
Extraction of Basic Features and Typical Operating Conditions of Wind Power Generation for Sustainable Energy Systems

Abstract
1. Introduction
2. Literature Review
3. Methods and Analysis
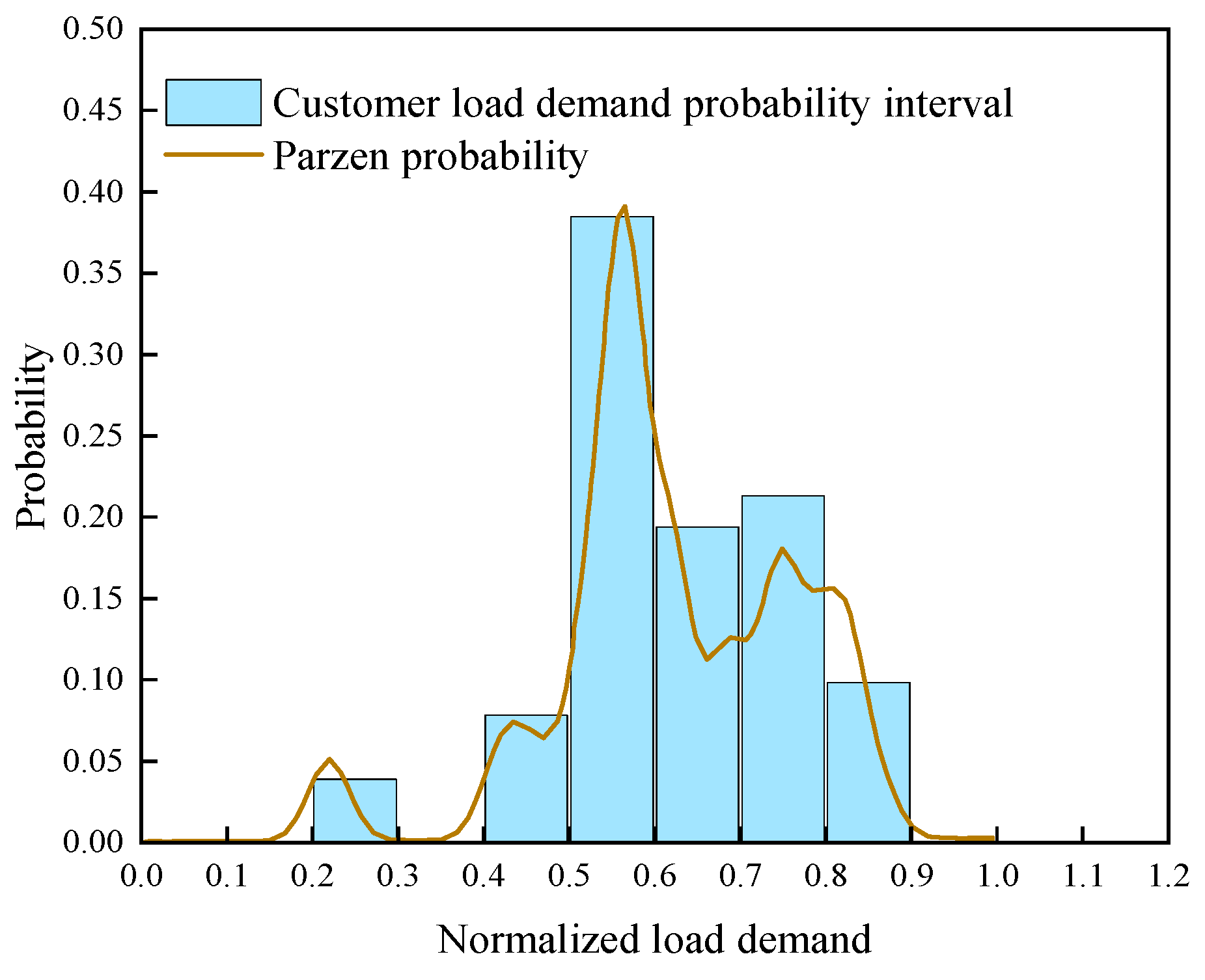
3.1. Parzen Window Estimation Method
3.2. Extract Typical Data Features
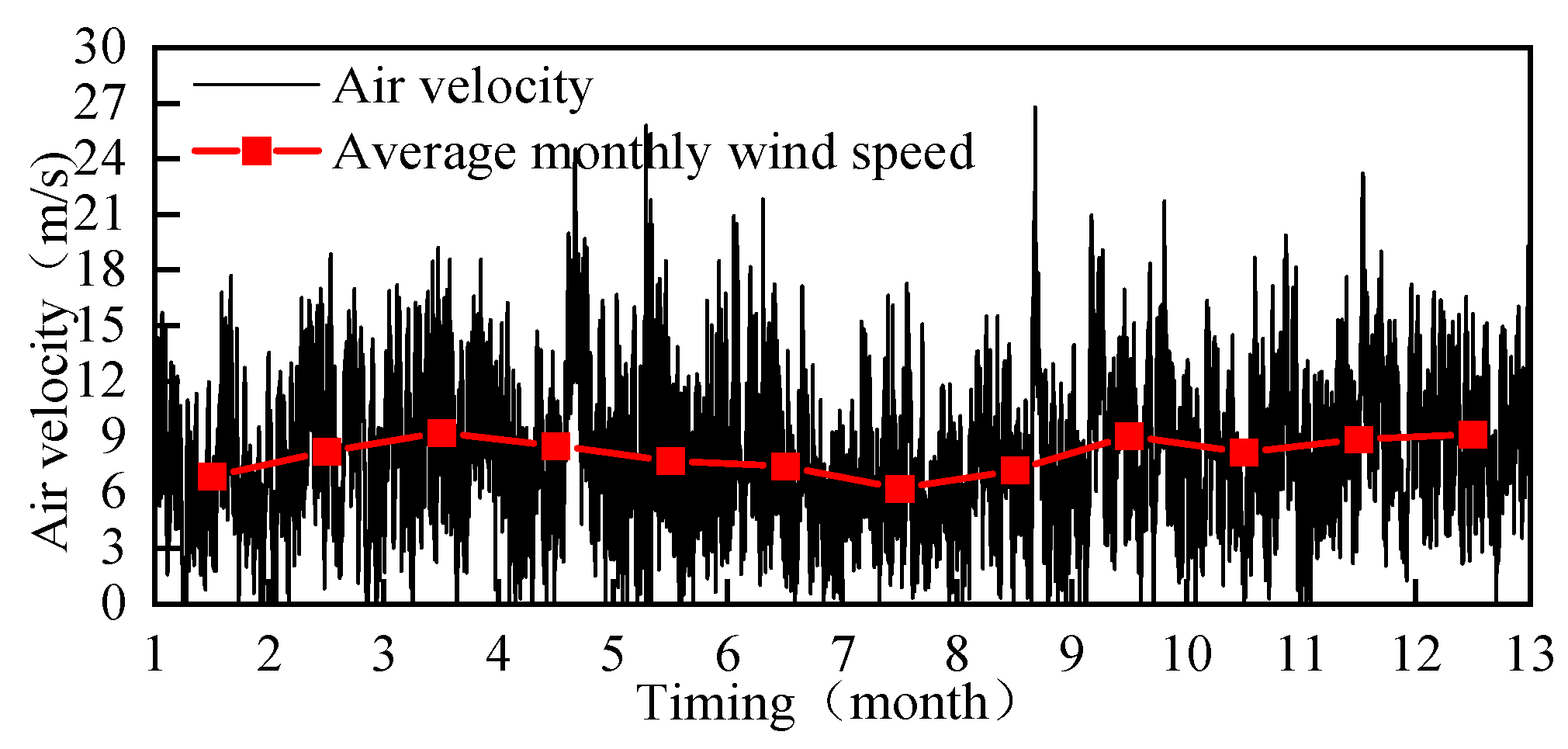
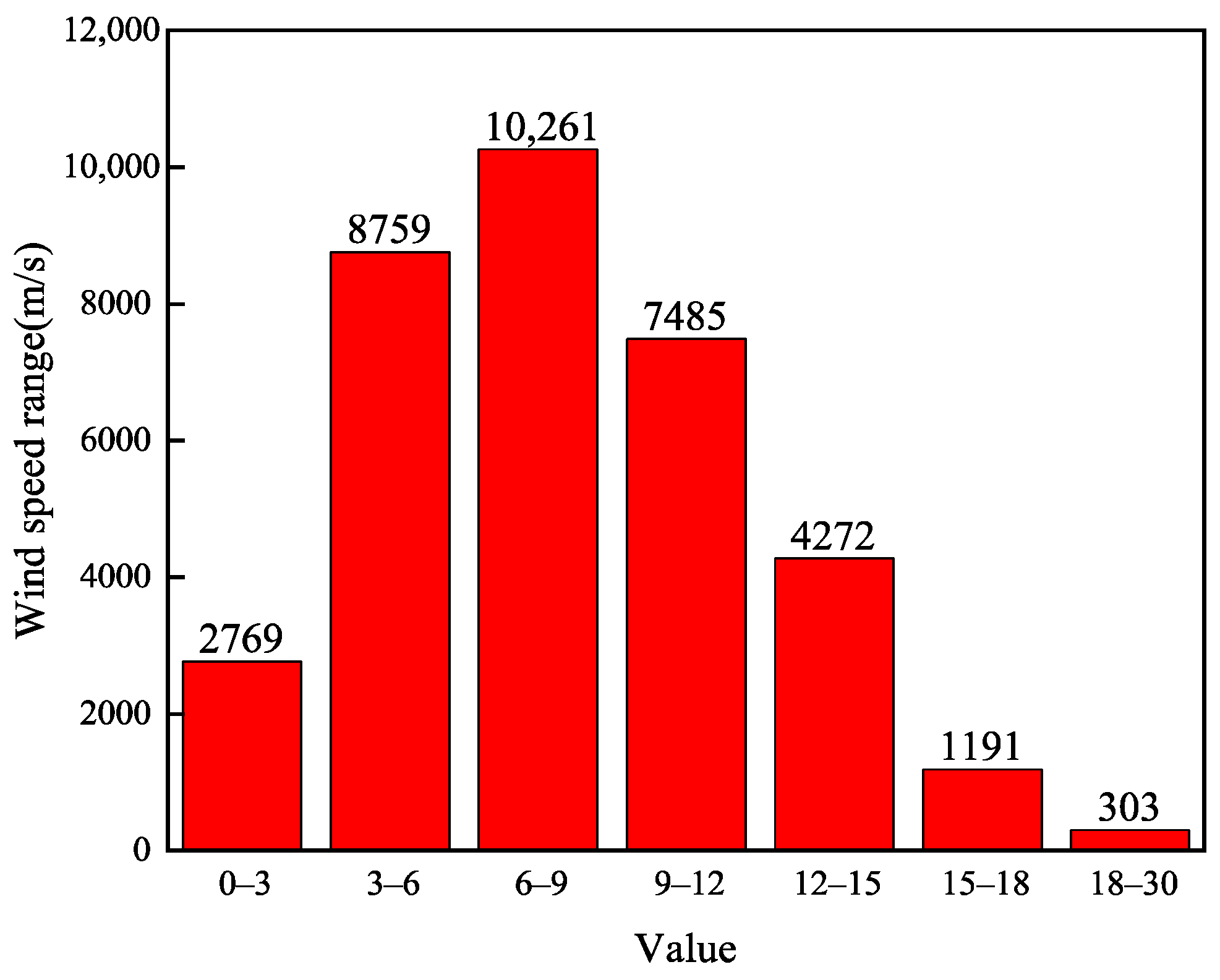
