Two-Path Network with Feedback Connections for Pan-Sharpening in Remote Sensing


 ,
,  ,
,
Abstract
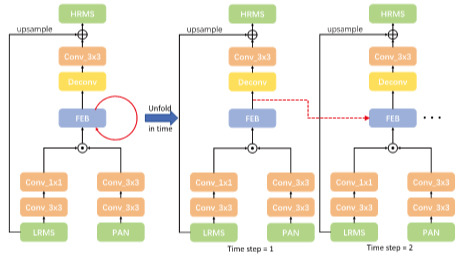
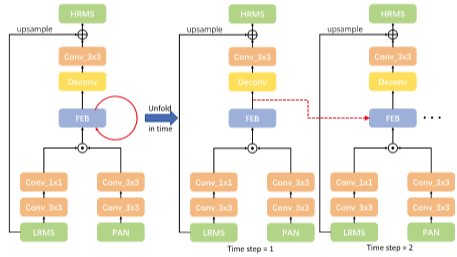
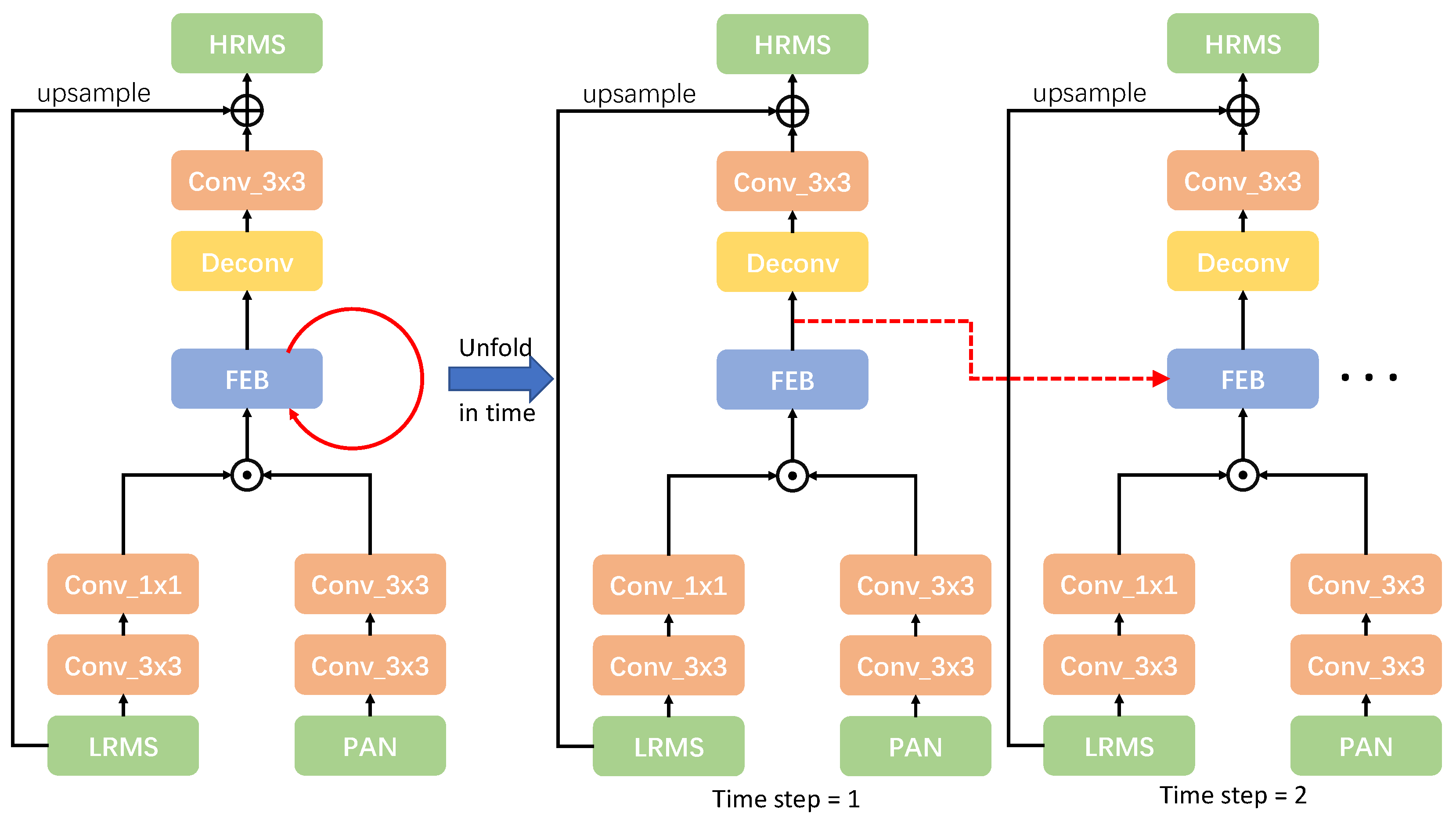
1. Introduction
- We propose a two-path feedback network to extract features from the MS image and the PAN image separately and to achieve feedback mechanism which can carry powerful deep features to improve the poor shallow features in a feedback manner for better reconstruction performance.
- We attach losses to each time step to supervise the output of the network. In this way, the feedback deep features contain useful information, which comes from the coarsely-reconstructed HRMS at early time steps, to reconstruct better HRMS image at late time steps.
