Boosting Memory with a Persistent Memory Mechanism for Remote Sensing Image Captioning

Abstract
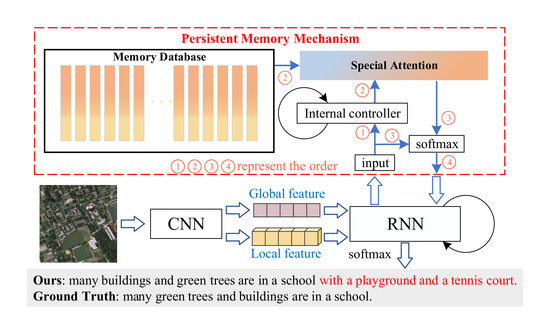
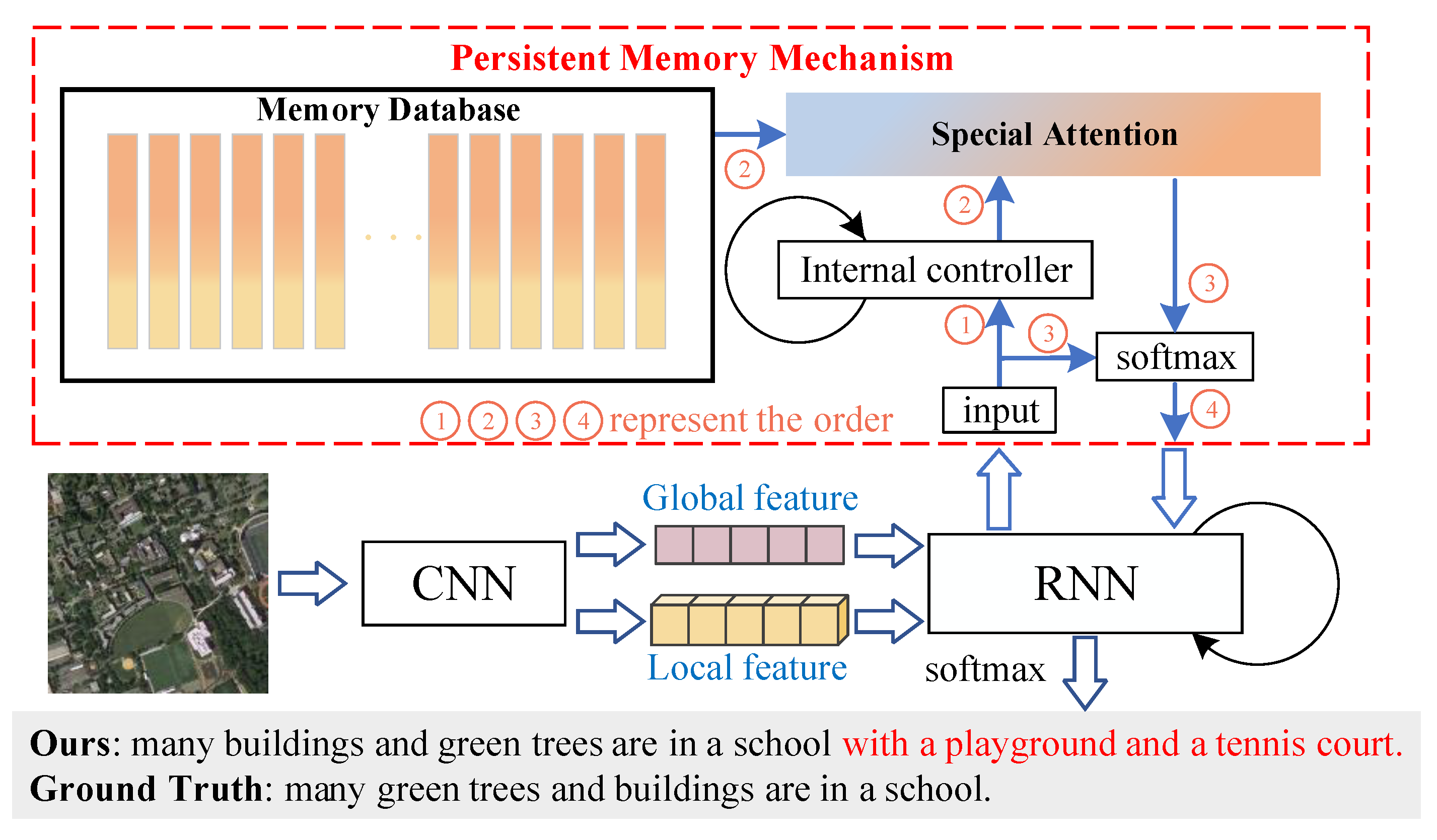
:
1. Introduction
- We firstly present a novel model component named the Persistent Memory Mechanism (PMM) for the remote sensing image captioning task. This new method gives a new perspective to better solve the image caption task in the remote sensing domain.
