An Efficient and Accurate Method for Different Configurations Railway Extraction Based on Mobile Laser Scanning

Abstract
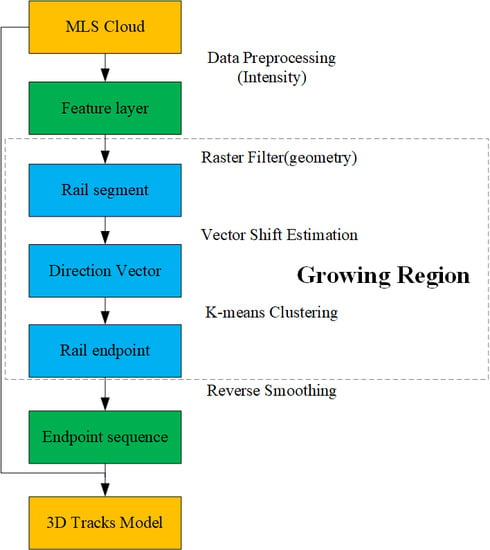
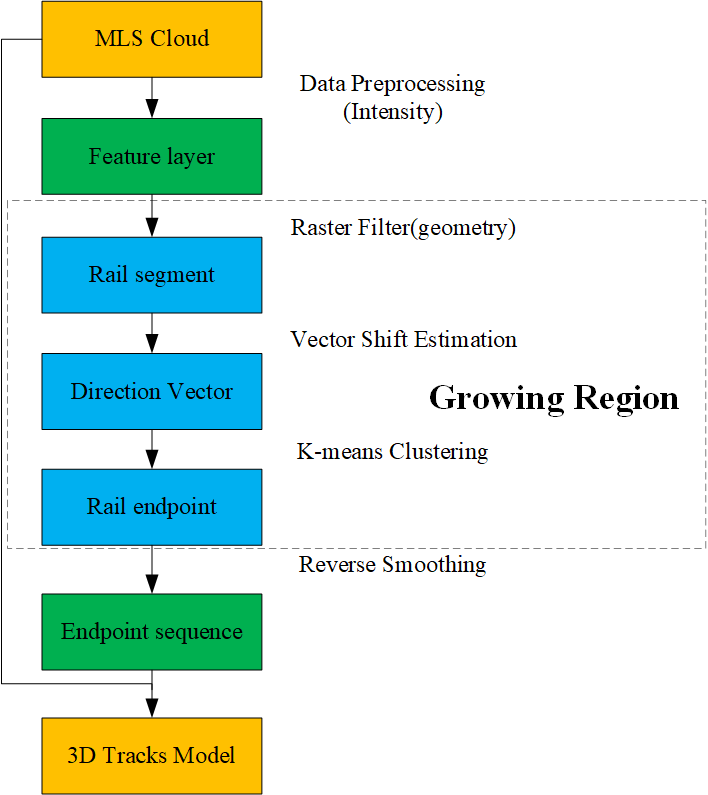
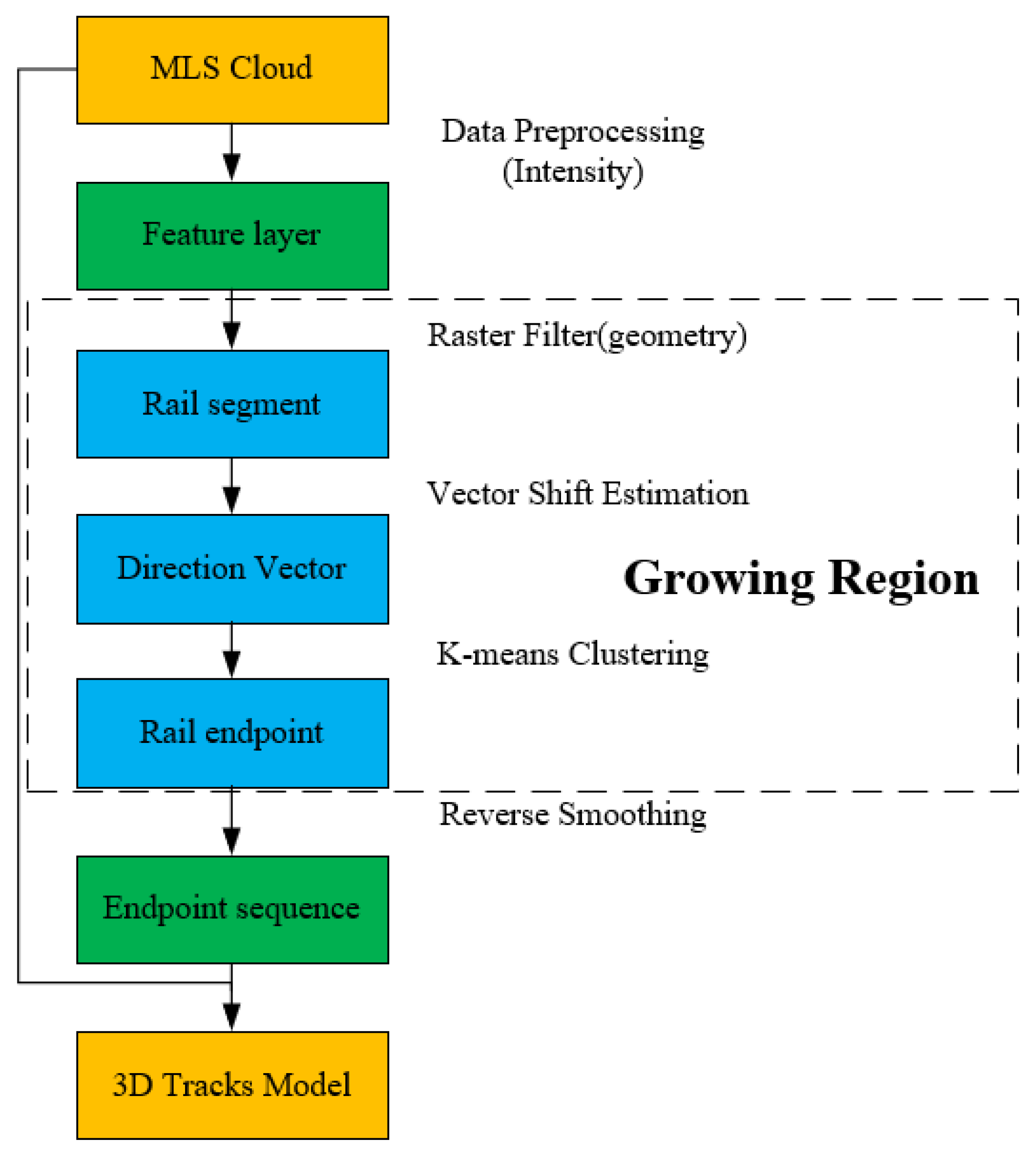
