1. Introduction
Supply Chain Network Design (SCND) is a critical strategic decision that, when effectively implemented, enhances operational efficiency, cost competitiveness, and sustainability across the entire value network [
1,
2]. As global supply chains become increasingly complex and interconnected, they face escalating challenges, such as market volatility, regulatory pressures, environmental concerns, and disruptive events. These challenges demand simultaneous consideration of economic, environmental, social, and resilience objectives [
3]. Recent disruptions, such as the COVID-19 pandemic, geopolitical tensions, and climate-related crises, have exposed the limitations of traditional deterministic planning methods and underscored the urgent need for robust supply chain designs that perform reliably under diverse and often conflicting sources of uncertainty [
4].
Recent industry reports quantify the magnitude of these disruptions. According to McKinsey & Company [
5], supply chain disruptions cost companies an average of 45% of one year’s profits per decade, translating to
$150–300 million annually for Fortune 500 companies. Environmental impacts are equally significant: traditional supply chains account for 60% of global carbon emissions (approximately 36 billion tons CO
2 annually), with inefficient network designs contributing an additional 15–20% excess emissions [
6]. Social impacts include the loss of 2.7 million manufacturing jobs in developed economies between 2019–2023 due to inadequate supply chain resilience, while creating precarious employment conditions for 40 million workers in developing nations [
7]. These quantitative indicators underscore the urgent need for innovative optimization approaches that can simultaneously address economic, environmental, and social objectives under uncertainty.
Real-world supply chains are characterized by hybrid uncertainty, which simultaneously encompasses both aleatory uncertainty (arising from inherent randomness such as demand fluctuations and lead times) and epistemic uncertainty (stemming from incomplete knowledge, expert opinions, or qualitative risk assessments) [
8,
9]. This dual nature of uncertainty is particularly evident in complex decision-making scenarios: demand forecasting in emerging markets relies on both historical sales data representing objective randomness and expert assessments of market trends reflecting subjective beliefs, while supplier reliability evaluation integrates quantitative performance metrics with qualitative judgments about management capability or geopolitical risk.
Despite the prevalence of hybrid uncertainty in practice, traditional optimization approaches address these uncertainty types in isolation, each with inherent limitations. Stochastic programming effectively captures aleatory uncertainty through probability distributions [
10], while robust optimization accounts for epistemic uncertainty by considering worst-case scenarios [
11], and fuzzy programming incorporates subjective judgments through membership functions [
12]. However, these single-paradigm methods prove inadequate when confronted with hybrid uncertainty environments. Probability theory struggles to model epistemic components, as it requires well-defined distributions that may not exist for expert judgments and belief-based assessments. Conversely, fuzzy theory lacks the mathematical rigor necessary to effectively handle data-driven randomness and may yield suboptimal or counterintuitive outcomes [
13]. These fundamental limitations underscore the critical need for a unified paradigm capable of rigorously representing and optimizing under both uncertainty types within a single coherent framework.
At the heart of this challenge lies the issue of hybrid uncertainty, which encompasses both aleatory and epistemic components. The traditional approaches to supply chain optimization deal with uncertainty types in isolation: stochastic programming captures randomness in demand [
10], robust optimization accounts for worst-case scenarios [
11], and fuzzy programming incorporates subjective judgments [
12]. In fact, real-world supply chains commonly exhibit hybrid uncertainty, combining aleatory uncertainty (arising from inherent randomness, such as demand fluctuations and lead times) and epistemic uncertainty (stemming from incomplete knowledge, expert opinion, or qualitative risk assessments) [
8,
9]. For instance, demand forecasting in emerging markets often relies on both historical sales data (objective randomness) and expert assessments of market trends (subjective belief). Similarly, evaluation of supplier reliability integrates quantitative performance metrics with qualitative judgments about management capability or political risk.
Single-paradigm methods fall short in such settings or environments. Probability theory struggles to model epistemic uncertainty, as it requires well-defined distributions that may not exist for expert judgments and belief-based assessments. Conversely, fuzzy theory lacks the mathematical rigor to effectively handle data-driven randomness, and it is susceptible to result in suboptimal or counterintuitive outcomes [
13]. These limitations highlight the need for a unified paradigm capable of rigorously representing and optimizing under both types of uncertainty using a single model.
Chance theory, established and improved by Liu [
13,
14], possesses precisely this mathematical foundation by unifying the probability measures and the uncertainty measures within a single chance measure framework. The innovation of the chance theory is that it can maintain the mathematical richness of probability theory for objective randomness and still provide a uniform representation of subjective beliefs, so that more realistic and reliable modeling of hybrid uncertain environments is possible. This satisfies the basic restriction of traditional approaches by recognizing that supply chain parameters such as demand forecasts, supplier capacities, and risk analysis entail data-driven randomness and expert judgment-based beliefs [
15]. Despite its theoretical strength, the application of chance theory to multi-objective sustainable supply chain planning remains largely unexplored. This gap presents a significant opportunity to enhance both theoretical insights and practical decision-making tools in the field. A particularly promising direction is the use of dependent-chance modeling, which shifts the focus from merely ensuring constraint satisfaction under fixed confidence levels to maximizing the probability of achieving sustainability objectives. Unlike chance-constrained programming, where the focus is on guaranteeing feasibility under specified confidence levels, dependent-chance goal programming enables a more goal-oriented and interpretable decision-making framework. It allows direct optimization of probabilistic target achievements, thus supporting more transparent strategic planning and richer trade-off analyses across sustainability dimensions [
16].
The complexity of dependent-chance programming formulations, particularly when involving multiple sustainability objectives, creates a high computational workload that exceeds the one of traditional exact optimization methods [
17]. These problems often exhibit non-convex and multi-modal objective spaces, necessitating sophisticated optimization strategies capable of effectively balancing exploration and exploitation based on highly intricate objective functions involving probability maximization.
