1. Introduction
Hyperspectral imaging technology has been used in a wide range of applications in the field of Earth observation, such as vegetation control, precision agriculture, or urban surveillance [
1]. The continuous evolution of this technology is building a promising future and bringing the dawn of new potential applications (e.g., future healthcare systems [
2]). However, hyperspectral image processing poses several challenges in terms of computing requirements and algorithm development, especially when taking into account the need for increased spatial and temporal resolution in hyperspectral sensors. In fact, the traditional approach relies on the use of High-Performance Computing (HPC) infrastructures to satisfy the required performance levels [
3].
Hence, on-Earth processing has been the mainstream solution for remote-sensing applications that use hyperspectral images, relying on supercomputing systems typically based on GPUs [
4], CPUs [
5], heterogeneous CPU/GPU architectures [
6], or even FPGAs [
7]. In this scenario, on-board data compression techniques are used to minimize the overhead of data transmissions between sensors and processing facilities. These hyperspectral image compressors are usually implemented in large and computationally powerful FPGAs due to the combination of flexibility and reliability that these devices offer [
8,
9].
Nevertheless, the on-board sensing and processing paradigm has changed in the past few years [
10]. The appearance of SmallSats, and more specifically CubeSats, has fostered the emergence of missions that target low-cost, -size, and -weight satellites and components. As a result, the overall price of spatial missions has decreased significantly, enabling the possibility of launching dozens of satellites in a single deployment. This approach was first envisioned for educational purposes and low-cost technology demonstrations, due to the satellites being limited in size (10 × 10 × 10 cm
3) and power consumption (a few watts). This, in turn, allowed the deployment of low-cost Commercial Off-The-Shelf (COTS) devices to evaluate their feasibility within space applications [
11].
Although limited at the beginning, new research lines have boosted the computing capabilities of CubeSat systems. An example can be found in satellite clustering [
12], which is an attempt to provide comparable or even greater performance than before [
13]. In fact, this approach offers new opportunities beyond the use of CubeSats as educational tools for low-cost science applications, creating an ecosystem for forthcoming paradigm shifts in space applications. In this scenario, on-board processing on the edge may see significant improvements, avoiding time-consuming data transmissions from satellite to on-Earth processing facilities and thus increasing temporal resolution. However, computing performance is not the only constraint, since severe restrictions in the available power budget make energy efficiency another key factor to take into account when evaluating platforms and applications for this kind of space missions [
14].
Taking into account these restrictions, many devices have been evaluated [
15], envisioning hybrid and reconfigurable computing systems as the target fabrics. Moreover, the combination of software- and hardware-based processing in a single board or even in a single device is hinted as the optimal choice. In this regard, Systems on Programmable Chip (SoPCs) can be used, since they provide multicore processing capabilities tightly coupled with dedicated hardware accelerators in an FPGA fabric. Furthermore, Dynamic and Partial Reconfiguration (DPR) capabilities can be exploited to provide not only functional adaptation, but also fault tolerance in the reconfigurable fabric [
16,
17]. However, the use of DPR at run time to search for an adaptive working point trade-off between performance, energy efficiency, and fault tolerance in low-cost COTS devices is something not commonly found in the literature.
In this paper, a distributed and hardware-accelerated implementation of a linear unmixing algorithm for on-board hyperspectral image processing is presented. Although hyperspectral image unmixing is an application that has been following the classical execution flow (i.e., on-board compression, and on-Earth decompression and processing), the use of a small and low-cost computing cluster with SoPC-based nodes, emulating real satellite deployment, provides a competitive alternative for distributed edge computing on CubeSats. Each node uses the ARTICo
3 architecture [
18], a hardware-based processing architecture for high-performance embedded systems, and its DPR infrastructure to support user-driven run-time adaptation of computing performance, energy consumption and fault tolerance. In addition, the ARTICo
3 toolchain has been used to automate the implementation of the mixed hardware/software system, leveraging High-Level Synthesis (HLS) engines, and thus rendering low development times, a key factor in CubeSat deployments. As entry point for the design flow, a high-level description of the Fast UNmixing (FUN) algorithm [
19] in C code has been modified to fully exploit data-level parallelism and enable a two-way scalable execution pattern: on the one hand, in the number of ARTICo
3 accelerators per computing node; on the other hand, in the number of SoPC-based nodes involved in the processing stage. Although the data-parallel extension of the FUN algorithm has been implemented and evaluated using the ARTICo
3 architecture, it is platform-agnostic and, thus, it can be deployed on any computing platform as long as the parallelism holds. Moreover, the proposed block-based partitioning scheme can provide enhanced fault tolerance to the final implementation, making it possible to extract nearly all endmembers from an input dataset even if the data associated to one of the blocks get corrupted (e.g., due to radiation in space).
In summary, the main contributions of this paper are:
A data-parallel linear unmixing algorithm for on-board hyperspectral image processing based on the FUN algorithm (originally conceived for on-Earth processing).