1. Introduction
2. Methodology
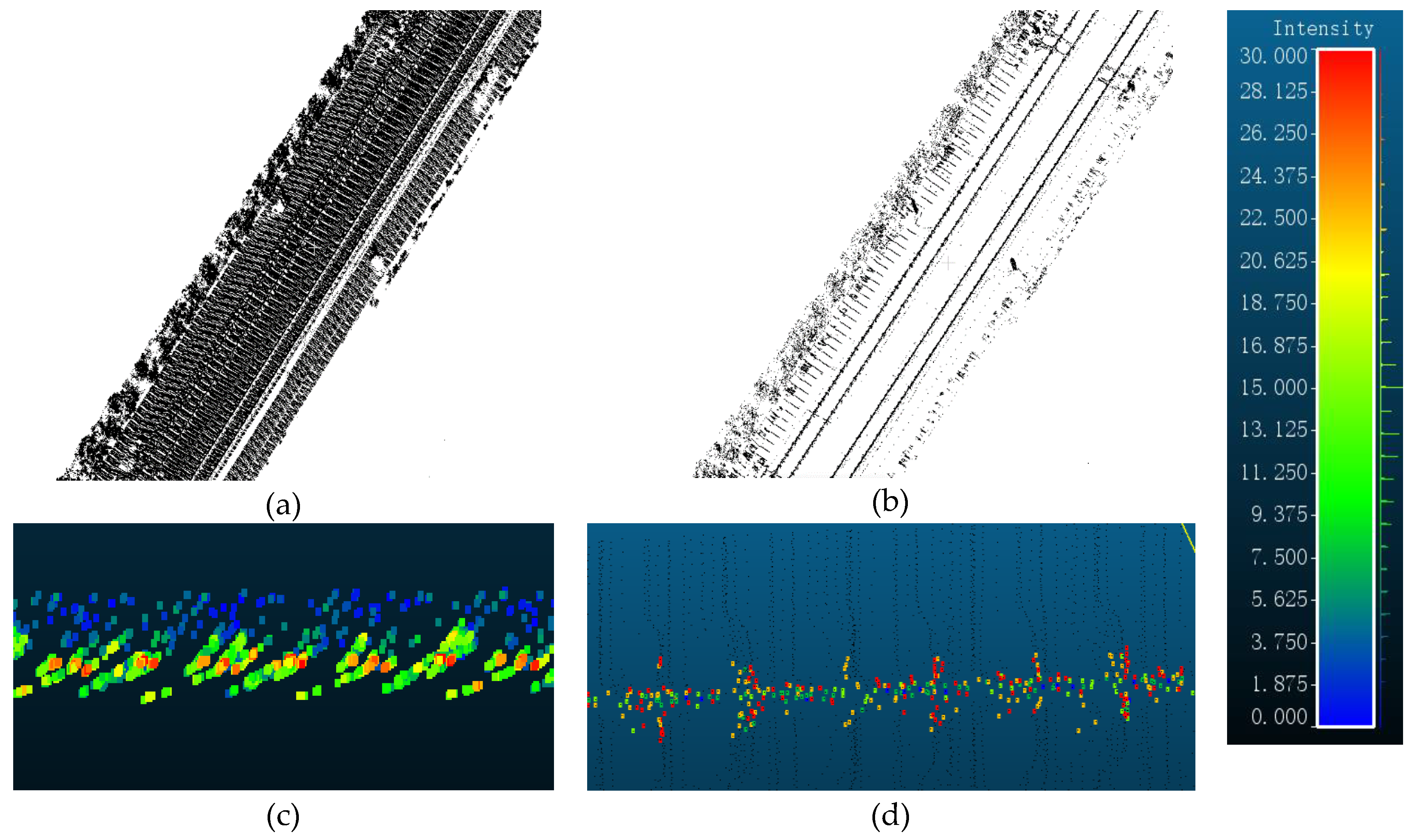
2.1. Data Preprocessing
2.2. Region Growing Estimation Method
2.2.1. Raster Filtering and Vector Shift Estimation
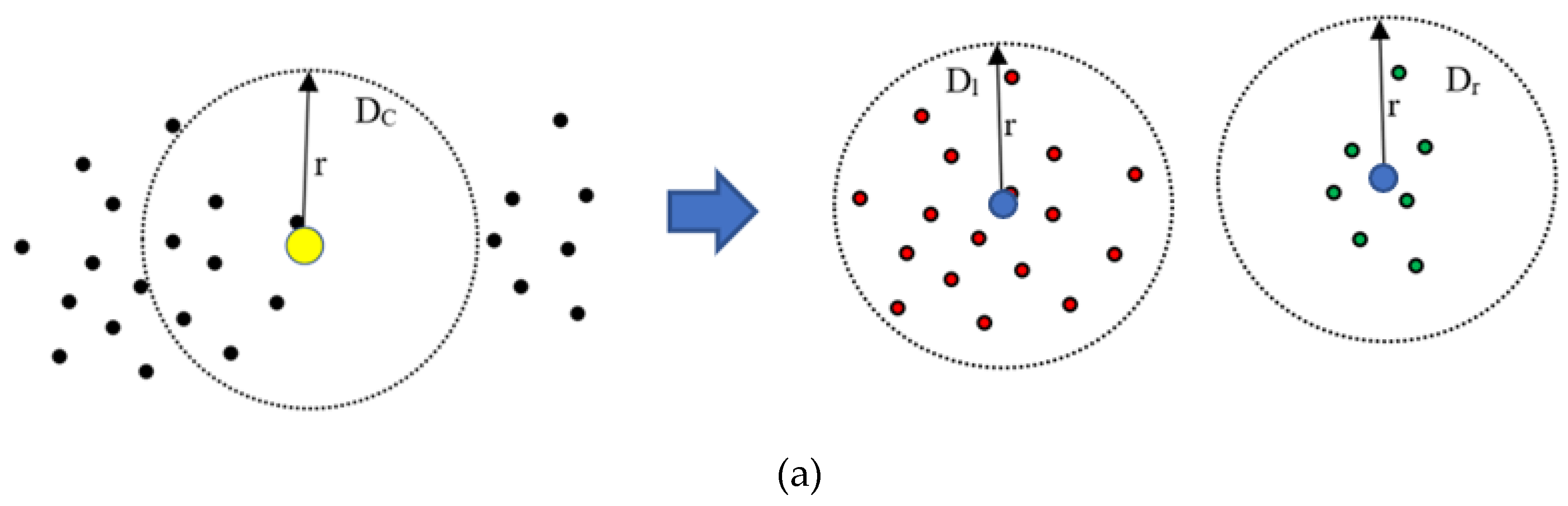
