1. Introduction
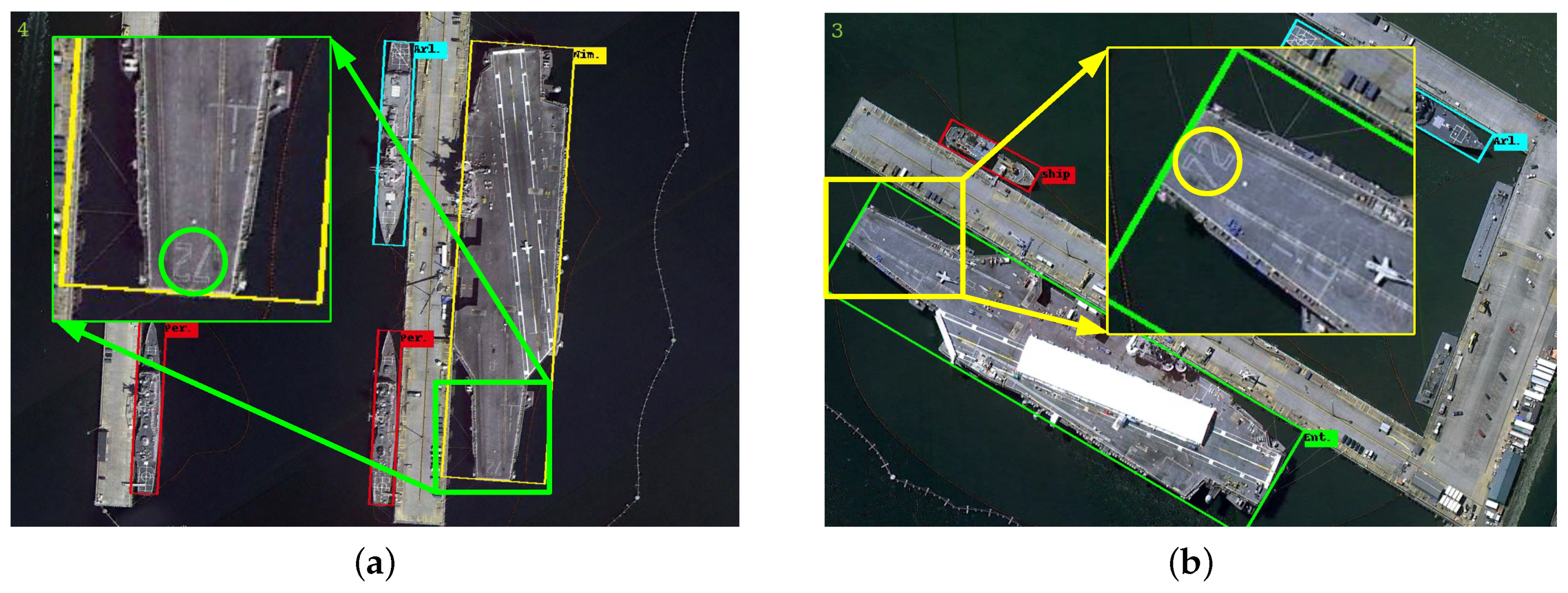
Ship detection and recognition in high-resolution aerial images are challenging tasks, which play an important role in many related applications, e.g., maritime security, naval construction, and port management. Although many ship classification methods have been proposed, they only roughly identify the ship as warship, container ship, oil tanker, etc., on the accurate image patch. However, what is needed to know for us is the more specific ship categories like Arleigh Burke, Perry, Ticonderoga, etc., and it is difficult to obtain high-quality sample patches by automatic ship detection. Some methods have tried to locate ships and identify their categories at the same time; nevertheless, the results are undesirable such that they lead to serious confusion, as shown in
Figure 1d.
Existing research on ship detection and classification can be divided into two aspects. One is the location problem, which finds the ships in the aerial images and expresses the location in some way. The other is the classification issue, which assigns the ships to different categories.
Object detection is a fundamental and challenging task in computer vision, aimed at determining whether there are any instances of targets in an image or not. In the field of remote sensing, ship and ship wake detection have attracted considerable attention of researchers. Iervolino et al. [
1] proposed a ship detector based on the Generalized Likelihood Ratio Test (GLRT) to improve the detection ability under low signal-to-noise/clutter ratios. The GLRT algorithm has proven to be effective and has been extensively used in [
2,
3,
4]. Graziano et al. [
5] exploited the Radon Transform (RT) to detect ship wake and validated the method’s robustness in [
6]. Biondi et al. [
7,
8,
9] first utilized the Low-Rank plus Sparse Decomposition (LRSD) algorithm assisted by RT to achieve excellent performance on ship wake detection. The inclination of ships also can be calculated by LRSD and RT for some regions of interest [
10].
Recently, with the development of Deep Convolutional Neural Networks (DCNN) [
11], an increasing number of efficient ship detection frameworks have been reported [
12,
13,
14,
15,
16]. Zou et al. [
12] proposed a novel SVD Network (SVDNet) based on the convolutional neural networks and the singular-value decompensation algorithm to learn features adaptively from remote sensing images. Huang et al. [
14] proposed Squeeze Excitation Skip-connection Path networks (SESPNets) to improve the feature extraction capability for ship detection and used soft Non-Maximum Suppression (NMS) to avoid deleting some correct bounding boxes for some targets. However, these methods are based on the Horizontal Bounding Box (HBB). Although this representation has no effect on the sparse targets at sea, it is not suitable for densely-docked inshore vessels. As shown in
Figure 1b, the angle of the ship can be in an arbitrary direction, and the aspect ratio of the ship is large, so the horizontal bounding box of one ship may contain a relatively large redundancy region, which is not conducive to the classification task. Therefore, we chose the representation shown in
Figure 1a.
With the improvement of the resolution of aerial images, more and more works have tried to detect inshore vessels and use the Rotated Bounding Box (RBB) to locate ships [
17,
18,
19,
20]. Liu et al. [
17] proposed the Rotated Region-based CNN (RR-CNN) to predict rotated objects and changed the Region of Interest (RoI) pooling layer in order to extract features only from the rotation proposal. Zhang et al. [
18] modified the Faster R-CNN [
21] and utilized the Rotation Region Proposal Networks (RRPN) [
22] and the Rotation Region of Interest (RRoI) Pooling layer to detect arbitrarily-oriented ships. Yang et al. [
19] proposed Rotation Dense Feature Pyramid Networks (RDFPN) to solve problems resulting from the narrow width of the ship and used multiscale RoIAlign [
23] to solve the problem of feature misalignment. However, the above networks ignored one problem that is important for classification. As shown in
Figure 1c, when the background is complex and the ships are densely docked, the rotated bounding box cannot accurately locate the ship. If the box is too small, the discriminative regions such as prow that are important for classification will be missed. If the box is too large, it will contain the background and the adjacent ships, which is not conducive to classification either. In order to better classify the ships into different categories, we must attach importance to how to generate more precise rotated ship bounding boxes. In other words, we do not meet the situation where the Intersection over Union (IoU) value is only greater than 0.5. Therefore, based on the arbitrarily-oriented ship detection network, we introduce the Sequence Local Context (SLC) module to predict more accurate rotated bounding boxes.
As for the ship category classification task, most methods are concentrated on a few large ship categories with distinctive features [
24,
25,
26,
27]. Wu et al. [
26] proposed a model named BDA-KELM, which combines Kernel Extreme Learning Machine (KELM) and the dragonfly Algorithm in Binary Space (BDA) to conduct the automatic feature selection and search for optimal parameter sets to classify the bulk carrier, container ship, and oil tanker. Some works tried to classify more types of ships. Oliveau et al. [
27] trained a nonlinear mapping between low-level image features and the attribute space to build discriminative attribute representations. Based on these attributes, a Support Vector Machine (SVM) classifier is built for the classification of image patches into 12 categories. However, these traditional methods need careful design and extraction of complex features, which increases the computational complexity. Motivated by advanced CNN models, such as VGGNet [
28], GoogleNet [
29], and DenseNet [
30], CNN models have been used in ship classification in high-resolution aerial images. Bentes et al. [
31] built a CNN model with four convolutional layers, four pooling layers, and a fully-connected layer to achieve good performance among the five categories of targets. However, previous methods on ship classification whether using traditional methods or based on the CNN model both concentrated on a few large categories of ships and achieved classification based on accurately-cropped image patches. To solve these problems, in this work, we achieve the classification of 19 classes of ships with large differences in scale and characteristics based on the patches from the output of our ship detector. The work most similar to ours is that of Ma et al. [
32]. However, they used a horizontal bounding box, which cannot handle the inshore vessels and only classified sparse ships in the sea with a single background into eight categories.
In conclusion, the challenges of ship detection and classification in high-resolution aerial images are mainly in the following three aspects: (i) It is an important basis for classification to find as many ships as possible and predict accurate target locations, especially including the most discriminative regions and excluding noise information (background and the part of adjacent targets). (ii) The size of the different types of ships varies greatly, which is not conducive to classification. (iii) The scarcity of training data causes class imbalance, which can result in overfitting to more frequent ones and ignoring the classes with a limited number of samples.
In this paper, based on the challenges above, we propose a rotation-based ship detection network to capture accurate location and three different ship category classification networks to solve the problem of large difference in ship scale. Finally, a Proposals Simulation Generator (PSG) is introduced to address the problem of insufficient samples and class imbalance. The main contributions of this paper are as follows:
We build a new rotation-based ship detection network. The trade-off between recall and precision is different compared with the previous ship detection methods such that the recall rate is ensured with the condition of high precision.
The SLC module is introduced to extract local context features, which makes the rotated bounding box fit tightly with the ship. The accurate bounding box can include the discriminative parts such as prow and exclude noise information such as background.
In order to reduce the burden of the classification network, we introduce the Spatial Transform Crop (STC) operation to obtain aligned image patches. Aiming at the problem of the large difference in ship scale, we propose three different ship category classification networks.
A PSG is designed to greatly augment the training data by simulating the output style of the ship detector, which can address the problem of insufficient samples and class imbalance.
We achieve state-of-the-art performances on two real-world datasets for ship detection and classification in high-resolution aerial images. The phenomenon of category confusion like
Figure 1d does not appear, and it is considered more suitable for practical application.
The rest of this paper is organized as follows:
Section 2 describes the details of the proposed method. In
Section 3, we describe the datasets and present experiments to validate the effectiveness of the proposed algorithm.
Section 4 discusses the results of the proposed method. Finally,
Section 5 concludes this paper.
