1. Introduction
Understanding land cover and land use (LCLU) change is important [
1,
2]. LCLU changes are caused by human activity and natural processes [
2,
3]. Accurate and timely measures of LCLU change can inform local decision making and planning [
4]. Remote sensing data provide an opportunity to monitor land surfaces both spatially and temporally. This paper proposes and applies a change vector analysis (CVA) of land cover and land use change. It combines direct multi-date classification [
5] with CVA measures (magnitude, spectral direction and spectral angle) and with image band reflectance values. These are used to train a Random Forest model of LCLU change. The predictive models of class-to-class changes are applied to bi-temporal Landsat data to estimate LCLU changes for a case study in the Pearl River Delta, China. This paper reflects a shift in emphasis in current approaches to LCLU monitoring away from a focus of LCLU states towards one of LCLU change processes, although inevitably the former are associated with the latter. It seeks to quantify change processes and, in so doing, build on approaches and philosophies being applied in large scale land cover inventories [
6,
7]. These focus explicitly on process (LCLU change) rather than state (the LCLU class label), and do not seek to map land cover per se, rather they consider the strength of the signal of difference in imagery over time. The analysis presented in this paper has a similar focus on the identification of LCLU change as the primary analysis objective as in [
6,
7] but does this using methods that can be used in resource and infrastructure poor situations. The approach is to generate and manually label bi-temporal unsupervised LCLU layers from which reference data are sampled. These are used to calculate class-to-class change vectors and image characteristics which are used as inputs to train a classification model. The model is then used to predict and label land cover change directly and to quantify rates of urbanization.
There are many different approaches to land cover change detection methods and thorough reviews of these are provided by Hussain et al. [
8], Tewkesbury et al. [
9] and Zhu [
10]. Commonly applied approaches include image differencing (e.g., [
11]), image ratio and transformation (e.g., [
12]), change vector analysis (CVA) (e.g., [
13,
14]) and post classification comparison (PCC) (e.g., [
15,
16]). The PCC approach is the most widely applied and reported in the literature [
9] but requires input data (classified maps) with accuracies that are beyond operational capacity of most land cover monitoring initiatives [
4,
17,
18,
19,
20]. Generally, PCC should not be used, even though it is conceptually elegant. CVA approaches characterize class-to-class change vectors in bi-temporal image feature space. They require the characteristics of change to be known [
8,
21] and the trajectories of changes in multi-dimensional image feature space to be sufficiently distinct and statistically separable. Thus, there are three core challenges for any direct multi-date approaches to LCLU change, whether supervised or unsupervised: the need for large amounts of reference data to sufficiently characterize each bi-temporal change class, the potential for high variability of any given change and the sensitivity of any approach to image mis-registration including Landsat [
22].
Because of these challenges, many large scale operational LCLU inventories have adopted approaches that first focus on identifying any LCLU change and then update baseline inventories retrospectively. Gómez et al. [
23] provided a theoretical review. This generic approach represents a significant shift in the way that LCLU inventory and update are undertaken from satellite imagery (e.g., [
24]), aerial photography (e.g., [
25]) and historical LCLU data updates (e.g., [
26]). Philosophically, these approaches represent a shift from a focus on the crisp, Boolean, object-based concept of land cover [
27], to one based on processes and fields, in which the attributes or qualities of LCLU are evaluated (e.g., [
21]). The focus on identifying change processes can be seen in many recent reports of large inventories [
6,
7] which seek to determine whether the
signals of change are sufficiently strong to be accepted and if so only then are LCLU class labels retrospectively updated. They are underpinned by access to long, wide and deep archives of time series data [
28] that form large spatiotemporal data cubes [
29,
30], and by the provision of Analysis Ready Data (ARD). ARD reduce pre-processing prior to analysis and include the latest image calibration and corrections to improve consistency and comparability of results. ARD are “stackable” such that a given pixel through time represents the same physical ground location.
However, the large-scale inventory approaches to LCLU change described above require resources and infrastructures that may be beyond many applications, especially in less developed countries, where measures of LCLU change are required to, for example, understand the dynamics of urbanization processes. PCC approaches require classified LCLU accuracies that are simply not possible, ARD are not available and the problems of variability in change signals and image co-registration persist. In this context, pragmatic, reproducible and easily applied approaches for generating reliable snapshots of LCLU change are needed. There are advantages to methods for determining LCLU change that focus only on processes rather than seeking to determine states. A modified Change Vector Analysis (CVA) offers a method that is potentially able to do this.
Classic CVA [
31] determines the change in position in image feature spaces (for example, composed Landsat image bands) of LCLU objects, usually pixels, over time. At each time, the object vector from the origin is determined in the feature space. The change vector is the difference between vectors at different times, with the change vector direction indicative of the type of LCLU change and its length indicative of the magnitude of change, which together can be used to label change [
32]. Magnitude is usually a simple Euclidean distance measure and is used to quantify change extent (e.g., [
33,
34]). The underpinning idea is that vector magnitude indicates changes in image radiance, but contains only limited thematic information, and the direction indicates the type of change. The key considerations in CVA are how to define the feature space within which the vectors are calculated—that is which image bands and variables to include—and whether to transform them. Carvalho Júnior et al. [
13] noted that a 2D feature space is often defined because of the difficulty in interpreting the vectors calculated over an
n-dimensional feature space [
35]. However, feature space selection may be driven by the application. Bovolo and Bruzzone [
32], for example, used a 2D feature space of Landsat bands 3 and 4 to map burnt area changes. Thus, determining which bands to use requires a degree of prior knowledge of the changes under investigation [
35]. Because of the difficulty of working with change vectors defined in multi-dimensional feature spaces, data transformations are frequently applied to reduce the dimensionality of the data. Commonly applied transformation approaches include tasseled cap [
36,
37,
38,
39] and principle components analysis [
3,
40]. In both cases, the original image data are transformed to new sets of variables and care has to be given to both input selection and interpreting the meaning of the outputs [
35]. A final consideration in CVA research is the use of the Spectral Angle Mapper (SAM) [
13]. SAM approaches generate similarity measures for vectors defined over
n-dimensional space from their inner product, and, although they do not provide information about land cover change, they have been used to inform CVA applications [
13]. Bovolo et al. [
35] argued that such developments in CVA have the potential for a universal change detection framework.
