
The Impact of Digitalization on Carbon Emission Efficiency: An Intrinsic Gaussian Process Regression Approach


Abstract
1. Introduction
2. Related Work
3. Data and Methodology
3.1. Variables and Data Sources
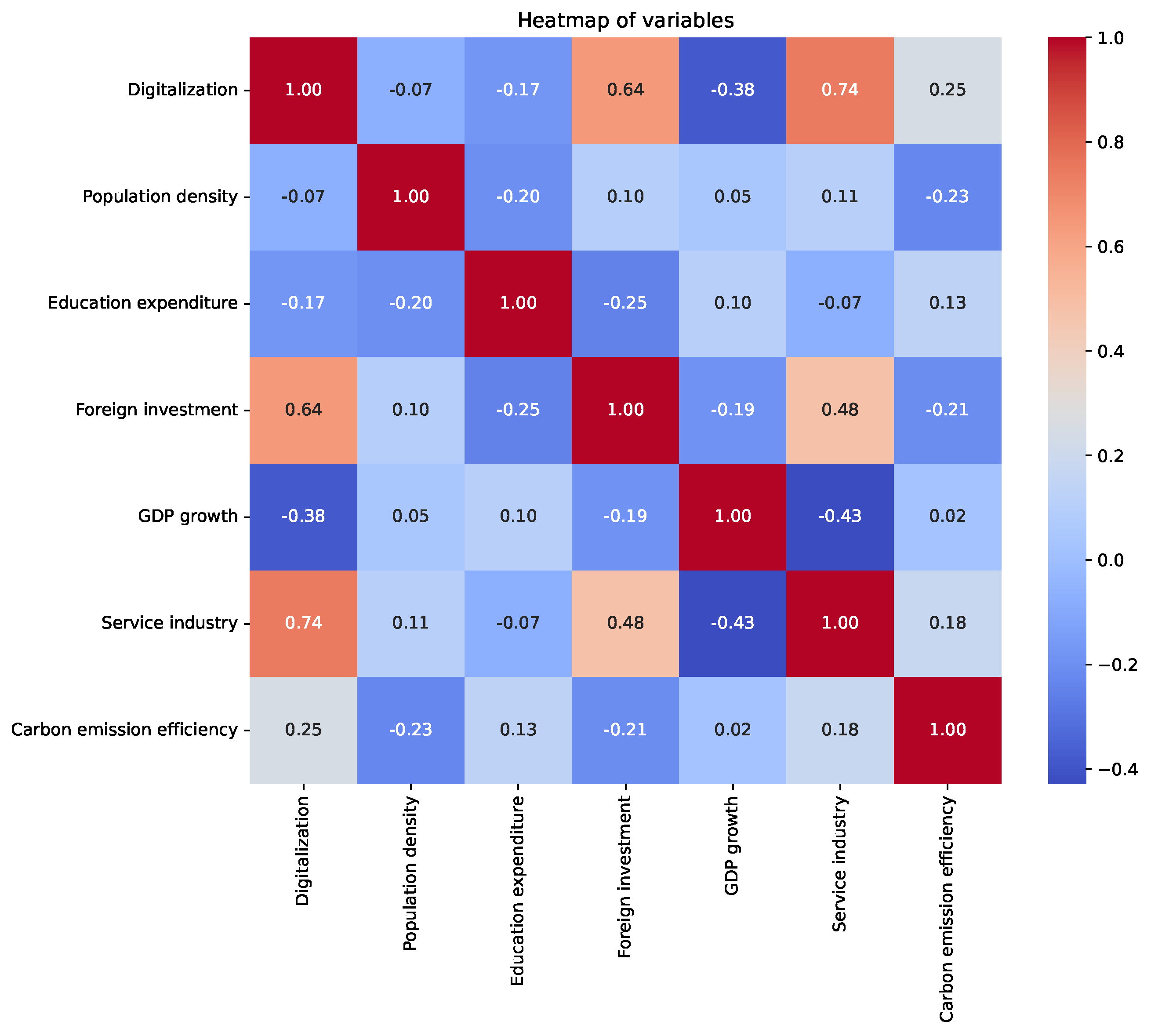
3.2. Data Pre-Processing
3.3. Model Setting
3.4. Parameter Estimation
4. Results and Discussion
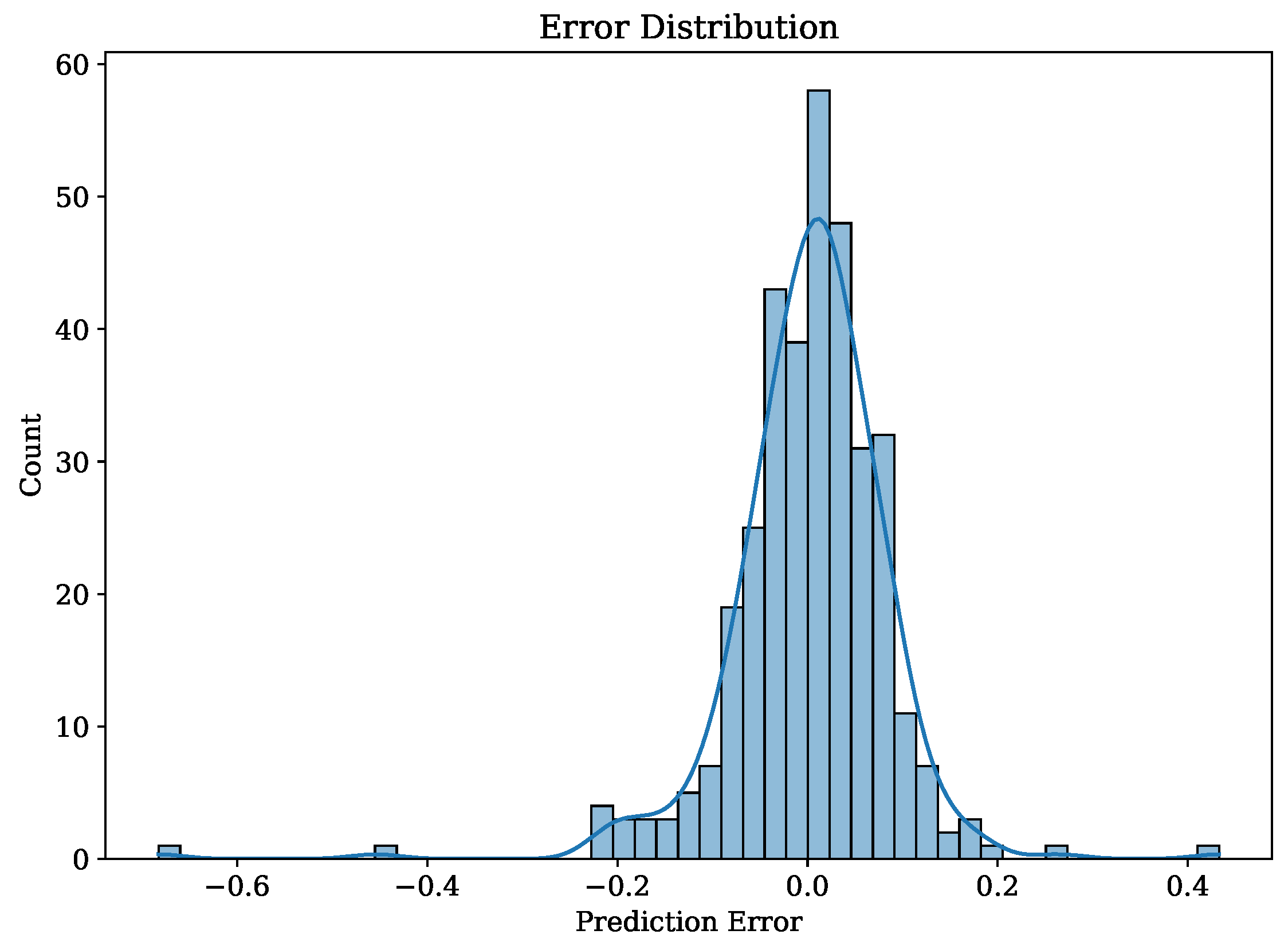
4.1. Baseline Results
4.2. Robustness Checks
4.3. Endogeneity Test
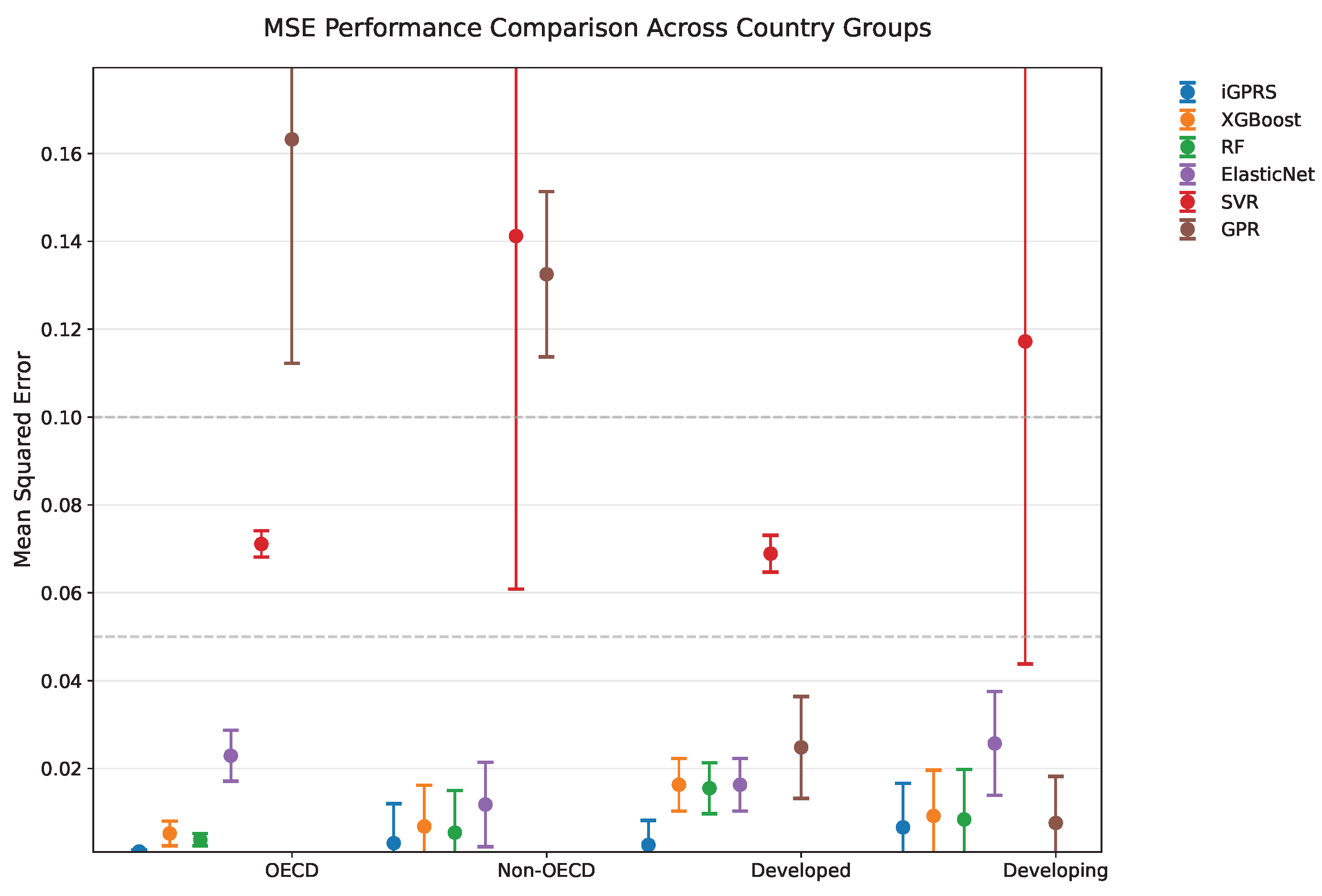
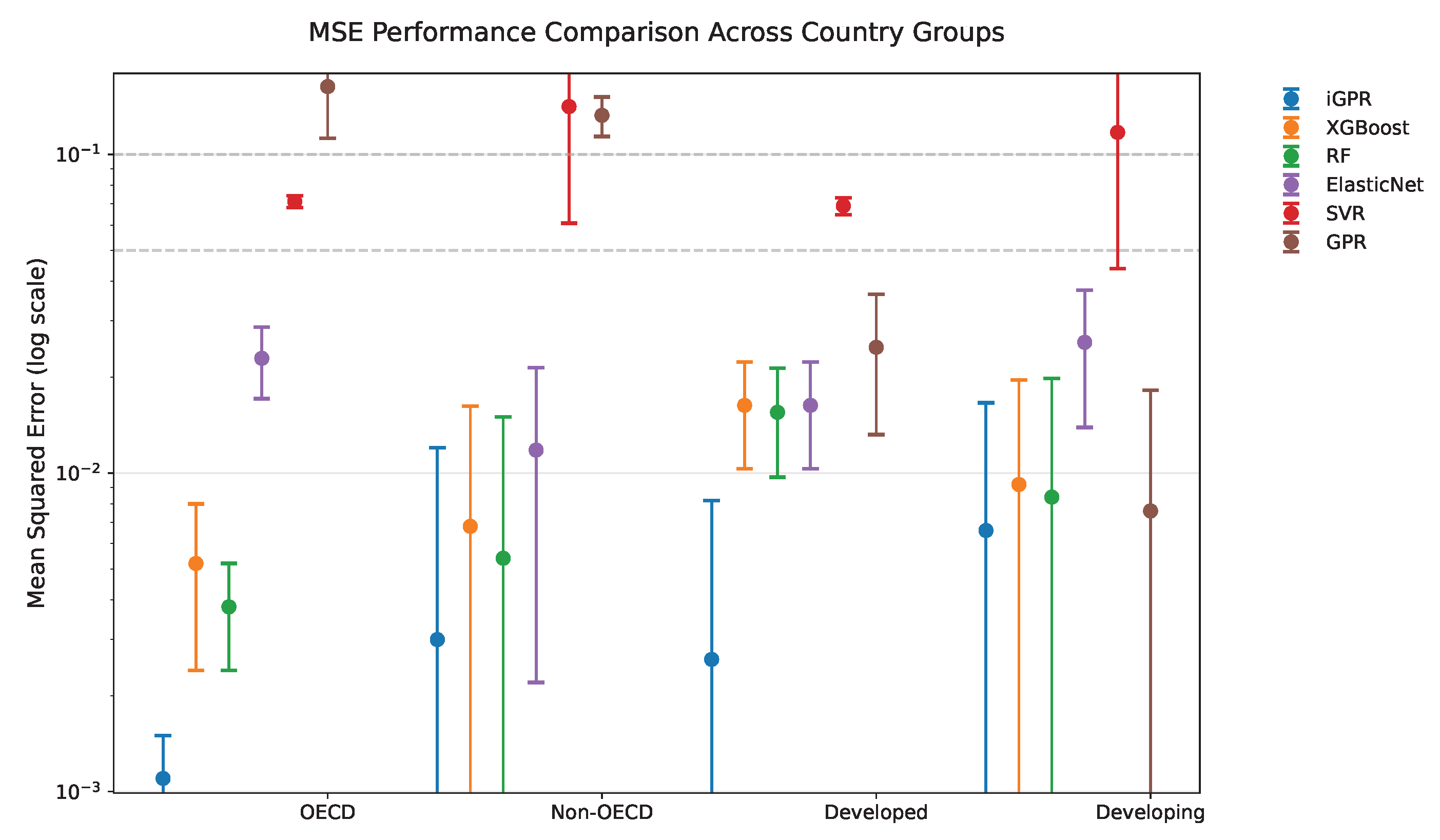
4.4. Country Heterogeneity Analysis
5. Conclusions and Policy Implications
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
Appendix A. Detailed Derivations and Pseudocode for iGPR Model
Appendix A.1. Heat-Kernel-Based Covariance on a Spatial Manifold
Appendix A.2. Penalized Likelihood and Model Estimation
| Algorithm A1 Intrinsic Gaussian Process Regression (iGPR) estimation. |
| Require: Panel data , number of heat-kernel simulations M, diffusion time t Ensure: Estimated regression coefficients , GP hyperparameters , fitted values
|
References
- Yoro, K.O.; Daramola, M.O. CO2 emission sources, greenhouse gases, and the global warming effect. In Advances in Carbon Capture; Elsevier: Amsterdam, The Netherlands, 2020; pp. 3–28. [Google Scholar]
- Min, J.; Yan, G.; Abed, A.M.; Elattar, S.; Khadimallah, M.A.; Jan, A.; Ali, H.E. The effect of carbon dioxide emissions on the building energy efficiency. Fuel 2022, 326, 124842. [Google Scholar] [CrossRef]
- Yang, Z.; Gao, W.; Han, Q.; Qi, L.; Cui, Y.; Chen, Y. Digitalization and carbon emissions: How does digital city construction affect China’s carbon emission reduction? Sustain. Cities Soc. 2022, 87, 104201. [Google Scholar] [CrossRef]