- We apply the PMM to the image caption model. The PMM takes the form of external memory storage so that it can extend the LSTM naturally with vector states and capture the information lost from the LSTM but useful for caption generation.
- We verify the new model on three publicly available remote sensing datasets including UCM-Captions, Sydney-Captions, and RSICD. In particular, the results show that the CIDEr scores increase by 3%, 5%, and 7%, respectively.
2. Related Works
2.1. Development of Natural Image Captioning
2.2. Development of Remote Sensing Image Captioning
3. Method
3.1. Encoder–Decoder Model for Image Captioning
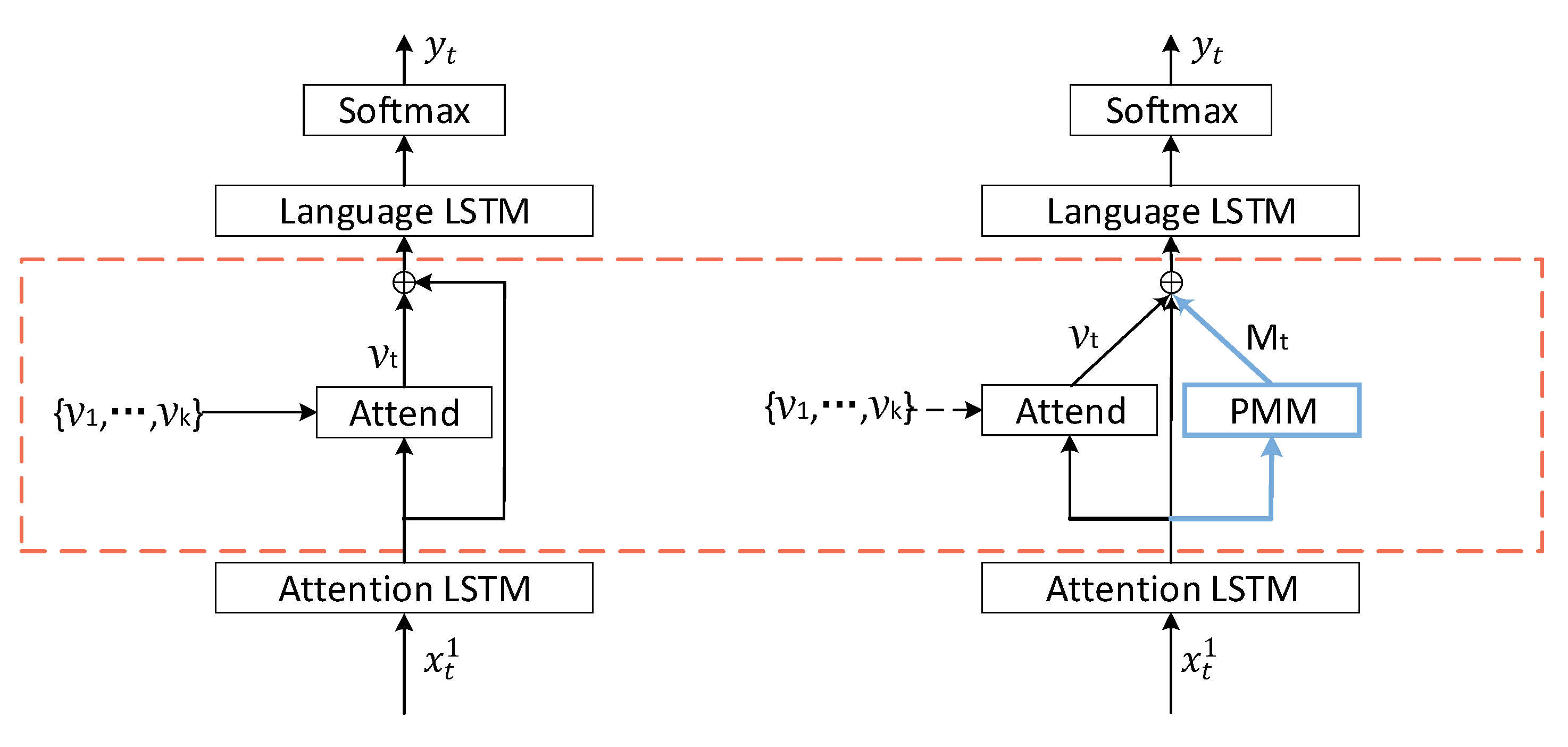
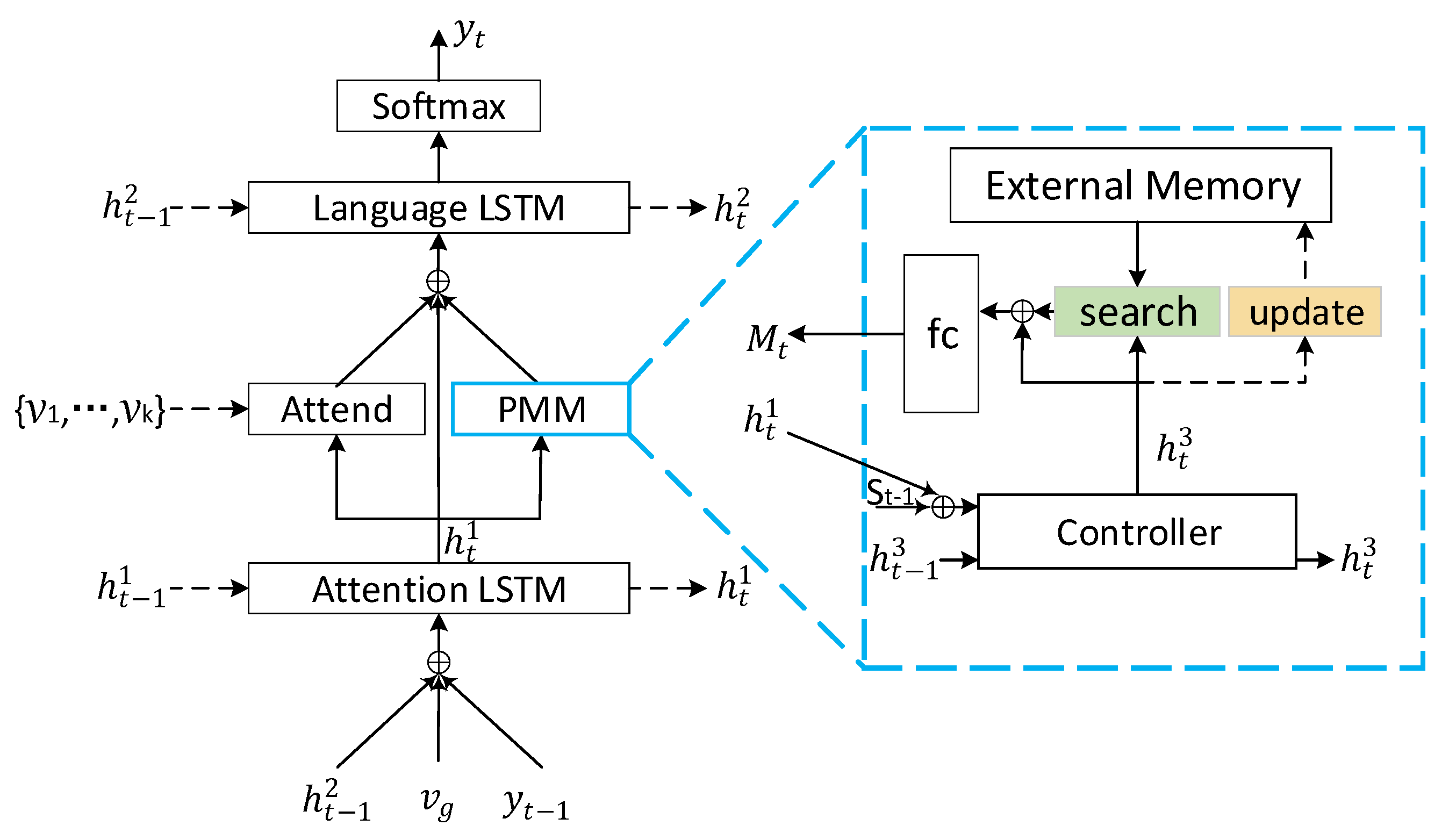
3.2. Model with Persistent Memory Mechanism
3.2.1. Generation of
3.2.2. Generation of
4. Experiments
4.1. Dataset
4.2. Evaluation Metrics
4.3. Implementation Details
4.3.1. Encoder
4.3.2. Decoder
4.4. Results of Experiments
4.5. Results Analysis
4.5.1. Quantitative Analysis
4.5.2. Qualitative Analysis
4.5.3. Parameter of Memory Database Analysis
5. Conclusions
Author Contributions
Funding
Acknowledgments
Conflicts of Interest
References
- Kanjir, U.; Greidanus, H.; Oštir, K. Vessel detection and classification from spaceborne optical images: A literature survey. Remote Sens. Environ. 2018, 207, 1–26. [Google Scholar] [CrossRef]
- Guan, X.; Qi, W.; He, J.; Wen, Q.; Wang, Z. PURIFICATION OF TRAINING SAMPLES BASED ON SPECTRAL FEATURE AND SUPERPIXEL SEGMENTATION. ISPRS - Int. Arch. Photogramm. Remote Sens. Spatial Inf. Sci. 2018, XLII-3, 425–430. [Google Scholar] [CrossRef] [Green Version]
- Wang, B.; Lu, X.; Zheng, X.; Li, X. Semantic descriptions of high-resolution remote sensing images. IEEE Geosci. Remote Sens. Lett. 2019, 16, 1274–1278. [Google Scholar] [CrossRef]
- Liu, D.; Zha, Z.J.; Zhang, H.; Zhang, Y.; Wu, F. Context-aware visual policy network for sequence-level image captioning. arXiv 2018, arXiv:1808.05864. [Google Scholar]
- Luo, R.; Price, B.; Cohen, S.; Shakhnarovich, G. Discriminability objective for training descriptive captions. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–22 June 2018; pp. 6964–6974. [Google Scholar]
