1. Introduction
High-resolution remote sensing images collected by satellites or unmanned drones are adequate to obtain detailed information about the observed surface and have been widely used in various applications, such as land-use analysis, precision agriculture, urban planning, and disaster warning [
1,
2]. Recent advances in remote sensing technology have significantly increased the availability of high-resolution image [
3]. With the support of sufficient high-quality data, dense semantic labeling has been a pivotal research domain in remote sensing [
4,
5,
6,
7].
Dense semantic labeling is a pixel-level classification task and aims to assign each pixel with a class label of given categories [
8,
9,
10]. In the past few years, many machine learning approaches have been developed to handle this challenge. Among them, convolutional neural network (CNN) based methods achieved the best performance [
11,
12,
13,
14]. Unlike the traditional manually designed methods, CNN is driven by data and can learn the feature extractor automatically through backpropagation. There are usually a large number of convolution layers and activation layers, which provide a better nonlinear fitting capability [
15]. Initially, CNN aimed at the classification of entire image and achieved remarkable improvements in ImageNet large scale visual recognition challenge (ILSVRC) [
16,
17]. After that, some outstanding networks such as visual geometry group (VGG) [
18], ResNet [
19], and DensNet [
20] deepened the network structure and enhanced the accuracy of classification further. However, the fully connected layers at the end of the network destroy the spatial structure of the feature maps, which make it impossible to apply CNN directly into dense semantic labeling tasks [
21]. To preserve spatial information, Long [
22] proposed the fully convolutional network (FCN), which utilizes upsampling operations for the replacement of fully connected layers. As a result, the extracted low-resolution feature maps can be recovered to the input resolution. FCN is the earliest dense semantic labeling network, and all the later networks follow this idea [
23,
24,
25,
26].
Currently, the accuracy of dense semantic labeling has been largely improved by the relative models. Classification of small objects and acquiring a sharper object boundary become the main challenge [
27]. To this end, deeper backbone networks [
28] and the network structure such as encoder-decoder [
29] are widely utilized. Deeper backbone networks with more convolution layers can better extract context information, while the encoder-decoder structure can recover the lost spatial information caused by downsampling operations by involving the low-level features from the shallow layers. These methods significantly improve the performance of dense semantic labeling. However, they also come with more network parameters and high computational overheads, which may cause slower inference speed, more hardware consumption and impeding practical large-scale applications.
To maintain efficient inference speed, a large number of works have focused on improving the real-time performance of dense semantic labeling. There are primarily four different approaches to speed up the network. First, the work proposed by Wu [
30] downsamples the input image to reduce computational complexity. However, the loss of spatial information in the input leads to an inaccurate prediction around object boundaries. Second, RefineNet [
31] compresses the channels of the network especially in the shallow layers to improve the inference speed. However, the simplifying of shallow layers weakens the extraction of spatial information. Third, ENet [
32] abandons the last stage of downsampling operation in pursuit of an extreme light-weight structure. Losing the downsampling operation has an obvious shortcoming: The receptive field is insufficient to cover large objects, leading to poor extraction of context information. Lastly, the dual-path structure proposed by BiSeNet [
33] introduces two separate sub-networks to extract context information and spatial information respectively. Among the above solutions, the dual-path structure is state-of-the-art, and both spatial and context information can be well extracted.
The dual-path structure consists of two parts: the spatial path and the context path. The spatial path usually adopts a simple structure with several convolution layers to extract high-resolution spatial information, while the context path uses a light-weight backbone network to extract context information. After the feature extraction, it can fuse both kinds of features to get the joint spatial-context features for the final prediction. Due to the respective extraction process, the dual-path structure could overcome the network redundancy and achieve high accuracy without involving much computational overhead.
To improve performance with dual-path structure, the light-weight backbone network in the context path plays an essential role, and a few attempts have been made. MobileNet [
34,
35] takes the advantages from the depthwise separable convolution. Unlike the standard convolution, depthwise convolution applies a single filter to each input channel, leading to an extreme decrease in computation cost. Afterward, ShuffleNet [
36,
37] introduces group convolution and channel shuffle, the information exchange between channels is taken into account with low computational complexity. However, the performance of these light-weight backbone networks is not comparable to the state-of-the-art.