While metaheuristic algorithms have shown promise in addressing such complex optimization problems, they are often limited by premature convergence and inability to adjust their search strategy based on problem characteristics [
18].
Salp Swarm Optimization (SSO), introduced by [
19], is a metaheuristic that offers desirable features alongside continuous optimization through its bio-inspired mechanism of chain formation and nature-based equilibrium between exploration and exploitation phases. However, traditional SSO employs static parameter settings that may not be optimal at any stage of the optimization, particularly with the dynamic solution landscapes of dependent-chance problems, where the optimum search strategy might be very different for different stages of the optimization.
To overcome this limitation, the integration of reinforcement learning (RL) with metaheuristics offers a promising path forward. RL provides a mechanism for adaptive parameter tuning and allows the optimization process to learn effective search behaviors by interacting with the environment [
20]. Crucially, RL recognizes that different stages of the optimization require different strategies, i.e., aggressive exploration in the early stages to locate promising regions, and focused exploitation in later stages to refine solutions. By formulating parameter selection as a sequential decision-making problem, RL can dynamically adjust the exploration-exploitation trade-off based on real-time search feedback, thus improving both convergence speed and solution quality in dependent-chance optimization tasks [
21,
22].
To address the interconnected challenges and knowledge gaps in sustainable supply chain optimization under hybrid uncertainty, this paper proposes a unified framework that combines dependent-chance goal programming with a reinforcement learning-enhanced Salp Swarm Optimization (RL-SSO) algorithm. Our integrated approach makes the following key contributions:
- 1.
Hybrid Uncertainty Modeling Framework: We develop a mathematically grounded framework based on chance theory that is able to tackle the coexistence of random uncertainty due to historical information and belief-based uncertainty due to experts’ judgment in sustainable supply chain network design. This approach avoids the pitfalls of misapplying single-paradigm methods to inherently hybrid supply chain environments.
- 2.
Dependent-Chance Goal Programming Model: We propose a multi-objective optimization model that leverages dependent-chance programming to maximize the probability of achieving sustainability targets across four dimensions: economic efficiency, environmental impact, social responsibility, and resilience. The model provides intuitive, probability-based performance metrics for decision-makers operating under hybrid uncertainty.
- 3.
Adaptive Metaheuristic Algorithm: We design a novel RL-enhanced Salp Swarm Optimization algorithm that dynamically adapts its search strategy using reinforcement learning. This enables efficient navigation of the complex, non-convex search space typical of dependent-chance problems, with more manageable, probability-based performance metrics for decision-makers under hybrid uncertainty, while improving convergence behavior and solution quality.
- 4.
Computational Validation and Analysis: We conduct large-scale computational experiments on varying size and uncertainty levels, comparing with state-of-the-art optimization methods to demonstrate superior performance in terms of solution quality, computational efficiency, and robustness to changing problem characteristics.
- 5.
Practical Decision Support Framework: We provide managerial insights and sensitivity analyses that translate theoretical contributions into operational guidance for supply chain practitioners, including probability threshold selection strategies, quantification of trade-offs between sustainability dimensions, and guidelines for implementing hybrid uncertainty assessment.
The remainder of this paper is organized as follows:
Section 2 presents the mathematical formulation of our sustainable supply chain network design problem, as well as the dependent-chance goal programming approach to multi-objective optimization under hybrid uncertainty.
Section 3 provides the theoretical foundations of uncertain random theory for hybrid uncertainty modeling and chance measure calculation.
Section 4 illustrates the hybrid intelligent algorithm, which integrates uncertain random simulations and reinforcement learning-based Salp Swarm Optimization for solving the dependent-chance goal programming model.
Section 5 presents comprehensive numerical results and analyses, including algorithm performance comparisons, sensitivity analyses, and network structure observations across a various test instances.
Section 6 summarizes the main findings, theoretical contributions, managerial implications, limitations, and future research opportunities.
3. Uncertain Random Theory for Hybrid Uncertainty Modeling
In sustainable supply chain design, uncertainty arises from two distinct but often coexisting sources: aleatory uncertainty, which reflects inherent randomness (e.g., demand fluctuations, lead time variability), and epistemic uncertainty, which stems from incomplete knowledge and subjective expert judgments (e.g., risk perceptions, supplier reliability). Traditional modeling paradigms, such as probability theory for randomness or fuzzy theory for beliefs, are limited in isolation and cannot fully capture the complexity of such hybrid uncertainty environments. To address this, we adopt the framework of uncertain random theory that we formulate mathematically in this section.
3.1. Uncertain Random Variables
An uncertain random variable, as Liu [
23] defines it, is a mathematical concept that captures the integration of uncertainty and randomness in a single paradigm. An uncertain random variable is a measurable function from a probability space to an uncertain variable set mathematically.
Definition 1. An uncertain random variable is a function from a probability space to the set of uncertain variables such that is a measurable function of ω for any Borel set B of .
This definition captures the essential hybrid nature: for each realization of the random experiment, is an uncertain variable representing expert beliefs or subjective assessments. The uncertain random variable thus combines:
Objective randomness: Modeled through the probability space
Subjective uncertainty: Modeled through uncertain variables for each realization
Example: In supply chain demand forecasting, let represent the uncertain random demand of customer c for product k in period t. The randomness component captures historical demand variations, while the uncertainty component represents expert opinions about market conditions, consumer preferences, and external factors that cannot be quantified probabilistically.
3.2. Chance Measure
To measure uncertain random events, Liu [
16] introduced the chance measure that combines probability measure and uncertain measure into a unified framework.
