1. Introduction
The growth of cities has led to an increase in noise levels, which affects people’s health at different levels. This phenomenon has been analyzed in different cities around the world, such as New York [
1], Guangzhou [
2], Sambalpur [
3], and other cities in China [
4] and Europe [
5], where there is increasing concern about this kind of pollution. In this way, reducing noise pollution in the built environment aligns with some of the UN’s Sustainable Development Goals [
6], especially Goals 3 (“
ensure healthy lives and promote well-being for all at all ages”) and 11 (“
make cities and human settlements inclusive, safe, resilient and sustainable”). Thus, many countries aim to promote sustainable land-use planning and management and promote sustainable industrial activities.
In order to create high-quality urban settings in response to societal, environmental, and economic concerns, such as noise pollution, it is crucial to consider the built environment’s quality [
7,
8]. Environmental acoustics addresses urban design for sustainable urban environments by relating mainly to several sub-areas of the earth sciences, life sciences, and engineering. Thus, environmental acoustics is a broad, interdisciplinary topic in which acousticians must collaborate with experts from different fields. Even though environmental acoustics includes all of the sounds in the environment, either natural or artificial, the main concern is those “unwanted sounds” that adversely affect people’s physiological and psychological well-being. These sounds make up environmental noise. In this sense, environmental noise is the unwanted or harmful outdoor sound created by human activity, such as noise emitted through transport, road traffic, rail traffic, air traffic, and industrial activity [
9].
Environmental noise created by artificial sources is not new. Humans are susceptible to sound, especially at night, when the background noise is significantly lower than during the day. Although several examples of environmental noise can be dated back to cities in ancient Greece and Rome, we may set the origin of modern environmental noise to the industrial revolution. This transition from an agrarian and handicraft economy to one dominated by industry and machine manufacturing resulted in technological changes that introduced novel ways of working and living and fundamentally transformed society, particularly in cities. These changes made possible the vastly increased use of natural resources and the mass production of manufactured goods. This process also resulted in populations moving from rural to urban centers, making for larger cities with greater population densities. Therefore, the noise became more intense, and the population exposed to noise increased as well.
On the other hand, the introduction of affordable automobiles at the beginning of the 20th century made cars available to middle-class urban residents. This fact resulted in the construction and expansion of new roads and a massive increase in road traffic flows, which became a significant source of environmental noise in big cities.
There are many different ways to measure and evaluate environmental noise, each typically resulting in a different noise measure, descriptor, or scale [
10]. From these measures and descriptors, criteria have been developed to decide on the acceptable noise levels for different activities.
A critical issue regarding environmental noise is the existence of noise regulations. In general, most countries have elaborated their legislation based on setting the maximum permitted levels in different zones and times of the day. The zones are defined by the local authorities and are related to the use of land, so lower limits are imposed in areas where the use is residential, while higher limits are set for exclusive industrial zones. Some regulations also include limits for rural zones requiring special treatment due to their lower background noise. Lower limits are defined for the night as well to prevent sleep disturbance. Usually, the maximum permitted levels are corrected according to the background noise, the presence of pure tones, and impulsive noise sources.
Real-time noise mapping is currently used in several countries, based on noise-monitoring networks that collect the noise data continuously and transmit it to a data center for further processing. Many of these monitoring networks are public, and people can access information from the internet. Dynamic noise maps are helpful for noise-sensitive areas and buildings, especially in the vicinity of airports, highways, and other primary-noise sources. This information is helpful for urban design in modern cities [
11]. Additionally, continuous monitoring stations are widely used as a part of mitigation plans to monitor excessive construction and entertainment noises in the built environment.
However, the amount of data collected from a noise-monitoring network could be thousands of audio files to be analyzed manually. A trained specialist should carefully listen to each audio file individually to identify and discriminate the presence of prohibited noise sources and levels exceeded by restricted sources from the natural sounds of the environment [
12]. This fact leads to a slow and time-consuming procedure. As a result, it is necessary to optimize the data analysis, which can be achieved by using the current advances in machine learning technology.
Machine learning (ML) technology has evolved rapidly and has found applications in different fields in recent years. Deep learning (DL) is a branch in the field of ML that is focused on training deep artificial neural networks (ANNs) to solve complex pattern-recognition problems [
13]. ANN are bio-inspired mathematical models formed by concatenating layers of simple processing elements called artificial neurons. In practice, the deeper a model is, i.e., the more layers it contains, the more flexibility it has to fit the training data. The remarkable results obtained by DL models have positioned them as the de-facto choice for perception-related problems such as computer vision [
14], speech recognition [
15], and natural language processing [
16]. One crucial challenge is that the deeper the models, the more labeled data are needed to train them effectively. Hence, large, good-quality datasets are critical.
The use of ML techniques in urban noise has been introduced previously. To estimate the energy-equivalent A-weighted sound-pressure level descriptor (LAeq), Torija and Ruiz [
17] investigated three ML regression techniques that are considered very robust in tackling non-linear problems. They also experimented with two feature-selection methods and a data-reduction method. Their study resulted in a proposal of various strategies based on data collection and accuracy requirements. In another study [
18], traffic-noise annoyance models were obtained by applying ML techniques. The study showed that the ML approach, in particular an ANN, performed better than traditional statistical models in producing accurate predictions of the impact of transportation noise in an urban context.
