

Interpretable Machine Learning for Assessing the Cumulative Damage of a Reinforced Concrete Frame Induced by Seismic Sequences
 , ,
, ,  ,
,  and
and
Abstract
:1. Introduction
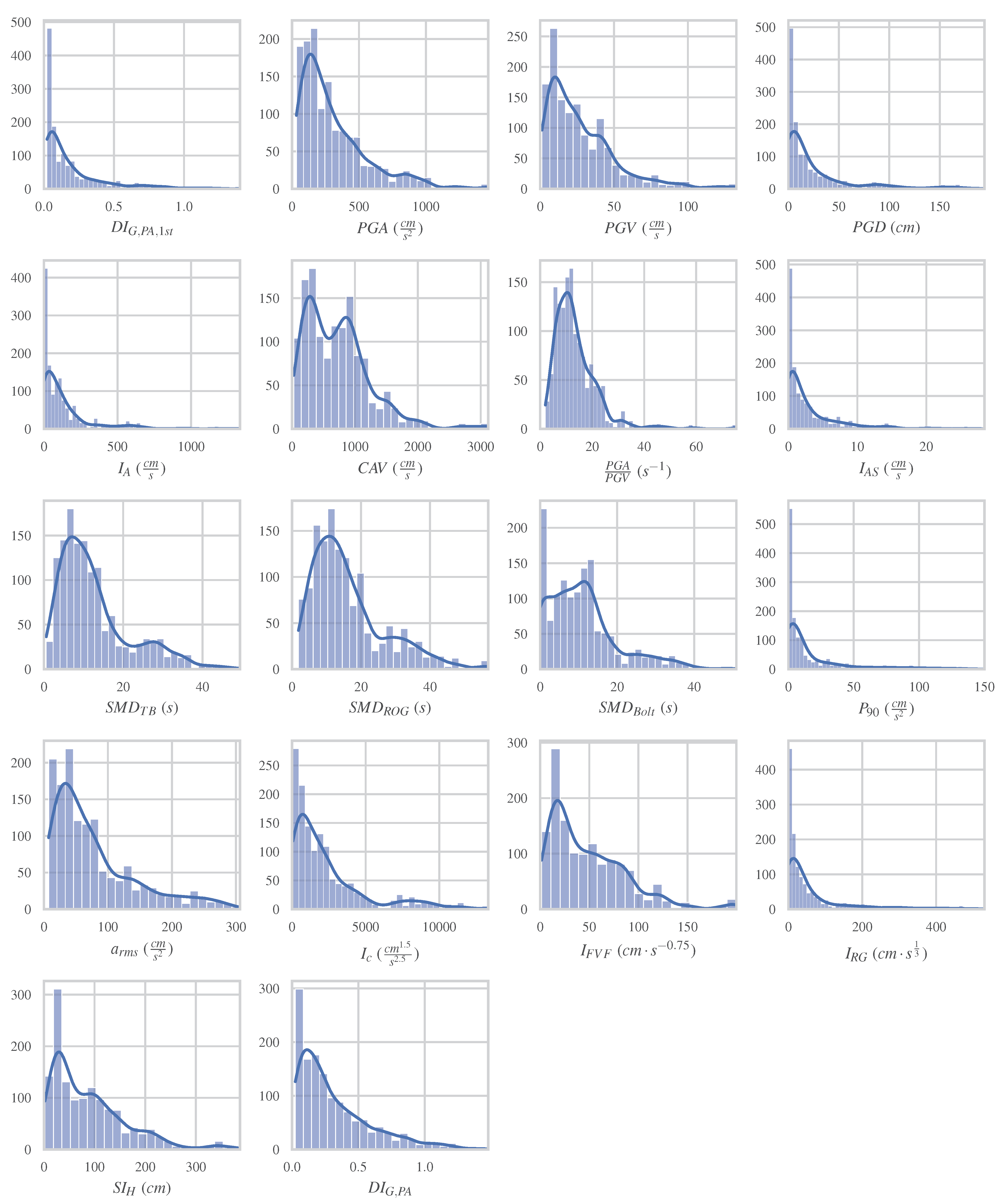
2. Feature Selection and Dataset Configuration and Preprocessing
2.1. Ground Motion IMs and Damage Index
2.1.1. Ground Motion IMs
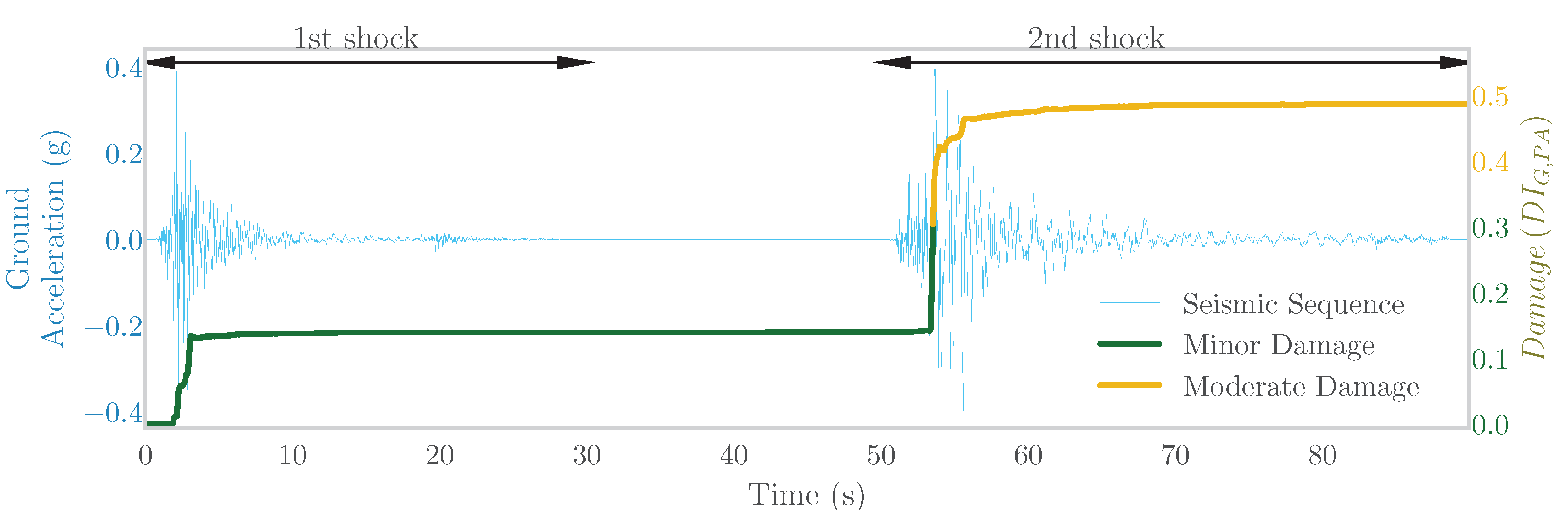
2.1.2. Damage Index
2.2. Description and Modelling of the Examined Building
2.3. Dataset Creation
2.4. Data Preprocessing (Feature Scaling)
