index, and conclude its class. For this reason, the traditional classification benchmark generally involves temporal information.
The relatively lower performance in the finer-scale classification problems, such as evergreen vs. semi-deciduous forest, and typical savanna vs. forested savanna (Q2), probably responds to both technical and biological factors. Firstly, the amount of data available for each physiognomical subcategory is significantly lower than for the biome classification problem (approximately half), and the amount of data for each class is unbalanced, due to the predominance of evergreen forests over semi-deciduous forests, and typical savannas over forested savannas in the study region. Those two factors are disadvantageous for most of the prediction tasks. However, discrimination by physiognomy within the same broader-scale biome type is, by itself, clearly a more complex biological problem. Moreover, while species composition could also be used to distinguish between these vegetation types, and different species can present different spectral signatures [
50,
51], species composition can substantially overlap among the vegetation types considered here [
52]. All of these factors could have contributed to the limited results that were obtained for these specific classification problems.
Unlike single-pixel classification, the time series classification approach showed that the accuracy of GPVI was not significantly superior to the baselines (Q3). The most relevant reason is the fact that GPVI was originally trained for pixel classification, and the fitness function used drives the convergence of the algorithm to indices that minimize intra-class variance. This is clear and can be seen in
Figure 8 and
Figure 9, in which the GPVI series are not only better separated, but also presented less variability through time. Part of the discriminative information in time series is, precisely, this variation, and the classification algorithm, which is based on DTW distance, took advantage of this variability in order to align/correct the series.
The experiments we conducted regarding sensor invariance, which was orthogonal to all of the experiments involving the Tropical South America regions, showed a consensus between Landsat and MODIS about the relevance of the bands for biome classification (Q4). Despite the sensor used, the most relevant channels are NIR and SWIR, which map, respectively, biomass content and soil moisture. This contrasts with indices traditionally used in vegetation studies in which the red channel has a leading role, meaning that, besides leaf reflectance (mapped by the NIR channel), soil moisture is more relevant to discriminate these types of biomes, rather than vegetation slope. A plausible explanation for this is that a closed canopy, as observed in forests, reduces light incidence and prevents soil water losses, reducing evapotranspiration and allowing for more water to be retained in the soil.
There was no consensus between the two sensors regarding the relevance of the bands for discriminating vegetation types within biomes. However, before concluding that these problems are unsolvable for spectral indices, factors, like the reduced quantity of data for training, the relatively low spectral resolution of the sensor, or the fact that MODIS includes noisy bands due to their low spatial resolution, must be considered. It is also important to notice that, unlike the forest/savanna problem, the experiments in MODIS sensor attributed a high relevance to channel NIR 2 (which is not provided by the Landsat sensor) when discriminating vegetation types. In both cases—evergreen forest vs. semi-deciduous forest and typical savanna vs. forested savanna—this channel was selected as the second most relevant. The fact that this channel is not provided by one of the sensors probably affected the consensus between the two. However, this area of the spectrum is not recognized as relevant for land-cover analysis in other studies and it is rather used to determine cirrus cloud contamination. Thus, no sound and straightforward interpretation could be made in these results alone. Nevertheless, we speculate that this result could be related to the role of forest in climate regulation given that forests can increase cloud formation above them [
53].
6. Conclusions and Future Work
We introduced a Genetic-Programming-based framework for learning specialized vegetation indices from data, and tested it for discriminating between tropical South American forests and savannas, as well as the vegetation types existing within them. The framework outputs an index, which we called GPVI, optimized to project the spectral data of each pixel into a space where they can be easily discriminated. In the case of pixel-level discrimination, GPVI, when applied on each multispectral pixel to project them into a one-dimensional space, outperformed traditional indices, such as NDVI, EVI, and EVI2, showing that it is possible to describe discriminative patterns of the land coverage, without the use of entire time-series. Based on the same GPVI training procedure, we also tested the index for time-series classification and obtained a performance equivalent to baseline indices, despite the fact that the index was designed for single time stamp discrimination. Our index also outperformed traditional ones at discriminating between vegetation types within biomes, despite the high complexity involved in this specific problem. We speculate that the GPVI performance for this task could be highly improved with larger data availability and higher spectral resolution. When considering that biomes and vegetation types within biomes are dynamic and they can be replaced by one another over time in response to natural and anthropogenic disturbances, our approach is a promising framework for understanding how biomes will respond to present and future human induced global change drivers.
Our GP framework is also effective on hyperspectral data, with no further changes on its configuration. Experiments supporting this claim have already been published [
36,
54], in which the GP framework was tested on hyperspectral multi-class datasets, which not only contain vegetation areas, but also other types of land cover categories, and consider more than two classes. This demonstrates the robustness of our method with respect to the number and variety of bands, implying that GP is an approach that can naturally select and combine bands, regardless of heterogeneous setups, such as spatial/spectral resolution, type of land cover, and number of classes.
As future work, one promising approach can be to explicitly express the GP framework as multi-objective, as has been done in previous works [
55,
56,
57,
58,
59,
60,
61]; this way, the relative importance between inter-class and intra-class distance of the examples can also be optimized, and novel objectives (e.g., precision and recall) can be considered.

 ,
, 























{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}