1. Introduction
1.1. Background and Significance
Groundwater is a vital strategic resource for maintaining ecological balance and supporting human development, playing an irreplaceable role in agricultural irrigation (accounting for 72% of total regional water consumption), industrial water supply, and urban living systems [
1]. However, the excessive exploitation of groundwater has caused a continuous decline in water levels [
2], triggering a series of ecological and environmental problems, such as land desertification, seawater intrusion, vegetation degradation [
3], river drying [
4], and accelerated land subsidence [
5]. These issues have severely undermined the ecological equilibrium and environmental stability. Accurate prediction of groundwater level variations is essential not only for achieving sustainable water resource management but also for preventing geo-environmental disasters and safeguarding ecological security [
6]. Regional differences in hydrogeological conditions add complexity to groundwater systems. In addition, variations in groundwater abstraction methods and intensities further increase the variability of groundwater level dynamics. Together, these factors present significant challenges for accurate prediction.
The Cangzhou region, in particular, is characterized by deep confined aquifers with structurally enclosed settings and limited lateral recharge. These features substantially reduce aquifer responsiveness to natural replenishment, making groundwater level forecasting more difficult and necessitating more robust and adaptable modeling approaches [
7].
1.2. Limitations of Traditional Models and the Rise of Machine Learning
Traditional groundwater level prediction methods mainly rely on physically based numerical models, such as MODFLOW, GMS, and FEFLOW. These models typically describe groundwater flow using partial differential equations, which possess clear physical interpretations. However, their effectiveness is constrained by the accuracy of hydrogeological parameters, and they are computationally intensive, limiting their applicability in data-scarce environments [
8]. In recent years, machine learning has gained attention as a promising alternative. It provides a data-driven modeling framework that can automatically learn complex nonlinear relationships between variables. This approach does not require predefined physical equations. This paradigm has been increasingly adopted in groundwater level forecasting research [
9]. For example, Singh et al. developed an AutoML-GWL framework using Bayesian optimization, which incorporated multiple features, such as precipitation, temperature, and soil type, achieving high accuracy with an RMSE of 1.22 [
10]. LaBianca et al. applied the CatBoost gradient boosting decision tree model, integrated with high-resolution urban features, to predict the minimum water table depth (MWTD), outperforming conventional physical models [
11]. Azizi et al. utilized the Group Method of Data Handling (GMDH) neural network to simulate groundwater levels under climate change scenarios [
12]. Despite these advancements, individual machine learning models—such as random forest—often fail to fully capture the complexity and nonlinearity of groundwater systems. This limitation is mainly due to restricted training data and the intrinsic constraints of the algorithms themselves. For instance, Lasso and Ridge regression are effective for modeling linear patterns but underperform in nonlinear environments. KNN models, on the other hand, are highly sensitive to noise and less robust to sparse or heterogeneous data distributions, resulting in unstable predictions and restricted model performance improvements [
13].
Furthermore, most current machine learning models used in groundwater prediction are purely data-driven and fail to incorporate essential physical constraints, such as mass conservation. This lack of physical interpretability reduces their extrapolation capabilities, particularly under changing environmental or management scenarios. Additionally, these models often overlook the delayed response behavior of deep confined aquifers—a key aspect of groundwater system dynamics. As a result, their predictive performance and generalization ability decline when applied to complex systems like those in Cangzhou. In such regions, groundwater responses are highly inertial and are mainly governed by slow recharge processes.
1.3. Advantages of Ensemble Learning and the Stacking Approach
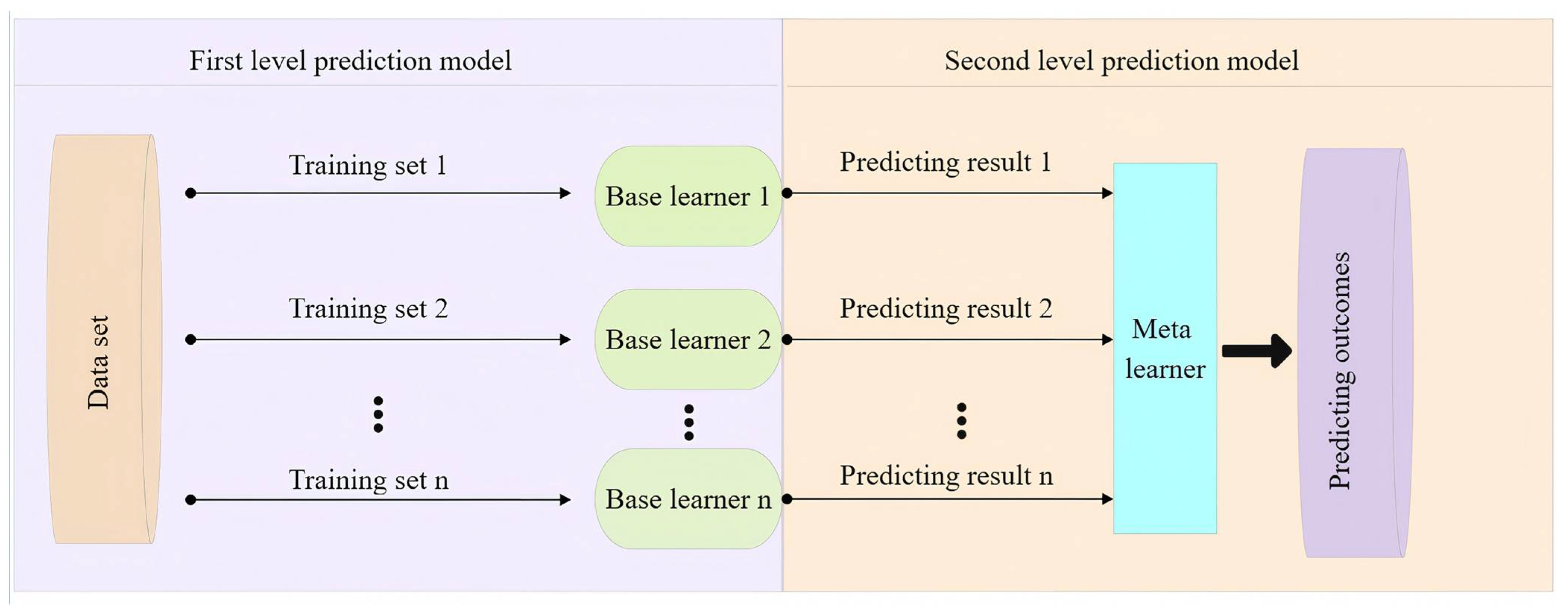
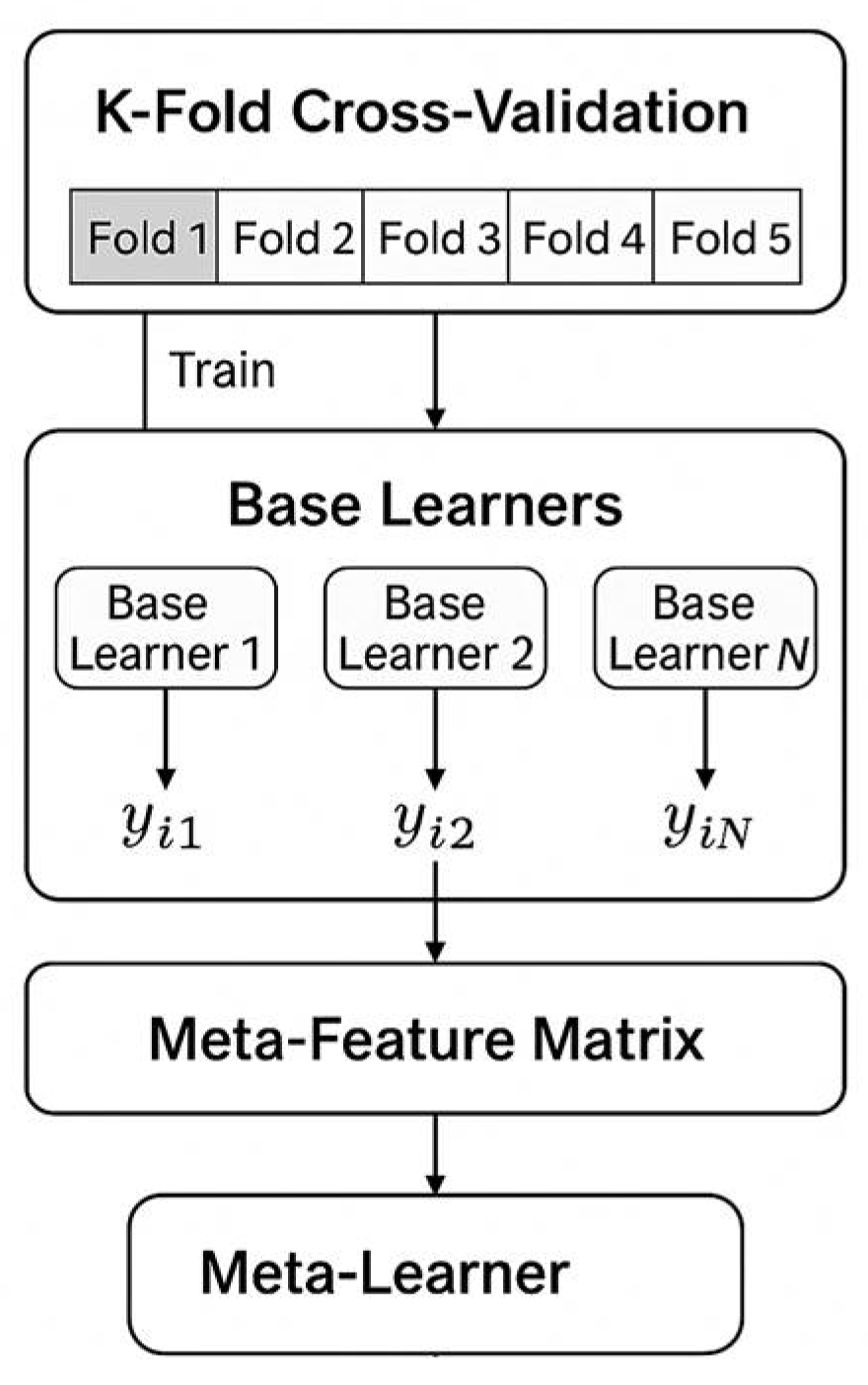
Many scholars have begun exploring ensemble learning models to overcome the limitations of individual models. Stacking is a multilayer ensemble learning method that integrates several base models, each with different predictive strengths. A meta-learner is then used to combine their outputs, producing final predictions with improved generalization capability. Unlike Bagging and Boosting, Stacking supports the integration of heterogeneous models, such as support vector machines, random forests, and neural networks, allowing it to leverage the strengths of each model in handling nonlinear relationships, feature redundancy, and high-dimensional data.
In groundwater modeling, challenges such as data noise, complex spatiotemporal scales, and nonlinear interactions are common. Stacking addresses these issues by aggregating the outputs of multiple models through secondary learning, thereby enhancing adaptability and improving prediction stability. In this study, the Stacking ensemble model is designed not only to combine multiple algorithms but also to incorporate domain knowledge by embedding lagged groundwater level terms as input features. These features reflect the delayed response of aquifers to external drivers, such as precipitation and extraction, enabling the model to capture the system’s memory and long-term behavior. This makes Stacking particularly suited for groundwater level modeling across different regions, scales, and future climate scenarios [
14]. Unlike Bagging, which uses simple averaging, or Boosting, which relies on weighted summation, Stacking employs a meta-model—such as logistic regression, GBDT, or neural networks—to flexibly learn complex relationships among the predictions of base models. This approach helps overcome the limitations of using a single ensemble strategy [
15]. The multi-stage ensemble model outperforms individual models in handling nonlinear, multi-scale hydrological data. For instance, Elzain deployed a stacked ensemble framework integrating multi-source data (remote sensing, meteorological, and hydrogeological data), significantly enhancing prediction robustness. Deep learning components like Transformers were incorporated to improve temporal feature extraction. In a case study in Saudi Arabia, this model achieved a 22% reduction in RMSE and an R
2 of 0.91, providing high-precision decision support for water resource management in water-scarce regions [
16]. In a decade-long study in the Huaibei Plain, Jiang et al. applied the Stacking ensemble model for groundwater level prediction under future climate scenarios. By integrating multiple base learners, including support vector regression (SVM), random forest (RF), and multilayer perceptron (MLP), and using linear regression as the meta-learner, the model demonstrated superior performance across all monitoring wells. RMSE reductions ranged from 4.26% to 96.97%, with the lowest MAE and highest R
2 among all models tested [
17]. In summary, ensemble learning models, especially Stacking, are more capable of capturing complex data patterns and dynamics compared to individual models, thereby improving the accuracy and stability of predictions.