- Sun, T.; Di, K.; Shi, Q. Digital economy and carbon emission: The coupling effects of the economy in Qinghai region of China. Heliyon 2024, 10, e26451. [Google Scholar] [CrossRef] [PubMed]
- Wang, Q.; Zhang, Q. Foreign direct investment and carbon emission efficiency: The role of direct and indirect channels. Sustainability 2022, 14, 13484. [Google Scholar] [CrossRef]
- Zhao, X.; Long, L.; Yin, S.; Zhou, Y. How technological innovation influences carbon emission efficiency for sustainable development? Evidence from China. Resour. Environ. Sustain. 2023, 14, 100135. [Google Scholar] [CrossRef]
- Zhang, C.; Lin, J. An empirical study of environmental regulation on carbon emission efficiency in China. Energy Sci. Eng. 2022, 10, 4756–4767. [Google Scholar] [CrossRef]
- Yu, Z.; Liu, Y.; Yan, T.; Zhang, M. Carbon emission efficiency in the age of digital economy: New insights on green technology progress and industrial structure distortion. Bus. Strategy Environ. 2024, 33, 4039–4057. [Google Scholar] [CrossRef]
- Wang, Q.; Zhang, C.; Li, R. Towards carbon neutrality by improving carbon efficiency-a system-GMM dynamic panel analysis for 131 countries’ carbon efficiency. Energy 2022, 258, 124880. [Google Scholar] [CrossRef]
- Jiang, H.; Hu, W.; Guo, Z.; Hou, Y.; Chen, T. E-commerce development and carbon emission efficiency: Evidence from 240 cities in China. Econ. Anal. Policy 2024, 82, 586–603. [Google Scholar] [CrossRef]
- Liu, L.; Li, M.; Gong, X.; Jiang, P.; Jin, R.; Zhang, Y. Influence mechanism of different environmental regulations on carbon emission efficiency. Int. J. Environ. Res. Public Health 2022, 19, 13385. [Google Scholar] [CrossRef] [PubMed]
