A Deep Learning Semantic Segmentation-Based Approach for Field-Level Sorghum Panicle Counting

 ,
,  , and
, and
Abstract

1. Introduction
2. Materials and Methods
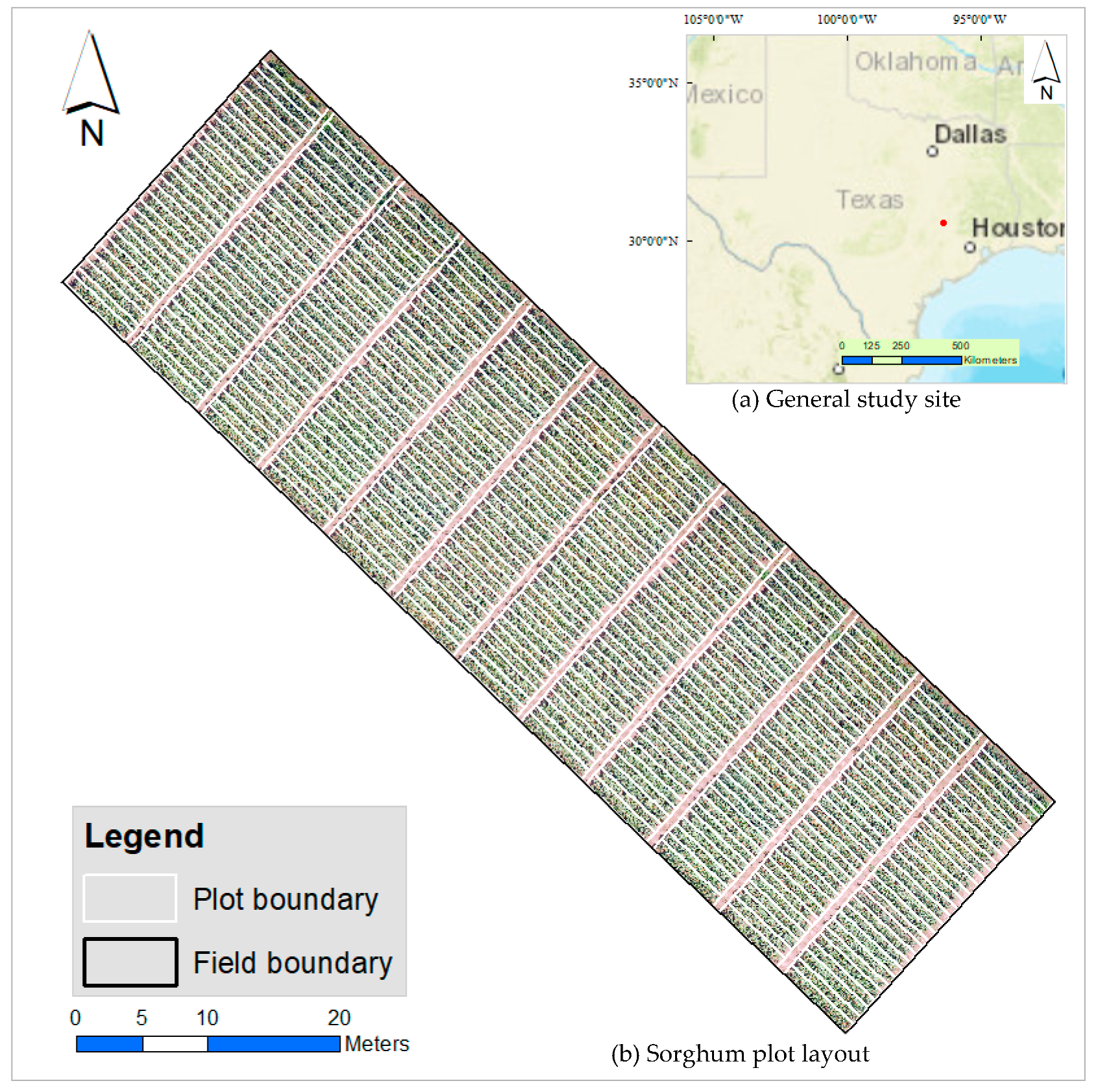
2.1. Study Site
2.2. Data
2.2.1. UAS Image Data and Plot Boundaries
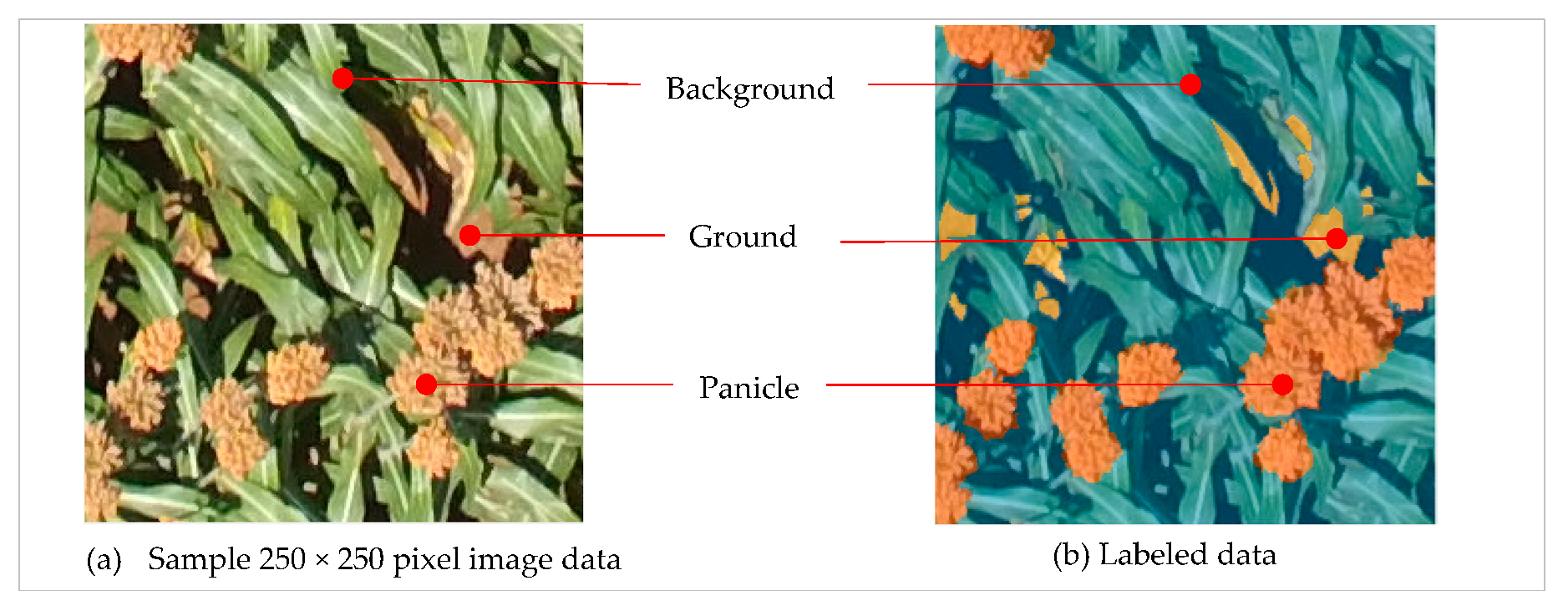
2.2.2. Labeled Panicle Data
2.3. Sorghum Panicle Counting Approach
2.3.1. Deep Learning Semantic Segmentation and Model Fitting
2.3.2. Post-Processing and Panicle Counting
2.3.3. Validating Detected Panicle Counts
3. Results
3.1. Deep Learning Semantic Segmentation
3.1.1. Overview of Results
3.1.2. Observed Sources of Error
3.2. Panicle Counting Performance and Field-Level Panicle Mapping
4. Discussion
5. Conclusions
Author Contributions
Funding
Acknowledgments
Conflicts of Interest
References
- Malambo, L.; Popescu, S.C.; Murray, S.C.; Putman, E.; Pugh, N.A.; Horne, D.W.; Richardson, G.; Sheridan, R.; Rooney, W.L.; Avant, R.; et al. Multitemporal field-based plant height estimation using 3d point clouds generated from small unmanned aerial systems high-resolution imagery. Int. J. Appl. Earth Obs. Geoinf. 2018, 64, 31–42. [Google Scholar] [CrossRef]
- Pugh, N.A.; Horne, D.W.; Murray, S.C.; Carvalho, G.; Malambo, L.; Jung, J.; Chang, A.; Maeda, M.; Popescu, S.; Chu, T.; et al. Temporal estimates of crop growth in sorghum and maize breeding enabled by unmanned aerial systems. Plant Phenome J. 2018, 1. [Google Scholar] [CrossRef]
- Gnädinger, F.; Schmidhalter, U. Digital counts of maize plants by unmanned aerial vehicles (uavs). Remote Sens. Basel 2017, 9, 544. [Google Scholar] [CrossRef]
- Shi, Y.; Thomasson, J.A.; Murray, S.C. Unmanned aerial vehicles for high-throughput phenotyping and agronomic research. PLoS ONE 2016, 11, e0159781. [Google Scholar] [CrossRef] [PubMed]