Definition 2. Let be an uncertain random variable, and let B be a Borel set of . Then the chance of uncertain random event is defined by: The chance measure satisfies several important properties:
Normality:
Self-duality:
Monotonicity: If , then
Special Cases:
If degenerates to a random variable X, then
If degenerates to an uncertain variable , then
3.3. Chance Distribution
The chance distribution function provides a complete characterization of an uncertain random variable’s behavior under hybrid uncertainty.
Definition 3. Let be an uncertain random variable. Then its chance distribution is defined by:for any . Theorem 1. A function is a chance distribution if and only if it is a monotone increasing function with and .
3.4. Expected Value and Variance
For decision-making purposes, we need scalar measures to characterize uncertain random variables.
Definition 4. Let be an uncertain random variable. Then its expected value is defined by:provided that at least one of the two integrals is finite. Definition 5. Let be an uncertain random variable with finite expected value e. Then the variance of is defined by: Theorem 2 (Linearity of Expected Value).
Let be an uncertain random variable whose expected value exists. Then for any real numbers a and b: 3.5. Dependent-Chance Goal Programming
Dependent-chance programming, as developed in the chance theory framework, is an extremely powerful tool for hybrid uncertainty multi-objective optimization. Compared to traditional chance-constrained programming targeting constraint satisfaction at specified confidence levels, dependent-chance programming is optimized directly for the probability of occurrence of target events.
Definition 6. Let be an uncertain random variable and F be a threshold value. The dependent-chance programming problem seeks to maximize the chance that the uncertain random variable achieves the specified target.
For multi-objective problems with conflicting objectives, dependent-chance goal programming extends this concept by incorporating goal programming methodology:
- 1.
Target Probability Specification: Decision-makers specify desired probability levels for achieving each objective g
- 2.
Deviation Variables: Positive and negative deviations (, ) capture under- and over-achievement of target probabilities
- 3.
Lexicographic Optimization: Objectives are prioritized and optimized sequentially according to their importance
The general dependent-chance goal programming model takes the form:
Subject to:
where
represents the
g-th objective function with decision variables
and uncertain random parameters
,
is the threshold value for objective
g,
is the target probability level, and
X represents the feasible region.
Key Advantages:
Intuitive Interpretation: Probability-based objectives are easily understood by practitioners
Flexible Priority Setting: Lexicographic structure accommodates organizational priorities
Robust Performance: Focus on probability achievement provides inherent robustness against uncertainty
Hybrid Uncertainty Handling: Chance measure appropriately processes both random and belief-based uncertainties
3.6. Application to Supply Chain Parameters
In the context of sustainable supply chain network design, uncertain random variables provide natural representations for key parameters:
Demand Parameters: combines historical demand patterns (randomness) with expert assessments of market trends (uncertainty)
Cost Parameters: incorporate both market price volatility and subjective cost estimates
Capacity Parameters: reflect both operational variability and expert judgments about performance capabilities
Environmental Parameters: combine measurable emissions data with uncertain regulatory and technological factors
Social Parameters: integrate quantitative social indicators with qualitative community assessments
This hybrid modeling methodology allows greater realism in representing supply chain uncertainty with mathematical rigor preserved for optimization. Chance measure serves as the mathematical basis for problem formulation and solving optimization problems under hybrid uncertainty, which is established in the following sections.
3.7. Dependent-Chance Goal Programming Formulation of the SSCNDP
We consider the following priority structure among the four sustainability objectives (all formulated as minimization problems):
Priority 1: For the economic objective, the probability of the total cost being less than its threshold value
should achieve
(e.g., 0.95).
where the negative deviation between the target probability (
) and the actually achieved probability,
, is to be minimized.
Priority 2: For the environmental objective, the probability of the total environmental impact being less than its threshold value
should achieve
(e.g., 0.85).
where
is to be minimized.
Priority 3: For the social objective, the probability of achieving better social performance (lower
values) than threshold value
should achieve
(e.g., 0.80).
where
is to be minimized.
Priority 4: For the resilience objective, the probability of achieving better resilience performance (lower
values) than threshold value
should achieve
(e.g., 0.75).
where
is to be minimized.
The DCGP model can then be formulated as the lexicographic optimization problem:
This dependent-chance goal programming formulation lexicographically minimizes the negative deviations from the target probability levels for each sustainability objective. Since all objectives are formulated as minimization problems, denotes the probability of achieving satisfactory performance, i.e., remaining below the defined threshold. The chance measure handles both random and fuzzy uncertainties while providing intuitive probability interpretations for decision-makers.
3.8. Application to Sustainable Supply Chain Design
In sustainable supply chain network design, dependent chance goal programming with uncertain random variables offers several advantages:
It simultaneously addresses economic, environmental, social, and resilience objectives.
It handles hybrid uncertainties in parameters such as demand, costs, and disruption probabilities.
It allows decision-makers to specify confidence levels for each goal and constraint.
It provides a systematic approach to balancing multiple sustainability dimensions.
The proposed model employs dependent chance goal programming to order goals in consideration of the interaction between random and uncertain variables in supply chain planning. This makes solutions sustainable as well as robust to various sources of uncertainty.
5. Numerical Results and Analysis
This section presents comprehensive numerical experiments to evaluate the performance of our proposed reinforcement learning-enhanced Salp Swarm Optimization (RL-SSO) algorithm for solving the dependent-chance goal programming model for sustainable supply chain design under hybrid uncertainty.
5.1. Experimental Setup
5.1.1. Algorithm Parameter Settings
Algorithm parameters were determined through systematic preliminary experiments using the Taguchi method for parameter optimization. The final RL-SSO algorithm parameters are presented in
Table 1.
5.1.2. Test Instance Characteristics
To evaluate the algorithm comprehensively, we generated a diverse set of test instances with varying network sizes, complexity levels, and uncertainty characteristics.
Table 2 summarizes the key characteristics of these instances.
