1. Introduction
Optimized processing of acquired optical satellite images requires removal of cloud interference prior to atmospheric correction. Ruled based classification through the application of static or dynamic thresholds is the most common cloud masking approach [
1,
2,
3]. This approach is derived by the assumption of higher reflectance and lower brightness temperature in clouds compared to other types of surfaces [
4,
5,
6]. Most widespread threshold methods are Automatic Cloud Cover Assessment (ACCA) [
7] and Function of mask (Fmask) [
5,
6], which was originally designed for Landsat imagery. A threshold based method is also used for the development of the Sentinel-2 cloud masks provided by the level 2A product [
8]. Multi-temporal methods based on the idea that abrupt changes in image time series are mainly caused by the presence of clouds have been extensively implemented as well [
9,
10,
11]. MAJA, which was designed for Sentinel-2 images, is among the most well-known in this category [
12].
Attention has also been drawn to cloud masking applications that are based on machine learning approaches. Methods that make use of artificial neural network (ANN) architectures are the most recent in this category thanks to the efficient exploitation of the increasing computational power. Multi-layer perceptrons (MLPs) and convolutional patch-to-pixel or encoder-decoder segmentation architectures are the most common types used in current research. MLPs have been used by Hughes and Hayes [
13] for Landsat 7 and by Taravat et al. [
14] for Landsat 7 and MSG/SEVIRI. Patch-to-pixel convolutional neural network (CNN) approaches have been applied by Mateo et al. [
15] for Proba-V and Le Goff et al. [
16] for Spot 6 and have been also combined with random forest [
17]. These approaches have been further proposed for the adaptation between different satellite platforms by Segal et al. [
18] for WV-2 and Sentinel-2, and by Mateo et al. [
19] for Landsat-8 and Proba-V. Concerning encoder-decoder segmentation approaches, architectures based on U-Net, Alexnet-FCN, ResNet-50 and Segnet models have been implemented in Landsat 7,8 [
20,
21,
22], Sentinel-2 [
23], ZY-3 [
24,
25], Gaofen-1 [
26] and high resolution [
27,
28] satellites.
For the separation of clouds from bright surfaces, use of thermal bands is supposed to improve non-cloud bright object commission error, since they lead to the estimation of cloud height [
5,
20,
29,
30]. However such kind of bands are unavailable in Sentinel-2. Rule based cloud masking approaches usually attempt to distinguish bright surfaces either through the use of texture operators as a pre-processing step or through the use of morphology and geometry operators as a post-processing step. Nonetheless, the results most often need to be improved as shown from several current research studies implemented in Landsat [
11,
31,
32], Gaofen-1 [
33] and Proba-V [
34] satellites that reported misclassification of bright built-up areas, soils and water bodies. A methodology designed for Sentinel-2 by Frantz et al. [
35] who used a cloud displacement index based on the parallax effects of three highly correlated near infrared (NIR) bands, has shown most promising results until now.
Convolutional patch-to-pixel and encoder-decoder segmentation architectures have produced in general more successful and more effortless results for the separation of clouds from bright surfaces due to their inherent ability to perceive spatial information. Such a conclusion was reached in studies conducted in WV-2 [
18], Sentinel-2 [
18,
36], Landsat [
37] and Gaofen-1 [
26] where bright non-cloud object misclassification was not observed. Satisfactory results were also produced by an artificial neural network architecture (ANN) that managed to separate sunglint and noise in Sentinel-2 ocean images [
38].
Self-organizing maps (SOMs) [
39,
40] are a type of competitive ANN that projects data of high dimensionality to a space of low dimensionality by simultaneously preserving topology relations. SOMs are related to vector quantization (VQ), with the difference of conservation of topologic information that makes them suitable for the organization and visualization of complex datasets. Their concept is based on the associative neural properties of the brain where neurons are operating on a localized manner [
41]. Contrary to other types of ANNs, SOMs do not perform error-correction learning but interpret the input information by the location of the response in the low-dimensional space without taking into account its magnitude. Even though SOMs are an unsupervised learning method, the produced clusters can be labeled given that available ground-truth data exists, and consequently the clusters can be converted to classes. Majority voting is the common approach to define the labels of the classes, represented by the neurons of the produced map [
39,
42,
43]. SOMs are weakly represented in current machine learning cloud masking research even though recent studies report successful results with the additional advantage of faster training/fine-tuning time and more interpretative behavior compared to other types of ANNs. This fact led to their inclusion in the creation of the operational cloud masking products of Sentinel-2 [
8] and Proba-V [
44] satellites. Relative studies have been also implemented for Landsat 7 and MODIS [
45,
46,
47,
48].