- Simonyan, K.; Zisserman, A. Very deep convolutional networks for large-scale image recognition. arXiv 2014, arXiv:1409.1556. [Google Scholar]
- Vinyals, O.; Toshev, A.; Bengio, S.; Erhan, D. Show and tell: A neural image caption generator. In Proceedings of the IEEE conference on computer vision and pattern recognition, Boston, MA, USA, 7–12 June 2015; pp. 3156–3164. [Google Scholar]
- Graves, A.; Wayne, G.; Danihelka, I. Neural turing machines. arXiv 2014, arXiv:1410.5401. [Google Scholar]
- Graves, A.; Wayne, G.; Reynolds, M.; Harley, T.; Hassabis, D. Hybrid computing using a neural network with dynamic external memory. Nature 2016, 538, 471–476. [Google Scholar] [CrossRef] [PubMed]
- Chunseong Park, C.; Kim, B.; Kim, G. Attend to you: Personalized image captioning with context sequence memory networks. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Honolulu, HI, USA, 21–26 July 2017; pp. 895–903. [Google Scholar]
- Mcqueen, D.J.; Johannes, M.R.S.; Post, J.R.; Stewart, T.J.; Lean, D.R.S. Bottom-Up and Top-Down Impacts on Freshwater Pelagic Community Structure. Ecol. Monogr. 1989, 59, 289–309. [Google Scholar] [CrossRef]
- Farhadi, A.; Hejrati, M.; Sadeghi, M.A.; Young, P.; Rashtchian, C.; Hockenmaier, J.; Forsyth, D. Every Picture Tells a Story: Generating Sentences from Images. In European Conference on Computer Vision; Springer: Berlin/Heidelberg, Germany, 2010; pp. 15–29. [Google Scholar]
- Sun, C.; Gan, C.; Nevatia, R. Automatic concept discovery from parallel text and visual corpora. In Proceedings of the IEEE International Conference on Computer Vision, Santiago, Chile, 7–13 December 2015; pp. 2596–2604. [Google Scholar]
- Kulkarni, G.; Premraj, V.; Ordonez, V.; Dhar, S.; Li, S.; Choi, Y.; Berg, A.C.; Berg, T.L. Babytalk: Understanding and generating simple image descriptions. IEEE Trans. Pattern Anal. Mach. Intell. 2013, 35, 2891–2903. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Kuznetsova, P.; Ordonez, V.; Berg, A.C.; Berg, T.L.; Choi, Y. Collective generation of natural image descriptions. In Proceedings of the 50th Annual Meeting of the Association for Computational Linguistics: Long Papers-Volume 1, Association for Computational Linguistics, Jeju Island, Korea, 8 July 2012; pp. 359–368. [Google Scholar]