1.4. Research Objective and Innovation
As a typical deep groundwater overextraction area in the North China Plain, the evolution of groundwater levels in Cangzhou is influenced by both natural processes and human activities. To address the significant spatiotemporal heterogeneity of groundwater in the region, this study proposes a Stacking ensemble model. The model integrates meteorological variables, spatial attributes, groundwater extraction intensity, and historical groundwater level time series to enhance prediction accuracy.
Through multi-model integration, the framework explores the spatiotemporal interactions between groundwater levels and multi-source drivers. In addition, this study conducts a comparative simulation under two scenarios—with and without water diversion from the South-to-North Water Transfer Project—to quantitatively evaluate the impact of such interventions on the recovery of deep groundwater. The proposed approach offers both a degree of mechanistic interpretability and high predictive accuracy, providing valuable support for the refined management of water resources in overexploited aquifer systems.
The major innovations of this study are threefold: (a) incorporation of physically meaningful lagged groundwater levels to represent aquifer memory, (b) development of a hybrid Stacking framework that fuses multi-source data with temporal and spatial dependencies, and (c) scenario-based simulation to quantitatively assess the role of inter-basin water diversion in groundwater recovery. These advancements collectively enhance the interpretability, generalization capacity, and practical value of the model.
2. Study Area
Cangzhou is located along the Bohai Bay coast in southeastern Hebei Province and has a warm temperate, semi-humid continental monsoon climate. With an average annual precipitation of around 500 mm, the region suffers from limited surface water resources and elevated salinity levels in shallow groundwater. As a result, agricultural production in Cangzhou relies heavily on the extraction of deep groundwater. Influenced by monsoonal patterns, the temporal and spatial distribution of precipitation is highly uneven, significantly misaligned with the water demand cycle of major crops, such as wheat and corn. This imbalance has resulted in severe overextraction of groundwater and the development of a large-scale regional cone of depression. In the central part of the region, groundwater levels have dropped to below −90 m. The South-to-North Water Diversion Project (SNWDP) is China’s largest inter-basin water transfer initiative, designed to mitigate the uneven distribution of water resources between the north and south. Since the launch of the Middle Route in 2017, Cangzhou—one of the project’s receiving regions—has received approximately 453 million cubic meters of water annually from the Yangtze River. This external supply has been used to reduce reliance on deep groundwater extraction. As a result, groundwater levels in the region have begun to recover. By 2022, the deep groundwater level in Cangzhou had risen by 2.8 m compared to 2017 [
18].
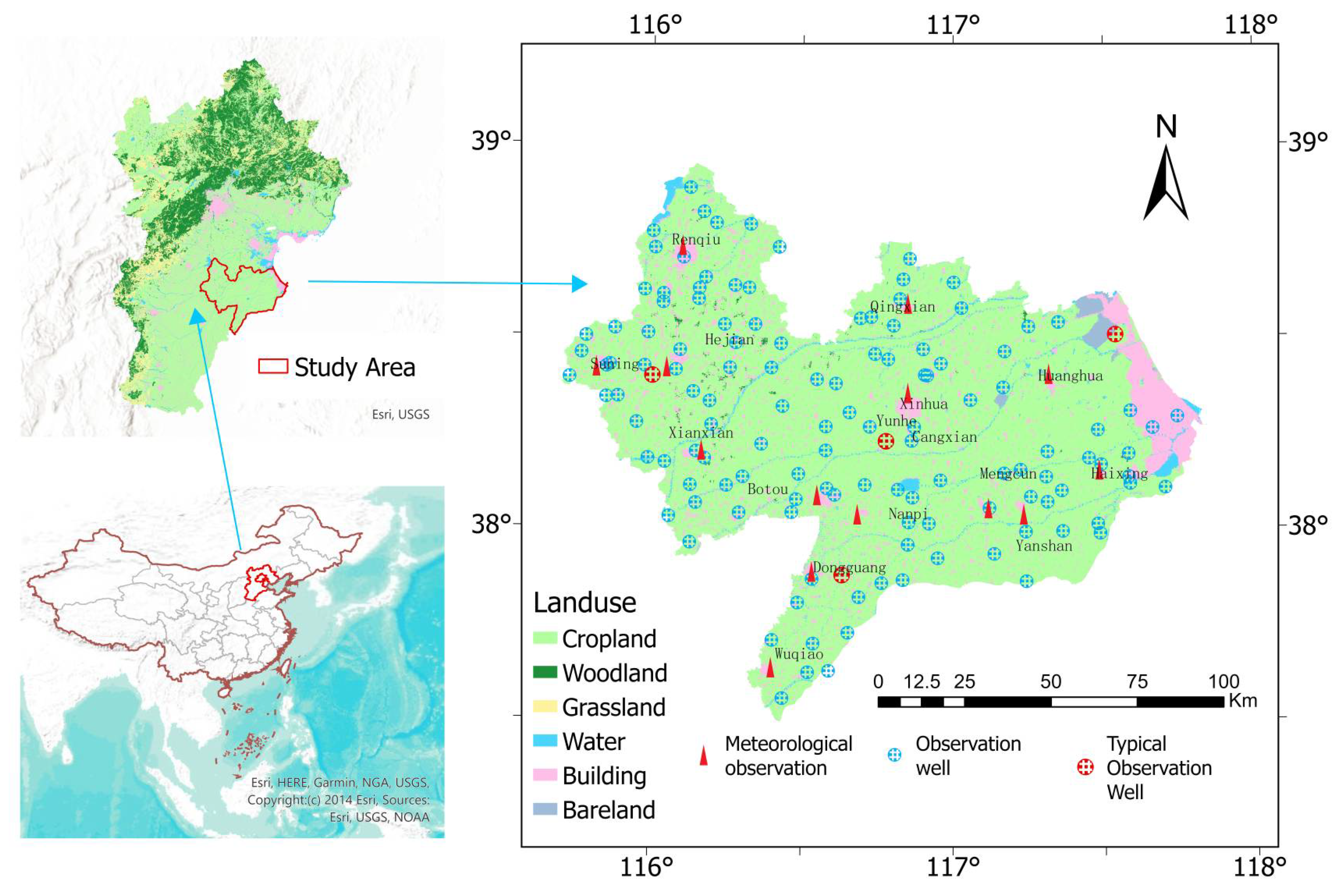
Figure 1 illustrates the spatial distribution of land use types, groundwater observation wells, and meteorological stations across the Cangzhou region. Among the observation wells, four representative wells were selected as typical monitoring points for further analysis. As shown in the figure, most wells are located in cropland areas, highlighting the region’s dominant agricultural land use. A smaller number of wells are situated within built-up areas, while only a few are located near grasslands, woodlands, water bodies, or bare land. This distribution pattern suggests that the monitoring network is predominantly situated within agricultural landscapes. As a result, it offers a solid data foundation for analyzing groundwater dynamics under agricultural land use and their interactions with meteorological factors.
This land use dataset was based on Landsat satellite imagery and interpreted through manual visual interpretation. It adopts a hierarchical classification system, including six primary land use categories.
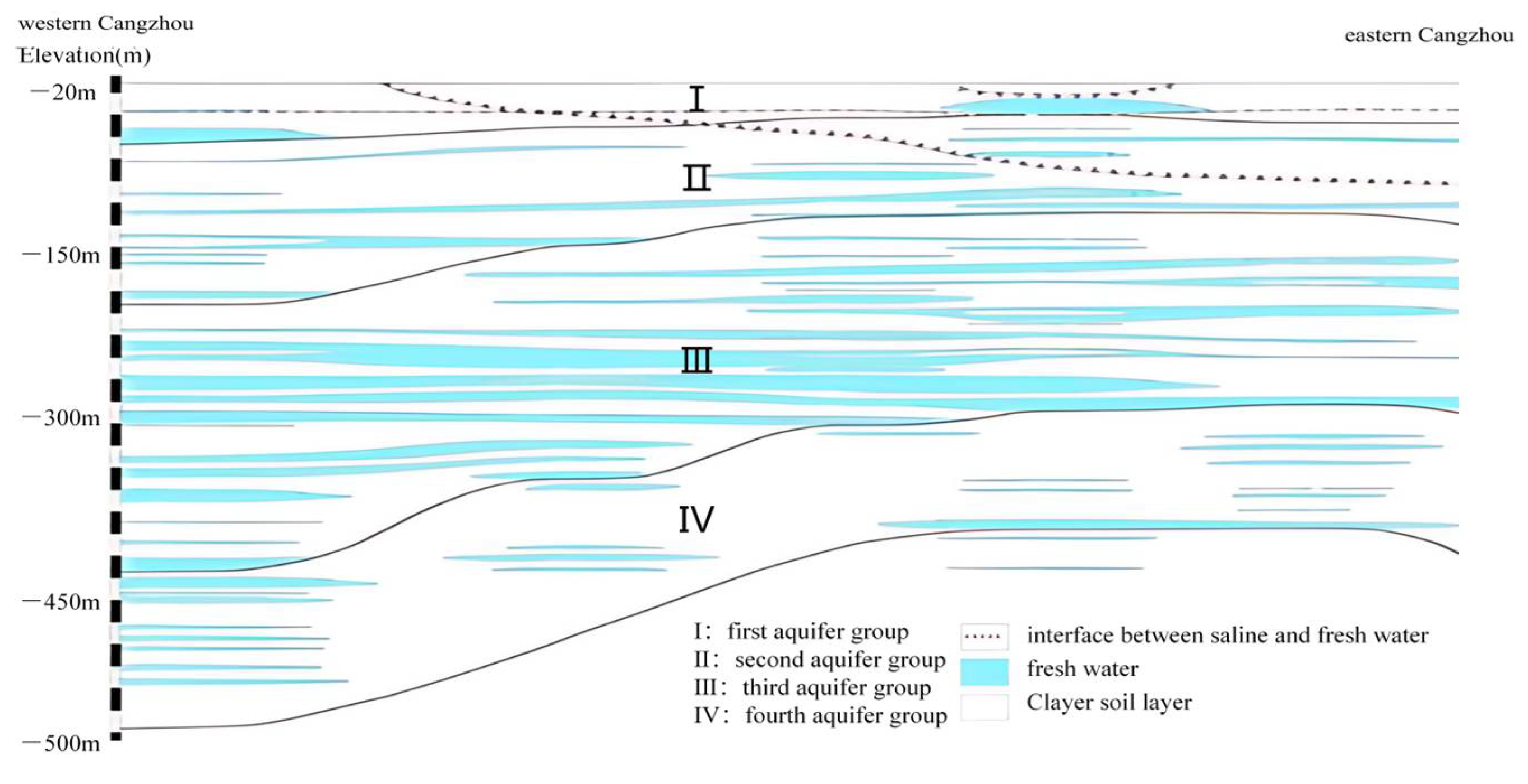
The hydrogeological structure of the study area exhibits distinct vertical stratification. The Quaternary aquifer system can be subdivided into four aquifer units from top to bottom, each with distinct hydraulic properties. The first aquifer unit is a shallow unconfined aquifer directly recharged by atmospheric precipitation, with individual well discharge rates ranging from 8 to 20 m
3/h. Water quality in this layer transitions gradually from fresh to slightly brackish as one moves from west to east. The second aquifer unit is confined and located at depths of 120–220 m. It is overlain by a stable aquiclude, which significantly limits lateral recharge. The third aquifer unit, currently the primary target for groundwater extraction, lies at depths of 250–420 m and consists mainly of alluvial fine sands. This unit supports high discharge rates (20–80 m
3/h) and generally contains groundwater with mineralization levels below 2 g/L, offering both high yield and good water quality. The fourth aquifer unit is found below approximately 380 m and is characterized by markedly reduced permeability and a low unit yield of only 1.0–1.5 m
3/h, thus representing the least favorable recharge conditions. Owing to its superior water quality and high productivity, the third aquifer unit serves as the main exploitation layer in the study area [
19]. The specific zoning is shown in
Figure 2 (adapted from the Hydrogeological Report of Cangzhou City).