2. Materials
2.1. Datasets
2.2. Feedback Mechanism
3. Methods
3.1. Implementation Details
3.2. Evaluation Metrics
- SAM. The spectral angle mapper (SAM) [39] evaluates the spectral distortions of the pan-sharpened image. It is defined as:where and are two spectral vectors.
- CC. The correlation coefficient (CC) [5] is used to evaluate the spectral quality of the pan-sharpened images. The CC is calculated by a pan-sharpened image I and the corresponding reference image Y.where is the covariance between I and Y, and denotes the variance of n.
- RMSE. The root mean square error (RMSE) [25] is a frequently used measure of the differences between the pan-sharpened image I and the reference image Y.where w and h are the width and height of the pan-sharpened image.
- RASE. The relative average spectral error (RASE) [41] estimates the global spectral quality of the pan-sharpened image. It is defined as:where is the root mean square error between the i-th band of the pan-sharpened image and the i-th band of the reference image. M is the mean value of the N spectral bands ().
- ERGAS. The relative global dimensional synthesis error (ERGAS) [42] is a commonly used index to measure the global quality. ERGAS is computed as the following expression:where h is the resolution of the pan-sharpened image, and l is the resolution of the low spatial resolution image. is the root mean square error between the i-th band of the pan-sharpened image and the i-th band of the reference image. is the mean value of the i-th band of the low-resolution MS image. N is the number of the spectral bands.
3.3. Network Structure
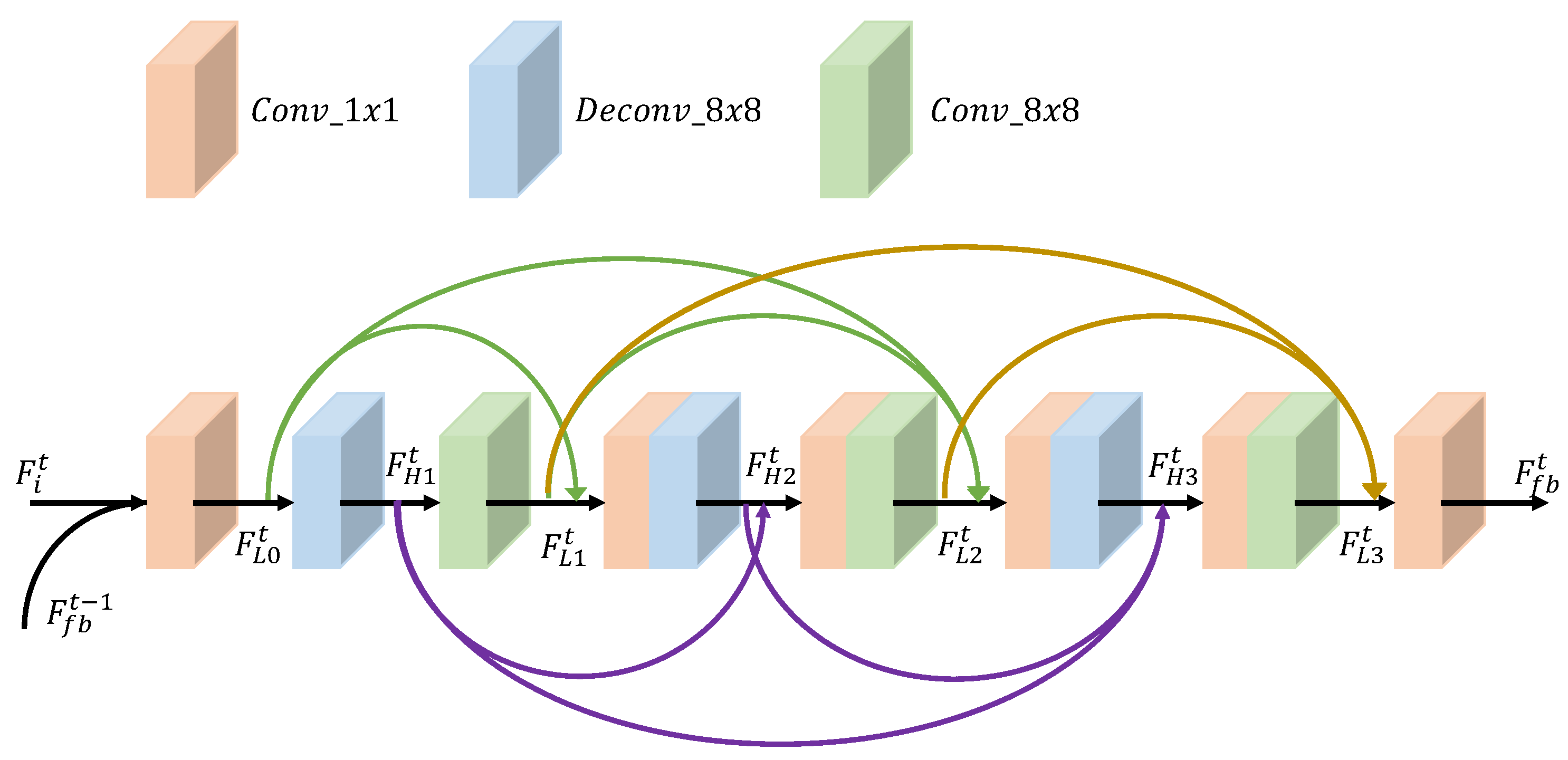
3.4. Feature Extraction Block
3.5. Loss Function
4. Results
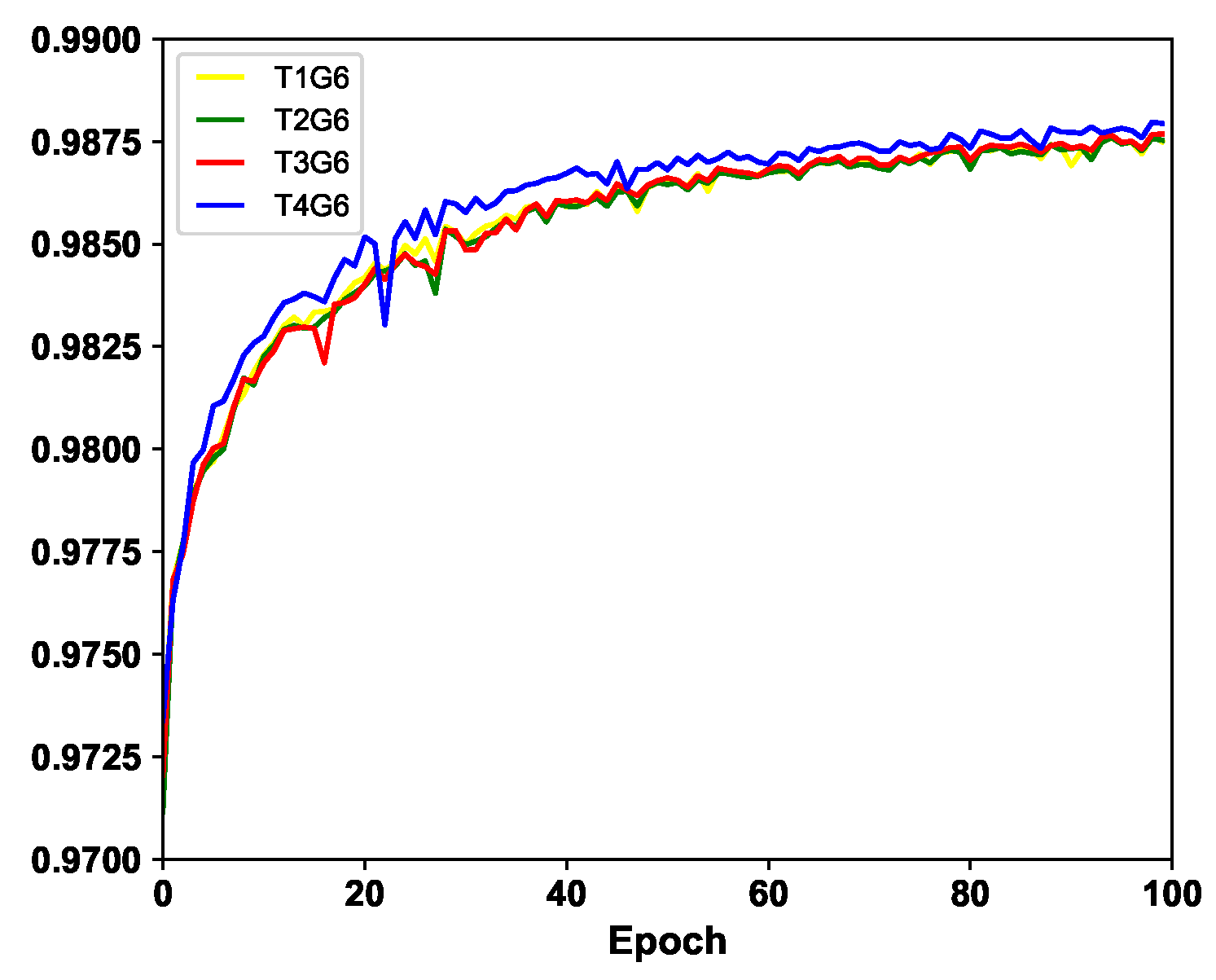
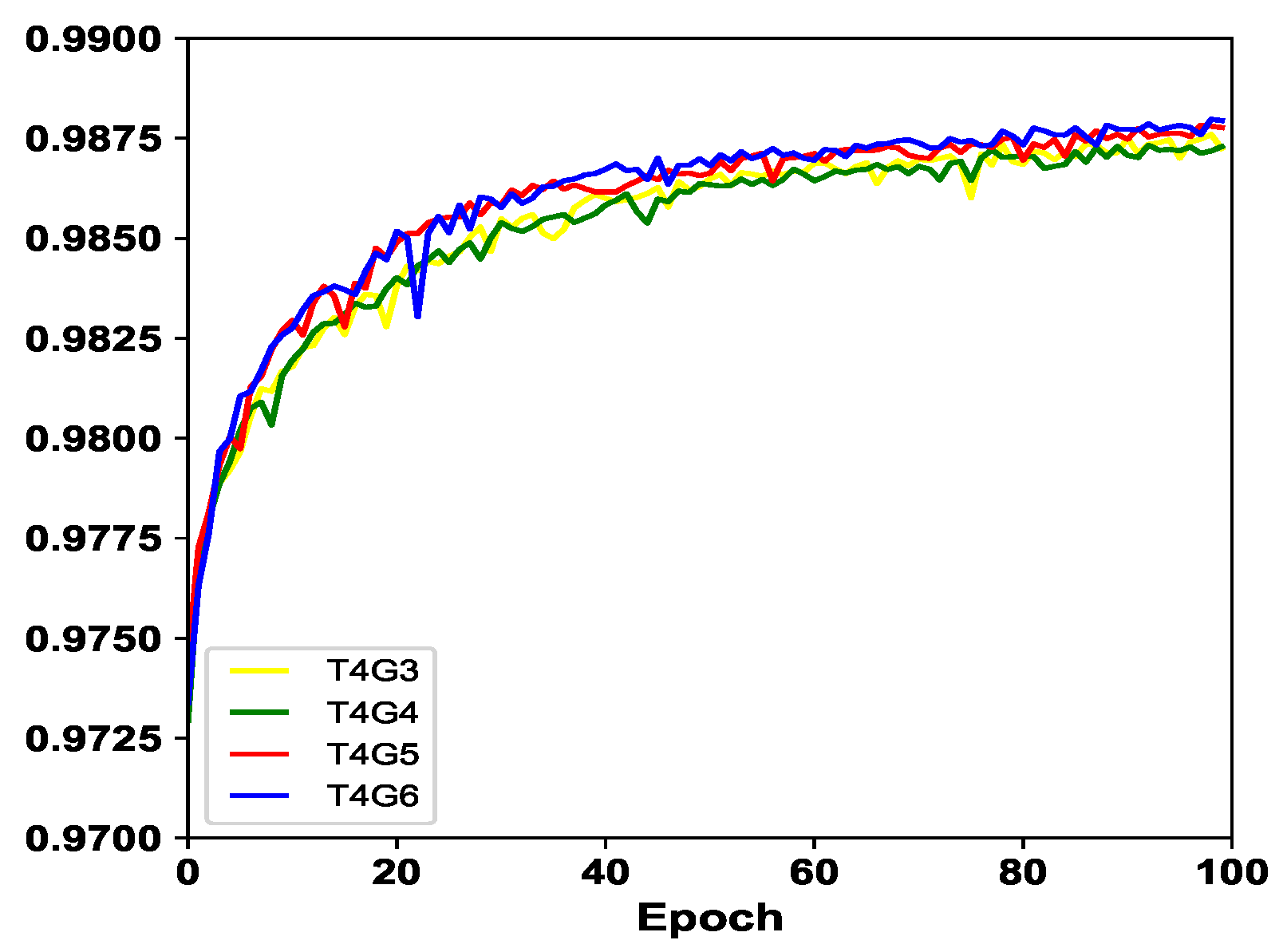
4.1. Impacts of G and T
4.2. Comparisons with Other Methods
5. Discussions
5.1. Discussions on Loss Functions
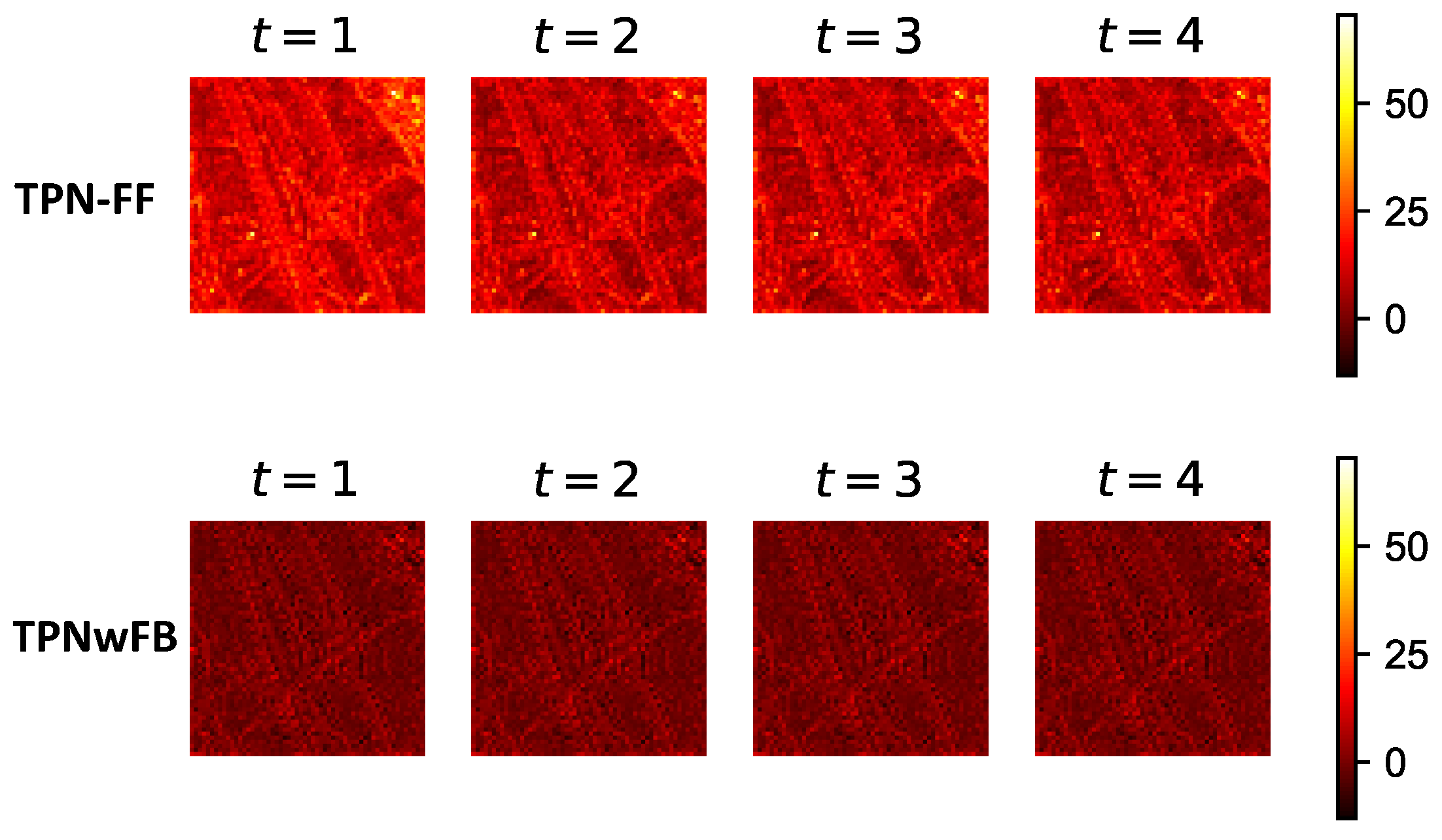
5.2. Discussions on Feedback Mechanism
6. Conclusions
Author Contributions
Funding
Acknowledgments
Conflicts of Interest