A low-cost, networked, and hardware-accelerated implementation of that algorithm with two scalability levels and run-time adaptation capabilities in terms of computing performance and energy efficiency.
The rest of this paper is organized as follows.
Section 2 presents an overview of the related work. The FUN algorithm and the ARTICo
3 framework, which constitute the technological foundations of the presented work, are presented on
Section 3.
Section 4 gives an overview of the implementation details, including algorithmic modifications, hardware-optimization techniques, and network-distribution approaches.
Section 5 shows the experimental validation and the obtained results, and
Section 6 provides the conclusions and future work.
3. Technology Background
In this section, descriptions of both the linear unmixing algorithm and the hardware-based processing architecture used in this work are presented.
3.1. FUN
Linear unmixing is a key processing technique for hyperspectral images. It assumes that the effect of secondary reflections and scattering effects are negligible and, thus, each pixel in the image can be represented as a linear combination of a subset of elements whose spectrum is considered pure. These elements are called endmembers, and their presence in each pixel of the image is weighted by the so-called abundances. The main purpose of linear unmixing algorithms is to obtain both the endmembers and their abundances from a hyperspectral image.
The Fast UNmixing (FUN) algorithm [
19] allows the simultaneous estimation of the number of endmembers and endmember extraction. The FUN algorithm selects the first endmember as the pixel of the hyperspectral image with the largest orthogonal projection to the centroid pixel. The centroid pixel is an artificial pixel that averages all the information present in the image. Afterwards, it sequentially performs orthogonal projections of the hyperspectral image in the direction spanned by the last extracted endmembers. This process is performed in such a way that information of the hyperspectral image that can be represented by the already-extracted endmembers is subtracted from the image, and the pixel with more remaining information is selected as the next endmember. After selecting each endmember, the FUN algorithm estimates the percentage of information that cannot be represented with the already selected endmembers using stop factor
s. If the value obtained is smaller than input threshold
, the algorithm finishes, thus obtaining the total number of endmembers present in the image plus the extracted endmembers.
The orthogonal projections of the hyperspectral image can be obtained using different methods. The FUN algorithm employs a modified version of the Gram–Schmidt method, which features low computational complexity and allows the reuse of previously computed information, speeding up the overall process, without using too-complex matrix calculations.
The FUN algorithm, as other geometrical approaches to hyperspectral unmixing (e.g., OSP [
41], N-FINDR [
42], VCA [
43]), selects highly characteristic pixels as endmembers. In the presence of outliers, the set of extracted endmembers would contain actual endmembers (the algorithm would still find them) and, most probably, the outliers. Although this situation can be avoided when processing data in ground facilities (e.g., through direct supervision made by an expert), it becomes a critical issue to be addressed in on-board processing scenarios. In this context, a preprocessing stage is required to remove the outliers from input hyperspectral data (e.g., by using filtering or interpolation). In the rest of this paper, it is assumed that no outliers are present in the input datasets and, thus, no preprocessing stage is required.
The pseudocode shown in Algorithm 1 describes the process followed by the FUN algorithm to extract the endmembers. Lines 1 to 9 of this pseudocode correspond to the initialization of the algorithm by selecting the first endmember,
. In Line 12, the information of each pixel of the image that can be represented by the last extracted endmember is subtracted from the image. Hence,
contains the information of the
i-pixel that cannot be represented by the already-extracted endmembers. The amount of information remaining in each pixel,
, is measured in Line 13. The pixel with the maximum amount of remaining information is the next candidate to be endmember. The index of this pixel,
, is calculated in Line 15 of this pseudocode. After doing so, the amount of remaining information in this pixel is used for evaluating the stopping condition, as described in Line 16. If the amount of remaining information is high according to the stopping condition, and more endmembers are required, the
-
pixel is selected as the next endmember (Lines 19 to 22) and the process is repeated. Otherwise, the process finishes (Line 17). Please note that the stopping condition is the same as the one presented in Reference [
19], but implemented in a more computationally efficient way, as proposed in Reference [
25].
After extracting the endmembers, the FUN algorithm computes their abundances. This process is done by generating an orthonormal set of vectors using the obtained endmembers as the starting point. The pseudocode shown in Algorithm 2 describes the process followed by the FUN algorithm to obtain the abundances. Gram–Schmidt orthogonalization is performed
P times (lines 5 to 19) over the endmembers, using a different order each time, to fill the
U matrix (line 16). Abundances are then computed by projecting the hyperspectral image using the orthonormalized vectors contained in
U (line 20). It is important to highlight that not only Algorithm 1 (as seen in the previous paragraph), but also Algorithm 2 corresponds to the computationally efficient implementation of the FUN algorithm presented in Reference [
25]. In this implementation, several functions were optimized to reduce the number of complex and time-consuming mathematical operations. For instance, the indexing of the endmembers in Line 9 is simplified using a linear access (i.e.,
) instead of using integer division, even though it slightly increases memory overhead by replicating endmember matrix E in Line 1.
