
Enhanced Parallel Convolution Architecture YOLO Photovoltaic Panel Detection Model for Remote Sensing Images


Abstract
1. Introduction
2. Methodology and Model
2.1. Data Preprocessing Techniques
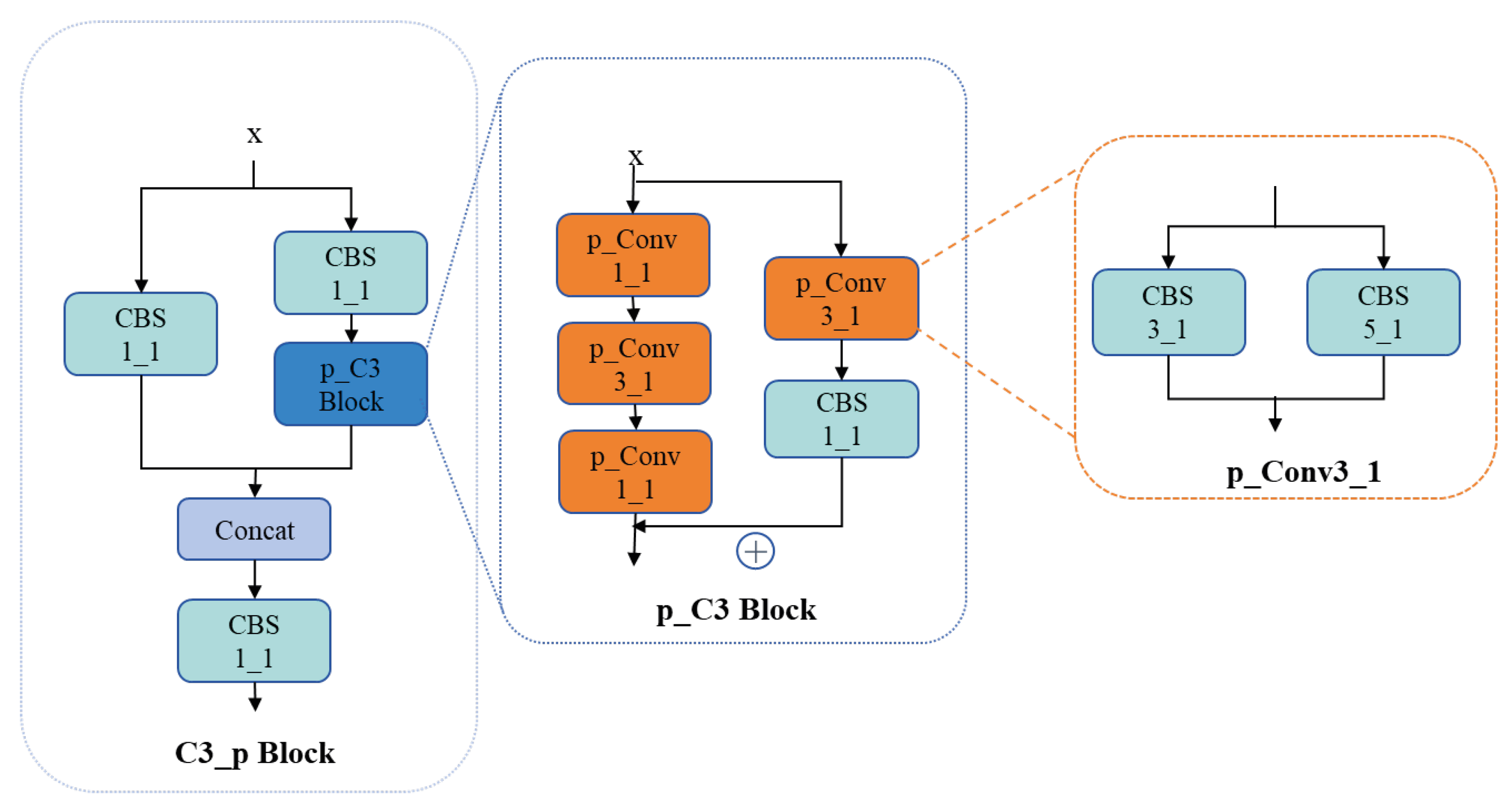
2.2. Model Architecture
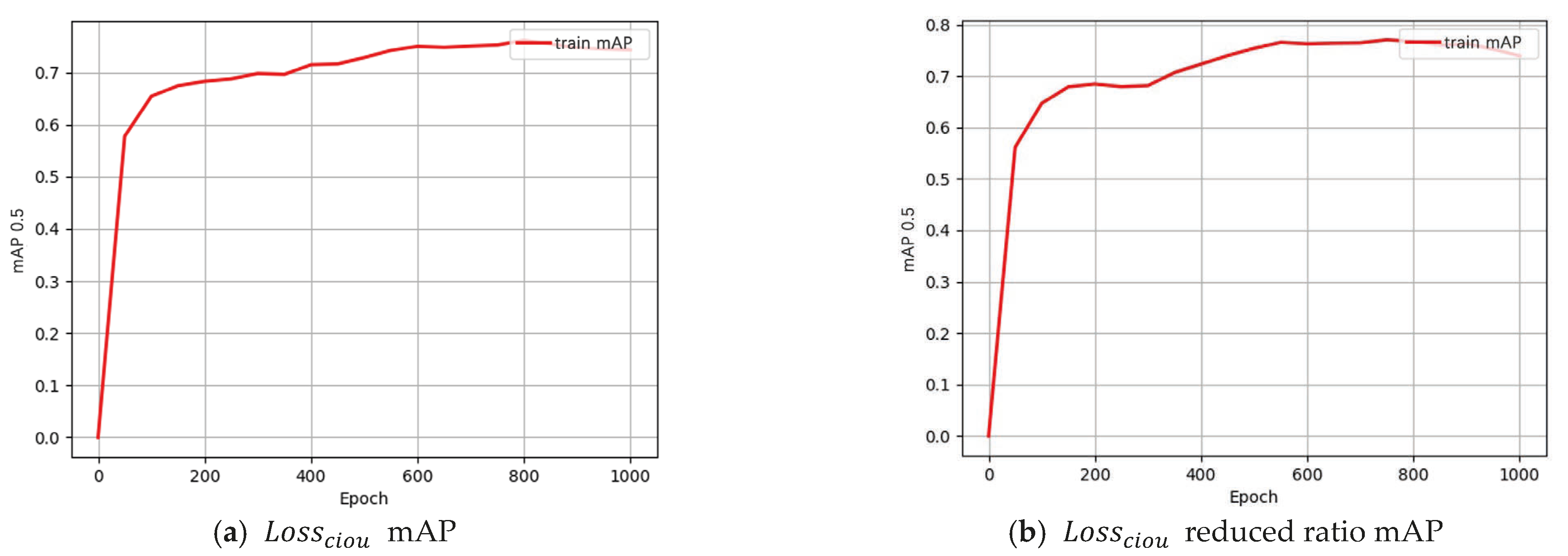
2.3. Loss Function Definition
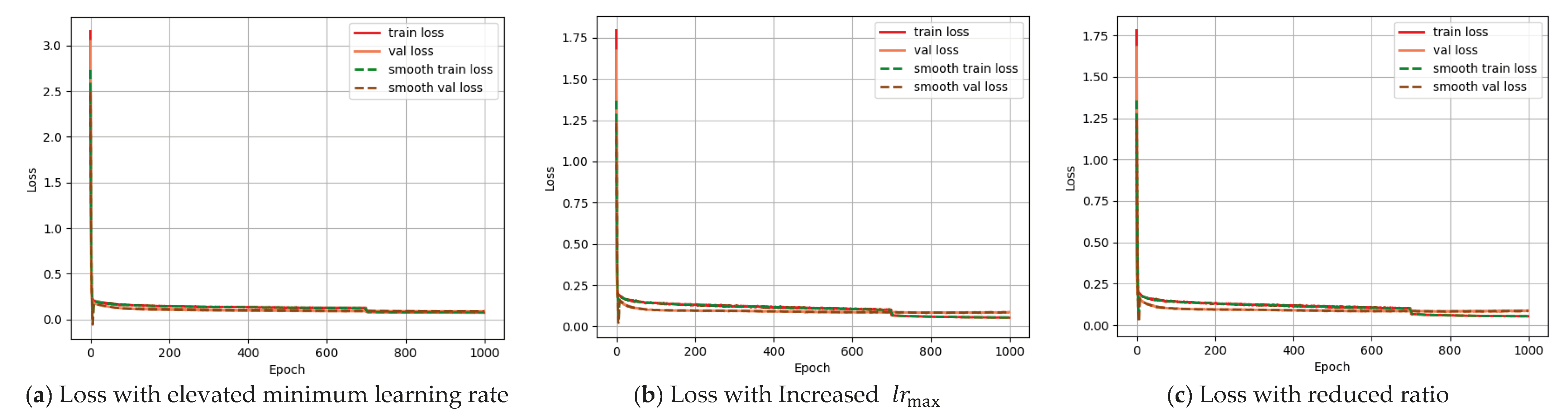
2.4. Learning Rate Adjustment Strategy