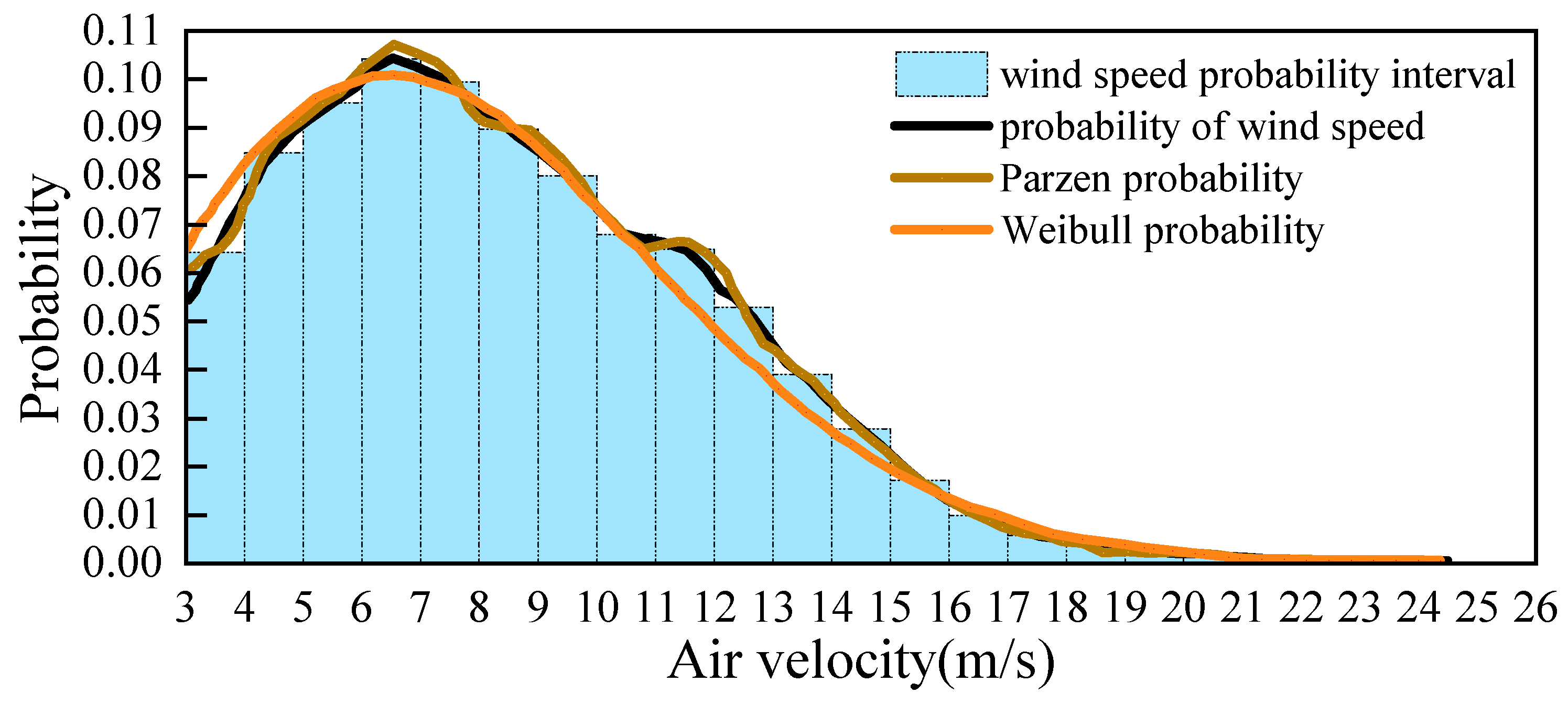
3.2.1. Extraction of Typical Data Features for Wind Power
- (1)
- Based on the IEC 61400–12-1 standard [23], valid wind speed measurements from all available days are collected at 1-min intervals during the 0:00–0:15 time period. This yields a sample set of wind speeds {x1, x2, ..., xn} for that time window.