2. Materials and Methods
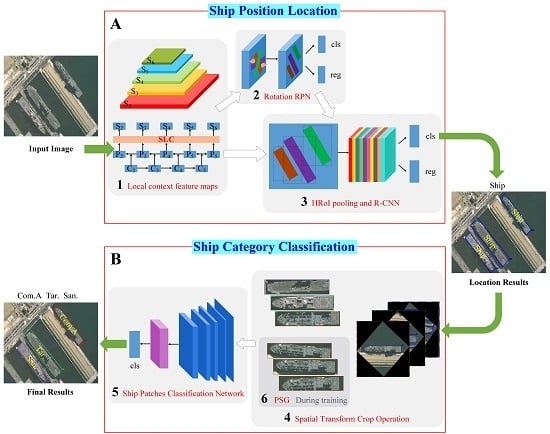
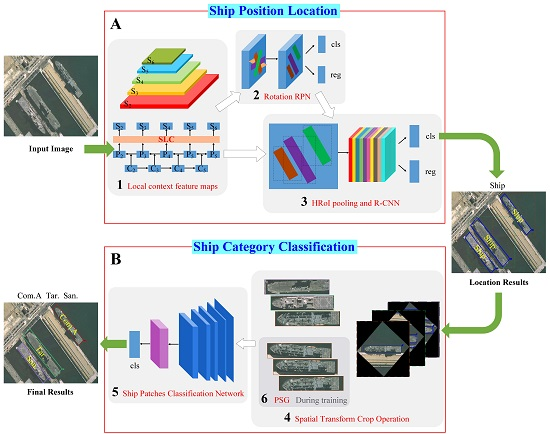
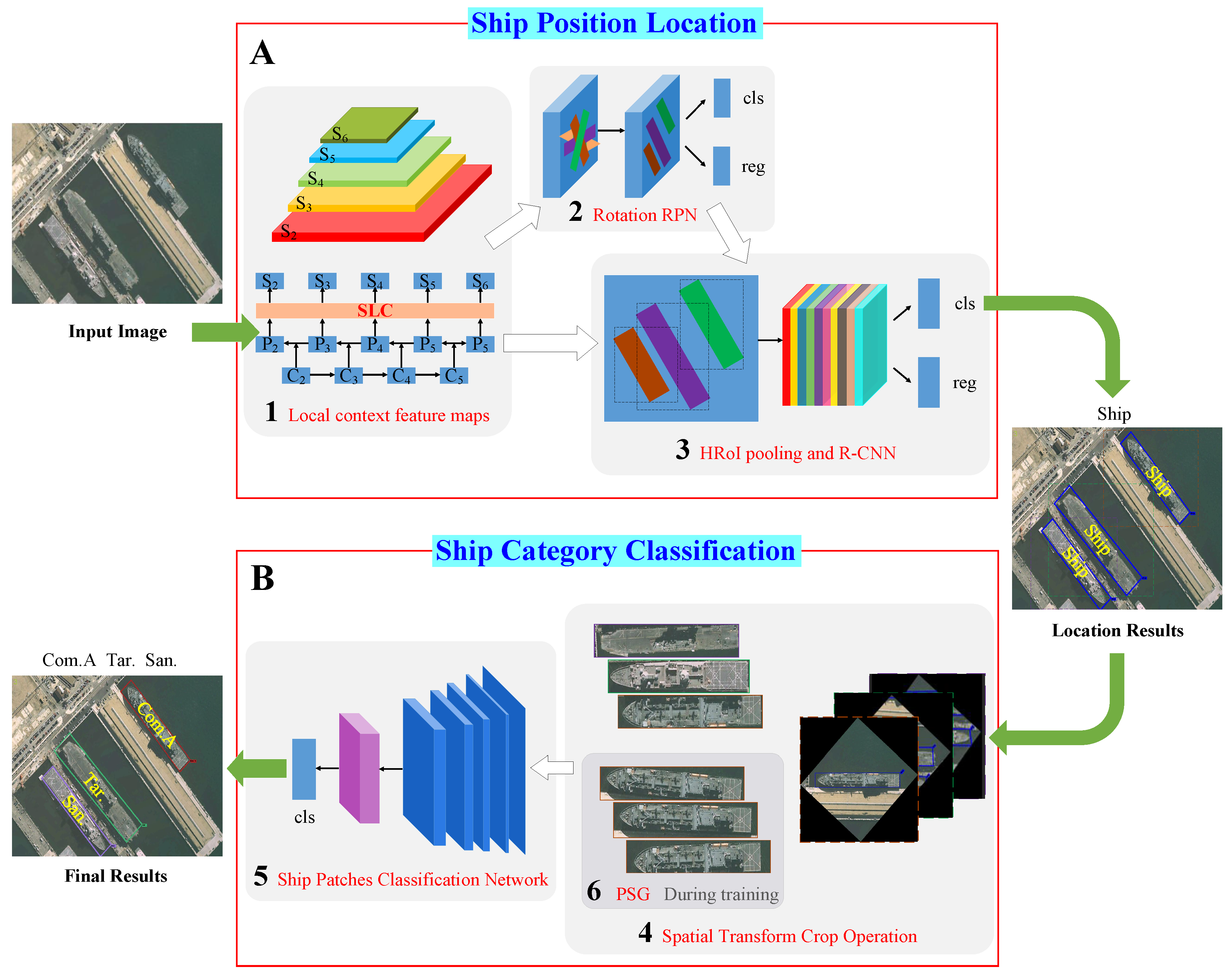
The pipeline of our proposed framework is illustrated in
Figure 2. The whole system is mainly divided into two phases: the location phase and the classification phase. Give an input image with size
, the ship location is first obtained through the red box A, and then, the red box B is used to get the category of each ship target. The computational Block Number 1 extracts the local context feature maps with size
, where
s is the output stride. Block Number 2 regards the feature maps as input and outputs a set of rotated rectangular object proposals, each with an objectness score. We randomly sampled 256 proposals in an image to compute the loss function. The computational Block Number 3 crops and resizes the feature maps inside these proposals into the fixed spatial extent by max pooling (such as
) and outputs the ship location. Block Number 4, which is used to crop and resize the ship regions from the input image to the same size, does not participate in the training process. Finally, the computational Block Number 5 takes the ship regions as input and outputs the specific ship categories such as Arleigh Burke, Perry, Ticonderoga, etc. Block Number 6, which is used in the training process, generates large training samples to address the problem of insufficient annotated pictures. In our framework, the computational Block Numbers 1, 2, 3, and 5 are devoted to training the model, and Block Numbers 4 and 6 are dedicated to decoding features. Subsequently, the main parts of our framework are presented in detail.
2.1. Rotation Proposals and HRoI Pooling Layer
In most object detection tasks, the ground-truth of the object is described by the horizontal bounding box with
, where
is the center of the bounding box, and the width
w and height
h represent the long side and the short side of the horizontal bounding box, respectively [
33]. However, the bounding box represented in this way cannot perfectly outline the strip-like rotated ship. In our task, the rotated bounding box with five tuples
was introduced to represent the location of the ship, and the parameter
(between zero and 180) describes the angle from the horizontal direction of the standard bounding box.
Similar to the way of RRPN, we added the angle parameter outside of the scale and aspect ratio to generate the rotation anchors. The value of the angle parameter was defined as
. The zero means generating the horizontal anchors, and the other two generate oriented anchors. In addition, as ships always have special shapes, we analyzed the shape of the ship targets in the dataset and refer to the setting of the relevant work [
18,
34,
35,
36,
37]. We set 1:3, 1:7 as the aspect ratios. The scale of anchors were set from 32–512 by a multiple of two on different Feature Pyramid Networks (FPN) [
38] layer. An extra anchor scale of 1.414 was introduced on each layer to reduce the spacing of the scale [
39]. In summary, for each point on different feature maps of FPN, 12 rotation anchors (3 angles, 2 aspect ratios, and 3 scales) were generated, and the total number of anchors on the feature map with height
H and width
W was
. For the rotated bounding boxes regression, we adopted smooth
loss [
40] for the rotation proposals:
where variables
d and
represent the detection proposal and ground-truth label, respectively. The five coordinates of
d and
are calculated as follows:
where variables
, and
are for the predicted box, anchor box, and ground-truth box, respectively, and the variables
are the same. The operation
rescales the angle within the range
.
For the rotation proposals, the traditional IoU computation method cannot obtain the IoU value accurately to distinguish whether it is a positive rotation proposal or a negative rotation proposal. The skew IoU computation method was introduced to solve this problem. We divided the convex polygon of intersection points set into multiple triangles by the triangulation [
41] and calculated the area of each triangle. Then, the sum of the areas was the IoU value.