The term “fine-tuning” for other types of neural networks (e.g., CNNs) refers to the use of pre-trained neural networks for different applications [
19,
24,
26] than those that they were originally trained for. During fine-tuning, the pre-trained weights are used as initial weights and the network is further trained on the new dataset. As for SOMs, in the cases where fine-tuning is performed, the weights of the map neurons are updated through further training by taking into account the correctness or incorrecteness of the prediction [
39,
43]. Fine-tuning is supposed to highly increase classification accuracy in SOMs [
39].
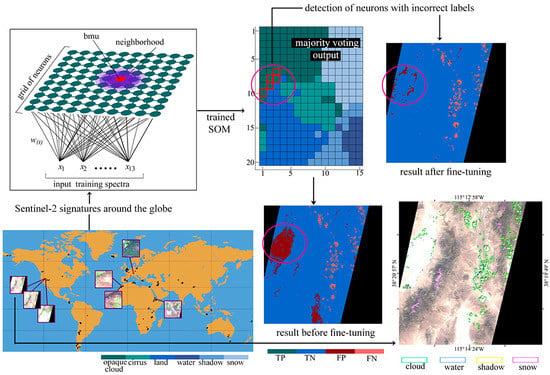
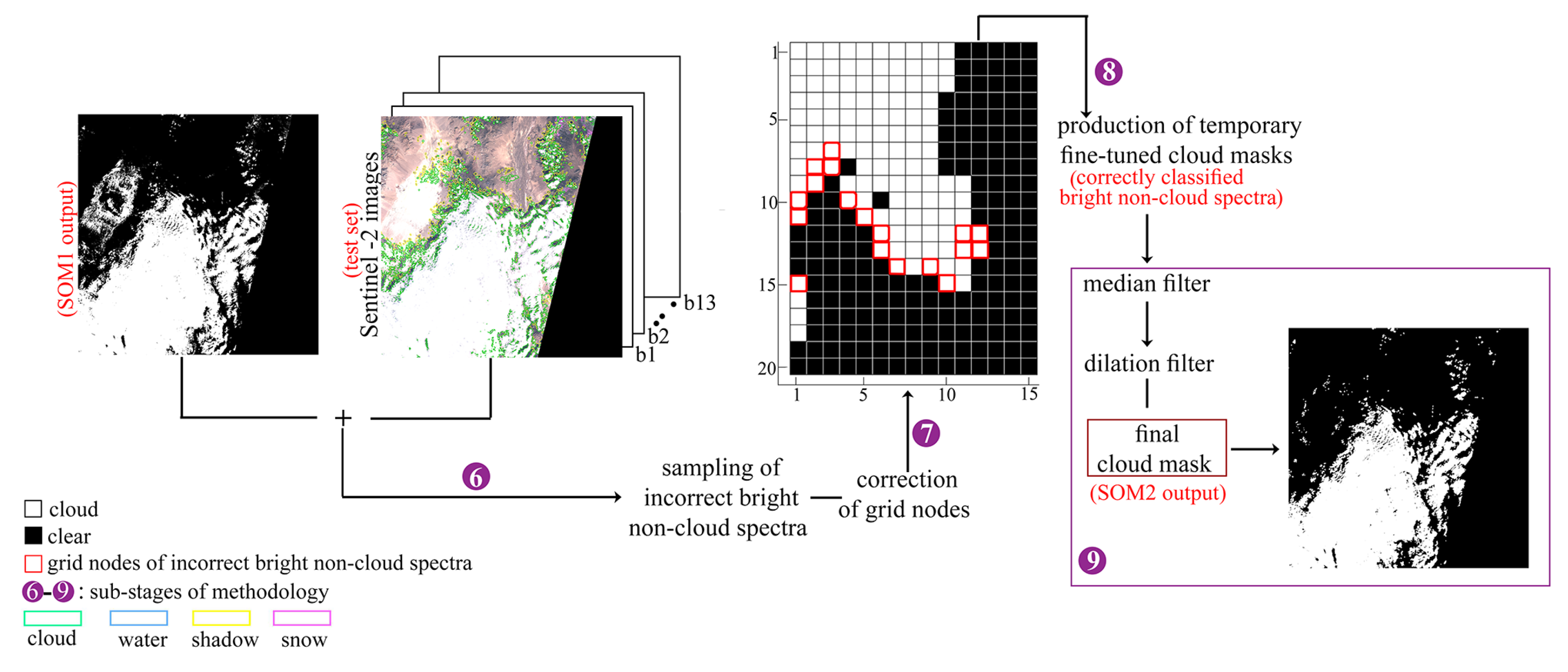
This study evaluates a SOM for cloud masking Sentinel-2 images and proposes a fine-tuning methodology based on the output of the non-fine-tuned network. The fine-tuning process manages to correct the misclassified predictions of bright non-cloud spectra without applying further training. It is important to note that the fine-tuning method follows a general procedure, thus its applicability is broad and not confined only in the field of cloud-masking. The study takes direct advantage of the similarities of the SOM to a brain map. In more detail, it is based on the fact that a detailed topographical map of the cerebral cortex of the brain can be deduced by various functional or behavioral impairments, or through stimulation of a particular site which leads to the disruption of a cognitive ability [
39]. A SOM is trained on a spectral database created by Hollstein et al. [
49] which is the largest publicly available for Sentinel-2 cloud applications and is tested on a truly independent (non-overlapping) database of Sentinel-2 cloud masks recently created by Baetens et al. [
50] which is also publicly available. The trained SOM neurons are labeled through majority voting by use of the ground truth labels provided in the training database. Finding the neuron with the minimum Euclidean distance from each pixel of the images of the test database, leads to the production of the predicted cloud masks. In a next step, after observation of the cloud masks produced by the non-fine-tuned SOM, the fine-tuning process is applied. During fine-tuning, the SOM neurons that correspond to the bright misclassified non-cloud areas are detected by feeding the corresponding