Abbreviations
| HRMS | High-resolution multi-spectral |
| LRMS | Low-resolution multi-spectral |
| PAN | Panchromatic |
| RNN | Recurrent neural network |
| CNN | Convolutional neural network |
| TPNwFB | two-path pan-sharpening network with feedback connections |
| FEB | Feature extraction block |
| SRCNN | Super-Resolution Convolutional Neural Network |
References
- Ghassemian, H. A review of remote sensing image fusion methods. Inf. Fusion 2016, 32, 75–89. [Google Scholar] [CrossRef]
- Nikolakopoulos, K.G. Comparison of nine fusion techniques for very high resolution data. Photogramm. Eng. Remote Sens. 2008, 74, 647–659. [Google Scholar] [CrossRef]
- Pohl, C.; Van Genderen, J.L. Review article multisensor image fusion in remote sensing: Concepts, methods and applications. Int. J. Remote Sens. 1998, 19, 823–854. [Google Scholar] [CrossRef]
- Vivone, G.; Alparone, L.; Chanussot, J.; Dalla Mura, M.; Garzelli, A.; Licciardi, G.A.; Restaino, R.; Wald, L. A critical comparison among pansharpening algorithms. IEEE Trans. Geosci. Remote Sens. 2014, 53, 2565–2586. [Google Scholar] [CrossRef]
- Liu, X.; Liu, Q.; Wang, Y. Remote sensing image fusion based on two-stream fusion network. Inf. Fusion 2020, 55, 1–15. [Google Scholar] [CrossRef]
- Wei, Y.; Yuan, Q.; Shen, H.; Zhang, L. Boosting the accuracy of multispectral image pansharpening by learning a deep residual network. IEEE Geosci. Remote Sens. Lett. 2017, 14, 1795–1799. [Google Scholar] [CrossRef]
- Masi, G.; Cozzolino, D.; Verdoliva, L.; Scarpa, G. Pansharpening by convolutional neural networks. Remote Sens. 2016, 8, 594. [Google Scholar] [CrossRef]
- Tu, T.M.; Su, S.C.; Shyu, H.C.; Huang, P.S. A new look at IHS-like image fusion methods. Inf. Fusion 2001, 2, 177–186. [Google Scholar] [CrossRef]
- Tu, T.M.; Huang, P.S.; Hung, C.L.; Chang, C.P. A fast intensity-hue-saturation fusion technique with spectral adjustment for IKONOS imagery. IEEE Geosci. Remote Sens. Lett. 2004, 1, 309–312. [Google Scholar] [CrossRef]
