1. Introduction
Thanks to vertical indoor farming (VIF) with hydroponics, salads, fruit, vegetables, and spices could grow directly in the city in the future. The pioneers of the technology [
1] hope that
vertical indoor farms, also known as
vertical plant factories, can ensure a greater food supply for the rapidly growing world population and will lead to greater sustainability and better flavour. At present, VIF is still a niche market, but it is recognised as an expanding sector.
To date, most vertical plant factories have focused primarily on the production of leafy vegetables, salads, and micro-vegetables, but also many spices/herbs, as their production cycles and environmental requirements are relatively simple. In contrast, there is only a very limited selection of fruit and fruiting vegetables that can be grown well in a vertically controlled environment. Fruit plants such as tomatoes, peppers, cucumbers, and strawberries, among others, are much more difficult to cultivate than other plants. They need more nutrients, more light, and more care than leafy vegetables or herbs [
2].
Chilli peppers are used in countless dishes in many cultures and are appreciated for their flavour and spiciness. There are around 4000 varieties of chilli worldwide. These are divided into five varieties:
Capsicum annuum (
C. annuum),
Capsicum baccatum,
Capsicum chinense,
Capsicum frutescens, and
Capsicum pubescens. The largest and industrially most important variety is
C. annuum [
3], which is considered in this study. Chillies were harvested as early as 8000 BC and were only native to the American continent until the discovery of America in 1492 [
4]. The pods of chilli plants are a rich source of vitamins and contain antioxidants, which are of therapeutic importance in the treatment of metabolic disorders and obesity [
5]. Species of
C. annuum can grow up to 1.5 m tall and their flowers and fruits usually hang downwards. The growth temperature is 25 degrees Celsius [
6].
Chilli plants belong to the nightshade family and are divided into 10 macro-stages according to the BBCH scale (Biologische Bundesanstalt für Land- und Forstwirtschaft, Bundessortenamt und Chemische Industrie), which shows the sequence of the main growth stages. This detailed description covers plant growth from germination to death [
7]. The scale was updated in 2021 by Feldmann et al. [
8]. Paul et al. [
9] divided the chilli plants into three growth stages to examine them for fungal infestation. Paul et al. [
10] divided the growth cycle of pepper plants into six stages for image recognition: buds, flowers, unripe, ripe, and overripe peppers.
Machine vision systems with convolutional neural networks (CNNs) are used in many areas of modern agriculture, for example, to classify plant varieties, count fruit, detect diseases, localise weeds, automate harvesting, and monitor fields [
11,
12]. Many reviews have reported the MV application status in agriculture. They are mainly involved in field crops, for example, [
13], but only a few of them refer to plant factories, for example, [
12].
Automatic monitoring systems are implemented in indoor farms for the visual inspection of plants. The cameras are mounted in a bird’s-eye view and are positioned above the plants using moving axes [
14]. For example, the cultivation of seedlings is monitored [
15]. These systems are also used to measure the size of plants with stereo cameras and are suitable for vertical cultivation [
16,
17]. Camera motion systems are also used in the field of plant phenotyping, which quantitatively analyses and measures the external appearance (phenotype) of plants [
18,
19].
You Only Look Once (YOLO) models, introduced in [
20], are mainly used in the field of object recognition for fruit detection and achieve very good results in terms of accuracy, processing speed, and the processing of high-resolution images [
21]. Coleman et al. [
22] investigated the recognition of cotton growth stages using various YOLO models. The v8x model performed best for recognising the eight classes considered; a precision of up to 89.7% was achieved. Paul et al. [
10] have successfully developed a YOLOv8 model for recognising the growth stages of pepper plants in greenhouses. Their dataset consists of images mainly from the side view, focused on flowers and fruits. They state that YOLOv8m and YOLOv8n emerged as superior choices for capsicum detection and growth stage determination, achieving mean average precision (mAP) scores of 95.2% and 75.1%, respectively. The recognition of growth stages in hydroponic systems has been successfully implemented on lettuce using images from above only [
23]. The authors achieved 96.0% for recall, precision, and F1 score using a modified YOLOv5 version. Xiao et al. [
24] proposed an improved YOLOv5 algorithm for the recognition of blueberry fruit maturity stages. The algorithm achieved a precision of 96.3%, a recall of 92%, and an mAP of 91.5%.
The challenges that MV systems and algorithms face in VIF are [
12]:
Changing lighting conditions and complex indoor backgrounds make it difficult for MV algorithms to segment feature areas from images. In addition to the plant itself, there are irrigation pipes, suspension cables, mechanical equipment, and other support facilities. The lighting also changes periodically according to the needs of the plants, i.e., growth stages.