Alvares-Sanches et al. [
19] recently used audio recordings obtained in walking surveys carried out in Southampton, UK, combined with ML, to predict noise levels across the entire city. They claimed that their technique could be suitable for noise data collected by individuals, from noise-monitoring networks, or by structured surveys. In a more recent study, Fredianelli et al. [
20] proposed an ML application for road-traffic noise mapping. They created a system that complies with the standards of the CNOSSOS-EU noise-assessment model [
21] by utilizing inexpensive video cameras and vehicle recognition and a counting procedure using ML approaches. The technique was successfully used in a small Italian city to create noise maps and determine the population exposed to road-traffic noise.
Tasks associated with audio data have had greater visibility thanks to challenges such as DCASE (
https://dcase.community/, accessed on 1 November 2022). Since its first edition in 2013, this challenge has promoted the resolution of tasks such as acoustic-scene classification (ASC), sound-event detection (SED), and audio tagging by implementing deep learning algorithms. Audio tagging is an essential task of audio-pattern recognition, which aims to predict the presence or absence of labeled sound sources in an audio file. Consequently, implementing deep neural network models for audio tagging has yielded promising results in the last few years [
22,
23,
24,
25,
26].
Bianco et al. [
27] comprehensively reviewed the recent advances in ML, including DL, in the field of acoustics. They reported that ML-based methods exhibited better performance than conventional signal-processing techniques despite the fact that they require a large amount of data for testing and training.
The Institutes of Acoustics and Informatics at the College of Engineering Sciences of the University Austral of Chile have been working on a joint project titled “Integrated System for the Analysis of Environmental Sound Sources: FuSA System”. The project is funded through a grant from the Chilean Science Ministry. The project aims to create a machine-learning-based system that automatically recognizes sound sources in audio files recorded in the built environment to assist in their analysis.