The aim of this research was to quantify the LCLU change processes, and not necessarily the start and end states. Two main approaches to LCLU change have been adopted: supervised and unsupervised methods [
5,
41]. Supervised approaches are based on supervised classification methods and require the availability of multi-temporal reference data. Unsupervised ones make a direct comparison of the two multispectral images without relying on any additional information. Here, a hybrid approach was applied which manually labeled broad scale unsupervised classifications of images at both dates. These reference data were randomly selected from the center of homogenously classified regions to avoid edge and bi-temporal image mis-registration effects which are well known in Landsat data [
22]. The reference data were used to construct a set of change vectors from which vector characteristics were calculated (magnitude, spectral direction and spectral angle) for each labeled change. These were used to train statistical classifier and used to predict class-to-class change, including no change. Regional variations in LCLU change were determined using the methods described in Comber et al. [
42]. This is a novel approach for determining LCLU change, one that uses measures derived from change vectors and applied to bi-temporal image data. The analysis has an explicit focus on the change vector measures, and not the individual vectors at Time 1 and Time 2.
2. Materials and Methods
2.1. Data and Study Area
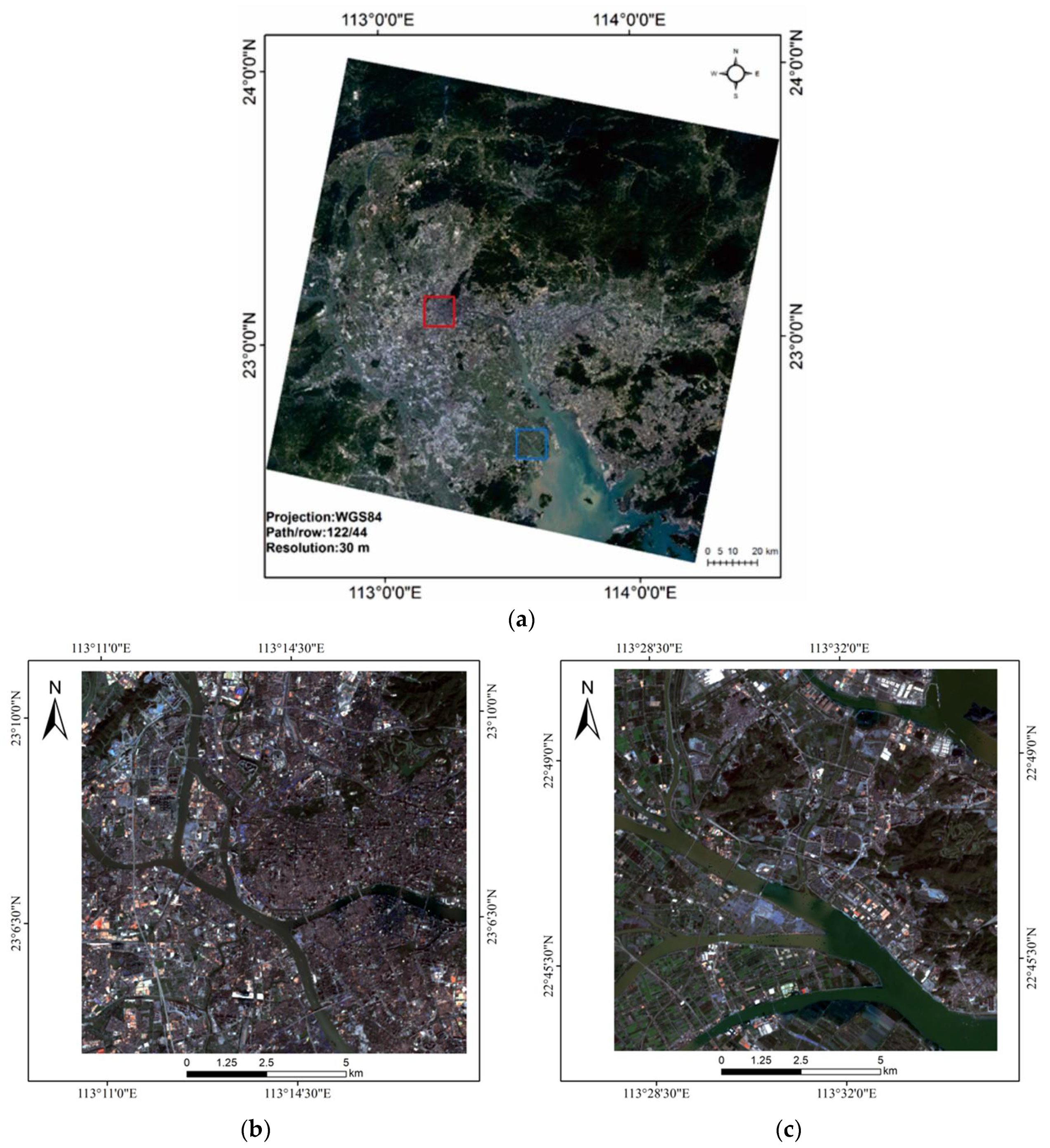
The Pearl River Delta is located in southern part of China (
Figure 1a). It has a humid climate that results in rainy weather all year around and annual precipitation and average temperature of ~1500 mm and 23 °C, respectively. This region is rich in natural vegetation with a dense river and drainage network and the climate supports a variety of agricultural systems including banana, pineapple, carambola, mango and grapefruit plantations. The urban area is surrounded by natural and semi-natural land cover types. The region has a number of large, active economic centers including the cities of Guangzhou, Shenzhen and Hong Kong which have experienced long and sustained urbanization. Two sub-regions of 400 by 400 pixels with an area of 144 km
2 each were selected for comparison to represent urban and peri-urban contexts (
Figure 1b,c). Region 1 was characterized by high density settlements located in the core urban area and Region 2 by high levels of agricultural activities located in the peri-urban area. Both regions are subject to highly intensive human activity and disturbance and provide proto-typical examples of contrasting but common land use mixes. These two areas were selected to support a deeper discussion of the results.
