Aircraft Type Recognition in Remote Sensing Images Based on Feature Learning with Conditional Generative Adversarial Networks


Abstract
1. Introduction
- We propose a framework to deal with the aircraft type recognition problem, which can learn distinctive features for aircraft recognition from abundant data without type labels. Only a modest number of labeled samples are required to build the recognition model with strong generalization ability.
- We build a model to detect aircraft keypoints in images by generating heat maps. This improves the keypoints’ precision significantly by integrating both local and global features. Meanwhile, we design a strategy to correct the incorrect detections between symmetric keypoints (e.g., left and right wingtips), which further refines the model’s performance.
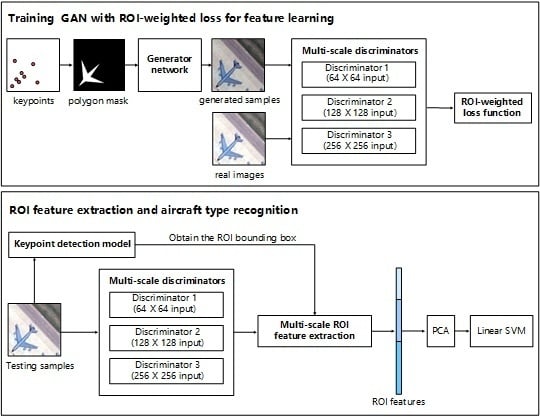
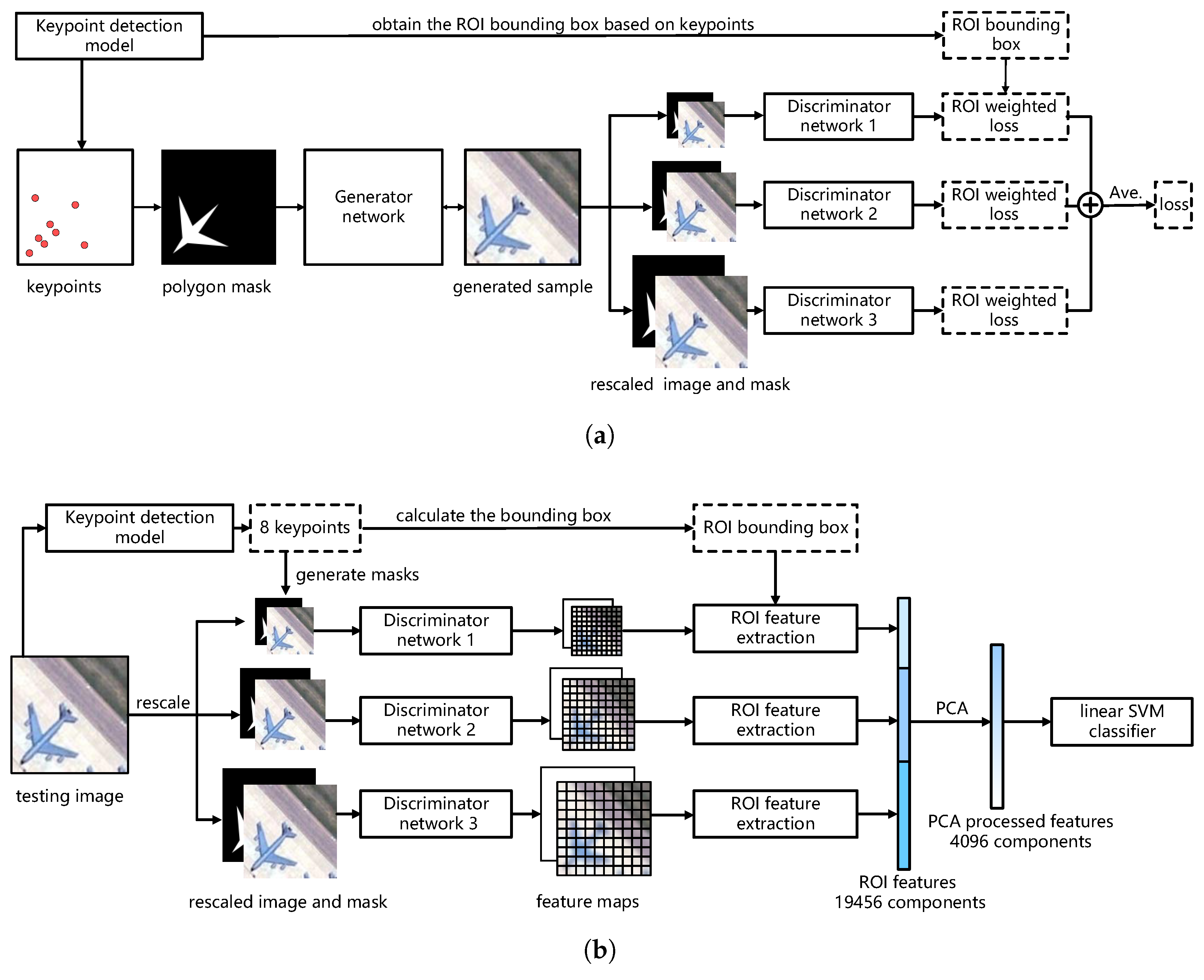
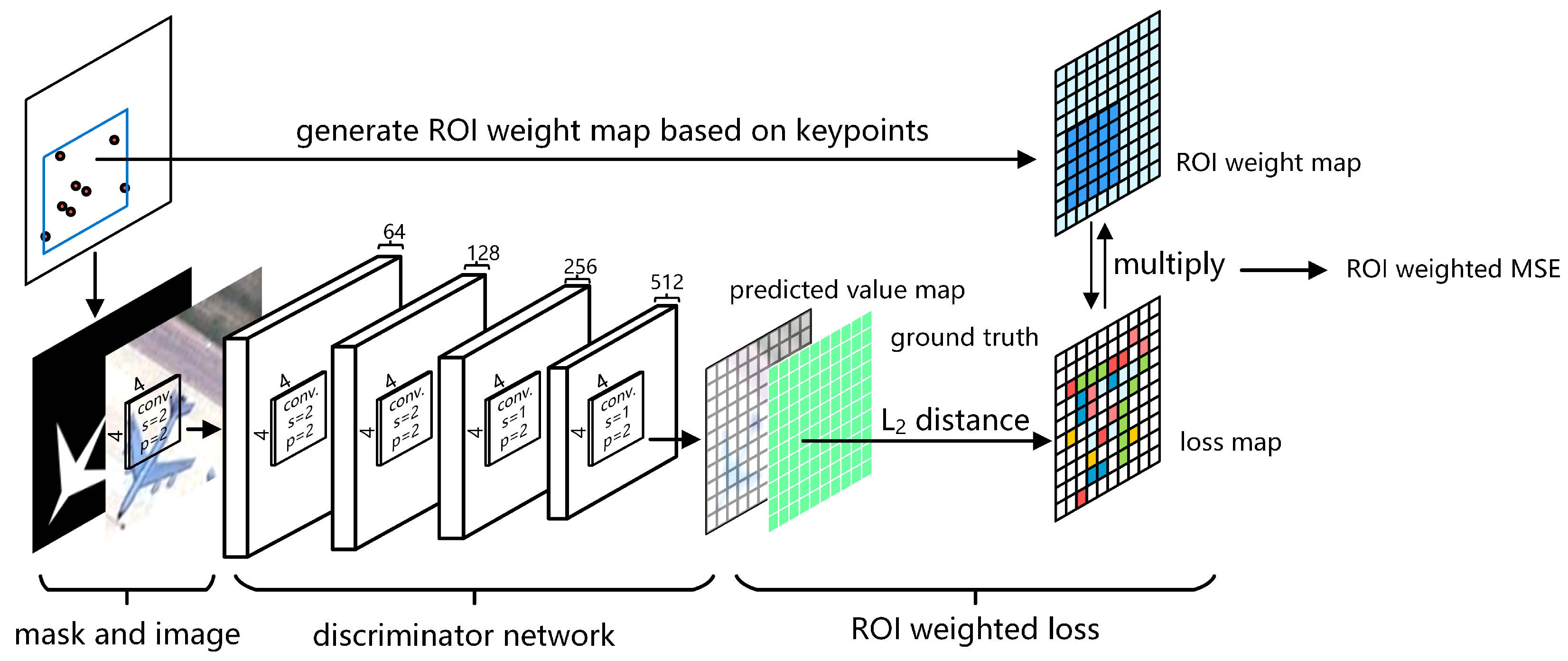
- We build a conditional GAN model based on Reference [20] to learn aircraft features. First, we replace the pixel-wise semantic labels with the masks generated by keypoints as the conditional input, which avoids the heavy labeling work. Then, to learn more representative features, an region of interest (ROI)-weighted loss function is designed to make the model focus on the regions of aircrafts instead of the background.