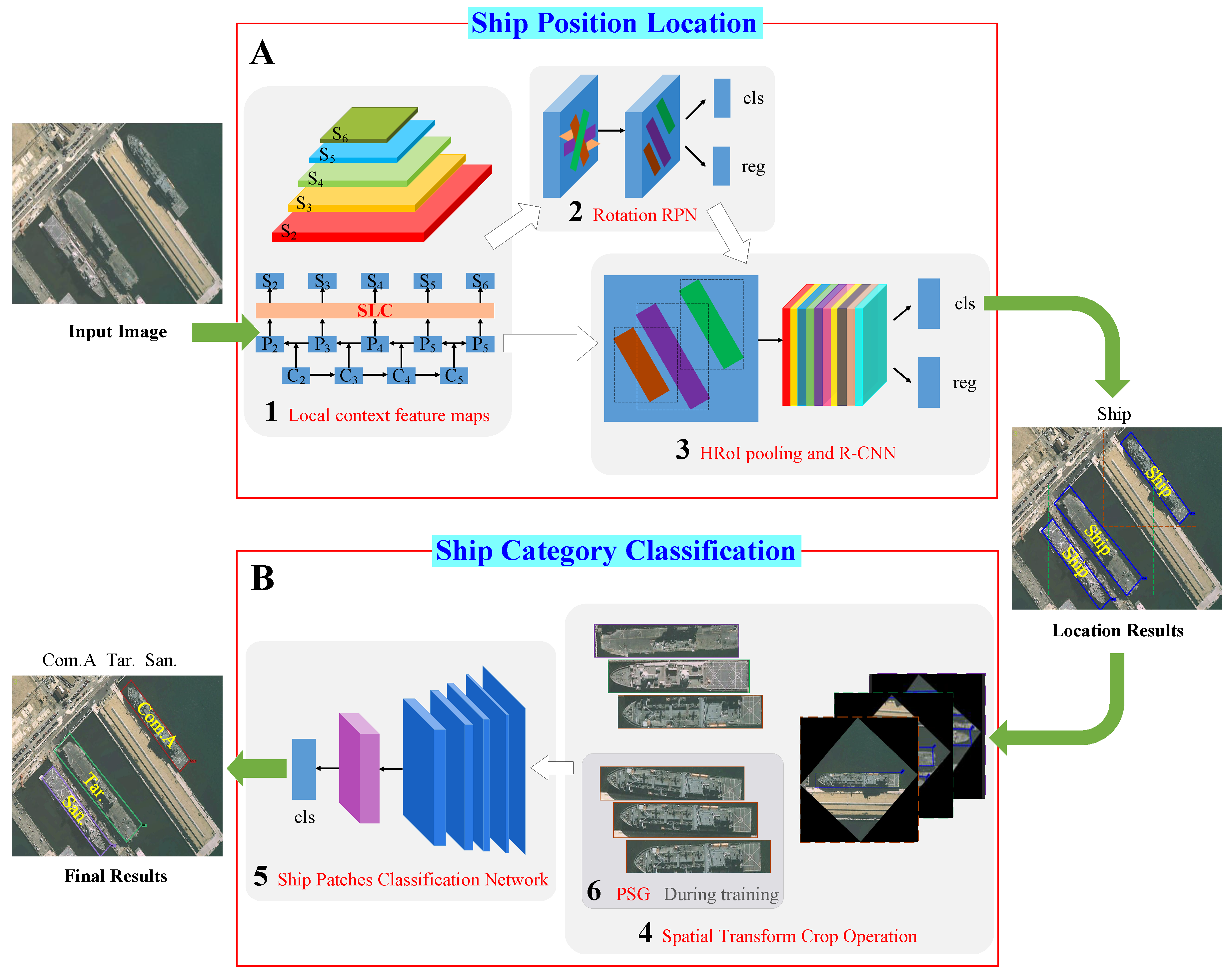
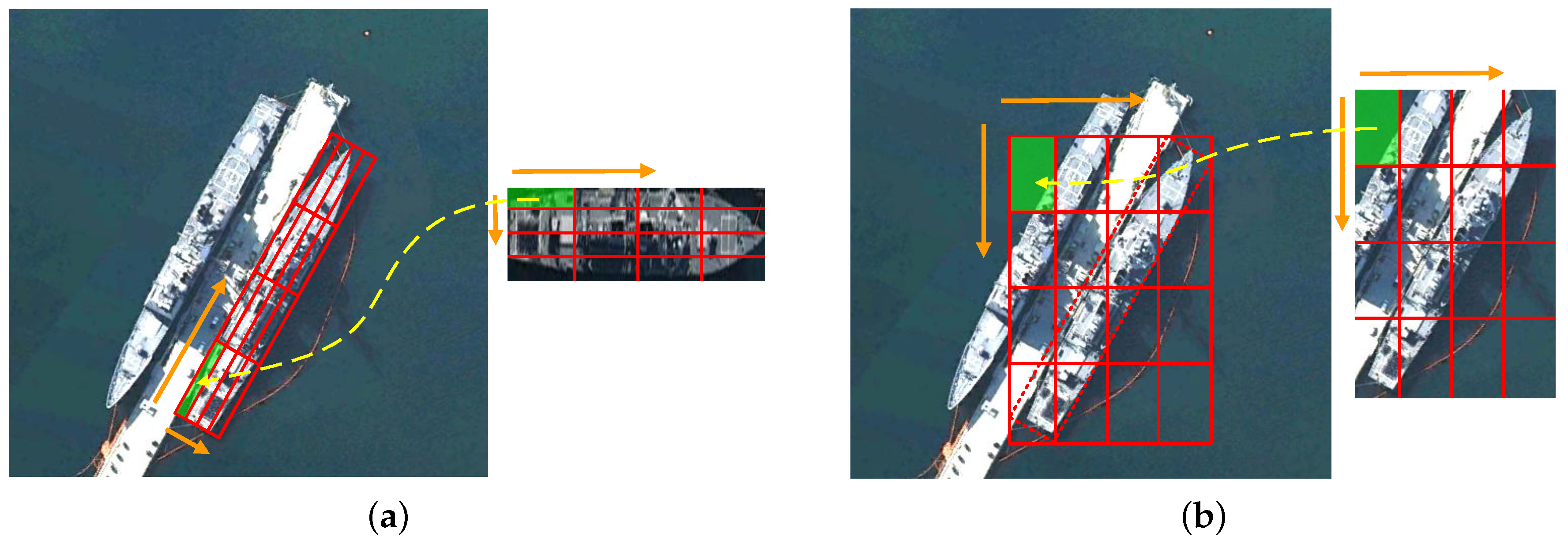
The arbitrarily-oriented object detection methods always use the RRoI pooling layer to extract features of object regions accurately [
18,
19,
42]. As a hypothesis, we set the RRoI layer hyper-parameters to
and
. The rotated ship proposal region can be divided into
subregions of
size for a proposal with height
h and width
w (as shown in
Figure 3a). Then, max pooling was performed in every subregion, and max-pooled values were saved in the matrix of each RRoI. This operation is very common in high-resolution aerial images like DOTA [
43] and NWPUVHR-10 [
44] to eliminate the mismatching between RRoIs and corresponding objects for classification and regression. In general, the RRoI pooling layer should be used for our detection network. However, different from other arbitrarily-oriented object detection, we did not need to classify the ships into more specific categories like Arleigh Burke, Perry, Ticonderoga, etc. Our detection network only needed to distinguish whether the proposal was a target or not. We hoped the ship detection network could achieve a higher recall rate, which is a different choice for the trade-off between recall and precision compared with other methods. Although the RRoI pooling layer can reduce the influence of the irrelevant background and other incomplete ships, the large aspect ratio of the ship may lead to misalignment of the rotating bounding box, resulting in a lower recall rate. In contrast, the Horizontal Region of Interest (HRoI) pooling layer [
21,
45] can extract more features, such as the features of ship shadows and adjoining ships, which can improve the target confidence and recall rate. Therefore, we applied the HRoI pooling layer, as shown in
Figure 3b. We calculated the horizontal bounding box of the rotation proposal, then the HRoI pooling layer used max pooling to crop and resize the feature map inside the horizontal bounding box into the fixed spatial extent of
, where
and
are layer hyper-parameters. Finally, through the
cls branch and
reg branch, we obtained the predicted result, i.e., either ship or background.
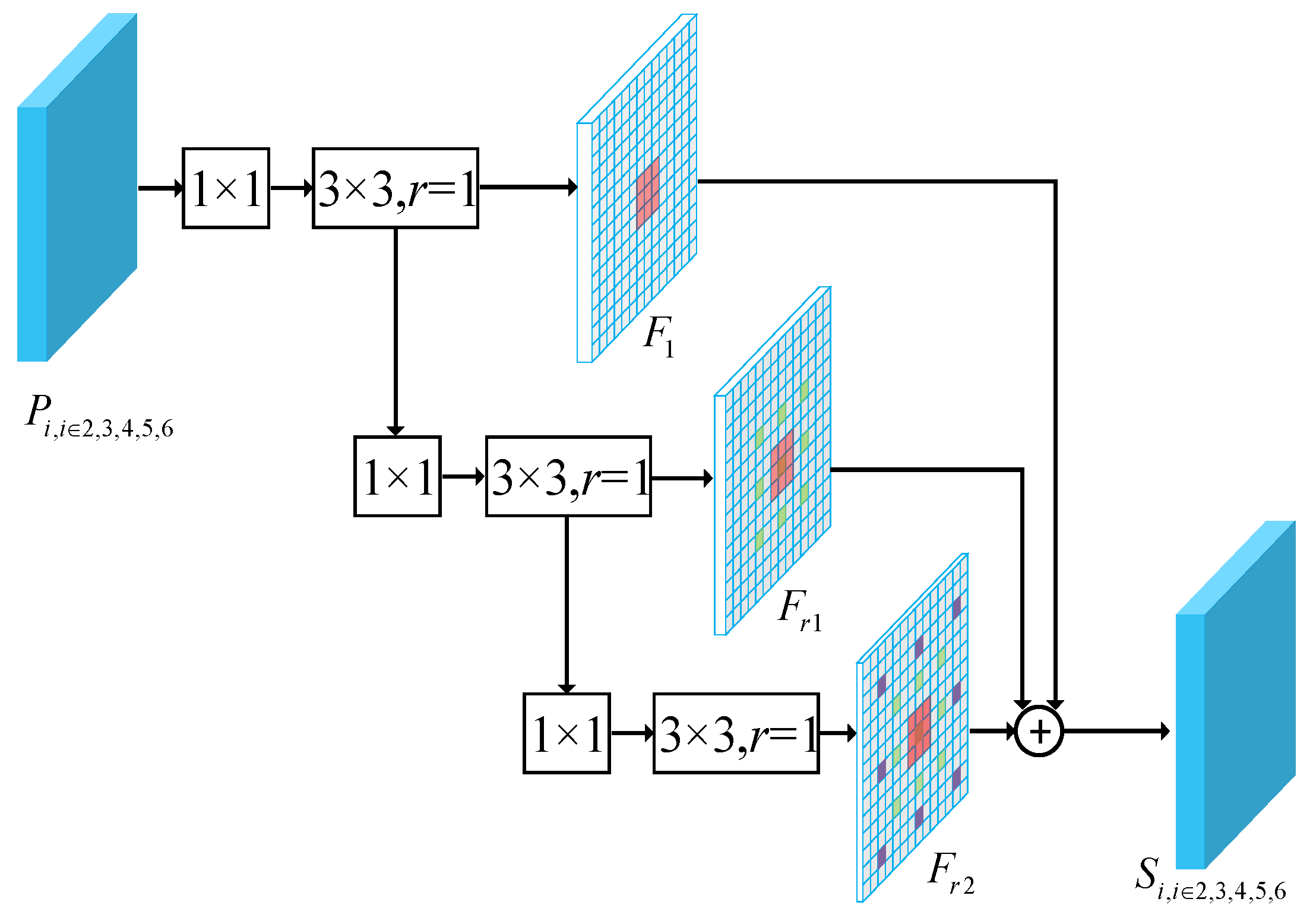
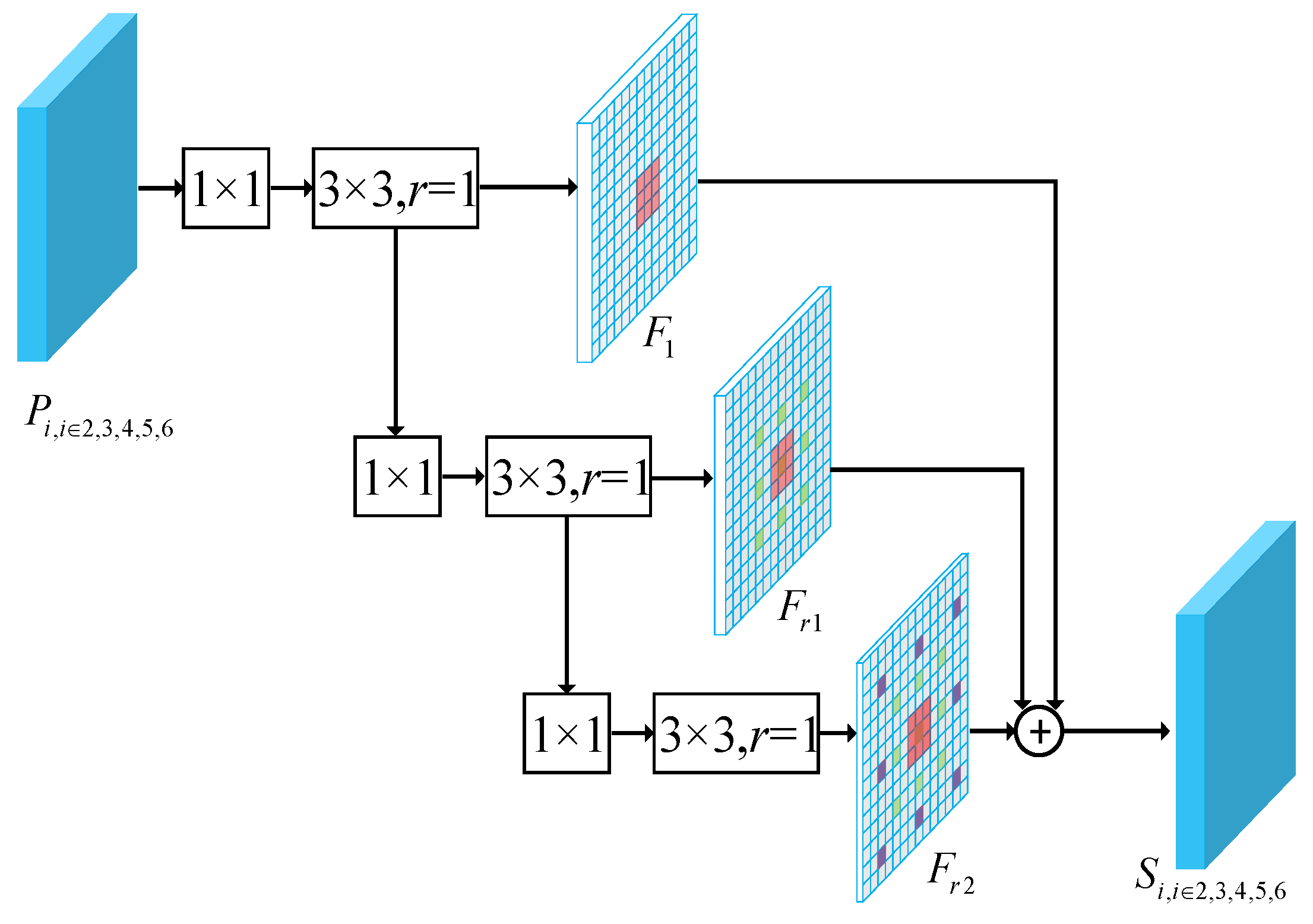
2.2. Sequence Local Context Module
The features of high layers have strong semantics and of low layers have accurate location information. The FPN structure makes use of the feature hierarchy of a convolutional network, which combines the advantages of different layers via a top-down path to make all features have strong classification and regression capability. However, as shown in
Figure 1, it was not enough for the ships densely docked in the harbor, and we hoped our network could distinguish the pixels belonging to different ships to predict a more accurate position. An intuitive idea is to learn the local context information around the objects based on the FPN structure. In our previous work [
46], a flexible module called the sequence local context module was proposed to learn multi-scale local context features. Specifically, we utilized the dilated convolution with different dilation rates to integrate multi-scale context features. As shown in
Figure 4, the SLC module consisted of three sequence convolutional blocks, each with a 1 × 1 convolution followed by a 3 × 3 dilated convolution with different dilation rates. The SLC module captures context information at different scales and fuses the outputs of three layers by element-wise summation operation. The module can be formulated as follows:
where
is the input feature and
,
,
are the functions of convolution blocks with dilation rates 1,
,
, respectively.