incorrectly classified spectral signatures into the network and consequently identifying the stimulated neurons. Then, the incorrect labels of the respective neurons are directly altered without applying further training. The network is evaluated both qualitatively and quantitatively with the interpretation of its behavior through multiple visualization techniques being a main part of the evaluation. The cloud masks are not only compared with ground truth data, but also with results produced by two state-of-the-art algorithms: Sen2Cor, Fmask. It is noted that in the context of this study, the term “bright non-cloud areas“ refers to built-up areas, soils (e.g., desert) and coastal surfaces. It is also mentioned that the fine-tuning methodology proposed in this study was also applied in experiments that specifically targeted incorrectly classified snow pixels. Yet, the results were considered unsatisfactory since the correct classification of the snow pixels led to a large omission error of clouds. These experiments are not presented in the study.
4. Discussion
This section highlights the main points that distinguish the proposed method from: (a) other types of neural networks (MLPs, CNNs), (b) the most commonly applied state-of-the-art algorithms (Sen2Cor, Fmask) and (c) the most widely used unsupervised classification method (k-means). The discussion also includes comments on the potential risk of the proposed fine-tuning approach.
To begin with, time-efficiency is one of their main benefits of SOMs compared to other types of artificial neural networks such as MLPs and CNNs which are widely and most frequently applied in current research and industrial applications. MLPs and CNNs require multiple hours for training while SOMs usually need only a few minutes. As a matter of fact, the SOM proposed in this study was trained in two minutes and required 18 min to acquire its labeling in order to produce cloud masks. Concerning fine-tuning for MLPs and CNNs, the main difference of the fine-tuning stage from the initial training stage is that during fine-tuning a smaller training set and fewer hidden layers are used, but the process is still slower compared to the proposed fine-tuning method (SOM2). In addition, the proposed fine-tuning method required only a small labeled dataset in order to detect the BMUs of the bright non-cloud spectra and then alter their labels.