- Malambo, L.; Popescu, S.C.; Horne, D.W.; Pugh, N.A.; Rooney, W.L. Automated detection and measurement of individual sorghum panicles using density-based clustering of terrestrial lidar data. ISPRS J. Photogramm. Remote Sens. 2019, 149, 1–13. [Google Scholar] [CrossRef]
- Pound, M.P.; Atkinson, J.A.; Townsend, A.J.; Wilson, M.H.; Griffiths, M.; Jackson, A.S.; Bulat, A.; Tzimiropoulos, G.; Wells, D.M.; Murchie, E.H. Deep machine learning provides state-of-the-art performance in image-based plant phenotyping. GigaScience 2017, 6, gix083. [Google Scholar] [CrossRef]
- Najafabadi, M.M.; Villanustre, F.; Khoshgoftaar, T.M.; Seliya, N.; Wald, R.; Muharemagic, E. Deep learning applications and challenges in big data analytics. J. Big Data 2015, 2, 1. [Google Scholar] [CrossRef]
- Chopin, J.; Kumar, P.; Miklavcic, S.J. Land-based crop phenotyping by image analysis: Consistent canopy characterization from inconsistent field illumination. Plant Methods 2018, 14, 39. [Google Scholar] [CrossRef]
- Singh, A.; Ganapathysubramanian, B.; Singh, A.K.; Sarkar, S. Machine learning for high-throughput stress phenotyping in plants. Trends Plant Sci. 2016, 21, 110–124. [Google Scholar] [CrossRef]
- Ubbens, J.; Cieslak, M.; Prusinkiewicz, P.; Stavness, I. The use of plant models in deep learning: An application to leaf counting in rosette plants. Plant Methods 2018, 14, 6. [Google Scholar] [CrossRef]
- Kochsiek, A.E.; Knops, J.M. Maize cellulosic biofuels: Soil carbon loss can be a hidden cost of residue removal. GCB Bioenergy 2012, 4, 229–233. [Google Scholar] [CrossRef]
- Kumar, A.A.; Sharma, H.C.; Sharma, R.; Blummel, M.; Reddy, P.S.; Reddy, B.V.S. Phenotyping in sorghum [Sorghum bicolor (L.) moench]. In Phenotyping for Plant Breeding: Applications of Phenotyping Methods for Crop Improvement; Panguluri, S.K., Kumar, A.A., Eds.; Springer: New York, NY, USA, 2013; pp. 73–109. [Google Scholar]