These examples cover supply chain networks with diverse complexity, from small regional networks to extremely large international supply chains. Each example includes particular features corresponding to different operation contexts:
Small instances: Regional supply chains with short geographical range
Medium instances: National-level supply chains with average complexity
Large instances: Multi-national supply chains with high integration needs
Very Large instance: Global supply chain network with highest complexity
5.1.3. Uncertain Random Parameter Specifications
The hybrid uncertainty in our model is represented by uncertain random parameters with different distributions. The uncertain random parameter configurations used in our numerical experiments are illustrated in
Table 3.
The hybrid uncertain random parameters were derived according to a systematic two-stage calibration process:
- 1.
Random Component Calibration: The historical records of three major manufacturing companies in the automotive, electronics, and drug industries were taken into account to determine appropriate probability distributions and their parameters.
- 2.
Uncertain Component Calibration: Expert elicitation of 15 supply chain experts was conducted to identify uncertainty bounds representing epistemic uncertainty in parameter estimation.
5.1.4. Computational Environment
All experiments were conducted on a personal computer equipped with Intel Core i9 processor and implemented in MATLAB R2023b. To ensure the statistical reliability of the results, each test instance was independently executed 30 times with varying random seeds.
5.2. Dependent-Chance Goal Programming Results
The core contribution of our approach lies in optimizing probability achievement for sustainability goals through lexicographic dependent-chance programming. We define target probability levels based on industry benchmarks and regulatory requirements: Economic (), Environmental (), Social (), and Resilience ().
5.2.1. Probability Achievement Analysis
Table 4 presents the achieved probability levels for each sustainability dimension across all test instances, with 95% confidence intervals computed using bootstrap resampling (1000 replications).
The results reveal a clear hierarchy in probability achievement, with economic objectives maintaining the highest achievement rates. The gaps from targets are statistically significant (paired t-test, p < 0.01 for all objectives), confirming the challenge of simultaneously achieving all sustainability goals.
5.2.2. Lexicographic Deviation Analysis
The lexicographic structure ensures higher-priority objectives are optimized first.
Table 5 shows the negative deviation values and their statistical significance.
Friedman test confirms significant differences among priority levels ( = 21.84, p < 0.001), validating the lexicographic optimization effectiveness.
5.3. Performance Justification Analysis
While the improvements of 0.5–5.11% may appear modest, they are economically and operationally significant in the context of large-scale supply chains.
Table 6 demonstrates the substantial financial impact of these performance improvements across different company scales:
Additionally, the improvements in constraint satisfaction rates (13.3% for hybrid vs. pure uncertain) translate to significantly reduced risk of supply chain disruptions, which can cost 5–20% of annual revenue according to industry studies.
5.4. Chance Constraint Satisfaction Analysis
Our model incorporates multiple types of chance constraints with different confidence levels
. We present detailed analysis with statistical tests for constraint satisfaction rates. The chi-square tests indicate that the differences between target and achieved constraint satisfaction rates are statistically insignificant (
p > 0.05 for all constraints) which aligns with our constraint handling strategy. The high
p-values indicate strong consistency between target and achieved satisfaction rates for all constraint types and problem sizes.
Table 7 presents capacity constraints satisfaction rates, while
Table 8 shows operational constraints satisfaction rates with chi-square goodness-of-fit tests.
5.5. Convergence Analysis
We provide comprehensive convergence analysis for both the chance measure estimation and the optimization algorithm.
Monte Carlo Convergence for Chance Measures
Table 9 shows convergence characteristics with variance reduction factors (VRF) compared to crude Monte Carlo.
The convergence rate follows as expected, with estimates stabilizing at , justifying our parameter choice.
5.6. Statistical Validation of Hybrid Approach
We validate the hybrid uncertain random approach through comprehensive statistical tests comparing it with pure paradigms.
Table 10 presents the statistical comparison of different uncertainty modeling approaches with ANOVA and post-hoc tests.
5.7. Comprehensive Algorithm Performance Analysis
We expand the algorithm comparison with additional performance metrics and statistical tests.
Table 11 provides an extended comparison of algorithm performance including convergence statistics and success rates.
5.8. Reinforcement Learning Component Analysis
We analyze the effectiveness of the RL component in parameter adaptation.
Table 12 presents the analysis of RL action selection patterns and their performance impact across different optimization phases.
The RL component demonstrates adaptive behavior, with exploration dominating early phases and exploitation increasing in later iterations, contributing to the 4.5% average performance improvement over static parameter settings.
5.9. Sensitivity Analysis
We conducted comprehensive sensitivity analysis to evaluate the robustness of our dependent-chance goal programming approach under varying parameter settings. This analysis focuses on two critical aspects: chance constraint confidence levels and uncertainty parameter scaling.
