Parcel-Based Crop Classification Using Multi-Temporal TerraSAR-X Dual Polarimetric Data


Abstract
1. Introduction
2. Materials and Methods
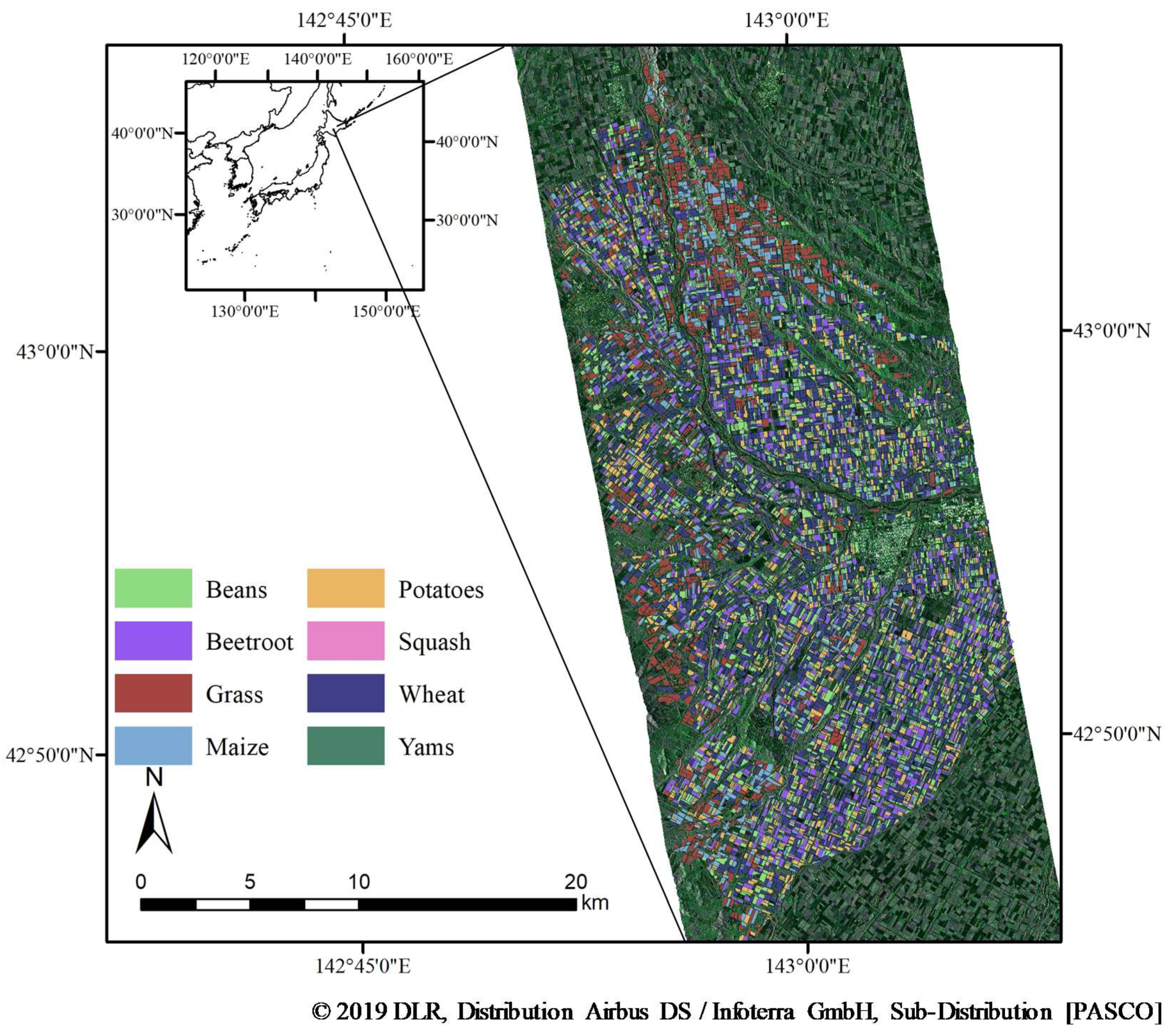
2.1. Study Area
2.2. Reference Data
2.3. Satellite Data
2.4. Classification Procedure
2.5. Accuracy Assessment
2.6. Statistical Comparison