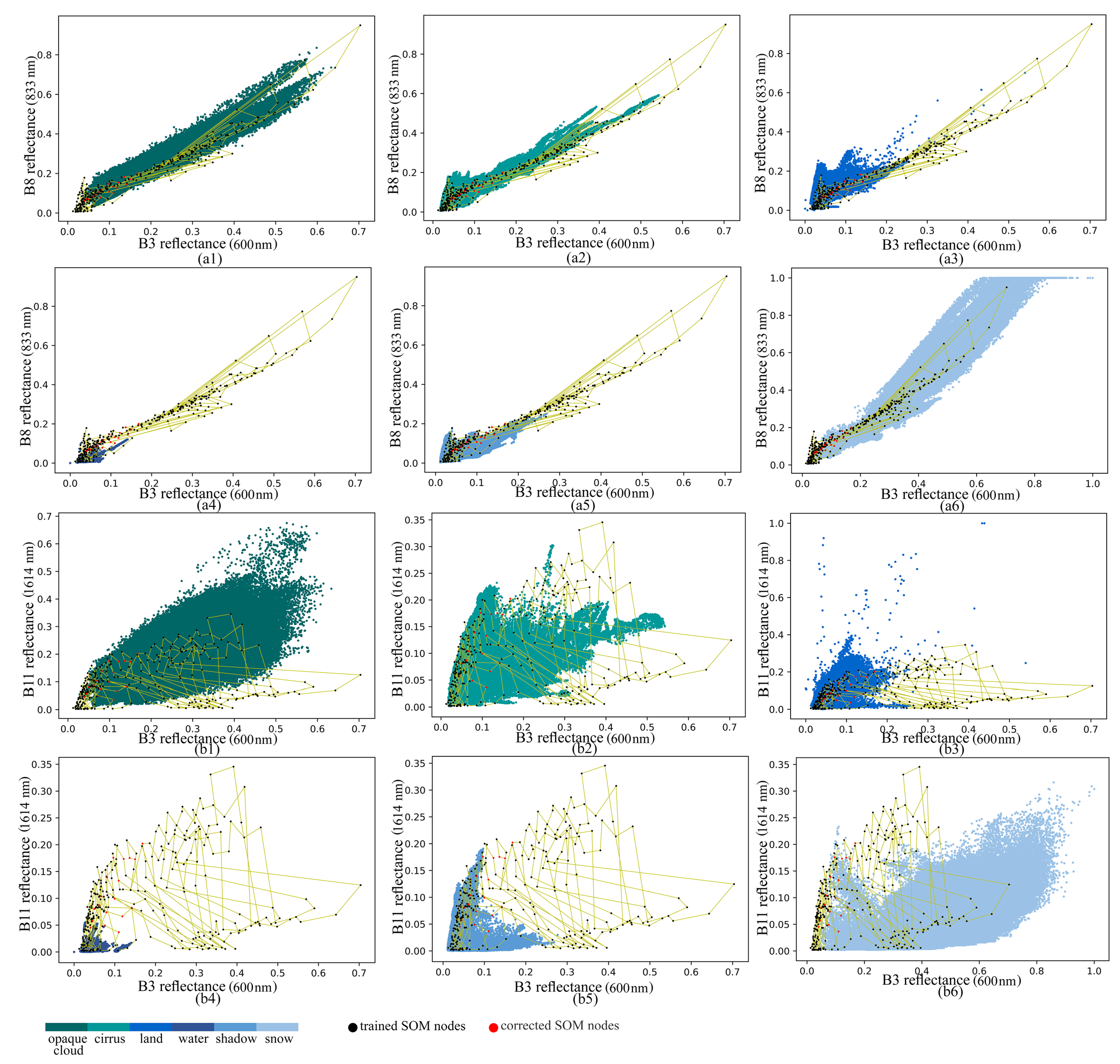
Another advantage of SOMs is that their behavior is much more interpretative compared MLPs/CNNs where the performance is mainly evaluated through the accuracy of the predictions on the test set. In contrast, in SOMs, the network can also be evaluated by useful visualization techniques that analyze the similarity/dissimilarity of the neighboring nodes, the uniformity of the activation of the neurons, the fast extraction of spectral properties from quantized data and the distribution of the SOM nodes among the data.
