Super-Resolution-Based Snake Model—An Unsupervised Method for Large-Scale Building Extraction Using Airborne LiDAR Data and Optical Image

 ,
,  , , and
, , and
Abstract
:1. Introduction
1.1. Motivation
1.2. Literature Review
1.3. Snake Model-Based Related Works
1.4. Contribution
- We propose an effective solution to compute the external energy for the snake model—which is initialized by the LiDAR-based boundaries. Such a solution enables the snake model to be insensitive to image noise and details, as well as easing the snake model parametrization. In addition, this snake model involves an improved balloon force that behaves adaptively by either shrinking or inflating the snake (as opposed to the classic balloon force that always inflates it).
- In order to build a reliable foundation for this novel snake model, a super-resolution process is proposed to reliably improve the LiDAR point cloud sparsity. Such a sparsity issue has been problematic to building extraction methods using LiDAR data, including snake models.
- Lastly, we present a comprehensive performance assessment of the proposed SRSM on two different geographical contexts, namely Europe (with the Vaihingen benchmark dataset) and North America (with the Quebec City dataset). Such contexts involve various differences in terms of compactness, density, and regularity of urban areas [43], demonstrating the scalability and versatility of the proposed method.
1.5. Paper Organization
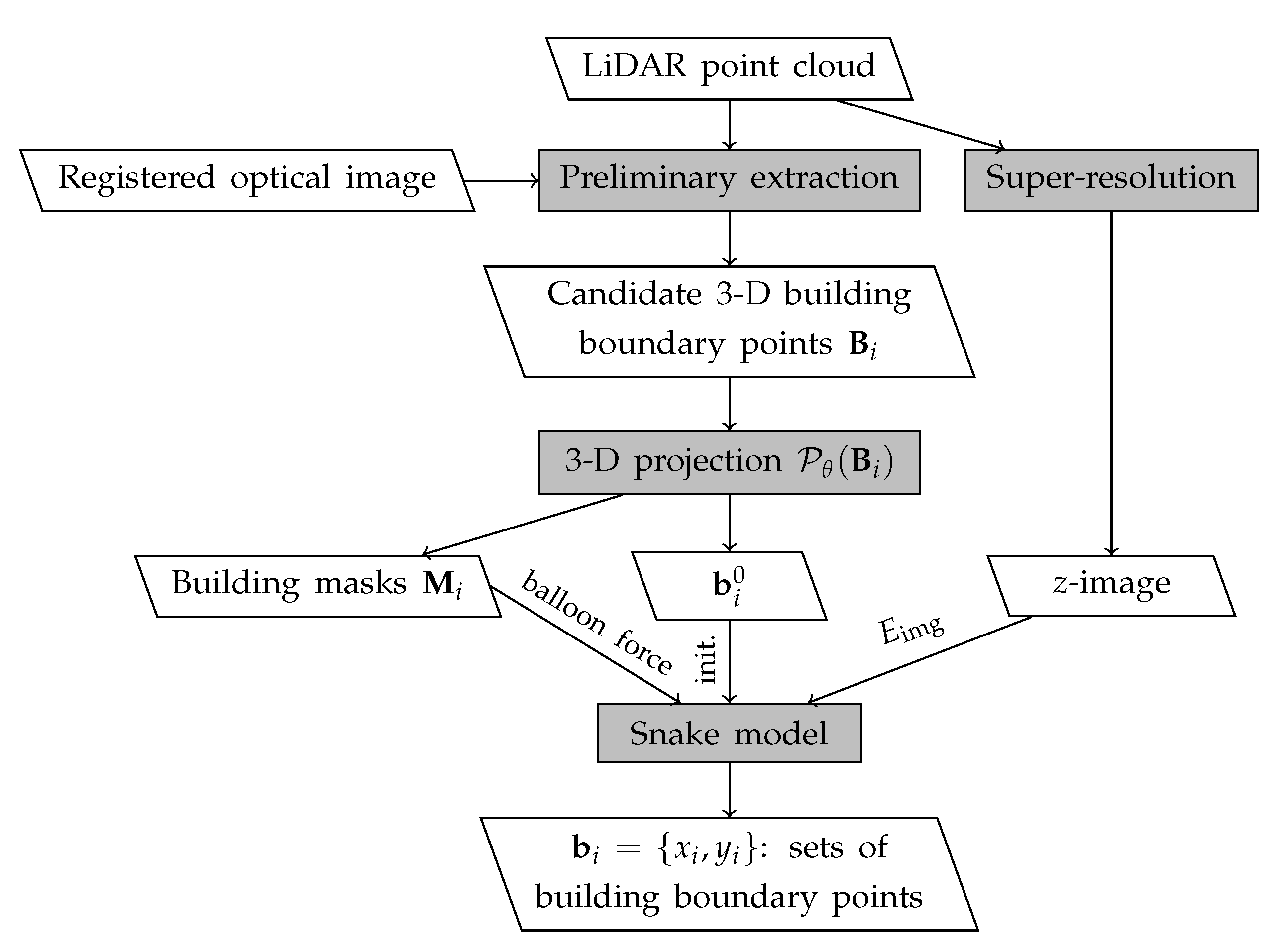
2. Proposed Method
2.1. Mathematical Formulation
2.2. Proposed Z-Image-Based Energy Term
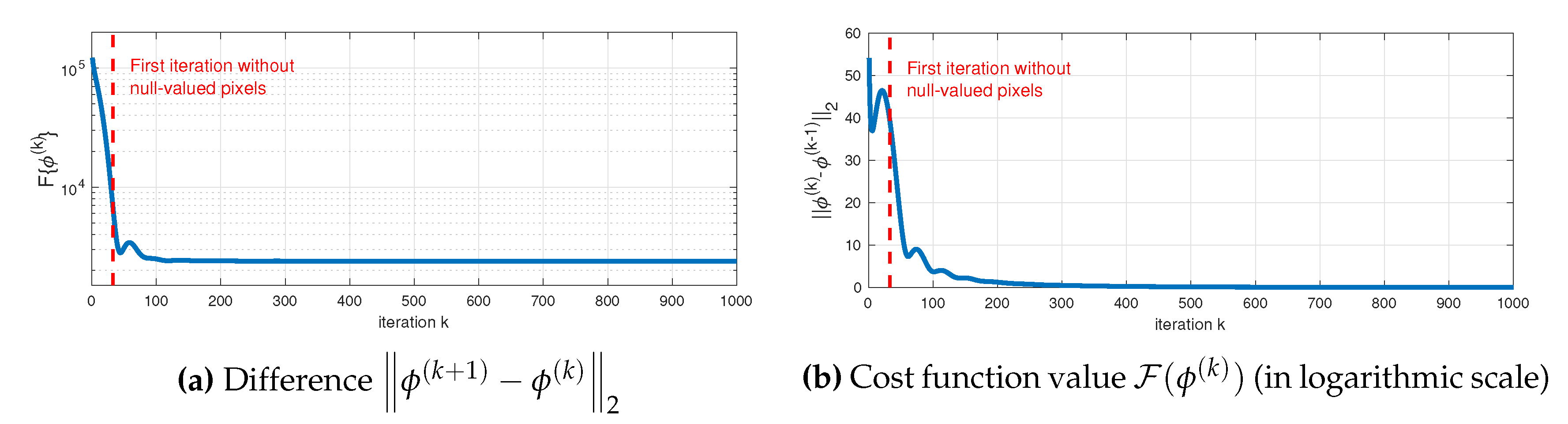
