


Integrating Unsupervised Machine Intelligence and Anomaly Detection for Spatio-Temporal Dynamic Mapping Using Remote Sensing Image Series
 ,
,  , , ,
, , ,  , and
, and {kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
Abstract
1. Introduction
- Aim: “Developing an accurate and flexible machine-learning-based method that detects and maps spatio-temporal dynamics by assuming only a time series of remotely sensed images as input.”
- Hypothesis: “Regions subject to frequent disturbances are mapped as anomalies in remote sensing image series.”
2. Theoretical Background
2.1. Preliminary Notations
2.2. Anomaly Detection
2.3. Spectral Indices
3. Anomaly-Detection-Based Framework for Mapping Landscape Disturbances
3.1. Conceptual Formalization
3.2. Implementation Details
- Programming language and libraries: The framework was implemented with the Python 3.8 programming language [58] and the Numpy [59], Pandas [60], Scikit-Learn [61], and GDAL [62] libraries. These libraries were fundamental when manipulating matrix data, applying anomaly detection methods, and representing the outputs.
- GEE Application Programming Interface (API): The Python-based version of GEE-API [63] was employed to access remote sensing image catalogs and produce image series according to the period, region, and sensor of interest, which included data from Landsat-8 OLI, Sentinel-2 MSI, and Terra MODIS.
- Data structure: The Pandas dataframe structure was adopted to organize and manipulate the image series obtained from GEE-API.
- Output representation: Functions from the GDAL library were adopted to convert the Pandas dataframes containing the landscape disturbance mapping into a “GeoTiff” image representation.
4. Experiments and Results
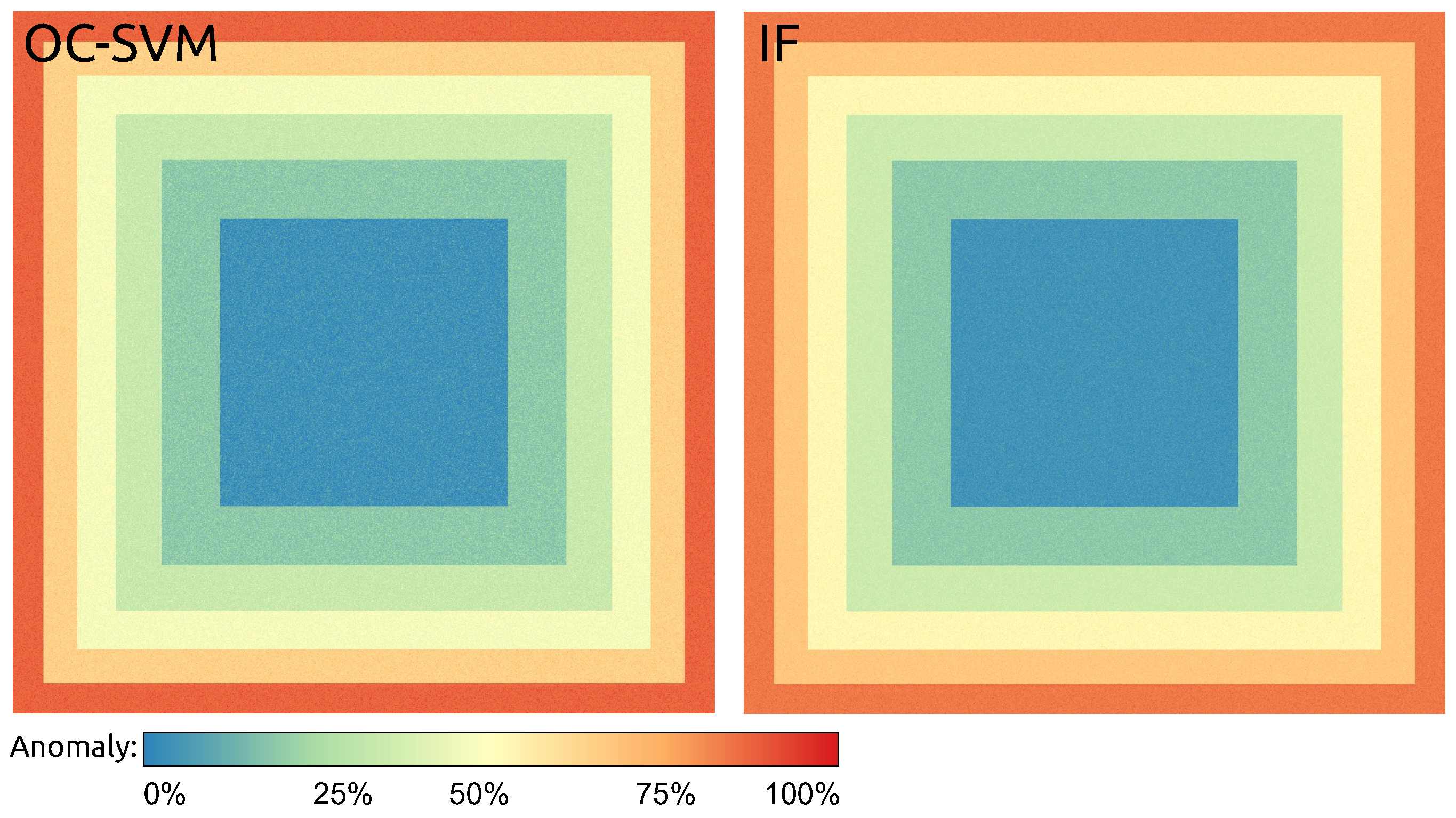
4.1. Synthetic Data
4.2. Real-World Applications
4.2.1. Study Areas and Datasets
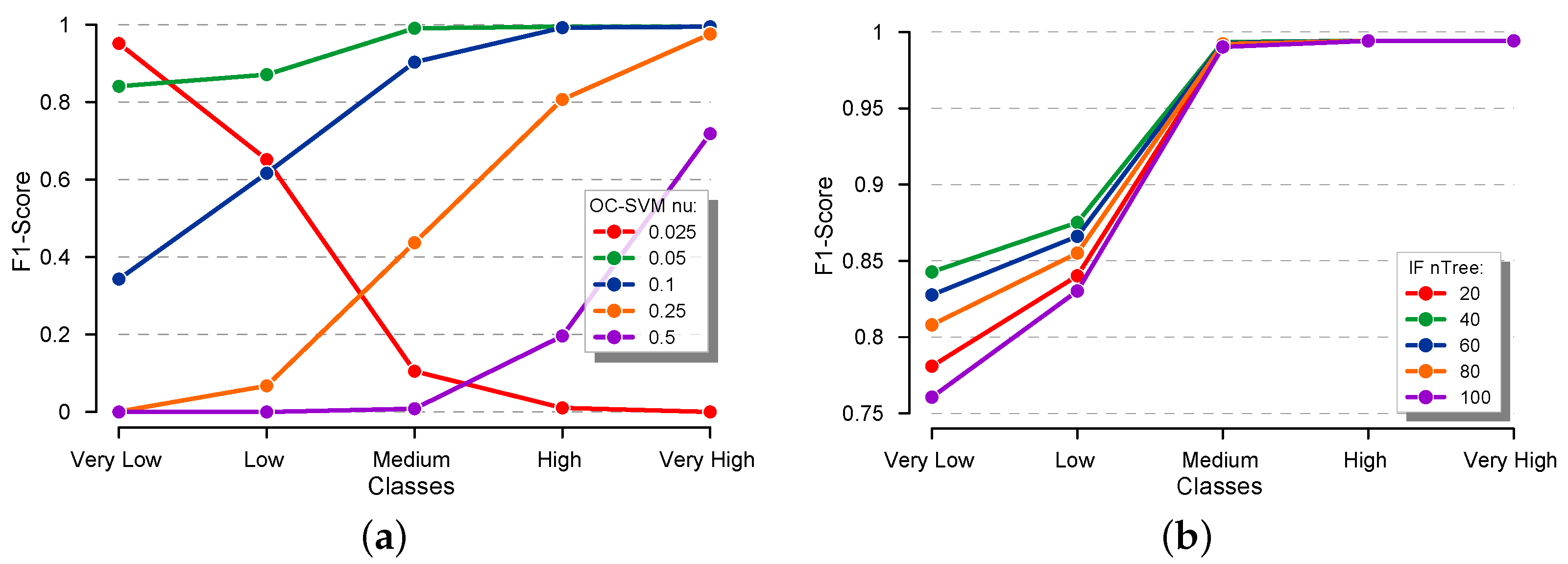
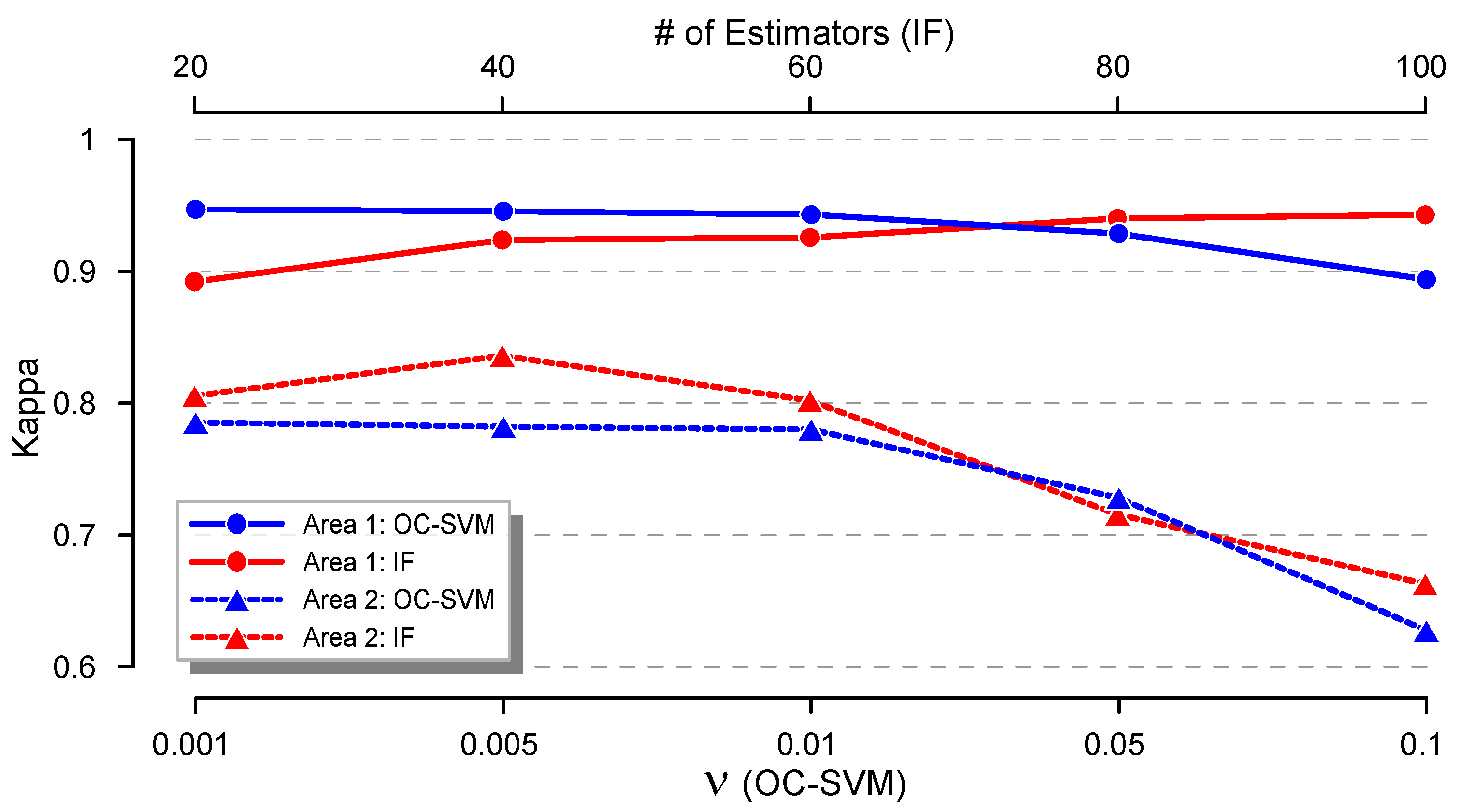
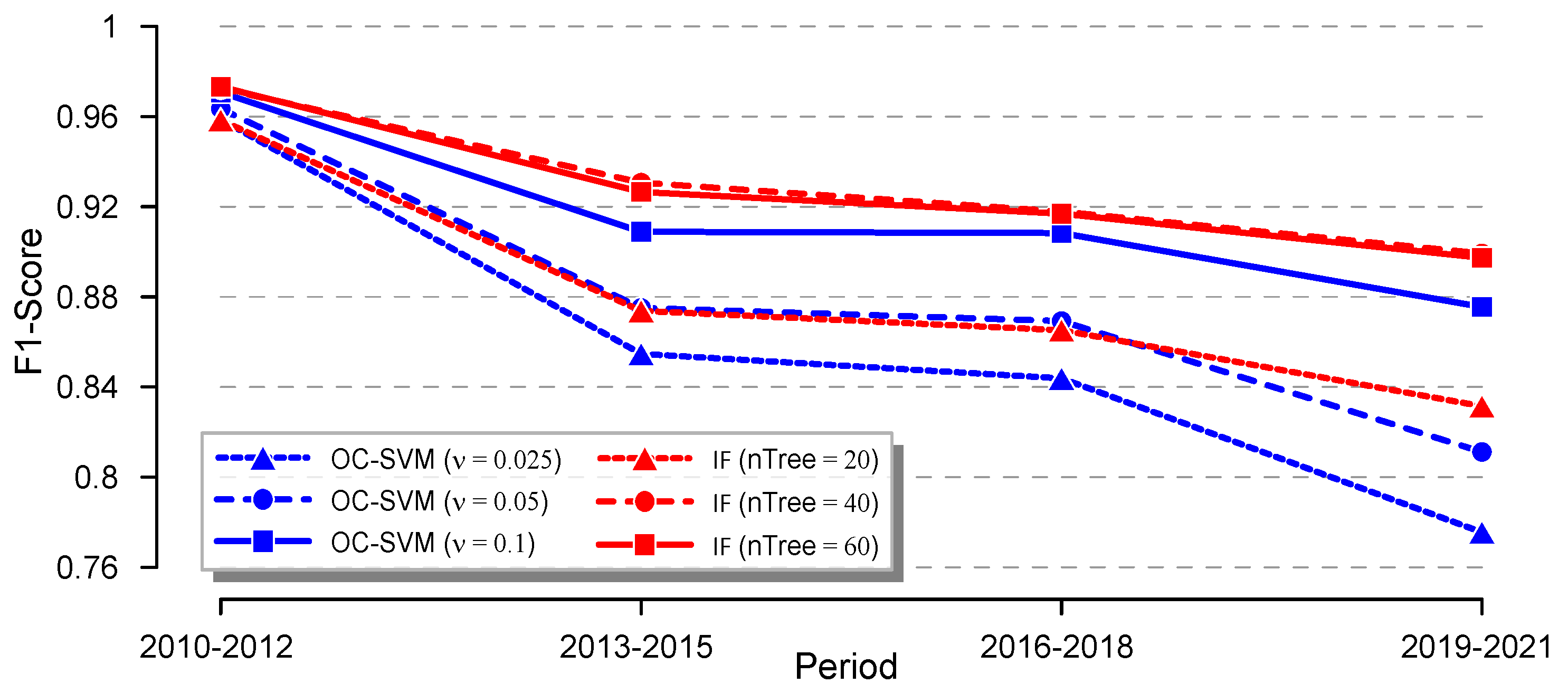
4.2.2. Results
5. Discussion
6. Conclusions
- A fully unsupervised framework designed to detect regions that are subject to relevant spatio-temporal disturbances. Our approach uses the Google Earth Engine platform to collect fresh data, allowing the training of data-driven models while discriminating the transient features present in time series of remotely sensed images.