- Fan, B.; Li, M. The effect of heterogeneous environmental regulations on carbon emission efficiency of the grain production industry: Evidence from China’s inter-provincial panel data. Sustainability 2022, 14, 14492. [Google Scholar] [CrossRef]
- Jiang, P.; Li, M.; Zhao, Y.; Gong, X.; Jin, R.; Zhang, Y.; Li, X.; Liu, L. Does environmental regulation improve carbon emission efficiency? Inspection of panel data from inter-provincial provinces in China. Sustainability 2022, 14, 10448. [Google Scholar] [CrossRef]
- Yao, S.; Su, X. Research on the nonlinear impact of environmental regulation on the efficiency of China’s regional green economy: Insights from the PSTR model. Discret. Dyn. Nat. Soc. 2021, 2021, 5914334. [Google Scholar] [CrossRef]
- Wang, Q.; Zhang, C.; Li, R. Does environmental regulation improve marine carbon efficiency? The role of marine industrial structure. Mar. Pollut. Bull. 2023, 188, 114669. [Google Scholar] [CrossRef] [PubMed]
- Xie, Z.; Wu, R.; Wang, S. How technological progress affects the carbon emission efficiency? Evidence from national panel quantile regression. J. Clean. Prod. 2021, 307, 127133. [Google Scholar] [CrossRef]
- Zhang, S.; Xue, Y.; Jin, S.; Chen, Z.; Cheng, S.; Wang, W. Does Urban Polycentric Structure Improve Carbon Emission Efficiency? A Spatial Panel Data Analysis of 279 Cities in China from 2012 to 2020. ISPRS Int. J.-Geo-Inf. 2024, 13, 462. [Google Scholar] [CrossRef]
- Zhang, Y.; Chen, M.; Zhong, S.; Liu, M. Fintech’s role in carbon emission efficiency: Dynamic spatial analysis. Sci. Rep. 2024, 14, 23941. [Google Scholar] [CrossRef] [PubMed]
- Wu, Z.; Xu, X.; He, M. The Impact of Green Finance on Urban Carbon Emission Efficiency: Threshold Effects Based on the Stages of the Digital Economy in China. Sustainability 2025, 17, 854. [Google Scholar] [CrossRef]