3. Experimental Procedure and Results
3.1. Dataset
3.2. Experimental Environment
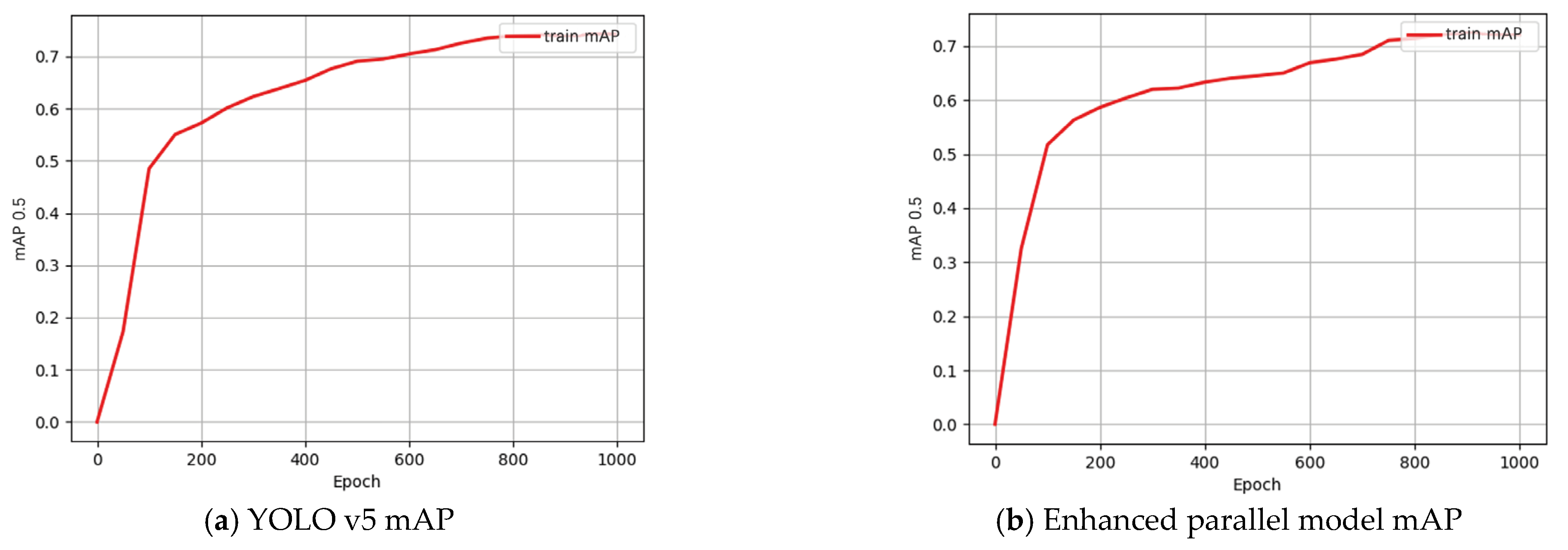
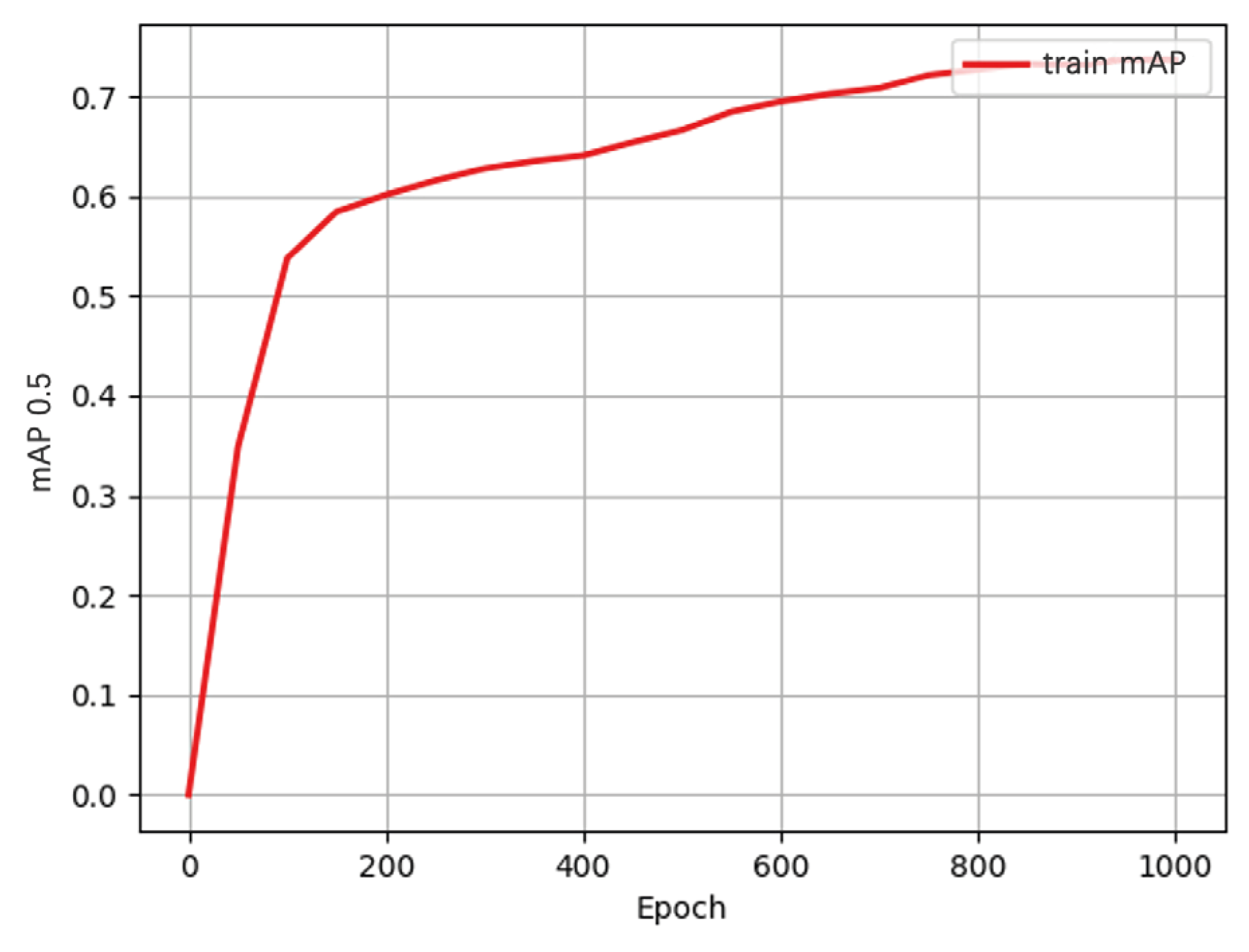
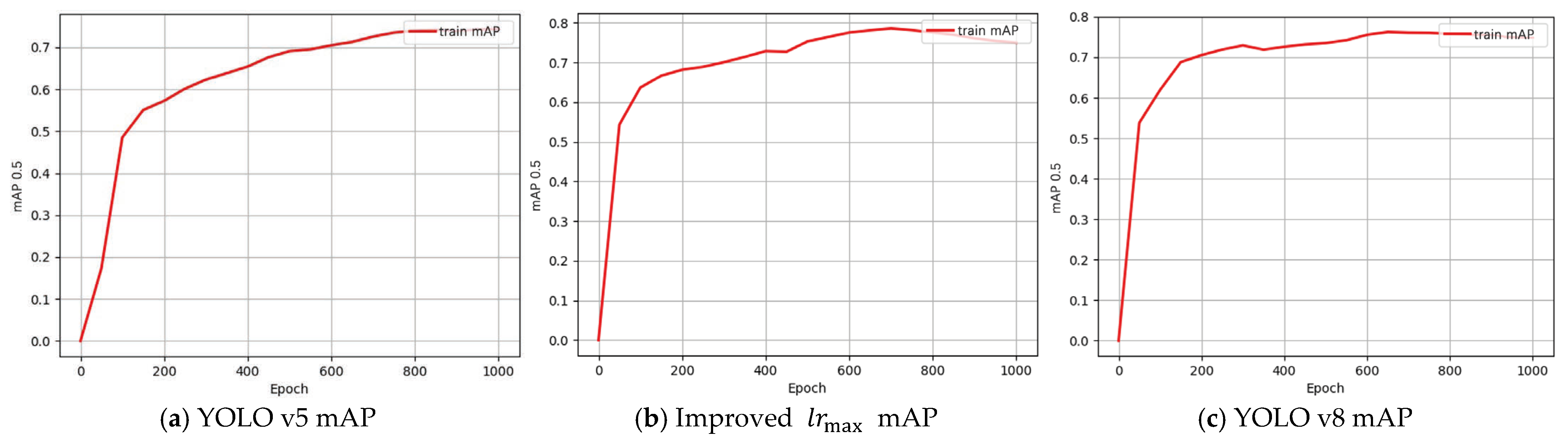