- Our approach is capable of accurately identifying and mapping concrete changes by assuming only a time series of remotely sensed images as input data.
- The proposed methodology allows the use of distinct anomaly detection models, as well as image time series acquired by various remote sensors, including Landsat-8 OLI, Sentinel-2 MSI, and Terra MODIS.
- An innovative conjunction of unsupervised machine learning concepts and remote sensing techniques for the identification of recurrent changes of an arbitrary nature, which is flexible enough to address a variety of anthropogenic actions, including deforestation and landscape changes caused by disaster events, such as dam failures.
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- Hawken, P.; Lovins, A.B.; Lovins, L.H. Natural Capitalism: The Next Industrial Revolution; Routledge: London, UK, 2013. [Google Scholar]
- Steffen, W.; Broadgate, W.; Deutsch, L.; Gaffney, O.; Ludwig, C. The trajectory of the Anthropocene: The great acceleration. Anthr. Rev. 2015, 2, 81–98. [Google Scholar] [CrossRef]
- Pradhan, P.; Costa, L.; Rybski, D.; Lucht, W.; Kropp, J.P. A systematic study of sustainable development goal (SDG) interactions. Earth’s Future 2017, 5, 1169–1179. [Google Scholar] [CrossRef]
- Jimenez, J.C.; Marengo, J.A.; Alves, L.M.; Sulca, J.C.; Takahashi, K.; Ferrett, S.; Collins, M. The role of ENSO flavours and TNA on recent droughts over Amazon forests and the Northeast Brazil region. Int. J. Climatol. 2019, 41, 3761–3780. [Google Scholar] [CrossRef]
- Silva Junior, C.H.; Pessoa, A.; Carvalho, N.S.; Reis, J.B.; Anderson, L.O.; Aragão, L.E. The Brazilian Amazon deforestation rate in 2020 is the greatest of the decade. Nat. Ecol. Evol. 2021, 5, 144–145. [Google Scholar] [CrossRef]
- Burton, C.; Betts, R.A.; Jones, C.D.; Feldpausch, T.R.; Cardoso, M.; Anderson, L.O. El Niño driven changes in global fire 2015/16. Front. Earth Sci. 2020, 8, 199. [Google Scholar] [CrossRef]
- Moura, M.M.; Dos Santos, A.R.; Pezzopane, J.E.M.; Alexandre, R.S.; da Silva, S.F.; Pimentel, S.M.; de Andrade, M.S.S.; Silva, F.G.R.; Branco, E.R.F.; Moreira, T.R.; et al. Relation of El Niño and La Niña phenomena to precipitation, evapotranspiration and temperature in the Amazon basin. Sci. Total Environ. 2019, 651, 1639–1651. [Google Scholar] [CrossRef] [PubMed]
