The imagery expression of product form is increasingly surpassing mere functional requirements in modern industrial design, emerging as a critical foundation for enhancing brand identity and emotional value [
1,
2,
3,
4]. As user demands become more diverse and personalized, product appearance is no longer a mere fusion of functionality and aesthetics; rather, it serves as a key medium for establishing a deep connection between users and products [
5,
6]. Moreover, as manufacturing technologies and marketing strategies continue to converge, distinctive and emotionally compelling form designs have become a primary means for enterprises to gain a competitive edge [
7,
8]. Concurrently, academic research, particularly from the perspective of cognitive psychology, has increasingly recognized that the impact of product appearance on consumer perception extends far beyond superficial visual stimuli. Instead, it embodies implicit emotional appeals and brand associations [
9,
10,
11,
12]. However, discrepancies often exist between designers’ interpretations and users’ perceptions in product evaluation, leading to cognitive asymmetry that hinders designers from accurately capturing user emotional preferences. Consequently, a significant gap exists between the physical characteristics of product form and the semantic imagery they convey, necessitating novel approaches to bridge this “form-imagery” disparity.
As a traditional approach to product form imagery recognition, Shape Grammar [
13] provides theoretical support for design by qualitatively analyzing the relationship between product form and consumer emotions. However, this method is often constrained by its reliance on the rule-based description of geometric forms, making it difficult to accommodate the diverse emotional needs of users when dealing with complex affective semantics. Similarly, Kansei Engineering [
14] has been widely applied since its inception to map users’ ambiguous affective imagery onto product design elements. It collects users’ emotional vocabulary through interviews and questionnaires, then employs statistical methods to establish correspondences between emotional descriptors and specific design elements, forming an “emotion–form” mapping table. With advancements in computing technology, some researchers have attempted to extract discriminative features from product contour, texture, and local details using handcrafted image analysis techniques. These features are then combined with machine learning algorithms for preliminary imagery style classification. For instance, Zhao et al. [
15] improved the BP neural network using the whale optimization algorithm, enabling the mapping between product form features and consumer affective imagery. Wu et al. [
16] employed a multi-layer perceptron (MLP) and genetic algorithm (GA) to develop an intelligent evaluation method for product form design, achieving a nonlinear mapping between form elements and user perceptual cognition. Zhang et al. [
17] optimized the mapping relationship between the front-end styling features of electric SUVs and consumer imagery requirements by integrating the BP neural network with the Seagull Optimization Algorithm for optimization. Fu et al. [
18] proposed a particle swarm optimization–support vector regression (PSO-SVR) model, which enables the precise mapping between Ming-style furniture design features and user affective needs, facilitating an objective correlation between user perception and design elements. However, these approaches often struggle to capture subtle affective semantics, making them inadequate for recognizing complex imagery representations of product form. In recent years, deep learning-driven computer vision has led to significant breakthroughs in product form imagery recognition. Since Krizhevsky et al. [
19] introduced AlexNet in 2012, surpassing handcrafted features in ImageNet classification, deep convolutional neural networks (DCNNs) have rapidly become the dominant algorithm for large-scale image recognition tasks. Successive architectures, including VGG [
20], GoogLeNet [
21], and ResNet [
22], have continuously increased the depth of feature extraction and improved recognition accuracy. These network structures and supporting techniques—such as activation functions, normalization methods, and training optimizations—have significantly alleviated deep network training challenges, laying the foundation for the intelligent recognition of product form imagery. Building upon this foundation, researchers have begun applying DCNNs to product form analysis, demonstrating their superior performance. For instance, Gong et al. [
23] developed an enhanced AlexNet-based model for pixel-level affective image analysis and recognition, enabling automatic mapping between product images and user sentiment evaluations. Hu et al. [
24] conducted comparative experiments between handcrafted feature-based Support Vector Machines (SVMs) and end-to-end trainable DCNNs, revealing the significant advantage of DCNNs in classification accuracy and generalization capability. Su et al. [