Medium resolution Landsat data support regional monitoring due to their consistent quality, radiometric and spectral resolution [
43]. Two cloud free Landsat-8 Operational Land Imager scenes (path/row: 122/44) from 2013 and 2017 were selected for the change analysis with similar seasonal dates (29 November 2013 and 23 November 2017) to reduce phenology effects [
4]. The atmospheric-corrected data were obtained through the USGS EarthExplorer and detailed information about this product can be found at
https://lta.cr.usgs.gov/L8Level2SR. Six spectral bands were used in the analysis: Blue (0.450 µm–0.515 µm), Green (0.525 µm–0.600 µm), Red (0.630 µm–0.680 µm), Near-infrared (NIR) (0.845 µm–0.885 µm), Short-wavelength infrared 1 (SWIR1) (1.560 µm–1.660 µm) and SWIR2 (2.100 µm–2.300 µm). No atmospheric correction was undertaken because of the unsupervised approach (see detail below). The data were rescaled and the co-registration of the two images was confirmed using a geographic link function in ENVI software (ITT visual information solutions, Boulder, CO, USA).
2.2. Methods Overview
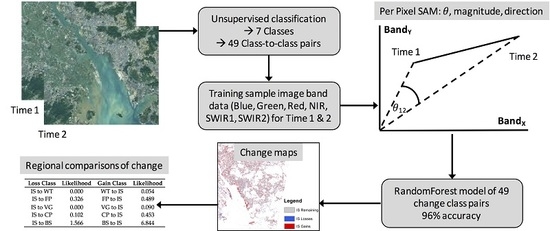
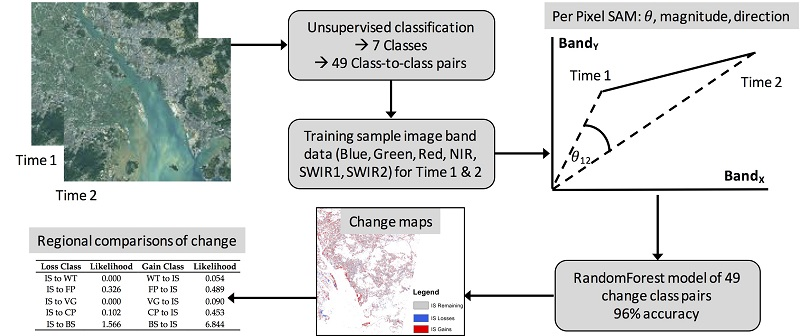
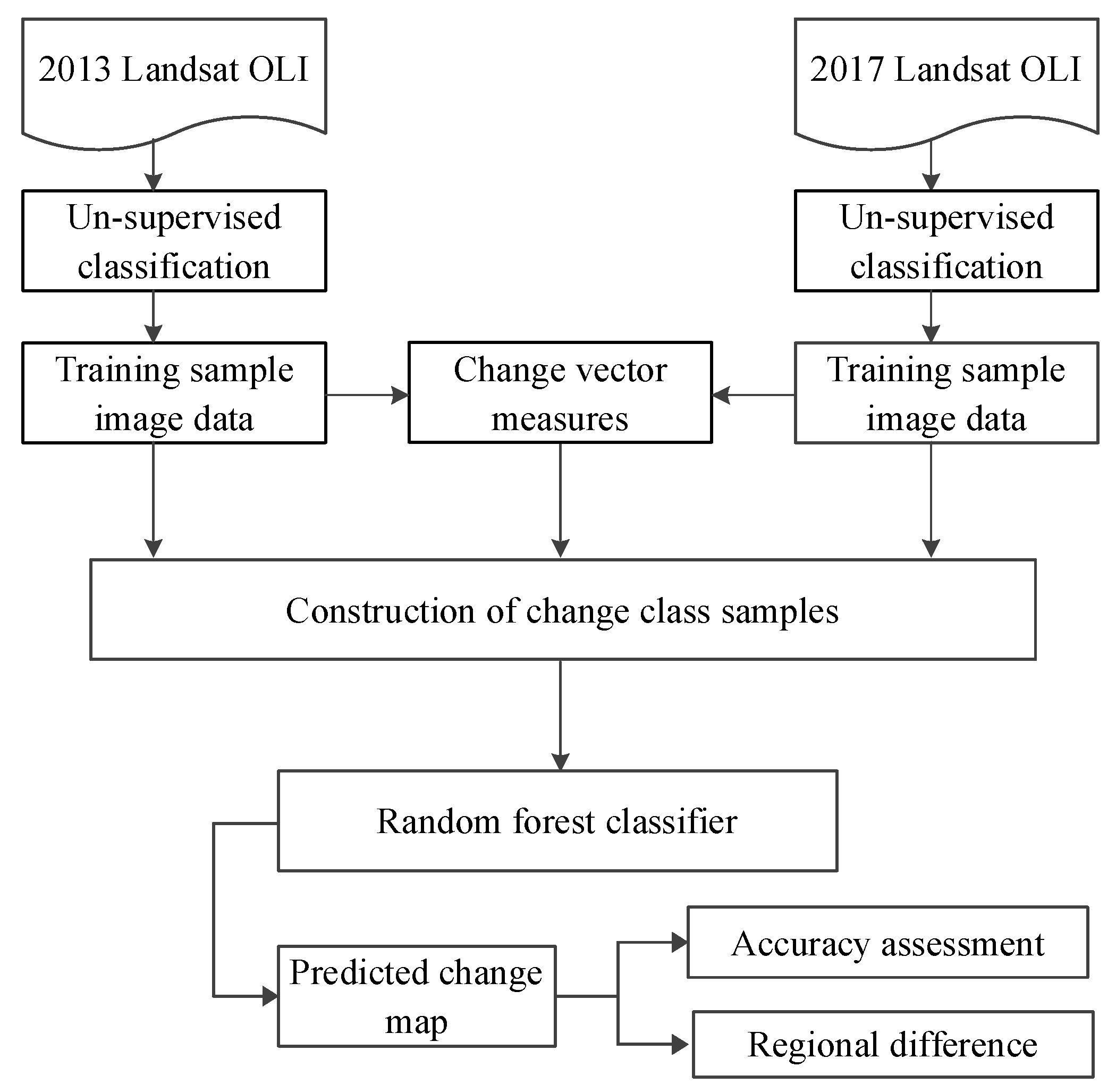
The analysis steps to model and identify changes between 2013 and 2017 from bi-temporal imagery are shown in
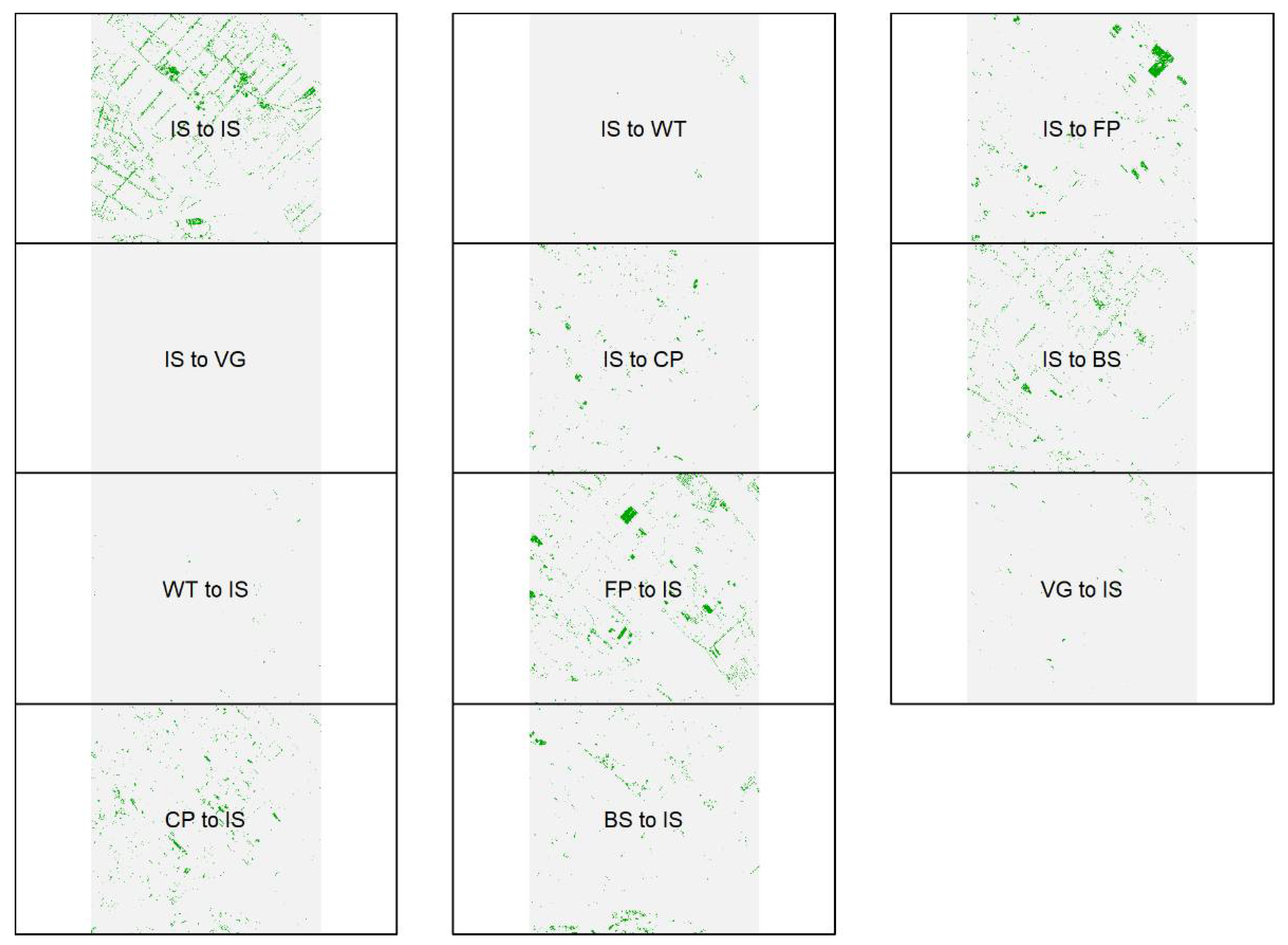
Figure 2. The process was as follows. First, a series of unsupervised classifications were undertaken using a minimum distance approach with percentage change threshold of 2% and a maximum of 10 iterations. The aim of these was to identify an appropriate classification scheme for this study area. This determined a set of seven classes that could be reliably identified in each image which were then manually labeled. Then, class-to-class training data were selected and labeled automatically with the change classes from the 2013 and 2017 unsupervised classifications. For each class-to-class pair, including no change class pairs, 100 sample locations were selected from within homogenous areas and subjected to a 70/30 training and validation split. From these, the start and end coordinates in six-dimensional image space from the 2013 and 2017 coupled