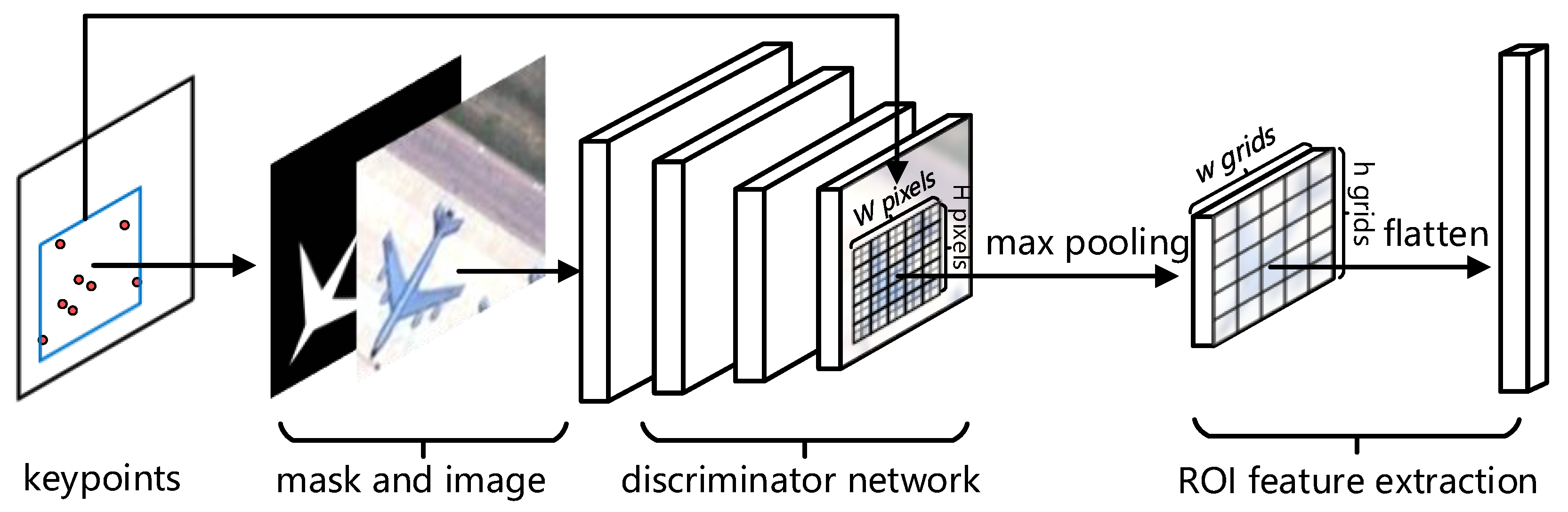
- To promote the quality of features, we design a method named ROI feature extraction to extract multi-scale features in the exact regions of the targets, which can eliminate the effects of complex backgrounds and deal with aircrafts of different scales and resolutions.
2. Proposed Method
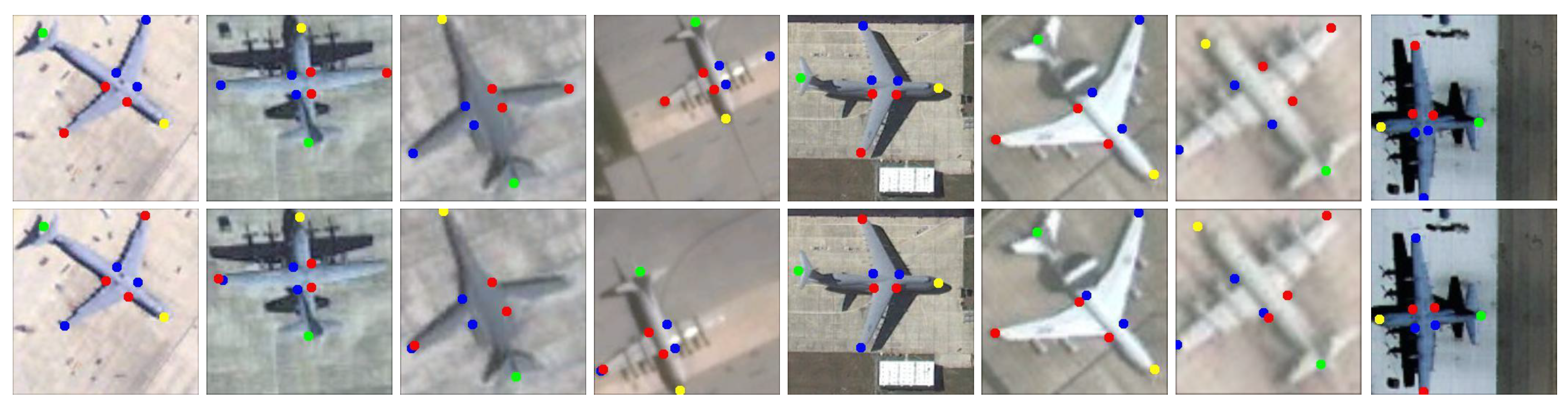
2.1. Aircraft Keypoint Detection
| Algorithm 1 The procedure of obtaining keypoints from heat maps. |
| Input: Five heat maps Output: The eight aircraft keypoint coordinates 1: Nose heat map: Find the position of the maximum value as the nose’s coordinate . 2: Tail heat map: Find the position of the maximum value as the tail’s coordinate . 3: Calculate the standard direction vector = 4: for each heat map of symmetric keypoints do 5: Find the position of the maximum value as the left coordinate . 6: Set the value to 0 in a circle whose center is and radius is 5 pixels. 7: Find the position of the maximum value as the right coordinate . 8: Calculate the direction vector = . 9: if < 0 then 10: Swap the left and right coordinates. 11: end if 12: end for |
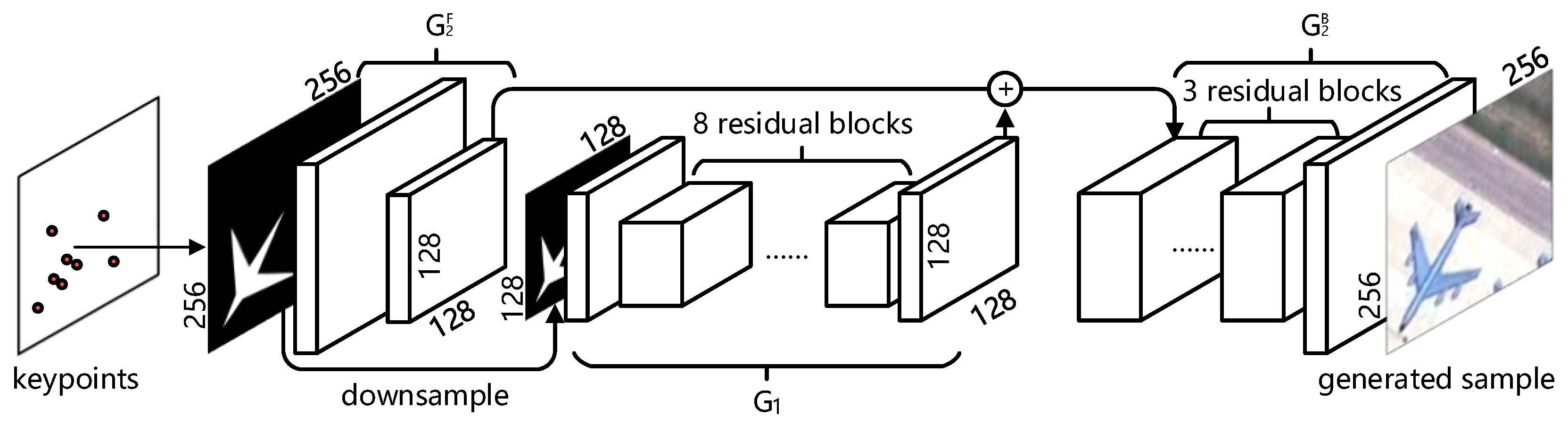
2.2. Conditional GAN with ROI-Weighted Loss Function
2.3. Multi-Scale ROI Feature Extraction
2.4. Aircraft Type Recognition
3. Experiments and Results
3.1. Dataset
| Algorithm 2 The procedure of obtaining aircraft crops from large images. |
| Input: Large images with keypoint annotations Output: Aircraft crops with keypoint annotations 1: for each aircraft in large images do 2: Calculate the minimum outer rectangle based on the keypoint annotation, whose size is 3: Calculate the minimum outer rectangle’s start point 4: Randomly select a scale ratio s in the range 5: Set the crop size tol 6 Randomly select crop start point x in range , y in range 7: Crop the image with start point and size 8: for each keypoint do 9: 10: 11: end for 12: end for |
3.2. Implementation Details
3.3. Aircraft Keypoint Accuracy Evaluation
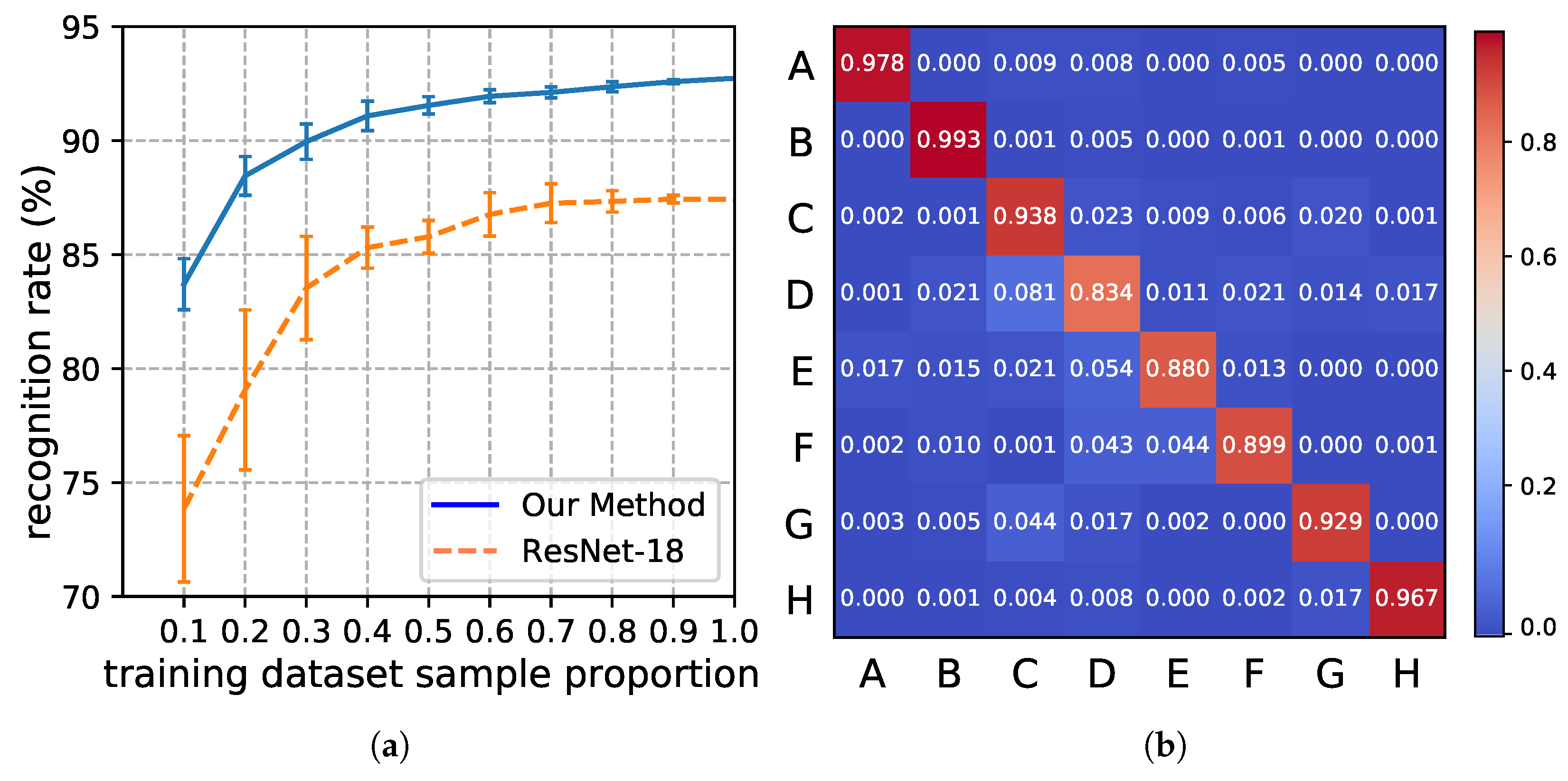
3.4. Aircraft Type Recognition Accuracy Evaluation
3.4.1. Evaluation of the ROI-Weighted Loss Function
