1. Introduction
With the construction of smart grid, more and more measurement terminals are deployed in the distribution power system, such as the micro-synchrophasor measurement unit (D-PMU) and advanced measurement infrastructure (AMI) units. These devices together with the traditional SCADA system constitute a new hybrid measurement and control system in the distribution grid. On the other hand, due to the widespread access of distributed renewable energy and electric vehicles to the distribution power system, it is necessary to predict the output of renewable energy and manage the charging of electric vehicles, so that the data of inverters, weather stations, and charging piles become very important. All these data are varied in time, space, frequency, dimension, and format, so it is necessary to study the multi-source information fusion mechanism in the distribution grid [
1,
2,
3,
4,
5].
The smart grid contains various types of data, and different types of data are very different in format and frequency. Traditional SCADA system measurement devices, such as switching station terminal equipment (DTU), feeder terminal equipment (FTU), and distribution transformer terminal equipment (TTU), have a data collection frequency of several seconds to several minutes, while the new D-PMU’s acquisition frequency reaches 30–60 times per second. In terms of accuracy, the relative error of voltage and current amplitude measurement of D-PMU is less than 0.2%, the frequency measurement error is less than 0.005 Hz, and the phase angle error is less than 0.05°, which are much higher than traditional measurement equipment. Due to the deployment of the time synchronization module, the data collected by D-PMU have time stamp information, and the timing error is less than 50 us. However, unlike the large-scale deployment of PMUs in the wide area measurement system (WAMS) for the transmission power system, the application of D-PMU devices is still in its infancy around the world. Therefore, solving the problem of the coexistence of the legacy of SCADA system data and newly emerged D-PMU data is vital for realizing a monitorable and controllable distribution power system [
6].
From the perspective of the load side, a large number of AMI smart meters is installed on the user side to collect electricity consumption data, and the data transmission interval is typically once every 5 min. The fusion of such marketing data will greatly improve the accuracy for some advanced applications, such as load forecasting, state estimation, and power theft prevention. At the same time, as loads of distributed photovoltaics are connected, it is necessary to control the micro grid power fluctuation of photovoltaic grid-connected points, so meteorological data and photovoltaic data need to be obtained. For fault diagnosis and location applications, in addition to the D-PMU data, the fault recording data of several cycles before and after the fault and the topology information of the network are also needed. Therefore, whether it is for state estimation, fault location, or coordinated control, the support of multi-source data is required. Only by establishing a multi-source data fusion platform can the wide-area measurement and control room can be effectively supported for the distribution power grid [
7,
8].
The concept and preliminary theory of information fusion were first proposed by Professor Y. Bar-Shalom, a famous system scientist at the University of Connecticut (Connecticut), in the 1970s, and then, the US military research institute discovered that the probabilistic interconnection filtering of multiple continuous sonar signals can improve the detection accuracy of the local fleet position, and developed a number of practical military information fusion systems, such as a multi-sensor multi-platform tracking intelligence related processing system, a marine surveillance fusion expert system, a radar and ESM intelligence correlation system, etc. [
9,
10,
11].
Since the beginning of this century, with the substantial improvement of intelligent terminal data collection capabilities and network communication capabilities, the multi-source information fusion for the power industry has received widespread attention. The China Southern Power Grid took the lead in building an information integration platform for integrated marketing and distribution in China. The distribution grid integration model of “substation-10 kV feeder-distribution transformer-low-voltage line-power customer” has preliminarily realized the power supply reliability management, customer outage time statistics, the rapid power recovery management, the intensive management of distribution power system dispatching, etc. The system has achieved considerable economic benefits in multiple business links, such as line loss management. Although the integrated information integration platform has realized the initial integration of the six major systems with the large-scale application of smart meters and the explosive growth of power distribution and consumption data brought about by the lean management of the power grid, the basic data are still heterogeneous. There are inherent deficiencies, such as low integration of data sources, serious shortage of massive data throughput, and low ability to process flawed data, while deep mining, knowledge discovery, and comprehensive utilization of large-scale data value are in their infancy [
12,
13].
The State Grid Corporation of China has carried out the construction of the urban distribution power system demonstration project in Tianjin. This project has realized the integration of intelligent power distribution equipment, communication systems, advanced measurement systems, information support platforms and self-healing control systems. The whole network data integration platform of the distribution power system was established, and an interactive application was carried out. The basis of this demonstration project construction is to integrate information systems to form a standard distribution power system information interaction system, realize the interaction of various real-time data, static data, and graphic data among various business systems, and eliminate information islands [
14].
The National Renewable Energy Laboratory (NREL) investigates the requirements for the multi-source data for the integration of renewable energy. It states the input data for integration studies may include the renewable energy resource data, load data, forecast and forecast error data, as well as the wind and solar equipment characteristics data and conventional fleet characteristics data.
There are many studies that propose the use of multi-source fusion data to improve the advanced application of the power grid. Study [
15] analyzed state estimation using PMU measurement data and SCADA data, and demonstrated that, compared with the traditional state estimation using only SCADA data, adding PMU data can simplify the Jacobian matrix, speed up the state estimation speed, and improve the estimation efficiency. Study [
16] further proposes to use D-PMU, AMI and SCADA data to estimate the hybrid state of the distribution power system, and AMI data is used to replace the traditional pseudo-measurement data obtained through load forecasting. Study [
17] proposes an interturn short circuit fault diagnosis method in rotor windings based on multi-source information fusion. Study [
18] uses fused data to control power fluctuations at grid-connected points. Through theoretical analysis and measured data, it is verified that compared with a single data source, using fused data can more accurately control power fluctuations at grid-connected points. However, in these studies, the specific data fusion method is not described, but the fused data are directly used, so it is necessary to analyze the method of multi-source data fusion, especially for the emerging D-PMU data.