25] proposed an automated product affective attribute evaluation model using DFL-CNN, achieving fine-grained classification in automotive design evaluation. Zhou et al. [
26] applied VGG-11 to classify automobile form imagery, enabling automatic aesthetic grade assessment. Lin et al. [
27] developed a ResNet-based sustainable product design evaluation model, enhancing the efficiency and reliability of automated affective design assessment. These findings demonstrate that deep learning has achieved remarkable success in form style classification, affective imagery recognition, and aesthetic evaluation. Furthermore, DCNNs’ capability of automatic feature extraction effectively compensates for the limitations of handcrafted features, significantly improving the recognition accuracy of complex product form imagery. However, existing studies predominantly adopt classical network architectures, with few investigations focusing on fine-grained feature extraction models optimized for product form imagery. Additionally, most of these approaches exclusively leverage visual modality data, with insufficient integration of semantic descriptions, making it difficult to bridge the gap between product form features and semantic imagery representations. To narrow this gap, emerging multimodal learning techniques have been introduced into design research. This approach simultaneously exploits image and textual modalities to achieve joint encoding and alignment of visual–semantic information [
28]. For instance, Mansimov et al. [
29] took an early step toward explicit text–image alignment by introducing a recurrent “attention–write” mechanism that links individual words with local pixel regions. Building on this idea of fine-grained correspondence, Wang et al. [
30] extended the paradigm to the automotive domain: they fused multi-view car-exterior photographs with user affective words, proving that cross-modal alignment can directly support design optimization. Recognizing that single-stage fusion limits interaction depth, Lao et al. [
31] proposed a multi-stage hybrid-embedding network for VQA; their design passes intermediate representations back and forth across modalities, thereby deepening semantic exchange and improving answer accuracy. Verma et al. [
32] pushed the concept further by adding demand adaptivity: their framework conditions multimodal generation on user intent, enabling not only alignment but also style-controlled synthesis of product imagery and text. Tao et al. [
33] then demonstrated that introducing contrastive objectives with momentum encoding sharpens cross-modal retrieval and generation consistency, effectively regularizing the shared latent space learned by earlier fusion models. Most recently, Yuan et al. [
34] closed the loop from perception to creation by coupling multimodal fusion with a deep generative evaluator, which maps automatically produced product concepts back to user requirements, realizing an end-to-end “generate-and-judge” workflow. Despite the progress made in the studies mentioned earlier, current multimodal approaches still face challenges in two critical areas for product-form imagery research: fine-grained feature extraction and accurate cross-modal mapping between visual form and affective semantics. The recent emergence of contrastive learning (CL) [
35] presents a promising opportunity to address these challenges. By explicitly imposing distance constraints on positive and negative samples, CL enhances both feature discriminability and semantic consistency in the shared latent space, thereby improving the alignment between different modalities. Although CL is still in its early stages in product design applications, significant advances have been made in other fields. For instance, Yang et al. [
36] introduced a cross-modal CL framework that effectively handles the heterogeneity between modalities, greatly improving the performance of emotion recognition models. Building on this, Yu and Shi [
37] proposed a deep attention mechanism combined with a two-stage fusion process, which significantly strengthens the interaction between image and text. In document classification, Bakkali et al. [
38] introduced the VLCDoC model, which applies cross-modal CL to optimize the fusion of visual and linguistic information. Additionally, An et al. [
39] extended the contrastive learning framework with enhanced alignment, improving image–text coherence in general multimodal tasks. These studies highlight how contrastive learning can address the limitations of traditional fusion methods, offering more robust and coherent multimodal representations. In the context of product-form imagery, a CL-based multi-encoder architecture can project visual shape vectors and textual affective embeddings into a unified latent space, allowing for consistent high-dimensional similarity measurements. Through iterative training, the model adapts to capture subtle design variations and latent emotional cues, significantly enhancing the robustness and generalization of imagery-label prediction. This approach holds substantial potential to improve the quantification and precise recognition of product-form imagery, overcoming the limitations of existing methods.