- do Carmo, F.F.; Kamino, L.H.Y.; Junior, R.T.; de Campos, I.C.; do Carmo, F.F.; Silvino, G.; Mauro, M.L.; Rodrigues, N.U.A.; de Souza Miranda, M.P.; Pinto, C.E.F.; et al. Fundão tailings dam failures: The environment tragedy of the largest technological disaster of Brazilian mining in global context. Perspect. Ecol. Conserv. 2017, 15, 145–151. [Google Scholar] [CrossRef]
- Rotta, L.H.S.; Alcantara, E.; Park, E.; Negri, R.G.; Lin, Y.N.; Bernardo, N.; Mendes, T.S.G.; Souza Filho, C.R. The 2019 Brumadinho tailings dam collapse: Possible cause and impacts of the worst human and environmental disaster in Brazil. Int. J. Appl. Earth Obs. Geoinf. 2020, 90, 102119. [Google Scholar]
- Hansen, M.C.; Potapov, P.V.; Moore, R.; Hancher, M.; Turubanova, S.A.; Tyukavina, A.; Thau, D.; Stehman, S.V.; Goetz, S.J.; Loveland, T.R.; et al. High-Resolution Global Maps of 21st-Century Forest Cover Change. Science 2013, 342, 850–853. [Google Scholar] [CrossRef]
- Berger, K.; Machwitz, M.; Kycko, M.; Kefauver, S.C.; Van Wittenberghe, S.; Gerhards, M.; Verrelst, J.; Atzberger, C.; van der Tol, C.; Damm, A.; et al. Multi-sensor spectral synergies for crop stress detection and monitoring in the optical domain: A review. Remote Sens. Environ. 2022, 280, 113198. [Google Scholar] [CrossRef]
- Sagan, V.; Peterson, K.T.; Maimaitijiang, M.; Sidike, P.; Sloan, J.; Greeling, B.A.; Maalouf, S.; Adams, C. Monitoring inland water quality using remote sensing: Potential and limitations of spectral indices, bio-optical simulations, machine learning, and cloud computing. Earth-Sci. Rev. 2020, 205, 103187. [Google Scholar] [CrossRef]
- Lary, D.J.; Alavi, A.H.; Gandomi, A.H.; Walker, A.L. Machine learning in geosciences and remote sensing. Geosci. Front. 2016, 7, 3–10. [Google Scholar] [CrossRef]
- Holloway, J.; Mengersen, K. Statistical machine learning methods and remote sensing for sustainable development goals: A review. Remote Sens. 2018, 10, 1365. [Google Scholar] [CrossRef]