2.7. Sensitivity Analysis
3. Results and Discussion
3.1. Acquired Data
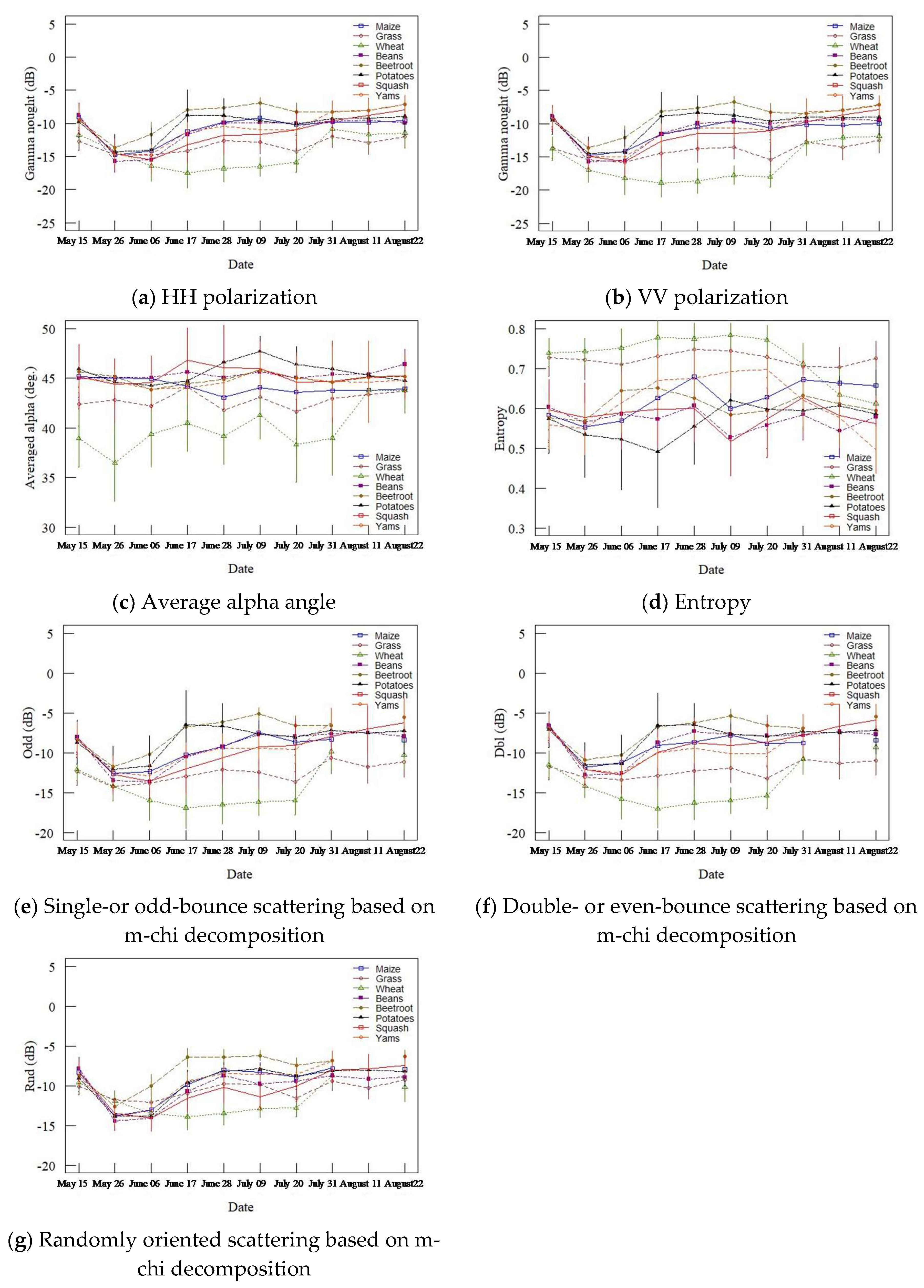
3.2. Selected Indices Based on LDA
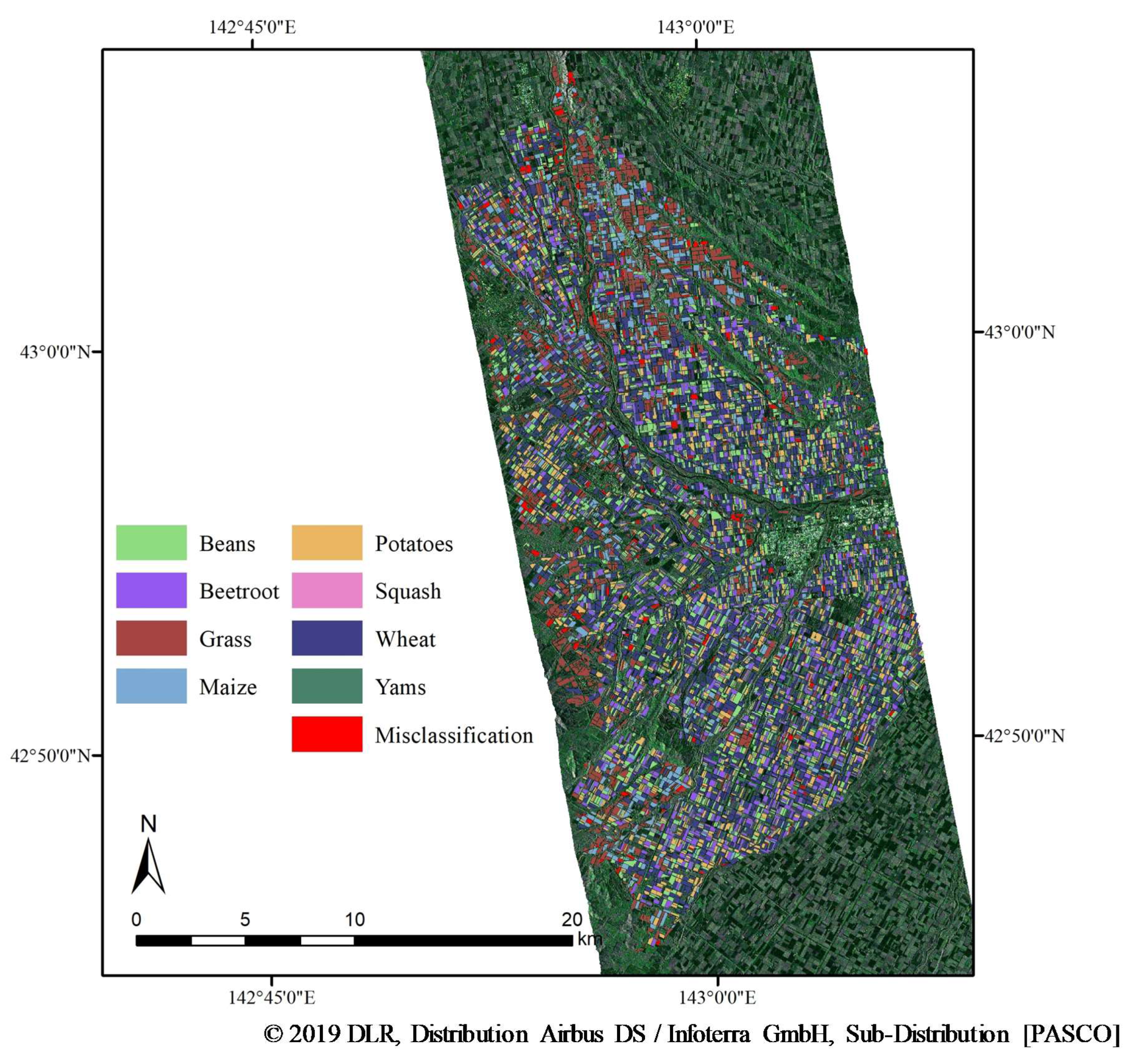
3.3. Accuracy Assessment
3.4. Statistical Comparison
3.5. Sensitivity Analysis
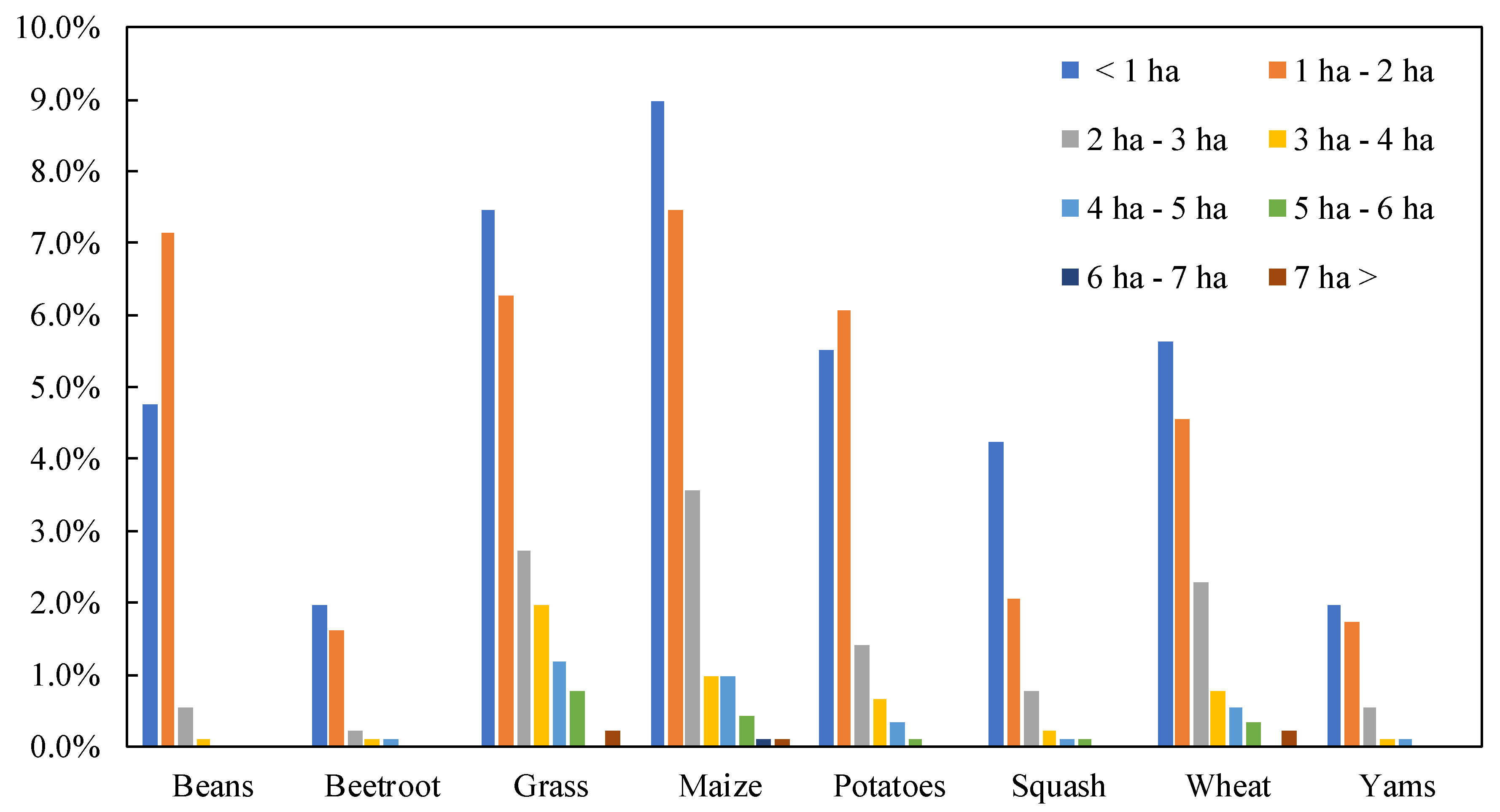
3.6. Relationship between Field Area and Misclassified Fields
4. Conclusions
Author Contributions
Funding
Acknowledgments
Conflicts of Interest
References
- Ministry of Agriculture, Forestry and Fisheries. Available online: http://www8.cao.go.jp/space/comittee/dai36/siryou3-5.pdf (accessed on 1 April 2019).