| Algorithm 1 FUN algorithm: endmember extraction |
| Inputs: |
| | ▹ Input hyperspectral image |
| | ▹ Stop factor |
| Outputs: |
| | ▹ Endmembers |
| P | ▹ Number of endmembers |
| 1: | ▹ Auxiliary copy of the hyperspectral image |
| 2: | ▹ Endmembers matrix |
| 3: | ▹ Gram Schmidt orthogonalization of Endmembers |
| 4: | ▹ Gram Schmidt orthogonalization (normalized) of Endmembers |
| 5: | ▹ Select first endmember according to initialization criteria |
| 6: |
| 7: |
| 8: |
| 9: |
| 10: while do |
| 11: for to do |
| 12: |
| 13: |
| 14: end for |
| 15: |
| 16: if then |
| 17: |
| 18: else |
| 19: |
| 20: |
| 21: |
| 22: |
| 23: end if |
| 24: end while |
| Algorithm 2 FUN algorithm: abundances computation |
| Inputs: |
| | ▹ Input hyperspectral image |
| | ▹ Endmembers |
| P | ▹ Number of endmembers |
| Outputs: |
| | ▹ Abundances |
| 1: |
| 2: |
| 3: |
| 4: |
| 5: for to do |
| 6: |
| 7: |
| 8: for to P do |
| 9: |
| 10: for to do |
| 11: |
| 12: end for |
| 13: |
| 14: |
| 15: end for |
| 16: |
| 17: |
| 18: |
| 19: end for |
| 20: |
3.2. ARTICo3
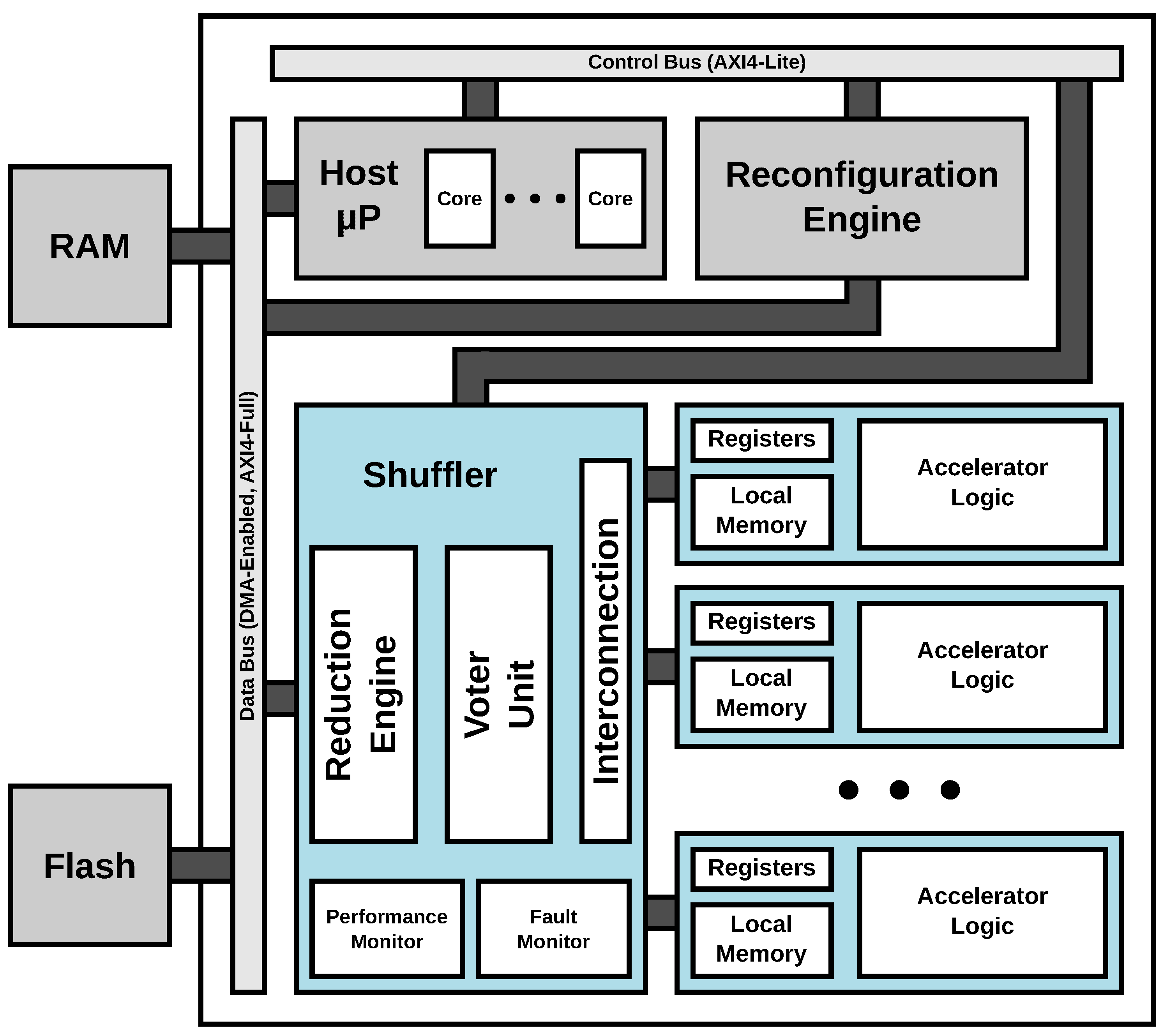
ARTICo
3 [
18] is a hardware-based high-performance embedded processing architecture that enables user-driven adaptation at runtime, creating a dynamic solution space in which tradeoffs between computing performance, energy consumption, and fault tolerance can be established. The architecture relies on the use of Dynamic and Partial Reconfiguration (DPR) in Xilinx FPGAs to provide software-like flexibility while maintaining hardware-like performance during execution. The top-level block diagram of the ARTICo
3 architecture is shown in
Figure 1.