- Shaukat, K.; Alam, T.M.; Luo, S.; Shabbir, S.; Hameed, I.A.; Li, J.; Abbas, S.K.; Javed, U. A review of time-series anomaly detection techniques: A step to future perspectives. In Proceedings of the Future of Information and Communication Conference, Vancouver, BC, Canada, 29–30 April 2021; pp. 865–877. [Google Scholar]
- Racetin, I.; Krtalić, A. Systematic review of anomaly detection in hyperspectral remote sensing applications. Appl. Sci. 2021, 11, 4878. [Google Scholar] [CrossRef]
- Marzuoli, A.; Liu, F. Monitoring of natural disasters through anomaly detection on mobile phone data. In Proceedings of the 2019 IEEE International Conference on Big Data (Big Data), Los Angeles, CA, USA, 9–12 December 2019; pp. 4089–4098. [Google Scholar]
- Bijlani, N.; Nilforooshan, R.; Kouchaki, S. An Unsupervised Data-Driven Anomaly Detection Approach for Adverse Health Conditions in People Living With Dementia: Cohort Study. JMIR Aging 2022, 5, e38211. [Google Scholar] [CrossRef] [PubMed]
- Guo, Q.; Pu, R.; Cheng, J. Anomaly detection from hyperspectral remote sensing imagery. Geosciences 2016, 6, 56. [Google Scholar] [CrossRef]
- Chi, M.; Plaza, A.; Benediktsson, J.A.; Sun, Z.; Shen, J.; Zhu, Y. Big data for remote sensing: Challenges and opportunities. Proc. IEEE 2016, 104, 2207–2219. [Google Scholar] [CrossRef]
- Luz, A.E.O.; Negri, R.G.; Massi, K.G.; Colnago, M.; Silva, E.A.; Casaca, W. Mapping Fire Susceptibility in the Brazilian Amazon Forests Using Multitemporal Remote Sensing and Time-Varying Unsupervised Anomaly Detection. Remote Sens. 2022, 14, 2429. [Google Scholar] [CrossRef]
- Hamunyela, E.; Brandt, P.; Shirima, D.; Do, H.T.T.; Herold, M.; Roman-Cuesta, R.M. Space-time detection of deforestation, forest degradation and regeneration in montane forests of Eastern Tanzania. Int. J. Appl. Earth Obs. Geoinf. 2020, 88, 102063. [Google Scholar] [CrossRef]
- Dias, M.A.; Silva, E.A.D.; Azevedo, S.C.D.; Casaca, W.; Statella, T.; Negri, R.G. An Incongruence-Based Anomaly Detection Strategy for Analyzing Water Pollution in Images from Remote Sensing. Remote Sens. 2020, 12, 43. [Google Scholar] [CrossRef]
- Nasrabadi, N.M. Hyperspectral target detection: An overview of current and future challenges. IEEE Signal Process. Mag. 2013, 31, 34–44. [Google Scholar] [CrossRef]