This paper studies the method and technical route of multi-source information fusion in a distribution power system. Through the analysis of the general multi-source information fusion model, combined with the characteristics of distribution power system data, the D-PMU data are modeled in accordance with the IEC 61850 standard, and a unified information model is proposed. The method is applied to a distribution power system wide-area measurement and control station. It is worth noting that this paper is based mostly on actual engineering to explain the method and technical route of the multi-source data fusion of the distribution power system including D-PMU, rather than detailing the specific fusion algorithm. The novelty of this paper can be summarized as follows:
The D-PMU data are modified to comply with the international standards, which is the common information model (CIM). In this paper, the attributes of the classes of the D-PMU data are extended. When extending the model, all the contents of the original model are retained to ensure that the original standard model is a subset of the extended model;
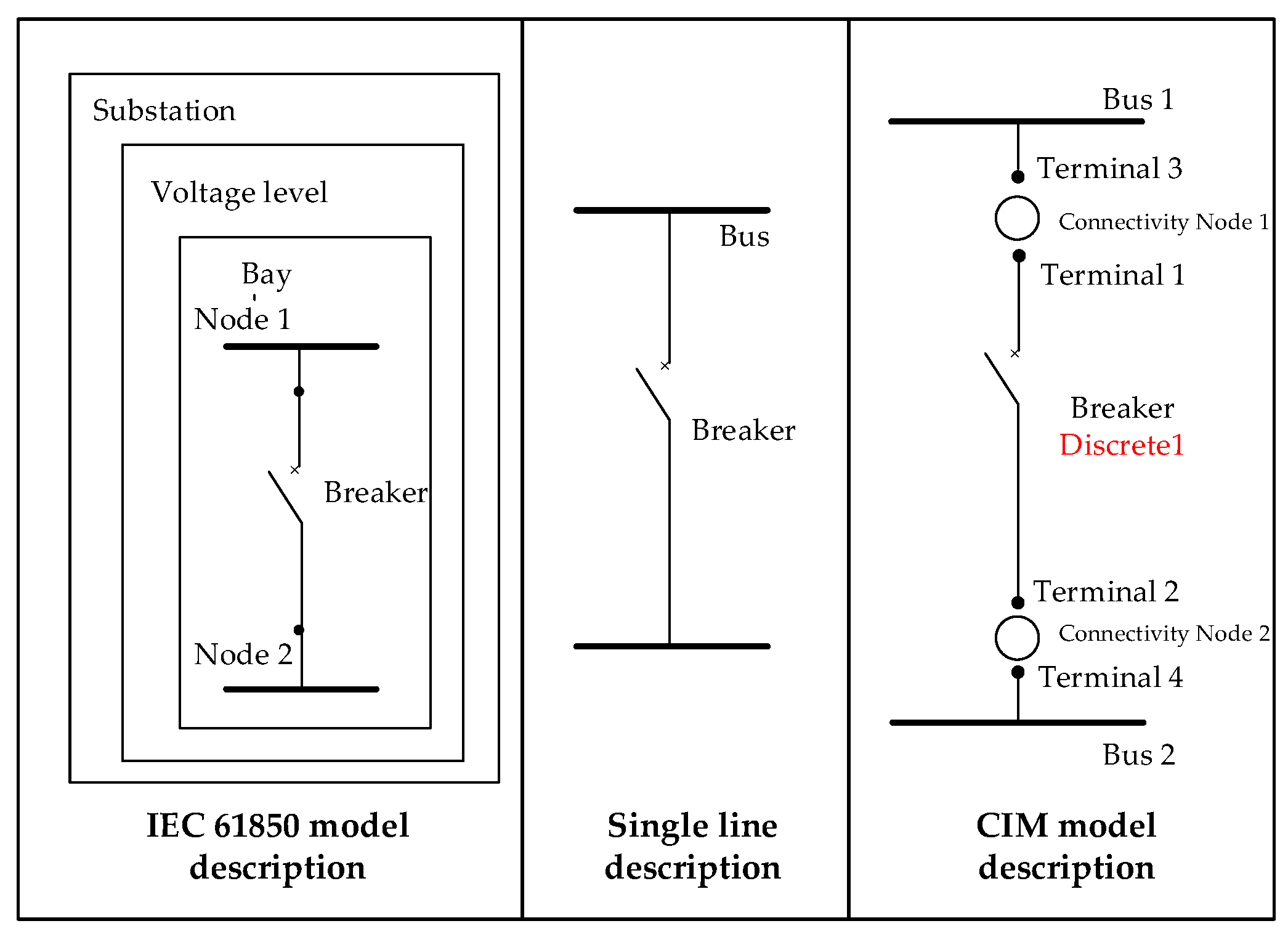
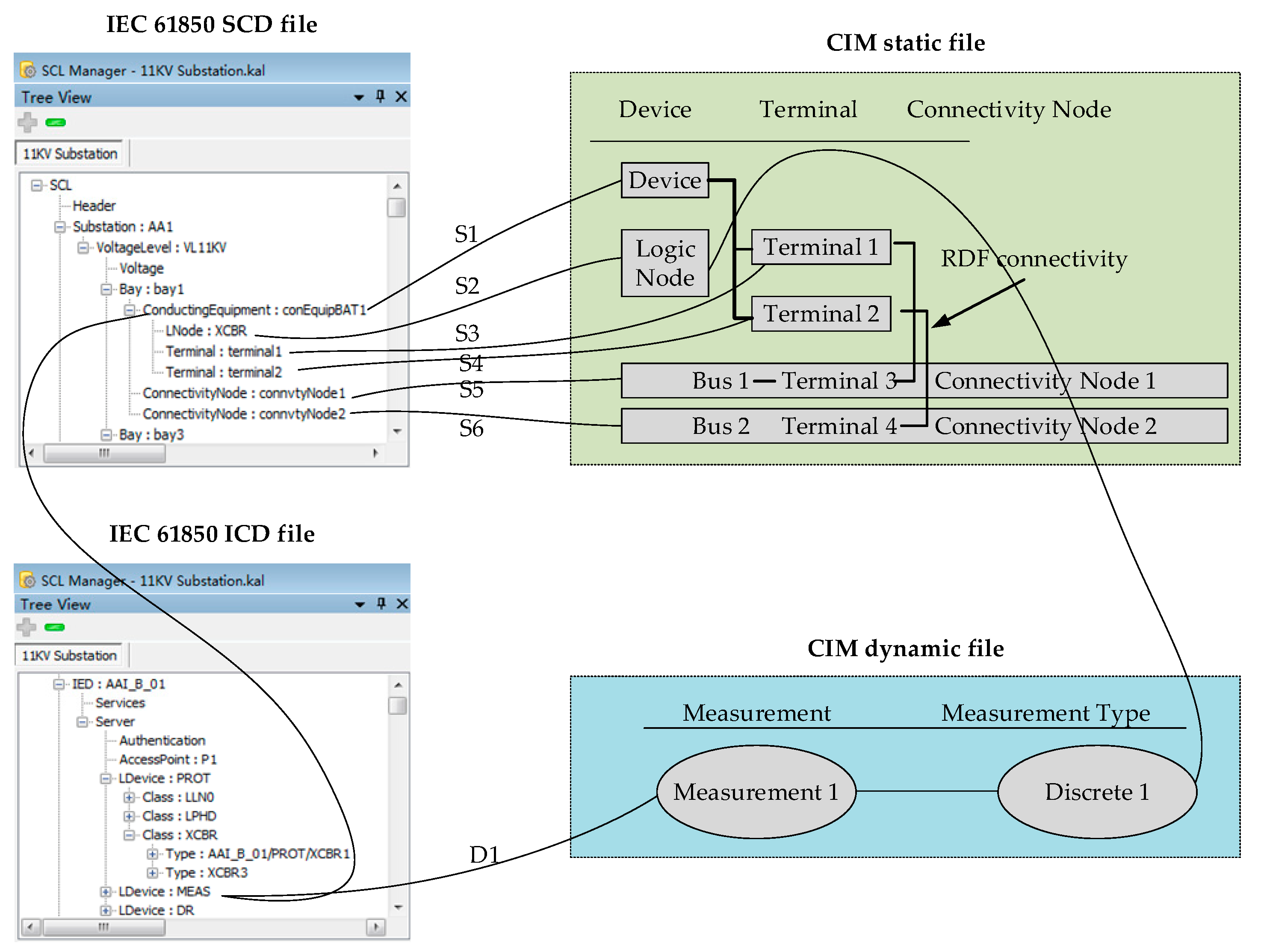
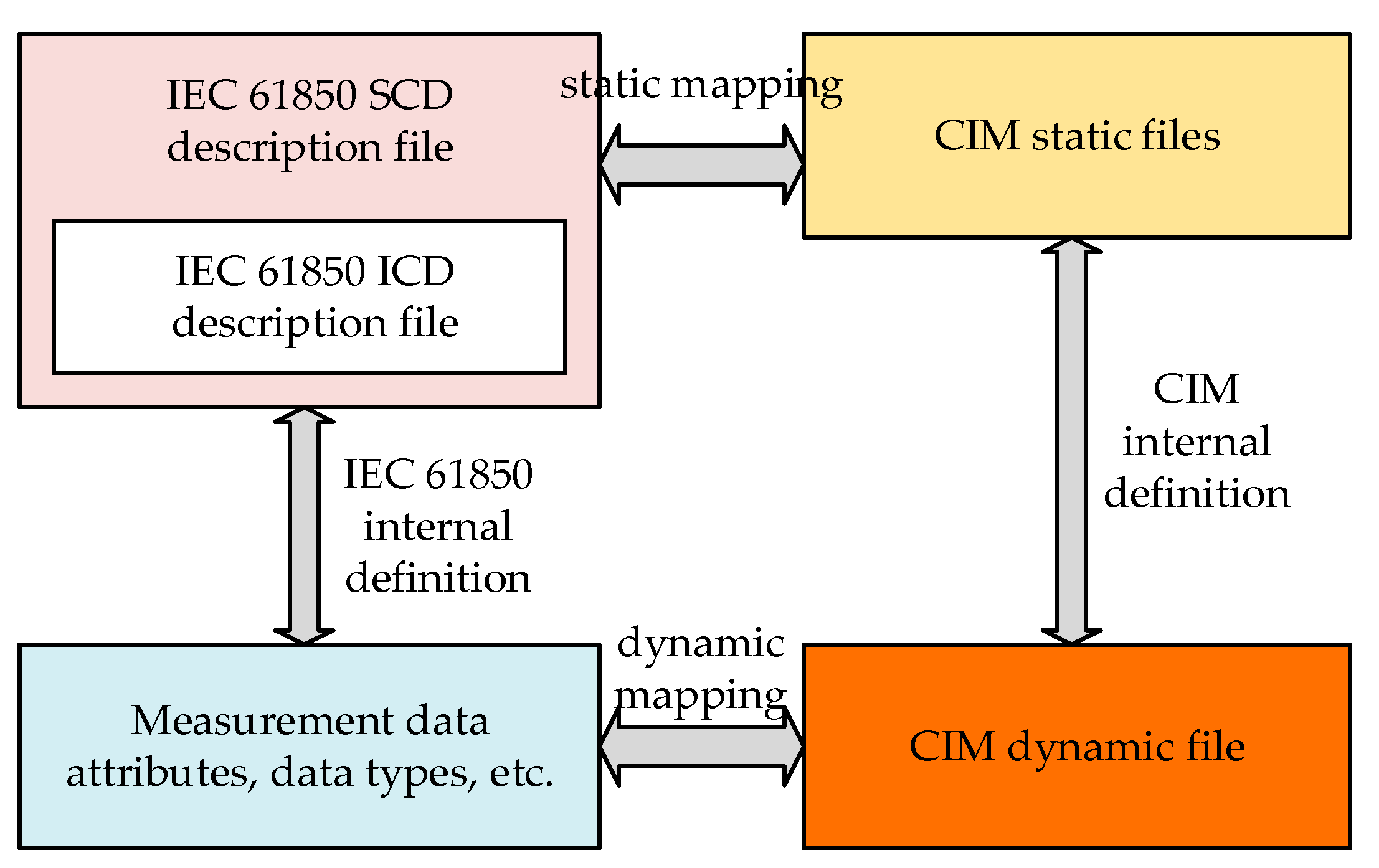
A unified information model (UIM) is proposed. The “SCL Manager” developed by Kalki Company is used to establish the SCD and ICD files of the