There are gaps in the knowledge of the application of MV in specific indoor scenarios, which affect the effectiveness of the technology.
In this paper, the recognition of the growth stages from two configurations: (a) a bird’s-eye view and (b) the combined bird’s-eye and side views are presented and discussed. The effects on the accuracy of extending the datasets with images from the side view as well as the performance of different YOLOv8 model architectures are investigated. In contrast, the state of the art is that camera systems are placed only above the planting bed. The growth stages of the chilli plant are divided into three classes: growing, flowering, and fruiting. This categorisation results from the necessary adjustment of the hydroponic system parameters in relation to light and nutrient solution. Furthermore, we install industrial cameras while most references use digital cameras to obtain images manually, which inevitably causes uneven and non-reproducible image quality.
The remaining sections of the paper are organised as follows:
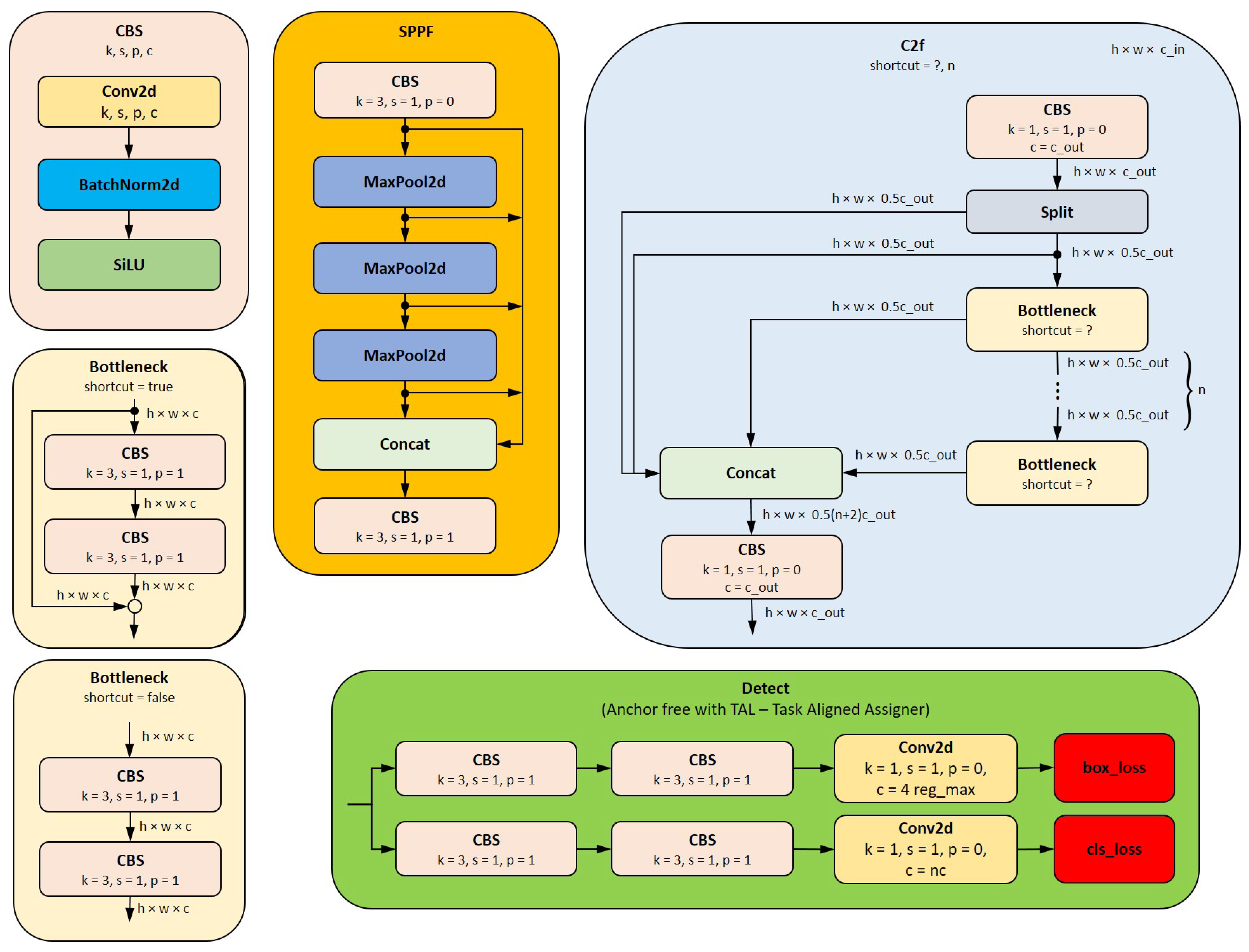
Section 2 describes the experimental setup (hydroponic environment developed for cultivation of chilli plants) and introduces the methods for pre-processing the image datasets, including image acquisition, image data augmentation, the creation of image datasets, and the methods and algorithms (YOLOv8) implemented for the detection of the growth stages of chilli plants.