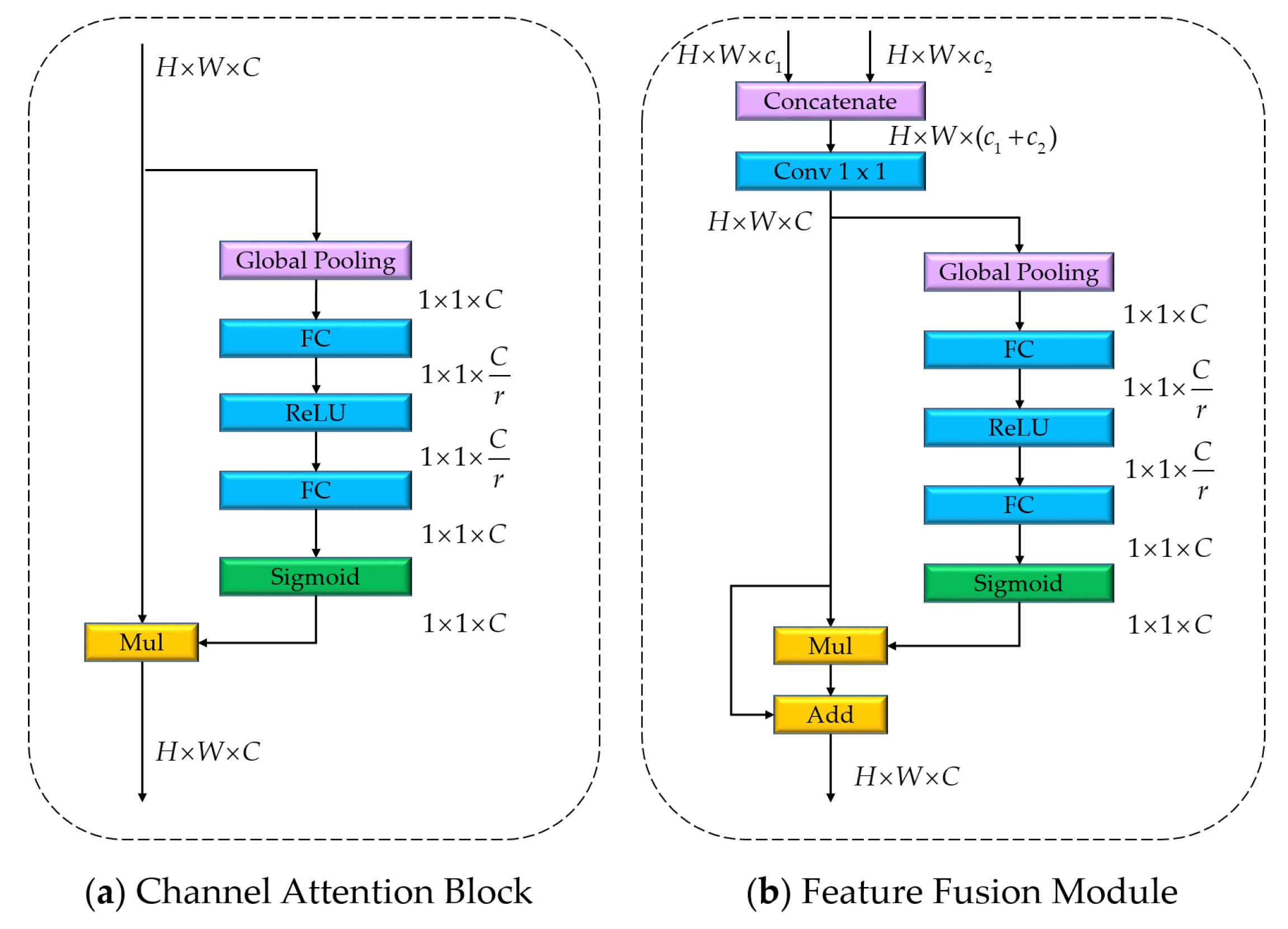
In addition to the network structure and backbone, other components such as channel attention block and pyramid pooling module (PPM) are also helpful in the pursuit of better accuracy without loss of speed. The channel attention block from SENet [
38] uses global average pooling followed by fully connected layers and the sigmoid operation to weight each channel according to its importance, and it is an effective filter after feature extraction. The PPM module from PSPNet [
39] consists of several branches of pooling operations with different sizes of kernels to enhance the context information after the backbone network. These network components can significantly improve performance without involving too many parameters and computational overheads.