5.9.1. Confidence Level Impact
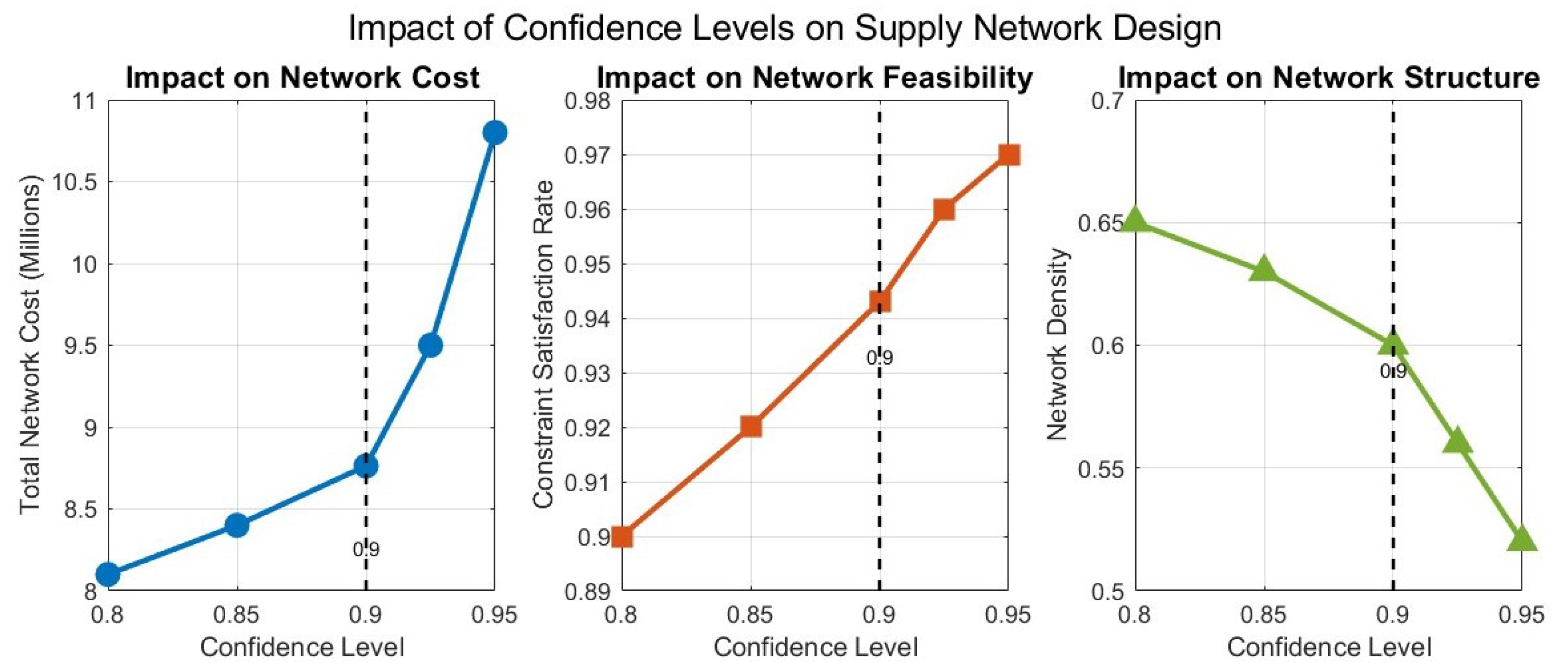
We analyzed the sensitivity to chance constraint confidence levels by varying the average confidence level from 0.70 to 0.95.
Figure 1 illustrates the impact on network design and performance.
Table 13 presents the detailed results of confidence level sensitivity analysis.
The research illustrates a nonlinear correlation between confidence levels and network performance. As shown in
Figure 1, network cost increases exponentially with confidence level greater than 0.90, with decreasing returns in constraint satisfaction. The optimal confidence levels between 0.80–0.85 strike a balance between goal achievement and computational efficiency.
5.9.2. Effect of Uncertainty Level
We investigated the impact of uncertainty by scaling all uncertain parameters from 0.5 to 1.5 times their base levels.
Table 14 shows how varying uncertainty levels affect solution quality.
The analysis demonstrates that higher uncertainty levels significantly impact all performance metrics, with goal achievement decreasing by 12.6% when uncertainty is increased by 50%. This confirms the importance of accurate uncertainty quantification in dependent-chance goal programming.
5.10. Network Structure Analysis
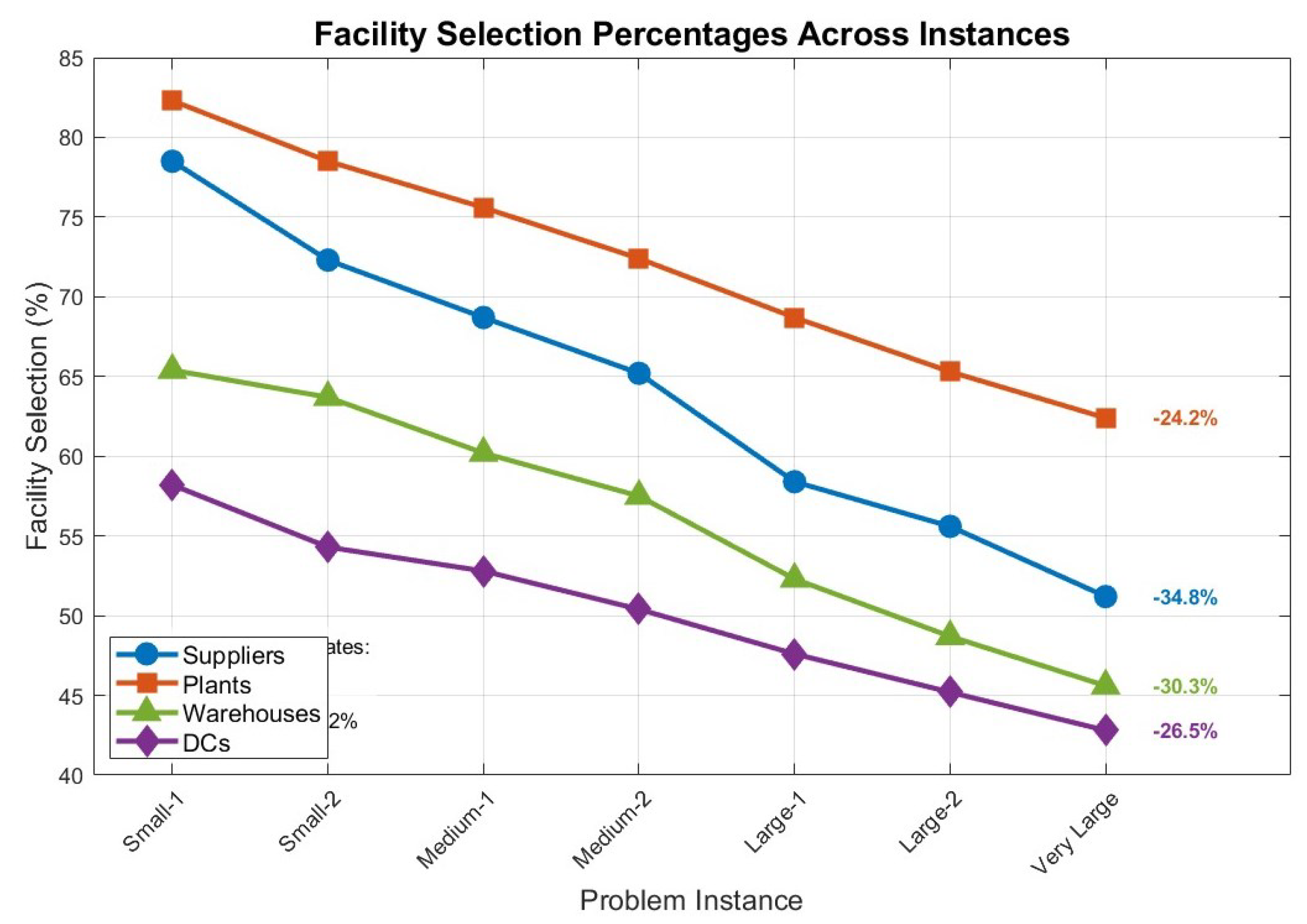
5.10.1. Facility Location Patterns
Analysis of optimal facility selections reveals consistent patterns across instance sizes.