- Manolakis, D.; Shaw, G. Detection algorithms for hyperspectral imaging applications. IEEE Signal Process. Mag. 2002, 19, 29–43. [Google Scholar] [CrossRef]
- Kim, S.; Choi, K.; Choi, H.S.; Lee, B.; Yoon, S. Towards a Rigorous Evaluation of Time-Series Anomaly Detection. In Proceedings of the AAAI Conference on Artificial Intelligence, Palo Alto, CA, USA, 22 February–1 March 2022; Volume 36, pp. 7194–7201. [Google Scholar]
- Bishop, C.M. Pattern Recognition and Machine Learning, 1st ed.; Springer: New York, NY, USA, 2007. [Google Scholar]
- Webb, A.R.; Copsey, K.D. Statistical Pattern Recognition, 3rd ed.; John Wiley & Sons Ltd.: Hoboken, NJ, USA, 2011. [Google Scholar] [CrossRef]
- Negri, R.G.; Frery, A.C.; Casaca, W.; Azevedo, S.; Dias, M.A.; Silva, E.A.; Alcântara, E.H. Spectral–Spatial-Aware Unsupervised Change Detection With Stochastic Distances and Support Vector Machines. IEEE Trans. Geosci. Remote Sens. 2021, 59, 2863–2876. [Google Scholar] [CrossRef]
- Yan, J.; Wang, X. Unsupervised and semi-supervised learning: The next frontier in machine learning for plant systems biology. Plant J. 2022, 111, 1527–1538. [Google Scholar] [CrossRef]
- Akoglu, L.; Tong, H.; Koutra, D. Graph based anomaly detection and description: A survey. Data Min. Knowl. Discov. 2015, 29, 626–688. [Google Scholar] [CrossRef]
- Zhang, J.; Roy, D.; Devadiga, S.; Zheng, M. Anomaly detection in MODIS land products via time series analysis. Geo-Spat. Inf. Sci. 2007, 10, 44–50. [Google Scholar] [CrossRef]
- Alvera-Azcárate, A.; Sirjacobs, D.; Barth, A.; Beckers, J.M. Outlier detection in satellite data using spatial coherence. Remote Sens. Environ. 2012, 119, 84–91. [Google Scholar] [CrossRef]
- Gu, J.; Wang, L.; Wang, H.; Wang, S. A novel approach to intrusion detection using SVM ensemble with feature augmentation. Comput. Secur. 2019, 86, 53–62. [Google Scholar] [CrossRef]
- Dereszynski, E.W.; Dietterich, T.G. Spatiotemporal models for data-anomaly detection in dynamic environmental monitoring campaigns. ACM Trans. Sens. Netw. (TOSN) 2011, 8, 1–36. [Google Scholar] [CrossRef]
- Ananias, P.H.M.; Negri, R.G.; Dias, M.A.; Silva, E.A.; Casaca, W. A Fully Unsupervised Machine Learning Framework for Algal Bloom Forecasting in Inland Waters Using MODIS Time Series and Climatic Products. Remote Sens. 2022, 14, 4283. [Google Scholar] [CrossRef]