Section 3 presents the experimental results and a comparative analysis. In
Section 4, the results are discussed.
Section 5 provides the conclusions and directions for subsequent work and improvement.
4. Discussion
4.1. Image Quality
The successful acquisition of data by the camera system over the entire survey period suggests that the chosen image resolution was sufficient to allow reliable identification of features such as buds, flowers, fruit set, and fruit. This is confirmed by the results, as all trained models showed an accuracy of over 98% in identifying the classes.
The influence of image quality on model training, in terms of barrel distortion, yellowing, and widened bounding boxes due to image rotation, cannot be determined from the results presented. Further research is required to gain a full understanding of the impact of these image quality factors.
4.2. Data and Model Discussion
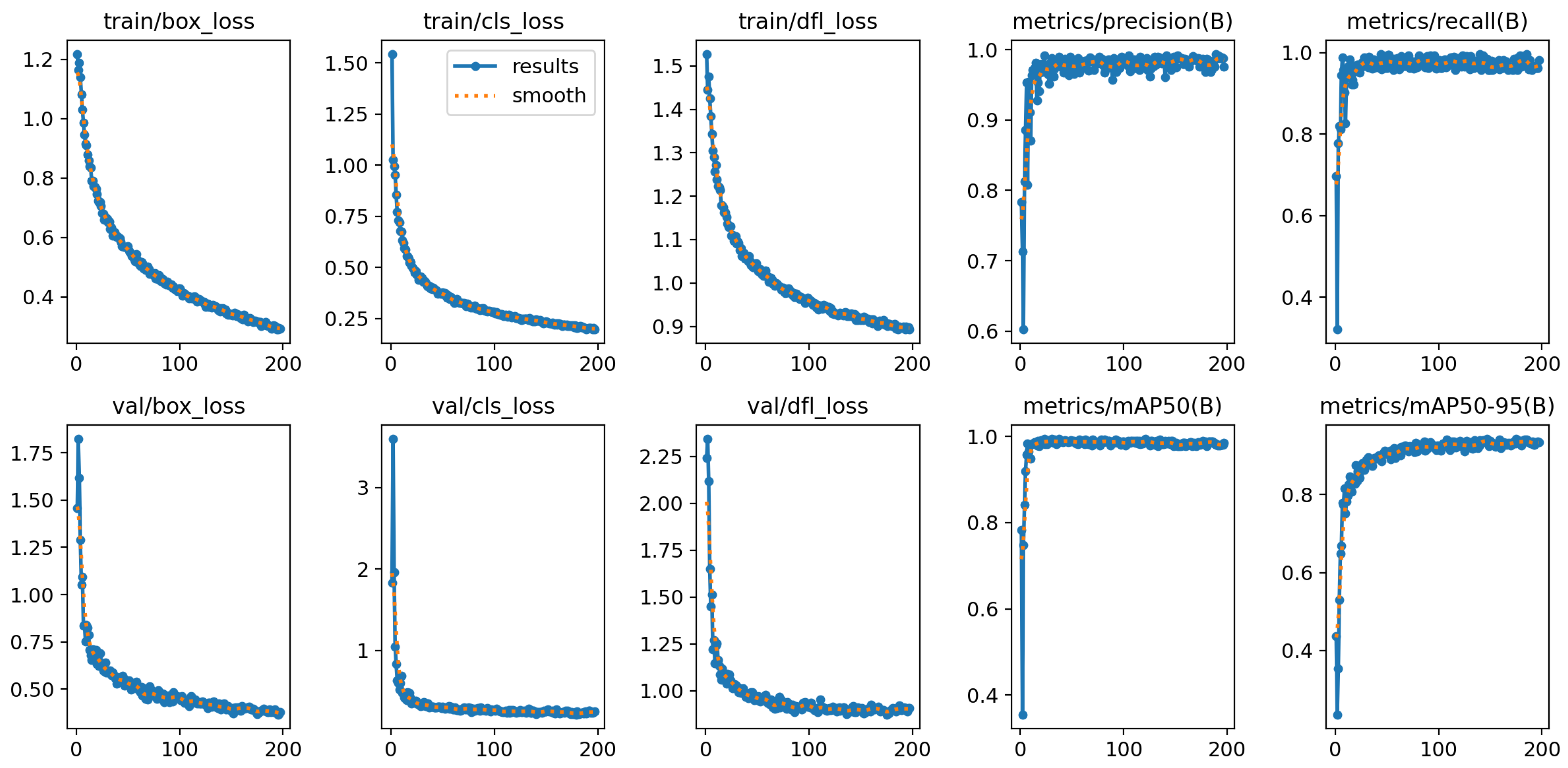
The results show that all the models are able to identify the three growth stages of the plants. They achieved an accuracy of at least 92.6% on the test dataset BV with respect to the metric .