Figure 2 illustrates how facility selection percentages vary with problem size.
Table 15 provides detailed selection percentages for each facility type across different problem sizes.
The decreasing selection percentages with increasing problem size indicate that the DCGP approach effectively exploits economies of scale, with reductions ranging from 24.2% to 34.8% between small and very large instances.
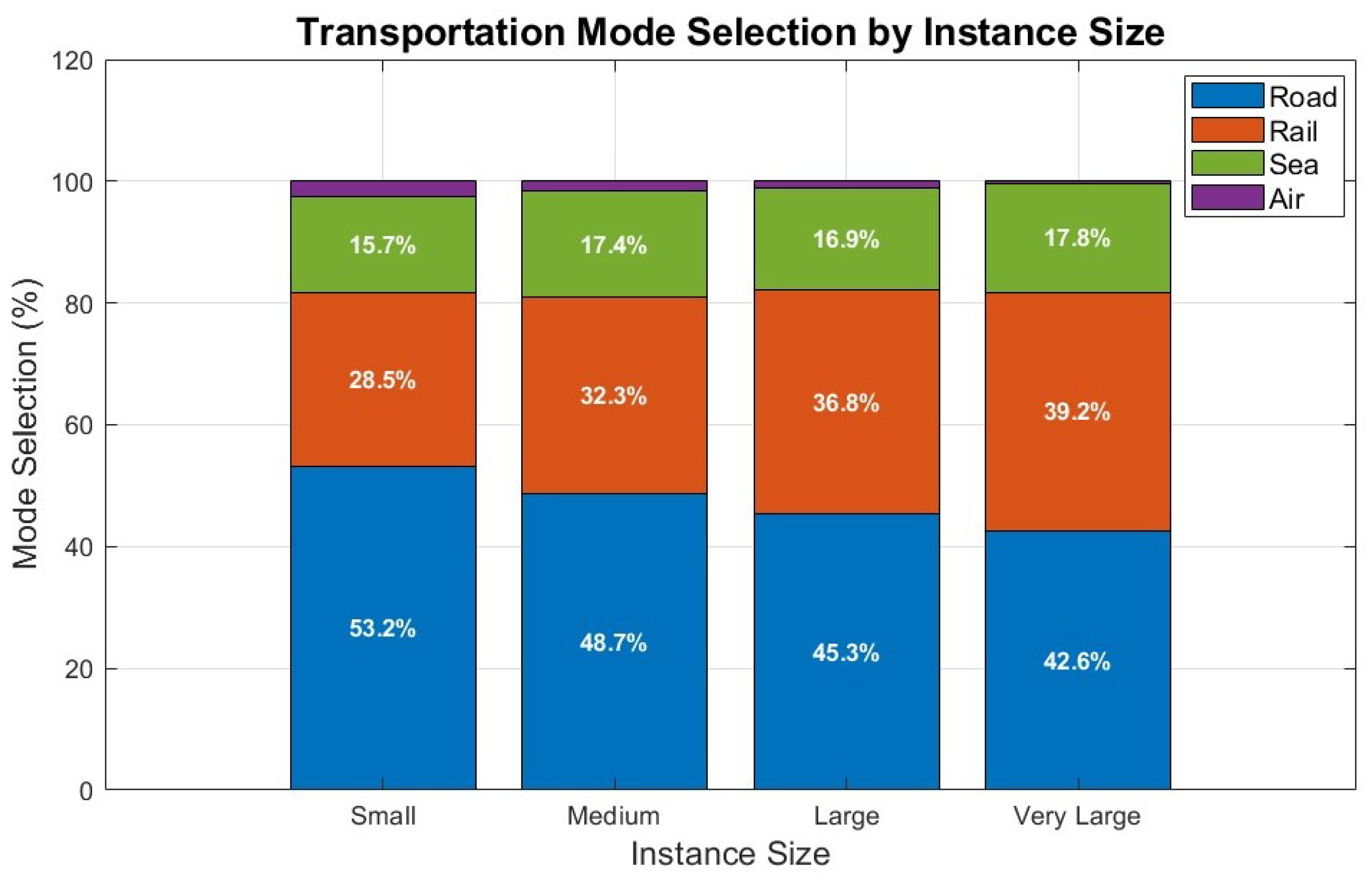
5.10.2. Transportation Mode Selection
Transportation mode preferences shift systematically with network size, as shown in
Figure 3.