ARTICo3-based computing platforms work in a processor–coprocessor scheme, where the application code is executed in the host microprocessor, and only those program sections that exhibit significant levels of data parallelism (called kernels) are offloaded to the hardware accelerators. This execution model, based on data independences between blocks, provides transparent scalability in terms of computing performance when coupled with DPR-based hardware replication, since the available number of processing elements (i.e., hardware accelerators) for a given kernel can be altered on demand even during application execution. In addition, the architecture can benefit from module replication not only to increase computing performance (different blocks working on different data, SIMD-like execution), but also to increase fault tolerance using DMR or TMR (different blocks working on the same data, with an embedded voter unit to mask faults).
The ARTICo3 architecture is part of a framework that also includes a toolchain to transparently generate dynamically reconfigurable systems from the descriptions of both hardware accelerators and host application. The design-time support of the framework requires users to provide an already partitioned hardware/software system, where host code is specified in C/C++ and kernels are specified in low-level HDL (VHDL, Verilog) or C/C++ to be used with High-Level Synthesis (HLS) tools. Using these elements as inputs, the toolchain automatically performs three tasks: instantiates the user-defined kernel logic in a standard wrapper, generates the on-chip DMA-powered communication infrastructure, and builds both hardware and software components to obtain the required binaries that are used in the target platform.
From the programming point of view, user code interfaces with the accelerators using a runtime library, which transparently handles (and thus, hides from the user) two complex processes: FPGA reconfiguration, and parallel execution management. This is supported by the ARTICo3 programming model, which is based on a reduced API to favor user-friendly reconfigurable computing.
4. Implementation Details
As stated in previous sections, ARTICo
3-based high-performance embedded computing relies on user-driven application partitioning in sequential host code and data-parallel hardware kernels. As a result, the first step that needs to be addressed is the profiling of the application in order to identify and extract potential data-level parallelism. A sequential C-based and single-core implementation of the original FUN algorithm has been developed and analyzed in a Zynq-7000 device. The obtained results can be seen in
Table 1, and show that, among the two parts of the linear unmixing algorithm (i.e., endmember extraction and abundances computation), endmember extraction is the most time-consuming (75%).
Taking these results as starting point, it seems reasonable to focus on optimizing the endmember extraction process. The rest of this section details the proposed modifications to the algorithm to exploit data-level parallelism (as required by ARTICo3 itself), the design-time decisions made to balance data precision, execution performance, and area overhead in the generated HLS-based hardware accelerators (to fit in resource-constrained ARTICo3 slots and still provide accurate results), and the extension from single-node to networked multi-FPGA solutions (to add a second level of scalability to the hardware-accelerated deployment).
4.1. Parallelization Approach
The original FUN algorithm uses the full hyperspectral image to extract the underlying endmembers. In the reference C code, this fact generates huge overheads in terms of processing latency (clock cycles), since several operations are implemented as nested loops that depend on the size of the input hyperspectral cube. Moreover, this dependency also imposes huge memory requirements that, for large hyperspectral images, may result in nonfeasible hardware-accelerated solutions that do not fit within the available FPGA resources.
In order to not only mitigate these problems, but also to enable data-level parallelism (and thus potentially scalable execution), a reduction-based parallelization approach has been proposed for the original algorithm, and it is one of the main contributions of this paper. First, the input hyperspectral image is split in fixed-size hyperspectral subimages. The total number of subimages may change, since it depends on the size of the input image. Then, the FUN algorithm is used independently in each of those subimages to extract partial endmembers. An iterative process follows in which fixed-size artificial hyperspectral subimages are made up from the pool of resulting partial endmembers, and the FUN algorithm is used again to achieve dimensional reduction, up to the point where only one fixed-size artificial subimage remains, and the actual endmembers are obtained. In summary, the main idea of the proposed approach is to iteratively extract endmembers from the endmembers in the partial subimages until all the actual ones have been found.