The best training results were achieved by the YOLO models trained only on the bird’s-eye view dataset. This does not confirm the assumption that extending the dataset to include the side view improves training performance. YOLOv8l-BV achieved the highest training values with 94.8% , which supports the assumption that larger models achieve better accuracies. The smallest YOLOv8n-BV was just behind with 94.4%. In addition, the model did not converge after 300 epochs. In contrast to YOLOv8l-BV, YOLOv8n-BV shows the potential for improvement by increasing the number of epochs. With regard to the training evaluation, the assumption of higher accuracy with larger models cannot be confirmed and requires further investigation.
The test results paint a mixed picture of accuracy depending on model size and data influence. On average, YOLOv8n-BV, YOLOv8m-BV, and YOLO-V8l-BV have lower accuracies than YOLOv8n-BSV, YOLOv8m-BSV, and YOLOv8l-BSV. This indicates that models trained on the extended dataset BSV show better generalisation. Of all the models, the medium model (YOLOv8m-BSV) trained on the BSV dataset performed best, followed by the two large models YOLOv8l-BSV and YOLOv8l-BV. This suggests that larger models tend to perform better, although this assumption cannot be conclusively confirmed as the medium model (YOLOv8m-BSV) performed best in this particular application.
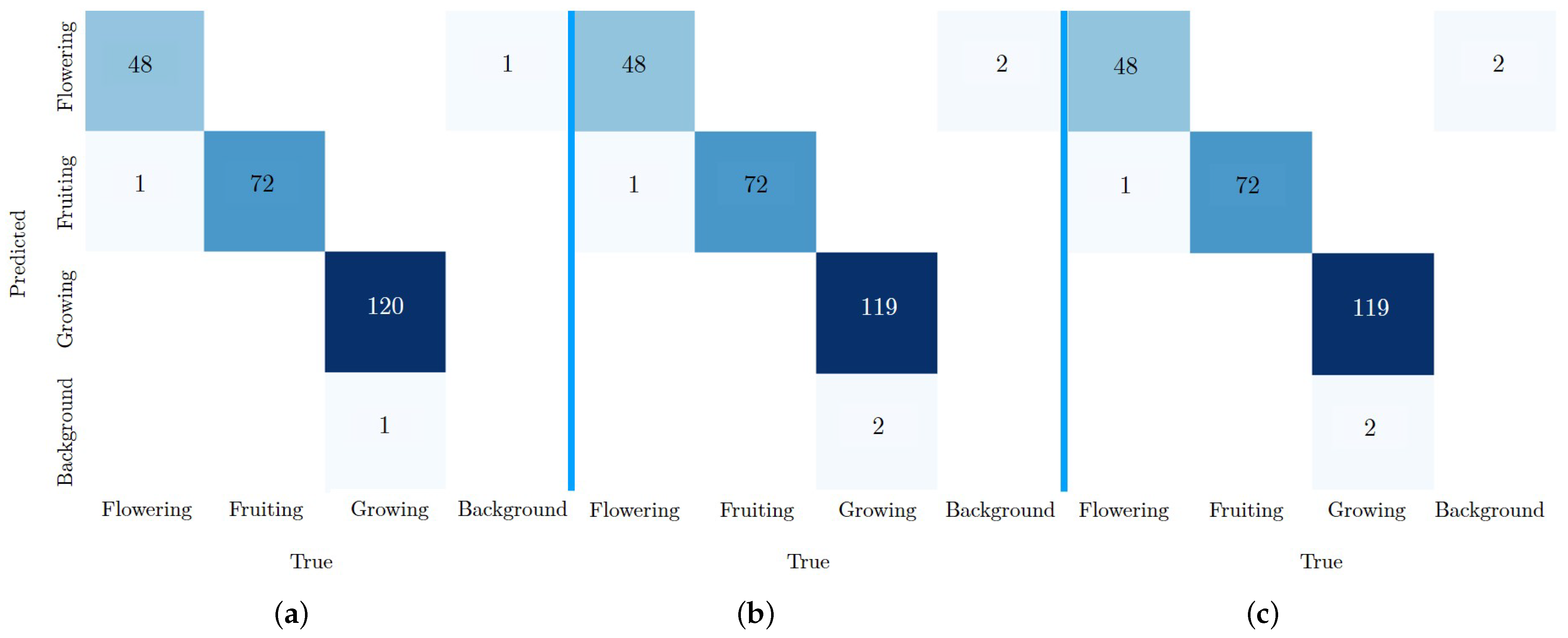
Looking at the individual classes in more detail, it is noticeable that all the models achieved the lowest
values in the growing class, even though this class had the most labels (see
Table 2). This observation may be due to the quality of the dataset. It is possible that the recording of four images per day and additional augmentation resulted in some redundancy in the data. This may lead to overfitting of the class during training and affect the ability of the models to generalise to previously unseen data.