IEC 61850 model, the static file and the dynamic file of the CIM model. The corresponding relations between the elements of IEC 61850 and CIM are elaborated using a network with two busbars and one circuit breaker;
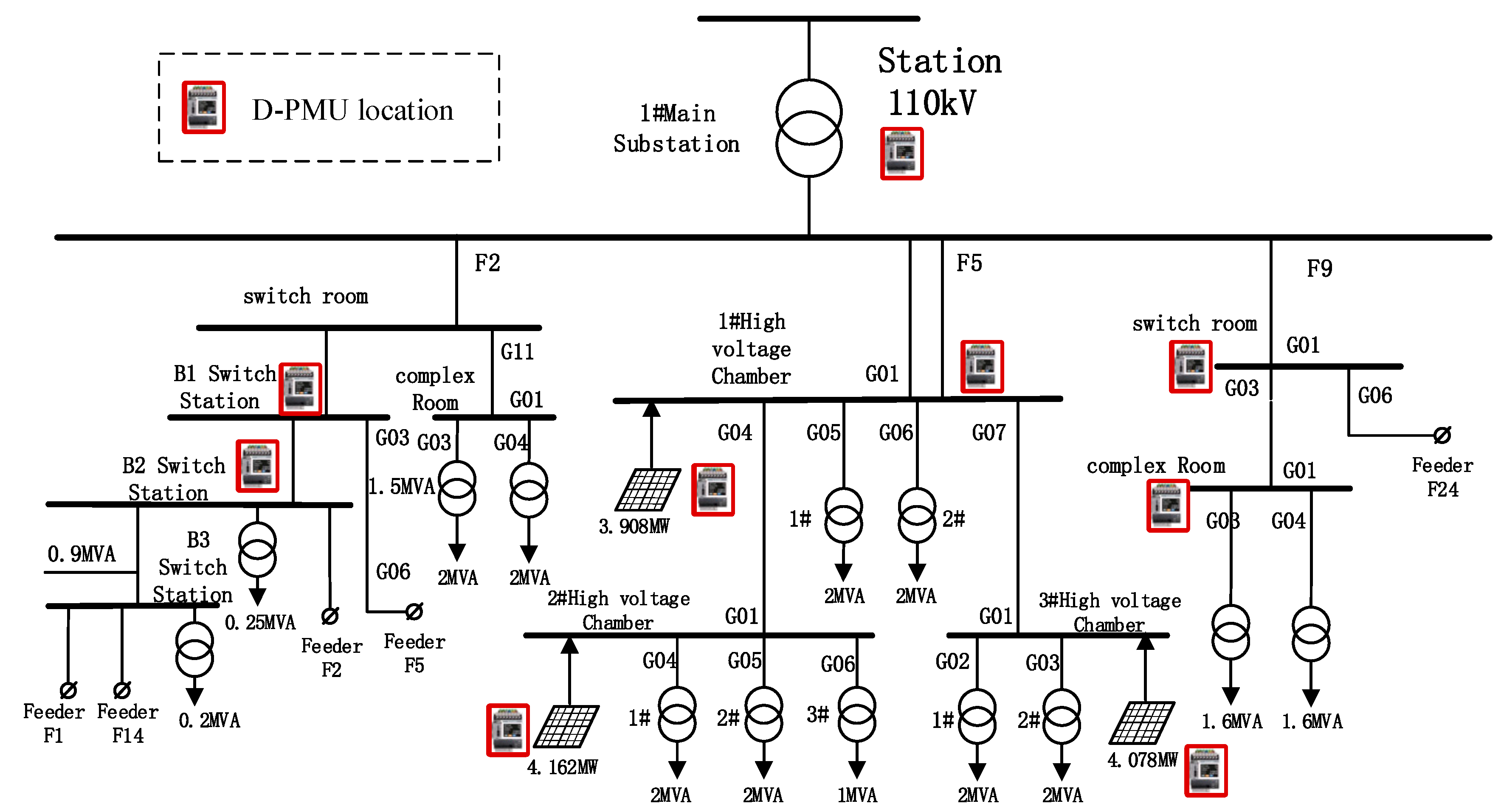
A multi-source data fusion platform architecture is proposed and verified on a field project. Based on the proposed method, a distribution power system wide-area measurement and control platform was developed. Due to the adoption of the distributed Spark stream data processing architecture, the number of D-PMUs that the platform can support is >1000, and the access measurement point scale is ≥50,000 measurement points (10-ms refresh).
