A Statistical Modeling Framework for Characterising Uncertainty in Large Datasets: Application to Ocean Colour

 , , and
, , and
Abstract

1. Introduction
1.1. The Problem: Remote Sensing Uncertainty Accounting
1.2. Statistical Modeling
- location or central tendency (e.g., the mean);
- scale or range of variation (e.g., the SD);
- shape (e.g., skewness or kurtosis).
2. Materials and Methods
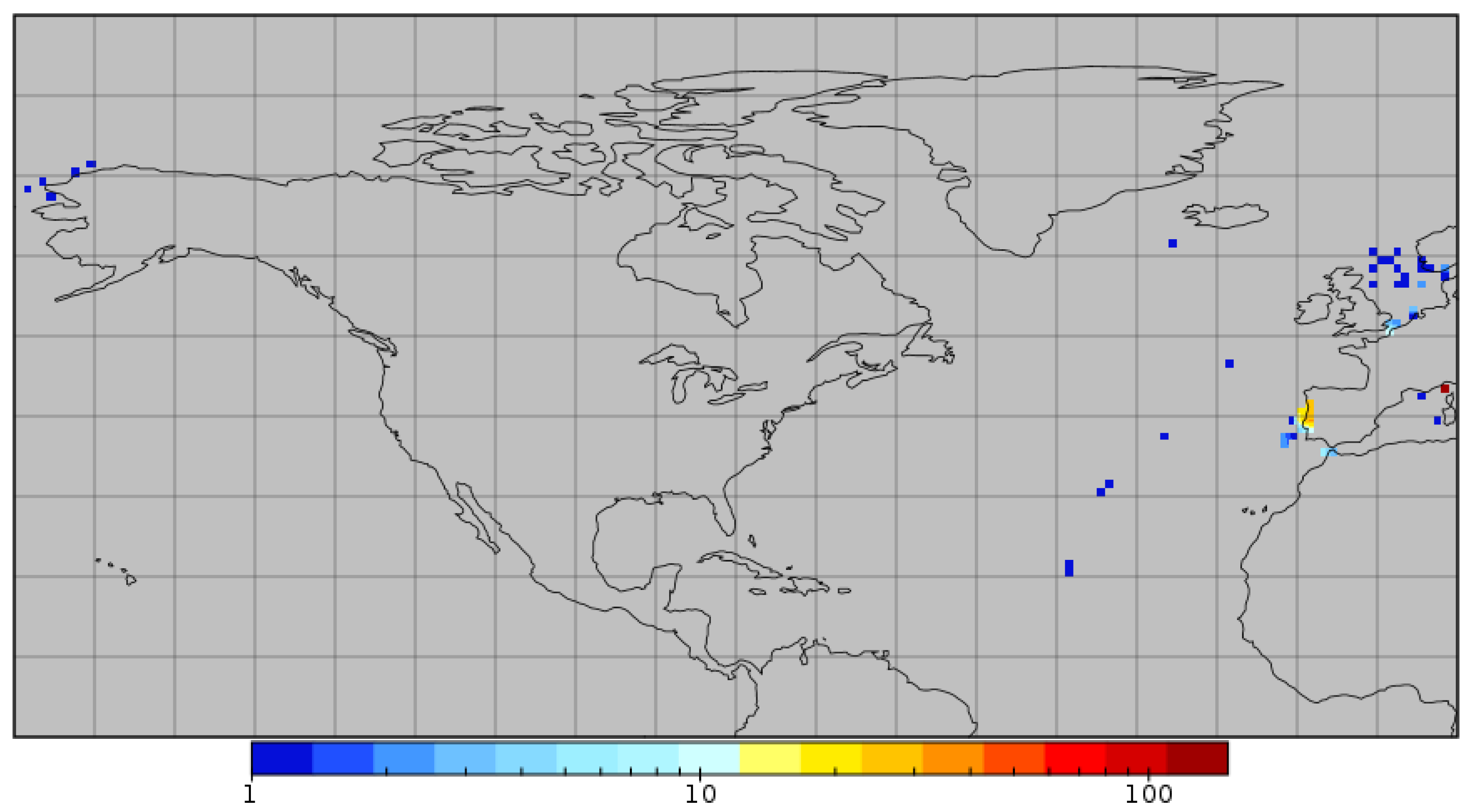
2.1. Data—The Matchups Database
2.2. Candidate Explanatory Variables
- We expect chlSAT itself to be related to chl errors. The first indication that the chl retrieval has failed is usually the presence of outliers, or implausible values of chlSAT. Also, the task of retrieving chl in oligotrophic waters is very different from that in highly eutrophic waters, so we expect retrieval uncertainty to vary with chl [15]. We therefore included ln(chlSAT) as a candidate explanatory variable. Other derived geophysical products that could give insight into the performance of the chl algorithm, such as inherent optical properties, could also be used.
- The standard OC3 MODIS-Aqua chl algorithm is based on ratios of Rrs [13], so we expect Rrs at different wavelengths to affect errors in different ways. The Rrs spectrum is also indicative of water type [6], with different water types having different effects on atmospheric correction (e.g., highly scattering waters are bright in the near infrared) and on the quality of chl retrievals (e.g., highly absorbing waters can give erroneously high chl values) [15]. Here, we represented the Rrs spectrum by simply including all visible wavelength spectral bands of Rrs, though many other combinations such as Rrs ratios may also be useful. See Table A1 for a list of spectral bands used.
- The solar and view zenith angles affect retrievals through atmospheric and surface effects. When light passes obliquely through the atmosphere, it is attenuated more than a vertical beam, and it also becomes harder to predict the effect of interaction of the light with the atmosphere and the sea surface; hence, atmospheric correction uncertainty is expected to increase [16]. The solar zenith angle also affects the amount of light available to phytoplankton at the time of measurement. We represented solar and view zenith angles with 1/cos(zenith angle), a measure of how much atmosphere light has to pass through without being absorbed or scattered. We also represented the airmass as 1/cos(solar zenith angle) + 1/cos(view zenith angle), a measure of the total atmospheric path length from sun to satellite via the sea surface.
- Wind speed affects retrievals through disturbance of the sea surface, making it more difficult to predict its effect on incident light, particularly at high zenith angles [17]. Wind can also create wave breaking and surface foam, which appears bright in the near infrared, potentially causing problems for atmospheric correction [18].
- Sun glint is bright in the near infrared and can cause problems for atmospheric correction. It can be modeled as a function of wind speed, view geometry, and wavelength [17], and we would like to represent sun glint with the modeled glint at 869 nm. However, in the matchups database there were many pixels for which this product was missing, and we could find no satisfactory way of including an explanatory variable with so much missing data, so this variable was excluded from analysis.
