Abstract
Current new developments in remote sensing imagery enable satellites to capture videos from space. These satellite videos record the motion of vehicles over a vast territory, offering significant advantages in traffic monitoring systems over ground-based systems. However, detecting vehicles in satellite videos are challenged by the low spatial resolution and the low contrast in each video frame. The vehicles in these videos are small, and most of them are blurred into their background regions. While region proposals are often generated for efficient target detection, they have limited performance on satellite videos. To meet this challenge, we propose a Local Region Proposing approach (LRP) with three steps in this study. A video frame is segmented into semantic regions first and possible targets are then detected in these coarse scale regions. A discrete Histogram Mixture Model (HistMM) is proposed in the third step to narrow down the region proposals by quantifying their likelihoods towards the target category, where the training is conducted on positive samples only. Experiment results demonstrate that LRP generates region proposals with improved target recall rates. When a slim Fast-RCNN detector is applied, LRP achieves better detection performance over the state-of-the-art approaches tested.
1. Introduction
As one of the most promising developments in remote sensing imagery, the satellite videos captured by Skybox and JL-1, have facilitated several emerging research and applications, including super resolution [,], video encoding [,] and target tracking [,]. They expand the earth observation capacity to rapid motion monitoring, such as vehicle and ship tracking [,,]. To reveal these rapid motions, targets of interests need to be located throughout the satellite video first, and the extracted targets in each frame are then associated to construct the trajectories of targets of interest. Therefore, target detection in satellite videos is a fundamental and critical step for target tracking and motion pattern analysis.
Detecting objects of interest in a video can be achieved by the motion-based detectors, which search the changed pixels in a sequence of images by comparing with an estimated background model [,]. Various algorithms, such as Frame-Difference [,,], Median Background [], Gaussian Mixture Model (GMM) [,] and Visual Background Extractor (ViBe) [,,], were developed for moving object detection. However, these approaches are prone to the inadequate background modelling and affected by the problem of parallax caused by the motion of the camera.
Alternatively, the image-based object detectors can extract objects of interest from a video frame by frame [], whose performance is less affected by the parallax motion. By taking the advantage of the discriminative learning methods, these approaches employ a classifier to scan over possible locations of targets in an image by sliding window [,,]. To reduce the number of the candidate locations to examine, region proposals, which refer a sparse set of potential target locations, are introduced to replace sliding windows over the entire image. For common computer vision tasks, generating region proposals are commonly guided by the object saliency, such as the edges [,,], or based on superpixels [,,,,] or segmentation masks [,]. In aerial videos, the coherent regions extracted by Maximally Stable Extremal Regions (MSER) [,] or Top-hat-Otsu [] are also adopted for region proposal generation. Due to the weak contrast between targets and background in satellite videos, saliency-based approaches result in degraded region proposal performance —either generating too many region proposals or producing a low target recall rate. These approaches also lack the mechanisms for quantifying the region proposals’ likelihood of being a target, and place the entire burden of handling a large number of region proposals in the target recognition stage. Convolutional Neural Networks were applied for searching region proposals in recent years. These approaches can provide the confidence score for each region proposal, and a significant portion of false alarms in the region proposals are removed before the recognition state [,,,]. However, they heavily rely on the training of a reliable region proposal network using a large amount of training samples.
To improve the region proposal performance to handle dim and small target detection in satellite video, we propose a Local Region Proposing (LRP) approach with three steps in this study. Our observation is that vehicles in satellite videos appear small and dim globally. Therefore we propose to perform segmentation at a coarse scale to form semantic region first. Possible locations of small targets in each semantic region are then extracted. To reduce the false alarm further and alleviate the computation burden on further target recognition stage, a discrete Histogram Mixture Model (HistMM) is proposed to quantify their likelihoods towards the target category. HistMM presents little difficulty in cooperating with most detectors, as it is estimated separately and only positive samples are required for estimating the model.
2. Local Region Proposing
Figure 1 shows the Local Region Proposing approach (LRP) developed in this study is composed of three steps. First semantic regions are extracted by coarse-scale segmentation, then possible target locations are searched in each extracted region. The Histogram Mixture Model is developed for removing obvious false alarms from the region proposals.
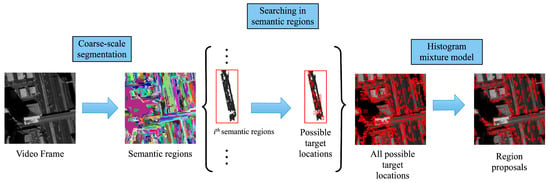
Figure 1.