,
are the output features of
,
.
,
, and
are respective parameters, and
is the output feature. The SLC module progressively enhances the connection of context information from different blocks and avoids losing too much information caused by the dilation rate.
In order to distinguish the adjacent ships and provide accurate locations for the second phase, we added the SLC module after the FPN structure to make the features learn the local context information. The reason is as follows: Firstly, the module was proven to be effective at ship detection tasks. Secondly, the feature size of the input and of the output from the SLC module were identical, so it could be embedded between any two convolutional layers and did not require major modifications. By the way, this was another reason to apply the HRoI pooling layer, because the RRoI pooling layer could not extract the local context feature learned by the SLC module. The SLC module took the feature from the FPN structure as input and output the feature .
2.3. Spatial Transform Crop Operation
With the increase in the categories of ship classification, the type of ship becomes complex and highly similar, especially for smaller ships. Without the corresponding expertise, it is difficult for humans to distinguish between different types of ships. Therefore, it is necessary to build a classification network to better identify categories of different ships.
The STC operation was introduced to crop the rotated bounding boxes from the corresponding images, which can eliminate the noise information and align ship patches to better extract marginal visual differences between different types of ships. The detailed operation can be seen in Algorithm 1. Therefore, the detection part did not need to classify the different ships. The phenomenon of category confusion like
Figure 1d did not appear. We only needed to consider the NMS within classes, not the NMS between classes [
17].
| Algorithm 1: Spatial Transform Crop (STC) algorithm. |
![Remotesensing 11 01901 i001]() |
2.4. Ship Category Classification
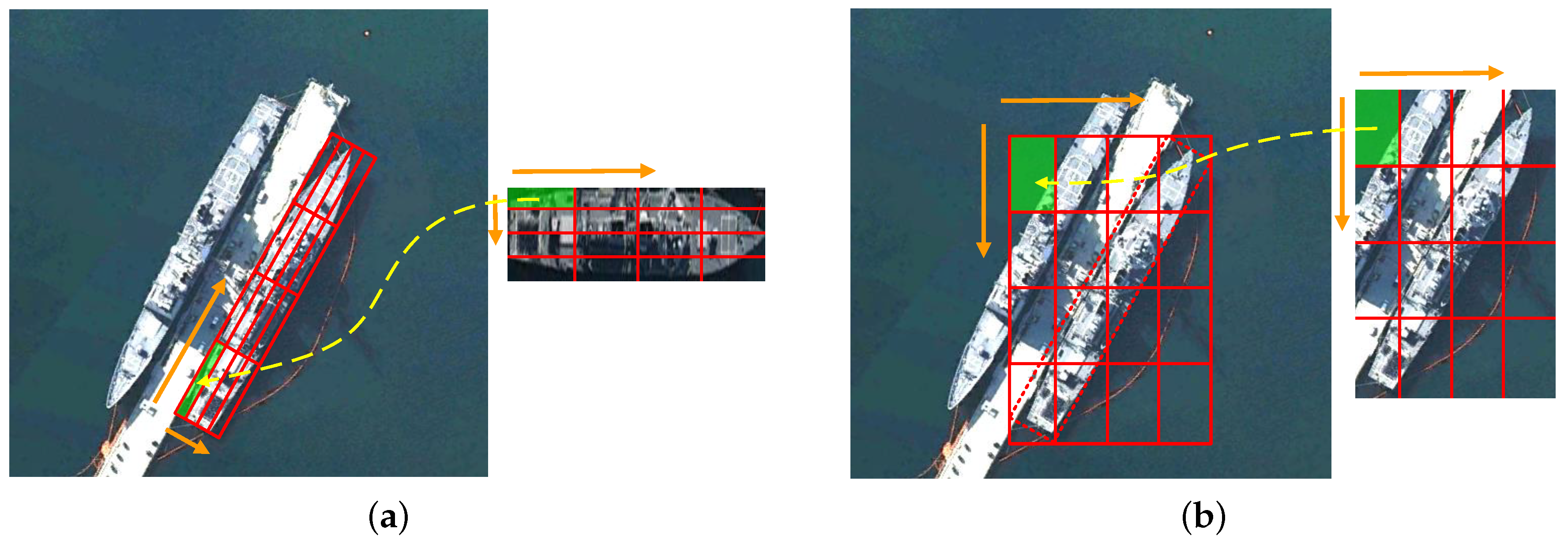
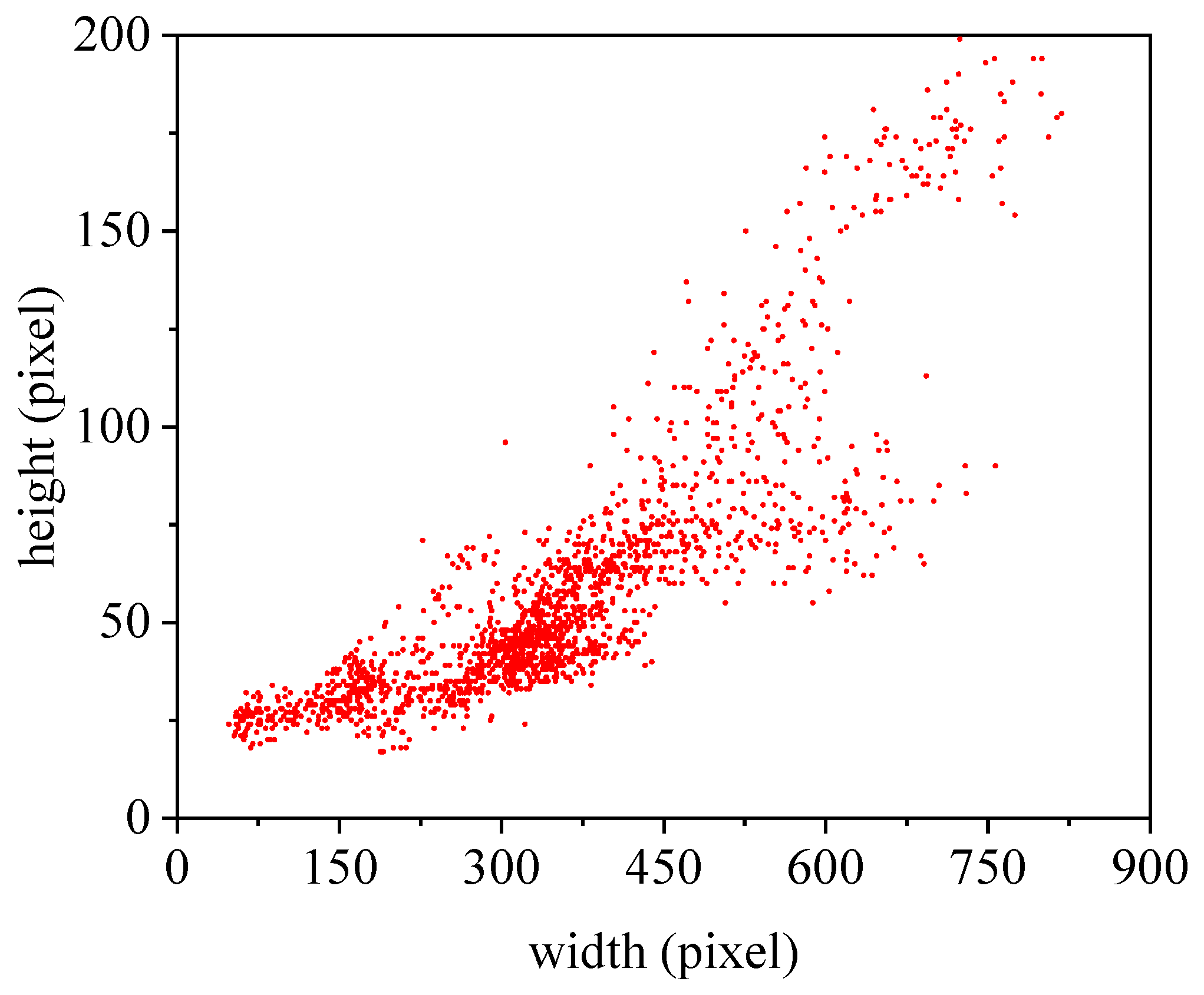
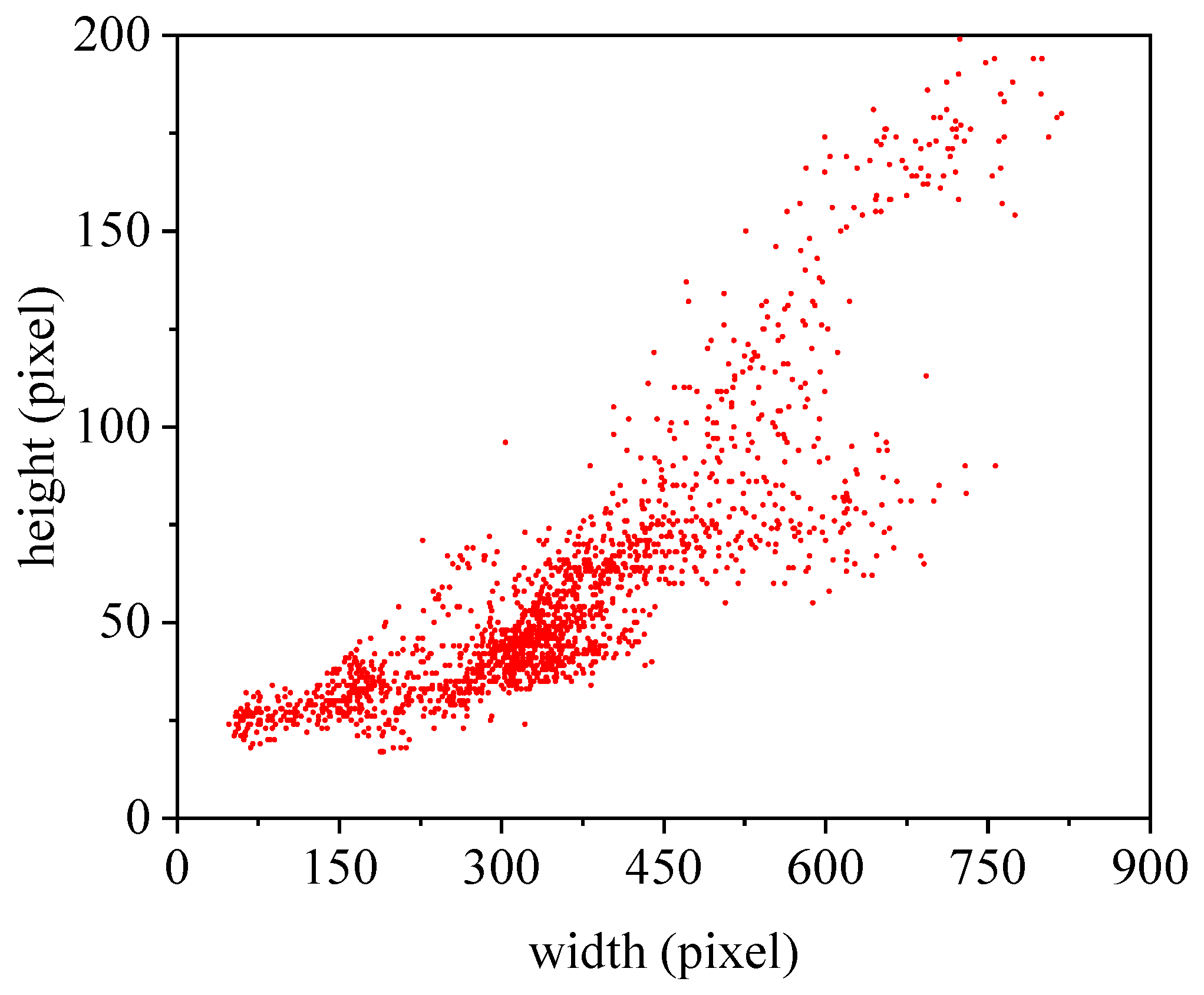
After STC operation, we found that the size of the patches was not uniform, because the length and width of different types of ships varied widely (as shown in
Figure 5). However, the traditional classification networks needed a fixed-size input image, because the fully-connected layers required a fixed-size/-length input. The most intuitive method to handle this problem is that we resized the patches to the fixed size for the classification network. In general, this operation may reduce the recognition accuracy. In SPP-Net [