3.3. Experimental Results
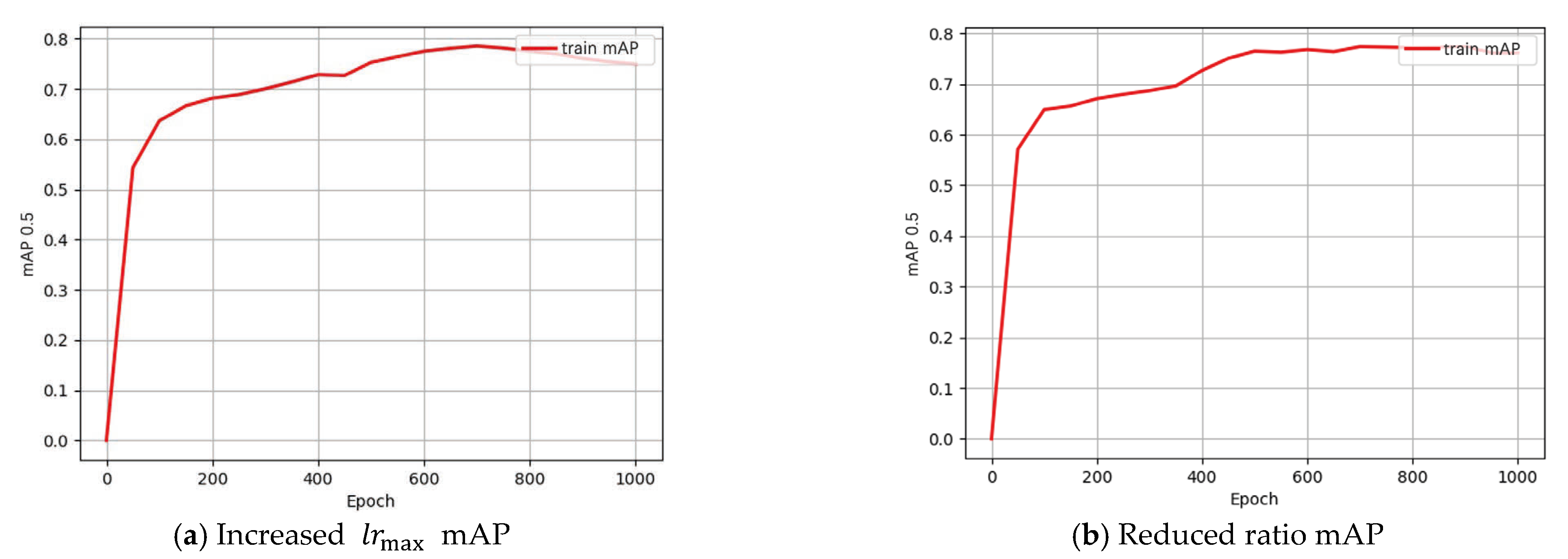
- When both and were set to 0.05, maximizing warmup iterations to 3 and fine-tuning iterations to 15, reducing to one-tenth of its original value resulted in only a 0.6% decrease in mAP during the first 50 epochs. This indicates that the initial learning rate in the warmup stage has minimal impact on early training performance.