- Shahdoosti, H.R.; Ghassemian, H. Combining the spectral PCA and spatial PCA fusion methods by an optimal filter. Inf. Fusion 2016, 27, 150–160. [Google Scholar] [CrossRef]
- Xu, Q.; Li, B.; Zhang, Y.; Ding, L. High-fidelity component substitution pansharpening by the fitting of substitution data. IEEE Trans. Geosci. Remote Sens. 2014, 52, 7380–7392. [Google Scholar]
- Parente, C.; Santamaria, R. Increasing geometric resolution of data supplied by quickbird multispectral sensors. Sens. Transducers 2013, 156, 111. [Google Scholar]
- Pradhan, P.S.; King, R.L.; Younan, N.H.; Holcomb, D.W. Estimation of the number of decomposition levels for a wavelet-based multiresolution multisensor image fusion. IEEE Trans. Geosci. Remote Sens. 2006, 44, 3674–3686. [Google Scholar] [CrossRef]
- Nunez, J.; Otazu, X.; Fors, O.; Prades, A.; Pala, V.; Arbiol, R. Multiresolution-based image fusion with additive wavelet decomposition. IEEE Trans. Geosci. Remote Sens. 1999, 37, 1204–1211. [Google Scholar] [CrossRef]
- Nencini, F.; Garzelli, A.; Baronti, S.; Alparone, L. Remote sensing image fusion using the curvelet transform. Inf. Fusion 2007, 8, 143–156. [Google Scholar] [CrossRef]
- Fang, F.; Li, F.; Shen, C.; Zhang, G. A variational approach for pan-sharpening. IEEE Trans. Image Process. 2013, 22, 2822–2834. [Google Scholar] [CrossRef]
- Jiang, C.; Zhang, H.; Shen, H.; Zhang, L. Two-step sparse coding for the pan-sharpening of remote sensing images. IEEE J. Sel. Top. Appl. Earth Obs. Remote Sens. 2013, 7, 1792–1805. [Google Scholar] [CrossRef]
- Padwick, C.; Deskevich, M.; Pacifici, F.; Smallwood, S. WorldView-2 pan-sharpening. In Proceedings of the ASPRS 2010 Annual Conference, San Diego, CA, USA, 26–30 April 2010; Volume 2630. [Google Scholar]
- Choi, J.; Yu, K.; Kim, Y. A new adaptive component-substitution-based satellite image fusion by using partial replacement. IEEE Trans. Geosci. Remote Sens. 2010, 49, 295–309. [Google Scholar] [CrossRef]
- Hussain, S.; Keung, J.; Khan, A.A.; Ahmad, A.; Cuomo, S.; Piccialli, F.; Jeon, G.; Akhunzada, A. Implications of deep learning for the automation of design patterns organization. J. Parallel Distrib. Comput. 2018, 117, 256–266. [Google Scholar] [CrossRef]
