
Developing Chatbots for Cyber Security: Assessing Threats through Sentiment Analysis on Social Media



Abstract
:1. Introduction
- RQ1. What are the different types of chatbots and chatbot tools available to counter or neutralize cybersecurity threats that target human vulnerabilities?
- RQ2. How can chatbots be developed and tested for cybersecurity using social media?
- RQ3. How can one assess these chatbots and their effectiveness for cybersecurity on Twitter?
2. Background and Related Work
3. Methods and Data Analysis
3.1. Development and Deployment of the Chatbot
3.2. Sentiment Analysis
3.2.1. Data Collection
3.2.2. Data Pre-Processing
- (a)
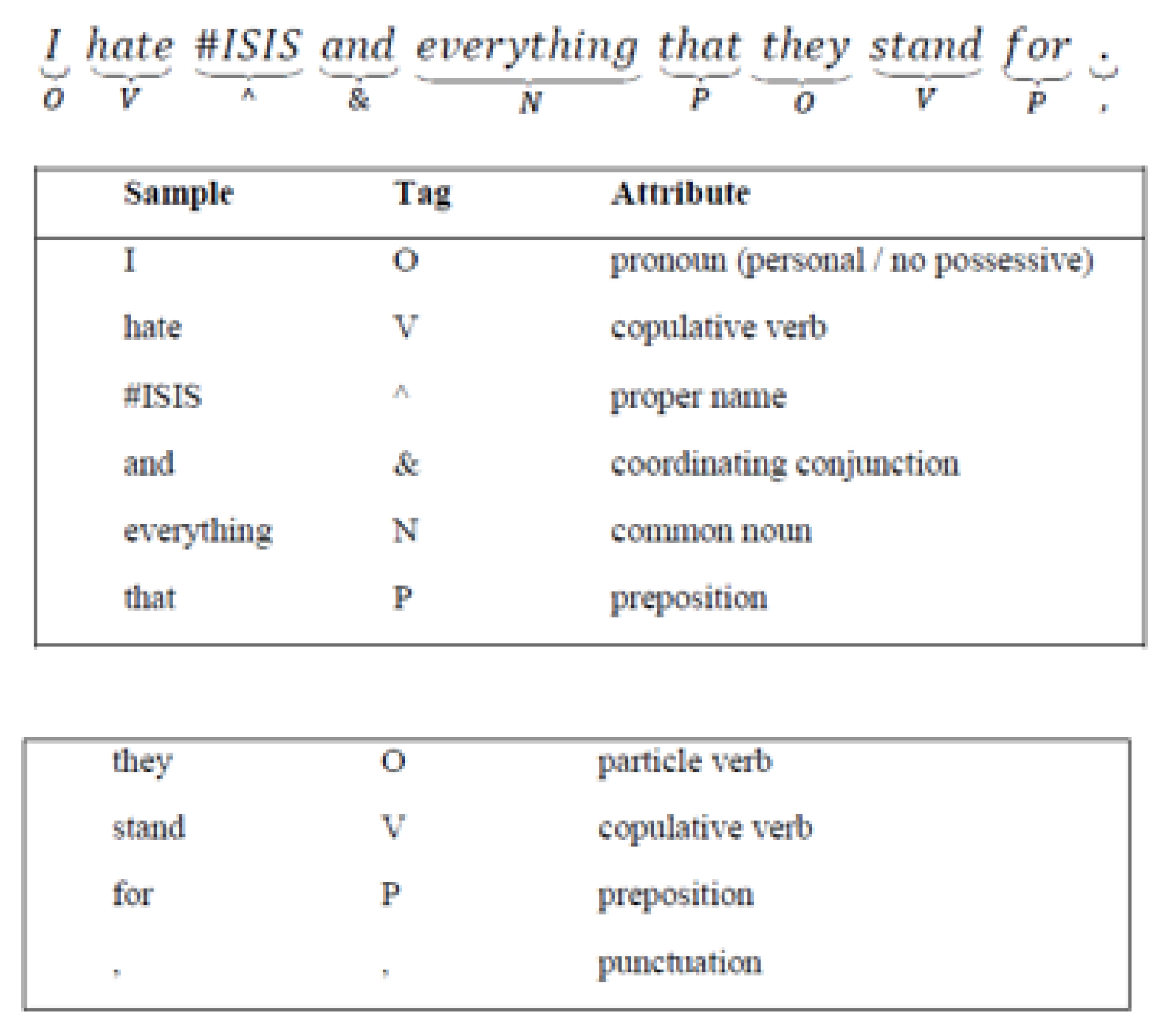
- Speech tagging is a process of assigning a specific tag to each word in the corpus of tweets. These tags divide the textual data, e.g., tweets, into verbs, adverbs, nouns, adjectives, etc., which can be used as potential markers to determine the polarity (or sentiment) of tweets. The polarity (or sentiment) can be positive, neutral, or negative. Exclamation marks, question marks, and emoticons are also considered for determining polarity. The tags utilized in this study are an optimized version of Penn Treebank’s compendium [31]. Below is an example of the speech tagging of a sample tweet [8] (Figure 2).