4. Results
This section provides a comprehensive evaluation of model performance and offers an in-depth analysis of the Stacking ensemble strategy in the context of groundwater level forecasting.
The analysis focused on four key aspects:
- (1)
overall predictive performance across different models,
- (2)
single-well performance under spatially heterogeneous hydrogeological conditions,
- (3)
error analysis from both statistical and spatiotemporal perspectives, and
- (4)
interpretation of feature importance.
Visual and quantitative comparisons demonstrated that the Stacking ensemble model consistently outperformed individual base learners in terms of accuracy, robustness, and generalization. Its superior performance is primarily attributed to its ability to integrate the complementary strengths of diverse algorithms while mitigating the limitations inherent in single models.
The following subsections aim to explain not only the predictive performance of the model but also the underlying mechanisms that drive its effectiveness. This dual focus provides deeper insights into the reliability and applicability of the proposed approach in complex, multi-factor groundwater systems.
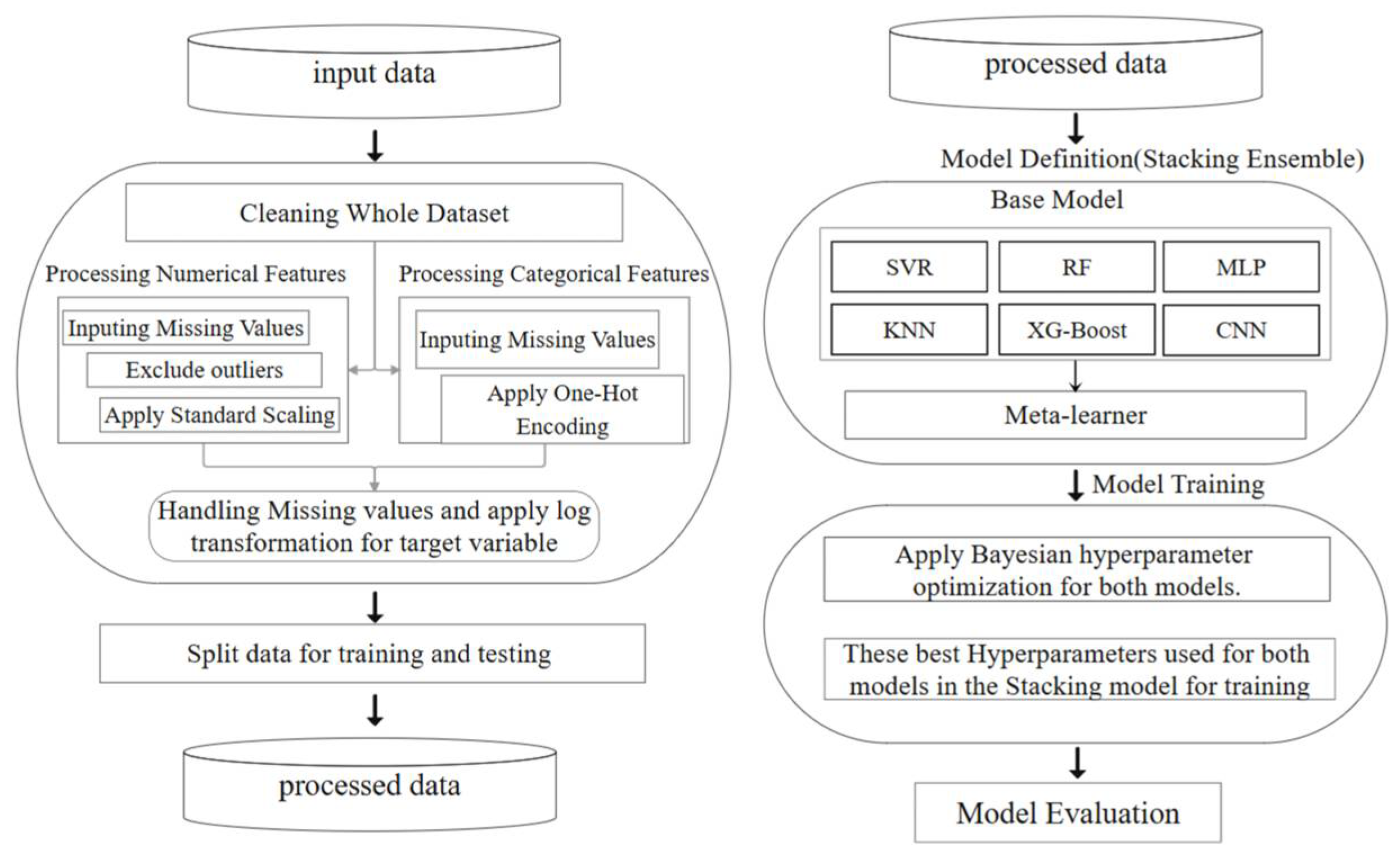
4.1. Feature Relevance Analysis
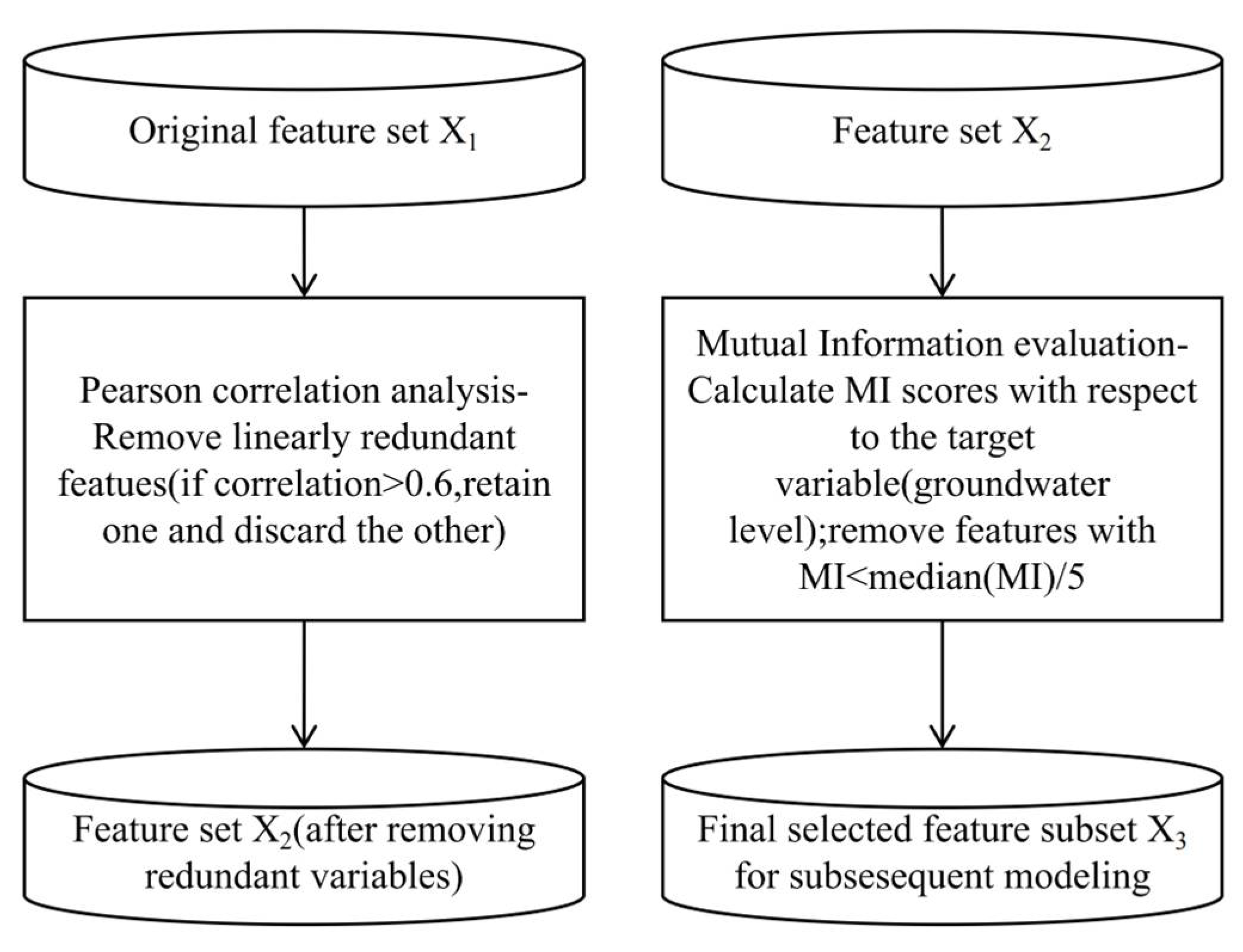
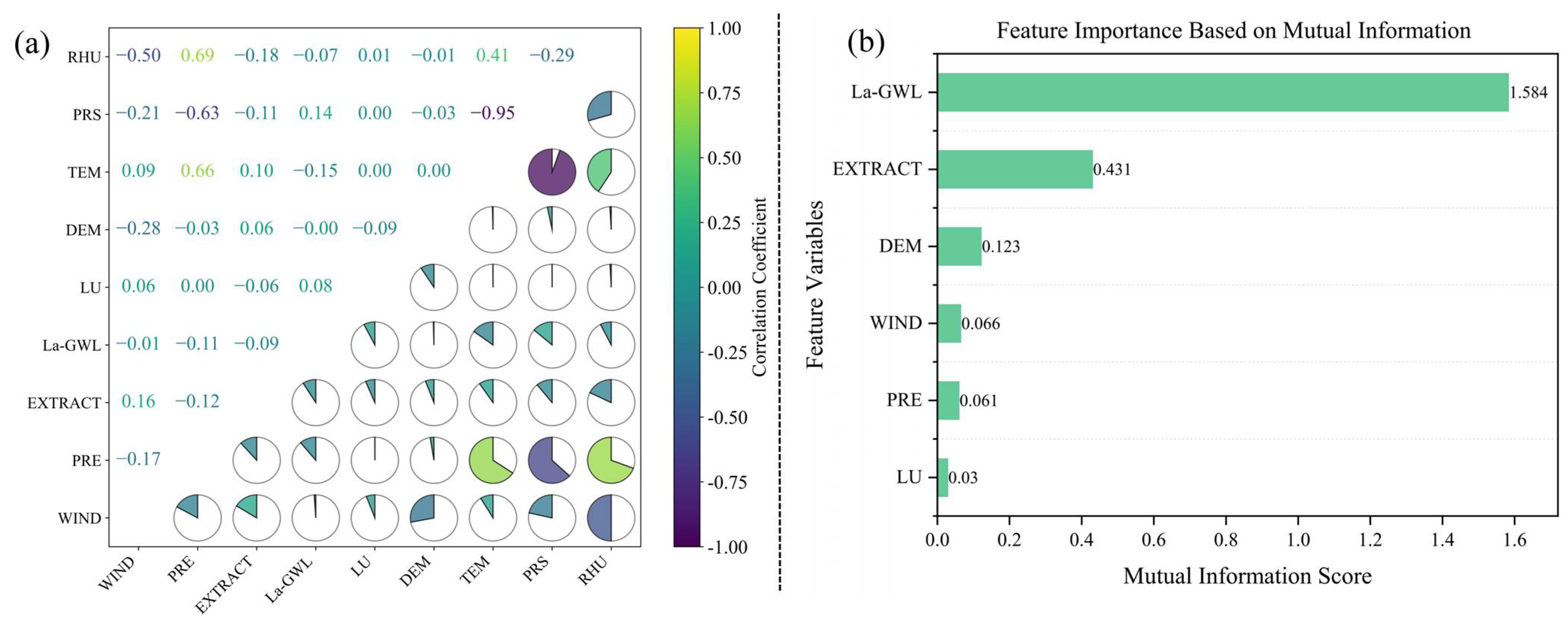
To improve model interpretability and reduce feature redundancy, a two-stage feature selection process was applied based on the Pearson correlation coefficient and mutual information (MI).