- (2)
- The sample values are first discretized using a binning method. The wind speed axis is divided into intervals (bins) centered at integer multiples of 0.5 m/s (e.g., 0.5, 1.0, 1.5,...). These bins provide reference points at which the probability density function will be estimated.
- (3)
- For each bin center x, the Parzen window density estimate f(x) is calculated using a kernel function K and bandwidth h, as defined in Equation (1).
- (4)
- The resulting density estimates across all bins form a smooth probability distribution curve, representing the wind speed pattern during 0:00–0:15. This curve is then used to identify typical power profiles under varying conditions.
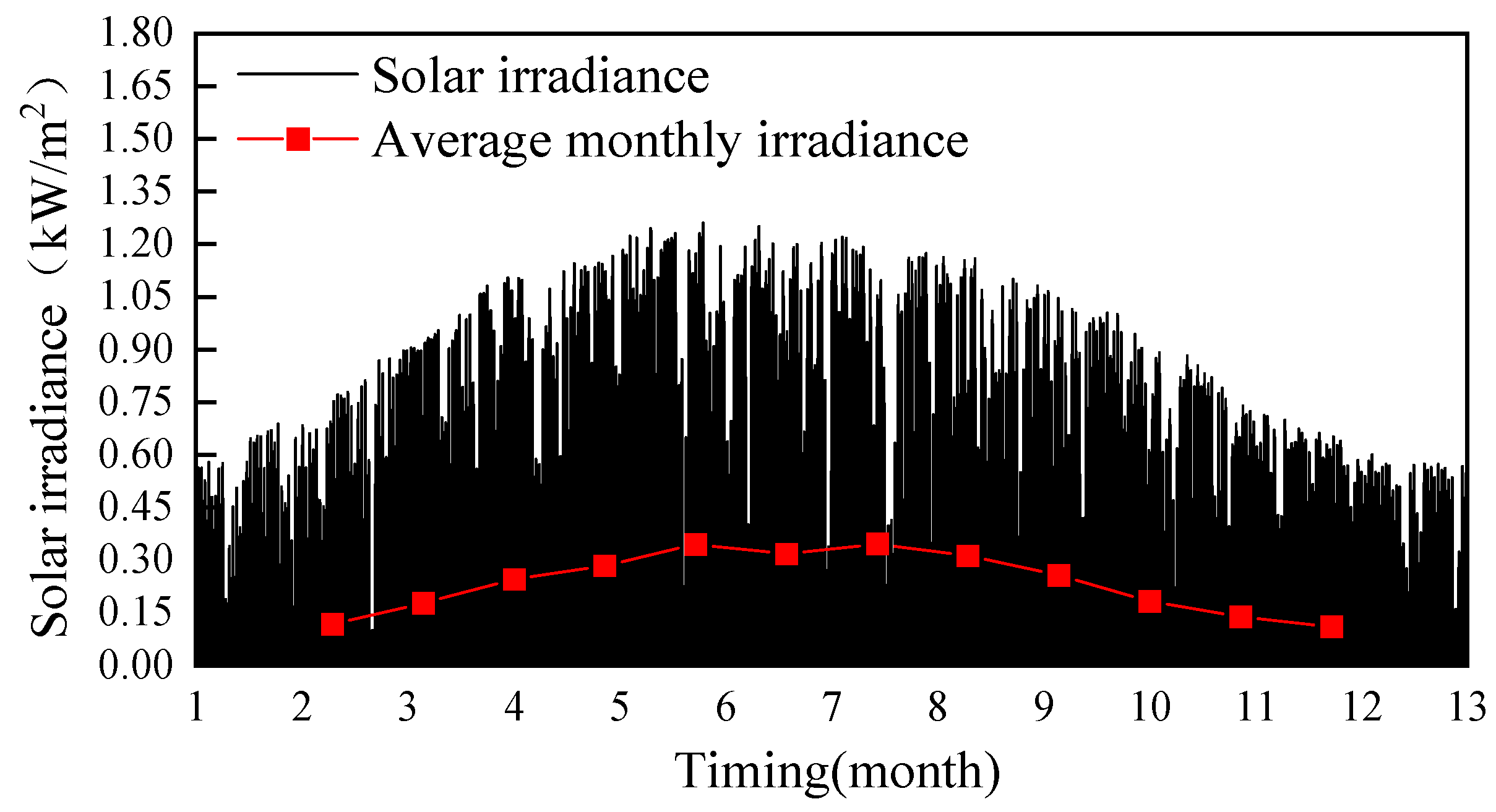
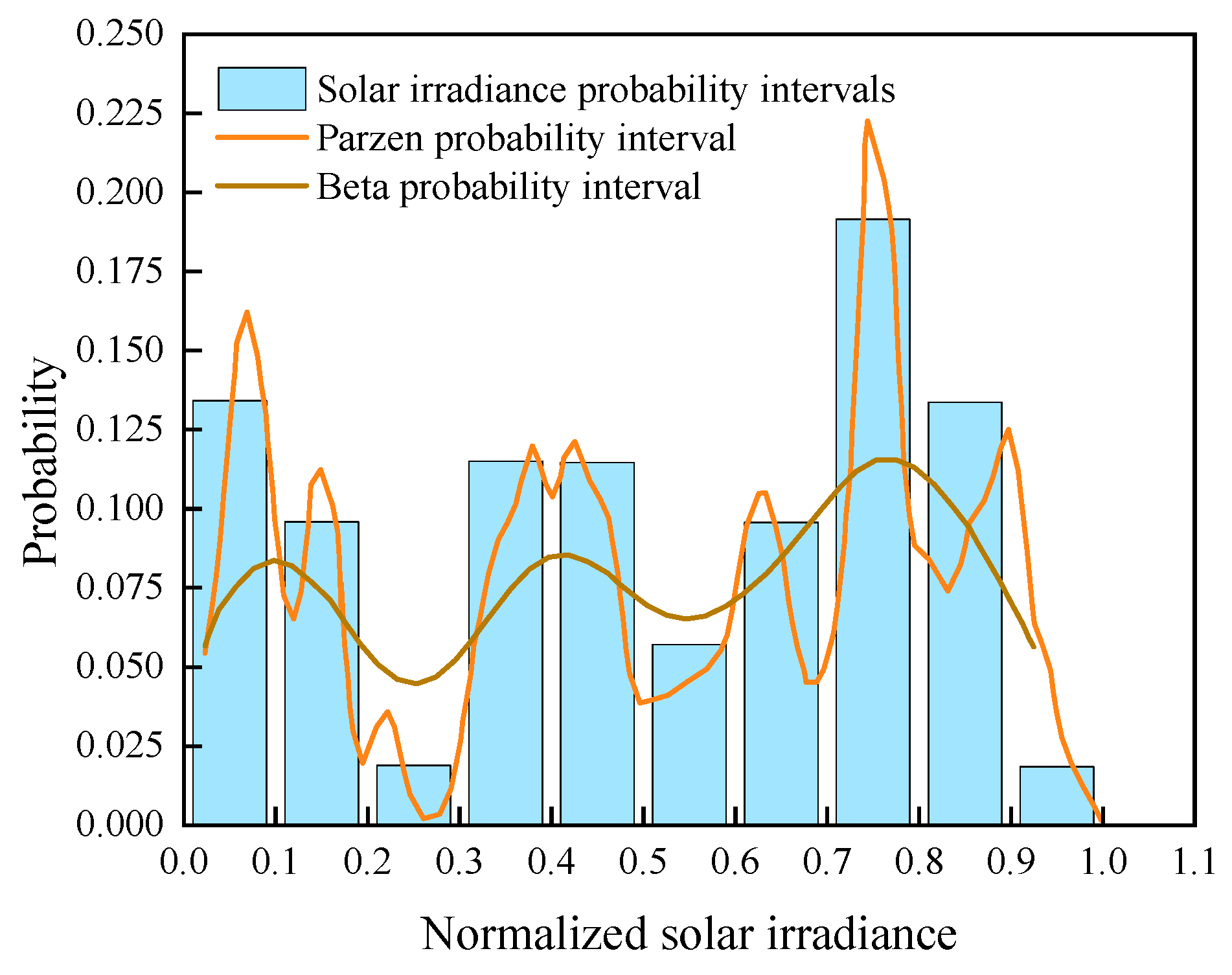
3.2.2. Extracting Typical Data Characteristics of PV
- (1)
- Normalize the dataset and consider the solar radiation exceeding 1000 W/m2 as 1000 W/m2.
- (2)
- Use Bin’s method to divide the intervals, and use 0.1 W/m2 as an integer multiple of 0.1 W/m2 as the center point, and calculate the probability density of each interval.
- (3)
- Summarize all the probability densities to build the Parzen window probability distribution curve.
3.2.3. Extract Typical Data Features of User Requirements
- (1)
- Normalize the dataset;
- (2)
- Use Bin’s method to partition the intervals, using an integer multiple of 0.1 MW as the center point, and calculate the probability density of each interval.
- (3)
- Summarize all probability densities to create a Parzen window probability distribution curve.
4. Results
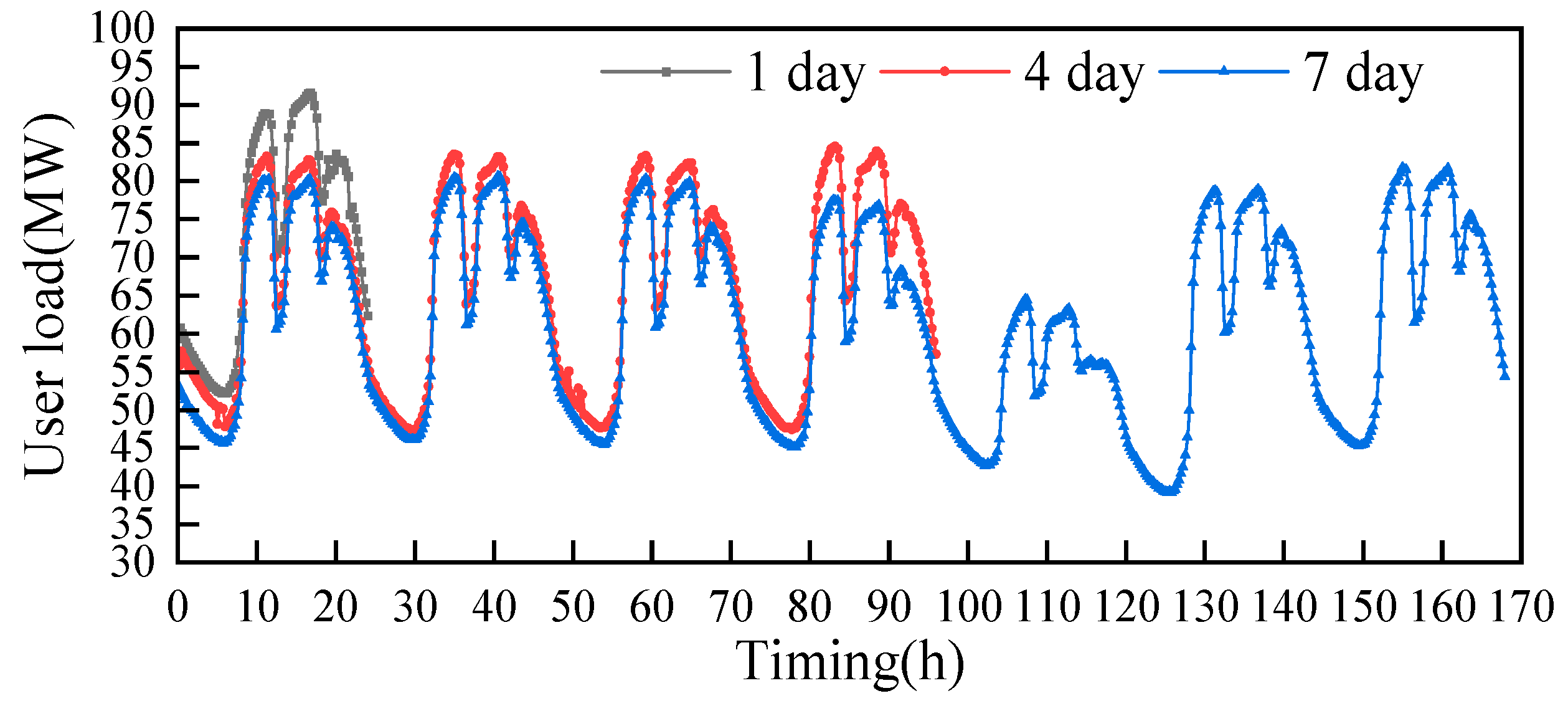
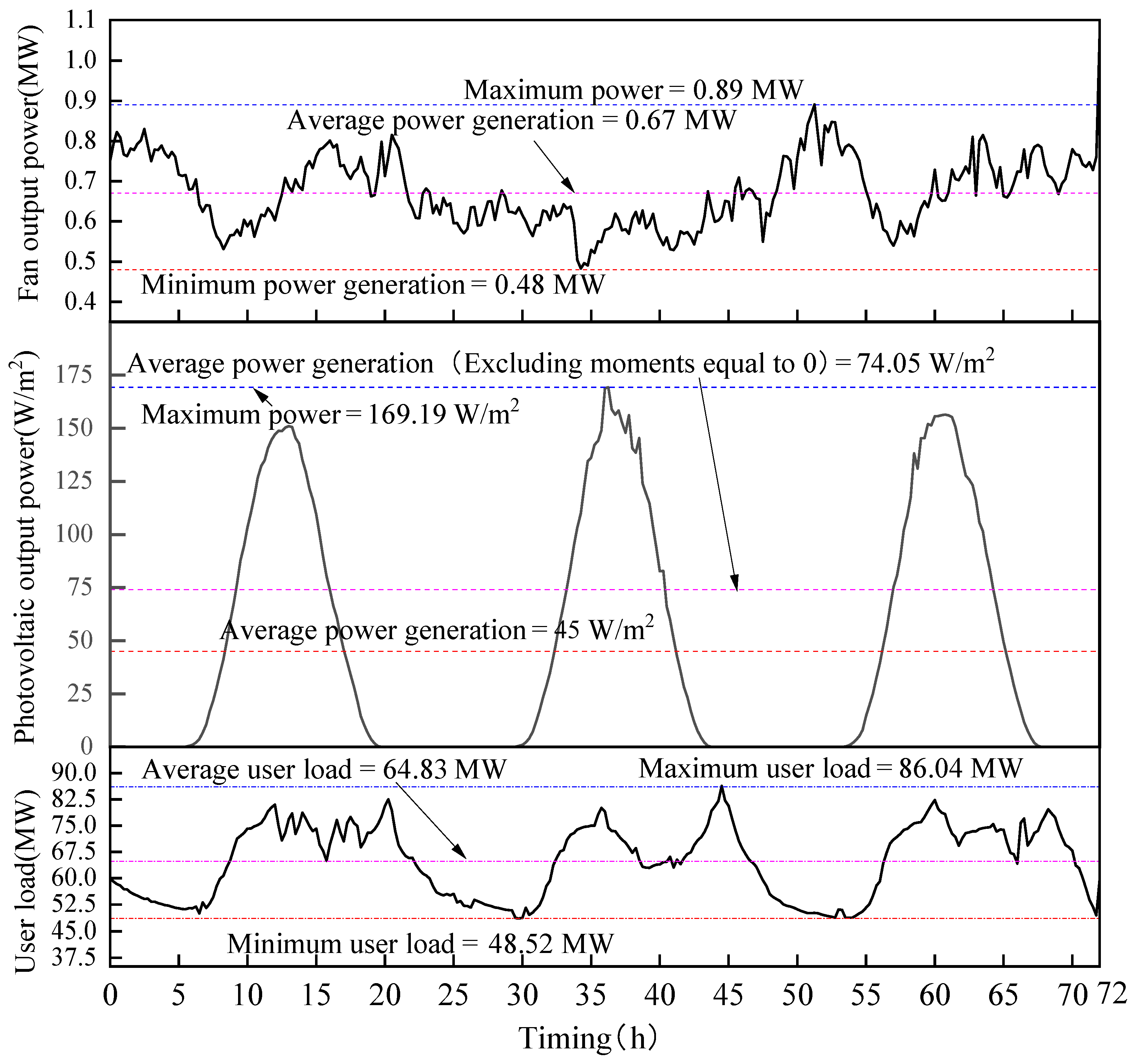
4.1. Typical Time Scale Selection
4.2. Development of Evaluation Criteria
4.3. Evaluation Methodology
4.4. Implications for Grid Operators: A Practical Perspective
5. Discussion
6. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- Tiejiang, Y.; Yong, C.; Yiqian, S.; Long, Z.; Shengwei, M. Optimized proportion of energy storage capacity in wind-storage system based on timing simulation and GA algorithm. High Volt. Eng. 2017, 43, 2122–2130. [Google Scholar]
- Zhu, R.; Zhao, A.L.; Wang, G.C.; Xia, X.; Yang, Y. An Energy Storage Performance Improvement Model for Grid-Connected Wind-Solar Hybrid Energy Storage System. Comput. Intell. Neurosci. 2020, 2020, 8887227. [Google Scholar] [CrossRef] [PubMed]
- Ding, Z.; Bu, W.; Xu, R.; Feng, S. Application of Energy Storage Technology in Photovoltaic Power Generation System. In Proceedings of the 8th International Conference on Management and Computer Science (ICMCS 2018), Shenyang, China, 10–12 August 2018; Atlantis Press: Dordrecht, The Netherlands, 2018; pp. 463–466. [Google Scholar]
- Tong, F.; Yuan, M.; Lewis, N.S.; Davis, S.J.; Caldeira, K. Effects of deep reductions in energy storage costs on highly reliable wind and solar electricity systems. iScience 2020, 23, 101484. [Google Scholar] [CrossRef] [PubMed]
- Nasser, M.; Megahed, T.F.; Ookawara, S.; Hassan, H. A review of water electrolysis–based systems for hydrogen production using hybrid/solar/wind energy systems. Environ. Sci. Pollut. Res. 2022, 29, 86994–87018. [Google Scholar] [CrossRef] [PubMed]
- Ahmed, M.M.R.; Mirsaeidi, S.; Koondhar, M.A.; Karami, N.; Tag-Eldin, E.M.; Ghamry, N.A.; El-Sehiemy, R.A.; Alaas, Z.M.; Sharaf, A.M. Mitigating Uncertainty Problems of Renewable Energy Resources Through Efficient Integration of Hybrid Solar PV/Wind Systems into Power Networks. IEEE Access 2024, 12, 30311–30328. [Google Scholar] [CrossRef]
- Lamadrid, A.J. Optimal use of energy storage systems with renewable energy sources. Int. J. Electr. Power Energy Syst. 2015, 71, 101–111. [Google Scholar] [CrossRef]