47], the Spatial Pyramid Pooling layer is proposed to generate fixed-length representations regardless of image size/scale, which was proved to achieve much better classification results. However, could this similar operation work well in our task?
The objects with the same category, such as cats, dogs, and birds, may present large appearance variations due to changes of posture or viewpoints, complex backgrounds, and occlusions [
48]. For example, the appearance of one bird can be very different when it is preying, resting, or flying, which makes intra-class variance great. The operation of resizing can exacerbate this situation to reduce the recognition accuracy. However, in aerial images, a powerful prior constraint is that we can only get the top view of targets, which makes our analysis easier. In addition, the ship is a rigid body, and we used the rotated bounding box. Therefore, it was unnecessary for us to consider the impact of the above factors. We propose the view that in high-resolution aerial images, the operation of resizing may produce a smaller negative impact than other operations.
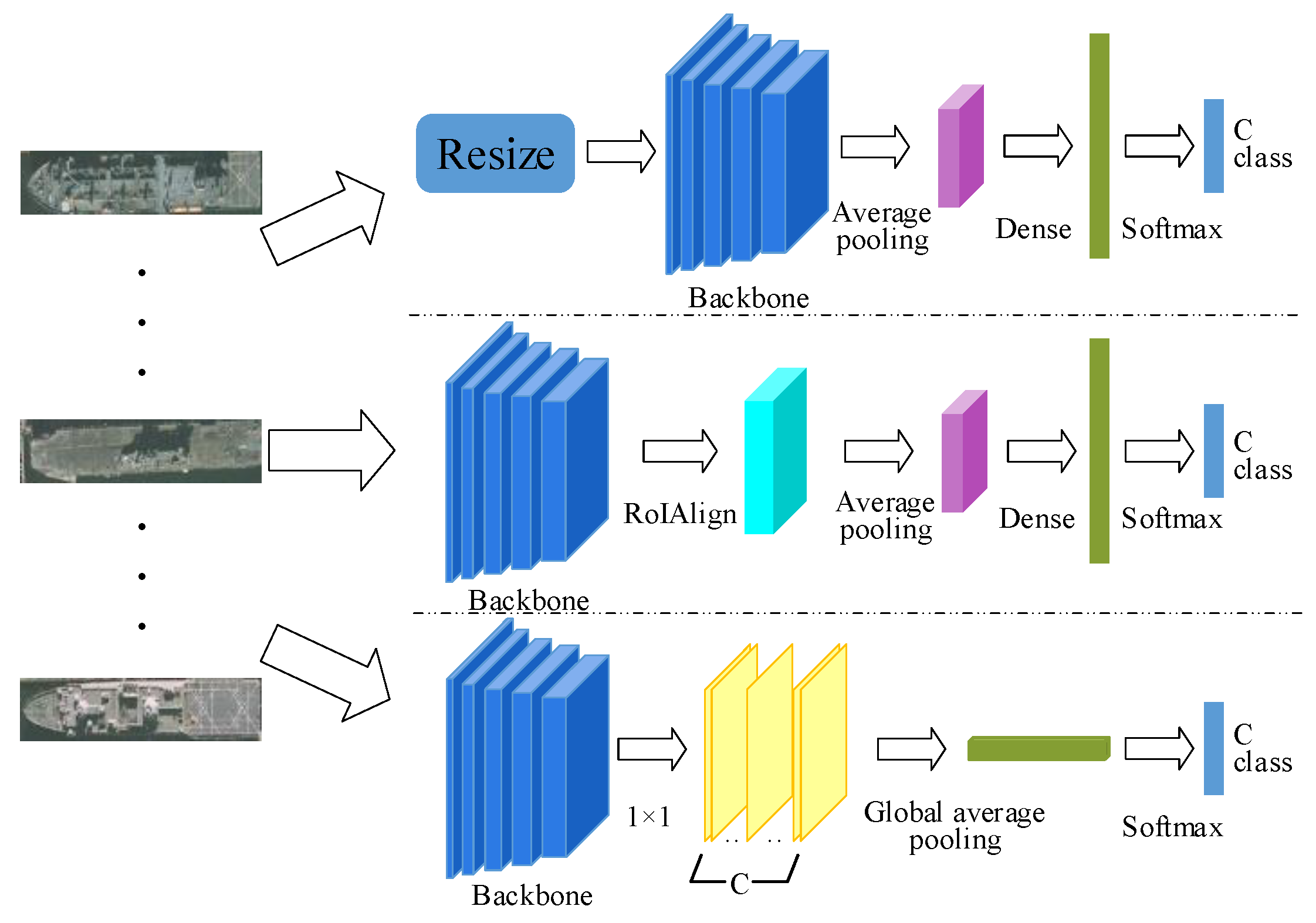
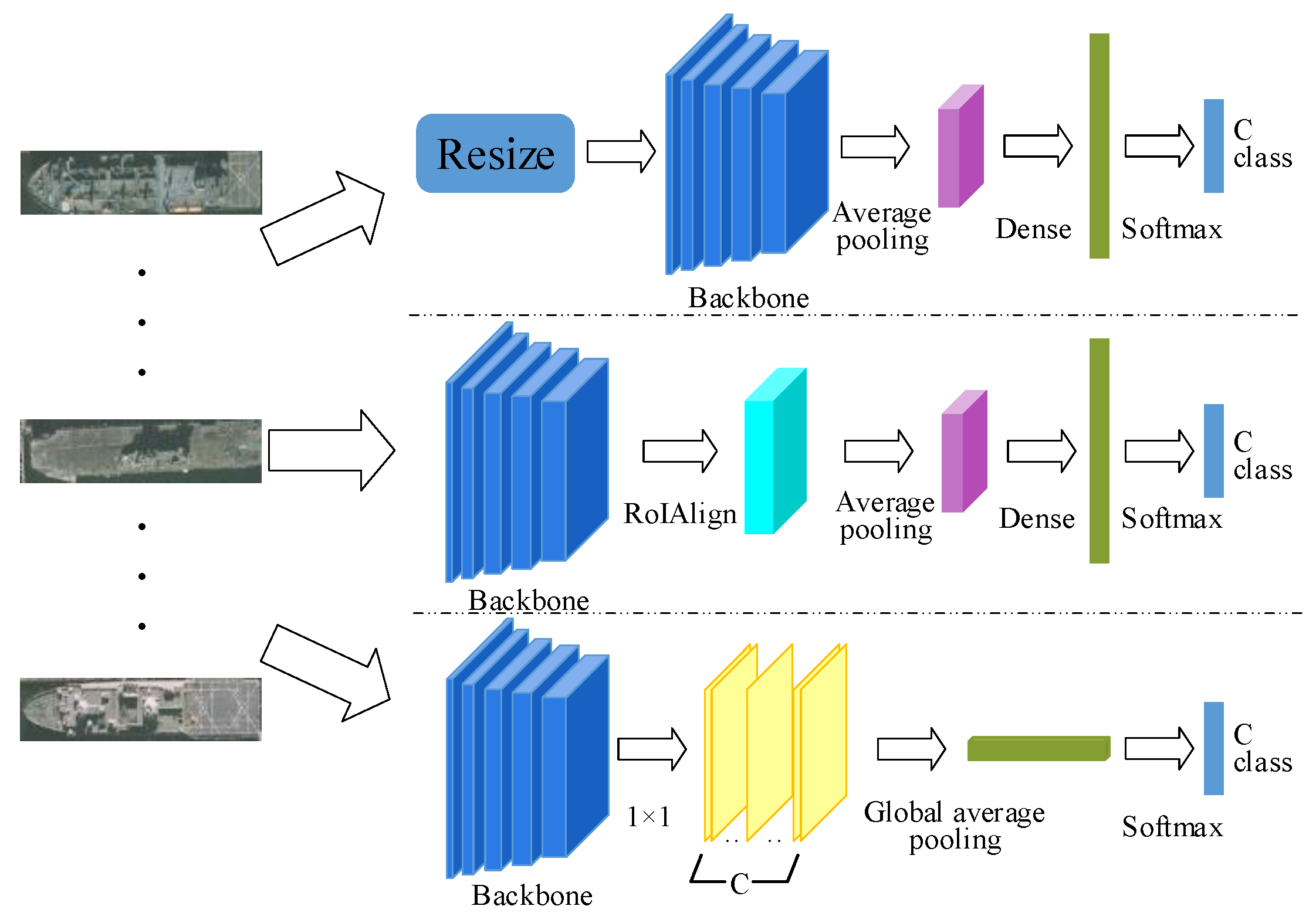
In order to verify our idea, in this paper, we propose three different methods to compare the effects of fixed-size and arbitrarily-sized input images on recognition accuracy. As shown in
Figure 6, the classification network took the ship patches as input and output the specific ship categories such as Arleigh Burke, Perry, Ticonderoga, etc. For the first row, we fit the patches to the fixed size and then extracted the feature maps using the backbone network. The average pooling layer was introduced to reduce the feature dimension and preserve the important features. Finally, the fully-connected layers output the predicted class. The second row did not require a fixed patch size. We introduced the RoIAlign layer, which can aggregate the feature maps of the backbone network to meet the requirement of fully-connected layers. The third row was to use only a convolutional network like FCN [
49] and ACoL [
50]. We removed the fully-connected layers and added a convolutional layer of C (C is the number of classes) channels with the kernel size of 1 × 1, stride one on top of the feature maps. Then, the output was fed into a Global Average Pooling (GAP) layer followed by a softmax layer for classification. The conclusion will be elaborated in
Section 3.2.2.