Figure 9a,b present the outcomes derived from the Pearson correlation coefficient and mutual information analyses, respectively.
In the first stage, the Pearson correlation matrix was used to identify feature pairs with high linear correlation (|PCC| > 0.6). Strong correlations were observed between several meteorological features, including rainfall–pressure, rainfall–relative humidity, rainfall–temperature, and pressure–relative humidity. Based on the established criterion, one variable from each highly correlated pair was removed. Given the direct hydrological impact of rainfall on groundwater recharge, rainfall was retained, while pressure, temperature, and relative humidity were excluded.
In the second stage, mutual information scores were computed between each remaining feature and the target variable (groundwater level) to assess their nonlinear relationships. All retained features showed MI scores above one-fifth of the median threshold, indicating their substantial contribution to groundwater level prediction. As a result, no further features were excluded at this stage.
Following the two-stage screening, the final selected features included rainfall, wind speed, groundwater extraction volume, land use type, lagged groundwater level, and surface elevation, which were subsequently used as model inputs.
4.2. Overall Prediction Performance
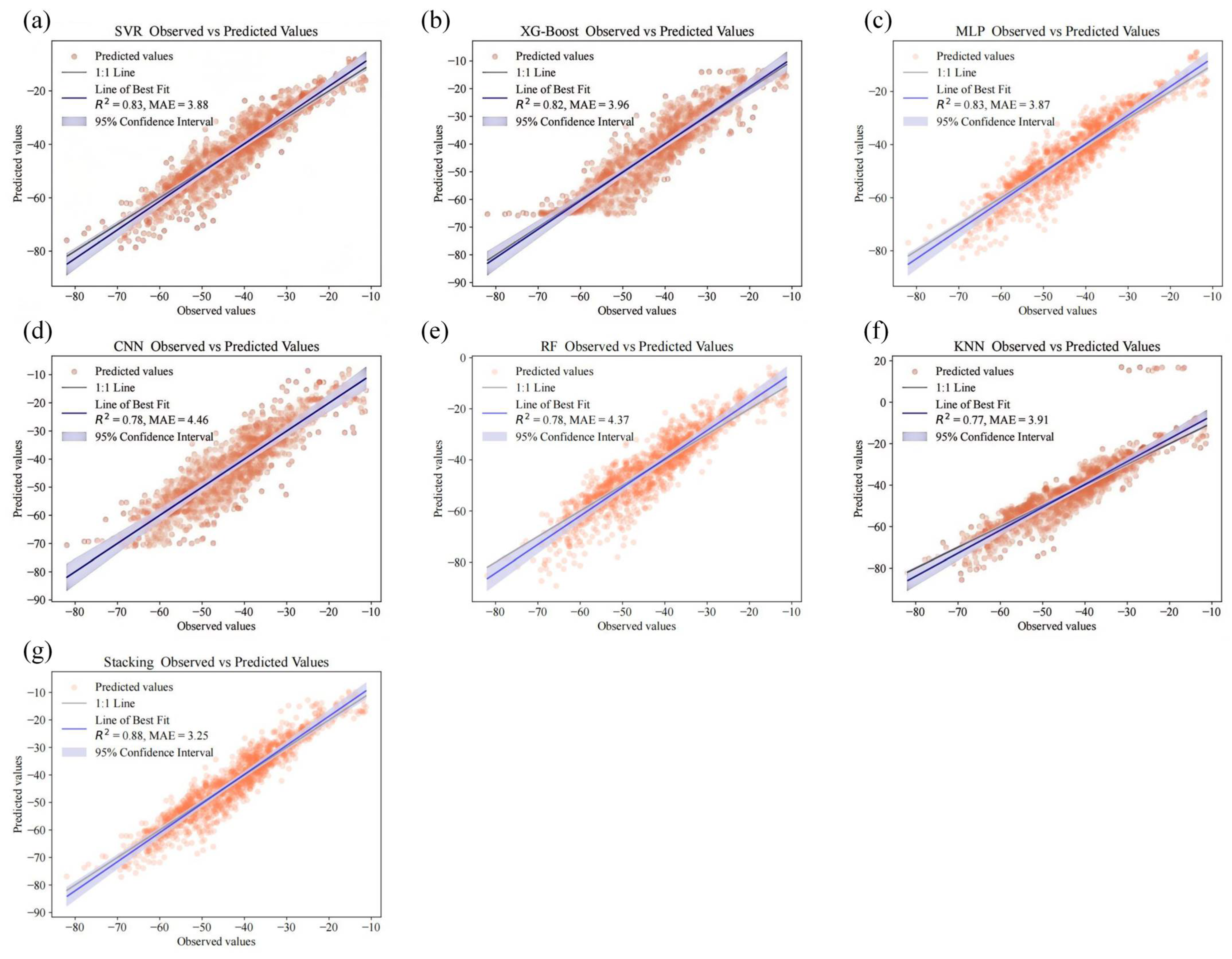
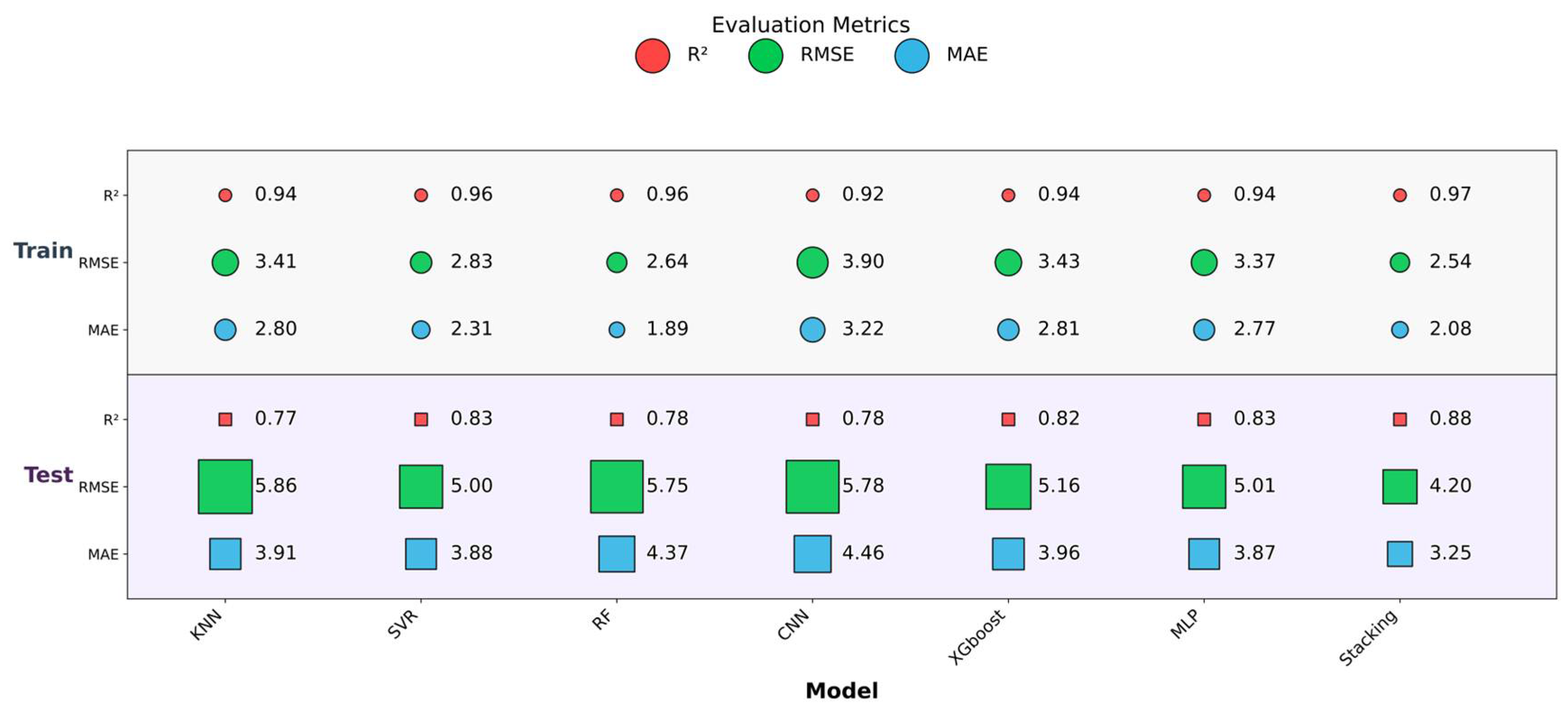
A comprehensive evaluation of model performance (
Figure 10) highlighted the superior predictive ability of the Stacking ensemble model over individual base learners. In the scatter plot comparing observed and predicted groundwater levels, the Stacking model’s predictions exhibited a tighter clustering along the 1:1 reference line, indicating a stronger agreement between predicted and actual values. This visual correspondence was further corroborated by quantitative evaluation metrics (
Figure 11), where the ensemble model consistently outperformed its individual components across all indicators.
Specifically, on the test set, the Stacking model achieved an MAE of 3.25 m and RMSE of 4.20 m, representing a reduction of 16.2% and 16.0%, respectively, compared to the best-performing individual model (SVR). Furthermore, the R2 value increased from 0.83 (MLP) to 0.88, demonstrating a marked improvement in the explained variance. These improvements suggest that the ensemble model not only enhanced accuracy but also achieved better generalization performance on unseen data.
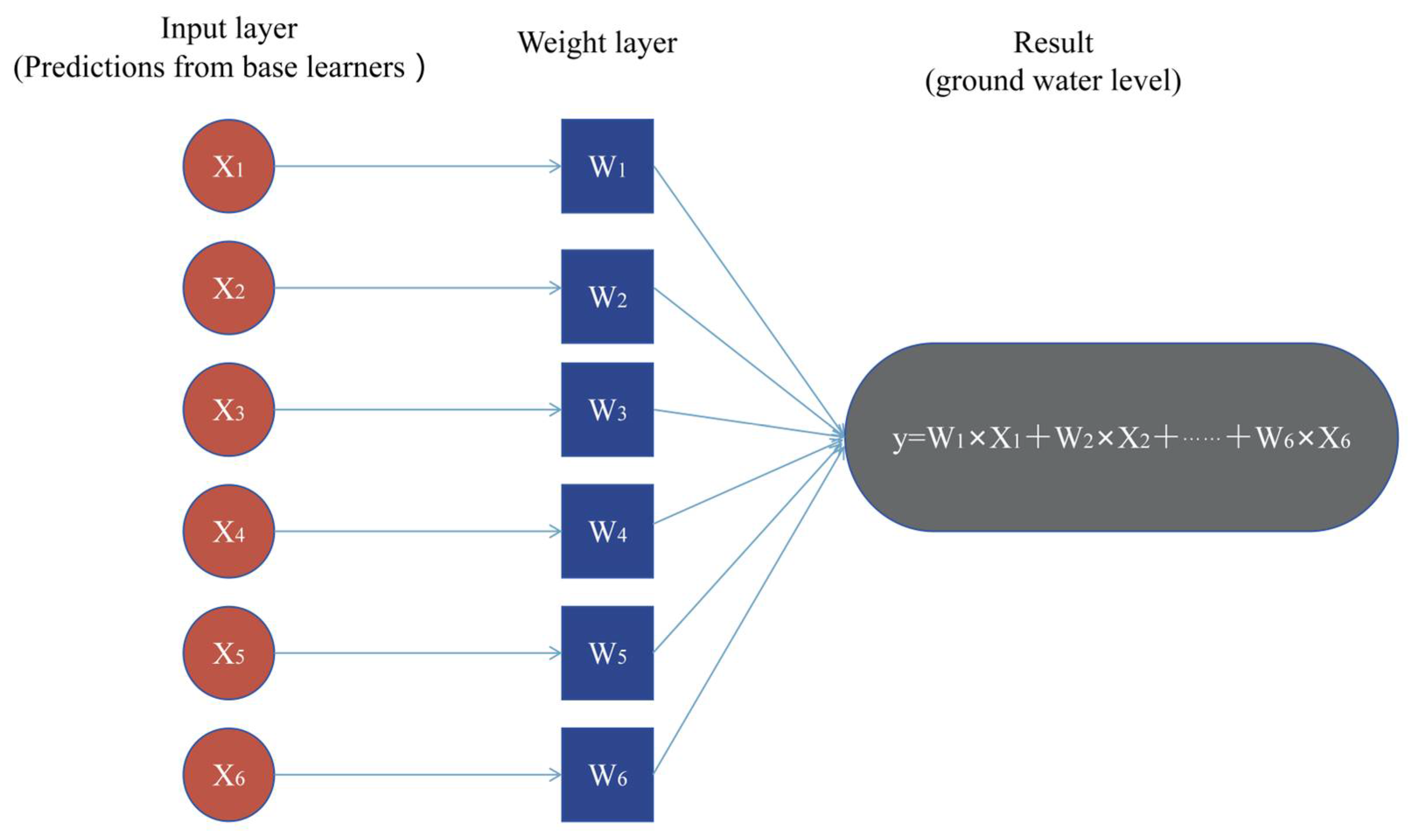
The improved performance of the Stacking model can be attributed to its ability to integrate complementary strengths of heterogeneous base learners, including KNN, CNN, RF, SVR, XG-Boost, and MLP. For example, while tree-based methods (RF and XG-Boost) are effective in capturing nonlinear relationships and handling variable importance, models like CNN and MLP excel at recognizing complex patterns in high-dimensional spaces. The Stacking strategy leverages these diverse modeling perspectives by assigning optimized weights through a meta-learner—here, a weighted average approach—which effectively balances the prediction biases and variances of individual models.