3.4.2. Evaluation of the ROI Feature Extraction Method
3.4.3. Evaluation of the Multi-Scale ROI Features
3.4.4. Comparison with Other Methods
4. Discussion
5. Conclusions
Author Contributions
Funding
Acknowledgments
Conflicts of Interest
References
- Hsieh, J.W.; Chen, J.M.; Chuang, C.H.; Fan, K.C. Aircraft type recognition in satellite images. IEE Proc. Vis. Image Signal Process. 2005, 152, 307. [Google Scholar] [CrossRef]
- Liu, G.; Sun, X.; Fu, K.; Wang, H. Aircraft Recognition in High-Resolution Satellite Images Using Coarse-to-Fine Shape Prior. IEEE Geosci. Remote Sens. Lett. 2013, 10, 573–577. [Google Scholar] [CrossRef]
- Xu, C.; Duan, H. Artificial bee colony (ABC) optimized edge potential function (EPF) approach to target recognition for low-altitude aircraft. Pattern Recognit. Lett. 2010, 31, 1759–1772. [Google Scholar] [CrossRef]
- Wang, D.; He, X.; Zhonghui, W.; Yu, H. A method of aircraft image target recognition based on modified PCA features and SVM. In Proceedings of the 2009 9th International Conference on Electronic Measurement & Instruments, Beijing, China, 16–19 August 2009. [Google Scholar] [CrossRef]
- Fang, Z.; Yao, G.; Zhang, Y. Target recognition of aircraft based on moment invariants and BP neural network. In Proceedings of the World Automation Congress, Puerto Vallarta, Mexico, 24–28 June 2012; pp. 1–5. [Google Scholar]
- Wu, H.; Li, D.; Wang, H.; Liu, Y.; Sun, X. Research on Aircraft Object Recognition Model Based on Neural Networks. In Proceedings of the 2012 International Conference on Computer Science and Electronics Engineering, Hangzhou, China, 23–25 March 2012; Volume 1, pp. 160–163. [Google Scholar] [CrossRef]
- Diao, W.; Sun, X.; Dou, F.; Yan, M.; Wang, H.; Fu, K. Object recognition in remote sensing images using sparse deep belief networks. Remote Sens. Lett. 2015, 6, 745–754. [Google Scholar] [CrossRef]
- Krizhevsky, A.; Sutskever, I.; Hinton, G.E. ImageNet classification with deep convolutional neural networks. Commun. ACM 2017, 60, 84–90. [Google Scholar] [CrossRef]
- Simonyan, K.; Zisserman, A. Very Deep Convolutional Networks for Large-Scale Image Recognition. arXiv, 2014; arXiv:1409.1556. [Google Scholar]