2.5. Proposals Simulation Generator
Due to insufficient training samples, the number of instances belonging to different types of ship would be unbalanced, and even several ship types would have very few samples. A proper data augmentation was necessary to increase the training samples and avoid the class imbalance. Since we already had the ground-truth box and predicted box for each ship, we could generate a large training sample with the same distribution as the predicted box. In this way, we could solve the above problems and improve the performance of our network.
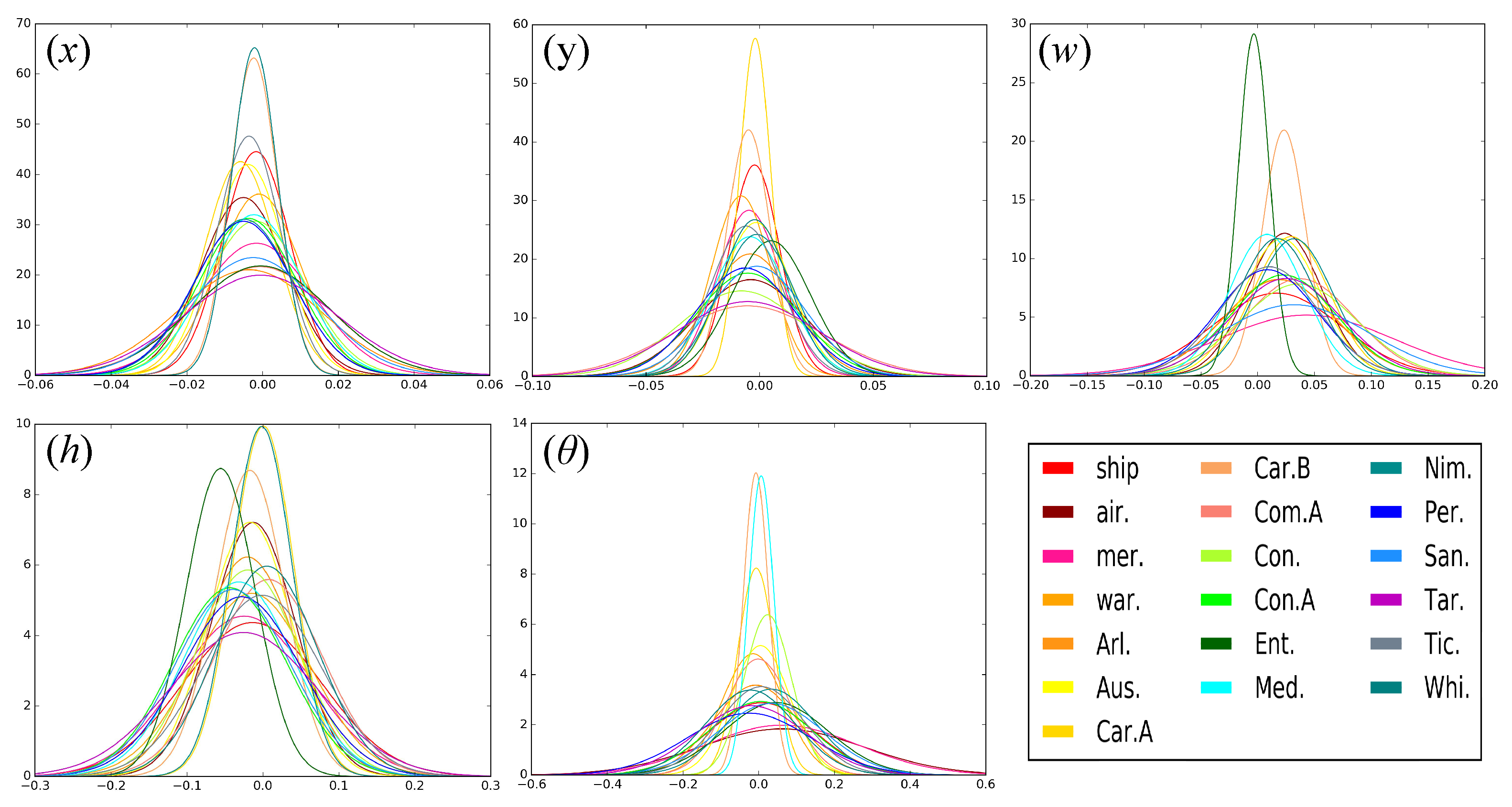
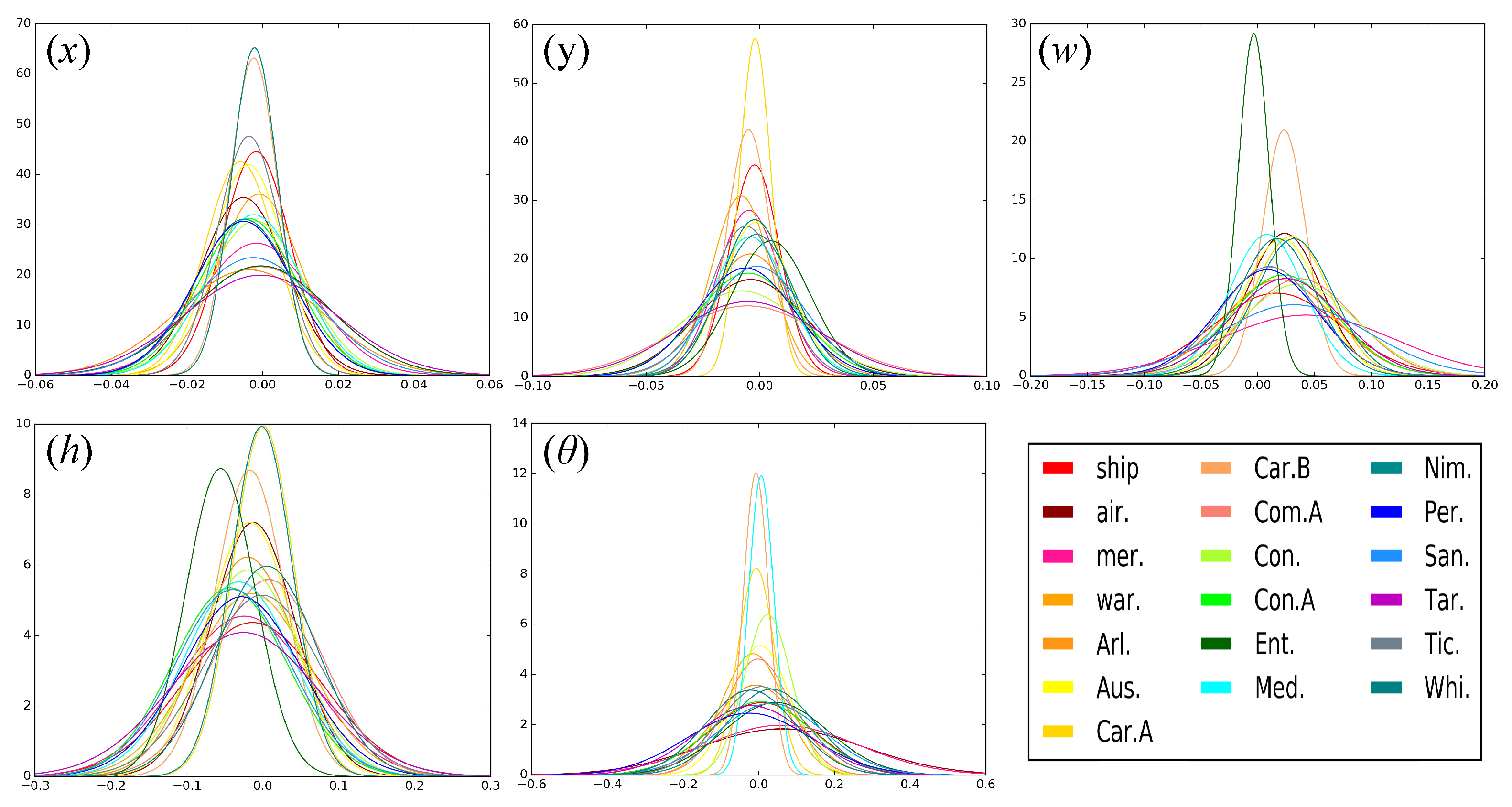
Due to the different sizes and characteristics of different types of ships, we analyzed the distribution of the relative offsets between the predicted proposal and the ground-truth proposal for each class. Since the ship in the aerial images was a rigid body and oriented upward, it was simple to learn the distribution
, where
represents the offset between the coordinates of the predicted proposal and the coordinates of the ground-truth proposal and
T is the ground-truth proposal for each ship. For each proposal, we calculated the offsets between its ground-truth bounding proposal and detected bounding proposal. The offsets were then normalized by the corresponding coordinate of the ground-truth. After these operations, we fit the offset to a Gaussian distribution and show it in
Figure 7.