2. A Novel Technical Route
Most of the information systems of the distribution power system are developed based on the business needs of each department, so there are multiple platforms with different structures, and the data content, data format, and data calling methods are different, resulting in scattered information and resources, and forming serious heterogeneous information islands. In addition, the coverage area of the distribution power system is large, and the measurement devices are scattered in different locations, which brings spatial complexity. Meanwhile the data collection frequency of each measurement device is inconsistent, and the time-scale information is uncertain, which brings time complexity. In recent years, there have been some studies on the fusion of multi-source data, such as the alignment of time-scale data and non-time-scale data, the interpolation of coarse-grained data and fine-grained data and the analysis of data spatial correlation [
19,
20,
21]. However, the information fusion of the newly emerging D-PMU data has not been reported. With the addition of the new D-PMU measurement, the following two key problems need to be solved in the multi-source data fusion of the distribution power system:
- (1)
Interoperability issues. For example, how the SCADA, EMS and BMS systems that follow the IEC 61970-301 (CIM) protocol interact with the substation integrated automation system that follows the IEC 61850 protocol and the IED devices installed below it for data and model interaction.
- (2)
The problem of real-time processing of large-scale streaming data. Assuming that 100 sets of D-PMU devices are installed, the amount of data collected every day will reach about 60 GB, and this is only a small part of the measurement of the smart distribution power system. D-PMU data is streaming data, which is different from traditional batch data processing methods. Therefore, it is very important to develop a multi-source data fusion platform suitable for the real-time processing of streaming big data.
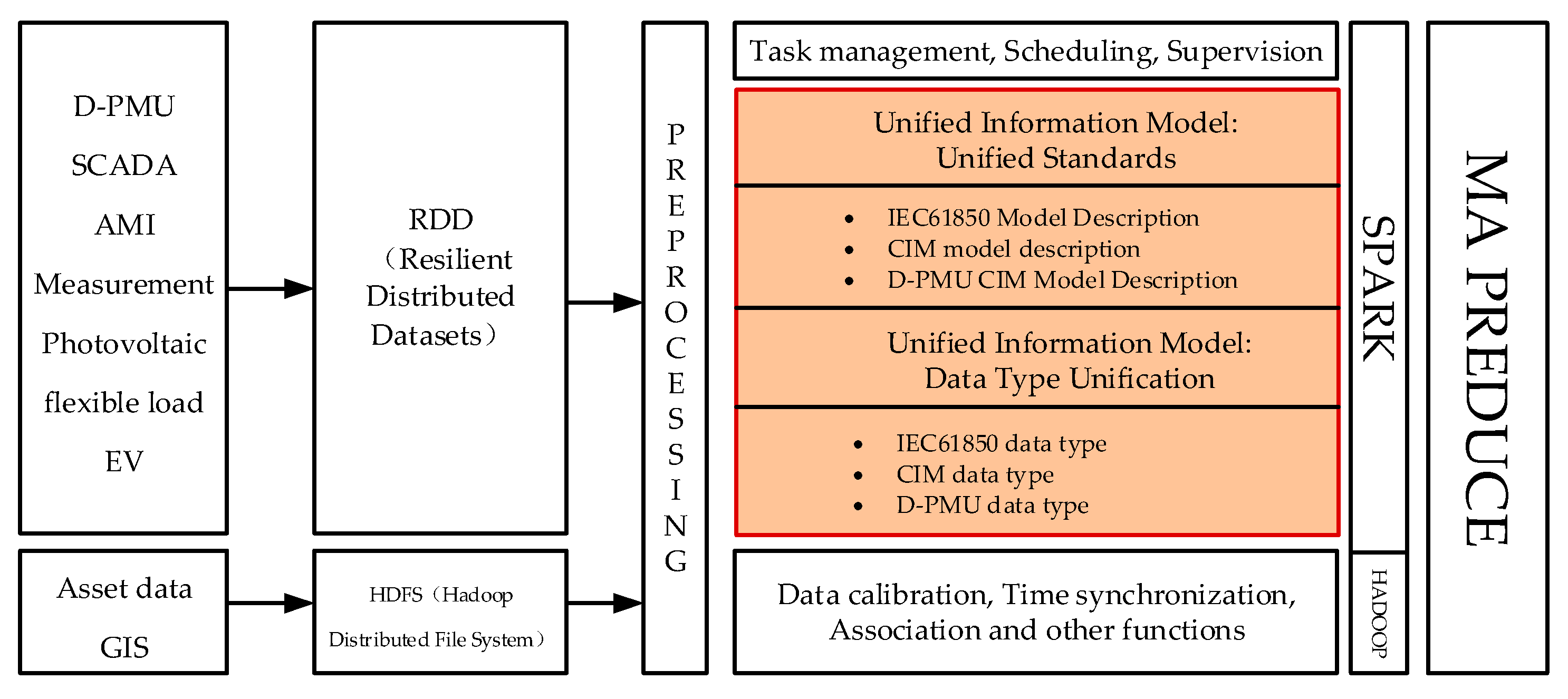
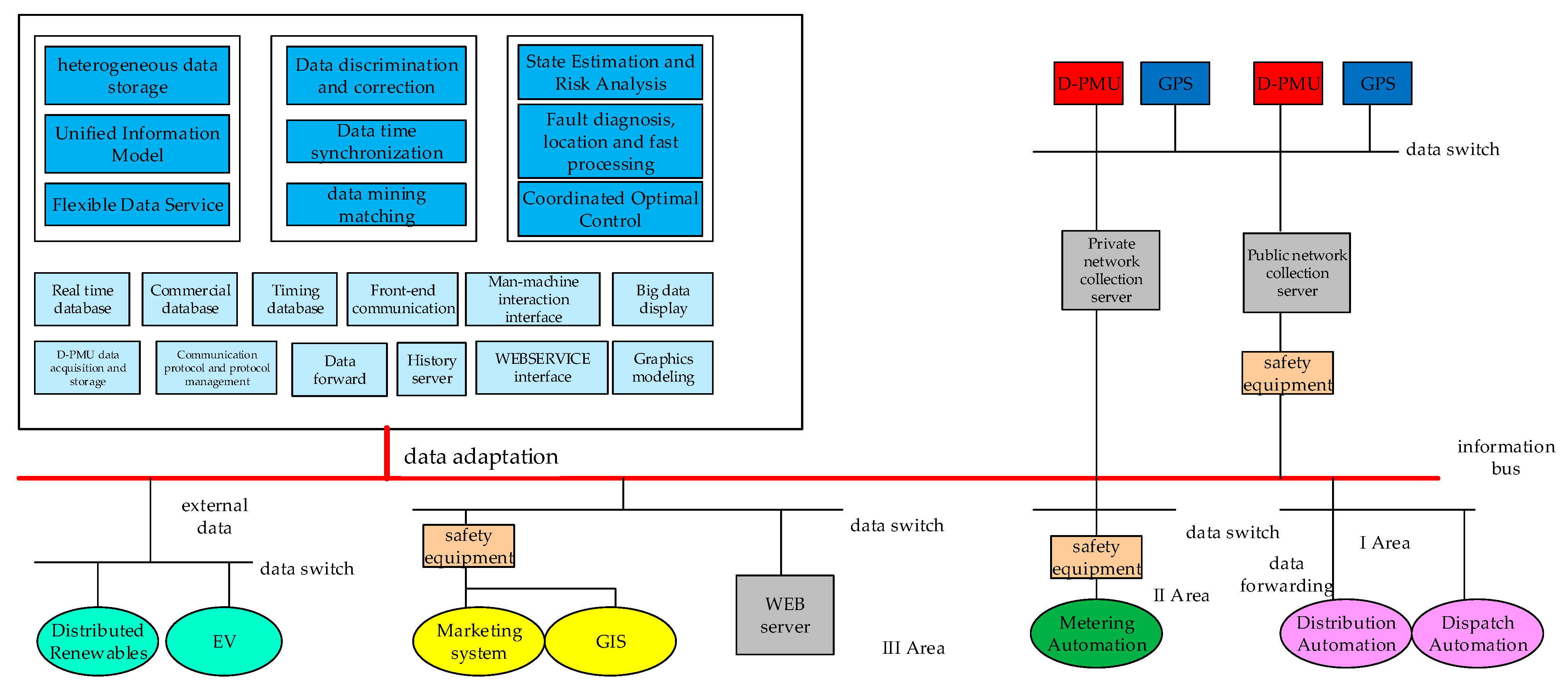
Figure 1 shows the multi-source information fusion model of distribution power system proposed in this paper. The functional part and structural part of this model are designed simultaneously.