In this paper, we present the results of using the tools developed in the FuSA project to analyze the environmental noise recorded at two points in the city of Valdivia, applying the current Chilean environmental noise regulation. The study reported here contributes to efficiently assisting trained experts in enforcing noise legislation through machine-assisted environmental noise monitoring.
3. Results
Table 4 summarizes the results from the audio reduction pipeline described in
Section 2.4. The two monitoring stations recorded 30,240 min during their two-week and one-week operation periods. From this dataset, only 115 min were flagged as surpassing the established sound pressure level, and their corresponding waveforms were uploaded to a database. The FuSA system was then used to obtain class predictions for the 115-min subset. This subset was further reduced to 28 min after applying the persistence filter, i.e., only 28 of the 1-min audio segments contain strong and uninterrupted sound events. In this case, a detection threshold
was used. The distribution of sound events at this stage of the pipeline is given in
Table 5. The last automatic filter selected three 1-min audios, which contain sound events originating from sources where the Chilean noise regulation applies. The detailed metadata of these audios are shown in
Table 6.
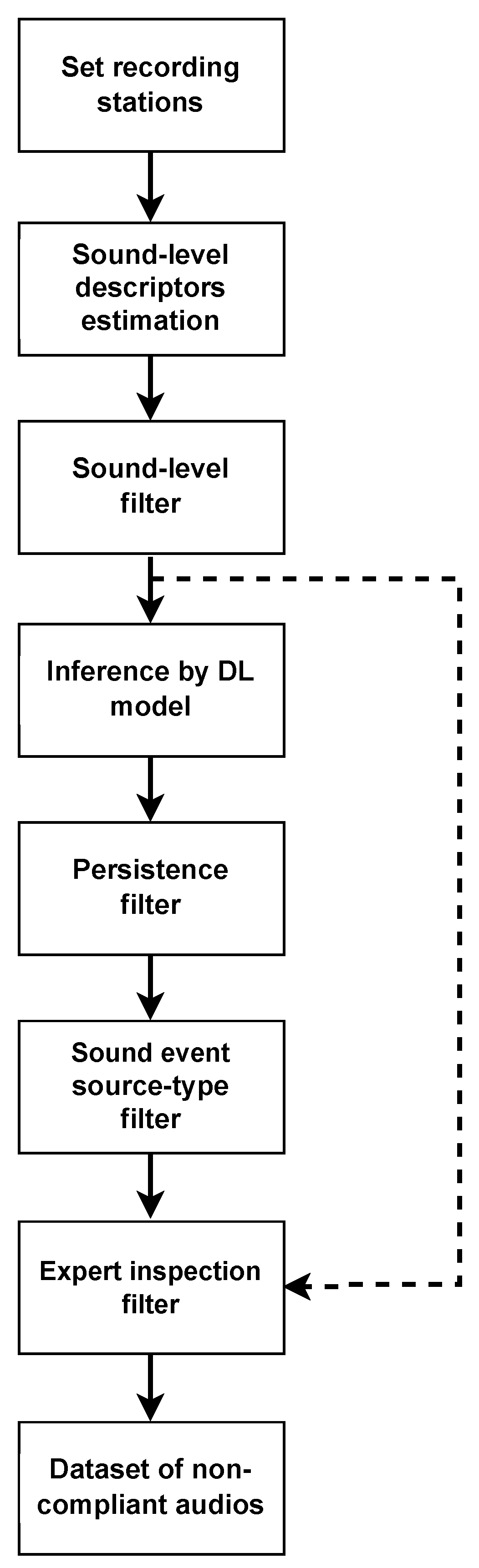
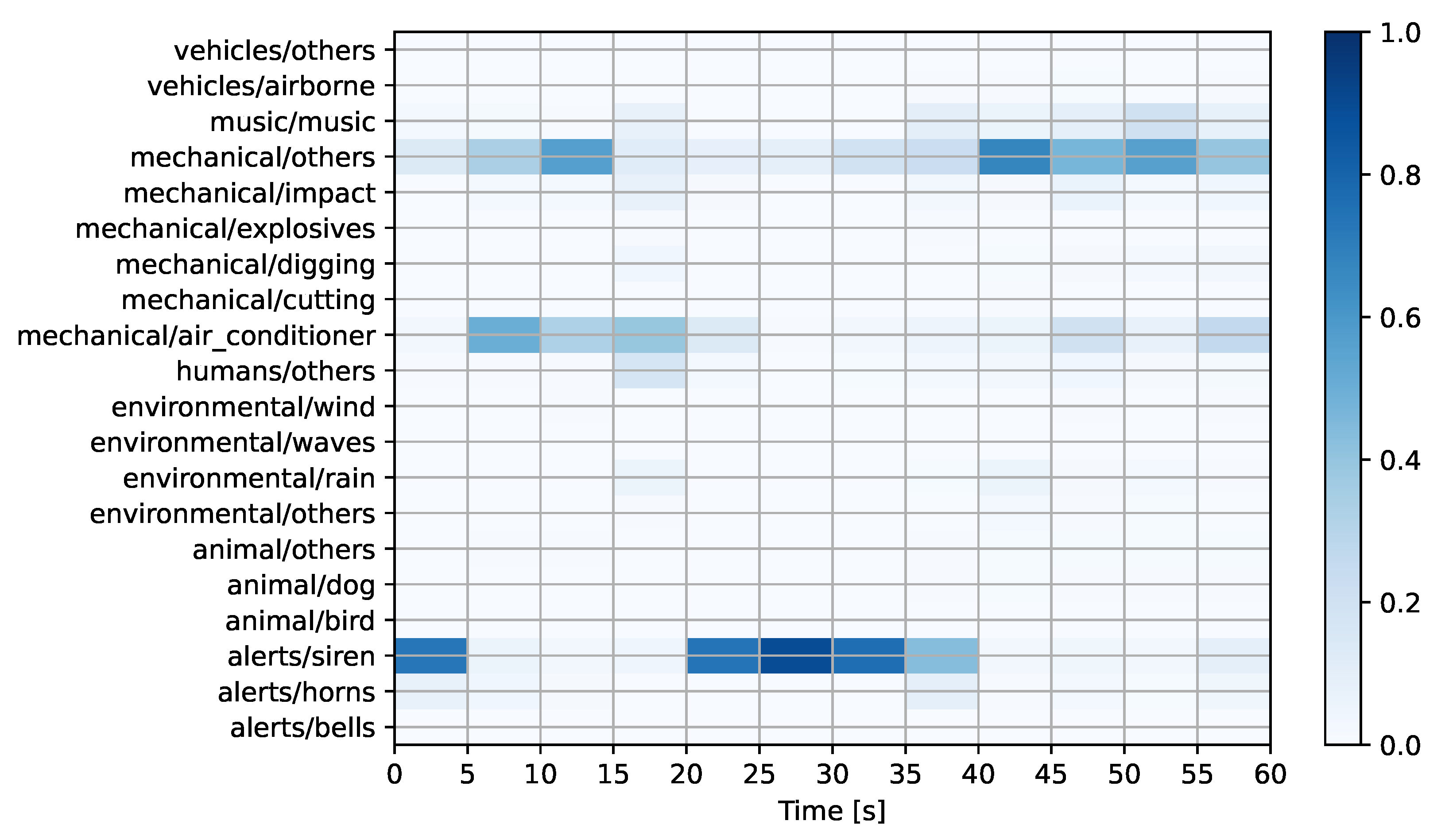
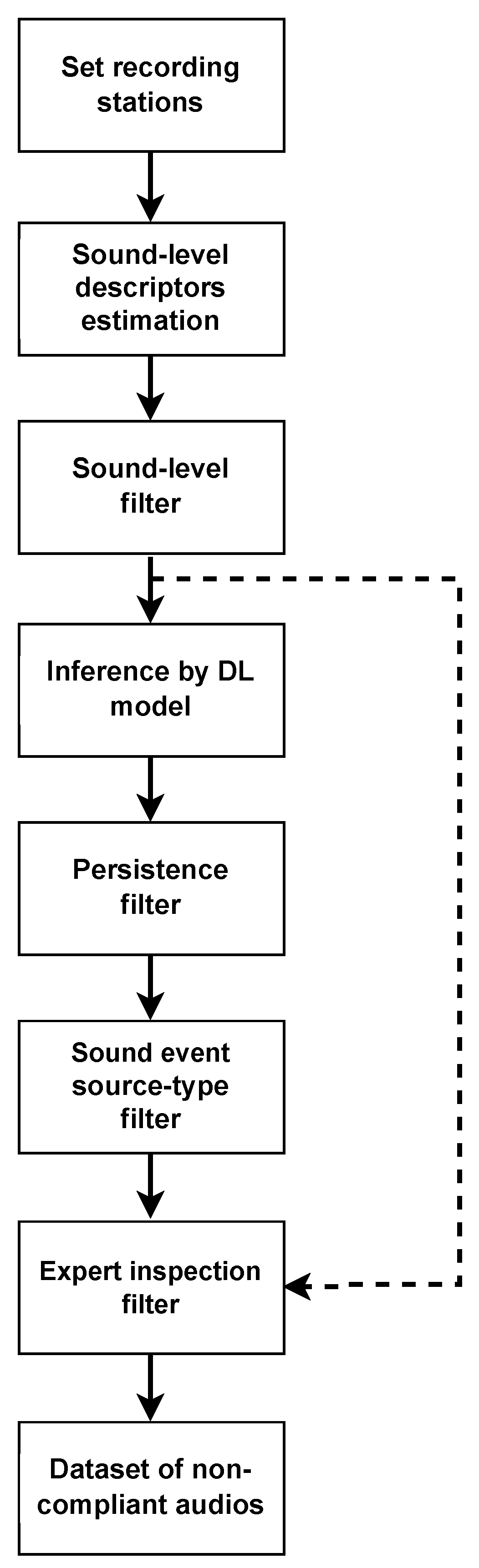
Figure 6,
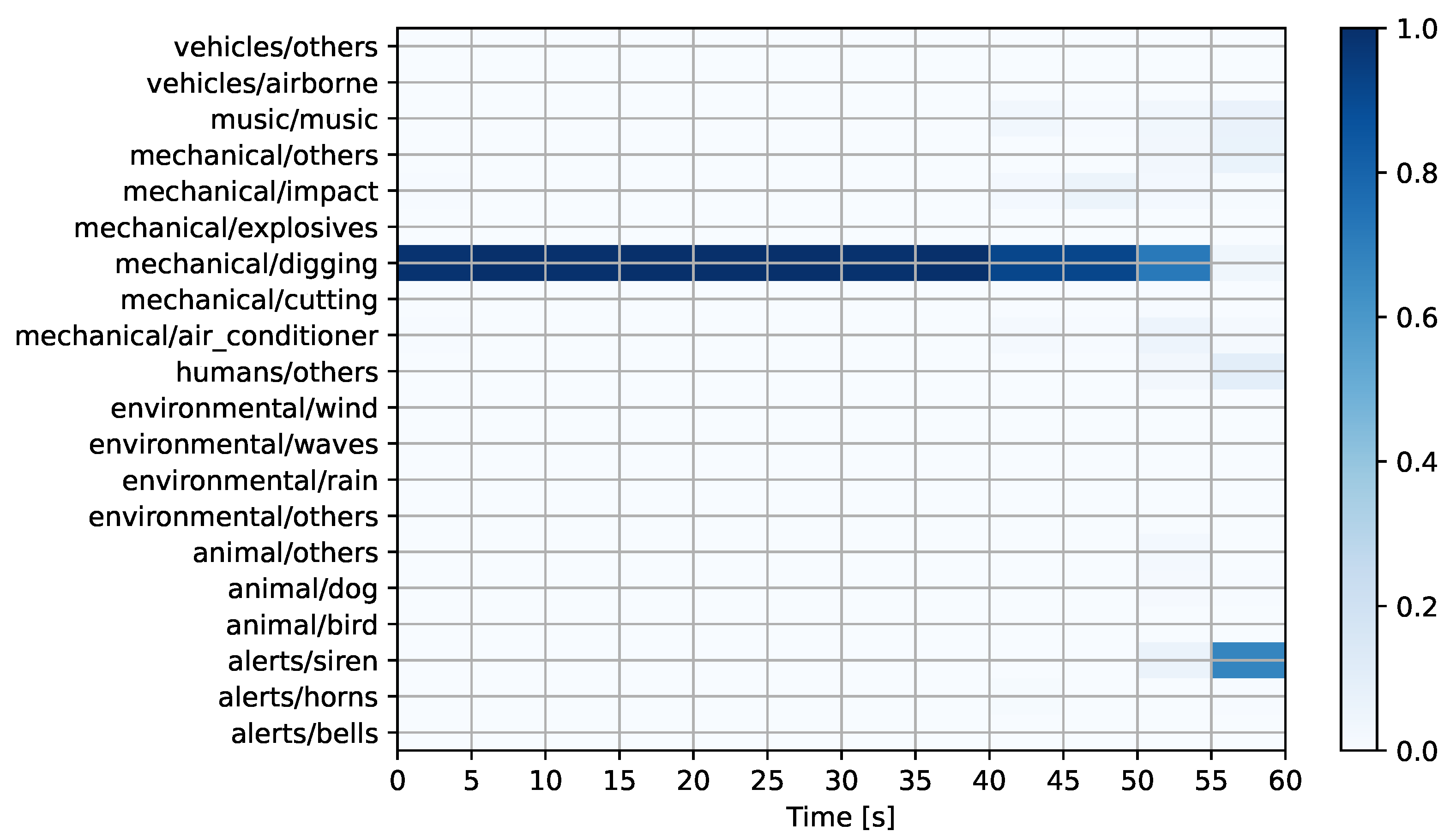
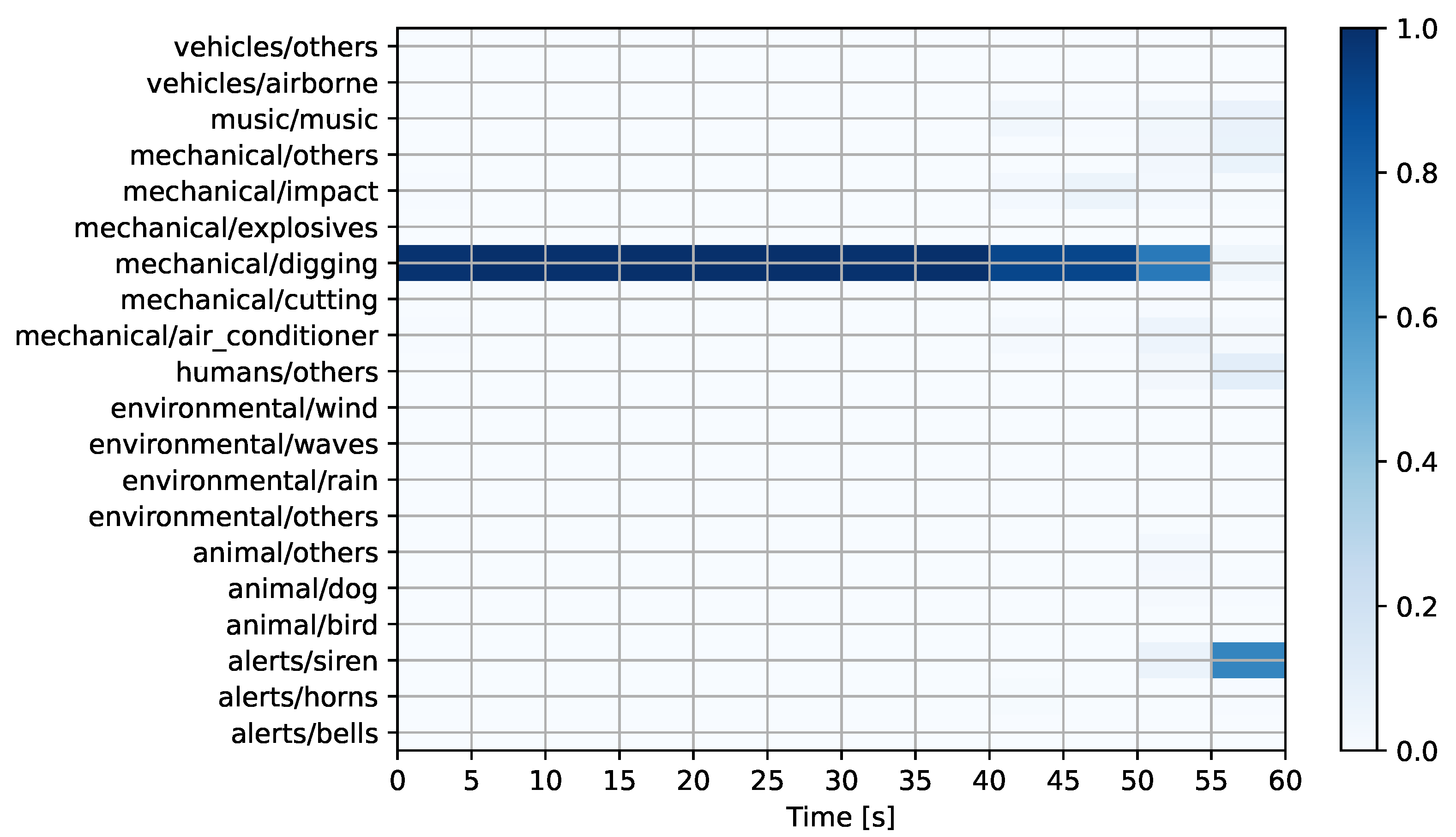
Figure 7 and
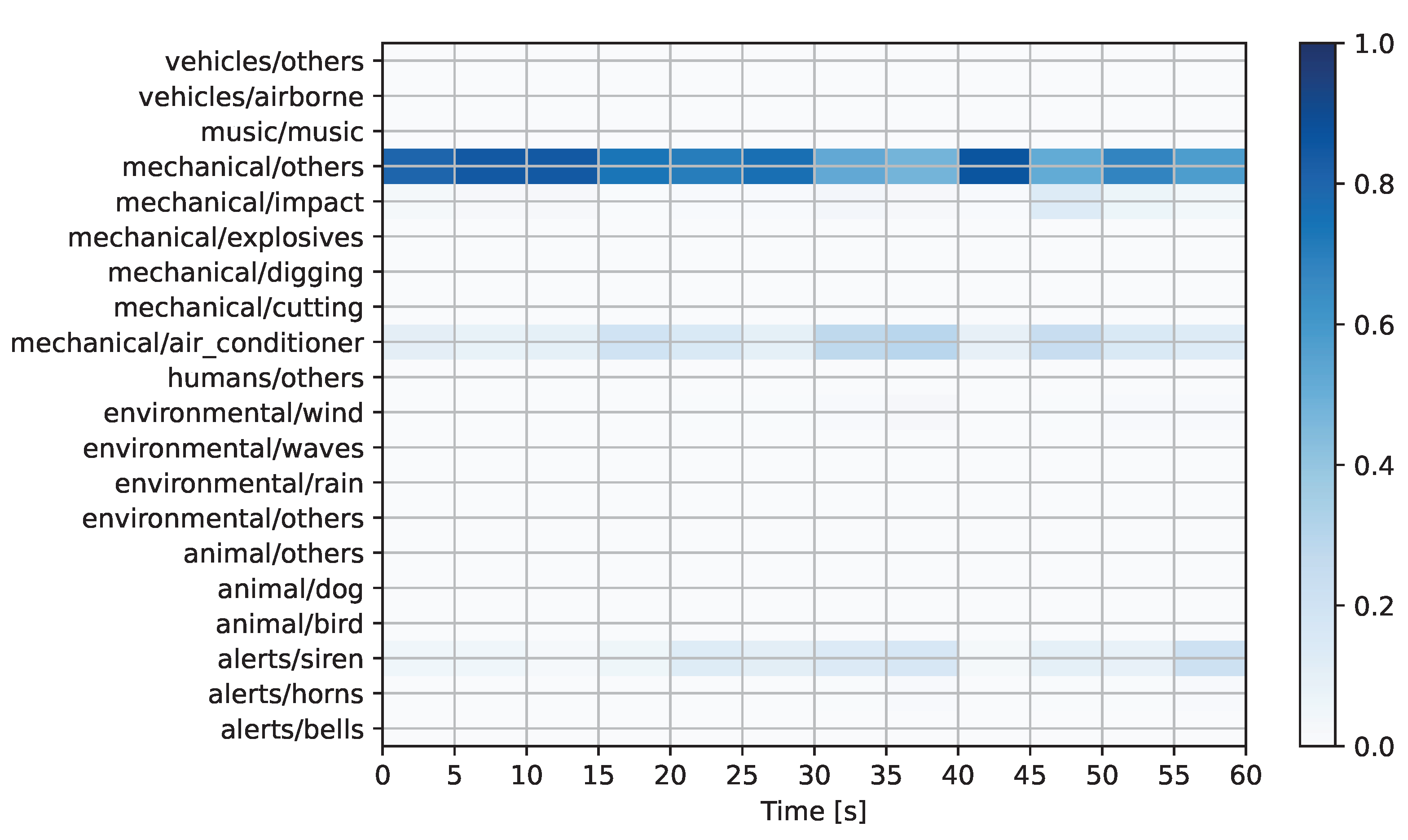
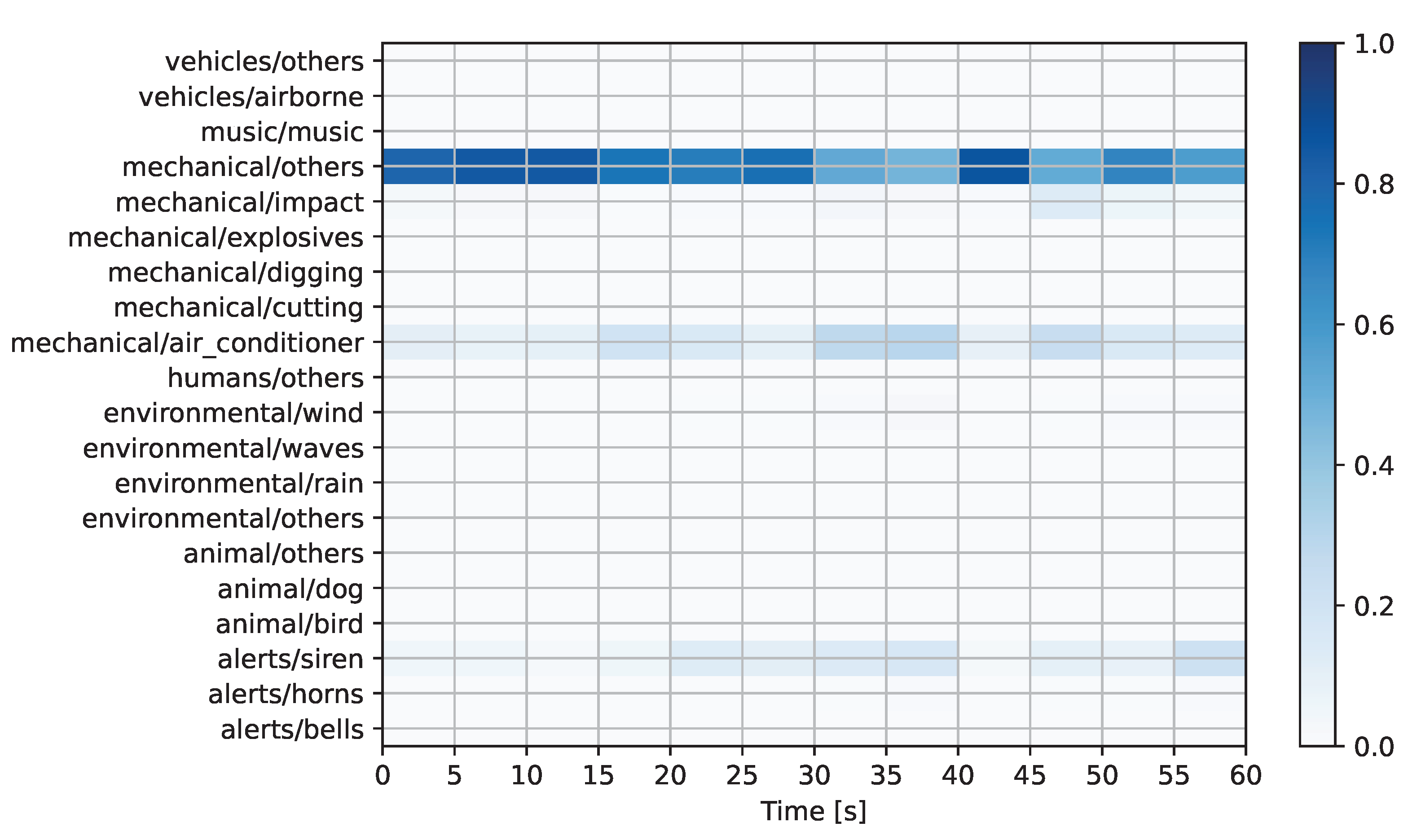
Figure 8 show the prediction matrices corresponding to the automatically detected regulation-offending audio candidates from
Table 6. For the first audio (see
Figure 6), the system predicts a mechanical sound event related to digging activities. This sound event has a high probability, except during the last five seconds of the recording. The accuracy of this prediction was later confirmed upon inspection by experts. For the second audio (see
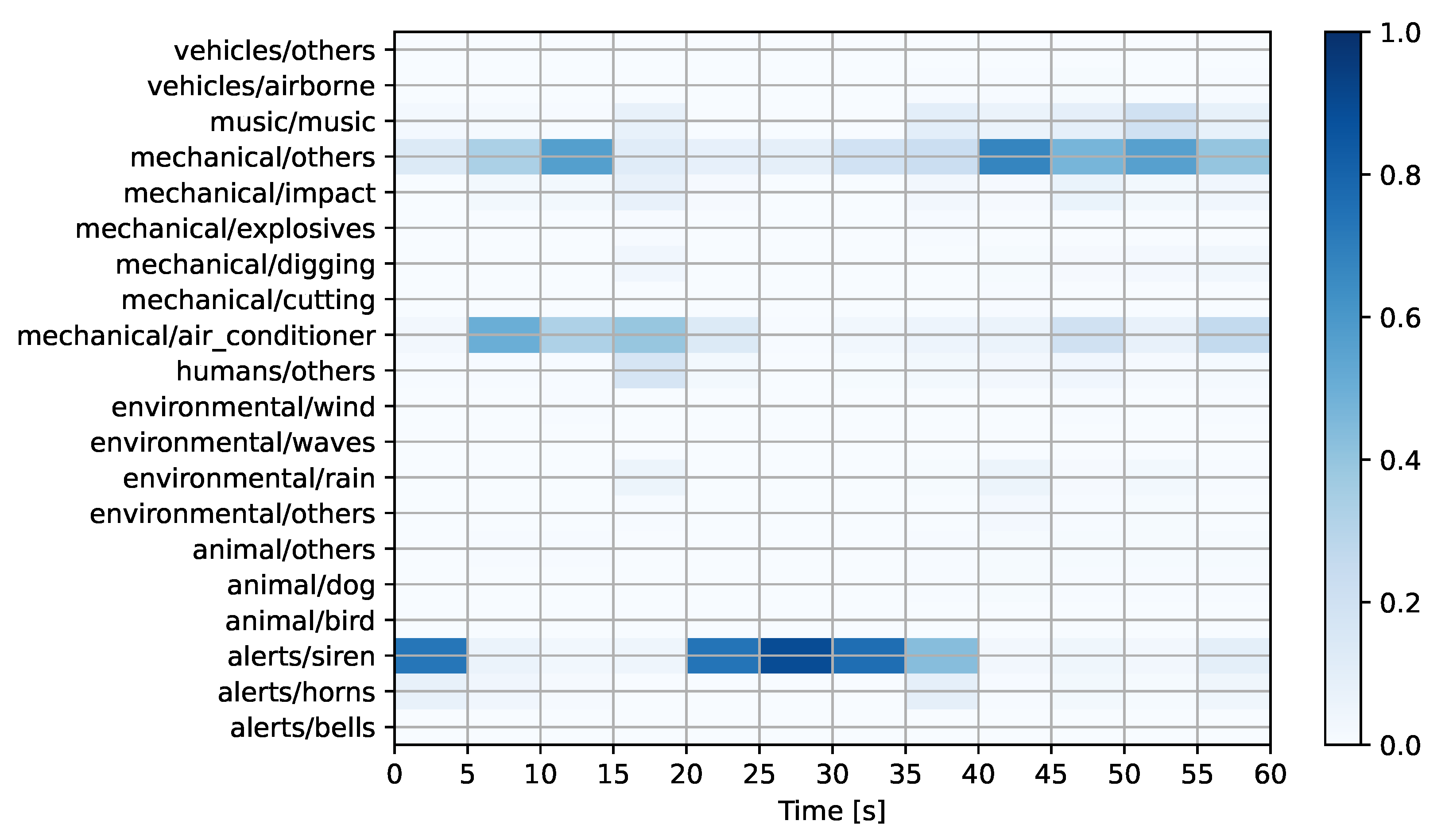