- Aerosol haze makes retrieval of chl more difficult by scattering and absorbing light [19]. Thin or sub-pixel cloud that does not trigger the CLDICE flag is also interpreted as aerosol in MODIS-Aqua processing [20]. We would like to represent aerosol with the retrieved aerosol optical depth at 869 nm, but again there were many pixels for which this product was missing, so it was excluded. Although sun glint and aerosol are not used in this analysis, they are mentioned because they are likely to be important sources of uncertainty in satellite ocean colour.
- The date could influence chl uncertainty in two ways, through long-term changes and through seasonal variations. Long-term changes could be due to sensor degradation with time [21], or to climatological ecosystem changes, which could affect the quality of chl retrievals from space. We represented long-term changes with the satellite age in days to try to detect sensor degradation effects, since here we are only dealing with one satellite. If multiple sensors were used, we could try to distinguish changes due to sensor degradation from those due to ecosystem changes by looking for sensor-specific changes. Seasonal variations could be due to the seasonal cycle of phytoplankton, or to optical changes, the most obvious of which is the change in sun zenith angle. We represented this with the day of year, which should be represented as a cyclic function with a 365-day cycle. Our data are all in the northern hemisphere, but if data from both hemispheres are used, it may be necessary to create an interaction term between latitude and day of year.
- Latitude (together with day of year) determines the day length, a fundamental influence on phytoplankton ecology, as well as the solar zenith angle. Ocean circulation patterns also tend to segregate the oceans into zonal provinces (e.g., [22]). Our in situ data are geographically too sparse to reliably distinguish provinces, so instead of using latitude directly, we used day length calculated from latitude and day of year, as well as solar zenith angle (see above).
- The time difference between satellite and in situ measurements obviously has a potential impact on the quality of the retrieval, and this is traditionally accounted for by imposing a maximum time difference on matchups, e.g., ±6 h. This approach has the same drawback as the Level 2 flags: that a measurement slightly less than 6 h away from the in situ measurement, that almost exceeds several other mask thresholds, is given full weight in calibration or validation exercises, while one slightly more than 6 h away that is otherwise exemplary is given zero weight. We included time difference as an explanatory variable in order to try to quantify its effect. This might shed light on the choice of maximum time difference, as well as allowing us to weigh calibration or validation measurements according to time differences. We would actually expect this uncertainty to be dependent on how rapidly chl is changing at the point of measurement. Given sufficient data, it may be possible to distinguish different weightings or maximum time differences in different regions. Another possible way that time differences could influence retrieval quality is through diurnal changes in chl. Since a sun-synchronous satellite measures at approximately the same time of day everywhere, this effect would be seen as a bias due to time difference for a given satellite orbit, while we might expect differences due to non-diurnal changes to occur as often in one direction as the other, and so appear as an increase in SD.
- Level 2 flags are intended to inform users of the circumstances surrounding the pixel measurement. Some are simply informative (e.g., this is a land or shallow water pixel), some are warnings (e.g., suspected sun glint), and some denote errors (e.g., atmospheric correction or chl algorithm failure). The aim of this work is to replace flag-based approaches with continuously varying uncertainties, so we did not include Level 2 flags. However, we did examine the effectiveness of level 3 masking in eliminating pixels with large errors, and the results were not as expected. Histograms of δln(chl) = ln(chlSAT) − ln(chlIS) for both the whole dataset and only pixels masked at level 3 showed that the pixels masked at level 3 had a consistently lower bias, with a root mean squared δln(chl) of 0.871 for the whole dataset and 0.714 for the pixels masked (i.e., rejected as suspected low quality) at level 3. This is the opposite of the intended effect of masking.
- Chlorophyll can exhibit high variability on many spatiotemporal scales, and we would expect high variability on the scale of the satellite-in situ comparison (up to a few km and hours) or smaller to result in increased chl discrepancies. We represented spatial variability with the SD of the ln(chlSAT) associated with each chlIS, of which there can be up to nine. This combines two possible effects, spatial variability in chl, and effects causing changes in chlSAT such as stray light. MODIS-Aqua data generally recur in a given location once a day at best except at high latitudes, so representation of temporal variability is not possible using these data. HPLC is time consuming and expensive, so in situ HPLC data with high spatiotemporal resolution are rare. However, if this analysis were repeated using in situ data with the appropriate resolution, such as fluorometric chl from autonomous sensors, the effect of in situ chl variability could be studied.
- The number of valid chl values in the 3 × 3 grid, either at level 2 or 3, is an indication of the presence or absence of features such as clouds or land that may increase uncertainty in the remaining values. Here, we used the number of valid chl values at level 2.
- If a more analytic uncertainty model is available, then the outputs of this (e.g., bias and SD, or just overall uncertainty) may be used as inputs to this model. If the prior model is perfectly successful, then, e.g., output bias will equal input bias with no other dependencies. It is far more likely that other dependencies exist, giving insight into how the prior model can be improved.
2.3. Statistical Modeling
- Start with a basic model (we used constant mean and SD);
- Try adding each explanatory variable in turn to the mean and keep only the one with the lowest global deviance;
- Repeat 2, adding further variables to the mean until no variable improves the global deviance;
- Repeat 2–3, adding variables to the SD;
- Try removing each variable in turn from the SD and keep only the removal that results in the lowest global deviance. Repeat until no variable removal improves the global deviance;
- Repeat 5, removing variables from the mean.