- According to cosine annealing, decay phase learning rate is mainly affected by decay period duration. With fixed min/max learning rates, decay duration dominates performance at decay onset. For instance:, , warmup = 2 iterations, and fine-tuning = 15 iterations led to a 2.8% mAP drop, suggesting that reduced warmup iterations or insufficient learning rate ramping during warmup adversely affect training stability., , warmup = 3 iterations, and fine-tuning = 5 iterations resulted in a 6.8% mAP decline. When the number of iterations in the fine-tuning stage is small, the total number of decayed iterations is greater. Under the same training time, the larger the value of , the larger the . However, each change in becomes smaller, indicating that in the initial stage of the decay phase, the degree of learning rate × decay has a greater impact on the experiment than the relative size of itself. At this time, we also verified that increasing to 5 times and reducing the number of warm-up iterations by one still results in a 0.009 decrease. This shows that even if the learning rate value is significantly increased within a certain range, it cannot compensate for the impact of the reduction in the learning rate decay degree on the experiment.
4. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- Zhang, D.D.; Wang, C.P.; Fu, Q. A new benchmark for camouflaged object detection: RGB-D camouflaged object detection dataset. Gruyter 2024, 22, 20240060. [Google Scholar] [CrossRef]
- Liu, H.M.; Jin, F.; Zeng, H.; Pu, H.Y.; Fan, B. Image Enhancement Guided Object Detection in Visually Degraded Scenes. IEEE Trans. Neural Learn. Syst. 2024, 35, 14164–14177. [Google Scholar] [CrossRef]
- Zhao, E.Y.; Li, L.; Song, M.P.; Cao, Y.J.; Chen, S.H.; Shang, X.D.; Li, F.; Dai, S.; Bao, H. Research on Image Registration Algorithm and Its Application in Photovoltaic Images. IEEE J. Photovolt. 2020, 10, 595–606. [Google Scholar] [CrossRef]
- Xiong, J.; He, Z.G.; Zhou, Q.J.; Yang, R. Photovoltaic glass edge defect detection based on improved SqueezeNet. Signal Image Video Process 2024, 18, 2841–2856. [Google Scholar] [CrossRef]
- Li, C.X.; Yang, Y.H.; Zhang, K.J.; Zhu, C.L.; Wei, H.K. A fast MPPT-based anomaly detection and accurate fault diagnosis technique for PV arrays. Energy Convers. Manag. 2021, 234, 113950. [Google Scholar] [CrossRef]
- Dhoke, A.; Sharma, R.; Saha, T.K. A technique for fault detection, identification and location in solar photovoltaic systems. Solar Energy. 2020, 206, 864–874. [Google Scholar] [CrossRef]
- Liu, H.D.; Huang, B.J.; Chen, W.Y.; Shih, J.W. A solar energy system with a dual-input power converter and global MPPT for off-grid applications. Electr. Power Syst. Res. 2025, 243, 111497. [Google Scholar] [CrossRef]
- Han, M.Y.; Xiong, J.; Wang, S.Y.; Yang, Y. Chinese photovoltaic poverty alleviation: Geographic distribution, economic benefits and emission mitigation. Energy Policy 2020, 144, 111685. [Google Scholar] [CrossRef]
- Song, C.C.; Guo, Z.L.; Liu, Z.G.; Zhang, H.Y.; Liu, R.; Zhang, H.R. Application of photovoltaics on different types of land in china: Opportunities, status and challenges. Renew. Sustain. Energy Rev. 2024, 191, 114146. [Google Scholar] [CrossRef]
- Karteris, M.; Theodoridou, I.; Mallinis, G.; Papadopoulos, A.M. Façade photovoltaic systems on multifamily buildings: An urban scale evaluation analysis using geographical information systems. Renew. Sustain. Energy Rev. 2014, 39, 912–933. [Google Scholar] [CrossRef]