Overview of the proposed region proposal algorithm.
2.1. Semantic Region Extraction
Extracting semantic regions from a video frame can be by segmentation at a coarse scale, and the majority of pixels in each extracted region are more likely from a single land cover type. The Felzenszwalb’s graph-based segmentation approach [] is a typical method for extracting the semantic regions.
By this graph-based segmentation approach, the scale of the generated superpixels can be controlled by a parameter k. Increasing k would lead to more coarse-scale superpixels, and these superpixels tend to present regions from different land cover types. The semantic regions are allowed to be larger than the target size on purpose. Decreasing k would generate fine-scale superpixels. However, it is often difficult to make superpixels to associate with small targets in satellite videos, due to the low spatial resolution and the low contrast of targets, for example, vehicles, to the background in satellite videos.
2.2. Searching Possible Locations in Semantic Regions
Unlike most dominating saliency object-based approaches, such as Selective Search [,], which merge superpixels to form region proposals, the proposed LRP searches region proposals inside semantic regions, where an adaptive threshold is introduced to accommodate the statistics of individual regions.
Note the set of extracted semantic regions as , for a semantic region that contains m pixels, the set of the pixels’ coordinates is noted as . The intensity of a pixel at location is referred to . The blobs with high local saliency are constructed by the pixels with intensities over a threshold , . The threshold is defined by
where and are the mean and standard deviation of pixel intensities in this local region r. The factor f is the expected saliency against the backgrounds. For each extracted blob, a corresponding boundary box is extracted as a possible location.
In the complex scenarios of satellite videos, this searching strategy may be affected by the presence of crowded vehicles and the blurred boundaries of vehicles, which results in merged proposals or incomplete proposals within an original boundary box extracted. We handle these cases by generating multiple proposals. The large boxes should be divided into sub regions to match the target size approximately and the small boxes should be expanded by half of the target size in each direction as a conservative treatment. Figure 2a shows an example where 4 region proposals are generated. To address those incomplete proposals, as shown in Figure 2b, the given bounding box is expanded in each directions.
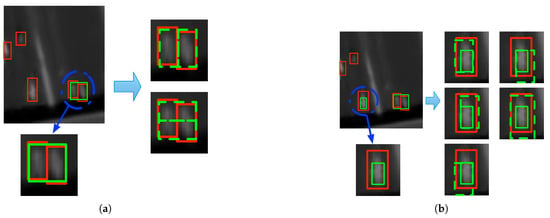
Figure 2.
Generating multiple region proposals from a possible location. The red box refers to the groundtruth, green solid box refers to the extracted possible location, and green dash boxes refer to the generated region proposals. (a) and (b) illustrate two examples of generating region proposals by splitting and expanding original region proposals, respectively.
2.3. Histogram Mixture Model
2.3.1. Histogram Mixture Model for Removing Obvious False Alarms
The proposed Histogram Mixture Model (HistMM) measures the likelihoods of the generated region proposals towards their corresponding target category, so that obvious false alarms could be removed at an early stage. The HistMM is a mixture model built on a set of histograms, and training or estimating HistMM depends only on positive training samples.
Note the entire set of initial region proposals on a video frame as , and is the number of initial region proposal on a given frame. For a region proposal , it is marked as either target or background. We decide if x belongs to the target category (T) or the background category (B) by a Bayesian decision function,
in which R measures the membership rate of x belonging to the target category versus belonging to the background category. implies x is a target. The corresponding decision function for x that belongs to T can be simplified as
where is a threshold.
The refers to the likelihood of a region proposal x to the target category. We model it by a mixture model composed by a set of histograms, . In this paper, we assume that each histogram contributes equally to the likelihood , therefore, the possibility of a proposal r that belongs to T is defined as,
The decision function in Equation (3) can be then interpreted as
which means the likelihood to at least one histogram in is larger than . On the contrary, a region proposals is a background when all likelihoods toward histograms in are less than the threshold , as
For a given pair of a region proposal x and a histogram in , we appropriate by the Intersection of Histogram () between the histogram h and the histogram extracted from the region proposal x. For simplicity, we employ the Histogram of Color () for calculating , as
which sums up the minimum values in all pairs of corresponding bins from h and . As shown in Figure 3, the s on s are distinct for distinguishing targets and backgrounds, although less information is provided due to the dim appearance of the vehicles.