3. Machine Learning Methods, Hyperparameter Tuning and Interpretation Techniques
3.1. Linear Models
3.2. Non-Parametric Algorithms
3.3. Ensemble Trees
3.4. Feedforward Neural Networks
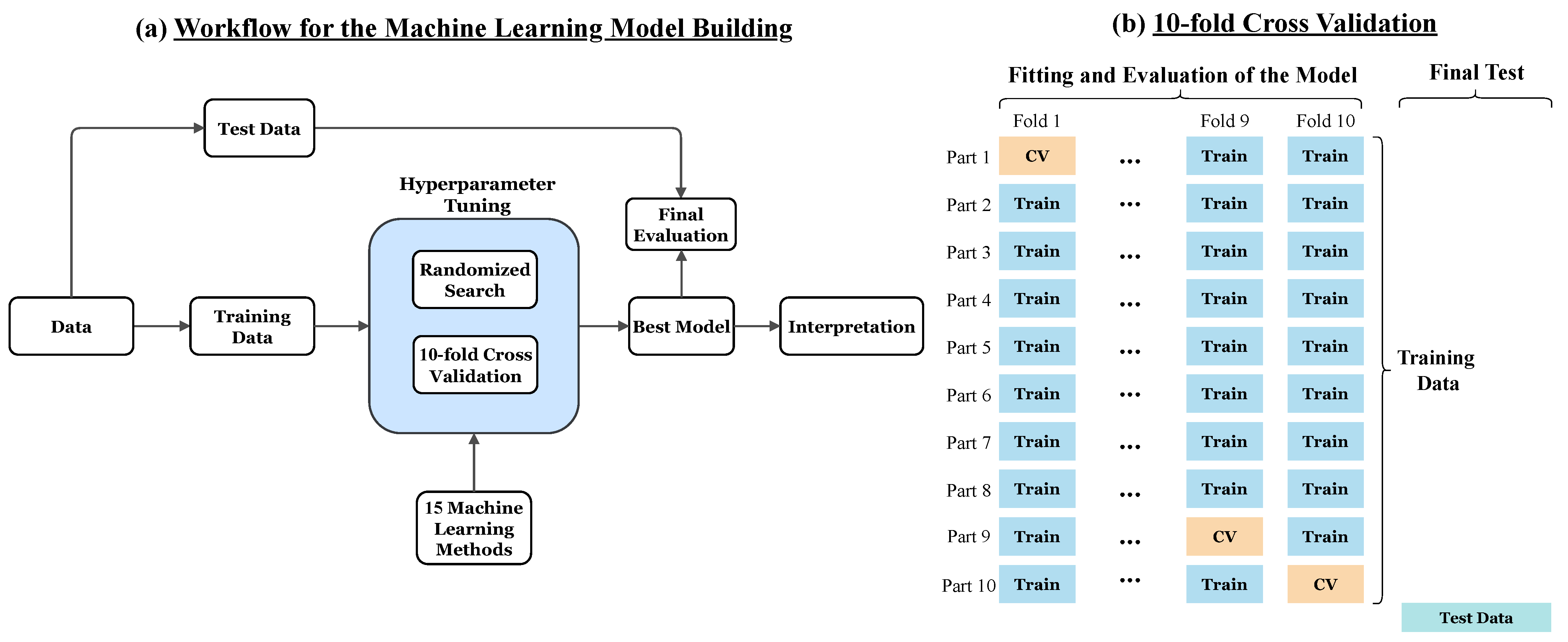
3.5. Hyperparameter Tuning and K-Fold Cross-Validation
3.6. Interpretation Methods
3.6.1. Global Interpretation Methods
3.6.2. Local Interpretation Methods
4. Results and Discussion
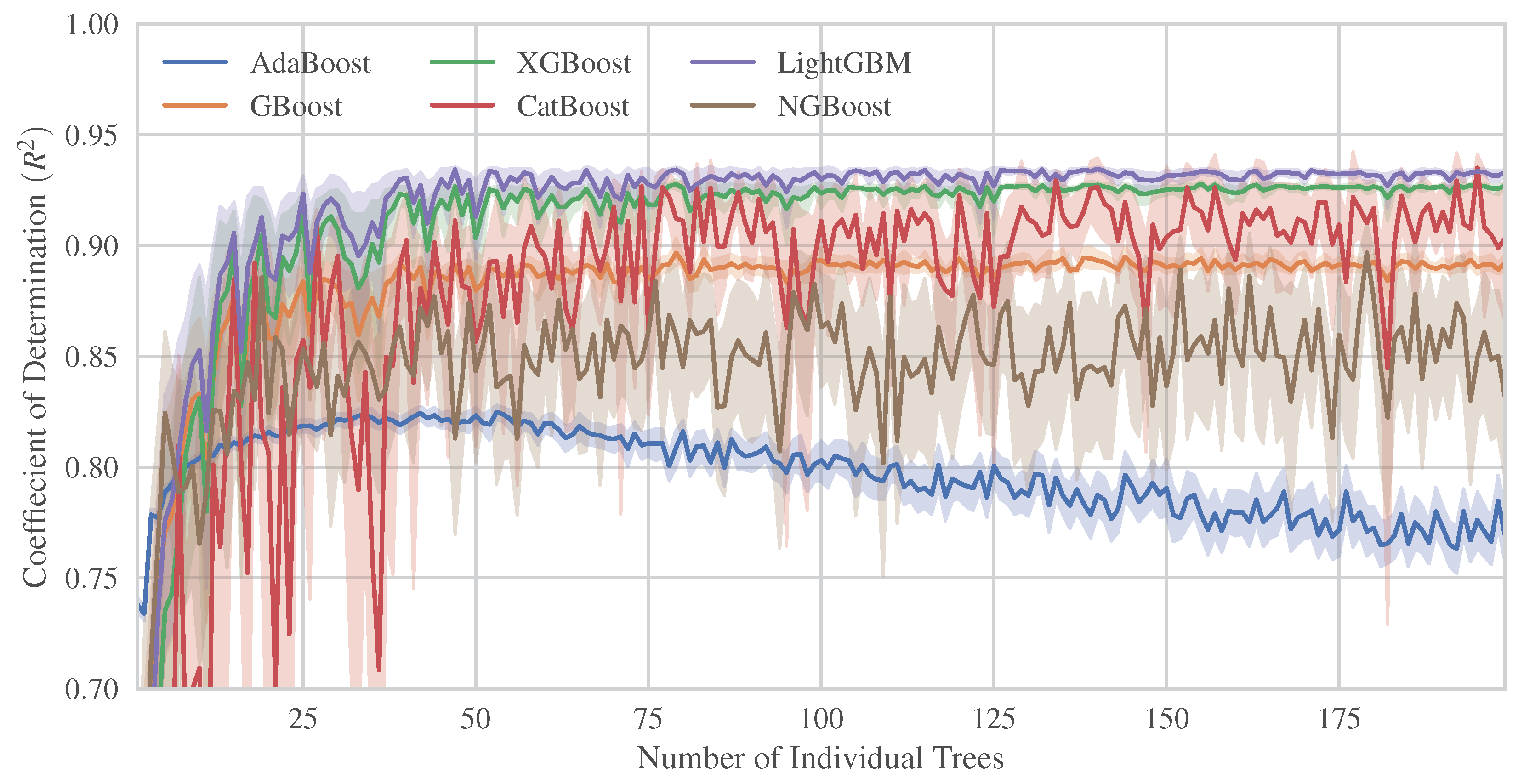
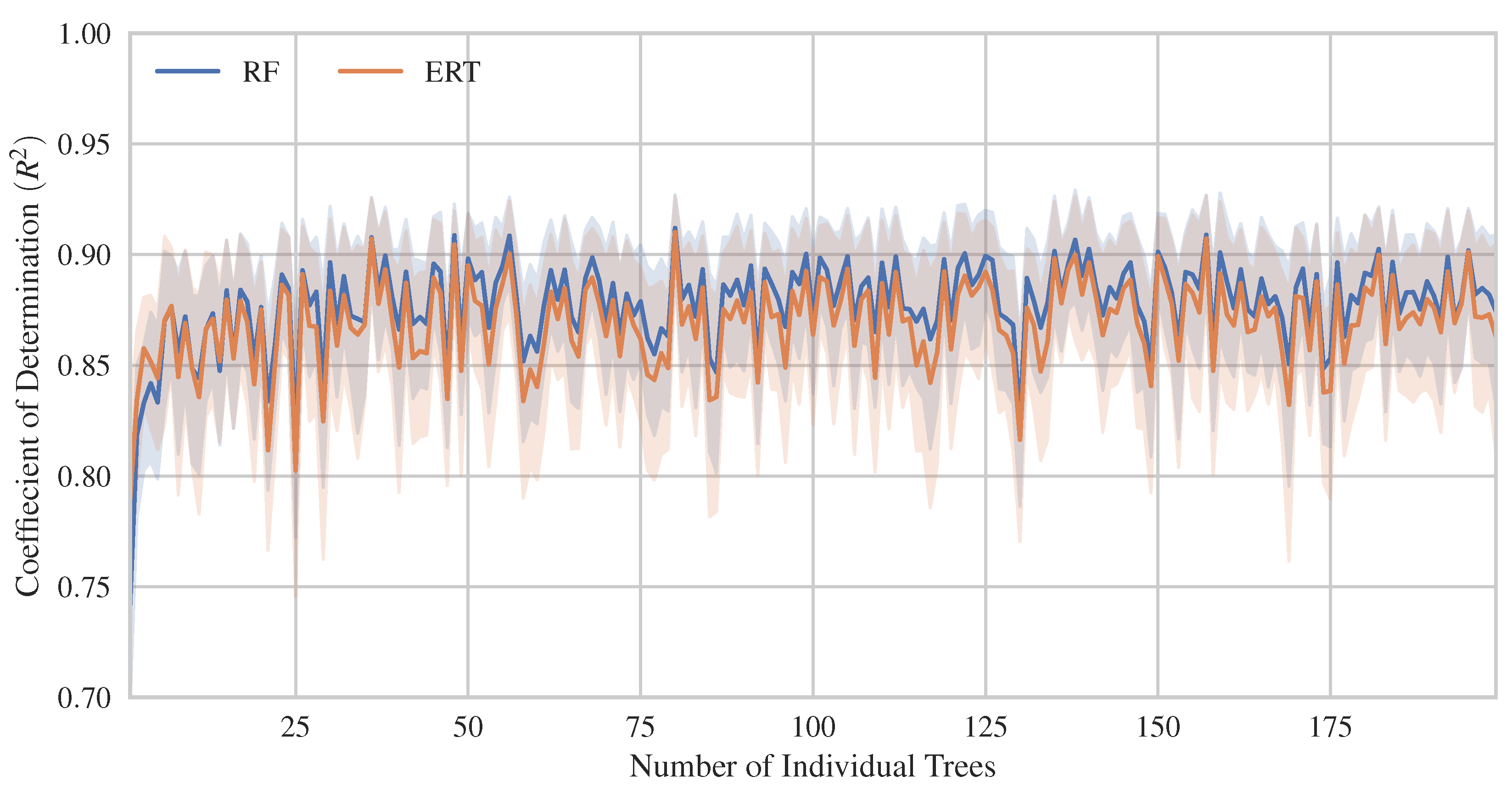
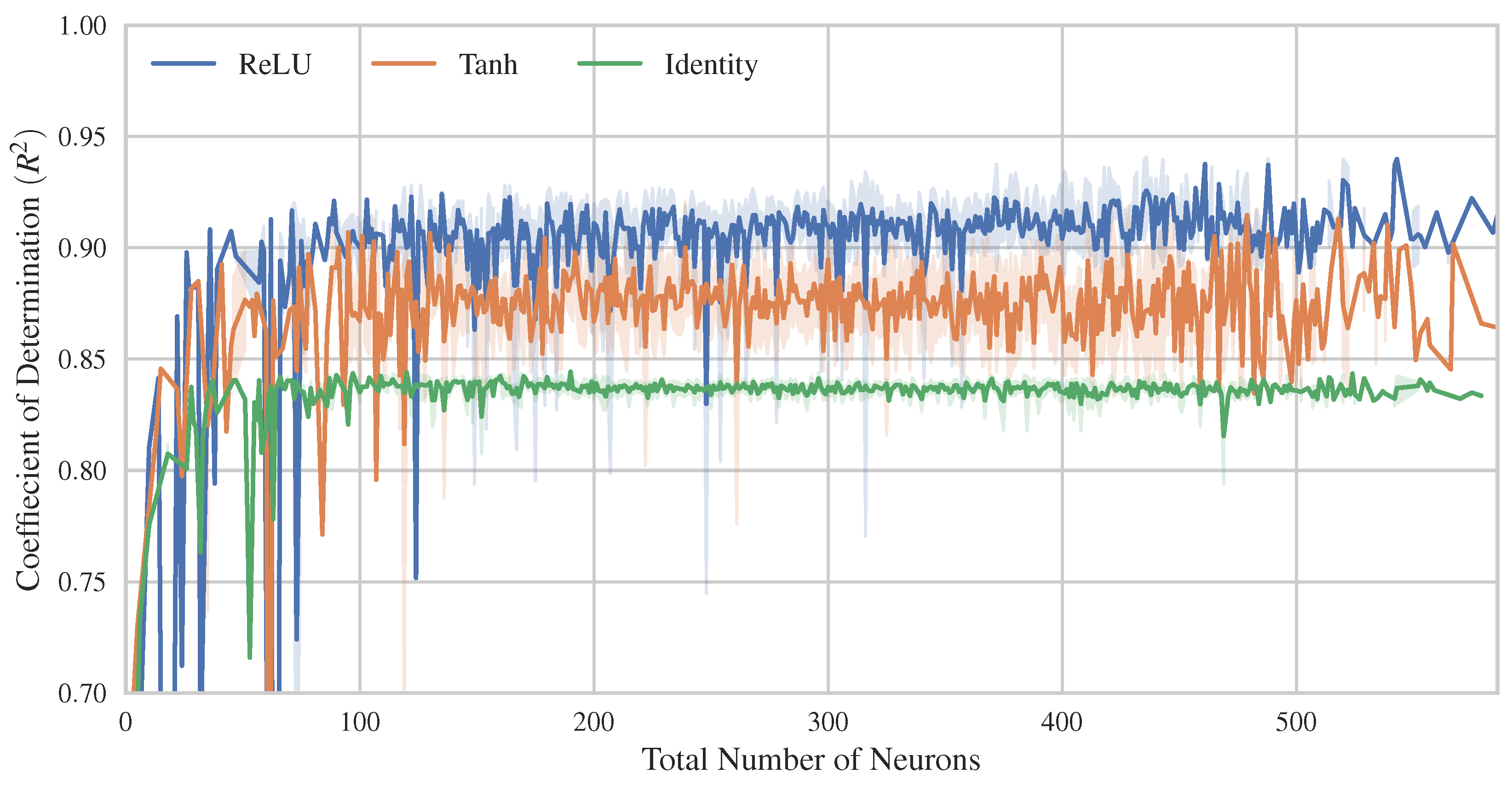
4.1. Hyperparameter Tuning and ML Models Comparison