- Wang, F.; Zhen, Z.; Mi, Z.; Sun, H.; Su, S.; Yang, G. Solar irradiance feature extraction and support vector machines based weather status pattern recognition model for short-term photovoltaic power forecasting. Energy Build. 2015, 86, 427–438. [Google Scholar] [CrossRef]
- Ul Hassan, R.; Yan, J.; Liu, Y. Security risk assessment of wind integrated power system using Parzen window density estimation. Electr. Eng. 2022, 104, 1997–2008. [Google Scholar] [CrossRef]
- Xiong, F.; Zhang, Z.; Ling, Y.; Zhang, J. Image thresholding segmentation based on weighted Parzen-window and linear programming techniques. Sci. Rep. 2022, 12, 13635. [Google Scholar] [CrossRef] [PubMed]
- Stanković, D.; Draganić, A.; Lekić, N.; Ioana, C.; Orović, I. An architecture for Parzen-based multivariate probability density estimation. In Proceedings of the 2024 32nd Telecommunications Forum (TELFOR), Belgrade, Serbia, 26–27 November 2024; IEEE: New York, NY, USA, 2024; pp. 1–4. [Google Scholar]
- de Souza Rebouças, E.; De Medeiros, F.N.; Marques, R.C.; Chagas, J.V.; Guimarães, M.T.; Santos, L.O.; Medeiros, A.G.; Peixoto, S.A. Level set approach based on Parzen Window and floor of log for edge computing object segmentation in digital images. Appl. Soft Comput. 2021, 105, 107273. [Google Scholar] [CrossRef]
- Yu, Q.; Gao, S.; Sun, G.; Qin, R. Optimization of wind and solar energy storage system capacity configuration based on the Parzen window estimation method. J. Renew. Sustain. Energy 2023, 15, 064103. [Google Scholar] [CrossRef]
- Rouhani, M.; Mohammadi, M.; Kargarian, A. Parzen window density estimator-based probabilistic power flow with correlated uncertainties. IEEE Trans. Sustain. Energy 2016, 7, 1170–1181. [Google Scholar] [CrossRef]
- Xiong, F.; Zhang, J.; Ling, Y.; Zhang, Z. A novel image thresholding method combining entropy with Parzen window estimation. Comput. J. 2022, 65, 2231–2244. [Google Scholar] [CrossRef]