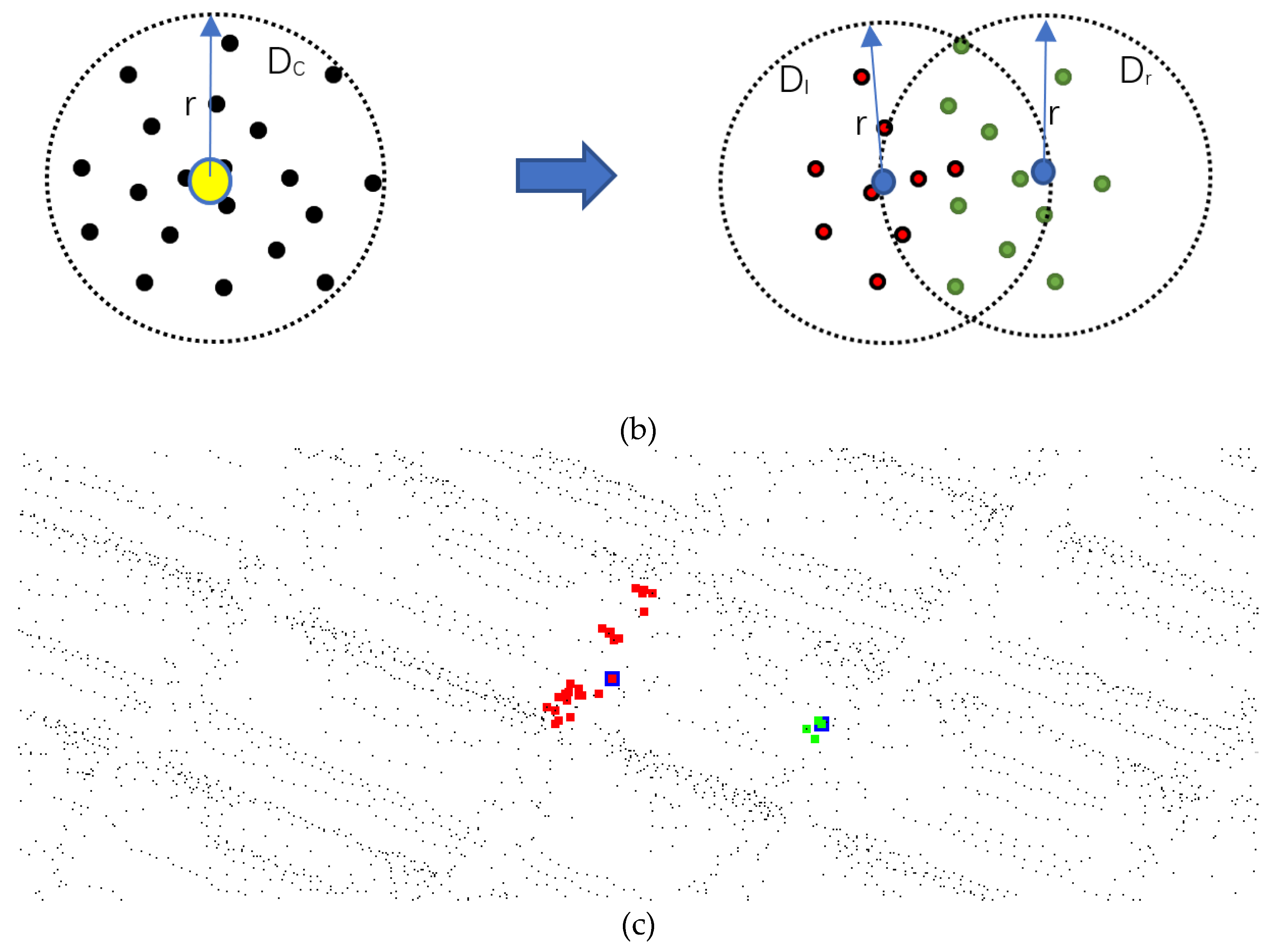
2.2.2. K-means Clustering
2.3. Reverse Smoothing
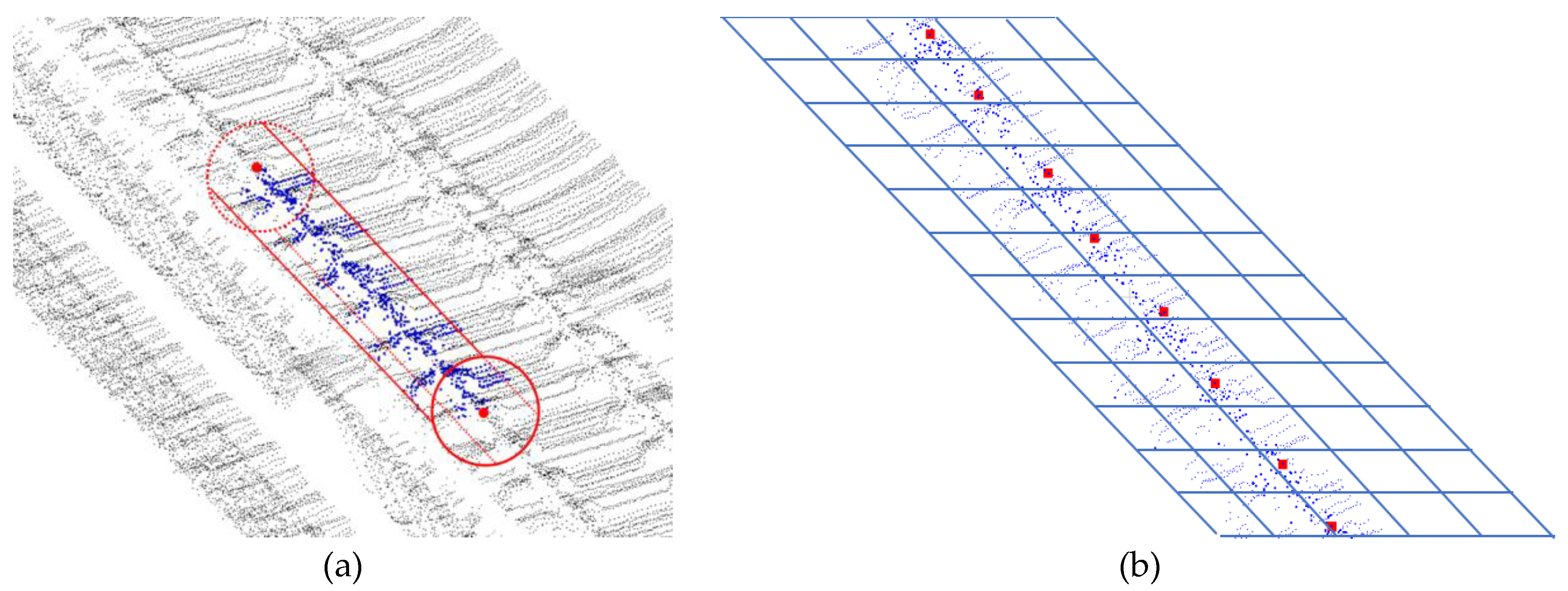
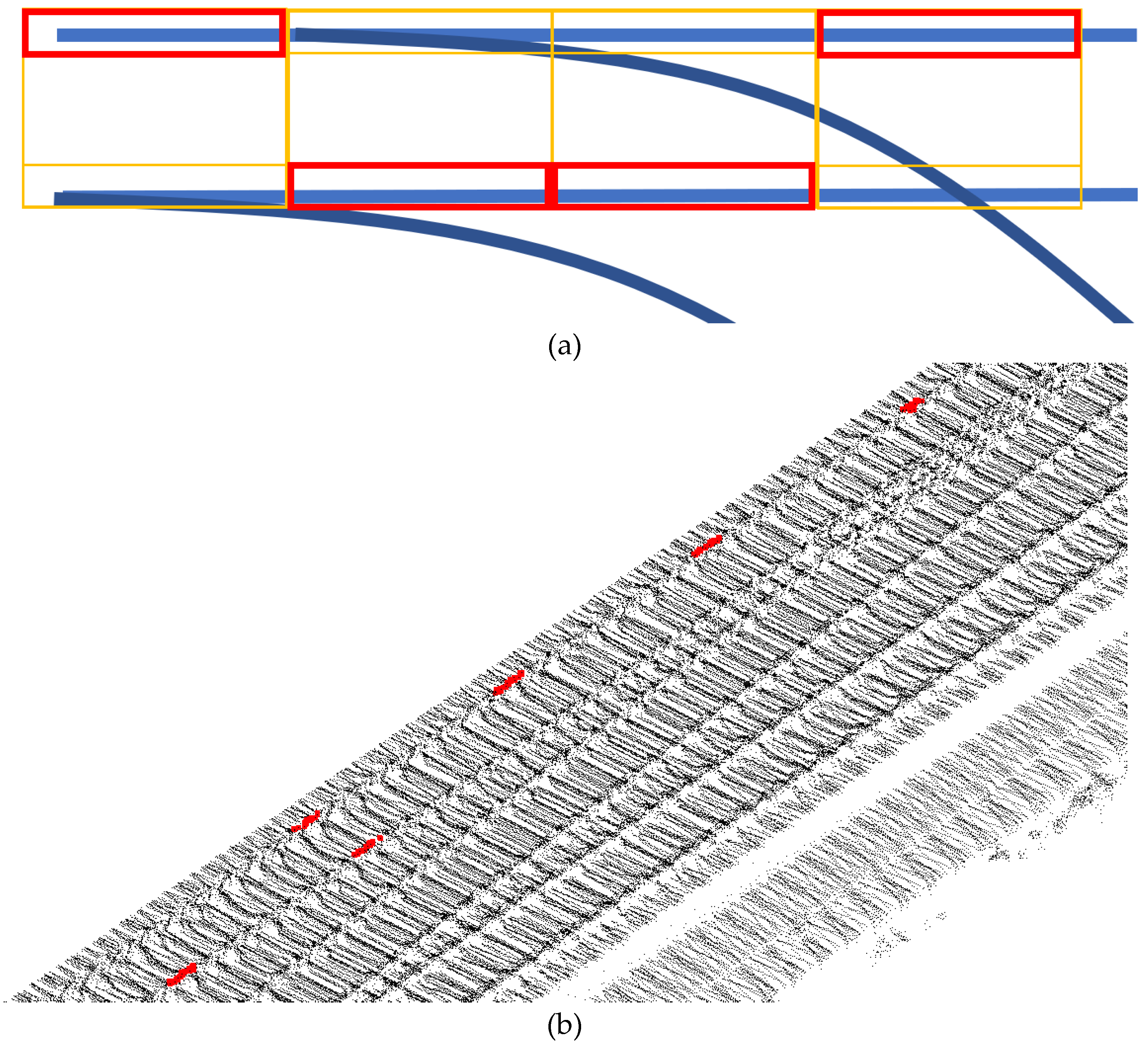
- The point of track turnout cannot be smoothed in reverse. The error of the rail region of the endpoint can be calculated to exclude the point of turnout being relocated.
- The density of point compensated by reverse smoothing is less than two adjacent point and .