Figure 3.
Histogram of Color can distinguish targets from backgrounds. Region proposal A and B are vehicles, whereas the region proposal C and D are obvious false alarms. For the four selected region proposals, their corresponding HoC are extracted, as shown in the right part of the figure. For A and B, the is high, while both C and D have low due to the extremely low similarities.
Our HistMM removes obvious false alarms by the threshold . A larger tends to removal more possible false alarms, whereas it also risks abandoning some target instances. A smaller may improve the coverage of targets in the region proposals, but the remaining number of proposals would be high. The detailed effects of different parameter settings are discussed in Section 3.2.
2.3.2. Estimating Histogram Mixture Model
For a set of possible region proposals on a video frame, we predict a region proposal as a target or a background by Equation (6), as summarized in Algorithm 1. The complexity for predicting region proposals by HistMM grows linearly with the size of , . Therefore, our proposed HistMM is computationally feasible and scalable for the case with a large number of region proposals.
| Algorithm 1 Removing Obvious False Alarms by Histogram Mixture Model (HistMM) |
|
HistMM is estimated by a recursive learning algorithm on the positive samples of groundtruths [,]. Note the estimated set of histograms by , and all the positive samples in the groundtruths is denoted by . For a groundtruth , a histogram , , is updated by
where counts the updates of estimated histogram , and, as increases, the lower fraction of the new samples are taken into . defines the ’s ownership of an estimated histogram as
by which indicts that the new sample updates the histogram by Equation (8). Otherwise, means no nearby histogram component exists for this sample , and a new histogram component is added to . is then initialized as 1 and the added histogram component is initialized by . This update procedure continues until it finishes iterating over the groundtruth set , as summarized in Algorithm 2.
| Algorithm 2 Training procedure of Histogram Mixture Model (HistMM) |
|
3. Experimental Results
3.1. Datasets
Two satellite video datasets, SkySat-Las Vegas dataset and SkySat-Burj Khalifa dataset, were used for experimental evaluation of the proposed method for efficient region proposal. For both datasets, the satellite videos were collected by SkySat, which recorded 1800 frames with 30 frames per second. The spatial resolution of each frame in this video is 1.5 m and the frame size is pixels.
The SkySat-Las Vegas dataset refers to the satellite video captured over Las Vegas, USA in March 2014. As illustrated in Figure 4a, two sub-regions were selected for training and one sub-region was selected for evaluation.

Figure 4.
Two typical frames from the two satellite video datasets used. (The regions surrounded by the rectangle in yellow color are for training, while the regions in green color are for testing.)
The SkySat-Burj Khalifa dataset refers to the satellite video, which is captured over Burj Khalifa, United Arab Emirates on April, 2014. This video is 60 seconds long, which counts up to 30 frames per second. As shown in Figure 4b, 3 sub-regions were selected from the original video, two of which were for training and the remaining one for evaluation.
For both datasets, vehicles on five frames from each datasets were annotated, and their corresponding boundary boxes were provided as labelled samples. As we can see in Table 1, the average target sizes are very small.

Table 1.
Detailed information for the datasets.
3.2. Parameter Discussion
The LRP approach is mainly controlled by 3 parameters: the local region scale k, the threshold factor f and the threshold in HistMM. The effect of each of them is discuss below. Their performance were evaluated in terms of the coverage of targets (recall), where a targets is recalled if there is at least 50% of IoU between any proposals and the ground-truth bounding box. These evaluations were conducted by the Leave-One-Out Cross Validation (LOOCV) strategy on training set of the SkySat-Las Vegas dataset.
- Semantic region Scale k controls size of the semantic regions generated. A larger k is preferred as it will generate a coarse segmentation as required. The semantic regions are allowed to be larger than the target size on purpose. As presented in Figure 5, reducing k gives fine-scale segmentation and leads to an increased number of region proposals with lower recall rate, while with increasing k, LRP generates fewer region proposals with improved recall rate.
- Threshold Factor f controls the segmentation threshold in each semantic region. Selecting a large f would result in fragmented region proposals and decrease recall scores. As illustrated in Figure 5, increasing f from 1.0 to 3.5, the recall scores experience a drop of over 40%.