images were determined for each sample and three change vector variables were calculated: magnitude, spectral direction and spectral angle. Thus, the reference samples were labeled with the from-to change classes and contained 15 predictor variables of the six spectral bands for each year and the three derived vector measures. These were used input parameters to a Random Forest classifier to create a predictive model of land cover change. The model was then applied to the combined bi-temporal Landsat images to predict change areas. Finally, regional comparisons were undertaken to compare the magnitude and direction of change in different landscape contexts.
2.3. Land Cover Classes
Iterative investigations of un-supervised classifications confirmed that seven LCLU classes could be identified reliably and repeatably in both images that characterized the mix of land cover and land use in the study area. The seven classes included Low-albedo Impervious Surface (LIS), High-albedo Impervious Surface (HIS), Water (WT), Fishing ponds (FP), Vegetation (VG), Crops (CP), and Bare Soil (BS). These are listed in
Table 1 with more detailed descriptions of each class.
It was important that the classification scheme adequately characterized the different land uses in the study area, and one that specifically supported inference about the nature of urban expansion whilst at the same time offered sufficient spectral difference between the classes for them to be reliably identified. As a result, some land covers were split (water and impervious surface) because of their different spectral characteristics associated with different land uses and intensities of land use. For example, HIS has high reflectance because of metal roofs and is commonly found in newly developed suburban areas, whereas LIS is more commonly founded in older urban areas with building materials eroded by air pollution and rain. The difference between WT (water) and FP (fishing ponds) relates to the presence of elements such as vegetation in fishing ponds with the result that the NIR is higher for fishing ponds due to chlorophyll. The difference between VG (vegetation) and CP (crop) relates to the vegetation intensity as recorded in normalized difference vegetation index (NDVI). Vegetation here refers to perennial woody plants or grasses that are not harvested, such that chlorophyll accumulates resulting in a high NDVI. By contrast, crops are harvested annually (sometimes twice) and hence have a lower NDVI value than vegetation.
