Infrared Small Target Detection Based on Partial Sum of the Tensor Nuclear Norm


Abstract

1. Introduction
1.1. Related Works on Single-Frame-Based Infrared Small Target Detection
1.2. Motivation
- First, to avoid the problem of equal treatment on singular values and reduce some biases, we develop a nonconvex infrared small target detection model based on partial sum of tensor nuclear norm (PSTNN), which can approximate the tensor rank better, and convert the detection task into a problem of solving the tensor robust principle component analysis model.
- Second, by introducing the local prior which relates to background and target simultaneously as the local weight map, coupled with the reweighted scheme, thus the proposed model can preserve the target and suppress the background better, which assists us to complete the infrared small target detection task with good performance.
- Third, an efficient algorithm based on the alternating direction method of multipliers (ADMM) is designed for solving the proposed model accurately. Meanwhile, with the help of tensor singular value decomposition (t-SVD) and an extra stopping condition, the algorithm complexity and computation time are dramatically reduced, leading to a faster speed in comparison with similar state-of-the-art methods.
2. Notations and Preliminaries
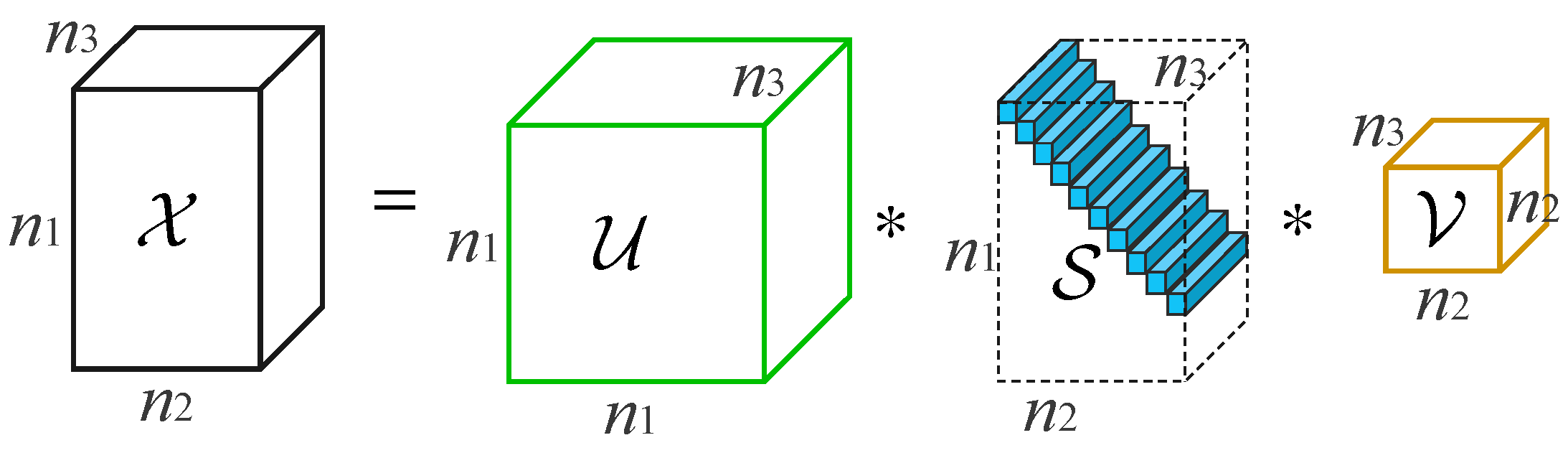
2.1. Tensor Singular Value Decomposition