- HistMM Threshold is the Bayesian decision threshold in the HistMM for removing obvious false alarms as presented Section 2.3. The HistMM model with a smaller tends to keep more obvious false alarms, which leads to unnecessarily more region proposals decreases. On the other hand, increasing would filter out more obvious false alarms from the searched region proposals. As shown in Figure 6, when increases to 0.5, the number of region proposals () reduces significantly, while the recall scores holds nearly stable about 80%, which presents the most efficient case.
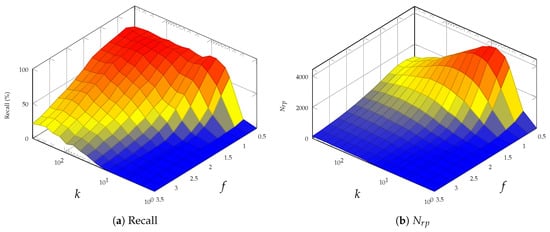
Figure 5.
Region performance evaluation with different k and f.
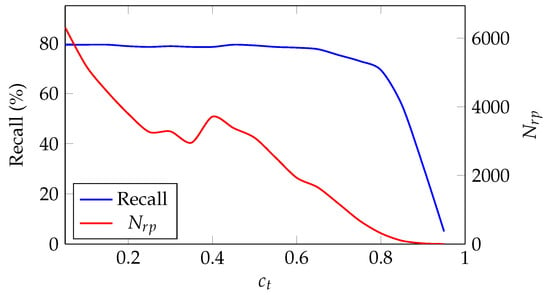
Figure 6.
Region proposal performance by different with .
When was set to based on the cross validation on using the training data, the number of region proposals are reduced by over 60% by HistMM with almost no decrease in recall rate, las presented in Table 2 and Figure 7, which demonstrates the effectiveness of the proposed HistoMM model.
Table 2.
Evaluation on the effectiveness of HistMM.

Figure 7.
Visualization on region proposals before and after HistoMM.
3.3. Comparison of Region Proposal Approaches
The region proposal performance was compared with a set of existing region proposals approaches for both common object detection tasks as well as aerial object detection tasks. Inspired by the systematic region proposal evaluation research [], the proposed region proposal scheme was evaluated against Superpixels (SP) [,], Selective Search (SS) [] and Region Proposal Network (RPN) []. SP generates a region proposal for each extracted superpixel, and SS merges neighboring superpixels as region proposals. For both SS and SP the extraordinarily tiny or large region proposals are considered impossible for vehicles in satellite videos and removed by post-processing. In addition to these well-known region proposals techniques, two approaches for aerial object detection are also included for comparison, which are Maximally Stable Extremal Regions (MSER) [] or Top-hat-Otsu [].
Qualitatively, the region proposals generated by our LRP are more concentrated on possible targets, while those saliancy object-based approaches, SS and SP, produce more evenly distributed region proposals, as shown in Figure 8. A similar phenomenon is observed on the results by RPN, as both RPN and our LRP remove those obvious false alarms from the background.

Figure 8.
Visualization on generated region proposals by different approaches on SkySat-Las Vegas Dataset.
Then quantitative performance evaluation on different approaches was conducted in terms of recall scores. Benefiting from the adopted searching strategy and the HistMM, LRP generates a reasonable number of region proposals with good coverage of the possible targets. As presented in Table 3 and Figure 9, our LRP achieves the highest recall scores on both evaluation datasets. In term of the number of the generated region proposals, it seems like our LRP generates more region proposals than SP, but it should be noted that more than one region proposals are generated by LRP for most possible targets, as shown in Figure 8. Although RPN generates more region proposals with better recall rates, it takes advantage of the finetune scheme from our Fast R-CNN model.
Table 3.
Evaluation on region proposal performance.
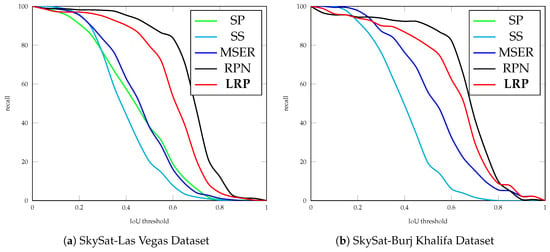
Figure 9.
Recall rates over different IoU thresholds.
