
Real Estate Industry Sustainable Solution (Environmental, Social, and Governance) Significance Assessment—AI-Powered Algorithm Implementation



Abstract
1. Introduction
- the individual nature of the transactions;
- the heterogeneity of the market;
- the volatility of prices and costs;
- the demand and supply of the commodity.
2. The Problem of Real Estate Feature Significance Assessment
- significant differences in the amount of information available are determined with the type of market analyzed;
- ambiguous and unclear assumptions and principles of the relevant methods in the analysis of the relevance of real estate features (e.g., differences in the scale of the description of real estate features, description of real estate features fully dependent on the expert performing the analysis);
- lack of comprehensive (complete) information;
- imprecise nature of real estate data;
- lack of homogeneous functional relationships between real estate features;
- non-linear nature of real estate data.
- results of the analysis of data on prices and market characteristics of similar properties traded on the real estate market specified for valuation purposes;
- analogy to local markets similar in terms of type and area;
- research and/or observation of the preferences of potential real estate buyers.
- filter methods—the final set of features is selected based on the method adopted, for example, by assessing the size of the correlation coefficient of the analyzed feature with the explanatory variable. These methods are based on data features and do not use machine learning algorithms;
- embedded methods—use algorithms that have built-in iterative feature selection methods; the iterative learning process extracts those features that most affect the learning of the model in a given iteration;
- wrapper methods—the selection of variables is treated as a selection search and is based on fitting a specific algorithm to a given set of data while looking for an optimal set of features;
- hybrid methods—these methods combine elements of the aforementioned methods.
3. AI-Driven Algorithms in Real Estate Industry Solution Analysis
- resistance to a variety of data problems (e.g., missing data, explanatory variables without significance, a large number of explanatory variables or outliers);
- the ability to reproduce complex relationships more accurately than decision trees, even though the predictive power of a random forest is usually somewhat lower, but still comparable to neural networks;
- resistance to overfitting;
- stability;
- possibility of interaction between variables;
- the ability to determine various misclassification costs.
4. Materials and Methods
4.1. Data Acquisition and Preprocessing
- the annual usable energy demand index (EU) (the EU index provides information on the amount of energy required to supply each square meter of a house. It is the most important parameter in calculating the energy costs of a house already at the stage of project formulation for its construction).
- the annual final energy demand index (EK) (the EK index provides information on the amount of energy required to supply the building to guarantee the right temperature and considering any losses in the generation and transmission of heat inside the entire building. The amount of this indicator is mainly affected by the efficiency of the heat source).
- the index of annual demand for non-renewable primary energy (EP) (the EP index is an indicator that is important for a formal reason, since it considers the entity’s need to adapt to changes in construction law. European and Polish law constantly emphasize the need to reduce energy from non-renewable sources at the expense of promoting energy from renewable sources).
- the share of renewable energy sources in annual final energy demand (UOZE) (the UOZE index constitutes a ratio of renewable energy sources in annual final energy demand) (%).
- the unit volume of emissions (CO2ECO2) (the CO2ECO2 index provides information on the volume of CO2 emission) (t CO2/(1 m2·year)).
4.2. HO-MAR Algorithm Utilization
4.3. RE Method Utilization and ESG Solution Significance Assessment
- Drawing with a replacement from a subset (cases), D’, from the available training sample D (bootstrap aggregating)—the observations that did not enter it are called out-of-bag (OOB) data and are later used to estimate the classification error.
- Creating a tree for the drawn subset:
- checking whether the divided set is homogeneous or too small to divide;
- drawing a number of explanatory variables;
- finding the best division using the drawn subset of variables;
- dividing the set into two parts and repeating the procedure for each part.
- The termination of training, if the number of trees reached the set maximum or the test sampling error stopped decreasing (otherwise, the procedure repeats).
- —random error;
- —the square of the difference between the expected value of the predictions of models (created for different samples) regarding the true value, the so-called bias;
- —variance.
- for each ith tree:
- 1.1.
- determining the number of correct ki classifications on its OOB set;
- 1.2.
- for each attribute:
- random reordering of the values of the attribute under consideration, j;
- the determination of the number of correctly classified samples on the set with a changed order of values in the jth attribute;
- restore the original order of values in the kth attribute.