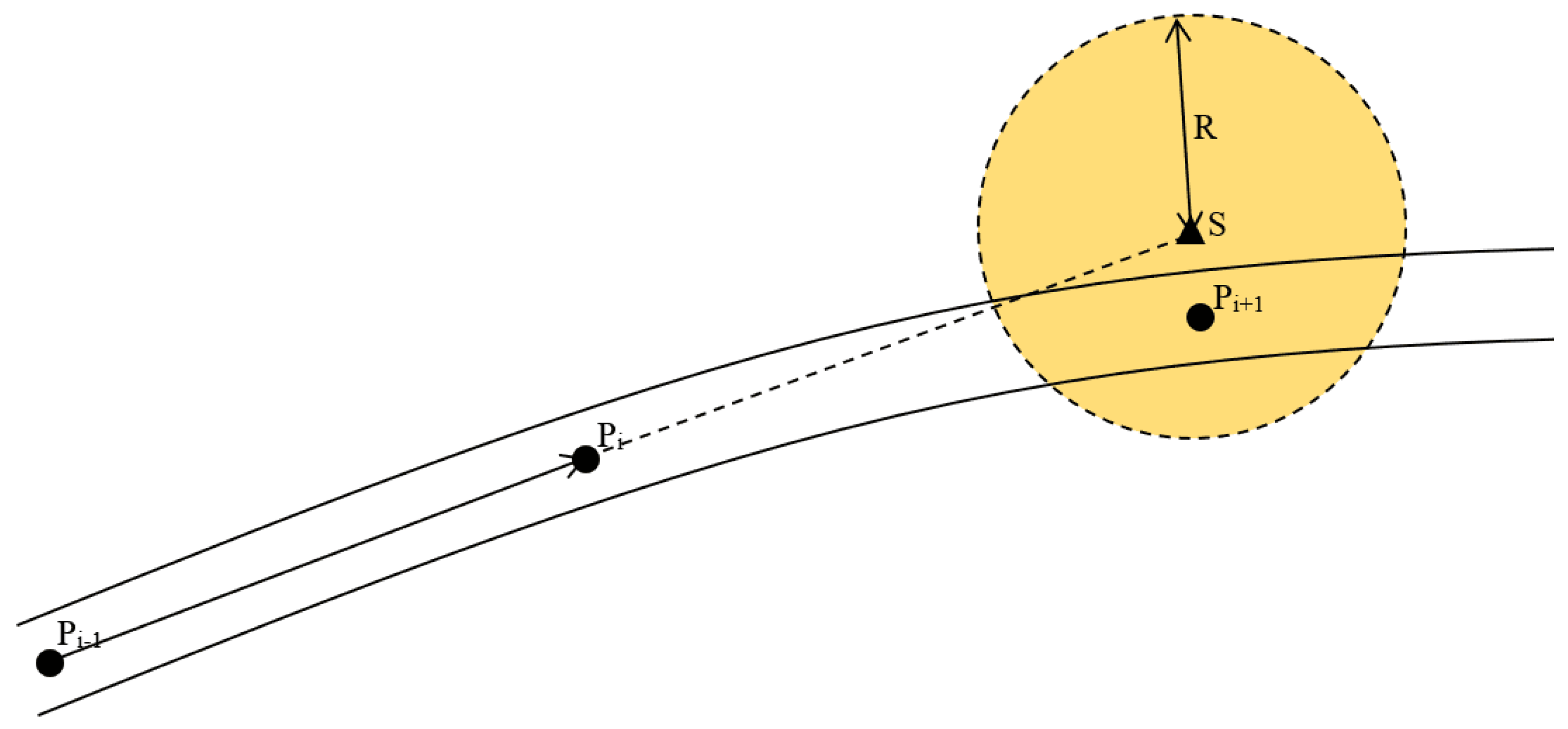
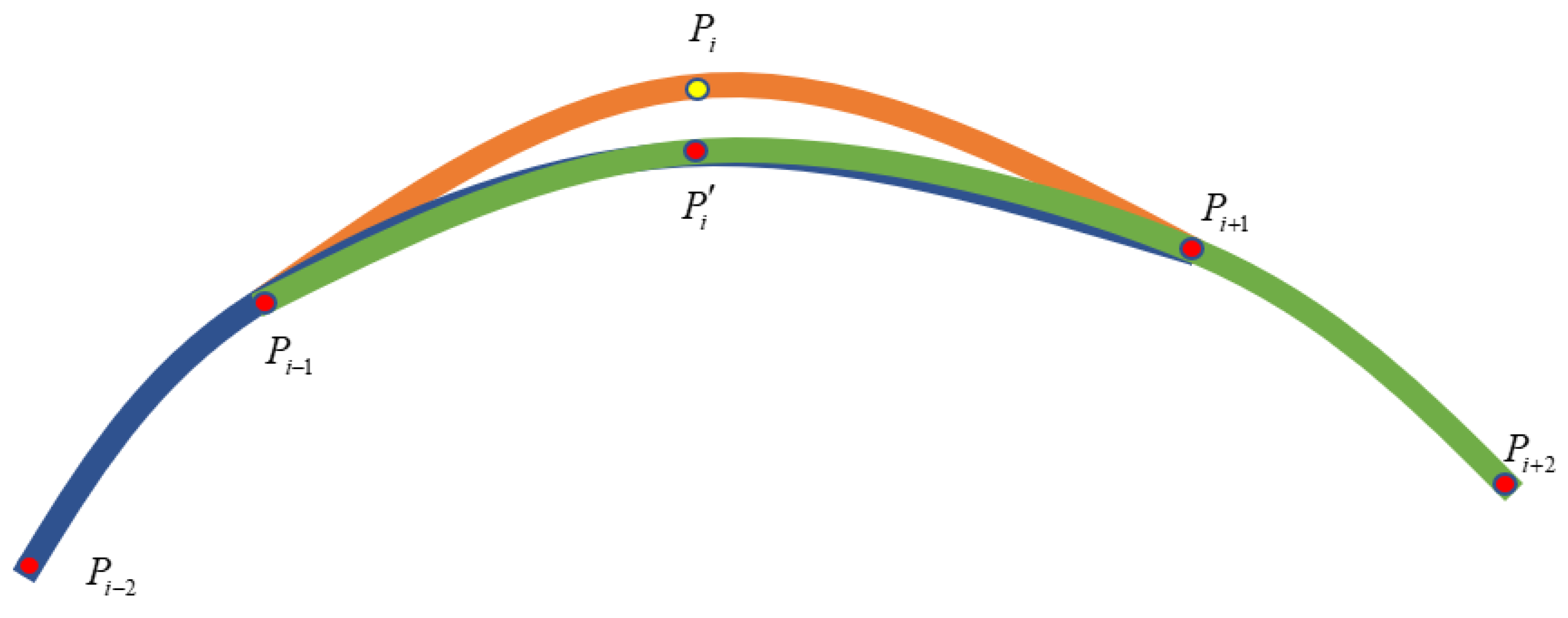
- As shown in the Figure 7, the two groups that are adjacent endpoints of are selected as blue and green lines, respectively, and a new endpoint is fitted by circular curve on plane expressed in the Formula (5). Bring the plane coordinates of , , and into the Formula (5) to get a set of parameters of the circular curve. The same process fits another circular curve by , and, of the green line. Next, take into these two functions. is the average value of corresponding points in the two functions.If radius of the functions is greater than empirical threshold 3000m, they’re considered lines. The following is the calculation formula (6) of radius .
- Comparing the densities of clustering centers and , which is the same as the density mentioned in Section 2.2.2. If the density of the corrected endpoint is significantly greater than that of the original endpoint , the endpoint is corrected to .