During the training phase of the classification network, for each sample in the training set, we could generate many different offsets based on the distribution to obtain large augmented training samples.
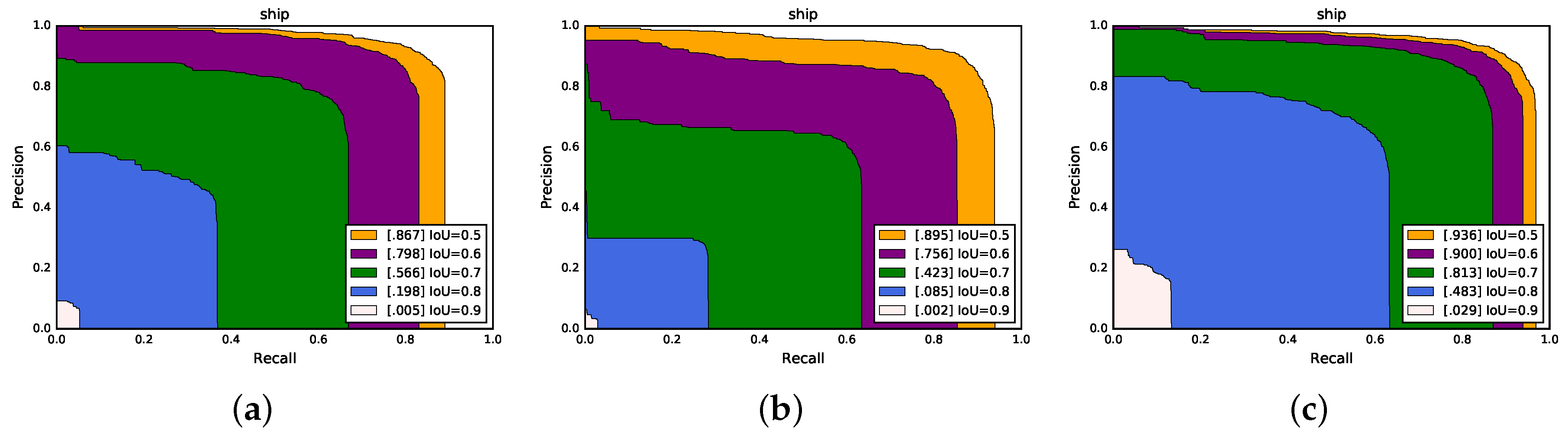
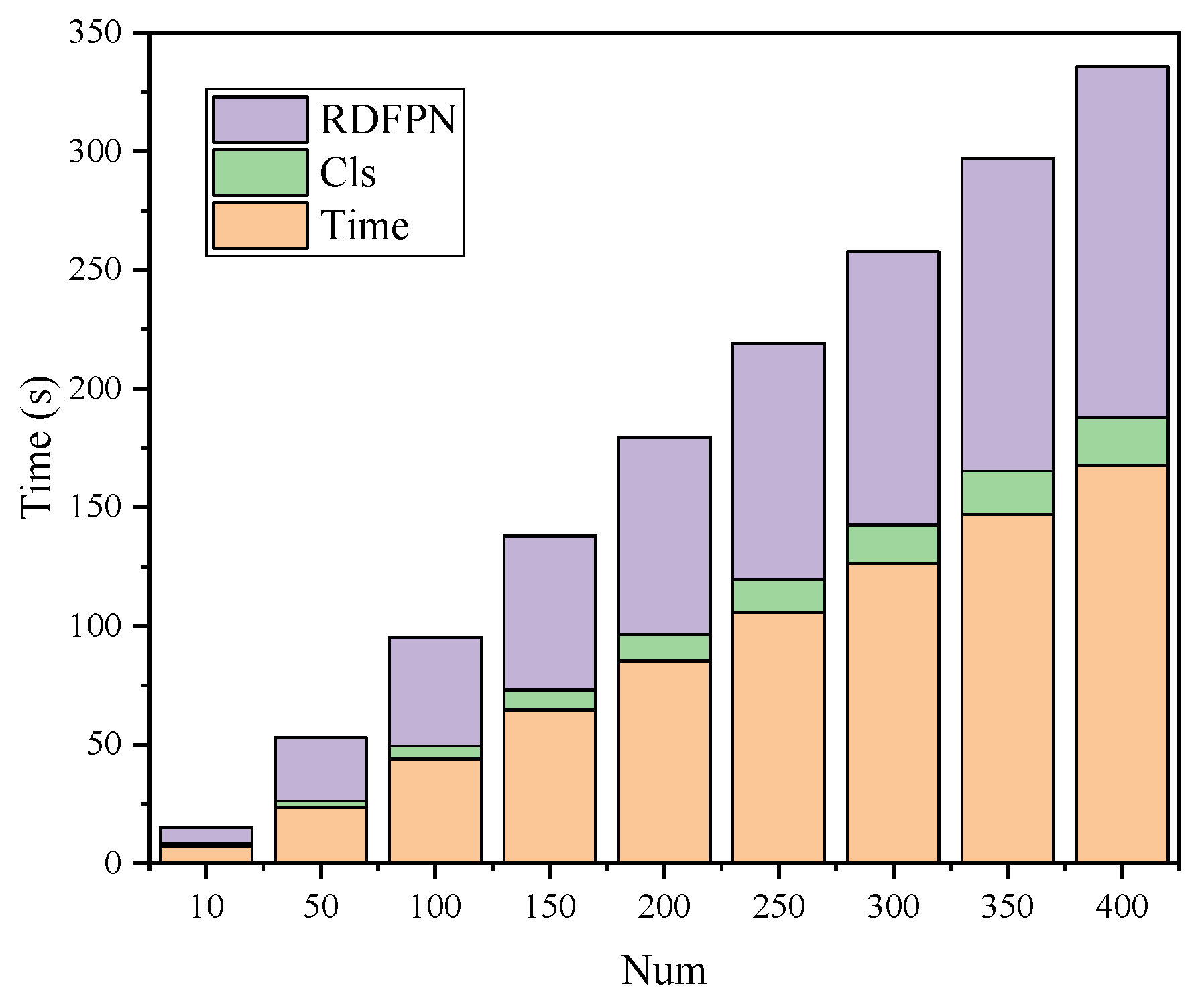
4. Discussion
Through the comparative analysis in
Section 3.2 and the experimental results in
Section 3.3, the validity of the proposed method was verified, and the framework had a performance improvement over other methods. However, there were still some unsatisfactory results. As shown in
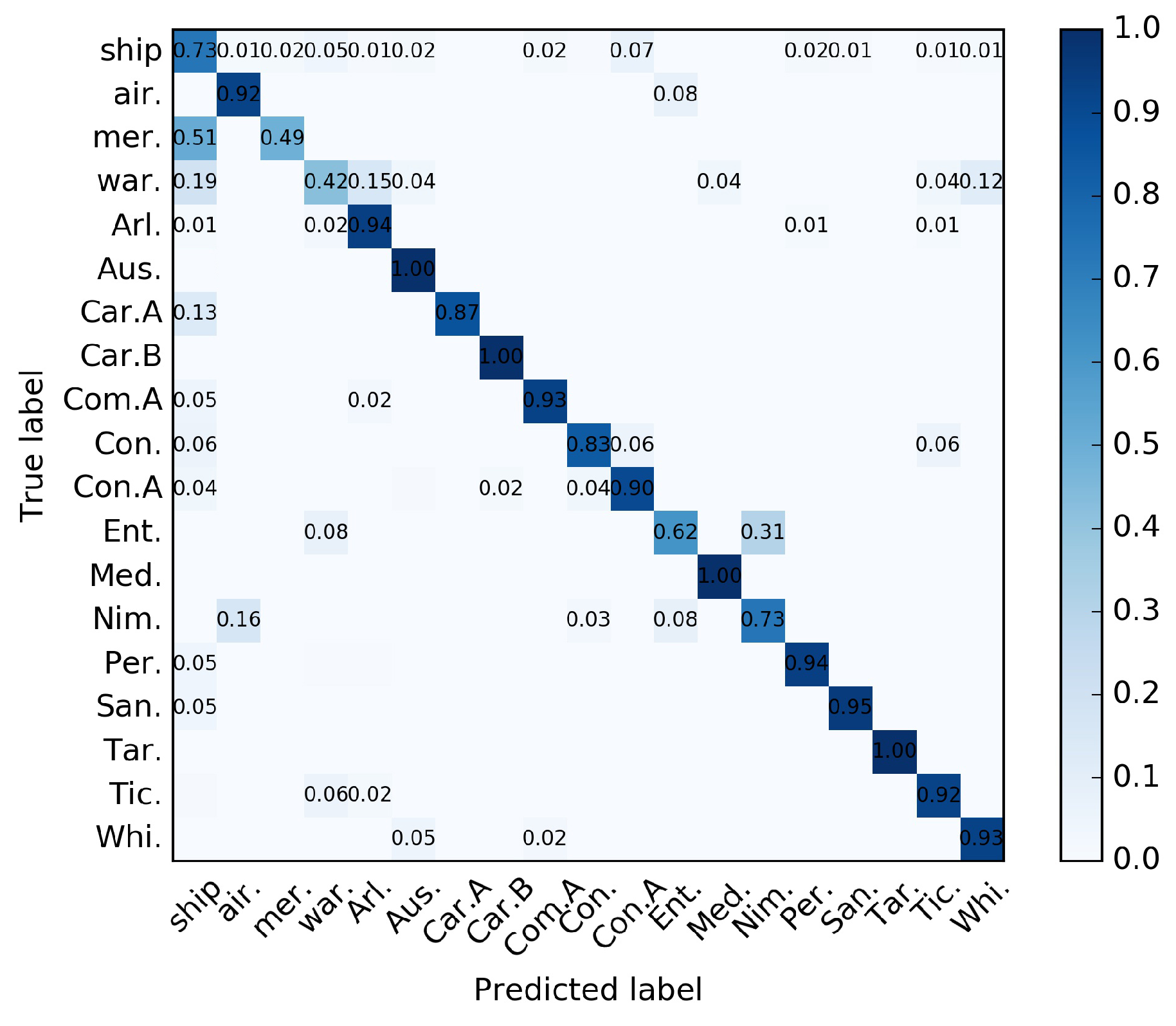
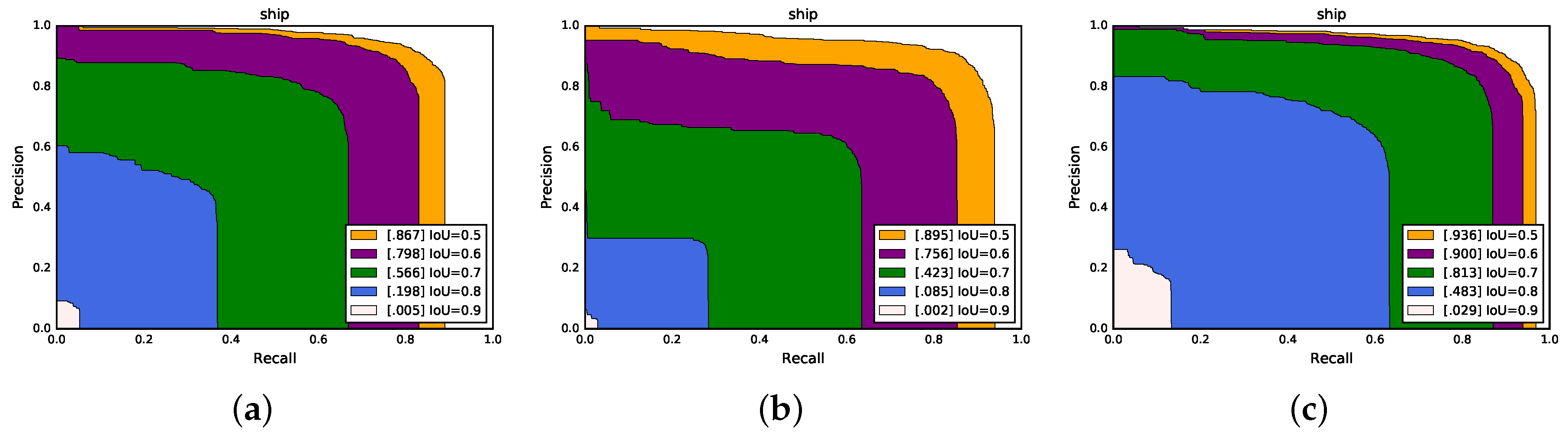
Table 6, we found the results of the classes belonging to L2 level to be poor, especially for the classes mer. and war. The AP values were only obtained 17.9% and 11.5%, respectively. Besides, we found that the accuracy of class Nim. was worse than other methods.