- (b)
- Next, we focus on the removal of noise from data. Sometimes, tweets may include text and other markers that seem to be unrelated to the expressed sentiment, which need to be removed before data analysis. Noise in twitter data may be in the form of URLs, replies to other users, retweets, and common stop words which do not add value to the meaning of a tweet [8,32]. To eliminate these occurrences, a noise removal procedure is used which includes the removal of @mentions, symbols such as ‘#’ and ‘:’, and hyperlinks. Pre-processing of the corpus of tweets also included removing retweets (or reposts of original tweets). Each tweet in the corpus has a unique identification number which is retained each time the original one is retweeted.
- (c)
- Lemmatization is the process of obtaining lemmas of words from the corpus of tweets. A lemma is a word as it is presented in a dictionary. For example, the lemma for the words ‘run’, ‘ran’, ‘running’, ‘runs’ is run. In TextBlob, the lemmatization process is based on WordNet developed by Princeton University [33] which is an open-source database.
3.2.3. Sentiment Extraction
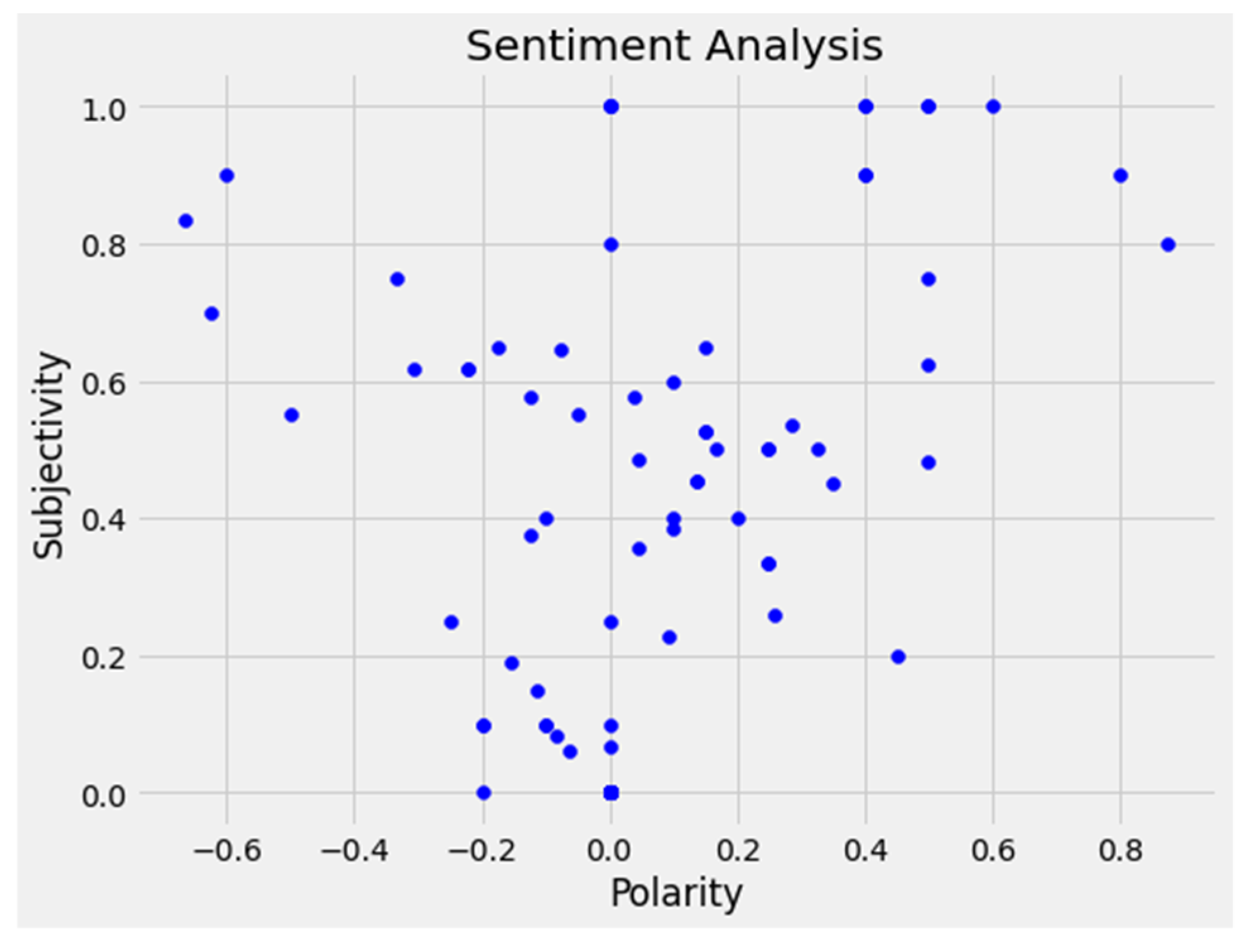
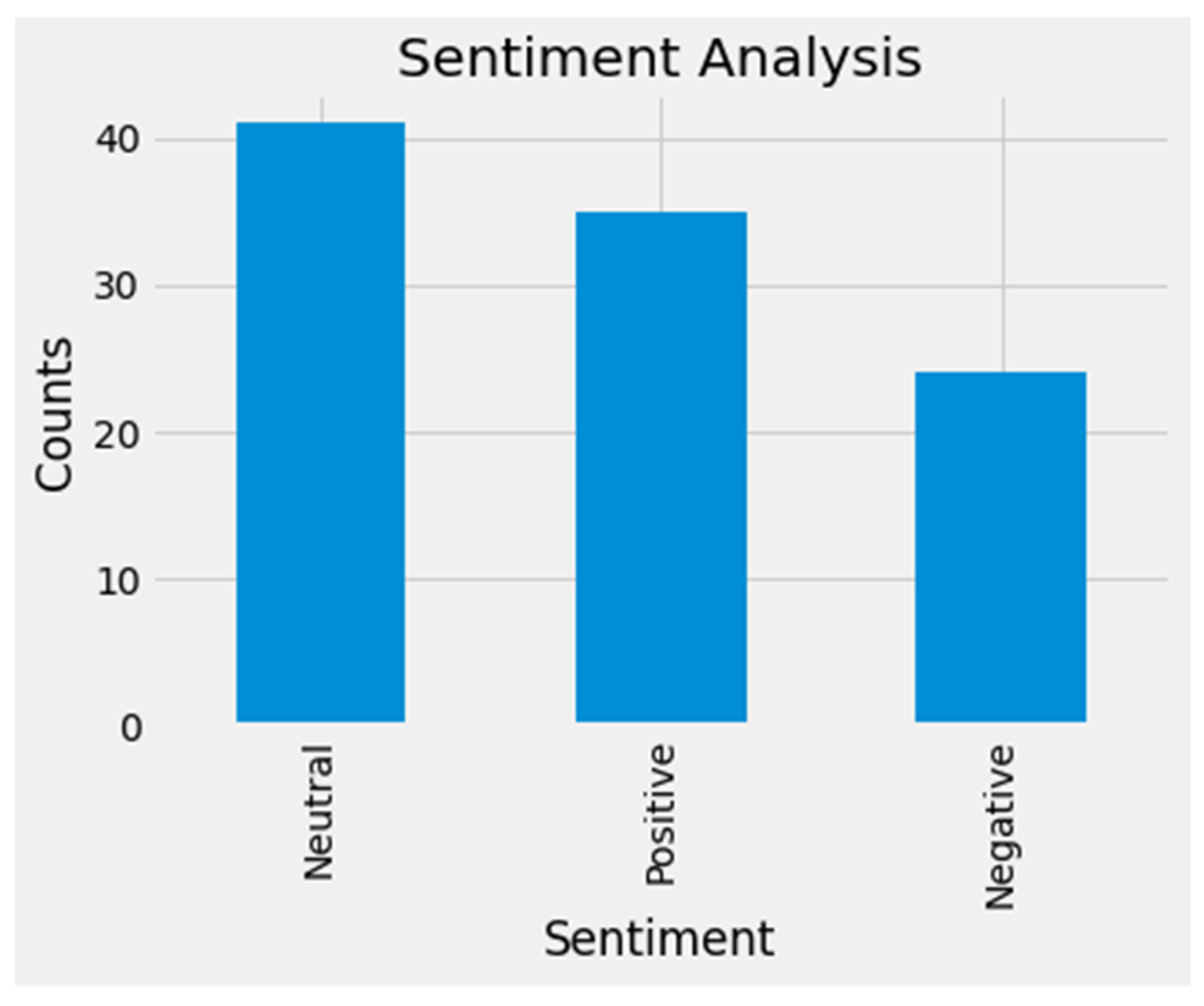