3. Environments and Data Description
3.1. Data Description
3.2. Test Area Description
4. Results and Discussion
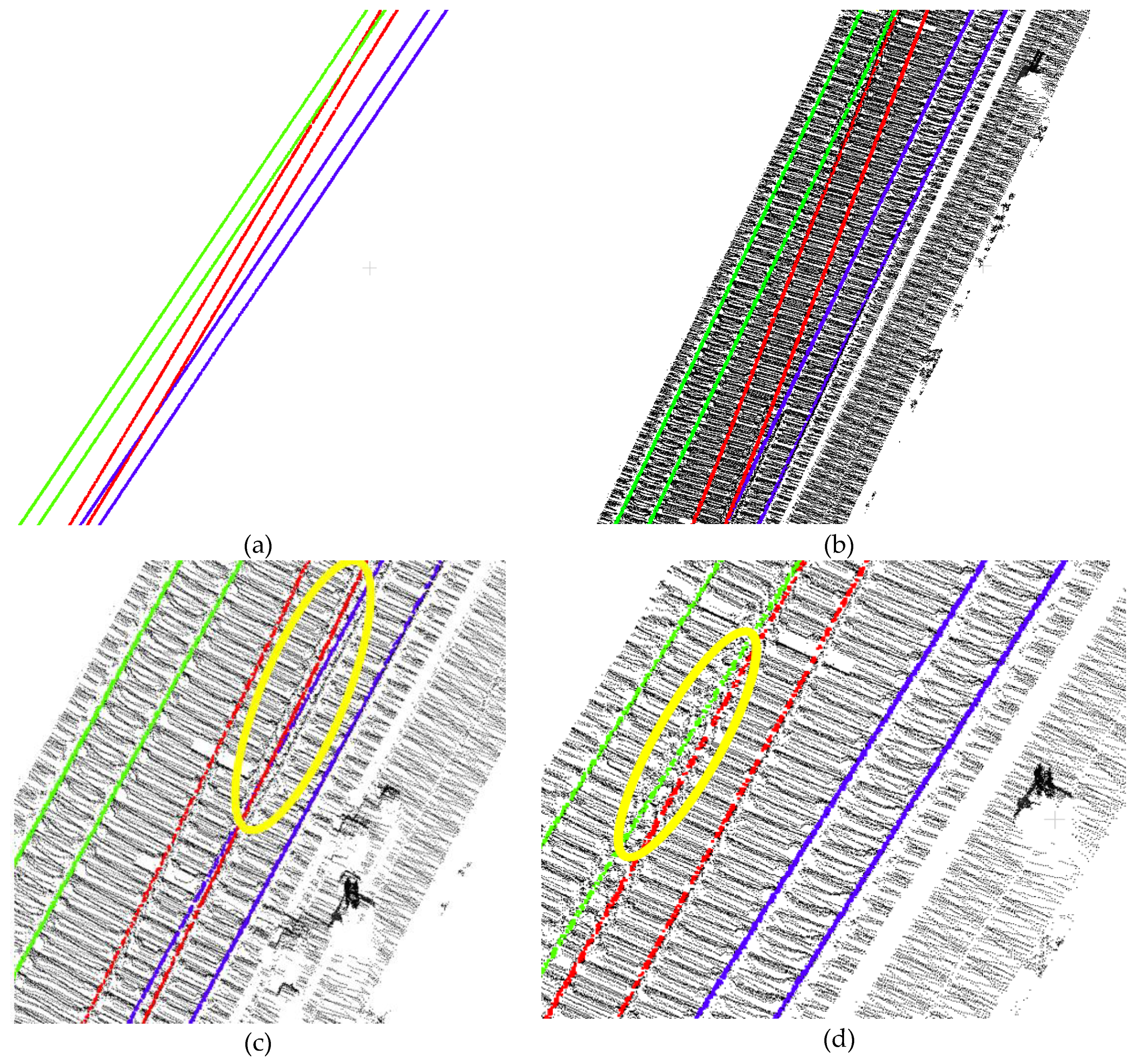
4.1. Results
4.2. Parameter Analysis
4.2.1. Strip Length
4.2.2. Raster Size
4.3. Quantitative Evaluation
5. Conclusions
Author Contributions
Funding
Acknowledgments
Conflicts of Interest
References
- Yu, X.; Lang, M.; Gao, Y.; Wang, K.; Su, C.-H.; Tsai, S.-B.; Huo, M.; Yu, X.; Li, S. An Empirical Study on the Design of China High-Speed Rail Express Train Operation Plan-From a Sustainable Transport Perspective. Sustainability 2018, 10, 2478. [Google Scholar] [CrossRef]
- Ma, L.; Li, Y.; Li, J.; Wang, C.; Wang, R.; Chapman, M. Mobile Laser Scanned Point-Clouds for Road Object Detection and Extraction: A Review. Remote Sens. 2018, 10, 1531. [Google Scholar] [CrossRef]
- Liu, J.; Liang, H.; Wang, Z.; Chen, X. A Framework for Applying Point Clouds Grabbed by Multi-Beam LIDAR in Perceiving the Driving Environment. Sensors 2015, 15, 21931–21956. [Google Scholar] [CrossRef] [PubMed]
- Al-Bayari, O. Mobile mapping systems in civil engineering projects (case studies). Appl. Geomat. 2019, 11, 1–13. [Google Scholar] [CrossRef]
- Dabeer, O.; Ding, W.; Gowaiker, R.; Grzechnik, S.K.; Lakshman, M.J.; Lee, S.; Reitmayr, G.; Sharma, A.; Somasundaram, K.; Sukhavasi, R.T.; et al. An end-to-end system for crowdsourced 3D maps for autonomous vehicles: The mapping component. In Proceedings of the 2017 IEEE/RSJ International Conference on Intelligent Robots and Systems (IROS), Vancouver, BC, Canada, 24–28 September 2017; pp. 634–641. [Google Scholar]
- Paterson, S.; Sheriff, C.; Ferguson, J. Metrolinx’s Toronto Electrification Project: Phase 1-the Engineering Survey. In Proceedings of the ASME Joint Rail Conference, 2017; AMER Soc Mechanical Engineers: Three Park Avenue, New York, NY, USA, 4–7 April 2017. [Google Scholar]
- Salah, I.B.; Kramm, S.; Demonceaux, C.; Vasseur, P. Summarizing Large Scale 3D Mesh. In Proceedings of the 2018 IEEE/RSJ International Conference on IN℡Ligent Robots and Systems (IROS), New York, NY, USA, 1–5 October 2018; pp. 6372–6377. [Google Scholar]
- Li, W.; Meng, X.; Wang, Z.; Fang, W.; Zou, J.; Li, H.; Sun, T.; Liang, J. Low-cost vector map assisted navigation strategy for autonomous vehicle. In Proceedings of the 2018 IEEE Asia Pacific Conference on Circuits and Systems (APCCAS 2018), New York, NY, USA, 26–30 October 2018; pp. 536–539. [Google Scholar]
- Hao, C.-Y.; Chen, M.-H.; Chou, T.-Y.; Lin, C.-W. Design of a Resource-oriented Framework for Point Cloud Semantic Annotation with Deep Learning. In Proceedings of the 2018 IEEE FIRST International Conference on Artificial IN℡Ligence and Knowledge Engineering (AIKE), New York, NY, USA, 26–28 September 2018; pp. 228–233. [Google Scholar]
- Che, E.; Jung, J.; Olsen, M. Object Recognition, Segmentation, and Classification of Mobile Laser Scanning Point Clouds: A State of the Art Review. Sensors 2019, 19, 810. [Google Scholar] [CrossRef]
- Tomljenovic, I.; Hoefle, B.; Tiede, D.; Blaschke, T. Building Extraction from Airborne Laser Scanning Data: An Analysis of the State of the Art. Remote Sens. 2015, 7, 3826–3862. [Google Scholar] [CrossRef]
- Matikainen, L.; Lehtomaki, M.; Ahokas, E.; Hyyppa, J.; Karjalainen, M.; Jaakkola, A.; Kukko, A.; Heinonen, T. Remote sensing methods for power line corridor surveys. ISPRS J. Photogramm. Remote Sens. 2016, 119, 10–31. [Google Scholar] [CrossRef]
- Li, F.; Lehtomäki, M.; Oude Elberink, S.; Vosselman, G.; Kukko, A.; Puttonen, E.; Chen, Y.; Hyyppä, J. Semantic segmentation of road furniture in mobile laser scanning data. ISPRS J. Photogramm. Remote Sens. 2019, 154, 98–113. [Google Scholar] [CrossRef]
- Wang, Z.; Wu, X.; Yan, Y.; Jia, C.; Cai, B.; Huang, Z.; Wang, G.; Zhang, T. An Inverse Projective Mapping-based Approach for Robust Rail Track Extraction. In Proceedings of the 2015 8th International Congress on Image and Signal Processing (CISP), New York, NY, USA, 14–16 October 2015; pp. 888–893. [Google Scholar]
- Liu, Z.; Liu, W.; Han, Z. A High-Precision Detection Approach for Catenary Geometry Parameters of Electrical Railway. IEEE Trans. Instrum. Meas. 2017, 66, 1798–1808. [Google Scholar] [CrossRef]