- For each attribute j, determine the average difference between the number of correct classifications on the original set and on the set that rearranged the order of values in the attribute, averaging the result after all T trees (Equation (4)):
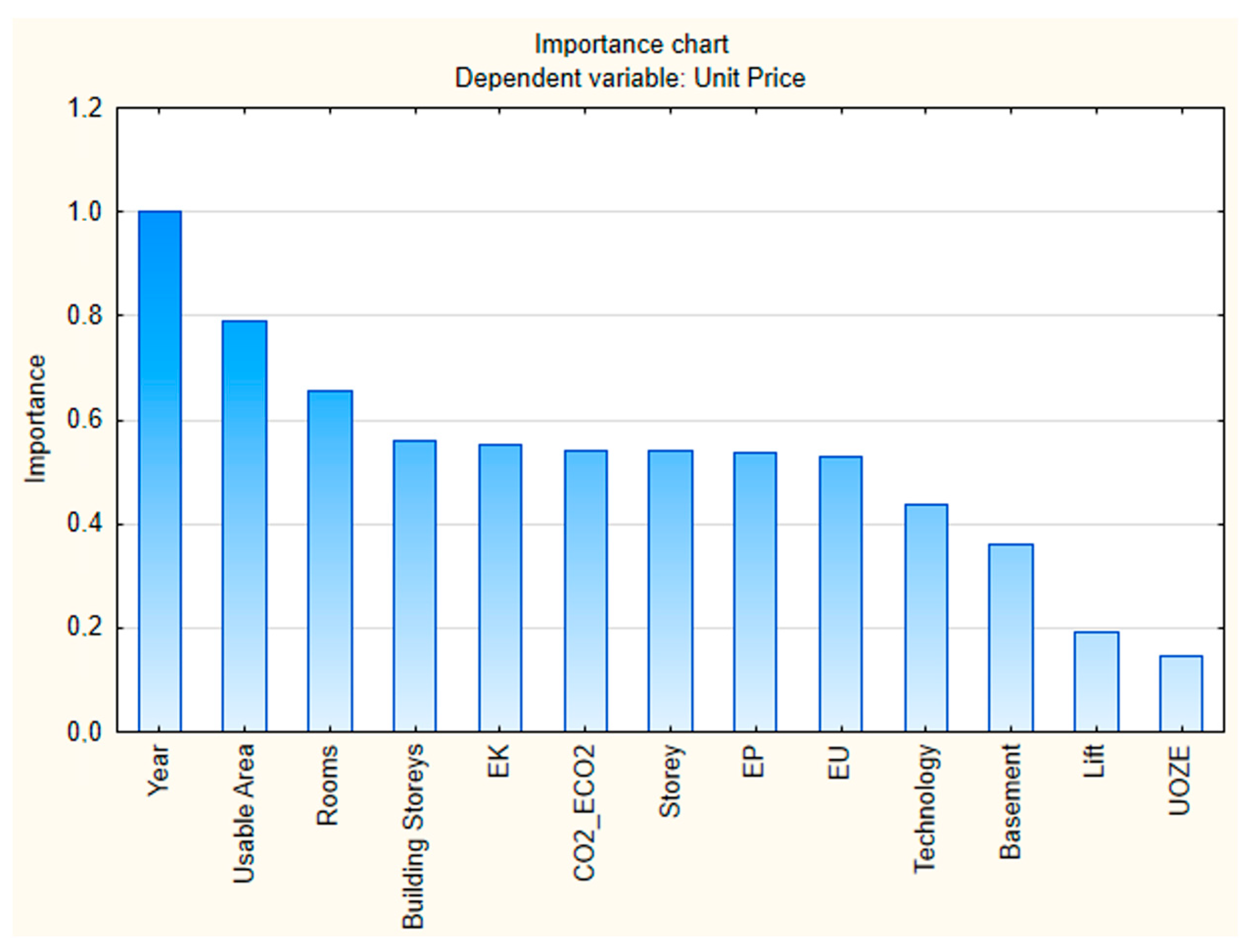
5. Results
6. Verification of the Results
- predictive accuracy: the identified optimal parameters of the random forest model enabled us to reach the prediction quality measured using the average distance between predicted and observed property values, at a level of 752.70 PLN compared to the multiple regression analysis—752.90 PLN;
- variable importance: the random forest method provided valuable insights into the importance of all the individual features in the assumed set, allowing for a more nuanced understanding of factors influencing property values in contrast to multiple regression that limited the range of included features (that results from the basic assumptions of the method utilization). The random forest can deal more effectively with a large number of features, considering their impact on prediction;
- handling non-linearity: random forests are well suited for capturing complex, non-linear relationships between variables, providing a more flexible modeling approach compared to linear regression;
- robustness: the normal distribution of residuals in the random forest model indicates the robustness of the predictions, enhancing confidence in the model’s reliability. The random forest is relatively robust to the presence of independent variables (i.e., variables irrelevant to the prediction) because it focuses on the most informative variables when building decision trees;
- interpretability: while the random forest model offers satisfactory predictive accuracy, it may lack interpretability compared to traditional linear regression, making it challenging to explain the rationale behind specific predictions;
7. Discussion and Conclusions
- expanding the set of ESG criteria used in the analysis, such as with water efficiency, waste management practices, or social impact metrics (adjusting the ESG criteria could enhance the model’s ability to capture the multifaceted nature of sustainability in real estate);
- exploring the integration of dynamic and real-time ESG data (sustainability factors can evolve over time and incorporating up-to-date information into the model may improve its predictive accuracy);
- investigating the long-term impact of ESG features on real estate values (assessing how sustainable practices influence property values over extended periods could provide insights into the resilience and lasting value of ESG investments).