- Ahmed, I.; Ahmad, A.; Piccialli, F.; Sangaiah, A.K.; Jeon, G. A robust features-based person tracker for overhead views in industrial environment. IEEE Internet Things J. 2017, 5, 1598–1605. [Google Scholar] [CrossRef]
- Dong, C.; Loy, C.C.; He, K.; Tang, X. Learning a deep convolutional network for image super-resolution. In European Conference on Computer Vision, Zurich, Switzerland, 6–12 September 2014; Springer: Berlin, Germany, 2014; pp. 184–199. [Google Scholar]
- Jeon, G.; Anisetti, M.; Wang, L.; Damiani, E. Locally estimated heterogeneity property and its fuzzy filter application for deinterlacing. Inf. Sci. 2016, 354, 112–130. [Google Scholar] [CrossRef]
- Zhong, J.; Yang, B.; Huang, G.; Zhong, F.; Chen, Z. Remote sensing image fusion with convolutional neural network. Sens. Imaging 2016, 17, 10. [Google Scholar] [CrossRef]
- Zhang, Y.; Liu, C.; Sun, M.; Ou, Y. Pan-Sharpening Using an Efficient Bidirectional Pyramid Network. IEEE Trans. Geosci. Remote Sens. 2019, 57, 5549–5563. [Google Scholar] [CrossRef]
- Zamir, A.R.; Wu, T.L.; Sun, L.; Shen, W.B.; Shi, B.E.; Malik, J.; Savarese, S. Feedback networks. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Honolulu, HI, USA, 21–26 July 2017; pp. 1308–1317. [Google Scholar]
- Li, Z.; Yang, J.; Liu, Z.; Yang, X.; Jeon, G.; Wu, W. Feedback Network for Image Super-Resolution. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Long Beach, CA, USA, 15–20 June 2019; pp. 3867–3876. [Google Scholar]
- Timofte, R.; Rothe, R.; Van Gool, L. Seven ways to improve example-based single image super resolution. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 27–30 June 2016; pp. 1865–1873. [Google Scholar]
- Haris, M.; Shakhnarovich, G.; Ukita, N. Deep back-projection networks for super-resolution. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Munich, Germany, 8–14 September 2018; pp. 1664–1673. [Google Scholar]
- Wald, L.; Ranchin, T.; Mangolini, M. Fusion of Satellite Images of Different Spatial Resolutions: Assessing the Quality of Resulting Images. Photogramm. Eng. Remote Sens. 1997, 63, 691–699. [Google Scholar]