| Algorithm 1 T-SVD for three-order tensors |
| Input: |
| Output: T-SVD components , and of . |
| 1. Compute |
| 2. Compute each frontal slice of , and from by |
| for do |
| ; |
| end for |
| for do |
| ; |
| ; |
| ; |
| end for |
| 3. Compute ,, and . |
2.2. Some Mathematical Preliminaries
3. Proposed Method
3.1. Infrared Patch-Tensor Model
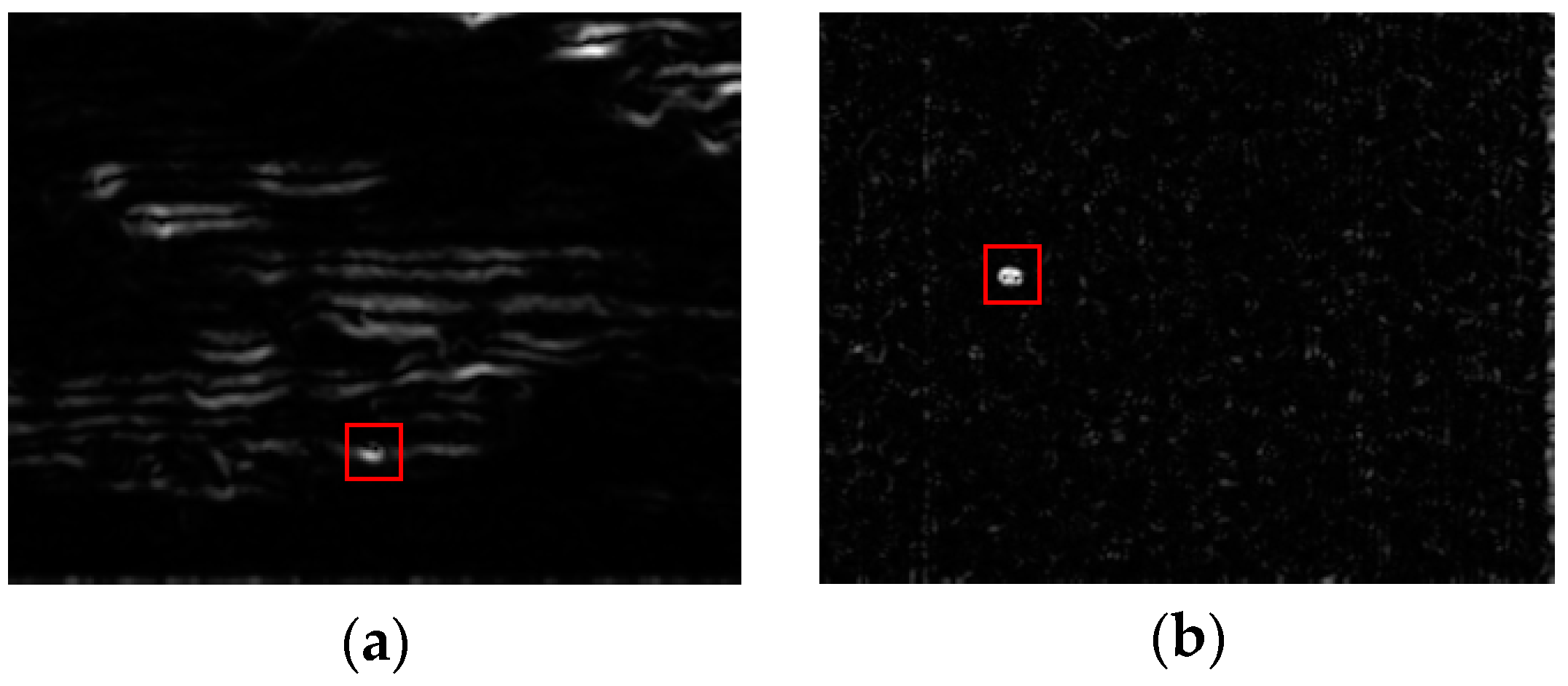
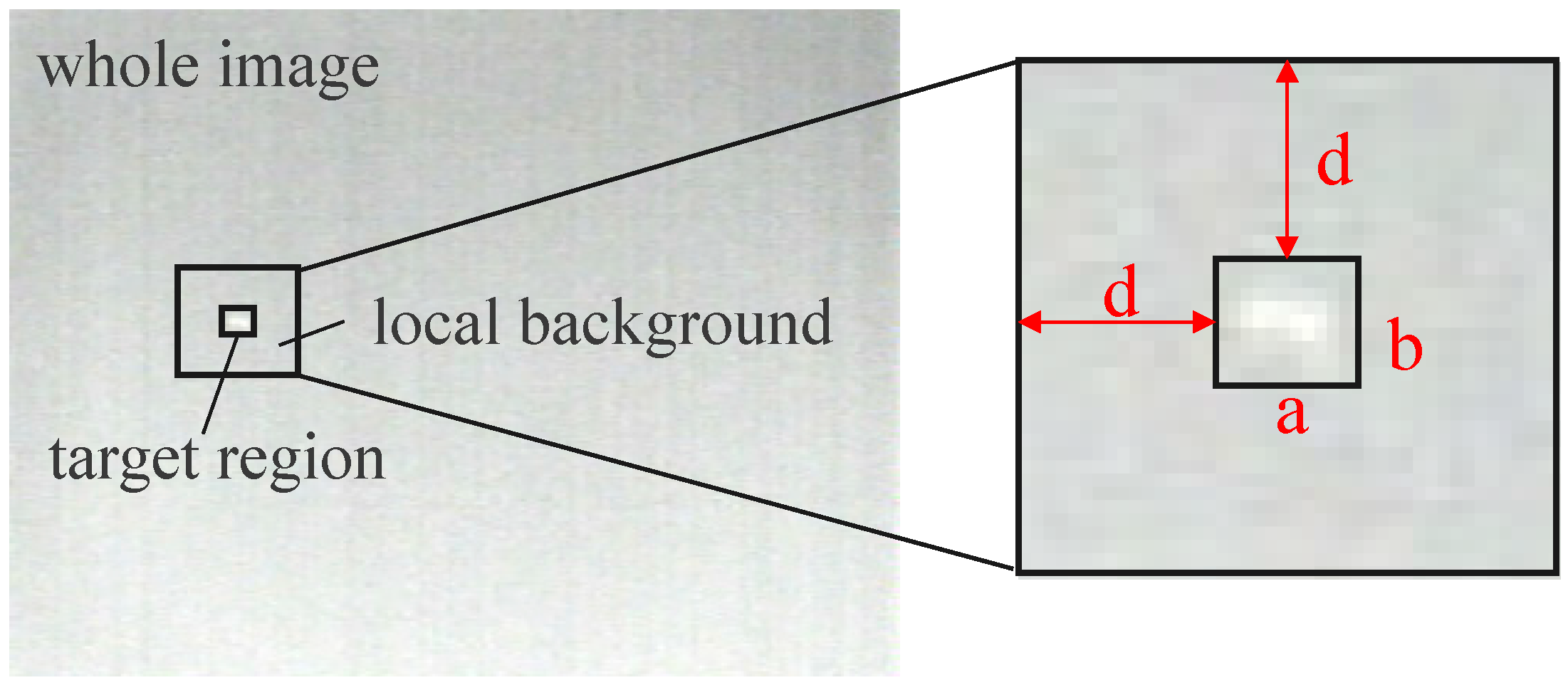
3.2. Local Prior Analysis
3.3. IPT Model Based on PSTNN
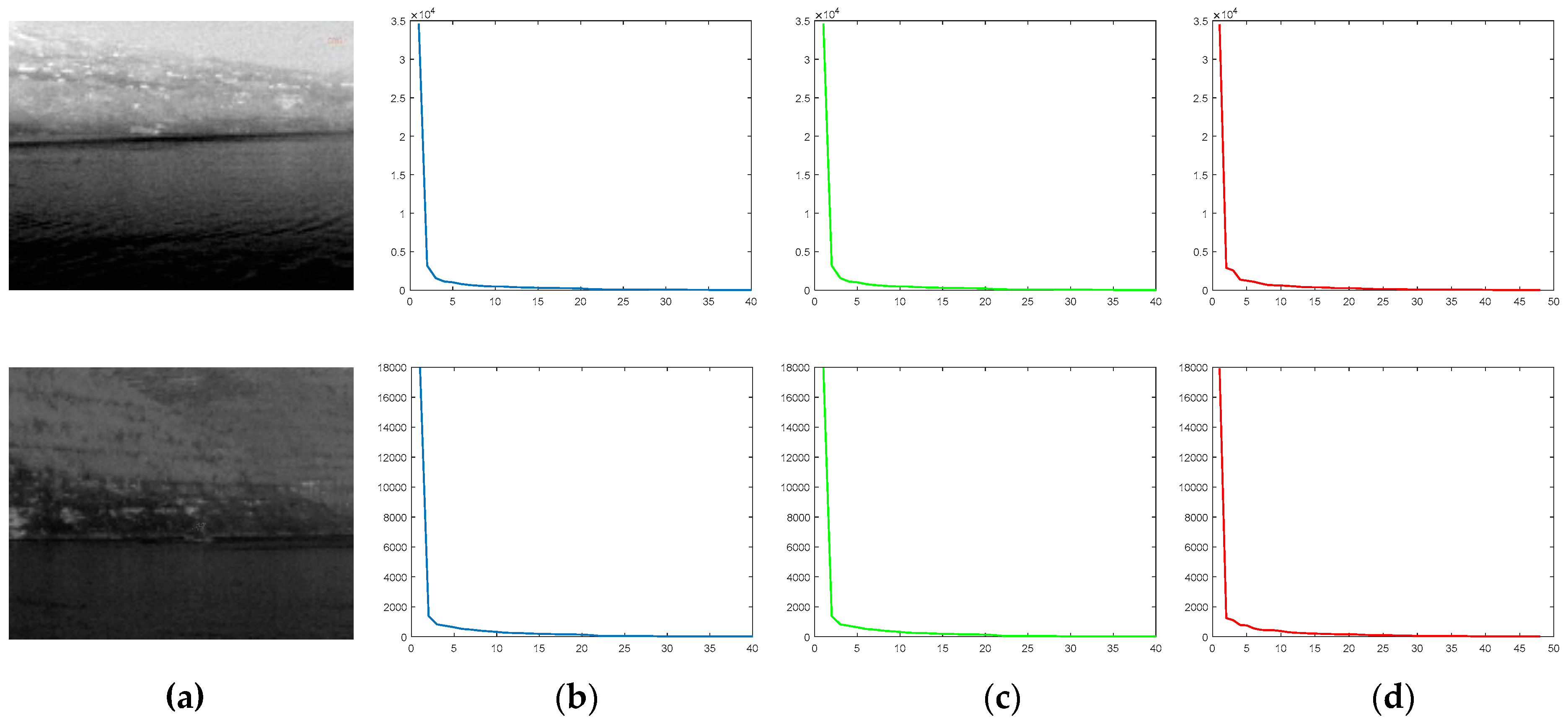
3.3.1. The Surrogate of Tensor Rank
3.3.2. Model Construction
3.3.3. Solution of the Proposed Model
| Algorithm 2 Solve Equation (25) using PSVT |
| Input:, , |
| 1. Compute |
| 2. Compute each frontal slice of by |
| for do |
| (Operator is defined in Equation (7)); |
| end for |
| for do |
| ; |
| end for |
| 3. Compute |
| Algorithm 3 ADMM solver to the proposed model |
| Input:, , , , , |
| Initialization:, , , , , c = 1, k = 0 |
| while not converge do |
| 1. Fix the others and update by Equation (26); |
| 2. Fix the others and update by Algorithm 2; |
| 3. Fix the others and update by Equation (27); |
| 4. Fix the others and update by |
| ; |
| ; |
| 5. Update by Equation (28); |
| 6. Check the convergence conditions |
| or ; |
| 7. Update k: k = k+1; |
| end while |
| 3. Output: , |
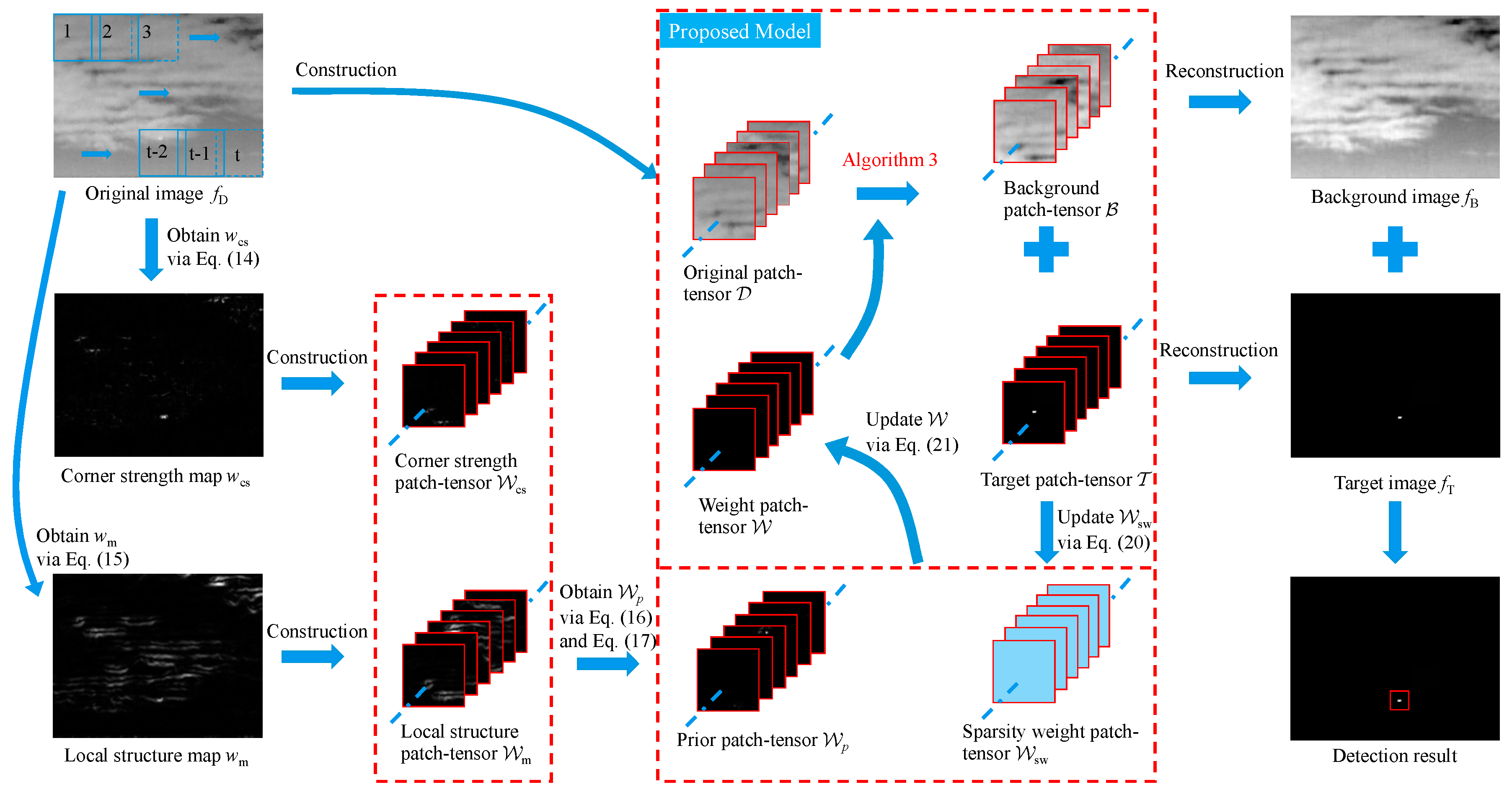
3.4. The Whole Procedure of the Proposed Method
- (1).