- Wang, Y.; Zou, R.; Liu, F.; Zhang, L.; Liu, Q. A review of wind speed and wind power forecasting with deep neural networks. Appl. Energy 2021, 304, 117766. [Google Scholar] [CrossRef]
- Dahunsi, F.M.; Olawumi, A.E.; Ale, D.T.; Sarumi, O.A. A systematic review of data pre-processing methods and unsupervised mining methods used in profiling smart meter data. AIMS Electron. Electr. Eng. 2021, 5, 284–314. [Google Scholar] [CrossRef]
- Wang, X.; Zhong, F.; Xu, Y.; Liu, X.; Li, Z.; Liu, J.; Zhao, Z. Extraction and Joint Method of PV–Load Typical Scenes Considering Temporal and Spatial Distribution Characteristics. Energies 2023, 16, 6458. [Google Scholar] [CrossRef]
- Balakishan, P.; Chidambaram, I.A.; Manikandan, M. Smart fuzzy control based hybrid PV-wind energy generation system. Mater. Today Proc. 2023, 80, 2929–2936. [Google Scholar] [CrossRef]
- Shi, M.; Yin, R.; Wang, Y.; Li, D.; Han, Y.; Yin, W. Photovoltaic power interval forecasting method based on kernel density estimation algorithm. IOP Conf. Ser. Earth Environ. Sci. 2020, 615, 012062. [Google Scholar] [CrossRef]
- Qadir, Z.; Khan, S.I.; Khalaji, E.; Munawar, H.S.; Al-Turjman, F.; Mahmud, M.P.; Kouzani, A.Z.; Le, K. Predicting the energy output of hybrid PV–wind renewable energy system using feature selection technique for smart grids. Energy Rep. 2021, 7, 8465–8475. [Google Scholar] [CrossRef]
- Yetis, Y.; Tehrani, K.; Jamshidi, M. Wind speed forecasting using machine learning approach based on meteorological data-a case study. Energy Environ. Res. 2022, 12, 1–11. [Google Scholar] [CrossRef]
- IEC 61400-12-1-2017; Wind Turbines Generator Systems-Part 12-1: Power Performance Measurements of Electricity Producing Wind Turbines. British Standard: London, UK, 2005.