- Szegedy, C.; Liu, W.; Jia, Y.; Sermanet, P.; Reed, S.; Anguelov, D.; Erhan, D.; Vanhoucke, V.; Rabinovich, A. Going deeper with convolutions. In Proceedings of the 2015 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Boston, MA, USA, 7–12 June 2015; pp. 1–9. [Google Scholar] [CrossRef]
- He, K.; Zhang, X.; Ren, S.; Sun, J. Deep Residual Learning for Image Recognition. In Proceedings of the 2016 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Las Vegas, NV, USA, 26 June–1 July 2016; pp. 770–778. [Google Scholar] [CrossRef]
- Deng, J.; Dong, W.; Socher, R.; Li, L.J.; Li, K.; Li, F.-F. ImageNet: A large-scale hierarchical image database. In Proceedings of the 2009 IEEE Conference on Computer Vision and Pattern Recognition, Miami, FL, USA, 20–25 June 2009; pp. 248–255. [Google Scholar] [CrossRef]
- Lin, T.Y.; Maire, M.; Belongie, S.; Hays, J.; Perona, P.; Ramanan, D.; Dollár, P.; Zitnick, C.L. Microsoft COCO: Common Objects in Context. In Computer Vision—ECCV 2014; Fleet, D., Pajdla, T., Schiele, B., Tuytelaars, T., Eds.; Springer International Publishing: Cham, Switzerland, 2014; pp. 740–755. [Google Scholar]
- Wu, Q.; Sun, H.; Sun, X.; Zhang, D.; Fu, K.; Wang, H. Aircraft Recognition in High-Resolution Optical Satellite Remote Sensing Images. IEEE Geosci. Remote Sens. Lett. 2015, 12, 112–116. [Google Scholar] [CrossRef]
- Zhao, A.; Fu, K.; Wang, S.; Zuo, J.; Zhang, Y.; Hu, Y.; Wang, H. Aircraft Recognition Based on Landmark Detection in Remote Sensing Images. IEEE Geosci. Remote Sens. Lett. 2017, 14, 1413–1417. [Google Scholar] [CrossRef]
- Zuo, J.; Xu, G.; Fu, K.; Sun, X.; Sun, H. Aircraft Type Recognition Based on Segmentation With Deep Convolutional Neural Networks. IEEE Geosci. Remote Sens. Lett. 2018, 15, 282–286. [Google Scholar] [CrossRef]
- Goodfellow, I.J.; Pouget-Abadie, J.; Mirza, M.; Xu, B.; Warde-Farley, D.; Ozair, S.; Courville, A.; Bengio, Y. Generative Adversarial Nets. In Proceedings of the 27th International Conference on Neural Information Processing Systems—Volume 2, NIPS’14; MIT Press: Cambridge, MA, USA, 2014; pp. 2672–2680. [Google Scholar]