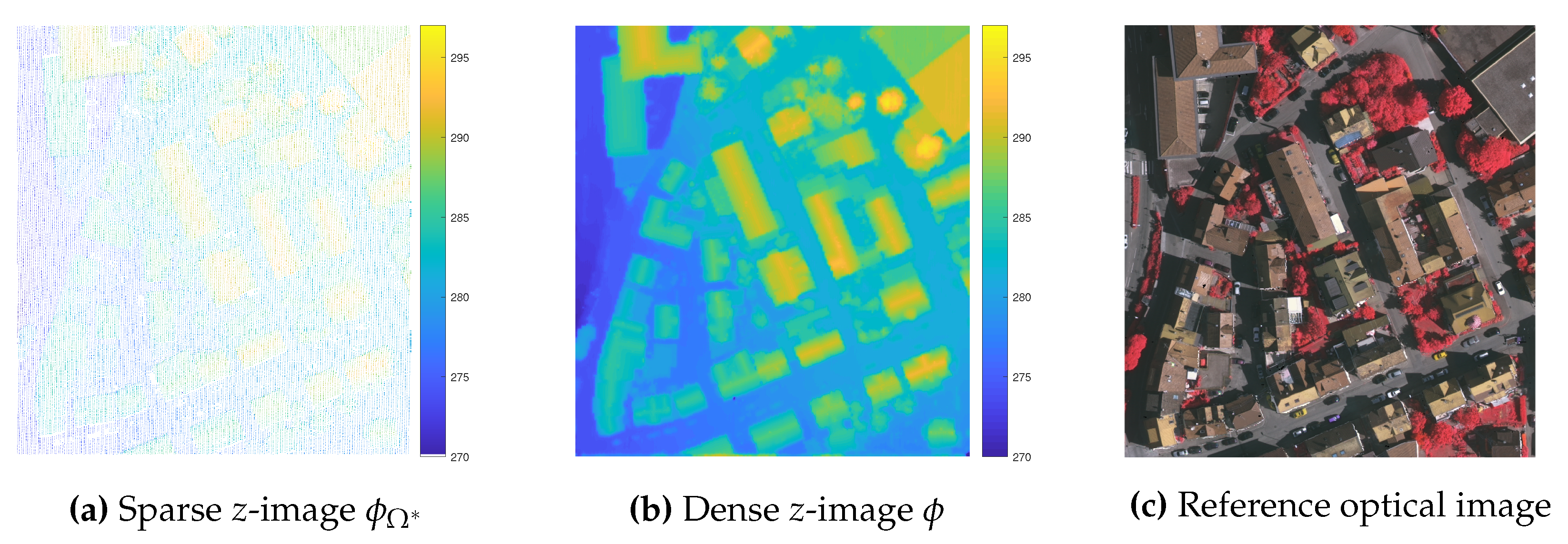
2.2.1. Generation of Z-Image by the Super-Resolution of LiDAR Data
- (a)
- Projection of LiDAR 3-D points
- (b)
- Propagation of the projected values
- (c)
- Propagation implementation
2.2.2. The Z-Image Based Energy Term
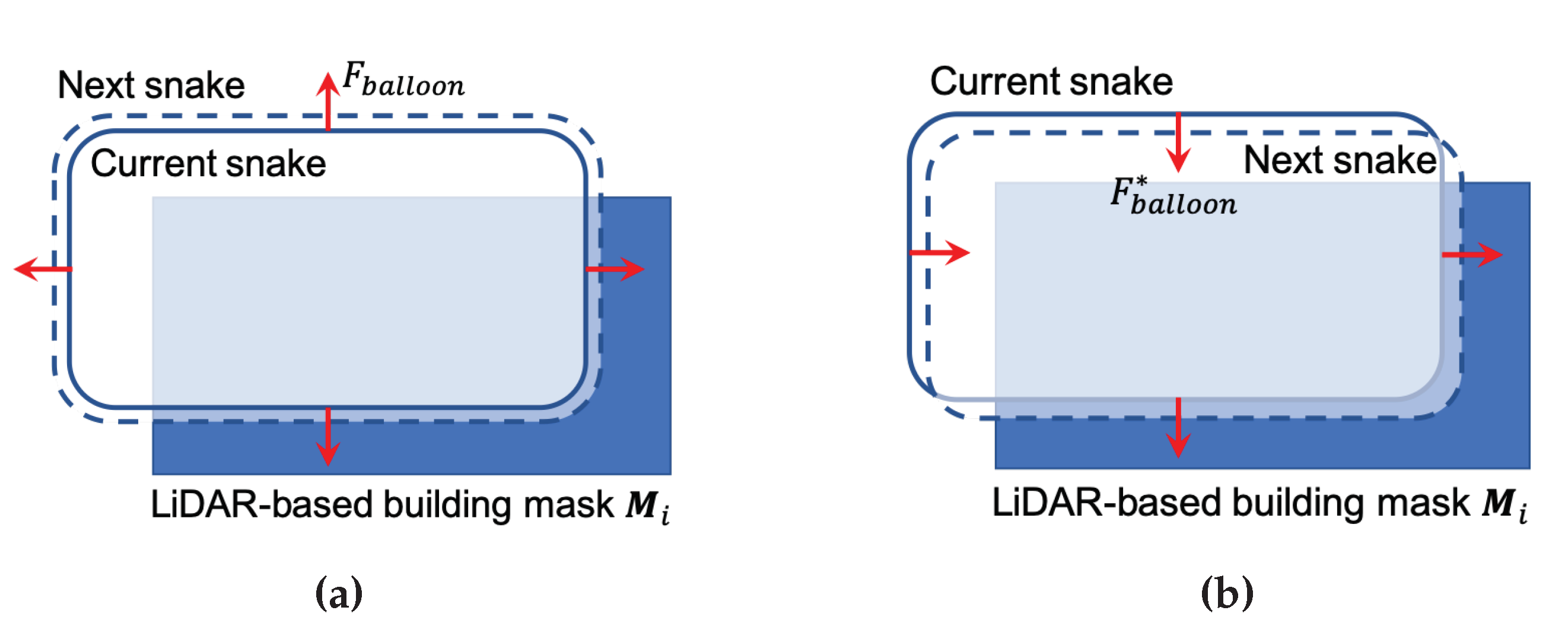
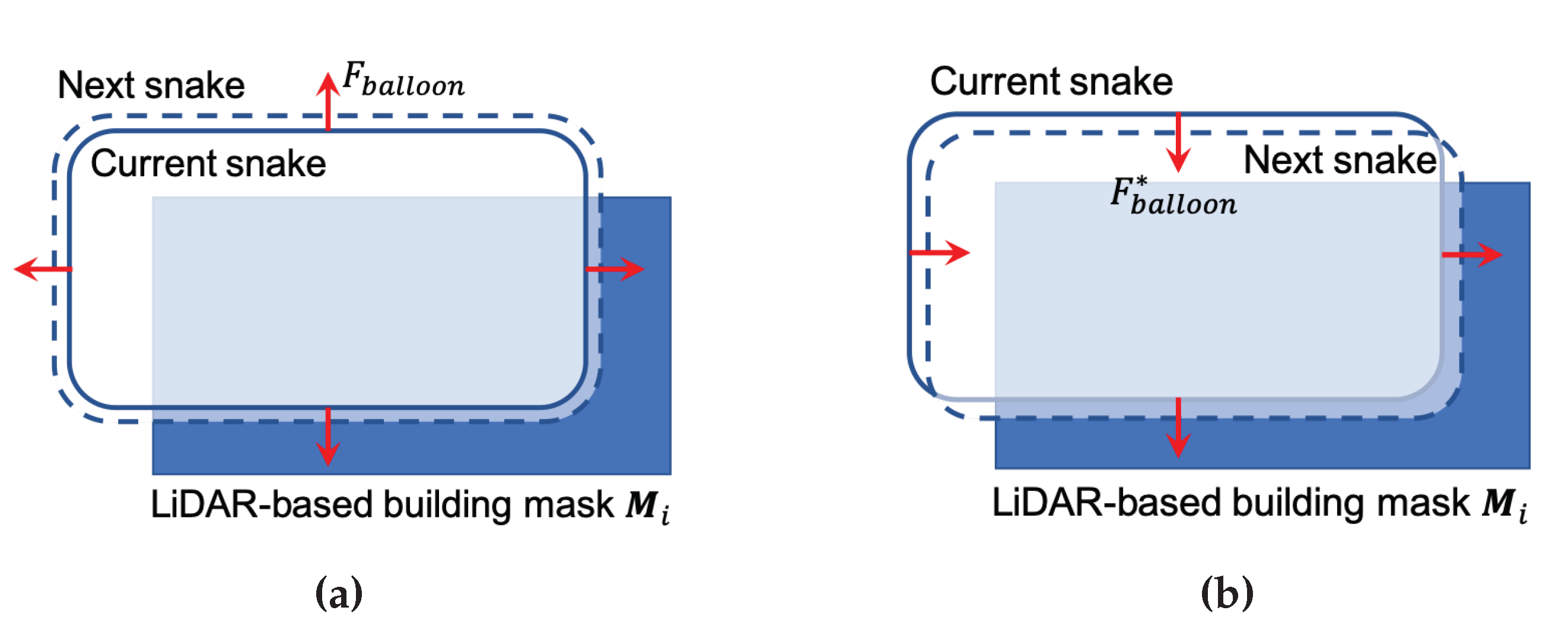
2.3. Improved Balloon Force
3. Experimental Results
3.1. Building Extraction Accuracy Metrics
3.1.1. Thematic Accuracy Metrics
3.1.2. Geometrical Accuracy Metrics
3.2. Study Areas and Involved Datasets
3.2.1. Vaihingen Dataset
3.2.2. Quebec City Dataset
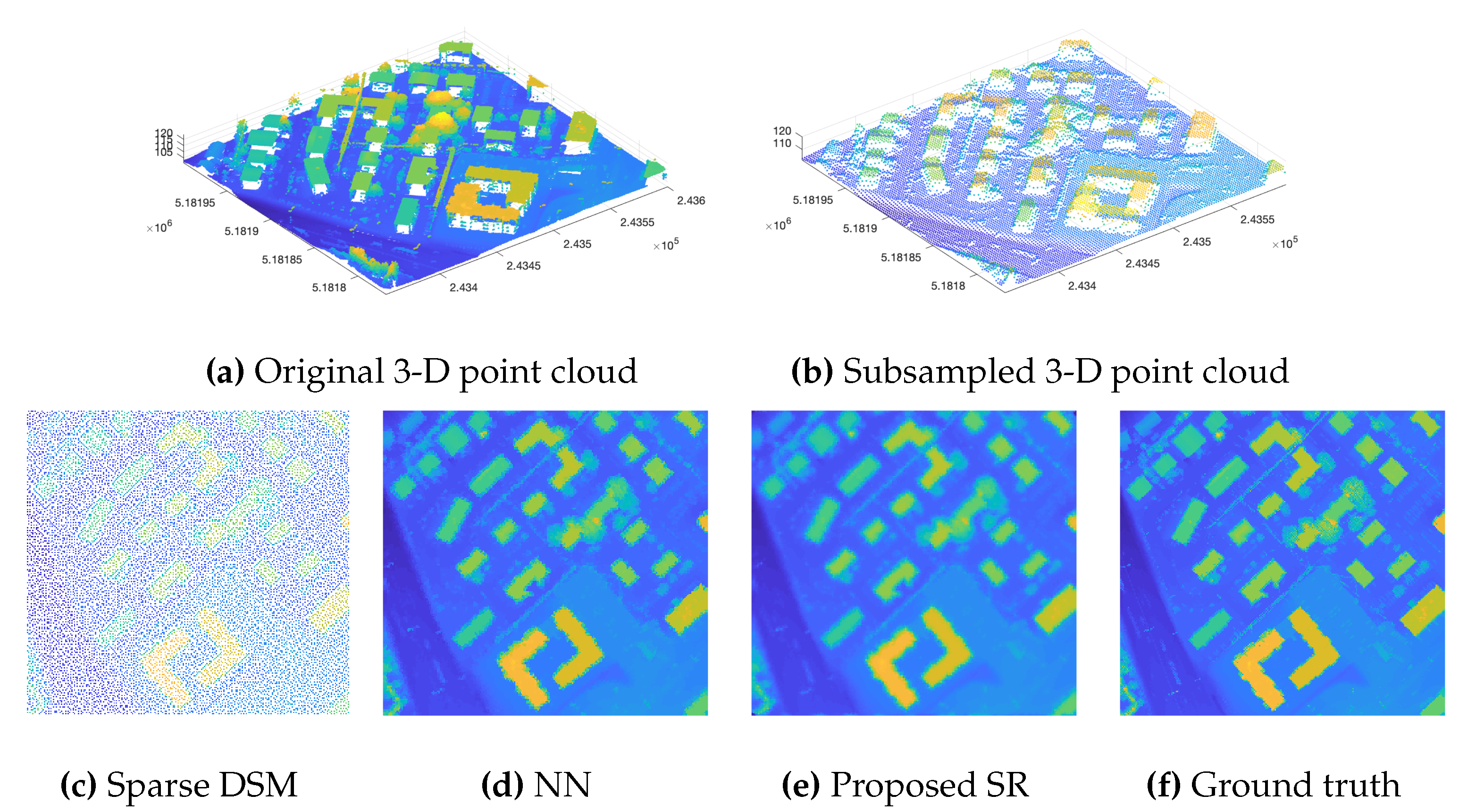
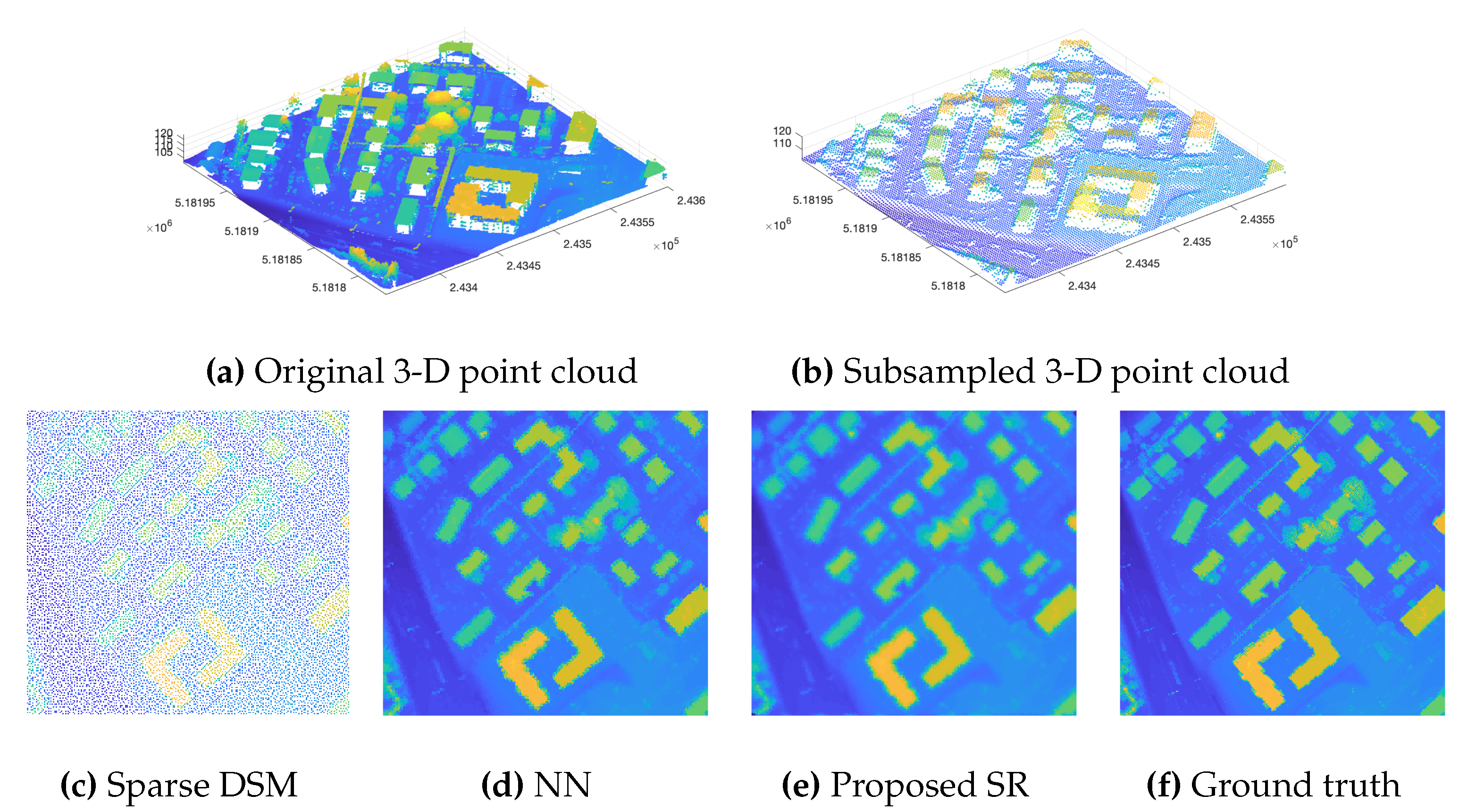
3.3. Performance Evaluation of the Super-Resolution
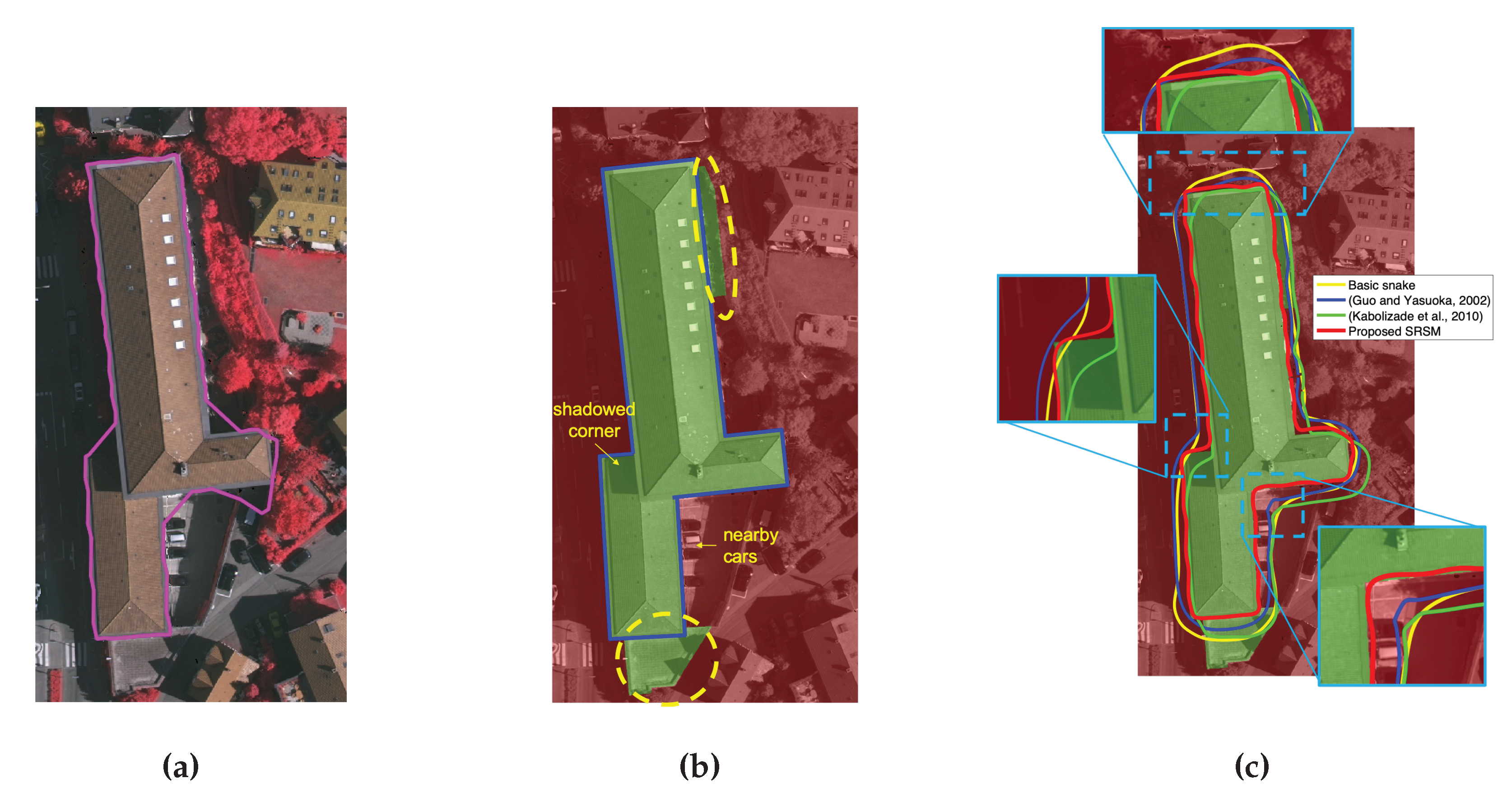
3.4. Comparison between Snake Models
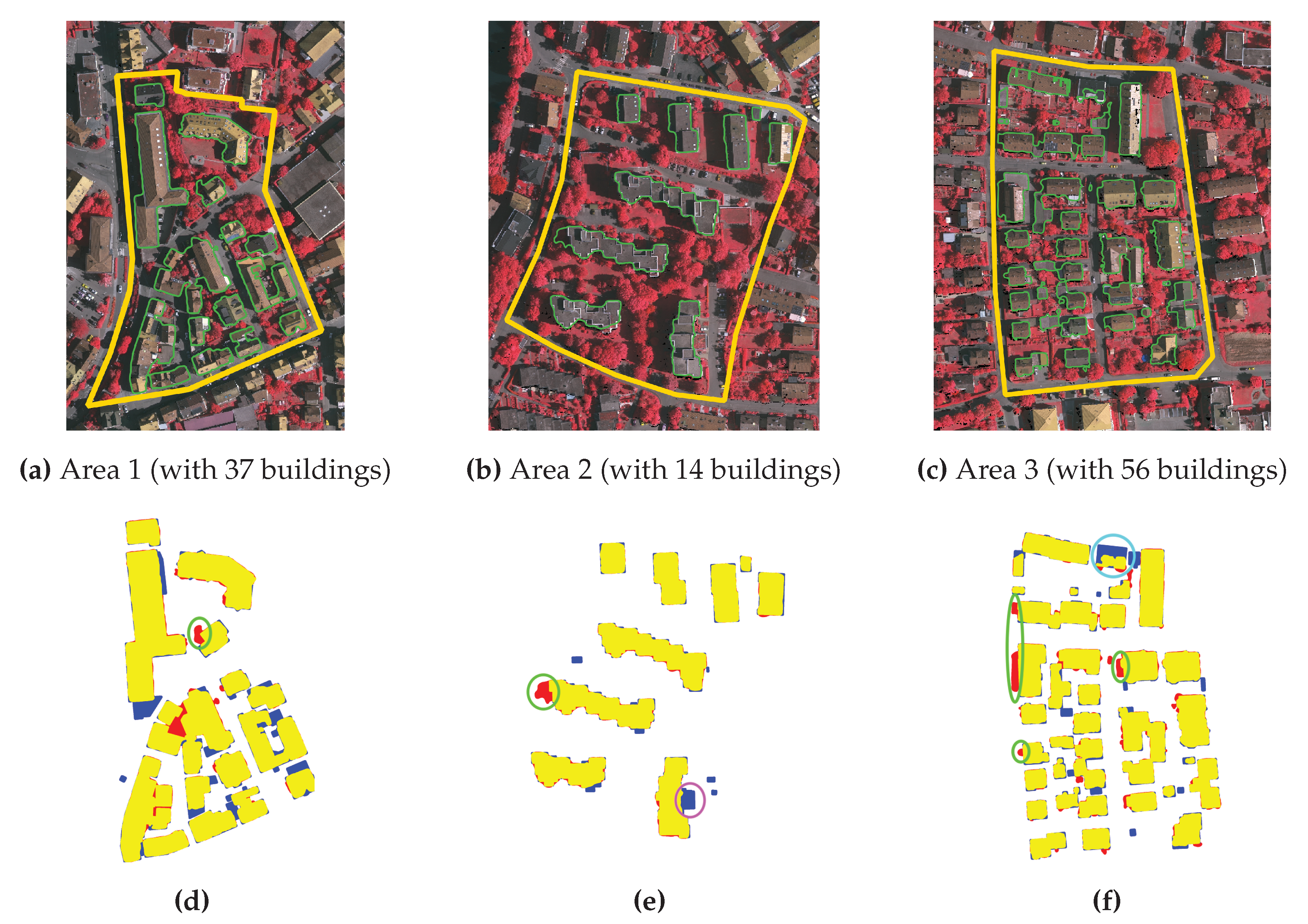
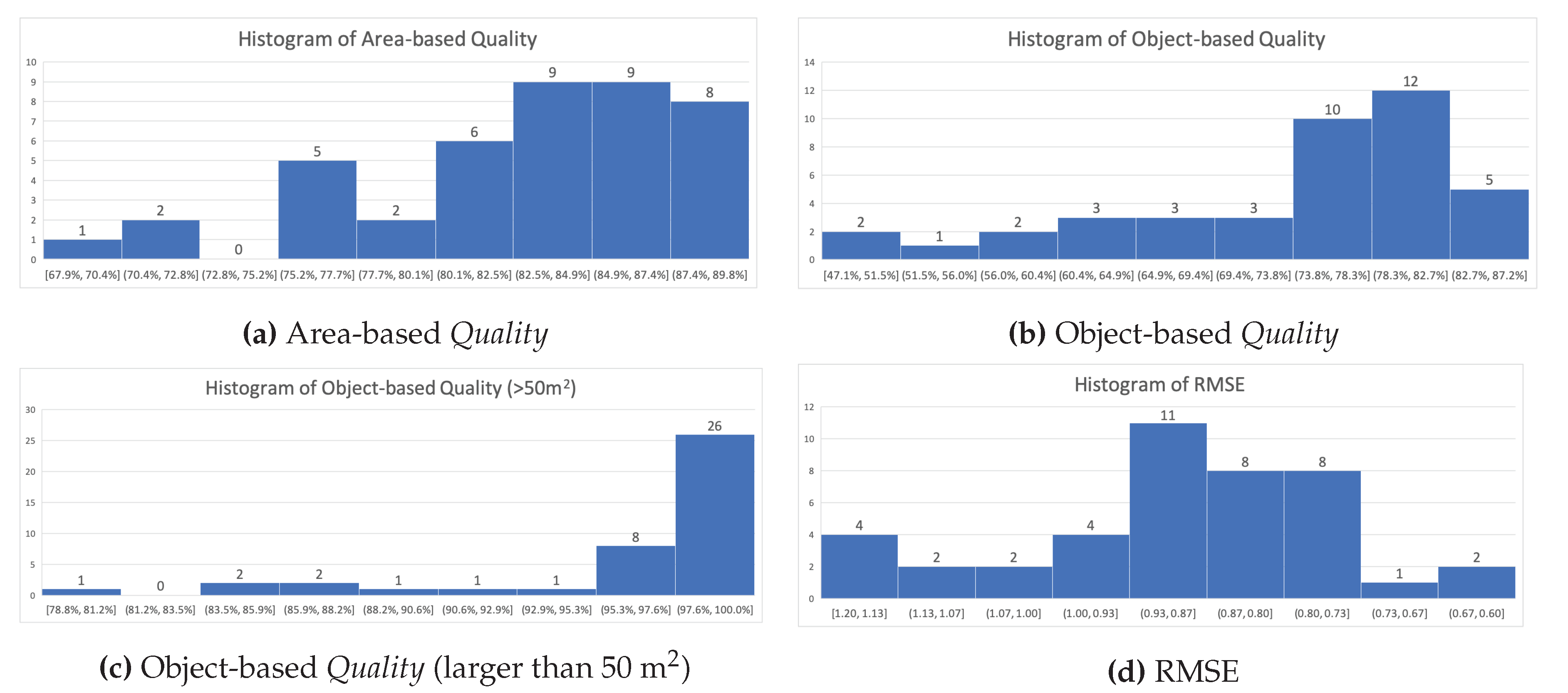
3.5. Performance on ISPRS Vaihingen Dataset
3.6. Performance on Quebec City
4. Discussions
4.1. Relevance of the Super-Resolution
4.2. Discussion on the SRSM Resulting Footprints
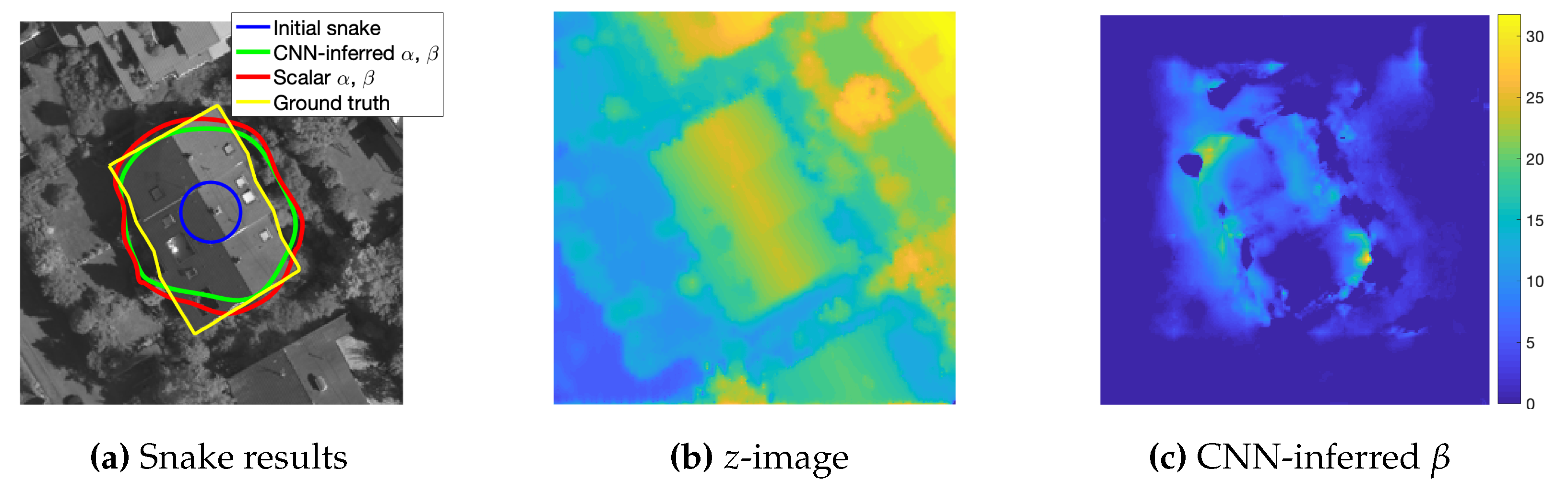
4.3. Impacts of Snake Parametrization
5. Conclusions
Author Contributions
Funding
Acknowledgments
Conflicts of Interest
Abbreviations
| CNN | Convolutional Neural Network |
| DSM | Digital Surface Model |
| DTM | Digital Terrain Model |
| FCN | Fully Convolutional Neural Network |
| FISTA | Fast Iterative Shrinkage-Thresholding Algorithm |
| GVF | Gradient Vector Flow |
| ISTA | Iterative Shrinkage-Thresholding Algorithm |
| LiDAR | Light Detection And Ranging |
| NDVI | Normalized Difference Vegetation Index |