- Hupé, J.; James, A.; Payne, B.; Lomber, S.; Girard, P.; Bullier, J. Cortical feedback improves discrimination between figure and background by V1, V2 and V3 neurons. Nature 1998, 394, 784. [Google Scholar] [CrossRef] [PubMed]
- Carreira, J.; Agrawal, P.; Fragkiadaki, K.; Malik, J. Human pose estimation with iterative error feedback. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 26 June–1 July 2016; pp. 4733–4742. [Google Scholar]
- Cao, C.; Liu, X.; Yang, Y.; Yu, Y.; Wang, J.; Wang, Z.; Huang, Y.; Wang, L.; Huang, C.; Xu, W.; et al. Look and think twice: Capturing top-down visual attention with feedback convolutional neural networks. In Proceedings of the IEEE International Conference on Computer Vision, Santiago, Chile, 7–13 December 2015; pp. 2956–2964. [Google Scholar]
- Han, W.; Chang, S.; Liu, D.; Yu, M.; Witbrock, M.; Huang, T.S. Image super-resolution via dual-state recurrent networks. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Long Beach, CA, USA, 8 September 2018; pp. 1654–1663. [Google Scholar]
- Lim, B.; Son, S.; Kim, H.; Nah, S.; Mu Lee, K. Enhanced deep residual networks for single image super-resolution. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition Workshops, Honolulu, HI, USA, 21–26 July 2017; pp. 136–144. [Google Scholar]
- He, K.; Zhang, X.; Ren, S.; Sun, J. Delving deep into rectifiers: Surpassing human-level performance on imagenet classification. In Proceedings of the IEEE International Conference on Computer Vision, Santiago, Chile, 7–13 December 2015; pp. 1026–1034. [Google Scholar]
- Paszke, A.; Gross, S.; Massa, F.; Lerer, A.; Bradbury, J.; Chanan, G.; Killeen, T.; Lin, Z.; Gimelshein, N.; Antiga, L.; et al. PyTorch: An Imperative Style, High-Performance Deep Learning Library. In Advances in Neural Information Processing Systems. 2019, pp. 8024–8035. Available online: http://papers.nips.cc/paper/9015-pytorch-an-imperative-style-high-performance-deep-learning-library (accessed on 13 April 2020).