4.2. Interpretation of the Best ML Model
4.2.1. Features Importances
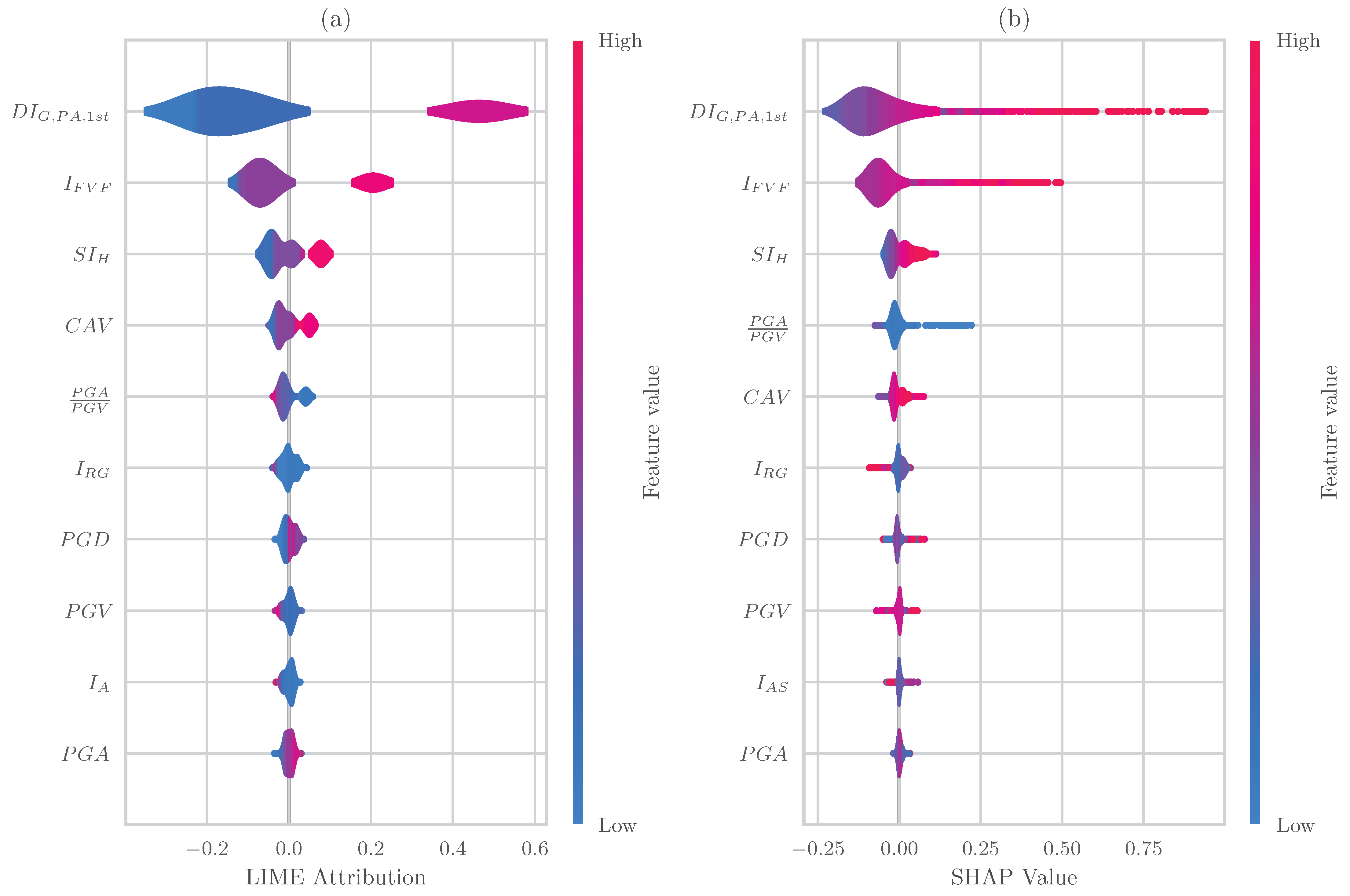
4.2.2. Local Explanation Methods (LIME, SHAP)
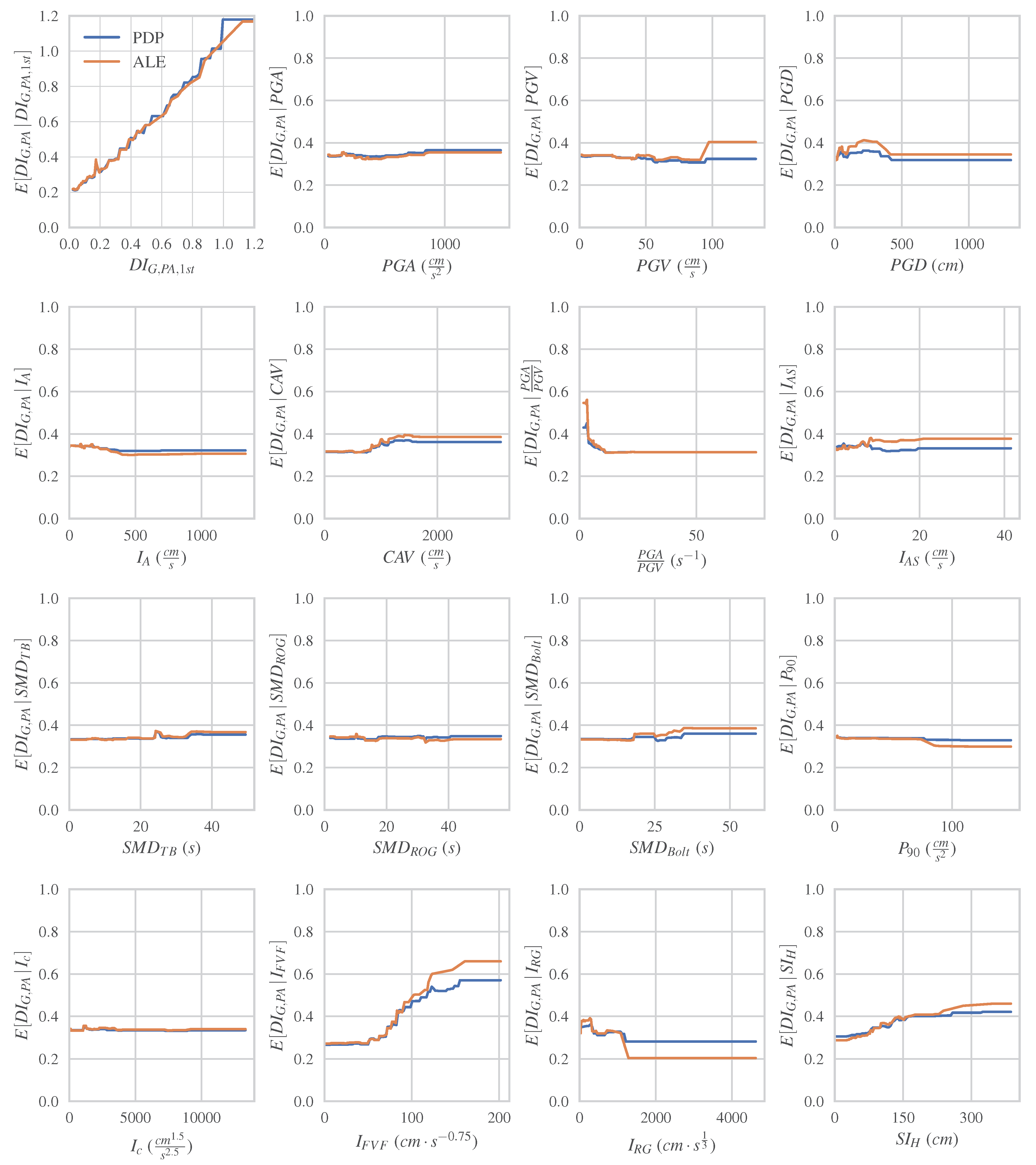
4.2.3. Global Explanation Methods (PDP and ALE)
5. Conclusions
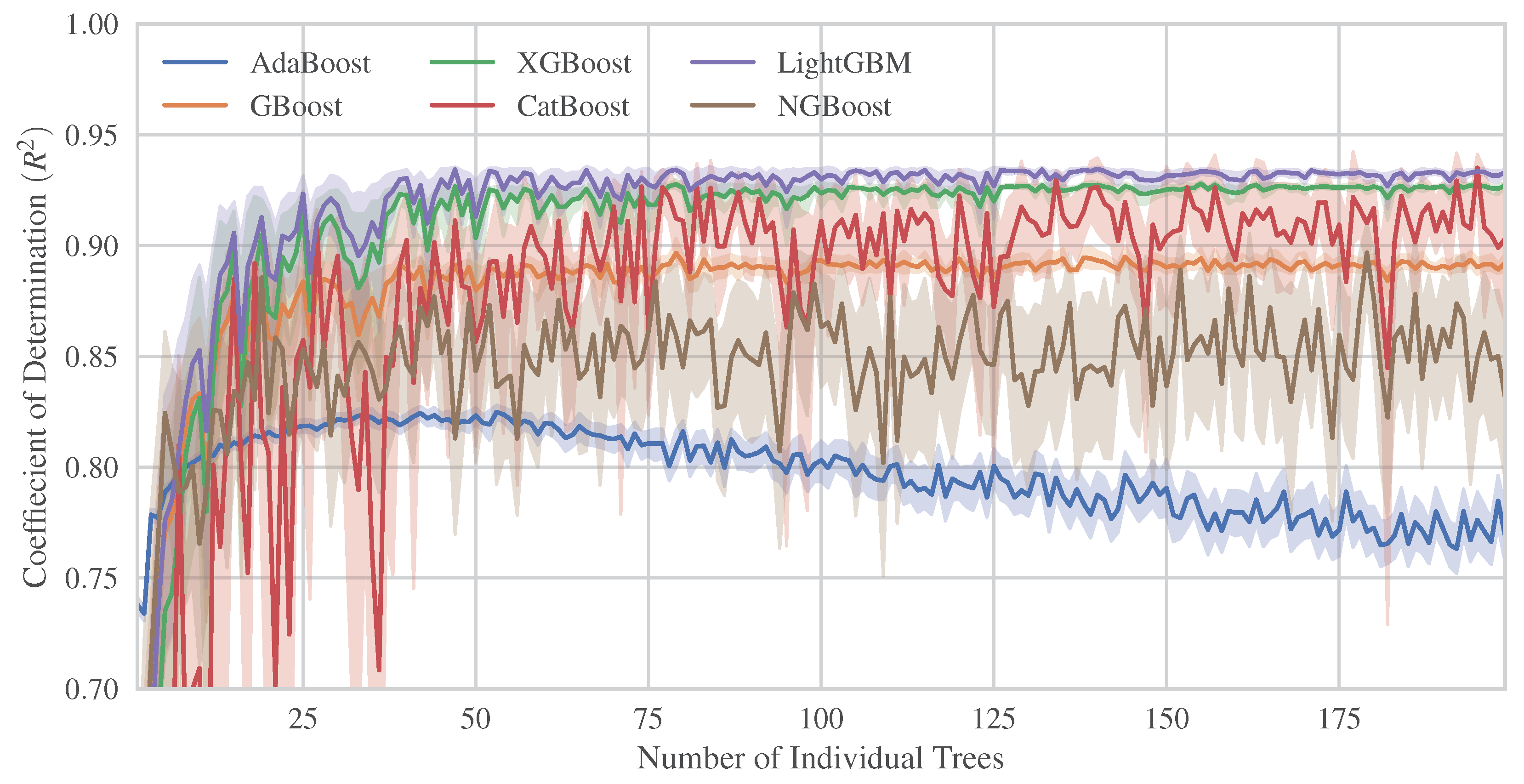
- The most efficient model for predicting final structural damage under seismic sequences was an instance of the LightGBM method with an greater than 0.95, while the method with the poorest performance was KNN, with an value of approximately 0.4.