As far as comparison with Fmask and Sen2Cor is concerned, the proposed fine-tuning method outperformed them by far in the separation of bright non-cloud objects from clouds. However, the newest versions of Fmask and Sen2cor produce a Sentinel-2 cloud mask faster i.e., ∼four minutes are required for Fmask and ∼two minutes for Sen2Cor against ∼six minutes for the proposed SOM.
Regarding the similarities of SOMs with the k-means, it can be indeed stated that the two methods are very similar with the main difference being that in SOMs the centers (neurons) interact with each other and create neighborhoods that carry topologic information. The centers in k-means do not interact with each other. It is noted that when the SOM grid consists of a small number of neurons, it is equivalent to k-means because the neighborhood concept is invalid for very few neurons. In practice, concerning our study, the main difference of the two methods lies in the fine-tuning process which would not be practically possible to be applied in the k-means algorithm. The reason is that it would require the number of clusters to be the same as the number of the SOM nodes, and thus the training process would be very slow. The common practice of fine-tuning the k-means algorithm is to run the method with an increasing number of classes until satisfying results are produced. This approach is still time-consuming and is even more cumbersome when the training set is different from the test set. In general, training a k-means is much slower than training a SOM, because in k-means every time the centers are updated, the distance between the new centers and all the data points needs to be calculated. In contrast, for the SOM training, data points are fed into the network one by one and every time a data point is fed into the network, only the distance of this data point with the nodes of the SOM grid needs to be calculated.
A final point to be discussed is the potential risk of “altering the incorrect labeling” in our proposed fine-tuning approach. The effect of altering the incorrect labeling in the case study analyzed in our paper is that the altered nodes (as explained in
Section 2.3.3) are not only the BMUs of the bright non-cloud spectra, but also of a few cloud pixels. In practice, that means that when we produce a cloud mask by using the fine-tuned SOM version (SOM2) it is probable that there are a few cloud pixels in the image that correspond to the altered neurons, and thus they will be misclassified to the clear class. In this paper, we alleviated this issue by running a median and a dilation filter in order to retrieve the cloud pixels that SOM2 had misclassified. Thus, we have proven, that concerning the 34 images of the test set, the effect of altering the incorrect labeling can be overcome. Since these images were captured around the globe in different seasons and times of the day, and represent a large variety of land cover, we believe that SOM2 would have a similar performance in images that were not included in our test dataset. Our opinion is reinforced by the fact that the proposed fine-tuned method alters the neurons of the borders of the opaque cloud and cirrus class with the land class and not the labels of the neurons that are situated in the center of the classes in the SOM grid.
5. Conclusions
This study evaluated a SOM for cloud masking Sentinel-2 images and proposed a fine-tuning methodology based on the output of the non-fine-tuned network. The fine-tuning process managed to correct the misclassified predictions of bright non-cloud spectra without applying further training. The proposed fine-tuning method is the most important contribution of the study since it follows a general procedure, thus its applicability is broad and not confined only in the field of cloud-masking. It was performed by directly locating the neurons that corresponded to the incorrectly predicted bright non-cloud objects and altering their labels. This process was chosen over the common practice of further training the network by feeding the label data (supervised training) since it was considered faster, simpler and more efficient. Further training would probably also require more data than those available. A median and a dilation filter was performed as the final step of fine-tuning to compensate both for remaining omission and commission errors caused by the fact that the altered neurons represented also a percentage of cloud pixels.
