1. Introduction
Food security represents a critical national strategy, with farmland serving as the foundation of agricultural production and a vital resource. Soil fertility plays a decisive role in determining both crop yield and quality and functions as the core carrier for implementing the strategies of “storing grain in the land, storing grain in technology” [
1,
2]. At present, traditional farmland production relies heavily on inputs such as labor, fertilizers, pesticides, and plastic mulch. The complex pattern of high input and output has intensified the conflict between production efficiency and quality demands [
3,
4,
5,
6]. High-quality farmland fertility enhancement projects, such as those centered on soil conditioning, deep plowing and loosening, optimized fertilization, and straw return, have emerged as key approaches to improving soil structure and nutrient use efficiency. The systematic implementation of such projects can protect arable land, reduce environmental risks, and provide long-term support for sustainable agricultural development [
7,
8,
9].
Significant gaps remain in current research regarding the economic evaluation and technological dissemination of farmland fertility enhancement projects. In particular, the lack of scientifically supported cost estimation models poses substantial challenges, including high investment risks and difficulties in controlling fertilization costs [
10,
11,
12,
13]. The present study focuses on developing a predictive model for cost indicators in fertility enhancement projects, aiming to establish quantitative relationships between influencing factors and cost metrics. This model is intended to serve as a decision-making tool for optimizing resource allocation and formulating targeted investment strategies, thereby promoting the transformation of fertility enhancement efforts from technical implementation to system-level efficiency optimization in support of national food security goals.
Cost indicator prediction methods have been widely applied across various engineering domains, with numerous scholars proposing effective modeling approaches that have yielded notable results. These methods can generally be categorized into statistical prediction techniques and machine learning-based approaches.
Statistical prediction methods include the autoregressive (AR) model [
14], multiple linear regression (MLR) analysis [
15], and grey system prediction [
16]. Lin et al. [
17] proposed an MLR model to estimate product manufacturing costs, demonstrating through empirical analysis that the model achieves high fitting accuracy and predictive performance. Ottaviani et al. [
18] applied MLR to develop an engineering management optimization model and introduced a novel EAC prediction formula with improved accuracy and reduced error. However, both AR and linear regression models are limited to capturing linear relationships in raw data. Grey system prediction, while theoretically flexible, exhibits low tolerance to data uncertainty and requires a large volume of samples. These limitations hinder its effectiveness in modeling nonlinear patterns, making it unsuitable for predicting cost indicators in fertility enhancement projects, where nonlinearity is a prominent feature.
With the rapid development of artificial intelligence, machine learning models have been increasingly adopted by researchers and engineers to address a range of predictive challenges in the engineering domain. Models such as support vector regression (SVR) [
19,
20], backpropagation (BP) neural networks, random forests (RFs) [
21,
22], and convolutional neural networks (CNNs) [
23] have been widely applied in construction management, cost estimation, and soil fertility assessment [
24,
25,
26,
27]. For example, Khanal et al. [
28] integrated remote sensing imagery to build six predictive models, including linear regression, RF, and XGBoost, and demonstrated that the RF model outperformed the others in predicting maize yield and soil characteristics with higher accuracy and robustness. Hu et al. [
29] considered both natural and anthropogenic drivers of soil nutrient variation and developed an RF model to estimate nutrient levels. The model outperformed XGBoost in mapping nitrogen, phosphorus, and potassium concentrations, confirming its superior predictive capability. Zhang et al. [
30] employed principal component analysis (PCA) and Pearson correlation to identify key logging parameters for coalbed methane prediction. A BP neural network model constructed using these variables achieved approximately 61% higher prediction accuracy compared to RF, XGBoost, and k-nearest neighbor (KNN) models. This model demonstrated high efficiency and precision in estimating gas content, offering strong applicability in coal seam exploration and resource evaluation. Among existing machine learning approaches, BP neural networks are particularly effective in modeling nonlinear relationships between variables, making them well-suited for predicting cost indicators in farmland fertility enhancement projects [
31].