- Demarez, V.; Helen, F.; Marais-Sicre, C.; Baup, F. In-Season Mapping of Irrigated Crops Using Landsat 8 and Sentinel-1 Time Series. Remote Sens. 2019, 11, 118. [Google Scholar] [CrossRef]
- Sonobe, R.; Yamaya, Y.; Tani, H.; Wang, X.F.; Kobayashi, N.; Mochizuki, K.I. Evaluating metrics derived from Landsat 8 OLI imagery to map crop cover. Geocarto Int. 2018, 1–17. [Google Scholar] [CrossRef]
- Sonobe, R.; Yamaya, Y.; Tani, H.; Wang, X.F.; Kobayashi, N.; Mochizuki, K. Mapping crop cover using multi-temporal Landsat 8 OLI imagery. Int. J. Remote Sens. 2017, 38, 4348–4361. [Google Scholar] [CrossRef]
- Liu, J.H.; Zhu, W.Q.; Atzberger, C.; Zhao, A.Z.; Pan, Y.Z.; Huang, X. A Phenology-Based Method to Map Cropping Patterns under a Wheat-Maize Rotation Using Remotely Sensed Time-Series Data. Remote Sens. 2018, 10, 25. [Google Scholar] [CrossRef]
- Pan, H.Z.; Chen, Z.X.; Ren, J.Q.; Li, H.; Wu, S.R. Modeling Winter Wheat Leaf Area Index and Canopy Water Content With Three Different Approaches Using Sentinel-2 Multispectral Instrument Data. IEEE J. Sel. Top. Appl. Earth Obs. Remote Sens. 2019, 12, 482–492. [Google Scholar] [CrossRef]
- Chemura, A.; Mutanga, O.; Odindi, J. Empirical Modeling of Leaf Chlorophyll Content in Coffee (Coffea Arabica) Plantations with Sentinel-2 MSI Data: Effects of Spectral Settings, Spatial Resolution, and Crop Canopy Cover. IEEE J. Sel. Top. Appl. Earth Obs. Remote Sens. 2017, 10, 5541–5550. [Google Scholar] [CrossRef]
- Sonobe, R.; Yamaya, Y.; Tani, H.; Wang, X.F.; Kobayashi, N.; Mochizuki, K. Crop classification from Sentinel-2-derived vegetation indices using ensemble learning. J. Appl. Remote Sens. 2018, 12, 026019. [Google Scholar] [CrossRef]
- Ottosen, T.B.; Lommen, S.T.E.; Skjoth, C.A. Remote sensing of cropping practice in Northern Italy using time-series from Sentinel-2. Comput. Electron. Agric. 2019, 157, 232–238. [Google Scholar] [CrossRef]
- McNairn, H.; Jiao, X.F.; Pacheco, A.; Sinha, A.; Tan, W.K.; Li, Y.F. Estimating canola phenology using synthetic aperture radar. Remote Sens. Environ. 2018, 219, 196–205. [Google Scholar] [CrossRef]
- Sonobe, R.; Tani, H. Application of the Sahebi model using ALOS/PALSAR and 66.3 cm long surface profile data. Int. J. Remote Sens. 2009, 30, 6069–6074. [Google Scholar] [CrossRef]
- Gao, Q.; Zribi, M.; Escorihuela, M.J.; Baghdadi, N.; Segui, P.Q. Irrigation Mapping Using Sentinel-1 Time Series at Field Scale. Remote Sens. 2018, 10, 1495. [Google Scholar] [CrossRef]
- Amazirh, A.; Merlin, O.; Er-Raki, S.; Gao, Q.; Rivalland, V.; Malbeteau, Y.; Khabba, S.; Escorihuela, M.J. Retrieving surface soil moisture at high spatio-temporal resolution from a synergy between Sentinel-1 radar and Landsat thermal data: A study case over bare soil. Remote Sens. Environ. 2018, 211, 321–337. [Google Scholar] [CrossRef]
- Bargiel, D.; Herrmann, S. Multi-temporal land-cover classification of agricultural areas in two European regions with high resolution Spotlight TerraSAR-X data. Remote Sens. 2011, 3, 859–877. [Google Scholar] [CrossRef]
- Sonobe, R.; Tani, H.; Wang, X.; Kobayashi, N.; Shimamura, H. Discrimination of crop types with TerraSAR-X-derived information. Phys. Chem. Earth 2015, 83–84, 2–13. [Google Scholar] [CrossRef]
- Song, Y.; Wang, J. Mapping Winter Wheat Planting Area and Monitoring Its Phenology Using Sentinel-1 Backscatter Time Series. Remote Sens. 2019, 11, 449. [Google Scholar] [CrossRef]
- Xu, L.; Zhang, H.; Wang, C.; Zhang, B.; Liu, M. Crop Classification Based on Temporal Information Using Sentinel-1 SAR Time-Series Data. Remote Sens. 2019, 11, 53. [Google Scholar] [CrossRef]
- Park, S.; Im, J.; Yoo, C.; Han, H.; Rhee, J. Classification and Mapping of Paddy Rice by Combining Landsat and SAR Time Series Data. Remote Sens. 2018, 10, 22. [Google Scholar] [CrossRef]
- Stendardi, L.; Karlsen, S.R.; Niedrist, G.; Gerdol, R.; Zebisch, M.; Rossi, M.; Notarnicola, C. Exploiting Time Series of Sentinel-1 and Sentinel-2 Imagery to Detect Meadow Phenology in Mountain Regions. Remote Sens. 2019, 11, 542. [Google Scholar] [CrossRef]
- Carrasco, L.; O’Neil, A.W.; Morton, R.D.; Rowland, C.S. Evaluating Combinations of Temporally Aggregated Sentinel-1, Sentinel-2 and Landsat 8 for Land Cover Mapping with Google Earth Engine. Remote Sens. 2019, 11, 288. [Google Scholar] [CrossRef]
- Santos, C.; Lamparelli, R.A.C.; Figueiredo, G.; Dupuy, S.; Boury, J.; Luciano, A.C.D.; Torres, R.D.; Maire, G. Classification of Crops, Pastures, and Tree Plantations along the Season with Multi-Sensor Image Time Series in a Subtropical Agricultural Region. Remote Sens. 2019, 11, 334. [Google Scholar] [CrossRef]
- Bousbih, S.; Zribi, M.; El Hajj, M.; Baghdadi, N.; Lili-Chabaane, Z.; Gao, Q.; Fanise, P. Soil Moisture and Irrigation Mapping in A Semi-Arid Region, Based on the Synergetic Use of Sentinel-1 and Sentinel-2 Data. Remote Sens. 2018, 10, 1953. [Google Scholar] [CrossRef]
- Ager, T.P.; Bresnahan, P.C. Geometric precision in space radar imaging: Results from TerraSAR-X. In Proceedings of the ASPRS Annual Conference, Baltimore, ML, USA, 27–31 January 2009; pp. 9–13. [Google Scholar]