- Local prior extraction. Given an infrared image, by calculating Equation (16), the prior weight map related to the target and background information is obtained.
- (2).
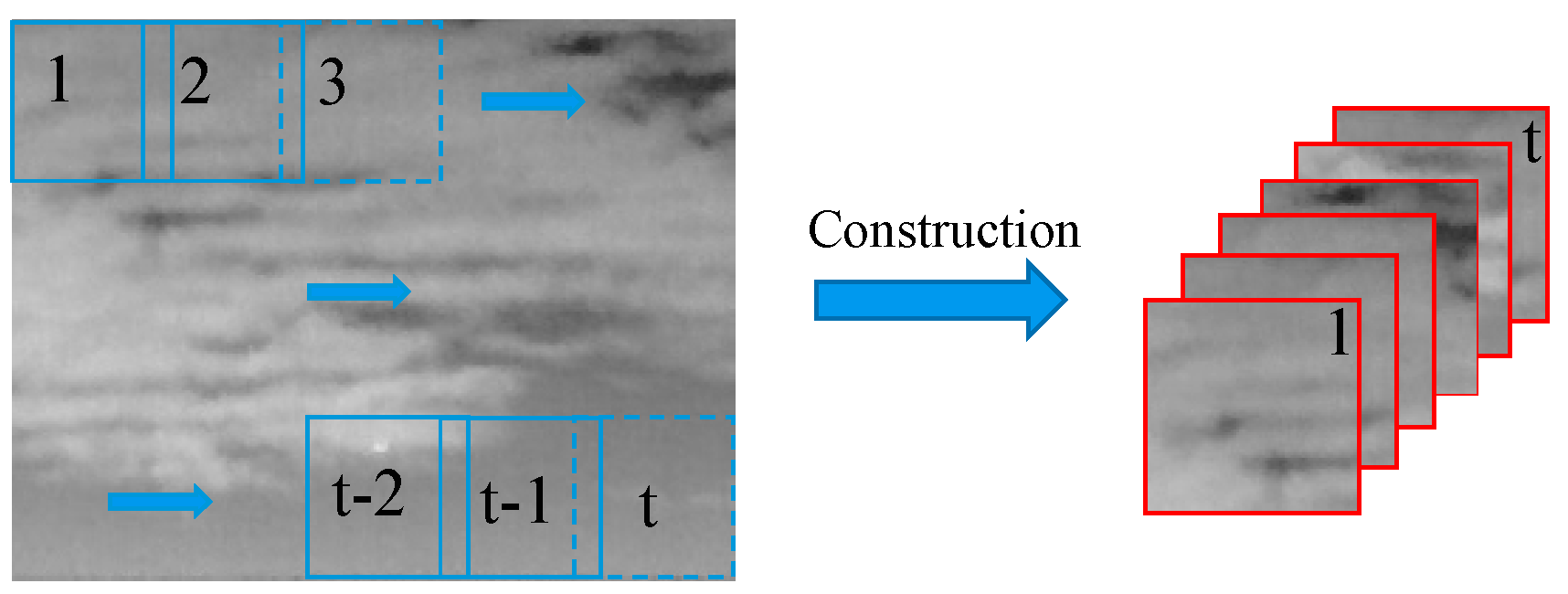
- Patch-tensor construction. By sliding a window of size k × k from top left to bottom right to transform the original infrared image and the prior weight map into the original patch-tensor and the prior weight patch-tensor respectively, where t is the number of window sliding.
- (3).
- Target-background separation. The input patch-tensor is decomposed into a low-rank patch-tensor and a sparse patch-tensor via Algorithm 3.
- (4).
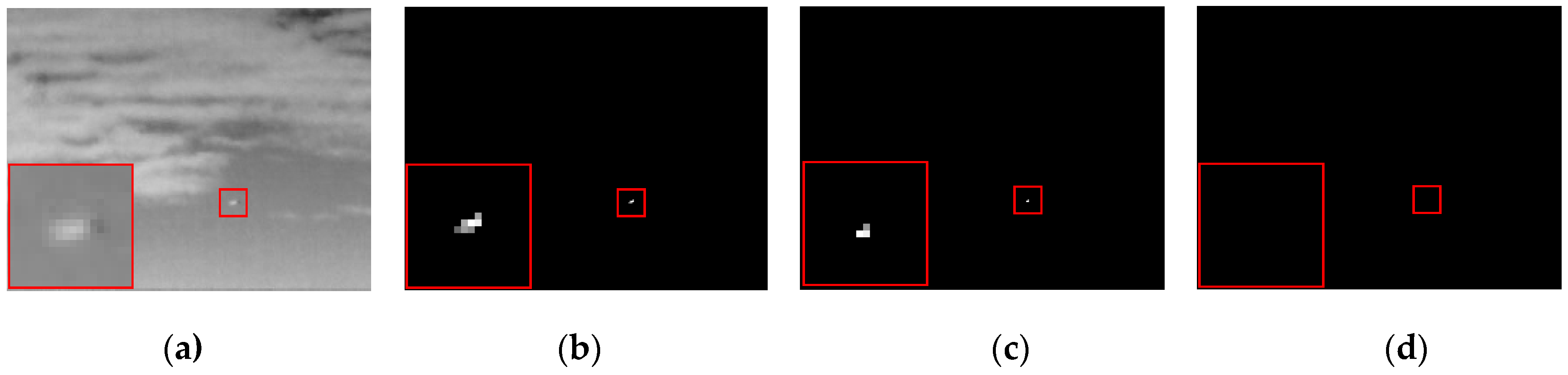
- Image reconstruction and target detection. The target image and background image are reconstructed from the low-rank patch-tensor and sparse patch-tensor , and the process of reconstruction is contrary to that of construction. Meanwhile, a one-dimensional median filter is exploited to determine the value of the position overlapped by several patches. Once the reconstruction is done, small targets are detected easily via adaptive threshold segmentation as in [20].