3.2.4. Sentiment Orientation and Analysis
4. General Discussion
- Which AI-related technological advancements are better suited to promote environmental, economic, and social sustainability for global organizations?
- To what extent do privacy and security risks affect sustainability? How can social media chatbots prevent these risks and challenges?
- To what extent do technical factors (e.g., infrastructure, design) affect environmental, economic, and social sustainability for global organizations?
- Which sustainable business models can be developed and evaluated for AI and AI-related technology adoption, including circular and sharing economy models?
- What are the drivers and barriers to promoting sustainable AI-based systems, and how can AI-technology adoption support sustainable business practices globally?
5. Conclusions and Future Directions
Author Contributions
Funding
Conflicts of Interest
Appendix A
- Procedure findOrientation
- (frequent_markers, compendium_of_samples)
- begin
- for each marker ai in frequent_markers
- for each sample bj in compendium_of_samples
- if(ai = bj {
- if(searchForNegative(ai)! = false){
- compendium_of_negativemarkers = bj}
- endfor
- endfor
- End
- Procedure searchForNagative
- (marker, sentiwordnet)
- begin
- for each synset si in sentiwordnet
- if(marker = si){
- if(snegative > spositive)
- return marker}
- else {
- return false}
- endfor
- end
References
- Cutter, S.; Wilbank, T.J. (Eds.) Geographical Dimensions of Terrorism; Taylor & Francis, Inc.: Oxford, UK, 2003. [Google Scholar]
- Kennedy, L.; Lum, C. Developing a Foundation for Policy Relevant Terrorism Research in Criminology; Prepared for the Center for the Study of Public Security, Rutgers University: Newark, NJ, USA, 2003. [Google Scholar]
- Reid, E.; Qin, J.; Chung, W.; Xu, J.; Zhou, Y.; Schumaker, R.; Chen, H. Terrorism Knowledge Discovery Project: A Knowledge Discovery Approach to Addressing the Threats of Terrorism. In International Conference on Intelligence and Security Informatics; Springer: Berlin/Heidelberg, Germany, 2004; pp. 125–145. [Google Scholar]
- James, N. 160 Cybersecurity Statistics. 2023. Available online: https://www.getastra.com/blog/security-audit/cyber-security-statistics/ (accessed on 11 June 2023).
- Gartner Research. “Forecast Analysis: Information Security Worldwide 2Q18 Update”. March 2020. Available online: https://www.gartner.com/en/documents/3889055 (accessed on 13 June 2023).