- Azad, A.K.; Rasul, M.G.; Alam, M.M.; Uddin, S.A.; Mondal, S.K. Analysis of wind energy conversion system using Weibull distribution. Procedia Eng. 2014, 90, 725–732. [Google Scholar] [CrossRef]
- Chen, H.; Li, H.; Xu, Y.; Chen, M.; Wang, L.; Dai, H.; Xu, D.; Tang, X.; Li, X.; Hu, Y.; et al. Research Progress of Energy Storage Technologies in China in 2022. Energy Storage Sci. Technol. 2023, 12, 1516–1552. (In Chinese) [Google Scholar]
- Jani, V.; Abdi, H. Optimal allocation of energy storage systems considering wind power uncertainty. J. Energy Storage 2018, 20, 244–253. [Google Scholar] [CrossRef]
- He, J.; Zhang, Z. Optimization Study of Wind Power Prediction in Mountainous Wind Farms. In Proceedings of the 2023 3rd International Conference on Energy, Power and Electrical Engineering (EPEE), Wuhan, China, 15–17 September 2023; IEEE: New York, NY, USA, 2023; pp. 150–154. [Google Scholar]
- Junxi, T.; Huazhen, C.; Chong, G.; Wu, Z.; Ying, S. A User Load Curve Analysis Method Based on Time Series Data Mining. Power Syst. Prot. Control. 2021, 49, 140–148. (In Chinese) [Google Scholar]
- Guohua, F.; Xiaojing, Y.; Huaizhu, Y.; Tao, L.; Ziqi, S. Evaluation of Rural River Ecological Status Based on Fuzzy Matter-element Method. China Rural. Water Hydropower 2022, 4, 80–84. (In Chinese) [Google Scholar]
- Shuqiang, Z.; Shanfa, T. Comprehensive Evaluation of Power Transmission Network Planning Schemes Based on Improved Analytic Hierarchy Process, CRITIC Method and Technique for Order Preference by Similarity to an Ideal Solution. Electr. Power Autom. Equip. 2019, 39, 143–148, 162. (In Chinese) [Google Scholar]
- Hao, L.I.; Liang, G.A.; Peigen, L.I. Topology optimization of structures under multiple loading cases with a new compliance-volume product. Eng. Optim. 2014, 46, 725–744. [Google Scholar]
- Tehrani, K.; Beikbabaei, M.; Mehrizi-Sani, A.; Jamshidi, M. A smart multiphysics approach for wind turbines design in industry 5.0. J. Ind. Inf. Integr. 2024, 42, 100704. [Google Scholar] [CrossRef]

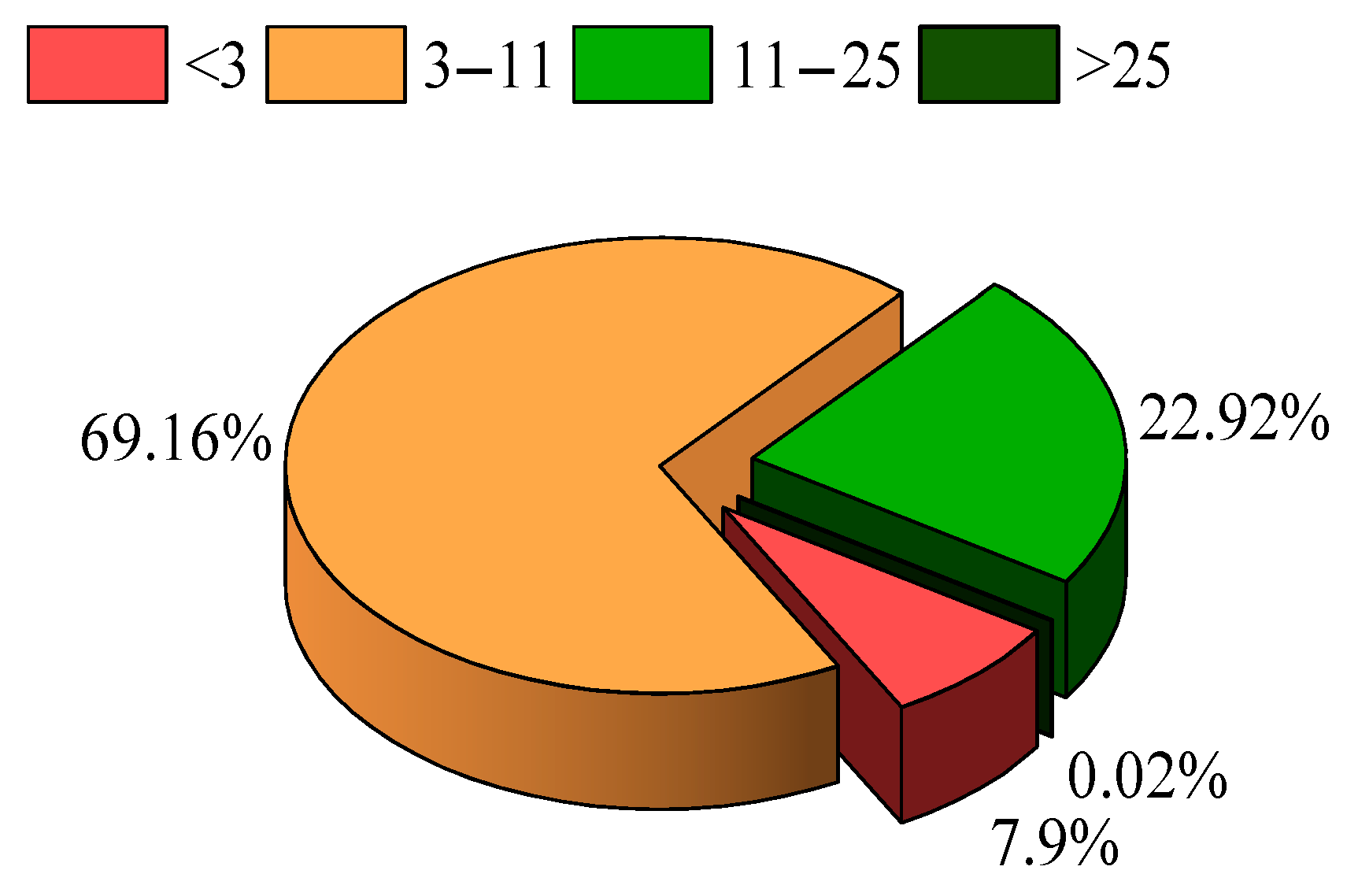





{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
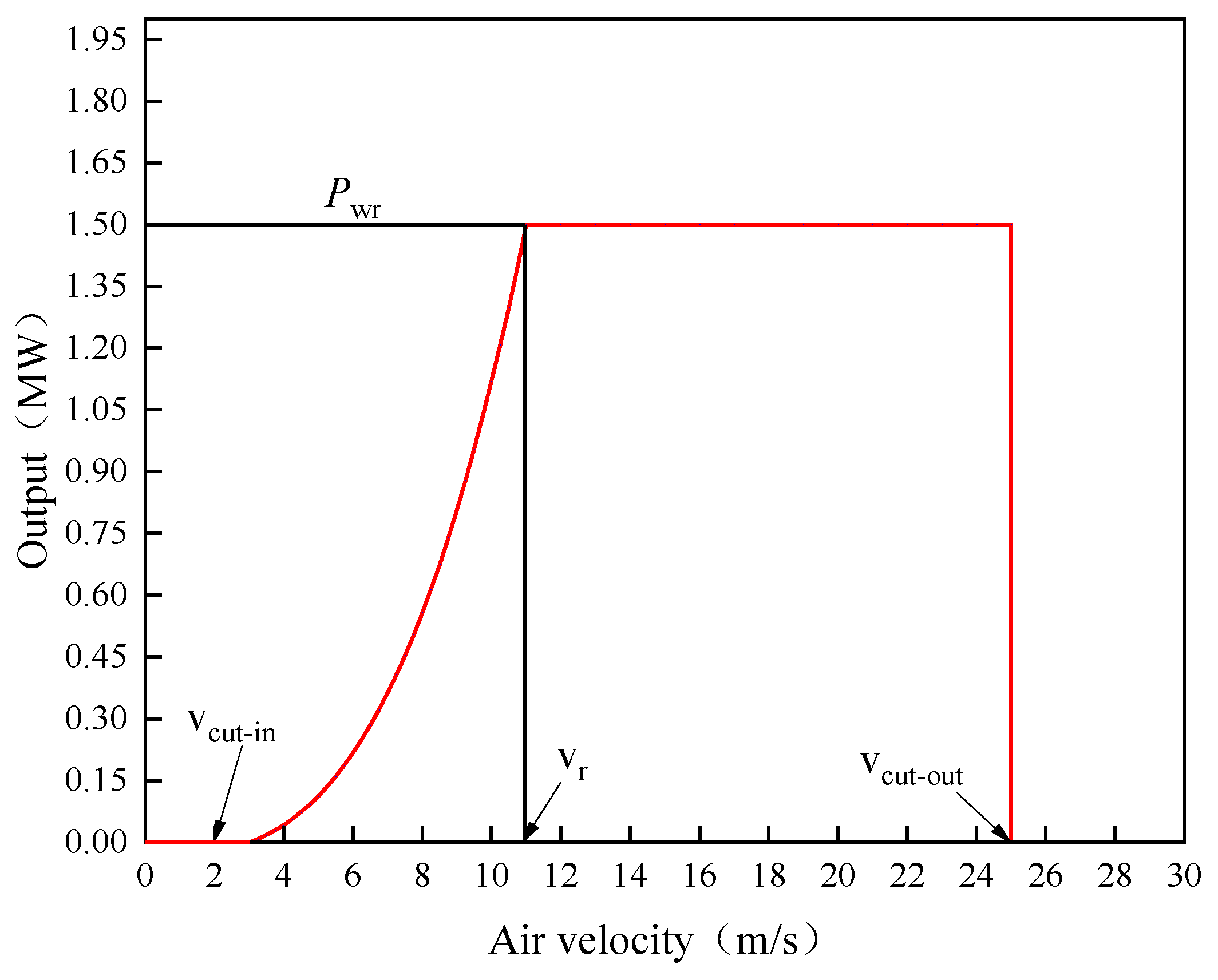
| Parametes | Rating (MW) | Cut-in Wind Speed (m/s) | Rated Wind Speed (m/s) | Cut Out Air Speed (m/s) | Blade Length (m) |
|---|---|---|---|---|---|
| Value | 1.5 | 3 | 11 | 25 | 34 |
| Parameters | Rating (W) | Conversion Efficiency (%) | Theoretical Temperature (K) | Best Angle (°) |
|---|---|---|---|---|
| Value | 250 | 25 | 296 | 30 |
| Symbol | Description | Unit | Typical Value/Notes |
|---|---|---|---|
| v | Wind speed | m/s | 0–25 (from dataset) |
| vr | Rated wind speed | m/s | 11 |
| vcut-in | Cut-in wind speed | m/s | 3 |
| vcut-out | Cut-out wind speed | m/s | 25 |
| Pr | Rated power | MW | 1.5 |
| I | Solar irradiance | W/m2 | 0–1000 |
| A | PV panel area | m2 | 1 m2 assumed |