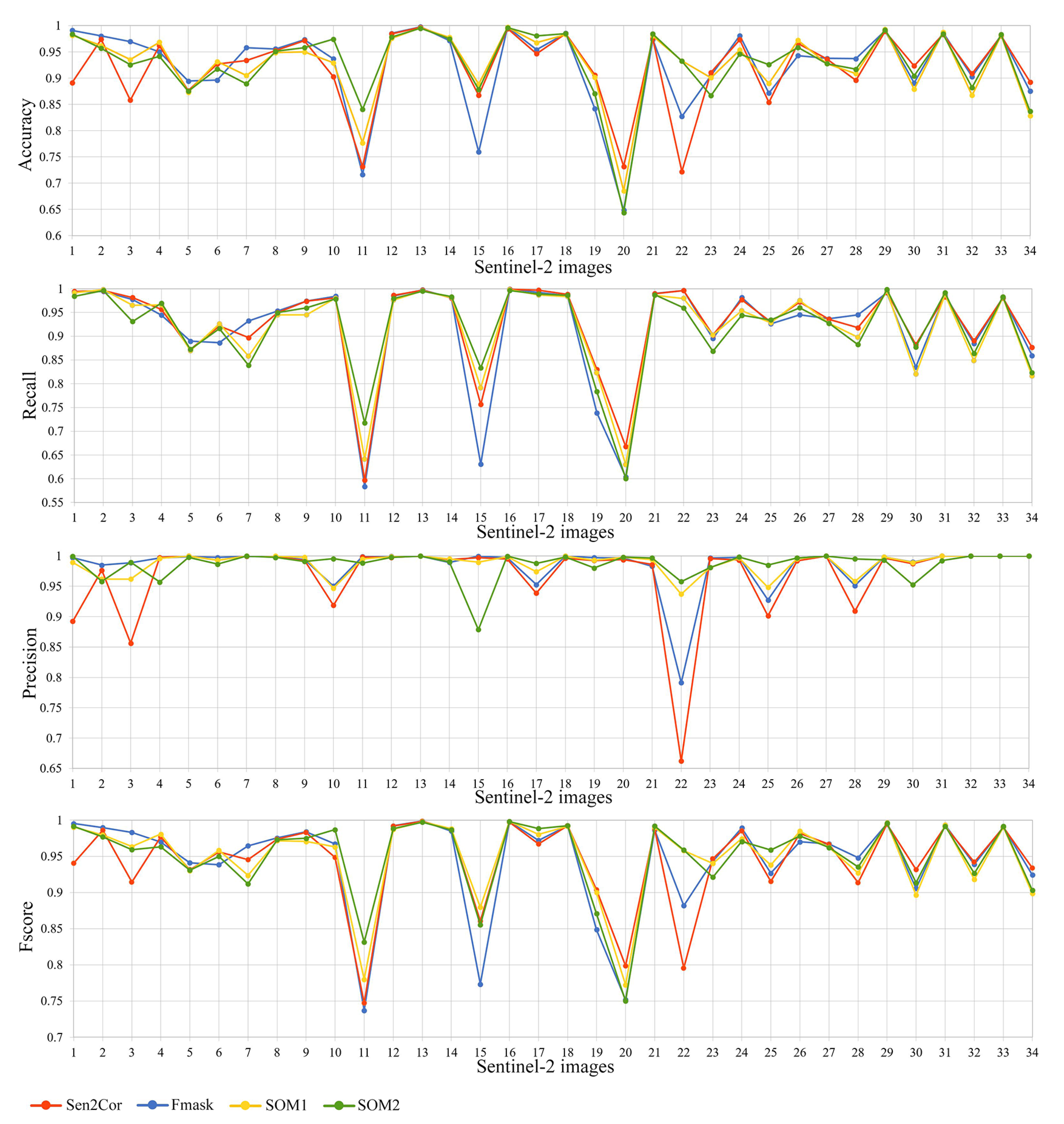
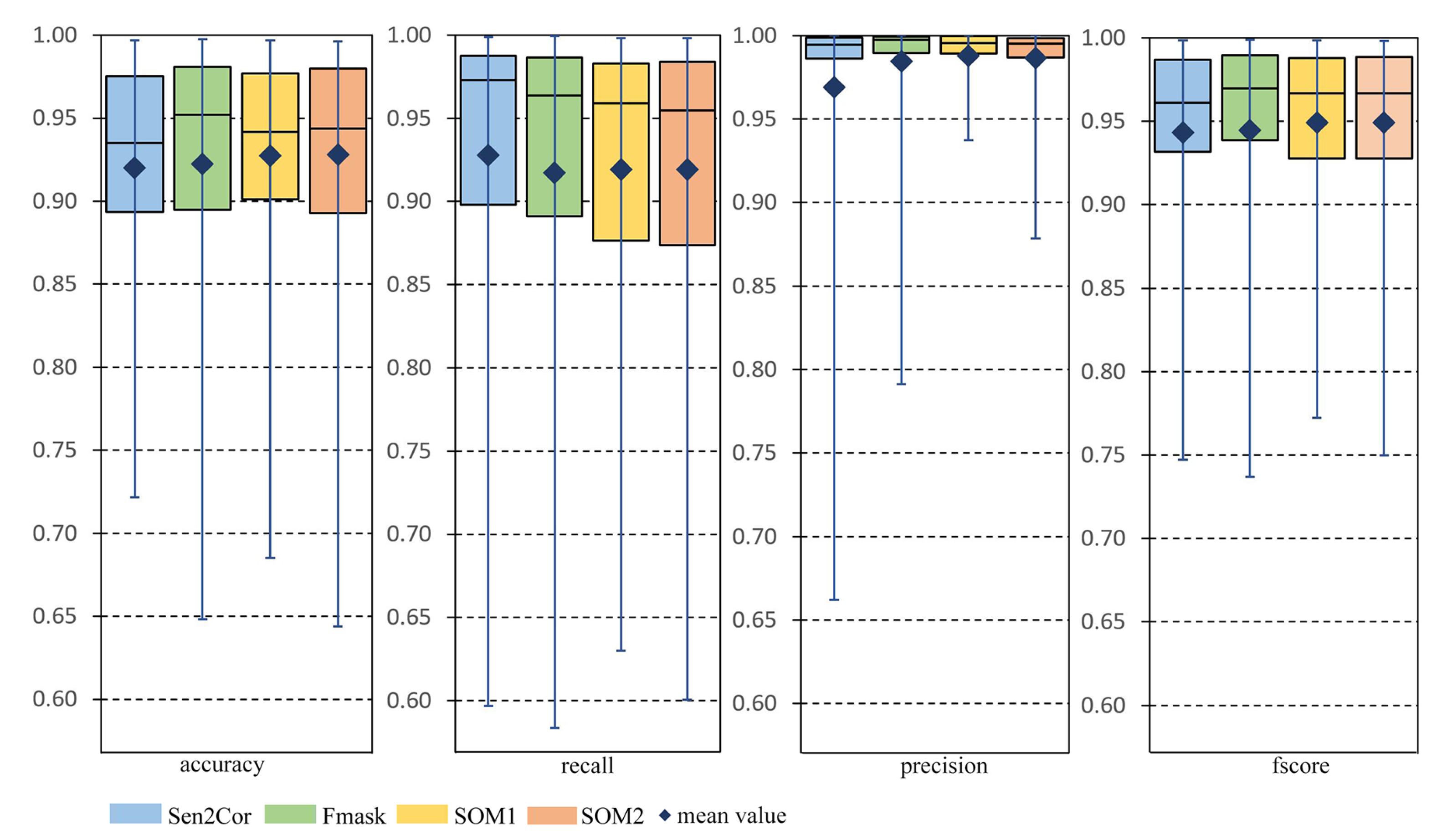
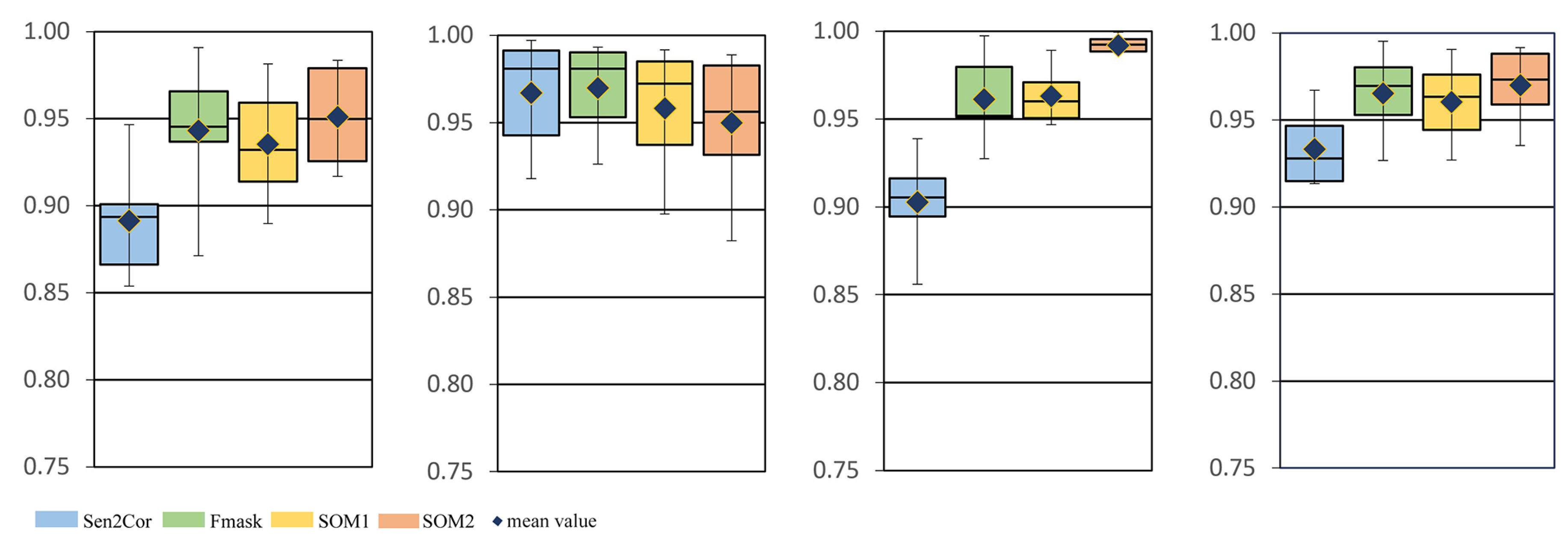
The SOM was trained on approximately nine million spectral signatures extracted from the largest publicly available database of Sentinel-2 signatures for cloud masking applications. After the completion of the training, the non-fine-tuned network was at first evaluated (a) by employing several visualization techniques which illustrated essential spectral properties of the nodes based on topologic information and lead to the interpretation of its behavior and (b) by calculating the confusion matrix on the training set where it produced an overall accuracy ∼96%. Then, evaluation of the non-fine-tuned (SOM1) and the non-fine-tuned (SOM2) versions was performed on a truly independent test set of 34 Sentinel-2 ground truth cloud masks provided by the