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- The World Bank. Global Program on Sustainability Annual Report FY22. 2022. Available online: https://thedocs.worldbank.org/en/doc/d3294f3f7a7aefa874c4cd794d098711-0320052023/original/global-program-on-sustainability-FY22-annual-report.pdf (accessed on 27 December 2023).
- FIG. Geospatial Data in the 2020s: Transformative Power and Pathways to Sustainability; FIG Publication: Copenhagen, Denmark, 2022. [Google Scholar]
- OECD. Better Policies for 2030 an OECD Action Plan on the Sustainable Development Goals; OECD Publishing: Paris, France, 2016. [Google Scholar]
- FAO. FAO’s Blue Growth Initiative: Blue finance Guidance Notes. Blue Bonds; FAO: Rome, Italy, 2020. [Google Scholar]
- The 5 Main Challenges of ESG Reporting|Blog. Available online: https://bedfordconsulting.com/the-5-main-challenges-of-esg-reporting-and-best-practice/ (accessed on 6 January 2024).
- Mazur, Ł.; Resler, M.; Koda, E.; Walasek, D.; Daria Vaverková, M. Energy saving and Green building Certification: Case study of commercial buildings in Warsaw, Poland. Sustain. Energy Technol. Assess. 2023, 60, 103520. [Google Scholar] [CrossRef]
- Moghayedi, A.; Awuzie, B. Towards a net-zero carbon economy: A sustainability performance assessment of innovative prefabricated construction methods for affordable housing in Southern Africa. Sustain. Cities Soc. 2023, 99, 104907. [Google Scholar] [CrossRef]
- Basse, T.; Desmyter, S.; Saft, D.; Wegener, C. Leading indicators for the US housing market: New empirical evidence and thoughts about implications for risk managers and ESG investors. Int. Rev. Financ. Anal. 2023, 89, 102765. [Google Scholar] [CrossRef]
- Lorenz, D.; Dent, P.; Kauko, T. Value in a Changing Built Environment; John Wiley & Sons, Ltd.: New York, NY, USA, 2017; pp. 1–234. [Google Scholar] [CrossRef]
- Lorenz, D.; Lützkendorf, T.; d’Amato, M.; Des Rosiers, F.; Elder, B.; van Genne, F.; Hartenberger, U.; Hill, S.; Jones, K.; Kauko, T.; et al. Sustainable Property Investment & Management—Key Issues & Major Challenges; RICS (Royal Institution of Chartered Surveyors): London, UK, 2008. [Google Scholar]
- Lorenz, D.P.; Lützkendorf, T.; Trück, S. Exploring the relationship between the sustainability of construction and market value: Theoretical basics and initial empirical results from the residential property sector. Prop. Manag. 2007, 25, 119–149. [Google Scholar] [CrossRef]
- Walacik, M.; Renigier-Biłozor, M.; Chmielewska, A.; Janowski, A. Property sustainable value versus highest and best use analyzes. Sustain. Dev. 2020, 28, 1755–1772. [Google Scholar] [CrossRef]