Besides, we also compare the detection performance by using a slim Fast-RCNN detector. This slim Fast-RCNN receives video frame as input, and it includes two groups of convolutional layers and a branch of fully connected layers for classification, where the branch for boundary box regression are replaced with carefully selected anchor distribution. Each group of convolutional layers contains three layers with kernel in the same size of , and the number of output channels is 16 and 32 for the first and second convolutional layer group, respectively. After each convolutional layer, a non-linear transformation is conducted by a Rectifier Linear Unit (ReLU) [,], which is followed by a Batch Normalization (BN) layer []. The output size by Roi Pooling is , which is followed by two fully connected layers with 512 and 32 hidden neural units, respectively. A Faster R-CNN model is also included for comparison. Due to the limited number of training samples, directly training a Faster R-CNN model is challenging, therefore, this Faster R-CNN model is finetuned from our Fast R-CNN-LRP. The performance evaluation is based on the PASCAL VOC metrics, where we use Average Precision (AP) instead of Mean Average Precision (mAP), since only one target category is contained in both datasets.
Compared with detection results by SP and SS approaches, our approach recalls most of the targets with the highest AP scores, as presented in Table 4 and Figure 10. Compared with the state-of-the-art Faster-RCNN model, the developed LRP with Fast-RCNN model achieves slightly improved detection performance. As illustrated in Figure 11, fewer false alarms with higher detection scores are produced by the Fast R-CNN model using the proposed LRP approach.
Table 4.
Detection performance evaluation.

Figure 10.
Visualization on detection results by selected approaches on SkySat-Burj Khalifsa dataset.
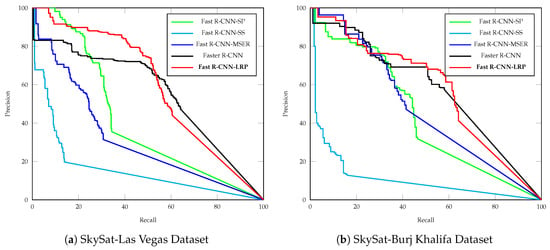
Figure 11.
Precision-recall curve.
In addition to aforementioned single-frame-based detection approach, we also compare our approach with three popular background subtraction-based approaches —Gaussian Mixture Model (GMM) [], GMMv2 [] and Visual Background Extractor (ViBe) [] approaches (A post-processing is applied to all these background subtraction-based approaches for removing extremely small or large blobs.). Their performance are compared in terms of recall, precision and scores at IoU . Compared with these background subtraction-based approaches, Fast-RCNN-LRP that uses our region proposals generates better scores, and the background subtraction-based approaches suffer from poor precision, as shown in Table 5.
Table 5.
Detection results comparisons.
4. Discussion and Conclusions
Region proposal extraction is a valuable step to make target detection efficient. However, it is challenging to generate a small number of region proposals without missing any targets. This is more difficult when the targets are small and dim, such as those presented in satellite videos, due to their limited spatial resolution.
To address the degraded performance of current region proposal extraction methods for satellite videos, we proposed a novel region proposal approach (LRP), in which possible locations of targets are searched in semantic regions by coarse-scale segmentation and a Histogram Mixture Model (HistMM) is proposed to select region proposals with high likelihood from them.
The proposed LRP achieves improved recall rates of the targets with an acceptable increase in time cost, when compared with saliency object-based region proposal approaches, such as Superpixels (SP), Selective Search (SS), Maximally Stable Extremal Regions (MSER) and Top-hat-Otsu. Although the Region Proposal Network (RPN) recalls more targets with less time cost, it requires sufficient training samples or finetuning from a pre-trained model, such as the one obtained from LRP. Another advantage of the proposed LRP is that its training procedure only relies on positive training samples, even when a limited number of training samples is available.
With the improved recall rates by LRP, the detection performance by it with a slim Fast R-CNN is also superior to other saliency object-based region proposal approaches. The detection results are comparable with those by a finetuned Faster R-CNN model from our Fast R-CNN model. Compared with those background subtraction techniques, the proposal LRP approach outperforms them in term of precision, as fewer false alarms are generated.
As more satellite video data are available, more extensive testing can be conducted in the future study. In addition, the approach proposed in this manuscript is developed and tested on a panchromatic video data without color information. It may be extended to multi-channel data in the future research and improved detection performance can be expected.
Author Contributions
Conceptualization, J.Z.; methodology, J.Z. and X.J.; software, J.Z.; validation, J.Z.; writing–original draft preparation, J.Z. and X.J.; visualization, X.J.; supervision, X.J. and J.H.; project administration, X.J. and J.H.; funding acquisition, X.J.