- Ma, H.; Hu, Y.; Shi, H. Fault detection and identification based on the neighborhood standardized local outlier factor method. Ind. Eng. Chem. Res. 2013, 52, 2389–2402. [Google Scholar] [CrossRef]
- Hoyle, B.; Rau, M.M.; Paech, K.; Bonnett, C.; Seitz, S.; Weller, J. Anomaly detection for machine learning redshifts applied to SDSS galaxies. Mon. Not. R. Astron. Soc. 2015, 452, 4183–4194. [Google Scholar] [CrossRef]
- SchÖlkopf, B.; Smola, A.J. Learning with Kernels: Support Vector Machines, Regularization, Optimization, and Beyond; Adaptive computation and machine learning; MIT Press: Cambridge, MA, USA, 2002. [Google Scholar]
- Liu, F.T.; Ting, K.M.; Zhou, Z.H. Isolation forest. In Proceedings of the 2008 Eighth IEEE International Conference on Data Mining, Pisa, Italy, 15–19 December 2008; pp. 413–422. [Google Scholar]
- Rembold, F.; Atzberger, C.; Savin, I.; Rojas, O. Using low resolution satellite imagery for yield prediction and yield anomaly detection. Remote Sens. 2013, 5, 1704–1733. [Google Scholar] [CrossRef]
- Ananias, P.H.M.; Negri, R.G. Anomalous behaviour detection using one-class support vector machine and remote sensing images: A case study of algal bloom occurrence in inland waters. Int. J. Digit. Earth 2021, 14, 921–942. [Google Scholar] [CrossRef]
- Shawe-Taylor, J.; Cristianini, N. Kernel Methods for Pattern Analysis; Cambridge University Press: Cambridge, UK, 2004. [Google Scholar]
- Li, S.; Zhang, K.; Duan, P.; Kang, X. Hyperspectral anomaly detection with kernel isolation forest. IEEE Trans. Geosci. Remote Sens. 2019, 58, 319–329. [Google Scholar] [CrossRef]
- Alonso-Sarria, F.; Valdivieso-Ros, C.; Gomariz-Castillo, F. Isolation forests to evaluate class separability and the representativeness of training and validation areas in land cover classification. Remote Sens. 2019, 11, 3000. [Google Scholar] [CrossRef]
- Lesouple, J.; Baudoin, C.; Spigai, M.; Tourneret, J.Y. Generalized isolation forest for anomaly detection. Pattern Recognit. Lett. 2021, 149, 109–119. [Google Scholar] [CrossRef]
- Havil, J. Gamma: Exploring Euler’s constant. Aust. Math. Soc. 2003, 250. Available online: http://www.jstor.org/stable/j.ctt7sd75 (accessed on 3 March 2023).