4. Experiment and Results
4.1. Experimental Setup and Description
4.2. Evaluation Metrics
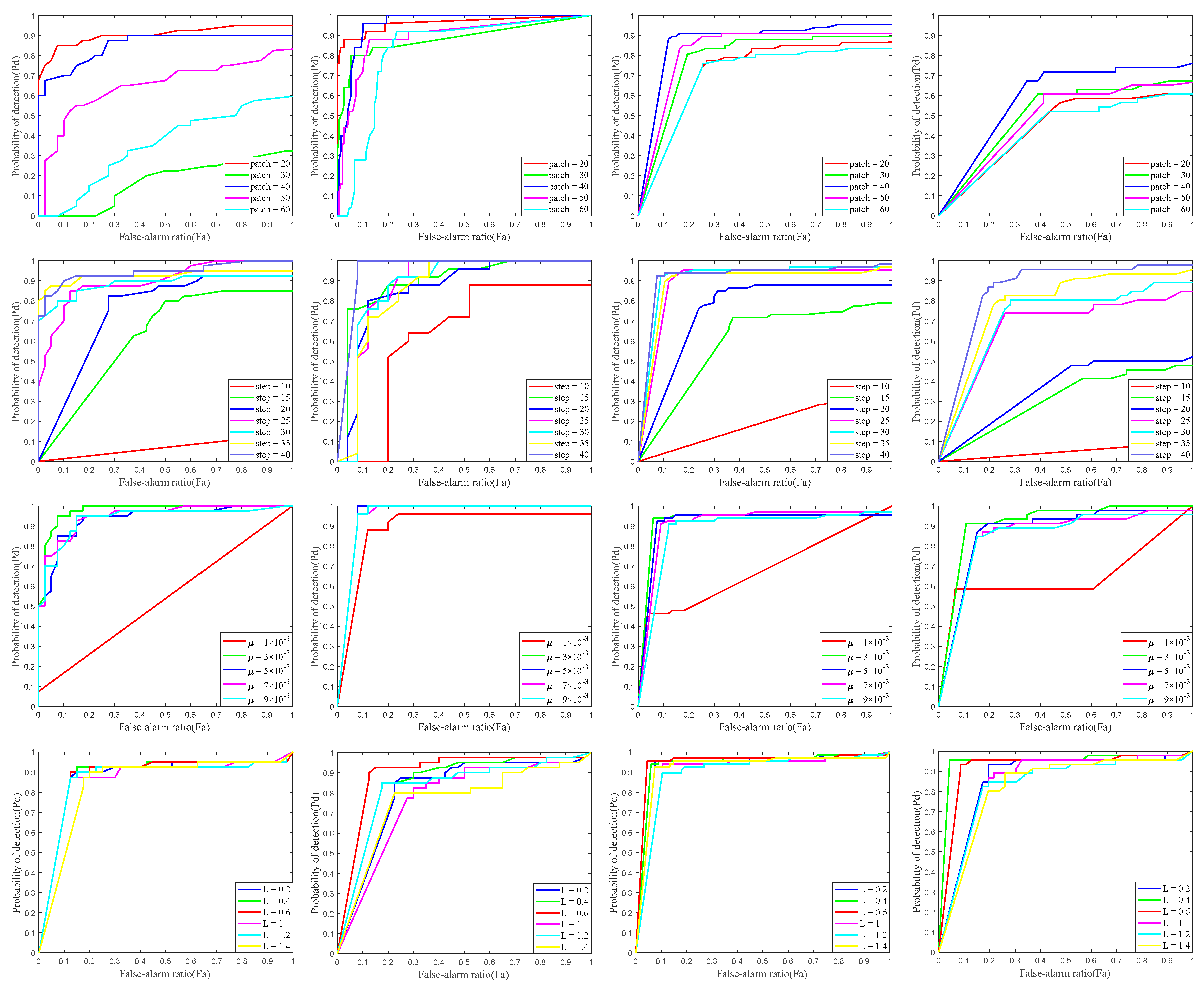
4.3. Parameter Analysis
4.3.1. Patch Size
4.3.2. Sliding Step
4.3.3. Penalty Factor
4.3.4. Compromising Parameter
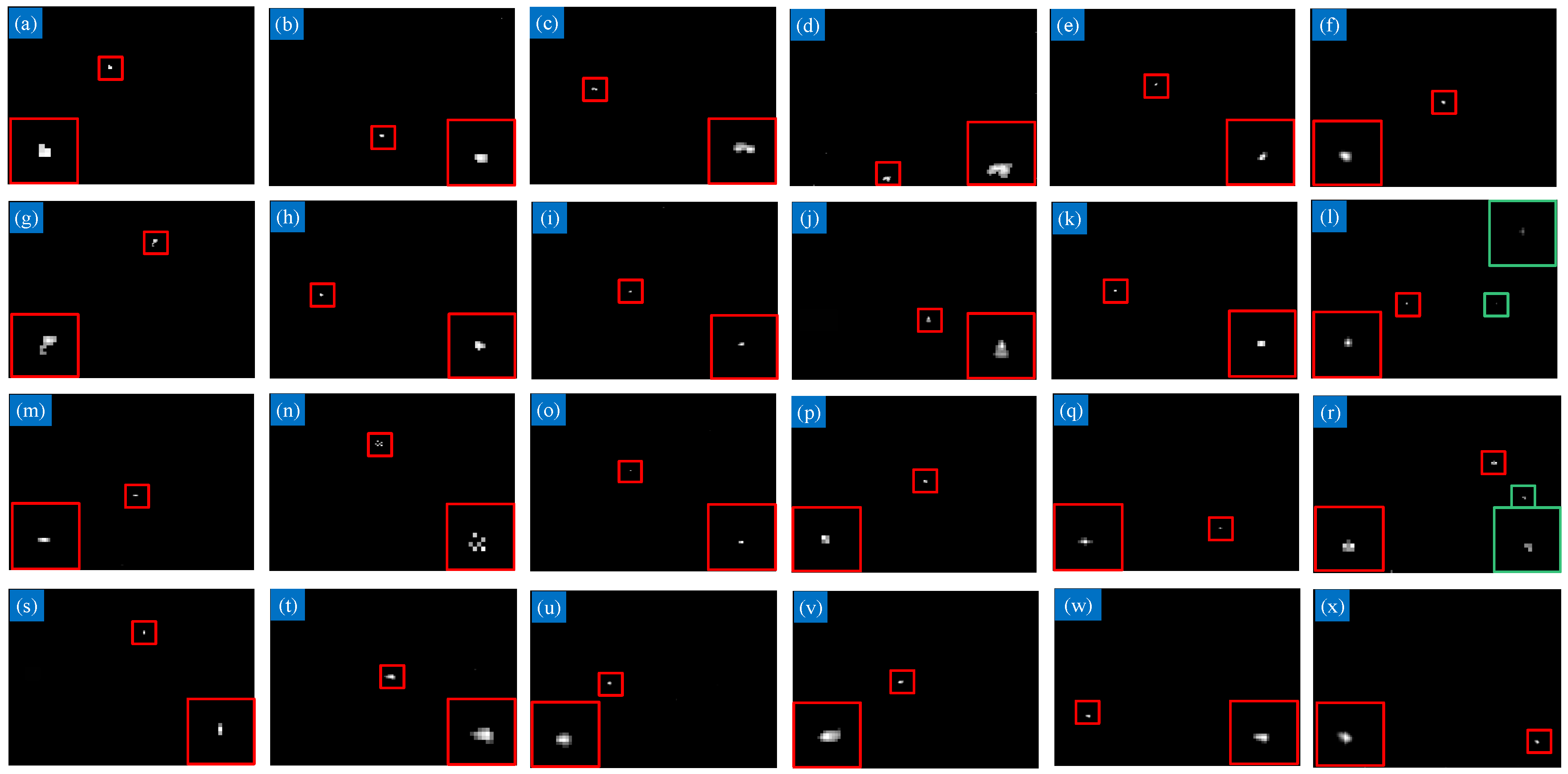
4.4. Qualitative Evaluation
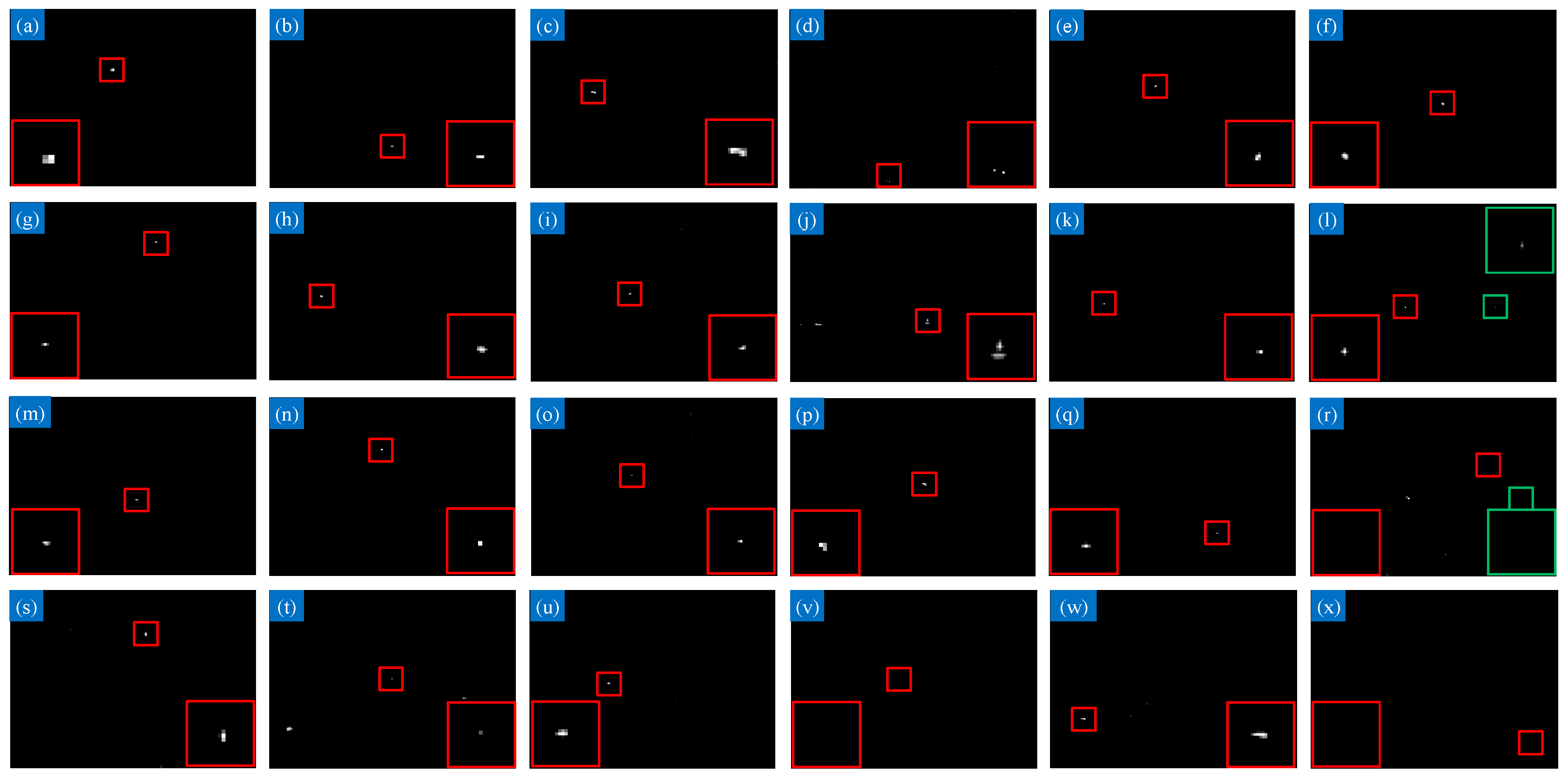
4.4.1. Robustness to Different Scenes
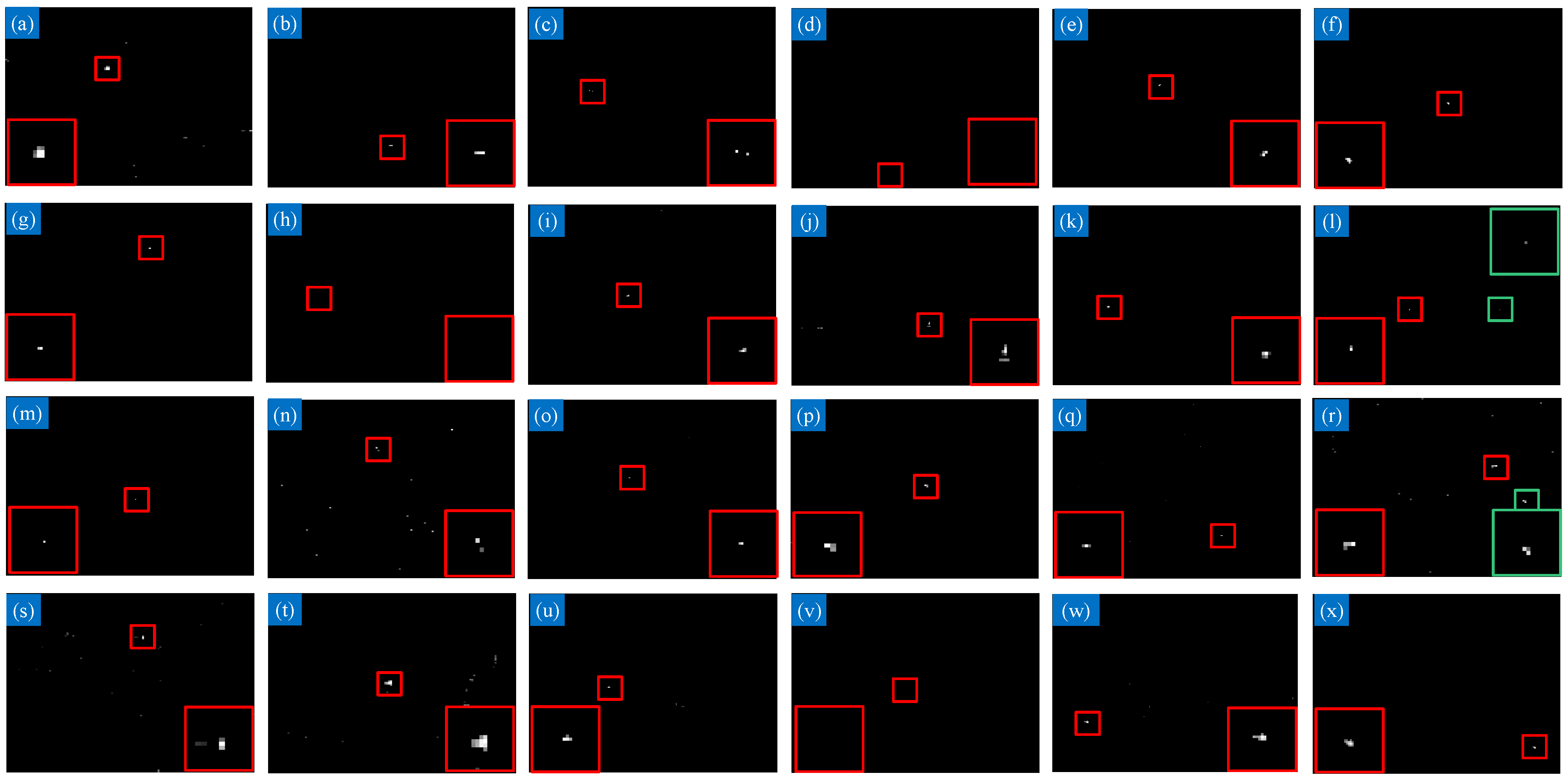
4.4.2. Robustness to Noise
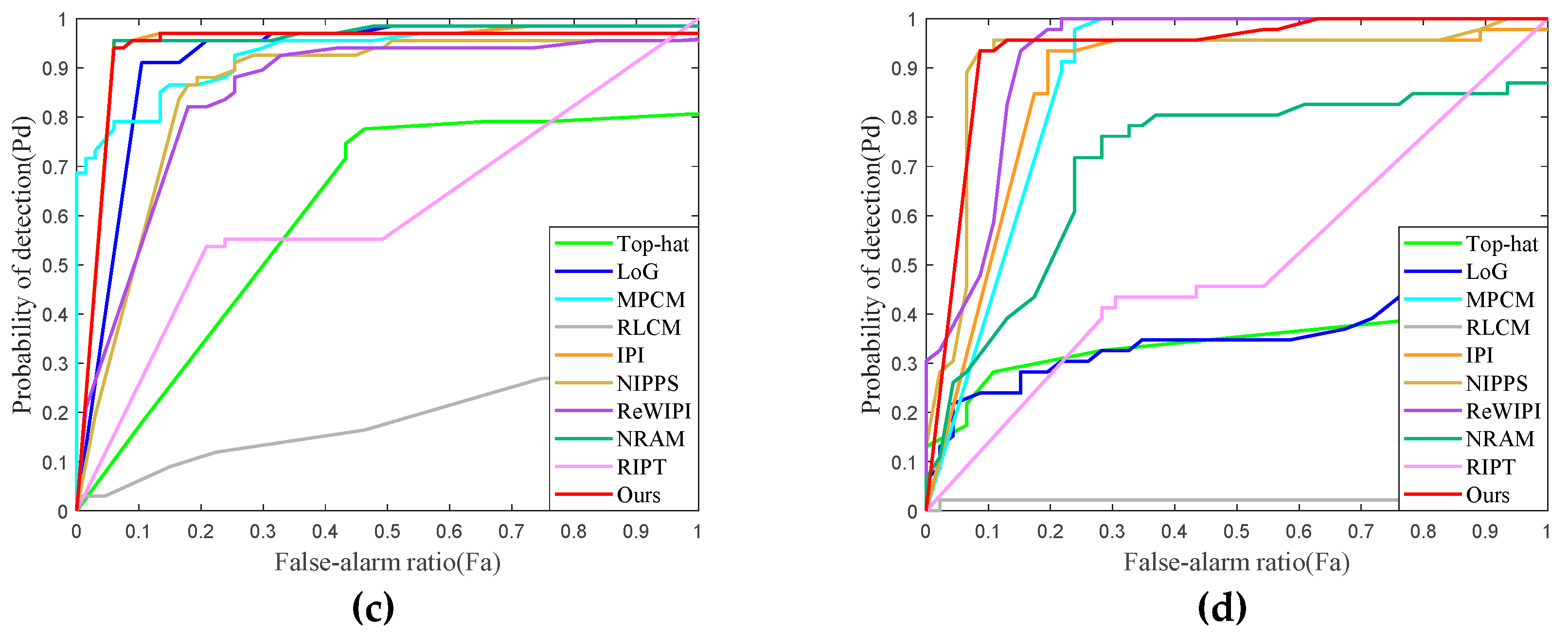
4.4.3. Visual Comparison with Baselines
4.5. Quantitative Evaluation
4.6. Algorithm Complexity and Computational Time
5. Discussion
6. Conclusions
Author Contributions
Funding
Acknowledgments
Conflicts of Interest
Appendix A








Appendix B




References
- Wang, B.; Xu, W.H.; Zhao, M.; Wu, H.D. Antivibration pipeline-filtering algorithm for maritime small target detection. Opt. Eng. 2014, 53. [Google Scholar] [CrossRef]
- Reed, I.S.; Gagliardi, R.M.; Stotts, L.B. Optical moving target detection with 3-D matched filtering. IEEE Trans Aerosp Electron. Syst. 1988, 24, 327–336. [Google Scholar] [CrossRef]
- Blostein, S.D.; Richardson, H.S. A sequential detection approach to target tracking. IEEE Trans. Aerosp. Electron. Syst. 1994, 30, 197–212. [Google Scholar] [CrossRef]
- Fan, X.S.; Xu, Z.Y.; Zhang, J.L.; Huang, Y.M.; Peng, Z.M. Infrared Dim and Small Targets Detection Method Based on Local Energy Center of Sequential Image. Math. Probl. Eng. 2017, 2017. [Google Scholar] [CrossRef]
- Peng, Z.M.; Zhang, Q.H.; Wang, J.R.; Zhang, Q.P. Dim target detection based on nonlinear multifeature fusion by Karhunen-Loeve transform. Opt. Eng. 2004, 43, 2954–2958. [Google Scholar] [CrossRef]
- Liu, D.P.; Cao, L.; Li, Z.Z.; Liu, T.M.; Che, P. Infrared Small Target Detection Based on Flux Density and Direction Diversity in Gradient Vector Field. IEEE J. Sel. Top. Appl. Earth Obs. Remote Sens. 2018, 11, 2528–2554. [Google Scholar] [CrossRef]
- Gao, C.Q.; Wang, L.; Xiao, Y.X.; Zhao, Q.; Meng, D.Y. Infrared small-dim target detection based on Markov random field guided noise modeling. Pattern Recognit. 2018, 76, 463–475. [Google Scholar] [CrossRef]
- Fan, X.S.; Xu, Z.Y.; Zhang, J.L.; Huang, Y.M.; Peng, Z.M. Dim small targets detection based on self-adaptive caliber temporal-spatial filtering. Infrared Phys. Technol. 2017, 85, 465–477. [Google Scholar] [CrossRef]
- Wang, Q.; Gao, J.Y.; Yuan, Y. Embedding Structured Contour and Location Prior in Siamesed Fully Convolutional Networks for Road Detection. IEEE Trans. Intell. Transp. Syst. 2018, 19, 230–241. [Google Scholar] [CrossRef]
- He, K.M.; Sun, J.; Tang, X.O. Single Image Haze Removal Using Dark Channel Prior. IEEE Trans. Pattern Anal. Mach. Intell. 2011, 33, 2341–2353. [Google Scholar] [CrossRef]
- Peng, X.; Feng, J.S.; Xiao, S.J.; Yau, W.Y.; Zhou, J.T.; Yang, S.F. Structured AutoEncoders for Subspace Clustering. IEEE Trans. Image Process. 2018, 27, 5076–5086. [Google Scholar] [CrossRef] [PubMed]
- Tom, V.T.; Peli, T.; Leung, M.; Bondaryk, J.E. Morphology-based algorithm for point target detection in infrared backgrounds. In Proceedings of the Signal and Data Processing of Small Targets 1993, Orlando, FL, USA, 12–14 April 1993; pp. 2–12. [Google Scholar]
- Deshpande, S.D.; Er, M.H.; Venkateswarlu, R.; Chan, P. Max-mean and max-median filters for detection of small targets. In Proceedings of the Signal and Data Processing of Small Targets 1999, Denver, CO, USA; pp. 74–84.
- Gu, Y.F.; Wang, C.; Liu, B.X.; Zhang, Y. A Kernel-Based Nonparametric Regression Method for Clutter Removal in Infrared Small-Target Detection Applications. IEEE Geosci. Remote Sens. Lett. 2010, 7, 469–473. [Google Scholar] [CrossRef]
- Hadhoud, M.M.; Thomas, D.W. The two-dimensional adaptive LMS (TDLMS) algorithm. IEEE Trans. Circuits Syst. 1988, 35, 485–494. [Google Scholar] [CrossRef]