Figure 7), the system predicts a mechanical sound in the “others” category, with minor contributions from the air conditioner and siren classes. Later inspection by experts revealed that the prediction was incorrect as the only discernible events in the recording are of environmental origin (wind and rain). For the third audio (see
Figure 8), the system once again predicts a mechanical sound in the “others” category. In this case, the prediction was accurate as human experts confirmed that the event corresponded to an engine running within a construction site.
The last stage of the pipeline involved experts auditing the model’s predictions by inspecting the outcome of the persistence filter (three audios). In this case, and for completeness, the entire 115-min subset was inspected by a team of trained specialists that labeled audio events following the taxonomy presented in
Table 2. In total, the experts found that three audios of this subset contained the strong and persistent presence of regulation-offending sound events. The performance of the model was then compared to the expert labels (ground-truth), and the results are shown in
Table 7, where:
True positive (TP): A regulation-offending audio correctly detected by the model.
False negative (FN): A regulation-offending audio missed by the model.
False positive (FP): An audio that was incorrectly predicted as regulation-offending.
True negative (TN): An audio that was correctly predicted as non-regulation-offending.
From
Table 7, we can see that for a threshold of
, the model misses one regulation-offending audio while presenting a single false alarm. By decreasing the detection threshold to
, all of the true regulation-offending audios are recovered, but the number of false positives (FPs) increases to three. These FPs (e.g., audio 1654224726 in
Table 6) were predicted by the model as mechanical noise, but according to the experts, their content is dominated by environmental sounds of rain and wind with no discernible traces of mechanical sounds. This fact suggests that the robustness of the model predictions could be improved by collecting, labeling, and training with more audio recordings affected by these weather conditions.