- Among the examined boosted trees, LightGBM and XGBoost demonstrated the most optimized and robust performance even against small changes in their hyperparameters. Moreover, they present great resistance to overfitting as the number of trees increases.
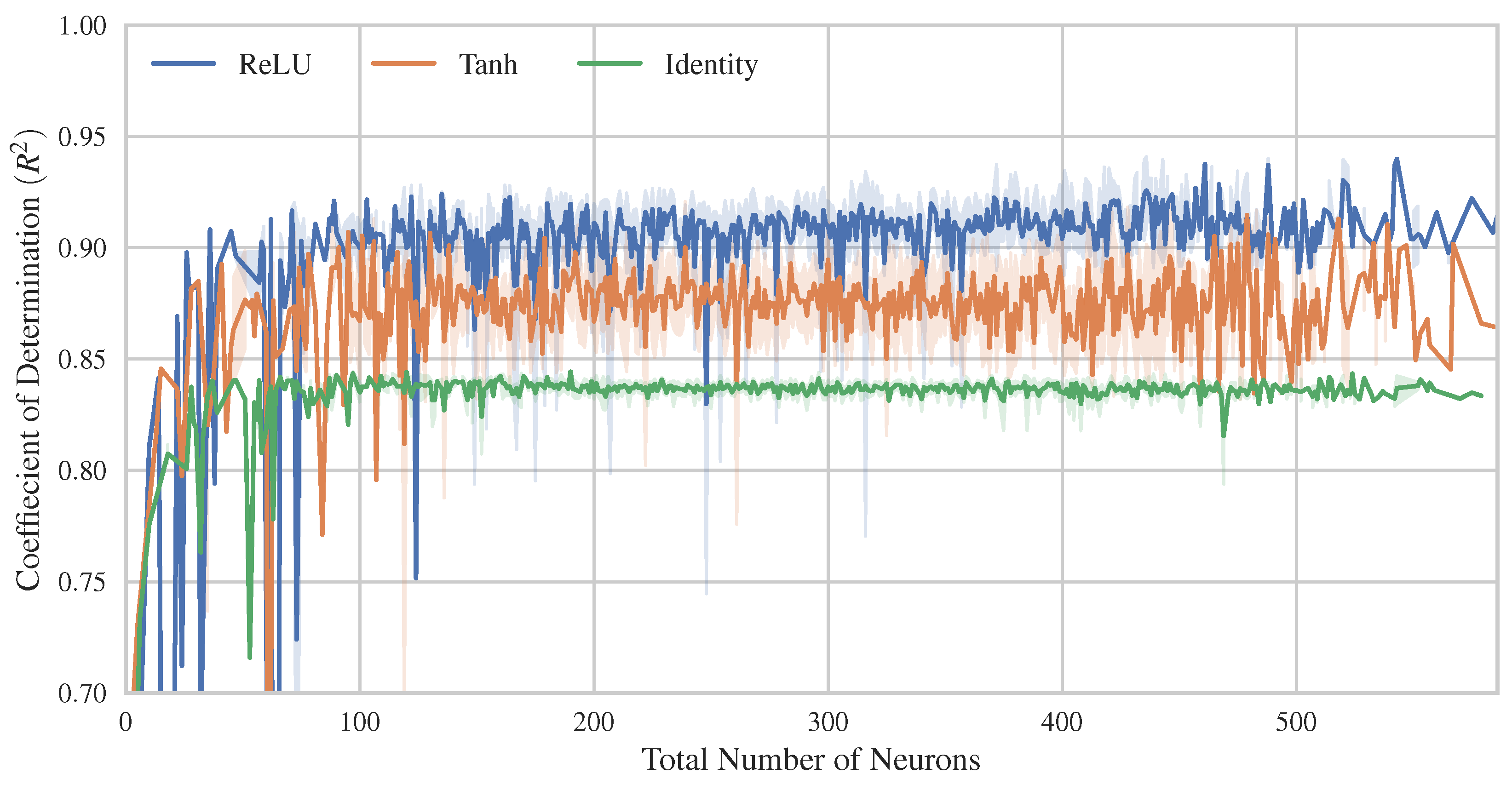
- In the case of Multi-Layer Perceptrons (MLPs), the ReLU activation function appeared to yield better performance, followed by the Tanh activation function. In addition, the MLP model presents slightly better bias-variance balance than the other advanced ML models.
- All the interpretation methods identified the initial damage as the most significant feature followed by the IMs of the subsequent seismic shock. However, the ranking of the IMs importance is varying between the adopted approaches. The majority of interpretation methods indicate the as the most important IM, except for the impurity-based explanation, which identified . As the second most important IM, LIME and SHAP ranked , although permutation ranked , and impurity ranked .
- In case of examining the effect of all the IMs in total, both LIME and SHAP local explanation methods show that the contribution of the subsequent ground motion is larger than that of initial damage . In general, the effect of the initial damage tends to increase as the final increases. However, they differ in their estimation of contributions for higher damage states.
- The analysis of PDPs and ALE reveals key insights into the effects of damage predictors on the final damage. The pre-existing damage demonstrates a positive influence across the entire range of cumulative damage. Additionally, and present a notable positive impact on moderate final damages. In contrast, values smaller than 15 seems to have a negative impact on moderate final damages, while and demonstrate more complex effects in a narrower range of the final damage.
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Acknowledgments
Conflicts of Interest
Abbreviations
| ML | Machine learning |
| RC | Reinforced Concrete |
| IM | Intensity Measure |
| NN | Neural Network |
| ANN | Artificial Neural Network |
| MLP | Multi-Layer Perceptron |
| LIME | Local Interpretable Model-agnostic Explanations |
| SHAP | SHapley Additive exPlanations |
| ALE | Accumulated Local Effects |
| PDP | Partial Dependence Plot |
| ground acceleration signal | |
| ground velocity acceleration signal | |
| ground displacement signal | |
| Husid Diagram | |
| Pseudo-velocity spectrum | |
| PGA | Peak Ground Acceleration |
| PGV | Peak Ground Velocity |
| PGD | Peak Ground Displacement |
| Arias intensity | |
| CAV | Cumulative Absolute Velocity |
| Seismic intensity after Araya and Saragoni | |
| Strong motion duration after Trifunac and Brady | |
| Strong motion duration after Reinoso, Ordaz and Guerrero | |
| Strong motion duration after Bolt | |
| Root-mean-squared of ground acceleration signal | |
| Characteristic Intensity | |
| Potential damage measure after Fajfar, Vidic and Fischinger | |
| Intensity measure after Riddel and Garcia | |
| Spectral intensity after Housner | |
| The overall Park and Ang damage index after the first seismic shock (input feature) | |
| The overall Park and Ang damage index after the second seismic shock (target) | |
| CV | Cross-Validation |
| AdaBoost | Adaptive Boosting |
| DT | Decision tree |
| ERT | Extremely Randomized Trees |
| GBoost | Gradient boosting |
| KNN | K nearest neighbors |
| LightGBM | Light Gradient Boosting Machine |
| LR | Linear Regression |
| Lasso | Lasso Regression |
| RR | Ridge Regression |
| EN | Elastic Net |
| RF | Random forest |
| NGBoost | Natural Gradient Boosting |
| XGBoost | eXtreme Gradient Boosting |
| CatBoost | Categorical Boosting |
Appendix A

{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Region | First Shock | Second Shock | Station Code/Name | Component | PGA1st (g) | PGA2nd (g) | ||
|---|---|---|---|---|---|---|---|---|
| Date | M | Date | M | |||||
| Ancona | 14-06-1972 | 4.2 | 21-06-1972 | 4.0 | ANP | N-S | 0.220 | 0.410 |
| Friuli | 11-09-1976 | 5.8 | 15-09-1976 | 6.1 | BUI | N-S | 0.233 | 0.110 |
| E-W | 0.108 | 0.093 | ||||||
| GMN | N-S | 0.328 | 0.324 | |||||
| E-W | 0.299 | 0.644 | ||||||
| Montenegro | 15-04-1979 | 6.9 | 15-04-1979 | 5.8 | PETO | E-W | 0.304 | 0.089 |
| 24-05-1979 | 6.2 | BAR | N-S | 0.371 | 0.201 | |||
| E-W | 0.360 | 0.267 | ||||||
| HRZ | N-S | 0.215 | 0.066 | |||||
| E-W | 0.254 | 0.076 | ||||||
| ULO | N-S | 0.282 | 0.033 | |||||
| E-W | 0.236 | 0.030 | ||||||
| Imperial Valley | 15-10-1979 | 6.5 | 15-10-1979 | 5.0 | Holtville Post Office | 315 | 0.221 | 0.254 |
| Mammoth Lakes | 25-05-1980 | 6.1 | 25-05-1980 | 5.7 | Convict Creek | 90 | 0.419 | 0.371 |
| Irpinia | 23-11-1980 | 6.9 | 24-11-1980 | 5.0 | BGI | N-S | 0.129 | 0.031 |
| E-W | 0.189 | 0.033 | ||||||
| STR | N-S | 0.224 | 0.018 | |||||
| E-W | 0.320 | 0.032 | ||||||
| Gulf of Corinth | 24-02-1981 | 6.6 | 25-02-1981 | 6.3 | KORA | Trans | 0.296 | 0.121 |
| Logn | 0.240 | 0.121 | ||||||
| Coalinga | 22-07-1983 | 5.8 | 25-07-1983 | 5.2 | Elm (Old CHP) | 90 | 0.519 | 0.677 |
| 0 | 0.341 | 0.481 | ||||||
| Kalamata | 13-09-1986 | 5.9 | 15-09-1986 | 4.8 | KAL1 | Trans | 0.269 | 0.140 |
| Logn | 0.232 | 0.237 | ||||||
| KALA | Trans | 0.296 | 0.152 | |||||
| Logn | 0.216 | 0.334 | ||||||
| Spitak | 07-12-1988 | 6.7 | 07-12-1988 | 5.9 | GUK | N-S | 0.181 | 0.144 |
| E-W | 0.182 | 0.099 | ||||||
| 08-01-1989 | 4.0 | 08-01-1989 | 4.1 | NAB | E-W | 0.206 | 0.217 | |
| Georgia | 03-05-1991 | 5.6 | 03-05-1991 | 5.2 | SAMB | N-S | 0.354 | 0.208 |
| E-W | 0.504 | 0.122 | ||||||
| Erzican | 13-03-1992 | 6.6 | 15-03-1992 | 5.9 | AI 178 ERC MET | N-S | 0.411 | 0.032 |