- Chen, C.L.P.; Li, H.; Wei, Y.T.; Xia, T.; Tang, Y.Y. A Local Contrast Method for Small Infrared Target Detection. IEEE Trans. Geosci. Remote Sens. 2014, 52, 574–581. [Google Scholar] [CrossRef]
- Han, J.H.; Ma, Y.; Zhou, B.; Fan, F.; Liang, K.; Fang, Y. A Robust Infrared Small Target Detection Algorithm Based on Human Visual System. IEEE Geosci. Remote Sens. Lett. 2014, 11, 2168–2172. [Google Scholar] [CrossRef]
- Dong, X.B.; Huang, X.S.; Zheng, Y.B.; Shen, L.R.; Bai, S.J. Infrared dim and small target detecting and tracking method inspired by Human Visual System. Infrared Phys. Technol. 2014, 62, 100–109. [Google Scholar] [CrossRef]
- Han, J.H.; Liang, K.; Zhou, B.; Zhu, X.Y.; Zhao, J.; Zhao, L.L. Infrared Small Target Detection Utilizing the Multiscale Relative Local Contrast Measure. IEEE Geosci. Remote Sens. Lett. 2018, 15, 612–616. [Google Scholar] [CrossRef]
- Gao, C.Q.; Meng, D.Y.; Yang, Y.; Wang, Y.T.; Zhou, X.F.; Hauptmann, A.G. Infrared Patch-Image Model for Small Target Detection in a Single Image. IEEE Trans. Image Process. 2013, 22, 4996–5009. [Google Scholar] [CrossRef] [PubMed]
- Dai, Y.M.; Wu, Y.Q.; Song, Y.; Guo, J. Non-negative infrared patch-image model: Robust target-background separation via partial sum minimization of singular values. Infrared Phys. Technol. 2017, 81, 182–194. [Google Scholar] [CrossRef]
- Wang, X.Y.; Peng, Z.M.; Zhang, P.; He, Y.M. Infrared Small Target Detection via Nonnegativity-Constrained Variational Mode Decomposition. IEEE Geosci. Remote Sens. Lett. 2017, 14, 1700–1704. [Google Scholar] [CrossRef]
- Wang, X.Y.; Peng, Z.M.; Kong, D.H.; Zhang, P.; He, Y.M. Infrared dim target detection based on total variation regularization and principal component pursuit. Image Vis. Comput. 2017, 63, 1–9. [Google Scholar] [CrossRef]
- He, Y.J.; Li, M.; Zhang, J.L.; An, Q. Small infrared target detection based on low-rank and sparse representation. Infrared Phys. Technol. 2015, 68, 98–109. [Google Scholar] [CrossRef]
- Bai, X.Z.; Zhou, F.Z.; Xie, Y.C.; Jin, T. Modified Top-hat transformation based on contour structuring element to detect infrared small target. In Proceedings of the 3rd IEEE Conference on Industrial Electronics and Applications, Singapore, 3–5 June 2008. [Google Scholar]
- Bai, X.Z.; Zhou, F.G. Analysis of new top-hat transformation and the application for infrared dim small target detection. Pattern Recognit. 2010, 43, 2145–2156. [Google Scholar] [CrossRef]
- Bae, T.W.; Zhang, F.; Kweon, I.S. Edge directional 2D LMS filter for infrared small target detection. Infrared Phys. Technol. 2012, 55, 137–145. [Google Scholar] [CrossRef]
- Cao, Y.; Liu, R.M.; Yang, J. Small target detection using two-dimensional least mean square (TDLMS) filter based on neighborhood analysis. Int. J. Infrared Millimeter Waves 2008, 29, 188–200. [Google Scholar] [CrossRef]
- Kim, S.; Lee, J. Scale invariant small target detection by optimizing signal-to-clutter ratio in heterogeneous background for infrared search and track. Pattern Recognit. 2012, 45, 393–406. [Google Scholar] [CrossRef]
- Wang, X.; Lv, G.F.; Xu, L.Z. Infrared dim target detection based on visual attention. Infrared Phys. Technol. 2012, 55, 513–521. [Google Scholar] [CrossRef]
- Wei, Y.T.; You, X.G.; Li, H. Multiscale patch-based contrast measure for small infrared target detection. Pattern Recognit. 2016, 58, 216–226. [Google Scholar] [CrossRef]
- Deng, H.; Sun, X.P.; Liu, M.L.; Ye, C.H.; Zhou, X. Small Infrared Target Detection Based on Weighted Local Difference Measure. IEEE Trans. Geosci. Remote Sens. 2016, 54, 4204–4214. [Google Scholar] [CrossRef]
- Gao, J.; Guo, Y.; Lin, Z.; An, W.; Li, J. Robust Infrared Small Target Detection Using Multiscale Gray and Variance Difference Measures. IEEE J. Sel. Top. Appl. Earth Obs. Remote Sens. 2018. [Google Scholar] [CrossRef]