| RMSE | Root Mean Square Error |
| SSDG | Sum of squared directional gradients |
| SR | Super-resolution |
| SRSM | Super-resolution-based Snake Model |
Appendix A. External Image-Based Energy Term of Snake Model
Appendix B. Super-Solution Quality Metrics
References
- Frédéricque, B.; Daniel, S.; Bédard, Y.; Paparoditis, N. Populating a building Multi Representation Data Base with photogrammetric tools: Recent progress. ISPRS J. Photogramm. Remote Sens. 2008, 63, 441–460. [Google Scholar] [CrossRef]
- Daniel, S.; Doran, M.A. GeoSmartCity: Geomatics Contribution to the Smart City. In Proceedings of the 14th Annual International Conference on Digital Government Research, Quebec, QC, Canada, 17–20 June 2013; pp. 65–71. [Google Scholar]
- Xie, Y.; Weng, A.; Weng, Q. Population estimation of urban residential communities using remotely sensed morphologic data. IEEE Geosci. Remote Sens. Lett. 2015, 12, 1111–1115. [Google Scholar]
- Al-Khudhairy, D.H. Geo-spatial information and technologies in support of EU crisis management. Int. J. Digit. Earth 2010, 3, 16–30. [Google Scholar] [CrossRef]
- Alamdar, F.; Kalantari, M.; Rajabifard, A. Towards multi-agency sensor information integration for disaster management. Comput. Environ. Urban Syst. 2016, 56, 68–85. [Google Scholar] [CrossRef]
- Blin, P.; Leclerc, M.; Secretan, Y.; Morse, B. Cartographie du risque unitaire d’endommagement (CRUE) par inondations pour les résidences unifamiliales du Québec. Rev. Sci. EAU 2005, 18, 427–451. [Google Scholar] [CrossRef] [Green Version]