- Moreira, R.D.C. Influência do Posicionamento e da Largura de Bandas de Sensores Remotos e dos Efeitos Atmosféricos na Determinação de índices de Vegetação. Master’s Thesis, Instituto Nacional de Pesquisas Espaciais, São José dos Campos, Brazil, 2000; 181p. [Google Scholar]
- Kaur, R.; Pandey, P. A review on spectral indices for built-up area extraction using remote sensing technology. Arab. J. Geosci. 2022, 15, 1–22. [Google Scholar] [CrossRef]
- Rouse, J.W.; Haas, R.H.; Schell, J.A.; Deering, D.W. Monitoring vegetation systems in the Great Plains with ERTS. NASA Spec. Publ. 1974, 351, 309. [Google Scholar]
- Xue, J.; Su, B. Significant Remote Sensing Vegetation Indices: A Review of Developments and Applications. J. Sens. 2017, 2017, 1353691:1–1353691:17. [Google Scholar] [CrossRef]
- Gao, B.C. NDWI—A normalized difference water index for remote sensing of vegetation liquid water from space. Remote Sens. Environ. 1996, 58, 257–266. [Google Scholar] [CrossRef]
- Ceccato, P.; Gobron, N.; Flasse, S.; Pinty, B.; Tarantola, S. Designing a spectral index to estimate vegetation water content from remote sensing data: Part 1: Theoretical approach. Remote Sens. Environ. 2002, 82, 188–197. [Google Scholar] [CrossRef]
- Glenn, E.P.; Nagler, P.L.; Huete, A.R. Vegetation index methods for estimating evapotranspiration by remote sensing. Surv. Geophys. 2010, 31, 531–555. [Google Scholar] [CrossRef]
- Sow, M.; Mbow, C.; Hély, C.; Fensholt, R.; Sambou, B. Estimation of Herbaceous Fuel Moisture Content Using Vegetation Indices and Land Surface Temperature from MODIS Data. Remote Sens. 2013, 5, 2617–2638. [Google Scholar] [CrossRef]
- Zeng, J.; Zhang, R.; Qu, Y.; Bento, V.A.; Zhou, T.; Lin, Y.; Wu, X.; Qi, J.; Shui, W.; Wang, Q. Improving the drought monitoring capability of VHI at the global scale via ensemble indices for various vegetation types from 2001 to 2018. Weather Clim. Extrem. 2022, 35, 100412. [Google Scholar] [CrossRef]
- Gorelick, N.; Hancher, M.; Dixon, M.; Ilyushchenko, S.; Thau, D.; Moore, R. Google Earth Engine: Planetary-scale geospatial analysis for everyone. Remote Sens. Environ. 2017, 202, 18–27. [Google Scholar] [CrossRef]
- van Rossum, G.; Drake, F.L. The Python Language Reference Manual; Network Theory Ltd.: Surrey, UK, 2011. [Google Scholar]
- Van Der Walt, S.; Colbert, S.C.; Varoquaux, G. The NumPy array: A structure for efficient numerical computation. Comput. Sci. Eng. 2011, 13, 22. [Google Scholar] [CrossRef]
- McKinney, W. Data structures for statistical computing in Python. In Proceedings of the 9th Python in Science Conference, Austin, TX, USA, 28 June–3 July 2010; Volume 445, pp. 51–56. [Google Scholar]
- Pedregosa, F.; Varoquaux, G.; Gramfort, A.; Michel, V.; Thirion, B.; Grisel, O.; Blondel, M.; Prettenhofer, P.; Weiss, R.; Dubourg, V.; et al. Scikit-learn: Machine learning in Python. J. Mach. Learn. Res. 2011, 12, 2825–2830. [Google Scholar]
- Warmerdam, F. The geospatial data abstraction library. In Open Source Approaches in Spatial Data Handling; Springer: Berlin/Heidelberg, Germany, 2008; pp. 87–104. [Google Scholar]
- GEE-API. Google Earth Engine API. 2022. Available online: https://developers.google.com/earth-engine (accessed on 29 October 2022).