Redundant information increases the computational burden and compromises both the robustness and generalization capability of predictive models. The accuracy of model predictions is highly dependent on the quality of input data, underscoring the importance of feature selection to reduce the dimensionality of raw datasets. Wyke et al. [
32] utilized PCA to eliminate redundancy in high-dimensional data and to ensure variable independence, thereby enhancing compatibility with predictive modeling [
33]. In addition to data preprocessing, model performance is critically influenced by hyperparameter selection. Recent studies have increasingly adopted optimization algorithms to improve prediction accuracy through automated hyperparameter tuning [
34,
35]. Li et al. [
36] employed a genetic algorithm (GA) to optimize the weights and thresholds of a BP neural network, developing a GA–BP model for construction cost prediction in Guangdong Province that achieved a coefficient of determination of 0.94, validating its effectiveness. Chang et al. [
37] constructed a BP neural network model. To improve predictive performance, they applied the Northern Goshawk Optimization (NGO) algorithm for parameter optimization and demonstrated that the NGO–BP model outperformed the DBO–BP model in accuracy. Among various optimization methods, NGO has demonstrated a strong global search capacity and rapid convergence toward near-optimal solutions [
38,
39], making it well-suited for hyperparameter tuning in BP neural networks. Given the non-temporal and nonlinear nature of the engineering cost data in this study, four widely used models (RF, XGBoost, BP, and GA–BP) were selected for comparative analysis against the proposed NGO–BP model.
The construction of farmland fertility enhancement projects serves as a fundamental strategy for improving soil structure and increasing nutrient use efficiency, underscoring the necessity of accurate cost prediction models. A review of the literature on cost indicator modeling shows that most existing models are applied in sectors such as building construction, water conservancy, and power transmission [
40,
41,
42], while research specifically addressing cost prediction in fertility enhancement projects remains limited. In this study, PCA was applied to identify and reduce the dimensionality of relevant influencing factors, isolating the key variables associated with project costs. Qualitative variables were subsequently quantified, and a BP neural network optimized by the NGO algorithm was developed. The proposed NGO–BP model enables cost indicator prediction across diverse engineering types and environmental conditions. This modeling