- Mitchell, M.; Han, X.; Dodge, J.; Mensch, A.; Goyal, A.; Berg, A.; Yamaguchi, K.; Berg, T.; Stratos, K.; Daumé, H., III. Midge: Generating image descriptions from computer vision detections. In Proceedings of the 13th Conference of the European Chapter of the Association for Computational Linguistics. Association for Computational Linguistics, Avignon, France, 23 April 2012; pp. 747–756. [Google Scholar]
- Bahdanau, D.; Cho, K.; Bengio, Y. Neural machine translation by jointly learning to align and translate. arXiv 2014, arXiv:1409.0473. [Google Scholar]
- Nakayama, H.; Nishida, N. Zero-resource Machine Translation by Multimodal Encoder-decoder Network with Multimedia Pivot. Mach. Transl. 2016, 31, 49–64. [Google Scholar] [CrossRef] [Green Version]
- Sutskever, I.; Vinyals, O.; Le, Q. Sequence to sequence learning with neural networks. Adv. NIPS 2014, 2, 3104–3112. [Google Scholar]
- He, K.; Zhang, X.; Ren, S.; Sun, J. Deep residual learning for image recognition. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Madison, WI, USA, 26 June–1 July 2016; pp. 770–778. [Google Scholar]
- Kiros, R.; Salakhutdinov, R.; Zemel, R. Multimodal neural language models. In Proceedings of the International Conference on Machine Learning, Beijing, China, 10 November 2014; pp. 595–603. [Google Scholar]
- Mao, J.; Xu, W.; Yang, Y.; Wang, J.; Yuille, A.L. Explain images with multimodal recurrent neural networks. arXiv 2014, arXiv:1410.1090. [Google Scholar]
- Chen, X.; Zitnick, C.L. Learning a recurrent visual representation for image caption generation. arXiv 2014, arXiv:1411.5654. [Google Scholar]
- Fang, H.; Gupta, S.; Iandola, F.; Srivastava, R.K.; Deng, L.; Dollár, P.; Gao, J.; He, X.; Mitchell, M.; Platt, J.C.; et al. From captions to visual concepts and back. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Boston, MA, USA, 7–12 June 2015; pp. 1473–1482. [Google Scholar]