- Congalton, R.G.; Green, K. Assessing the Accuracy of Remotely Sensed Data; CRC Press: Boca Raton, FL, USA, 2009; p. 183. [Google Scholar]
- Rijsbergen, C.J.V. Information Retrieval, 2nd ed.; Butterworth-Heinemann: Ann Arbor, MI, USA, 1979. [Google Scholar]
- IBGE. Monitoramento da Cobertura e Uso da Terra. 2022. Available online: https://www.ibge.gov.br/geociencias/cartas-e-mapas/informacoes-ambientais/15831-cobertura-e-uso-da-terra-do-brasil.html (accessed on 29 October 2022).
- Brovelli, M.A.; Sun, Y.; Yordanov, V. Monitoring Forest Change in the Amazon Using Multi-Temporal Remote Sensing Data and Machine Learning Classification on Google Earth Engine. ISPRS Int. J. Geo-Inf. 2020, 9, 580. [Google Scholar] [CrossRef]
- Nakalembe, C.; Becker-Reshef, I.; Bonifacio, R.; Hu, G.; Humber, M.L.; Justice, C.J.; Keniston, J.; Mwangi, K.; Rembold, F.; Shukla, S.; et al. A review of satellite-based global agricultural monitoring systems available for Africa. Glob. Food Secur. 2021, 29, 100543. [Google Scholar] [CrossRef]
- FG Assis, L.F.; Ferreira, K.R.; Vinhas, L.; Maurano, L.; Almeida, C.; Carvalho, A.; Rodrigues, J.; Maciel, A.; Camargo, C. TerraBrasilis: A spatial data analytics infrastructure for large-scale thematic mapping. ISPRS Int. J. Geo-Inf. 2019, 8, 513. [Google Scholar] [CrossRef]
- Wang, X.; Liu, S.; Du, P.; Liang, H.; Xia, J.; Li, Y. Object-Based Change Detection in Urban Areas from High Spatial Resolution Images Based on Multiple Features and Ensemble Learning. Remote Sens. 2018, 10, 276. [Google Scholar] [CrossRef]
- Zhu, X.; Cai, F.; Tian, J.; Williams, T.K.A. Spatiotemporal Fusion of Multisource Remote Sensing Data: Literature Survey, Taxonomy, Principles, Applications, and Future Directions. Remote Sens. 2018, 10, 527. [Google Scholar] [CrossRef]
- Wang, X.; Zhang, J.; Xun, L.; Wang, J.; Wu, Z.; Henchiri, M.; Zhang, S.; Zhang, S.; Bai, Y.; Yang, S.; et al. Evaluating the Effectiveness of Machine Learning and Deep Learning Models Combined Time-Series Satellite Data for Multiple Crop Types Classification over a Large-Scale Region. Remote Sens. 2022, 14, 2341. [Google Scholar] [CrossRef]
- Jiang, H.; Peng, M.; Zhong, Y.; Xie, H.; Hao, Z.; Lin, J.; Ma, X.; Hu, X. A Survey on Deep Learning-Based Change Detection from High-Resolution Remote Sensing Images. Remote Sens. 2022, 14, 1552. [Google Scholar] [CrossRef]
- Pătru-Stupariu, I.; Nita, A. Impacts of the European Landscape Convention on interdisciplinary and transdisciplinary research. Landsc. Ecol. 2022, 37, 1211–1225. [Google Scholar] [CrossRef]













Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Gino, V.L.S.; Negri, R.G.; Souza, F.N.; Silva, E.A.; Bressane, A.; Mendes, T.S.G.; Casaca, W. Integrating Unsupervised Machine Intelligence and Anomaly Detection for Spatio-Temporal Dynamic Mapping Using Remote Sensing Image Series. Sustainability 2023, 15, 4725. https://doi.org/10.3390/su15064725
Gino VLS, Negri RG, Souza FN, Silva EA, Bressane A, Mendes TSG, Casaca W. Integrating Unsupervised Machine Intelligence and Anomaly Detection for Spatio-Temporal Dynamic Mapping Using Remote Sensing Image Series. Sustainability. 2023; 15(6):4725. https://doi.org/10.3390/su15064725
Chicago/Turabian StyleGino, Vinícius L. S., Rogério G. Negri, Felipe N. Souza, Erivaldo A. Silva, Adriano Bressane, Tatiana S. G. Mendes, and Wallace Casaca. 2023. "Integrating Unsupervised Machine Intelligence and Anomaly Detection for Spatio-Temporal Dynamic Mapping Using Remote Sensing Image Series" Sustainability 15, no. 6: 4725. https://doi.org/10.3390/su15064725
APA StyleGino, V. L. S., Negri, R. G., Souza, F. N., Silva, E. A., Bressane, A., Mendes, T. S. G., & Casaca, W. (2023). Integrating Unsupervised Machine Intelligence and Anomaly Detection for Spatio-Temporal Dynamic Mapping Using Remote Sensing Image Series. Sustainability, 15(6), 4725. https://doi.org/10.3390/su15064725