- Li, J.; Duan, L.Y.; Chen, X.W.; Huang, T.J.; Tian, Y.H. Finding the Secret of Image Saliency in the Frequency Domain. IEEE Trans. Pattern Anal. Mach. Intell. 2015, 37, 2428–2440. [Google Scholar] [CrossRef] [PubMed]
- Tang, W.; Zheng, Y.B.; Lu, R.T.; Huang, X.S. A Novel Infrared Dim Small Target Detection Algorithm based on Frequency Domain Saliency. In Proceedings of the 2016 IEEE Advanced Information Management, Communicates, Electronic and Automation Control Conference (IMCEC 2016), Xi’an, China, 3–5 October 2016; pp. 1053–1057. [Google Scholar]
- Lin, Z.; Chen, M.; Ma, Y. The Augmented Lagrange Multiplier Method for Exact Recovery of Corrupted Low-Rank Matrices. arXiv, 2010; arXiv:1009.5055v3. [Google Scholar]
- Dai, Y.M.; Wu, Y.Q.; Song, Y. Infrared small target and background separation via column-wise weighted robust principal component analysis. Infrared Phys. Technol. 2016, 77, 421–430. [Google Scholar] [CrossRef]
- Guo, J.; Wu, Y.Q.; Dai, Y.M. Small target detection based on reweighted infrared patch-image model. IET Image Process. 2018, 12, 70–79. [Google Scholar] [CrossRef]
- Zhang, L.; Peng, L.; Zhang, T.; Cao, S.; Peng, Z. Infrared Small Target Detection via Non-Convex Rank Approximation Minimization Joint l2, 1 Norm. Remote Sens. 2018, 10, 1821. [Google Scholar] [CrossRef]
- Liu, D.P.; Li, Z.Z.; Liu, B.; Chen, W.H.; Liu, T.M.; Cao, L. Infrared small target detection in heavy sky scene clutter based on sparse representation. Infrared Phys. Technol. 2017, 85, 13–31. [Google Scholar] [CrossRef]
- Wang, X.Y.; Peng, Z.M.; Kong, D.H.; He, Y.M. Infrared Dim and Small Target Detection Based on Stable Multisubspace Learning in Heterogeneous Scene. IEEE Trans. Geosci. Remote Sens. 2017, 55, 5481–5493. [Google Scholar] [CrossRef]
- Dai, Y.M.; Wu, Y.Q. Reweighted Infrared Patch-Tensor Model With Both Nonlocal and Local Priors for Single-Frame Small Target Detection. IEEE J. Sel. Top. Appl. Earth Obs. Remote Sens. 2017, 10, 3752–3767. [Google Scholar] [CrossRef]
- Goldfarb, D.; Qin, Z.W. Robust Low-Rank Tensor Recovery: Models and Algorithms. Siam J. Matrix Anal. A 2014, 35, 225–253. [Google Scholar] [CrossRef]
- Liu, J.; Musialski, P.; Wonka, P.; Ye, J.P. Tensor Completion for Estimating Missing Values in Visual Data. IEEE Trans. Pattern Anal. Mach. Intell. 2013, 35, 208–220. [Google Scholar] [CrossRef]
- Romera-Paredes, B.; Pontil, M. A New Convex Relaxation for Tensor Completion. In Proceedings of the Advances in Neural Information Processing Systems, Harrahs and Harveys, Lake Tahoe, 5–10 December 2013; pp. 2967–2975. [Google Scholar]
- Jiang, T.X.; Huang, T.Z.; Zhao, X.L.; Deng, L.J. A novel nonconvex approach to recover the low-tubal-rank tensor data: when t-SVD meets PSSV. arXiv, 2017; arXiv:1712.05870. [Google Scholar]
- Kilmer, M.E.; Martin, C.D. Factorization strategies for third-order tensors. Linear Algebra Appl 2011, 435, 641–658. [Google Scholar] [CrossRef]
- Lu, C.Y.; Feng, J.S.; Chen, Y.D.; Liu, W.; Lin, Z.C.; Yan, S.C. Tensor Robust Principal Component Analysis: Exact Recovery of Corrupted Low-Rank Tensors via Convex Optimization. In Proceedings of the 2016 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Las Vegas, NV, USA, 27–30 June 2016; pp. 5249–5257. [Google Scholar] [CrossRef]
- Boyd, S.; Parikh, N.; Chu, E.; Peleato, B.; Eckstein, J. Distributed optimization and statistical learning via the alternating direction method of multipliers. Found. Trends® Mach. Learn. 2011, 3, 1–122. [Google Scholar] [CrossRef]
- Oh, T.H.; Tai, Y.W.; Bazin, J.C.; Kim, H.; Kweon, I.S. Partial Sum Minimization of Singular Values in Robust PCA: Algorithm and Applications. IEEE Trans. Pattern Anal. Mach. Intell. 2016, 38, 744–758. [Google Scholar] [CrossRef] [PubMed]
- Zhang, Z.M.; Ely, G.; Aeron, S.; Hao, N.; Kilmer, M. Novel methods for multilinear data completion and de-noising based on tensor-SVD. IEEE Conf. Comput. Vis. Pattern Recognit. (CVPR) 2014, 3842–3849. [Google Scholar] [CrossRef]