The pseudocode of the reduction-based FUN algorithm for endmember extraction can be seen in Algorithm 3. Notice that, when the same endmembers are extracted in two consecutive rounds (i.e., there is no dimensional reduction), the algorithm forces the generation of artificial subimage blocks with double the size while keeping the maximum number of endmembers that have to be extracted per block. This failsafe mechanism, which is meant to solve situations where the same endmembers are present in two or more data-independent subimages, ensures no deadlocks occur during the reduction process. Note also that, in any other situation and in order to avoid information loss, the maximum number of endmembers that can be extracted from each subimage block during the reduction process equals the number of pixels in that subimage. To better understand this, consider a scenario where all endmembers are present in one of the initial subimages: the algorithm needs to allow all these pixels to reach the final reduction round.
| Algorithm 3 Reduction-based FUN algorithm: endmember extraction |
| Inputs: |
| | ▹ Input hyperspectral image |
| | ▹ Maximum number of endmembers to extract |
| | ▹ Stop factor |
| | ▹ Number of pixels per parallel block |
| Outputs: |
| | ▹ Endmembers |
| P | ▹ Number of endmembers |
| 1: |
| 2: [X1⋯XN] ← split | ▹ Divide input image in subimages |
| 3: while do | ▹ Repeat until there is only one subimage block remaining |
| 4: |
| 5: for to N do |
| 6: Eaux ← endmembers | ▹ Extract endmembers from subimage |
| 7: | ▹ Generate artificial image |
| 8: end for |
| 9: Paux ← size |
| 10: if then | ▹ Avoid deadlock (no dimensional reduction) |
| 11: [X1⋯XN] ← split | ▹ Divide artificial image in subimages |
| 12: else | ▹ Number of endmembers |
| 13: [X1⋯XN] ← split | ▹ Divide artificial image in subimages |
| 14: end if |
| 15: | ▹ Number of endmembers |
| 16: end while | ▹ Number of endmembers |
| 17: E ← endmembers | ▹ Extract actual endmembers |
| 18: P ← size | ▹ Get number of actual endmembers |
The accuracy of the proposed algorithm has been evaluated in two scenarios: on the one hand, using synthetic hyperspectral images (256 bands, 128 lines, 128 samples) with different noise levels, number of endmembers, and abundance distributions (see
Table 2); on the other hand, using well-known real hyperspectral datasets [
44] (see
Table 3). In both scenarios,
has been set to 32, which is the maximum number of pixels that can be stored in the local memory inside ARTICo
3 accelerators. An experimental evaluation (see
Table 4) shows that the impact of
on the extraction effectiveness is negligible when this parameter is large enough (i.e., when
). The distance between extracted and real endmembers has been measured using the spectral angle, which can be calculated using Equation (
1):
where
represents known endmembers (a pixel with all its spectral bands) and
represents endmembers obtained with the algorithm. Perfect matches between real and extracted endmembers would render a spectral angle of 0°, whereas for completely unrelated pixels, the spectral angle would tend to 90°. It is important to note that, for real hyperspectral images, if the algorithm finds
P endmembers and the image is known to have only
, with
, the spectral angle is computed as the minimum value from all possible combinations (i.e., the extracted
endmembers that are closer to the real ones).
As it can be seen, the reduction-based endmember extraction provides results that are close to the ones obtained using the original FUN algorithm, which in turn are not far from the actual endmembers present in the image. A comparison with state-of-the-art alternatives (
Table 3) shows that deviations in the spectral angle are acceptable either because it is still below the value obtained with some of the most widely used unmixing algorithms (e.g., VCA or NMF), or because (even with comparable results) the algorithm is too complex to enable a runtime adaptive hardware implementation as the one presented in this work (e.g., DgS-NMF).
4.2. Hardware Tradeoffs
The reduction process detailed in Algorithm 3 has a sequential component (i.e., dimensional reduction) and a data-parallel section (i.e., endmember extraction for each subimage, Lines 5 to 8), which has been selected as the functionality to be moved to hardware. As a consequence of this decision, the transparent scalability provided by the ARTICo3 architecture, and enabled by the use of a configurable number of hardware accelerators, can be used to dynamically adapt the loop unrolling depth during application execution.
While the ARTICo
3 toolchain supports both HDL and C/C++ descriptions of the kernels, only the HLS-based entry point has been used to implement the FUN endmember extraction, since a C-based version of the whole linear unmixing chain was already available (i.e., the one used during the initial application profiling stage). As stated in the previous section, low-level FPGA limitations make it mandatory to develop resource-constrained, yet performance-oriented, hardware accelerators. In the following, two different HLS-based solutions are analyzed taking into account their execution latency and resource utilization. Both solutions have been implemented using Vivado HLS with the configuration parameters shown in
Table 5.
The first solution uses single-precision (i.e., 32-bit) floating-point arithmetic, and relies on tool-based automatic optimizations (mainly, datapath pipelining). The second solution, on the other hand, uses half-precision (i.e., 16-bit) floating-point arithmetic, and relies on tool-based automatic optimizations to improve performance (datapath pipelining) as well as on user-driven code optimization techniques to improve the performance/area ratio (manual loop unrolling). Experimental results showed no functional difference between both solutions when processing normalized input subimages (i.e., whose pixel values range from 0 to 1), since the same endmembers were obtained as output.