Distribution power system data can be mainly divided into dynamic measurement data and static equipment or topology data. In the model shown in
Figure 1, the Spark architecture is used for the fusion processing of streaming data, and the Hadoop architecture is used for the fusion processing of batch data. The difference between the two is that streaming computing is needed to perform real-time data calculation directly in memory after online data arrives, and the intermediate results of the calculation will also be cached in memory, so that high-density data can be processed quickly.
The batch processing model stores static data in the HDFS (Hadoop distributed data system) first, and then, processes the static data offline. The dynamic measurement data first enters the RDD (resilient distributed data set) unique to the Spark architecture, and the static data enters the HDFS. Afterwards, the preprocess begins, and then, the unified information model is used to unify the model description and data types stipulated by each standard. There are also some functional modules for data calibration, time synchronization and association. The entire information fusion process adopts the idea of MapReduce for parallel processing.
3. Model Modification for D-PMU Data
To solve the compatibility and interoperability problems between different information models and communication protocols in the power grid, the International Electrotechnical Commission has proposed a number of standards and specifications in the past ten years, among which the IEC61968-301 (CIM) and IEC61850 standards are two standards generally recognized by the industry. The former is aimed at the data interaction of power control centers, such as SCADA (supervisory control and data acquisition), EMS (energy management system) and DMS (distribution power system management system), while the latter is aimed at the field of smart substation interoperability issues [
22,
23]. With the emergence of a new type of micro-synchrophasor measurement unit (D-PMU) for distribution power systems, it is necessary to analyze its model, and then, integrate the two models of CIM and IEC61850.