- Zhang, Y.; Hong, W. A significance of smart city pilot policies in China for enhancing carbon emission efficiency in construction. Environ. Sci. Pollut. Res. 2024, 31, 38153–38179. [Google Scholar] [CrossRef] [PubMed]
- Pang, G.; Li, L.; Guo, D. Does the integration of the digital economy and the real economy enhance urban green emission reduction efficiency? Evidence from China. Sustain. Cities Soc. 2025, 122, 106269. [Google Scholar] [CrossRef]
- Haefner, L.; Sternberg, R. Spatial implications of digitization: State of the field and research agenda. Geogr. Compass 2020, 14, e12544. [Google Scholar] [CrossRef]
- Nan, S.; Huo, Y.; You, W.; Guo, Y. Globalization spatial spillover effects and carbon emissions: What is the role of economic complexity? Energy Econ. 2022, 112, 106184. [Google Scholar] [CrossRef]
- Ritchie, H.; Roser, M. CO2 Emissions. Our World Data. 2020. Available online: https://ourworldindata.org/co2-emissions (accessed on 20 May 2025).
- Aigner, D.; Lovell, C.K.; Schmidt, P. Formulation and estimation of stochastic frontier production function models. J. Econom. 1977, 6, 21–37. [Google Scholar] [CrossRef]
- Tone, K. A slacks-based measure of efficiency in data envelopment analysis. Eur. J. Oper. Res. 2001, 130, 498–509. [Google Scholar] [CrossRef]
- Wu, D.; Mei, X.; Zhou, H. Measurement and Analysis of Carbon Emission Efficiency in the Three Urban Agglomerations of China. Sustainability 2024, 16, 9050. [Google Scholar] [CrossRef]
- Jiang, H.; Yin, J.; Qiu, Y.; Zhang, B.; Ding, Y.; Xia, R. Industrial carbon emission efficiency of cities in the pearl river basin: Spatiotemporal dynamics and driving forces. Land 2022, 11, 1129. [Google Scholar] [CrossRef]