- Hmon, K.P.W.; Shehzad, T.; Okuno, K. Qtls underlying inflorescence architecture in sorghum (Sorghum bicolor (L.) moench) as detected by association analysis. Genet. Resour. Crop Evol. 2014, 61, 1545–1564. [Google Scholar] [CrossRef]
- Maman, N.; Mason, S.C.; Lyon, D.J.; Dhungana, P. Yield components of pearl millet and grain sorghum across environments in the central great plains. Crop Sci. 2004, 44, 2138–2145. [Google Scholar] [CrossRef]
- Sinha, S.; Kumaravadivel, N. Understanding genetic diversity of sorghum using quantitative traits. Scientifica 2016, 2016, 3075023. [Google Scholar] [CrossRef]
- Mofokeng, A.M.; Shimelis, H.A.; Laing, M.D. Agromorphological diversity of south african sorghum genotypes assessed through quantitative and qualitative phenotypic traits. S. Afr. J. Plant Soil 2017, 34, 361–370. [Google Scholar] [CrossRef]
- Boyles, R.E.; Pfieffer, B.K.; Cooper, E.A.; Zielinski, K.J.; Myers, M.T.; Rooney, W.L.; Kresovich, S. Quantitative trait loci mapping of agronomic and yield traits in two grain sorghum biparental families. Crop Sci. 2017, 57, 2443–2456. [Google Scholar] [CrossRef]
- Rooney, W.; Smith, C.W. Techniques for developing new cultivars. In Sorghum, Origin, History, Technology and Production; Wayne, S.C., Frederiksen, R.A., Eds.; John Wiley & Sons: New York, NY, USA, 2000; pp. 329–347. [Google Scholar]
- Vogel, F. Objective Yield Techniques for Estimating Grain Sorghum Yields. Available online: https://www.nass.usda.gov/Education_and_Outreach/Reports,_Presentations_and_Conferences/Yield_Reports/Objective%20Yield%20Techniques%20for%20Estimating%20Grain%20Sorghum%20Yields.pdf (accessed on 7 December 2019).