- Kingma, D.P.; Ba, J. Adam: A method for stochastic optimization. arXiv 2014, arXiv:1412.6980. [Google Scholar]
- Yuhas, R.H.; Goetz, A.F.; Boardman, J.W. Discrimination among semi-arid landscape endmembers using the spectral angle mapper (SAM) algorithm. In Proceedings of the Summaries 3rd Annual JPL Airborne Geoscience Workshop, Pasadena, CA, USA, 1–5 June 1992; pp. 147–149. [Google Scholar]
- Alparone, L.; Baronti, S.; Garzelli, A.; Nencini, F. A global quality measurement of pan-sharpened multispectral imagery. IEEE Geosci. Remote Sens. Lett. 2004, 1, 313–317. [Google Scholar] [CrossRef]
- Pushparaj, J.; Hegde, A.V. Evaluation of pan-sharpening methods for spatial and spectral quality. Appl. Geomat. 2017, 9, 1–12. [Google Scholar] [CrossRef]
- Wald, L. Quality of high resolution synthesised images: Is there a simple criterion? In Proceedings of the Fusion of Earth Data: Merging Point Measurements, Raster Maps, and Remotely Sensed Image, Nice, France, 26–28 January 2000. [Google Scholar]
- Yang, J.; Fu, X.; Hu, Y.; Huang, Y.; Ding, X.; Paisley, J. PanNet: A deep network architecture for pan-sharpening. In Proceedings of the IEEE International Conference on Computer Vision, Venice, Italy, 22–29 October 2017; pp. 5449–5457. [Google Scholar]
- Kim, J.; Kwon Lee, J.; Mu Lee, K. Accurate image super-resolution using very deep convolutional networks. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 26 June–1 July 2016; pp. 1646–1654. [Google Scholar]
- Zhao, H.; Gallo, O.; Frosio, I.; Kautz, J. Loss functions for image restoration with neural networks. IEEE Trans. Comput. Imaging 2016, 3, 47–57. [Google Scholar] [CrossRef]
- Jin, B.; Kim, G.; Cho, N.I. Wavelet-domain satellite image fusion based on a generalized fusion equation. J. Appl. Remote Sens. 2014, 8, 080599. [Google Scholar] [CrossRef]
- Kang, X.; Li, S.; Benediktsson, J.A. Pansharpening with matting model. IEEE Trans. Geosci. Remote Sens. 2013, 52, 5088–5099. [Google Scholar] [CrossRef]
- Yin, H. Sparse representation based pansharpening with details injection model. Signal Proc. 2015, 113, 218–227. [Google Scholar] [CrossRef]










{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Spot-6 | Pléiades | IKONOS | QuickBird | WorldView-2 | |||
|---|---|---|---|---|---|---|---|
| Spectral Wavelength (nm) | PAN | 455–745 | 470–830 | 450–900 | 450–900 | 450–800 | |
| MS | Blue | 455–525 | 430–550 | 400–520 | 450–520 | 450–510 | |
| Green | 530–590 | 500–620 | 520–610 | 520–600 | 510–580 | ||
| Red | 625–695 | 590–710 | 630–690 | 630–690 | 630–690 | ||
| NIR(Near-infrared) | 760–890 | 740–940 | 760–900 | 760–900 | 770–895 | ||
| Spatial Resolution (m) | PAN | 1.5 | 0.5 | 1.0 | 0.6 | 0.5 | |
| MS | 6.0 | 2.0 | 4.0 | 2.4 | 1.9 |
| CC↑ | ERGAS↓ | ↑ | SAM↓ | RASE↓ | RMSE ↓ | |
|---|---|---|---|---|---|---|
| LS [46] | 0.9239 | 3.4313 | 0.9230 | 0.0613 | 13.6192 | 38.6125 |
| MMP [47] | 0.9367 | 3.2491 | 0.9280 | 0.0610 | 13.1180 | 37.0925 |
| PRACS [19] | 0.9450 | 3.0492 | 0.9407 | 0.0634 | 12.3820 | 35.0980 |
| SRDIP [48] | 0.9488 | 2.7737 | 0.9414 | 0.0660 | 11.6139 | 32.8202 |
| ResTFNet- [5] | 0.9823 | 1.6693 | 0.9819 | 0.0443 | 7.1958 | 20.2944 |
| BDPN [25] | 0.9831 | 1.6320 | 0.9828 | 0.0436 | 7.0527 | 19.9081 |
| TPNwFB | 0.9880 | 1.3579 | 0.9879 | 0.0347 | 5.8065 | 16.3381 |
| CC↑ | ERGAS↓ | ↑ | SAM↓ | RASE↓ | RMSE ↓ | |
|---|---|---|---|---|---|---|
| LS [46] | 0.9518 | 3.2946 | 0.9515 | 0.0513 | 13.9496 | 84.43999 |