- El-Rewini, H.; Abd-El-Barr, M. Advanced Computer Architecture and Parallel Processing; John Wiley & Sons: Hoboken, NJ, USA, 2005; Volume 42. [Google Scholar]
- Kim, T.; Muller, J.P. Development of a graph-based approach for building detection. Image Vision Comput. 1999, 17, 3–14. [Google Scholar] [CrossRef]
- Karantzalos, K.; Paragios, N. Recognition-driven two-dimensional competing priors toward automatic and accurate building detection. IEEE Trans. Geosci. Remote Sens. 2008, 47, 133–144. [Google Scholar] [CrossRef]
- Ngo, T.T.; Mazet, V.; Collet, C.; De Fraipont, P. Shape-based building detection in visible band images using shadow information. IEEE J. Sel. Top. Appl. Earth Obs. Remote Sens. 2016, 10, 920–932. [Google Scholar] [CrossRef]
- Gruen, A.; Wang, X. News from CyberCity-Modeler. In Proceedings of the 3rd International Workshop on Automatic Extraction of Man-Made Objects from Aerial and Space Images. Monte Verita, Ascona, Switzerland, 10–15 June 2001; pp. 93–101. [Google Scholar]
- Tomljenovic, I.; Höfle, B.; Tiede, D.; Blaschke, T. Building extraction from airborne laser scanning data: An analysis of the state of the art. Remote Sens. 2015, 7, 3826–3862. [Google Scholar] [CrossRef] [Green Version]
- Huertas, A.; Nevatia, R. Detecting buildings in aerial images. Comput. Vis. Graph. Image Process. (CVGIP) 1988, 41, 131–152. [Google Scholar] [CrossRef]
- Lee, D.S.; Shan, J.; Bethel, J.S. Class-guided building extraction from Ikonos imagery. Photogramm. Eng. Remote Sens. 2003, 69, 143–150. [Google Scholar] [CrossRef] [Green Version]