Another critical advantage of the Stacking framework lies in its robustness to overfitting. Unlike individual learners that may tailor closely to specific features or patterns in the training set (e.g., CNN’s sensitivity to spatial correlations), the ensemble mitigates such tendencies by aggregating multiple decision boundaries. This was evident in the consistent superiority of Stacking across both training and test sets, suggesting that the model not only fit the training data well but also maintained predictive reliability under varying input conditions.
In summary, the Stacking ensemble model demonstrated significant advantages over standalone algorithms in terms of both predictive accuracy and generalization ability. Its performance benefits arose from its integrative architecture, which effectively fused the complementary modeling capabilities of diverse learners and mitigated the limitations of any single model. This confirmed the suitability of ensemble learning, particularly Stacking, as a powerful approach for groundwater level prediction in complex, multi-factor environments.
4.3. Well-Level Performance in Heterogeneous Aquifers
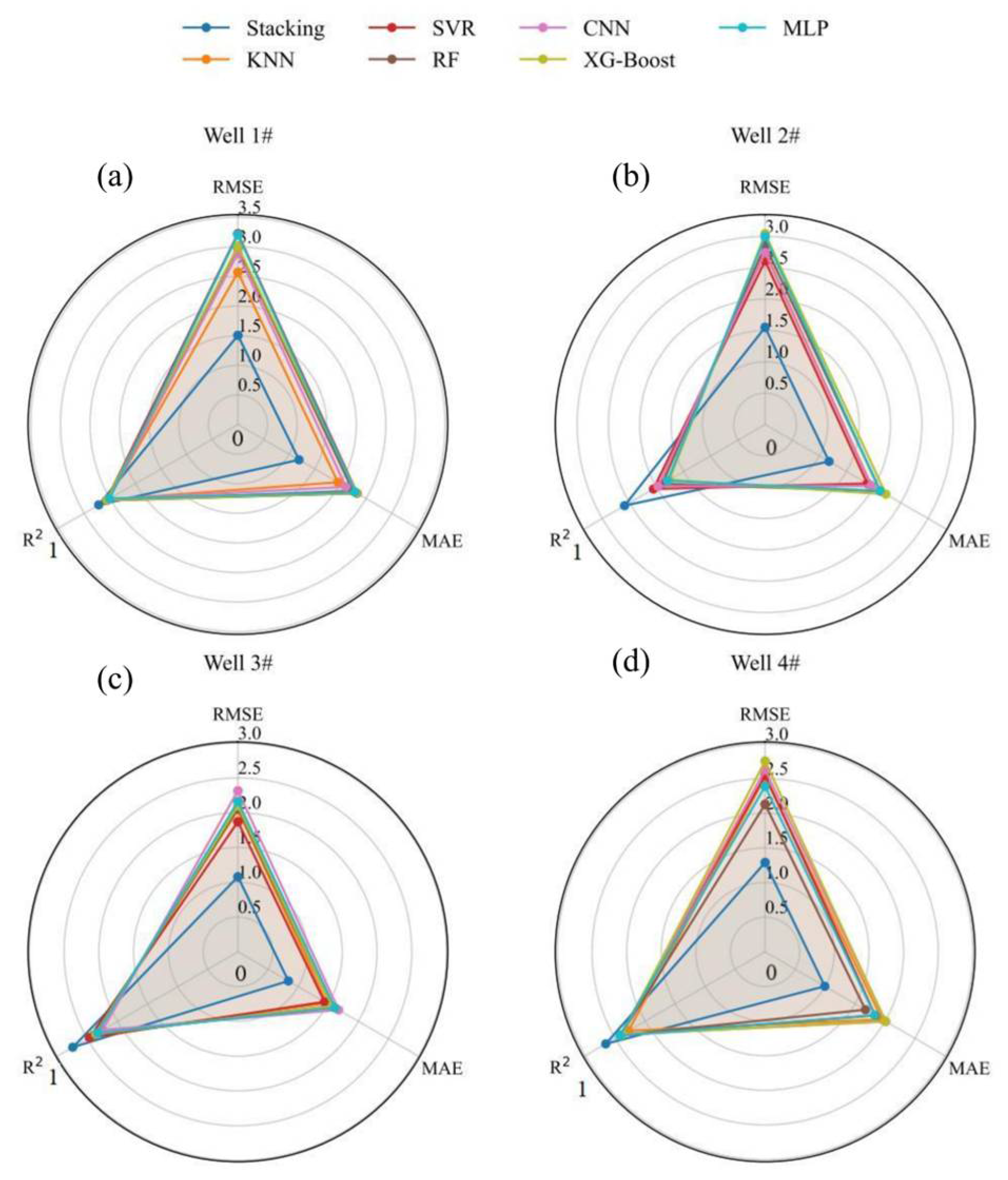
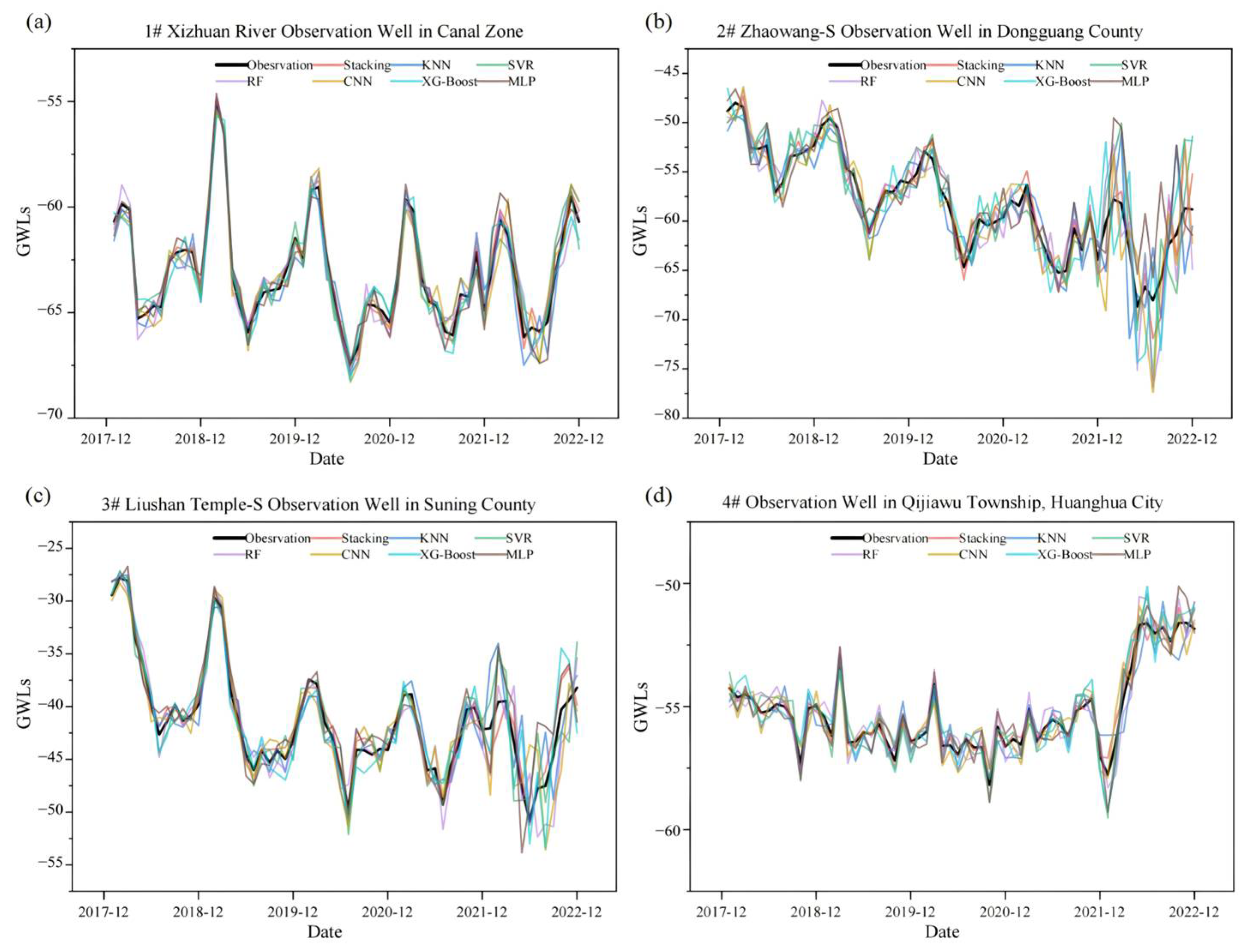
To further evaluate the generalization capability of the proposed Stacking ensemble model under varying hydrogeological conditions, this study conducted a single-well analysis based on four representative observation wells distributed across spatially heterogeneous regions. These wells were selected to capture diverse aquifer characteristics, including variations in lithology, groundwater depth, and anthropogenic influence. By comparing the prediction performance at each well, we aimed to assess the local adaptability and robustness of the Stacking framework relative to individual learning algorithms.
As shown in
Figure 12, the Stacking ensemble consistently achieved superior prediction accuracy across all selected wells, outperforming baseline models, such as CNN, KNN, SVR, RF, XG-Boost, and MLP, in terms of RMSE, MAE, and R
2. Specifically, the ensemble model achieved RMSE values ranging from 1.08 m to 2.08 m and MAE values between 0.52 m and 1.54 m, reflecting reductions of 34–66% and 28–49%, respectively, when compared to the best-performing individual learners. Furthermore, the coefficient of determination (R
2) ranged from 0.76 to 0.83, representing an improvement of 12–60% over the standalone models. As illustrated in
Figure 13, the prediction results of the Stacking ensemble model exhibit closer alignment with observed outcomes compared to alternative models.
This consistent performance advantage across spatially distinct wells highlighted several important attributes of the Stacking model. First, its ensemble architecture enabled the integration of diverse base learners with complementary modeling capabilities. For instance, CNN and MLP are adept at capturing high-dimensional and nonlinear patterns, while tree-based models like RF and XG-Boost excel at handling feature interactions and noise robustness. The meta-learner, implemented as a weighted average in this study, dynamically balanced the contributions of these base learners based on their local strengths, thus enhancing the model’s adaptability to varying geological settings.
Second, the superior generalization performance of the Stacking model is particularly notable given the pronounced heterogeneity in aquifer conditions. In individual models, performance is often sensitive to local data characteristics—for example, KNN may struggle in sparsely sampled wells, and SVR may be less robust to outliers or non-stationary inputs. By contrast, the ensemble approach mitigated such model-specific weaknesses, yielding more stable predictions across different wells.