- Ciampitti, I.A. Estimating Seed Counts in Sorghum Heads for Making Yield Projections. Available online: https://webapp.agron.ksu.edu/agr_social/eu_article.throck?article_id=344 (accessed on 5 March 2018).
- Ghanem, M.E.; Marrou, H.; Sinclair, T.R. Physiological phenotyping of plants for crop improvement. Trends Plant Sci. 2015, 20, 139–144. [Google Scholar] [CrossRef]
- Araus, J.L.; Cairns, J.E. Field high-throughput phenotyping: The new crop breeding frontier. Trends Plant Sci. 2014, 19, 52–61. [Google Scholar] [CrossRef]
- Simonyan, K.; Zisserman, A. Very deep convolutional networks for large-scale image recognition. arXiv 2014, arXiv:preprint 1409.1556. [Google Scholar]
- He, K.; Zhang, X.; Ren, S.; Sun, J. Deep residual learning for image recognition. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR 2016), Las Vegas, NV, USA, 27–30 June 2016; pp. 770–778. [Google Scholar]
- Long, J.; Shelhamer, E.; Darrell, T. Fully convolutional networks for semantic segmentation. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR 2015), Boston, MA, USA, 7–12 June 2015; pp. 3431–3440. [Google Scholar]
- Goodfellow, I.; Bengio, Y.; Courville, A. Deep Learning; MIT Press: Cambridge, MA, USA, 2016. [Google Scholar]
- Szegedy, C.; Liu, W.; Jia, Y.; Sermanet, P.; Reed, S.; Anguelov, D.; Erhan, D.; Vanhoucke, V.; Rabinovich, A. Going deeper with convolutions. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR 2015), Boston, MA, USA, 7–12 June 2015; pp. 1–9. [Google Scholar]
- Girshick, R.; Donahue, J.; Darrell, T.; Malik, J. Rich feature hierarchies for accurate object detection and semantic segmentation. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR 2014), Columbis, OH, USA, 24–27 June 2014; pp. 580–587. [Google Scholar]
- Mohanty, S.P.; Hughes, D.P.; Salathé, M. Using deep learning for image-based plant disease detection. Front. Plant Sci. 2016, 7, 1419. [Google Scholar] [CrossRef]
- Pawara, P.; Okafor, E.; Surinta, O.; Schomaker, L.; Wiering, M. Comparing Local Descriptors and Bags of Visual Words to Deep Convolutional Neural Networks for Plant Recognition. In Proceedings of the International Conference on Pattern Recognition Applications and Methods (ICPRAM 2017), Porto, Portugal, 24–26 February 2017; pp. 479–486. [Google Scholar]
- Lu, H.; Cao, Z.; Xiao, Y.; Zhuang, B.; Shen, C. Tasselnet: Counting maize tassels in the wild via local counts regression network. Plant Methods 2017, 13, 79. [Google Scholar] [CrossRef] [PubMed]
- Xiong, X.; Duan, L.; Liu, L.; Tu, H.; Yang, P.; Wu, D.; Chen, G.; Xiong, L.; Yang, W.; Liu, Q. Panicle-seg: A robust image segmentation method for rice panicles in the field based on deep learning and superpixel optimization. Plant Methods 2017, 13, 104. [Google Scholar] [CrossRef] [PubMed]
- Chang, A.; Jung, J.; Yeom, J.; Maeda, M.; Landivar, J. Sorghum panicle extraction from unmanned aerial system data. In Proceedings of the 2017 IEEE International Geoscience and Remote Sensing Symposium (IGARSS), Fort Worth, TX, USA, 23–28 July 2017; pp. 4350–4353. [Google Scholar]
- Olsen, P.A.; Ramamurthy, K.N.; Ribera, J.; Chen, Y.; Thompson, A.M.; Luss, R.; Tuinstra, M.; Abe, N. Detecting and counting panicles in sorghum images. In Proceedings of the 2018 IEEE 5th International Conference on Data Science and Advanced Analytics (DSAA), Turin, Italy, 1–3 October 2018; pp. 400–409. [Google Scholar]
- Achanta, R.; Shaji, A.; Smith, K.; Lucchi, A.; Fua, P.; Süsstrunk, S. Slic Superpixels. Available online: https://infoscience.epfl.ch/record/149300/files/SLIC_Superpixels_TR_2.pdf (accessed on 7 December 2019).