- Radford, A.; Metz, L.; Chintala, S. Unsupervised Representation Learning with Deep Convolutional Generative Adversarial Networks. arXiv, 2015; arXiv:1511.06434. [Google Scholar]
- Isola, P.; Zhu, J.Y.; Zhou, T.; Efros, A.A. Image-to-Image Translation with Conditional Adversarial Networks. In Proceedings of the 2017 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Honolulu, HI, USA, 21–26 July 2017; pp. 5967–5976. [Google Scholar] [CrossRef]
- Wang, T.C.; Liu, M.Y.; Zhu, J.Y.; Tao, A.; Kautz, J.; Catanzaro, B. High-Resolution Image Synthesis and Semantic Manipulation with Conditional GANs. arXiv, 2017; arXiv:1711.11585. [Google Scholar]
- Corres, C. Support vector networks. Mach. Learn. 1995, 20, 273–297. [Google Scholar]
- Newell, A.; Yang, K.; Deng, J. Stacked Hourglass Networks for Human Pose Estimation. In Computer Vision—ECCV 2016; Leibe, B., Matas, J., Sebe, N., Welling, M., Eds.; Springer International Publishing: Cham, Switzerland, 2016; pp. 483–499. [Google Scholar]
- Mirza, M.; Osindero, S. Conditional Generative Adversarial Nets. arXiv, 2014; arXiv:1411.1784. [Google Scholar]
- Salimans, T.; Goodfellow, I.; Zaremba, W.; Cheung, V.; Radford, A.; Chen, X.; Chen, X. Improved Techniques for Training GANs. In Advances in Neural Information Processing Systems 29; Lee, D.D., Sugiyama, M., Luxburg, U.V., Guyon, I., Garnett, R., Eds.; Curran Associates, Inc.: Red Hook, NY, USA, 2016; pp. 2234–2242. [Google Scholar]
- Arjovsky, M.; Chintala, S.; Bottou, L. Wasserstein GAN. arXiv, 2017; arXiv:stat.ML/1701.07875. [Google Scholar]
- Fergus, R.; Fergus, R.; Fergus, R.; Fergus, R. Deep generative image models using a Laplacian pyramid of adversarial networks. In Proceedings of the International Conference on Neural Information Processing Systems, Montréal, QC, Canada, 7–12 December 2015; pp. 1486–1494. [Google Scholar]
- Huang, X.; Li, Y.; Poursaeed, O.; Hopcroft, J.; Belongie, S. Stacked Generative Adversarial Networks. In Proceedings of the 2017 Conference on Computer Vision and Pattern Recognition, Honolulu, HI, USA, 21–26 July 2017. pp. 1866–1875.