Funding
This research received no external funding.
Acknowledgments
This work is partially supported by China Scholarship Council. The authors would like to thank Planet Team for providing the data in this research [].
Conflicts of Interest
The authors declare no conflict of interest.
References
- Luo, Y.; Zhou, L.; Wang, S.; Wang, Z. Video Satellite Imagery Super Resolution via Convolutional Neural Networks. IEEE Geosci. Remote Sens. Lett. 2017, 14, 2398–2402. [Google Scholar] [CrossRef]
- Xiao, A.; Wang, Z.; Wang, L.; Ren, Y. Super-Resolution for “Jilin-1” Satellite Video Imagery via a Convolutional Network. Sensors 2018, 18, 1194. [Google Scholar] [CrossRef] [PubMed]
- Wang, X.; Hu, R.; Wang, Z.; Xiao, J. Virtual Background Reference Frame Based Satellite Video Coding. IEEE Signal Process. Lett. 2018, 25, 1445–1449. [Google Scholar] [CrossRef]
- Xiao, J.; Zhu, R.; Hu, R.; Wang, M.; Zhu, Y.; Chen, D.; Li, D. Towards Real-Time Service from Remote Sensing: Compression of Earth Observatory Video Data via Long-Term Background Referencing. Remote Sens. 2018, 10, 876. [Google Scholar] [CrossRef]
- Du, B.; Sun, Y.; Cai, S.; Wu, C.; Du, Q. Object Tracking in Satellite Videos by Fusing the Kernel Correlation Filter and the Three-Frame-Difference Algorithm. IEEE Geosci. Remote Sens. Lett. 2018, 15, 168–172. [Google Scholar] [CrossRef]
- Zhang, J.; Jia, X.; Hu, J.; Tan, K. Satellite Multi-Vehicle Tracking under Inconsistent Detection Conditions by Bilevel K-Shortest Paths Optimization. In Proceedings of the 2018 International Conference on Digital Image Computing: Techniques and Applications (DICTA), Canberra, Australia, 10–13 December 2018; pp. 1–8. [Google Scholar]
- Yang, T.; Wang, X.; Yao, B.; Li, J.; Zhang, Y.; He, Z.; Duan, W. Small moving vehicle detection in a satellite video of an urban area. Sensors 2016, 16, 1528. [Google Scholar] [CrossRef] [PubMed]
- Mou, L.; Zhu, X.X. Spatiotemporal scene interpretation of space videos via deep neural network and tracklet analysis. In Proceedings of the 2016 IEEE International Geoscience and Remote Sensing Symposium (IGARSS), Beijing, China, 10–15 July 2016; pp. 1823–1826. [Google Scholar]
- Cristani, M.; Farenzena, M.; Bloisi, D.; Murino, V. Background subtraction for automated multisensor surveillance: A comprehensive review. EURASIP J. Adv. Signal Process. 2010, 2010, 343057. [Google Scholar] [CrossRef]
- Piccardi, M. Background subtraction techniques: A review. In Proceedings of the 2004 IEEE International Conference on Systems, Man and Cybernetics, The Hague, The Netherlands, 10–13 October 2004; Volume 4, pp. 3099–3104. [Google Scholar]
- Reilly, V.; Idrees, H.; Shah, M. Detection and tracking of large number of targets in wide area surveillance. In Proceedings of the European Conference on Computer Vision, Heraklion, Crete, Greece, 5–11 September 2010; Springer: Berlin, Germany, 2010; pp. 186–199. [Google Scholar]
- Xiao, J.; Cheng, H.; Sawhney, H.; Han, F. Vehicle detection and tracking in wide field-of-view aerial video. In Proceedings of the 2010 IEEE Computer Society Conference on Computer Vision and Pattern Recognition, San Francisco, CA, USA, 13–18 June 2010; pp. 679–684. [Google Scholar]
- Sommer, L.W.; Teutsch, M.; Schuchert, T.; Beyerer, J. A survey on moving object detection for wide area motion imagery. In Proceedings of the 2016 IEEE Winter Conference on Applications of Computer Vision (WACV), Lake Placid, NY, USA, 7–10 March 2016; pp. 1–9. [Google Scholar]
- Zivkovic, Z. Improved adaptive Gaussian mixture model for background subtraction. In Proceedings of the Proceedings of the 17th International Conference on Pattern Recognition (ICPR 2004), Cambridge, UK, 26 August 2004; Volume 2, pp. 28–31. [Google Scholar]