- Zhang, Y.; Jin, R.; Zhou, Z.-H. Understanding bag-of-words model: A statistical framework. Int. J. Mach. Learn. Cybern. 2010, 1, 43–52. [Google Scholar] [CrossRef]
- Guo, W.; Zheng, B.; Potgieter, A.B.; Diot, J.; Watanabe, K.; Noshita, K.; Jordan, D.R.; Wang, X.; Watson, J.; Ninomiya, S.; et al. Aerial imagery analysis–quantifying appearance and number of sorghum heads for applications in breeding and agronomy. Front. Plant Sci. 2018, 9, 1544. [Google Scholar] [CrossRef] [PubMed]
- Ghosal, S.; Zheng, B.; Chapman, S.C.; Potgieter, A.B.; Jordan, D.R.; Wang, X.; Singh, A.K.; Singh, A.; Hirafuji, M.; Ninomiya, S. A weakly supervised deep learning framework for sorghum head detection and counting. Plant Phenomics 2019, 2019, 1525874. [Google Scholar] [CrossRef]
- Chen, L.-C.; Papandreou, G.; Kokkinos, I.; Murphy, K.; Yuille, A.L. Deeplab: Semantic image segmentation with deep convolutional nets, atrous convolution, and fully connected crfs. IEEE Trans. Pattern Anal. Mach. Intell. 2018, 40, 834–848. [Google Scholar] [CrossRef]
- Erhan, D.; Szegedy, C.; Toshev, A.; Anguelov, D. Scalable object detection using deep neural networks. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR 2014), Columbus, OH, USA, 24–27 June 2014; pp. 2147–2154. [Google Scholar]
- Peel, M.C.; Finlayson, B.L.; McMahon, T.A. Updated world map of the köppen-geiger climate classification. Hydrol. Earth Syst. Sci. Discuss. 2007, 4, 439–473. [Google Scholar] [CrossRef]
- Hayes, C.M.; Rooney, W.L. Agronomic performance and heterosis of specialty grain sorghum hybrids with a black pericarp. Euphytica 2014, 196, 459–466. [Google Scholar] [CrossRef]
- Ronneberger, O.; Fischer, P.; Brox, T. U-net: Convolutional networks for biomedical image segmentation. In International Conference on Medical Image Computing and Computer-Assisted Intervention; Springer: Berlin, Germany, 2015; pp. 234–241. [Google Scholar]
- Badrinarayanan, V.; Kendall, A.; Cipolla, R. Segnet: A deep convolutional encoder-decoder architecture for image segmentation. IEEE Trans. Pattern Anal. Mach. Intell. 2017, 39, 2481–2495. [Google Scholar] [CrossRef]
- Shorten, C.; Khoshgoftaar, T.M. A survey on image data augmentation for deep learning. J. Big Data 2019, 6, 60. [Google Scholar] [CrossRef]
- Yu, X.; Wu, X.; Luo, C.; Ren, P. Deep learning in remote sensing scene classification: A data augmentation enhanced convolutional neural network framework. Gisci. Remote Sens. 2017, 54, 741–758. [Google Scholar] [CrossRef]
- Najman, L.; Schmitt, M. Watershed of a continuous function. Signal Process. 1994, 38, 99–112. [Google Scholar] [CrossRef]
- Hanbury, A. Mathematical morphology applied to circular data. In Advances in Imaging and Electron Physics; Hawkes, P.W., Ed.; Elsevier: Amsterdam, The Netherlands, 2003; Volume 128, pp. 124–205. [Google Scholar]
- Roerdink, J.B.; Meijster, A. The watershed transform: Definitions, algorithms and parallelization strategies. Fund. Inform. 2000, 41, 187–228. [Google Scholar] [CrossRef]
- Malambo, L. A region based approach to image classification. Appl. Geoinform. Soc. Environ. 2009, 103, 96–100. [Google Scholar]
- Blaschke, T. Object based image analysis for remote sensing. ISPRS J. Photogramm. Remote Sens. 2010, 65, 2–16. [Google Scholar] [CrossRef]