2.4. From-to Land Cover Changes
Training samples were labeled from the Landsat images and from historical Google Earth images as needed. A false-color combination in RGB (4-5-3) was used to identify the vegetation and water classes. A true color combination in RGB (4-3-2) was used to identify Bare Soil (BS) and to distinguish it from other classes, especially from impervious surface classes. In theory, there are 49 possible class-to-class pairs of change and no-change. Not all of the possible combinations were evaluated. Specifically, because of the aim of understanding urbanization in the Pearl River Delta, changes in impervious surface quality (HIS and LIS), amongst the water classes (WT and FP) and between the vegetation, crop and soil classes were ignored. The 32 class change pairs that were considered are summarized in
Table 2.
2.5. Constructing “from-to” Training Samples
The 2012 and 2017 spectral properties of each land cover change sample data were linked together for each training pixel in the form {XBLUE, XGREEN, XRED, XNIR, XSWIR1, XSWIR2, YBLUE, YGREEN, YRED, YNIR, YSWIR1, YSWIR2}, where X and Y refer to 2013 and 2017 data, respectively. For each sample pixel, the distance, magnitude, change vector direction angle and spectral angle were determined from these.
First, the distance
d, for each image band pair was calculated:
Then, the magnitude of the change in reflectance intensity
ED, was calculated:
There are a number of alternatives for determining change vector direction angle [
17,
44]. Here, the approach proposed by Bovolo et al. [
45] was chosen as in Equation (3) to describe the change vector direction angle (
DA):
Finally, the spectral angle mapper (
SAM) records the angle between two vectors [
46] as described in Equation (4):
where the
Xi and
Yi represent the spectral information of initial and final stage (2013 and 2017 in this study). ‖ ‖ represents the length of each vector.