Based on the above discussion, traditional methods exhibit strong interpretability and leverage accumulated human expertise, yet they struggle to handle increasingly complex affective imagery at scale and with high efficiency. While deep learning has significantly enhanced visual recognition performance, it remains constrained by single-modal morphological representation. Meanwhile, multimodal approaches have demonstrated substantial potential for cross-modal fusion, yet their application in product form imagery recognition remains in an exploratory phase. These observations highlight a significant research gap and application value in leveraging contrastive learning for vision-language alignment and integrating deep models for imagery classification. To address this gap, this study proposes a product form imagery recognition method incorporating cross-modal information fusion and contrastive learning strategies. The aim is to overcome the limitations of single-modal analysis and enhance the model’s ability to comprehend the relationship between product form visual features and affective semantics. Specifically, this research focuses on the cross-modal recognition of product form imagery, using the front-end design of new energy vehicles (NEVs) as a case study, and establishes a comprehensive research pipeline encompassing textual semantic analysis, visual feature extraction, and multimodal fusion-based classification. At the data level, large-scale NEV front-end images and corresponding user-generated online reviews are collected from the “Autohome” platform using Python-based web scraping techniques, providing a rich foundation of visual and semantic information for model training. Next, the Biterm Topic Model (BTM) [
40] is employed to perform topic mining on the collected review texts, identifying potential imagery themes and extracting high-frequency, discriminative descriptors under each theme. To refine this initial set of imagery descriptors, an expert focus group evaluation is conducted using the Analytic Hierarchy Process (AHP) [