- Hand, E.M.; Castillo, C.; Chellappa, R. Doing the best we can with what we have: Multi-label balancing with selective learning for attribute prediction. In Proceedings of the Thirty-Second AAAI Conference on Artificial Intelligence, New Orleans, LA, USA, 2–7 February 2018. [Google Scholar]
- Kampffmeyer, M.; Salberg, A.-B.; Jenssen, R. Semantic segmentation of small objects and modeling of uncertainty in urban remote sensing images using deep convolutional neural networks. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition Workshops (CVPR 2016), Las Vegas, NV, USA, 27–30 June 2016; pp. 1–9. [Google Scholar]
- Song, H.; Yang, C.; Zhang, J.; Hoffmann, W.C.; He, D.; Thomasson, J.A. Comparison of mosaicking techniques for airborne images from consumer-grade cameras. J. Appl. Remote Sens. 2016, 10, 016030. [Google Scholar] [CrossRef]
- Gross, J.W. A comparison of orthomosaic software for use with ultra high resolution imagery of a wetland environment. In Center for Geographic Information Science and Geography Department; Central Michigan University: Mount Pleasant, MI, USA, 2015; Available online: http://www. imagin. org/awards/sppc/2015/papers/john_gross_paper (accessed on 7 December 2019).
- Duan, T.; Zheng, B.; Guo, W.; Ninomiya, S.; Guo, Y.; Chapman, S.C. Comparison of ground cover estimates from experiment plots in cotton, sorghum and sugarcane based on images and ortho-mosaics captured by uav. Funct. Plant Biol. 2017, 44, 169–183. [Google Scholar] [CrossRef]
- Qi, C.R.; Su, H.; Mo, K.; Guibas, L.J. Pointnet: Deep learning on point sets for 3d classification and segmentation. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR 2017), Honolulu, HI, USA, 22–25 July 2017; pp. 652–660. [Google Scholar]
- Li, Y.; Bu, R.; Sun, M.; Wu, W.; Di, X.; Chen, B. Pointcnn: Convolution on x-transformed points. In Proceedings of the Advances in Neural Information Processing Systems (NIPS 2018), Montreal, QC, Canada, 4–6 December 2018; pp. 820–830. [Google Scholar]
- Robertson, M.; Isbister, B.; Maling, I.; Oliver, Y.; Wong, M.; Adams, M.; Bowden, B.; Tozer, P. Opportunities and constraints for managing within-field spatial variability in western australian grain production. Field Crop. Res. 2007, 104, 60–67. [Google Scholar] [CrossRef]
- Zhang, C.; Kovacs, J.M. The application of small unmanned aerial systems for precision agriculture: A review. Precis. Agric. 2012, 13, 693–712. [Google Scholar] [CrossRef]
- Beil, G.; Atkins, R. Estimates of general and specific combining ability in f1 hybrids for grain yield and its components in grain sorghum, sorghum vulgare pers. 1. Crop Sci. 1967, 7, 225–228. [Google Scholar] [CrossRef]
- Potgieter, A.B.; George-Jaeggli, B.; Chapman, S.C.; Laws, K.; Suárez Cadavid, L.A.; Wixted, J.; Watson, J.; Eldridge, M.; Jordan, D.R.; Hammer, G.L. Multi-spectral imaging from an unmanned aerial vehicle enables the assessment of seasonal leaf area dynamics of sorghum breeding lines. Front. Plant Sci. 2017, 8, 1532. [Google Scholar] [CrossRef] [PubMed]
- Li, J.; Shi, Y.; Veeranampalayam-Sivakumar, A.-N.; Schachtman, D.P. Elucidating sorghum biomass, nitrogen and chlorophyll contents with spectral and morphological traits derived from unmanned aircraft system. Front. Plant Sci. 2018, 9, 1406. [Google Scholar] [CrossRef] [PubMed]