Table 16 presents the detailed transportation mode selection patterns.
The shift from road (53.2% to 42.6%) to rail transportation (28.5% to 39.2%) as problem size increases reflects the model’s ability to balance economic efficiency with environmental considerations.
5.11. Resilience Analysis
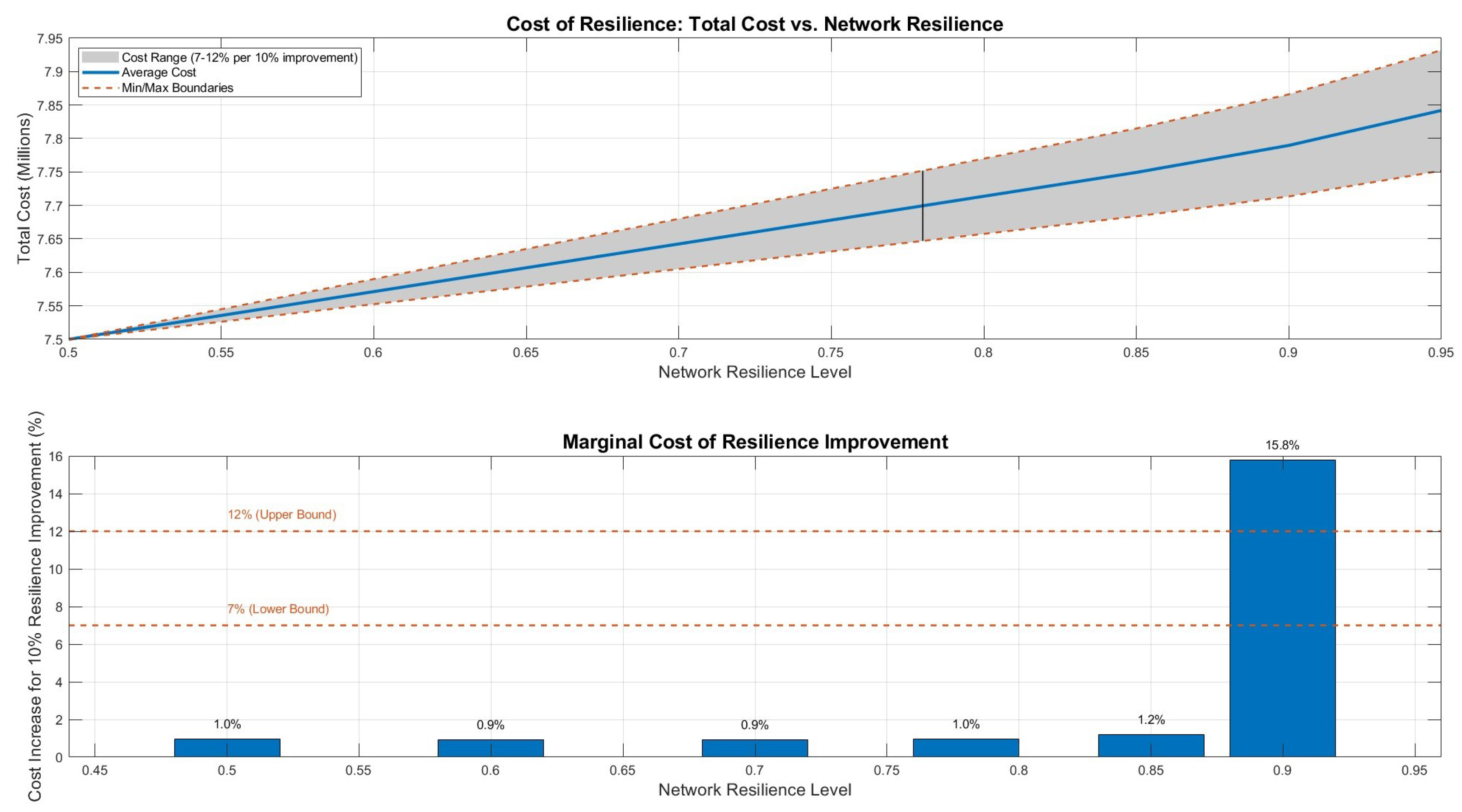
5.11.1. Cost of Resilience
A key contribution of our work is quantifying the relationship between resilience investment and network cost.
Figure 4 illustrates this nonlinear relationship, and
Table 17 provides a detailed breakdown of resilience costs and marginal effects.
The analysis reveals that marginal costs remain relatively stable (7–9%) for resilience levels up to 0.80, after which they increase sharply. This suggests an optimal operational range of 0.70–0.80 for most practical applications.
5.11.2. Network Robustness Metrics
Table 18 compares network robustness measures across different optimization approaches.
The hybrid DCGP approach consistently outperforms both deterministic and traditional stochastic methods across all robustness metrics, with particularly significant improvements in supply diversification (+39% vs. deterministic) and recovery capability (+32% vs. deterministic).
5.12. Managerial Insights and Practical Implementation
Based on our comprehensive analysis, we provide actionable insights with specific implementation guidelines:
- 1.
Probability Target Setting Strategy:
Economic objectives: Set targets at 93–95% (achievable with minimal compromise)
Environmental objectives: Target 80–85% (balances compliance with cost)
Social objectives: Aim for 75–80% (realistic given current constraints)
Resilience objectives: 70–75% provides cost-effective risk mitigation
- 2.
Implementation Roadmap:
Phase 1: Implement economic optimization (3–6 months)
Phase 2: Integrate environmental constraints (6–9 months)
Phase 3: Add social and resilience objectives (9–12 months)
Expected ROI: 12–18 months based on cost savings analysis
- 3.