| E-W | 0.487 | 0.039 | ||||||
| Ilia | 26-03-1993 | 4.7 | 26-03-1993 | 4.9 | PYR1 | Logn | 0.109 | 0.100 |
| Northridge | 17-01-1994 | 6.7 | 17-01-1994 | 5.9 | Moorpark—Fire Station | 90 | 0.193 | 0.139 |
| 180 | 0.291 | 0.184 | ||||||
| 17-01-1994 | 5.2 | Pacoima Kagel Canyon | 360 | 0.432 | 0.053 | |||
| 20-03-1994 | 5.3 | Rinaldi Receiving Station | 228 | 0.874 | 0.529 | |||
| Sepulveda Hospital | 270 | 0.752 | 0.102 | |||||
| Sylmar—Olive Med | 90 | 0.605 | 0.181 | |||||
| Umbria Marche | 26-09-1997 | 5.7 | 26-09-1997 | 6.0 | CLF | N-S | 0.276 | 0.197 |
| E-W | 0.256 | 0.227 | ||||||
| NCR | N-S | 0.395 | 0.502 | |||||
| Kalamata | 13-10-1997 | 6.5 | 18-11-1997 | 6.4 | KRN1 | Trans | 0.119 | 0.071 |
| Logn | 0.118 | 0.092 | ||||||
| Bovec | 12-04-1998 | 5.7 | 31-08-1998 | 4.3 | FAGG | N-S | 0.024 | 0.023 |
| E-W | 0.023 | 0.026 | ||||||
| Azores Islands | 09-07-1998 | 6.2 | 11-07-1998 | 4.7 | HOR | N-S | 0.405 | 0.082 |
| E-W | 0.369 | 0.092 | ||||||
| Izmit | 17-08-1999 | 7.6 | 12-11-1999 | 7.3 | ARC | N-S | 0.210 | 0.007 |
| E-W | 0.132 | 0.007 | ||||||
| ATK | N-S | 0.102 | 0.016 | |||||
| E-W | 0.167 | 0.016 | ||||||
| DHM | N-S | 0.090 | 0.017 | |||||
| E-W | 0.084 | 0.017 | ||||||
| FAT | N-S | 0.181 | 0.034 | |||||
| E-W | 0.161 | 0.024 | ||||||
| KMP | N-S | 0.102 | 0.014 | |||||
| E-W | 0.127 | 0.017 | ||||||
| ZYT | N-S | 0.119 | 0.021 | |||||
| E-W | 0.109 | 0.029 | ||||||
| Athens | 07-09-1999 | 5.9 | 07-09-1999 | 4.3 | SPLB | Trans | 0.324 | 0.059 |
| Logn | 0.341 | 0.071 | ||||||
| Chi-Chi | 20-09-1999 | 7.6 | 20-09-1999 | 6.2 | TCU071 | N-S | 0.651 | 0.382 |
| E-W | 0.528 | 0.193 | ||||||
| TCU129 | N-S | 0.624 | 0.398 | |||||
| E-W | 1.005 | 0.947 | ||||||
| 25-09-1999 | 6.3 | TCU078 | N-S | 0.307 | 0.387 | |||
| E-W | 0.447 | 0.266 | ||||||
| TCU079 | N-S | 0.424 | 0.626 | |||||
| E-W | 0.592 | 0.776 | ||||||
| Duzce | 12-11-1999 | 7.3 | 12-11-1999 | 4.7 | AI 010 BOL | E-W | 0.820 | 0.060 |
| Bingöl | 01-05-2003 | 6.3 | 01-05-2003 | 3.5 | AI 049 BNG | N-S | 0.519 | 0.147 |
| E-W | 0.291 | 0.068 | ||||||
| L Aquila | 06-04-2009 | 6.1 | 07-04-2009 | 5.5 | AQK | N-S | 0.353 | 0.081 |
| E-W | 0.330 | 0.090 | ||||||
| AQV | N-S | 0.545 | 0.146 | |||||
| E-W | 0.657 | 0.129 | ||||||
| AVZ | N-S | 0.069 | 0.021 | |||||
| 09-04-2009 | 5.4 | AQA | N-S | 0.442 | 0.057 | |||
| Darfield | 03-09-2010 | 7.0 | 21-02-2011 | 6.2 | Botanical Gardens | S01W | 0.190 | 0.452 |
| N89W | 0.155 | 0.552 | ||||||
| Cashmere High School | S80E | 0.251 | 0.349 | |||||
| Cathedral College | N26W | 0.194 | 0.384 | |||||
| N64E | 0.233 | 0.478 | ||||||
| Christchurch Hospital | N01W | 0.209 | 0.346 | |||||
| S89W | 0.152 | 0.363 | ||||||
| Emilia | 20-05-2012 | 6.1 | 29-05-2012 | 6.0 | MRN | N-S | 0.263 | 0.294 |
| E-W | 0.262 | 0.222 | ||||||
| 03-06-2012 | 5.1 | 12-06-2012 | 4.9 | T0827 | N-S | 0.490 | 0.585 | |
| E-W | 0.263 | 0.234 | ||||||
| Central Italy | 24-08-2016 | 6.0 | 24-08-2016 | 5.4 | AQK | E-W | 0.050 | 0.010 |
| 26-08-2016 | 4.8 | AMT | N-S | 0.375 | 0.336 | |||
| E-W | 0.867 | 0.325 | ||||||
| 26-10-2016 | 5.4 | 26-10-2016 | 5.9 | CMI | N-S | 0.341 | 0.308 | |
| E-W | 0.720 | 0.651 | ||||||
| CNE | E-W | 0.556 | 0.537 | |||||
| 30-10-2016 | 6.5 | CIT | N-S | 0.052 | 0.213 | |||
| E-W | 0.092 | 0.325 | ||||||
| 26-10-2016 | 5.9 | 30-10-2016 | 6.5 | CLO | N-S | 0.193 | 0.582 | |
| E-W | 0.183 | 0.427 | ||||||
| CNE | N-S | 0.380 | 0.294 | |||||
| MMO | N-S | 0.168 | 0.188 | |||||
| E-W | 0.170 | 0.189 | ||||||
| NOR | E-W | 0.215 | 0.311 | |||||
| 30-10-2016 | 6.5 | 31-10-2016 | 4.2 | T1213 | N-S | 0.867 | 0.185 | |
| E-W | 0.794 | 0.212 | ||||||
| 18-01-2017 | 5.5 | 18-01-2017 | 5.4 | PCB | N-S | 0.586 | 0.561 | |
| E-W | 0.408 | 0.388 | ||||||
| Dodecanese Islands | 08-08-2019 | 4.8 | 30-10-2020 | 7.0 | GMLD | N-S | 0.450 | 0.899 |
| E-W | 0.673 | 0.763 | ||||||
References
- Atwater, B.F. Evidence for great Holocene earthquakes along the outer coast of Washington State. Science 1987, 236, 942–944. [Google Scholar] [CrossRef] [PubMed]
- Plafker, G.; Savage, J.C. Mechanism of the Chilean earthquakes of 21 and 22 May 1960. Geol. Soc. Am. Bull. 1970, 81, 1001–1030. [Google Scholar] [CrossRef]
- Chiaraluce, L.; Di Stefano, R.; Tinti, E.; Scognamiglio, L.; Michele, M.; Casarotti, E.; Cattaneo, M.; De Gori, P.; Chiarabba, C.; Monachesi, G.; et al. The 2016 central Italy seismic sequence: A first look at the mainshocks, aftershocks, and source models. Seismol. Res. Lett. 2017, 88, 757–771. [Google Scholar] [CrossRef]
- Gatti, M. Peak horizontal vibrations from GPS response spectra in the epicentral areas of the 2016 earthquake in central Italy. Geomat. Nat. Hazards Risk 2018, 9, 403–415. [Google Scholar] [CrossRef]
- Brandenberg, S.J.; Wang, P.; Nweke, C.C.; Hudson, K.; Mazzoni, S.; Bozorgnia, Y.; Hudnut, K.W.; Davis, C.A.; Ahdi, S.K.; Zareian, F.; et al. Preliminary Report on Engineering and Geological Effects of the July 2019 Ridgecrest Earthquake Sequence; Technical Report; Geotechnical Extreme Event Reconnaissance Association: Berkeley, CA, USA, 2019. [Google Scholar] [CrossRef]
- Naddaf, M. Turkey-Syria earthquake: What scientists know. Nature 2023, 614, 398–399. [Google Scholar] [CrossRef]
- İlki, A.; Demir, C.; Goksu, C.; Sarı, B. A brief outline of February 6, 2023 Earthquakes (M7.8-M7.7) in Türkiye with a focus on performance/failure of structures. In Proceedings of the Workshop on Innovative Seismic Protection of Structural Elements and Structures with Novel Materials, Civil Engineering Department (DUTh), Xanthi, Greece, 24 February 2023; Available online: https://drive.google.com/file/d/1acQRyrNnHlba87xAdTI3iUHBphFEAbIx/view (accessed on 15 March 2023).