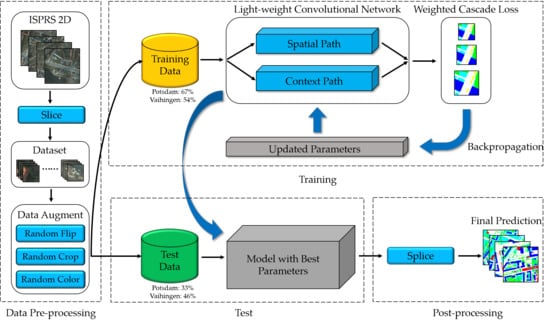
Inspired by the analysis above, in this paper, we propose a novel light-weight CNN to bridge the gap between model efficiency and accuracy for dense semantic labeling of high-resolution remote sensing image. Our model is designed under the efficient dual-path architecture, which can separate the feature extraction process and avoid network redundancy. In the spatial path, a simple structure of three convolution layers with stride two are utilized to preserve affluent spatial information. For the context path, a deep network structure is needed to supply a sufficient receptive field, and we adopt the multi-fiber network (MFNet) [
40] as the backbone due to the characteristics of excellent feature extraction ability and low computational complexity.
To further enhance the context features, we analyze the existing methods and append the pyramid pooling module (PPM) after the backbone, without involving too many computational overheads. On top of these two paths, we explore the attention mechanism and apply the channel attention block to refine the context features and the fused spatial-context features further. Moreover, a weighted cascade loss function is developed to guide the training procedure. Unlike the single loss function, the proposed loss function can better optimize the network parameters at different stages. Experiments on the Potsdam and Vaihingen datasets [
41,
42] demonstrate that the proposed network performs better than other light-weight networks even some state-of-the-art networks and achieves 87.5% and 86.1% overall accuracy respectively with only 8.7 M network parameters and 7.4 G floating point operations (FLOPs). The main contributions of this work are listed as follows:
We propose a novel light-weight CNN with a dual-path architecture, which applies MFNet as the backbone network of the context path.
We improve the performance by applying the channel attention block and the pyramid pooling module without involving too many computational overheads.
We enhance the training procedure by developing a weighted cascade loss function.
The remainder of this paper is organized as follows:
Section 2 describes the pre-processing methods, the proposed light-weight network, the datasets and the training protocol.