approach provides a practical reference for regional investment planning, promotes more refined cost management throughout the entire lifecycle of high-standard farmland construction, and supports optimal resource allocation and evidence-based investment decisions. Accordingly, this study offers not only a theoretical framework for cost prediction in fertility enhancement projects but also a technical foundation to advance the sustainable development of agricultural production.
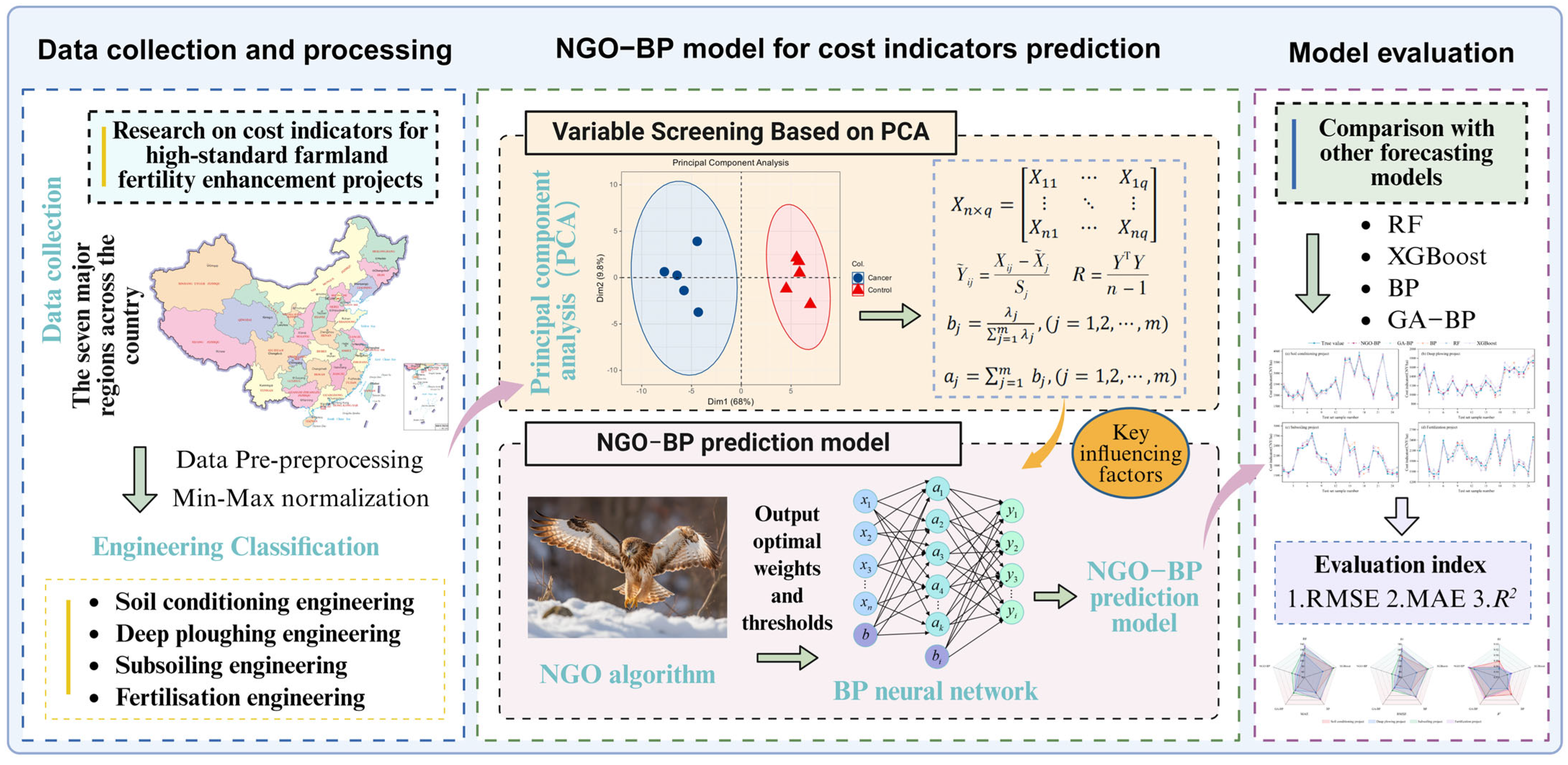
The innovation of this study lies in constructing a cost indicator prediction model for fertility enhancement projects. Based on PCA screening, an indicator system of influencing factors for fertility enhancement project costs is established. The NGO algorithm optimizes the BP model to establish a combined NGO–BP prediction model. This algorithm outperforms others in parameter optimization. Simultaneously, the prediction model precisely captures nonlinear variations among different soil fertility improvement project data. The overall model performance surpasses other prediction models. Through variable screening and algorithm optimization, it aims to enhance prediction accuracy and generalization capability.
The remainder of this paper is organized as follows:
Section 2 introduces the study area and data sources, along with the principal component analysis, BP neural network model, and NGO algorithm. Specific steps for predicting fertility enhancement project cost indicators are also presented.
Section 3 screens and reduces the dimensions of influencing factors using the PCA method, constructs five different prediction models to compare their accuracy and stability, and ultimately demonstrates the optimal performance of the NGO–BP model in predicting fertility enhancement project cost indicators.
Section 4 discusses the results.
Section 5 contains conclusions and future work.
4. Discussion
High-standard farmland fertility enhancement projects play a vital role in improving soil structure and ensuring stable, high crop yields. By enhancing soil physicochemical properties and promoting nutrient cycling, these projects support the sustainable use of arable land, reduce dependence on chemical fertilizers and pesticides, and contribute to both food security and ecological balance. However, the absence of accurate and scientific cost prediction during project implementation constrains resource allocation efficiency, increases investment risk, and impedes the translation of technology into practical benefits. Establishing a dynamic and robust cost prediction model is essential to guide decision-making throughout project planning and execution.