Table 6 shows the accelerator latency bounds for both solutions. It is important to highlight that the latency of the accelerator is data-dependent (although it will always be between the reported bounds), since the algorithm contains a loop whose trip count depends on the number of pixels with relevant information. Hence, the results shown in
Table 6 refer either to an execution that finds one endmember (minimum value) or to an execution that finds
endmembers (maximum value).
Table 7, on the other hand, shows the resource-utilization reports. Note that these reports include: combinational logic expressed as Look-Up Tables (LUTs); sequential logic expressed as Flip-Flops (FFs); dedicated logic for arithmetic operations, expressed as Digital Signal Processing blocks (DSPs); and memory elements, expressed as Block RAM (BRAMs). When comparing both alternatives, it is possible to see that the combination of half-precision floating-point arithmetic and manual loop unrolling reduces the memory footprint, but increases the rest of the resources. However, both implementations can fit in regular ARTICo
3 slots, and the slightly superior resource utilization of the half-precision implementation is an affordable cost given the performance increase that can be achieved (roughly speaking,
resources generate
performance).
4.3. Network Infrastructure
The ARTICo
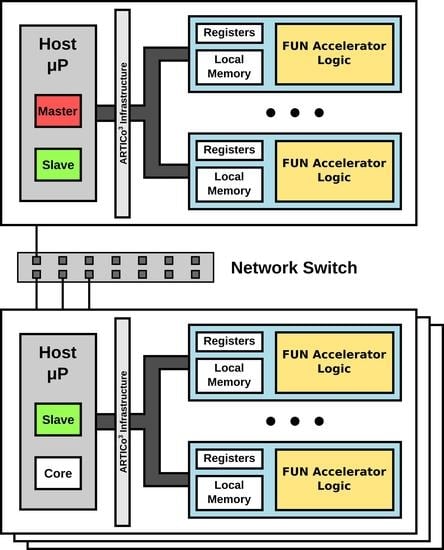
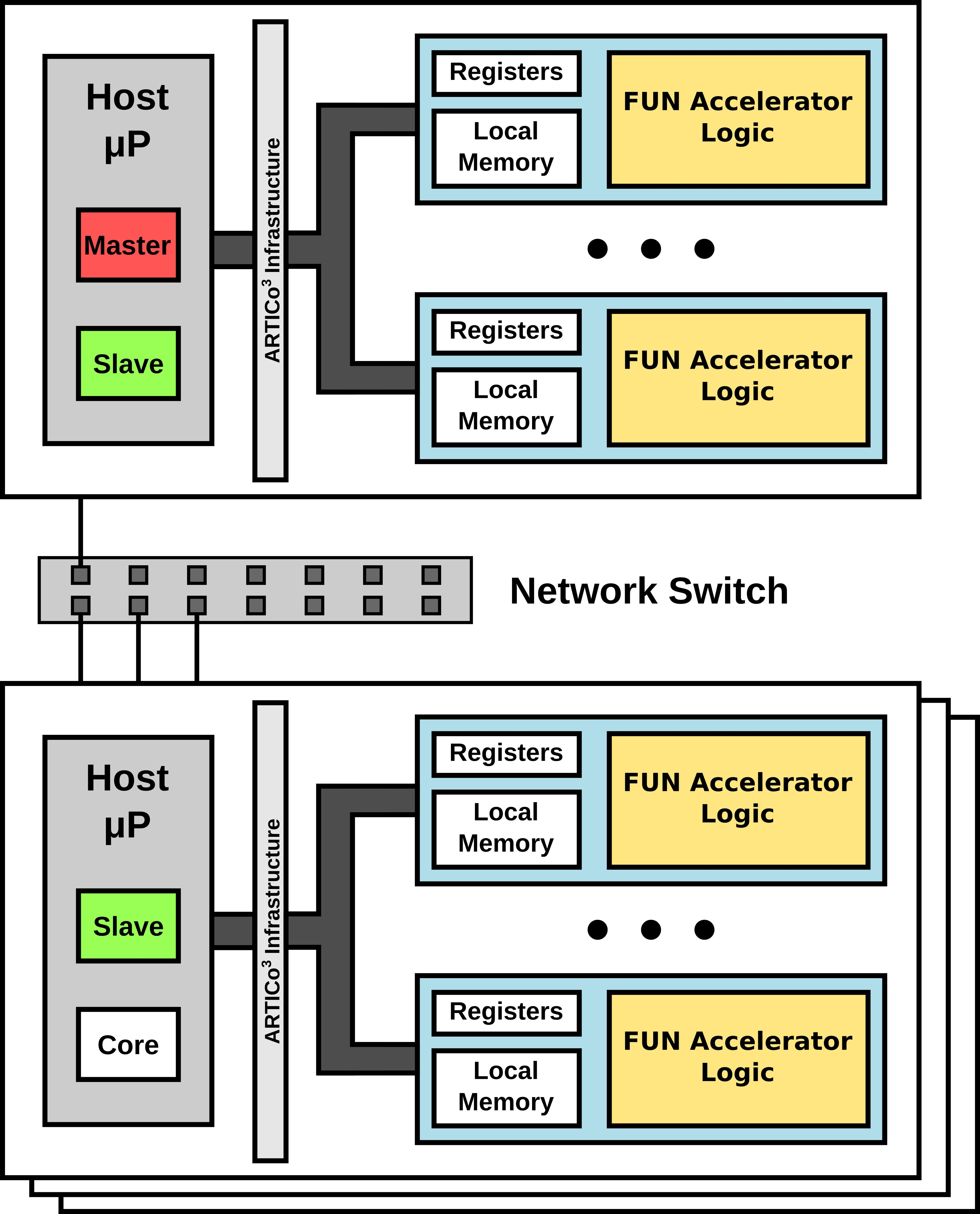
3 architecture provides performance scalability on a single node, relying on the application developer to decide how many accelerators to load for a given kernel. In order to extend the scalability to a multi-FPGA context, thus enabling a two-way scalable system, a networked approach has been implemented. The proposed solution is built upon a small cluster of parallel-processing elements, referred to as nodes, in a master/slave(s) approach (see
Figure 2), where data-level parallelism can be further exploited by dividing the computational workload between all available nodes.