After these calculations, the final training samples could be denoted as {XBLUE, XGREEN, XRED, XNIR, XSWIR1, XSWIR2, YBLUE, YGREEN, YRED, YNIR, YSWIR1, YSWIR2, ED, DA, SAM}. Thus, the resulting training data included 12 variables from the Landsat 8 image bands of 2013 and 2017, and the derived change vector variables (direction, angle and the spectral angle). These variables were used to train a Random Forest model.
2.6. Random Forest Classifier
The Random Forest (RF) classifier is an ensemble classifier that uses a set of classification and regression trees to make a predictive model [
47]. RF uses training sets to generate multiple (deep) decision trees and have been found to solve some of the problems of over-fitting with other decision trees. When predicting, each tree predicts a result and each result is weighted by the number of votes it receives. The final classification is obtained after some degree of convergence in fitting and majority voting. The number of trees (
Ntree) and the number of variables randomly sampled as candidates at each split (
Mtry) are two important parameters in the implementation of a RF classifier. The out of bag (OOB) estimate provides a measure of the RF prediction error and an assessment of the accuracy of model. Studies have reported that setting
Ntree = 500 is appropriate as the errors are stable around this number [
36]. A tuning function in the randomForest R package was used to determine the optimal
Mtry parameter. The RF was used to generate a land cover change model. This was then applied to combined 2013 and 2017 image data, plus the three derived vector measures—ED, DA and SAM—to generate a predicated map of land cover change. The accuracy of the RF classification was evaluated using 30% of the reference data samples that were withheld.
2.7. Inter-Regional Analysis
To explore indicative differences in land cover change in different types of regions in the study areas, the ratio of the odds of change between Region 1 and Region 2 was calculated, as described in Comber et al. [
42]. These approaches can be used to compare per class differences in change, specific class-to-class changes as well as regional differences. The ratio of change,
θ, is as follows:
where
θ equals or is near to 1, then change is equally likely in each treatment (region, class, class-to-class change). Essentially, what this approach does is compare the odds of change (i.e., it compares the proportions of change and no change in different study areas (or regions).
4. Discussion