- Liu, Q.; Hao, J. Regional differences and influencing factors of carbon emission efficiency in the Yangtze River economic belt. Sustainability 2022, 14, 4814. [Google Scholar] [CrossRef]
- Wang, H.; Liu, W.; Liang, Y. Measurement of CO2 Emissions Efficiency and Analysis of Influencing Factors of the Logistics Industry in Nine Coastal Provinces of China. Sustainability 2023, 15, 14423. [Google Scholar] [CrossRef]
- Jiang, X.; Ma, J.; Zhu, H.; Guo, X.; Huang, Z. Evaluating the carbon emissions efficiency of the logistics industry based on a Super-SBM Model and the Malmquist Index from a strong transportation strategy perspective in China. Int. J. Environ. Res. Public Health 2020, 17, 8459. [Google Scholar] [CrossRef] [PubMed]
- Gu, R.; Duo, L.; Guo, X.; Zou, Z.; Zhao, D. Spatiotemporal heterogeneity between agricultural carbon emission efficiency and food security in Henan, China. Environ. Sci. Pollut. Res. 2023, 30, 49470–49486. [Google Scholar] [CrossRef] [PubMed]
- Li, J.; Li, S.; Liu, Q.; Ding, J. Agricultural carbon emission efficiency evaluation and influencing factors in Zhejiang province, China. Front. Environ. Sci. 2022, 10, 1005251. [Google Scholar] [CrossRef]
- Liang, Z.; Chiu, Y.h.; Guo, Q.; Liang, Z. Low-carbon logistics efficiency: Analysis on the statistical data of the logistics industry of 13 cities in Jiangsu Province, China. Res. Transp. Bus. Manag. 2022, 43, 100740. [Google Scholar] [CrossRef]
- Song, C.; Liu, Q.; Song, J.; Ma, W. Impact path of digital economy on carbon emission efficiency: Mediating effect based on technological innovation. J. Environ. Manag. 2024, 358, 120940. [Google Scholar] [CrossRef] [PubMed]