- Dabrowska-Zielinska, K.; Inoue, Y.; Kowalik, W.; Gruszczynska, M. Inferring the effect of plant and soil variables on C- and L-band SAR backscatter over agricultural fields, based on model analysis. Adv. Space Res. 2007, 39, 139–148. [Google Scholar] [CrossRef]
- Blaes, X.; Defourny, P. Retrieving crop parameters based on tandem ERS 1/2 interferometric coherence images. Remote Sens. Environ. 2003, 88, 374–385. [Google Scholar] [CrossRef]
- Raney, R.K. Hybrid-polarity SAR architecture. IEEE Trans. Geosci. Remote Sens. 2007, 45, 3397–3404. [Google Scholar] [CrossRef]
- Raney, R.K.; Cahill, J.T.S.; Patterson, G.W.; Bussey, D.B.J. The m-chi decomposition of hybrid dual-polarimetric radar data. In Proceedings of the IEEE International Geoscience and Remote Sensing Symposium (IGARSS’12), Munich, Germany, 22–27 July 2012; pp. 5093–5096. [Google Scholar]
- Cloude, S.R. The dual polarization entropy/alpha decomposition: A PALSAR case study. In Proceedings of the 3rd International Workshop on Science and Applications of SAR Polarimetry and Polarimetric Interferometry, Frascati, Italy, 22–26 January 2007. [Google Scholar]
- Arii, M.; van Zyl, J.J.; Kim, Y. A General Characterization for Polarimetric Scattering From Vegetation Canopies. IEEE Trans. Geosci. Remote Sens. 2010, 48, 3349–3357. [Google Scholar] [CrossRef]
- Kim, Y.; Jackson, T.; Bindlish, R.; Lee, H.; Hong, S. Radar Vegetation Index for Estimating the Vegetation Water Content of Rice and Soybean. IEEE Geosci. Remote Sens. Lett. 2012, 9, 564–568. [Google Scholar] [CrossRef]
- Hartfield, K.; Marsh, S.; Kirk, C.; Carriere, Y. Contemporary and historical classification of crop types in Arizona. Int. J. Remote Sens. 2013, 34, 6024–6036. [Google Scholar] [CrossRef]
- Sonobe, R.; Yamaya, Y.; Tani, H.; Wang, X.F.; Kobayashi, N.; Mochizuki, K.I. Assessing the suitability of data from Sentinel-1A and 2A for crop classification. GISci. Remote Sens. 2017, 54, 918–938. [Google Scholar] [CrossRef]
- Foody, G.; Mathur, A. A relative evaluation of multiclass image classification by support vector machines. IEEE Trans. Geosci. Remote Sens. 2004, 42, 1335–1343. [Google Scholar] [CrossRef]
- Biau, G.; Scornet, E. A random forest guided tour. Test 2016, 25, 197–227. [Google Scholar] [CrossRef]
- Huang, G.B.; Zhou, H.M.; Ding, X.J.; Zhang, R. Extreme learning machine for regression and multiclass classification. IEEE Trans. Syst. Man Cybern. Part B-Cybern. 2012, 42, 513–529. [Google Scholar] [CrossRef]
- Sonobe, R.; Sano, T.; Horie, H. Using spectral reflectance to estimate leaf chlorophyll content of tea with shading treatments. Biosyst. Eng. 2018, 175, 168–182. [Google Scholar] [CrossRef]
- Sonobe, R.; Miura, Y.; Sano, T.; Horie, H. Monitoring Photosynthetic Pigments of Shade-Grown Tea from Hyperspectral Reflectance. Can. J. Remote Sens. 2018, 44, 104–112. [Google Scholar] [CrossRef]
- Pal, M.; Maxwell, A.E.; Warner, T.A. Kernel-based extreme learning machine for remote-sensing image classification. Remote Sens. Lett. 2013, 4, 853–862. [Google Scholar] [CrossRef]
- Bengio, Y. Learning deep architectures for ai. Found. Trends Mach. Learn. 2009, 2, 1–127. [Google Scholar] [CrossRef]
- LeCun, Y.; Bengio, Y.; Hinton, G. Deep learning. Nature 2015, 521, 436–444. [Google Scholar] [CrossRef] [PubMed]
- Gonen, M.; Alpaydin, E. Multiple Kernel Learning Algorithms. J. Mach. Learn. Res. 2011, 12, 2211–2268. [Google Scholar]
- Gonen, M.; Alpaydin, E. Localized algorithms for multiple kernel learning. Pattern Recognit. 2013, 46, 795–807. [Google Scholar] [CrossRef]
- Liu, X.W.; Wang, L.; Huang, G.B.; Zhang, J.; Yin, J.P. Multiple kernel extreme learning machine. Neurocomputing 2015, 149, 253–264. [Google Scholar] [CrossRef]
- Pottier, E.; Ferro-Famil, L.; Allain, S.; Cloude, S.R.; Hajnsek, I.; Papathanassiou, K.; Moreira, A.; Williams, M.; Minchella, A.; Lavalle, M.; et al. Overview of the PolSARpro v4.0: The open source toolbox for polarimetric and interferometric polarimetric SAR data processing. In Proceedings of the IGARSS, Cape Town, South Africa, 12–17 July 2009; pp. 936–939. [Google Scholar]
- Gens, R.; Logan, T. Alaska Satellite Facility Software Tools: Manual; Geophysical Institute, University of Alaska: Fairbanks, AK, USA, 2003. [Google Scholar]
- Buckreuss, S.; Werninghaus, R.; Pitz, W. The German satellite mission TerraSAR-X. In Proceedings of the IEEE Radar Conference (RadarCon), Rome, Italy, 26–30 May 2008; pp. 1–5. [Google Scholar]
- Betbeder, J.; Fieuzal, R.; Philippets, Y.; Ferro-Famil, L.; Baup, F. Contribution of multitemporal polarimetric synthetic aperture radar data for monitoring winter wheat and rapeseed crops. J. Appl. Remote Sens. 2016, 10, 19. [Google Scholar] [CrossRef]
- Phalke, A.R.; Ozdogan, M. Large area cropland extent mapping with Landsat data and a generalized classifier. Remote Sens. Environ. 2018, 219, 180–195. [Google Scholar] [CrossRef]
- Roever, C.; Raabe, N.; Luebke, K.; Ligges, U.; Szepannek, G.; Zentgraf, M. Classification and Visualization. Available online: https://cran.r-project.org/web/packages/klaR/klaR.pdf (accessed on 12 December 2018).