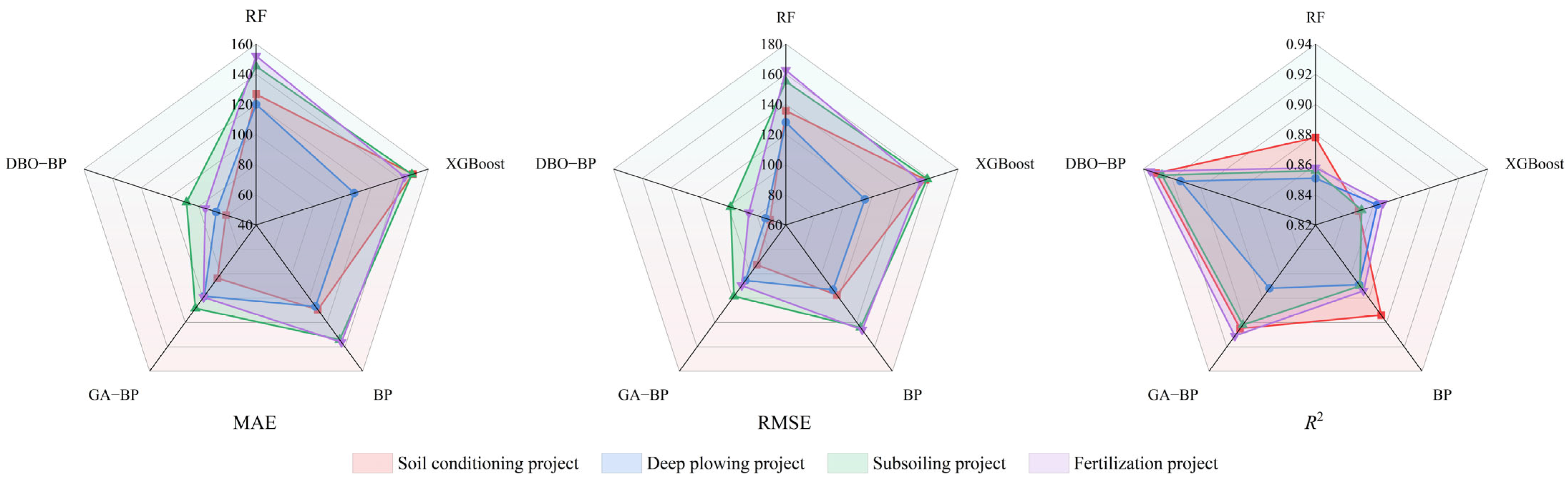
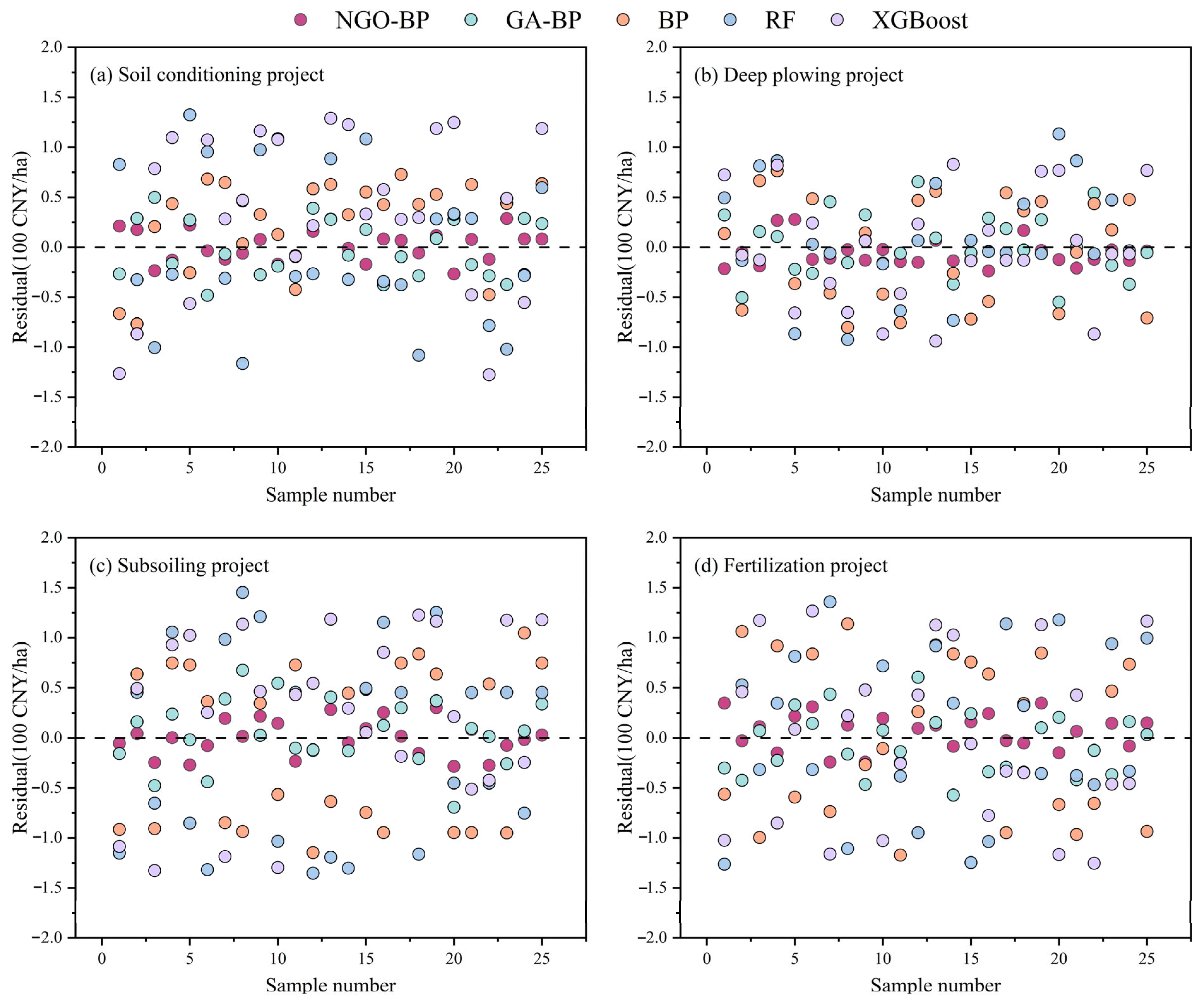
The NGO–BP prediction model developed in this study demonstrated significantly better performance in terms of MAE, RMSE, and
R2 compared to conventional machine learning models, indicating strong applicability and predictive accuracy. Elmousalami et al. [
45] selected factors such as project characteristics, construction location, and duration when designing a cost-influencing factor system. Drawing from similar methodological principles, the present study established a quantifiable framework of cost indicators based on geographic, engineering, and financial dimensions. Due to the initially large number of influencing factors, dimensionality reduction was required to minimize redundancy, reduce computational time, and maintain model accuracy. Zhang et al. [
30] developed a BP neural network model to predict coalbed methane content by analyzing the correlation between logging parameters using principal component analysis and Pearson correlation and constructing composite input variables. Their findings confirmed that targeted parameter transformation enhances model efficiency and precision. The application of PCA in the present study similarly improved prediction performance by identifying the most relevant variables. Experimental outcomes confirmed that PCA-based preprocessing substantially increased the accuracy of the NGO–BP model.
Zhang et al. [
30] evaluated several prediction models, including KNN, Ridge regression, RF, XGBoost, and BP neural networks, for estimating coalbed methane content. The models were assessed using the coefficient of determination, root mean square error, and relative error. Among these, the BP neural network exhibited the highest prediction accuracy, achieving a relative error of 4.5% and improving prediction precision by approximately 61%. These results demonstrate the BP model’s strong capability to capture variations in coalbed methane content and deliver rapid, accurate predictions. Based on this evidence, the present study adopted BP neural networks [