- Turker, M.; Koc-San, D. Building extraction from high-resolution optical spaceborne images using the integration of support vector machine (SVM) classification, Hough transformation and perceptual grouping. Int. J. Appl. Earth Obs. Geoinf. 2015, 34, 58–69. [Google Scholar] [CrossRef]
- Huang, J.; Zhang, X.; Xin, Q.; Sun, Y.; Zhang, P. Automatic building extraction from high-resolution aerial images and LiDAR data using gated residual refinement network. ISPRS J. Photogramm. Remote Sens. 2019, 151, 91–105. [Google Scholar] [CrossRef]
- Ekhtari, N.; Zoej, M.J.V.; Sahebi, M.R.; Mohammadzadeh, A. Automatic building extraction from LIDAR digital elevation models and WorldView imagery. J. Appl. Remote Sens. 2009, 3, 033571. [Google Scholar] [CrossRef]
- Khoshelham, K.; Elberink, S.O.; Xu, S. Segment-based classification of damaged building roofs in aerial laser scanning data. IEEE Geosci. Remote Sens. Lett. 2013, 10, 1258–1262. [Google Scholar] [CrossRef]
- Zhang, J.; Lin, X.; Ning, X. SVM-based classification of segmented airborne LiDAR point clouds in urban areas. Remote Sens. 2013, 5, 3749–3775. [Google Scholar] [CrossRef] [Green Version]
- Zhang, J.; Lin, X. Advances in fusion of optical imagery and LiDAR point cloud applied to photogrammetry and remote sensing. Int. J. Image Data Fusion 2017, 8, 1–31. [Google Scholar] [CrossRef]
- Chen, L.; Zhao, S.; Han, W.; Li, Y. Building detection in an urban area using lidar data and QuickBird imagery. Int. J. Remote Sens. 2012, 33, 5135–5148. [Google Scholar] [CrossRef]
- Sohn, G.; Dowman, I. Data fusion of high-resolution satellite imagery and LiDAR data for automatic building extraction. ISPRS J. Photogramm. Remote Sens. 2007, 62, 43–63. [Google Scholar] [CrossRef]