- Pugh, N.A.; Han, X.; Collins, S.D.; Thomasson, J.A.; Cope, D.; Chang, A.; Jung, J.; Isakeit, T.S.; Prom, L.K.; Carvalho, G.; et al. Estimation of plant health in a sorghum field infected with anthracnose using a fixed-wing unmanned aerial system. J. Crop Improv. 2018, 32, 861–877. [Google Scholar] [CrossRef]
- Li, L.; Zhang, Q.; Huang, D. A review of imaging techniques for plant phenotyping. Sensors 2014, 14, 20078–20111. [Google Scholar] [CrossRef] [PubMed]
- Ludovisi, R.; Tauro, F.; Salvati, R.; Khoury, S.; Mugnozza Scarascia, G.; Harfouche, A. Uav-based thermal imaging for high-throughput field phenotyping of black poplar response to drought. Front. Plant Sci. 2017, 8, 1681. [Google Scholar] [CrossRef]
- Gómez-Candón, D.; Virlet, N.; Labbé, S.; Jolivot, A.; Regnard, J.-L. Field phenotyping of water stress at tree scale by uav-sensed imagery: New insights for thermal acquisition and calibration. Precis. Agric. 2016, 17, 786–800. [Google Scholar] [CrossRef]
- Chapman, S.C.; Zheng, B.; Potgieter, A.; Guo, W.; Frederic, B.; Liu, S.; Madec, S.; de Solan, B.; George-Jaeggli, B.; Hammer, G. Visible, near infrared, and thermal spectral radiance on-board uavs for high-throughput phenotyping of plant breeding trials. Biophys. Biochem. Charact. Plant Species Stud. 2018, 3, 275. [Google Scholar]
- Ni, W.; Sun, G.; Pang, Y.; Zhang, Z.; Liu, J.; Yang, A.; Wang, Y.; Zhang, D. Mapping three-dimensional structures of forest canopy using uav stereo imagery: Evaluating impacts of forward overlaps and image resolutions with lidar data as reference. IEEE J. Stars 2018, 11, 3578–3589. [Google Scholar] [CrossRef]
- Domingo, D.; Ørka, H.O.; Næsset, E.; Kachamba, D.; Gobakken, T. Effects of uav image resolution, camera type, and image overlap on accuracy of biomass predictions in a tropical woodland. Remote Sens Basel 2019, 11, 948. [Google Scholar] [CrossRef]
- Torres-Sánchez, J.; López-Granados, F.; Serrano, N.; Arquero, O.; Peña, J.M. High-throughput 3-d monitoring of agricultural-tree plantations with unmanned aerial vehicle (uav) technology. PLoS ONE 2015, 10, e0130479. [Google Scholar] [CrossRef]
- Dodge, S.; Karam, L. Understanding how image quality affects deep neural networks. In Proceedings of the 2016 Eighth International Conference on Quality of Multimedia Experience (QoMEX), Lisbon, Portugal, 6–8 June 2016; pp. 1–6. [Google Scholar]
- Koziarski, M.; Cyganek, B. Impact of low resolution on image recognition with deep neural networks: An experimental study. Int. J. Appl. Math. Comput. Sci. 2018, 28, 735. [Google Scholar] [CrossRef]
- Krizhevsky, A.; Sutskever, I.; Hinton, G.E. Imagenet classification with deep convolutional neural networks. In Proceedings of the Advances in Neural Information Processing Systems (NIPS 2012), Lake Tahoe, NV, USA, 3–8 December 2012; pp. 1097–1105. [Google Scholar]
- Bao, Y.; Tang, L. Field-based robotic phenotyping for sorghum biomass yield component traits characterization using stereo vision. IFAC Pap. 2016, 49, 265–270. [Google Scholar] [CrossRef]
- Lin, Y.; Jiang, M.; Yao, Y.; Zhang, L.; Lin, J. Use of uav oblique imaging for the detection of individual trees in residential environments. Urban For. Urban Green. 2015, 14, 404–412. [Google Scholar] [CrossRef]