In summary, the single-well analysis reinforced the conclusion that the Stacking ensemble learning model is not only accurate on a global scale but also robust and adaptable under localized hydrogeological variability. This makes it particularly suitable for groundwater prediction tasks in regions with complex spatial heterogeneity, where single-model solutions often fall short.
4.4. Error Analysis: Distribution Structure and Spatiotemporal Deviations
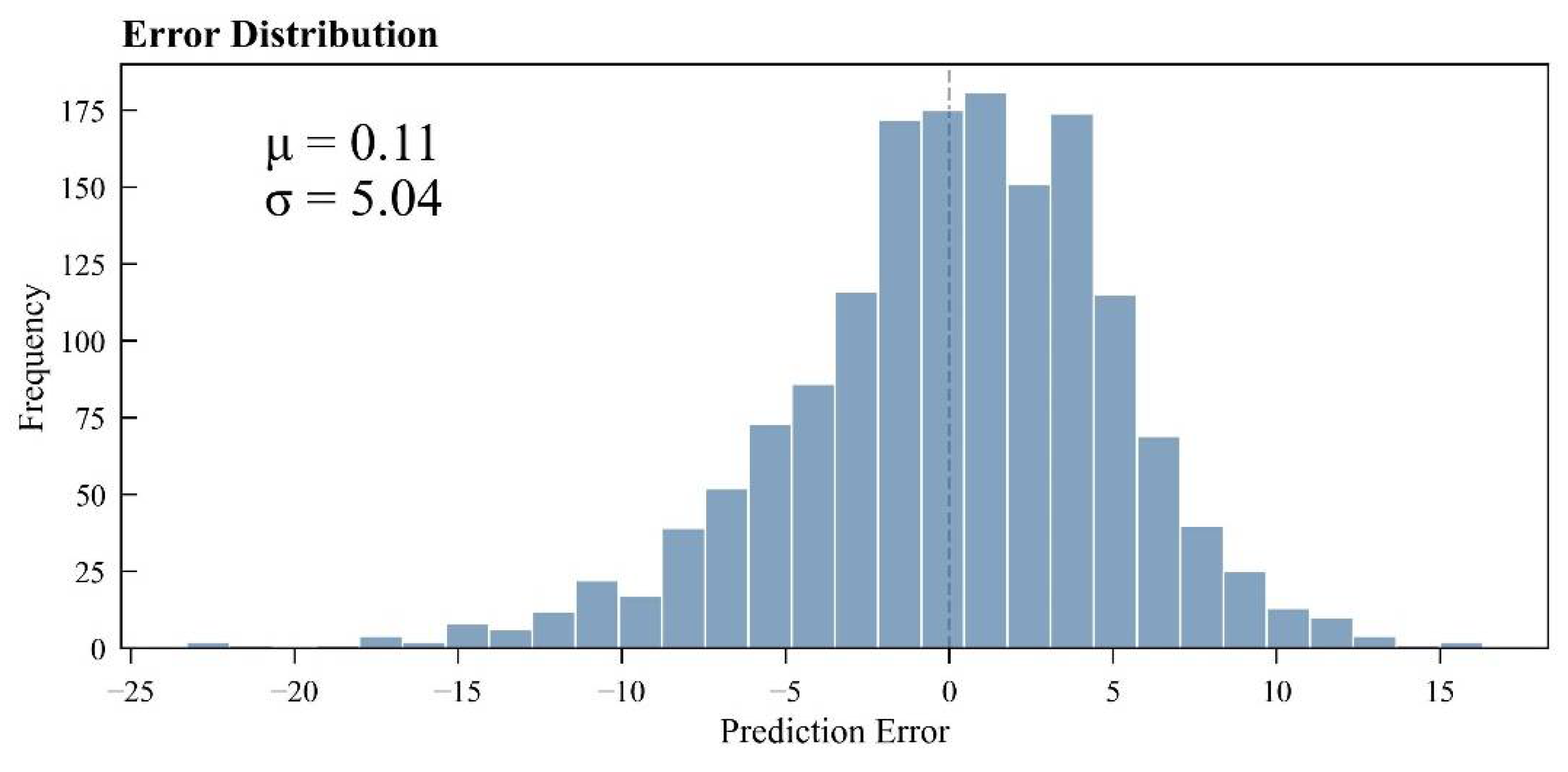
To further evaluate the reliability and robustness of the Stacking ensemble learning model, a detailed residual analysis was performed using prediction errors—defined as the differences between predicted and observed groundwater levels on the test set.
As shown in
Figure 14, the histogram of residuals closely approximated a symmetric bell-shaped distribution. The Shapiro–Wilk normality test (
p > 0.05) confirmed that the residuals did not significantly deviate from normality, indicating that the model’s overall error structure was statistically stable and well-behaved.
Two key insights emerged from the residual statistics. First, the residual mean was slightly positive (+0.11 m), indicating a mild systematic overestimation. This bias may stem from an uneven distribution of high-value samples in the training set or insufficient regularization in certain base learners (e.g., CNN), leading to minor overfitting in high groundwater level ranges. Second, the 95% confidence interval spanned from −9.76 m to +9.98 m, suggesting that the vast majority of errors fell within ±10 m—well within the acceptable range for practical groundwater management and engineering applications.
It should also be noted that the data used in this study spanned only from 2018 to 2022, as the groundwater monitoring network in the study area was not fully established until 2018. Prior to that, the number of monitoring stations was limited, and continuous, reliable data were unavailable. Although the use of lagged groundwater levels and monthly cumulative sequences helped mitigate this limitation, the relatively short time span may still affect the model’s ability to capture long-term trends, such as climate variability or cumulative overextraction. With the continuous accumulation of monitoring data in the future, the model can be further improved, and prediction errors are expected to decrease accordingly.
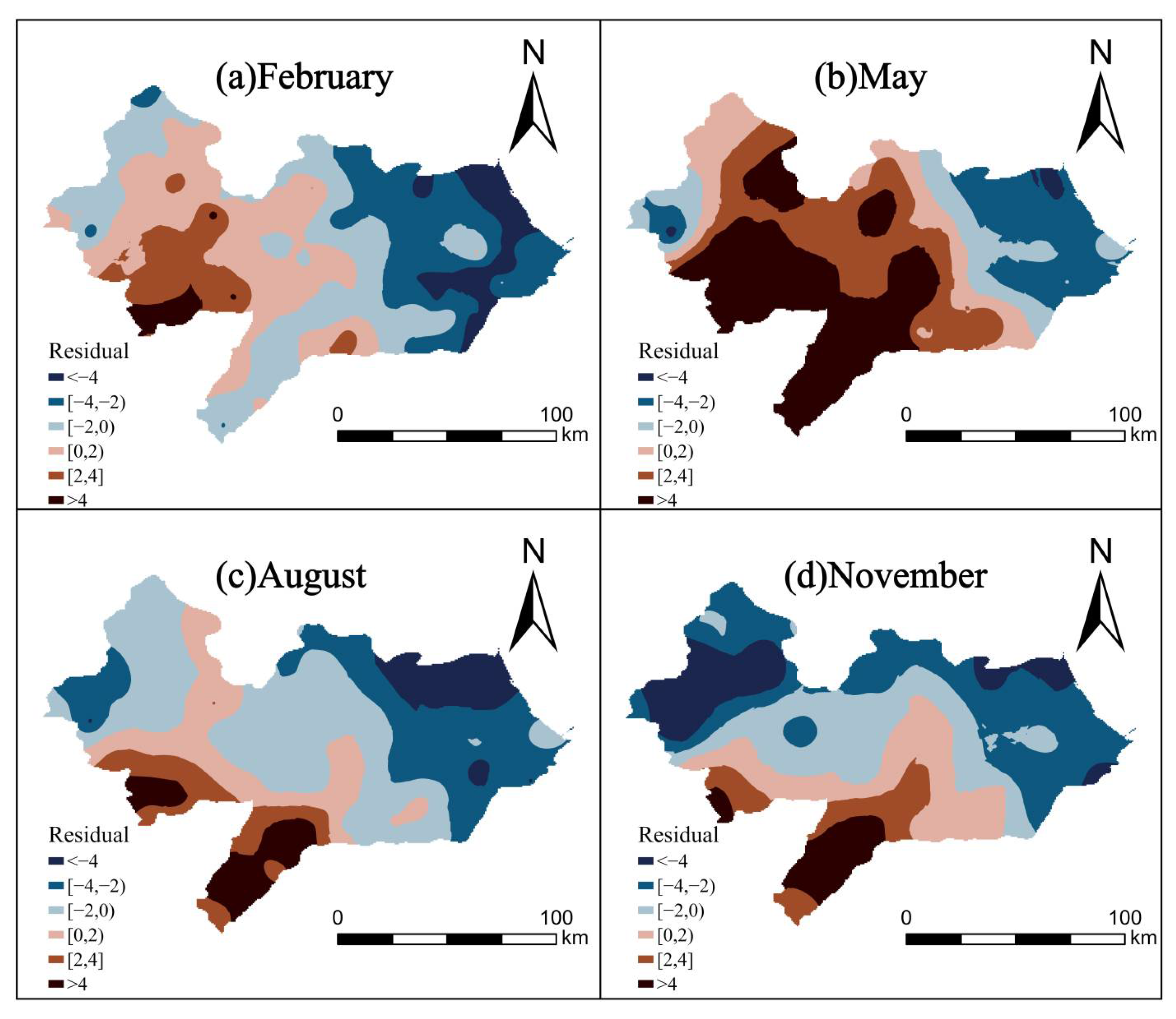
To examine the spatiotemporal distribution of prediction errors, a residual map was generated for the test set (
Figure 15). Spatial analysis revealed notable regional variation: predictions in southern Cangzhou tended to be slightly overestimated, while those in the western and eastern regions tended to be underestimated. These spatially systematic errors may reflect underlying hydrogeological heterogeneity. For example, the southern region may have higher hydraulic conductivity or better aquifer connectivity, enabling faster recovery of groundwater levels following recharge or reduced extraction—dynamics that may not be fully captured by the current feature set.
In contrast, the western and eastern areas may be characterized by lower transmissivity or more confined aquifer conditions, leading to slower recovery and underestimation by the model. Moreover, spatial heterogeneity in extraction intensity—such as concentrated agricultural groundwater extraction in specific zones—can further impact prediction accuracy if not adequately represented in spatial features. These findings suggest that future model improvements may benefit from incorporating detailed geological cross-sections, borehole profiles, and high-resolution groundwater extraction records to account for localized hydrogeological variability.
In summary, the residual analysis confirmed that the Stacking ensemble model demonstrated strong predictive stability. The residuals were approximately normally distributed with minimal bias and were tightly bounded. Furthermore, the model maintained acceptable predictive accuracy even under spatially heterogeneous and temporally dynamic conditions. These results underscore a key advantage of ensemble learning—its capacity to mitigate the weaknesses of individual models and deliver robust, generalizable predictions for complex groundwater systems.