| MMP [47] | 0.9485 | 3.3855 | 0.9479 | 0.0568 | 14.3319 | 86.7706 |
| PRACS [19] | 0.9554 | 3.2297 | 0.9538 | 0.0563 | 13.8094 | 83.7290 |
| SRDIP [48] | 0.9541 | 3.0962 | 0.9518 | 0.0523 | 12.9734 | 78.4699 |
| ResTFNet- [5] | 0.9860 | 1.7609 | 0.9858 | 0.0360 | 7.4630 | 44.0964 |
| BDPN [25] | 0.9870 | 1.6828 | 0.9868 | 0.0386 | 7.1209 | 41.9430 |
| TPNwFB | 0.9952 | 0.9987 | 0.9952 | 0.0246 | 4.2994 | 25.4422 |
| CC↑ | ERGAS↓ | ↑ | SAM↓ | RASE↓ | RMSE ↓ | |
|---|---|---|---|---|---|---|
| LS [46] | 0.9177 | 3.1834 | 0.9139 | 0.0644 | 15.1032 | 34.5074 |
| MMP [47] | 0.9126 | 3.1986 | 0.9071 | 0.0626 | 14.8303 | 34.2762 |
| PRACS [19] | 0.9164 | 3.2966 | 0.9098 | 0.0682 | 16.0026 | 36.4808 |
| SRDIP [48] | 0.8896 | 3.4935 | 0.8743 | 0.0808 | 16.7381 | 37.2496 |
| ResTFNet- [5] | 0.9155 | 3.4025 | 0.9110 | 0.0693 | 15.7161 | 34.6267 |
| BDPN [25] | 0.9155 | 3.5082 | 0.9109 | 0.0690 | 15.8580 | 35.3906 |
| TPNwFB | 0.9612 | 2.0791 | 0.9602 | 0.0436 | 8.45813 | 18.4247 |
| CC↑ | ERGAS↓ | ↑ | SAM↓ | RASE↓ | RMSE ↓ | |
|---|---|---|---|---|---|---|
| LS [46] | 0.8989 | 5.4750 | 0.8953 | 0.0792 | 22.5279 | 65.7696 |
| MMP [47] | 0.8906 | 5.5598 | 0.8865 | 0.0798 | 22.8671 | 66.5725 |
| PRACS [19] | 0.8888 | 5.9043 | 0.8814 | 0.0832 | 24.9431 | 73.1840 |
| SRDIP [48] | 0.8940 | 5.4674 | 0.8880 | 0.0851 | 22.7510 | 66.4857 |
| ResTFNet- [5] | 0.9358 | 4.6079 | 0.9315 | 0.0646 | 18.3931 | 53.5033 |
| BDPN [25] | 0.9330 | 4.6347 | 0.9296 | 0.0725 | 18.8396 | 55.1684 |
| TPNwFB | 0.9817 | 2.3485 | 0.9813 | 0.0422 | 9.7115 | 28.7936 |
| CC↑ | ERGAS↓ | ↑ | SAM↓ | RASE↓ | RMSE ↓ | |
|---|---|---|---|---|---|---|
| LS [46] | 0.9185 | 1.7127 | 0.9119 | 0.0395 | 6.8397 | 17.3581 |
| MMP [47] | 0.9181 | 1.7208 | 0.9001 | 0.0385 | 6.7145 | 17.0175 |
| PRACS [19] | 0.9031 | 1.7602 | 0.8852 | 0.0380 | 6.8669 | 17.4504 |
| SRDIP [48] | 0.8939 | 2.0369 | 0.8806 | 0.0544 | 8.3373 | 21.1365 |
| ResTFNet- [5] | 0.9500 | 1.3077 | 0.9474 | 0.0300 | 5.1326 | 13.0150 |
| BDPN [25] | 0.9445 | 1.3580 | 0.9418 | 0.0321 | 5.2913 | 13.4129 |
| TPNwFB | 0.9710 | 0.9643 | 0.9703 | 0.0221 | 3.7357 | 9.4888 |
| SAM↓ | CC↑ | |||||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|
| Time step | 1st | 2nd | 3rd | 4th | 1st | 2nd | 3rd | 4th | 1st | 2nd | 3rd | 4th |
| TPNwFB | 0.0321 | 0.0319 | 0.0319 | 0.0319 | 0.9875 | 0.9875 | 0.9876 | 0.9876 | 0.9874 | 0.9874 | 0.9875 | 0.9875 |
| TPN-FF | 0.0427 | 0.0335 | 0.0326 | 0.0320 | 0.9776 | 0.9862 | 0.9871 | 0.9874 | 0.9769 | 0.9859 | 0.9871 | 0.9873 |
© 2020 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Fu, S.; Meng, W.; Jeon, G.; Chehri, A.; Zhang, R.; Yang, X. Two-Path Network with Feedback Connections for Pan-Sharpening in Remote Sensing. Remote Sens. 2020, 12, 1674. https://doi.org/10.3390/rs12101674
Fu S, Meng W, Jeon G, Chehri A, Zhang R, Yang X. Two-Path Network with Feedback Connections for Pan-Sharpening in Remote Sensing. Remote Sensing. 2020; 12(10):1674. https://doi.org/10.3390/rs12101674
Chicago/Turabian StyleFu, Shipeng, Weihua Meng, Gwanggil Jeon, Abdellah Chehri, Rongzhu Zhang, and Xiaomin Yang. 2020. "Two-Path Network with Feedback Connections for Pan-Sharpening in Remote Sensing" Remote Sensing 12, no. 10: 1674. https://doi.org/10.3390/rs12101674
APA StyleFu, S., Meng, W., Jeon, G., Chehri, A., Zhang, R., & Yang, X. (2020). Two-Path Network with Feedback Connections for Pan-Sharpening in Remote Sensing. Remote Sensing, 12(10), 1674. https://doi.org/10.3390/rs12101674