- Chmielewska, A.; Renigier-Biłozor, M.; Janowski, A. Representative Residential Property Model—Soft Computing Solution. Int. J. Environ. Res. Public Health 2022, 19, 15114. [Google Scholar] [CrossRef]
- Kauškale, L.; Geipele, I. Integrated Approach of Real Estate Market Analysis in Sustainable Development Context for Decision Making. Procedia Eng. 2017, 172, 505–512. [Google Scholar] [CrossRef]
- Kobylińska, K.; Cellmer, R. Modelling and Simulation of Selected Real Estate Market Spatial Phenomena. ISPRS Int. J. Geo-Inf. 2019, 8, 446. [Google Scholar] [CrossRef]
- Zhou, W.X.; Sornette, D. Analysis of the real estate market in Las Vegas: Bubble, seasonal patterns, and prediction of the CSW indices. Phys. A Stat. Mech. Its Appl. 2008, 387, 243–260. [Google Scholar] [CrossRef][Green Version]
- Wisniewski, R.; Brzezicka, J. Translocality on the real estate market: A new extended approach. Land Use Policy 2020, 97, 104731. [Google Scholar] [CrossRef]
- McCluskey, W.J.; McCord, M.; Davis, P.T.; Haran, M.; McIlhatton, D. Prediction accuracy in mass appraisal: A comparison of modern approaches. J. Prop. Res. 2013, 30, 239–265. [Google Scholar] [CrossRef]
- Abidoye, R.B.; Chan, A.P.C. Critical determinants of residential property value: Professionals’ perspective. J. Facil. Manag. 2016, 14, 283–300. [Google Scholar] [CrossRef]
- Foryś, I.; Kokot, S. Preferencje potencjalnych nabywców w określaniu wag cech rynkowych nieruchomości. Stud. Mater. Tow. Nauk. Nieruchom. 2008, 16, 45–61. [Google Scholar]
- Tan, T. Locational, neighborhood, structural and socio-cultural attributes of housing in homeownership decisions. In Proceedings of the International Real Estate Symposium (IRERS) 2012: Globalization of Real Estate: Transforming and Opportunities (6th), Putrajaya, Malaysia, 24–25 April 2012. [Google Scholar]
- García, J.L.; Alvarado, A.; Blanco, J.; Jiménez, E.; Maldonado, A.A.; Cortés, G. Multi-attribute evaluation and selection of sites for agricultural product warehouses based on an Analytic Hierarchy Process. Comput. Electron. Agric. 2014, 100, 60–69. [Google Scholar] [CrossRef]
- Ghumare, P.N.; Chauhan, K.A.; Yadav, S.K.M. Housing attributes affecting buyers in India: Analysis of perceptions in the context of EWS/LIG consumers view. Int. J. Hous. Mark. Anal. 2020, 13, 533–552. [Google Scholar] [CrossRef]
- Głuszak, M.; Małkowska, A. Preferencje mieszkaniowe młodych najemców lokali mieszkalnych w Krakowie. Świat Nieruchom. 2017, 100/6, 39–44. [Google Scholar] [CrossRef]
- Hurtubia, R.; Gallay, O.; Bierlaire, M. Attributes of Households, Locations and Real-Estate Markets for Land Use Modeling. 2010. Available online: https://transp-or.epfl.ch/documents/technicalReports/sustaincity_WP2_7.pdf (accessed on 27 December 2023).