only publicly available source. By evaluating this entire test set through several evaluation metrics and plots, and comparing them with two state-of-the-art algorithms (Sen2Cor, Fmask), it was deduced that both the two SOM versions and the two state-of-the-art algorithms produced similar results (accuracy: ∼93%, recall: ∼92%, precision: ∼98% and fscore: ∼95%). However, when performing quantitative and qualitative evaluation process for the cases with bright non-cloud objects, it was shown that the fine-tuned version performed more successfully with average commission error less than 1%. The respective values for the SOM before fine-tuning were ∼3%, for Fmask ∼4% and for Sen2Cor ∼8%. The fine-tuning method proposed in this study was also applied in experiments that specifically targeted incorrectly classified snow pixels. However, the results were considered unsatisfactory because a large omission error of clouds was produced. Thus, these experiments were not presented in this study.
As a general conclusion, the study showed that the proposed method for fine-tuning SOMs is very effective for separating bright non-cloud objects from clouds, while the commonly used state-of-the-art algorithms failed in this task. In addition, the method is simple in its implementation and time-efficient, since it only involves the detection of the BMUs of interest and it requires very few data points as input. Thus, in our future work we intend to investigate the potential of the method in different scenarios, especially for big data analysis where processing time is crucial. We will also consider testing the method in datasets with greater availability of ground-truth data.



















{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}