- Lu, C.; Feng, J.; Chen, Y.; Liu, W.; Lin, Z.; Yan, S. Tensor Robust Principal Component Analysis with A New Tensor Nuclear Norm. arXiv, 2018; arXiv:1804.03728. [Google Scholar]
- Hale, E.T.; Yin, W.T.; Zhang, Y. FIXED-POINT CONTINUATION FOR l(1)-MINIMIZATION: METHODOLOGY AND CONVERGENCE. SIAM J. Optim. 2008, 19, 1107–1130. [Google Scholar] [CrossRef]
- Turk, M.; Pentland, A. Eigenfaces for Recognition. J. Cogn. Neurosci. 1991, 3, 71–86. [Google Scholar] [CrossRef] [PubMed]
- Huang, Z.; Zhu, H.; Zhou, J.T.; Peng, X. Multiple Marginal Fisher Analysis. IEEE Trans. Ind. Electron. 2018, 99. [Google Scholar] [CrossRef]
- Chen, Y.W.; Song, B.; Wang, D.J.; Guo, L.H. An effective infrared small target detection method based on the human visual attention. Infrared Phys. Technol. 2018, 95, 128–135. [Google Scholar] [CrossRef]
- Liu, J.; He, Z.; Chen, Z.; Shao, L. Tiny and Dim Infrared Target Detection Based on Weighted Local Contrast. IEEE Geosci. Remote Sens. Lett. 2018, 15, 1780–1784. [Google Scholar] [CrossRef]
- Deng, H.; Sun, X.P.; Liu, M.L.; Ye, C.H.; Zhou, X. Infrared Small-Target Detection Using Multiscale Gray Difference Weighted Image Entropy. IEEE Trans. Aerosp. Electron. Syst. 2016, 52, 60–72. [Google Scholar] [CrossRef]
- Bai, X.Z.; Bi, Y.G. Derivative Entropy-Based Contrast Measure for Infrared Small-Target Detection. IEEE Trans. Geosci. Remote Sens. 2018, 56, 2452–2466. [Google Scholar] [CrossRef]
- Guo, Y.; Lin, Z.; An, W. Infrared Small Target Detection Using Multiscale Gray and Variance Difference. Proceedings of Chinese Conference on Pattern Recognition and Computer Vision (PRCV), Guangzhou, China, 19 November 2018; pp. 53–64. [Google Scholar]
- Bigun, J.; Granlund, G.H.; Wiklund, J. Multidimensional Orientation Estimation with Applications To Texture Analysis and Optical-Flow. IEEE Trans. Pattern Anal. Mach. Intell. 1991, 13, 775–790. [Google Scholar] [CrossRef]
- Wang, H.; Yang, F.; Zhang, C.; Ren, M. Infrared Small Target Detection Based on Patch Image Model with Local and Global Analysis. Int. J. Image Graph. 2018, 18, 1850002. [Google Scholar] [CrossRef]
- Brown, M.; Szeliski, R.; Winder, S. Multi-image matching using multi-scale oriented patches. IEEE Comput. Soc. Conf. 2005, 1, 510–517. [Google Scholar]
- Carroll, J.D.; Chang, J.J. Analysis of individual differences in multidimensional scaling via an N-way generalization of “Eckart-Young” decomposition. Psychometrika 1970, 35, 283–319. [Google Scholar] [CrossRef]
- Tucker, L.R. Some mathematical notes on three-mode factor analysis. Psychometrika 1966, 31, 279–311. [Google Scholar] [CrossRef] [PubMed]
- Hillar, C.J.; Lim, L.H. Most Tensor Problems Are NP-Hard. J. ACM 2013, 60. [Google Scholar] [CrossRef]
- Candes, E.J.; Wakin, M.B.; Boyd, S.P. Enhancing Sparsity by Reweighted l(1) Minimization. J. Fourier Anal. Appl. 2008, 14, 877–905. [Google Scholar] [CrossRef]
- Gu, S.H.; Xie, Q.; Meng, D.Y.; Zuo, W.M.; Feng, X.C.; Zhang, L. Weighted Nuclear Norm Minimization and Its Applications to Low Level Vision. Int. J. Comput. Vis. 2017, 121, 183–208. [Google Scholar] [CrossRef]
- Lu, C.Y.; Tang, J.H.; Yan, S.C.; Lin, Z.C. Nonconvex Nonsmooth Low Rank Minimization via Iteratively Reweighted Nuclear Norm. IEEE Trans. Image Process. 2016, 25, 829–839. [Google Scholar] [CrossRef]
- Peng, Y.G.; Suo, J.L.; Dai, Q.H.; Xu, W.L. Reweighted Low-Rank Matrix Recovery and its Application in Image Restoration. IEEE Trans. Cybern. 2014, 44, 2418–2430. [Google Scholar] [CrossRef]





















{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Tophat | LCM | MPCM | IPI | NIPPS | ReWIPI | SMSL | NRAM | |
|---|---|---|---|---|---|---|---|---|
| Time (s) | 0.022 | 0.074 | 0.089 | 11.907 | 7.486 | 15.469 | 1.245 | 3.378 |
| Score | 1 | 1 | 2 | 3 | 3.5 | 3 | 2.5 | 4 |
| Acronym | Full name |
|---|---|
| IPT [42] | Image Patch-Tensor |