- Pastucha, E. Catenary System Detection, Localization and Classification Using Mobile Scanning Data. Remote Sens. 2016, 8, 801. [Google Scholar] [CrossRef]
- Arastounia, M. Automated Recognition of Railroad Infrastructure in Rural Areas from LIDAR Data. Remote Sens. 2015, 7, 14916–14938. [Google Scholar] [CrossRef]
- Sánchez-Rodríguez, A.; Riveiro, B.; Soilán, M.; González-deSantos, L.M. Automated detection and decomposition of railway tunnels from Mobile Laser Scanning Datasets. Autom. Constr. 2018, 96, 171–179. [Google Scholar] [CrossRef]
- Chen, C.; Yang, B.; Song, S.; Peng, X.; Huang, R. Automatic Clearance Anomaly Detection for Transmission Line Corridors Utilizing UAV-Borne LIDAR Data. Remote Sens. 2018, 10, 613. [Google Scholar] [CrossRef]
- Lou, Y.; Zhang, T.; Tang, J.; Song, W.; Zhang, Y.; Chen, L. A Fast Algorithm for Rail Extraction Using Mobile Laser Scanning Data. Remote Sens. 2018, 10, 1998. [Google Scholar] [CrossRef]
- Qiu, K.; Sun, K.; Ding, K.; Shu, Z. A Fast and Robust Algorithm for Road Edges Extraction from Lidar Data. ISPRS Int. Arch. Photogramm. Remote Sens. Spat. Inf. Sci. 2016, XLI-B5, 693–698. [Google Scholar] [CrossRef]
- Stein, D.; Spindler, M.; Lauer, M. Model-based rail detection in mobile laser scanning data. In Proceedings of the 2016 IEEE Intelligent Vehicles Symposium (IV), Gotenburg, Sweden, 19–22 June 2016; pp. 654–661. [Google Scholar]
- Arastounia, M.; Oude Elberink, S. Application of Template Matching for Improving Classification of Urban Railroad Point Clouds. Sensors 2016, 16, 2112. [Google Scholar] [CrossRef]
- Oude Elberink, S.; Khoshelham, K.; Arastounia, M.; Diaz Benito, D. Rail Track Detection and Modelling in Mobile Laser Scanner Data. ISPRS Ann. Photogramm. Remote Sens. Spat. Inf. Sci. 2013, II-5/W2, 223–228. [Google Scholar] [CrossRef]
- Yang, B.; Fang, L. Automated Extraction of 3-D Railway Tracks from Mobile Laser Scanning Point Clouds. IEEE J. Sel. Top. Appl. Earth Obs. Remote Sens. 2014, 7, 4750–4761. [Google Scholar] [CrossRef]
- Leary, R.D.; Brennan, S.N. Extracting Geometric Road Centerline and Lane Edges from Single-Scan LiDAR Intensity Using Optimally Filtered Extrema Features. In Proceedings of the 2018 IEEE Conference on Control Technology and Applications (CCTA), Copenhagen, Denmark, 21–24 August 2018; pp. 1133–1138. [Google Scholar]
- Andani, M.T.; Mohammed, A.; Jain, A.; Ahmadian, M. Application of LIDAR technology for rail surface monitoring and quality indexing. Proc. Inst. Mech. Eng. Part F J. Rail Rapid Transit 2018, 232, 1398–1406. [Google Scholar] [CrossRef]
- Gorte, B.; Oude Elberink, S.; Sirmacek, B.; Wang, J. IQPC 2015 Track: Tree Separation and Classification in Mobile Mapping Lidar Data. ISPRS Int. Arch. Photogramm. Remote Sens. Spat. Inf. Sci. 2015, XL-3/W3, 607–612. [Google Scholar] [CrossRef]
- Telke, C.; Quarz, V.; Beitelschmidt, M.; Schulz, A. A novel modular measurement system for the development of light rail vehicles. In The Dynamics of Vehicles on Roads and Tracks; Osenberger, M., Plochl, M., Six, K., Edelmann, J., Eds.; CRC Press: Boca Raton, FL, USA, 2016; pp. 1451–1460. [Google Scholar]
- Tang, C.; Tian, G.Y.; Chen, X.; Wu, J.; Li, K.; Meng, H. Infrared and visible images registration with adaptable local-global feature integration for rail inspection. Infrared Phys. Technol. 2017, 87, 31–39. [Google Scholar] [CrossRef]
- Li, S.; Xu, C.; Chen, L.; Liu, Z. Speed Regulation of Overhead Catenary System Inspection Robot for High-Speed Railway through Reinforcement Learning. In Proceedings of the 2018 IEEE Smartworld, Ubiquitous IN℡Ligence & Computing, Advanced & Trusted Computing, Scalable Computing & Communications, Cloud & Big Data Computing, Internet of People and Smart City Innovation (SMARTWORLD/SCALCOM/UIC/ATC/CBDCOM/IOP/SCI), New York, NY, USA, 8–12 October 2018; pp. 1378–1383. [Google Scholar]
- Wang, A.; He, X.; Ghamisi, P.; Chen, Y. LiDAR Data Classification Using Morphological Profiles and Convolutional Neural Networks. IEEE Geosci. Remote Sens. Lett. 2018, 15, 774–778. [Google Scholar] [CrossRef]
- Rachmadi, R.F.; Uchimura, K.; Koutaki, G.; Ogata, K. Road edge detection on 3D point cloud data using Encoder-Decoder Convolutional Network. In Proceedings of the 2017 International Electronics Symposium on Knowledge Creation and Intelligent Computing (IES-KCIC), Surabaya, Indonesia, 26–27 September 2017; pp. 95–100. [Google Scholar]