2.4. Application to Satellite Data
3. Results
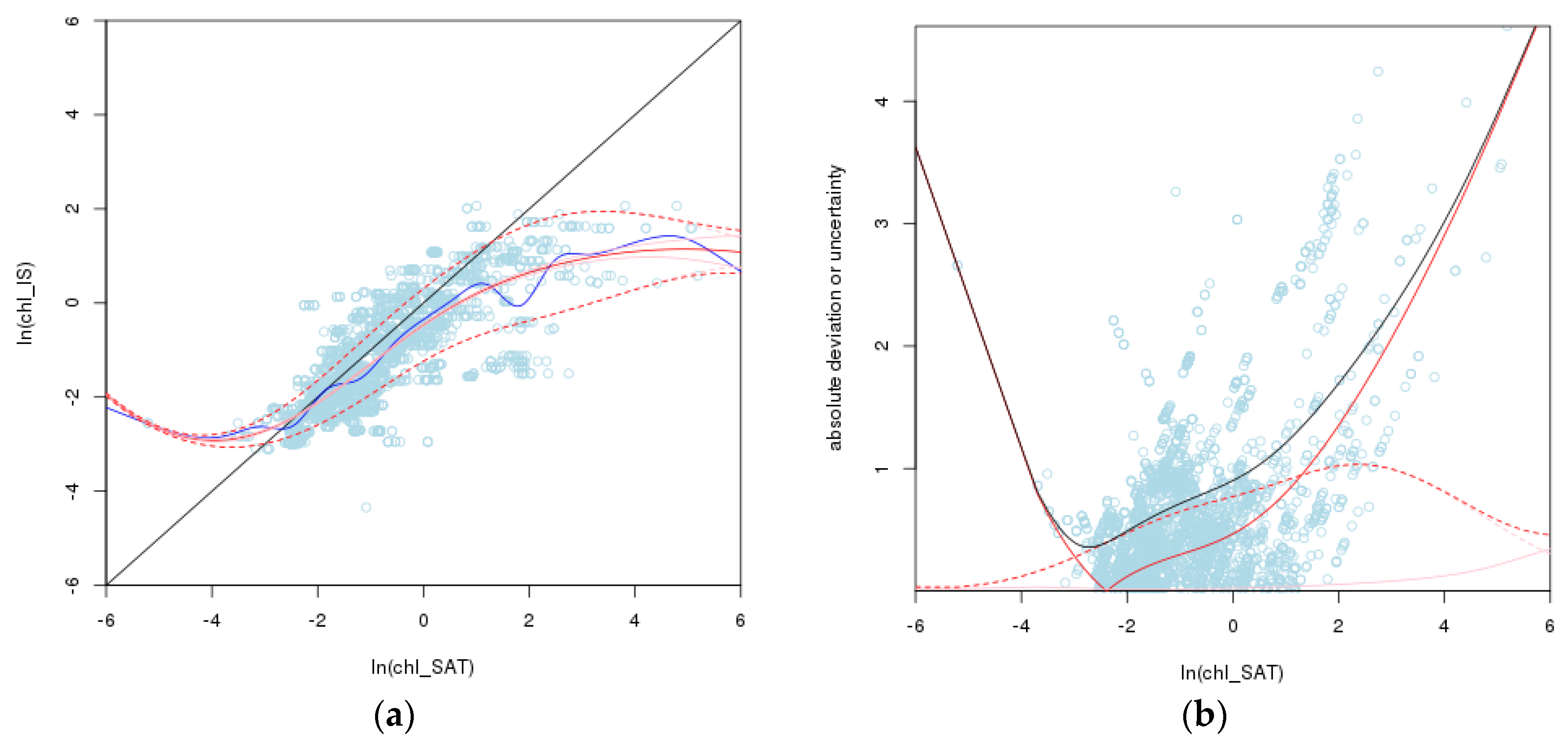
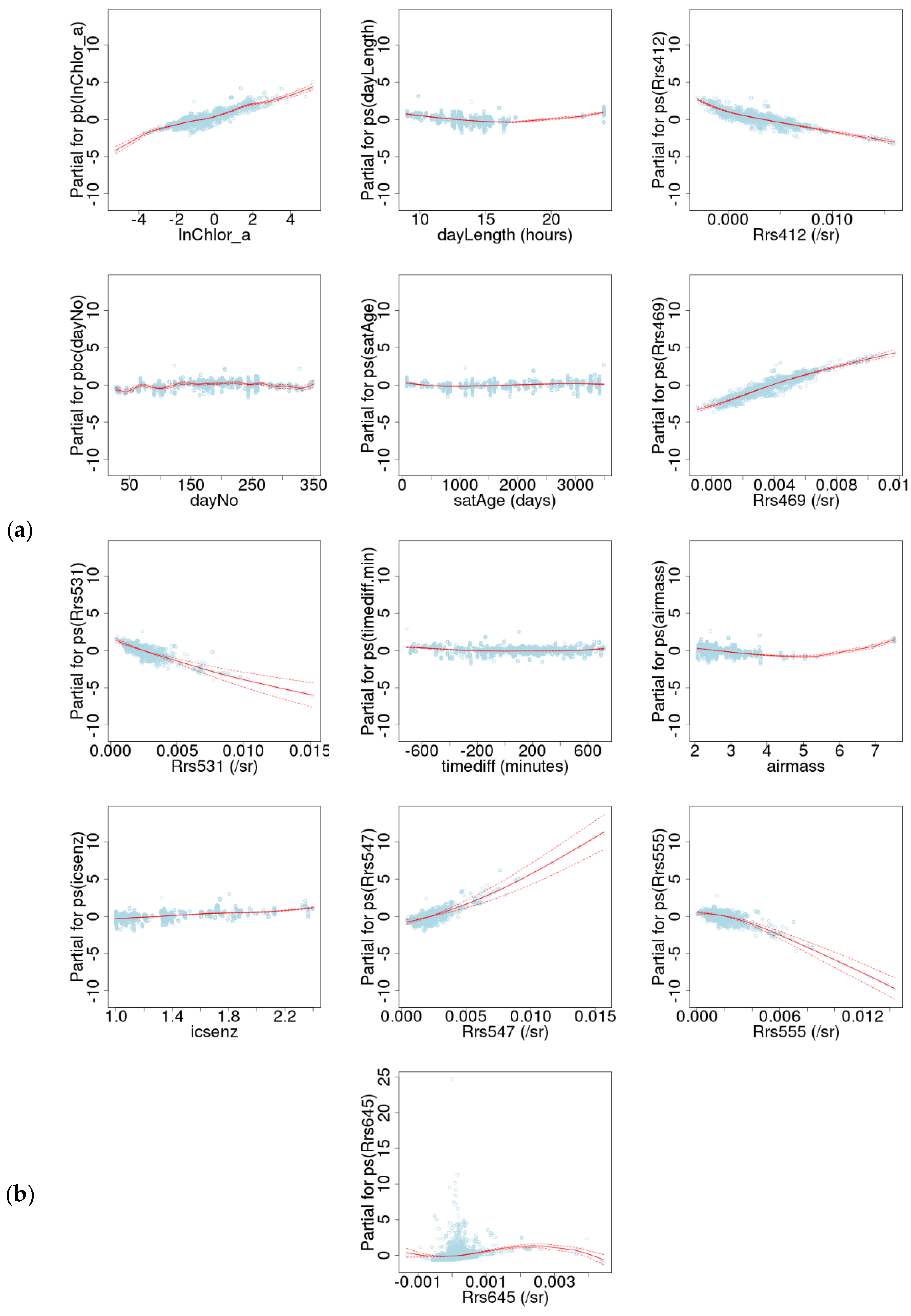
3.1. Model Dependencies
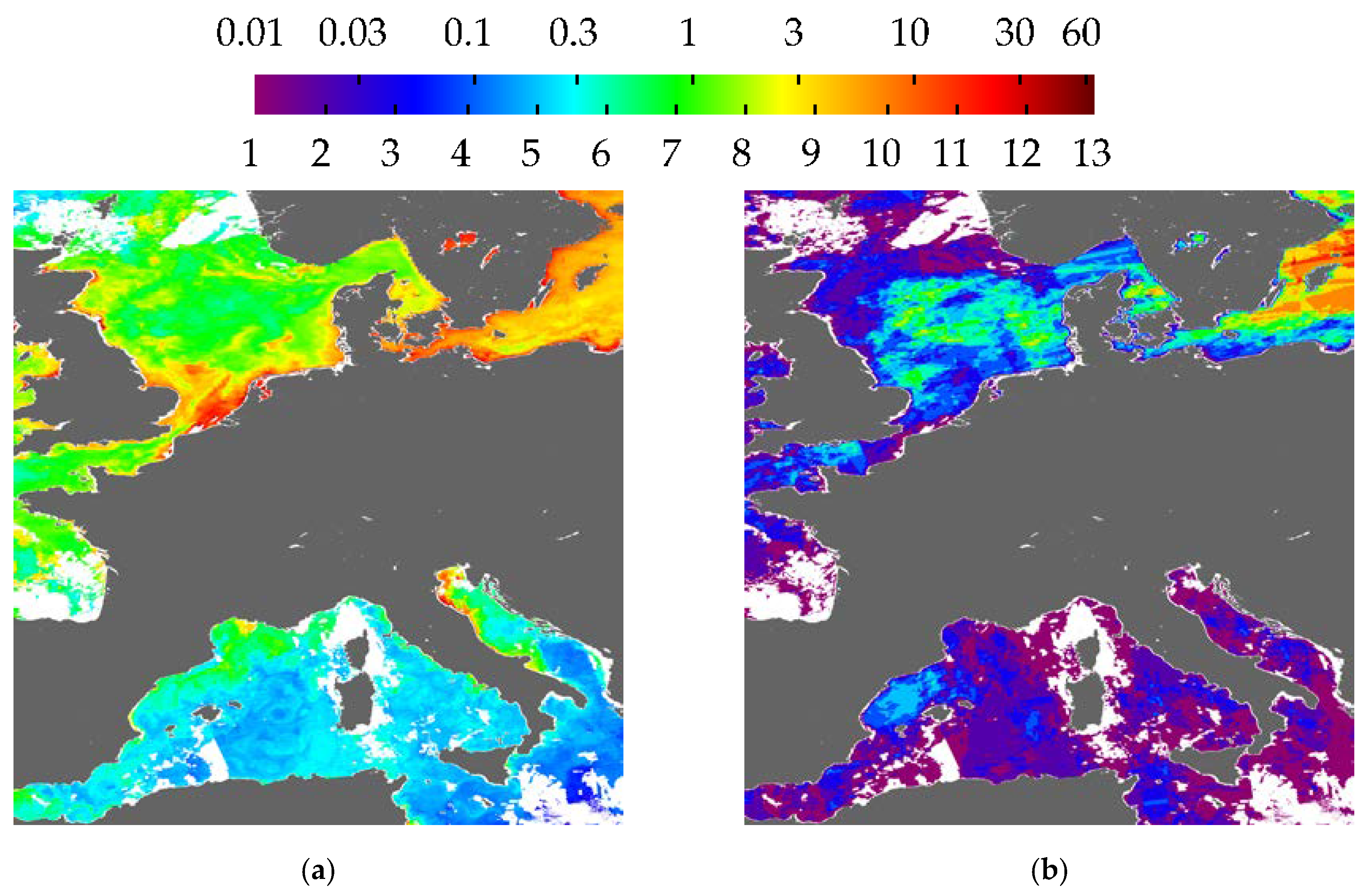
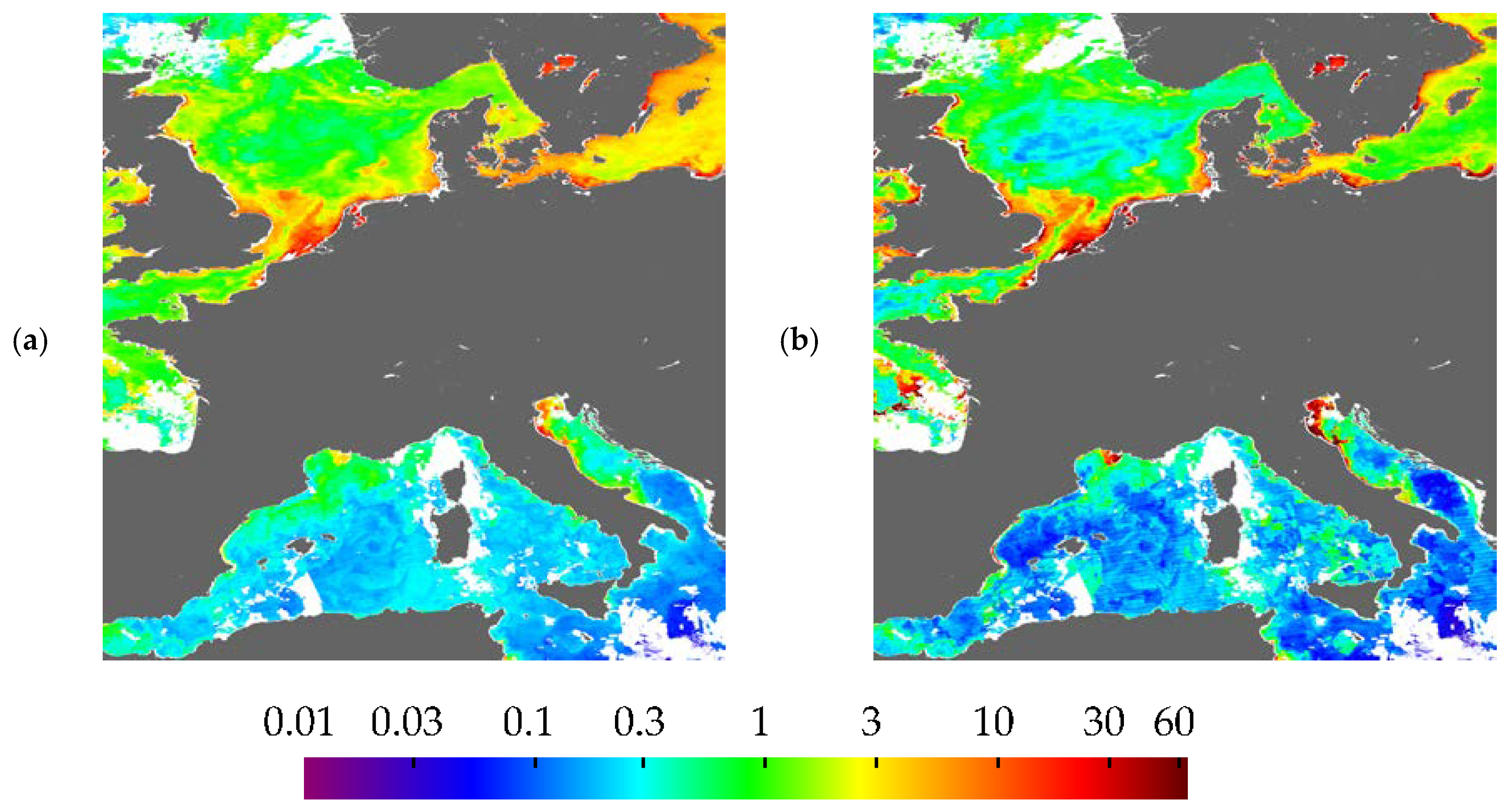
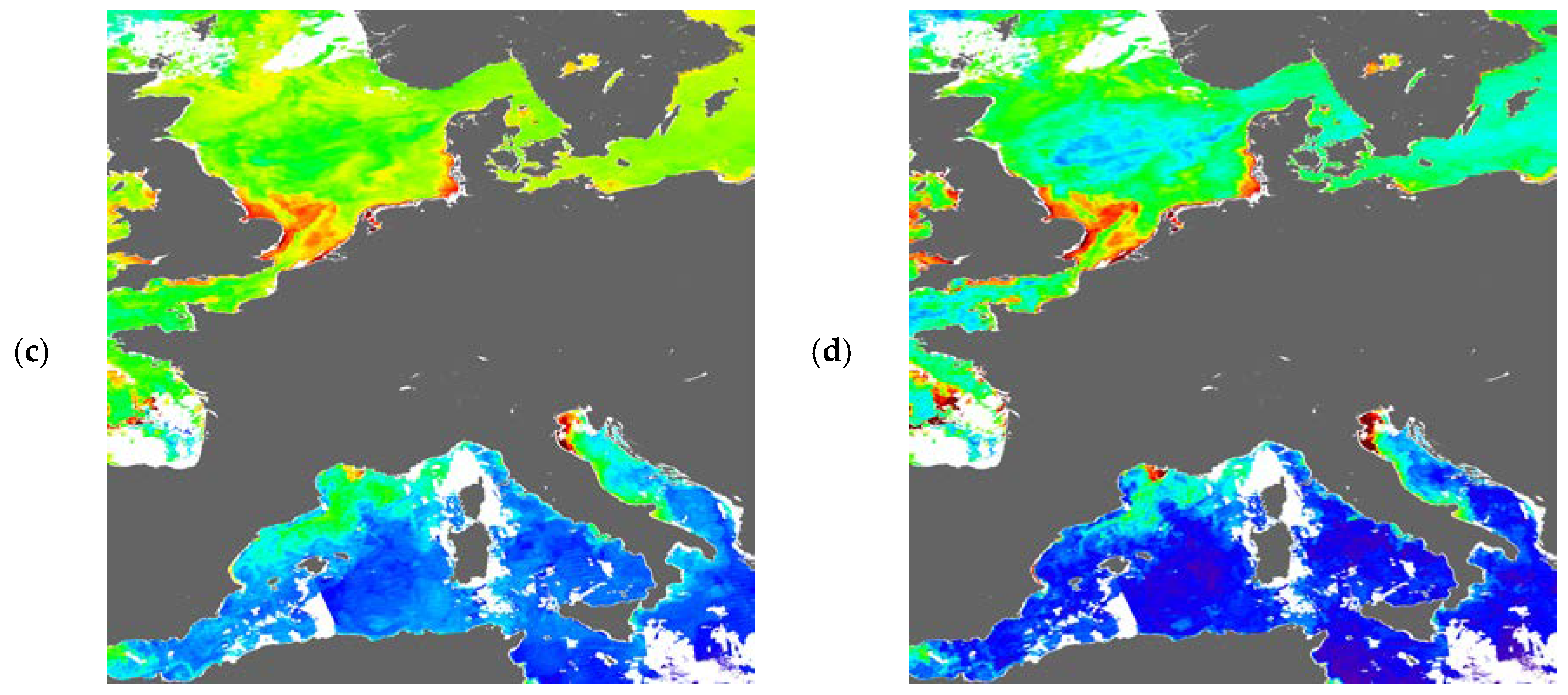
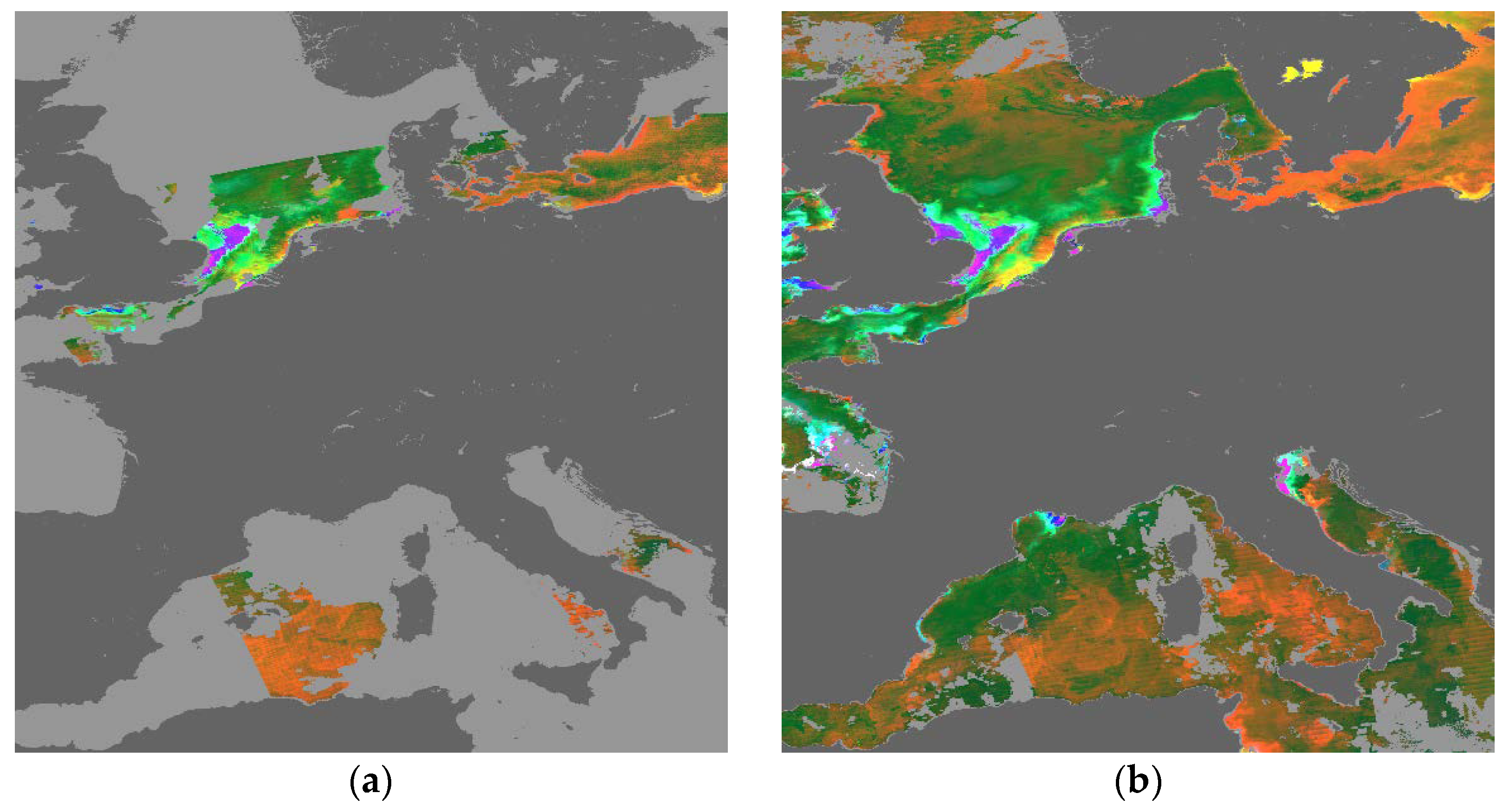
3.2. Visualisation of Uncertainties
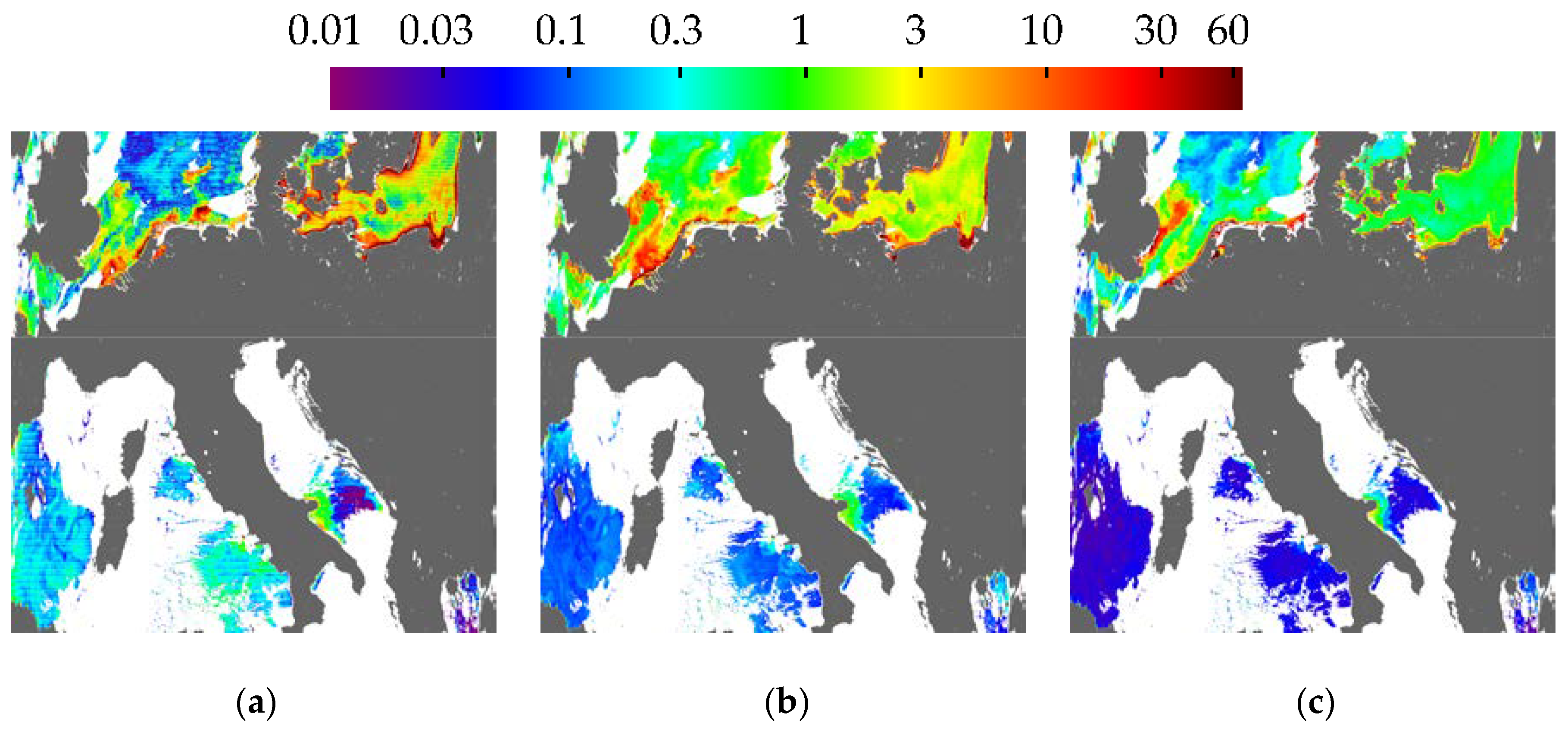
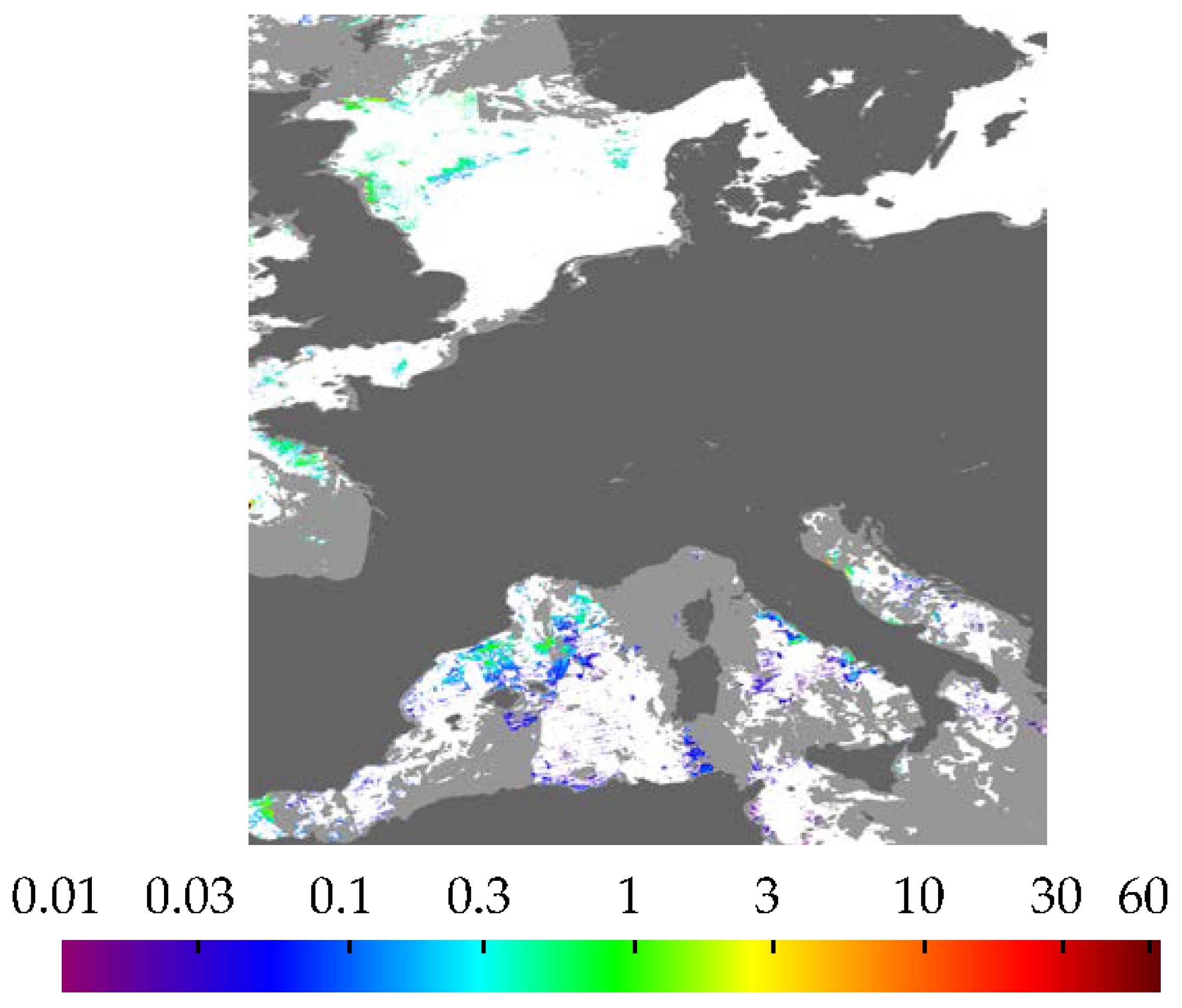
3.3. Effect on Composites
4. Discussion
5. Conclusions
Supplementary Materials
Author Contributions
Funding
Acknowledgments
Conflicts of Interest
Appendix A

{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Variable | Functional form in Mean Model | Order of Addition to Mean Model | SDpred | Functional form in SD Model |
|---|---|---|---|---|
| ln(chlSAT) | pb | 1 | 0.79 | |
| Day of year | pbc | 4 | 0.28 | |