- Awrangjeb, M.; Zhang, C.; Fraser, C.S. Automatic extraction of building roofs using LIDAR data and multispectral imagery. ISPRS J. Photogramm. Remote Sens. 2013, 83, 1–18. [Google Scholar] [CrossRef] [Green Version]
- Zhang, J. Multi-source remote sensing data fusion: Status and trends. Int. J. Image Data Fusion 2010, 1, 5–24. [Google Scholar] [CrossRef] [Green Version]
- Gilani, S.; Awrangjeb, M.; Lu, G. An automatic building extraction and regularisation technique using lidar point cloud data and orthoimage. Remote Sens. 2016, 8, 258. [Google Scholar] [CrossRef] [Green Version]
- Rottensteiner, F.; Sohn, G.; Gerke, M.; Wegner, J.D.; Breitkopf, U.; Jung, J. Results of the ISPRS benchmark on urban object detection and 3D building reconstruction. ISPRS J. Photogramm. Remote Sens. 2014, 93, 256–271. [Google Scholar] [CrossRef]
- Niemeyer, J.; Rottensteiner, F.; Soergel, U. Conditional random fields for lidar point cloud classification in complex urban areas. ISPRS Ann. Photogramm. Remote Sens. Spat. Inf. Sci 2012, 1, 263–268. [Google Scholar] [CrossRef] [Green Version]
- Chai, D. A probabilistic framework for building extraction from airborne color image and DSM. IEEE J. Sel. Top. Appl. Earth Obs. Remote Sens. 2016, 10, 948–959. [Google Scholar] [CrossRef]
- Bayer, S.; Poznanska, A.; Dahlke, D.; Bucher, T. Brief description of Procedures Used for Building and Tree Detection at Vaihingen Test Site. Available online: http://ftp.ipi.uni-hannover.de/ISPRS_WGIII_website/ISPRSIII_4_Test_results/papers/Bayer_etal_DLR_detection_buildings_trees_Vaihingen.pdf (accessed on 26 January 2020).