Setting a lower detection threshold enables the correct detection of all of the audios in the dataset that infringe upon the regulations, but at the expense of producing more false alarms. The latter directly impacts the labor of the expert in charge of auditing the model’s prediction. However, we note that, even when accounting for the false positives, the number of audios to be reviewed is significantly lower than the entire 115-min subset. In summary, selecting an appropriate detection threshold depends on the available auditing expert capacity as well as the acceptable detection rates that may be expected or required by authorities.
4. Discussion
We noted that only three audios were selected for human inspection by using the machine-assisted pipeline. Compared to the 115 audio files filtered merely by SPL, this quantity indicates a 97% reduction. As a reference, taking the SINGA:PURA urban sound dataset [
34], which recorded 1092 min of urban sounds, the application of the FuSA system would return a set of audio files of approximately 29 min, to be analyzed by a trained specialist. As a result, the expert only needs to examine 29 audio files individually rather than 1092. The latter is a significant reduction in the number of audio files to be examined for regulatory purposes. Filtering audio only by SPL does not exclude sound events that do not fall into the categories considered in the regulation, for example, environmental or nature sounds (see
Table 3). The manual evaluation of the audio recordings is a laborious, time-consuming operation with minimal efficiency since many audios exceeding the SPL threshold do not correspond to a sound event considered by the regulation.
Taking the above example, a coarse estimation of the time required for this task can be made. Supposing that a human expert needs at least one minute to decide on each audio file, using the conventional methodology, it would take at least 18 hours to analyze the entire dataset. However, with the help of machine learning technology, an equivalent result can be obtained in only about half an hour. Note that the time required to infer the classes for one minute of audio using the neural network is on the order of milliseconds using a single GPU co-processor. This inference time can be further reduced by increasing the hardware capacity.
Performing large-scale out-of-norm detection should be developed further in smart cities. If compliance with environmental noise regulations were automated, it would significantly reduce costs and resources, driving sustainability in cities. Under this scenario, to carry out the inspection, it would only be necessary for the noise measurement stations to be connected to the automatic-noise-source-recognition system and to associate the noise levels with the emissions of the regulated sources. The goal is to improve active real-time noise emissions’ compliance significantly and, as a result, regulatory compliance, which would benefit all stakeholders. First, it would benefit noise-emitting sources as they could better plan their environmental management measures. Second, it would benefit all citizens, who would be protected as the regulation would be widely followed. Finally, it would benefit the authorities because they could enforce the regulations efficiently and timely, thanks to the neural network-based system.
A significant challenge for applying the proposed methodology in other situations is assuring that FuSA’s deep learning model can generalize effectively. As with machine learning applications in general, the generalization capability of a model is limited by how well the training dataset represents the scenario in which the model will be operating. In the case presented here, the FuSA model was trained using data collected from the city of Valdivia using specific recording hardware and settings. If the class distribution changes drastically (e.g., applying the trained model in a city of different characteristics), we would expect a decrease in the model’s performance. This problem may be addressed using transfer learning methodologies, i.e., using a relatively small number of labeled examples from the new scenario (target) to continue fine-tuning the model from the original scenario (source) [
26,
30].
Future work might use specific technological and methodological developments. The data’s traceability is one crucial example (measurements). Progress must be made in data traceability to ensure there are no risks of data tampering. This issue arises because a certifying officer is responsible for determining whether or not the audited noise source complies with the regulations. Therefore, it would be necessary to devise a system to ensure or attest that the audio recordings and measurements (noise levels) correspond to the audited noise source.
Data privacy is another issue to be addressed. A privacy protection mechanism should be established, especially with speech-related sounds (conversations). The same artificial neural network system should establish a different treatment for audio recordings with human voices or other sounds that may compromise people’s privacy. However, this conflict exists today, as the expert must listen to each of the analyzed recordings.
5. Conclusions and Future Work
Noise sources in urban areas are regulated to operate only at a certain level of intensity and for a limited amount of time. In the regulation process, various stakeholders work together to keep noise pollution at acceptable levels. Collecting information as audio recordings to enforce the regulation is essential. Several monitoring stations are installed at specific city points for this purpose. However, a significantly associated challenge is the large volume of data that must be examined by trained specialists (listening to the audio files one by one). This fact leads to a very high demand for various resources to carry out the work of noise regulation. In this sense, the machine learning tools developed in the FuSA project for environmental noise analysis are presented, applying the current Chilean regulation on environmental noise. The system proved helpful for this purpose, and the number of audio files that required expert analysis was reduced by 97% by using machine learning.
Audio recordings containing significant wind and rain sound affected the system’s performance. Thus, the robustness of the model predictions could be improved by collecting, labeling, and training it with more audio recordings affected by environmental conditions.
The model’s performance relies upon the detection threshold defined in the persistence filter. The correct detection of all of the regulation-infringing audios in the dataset was achieved by setting a lower detection threshold. However, a threshold reduction produces more false alarms. Thus, selecting an appropriate detection threshold depends on the available expert auditing capacity and the acceptable detection rates that may be expected or required by authorities.
The use of additional monitoring stations distributed throughout the city is intended as further work. As part of action plans to reduce noise pollution, the FuSA system is also expected to help keep track of strictly regulated environmental noise sources at sensitive receivers.
Finally, it is anticipated that machine learning methods will continue to be encouraged. Their implementation in the pertinent public services and environmental noise inspections could optimize the procedures for securing the urban environment from the effects of noise; protecting public health; and reducing noise pollution.




 ,
, 



{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}