- Su, H.; Maji, S.; Kalogerakis, E.; Learned-Miller, E. Multi-view Convolutional Neural Networks for 3D Shape Recognition. In Proceedings of the 2015 IEEE International Conference on Computer Vision (ICCV), New York, NY, USA, 7–13 December 2015; pp. 945–953. [Google Scholar]
- Qin, N.; Hu, X.; Dai, H. Deep fusion of multi-view and multimodal representation of ALS point cloud for 3D terrain scene recognition. ISPRS J. Photogramm. Remote Sens. 2018, 143, 205–212. [Google Scholar] [CrossRef]
- Maturana, D.; Scherer, S. VoxNet: A 3D Convolutional Neural Network for Real-Time Object Recognition. In Proceedings of the 2015 IEEE/RSJ International Conference on IN℡Ligent Robots and Systems (IROS), New York, NY, USA, 28 September–2 October 2015; pp. 922–928. [Google Scholar]
- Huang, J.; You, S. Point Cloud Labeling using 3D Convolutional Neural Network. In Proceedings of the 2016 23rd International Conference on Pattern Recognition (ICPR), Cancun, Mexico, 4–8 December 2016; pp. 2670–2675. [Google Scholar]
- Qi, C.R.; Su, H.; Mo, K.; Guibas, L.J. PointNet: Deep Learning on Point Sets for 3D Classification and Segmentation. In Proceedings of the 30th IEEE Conference on Computer Vision and Pattern Recognition (CVPR 2017), Honolulu, HI, USA, 21–26 July 2017; pp. 77–85. [Google Scholar]
- Hackel, T.; Wegner, J.D.; Savinov, N.; Ladicky, L.; Schindler, K.; Pollefeys, M. Large-Scale Supervised Learning For 3D Point Cloud Labeling: Semantic3d.Net. Photogramm. Eng. Remote Sens. 2018, 84, 297–308. [Google Scholar] [CrossRef]
- Zhou, W.; Peng, R.; Dong, J.; Wang, T. Automated extraction of 3D vector topographic feature line from terrain point cloud. Geocarto Int. 2018, 33, 1036–1047. [Google Scholar] [CrossRef]
- Qin, X.; Wu, G.; Lei, J.; Fan, F.; Ye, X. Detecting Inspection Objects of Power Line from Cable Inspection Robot LiDAR Data. Sensors 2018, 18, 1284. [Google Scholar] [CrossRef]
- Zhang, S.; Wang, C.; Yang, Z.; Chen, Y.; Li, J. Automatic Railway Power Line Extraction Using Mobile Laser Scanning Data. Int. Arch. Photogramm. Remote Sens. Spat. Inf. Sci. 2016, XLI-B5, 615–619. [Google Scholar] [CrossRef]
- Jwa, Y.; Sonh, G. Kalman Filter Based Railway Tracking from Mobile Lidar Data. ISPRS Ann. Photogramm. Remote Sens. Spat. Inf. Sci. 2015, II-3/W5, 159–164. [Google Scholar] [CrossRef]
- Mohamad, M.; Kusevic, K.; Mrstik, P.; Greenspan, M. Automatic Rail Extraction in Terrestrial and Airborne LiDAR Data. In Proceedings of the 2013 International Conference on 3D Vision-3DV 2013, Seattle, WA, USA, 29 June–1 July 2013; pp. 303–309. [Google Scholar]
















{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Parameter | Description | Values |
|---|---|---|
| LEN | Strip length (Straight-line) Strip length (Divided-deck) Strip length (bends) | 15 m 15 m 8 m |
| R | Radius of pseudo-track point Raster size | 0.3 m 0.15 m |
| INTEN | intensity threshold | 5 |
| Method | Precision (%) | Sensitivity (%) |
|---|---|---|
| Kalman | 82.28 | 91.96 |
| Region growing | 96.70 | 89.47 |
| Scene | Precision (%) | Sensitivity (%) |
|---|---|---|
| Bends | 90.32 | 83.27 |
| Turnouts | 81.31 | 83.33 |
© 2019 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Zou, R.; Fan, X.; Qian, C.; Ye, W.; Zhao, P.; Tang, J.; Liu, H. An Efficient and Accurate Method for Different Configurations Railway Extraction Based on Mobile Laser Scanning. Remote Sens. 2019, 11, 2929. https://doi.org/10.3390/rs11242929
Zou R, Fan X, Qian C, Ye W, Zhao P, Tang J, Liu H. An Efficient and Accurate Method for Different Configurations Railway Extraction Based on Mobile Laser Scanning. Remote Sensing. 2019; 11(24):2929. https://doi.org/10.3390/rs11242929
Chicago/Turabian StyleZou, Rong, Xiaoyun Fan, Chuang Qian, Wenfang Ye, Peng Zhao, Jian Tang, and Hui Liu. 2019. "An Efficient and Accurate Method for Different Configurations Railway Extraction Based on Mobile Laser Scanning" Remote Sensing 11, no. 24: 2929. https://doi.org/10.3390/rs11242929
APA StyleZou, R., Fan, X., Qian, C., Ye, W., Zhao, P., Tang, J., & Liu, H. (2019). An Efficient and Accurate Method for Different Configurations Railway Extraction Based on Mobile Laser Scanning. Remote Sensing, 11(24), 2929. https://doi.org/10.3390/rs11242929