- Wierzbicki, D. Multi-camera imaging system for uav photogrammetry. Sensors 2018, 18, 2433. [Google Scholar] [CrossRef]
- Nesbit, P.R.; Hugenholtz, C.H. Enhancing uav–sfm 3d model accuracy in high-relief landscapes by incorporating oblique images. Remote Sens Basel 2019, 11, 239. [Google Scholar] [CrossRef]
- Romera-Paredes, B.; Torr, P.H.S. Recurrent instance segmentation. In European Conference on Computer Vision; Springer: Berlin, Germany, 2016; pp. 312–329. [Google Scholar]
- Fiaschi, L.; Köthe, U.; Nair, R.; Hamprecht, F.A. Learning to count with regression forest and structured labels. In Proceedings of the 21st International Conference on Pattern Recognition (ICPR 2012), Tsukuba, Japan, 11–15 November 2012; pp. 2685–2688. [Google Scholar]
- Boominathan, L.; Kruthiventi, S.S.; Babu, R.V. Crowdnet: A deep convolutional network for dense crowd counting. In Proceedings of the 24th ACM International Conference on Multimedia; ACM: New York, NY, USA, 2016; pp. 640–644. [Google Scholar]
- Onoro-Rubio, D.; López-Sastre, R.J. Towards perspective-free object counting with deep learning. In European Conference on Computer Vision; Springer: Berlin, Germany, 2016; pp. 615–629. [Google Scholar]
- Dobrescu, A.; Valerio Giuffrida, M.; Tsaftaris, S.A. Leveraging multiple datasets for deep leaf counting. In Proceedings of the IEEE International Conference on Computer Vision (ICCV 2017), Venice, Italy, 22–29 October 2017; pp. 2072–2079. [Google Scholar]
- Arend, D.; Junker, A.; Scholz, U.; Schüler, D.; Wylie, J.; Lange, M. Pgp repository: A plant phenomics and genomics data publication infrastructure. Database 2016, 2016. [Google Scholar] [CrossRef]
- Murray, S.C.; Malambo, L.; Popescu, S.; Cope, D.; Anderson, S.L.; Chang, A.; Jung, J.; Cruzato, N.; Wilde, S.; Walls, R.L. G2f Maize uav Data, College Station, Texas 2017. CyVerse Data Commons: 2019. Available online: https://www.doi.org/10.25739/4ext-5e97 (accessed on 7 December 2019).









{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Overall Performance | Per-Class Performance | |||
|---|---|---|---|---|
| Metric | Value | Class | Accuracy | IoU |
| Overall Accuracy | 95% | Background | 94% | 93% |
| Mean IoU | 87% | Panicle | 95% | 80% |
| Ground | 98% | 90% | ||
© 2019 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Malambo, L.; Popescu, S.; Ku, N.-W.; Rooney, W.; Zhou, T.; Moore, S. A Deep Learning Semantic Segmentation-Based Approach for Field-Level Sorghum Panicle Counting. Remote Sens. 2019, 11, 2939. https://doi.org/10.3390/rs11242939
Malambo L, Popescu S, Ku N-W, Rooney W, Zhou T, Moore S. A Deep Learning Semantic Segmentation-Based Approach for Field-Level Sorghum Panicle Counting. Remote Sensing. 2019; 11(24):2939. https://doi.org/10.3390/rs11242939
Chicago/Turabian StyleMalambo, Lonesome, Sorin Popescu, Nian-Wei Ku, William Rooney, Tan Zhou, and Samuel Moore. 2019. "A Deep Learning Semantic Segmentation-Based Approach for Field-Level Sorghum Panicle Counting" Remote Sensing 11, no. 24: 2939. https://doi.org/10.3390/rs11242939
APA StyleMalambo, L., Popescu, S., Ku, N.-W., Rooney, W., Zhou, T., & Moore, S. (2019). A Deep Learning Semantic Segmentation-Based Approach for Field-Level Sorghum Panicle Counting. Remote Sensing, 11(24), 2939. https://doi.org/10.3390/rs11242939