- Abdelnaby, A. Multiple Earthquake Effects on Degrading Reinforced Concrete Structures. Ph.D. Thesis, University of Illinois at Urbana-Champaign, Urbana and Champaign, IL, USA, 2012. [Google Scholar]
- Hatzivassiliou, M.; Hatzigeorgiou, G.D. Seismic sequence effects on three-dimensional reinforced concrete buildings. Soil Dyn. Earthq. Eng. 2015, 72, 77–88. [Google Scholar] [CrossRef]
- Kavvadias, I.E.; Rovithis, P.Z.; Vasiliadis, L.K.; Elenas, A. Effect of the aftershock intensity characteristics on the seismic response of RC frame buildings. In Proceedings of the 16th European Conference on Earthquake Engineering, Thessaloniki, Greece, 18–21 June 2018. [Google Scholar]
- Trevlopoulos, K.; Guéguen, P. Period elongation-based framework for operative assessment of the variation of seismic vulnerability of reinforced concrete buildings during aftershock sequences. Soil Dyn. Earthq. Eng. 2016, 84, 224–237. [Google Scholar] [CrossRef]
- Shokrabadi, M.; Burton, H.V.; Stewart, J.P. Impact of sequential ground motion pairing on mainshock-aftershock structural response and collapse performance assessment. J. Struct. Eng. 2018, 144, 04018177. [Google Scholar] [CrossRef]
- Furtado, A.; Rodrigues, H.; Varum, H.; Arêde, A. Mainshock-aftershock damage assessment of infilled RC structures. Eng. Struct. 2018, 175, 645–660. [Google Scholar] [CrossRef]
- Di Sarno, L.; Pugliese, F. Seismic fragility of existing RC buildings with corroded bars under earthquake sequences. Soil Dyn. Earthq. Eng. 2020, 134, 106169. [Google Scholar] [CrossRef]
- Iervolino, I.; Chioccarelli, E.; Suzuki, A. Seismic damage accumulation in multiple mainshock–aftershock sequences. Earthq. Eng. Struct. Dyn. 2020, 49, 1007–1027. [Google Scholar] [CrossRef]
- Rajabi, E.; Ghodrati Amiri, G. Behavior factor prediction equations for reinforced concrete frames under critical mainshock-aftershock sequences using artificial neural networks. Sustain. Resilient Infrastruct. 2021, 7, 552–567. [Google Scholar] [CrossRef]
- Soureshjani, O.K.; Massumi, A. Seismic behavior of RC moment resisting structures with concrete shear wall under mainshock–aftershock seismic sequences. Bull. Earthq. Eng. 2022, 20, 1087–1114. [Google Scholar] [CrossRef]
- Khansefid, A. An investigation of the structural nonlinearity effects on the building seismic risk assessment under mainshock–aftershock sequences in Tehran metro city. Adv. Struct. Eng. 2021, 24, 3788–3791. [Google Scholar] [CrossRef]
- Hu, J.; Wen, W.; Zhai, C.; Pei, S.; Ji, D. Seismic resilience assessment of buildings considering the effects of mainshock and multiple aftershocks. J. Build. Eng. 2023, 68, 106110. [Google Scholar] [CrossRef]
- Askouni, P.K. The Effect of Sequential Excitations on Asymmetrical Reinforced Concrete Low-Rise Framed Structures. Symmetry 2023, 15, 968. [Google Scholar] [CrossRef]
- Zhao, J.; Ivan, J.N.; DeWolf, J.T. Structural damage detection using artificial neural networks. J. Infrastruct. Syst. 1998, 4, 93–101. [Google Scholar] [CrossRef]
- Stavroulakis, G.E.; Antes, H. Nondestructive elastostatic identification of unilateral cracks through BEM and neural networks. Comput. Mech. 1997, 20, 439–451. [Google Scholar] [CrossRef]
- De Lautour, O.R.; Omenzetter, P. Prediction of seismic-induced structural damage using artificial neural networks. Eng. Struct. 2009, 31, 600–606. [Google Scholar] [CrossRef]
- Lagaros, N.D.; Papadrakakis, M. Neural network based prediction schemes of the non-linear seismic response of 3D buildings. Adv. Eng. Softw. 2012, 44, 92–115. [Google Scholar] [CrossRef]
- Sánchez Silva, M.; García, L. Earthquake damage assessment based on fuzzy logic and neural networks. Earthq. Spectra 2001, 17, 89–112. [Google Scholar] [CrossRef]
- Alvanitopoulos, P.; Andreadis, I.; Elenas, A. Neuro–fuzzy techniques for the classification of earthquake damages in buildings. Measurement 2010, 43, 797–809. [Google Scholar] [CrossRef]
- Vrochidou, E.; Alvanitopoulos, P.F.; Andreadis, I.; Elenas, A. Intelligent systems for structural damage assessment. J. Intell. Syst. 2018, 29, 378–392. [Google Scholar] [CrossRef]
- Mangalathu, S.; Sun, H.; Nweke, C.C.; Yi, Z.; Burton, H.V. Classifying earthquake damage to buildings using machine learning. Earthq. Spectra 2020, 36, 183–208. [Google Scholar] [CrossRef]
- Wang, S.; Cheng, X.; Li, Y.; Song, X.; Guo, R.; Zhang, H.; Liang, Z. Rapid visual simulation of the progressive collapse of regular reinforced concrete frame structures based on machine learning and physics engine. Eng. Struct. 2023, 286, 116129. [Google Scholar] [CrossRef]
- Wen, W.; Zhang, C.; Zhai, C. Rapid seismic response prediction of RC frames based on deep learning and limited building information. Eng. Struct. 2022, 267, 114638. [Google Scholar] [CrossRef]
- Natarajan, Y.; Wadhwa, G.; Ranganathan, P.A.; Natarajan, K. Earthquake Damage Prediction and Rapid Assessment of Building Damage Using Deep Learning. In Proceedings of the 2023 International Conference on Advances in Electronics, Communication, Computing and Intelligent Information Systems (ICAECIS), Bengaluru, India, 19–21 April 2023; pp. 540–547. [Google Scholar] [CrossRef]
- Sri Preethaa, K.; Munisamy, S.D.; Rajendran, A.; Muthuramalingam, A.; Natarajan, Y.; Yusuf Ali, A.A. Novel ANOVA-Statistic-Reduced Deep Fully Connected Neural Network for the Damage Grade Prediction of Post-Earthquake Buildings. Sensors 2023, 23, 6439. [Google Scholar] [CrossRef]
- Zhang, R.; Liu, Y.; Sun, H. Physics-guided convolutional neural network (PhyCNN) for data-driven seismic response modeling. Eng. Struct. 2020, 215, 110704. [Google Scholar] [CrossRef]
- Muradova, A.D.; Stavroulakis, G.E. Physics-informed neural networks for elastic plate problems with bending and Winkler-type contact effects. J. Serbian Soc. Comput. Mech. 2021, 15, 45–54. [Google Scholar] [CrossRef]
- Katsikis, D.; Muradova, A.D.; Stavroulakis, G.E. A Gentle Introduction to Physics-Informed Neural Networks, with Applications in Static Rod and Beam Problems. J. Adv. Appl. Comput. Math. 2022, 9, 103–128. [Google Scholar] [CrossRef]
- Morfidis, K.; Kostinakis, K. Seismic parameters’ combinations for the optimum prediction of the damage state of R/C buildings using neural networks. Adv. Eng. Softw. 2017, 106, 1–16. [Google Scholar] [CrossRef]
- Hwang, S.H.; Mangalathu, S.; Shin, J.; Jeon, J.S. Machine learning-based approaches for seismic demand and collapse of ductile reinforced concrete building frames. J. Build. Eng. 2021, 34, 101905. [Google Scholar] [CrossRef]
- Kalakonas, P.; Silva, V. Earthquake scenarios for building portfolios using artificial neural networks: Part I—Ground motion modelling. Bull. Earthq. Eng. 2022, 20, 1–22. [Google Scholar] [CrossRef]
- Zhang, H.; Cheng, X.; Li, Y.; He, D.; Du, X. Rapid seismic damage state assessment of RC frames using machine learning methods. J. Build. Eng. 2022, 65, 105797. [Google Scholar] [CrossRef]
- Yuan, X.; Chen, G.; Jiao, P.; Li, L.; Han, J.; Zhang, H. A neural network-based multivariate seismic classifier for simultaneous post-earthquake fragility estimation and damage classification. Eng. Struct. 2022, 255, 113918. [Google Scholar] [CrossRef]
- Kazemi, P.; Ghisi, A.; Mariani, S. Classification of the Structural Behavior of Tall Buildings with a Diagrid Structure: A Machine Learning-Based Approach. Algorithms 2022, 15, 349. [Google Scholar] [CrossRef]
- Karbassi, A.; Mohebi, B.; Rezaee, S.; Lestuzzi, P. Damage prediction for regular reinforced concrete buildings using the decision tree algorithm. Comp. Struct. 2014, 130, 46–56. [Google Scholar] [CrossRef]
- Ghiasi, R.; Torkzadeh, P.; Noori, M. A machine-learning approach for structural damage detection using least square support vector machine based on a new combinational kernel function. Struct. Health Monit. 2016, 15, 302–316. [Google Scholar] [CrossRef]
- Chen, S.Z.; Feng, D.C.; Wang, W.J.; Taciroglu, E. Probabilistic Machine-Learning Methods for Performance Prediction of Structure and Infrastructures through Natural Gradient Boosting. J. Struct. Eng. 2022, 148, 04022096. [Google Scholar] [CrossRef]
- Jia, D.W.; Wu, Z.Y. Structural probabilistic seismic risk analysis and damage prediction based on artificial neural network. Structures 2022, 41, 982–996. [Google Scholar] [CrossRef]
- Kiani, J.; Camp, C.; Pezeshk, S. On the application of machine learning techniques to derive seismic fragility curves. Comp. Struct. 2019, 218, 108–122. [Google Scholar] [CrossRef]
- Kazemi, F.; Asgarkhani, N.; Jankowski, R. Machine learning-based seismic fragility and seismic vulnerability assessment of reinforced concrete structures. Soil Dyn. Earthq. Eng. 2023, 166, 107761. [Google Scholar] [CrossRef]
- Dabiri, H.; Faramarzi, A.; Dall’Asta, A.; Tondi, E.; Micozzi, F. A machine learning-based analysis for predicting fragility curve parameters of buildings. J. Build. Eng. 2022, 62, 105367. [Google Scholar] [CrossRef]
- Yang, J.; Zhuang, H.; Zhang, G.; Tang, B.; Xu, C. Seismic performance and fragility of two-story and three-span underground structures using a random forest model and a new damage description method. Tunn. Undergr. Space Technol. 2023, 135, 104980. [Google Scholar] [CrossRef]
- De-Miguel-Rodríguez, J.; Morales-Esteban, A.; Requena-García-Cruz, M.; Zapico-Blanco, B.; Segovia-Verjel, M.; Romero-Sánchez, E.; Carvalho-Estêvão, J.M. Fast seismic assessment of built urban areas with the accuracy of mechanical methods using a feedforward neural network. Sustainability 2022, 14, 5274. [Google Scholar] [CrossRef]
- Gravett, D.Z.; Mourlas, C.; Taljaard, V.L.; Bakas, N.; Markou, G.; Papadrakakis, M. New fundamental period formulae for soil-reinforced concrete structures interaction using machine learning algorithms and ANNs. Soil Dyn. Earthq. Eng. 2021, 144, 106656. [Google Scholar] [CrossRef]
- Morfidis, K.; Stefanidou, S.; Markogiannaki, O. A Rapid Seismic Damage Assessment (RASDA) Tool for RC Buildings Based on an Artificial Intelligence Algorithm. Appl. Sci. 2023, 13, 5100. [Google Scholar] [CrossRef]
- Lazaridis, P.C.; Kavvadias, I.E.; Demertzis, K.; Iliadis, L.; Papaleonidas, A.; Vasiliadis, L.K.; Elenas, A. Structural Damage Prediction Under Seismic Sequence Using Neural Networks. In Proceedings of the 8th International Conference on Computational Methods in Structural Dynamics and Earthquake Engineering (COMPDYN 2021), Athens, Greece, 28–30 June 2021. [Google Scholar] [CrossRef]