In this work, data distribution and execution synchronization are made using MPI, a well-known parallel programming API used in high-performance systems with distributed memory, which has also been used in the past to prototype communications in space [
45]. However, it is important to highlight that the proposed distribution methods can be implemented using any other type of communication primitives. Regarding data distribution, two different methods have been proposed and evaluated: the application developer can decide on whether to maximize parallelism, or to minimize data transactions (communication packets). Both alternatives start with the master dividing the input hyperspectral image in as many blocks as slaves are involved in the processing stage, but they differ in the next steps.
In the maximum parallelization approach, each slave further divides the image in blocks whose size can be directly processed by the core reduction algorithm (). Then, partial endmembers are extracted from each of these blocks. The whole set of partial endmembers are then sent back to the master, which regroups them before sending new artificial image blocks to the slaves for another round of endmember extraction. This procedure continues until one block remains and all endmembers are finally obtained. In the minimum data transactions approach, on the other hand, each slave performs a local reduction on its own, only sending back to the master the reduced endmembers contained in the corresponding input subimage. The master then performs a final reduction round to obtain the actual endmembers present in the original hyperspectral image.
Although the maximum parallelization approach should ideally be better, communication latency discourages its use due to the excessive data traffic over the network. As it can be seen in
Figure 3, the approach that targets minimum data transactions between master and slave nodes has provided better experimental results (100 ms faster on average). All network experiments performed in this work use the MPICH implementation of the MPI API, since it has already been proven that it renders better communication performance than other alternatives such as OpenMPI [
46].
5. Experimental Results
Two experimental setups have been used to evaluate the runtime scalability of the ARTICo3-based endmember extraction. Single-node scalability has been tested using an in-house custom Zynq-7000 board (XC7Z020-1CLG484) with integrated power measurement circuitry and thus, energy efficiency metrics have also been obtained. Multi-FPGA scalability, on the other hand, has been evaluated only in terms of computing performance using up to 8 commercial MicroZed development boards (XC7Z020-1CLG400) arranged in a small Ethernet-based computing cluster. Both scenarios implement the reduction-based FUN endmember extraction using half-precision floating point hardware accelerators and, in the multi-FPGA setup, the data distribution approach for minimum communication over the network.
In addition, all tests reported in this section have been performed using three synthetic hyperspectral images, since they enable the evaluation of a wider range of scenarios (e.g., different number of endmembers, different input sizes, etc.) than any of the represented by the real hyperspectral datasets used to validate the parallelization approach (see
Section 4.1): one with a size of
and 10 endmembers, one with a size of
and 16 endmembers, and a final one with a size of
and 16 endmembers. The size of the input hyperspectral images is expressed as
, being
z bands,
y lines, and
x samples.
Table 8 reports the resource utilization for the ARTICo
3 infrastructure (per node), as well as for the final ARTICo
3 kernel (FUN + wrapper logic per accelerator). Since this kernel does not require any configuration register, the overhead introduced by wrapping the HLS-generated HDL is almost negligible in terms of LUTs and FFs, while there is a sharp increase in the BRAM count due to the local memory inside the hardware accelerator.
5.1. Standalone ARTICo3
The ARTICo3 solution space for single-node deployments represents all possible combinations of computing performance, energy consumption, and fault-tolerance level (i.e., hardware redundancy) when changing the number of accelerators and their configuration for a given kernel. However, the results presented in this section are only focused on computing performance and energy consumption.