| PPV | PV output power | W | Calculated from I × A × η |
| PV efficiency | % | 25–30 | |
| h | Bandwidth in Parzen estimation | - | 0.02–0.32 |
| K(x) | Kernel function | - | Gaussian, Triangle, Epanechnikov |
| f(x) | Estimated probability density | - | Computed using Parzen window method |
| Name | 1 | 2 | 3 | 4 | 5 | 6 | 7 | |
|---|---|---|---|---|---|---|---|---|
| Wind energy | ΔC1 | 0.0112 | 0.0094 | 0.0087 | 0.0083 | 0.0089 | 0.0086 | 0.0090 |
| ΔC2 | 0.9643 | 0.9766 | 0.9853 | 0.9925 | 0.9923 | 0.9923 | 0.9919 | |
| ΔC3 | 0.0471 | 0.032 | 0.0217 | 0.0136 | 0.0138 | 0.0149 | 0.0139 | |
| Photovoltaic | ΔC1 | 0.0141 | 0.0125 | 0.0109 | 0.0126 | 0.0137 | 0.0153 | 0.0168 |
| ΔC2 | 0.9835 | 0.9885 | 0.9839 | 0.9803 | 0.9699 | 0.9626 | 0.9516 | |
| ΔC3 | 0.0394 | 0.0241 | 0.0267 | 0.0343 | 0.0413 | 0.0457 | 0.0460 | |
| Burden | ΔC1 | 0.0182 | 0.0116 | 0.0076 | 0.0151 | 0.0188 | 0.0209 | 0.0264 |
| ΔC2 | 0.9634 | 0.9747 | 0.9822 | 0.9746 | 0.9725 | 0.9535 | 0.9486 | |
| ΔC3 | 0.3423 | 0.2513 | 0.0125 | 0.0241 | 0.0417 | 0.0523 | 0.0619 | |
| Norm | Wind Power | Photovoltaic | User Load | ||||||
|---|---|---|---|---|---|---|---|---|---|
| ΔC1 | ΔC2 | ΔC3 | ΔC1 | ΔC2 | ΔC3 | ΔC1 | ΔC2 | ΔC3 | |
| Value | 0.1333 | 0.1334 | 0.1333 | 0.0333 | 0.0334 | 0.0333 | 0.1667 | 0.1667 | 0.1666 |
| Norm | Wind Power | Photovoltaic | User Load | ||||||
|---|---|---|---|---|---|---|---|---|---|
| ΔC1 | ΔC2 | ΔC3 | ΔC1 | ΔC2 | ΔC3 | ΔC1 | ΔC2 | ΔC3 | |
| Value | 0.1465 | 0.1759 | 0.0976 | 0.0428 | 0.0514 | 0.0105 | 0.1769 | 0.1801 | 0.1183 |
| Norm | Wind Power | Photovoltaic | User Load | ||||||
|---|---|---|---|---|---|---|---|---|---|
| ΔC1 | ΔC2 | ΔC3 | ΔC1 | ΔC2 | ΔC3 | ΔC1 | ΔC2 | ΔC3 | |
| Value | 0.1414 | 0.1595 | 0.1114 | 0.0391 | 0.0445 | 0.0193 | 0.173 | 0.1749 | 0.1369 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2025 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Sun, Y.; Yu, Q.; Wang, X.; Gao, S.; Sun, G. Extraction of Basic Features and Typical Operating Conditions of Wind Power Generation for Sustainable Energy Systems. Sustainability 2025, 17, 6577. https://doi.org/10.3390/su17146577
Sun Y, Yu Q, Wang X, Gao S, Sun G. Extraction of Basic Features and Typical Operating Conditions of Wind Power Generation for Sustainable Energy Systems. Sustainability. 2025; 17(14):6577. https://doi.org/10.3390/su17146577
Chicago/Turabian StyleSun, Yongtao, Qihui Yu, Xinhao Wang, Shengyu Gao, and Guoxin Sun. 2025. "Extraction of Basic Features and Typical Operating Conditions of Wind Power Generation for Sustainable Energy Systems" Sustainability 17, no. 14: 6577. https://doi.org/10.3390/su17146577
APA StyleSun, Y., Yu, Q., Wang, X., Gao, S., & Sun, G. (2025). Extraction of Basic Features and Typical Operating Conditions of Wind Power Generation for Sustainable Energy Systems. Sustainability, 17(14), 6577. https://doi.org/10.3390/su17146577