- Chen, Z.H.; Kang, Y.W.; Sun, Z.X.; Wu, F.; Zhang, Q. Extraction of photovoltaic plants using machine learning methods: A case study of the pilot energy city of golmud, China. Remote Sens. 2022, 14, 2697. [Google Scholar] [CrossRef]
- Zheng, Q.P.; Ma, J.M.; Liu, M.H.; Liu, Y.C.; Li, Y.X.; Shi, G. Lightweight hot-spot fault detection model of photovoltaic panels in UAV remote-sensing image. Sensors 2022, 22, 4617. [Google Scholar] [CrossRef] [PubMed]
- Jiang, L.J.; Yuan, B.X.; Du, J.W.; Chen, B.Y.; Xie, H.F.; Tian, J.; Yuan, Z.Q. MFFSODNet: Multiscale feature fusion small object detection network for UAV aerial images. IEEE Trans. Instrum. Meas. 2024, 73, 5015214. [Google Scholar] [CrossRef]
- Naeem, U.; Chadda, K.; Vahaji, S.; Ahmad, J.; Li, X.D.; Asadi, E. Aerial imaging-based soiling detection system for solar photovoltaic panel cleanliness inspection. Sensors 2025, 25, 738. [Google Scholar] [CrossRef] [PubMed]
- Huang, Y.P.; Kshetrimayum, S.; Sandnes, F.E. UAV-based automatic detection, localization, and cleaning of bird excrement on solar panels. IEEE Trans. Syst. Man. Cybern. Syst. 2025, 55, 1657–1670. [Google Scholar] [CrossRef]
- Vivone, G.; Marano, S.; Chanussot, J. Pansharpening: Context-based generalized laplacian pyramids by robust regression. IEEE Trans. Geosci. Remote Sens. 2020, 58, 6152–6166. [Google Scholar] [CrossRef]
- Zhang, X.F.; Feng, M.; Li, T.; Chen, J.Y.; Jiang, D.C.; Xu, J.H.; Yan, D.Z.; Zhou, X.Q.; Zhang, X.; Lu, J. High-resolutiondetection of periglacial landforms deformation using Radarsat-2 and GF-7 Stereo optical imagery. IEEE J. Sel. Top. Appl. Earth Obs. Remote Sens. 2024, 17, 10862–10876. [Google Scholar] [CrossRef]
- He, K.M.; Gkioxari, G.; Dollar, P.; Girshick, R. Mask R-CNN. In Proceedings of the IEEE International Conference on Computer Vision (ICCV), Venice, Italy, 2–29 October 2017; Volume 22, pp. 2980–2988. [Google Scholar]
- Uçar, G.; Dandıl, E. Enhanced detection of white matter hyperintensities via deep learning-enabled MR imaging segmentation. Trait. Signal 2024, 41, 1–21. [Google Scholar] [CrossRef]
- Hamed, B.; Ali, J. Fast uniform content-based satellite image registration using the scale-invariant feature transform descriptor. Front. Inf. Technol. Electron. Eng. 2017, 18, 1108–1116. [Google Scholar]
- Grimaccia, F.; Leva, S.; Niccolai, A. PV plant digital mapping for modules’ defects detection by unmanned aerial vehicles. IET Renew. Power Gener. 2017, 11, 1221–1228. [Google Scholar] [CrossRef]
- Zhou, J.X.; Liu, X.D.; Liu, W.Q.; Gan, J.H. Image retrieval based on effective feature extraction diffusion process. Multimed. Tools Appl. 2019, 78, 6163–6190. [Google Scholar] [CrossRef]
- Atik, S.O.; Atik, M.E.; Ipbuker, C.Z. Comparative research on different backbone architectures of DeepLabV3+ for building segmentation. J. Appl. Remote Sens. 2022, 16, 024510. [Google Scholar] [CrossRef]
- Yahyaoui, Z.; Hajji, M.; Mansouri, M.; Bouzrara, K. One-class machine learning classifiers-based multivariate feature extraction for grid-connected PV systems monitoring under irradiance variations. Sustainability 2023, 15, 13758. [Google Scholar] [CrossRef]
- Tan, H.J.; Guo, Z.L.; Zhang, H.R.; Chen, Q.; Lin, Z.J.; Chen, Y.T.; Yan, J.Y. Enhancing PV panel segmentation in remote sensing images with constraint refinement modules. Appl. Energy 2023, 350, 121757. [Google Scholar] [CrossRef]
- David, M.T.; Kerry, N.B.; Eric, R. Detection of photovoltaic solar panels with longwave-infrared spectral imaging. IEEE Trans. Geosci. Remote Sens. 2024, 62, 5521209. [Google Scholar]