- Lazaridis, P.C.; Kavvadias, I.E.; Demertzis, K.; Iliadis, L.; Vasiliadis, L.K. Structural Damage Prediction of a Reinforced Concrete Frame under Single and Multiple Seismic Events Using Machine Learning Algorithms. Appl. Sci. 2022, 12, 3845. [Google Scholar] [CrossRef]
- Sun, H.; Burton, H.V.; Huang, H. Machine Learning Applications for Building Structural Design and Performance Assessment: State-of-the-Art Review. J. Build. Eng. 2020, 33, 101816. [Google Scholar] [CrossRef]
- Xie, Y.; Ebad Sichani, M.; Padgett, J.E.; DesRoches, R. The promise of implementing machine learning in earthquake engineering: A state-of-the-art review. Earthq. Spectra 2020, 36, 1769–1801. [Google Scholar] [CrossRef]
- Harirchian, E.; Hosseini, S.E.A.; Jadhav, K.; Kumari, V.; Rasulzade, S.; Işık, E.; Wasif, M.; Lahmer, T. A Review on Application of Soft Computing Techniques for the Rapid Visual Safety Evaluation and Damage Classification of Existing Buildings. J. Build. Eng. 2021, 43, 102536. [Google Scholar] [CrossRef]
- Sony, S.; Dunphy, K.; Sadhu, A.; Capretz, M. A systematic review of convolutional neural network-based structural condition assessment techniques. Eng. Struct. 2021, 226, 111347. [Google Scholar] [CrossRef]
- Tapeh, A.T.G.; Naser, M. Artificial Intelligence, Machine Learning, and Deep Learning in Structural Engineering: A Scientometrics Review of Trends and Best Practices. Arch. Comput. Methods Eng. 2022, 30, 115–159. [Google Scholar] [CrossRef]
- Thai, H.T. Machine learning for structural engineering: A state-of-the-art review. Structures 2022, 38, 448–491. [Google Scholar] [CrossRef]
- You, Z. Intelligent construction: Unlocking opportunities for the digital transformation of China’s construction industry. Eng. Constr. Archit. Manag. 2022, 29, 326. [Google Scholar] [CrossRef]
- Málaga-Chuquitaype, C. Machine learning in structural design: An opinionated review. Front. Built Environ. 2022, 8, 6. [Google Scholar] [CrossRef]
- Demertzis, K.; Demertzis, S.; Iliadis, L. A Selective Survey Review of Computational Intelligence Applications in the Primary Subdomains of Civil Engineering Specializations. Appl. Sci. 2023, 13, 3380. [Google Scholar] [CrossRef]
- Wang, C.; Song, L.H.; Yuan, Z.; Fan, J.S. State-of-the-Art AI-Based Computational Analysis in Civil Engineering. J. Ind. Inf. Integr. 2023, 2023, 100470. [Google Scholar] [CrossRef]
- Zhou, Z.; Yu, X.; Lu, D. Identifying Optimal Intensity Measures for Predicting Damage Potential of Mainshock–Aftershock Sequences. Appl. Sci. 2020, 10, 6795. [Google Scholar] [CrossRef]
- Amiri, S.; Di Sarno, L.; Garakaninezhad, A. Correlation between non-spectral and cumulative-based ground motion intensity measures and demands of structures under mainshock-aftershock seismic sequences considering the effects of incident angles. Structures 2022, 46, 1209–1223. [Google Scholar] [CrossRef]
- Demertzis, K.; Kostinakis, K.; Morfidis, K.; Iliadis, L. An interpretable machine learning method for the prediction of R/C buildings’ seismic response. J. Build. Eng. 2022, 2022, 105493. [Google Scholar] [CrossRef]
- Park, Y.J.; Ang, A.H.S. Mechanistic seismic damage model for reinforced concrete. J. Struct. Eng. 1985, 111, 722–739. [Google Scholar] [CrossRef]
- Elenas, A. Interdependency between seismic acceleration parameters and the behaviour of structures. Soil Dyn. Earthq. Eng. 1997, 16, 317–322. [Google Scholar] [CrossRef]
- Elenas, A.; Liolios, A.; Vasiliadis, L. Correlation Factors between Seismic Acceleration Parameters and Damage Indicators of Reinforced Concrete Structures; Balkema Publishers: Rotterdam, The Netherlands, 1999; Volume 2, pp. 1095–1100. [Google Scholar]
- Elenas, A. Correlation between seismic acceleration parameters and overall structural damage indices of buildings. Soil Dyn. Earthq. Eng. 2000, 20, 93–100. [Google Scholar] [CrossRef]
- Vrochidou, E.; Alvanitopoulos, P.; Andreadis, I.; Elenas, A. Correlation between seismic intensity parameters of HHT-based synthetic seismic accelerograms and damage indices of buildings. In Proceedings of the IFIP International Conference on Artificial Intelligence Applications and Innovations, Halkidiki, Greece, 27–30 September 2012; pp. 425–434. [Google Scholar] [CrossRef]
- Fontara, I.; Athanatopoulou, A.; Avramidis, I. Correlation between advanced, structure-specific ground motion intensity measures and damage indices. In Proceedings of the 15th World Conference on Earthquake Engineering, Lisbon, Portugal, 24–28 September 2012; pp. 24–28. [Google Scholar]
- Van Cao, V.; Ronagh, H.R. Correlation between seismic parameters of far-fault motions and damage indices of low-rise reinforced concrete frames. Soil Dyn. Earthq. Eng. 2014, 66, 102–112. [Google Scholar] [CrossRef]
- Kostinakis, K.; Athanatopoulou, A.; Morfidis, K. Correlation between ground motion intensity measures and seismic damage of 3D R/C buildings. Eng. Struct. 2015, 82, 151–167. [Google Scholar] [CrossRef]
- Lazaridis, P.C.; Kavvadias, I.E.; Vasiliadis, L.K. Correlation between Seismic Parameters and Damage Indices of Reinforced Concrete Structures. In Proceedings of the 4th Panhellenic Conference on Earthquake Engineering and Engineering Seismology, Athens, Greece, 5–7 September 2019. [Google Scholar]
- Palanci, M.; Senel, S.M. Correlation of earthquake intensity measures and spectral displacement demands in building type structures. Soil Dyn. Earthq. Eng. 2019, 121, 306–326. [Google Scholar] [CrossRef]
- Kramer, S.L. Geotechnical Earthquake Engineering; Prentice Hall: Upper Saddle River, NJ, USA, 1996. [Google Scholar]
- Arias, A. A measure of earthquake intensity. In Seismic Design for Nuclear Power Plants; Massachusetts Institute of Technology: Cambridge, MA, USA, 1970. [Google Scholar]
- Araya, R.; Saragoni, G.R. Earthquake accelerogram destructiveness potential factor. In Proceedings of the 8th World Conference on Earthquake Engineering, San Francisco, CA, USA, 11–18 July 1985; Volume 11, pp. 835–843. [Google Scholar]
- Trifunac, M.D.; Brady, A.G. A study on the duration of strong earthquake ground motion. Bull. Seismol. Soc. Am. 1975, 65, 581–626. [Google Scholar]
- Reinoso, E.; Ordaz, M.; Guerrero, R. Influence of strong ground-motion duration in seismic design of structures. In Proceedings of the 12th World Conference on Earthquake Engineering, Auckland, New Zealand, 30 January–4 February 2000; Volume 1151. [Google Scholar]
- Bolt, B.A. Duration of strong ground motion. In Proceedings of the 5th World Conference on Earthquake Engineering, Rome, Italy, 25–29 June 1973; Volume 292, pp. 25–29. [Google Scholar]
- Fajfar, P.; Vidic, T.; Fischinger, M. A measure of earthquake motion capacity to damage medium-period structures. Soil Dyn. Earthq. Eng. 1990, 9, 236–242. [Google Scholar] [CrossRef]
- Riddell, R.; Garcia, J.E. Hysteretic energy spectrum and damage control. Earthq. Eng. Struct. Dyn. 2001, 30, 1791–1816. [Google Scholar] [CrossRef]
- Housner, G.W. Spectrum intensities of strong-motion earthquakes. In Proceedings of the Symposium on Earthquake and Blast Effects on Structures, Los Angeles, CA, USA, 25–29 June 1952. [Google Scholar]
- Husid, R. Características de terremotos. Análisis general. Revista IDIEM 1969, 8, ág-21. [Google Scholar]
- Kunnath, S.K.; Reinhorn, A.M.; Lobo, R. IDARC Version 3.0: A Program for the Inelastic Damage Analysis of Reinforced Concrete Structures; Technical report; US National Center for Earthquake Engineering Research (NCEER), University at Buffalo 212: Ketter Hall Buffalo, NY, USA, 1992; pp. 14260–14300. [Google Scholar]
- Karabini, M.A.; Karabinis, A.J.; Karayannis, C.G. Seismic characteristics of a Π-shaped 4-story RC structure with open ground floor. Earthq. Struct. 2022, 22, 345. [Google Scholar] [CrossRef]
- Park, Y.J.; Ang, A.H.; Wen, Y.K. Damage-limiting aseismic design of buildings. Earthq. Spectra 1987, 3, 1585416. [Google Scholar] [CrossRef]
- Hatzigeorgiou, G.D.; Liolios, A.A. Nonlinear behaviour of RC frames under repeated strong ground motions. Soil Dyn. Earthq. Eng. 2010, 30, 1010–1025. [Google Scholar] [CrossRef]
- CEN. Eurocode 8: Design of Structures for Earthquake Resistance-Part 1: General Rules, Seismic Actions and Rules for Buildings; European Committee for Standardization: Brussels, Belgium, 2005. [Google Scholar]
- Chalioris, C.E. Analytical model for the torsional behaviour of reinforced concrete beams retrofitted with FRP materials. Eng. Struct. 2007, 29, 3263–3276. [Google Scholar] [CrossRef]
- Bantilas, K.E.; Kavvadias, I.E.; Vasiliadis, L.K. Capacity spectrum method based on inelastic spectra for high viscous damped buildings. Earthq. Struct. 2017, 13, 337–351. [Google Scholar] [CrossRef]
- Anagnostou, E.; Rousakis, T.C.; Karabinis, A.I. Seismic retrofitting of damaged RC columns with lap-spliced bars using FRP sheets. Compos. Part B Eng. 2019, 166, 598–612. [Google Scholar] [CrossRef]
- Thomoglou, A.K.; Rousakis, T.C.; Achillopoulou, D.V.; Karabinis, A.I. Ultimate shear strength prediction model for unreinforced masonry retrofitted externally with textile reinforced mortar. Earthq. Struct. 2020, 19, 411–425. [Google Scholar] [CrossRef]
- Rousakis, T.; Anagnostou, E.; Fanaradelli, T. Advanced Composite Retrofit of RC Columns and Frames with Prior Damages—Pseudodynamic Finite Element Analyses and Design Approaches. Fibers 2021, 9, 56. [Google Scholar] [CrossRef]
- Karabini, M.; Rousakis, T.; Golias, E.; Karayannis, C. Seismic Tests of Full Scale Reinforced Concrete T Joints with Light External Continuous Composite Rope Strengthening—Joint Deterioration and Failure Assessment. Materials 2023, 16, 2718. [Google Scholar] [CrossRef]
- Valles, R.; Reinhorn, A.M.; Kunnath, S.K.; Li, C.; Madan, A. IDARC2D Version 4.0: A Computer Program for the Inelastic Damage Analysis of Buildings; Technical Report; US National Center for Earthquake Engineering Research (NCEER), University at Buffalo 212: Ketter Hall Buffalo, NY, USA, 1996; pp. 14260–14300. [Google Scholar]
- Park, Y.J.; Reinhorn, A.M.; Kunnath, S.K. IDARC: Inelastic Damage Analysis of Reinforced Concrete Frame–Shear–Wall Structures; National Center for Earthquake Engineering Research Buffalo, University at Buffalo 212: Ketter Hall Buffalo, NY, USA, 1987; pp. 14260–14300. [Google Scholar]