- Raschka, S. Linear Discriminant Analysis Bit by Bit. Available online: https://sebastianraschka.com/Articles/2014_python_lda.html (accessed on 1 April 2019).
- Hastie, T.; Tibshirani, R.; Friedman, J. The Elements of Statistical Learning: Data Mining, Inference, and Prediction, 2nd ed.; Springer: New York, NY, USA, 2009; p. 745. [Google Scholar]
- R core team R: A Language and Environment for Statistical Computing. R Foundation for Statistical Computing. Available online: https://www.R-project.org/ (accessed on 1 April 2019).
- Ghosh, A.; Fassnacht, F.E.; Joshi, P.K.; Koch, B. A framework for mapping tree species combining hyperspectral and LiDAR data: Role of selected classifiers and sensor across three spatial scales. Int. J. Appl. Earth Obs. Geoinf. 2014, 26, 49–63. [Google Scholar] [CrossRef]
- Svozil, D.; Kvasnicka, V.; Pospichal, J. Introduction to multi-layer feed-forward neural networks. Chemom. Intell. Lab. Syst. 1997, 39, 43–62. [Google Scholar] [CrossRef]
- Huang, G.B.; Zhu, Q.Y.; Siew, C.K. Extreme learning machine: Theory and applications. Neurocomputing 2006, 70, 489–501. [Google Scholar] [CrossRef]
- Puertas, O.; Brenning, A.; Meza, F. Balancing misclassification errors of land cover classification maps using support vector machines and Landsat imagery in the Maipo river basin (Central Chile, 1975–2010). Remote Sens. Environ. 2013, 137, 112–123. [Google Scholar] [CrossRef]
- Bergstra, J.; Bengio, Y. Random Search for Hyper-Parameter Optimization. J. Mach. Learn. Res. 2012, 13, 281–305. [Google Scholar]
- Snoek, J.; Rippel, O.; Swersky, K.; Kiros, R.; Satish, N.; Sundaram, N.; Patwary, M.M.A.; Prabhat; Adams, R.P. Scalable Bayesian optimization using deep neural networks. In Proceedings of the 32nd International Conference on Machine Learning (ICML), Paris, France, 6–11 July 2015; pp. 2171–2180. [Google Scholar]
- Cusano, C.; Napoletano, P.; Schettini, R. Remote Sensing Image Classification Exploiting Multiple Kernel Learning. IEEE Geosci. Remote Sens. Lett. 2015, 12, 2331–2335. [Google Scholar] [CrossRef]
- Zamani, F.; Jamzad, M. A feature fusion based localized multiple kernel learning system for real world image classification. EURASIP J. Image Video Process. 2017, 78. [Google Scholar] [CrossRef]
- Pontius, R.; Millones, M. Death to Kappa: Birth of quantity disagreement and allocation disagreement for accuracy assessment. Int. J. Remote Sens. 2011, 32, 4407–4429. [Google Scholar] [CrossRef]
- McNemar, Q. Note on the sampling error of the difference between correlated proportions or percentages. Psychometrika 1947, 12, 153–157. [Google Scholar] [CrossRef] [PubMed]
- Congalton, R.G.; Green, K. Assessing the Accuracy of Remotely Sensed Data: Principles and Practices; CRC Press: Boca Raton, FL, USA, 2008. [Google Scholar]
- Benjankar, R.; Glenn, N.F.; Egger, G.; Jorde, K.; Goodwin, P. Comparison of field-observed and simulated map output from a dynamic floodplain vegetation model using remote sensing and GIS techniques. GISci. Remote Sens. 2010, 47, 480–497. [Google Scholar] [CrossRef]
- Cortez, P.; Embrechts, M.J. Using sensitivity analysis and visualization techniques to open black box data mining models. Inf. Sci. 2013, 225, 1–17. [Google Scholar] [CrossRef]
- Fontanelli, G.; Paloscia, S.; Zribi, M.; Chahbi, A. Sensitivity analysis of X-band SAR to wheat and barley leaf area index in the Merguellil Basin. Remote Sens. Lett. 2013, 4, 1107–1116. [Google Scholar] [CrossRef]
- Sonobe, R.; Tani, H.; Wang, X.F. An experimental comparison between KELM and CART for crop classification using Landsat-8 OLI data. Geocarto Int. 2017, 32, 128–138. [Google Scholar] [CrossRef]






{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| May | June | July | August | September | October | ||||||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| mid | late | early | mid | late | early | mid | late | early | mid | late | early | mid | late | early | mid | late | |