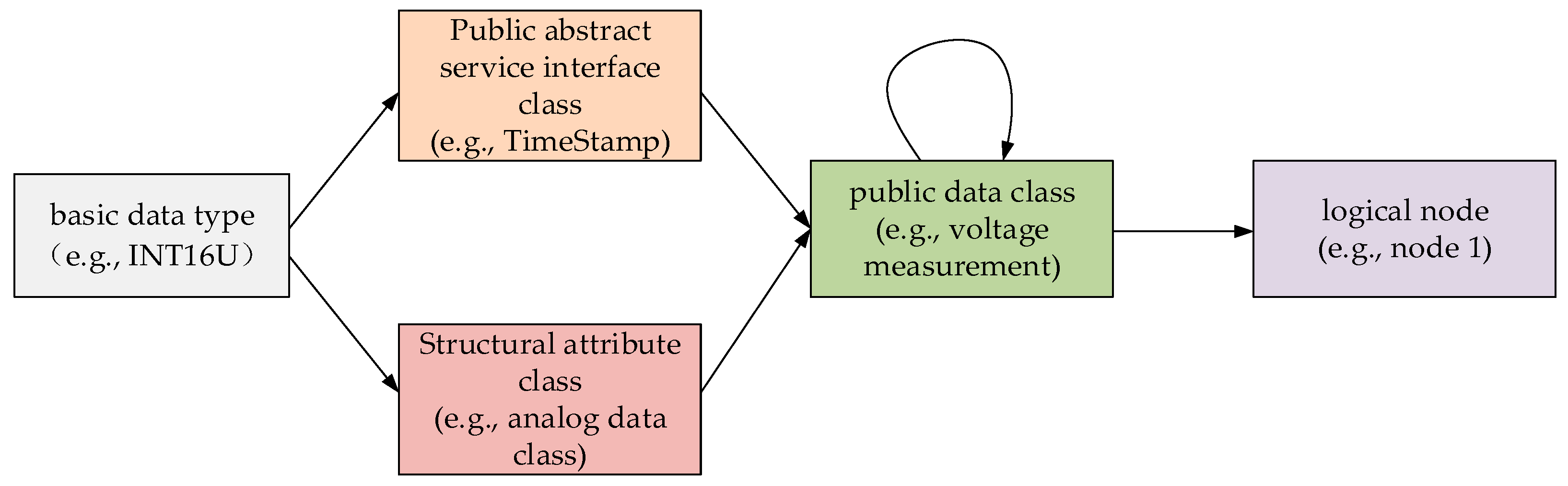
D-PMU physically consists of six main parts: the GPS receiving module, time synchronization module, A/D conversion module, filtering module, phasor estimation module and control module [
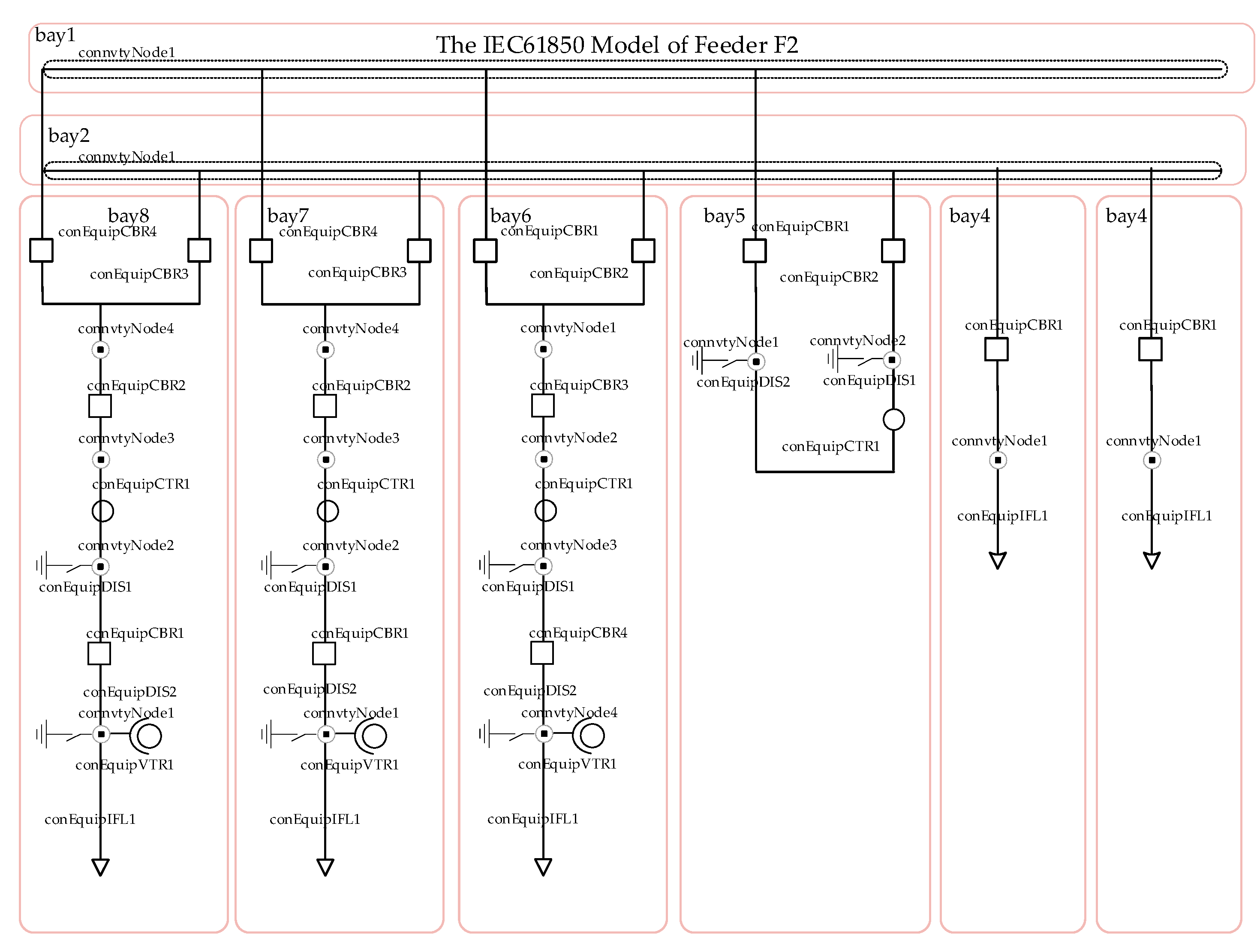
24]. Its design conforms to the IEC 61850 specification, so we build its IEC 61850 model. The IEC 61850 model consists of two parts: the ICD (IED capability description) and SCD (substation configuration description).The IEC 61850 Part 6 defines the extensible markup language (XML) architecture of the ICD, including logical nodes (LD), common data types (CDC), data attributes (DA) and enumerations (Enums), which form a tree structure. The SCD file description provides the structure and information of the substation and includes all the IEDs in the substation [
25].