This paper describes a modified change vector analysis approach for quantifying land cover change in bi-temporal data that combines direct multi-date classification [
5] with CVA measures (magnitude, spectral direction and spectral angle) and image band reflectance values, and uses these to train a Random Forest model of LCLU change. The method has not sought to identify change vectors or land cover classes at either Time 1 (2013) or Time 2 (2017). Rather, it used the bi-temporal image properties of labeled class-to-class transitions, with measures derived from the change vector (Euclidian Distance, change vector Direction Angle and Spectral Angle Mapper) to train a Random Forest classifier. The samples were automatically created from a supervised classification of Landsat images at both dates that generated seven classes, which were manually labeled. The results are promising, with high accuracies and the method provides an intuitive and quick way of quantifying the patterns of urban growth and change that is of use to planners and policy makers who frequently want to quantify and locate land cover/land use changes. The approach circumvents the problems associated with post classification change [
19] and does not require the technological, data and infrastructure resources described in [
7], although it operates under a similar philosophy: the identification of change is the primary aim before updating the baseline. This paper has not sought to update any baseline.
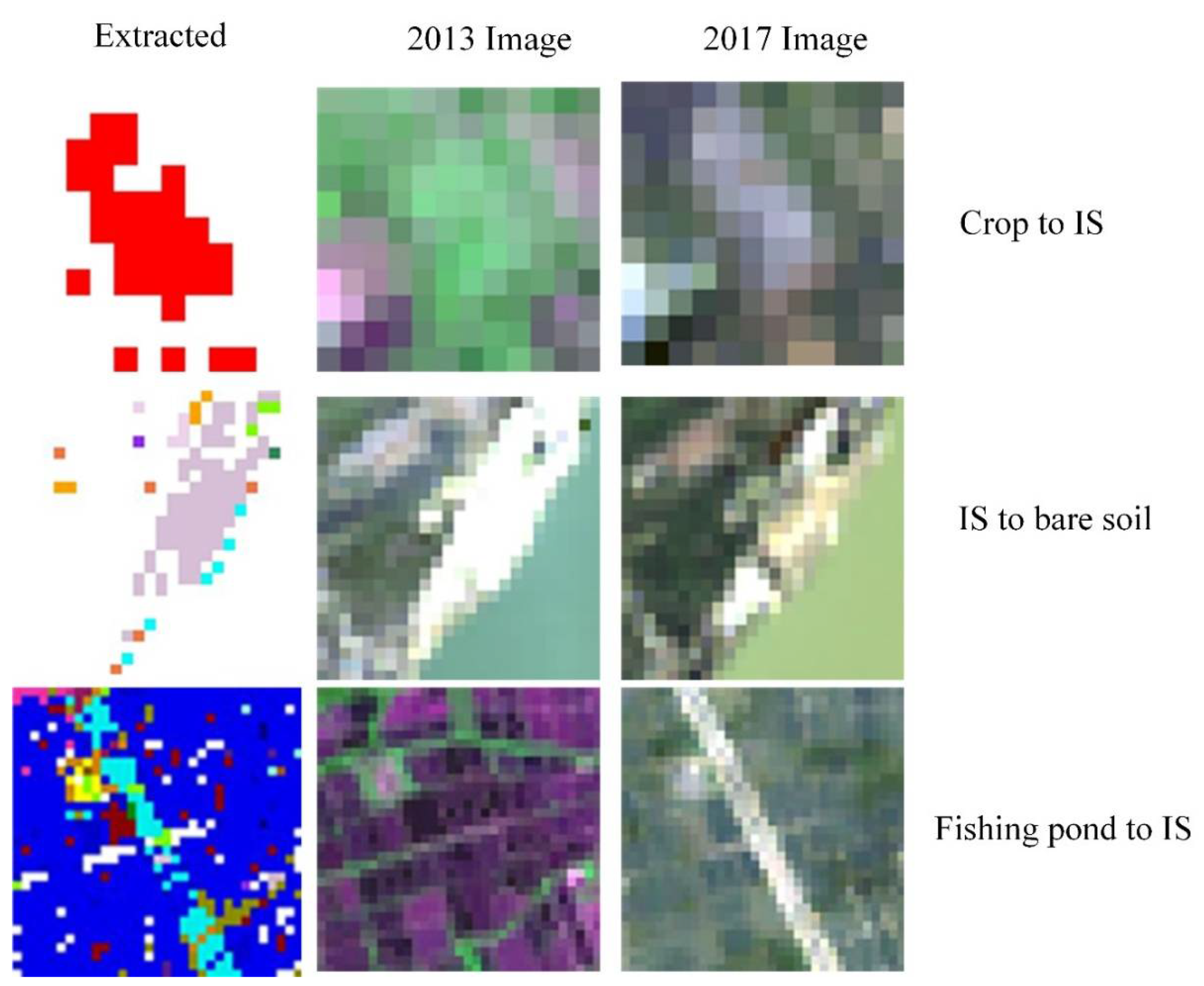
The method is sensitive to the reliability of the unsupervised classification. Reference data were selected from within homogenous areas to avoid edge and bi-temporal image mis-registration effects. Some degree of automated reference data generation is needed simply because of dimensionality imposed by trying to characterize transitions rather than start and end vectors: here, a seven-class nomenclature was used (49 transitions) but it is not uncommon for land cover initiatives to have 12–20 classes (144–400 transition classes).
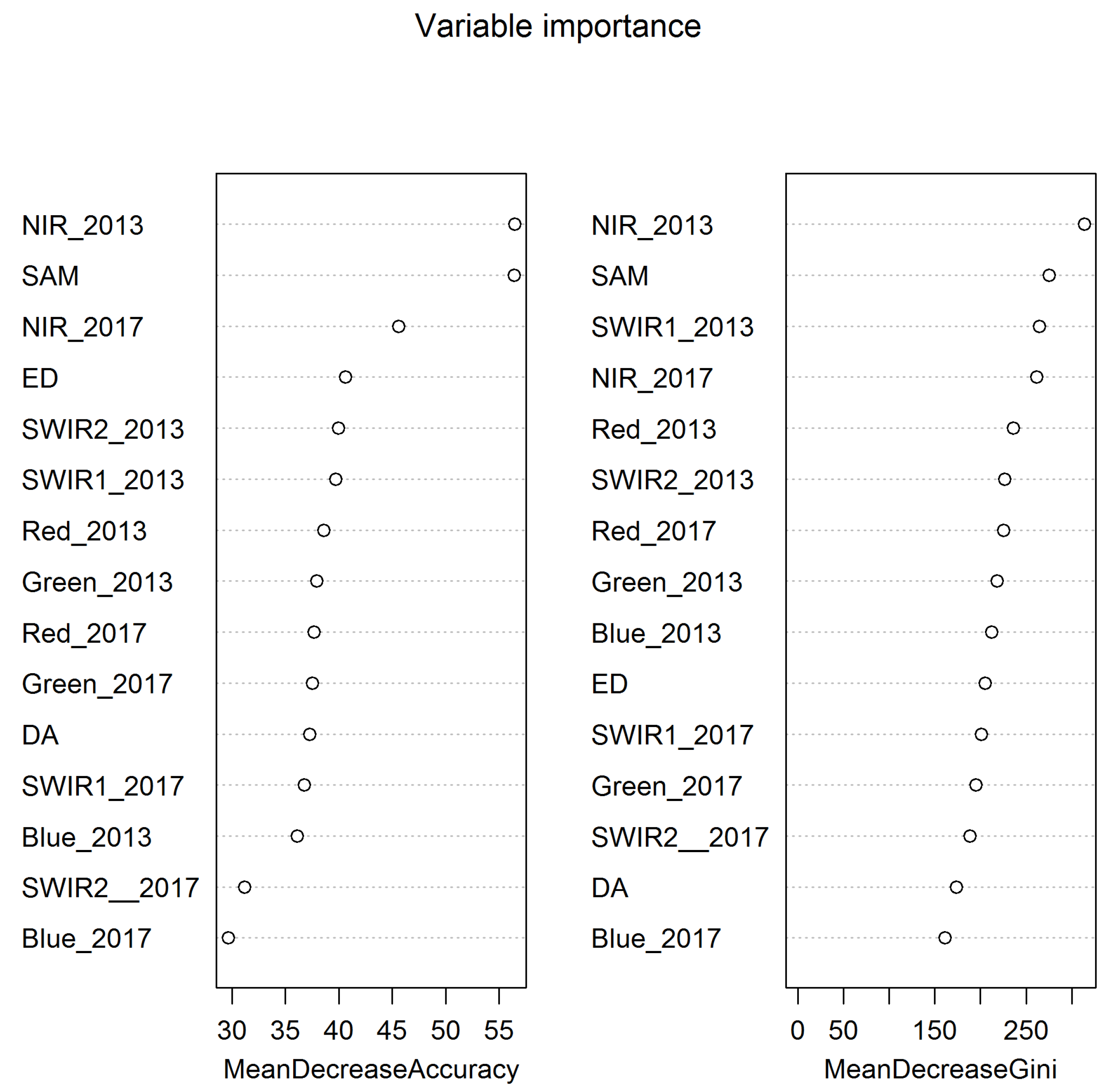
There are a number of areas of further work. First, this study considered bi-temporal data, providing a snapshot of urban land use changes between two time periods. The analysis of multi-temporal image data to provide a series of snapshots of change, covering both annual census dates and seasonal changes, would support the investigation of specific urban processes such as urban sprawl, landscape fragmentation and changes in land use diversity. Further, by considering different regions, as was done here using the methods described in [