- Lu, J.; Xiong, C.; Parikh, D.; Socher, R. Knowing when to look: Adaptive attention via a visual sentinel for image captioning. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Honolulu, HI, USA, 21–26 July 2017; pp. 375–383. [Google Scholar]
- Xu, K.; Ba, J.; Kiros, R.; Cho, K.; Courville, A.; Salakhudinov, R.; Zemel, R.; Bengio, Y. Show, attend and tell: Neural image caption generation with visual attention. In Proceedings of the International Conference on Machine Learning, Lille, France, 6–11 July 2015; pp. 2048–2057. [Google Scholar]
- Qu, B.; Li, X.; Tao, D.; Lu, X. Deep semantic understanding of high resolution remote sensing image. In Proceedings of the 2016 International Conference on Computer, Information and Telecommunication Systems, Kunming, China, 6–8 July 2016; pp. 1–5. [Google Scholar]
- Lu, X.; Wang, B.; Zheng, X.; Li, X. Exploring models and data for remote sensing image caption generation. IEEE Trans. Geosci. Remote Sens. 2017, 56, 2183–2195. [Google Scholar] [CrossRef] [Green Version]
- Zhang, Z.; Diao, W.; Zhang, W.; Yan, M.; Gao, X.; Sun, X. LAM: Remote Sensing Image Captioning with Label-Attention Mechanism. Remote Sens. 2019, 11, 2349. [Google Scholar] [CrossRef] [Green Version]
- Yang, Y.; Newsam, S. Bag-of-visual-words and spatial extensions for land-use classification. In Proceedings of the 18th SIGSPATIAL International Conference on Advances in Geographic Information Systems, San Jose, CA, USA, 2–5 November 2010; pp. 270–279. [Google Scholar]
- Zhang, F.; Du, B.; Zhang, L. Saliency-guided unsupervised feature learning for scene classification. IEEE Trans. Geosci. Remote Sens. 2014, 53, 2175–2184. [Google Scholar] [CrossRef]
- Papineni, K.; Roukos, S.; Ward, T.; Zhu, W.J. BLEU: A method for automatic evaluation of machine translation. In Proceedings of the 40th Annual Meeting on Association for Computational Linguistics, Philadelphia, PA, USA, 7–12 July 2002; pp. 311–318. [Google Scholar]