- Wu, G.; Liu, X.; Cai, Y. The impact of green finance on carbon emission efficiency. Heliyon 2024, 10, e23803. [Google Scholar] [CrossRef] [PubMed]
- Huang, Z.; Zhao, T.; Lai, R.; Tian, Y.; Yang, F. A comprehensive implementation of the log, Box-Cox and log-sinh transformations for skewed and censored precipitation data. J. Hydrol. 2023, 620, 129347. [Google Scholar] [CrossRef]
- van Buuren, S.; Groothuis-Oudshoorn, K. mice: Multivariate Imputation by Chained Equations in R. J. Stat. Softw. 2011, 45, 1–67. [Google Scholar] [CrossRef]
- Wang, Y.; Li, Y.; Li, H.; Dang, W.; Zheng, A. Study on the correlation between soil resistivity and multiple influencing factors using the entropy weight method and genetic algorithm. Electr. Power Syst. Res. 2025, 246, 111692. [Google Scholar] [CrossRef]
- Zhang, H.; Gan, J. A reproducing kernel-based spatial model in Poisson regressions. Int. J. Biostat. 2012, 8, 28. [Google Scholar] [CrossRef] [PubMed]
- Javed, H.; El-Sappagh, S.; Abuhmed, T. Robustness in deep learning models for medical diagnostics: Security and adversarial challenges towards robust AI applications. Artif. Intell. Rev. 2024, 58, 12. [Google Scholar] [CrossRef]
- Tang, Y.; Wang, X.; Zhu, J.; Lin, H.; Tang, Y.; Tong, T. Robust Inference for Censored Quantile Regression. J. Syst. Sci. Complex. 2024, 38, 1730–1746. [Google Scholar] [CrossRef]
- Farzana, A.; Samsudin, S.; Hasan, J. Drivers of economic growth: A dynamic short panel data analysis using system GMM. Discov. Sustain. 2024, 5, 393. [Google Scholar] [CrossRef]
- Hansen, L.P. Large Sample Properties of Generalized Method of Moments Estimators. Econometrica 1982, 50, 1029–1054. [Google Scholar] [CrossRef]