30,
36,
37], RF [
21,
22,
28], XGBoost [
28,
30], GA–BP [
36], and NGO–BP models for comparative analysis. The results confirm that the NGO–BP model is more suitable for predicting cost indicators in farmland fertility enhancement projects.
In terms of optimization strategies, Li et al. [
36] applied a GA to optimize the weights and thresholds of a BP neural network for predicting construction costs in Guangdong Province. The optimized model exhibited a significant performance gain, with an approximate 8% increase in the coefficient of determination, validating the use of GA in enhancing BP models. To further improve predictive accuracy, Chang et al. [
37] employed Northern Goshawk Optimization (NGO) to optimize BP neural network parameters and compared its results with those of the GA–BP model. The findings indicated the superior performance of the NGO–BP model, with a 1.6% increase in R
2 and reductions of 11.6% and 6.34% in RMSE and MAE, respectively. These comparisons validate the advantage of using NGO for optimizing BP neural networks, justifying the selection of GA–BP and NGO–BP models in the present study.
The proposed NGO–BP model enables accurate prediction of differentiated cost indicators for high-standard farmland fertility enhancement projects by incorporating regional and project-specific characteristics. This approach supports evidence-based project management, improves resource allocation, and enhances overall efficiency. By providing reliable cost estimates, the model contributes to national food security goals while promoting ecological sustainability and agricultural modernization. During feasibility assessments, key influencing factors can be entered into the model to generate real-time cost predictions, supporting design optimization and strategic financial planning throughout the construction process.






{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}