- Lavie, A.; Agarwal, A. METEOR: An automatic metric for MT evaluation with high levels of correlation with human judgments. In Proceedings of the Second Workshop on Statistical Machine Translation. Association for Computational Linguistics, Ann Arbor, MI, USA, 11 June 2005; pp. 228–231. [Google Scholar]
- Lin, C.Y. Rouge: A package for automatic evaluation of summaries. In Proceedings of the Text Summarization Branches out, Barcelona, Spain, 25–26 July 2004; pp. 74–81. [Google Scholar]
- Vedantam, R.; Lawrence Zitnick, C.; Parikh, D. Cider: Consensus-based image description evaluation. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Boston, MA, USA, 7–12 June 2015; pp. 4566–4575. [Google Scholar]
- Anderson, P.; Fernando, B.; Johnson, M.; Gould, S. SPICE: Semantic Propositional Image Caption Evaluation. Adapt. Behav. 2016, 11, 382–398. [Google Scholar]
- Deng, J.; Dong, W.; Socher, R.; Li, L.J.; Li, K.; Fei-Fei, L. Imagenet: A large-scale hierarchical image database. In Proceedings of the 2009 IEEE Conference on Computer Vision and Pattern Recognition, Miami, FL, USA, 20–25 June 2009; pp. 248–255. [Google Scholar]
- Rennie, S.J.; Marcheret, E.; Mroueh, Y.; Ross, J.; Goel, V. Self-critical sequence training for image captioning. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Honolulu, HI, USA, 20 July 2017; pp. 7008–7024. [Google Scholar]
- Zhang, X.; Wang, X.; Tang, X.; Zhou, H.; Li, C. Description generation for remote sensing images using attribute attention mechanism. Remote Sens. 2019, 11, 612. [Google Scholar] [CrossRef] [Green Version]


{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Methods | BLEU-1 | BLEU-4 | METEOR | ROUGE-L | CIDEr | SPICE |
|---|---|---|---|---|---|---|
| SAT [26] | 83.0 | 65.2 | 43.9 | 78.5 | 335.1 | 50.0 |
| Att2in [38] | 84.0 | 68.1 | 46.5 | 80.2 | 354.0 | 52.3 |
| SM-Att [39] | 81.1 | 63.0 | 43.5 | 77.9 | 338.6 | 48.8 |
| UpDown [11] | 84.7 | 69.0 | 46.9 | 81.3 | 355.3 | 53.3 |
| UpDown + PMM | 85.2 | 68.0 | 45.8 | 81.1 | 352.9 | 50.9 |
| UpDown + DF | 85.7 | 70.0 | 46.9 | 81.4 | 357.7 | 52.8 |
| UpDown + DF + PMM | 86.2 | 71.2 | 48.2 | 82.5 | 365.4 | 53.6 |
| Methods | BLEU-1 | BLEU-4 | METEOR | ROUGE-L | CIDEr | SPICE |