- Kokot, S.; Bas, M. Postrzeganie cech rynkowych przez rzeczoznawców majątkowych, pośredników w obrocie i nabywców nieruchomości—Wyniki badań ankietowych. Stud. Pr. WNEiZ US 2016, 1, 355–369. [Google Scholar] [CrossRef]
- Nilsson, P. Prediction of residential real estate selling prices using neural networks. Comput. Inf. Sci. 2019, 70, 37. [Google Scholar]
- Sarif, S.M.; Mohamed, S.F.P.; Khalid, M.S. Assessing Decision Factors for House Purchasing (Needs vs. Preferences) from Case Study of First-Time Potential Homebuyers in Klang Valley: Towards Technology-Mediated Individual Decision Aid. In Proceedings of the Knowledge Management International Conference, Turin, Italy, 22–26 October 2018. [Google Scholar]
- Sean, S.L.; Hong, T.T. Factors Affecting the Purchase Decision of Investors in the Residential Property Market in Malaysia. J. Surv. Constr. Prop. 2014, 5, 1–13. [Google Scholar] [CrossRef]
- Izquierdo-Verdiguier, E.; Zurita-Milla, R. An evaluation of Guided Regularized Random Forest for classification and regression tasks in remote sensing. Int. J. Appl. Earth Obs. Geoinf. 2020, 88, 102051. [Google Scholar] [CrossRef]
- Zurada, J.M.; Levitan, A.S.; Guan, J. Non-conventional approaches to property value assessment. J. Appl. Bus. Res. 2006, 22, 1–14. [Google Scholar] [CrossRef]
- Adomatis, S.K.; Molitor-Gennrich, D. Understanding Desktop (Bifurcated or Hybrid) Appraisals. Appraisal J. 2022, 90, 99. [Google Scholar]
- Starr, C.W.; Saginor, J.; Worzala, E. The rise of PropTech: Emerging industrial technologies and their impact on real estate. J. Prop. Invest. Financ. 2021, 39, 157–169. [Google Scholar] [CrossRef]
- Duan, Y.; Edwards, J.S.; Dwivedi, Y.K. Artificial intelligence for decision making in the era of Big Data—Evolution, challenges and research agenda. Int. J. Inf. Manag. 2019, 48, 63–71. [Google Scholar] [CrossRef]
- Shrestha, Y.R.; Ben-Menahem, S.M.; von Krogh, G. Organizational Decision-Making Structures in the Age of Artificial Intelligence. Calif. Manag. Rev. 2019, 61. [Google Scholar] [CrossRef]
- Ntoutsi, E.; Fafalios, P.; Gadiraju, U.; Iosifidis, V.; Nejdl, W.; Vidal, M.E.; Ruggieri, S.; Turini, F.; Papadopoulos, S.; Krasanakis, E.; et al. Bias in data-driven artificial intelligence systems—An introductory survey. Wiley Interdiscip. Rev. Data Min. Knowl. Discov. 2020, 10, e1356. [Google Scholar] [CrossRef]
- Renigier-Biłozor, M.; Źróbek, S.; Walacik, M.; Borst, R.; Grover, R.; d’Amato, M. International acceptance of automated modern tools use must-have for sustainable real estate market development. Land Use Policy 2022, 113, 105876. [Google Scholar] [CrossRef]
- Walacik, M.; Cellmer, R.; Źróbek, S. Mass Appraisal—International Background, Polish Solutions and Proposal of new Methods Application. Geod. List 2013, 67, 255–269. [Google Scholar]
- Mete, M.O.; Yomralioglu, T. A Hybrid Approach for Mass Valuation of Residential Properties through Geographic Information Systems and Machine Learning Integration. Geogr. Anal. 2023, 55, 535–559. [Google Scholar] [CrossRef]
- Abioye, S.O.; Oyedele, L.O.; Akanbi, L.; Ajayi, A.; Davila Delgado, J.M.; Bilal, M.; Akinade, O.O.; Ahmed, A. Artificial intelligence in the construction industry: A review of present status, opportunities and future challenges. J. Build. Eng. 2021, 44, 103299. [Google Scholar] [CrossRef]