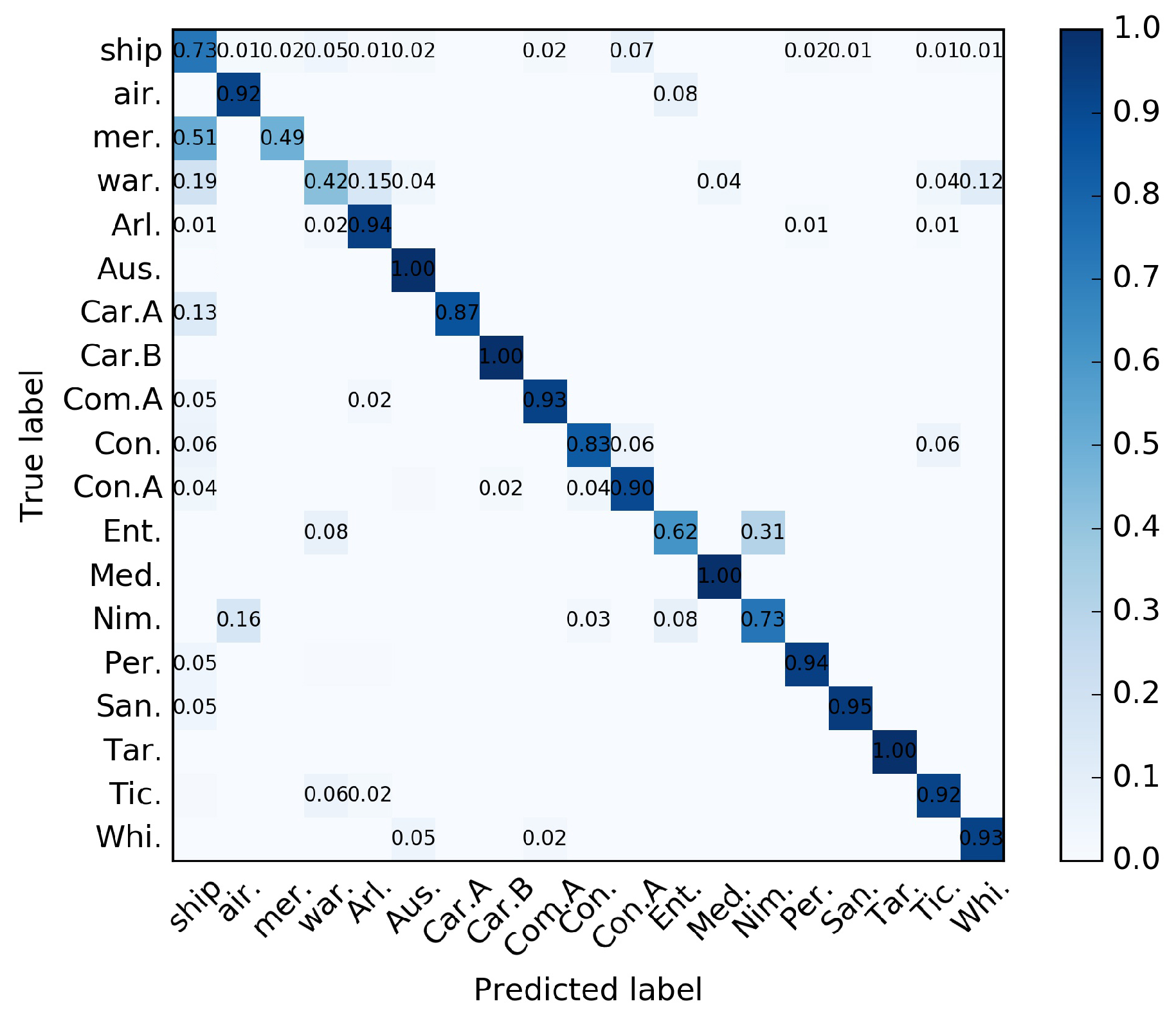
The confusion matrix was analyzed, of which the classes of the L2 level were easy to confuse and classified into other classes, as shown in
Figure 13. These classes consisted of different types of ships, making intra-class variance larger and inter-class variance decrease. As shown in
Figure 14, we show samples of training image patches obtained from the classes mer. and war. Different from the concrete types belonging to the L3 level, we can see a high diversity in sizes, textures, and colors among these examples belonging to the same class. On the other hand, we observed that some small-sized ships were assigned to the background because they did not have ground-truth labels in the dataset, which also enhanced the severity of the confusion. We will investigate how to improve the performance of the impure categories as described above in our future work.
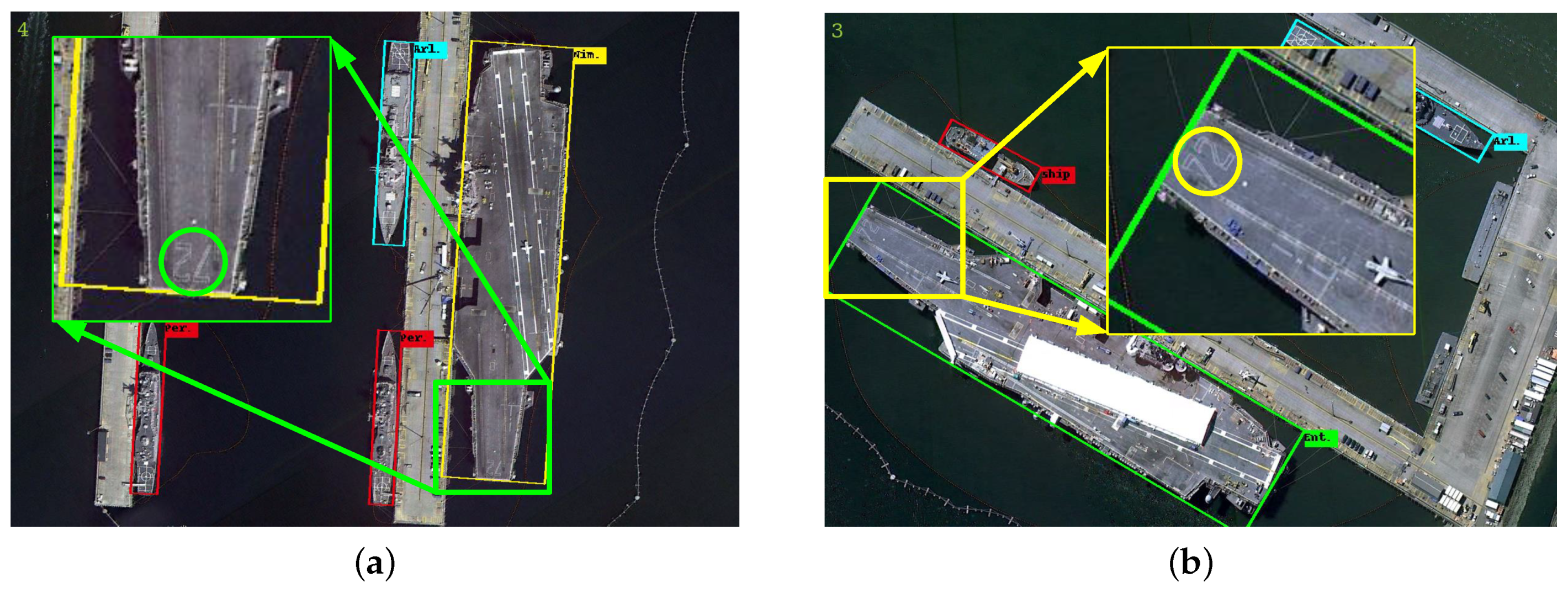
As for the problem about the Nimitz class, there were two factors contributing to this situation. One was the small inter-class variance and the inaccuracies of the ground-truth data. As shown in
Figure 15, there were no obvious differences between the classes air., Ent. and Nim.. In addition, we noticed the inaccuracies of the ground-truth data, such as those shown in
Figure 16. Obviously, the correct label of the aircraft carrier in
Figure 16b is Nim. Therefore, the PSG augmentation strategy may exacerbate this problem and lead to performance degradation. The confusion matrix in
Figure 13 could show a similar conclusion as well. The other was that the detection results of aircraft carrier targets were not ideal. As shown in
Figure 17, the rotated bounding box only contained part of the aircraft carrier targets, and even one target had two incomplete detection results. The reasons for the unsatisfactory examples will be investigated in our future work.
Although there are already many ship remote sensing datasets, there is a lack of specific category information for ships. Most of them only labeled categories as coarse-grained or even ignored categories. Furthermore, the ship number in different types has an unbalanced distribution. Therefore, because of the scarcity of training samples and the class imbalance, the improvement of its performance has been deeply influenced. In the future, while accumulating ship samples, we will carry out more detailed labeling of the ships.











{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}