- Franco, M.F.; Rodrigues, B.; Scheid, E.J.; Jacobs, A.; Killer, C.; Granville, L.Z.; Stiller, B. SecBot: A Business-Driven Conversational Agent for Cybersecurity Planning and Management. In Proceedings of the 2020 16th International Conference on Network and Service Management (CNSM), Izmir, Turkey, 2–6 November 2020; pp. 1–7. [Google Scholar]
- Thapa, B. Sentiment Analysis of Cybersecurity Content on Twitter and Reddit. arXiv 2022, arXiv:2204.12267. [Google Scholar]
- Hernández-García, Á.; Conde-González, M.A. Bridging the gap between LMS and social network learning analytics in online learning. J. Inf. Technol. Res. (JITR) 2016, 9, 1–15. [Google Scholar] [CrossRef]
- Chatzakou, D.; Koutsonikola, V.; Vakali, A.; Kafetsios, K. Micro-Blogging Content Analysis via Emotionally-Driven Clustering. In Proceedings of the 2013 Humaine Association Conference on Affective Computing and Intelligent Interaction, Geneva, Switzerland, 2–5 September 2013; IEEE: Piscataway, NJ, USA, 2013; pp. 375–380. [Google Scholar]
- Achrekar, H.; Gandhe, A.; Lazarus, R.; Yu, S.H.; Liu, B. Predicting Flu Trends Using Twitter Data. In Proceedings of the 2011 IEEE Conference on Computer Communications Workshops (INFOCOM WKSHPS), Shanghai, China, 10–15 April 2011; IEEE: Piscataway, NJ, USA, 2011; pp. 702–707. [Google Scholar]
- Thakur, N. Sentiment Analysis and Text Analysis of the Public Discourse on Twitter about COVID-19 and MPox. Big Data Cogn. Comput. 2023, 7, 116. [Google Scholar] [CrossRef]
- Fellnhofer, K. Positivity and higher alertness levels facilitate discovery: Longitudinal sentiment analysis of emotions on Twitter. Technovation 2023, 122, 102666. [Google Scholar] [CrossRef]
- Pinard, P. 4 Chatbot Security Measures You Absolutely Need to Consider—Dzone Security. dzone.com. Available online: https://dzone.com/articles/4-chatbots-security-measures-you-absolutely-need-t (accessed on 29 October 2021).
- Safa, N.S.; Sookhak, M.; Von Solms, R.; Furnell, S.; Ghani, N.A.; Herawan, T. Information security conscious care behaviour com formation in organizations. Comput. Secur. 2015, 53, 65–78. [Google Scholar] [CrossRef]
- Safa, N.S.; Von Solms, R.; Furnell, S. Information security policy compliance model in organizations. Comput. Secur. 2016, 56, 70–82. [Google Scholar] [CrossRef]
- Safa, N.S.; Maple, C.; Furnell, S.; Azad, M.A.; Perera, C.; Dabbagh, M.; Sookhak, M. Deterrence and prevention-based model to mitigate information security insider threats in organisations. Future Gener. Comput. Syst. 2019, 97, 587–597. [Google Scholar] [CrossRef]
- Siyongwana, G.M. The Enforcement of End-User Security Compliance Using Chatbot. Doctoral Dissertation; Cape Peninsula University of Technology: Cape Town, South Africa, 2022. [Google Scholar]
- Adamopoulou, E.; Moussiades, L. An Overview of Chatbot Technology. In Proceedings of the IFIP International Conference on Artificial Intelligence Applications and Innovations, Neos Marmaras, Greece, 5–7 June 2020; Springer: Cham, Switzerland, 2020; pp. 373–383. [Google Scholar]
- Epley, N.; Waytz, A.; Cacioppo, J.T. On seeing human: A three-factor theory of anthropomorphism. Psychol. Rev. 2007, 114, 864. [Google Scholar] [CrossRef] [PubMed]
- Blut, M.; Wang, C.; Wünderlich, N.V.; Brock, C. Understanding anthropomorphism in service provision: A meta-analysis of physical robots, chatbots, and other. AI. J. Acad. Mark. Sci. 2021, 49, 632–658. [Google Scholar] [CrossRef]