| Day length | ps | 2 | 0.32 | |
| Satellite age | ps | 5 | 0.14 | |
| 1/cos(solar zenith angle) | ||||
| 1/cos(view zenith angle) | ps | 10 | 0.30 | |
| Airmass | ps | 9 | 0.27 | |
| Wind speed | ||||
| Aerosol optical depth at 869 nm | ||||
| Glint radiance at 869 nm | ||||
| Rrs(412) | ps | 3 | 0.78 | |
| Rrs(443) | ||||
| Rrs(469) | ps | 6 | 1.21 | |
| Rrs(488) | ||||
| Rrs(531) | ps | 7 | 0.65 | |
| Rrs(547) | ps | 11 | 0.76 | |
| Rrs(555) | ps | 12 | 0.66 | |
| Rrs(645) | ps | |||
| Rrs(667) | ||||
| Rrs(678) | ||||
| Time difference | ps | 8 | 0.11 |
| Model or Change from Previous Model | Mean Deviance (Improvement over Previous Best Model) | gamlssCV-Gamlss | RMSD | Percentage of Squared Deviation Explained | |
|---|---|---|---|---|---|
| Gamlss | GamlssCV | ||||
| Original data | - | - | - | 0.87 | - |
| Constant mean and SD | 2.362 | 2.377 | 0.016 | 0.79 | 17% |