- Grigillo, D.; Kanjir, U. Urban object extraction from digital surface model and digital aerial images. ISPRS Ann. Photogramm. Remote Sens. Spat. Inf. Sci 2012, 3, 215–220. [Google Scholar] [CrossRef] [Green Version]
- Kass, M.; Witkin, A.; Terzopoulos, D. Snakes: Active contour models. Int. J. Comput. Vis. 1988, 1, 321–331. [Google Scholar] [CrossRef]
- Szeliski, R. Computer Vision: Algorithms and Applications, 1st ed.; Springer: Berlin/Heidelberg, Germany, 2010. [Google Scholar]
- Guo, T.; Yasuoka, Y. Snake-based approach for building extraction from high-resolution satellite images and height data in urban areas. In Proceedings of the 23rd Asian conference on remote sensing (ACRS), Kathmandu, Nepal, 25–29 November 2002; p. 6. [Google Scholar]
- Peng, J.; Zhang, D.; Liu, Y. An improved snake model for building detection from urban aerial images. Pattern Recognit. Lett. 2005, 26, 587–595. [Google Scholar] [CrossRef]
- Kabolizade, M.; Ebadi, H.; Ahmadi, S. An improved snake model for automatic extraction of buildings from urban aerial images and LiDAR data. Comput. Environ. Urban Syst. 2010, 34, 435–441. [Google Scholar] [CrossRef]
- Ahmadi, S.; Zoej, M.V.; Ebadi, H.; Moghaddam, H.A.; Mohammadzadeh, A. Automatic urban building boundary extraction from high resolution aerial images using an innovative model of active contours. Int. J. Appl. Earth Obs. Geoinf. 2010, 12, 150–157. [Google Scholar] [CrossRef]
- Fazan, A.J.; Dal Poz, A.P. Rectilinear building roof contour extraction based on snakes and dynamic programming. Int. J. Appl. Earth Obs. Geoinf. 2013, 25, 1–10. [Google Scholar] [CrossRef]
- Griffiths, D.; Boehm, J. Improving public data for building segmentation from Convolutional Neural Networks (CNNs) for fused airborne lidar and image data using active contours. ISPRS J. Photogramm. Remote Sens. 2019, 154, 70–83. [Google Scholar] [CrossRef]
- Nguyen, T.H.; Daniel, S.; Guériot, D.; Sintès, C.; Le Caillec, J.M. Unsupervised Automatic Building Extraction Using Active Contour Model on Unregistered Optical Imagery and Airborne LiDAR Data. ISPRS - Int. Arch. Photogramm. Remote Sens. Spatial Inf. Sci. 2019, XLII-2/W16, 181–188. [Google Scholar] [CrossRef] [Green Version]
- Awrangjeb, M.; Lu, G.; Fraser, C. Automatic building extraction from LiDAR data covering complex urban scenes. ISPRS - Int. Arch. Photogramm. Remote Sens. Spatial Inf. Sci. 2014, 40, 25. [Google Scholar] [CrossRef] [Green Version]
- Yang, B.; Xu, W.; Dong, Z. Automated extraction of building outlines from airborne laser scanning point clouds. IEEE Geosci. Remote Sens. Lett. 2013, 10, 1399–1403. [Google Scholar] [CrossRef]
- Marcos, D.; Tuia, D.; Kellenberger, B.; Zhang, L.; Bai, M.; Liao, R.; Urtasun, R. Learning deep structured active contours end-to-end. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–23 June 2018; pp. 8877–8885. [Google Scholar] [CrossRef] [Green Version]
- Huang, J.; Lu, X.X.; Sellers, J.M. A global comparative analysis of urban form: Applying spatial metrics and remote sensing. Landsc. Urban Plan. 2007, 82, 184–197. [Google Scholar] [CrossRef]
- Zhang, W.; Qi, J.; Wan, P.; Wang, H.; Xie, D.; Wang, X.; Yan, G. An easy-to-use airborne LiDAR data filtering method based on cloth simulation. Remote Sens. 2016, 8, 501. [Google Scholar] [CrossRef]
- Awrangjeb, M.; Ravanbakhsh, M.; Fraser, C.S. Automatic detection of residential buildings using LIDAR data and multispectral imagery. ISPRS J. Photogramm. Remote Sens. 2010, 65, 457–467. [Google Scholar] [CrossRef] [Green Version]
- Rottensteiner, F.; Trinder, J.; Clode, S.; Kubik, K. Building detection by fusion of airborne laser scanner data and multi-spectral images: Performance evaluation and sensitivity analysis. ISPRS J. Photogramm. Remote Sens. 2007, 62, 135–149. [Google Scholar] [CrossRef]
- Nguyen, T.H.; Daniel, S.; Guériot, D.; Sintes, C.; Le Caillec, J.M. Robust Building-Based Registration of Airborne Lidar Data and Optical Imagery on Urban Scenes. In Proceedings of the IGARSS 2019-2019 IEEE International Geoscience and Remote Sensing Symposium, Yokohama, Japan, 28 July–2 August 2019; pp. 8474–8477. [Google Scholar] [CrossRef] [Green Version]
- Nguyen, T.H.; Daniel, S.; Gueriot, D.; Sintes, C.; Le Caillec, J.M. Coarse-to-Fine Registration of Airborne LiDAR Data and Optical Imagery on Urban Scenes. IEEE J. Sel. Top. Appl. Earth Obs. Remote Sens. 2020. [Google Scholar] [CrossRef]
- Xu, C.; Prince, J.L. Gradient vector flow: A new external force for snakes. In Proceedings of the IEEE Computer Society Conference on Computer Vision and Pattern Recognition, San Juan, PR, USA, 17–19 June 1997; pp. 66–71. [Google Scholar] [CrossRef] [Green Version]
- Courant, R.; Hilbert, D. Methods of Mathematical Physics: Partial Differential Equations; John Wiley & Sons: Hoboken, NJ, USA, 2008. [Google Scholar]
- Cohen, L.D. On active contour models and balloons. CVGIP Image Underst. 1991, 53, 211–218. [Google Scholar] [CrossRef]
- Castorena, J.; Puskorius, G.; Pandey, G. Motion Guided LIDAR-camera Self-calibration and Accelerated Depth Upsampling. arXiv 2018, arXiv:1803.10681. [Google Scholar]
- Beck, A.; Teboulle, M. A Fast Iterative Shrinkage-Thresholding Algorithm for Linear Inverse Problems. SIAM J. Imaging Sci. 2009, 2, 183–202. [Google Scholar] [CrossRef] [Green Version]
- Rutzinger, M.; Rottensteiner, F.; Pfeifer, N. A comparison of evaluation techniques for building extraction from airborne laser scanning. IEEE J. Sel. Top. Appl. Earth Obs. Remote Sens. 2009, 2, 11–20. [Google Scholar] [CrossRef]
- Cramer, M. The DGPF-test on digital airborne camera evaluation–overview and test design. Photogramm. Fernerkund. Geoinform. 2010, 2010, 73–82. [Google Scholar] [CrossRef]
- Ville de Québec. Empreintes des Bâtiments. Available online: https://www.donneesquebec.ca/recherche/fr/dataset/empreintes-des-batiments (accessed on 4 March 2019).