- Pollard, T.; Antone, M. Detecting and tracking all moving objects in wide-area aerial video. In Proceedings of the 2012 IEEE Computer Society Conference on Computer Vision and Pattern Recognition Workshops (CVPRW), Providence, RI, USA, 16–21 June 2012; pp. 15–22. [Google Scholar]
- Barnich, O.; Van Droogenbroeck, M. ViBe: A universal background subtraction algorithm for video sequences. IEEE Trans. Image Process. 2011, 20, 1709–1724. [Google Scholar] [CrossRef]
- Xiang, X.; Zhai, M.; Lv, N.; El Saddik, A. Vehicle counting based on vehicle detection and tracking from aerial videos. Sensors 2018, 18, 2560. [Google Scholar] [CrossRef]
- Kang, K.; Ouyang, W.; Li, H.; Wang, X. Object detection from video tubelets with convolutional neural networks. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 26 June–1 July 2016; pp. 817–825. [Google Scholar]
- Cheng, G.; Han, J. A survey on object detection in optical remote sensing images. ISPRS J. Photogramm. Remote Sens. 2016, 117, 11–28. [Google Scholar] [CrossRef]
- Zhang, W.; Sun, X.; Fu, K.; Wang, C.; Wang, H. Object detection in high-resolution remote sensing images using rotation invariant parts based model. IEEE Geosci. Remote Sens. Lett. 2014, 11, 74–78. [Google Scholar] [CrossRef]
- Cheng, G.; Han, J.; Guo, L.; Liu, Z.; Bu, S.; Ren, J. Effective and efficient midlevel visual elements-oriented land-use classification using VHR remote sensing images. IEEE Trans. Geosci. Remote Sens. 2015, 53, 4238–4249. [Google Scholar] [CrossRef]
- Alexe, B.; Deselaers, T.; Ferrari, V. Measuring the objectness of image windows. IEEE Trans. Pattern Anal. Mach. Intell. 2012, 34, 2189–2202. [Google Scholar] [CrossRef] [PubMed]
- Cheng, M.M.; Zhang, Z.; Lin, W.Y.; Torr, P. BING: Binarized normed gradients for objectness estimation at 300fps. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Columbus, OH, USA, 23–28 June 2014; pp. 3286–3293. [Google Scholar]
- Zitnick, C.L.; Dollár, P. Edge boxes: Locating object proposals from edges. In Proceedings of the European Conference on Computer Vision, Zurich, Switzerland, 6–12 September 2014; Springer: Berlin, Germany, 2014; pp. 391–405. [Google Scholar]
- Gokberk Cinbis, R.; Verbeek, J.; Schmid, C. Segmentation driven object detection with fisher vectors. In Proceedings of the IEEE International Conference on Computer Vision, Sydney, NSW, Australia, 1–8 December 2013; pp. 2968–2975. [Google Scholar]
- Uijlings, J.R.; Van De Sande, K.E.; Gevers, T.; Smeulders, A.W. Selective search for object recognition. Int. J. Comput. Vis. 2013, 104, 154–171. [Google Scholar] [CrossRef]
- Manen, S.; Guillaumin, M.; Van Gool, L. Prime object proposals with randomized prim’s algorithm. In Proceedings of the IEEE International Conference on Computer Vision, Sydney, NSW, Australia, 1–8 December 2013; pp. 2536–2543. [Google Scholar]
- Rantalankila, P.; Kannala, J.; Rahtu, E. Generating object segmentation proposals using global and local search. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Columbus, OH, USA, 23–28 June 2014; pp. 2417–2424. [Google Scholar]
- Endres, I.; Hoiem, D. Category-independent object proposals with diverse ranking. IEEE Trans. Pattern Anal. Mach. Intell. 2014, 36, 222–234. [Google Scholar] [CrossRef] [PubMed]
- Carreira, J.; Sminchisescu, C. CPMC: Automatic object segmentation using constrained parametric min-cuts. IEEE Trans. Pattern Anal. Mach. Intell. 2011, 34, 1312–1328. [Google Scholar] [CrossRef] [PubMed]
- Pont-Tuset, J.; Arbelaez, P.; Barron, J.T.; Marques, F.; Malik, J. Multiscale combinatorial grouping for image segmentation and object proposal generation. IEEE Trans. Pattern Anal. Mach. Intell. 2016, 39, 128–140. [Google Scholar] [CrossRef] [PubMed]