| Beans | Sowing | Sprouting | Harvesting | ||||||||||||||
| Beetroot | Transplanting | Harvesting | |||||||||||||||
| Grass | Appearance of ears of grain | 1st Harvesting | 2nd Harvesting | ||||||||||||||
| Maize | Sowing | Sprouting | Appearance of ears of grain | Harvesting | |||||||||||||
| Potatoes | Sowing | Sprouting | Harvesting | ||||||||||||||
| Squash | Transplanting | Harvesting | |||||||||||||||
| Wheat | Appearance of ears of grain | Harvesting | Sowing | ||||||||||||||
| Yams | Sowing | Netting | Harvesting | ||||||||||||||
| Satellite | Acquisition Date | Mode | Incidence Angle (°) | Orbit Cycle | Pass Direction | |
|---|---|---|---|---|---|---|
| Near | Far | |||||
| TerraSAR-X | 15 May 2013 | StripMap | 41.736 | 42.977 | 197 | Ascending |
| TerraSAR-X | 26 May 2013 | StripMap | 41.734 | 42.975 | 198 | Ascending |
| TerraSAR-X | 6 June 2013 | StripMap | 41.739 | 42.979 | 199 | Ascending |
| TerraSAR-X | 17 June 2013 | StripMap | 41.737 | 42.976 | 200 | Ascending |
| TerraSAR-X | 28 June 2013 | StripMap | 41.733 | 42.973 | 201 | Ascending |
| TerraSAR-X | 9 July 2013 | StripMap | 41.738 | 42.977 | 202 | Ascending |
| TanDEM-X | 20 July 2013 | StripMap | 41.712 | 42.952 | 203 | Ascending |
| TerraSAR-X | 31 July 2013 | StripMap | 41.737 | 42.977 | 204 | Ascending |
| TanDEM-X | 11 August 2013 | StripMap | 41.730 | 42.971 | 205 | Ascending |
| TanDEM-X | 22 August 2013 | StripMap | 41.737 | 42.978 | 206 | Ascending |
| Training Data | Validation Data | Test Data | |
|---|---|---|---|
| Beans | 942 | 471 | 471 |
| Beetroot | 713 | 356 | 357 |
| Grass | 722 | 361 | 362 |
| Maize | 546 | 273 | 273 |
| Potatoes | 782 | 391 | 391 |
| Squash | 65 | 33 | 33 |
| Wheat | 1517 | 759 | 759 |
| Yams | 67 | 34 | 34 |
| Round | Selected Predictors | |||||
|---|---|---|---|---|---|---|
| 1 | γºVV_May26 | γºVV_July09 | γºVV_July20 | EntropyAugust11 | RndJune28 | DblAugust22 |
| ND(γºVV, Dbl)May15 | ND(Dbl, Rnd)June06 | ND(Odd, Rnd)June17 | ND(γºHH, Dbl)June28 | |||
| 2 | γºVV_May26 | γºVV_July09 | EntropyAugust11 | RndJune28 | DblAugust22 | D(Dbl, Odd)June17 |
| ND(γºHH, γºVV)May26 | ND(Dbl, Rnd)June06 | ND(γºVV, Dbl)June28 | ||||
| 3 | γºVV_May26 | γºVV_July09 | EntropyAugust11 | RndJune28 | DblAugust22 | D(Dbl, Odd)June17 |
| ND(Dbl, Rnd)June06 | ND(γºHH, Dbl)June28 | ND(γºHH, γºVV)July20 | ||||
| 4 | γºVV_May26 | γºVV_July09 | EntropyAugust11 | RndJune28 | DblAugust22 | D(Dbl, Odd)June17 |
| ND(γºVV, Dbl)May15 | ND(Dbl, Rnd)June06 | ND(γºVV, Dbl)June28 | ||||
| 5 | γºVV_May26 | γºVV_July09 | RndJune28 | DblAugust22 | D(Dbl, Odd)June17 | ND(γºVV, Odd)June06 |
| ND(Dbl, Rnd)June06 | ND(γºHH, Dbl)June28 | ND(Dbl, Rnd)June28 | ||||
| 6 | γºVV_May26 | γºVV_July09 | γºVV_July20 | RndJune28 | RndJuly31 | SR(γºHH, γºVV)July20 |
| D(Dbl, Odd)June17 | ND(Dbl, Rnd)June06 | ND(Dbl, Rnd)June28 | ND(γºVV, Rnd)August22 | |||
| 7 | γºVV_May26 | γºVV_July09 | γºVV_July20 | EntropyAugust11 | RndJune28 | RndJuly09 |
| DblAugust22 | ND(Dbl, Rnd)June06 | ND(Odd, Rnd)June17 | ND(γºHH, Dbl)June28 | ND(γºHH, γºVV)July09 | ||
| 8 | γºVV_May26 | γºVV_July09 | γºVV_July20 | EntropyAugust11 | RndJune28 | DblAugust22 |
| D(Dbl, Odd)June17 | ND(Dbl, Rnd)June06 | ND(γºHH, Dbl)June28 | ||||
| 9 | γºVV_May26 | γºVV_July09 | EntropyAugust11 | RndJune28 | DblAugust22 | D(Dbl, Odd)June17 |
| ND(Dbl, Rnd)June06 | ND(γºVV, Dbl)June28 | |||||
| 10 | γºVV_May26 | γºVV_July09 | EntropyAugust11 | RndJune28 | DblAugust22 | D(Dbl, Odd)June17 |
| ND(Dbl, Rnd)June06 | ND(γºVV, Dbl)June28 | |||||
| SVM | RF | FNN | KELM | MKL | MKELM | |
|---|---|---|---|---|---|---|
| PA | ||||||
| Beans | 0.928 ± 0.019 | 0.920 ± 0.021 | 0.924 ± 0.020 | 0.931 ± 0.020 | 0.925 ± 0.012 | 0.931 ± 0.019 |
| Beetroot | 0.966 ± 0.008 | 0.966 ± 0.008 | 0.963 ± 0.009 | 0.968 ± 0.009 | 0.966 ± 0.009 | 0.968 ± 0.009 |