4.5. Importance Analysis of Feature Variables
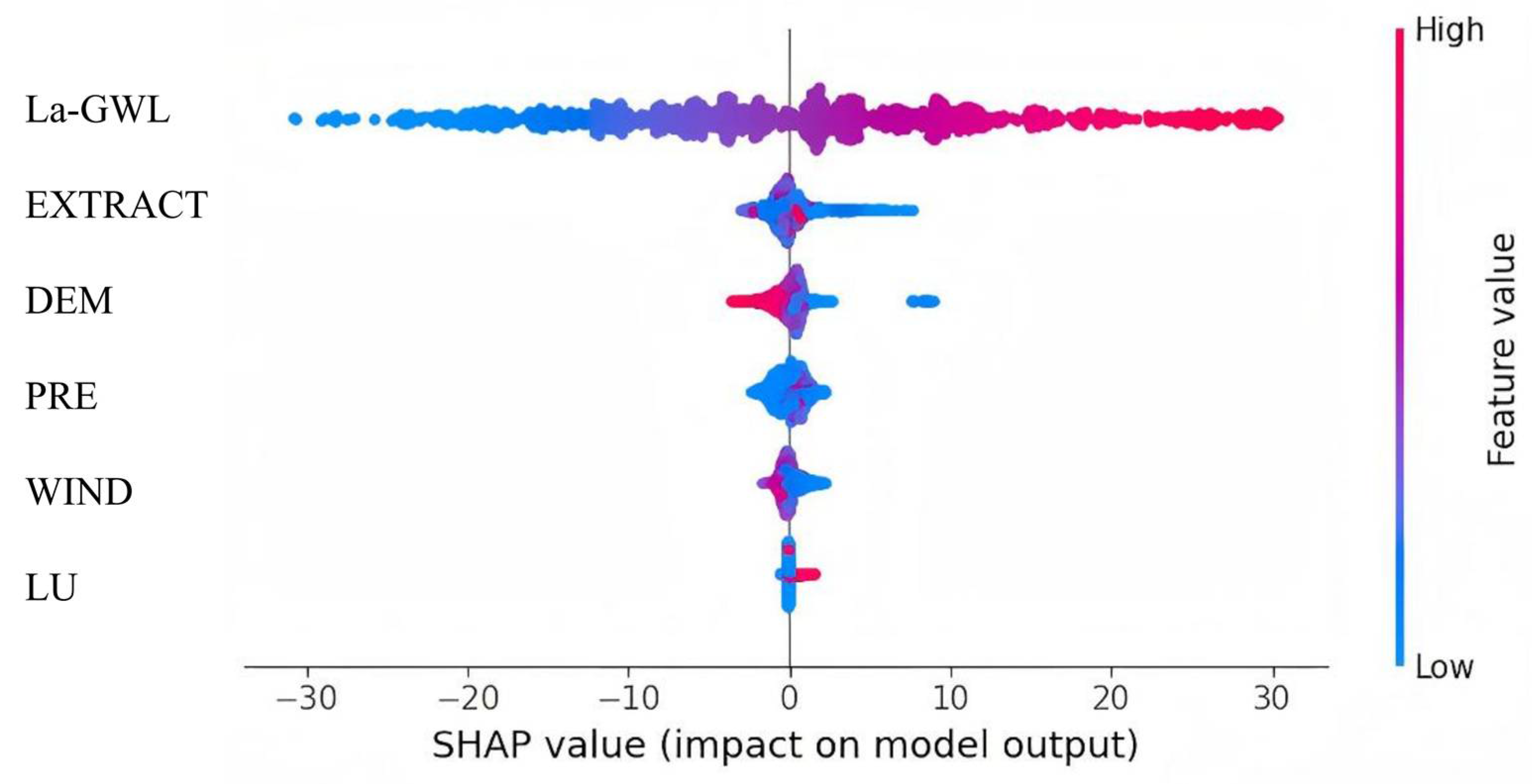
By calculating the SHAP values of feature variables and ranking their mean absolute values (
Figure 16), it was found that the lagged groundwater level exhibited the highest importance in predicting current groundwater levels. This dominance is not merely a statistical artifact but is underpinned by the physical behavior of deep confined aquifers. In such systems, hydraulic responses to external disturbances are inherently delayed due to low hydraulic diffusivity, thick overburden, and limited lateral recharge pathways. These conditions cause pressure waves to propagate slowly, resulting in strong system memory.
From a theoretical perspective, confined groundwater flow is governed by the diffusion equation, which exhibits first-order temporal dependence. The current hydraulic head is directly influenced by its past states, particularly in aquifers with low transmissivity and high storage coefficients. In the study area, the third aquifer group exhibited weak connectivity with surface recharge sources. As a result, changes in groundwater levels were mainly governed by internal hydraulic gradients and historical extraction pressures, rather than short-term meteorological fluctuations. Consequently, the lagged groundwater level captured both the autocorrelated dynamics and the delayed system response, making it a physically meaningful and information-rich predictor. This interpretation is consistent with findings in traditional time series groundwater models (e.g., ARIMA), where historical levels are key inputs. The SHAP-based feature importance results thus reflect not only statistical relevance but also sound hydrogeological reasoning, reinforcing the validity of the Stacking model’s design in this study.
The mean SHAP value of extraction volume ranked second, revealing the direct control effect of artificial pumping on groundwater levels [
37]. According to Theis’ theory of unsteady flow, the drawdown caused by extraction can be expressed as Equation (12):
where
represents the well function, and
denotes the transmissivity coefficient. The study area is in a state of overextraction, leading to a strong negative correlation between the water level and extraction volume. This is consistent with the water level decline pattern reported in global groundwater sustainability assessments for irrigated agricultural regions.
The mean SHAP values of climatic factors, such as rainfall and wind speed, were relatively low. This is because the study focused on deep groundwater levels. Rainfall infiltration experiences a long delay and cannot directly affect deep groundwater levels. Moreover, due to the relatively small temporal and spatial scales of this study, differences in land use types and ground elevation were not pronounced, and their impact on predicting deep groundwater levels was minimal [
38].
4.6. Summary of Findings
In summary, the Stacking ensemble learning model demonstrated clear superiority over individual models in predicting groundwater levels. By integrating the complementary strengths of multiple base learners, it achieved higher predictive accuracy and better agreement with observed values on the overall test set. Moreover, its strong generalization performance across wells with distinct spatial distributions highlighted its robustness to hydrogeological heterogeneity. Residual and spatial error analyses further confirmed the model’s stability and adaptability under varying conditions. Moreover, SHAP-based feature interpretation demonstrated that the model consistently responded to physically meaningful variables, such as lagged groundwater levels and groundwater extraction volume. These findings collectively highlight the effectiveness of the Stacking framework in modeling groundwater systems that are complex, nonlinear, and spatially heterogeneous. They provide a robust foundation for developing reliable forecasting and management strategies for sustainable groundwater use.
6. Conclusions
This study developed a Stacking ensemble learning framework that integrates multi-source data to predict deep groundwater levels in the Cangzhou region of Hebei Province. The model was further employed to simulate the regional groundwater recovery effects under both “with water diversion” and “without water diversion” scenarios. Physically meaningful variables—such as lagged groundwater levels—were embedded into the model structure, and its performance was systematically validated in terms of generalization capability, spatial adaptability, and interpretability. The key findings are as follows.