{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Variable | Description | Obs | Mean | Std | Min | Max |
|---|---|---|---|---|---|---|
| Digitization | DE index | 1160 | 0.00086 | 0.00041 | 0.000058 | 0.0016 |
| Population density | People per km2 of land area | 1160 | 4.35 | 1.24 | 1.25 | 7.16 |
| Education expenditure | Cost on education | 1160 | 13.65 | 3.86 | 5.26 | 32.59 |
| Foreign investment | Direct investment from foreign countries | 1160 | 21.78 | 2.70 | 6.91 | 27.11 |
| GDP growth | GDP growth annual | 1160 | 3.33 | 3.27 | −16.04 | 24.62 |
| Industry | Services, value added (% of GDP) | 1160 | 0.59 | 0.086 | 0.22 | 0.80 |
| Carbon emission efficiency | CEE index | 1160 | 0.39 | 0.14 | 0.18 | 1.67 |
| Mean | Std | |
|---|---|---|
| iGPR | 0.0047 | 0.0025 |
| XGBoost | 0.0082 | 0.0028 |
| RF | 0.0078 | 0.0026 |
| SVR | 0.1066 | 0.0327 |
| ElasticNet | 0.0226 | 0.0040 |
| GPR | 0.1479 | 0.0277 |
| Quantile | Parameter | Std Err | T-Stat | p-Value |
|---|---|---|---|---|
| 0.1 | 0.2000 | 0.073 | 2.752 | 0.006 |
| 0.25 | 0.2383 | 0.105 | 2.269 | 0.024 |
| 0.5 | 0.2612 | 0.035 | 7.496 | 0.001 |
| 0.75 | 0.2685 | 0.036 | 7.390 | 0.001 |
| 0.9 | 0.2705 | 0.040 | 6.755 | 0.001 |
| Variable | Obs | Mean | Std | Min | Max | Corr(DV) | Corr(EV) |
|---|---|---|---|---|---|---|---|
| working-age population ratio | 1160 | 4.19 | 0.07 | 3.92 | 4.31 | −0.015 | 0.501 |
| Research expenditure | 1160 | 1.3 | 1.05 | 0.005 | 5.22 | 0.008 | 0.75 |
| Variable | Type | Parameter | Std Err | T-Stat | p-Value |
|---|---|---|---|---|---|
| Digitalization | endogenous | 0.1913 | 0.0618 | 3.0925 | 0.0020 |
| Population density | control | −0.2339 | 0.0183 | −12.779 | 0.0000 |