- Zhu, G.J.; Liu, J.C.; Fan, Z.; Yuan, D.; Ma, P.L.; Wang, M.H.; Sheng, W.H.; Wang, K.C.P. A lightweight encoder-decoder network for automatic pavement crack detection. Comput. Aided Civ. Infrastruct. Eng. 2024, 39, 1743–1765. [Google Scholar] [CrossRef]
- Alberto, G.G.; Sergio, O.E.; Sergiu, O.; Victor, V.M.; Pablo, M.G.; Jose, G.R. A survey on deep learning techniques for image and video semantic segmentation. Appl. Soft Comput. 2018, 70, 41–65. [Google Scholar] [CrossRef]
- Jie, Y.S.; Yue, A.Z.; Liu, S.X.; Huang, Q.Q.; Chen, J.B.; Meng, Y.; Deng, Y.P.; Yu, Z.Y. Photovoltaic power station identification using refined encoder–decoder network with channel attention and chained residual dilated convolutions. J. Appl. Remote Sens. 2020, 14, 16506. [Google Scholar] [CrossRef]
- Guo, Z.L.; Zhuang, Z.; Tan, H.J.; Liu, Z.G.; Li, P.R.; Lin, Z.Y.; Shang, W.L.; Zhang, H.R.; Yan, J.Y. Accurate and generalizable photovoltaic panel segmentation using deep learning for imbalanced datasets. Renew. Energy 2023, 219, 119471. [Google Scholar] [CrossRef]
- Zhu, R.; Guo, D.X.; Wong, M.S.; Qian, Z.; Chen, M.; Yang, B.S.; Chen, B.Y.; Zhang, H.R.; You, L.L.; Heo, J.; et al. Deep solar PV refiner: A detail-oriented deep learning network for refined segmentation of photovoltaic areas from satellite imagery. Int. J. Appl. Earth Obs. Geoinf. 2023, 116, 103134. [Google Scholar] [CrossRef]
- Amiri, A.F.; Oudira, H.; Chouder, A.; Kichou, S. Faults detection and diagnosis of PV systems based on machine learning approach using random forest classifier. Energy Convers. Manag. 2024, 301, 118076. [Google Scholar] [CrossRef]
- Zhou, P.; Wang, R.; Wang, C.H.; Chen, H.Y.; Liu, K. SIIF: Semantic information interactive fusion network for photovoltaic defect segmentation. Appl. Energy 2024, 371, 123643. [Google Scholar] [CrossRef]
- Mahboob, Z.; Khan, M.A.; Lodhi, E.; Nawaz, T.; Khan, U.S. Using segformer for effective semantic cell segmentation for fault detection in photovoltaic arrays. IEEE J. Photolytic 2025, 15, 320–331. [Google Scholar] [CrossRef]
- Zhu, G.J.; Shen, S.L.; Yao, J.J.; Wang, M.H.; Zhuang, J.F.; Fan, Z. Automatic lightweight networks for real-time road crack detection with DPSO. Adv. Eng. Inform. 2025, 68, 103610. [Google Scholar] [CrossRef]



{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Model | Recall | Precision | F1 | mAP |
|---|---|---|---|---|
| YOLO v5 | 64.2% | 82.08% | 0.72 | 73.4% |
| Improved YOLO v5 | 71.17% | 88.1% | 0.79 | 78.6% |
| YOLO v8 | 66.46% | 88.08% | 0.76 | 76.25% |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2025 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Li, J.; Meng, X.; Wang, S.; Lu, Z.; Yu, H.; Qu, Z.; Wang, J. Enhanced Parallel Convolution Architecture YOLO Photovoltaic Panel Detection Model for Remote Sensing Images. Sustainability 2025, 17, 6476. https://doi.org/10.3390/su17146476
Li J, Meng X, Wang S, Lu Z, Yu H, Qu Z, Wang J. Enhanced Parallel Convolution Architecture YOLO Photovoltaic Panel Detection Model for Remote Sensing Images. Sustainability. 2025; 17(14):6476. https://doi.org/10.3390/su17146476
Chicago/Turabian StyleLi, Jinsong, Xiaokai Meng, Shuai Wang, Zhumao Lu, Hua Yu, Zeng Qu, and Jiayun Wang. 2025. "Enhanced Parallel Convolution Architecture YOLO Photovoltaic Panel Detection Model for Remote Sensing Images" Sustainability 17, no. 14: 6476. https://doi.org/10.3390/su17146476
APA StyleLi, J., Meng, X., Wang, S., Lu, Z., Yu, H., Qu, Z., & Wang, J. (2025). Enhanced Parallel Convolution Architecture YOLO Photovoltaic Panel Detection Model for Remote Sensing Images. Sustainability, 17(14), 6476. https://doi.org/10.3390/su17146476