| Linear mean | 2.095(0.266) | 2.121(0.256) | 0.025 | 0.70 | 37% |
| ps mean | 2.027(0.068) | 2.077(0.044) | 0.05 | 0.682 | 39% |
| pb mean | 1.964(0.063) | 2.065(0.012) | 0.101 | 0.68 | 40% |
| ps SD | 1.841(0.123) | 1.993(0.072) | 0.152 | 0.68 | 40% |
Appendix B

References
- Global Climate Observing System (GCOS). Systematic Observation Requirements for Satellite-Based Products for Climate 2011 Update, WMO GCOS Report 154; World Meteorological Organization (WMO): Geneva, Switzerland, 2011; p. 127. [Google Scholar]
- O’Reilly, J.E.; Maritorena, S.; Mitchell, B.G.; Siegel, D.A.; Carder, K.L.; Garver, S.A.; Kahru, M.; McClain, C. Ocean color chlorophyll algorithms for SeaWiFS. J. Geophys. Res. Oceans 1998, 103, 24937–24953. [Google Scholar] [CrossRef]
- Level 2 Ocean Color Flags. Available online: https://oceancolor.gsfc.nasa.gov/atbd/ocl2flags/ (accessed on 20 February 2018).
- Hu, C.; Carder, K.L.; Muller-Karger, F.E. How precise are SeaWiFS ocean color estimates? Implications of digitization-noise errors. Remote Sens. Environ. 2001, 76, 239–249. [Google Scholar] [CrossRef]
- Hu, C.; Feng, L.; Lee, Z.; Davis, C.O.; Mannino, A.; McClain, C.R.; Franz, B.A. Dynamic range and sensitivity requirements of satellite ocean color sensors: Learning from the past. Appl. Opt. 2012, 51, 6045–6062. [Google Scholar] [CrossRef] [PubMed]
- Moore, T.S.; Campbell, J.W.; Dowell, M.D. A class-based approach to characterizing and mapping the uncertainty of the MODIS ocean chlorophyll product. Remote Sens. Environ. 2009, 113, 2424–2430. [Google Scholar] [CrossRef]
- Joint Committee for Guides in Metrology. Evaluation of Measurement Data—Guide to the Expression of Uncertainty in Measurement; Joint Committee for Guides in Metrology: Paris, France, 2008. [Google Scholar]
- Merchant, C.J.; Paul, F.; Popp, T.; Ablain, M.; Bontemps, S.; Defourny, P.; Hollmann, R.; Lavergne, T.; Laeng, A.; de Leeuw, G. Uncertainty information in climate data records from Earth observation. Earth Syst. Sci. Data Discuss. 2017. [Google Scholar] [CrossRef]
- Stasinopoulos, D.M.; Rigby, R.A. Generalized Additive Models for Location Scale and Shape (GAMLSS) in R. J. Stat. Softw. 2008, 23. [Google Scholar] [CrossRef]
- Akaike, H. Likelihood of a model and information criteria. J. Econom. 1981, 16, 3–14. [Google Scholar] [CrossRef]
- Geisser, S. The predictive sample reuse method with applications. J. Am. Stat. Assoc. 1975, 70, 320–328. [Google Scholar] [CrossRef]
- MODIS-Aqua Reprocessing 2012. Available online: https://oceancolor.gsfc.nasa.gov/reprocessing/r2012/aqua/ (accessed on 13 February 2018).