Table 9 shows the obtained results for the single-node scenario, where a single-core software version of the reduction-based FUN algorithm has also been implemented to complement the analysis. As it can be seen, for small hyperspectral images, the software version is equivalent (in terms of computing performance) to the ARTICo
3-powered one using a single hardware accelerator. However, energy consumption is almost 50% less for the hardware-accelerated solution. For large hyperspectral images, on the other hand, the ARTICo
3-based solution outperforms the software in terms of computing performance (even when having only one accelerator), while maintaining a good energy-efficiency ratio.
Although execution time is reduced when increasing the number of hardware accelerators for a fixed input image, it is possible to notice that the scalability factor is not linear. This is due to the combination of kernels changing from computing- to almost memory-bounded behavior (in the solution space), and the memory-management overheads introduced by the ARTICo3 runtime. Nevertheless, energy consumption is also reduced, a fact that would still motivate the use of more hardware accelerators for processing in a real-world scenario.
5.2. Networked ARTICo3
In this second scenario, the small-size high-performance embedded computing cluster has been used. The cluster has eight nodes, each of them able to host one ARTICo
3 instance with up to four hardware accelerators. As a result, it is possible to evaluate the two-way scalability of the system (changing the number of nodes, or changing the number of hardware accelerators per node).
Figure 4 shows a picture of the Ethernet-based multi-FPGA embedded computing cluster.
The first set of tests performed with the cluster aims to show the aforementioned two-way scalability of the system.
Table 10 reports the execution times for different configurations of input image sizes, number of ARTICo
3 nodes, and number of hardware accelerators per node. It also reports, for each image size, the overall improvement of each configuration with respect to the solution with one node and one hardware accelerator (
). These results show that, for the same number of hardware accelerators, it is preferable to favor scalability in the number of nodes rather than in the number of accelerators per node, since the per-node memory-management overhead is slightly larger than the internode communication overhead. Notice that execution times when using one node, a scenario that should be similar to the one reported in the previous section, are slightly larger due to the overhead generated by the communication API.
The second set of tests performed with the multi-FPGA setup has been devised with a twofold objective: on the one hand, to compare the hardware-accelerated solution with a software-based alternative; on the other hand, to quantify the communication overheads in the system.
Using MPI terminology, the hardware version uses one slave process with up to four ARTICo
3 accelerators per node (with a master process running in one of the nodes), while the software version uses two slave processes per node to maximize the number of processing elements working potentially in parallel (although one node has the master process and one slave process instead). In addition, processing is carried out completely in the slave processes for the hardware version, while for the software version the master process also performs computations (again, to maximize the number of processing elements working potentially in parallel, and perform a fairer comparison against the hardware-based implementation). As a result, total execution times in
Table 11 equal communication time plus processing time for software, but not for hardware (ARTICo
3 finishes processing in each slave while the master is still sending or receiving data through the network). This phenomenon resembles the memory-bounded behavior in single-node deployments, where the memory bandwidth sets the maximum performance boundary for accelerators where DMA-enabled data transfers are more time-consuming than actual kernel execution.
Results from
Table 11 show that, for small hyperspectral images, the ARTICo
3-based solution is slower than the software-based alternative. However, this behavior is inverted when processing large images, even if communication time is still longer for the hardware-based solutions. It is important to highlight that, when only considering processing time, performance scales almost linearly for both ARTICo
3-powered and software versions. This, together with the partitioning that generates smaller images to be processed in each node, makes it better to scale in the number of nodes than in the number of accelerators per node.
6. Conclusions and Future Work
In this paper, a two-way scalable and runtime-adaptive implementation of a linear unmixing algorithm for on-board hyperspectral image processing has been presented. This implementation deploys a modified version of the FUN algorithm with explicit data-level parallelism over a low-cost cluster of ARTICo3-powered SoPC that emulates a collaborative constellation of CubeSats.
Regarding the algorithm, the proposed modifications enable seamless parallelization without compromising functional correctness, as demonstrated by experimental evaluation. In addition, the hardware-oriented optimizations applied to the algorithm itself do not affect the functionality of the algorithm either.
From an architectural point of view, the proposed implementation scheme provides transparent hardware acceleration and management, with two degrees of freedom to dynamically adapt the working point in a solution space defined by computing performance, energy efficiency and fault tolerance. These three elements are key aspects in low-cost deployments of COTS-based CubeSats, making the proposed solution highly relevant in this context.
Experimental results demonstrate the feasibility of the proposed approach and widen the solution space of the accelerated application, providing an additional degree of freedom (number of network nodes used for processing) that can be used to maintain performance levels, while also enabling fault tolerance by means of hardware redundancy.
The communication infrastructure has proven to be one of the major bottlenecks in the proposed approach. Thus, an optimized communication infrastructure, paired with efficient data-transmission mechanisms, is envisioned as future activity to further enhance system performance. In the long run, and after optimizing network communications, the goal is to generalize the proposed platform to support general-purpose computing in constellation-based on-board processing. To this end, intelligent load balancing and distribution algorithms are to be implemented to transparently manage the system from the application developer’s point of view.

 ,
, 





{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}