- Matas, J.; Chum, O.; Urban, M.; Pajdla, T. Robust wide-baseline stereo from maximally stable extremal regions. Image Vis. Comput. 2004, 22, 761–767. [Google Scholar] [CrossRef]
- Teutsch, M.; Krüger, W.; Beyerer, J. Evaluation of object segmentation to improve moving vehicle detection in aerial videos. In Proceedings of the 2014 11th IEEE International Conference on Advanced Video and Signal Based Surveillance (AVSS), Seoul, Korea, 26–29 August 2014; pp. 265–270. [Google Scholar]
- Zheng, Z.; Zhou, G.; Wang, Y.; Liu, Y.; Li, X.; Wang, X.; Jiang, L. A novel vehicle detection method with high resolution highway aerial image. IEEE J. Sel. Top. Appl. Earth Obs. Remote Sens. 2013, 6, 2338–2343. [Google Scholar] [CrossRef]
- Szegedy, C.; Reed, S.; Erhan, D.; Anguelov, D.; Ioffe, S. Scalable, high-quality object detection. arXiv, 2014; arXiv:1412.1441. [Google Scholar]
- Ren, S.; He, K.; Girshick, R.; Sun, J. Faster r-cnn: Towards real-time object detection with region proposal networks. In Proceedings of the Advances in Neural Information Processing Systems, Montreal, QC, Canada, 7–12 December 2015; pp. 91–99. [Google Scholar]
- Zhang, F.; Du, B.; Zhang, L.; Xu, M. Weakly supervised learning based on coupled convolutional neural networks for aircraft detection. IEEE Trans. Geosci. Remote Sens. 2016, 54, 5553–5563. [Google Scholar] [CrossRef]
- Xia, G.S.; Bai, X.; Ding, J.; Zhu, Z.; Belongie, S.; Luo, J.; Datcu, M.; Pelillo, M.; Zhang, L. DOTA: A large-scale dataset for object detection in aerial images. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–23 June 2018; pp. 3974–3983. [Google Scholar]
- Felzenszwalb, P.F.; Huttenlocher, D.P. Efficient graph-based image segmentation. Int. J. Comput. Vis. 2004, 59, 167–181. [Google Scholar] [CrossRef]
- Long, Y.; Gong, Y.; Xiao, Z.; Liu, Q. Accurate object localization in remote sensing images based on convolutional neural networks. IEEE Trans. Geosci. Remote Sens. 2017, 55, 2486–2498. [Google Scholar] [CrossRef]
- Zivkovic, Z.; van der Heijden, F. Recursive unsupervised learning of finite mixture models. IEEE Trans. Pattern Anal. Mach. Intell. 2004, 26, 651–656. [Google Scholar] [CrossRef] [PubMed]
- Hosang, J.; Benenson, R.; Dollár, P.; Schiele, B. What makes for effective detection proposals? IEEE Trans. Pattern Anal. Mach. Intell. 2016, 38, 814–830. [Google Scholar] [CrossRef]
- Maas, A.L.; Hannun, A.Y.; Ng, A.Y. Rectifier nonlinearities improve neural network acoustic models. In Proceedings of the ICML Workshop on Deep Learning for Audio, Speech and Language Processing, Atlanta, GA, USA, 16 June 2013. [Google Scholar]
- Krizhevsky, A.; Sutskever, I.; Hinton, G.E. Imagenet classification with deep convolutional neural networks. In Proceedings of the Advances in Neural Information Processing Systems, Lake Tahoe, NV, USA, 3–8 December 2012; pp. 1097–1105. [Google Scholar]
- Ioffe, S.; Szegedy, C. Batch Normalization: Accelerating Deep Network Training by Reducing Internal Covariate Shift. In Proceedings of the International Conference on Machine Learning, Lille, France, 6–11 July 2015; pp. 448–456. [Google Scholar]
- KaewTraKulPong, P.; Bowden, R. An improved adaptive background mixture model for real-time tracking with shadow detection. In Video-Based Surveillance Systems; Springer: Berlin, Germany, 2002; pp. 135–144. [Google Scholar]
- Team, P. Application Program Interface: In Space for Life on Earth. San Francisco, CA. Available online: https://api.planet.com (accessed on 31 August 2019).
© 2019 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).