- O’Reilly, J.E.; Maritorena, S.; Siegel, D.A.; O’Brien, M.C.; Toole, D.; Mitchell, B.G.; Kahru, M.; Chavez, F.P.; Strutton, P.; Cota, G.F. Ocean color chlorophyll a algorithms for SeaWiFS, OC2, and OC4: Version 4. In SeaWiFS Postlaunch Calibration and Validation Analyses Part 3; NASA: Washington DC, USA, 2000; pp. 9–23. [Google Scholar]
- Wolfe, R.E.; Roy, D.P.; Vermote, E. MODIS land data storage, gridding, and compositing methodology: Level 2 grid. IEEE Trans. Geosci. Remote Sens. 1998, 36, 1324–1338. [Google Scholar] [CrossRef]
- International Ocean-Colour Coordinating Group. Remote Sensing of Ocean Colour in Coastal, and Other Optically-Complex, Waters; IOCCG: Dartmouth, NS, Canada, 2000. [Google Scholar]
- Yang, H.; Gordon, H.R. Remote sensing of ocean color: Assessment of water-leaving radiance bidirectional effects on atmospheric diffuse transmittance. Appl. Opt. 1997, 36, 7887–7897. [Google Scholar] [CrossRef] [PubMed]
- Wang, M.; Bailey, S.W. Correction of sun glint contamination on the SeaWiFS ocean and atmosphere products. Appl. Opt. 2001, 40, 4790–4798. [Google Scholar] [CrossRef] [PubMed]
- Gordon, H.R.; Wang, M. Influence of oceanic whitecaps on atmospheric correction of ocean-color sensors. Appl. Opt. 1994, 33, 7754–7763. [Google Scholar] [CrossRef] [PubMed]
- Gordon, H.R.; Wang, M. Retrieval of water-leaving radiance and aerosol optical thickness over the oceans with SeaWiFS: A preliminary algorithm. Appl. Opt. 1994, 33, 443–452. [Google Scholar] [CrossRef] [PubMed]
- Wang, M.; Shi, W. Cloud masking for ocean color data processing in the coastal regions. IEEE Trans. Geosci. Remote Sens. 2006, 44, 3196–3205. [Google Scholar] [CrossRef]
- Xiong, X.; Sun, J.; Xie, X.; Barnes, W.L.; Salomonson, V.V. On-orbit calibration and performance of Aqua MODIS reflective solar bands. IEEE Trans. Geosci. Remote Sens. 2010, 48, 535–546. [Google Scholar] [CrossRef]
- Longhurst, A.; Sathyendranath, S.; Platt, T.; Caverhill, C. An estimate of global primary production in the ocean from satellite radiometer data. J. Plankton Res. 1995, 17, 1245–1271. [Google Scholar] [CrossRef]
- Campbell, J.W. The lognormal distribution as a model for bio-optical variability in the sea. J. Geophys. Res. Oceans 1995, 100, 13237–13254. [Google Scholar] [CrossRef]
- SeaDAS. Available online: https://seadas.gsfc.nasa.gov (accessed on 26 February 2018).
- Andersen, J.H.; Carstensen, J.; Conley, D.J.; Dromph, K.; Fleming-Lehtinen, V.; Gustafsson, B.G.; Josefson, A.B.; Norkko, A.; Villnäs, A.; Murray, C. Long-term temporal and spatial trends in eutrophication status of the Baltic Sea. Biol. Rev. 2017, 92, 135–149. [Google Scholar] [CrossRef] [PubMed]
- Brewin, R.J.W.; Sathyendranath, S.; Müeller, D.; Brockmann, C.; Deschamps, P.Y.; Devred, E.; Doerffer, R.; Fomferra, N.; Franz, B.; Grant, M. The ocean colour climate change initiative: A round-robin comparison of in-water bio-optical algorithms. Remote Sens. Environ. 2012. [Google Scholar] [CrossRef]
- Lee, K.; Tong, L.T.; Millero, F.J.; Sabine, C.L.; Dickson, A.G.; Goyet, C.; Park, G.H.; Wanninkhof, R.; Feely, R.A.; Key, R.M. Global relationships of total alkalinity with salinity and temperature in surface waters of the world’s oceans. Geophys. Res. Lett. 2006, 33. [Google Scholar] [CrossRef]
- International Ocean-Colour Coordinating Group. Guide to the Creation and Use of Ocean-Colour, Level-3, Binned Data Products; Antoine, D., Ed.; IOCCG: Dartmouth, NS, Canada, 2004; Volume 4. [Google Scholar]









© 2018 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Land, P.E.; Bailey, T.C.; Taberner, M.; Pardo, S.; Sathyendranath, S.; Nejabati Zenouz, K.; Brammall, V.; Shutler, J.D.; Quartly, G.D. A Statistical Modeling Framework for Characterising Uncertainty in Large Datasets: Application to Ocean Colour. Remote Sens. 2018, 10, 695. https://doi.org/10.3390/rs10050695
Land PE, Bailey TC, Taberner M, Pardo S, Sathyendranath S, Nejabati Zenouz K, Brammall V, Shutler JD, Quartly GD. A Statistical Modeling Framework for Characterising Uncertainty in Large Datasets: Application to Ocean Colour. Remote Sensing. 2018; 10(5):695. https://doi.org/10.3390/rs10050695
Chicago/Turabian StyleLand, Peter E., Trevor C. Bailey, Malcolm Taberner, Silvia Pardo, Shubha Sathyendranath, Kayvan Nejabati Zenouz, Vicki Brammall, Jamie D. Shutler, and Graham D. Quartly. 2018. "A Statistical Modeling Framework for Characterising Uncertainty in Large Datasets: Application to Ocean Colour" Remote Sensing 10, no. 5: 695. https://doi.org/10.3390/rs10050695
APA StyleLand, P. E., Bailey, T. C., Taberner, M., Pardo, S., Sathyendranath, S., Nejabati Zenouz, K., Brammall, V., Shutler, J. D., & Quartly, G. D. (2018). A Statistical Modeling Framework for Characterising Uncertainty in Large Datasets: Application to Ocean Colour. Remote Sensing, 10(5), 695. https://doi.org/10.3390/rs10050695