| PSTNN [46] | Partial Sum of Tensor Nuclear Norm |
| t-SVD [47] | Tensor Singular Value Decomposition |
| RPCA [36] | Robust Principle Component Analysis |
| TRPCA [48] | Tensor Robust Principle Component Analysis |
| ADMM [49] | Alternating Direction Method of Multipliers |
| SNN [44] | Sum of Nuclear Norms |
| PSSV [50] | Partial Sum of Singular Values |
| PSVT [50] | Partial Singular Value Thresholding operator |
| TNN [51] | Tensor Nuclear Norm |
| Method | Parameters |
|---|---|
| Top-hat [12] | Structure shape: disk, structure size: 3×3 |
| LoG [29] | |
| MPCM [31] | |
| RLCM [19] | |
| IPI [20] | |
| NIPPS [21] | |
| ReWIPI [38] | |
| NRAM [39] | |
| RIPT [42] | |
| Ours |
| Frame Number | Size | Background Description | Target Description | |
|---|---|---|---|---|
| Sequence 1 | 52 | 128×128 | Sky scene with banded cloud | Tiny and dim |
| Sequence 2 | 30 | 256×200 | Heavy banded cloud and floccus | Small, size varies a lot |
| Sequence 3 | 67 | 320×240 | Very bright, heavy noise | Moves fast with changing shape, brightness |
| Sequence 4 | 46 | 320×240 | Very blurry with black holes in the middle | Keeps moving in the sequence and changing shape and brightness |
| Method | Sequence 1 | Sequence 2 | Sequence 3 | Sequence 4 | ||||
|---|---|---|---|---|---|---|---|---|
| SCRG | BSF | SCRG | BSF | SCRG | BSF | SCRG | BSF | |
| Top-hat | 1.04 | 1.99 | 9.56 | 1.90 | 0.36 | 0.22 | 0.58 | 12.46 |
| LoG | 8.25 | 1.88 | 7.33 | 1.30 | 1.30 | 0.30 | 2.28 | 7.86 |
| MPCM | 9.77 | 23.72 | 14.4 | 4.1 | 8.72 | 7.90 | 20.38 | 14.54 |
| RLCM | 28.97 | 35.14 | 30.63 | 62.99 | 2.05 | 1.82 | 2.22 | 16.25 |
| IPI | 106.12 | 140.32 | 43.33 | 16.73 | 8.05 | 1.88 | 5.36 | 2.66 |
| NIPPS | 456.15 | 544.79 | 180.08 | 118.16 | 43.2 | 35032728557 | 13.71 | 24.33 |
| ReWIPI | 242.14 | 641.92 | 302.55 | 153.61 | 5.10 | 1.35 | 5.42 | 4.16 |
| NRAM | 1004.48 | 677.2 | 687.02 | 178.69 | 109.83 | inf | — | — |
| RIPT | 523.44 | 222.97 | 690.32 | 276.02 | 46.8 | inf | — | — |
| Ours | 1059.58 | 1229.65 | 697.77 | 315.87 | 147.67 | inf | 46.34 | 60.21 |
| Top-hat | LoG | MPCM | RLCM | IPI | NIPPS | ReWIPI | NRAM | RIPT | Ours | |
|---|---|---|---|---|---|---|---|---|---|---|
| Sequence 1 | 0.311 | 0.861 | 0.613 | 0.986 | 0.387 | 0.829 | 0.173 | 1 | 0.987 | 1 |
| Sequence 2 | 0.743 | 0.932 | 0.863 | 0.900 | 0.938 | 0.933 | 0.957 | 0.967 | 0.928 | 0.990 |
| Sequence 3 | 0.604 | 0.927 | 0.930 | 0.181 | 0.938 | 0.856 | 0.849 | 0.944 | 0.606 | 0.945 |
| Sequence 4 | 0.340 | 0.347 | 0.877 | 0.021 | 0.862 | 0.917 | 0.925 | 0.707 | 0.503 | 0.933 |
| Methods | Complexity | Sequence 1 | Sequence 2 | Sequence 3 | Sequence 4 |
|---|---|---|---|---|---|
| Top-hat | 0.015 | 0.015 | 0.018 | 0.016 | |
| LoG | 0.019 | 0.035 | 0.048 | 0.046 | |
| MPCM | 0.038 | 0.074 | 0.097 | 0.096 | |
| RLCM | 0.895 | 2.941 | 4.414 | 4.385 | |
| IPI | 0.327 | 8.717 | 22.063 | 21.941 | |
| NIPPS | 0.321 | 7.561 | 19.182 | 18.097 | |
| ReWIPI | 1.030 | 14.978 | 39.612 | 41.559 | |
| NRAM | 0.494 | 3.661 | 8.357 | 8.341 | |
| RIPT | 0.211 | 1.079 | 1.279 | 3.217 | |
| Ours | 0.081 | 0.136 | 0.127 | 0.217 |
© 2019 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Zhang, L.; Peng, Z. Infrared Small Target Detection Based on Partial Sum of the Tensor Nuclear Norm. Remote Sens. 2019, 11, 382. https://doi.org/10.3390/rs11040382
Zhang L, Peng Z. Infrared Small Target Detection Based on Partial Sum of the Tensor Nuclear Norm. Remote Sensing. 2019; 11(4):382. https://doi.org/10.3390/rs11040382
Chicago/Turabian StyleZhang, Landan, and Zhenming Peng. 2019. "Infrared Small Target Detection Based on Partial Sum of the Tensor Nuclear Norm" Remote Sensing 11, no. 4: 382. https://doi.org/10.3390/rs11040382
APA StyleZhang, L., & Peng, Z. (2019). Infrared Small Target Detection Based on Partial Sum of the Tensor Nuclear Norm. Remote Sensing, 11(4), 382. https://doi.org/10.3390/rs11040382