Section 3 presents the metrics and the results.
Section 4 is the discussion and
Section 5 concludes the whole work.
5. Conclusions
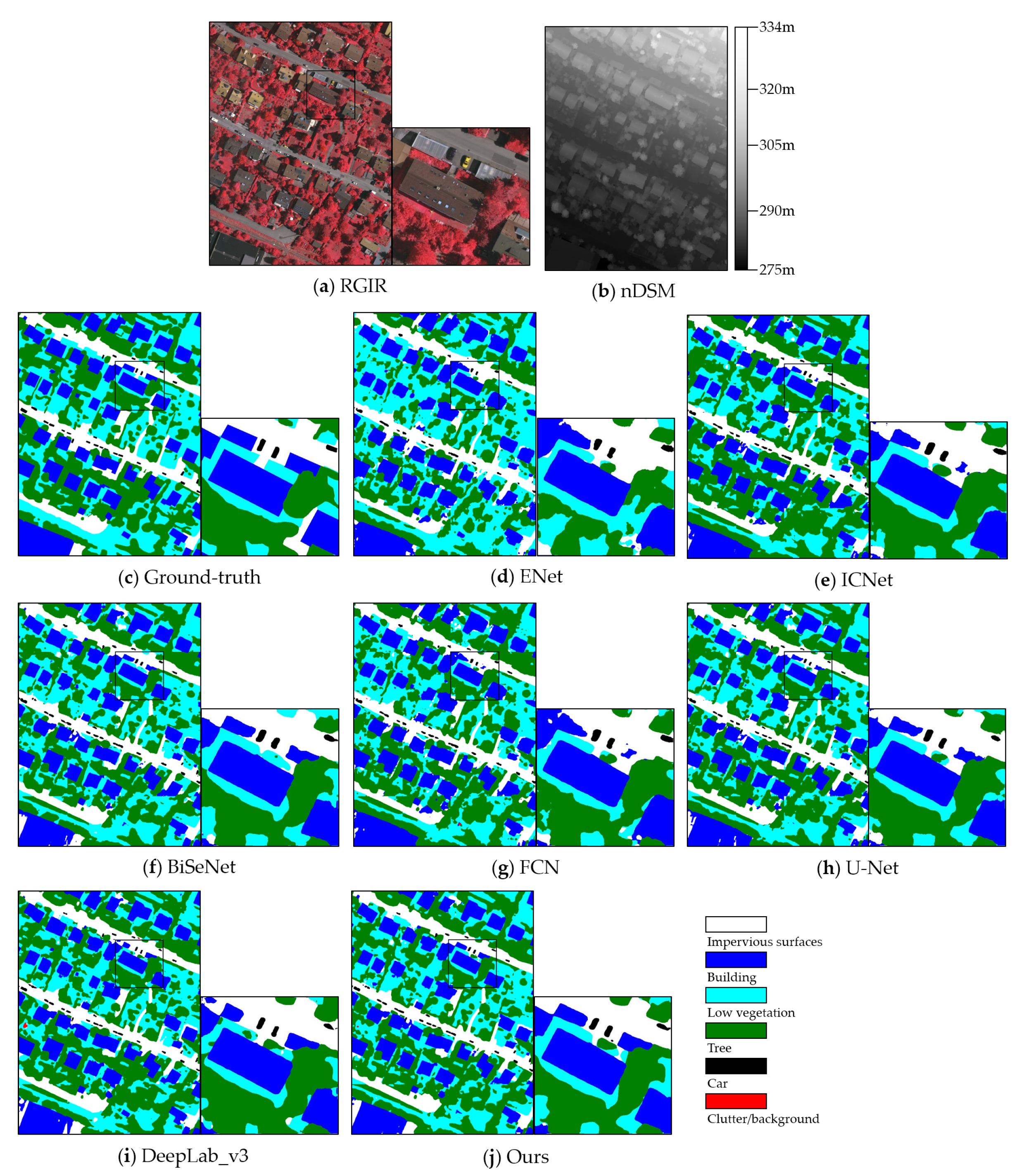
Real-time dense semantic labeling for high-resolution remote sensing images is a challenging task due to the consideration of precision and efficiency simultaneously. In this paper, an efficient light-weight CNN with the dual-path architecture is proposed to handle this issue. Our model utilizes a simple structure of three convolution layers as the spatial path to preserve spatial information. Meanwhile, we develop the context path with the efficient multi-fiber network followed by the pyramid pooling module to obtain a sufficient receptive field. Moreover, the channel attention block is adopted to refine the extracted context features and fused spatial-context features. During the training procedure, we append a weighted cascade loss function at different stages for the optimization of the network parameters. Experiments on the Potsdam and Vaihingen datasets demonstrate that the proposed network achieves a high labeling accuracy with fast speed and small computation cost. Compared to the classic U-Net, our model achieves higher labeling accuracy on the two datasets with 2.5 times less parameters and 22 times less computational FLOPs.
With the rapid development of remote sensing, more high-quality images are collected for practical applications. However, most existing methods are fully supervised based on manually annotated ground-truth, which takes too much labor and becomes the biggest challenge. In the future works, semi-supervised or weakly supervised methods should be considered. Semi-supervised methods using the generative adversarial network (GAN) can extend the dataset by generating new training samples, which may achieve the same labeling performance with fewer training samples. While weakly supervised methods based on image-level or bounding box ground-truth usually adopt traditional machine learning approaches to obtain a coarse pixel-level ground-truth and train the model with it, both kinds of methods can significantly save labor and will be the direction of future research.















{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}