- Chen, Q.; Koltun, V. Photographic Image Synthesis with Cascaded Refinement Networks. arXiv, 2017; arXiv:1707.09405. [Google Scholar]
- Zhang, H.; Xu, T.; Li, H. StackGAN: Text to Photo-Realistic Image Synthesis with Stacked Generative Adversarial Networks. arXiv, 2017; arXiv:1612.03242. [Google Scholar]
- Mao, X.; Li, Q.; Xie, H.; Lau, R.Y.K.; Wang, Z.; Smolley, S.P. Least Squares Generative Adversarial Networks. In Proceedings of the IEEE International Conference on Computer Vision (ICCV), Venice, Italy, 22–29 October 2017; pp. 2813–2821. [Google Scholar] [CrossRef]
- Kingma, D.P.; Ba, J. Adam: A Method for Stochastic Optimization. arXiv, 2014; arXiv:1412.6980. [Google Scholar]
- Pedregosa, F.; Varoquaux, G.; Gramfort, A.; Michel, V.; Thirion, B.; Grisel, O.; Blondel, M.; Prettenhofer, P.; Weiss, R.; Dubourg, V.; et al. Scikit-learn: Machine Learning in Python. J. Mach. Learn. Res. 2011, 12, 2825–2830. [Google Scholar]










{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Method | Nose | Joint-1 | LW | Joint-2 | Tail | Joint-3 | RW | Joint-4 | Mean |
|---|---|---|---|---|---|---|---|---|---|
| Method in Reference [16] | 5.47 | 4.52 | 5.75 | 4.28 | 5.93 | 4.30 | 5.63 | 4.34 | 5.03 |
| ResNet-18 Regression | 4.43 | 3.77 | 4.64 | 3.85 | 4.97 | 3.59 | 4.33 | 3.58 | 4.13 |
| Original Hourglass [22] | 4.54 | 3.34 | 4.39 | 3.12 | 5.20 | 3.17 | 4.58 | 3.20 | 3.94 |
| Proposed Method | 3.85 | 3.25 | 3.95 | 3.14 | 4.67 | 3.13 | 3.87 | 3.17 | 3.63 |
| Method | Nose | Joint-1 | LW | Joint-2 | Tail | Joint-3 | RW | Joint-4 | Mean |
|---|---|---|---|---|---|---|---|---|---|
| Method in Reference [16] | 8.84 | 7.35 | 9.15 | 6.93 | 9.89 | 6.96 | 8.93 | 7.09 | 8.10 |
| ResNet-18 Regression | 7.20 | 6.23 | 7.61 | 6.37 | 8.30 | 5.90 | 7.08 | 5.95 | 6.83 |
| Original Hourglass [22] | 7.57 | 5.46 | 7.18 | 5.02 | 8.80 | 5.16 | 7.42 | 5.26 | 6.48 |
| Proposed Method | 6.54 | 5.39 | 6.52 | 5.08 | 7.74 | 5.04 | 6.32 | 5.24 | 5.98 |
| Method | Type A | Type B | Type C | Type D | Type E | Type F | Type G | Type H | Mean |
|---|---|---|---|---|---|---|---|---|---|
| LSGAN Loss | 95.40 | 98.10 | 98.20 | 83.70 | 85.70 | 95.10 | 83.80 | 91.50 | 91.41 |
| RWL | 93.90 | 97.60 | 99.30 | 88.30 | 82.60 | 94.20 | 83.40 | 97.40 | 91.46 |
| RWL | 93.50 | 98.10 | 99.30 | 84.50 | 84.20 | 94.50 | 83.30 | 97.60 | 91.88 |
| RWL | 93.80 | 97.80 | 99.30 | 88.00 | 89.90 | 96.70 | 83.40 | 92.90 | 92.73 |
| RWL | 93.20 | 99.30 | 99.30 | 82.20 | 90.80 | 96.80 | 81.90 | 96.40 | 92.49 |
| RWL | 93.60 | 98.70 | 99.30 | 88.70 | 85.60 | 96.80 | 81.10 | 98.10 | 92.73 |
| Method | Type A | Type B | Type C | Type D | Type E | Type F | Type G | Type H | Mean |
|---|---|---|---|---|---|---|---|---|---|
| Overall Features | 91.80 | 94.90 | 96.60 | 83.10 | 88.00 | 94.10 | 66.60 | 89.60 | 88.09 |
| ROI Features | 93.80 | 97.80 | 99.30 | 88.00 | 89.90 | 96.70 | 83.40 | 92.90 | 92.73 |
| Features | Type A | Type B | Type C | Type D | Type E | Type F | Type G | Type H | Mean |