41] to assess the importance of candidate features. Through quantitative weighting and selection, the most representative imagery keywords under each theme are determined, providing clear textual semantic labels for subsequent modeling. Simultaneously, at the visual level, a pre-trained ResNet-50 deep convolutional neural network is used to extract high-level visual feature representations of NEV front-end images. In parallel, a pre-trained Transformer [
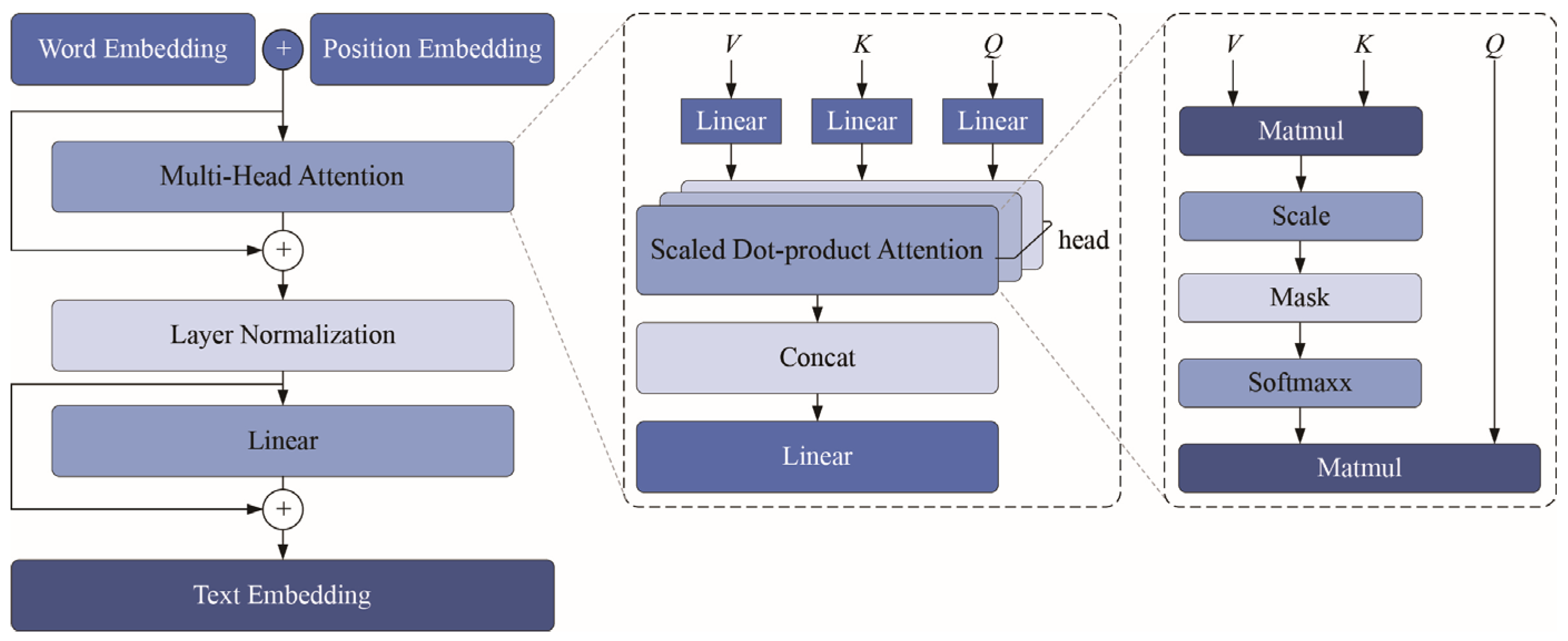
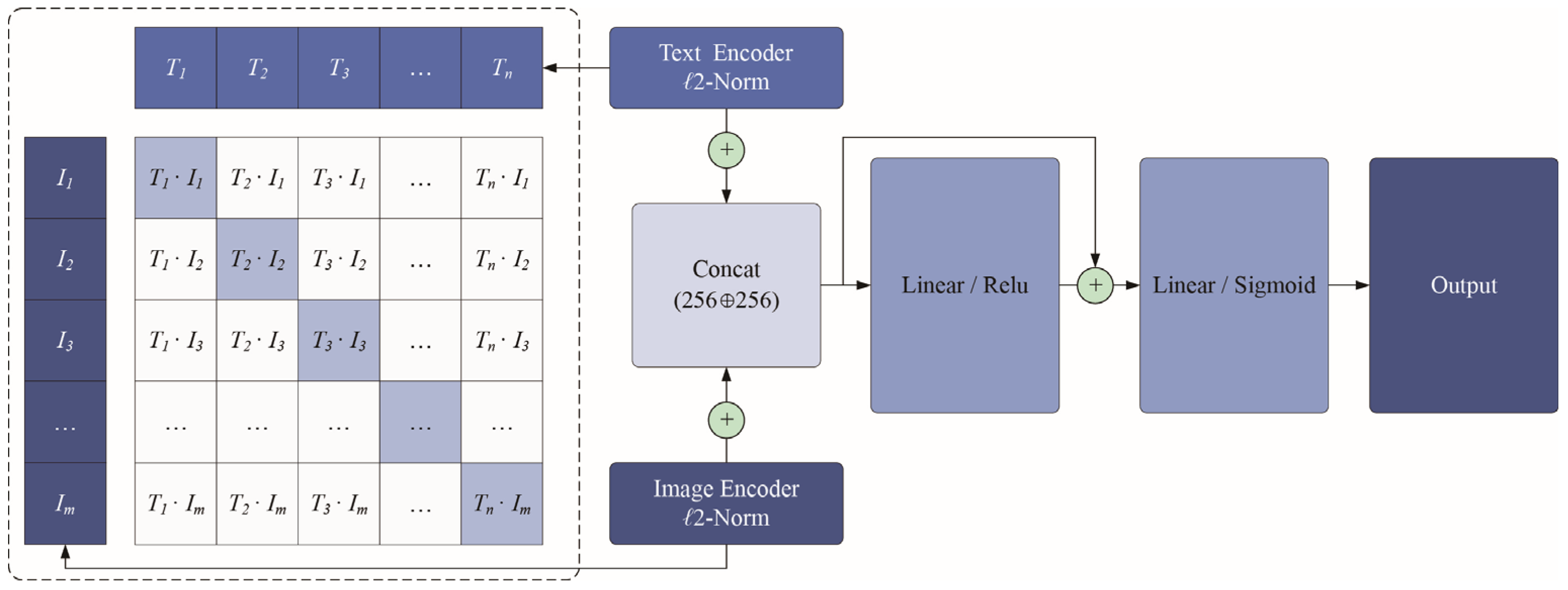
42] encoder is employed to vectorize the textual semantic labels, generating corresponding text feature representations. A Transformer and ResNet with Contrastive Learning (TRCL) model is then developed to facilitate cross-modal information fusion. This model aligns and integrates image and text features within a shared feature representation space. During model training, a contrastive learning loss function is introduced to optimize the text-image feature representations. Specifically, the model minimizes the cosine distance and increases the similarity between matched (positive) image–text pairs while simultaneously maximizing the cosine distance between mismatched (negative) pairs. Through this mechanism, the model effectively pulls together relevant image–text pairs while pushing apart irrelevant ones, thereby capturing the intrinsic correspondence between textual and visual information. After completing multimodal feature alignment and fusion, the TRCL model integrates a classifier composed of multi-layer fully connected (dense) neural networks to perform classification predictions on the fused features. By leveraging this classifier, the model can automatically categorize NEV front-end designs into predefined imagery style categories, providing a systematic and intelligent approach to product form imagery recognition.