- Latifi, S.; Zhang, Y.; Cheng, L.C. Blockchain-Based Real Estate Market: One Method for Applying Blockchain Technology in Commercial Real Estate Market. In Proceedings of the IEEE International Conference on Blockchain (Blockchain), Atlanta, GA, USA, 14–17 July 2019; pp. 528–535. [Google Scholar] [CrossRef]
- Al-Refaie, A.; Al-Hawadi, A.; Lepkova, N.; Abbasi, G. Blockchain of optimal multiple construction projects planning under probabilistic arrival and stochastic durations. J. Civ. Eng. Manag. 2023, 29, 15–34. [Google Scholar] [CrossRef]
- Golestanizadeh, M.; Sarvari, H.; Chan, D.W.M.; Banaitienė, N.; Banaitis, A. Managerial opportunities in application of business intelligence in construction companies. J. Civ. Eng. Manag. 2023, 29, 487–500. [Google Scholar] [CrossRef]
- Pham, B.T.; Luu, C.; Phong, T.V.; Nguyen, H.D.; Le, H.V.; Tran, T.Q.; Ta, H.T.; Prakash, I. Flood risk assessment using hybrid artificial intelligence models integrated with multi-criteria decision analysis in Quang Nam Province, Vietnam. J. Hydrol. 2021, 592, 125815. [Google Scholar] [CrossRef]
- Ziolkowski, P.; Niedostatkiewicz, M.; Kang, S.-B. Model-Based Adaptive Machine Learning Approach in Concrete Mix Design. Materials 2021, 14, 1661. [Google Scholar] [CrossRef] [PubMed]
- Bao, Y.; Hilary, G.; Ke, B. Artificial Intelligence and Fraud Detection. SSRN Electron. J. 2020. [Google Scholar] [CrossRef]
- Mcgrath, P.; Desai, K.; Junquera, P. Resistance is futile: How corporate real estate companies can deploy artificial intelligence as a competitive advantage. Corp. Real Estate J. 2019, 9, 121–129. [Google Scholar]
- Danilevsky, M.; Qian, K.; Aharonov, R.; Katsis, Y.; Kawas, B.; Sen, P. A Survey of the State of Explainable AI for Natural Language Processing. Comput. Lang. 2020. [Google Scholar] [CrossRef]
- Radzewicz, A.; Wiśniewski, R. Niepewność rynku nieruchomości. Stud. Mater. Tow. Nauk. Nieruchom. 2011, 19, 47–57. [Google Scholar]
- Chmielewska, A.; Adamiczka, J.; Romanowski, M. Genetic Algorithm as Automated Valuation Model Component in Real Estate Investment Decisions System. Real Estate Manag. Valuat. 2020, 28, 1–14. [Google Scholar] [CrossRef]
- Polkowski, L. Reductive Reasoning Rough and Fuzzy Sets as Frameworks for Reductive Reasoning. Intell. Syst. Ref. Libr. 2011, 20, 145–190. [Google Scholar] [CrossRef]
- Zhang, Z. A rough set approach to intuitionistic fuzzy soft set based decision making. Appl. Math. Model. 2012, 36, 4605–4633. [Google Scholar] [CrossRef]
- Stokey, N.L. Wait-and-see: Investment options under policy uncertainty. Rev. Econ. Dyn. 2016, 21, 246–265. [Google Scholar] [CrossRef]
- Del Giudice, V.; De Paola, P. Spatial analysis of residential real estate rental market with geoadditive models. In Advances in Automated Valuation Modeling; Springer: Cham, Switzerland, 2017; Volume 86, pp. 155–162. [Google Scholar]
- Zavadskas, E.K.; Kaklauskas, A.; Turskis, Z.; Tamošaitiene, J. Selection of the effective dwelling house walls by applying attributes values determined at intervals. J. Civ. Eng. Manag. 2010, 14, 85–93. [Google Scholar] [CrossRef]
- Kaklauskas, A.; Zavadskas, E.K.; Bardauskienė, D.; Dargis, R. Sustainable Development of Real Estate. Sustain. Dev. Real Estate 2015. [Google Scholar] [CrossRef]
- Zavadskas, E.K.; Turskis, Z. Multiple criteria decision making (MCDM) methods in economics: An overview. Technol. Econ. Dev. Econ. 2011, 17, 397–427. [Google Scholar] [CrossRef]
- D’Amato, M.; Kauko, T. (Eds.) Advances in Automated Valuation Modeling; Studies in Systems, Decision and Control; Springer: Cham, Switzerland, 2017; Volume 86, ISBN 978-3-319-49744-0. [Google Scholar]