|---|---|---|---|---|---|---|
| SAT [26] | 78.8 | 52.4 | 40.7 | 71.9 | 217.4 | 41.0 |
| Att2in [38] | 80.1 | 54.6 | 40.1 | 70.5 | 225.2 | 41.8 |
| SM-Att [39] | 74.3 | 51.8 | 36.4 | 67.7 | 234.0 | 39.8 |
| UpDown [11] | 81.5 | 55.3 | 40.3 | 71.9 | 225.2 | 40.2 |
| UpDown + PMM | 81.2 | 55.4 | 40.8 | 72.3 | 229.3 | 41.3 |
| UpDown + DF | 81.1 | 55.1 | 39.9 | 71.6 | 226.2 | 40.3 |
| UpDown + DF + PMM | 81.6 | 55.6 | 41.5 | 73.6 | 236.5 | 43.0 |
| Methods | BLEU-1 | BLEU-4 | METEOR | ROUGE-L | CIDEr | SPICE |
|---|---|---|---|---|---|---|
| SAT [26] | 73.2 | 44.3 | 36.2 | 65.2 | 244.2 | 46.1 |
| Att2in [38] | 72.6 | 43.8 | 36.0 | 64.4 | 245.6 | 45.9 |
| SM-Att [39] | 67.0 | 40.7 | 32.6 | 58.0 | 257.4 | 46.9 |
| UpDown [11] | 72.9 | 43.3 | 36.2 | 64.8 | 245.0 | 45.7 |
| UpDown + PMM | 73.9 | 45.2 | 36.5 | 65.4 | 253.7 | 46.8 |
| UpDown + DF | 73.2 | 44.7 | 37.2 | 65.3 | 257.9 | 47.4 |
| UpDown + DF + PMM | 73.6 | 45.4 | 37.3 | 66.0 | 263.4 | 47.7 |
| Size | BLEU-1 | BLEU-4 | METEOR | ROUGE-L | CIDEr | SPICE |
|---|---|---|---|---|---|---|
| 128 | 73.5 | 44.9 | 36.6 | 65.4 | 251.3 | 46.5 |
| 256 | 73.0 | 44.8 | 37.8 | 66.1 | 257.7 | 46.9 |
| 512 | 73.6 | 45.4 | 37.3 | 66.0 | 263.4 | 47.7 |
© 2020 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Fu, K.; Li, Y.; Zhang, W.; Yu, H.; Sun, X. Boosting Memory with a Persistent Memory Mechanism for Remote Sensing Image Captioning. Remote Sens. 2020, 12, 1874. https://doi.org/10.3390/rs12111874
Fu K, Li Y, Zhang W, Yu H, Sun X. Boosting Memory with a Persistent Memory Mechanism for Remote Sensing Image Captioning. Remote Sensing. 2020; 12(11):1874. https://doi.org/10.3390/rs12111874
Chicago/Turabian StyleFu, Kun, Yang Li, Wenkai Zhang, Hongfeng Yu, and Xian Sun. 2020. "Boosting Memory with a Persistent Memory Mechanism for Remote Sensing Image Captioning" Remote Sensing 12, no. 11: 1874. https://doi.org/10.3390/rs12111874
APA StyleFu, K., Li, Y., Zhang, W., Yu, H., & Sun, X. (2020). Boosting Memory with a Persistent Memory Mechanism for Remote Sensing Image Captioning. Remote Sensing, 12(11), 1874. https://doi.org/10.3390/rs12111874