| Foreign investment | control | −0.1794 | 0.0319 | −5.6220 | 0.0000 |
| GDP growth | control | 0.0661 | 0.0186 | 3.5496 | 0.0004 |
| Model | OECD | Non-OECD | Developed | Developing | ||||
|---|---|---|---|---|---|---|---|---|
| Mean | Std | Mean | Std | Mean | Std | Mean | Std | |
| iGPR | 0.0011 | 0.0002 | 0.0030 | 0.0045 | 0.0026 | 0.0028 | 0.0066 | 0.0050 |
| XGBoost | 0.0052 | 0.0014 | 0.0068 | 0.0047 | 0.0163 | 0.0030 | 0.0092 | 0.0052 |
| RF | 0.0038 | 0.0007 | 0.0054 | 0.0048 | 0.0155 | 0.0029 | 0.0084 | 0.0057 |
| SVR | 0.0711 | 0.0015 | 0.1412 | 0.0402 | 0.0689 | 0.0021 | 0.1172 | 0.0367 |
| ElasticNet | 0.0229 | 0.0029 | 0.0118 | 0.0048 | 0.0163 | 0.0030 | 0.0257 | 0.0059 |
| GPR | 0.1632 | 0.0255 | 0.1325 | 0.0094 | 0.0248 | 0.0058 | 0.0076 | 0.0053 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2025 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Hu, Y.; Xu, J.; Liu, T. The Impact of Digitalization on Carbon Emission Efficiency: An Intrinsic Gaussian Process Regression Approach. Sustainability 2025, 17, 6551. https://doi.org/10.3390/su17146551
Hu Y, Xu J, Liu T. The Impact of Digitalization on Carbon Emission Efficiency: An Intrinsic Gaussian Process Regression Approach. Sustainability. 2025; 17(14):6551. https://doi.org/10.3390/su17146551
Chicago/Turabian StyleHu, Yongtong, Jiaqi Xu, and Tao Liu. 2025. "The Impact of Digitalization on Carbon Emission Efficiency: An Intrinsic Gaussian Process Regression Approach" Sustainability 17, no. 14: 6551. https://doi.org/10.3390/su17146551
APA StyleHu, Y., Xu, J., & Liu, T. (2025). The Impact of Digitalization on Carbon Emission Efficiency: An Intrinsic Gaussian Process Regression Approach. Sustainability, 17(14), 6551. https://doi.org/10.3390/su17146551