- Yakubovsky, V.; Bychkov, O.; Scherba, A. Combined Neural Approach to Deterministic and Probabilistic Assets Cost Valuation. In Proceedings of the 2018 Baltic Geodetic Congress (BGC Geomatics), Olsztyn, Poland, 21–23 June 2018; pp. 132–137. [Google Scholar] [CrossRef]
- Fletcher, R. Practical Methods of Optimization; Wiley: New York, NY, USA, 2000. [Google Scholar]
- Helbich, M.; Brunauer, W.; Hagenauer, J.; Leitner, M. Data-Driven Regionalization of Housing Markets. Ann. Assoc. Am. Geogr. 2013, 103, 871–889. [Google Scholar] [CrossRef]
- Renigier-Biłozor, M.; Janowski, A.; Walacik, M.; Chmielewska, A. Human emotion recognition in the significance assessment of property attributes. J. Hous. Built Environ. 2022, 37, 23–56. [Google Scholar] [CrossRef]
- Giudice, V.D.; De Paola, P.; Forte, F. Using genetic algorithms for real estate appraisals. Buildings 2017, 7, 31. [Google Scholar] [CrossRef]
- Cheng, X.; Sun, Z.; Bao, W. Study on credit risk of real estate industry based on genetic algorithm KMV model. J. Phys. Conf. Ser. 2020, 1629, 012072. [Google Scholar] [CrossRef]
- Dubinskas, P.; Dubinskas, P.; Urbšienė, L. Investment Portfolio Optimization by Applying a Genetic Algorithm-based Approach. Ekonomika 2017, 96, 66–78. [Google Scholar] [CrossRef]
- Lin, C.S.; Lee, I.L.; Wu, M.C. Merits of using chromosome representations and shadow chromosomes in genetic algorithms for solving scheduling problems. Robot. Comput. Integr. Manuf. 2019, 58, 196–207. [Google Scholar] [CrossRef]
- Pereira, R. Genetic Algorithm Optimisation for Finance and Investments; MPRA Paper 8610; University Library of Munich, Germany: Munich, Germany, 2000. [Google Scholar]
- Ao, Y.; Li, H.; Zhu, L.; Ali, S.; Yang, Z. The linear random forest algorithm and its advantages in machine learning assisted logging regression modeling. J. Pet. Sci. Eng. 2019, 174, 776–789. [Google Scholar] [CrossRef]
- Sun, Z.; Wang, G.; Li, P.; Wang, H.; Zhang, M.; Liang, X. An improved random forest based on the classification accuracy and correlation measurement of decision trees. Expert Syst. Appl. 2024, 237, 121549. [Google Scholar] [CrossRef]
- Jiang, M.; Wang, J.; Hu, L.; He, Z. Random forest clustering for discrete sequences. Pattern Recognit. Lett. 2023, 174, 145–151. [Google Scholar] [CrossRef]
- Cai, C.; Yang, C.; Lu, S.; Gao, G.; Na, J.; Cai, C.; Yang, C.; Lu, S.; Gao, G.; Na, J. Human motion pattern recognition based on the fused random forest algorithm. Measurement 2023, 222, 113540. [Google Scholar] [CrossRef]
- Darst, B.F.; Malecki, K.C.; Engelman, C.D. Using recursive feature elimination in random forest to account for correlated variables in high dimensional data. BMC Genet. 2018, 19, 65. [Google Scholar] [CrossRef]
- Gabrielli, L.; Giuffrida, S.; Trovato, M.R. Gaps and overlaps of urban housing sub-market: Hard clustering and fuzzy clustering approaches. In Appraisal: From Theory to Practice: Results of SIEV 2015; Springer: Berlin/Heidelberg, Germany, 2017; pp. 203–219. [Google Scholar] [CrossRef]
- Warren, C.M.J.; Elliott, P.; Staines, J. The impacts of historic districts on residential property land values in Australia. Int. J. Hous. Mark. Anal. 2017, 10, 66–80. [Google Scholar] [CrossRef]
- Usman, H.; Lizam, M.; Adekunle, M.U. Property price modelling, market segmentation and submarket classifications: A review. Real Estate Manag. Valuat. 2020, 28, 24–35. [Google Scholar] [CrossRef]