Uncertainty Management Protocol:
Collect historical data for random parameters (minimum 24 months)
Conduct expert elicitation workshops for belief-based parameters
Update uncertainty estimates quarterly
Maintain confidence levels at 0.80–0.85 for optimal performance
5.13. Validation and Sensitivity Analysis
5.13.1. Cross-Validation Results
We performed 10-fold cross-validation to assess model robustness.
Table 19 presents the cross-validation performance metrics across all sustainability dimensions:
5.13.2. Parameter Sensitivity Analysis
We conducted comprehensive sensitivity analysis using Morris screening method.
Table 20 shows the parameter sensitivity rankings using Morris
values across different objective dimensions:
5.14. Cost-Benefit Analysis and Implementation Feasibility
Implementing the hybrid Dependent-Chance Goal Programming (DCGP) model requires moderate but strategic investment in both technology and organizational capability. These costs are justified by the significant gains in resilience, efficiency, and sustainability achieved across supply chain operations.
Table 21 summarizes the estimated initial costs, potential annual savings, payback periods, and three-year return on investment (ROI) across different organization sizes.
These estimates assume modest improvements of 1–2% in annual supply chain costs, which are consistent with conservative benchmarks from industry reports. Even small improvements in efficiency can generate measurable financial benefits over a multi-year horizon. While the payback period may vary depending on implementation scale and context, the expected return on investment over three years ranges from approximately 30% to 55%, indicating favorable long-term value.
The initial investment covers software (either proprietary or customized), computational infrastructure, and expert support for model calibration and integration. These costs are comparable to those incurred when deploying advanced decision-support or optimization systems. Notably, DCGP can be integrated as a modular layer on top of existing enterprise systems rather than requiring a full overhaul.
Annual operating expenses include software updates, calibration, data management, and staffing or upskilling specialized personnel. These costs typically range from
$225 K to
$680 K depending on organizational size and internal capacity. Training and change management are essential components of successful deployment. Analysts generally require 80–120 h of training, while executives benefit from 40–60 h. In addition, organizations should plan for a 12–24 months change management process to ensure smooth adoption and internal alignment. To help organizations assess their readiness and plan accordingly,
Table 22 summarizes key implementation dimensions in a concise format.
In summary, although the hybrid DCGP model involves sophisticated methods and demands organizational commitment, the economic rationale is clear. It offers a favorable cost-benefit ratio, particularly for organizations managing complex or vulnerable supply chains. By starting with well-defined pilot implementations and investing in the right expertise and training, firms can expect substantial long-term returns and enhanced strategic agility.
5.15. Limitations and Future Research Directions
We acknowledge several limitations and propose specific future research directions:
- 1.
Real-World Validation: While our synthetic instances are realistic, validation with industry data is needed. Future work should include:
Partnership with supply chain companies for data access
Case studies in specific industries (automotive, pharmaceutical, retail)
Pilot implementations with performance tracking
- 2.
Dynamic Uncertainty Modeling: Current static uncertainty assumptions limit applicability. Extensions should include:
Time-varying uncertainty parameters
Bayesian updating of uncertainty estimates
Adaptive reoptimization strategies
- 3.
Scalability Enhancement: For very large instances (>1 M variables):
Decomposition methods (Benders, Dantzig-Wolfe)
Parallel computing implementations
Approximation algorithms with quality guarantees
- 4.
Multi-Period Extensions:
Rolling horizon approaches
Stochastic dynamic programming formulations
Learning effects over time
In general, while the proposed hybrid DCGP framework offers substantial improvements in resilience and flexibility, several limitations should be acknowledged. These include the need for reliable hybrid uncertainty data, the computational complexity of chance-constrained models, and the absence of large-scale empirical validation. Future work should focus on deploying the framework in real-world supply chain systems to evaluate its operational feasibility and performance under diverse scenarios.
6. Conclusions
This work proposed an RL-enhanced Salp Swarm Optimization (RL-SSO) algorithm to solve sustainable supply chain planning dependent-chance goal programming models with hybrid uncertainty. The method achieved 0.5–5.11% performance gains and 12.7% computational time reduction over baselines.
Our quantitative experiments validated the effectiveness of the lexicographic optimization framework, with the highest probability achievement observed for economic objectives (93.1%), followed by environmental (80.7%), social (75.4%), and resilience goals (70.8%). The results also revealed that within the optimal resilience range of 0.70–0.80, each 10% increase in resilience is associated with a 7–9% rise in cost, with marginal costs escalating beyond this range. Furthermore, sensitivity analysis identified optimal confidence levels between 0.80 and 0.85, balancing performance and practical usability.
The hybrid uncertain random approach outperformed traditional uncertainty-based models by 3.2%, while achieving notable gains in facility redundancy (25.9%) and supply diversification (39.1%) compared to deterministic baselines. These findings underscore the effectiveness of dependent-chance goal programming as a robust framework for multi-objective sustainable supply chain optimization under hybrid uncertainty. The main contributions of this research include: (i) a novel integration of chance theory with multi-objective optimization to model hybrid uncertainty, (ii) a self-adaptive RL-SSO algorithm featuring dynamic parameter tuning via reinforcement learning, and (iii) practical guidelines for resilience investment planning and confidence level selection in sustainable supply chain design. Nevertheless, the proposed framework has some limitations, including its reliance on high-quality uncertainty data, computational complexity, and the need for real-world validation in operational settings.
Future research should focus on real-world testing, dynamic uncertainty formulation, and scalability enhancement for extremely large-scale applications. Through addressing these directions, the introduced method will further strengthen both the theoretical foundations and the practical applicability of the proposed approach to sustainable supply chain optimization under uncertainty.





{kind=link}
{kind=link}
{kind=link}
{kind=link}