- Microsoft. Microsoft Canadian Building Footprints. Available online: https://github.com/microsoft/CanadianBuildingFootprints (accessed on 17 September 2019).
- He, K.; Zhang, X.; Ren, S.; Sun, J. Deep residual learning for image recognition. In Proceedings of the 2016 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Las Vegas, NV, USA, 27–30 June 2016; pp. 770–778. [Google Scholar] [CrossRef] [Green Version]
- Sibson, R. A brief description of natural neighbour interpolation. In Interpreting Multivariate Data; John Wiley & Sons: New York, NY, USA, 1981; Volume 21, pp. 21–36. [Google Scholar]
- Wang, Z.; Bovik, A.C.; Sheikh, H.R.; Simoncelli, E.P. Image quality assessment: From error visibility to structural similarity. IEEE Trans. Image Process. 2004, 13, 600–612. [Google Scholar] [CrossRef] [Green Version]
- Hore, A.; Ziou, D. Image quality metrics: PSNR vs. SSIM. In Proceedings of the 2010 20th International Conference on Pattern Recognition, Istanbul, Turkey, 23–26 August 2010; pp. 2366–2369. [Google Scholar]
- ISPRS Test Project on Urban Classification and 3D Building Reconstruction: Results. Available online: http://www2.isprs.org/commissions/comm3/wg4/results.html (accessed on 26 January 2020).
- Ok, A.O. Automated detection of buildings from single VHR multispectral images using shadow information and graph cuts. ISPRS J. Photogramm. Remote Sens. 2013, 86, 21–40. [Google Scholar] [CrossRef]
- Luo, S.; Wang, C.; Xi, X.; Zeng, H.; Li, D.; Xia, S.; Wang, P. Fusion of airborne discrete-return LiDAR and hyperspectral data for land cover classification. Remote Sens. 2015, 8, 3. [Google Scholar] [CrossRef] [Green Version]







{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Vaihingen | Quebec City | ||||
|---|---|---|---|---|---|
| Specifications | Optical Image | LiDAR | Optical Image | LiDAR | |
| Spectral resolution | NIR, R, G | 1064 nm | R, G, B | 1064 nm | |
| Spatial resolution | 9 cm | 50 cm | 15 cm | 35.4 cm | |
| (point density) | - | (4 pts/m2) | - | (8 pts/m2) | |
| Acquisition time | July–August 2008 | 21 August 2008 | June 2016 | May 2017 | |
| Geometry/Properties | Orthorectified | Mostly single-return | Orthorectified | Multireturn (4) | |
| Georeferenced | Unclassified | Georeferenced | Classified | ||
| Relative misalignment | Less than 30 cm | 1.05 m (before registration), | |||
| 0.35 m (after registration [48]) | |||||
| Method | RMSE | SSIM | PSNR (dB) | RMSE | SSIM | PSNR (dB) | RMSE | SSIM | PSNR (dB) | ||
|---|---|---|---|---|---|---|---|---|---|---|---|
| NN | 2.18 | 0.40 | −6.76 | 2.47 | 0.30 | −7.85 | 3.08 | 0.18 | −9.76 | ||
| Bilinear | 2.08 | 0.37 | −6.36 | 2.41 | 0.34 | −7.65 | 4.39 | 0.24 | −12.86 | ||
| Natural | 2.00 | 0.40 | −6.03 | 2.34 | 0.36 | −7.40 | 4.33 | 0.25 | −12.74 | ||
| Proposed SR | 1.96 | 0.40 | −5.83 | 2.04 | 0.33 | −6.21 | 2.80 | 0.19 | −8.94 | ||
| Benchmark Ground Truth | Modified Ground Truth | ||||
|---|---|---|---|---|---|
| Model | Q | RMSE (m) | Q | RMSE (m) | |
| Basic snake model | 76.92% | 2.05 | 74.36% | 2.21 | |
| Guo and Yasuoka [33] | 77.38% | 1.90 | 78.15% | 1.92 | |
| Kabolizade et al. [35] | 79.66% | 2.08 | 76.01% | 2.36 | |
| SRSM | 86.25% | 1.80 | 95.57% | 1.75 | |
| Area | Q | RMSE | ||
|---|---|---|---|---|
| 1 | 90.42% | 94.20% | 85.65% | 1.24 |
| 2 | 93.47% | 94.75% | 88.87% | 1.11 |
| 3 | 91.00% | 93.02% | 85.18% | 0.92 |
| Average | 91.63% | 93.99% | 86.57% | 1.09 |
| Area | Q | |||||
|---|---|---|---|---|---|---|
| 1 | 83.78% | 100% | 83.78% | 100% | 100% | 100% |
| 2 | 78.57% | 100% | 78.57% | 100% | 100% | 100% |
| 3 | 83.93% | 97.92% | 82.46% | 97.30% | 100% | 97.30% |
| Average | 82.09% | 99.31% | 81.60% | 99.10% | 100% | 99.10% |
| Area-Based Accuracy | Object-Based Accuracy | ||||||
|---|---|---|---|---|---|---|---|
| Method | |||||||
| Microsoft building footprints | 77.42% | 87.61% | 69.77% | 59.01% | 93.16% | 56.56% | |
| SRSM footprints | 82.32% | 72.02% | 62.37% | 74.25% | 80.95% | 63.21% | |
| CNN-Inferred Energy Terms and Parameter | |||
|---|---|---|---|
| Feature | |||
| Corner | very positive | very negative | almost 0 |
| Edge | very positive | negative | very positive |
| Inside boundary | positive | positive | low but positive |
| Outside boundary | 0 | positive | low but positive |
© 2020 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Nguyen, T.H.; Daniel, S.; Guériot, D.; Sintès, C.; Le Caillec, J.-M. Super-Resolution-Based Snake Model—An Unsupervised Method for Large-Scale Building Extraction Using Airborne LiDAR Data and Optical Image. Remote Sens. 2020, 12, 1702. https://doi.org/10.3390/rs12111702
Nguyen TH, Daniel S, Guériot D, Sintès C, Le Caillec J-M. Super-Resolution-Based Snake Model—An Unsupervised Method for Large-Scale Building Extraction Using Airborne LiDAR Data and Optical Image. Remote Sensing. 2020; 12(11):1702. https://doi.org/10.3390/rs12111702
Chicago/Turabian StyleNguyen, Thanh Huy, Sylvie Daniel, Didier Guériot, Christophe Sintès, and Jean-Marc Le Caillec. 2020. "Super-Resolution-Based Snake Model—An Unsupervised Method for Large-Scale Building Extraction Using Airborne LiDAR Data and Optical Image" Remote Sensing 12, no. 11: 1702. https://doi.org/10.3390/rs12111702
APA StyleNguyen, T. H., Daniel, S., Guériot, D., Sintès, C., & Le Caillec, J.-M. (2020). Super-Resolution-Based Snake Model—An Unsupervised Method for Large-Scale Building Extraction Using Airborne LiDAR Data and Optical Image. Remote Sensing, 12(11), 1702. https://doi.org/10.3390/rs12111702