- Dawidowicz, A.; Nowak, M.; Gross, M. Land administration system and geoportal service for the need of a fit-for-purpose national urban greenery management system (UGMS). The concept for the EU member state of Poland. Acta Sci. Pol. Adm. Locorum 2022, 21, 53–81. [Google Scholar] [CrossRef]
- Renigier-Biłozor, M.; Janowski, A.; Walacik, M.; Chmielewska, A. Modern challenges of property market analysis-homogeneous areas determination. Land Use Policy 2022, 119, 106209. [Google Scholar] [CrossRef]
- Breiman, L. Random forests. Mach. Learn. 2001, 45, 5–32. [Google Scholar] [CrossRef]
- Ho, T.K. Random decision forests. In Proceedings of the 3rd International Conference on Document Analysis and Recognition, Montreal, QC, Canada, 14–16 August 1995; Volume 1, pp. 278–282. [Google Scholar] [CrossRef]
- Ho, T.K. The random subspace method for constructing decision forests. IEEE Trans. Pattern Anal. Mach. Intell. 1998, 20, 832–844. [Google Scholar] [CrossRef]
- Hastie, T.; Tibshirani, R.; Friedman, J.H.; Friedman, J.H. The Elements of Statistical Learning Data Mining, Inference, and Prediction; Springer: New York, NY, USA, 2009. [Google Scholar]
- Dembski, T. Od Pojedynczych Drzew do Losowego Lasu; StatSoft Polska: Kraków, Poland, 2011. [Google Scholar]
- Piotr, P. Zastosowanie Wybranych Metod Przekształcania i Selekcji Danych Oraz Konstrukcji Cech w Zadaniach Klasyfikacji i Klasteryzacji. 2016. Available online: https://repo.pw.edu.pl/info/phd/WUT638dedcf8af24ac694525aac84d795ec/Zastosowanie%2Bwybranych%2Bmetod%2Bprzekszta%25C5%2582cania%2Bi%2Bselekcji%2Bdanych%2Boraz%2Bkonstrukcji%2Bcech%2Bw%2Bzadaniach%2Bklasyfikacji%2Bi%2Bklasteryzacji?r=phd&tab=&lang=pl (accessed on 27 December 2023).










{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| N = 49 | Regression Summary: R2 = 0.5934; Adjusted R2 = 0.4996 F = 6.3241; p = 0.000018; Standard Error of the Estimate: 1148.91 | |||
|---|---|---|---|---|
| b | St. Error | t Stat | p | |
| EK | −10.80 | 5.85 | −1.84 | 0.07 |
| UOZE | 10.47 | 24.01 | 0.44 | 0.67 |
| CO2_ECO2 | 7238.52 | 14,092.14 | 0.51 | 0.61 |
| Story | −130.38 | 130.64 | −0.99 | 0.32 |
| Rooms | −669.64 | 213.77 | −3.13 | 0.00 |
| Basement | −156.45 | 506.61 | −0.31 | 0.76 |
| Year | 60.99 | 28.20 | 2.16 | 0.04 |
| Building Stories | −95.52 | 346.45 | −0.28 | 0.78 |
| Lift | 287.28 | 790.98 | 0.36 | 0.72 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2024 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Walacik, M.; Chmielewska, A. Real Estate Industry Sustainable Solution (Environmental, Social, and Governance) Significance Assessment—AI-Powered Algorithm Implementation. Sustainability 2024, 16, 1079. https://doi.org/10.3390/su16031079
Walacik M, Chmielewska A. Real Estate Industry Sustainable Solution (Environmental, Social, and Governance) Significance Assessment—AI-Powered Algorithm Implementation. Sustainability. 2024; 16(3):1079. https://doi.org/10.3390/su16031079
Chicago/Turabian StyleWalacik, Marek, and Aneta Chmielewska. 2024. "Real Estate Industry Sustainable Solution (Environmental, Social, and Governance) Significance Assessment—AI-Powered Algorithm Implementation" Sustainability 16, no. 3: 1079. https://doi.org/10.3390/su16031079
APA StyleWalacik, M., & Chmielewska, A. (2024). Real Estate Industry Sustainable Solution (Environmental, Social, and Governance) Significance Assessment—AI-Powered Algorithm Implementation. Sustainability, 16(3), 1079. https://doi.org/10.3390/su16031079