The proposed Stacking model significantly outperformed individual machine learning models and demonstrated strong competitiveness in horizontal comparisons. On the local test dataset, the Stacking model achieved a 16.1% reduction in MAE and a 16.0% reduction in RMSE compared to the best-performing benchmark models (e.g., RF and SVR), with R
2 increasing to 0.88, indicating excellent fit and generalization ability. Compared with recent studies, the proposed model also showed a leading performance. For example, Jiang et al. developed an ensemble model in a plain region of northern China that yielded RMSE values ranging from 3.4 to 7.2 m and R
2 values from 0.71 to 0.86. In contrast, our model maintained RMSE values between 1.08 and 4.20 m, with R
2 reaching 0.76–0.88, suggesting stronger local adaptability and predictive stability [
17].
The model structure is physically interpretable and generalizable, with good potential for integration into policy frameworks. SHAP analysis showed that lagged groundwater level and extraction volume were the most influential variables, reflecting the model’s ability to capture aquifer memory and anthropogenic impacts. Statistical tests confirmed that residuals were approximately normally distributed, with 95% of errors falling within ±10 m. The spatial pattern of residuals also aligned with variations in groundwater extraction intensity, validating the physical consistency and spatial robustness of the model.
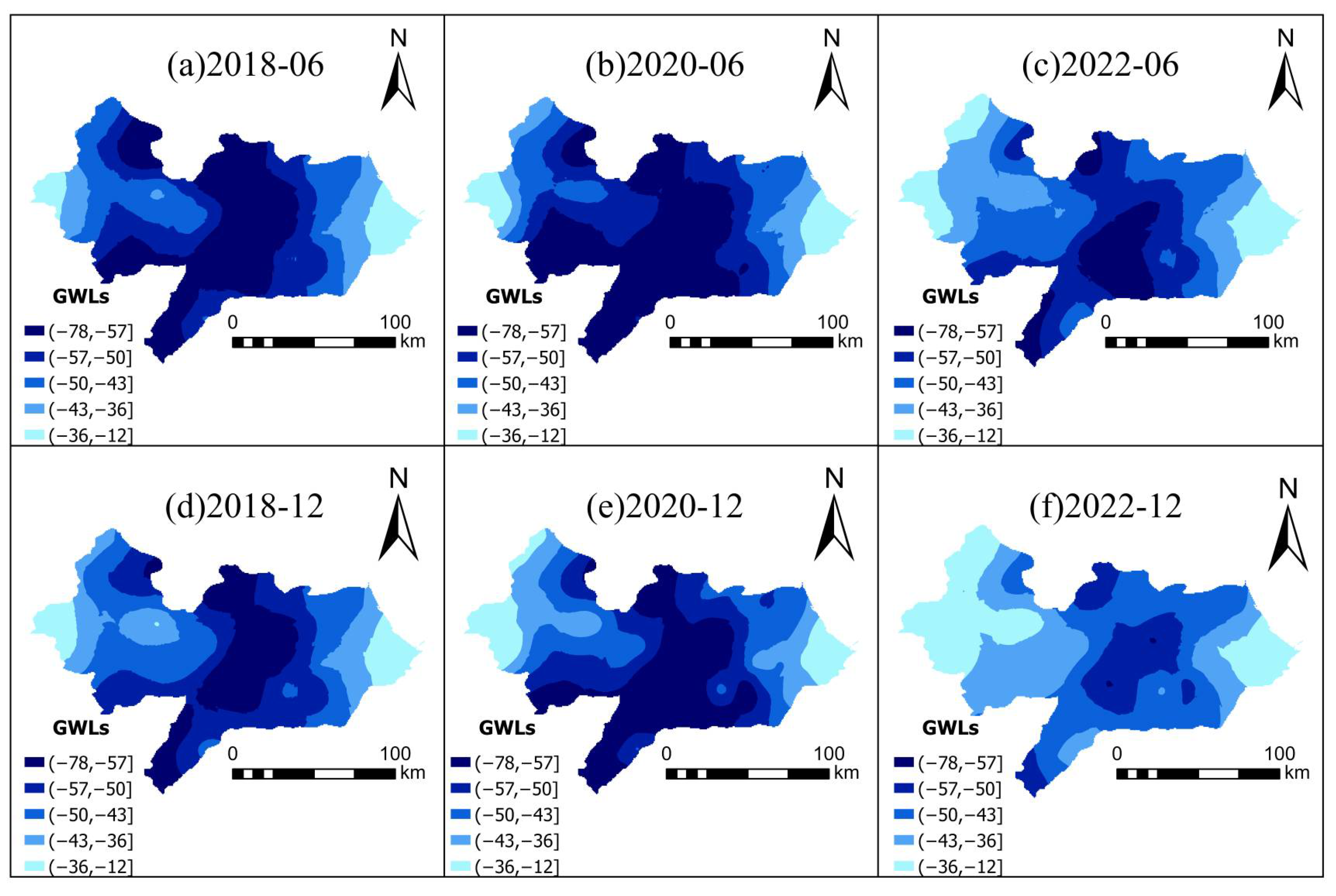
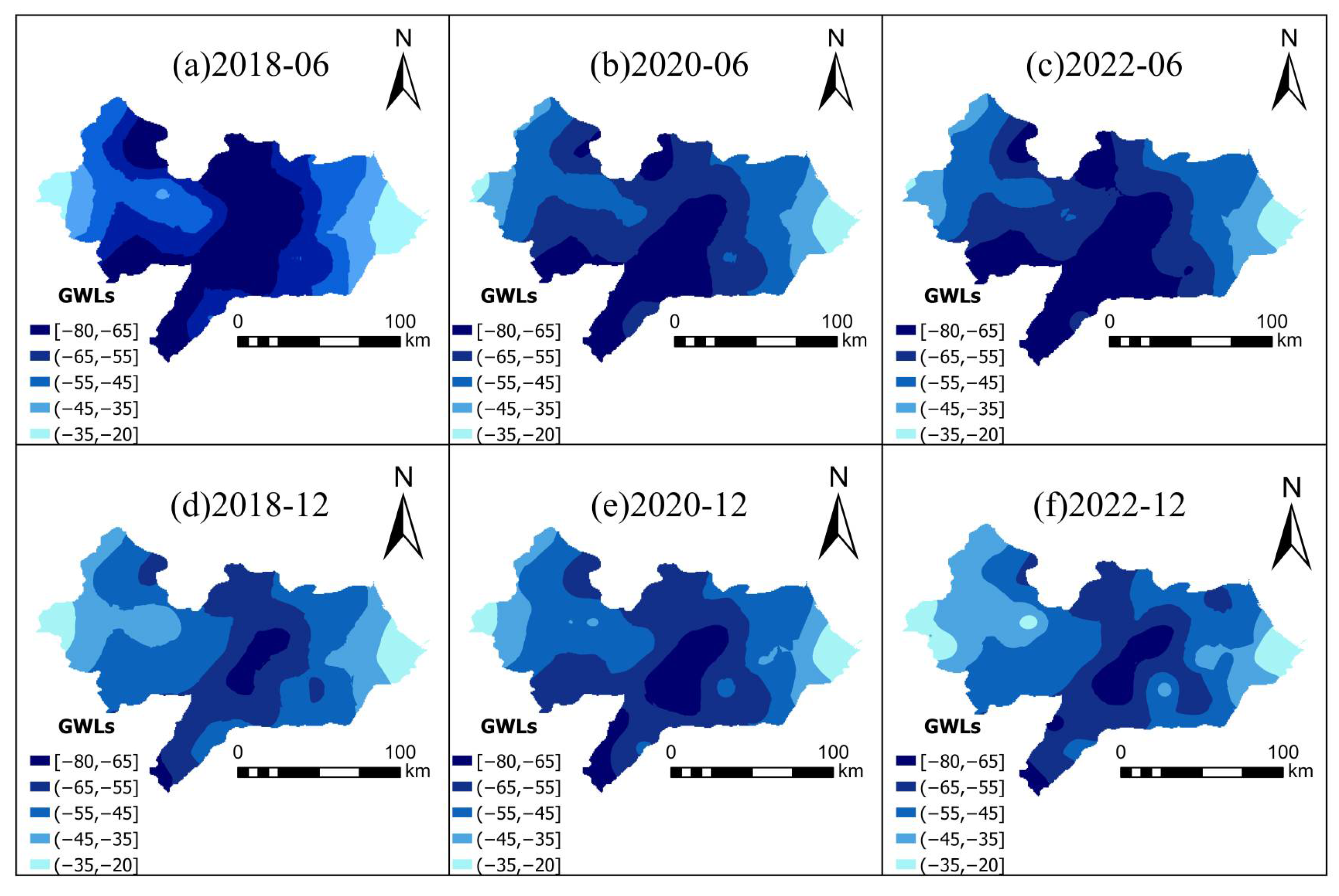
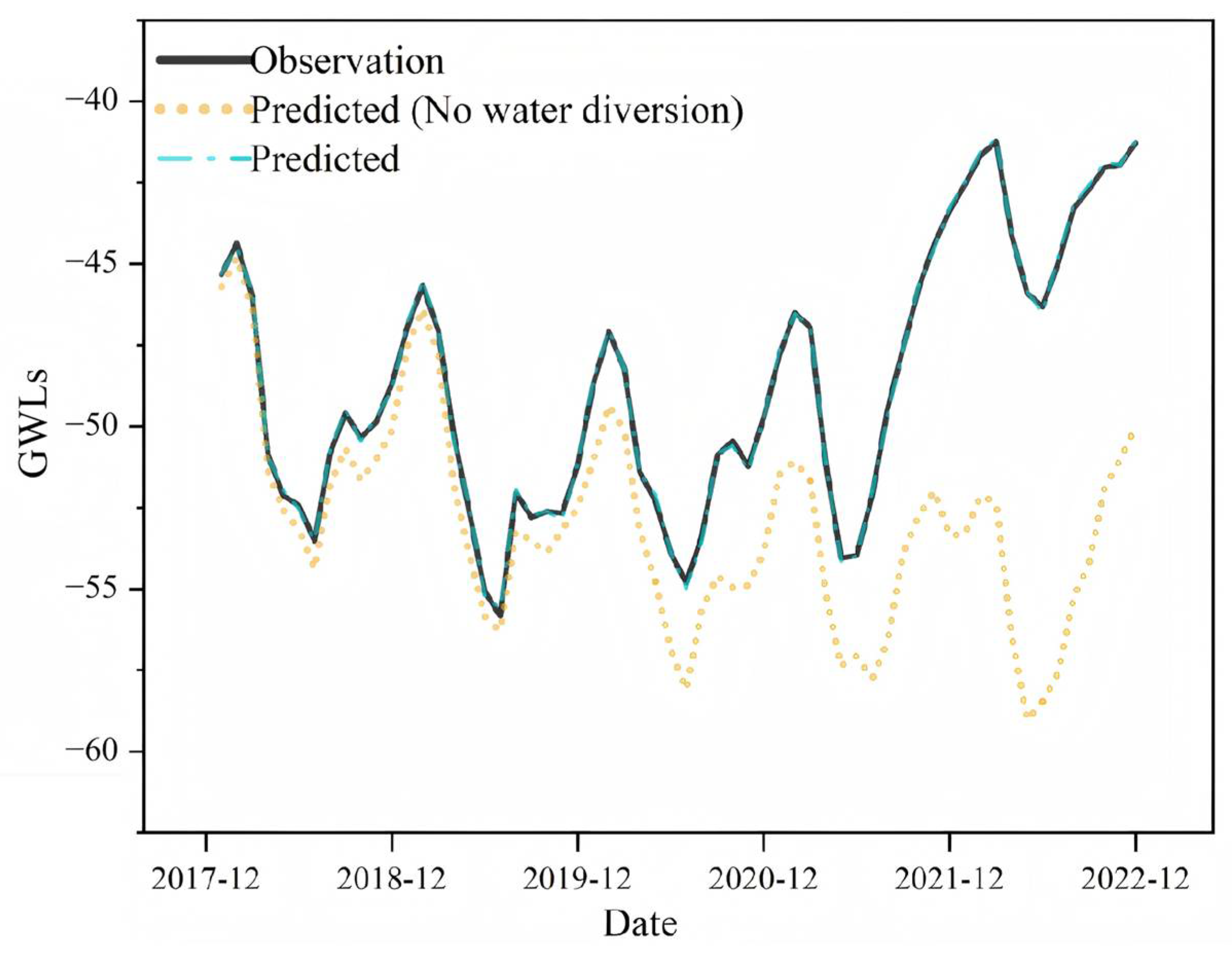
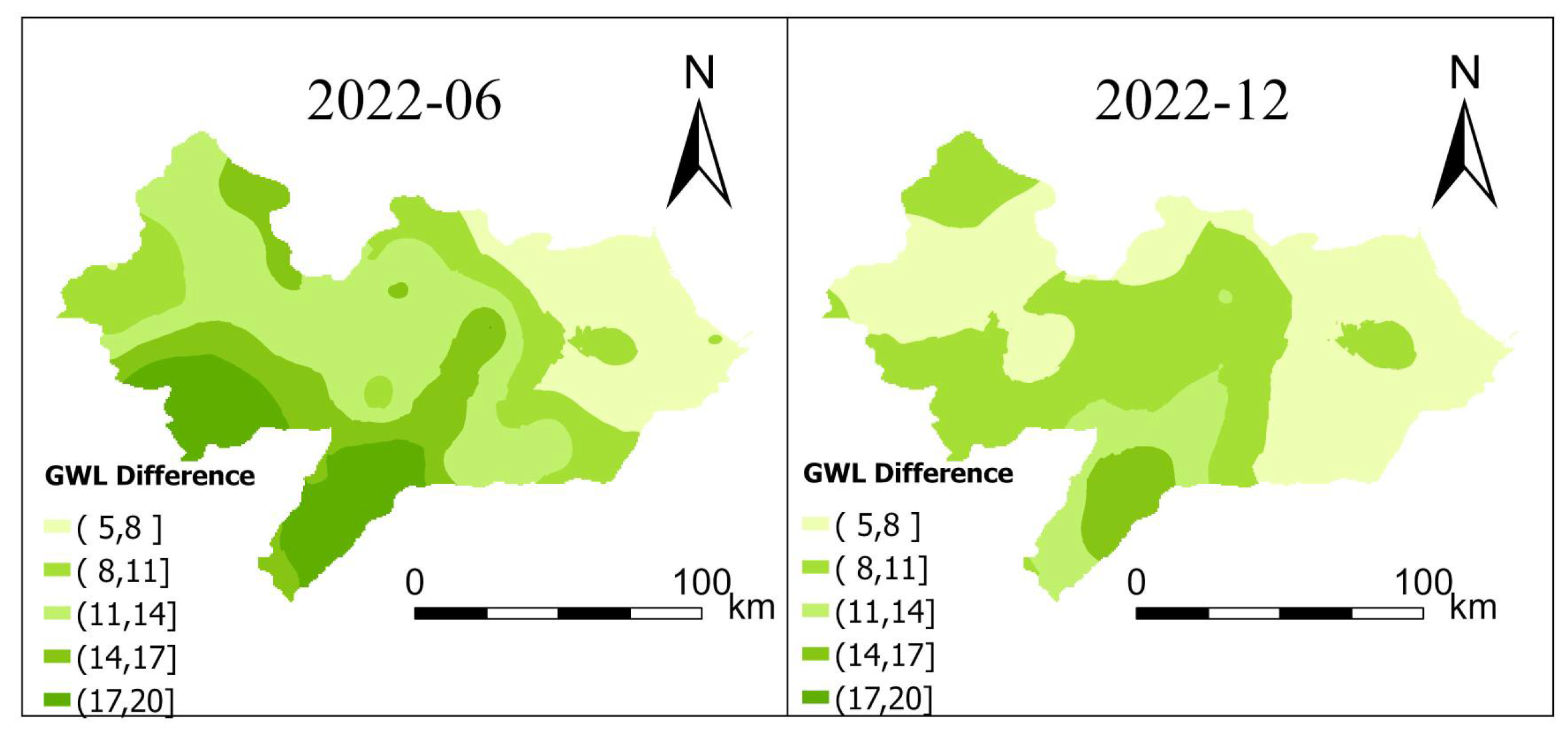
Counterfactual simulation results quantitatively confirmed the positive impact of the South-to-North Water Diversion Project (SNWDP) on groundwater recovery. Under the no-diversion scenario, the average regional groundwater level in 2022 was predicted to decline by 4–6 m, whereas observed values showed a rise of 5–7 m. In the most severely overexploited zones, the maximum difference reached 17 m, indicating that the SNWDP has played a critical ecological role in reshaping the regional water balance and mitigating groundwater overexploitation.
In terms of policy application, this study proposes two actionable water management strategies:
- (1)
Establishing a dynamic groundwater warning threshold system based on model predictions, with multi-level risk zones tailored to aquifer types (e.g., “green–normal”, “yellow–excessive decline”, and “red–overexploitation alert”). Early warning mechanisms can be triggered automatically based on forecasted trends.
- (2)
Optimizing the coordination between water diversion and groundwater extraction. Based on the model’s scenario simulations, a “dynamic water quota allocation” mechanism is proposed. When predicted groundwater levels fall below a predefined threshold, diversion volumes can be increased and extraction limited to restore balance. This strategy enhances the regulatory efficiency and ecological utility of large-scale diversion projects like the SNWDP.
Despite these contributions, the study has some limitations. First, the current model has not yet been validated on cross-regional or open-source datasets. Future work should benchmark the proposed model against recent approaches, such as AutoML-GWL and CatBoost-GWL. Second, the current simulation of the water diversion scenario was primarily based on extrapolated extraction data and lacks explicit representation of the groundwater–surface water interaction. We recommend integrating hybrid physical–data models (e.g., PINN and Hybrid-LSTM) in future studies to enhance long-term scenario reliability.
In conclusion, the proposed Stacking framework demonstrated strong advantages in model design, accuracy, and policy relevance. It improved the technical capacity for forecasting deep groundwater levels and offers an operational tool for adaptive groundwater regulation. The modeling approach and policy suggestions hold strong potential for replication in other water-stressed regions and can serve as a reference for sustainable groundwater management globally.



{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}