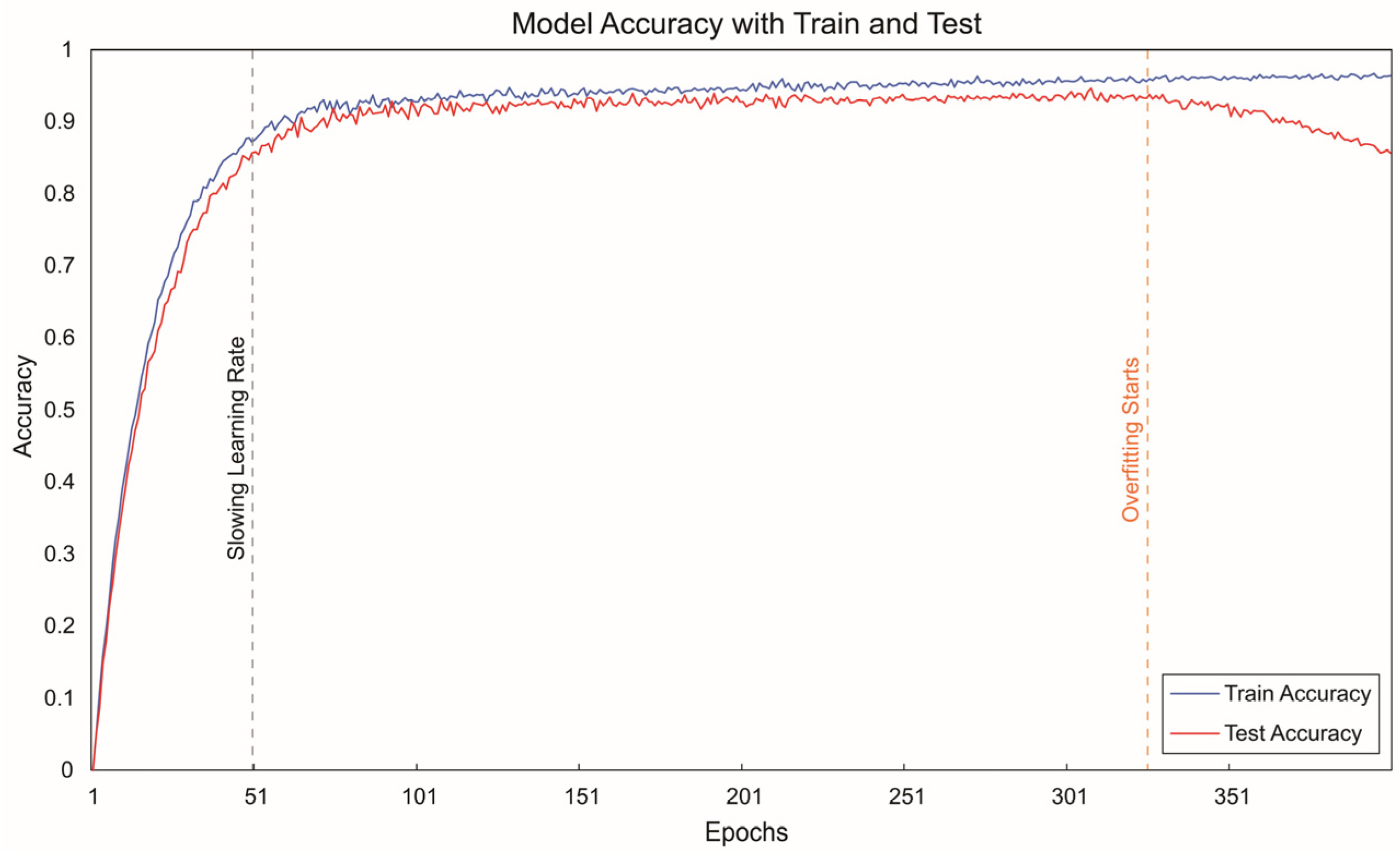
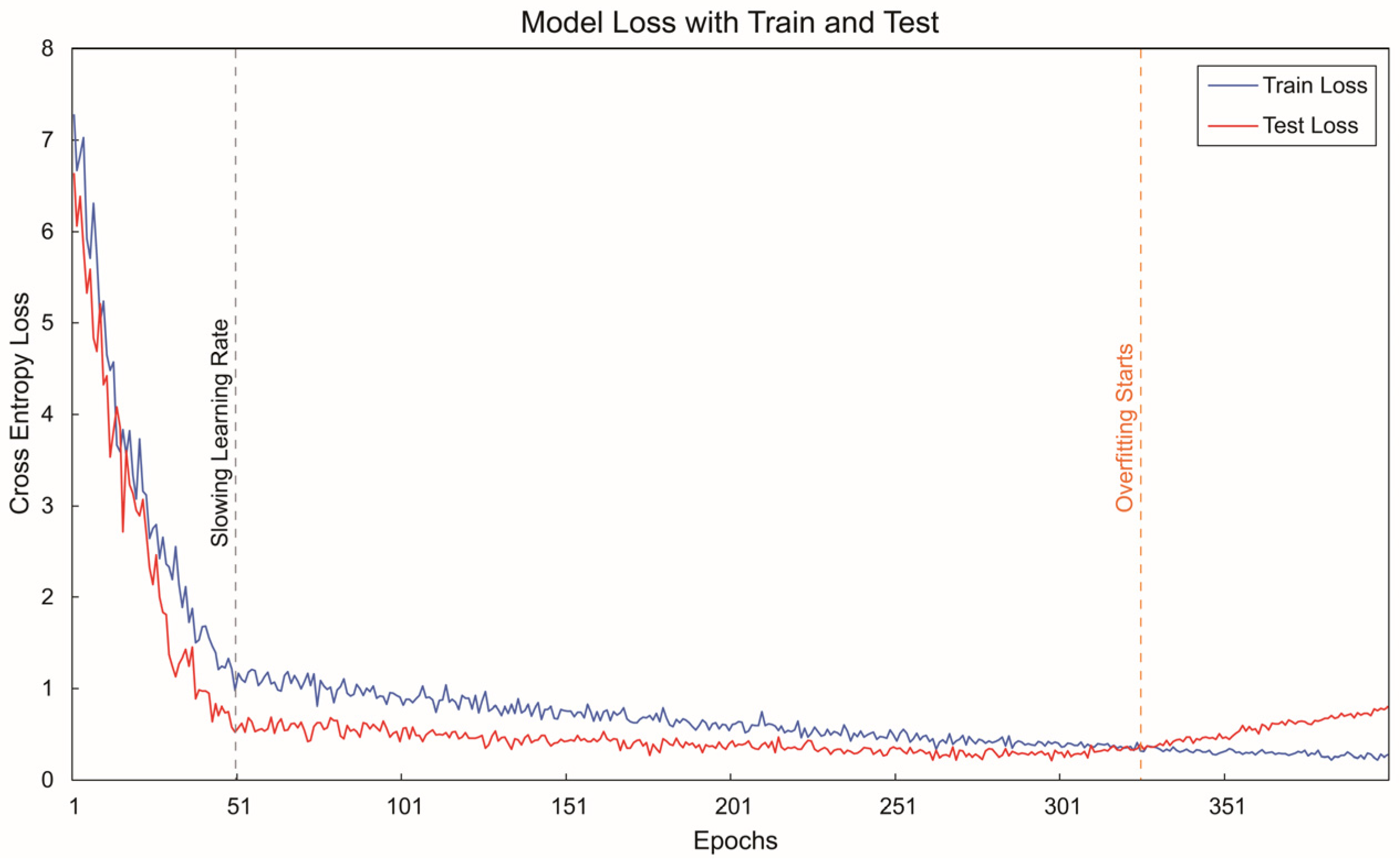
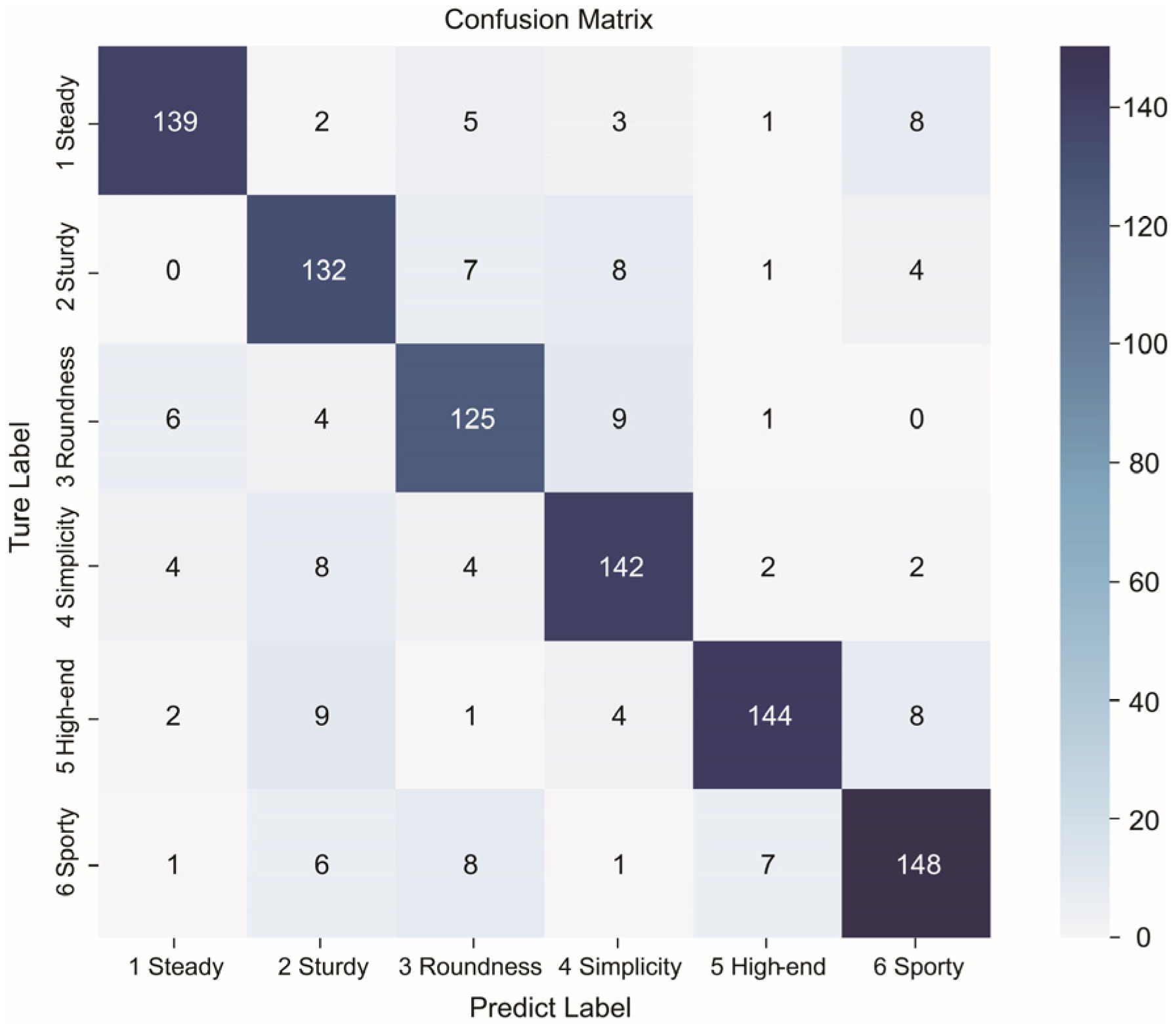
In summary, the various stages of this research framework are systematically interconnected, forming a logically rigorous cross-modal analysis pipeline that progresses from semantic theme extraction and expert evaluation-based filtering to deep feature extraction, contrastive learning-based fusion, and final classification decisions. This approach not only enhances the classification accuracy of product form imagery recognition but also provides an efficient assistive tool for design practice. Consequently, designers can leverage the proposed model to rapidly identify and evaluate the imagery style attributes of NEV front-end designs, thereby improving the efficiency of design analysis and decision-making.











{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}