Appendix A gives a sample of the ICD and SCD markup extension language (XML) description of the D-PMU. The attributes and data types of attributes of each module of D-PMU are modified as follows:
The sampling device (Sampling) inherits from Core: Measurement, and is associated with the synchronous clock module. Its basic function is to collect data and upload it in real time. The synchronous sampling pulse generated by the clock synchronization unit controls the sampling rate to obtain synchronous data. The attributes obtained by this class through inheritance are detailed in its parent class, measurement, and the extended attributes are shown in
Table 1.
- (2)
Communication link
Communication link (CommunicationLink) inherits from Core: Equipment. The synchronous sampling frequency of the device is about 25.6 KHz, and the number of sampling points per cycle reaches 512. In order not to cause data blockage, it is necessary to set up the communication module so that the cached data at the front end of the processor can be transmitted to the back end for data calculation in time. For details of the properties obtained by this class through inheritance, see its parent class, equipment, and the extended properties are shown in
Table 2.
- (3)
Phasor calculation unit
The phasor calculation unit (PhasorMeter) inherits from Core: Measurement and implements core functions, such as data reception, time stamp, synchrophasor calculation and upload server. Its specific functions include buffering the data of different channels in their respective buffer areas to realize data differentiation, analyzing GPS time information and status information, using a phasor estimation algorithm to calculate the voltage/current phase angle and the real-time uploading of calculated data. The attributes obtained by this class through inheritance are detailed in its parent class, measurement, and its extended attributes are shown in
Table 3.
- (4)
Clock synchronization unit
The clock synchronization unit (TimeSynchronization) inherits from Core: Equipment, and is used to generate the synchronous sampling pulses required for data acquisition and provide a high-precision synchronous clock source for each acquisition terminal. The clocks of all synchronization vector acquisition units are synchronized to a master clock, namely the GPS timing clock. PPS is a square wave signal with a frequency of 1 Hz sent by GPS, which provides the basic time synchronization second pulse for the ground timing system, and the rising edge of the pulse is synchronized with the international standard time UTC. The clock synchronization unit also converts the international standard time (UTC) into local time and multiplies the second pulse signal sent by GPS into the required synchronous sampling clock signal. The synchronous clock processing module sends the processed time and synchronous pulse information to the phasor measurement module. The extended attributes are shown in
Table 4.
- (5)
Time-keeping module
The time-keeping module (TimeKeeping) inherits from Core: Equipment. When the GPS receiving module detects that the satellite signal is interrupted through the status analysis function, the time-keeping module replaces the synchronous satellite, generates a local pulse signal PPS that is strictly synchronized and in phase with the satellite lock, and corrects the time caused by the satellite out of sync Error. This PPS can last for about 6 h. If no GPS locking signal is detected for more than 6 h, the local clock will fail, and an alarm signal will be generated. The extended attributes are shown in
Table 5.
6. Challenges and Prospects
Based on the characteristics of distribution power system data, this paper proposes a new idea of multi-source information fusion in the distribution power system and verifies it through actual demonstration project. In terms of structure, the proposed fusion model adopts Spark architecture to process stream data, which solves the bottleneck of high-frequency data stream processing; in terms of function, it adopts a unified information model to unify the two types of data specifications and performs a new type of D-PMU data model modification. At present, compared with other fields, the theoretical and practical research of multi-source information fusion in distribution power system is still in its infancy, and there are mainly difficulties and challenges in the following two aspects:
- (1)
The problem of deep data fusion. Compared with simple information fusion for the purpose of data interaction, deep fusion should also realize the mining of hidden relationships between various data and the extraction of feature data, involving principal component analysis (PCA), singular value decomposition, and other complex algorithms. Machine learning and data mining are effective methods to solve deep data fusion [
34,
35];
- (2)
Data security issues. The power system has extremely high security requirements. In recent years, the power grid has been repeatedly attacked by data manipulation, which has also sounded the alarm for the management and operation personnel of the power system. The data of the multi-source information fusion system come from various subsystems or acquisition devices, so they are vulnerable to attacks, and once an attack occurs, it will have a huge impact on the distribution power system [
36,
37,
38].
With the introduction of models and concepts such as the energy internet and “Internet + Electricity”, the degree of informatization of the power system will increase, and it will also bring new opportunities for the development of the power system, mainly reflected in the following aspects.
- (1)
Application of big data technology in information fusion. In recent years, big data technology has developed rapidly in many fields, such as commerce, medical care, and aviation, and power data are increasingly showing the characteristics of big data. Therefore, using big data thinking to carry out data fusion and analysis will promote the development of distribution power systems [
39,
40,
41];
- (2)
Machine learning and artificial intelligence. Artificial intelligence can solve the problem of inaccurate and uncertain information. The fusion method based on expert system and artificial neural network has been applied to some data fusion applications in the military field. At the heart of artificial intelligence, machine learning (ML) is the study of how to improve the performance of specific algorithms through empirical learning. Deep data fusion will be facilitated by machine learning and artificial intelligence [
42,
43,
44].

















{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}