42], local variations in these processes can be quantified. Second, different model selection approaches will be investigated to determine which variables to include for specific types of change. Here, all of the variables were included as potential descriptors (predictors) of change and
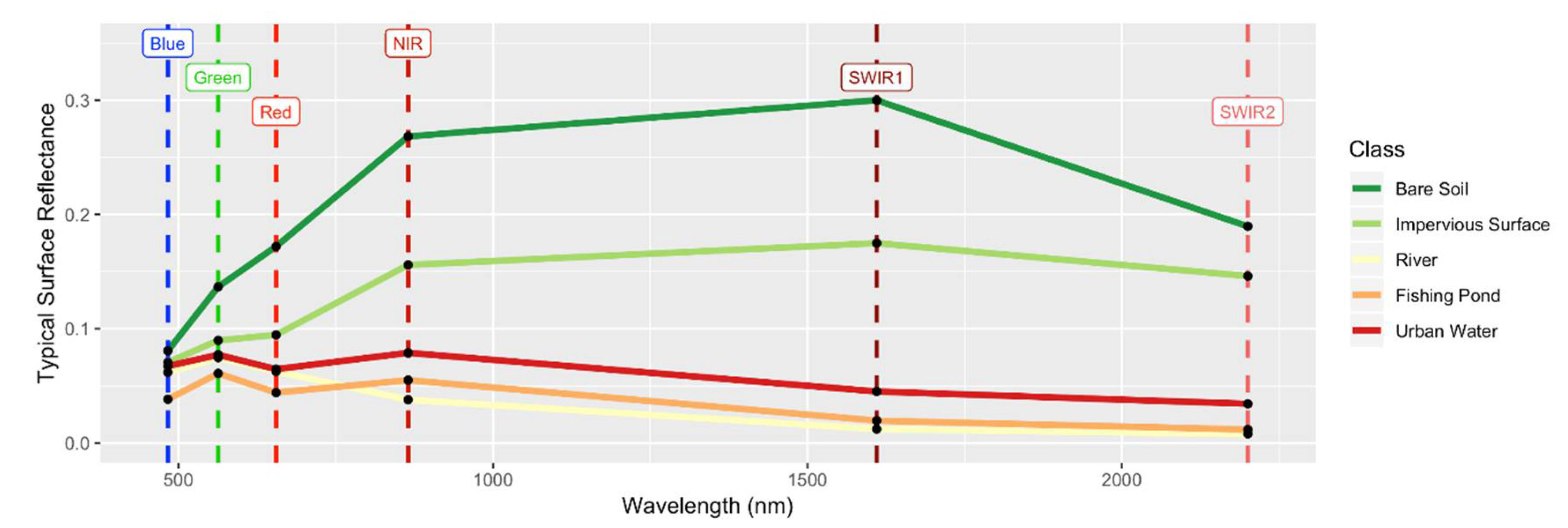
Figure 4 provides an indication of the relative utility of different variables in this study. For example, during the reference data collection process, some water bodies in urban regions (“Urban Water”) were labeled as Water, but may have been Fishing Ponds; Region 2 was dominated by agriculture related types (Crops and Fishing Ponds) and here misclassifications were found between Bare Soil and IS due to the similarity of their spectral characters. Typical spectral values are shown in
Figure 9 and illustrate the potential for these confusions. Hyperspectral images, especially with high spectral information in SWIR bands, may be a solution to this problem. Third, the method will be applied and evaluated in other environments, using different data, to further investigate the potential applicability and limitations of the approach. It will be applied to multi-temporal reference data to support analyses of the processes associated with changes land use in a large regional analysis in the Loess Plateau, China, using MODIS data. The aim here will be to quantify the coupled relationships between soil–water processes and multi-scale agro-ecosystem LCLU changes to evaluate the impacts on landscape re-greening and restoration agricultural sustainability initiatives. Finally, a further extension to this work is to examine fuzzy land cover class transitions [
51,
52]. Conceptualizing change classes in this way, based on a fuzzy sets approach, would require second order vagueness to be accommodated rather than a crisp, Boolean concept of change. This may address some of the sub-pixel issues associated with urban impervious surface estimation and working with medium resolution satellite imagery. Vague land cover change analysis could allow different memberships to the set of “change” to be explored, either globally or on a per change class basis. Finally, many large-scale operational monitoring initiatives use a sequence of change signals to generate increasingly confirmatory evidence to support a hypothesis of object level change. Such evidence could be included in the model specification by passing lagged image variables for Time 1 to Time
n into the classification algorithm rather than data from just two scenes.














{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}