- Sheehan, B.; Jin, H.S.; Gottlieb, U. Customer Service chatbots: Anthropomorphism and adoption. J. Bus. Res. 2020, 115, 14–24. [Google Scholar] [CrossRef]
- Sailunaz, K.; Alhajj, R. Emotion and sentiment analysis from Twitter text. J. Comput. Sci. 2019, 36, 101003. [Google Scholar] [CrossRef]
- Hassan, M.K.; Hudaefi, F.A.; Caraka, R.E. Mining netizen’s opinion on cryptocurrency: Sentiment analysis of Twitter data. Stud. Econ. Financ. 2022, 39, 365–385. [Google Scholar] [CrossRef]
- Saura, J.R.; Ribeiro-Soriano, D.; Saldana, P.Z. Exploring the challenges of remote work on Twitter users’ sentiments: From digital technology development to a post-pandemic era. J. Bus. Res. 2022, 142, 242–254. [Google Scholar] [CrossRef]
- Aljedaani, W.; Rustam, F.; Mkaouer, M.W.; Ghallab, A.; Rupapara, V.; Washington, P.B.; Ashraf, I. Sentiment analysis on Twitter data integrating TextBlob and deep learning models: The case of US airline industry. Knowl. Based Syst. 2022, 255, 109780. [Google Scholar] [CrossRef]
- Antony, J. Design of Experiments for Engineers and Scientists; Elsevier: Amsterdam, The Netherlands, 2023. [Google Scholar]
- Goh, G.S.; Ang, A.J.; Zhang, A.N. Optimizing Performance of Sentiment Analysis through Design of Experiments. In Proceedings of the 2016 IEEE International Conference on Big Data (Big Data), Washington, DC, USA, 5–8 December 2016; IEEE: Piscataway, NJ, USA, 2016; pp. 3737–3742. [Google Scholar]
- Feine, J.; Morana, S.; Gnewuch, U. Measuring Service Encounter Satisfaction with Customer Service Chatbots using Sentiment Analysis. In Proceedings of the 14th International Conference on Wirtschaftsinformatik (WI2019), Siegen, Germany, 23–27 February 2019. [Google Scholar]
- Küster, D.; Kappas, A. Measuring Emotions Online: Expression and Physiology. In Cyberemotions: Collective Emotions in Cyberspace; Holyst, J.A., Ed.; Springer International Publishing: Cham, Switzerland, 2017; pp. 71–93. [Google Scholar]
- Yang, Y.; Li, H.; Deng, G. A case study: Behavior study of chinese users on the internet and mobile internet. In Proceedings of the International Conference on Internationalization, Design and Global Development, Orlando, FL, USA, 9–14 July 2011; Springer: Berlin/Heidelberg, Germany, 2011; pp. 585–593. [Google Scholar]
- Marcus, M.; Santorini, B.; Marcinkiewicz, M.A. Building a Large Annotated Corpus of English: The Penn Treebank. 1993. Available online: https://repository.upenn.edu/items/ff9d17cd-1c74-4136-8c2c-3e824073a22c (accessed on 15 June 2023).
- Choy, M. Effective listings of function stop words for Twitter. arXiv 1993, arXiv:1205.6396. [Google Scholar] [CrossRef]
- Princeton University. About WordNet; WordNet; Princeton University: Princeton, NJ, USA, 2010. [Google Scholar]
- Agrawal, R.; Srikant, R. Fast algorithms for mining association rules. Proc. 20th Int. Conf. Very Large Data Bases VLDB 1994, 1215, 487–499. [Google Scholar]
- Hu, M.; Zheng, G.; Wang, H. Improvement and Research on Aprioriall Algorithm of Sequential Patterns Mining. In Proceedings of the 2013 6th International Conference on Information Management, Innovation Management and Industrial Engineering, Xi’an, China, 23–24 November 2013; IEEE: Piscataway, NJ, USA, 2013; Volume 2. [Google Scholar]
- U.S. Department of Homeland Security (DHS). National Initiative for Cybersecurity Careers and Studies. Glossary. 2020. Available online: https://niccs.us-cert.gov/glossary (accessed on 15 June 2023).