The precision and recall values of all the models on the test dataset BV are very close to each other at a high level. Precision plays a crucial role in this study, as accurate prediction of classes or growth stages should ensure that future environmental conditions for plant growth are optimised. The smallest model with the BSV dataset (YOLOv8n-BSV) gave the best results. However, due to the small differences between the values, no general statement can be made about the effect of datasets and model sizes on accuracy.
In particular, the evaluation of the test results showed incorrect predictions corresponding to the background class. These errors could be due to the lack of background images in the dataset. In order to minimise these FP errors and improve the generalisability of the model, it would be advisable to include a dataset with background images in the next calculations. In particular, these should include images of the growth box and future application areas.
It is important to emphasise that the models developed and the results obtained in this work are only valid for the specific use case with the considered plants in the defined grow box environment. The future challenge is to ensure that the developed models can prove their performance in different scenarios and that their robustness and applicability are validated in a broader context.
5. Conclusions and Future Directions
In this work, images of chilli plants of the species C. annuum, grown in a hydroponic environment, were taken from two views over their life cycle, from seedling to fruit. The bird’s-eye and side view data were collected over a period of four months and used to train the models. The three models YOLOv8n, YOLOv8m, and YOLOv8l were trained using the datasets BV and BSV. This resulted in the six models YOLO-V8n-BV, YOLO-V8m-BV, YOLO-V8l-BV, YOLO-V8n-BSV, YOLO-V8m-BSV, and YOLO-V8l-BSV.
All six models are able to recognise the growth stages of chilli plants from a bird’s-eye view. The high accuracy of the models confirms the objective. The HQ Raspberry Pi camera with a 6 mm wide angle lens provided images of sufficient quality to train the YOLO models.
The test results of all the models showed a comparably high level. Overall, the BSV dataset showed the best results in terms of and precision. The influence of the model size is not clear, as the medium architecture of YOLO gave the best results.
In order to improve the models in the future, the influence of image quality could be analysed. The short distance between the lens and the plants led to distortion of the images. In addition, part of the dataset has a yellowish tinge. These images could be corrected using image processing algorithms. It is necessary to check whether the corrected images have any effect on the calculation results. In general, these phenomena can be avoided by using appropriate software and high-quality hardware. In addition, the dataset should be checked for redundant or inconspicuous features and compared with the results obtained.
Further optimisation could be achieved by hyperparameter tuning. By increasing the number of epochs, the YOLOv8- BV could achieve better results. In addition, the image resolution (image size) could be increased and a k-fold cross-validation could be performed. Expanding the dataset to include background images could also lead to improvements and could be compared with the results obtained in this work.
The next step is to test the generalisability of the model on unknown data. This could be achieved by compiling a common set of data and evaluating the accuracy of the predictions. The reliability of the system could also be tested by growing new chilli plants. The newly generated images could directly contribute to the improvement of the system by increasing the diversity of the dataset.
In this work, the plant in the images was considered as a whole and fed into the model training. Further research could create a dataset with specific annotations of the buds, flowers, and fruits and compare the training results.
The trained models could be used as a holistic image processing system for targeted and intelligent control of the next cultivation process. Depending on the predictions, growth parameters such as light and nutrient composition could be adjusted. The main objectives of this study were energy consumption and yield, which could be compared with cultivation without an image processing system.
Another option that could be analysed is the need for computing power. Can edge computing, such as Raspberry Pi or Raspberry Pi Zero W, be used, or is centralised computing, such as cloud computing, be required? As larger models require more computing resources, the performance needs to be evaluated as a function of the processing speed or inference time of the models. These devices could be used in a mobile design in greenhouses or vertical indoor farms.
Other applications of machine vision in hydroponics include disease and nutrient deficiency detection, as well as flower and fruit detection for pollination and targeted harvesting. The YOLO models created can be used as pre-trained models and as a starting point for the development of new computations in these application areas.

























{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}