| Grass | 0.901 ± 0.019 | 0.903 ± 0.019 | 0.910 ± 0.024 | 0.897 ± 0.024 | 0.905 ± 0.015 | 0.896 ± 0.025 |
| Maize | 0.827 ± 0.023 | 0.814 ± 0.027 | 0.823 ± 0.042 | 0.819 ± 0.020 | 0.825 ± 0.018 | 0.814 ± 0.020 |
| Potatoes | 0.923 ± 0.018 | 0.913 ± 0.011 | 0.915 ± 0.024 | 0.929 ± 0.019 | 0.925 ± 0.018 | 0.931 ± 0.017 |
| Squash | 0.479 ± 0.097 | 0.397 ± 0.042 | 0.500 ± 0.091 | 0.355 ± 0.082 | 0.573 ± 0.069 | 0.464 ± 0.069 |
| Wheat | 0.964 ± 0.007 | 0.964 ± 0.007 | 0.955 ± 0.011 | 0.962 ± 0.009 | 0.961 ± 0.010 | 0.965 ± 0.010 |
| Yams | 0.747 ± 0.067 | 0.671 ± 0.081 | 0.774 ± 0.061 | 0.674 ± 0.056 | 0.788 ± 0.046 | 0.579 ± 0.083 |
| UA | ||||||
| Beans | 0.894 ± 0.013 | 0.895 ± 0.015 | 0.897 ± 0.026 | 0.887 ± 0.012 | 0.902 ± 0.015 | 0.895 ± 0.009 |
| Beetroot | 0.964 ± 0.008 | 0.960 ± 0.010 | 0.969 ± 0.014 | 0.960 ± 0.012 | 0.964 ± 0.011 | 0.959 ± 0.011 |
| Grass | 0.889 ± 0.013 | 0.880 ± 0.016 | 0.870 ± 0.019 | 0.887 ± 0.008 | 0.892 ± 0.013 | 0.885 ± 0.010 |
| Maize | 0.843 ± 0.026 | 0.812 ± 0.023 | 0.844 ± 0.028 | 0.851 ± 0.018 | 0.849 ± 0.023 | 0.855 ± 0.020 |
| Potatoes | 0.916 ± 0.014 | 0.907 ± 0.016 | 0.916 ± 0.036 | 0.909 ± 0.016 | 0.919 ± 0.010 | 0.901 ± 0.018 |
| Squash | 0.786 ± 0.075 | 0.829 ± 0.106 | 0.740 ± 0.076 | 0.785 ± 0.089 | 0.700 ± 0.152 | 0.869 ± 0.105 |
| Wheat | 0.969 ± 0.009 | 0.968 ± 0.006 | 0.972 ± 0.012 | 0.965 ± 0.011 | 0.973 ± 0.006 | 0.963 ± 0.012 |
| Yams | 0.836 ± 0.087 | 0.844 ± 0.076 | 0.745 ± 0.117 | 0.871 ± 0.052 | 0.813 ± 0.152 | 0.916 ± 0.069 |
| F1 | ||||||
| Beans | 0.911 ± 0.012 | 0.908 ± 0.012 | 0.910 ± 0.013 | 0.909 ± 0.010 | 0.913 ± 0.010 | 0.913 ± 0.010 |
| Beetroot | 0.965 ± 0.006 | 0.963 ± 0.007 | 0.966 ± 0.007 | 0.964 ± 0.009 | 0.965 ± 0.008 | 0.963 ± 0.008 |
| Grass | 0.895 ± 0.010 | 0.891 ± 0.012 | 0.890 ± 0.008 | 0.892 ± 0.010 | 0.898 ± 0.011 | 0.890 ± 0.010 |
| Maize | 0.835 ± 0.021 | 0.813 ± 0.015 | 0.834 ± 0.017 | 0.835 ± 0.015 | 0.836 ± 0.015 | 0.834 ± 0.016 |
| Potatoes | 0.919 ± 0.010 | 0.910 ± 0.005 | 0.915 ± 0.010 | 0.919 ± 0.009 | 0.922 ± 0.007 | 0.916 ± 0.008 |
| Squash | 0.595 ± 0.062 | 0.537 ± 0.042 | 0.597 ± 0.070 | 0.489 ± 0.086 | 0.620 ± 0.065 | 0.605 ± 0.066 |
| Wheat | 0.967 ± 0.005 | 0.966 ± 0.004 | 0.963 ± 0.006 | 0.963 ± 0.005 | 0.967 ± 0.006 | 0.964 ± 0.005 |
| Yams | 0.789 ± 0.060 | 0.748 ± 0.066 | 0.759 ± 0.075 | 0.760 ± 0.048 | 0.794 ± 0.085 | 0.710 ± 0.064 |
| OA | 0.921 ± 0.004 | 0.915 ± 0.004 | 0.918 ± 0.004 | 0.918 ± 0.004 | 0.921 ± 0.005 | 0.919 ± 0.005 |
| AD | 0.066 ± 0.007 | 0.070 ± 0.006 | 0.062 ± 0.004 | 0.064 ± 0.008 | 0.067 ± 0.005 | 0.062 ± 0.007 |
| QD | 0.013 ± 0.005 | 0.015 ± 0.005 | 0.021 ± 0.006 | 0.018 ± 0.004 | 0.012 ± 0.004 | 0.019 ± 0.003 |
| AD+QD | 0.079 ± 0.004 | 0.085 ± 0.004 | 0.082 ± 0.004 | 0.082 ± 0.004 | 0.078 ± 0.003 | 0.081 ± 0.005 |
| SVM | RF | FNN | KELM | MKL | |
|---|---|---|---|---|---|
| RF | 30.84 ± 5.26 | 55.78 ± 14.63 | 61.36 ± 13.62 | 43.55 ± 13.50 | 45.78 ± 11.57 |
| FNN | 59.14 ± 15.38 | 31.85 ± 7.45 | 62.30 ± 14.36 | 24.76 ± 9.40 | |
| KELM | 31.25 ± 10.89 | 41.89 ± 8.59 | 67.10 ± 17.21 | ||
| MKL | 35.54 ± 10.39 | 33.91 ± 8.10 | |||
| MKELM | 36.76 ± 9.63 |
© 2019 by the author. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Sonobe, R. Parcel-Based Crop Classification Using Multi-Temporal TerraSAR-X Dual Polarimetric Data. Remote Sens. 2019, 11, 1148. https://doi.org/10.3390/rs11101148
Sonobe R. Parcel-Based Crop Classification Using Multi-Temporal TerraSAR-X Dual Polarimetric Data. Remote Sensing. 2019; 11(10):1148. https://doi.org/10.3390/rs11101148
Chicago/Turabian StyleSonobe, Rei. 2019. "Parcel-Based Crop Classification Using Multi-Temporal TerraSAR-X Dual Polarimetric Data" Remote Sensing 11, no. 10: 1148. https://doi.org/10.3390/rs11101148
APA StyleSonobe, R. (2019). Parcel-Based Crop Classification Using Multi-Temporal TerraSAR-X Dual Polarimetric Data. Remote Sensing, 11(10), 1148. https://doi.org/10.3390/rs11101148