- Newhouse, W.; Keith, S.; Scribner, B.; Witte, G. National initiative for cybersecurity education (NICE) cybersecurity workforce framework. NIST Spec. Publ. 2017, 800, 181. [Google Scholar]
- Feng, S.; Wang, D.; Yu, G.; Yang, C.; Yang, N. Sentiment Clustering: A Novel Method to Explore in the Blogosphere. In Advances in Data and Web Management; Springer: Berlin/Heidelberg, Germany, 2009; pp. 332–344. [Google Scholar]
- Andreevskaia, A.; Bergler, S. Mining Wordnet for a Fuzzy Sentiment: Sentiment tag Extraction from Wordnet Glosses. In Proceedings of the 11th Conference of the European Chapter of the Association for Computational Linguistics, Trento, Italy, 6 April 2006. [Google Scholar]
- Fei, G.; Liu, B.; Hsu, M.; Castellanos, M.; Ghosh, R. A Dictionary-Based Approach to Identifying Aspects Implied by Adjectives for Opinion Mining. In Proceedings of COLING 2012: Posters; The COLING 2012 Organizing Committee: Mumbai, India, 2012; pp. 309–318. [Google Scholar]
- Owoputi, O.; O’Connor, B.; Dyer, C.; Gimpel, K.; Schneider, N.; Smith, N.A. Improved Part-of-Speech Tagging for Online Conversational Text with Word Clusters. In Proceedings of the 2013 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, Atlanta, GA, USA, 9–14 June 2013; pp. 380–390. [Google Scholar]
- Alenzi, B.M.; Khan, M.B.; Hasanat MH, A.; Saudagar AK, J.; AlKhathami, M.; AlTameem, A. Automatic Annotation Performance of TextBlob and VADER on Covid Vaccination Dataset. Intell. Autom. Soft Comput. 2022, 34, 1311–1331. [Google Scholar] [CrossRef]
- Ahamer, G. GISS and GISP Facilitate Higher Education and Cooperative Learning Design. In Geospatial Research: Concepts, Methodologies, Tools, and Applications; IGI Global: Hershey, PA, USA, 2016; pp. 810–833. [Google Scholar] [CrossRef]
- Al-Sharafi, M.A.; Al-Emran, M.; Iranmanesh, M.; Al-Qaysi, N.; Iahad, N.A.; Arpaci, I. Understanding the impact of knowledge management factors on the sustainable use of AI-based chatbots for educational purposes using a hybrid SEM-ANN approach. Interact. Learn. Environ. 2022, 1–20. [Google Scholar] [CrossRef]


{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Neutral Sentiment | I have enough problems of my own. I don’t care about the war really |
| (no sentiments about war or its outcome) | War or No War: my problems are not going anywhere |
| I don’t care about the war outcome | |
| Positive Sentiment | I hope that the Russian-Ukraine war ends amicably #Peace |
| (evidenced by peace, world order, stopping war) | Ukraine has put a brave front #StopWar #Peace |
| Happy to see that the oppressed is not giving up to his aggressor! #IStandWithUkraine #NATO #WorldPeace | |
| Negative Sentiment | #Terror #PutinWarCriminal #StopRussianAggression #StopRussia #StopPutin #Terrorist |
| (evidenced by fear, anger, and opposition to the Russian invasion of Ukraine) | I am Angry! I am Fearful about the outcome of the war #StopRussia |
| #IOpposeRussia; #IOpposePutin; #PutinBeDa..ed |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Arora, A.; Arora, A.; McIntyre, J. Developing Chatbots for Cyber Security: Assessing Threats through Sentiment Analysis on Social Media. Sustainability 2023, 15, 13178. https://doi.org/10.3390/su151713178
Arora A, Arora A, McIntyre J. Developing Chatbots for Cyber Security: Assessing Threats through Sentiment Analysis on Social Media. Sustainability. 2023; 15(17):13178. https://doi.org/10.3390/su151713178
Chicago/Turabian StyleArora, Amit, Anshu Arora, and John McIntyre. 2023. "Developing Chatbots for Cyber Security: Assessing Threats through Sentiment Analysis on Social Media" Sustainability 15, no. 17: 13178. https://doi.org/10.3390/su151713178
APA StyleArora, A., Arora, A., & McIntyre, J. (2023). Developing Chatbots for Cyber Security: Assessing Threats through Sentiment Analysis on Social Media. Sustainability, 15(17), 13178. https://doi.org/10.3390/su151713178