|---|---|---|---|---|---|---|---|---|---|
| 87.40 | 93.10 | 98.30 | 85.10 | 81.40 | 94.20 | 77.60 | 92.00 | 88.64 | |
| 87.30 | 94.10 | 95.50 | 83.30 | 82.00 | 96.20 | 71.30 | 91.60 | 87.66 | |
| 74.90 | 90.00 | 91.10 | 64.10 | 76.30 | 94.10 | 53.90 | 64.10 | 79.20 | |
| & | 92.90 | 96.70 | 99.00 | 87.20 | 88.30 | 95.00 | 81.60 | 91.40 | 91.51 |
| & | 93.00 | 96.20 | 98.80 | 83.00 | 86.70 | 95.90 | 78.40 | 92.90 | 90.53 |
| & | 87.40 | 96.70 | 97.40 | 82.90 | 86.70 | 92.20 | 74.20 | 92.20 | 89.24 |
| & & | 93.80 | 97.80 | 99.30 | 88.00 | 89.90 | 96.70 | 83.40 | 92.90 | 92.73 |
| Method | Type A | Type B | Type C | Type D | Type E | Type F | Type G | Type H | Mean |
|---|---|---|---|---|---|---|---|---|---|
| AlexNet [8] | 75.60 | 97.80 | 95.90 | 70.40 | 69.80 | 98.00 | 64.30 | 91.00 | 82.85 |
| VGG-16 [9] | 82.30 | 98.40 | 89.80 | 87.30 | 67.50 | 96.90 | 74.60 | 90.20 | 85.88 |
| ResNet-18 [11] | 86.10 | 99.30 | 96.60 | 82.60 | 69.80 | 99.70 | 79.20 | 84.60 | 87.24 |
| DBN [7] | 83.40 | 93.60 | 92.60 | 80.40 | 68.80 | 93.60 | 78.50 | 85.64 | 84.56 |
| Method in [16] | 91.70 | 80.70 | 91.10 | 79.50 | 17.40 | 47.80 | 30.10 | 72.60 | 63.86 |
| Method in [16] +R | 99.70 | 88.00 | 96.10 | 99.60 | 99.90 | 88.60 | 99.90 | 75.70 | 93.44 |
| Our Keypoints | 92.60 | 98.00 | 87.50 | 97.50 | 34.10 | 97.10 | 43.00 | 71.10 | 77.61 |
| Our Keypoints +R | 99.70 | 99.50 | 92.00 | 99.10 | 99.40 | 99.80 | 99.60 | 76.20 | 95.66 |
| Proposed Method | 93.80 | 97.80 | 99.30 | 88.00 | 89.90 | 96.70 | 83.40 | 92.90 | 92.73 |
| Method | Type A | Type B | Type C | Type D | Type E | Type F | Type G | Type H | Mean |
|---|---|---|---|---|---|---|---|---|---|
| Ground Truth | 93.60 | 98.50 | 99.40 | 89.40 | 91.00 | 96.60 | 84.30 | 96.50 | 93.65 |
| Predicted Result | 93.80 | 97.80 | 99.30 | 88.00 | 89.90 | 96.70 | 83.40 | 92.90 | 92.73 |
© 2018 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Zhang, Y.; Sun, H.; Zuo, J.; Wang, H.; Xu, G.; Sun, X. Aircraft Type Recognition in Remote Sensing Images Based on Feature Learning with Conditional Generative Adversarial Networks. Remote Sens. 2018, 10, 1123. https://doi.org/10.3390/rs10071123
Zhang Y, Sun H, Zuo J, Wang H, Xu G, Sun X. Aircraft Type Recognition in Remote Sensing Images Based on Feature Learning with Conditional Generative Adversarial Networks. Remote Sensing. 2018; 10(7):1123. https://doi.org/10.3390/rs10071123
Chicago/Turabian StyleZhang, Yuhang, Hao Sun, Jiawei Zuo, Hongqi Wang, Guangluan Xu, and Xian Sun. 2018. "Aircraft Type Recognition in Remote Sensing Images Based on Feature Learning with Conditional Generative Adversarial Networks" Remote Sensing 10, no. 7: 1123. https://doi.org/10.3390/rs10071123
APA StyleZhang, Y., Sun, H., Zuo, J., Wang, H., Xu, G., & Sun, X. (2018). Aircraft Type Recognition in Remote Sensing Images Based on Feature Learning with Conditional Generative Adversarial Networks. Remote Sensing, 10(7), 1123. https://doi.org/10.3390/rs10071123