- Eaton, J.W. GNU Octave and reproducible research. J. Process Control 2012, 22, 1433–1438. [Google Scholar] [CrossRef]
- Eaton, J.W.; Bateman, D.; Hauberg, S.; Wehbring, R. GNU Octave Version 6.1.0 Manual: A High-Level Interactive Language for Numerical Computations; Free Software Foundation: Bostoin, MA, USA, 2020. [Google Scholar]
- Luzi, L.; Lanzano, G.; Felicetta, C.; D’Amico, M.; Russo, E.; Sgobba, S.; Pacor, F.; ORFEUS Working Group 5. Engineering Strong Motion Database (ESM) (Version 2.0); Istituto Nazionale di Geofisica e Vulcanologia (INGV): Rome, Italy, 2020. [Google Scholar] [CrossRef]
- Goulet, C.A.; Kishida, T.; Ancheta, T.D.; Cramer, C.H.; Darragh, R.B.; Silva, W.J.; Hashash, Y.M.; Harmon, J.; Stewart, J.P.; Wooddell, K.E.; et al. PEER NGA-East Database; Technical Report; Pacific Earthquake Engineering Research Center: Berkeley, CA, USA, 2014. [Google Scholar]
- Van Rossum, G. Python Reference Manual; National Research Institute for Mathematics and Computer Science, Netherlands Organisation for Scientific Research: Amsterdam, The Netherlands, 1995. [Google Scholar]
- Harris, C.R.; Millman, K.J.; Van der Walt, S.J.; Gommers, R.; Virtanen, P.; Cournapeau, D.; Wieser, E.; Taylor, J.; Berg, S.; Smith, N.J.; et al. Array programming with NumPy. Nature 2020, 585, 357–362. [Google Scholar] [CrossRef]
- Papazafeiropoulos, G.; Plevris, V. OpenSeismoMatlab: A new open-source software for strong ground motion data processing. Heliyon 2018, 4, e00784. [Google Scholar] [CrossRef] [PubMed]
- Galton, F. Regression towards mediocrity in hereditary stature. J. Anthropol. Inst. Great Br. Irel. 1886, 15, 246–263. [Google Scholar] [CrossRef]
- Stanton, J.M. Galton, Pearson, and the peas: A brief history of linear regression for statistics instructors. J. Stat. Educ. 2001, 9, 1–13. [Google Scholar] [CrossRef]
- Tibshirani, R. Regression shrinkage and selection via the lasso. J. R. Stat. Soc. Ser. B 1996, 58, 267–288. [Google Scholar] [CrossRef]
- Hoerl, A.E.; Kennard, R.W. Ridge regression: Biased estimation for nonorthogonal problems. Technometrics 1970, 12, 55–67. [Google Scholar] [CrossRef]
- Zou, H.; Hastie, T. Regularization and variable selection via the elastic net. J. R. Stat. Soc. Ser. B 2005, 67, 301–320. [Google Scholar] [CrossRef]
- Altman, N.S. An introduction to kernel and nearest-neighbor nonparametric regression. Am. Stat. 1992, 46, 175–185. [Google Scholar] [CrossRef]
- Breiman, L.; Friedman, J.H.; Olshen, R.A.; Stone, C.J. Classification and Regression Trees; Routledge: London, UK, 2017. [Google Scholar] [CrossRef]
- Breiman, L. Random forests. Mach. Learn. 2001, 45, 5–32. [Google Scholar] [CrossRef]
- Friedman, J.H. Greedy function approximation: A gradient boosting machine. Ann. Stat. 2001, 1, 1189–1232. [Google Scholar] [CrossRef]
- Geurts, P.; Ernst, D.; Wehenkel, L. Extremely randomized trees. Mach. Learn. 2006, 63, 3–42. [Google Scholar] [CrossRef]
- Freund, Y.; Schapire, R.E. A decision-theoretic generalization of on-line learning and an application to boosting. J. Comput. Syst. Sci. 1997, 55, 119–139. [Google Scholar] [CrossRef]
- Drucker, H. Improving regressors using boosting techniques. In Proceedings of the 14th International Conference on Machine Learning (ICML), Nashville, TN, USA, 8–12 July 1997; Volume 97, pp. 107–115. [Google Scholar]
- Ke, G.; Meng, Q.; Finley, T.; Wang, T.; Chen, W.; Ma, W.; Ye, Q.; Liu, T.Y. LightGBM: A Highly Efficient Gradient Boosting Decision Tree. In Proceedings of the Advances in Neural Information Processing Systems (NIPS), Long Beach, CA, USA, 4–9 December 2017; Guyon, I., Luxburg, U.V., Bengio, S., Wallach, H., Fergus, R., Vishwanathan, S., Garnett, R., Eds.; Curran Associates Inc.: Red Hook, NY, USA, 2017; Volume 30. [Google Scholar]
- Dorogush, A.V.; Ershov, V.; Gulin, A. CatBoost: Gradient boosting with categorical features support. In Proceedings of the Workshop on ML Systems at NIPS, Long Beach, CA, USA, 8 December 2017. [Google Scholar]
- Prokhorenkova, L.; Gusev, G.; Vorobev, A.; Dorogush, A.V.; Gulin, A. CatBoost: Unbiased boosting with categorical features. In Proceedings of the Advances in Neural Information Processing Systems (NeurIPS), Montréal, QC, Canada, 3–8 December 2018; Bengio, S., Wallach, H., Larochelle, H., Grauman, K., Cesa Bianchi, N., Garnett, R., Eds.; Curran Associates Inc.: Red Hook, NY, USA, 2018; Volume 31. [Google Scholar]
- Chen, T.; Guestrin, C. XGBoost: A Scalable Tree Boosting System. In Proceedings of the 22nd ACM SIGKDD International Conference on Knowledge Discovery and Data Mining, San Francisco, CA, USA, 13–17 August 2016; pp. 785–794. [Google Scholar] [CrossRef]
- Duan, T.; Anand, A.; Ding, D.Y.; Thai, K.K.; Basu, S.; Ng, A.; Schuler, A. NGBoost: Natural Gradient Boosting for Probabilistic Prediction. In Proceedings of the 37th International Conference on Machine Learning (ICML), Virtual, 13–18 July 2020; Daumé, H., Singh, A., Eds.; Curran Associates Inc.: Red Hook, NY, USA, 2020; Volume 119, pp. 2690–2700. [Google Scholar]
- Rojas, R. Neural Networks: A Systematic Introduction; Springer Science & Business Media: Berlin/Heidelberg, Germany, 1996. [Google Scholar] [CrossRef]
- Minsky, M.; Papert, S.A. Perceptrons: An Introduction to Computational Geometry; MIT Press: Cambridge, MA, USA, 2017. [Google Scholar]
- Goodfellow, I.; Bengio, Y.; Courville, A. Deep Learning; MIT Press: Cambridge, MA, USA, 2016; Available online: http://www.deeplearningbook.org (accessed on 15 March 2023).
- Rumelhart, D.E.; Hinton, G.E.; Williams, R.J. Learning representations by back-propagating errors. Nature 1986, 323, 533–536. [Google Scholar] [CrossRef]
- LeCun, Y.A.; Bottou, L.; Orr, G.B.; Müller, K.R. Efficient backprop. In Neural Networks: Tricks of the Trade; Springer: Berlin/Heidelberg, Germany, 2012; pp. 9–48. [Google Scholar] [CrossRef]
- Bergstra, J.; Bardenet, R.; Bengio, Y.; Kégl, B. Algorithms for Hyper-Parameter Optimization. In Proceedings of the Advances in Neural Information Processing Systems (NIPS), Granada, Spain, 12–15 December 2011; Shawe Taylor, J., Zemel, R., Bartlett, P., Pereira, F., Weinberger, K., Eds.; Curran Associates Inc.: Red Hook, NY, USA, 2011; Volume 24. [Google Scholar]
- Bergstra, J.; Bengio, Y. Random search for hyper-parameter optimization. J. Mach. Learn. Res. 2012, 13, 281–305. [Google Scholar]
- Picard, R.R.; Cook, R.D. Cross-validation of regression models. J. Am. Stat. Assoc. 1984, 79, 575–583. [Google Scholar] [CrossRef]
- Pedregosa, F.; Varoquaux, G.; Gramfort, A.; Michel, V.; Thirion, B.; Grisel, O.; Blondel, M.; Prettenhofer, P.; Weiss, R.; Dubourg, V.; et al. Scikit-learn: Machine Learning in Python. J. Mach. Learn. Res. 2011, 12, 2825–2830. [Google Scholar]
- Lei, M.; Lin, D.; Huang, Q.; Shi, C.; Huang, L. Research on the construction risk control technology of shield tunnel underneath an operational railway in sand pebble formation: A case study. Eur. J. Environ. Civ. Eng. 2020, 24, 1558–1572. [Google Scholar] [CrossRef]
- Huang, L.; Huang, S.; Lai, Z. On the optimization of site investigation programs using centroidal Voronoi tessellation and random field theory. Comput. Geotech. 2020, 118, 103331. [Google Scholar] [CrossRef]
- Lin, Y.; Ma, J.; Lai, Z.; Huang, L.; Lei, M. A FDEM approach to study mechanical and fracturing responses of geo-materials with high inclusion contents using a novel reconstruction strategy. Eng. Fract. Mech. 2023, 282, 109171. [Google Scholar] [CrossRef]
- Lin, Y.; Yin, Z.Y.; Wang, X.; Huang, L. A systematic 3D simulation method for geomaterials with block inclusions from image recognition to fracturing modelling. Theor. Appl. Fract. Mech. 2022, 117, 103194. [Google Scholar] [CrossRef]
- Ma, J.; Chen, J.; Guan, J.; Lin, Y.; Chen, W.; Huang, L. Implementation of Johnson-Holmquist-Beissel model in four-dimensional lattice spring model and its application in projectile penetration. Int. J. Impact Eng. 2022, 170, 104340. [Google Scholar] [CrossRef]
- Ding, W.; Jia, S. An Improved Equation for the Bearing Capacity of Concrete-Filled Steel Tube Concrete Short Columns Based on GPR. Buildings 2023, 13, 1226. [Google Scholar] [CrossRef]
- Molnar, C. Interpretable Machine Learning—A Guide for Making Black Box Models Explainable, 2nd ed.; Independently Published; 2023; Available online: https://christophm.github.io/interpretable-ml-book (accessed on 15 March 2023).
- Mangalathu, S.; Karthikeyan, K.; Feng, D.C.; Jeon, J.S. Machine-learning interpretability techniques for seismic performance assessment of infrastructure systems. Eng. Struct. 2022, 250, 112883. [Google Scholar] [CrossRef]
- Wakjira, T.G.; Ibrahim, M.; Ebead, U.; Alam, M.S. Explainable machine learning model and reliability analysis for flexural capacity prediction of RC beams strengthened in flexure with FRCM. Eng. Struct. 2022, 255, 113903. [Google Scholar] [CrossRef]
- Junda, E.; Málaga-Chuquitaype, C.; Chawgien, K. Interpretable machine learning models for the estimation of seismic drifts in CLT buildings. J. Build. Eng. 2023, 2023, 106365. [Google Scholar] [CrossRef]
- Hastie, T.; Friedman, J.H.; Tibshirani, R. The Elements of Statistical Learning: Data Mining, Inference, and Prediction; Springer: New York, NY, USA, 2009; Volume 2. [Google Scholar] [CrossRef]
- Apley, D.W.; Zhu, J. Visualizing the effects of predictor variables in black box supervised learning models. J. R. Stat. Soc. Ser. B 2020, 82, 1059–1086. [Google Scholar] [CrossRef]
- Ribeiro, M.T.; Singh, S.; Guestrin, C. “Why Should I Trust You?”: Explaining the Predictions of Any Classifier. In Proceedings of the 22nd ACM SIGKDD International Conference on Knowledge Discovery and Data Mining, San Francisco, CA, USA, 13–17 August 2016; pp. 1135–1144. [Google Scholar] [CrossRef]
- Lundberg, S.M.; Lee, S.I. A Unified Approach to Interpreting Model Predictions. In Proceedings of the 31st Conference on Neural Information Processing Systems (NIPS 2017), Long Beach, CA, USA, 4–9 December 2017; Guyon, I., Luxburg, U.V., Bengio, S., Wallach, H., Fergus, R., Vishwanathan, S., Garnett, R., Eds.; Curran Associates Inc.: Red Hook, NY, USA, 2017; pp. 4765–4774. [Google Scholar]
- Shapley, L.S. A value for n-person games. Ann. Math. Stud. 1953, 28, 307–317. [Google Scholar]





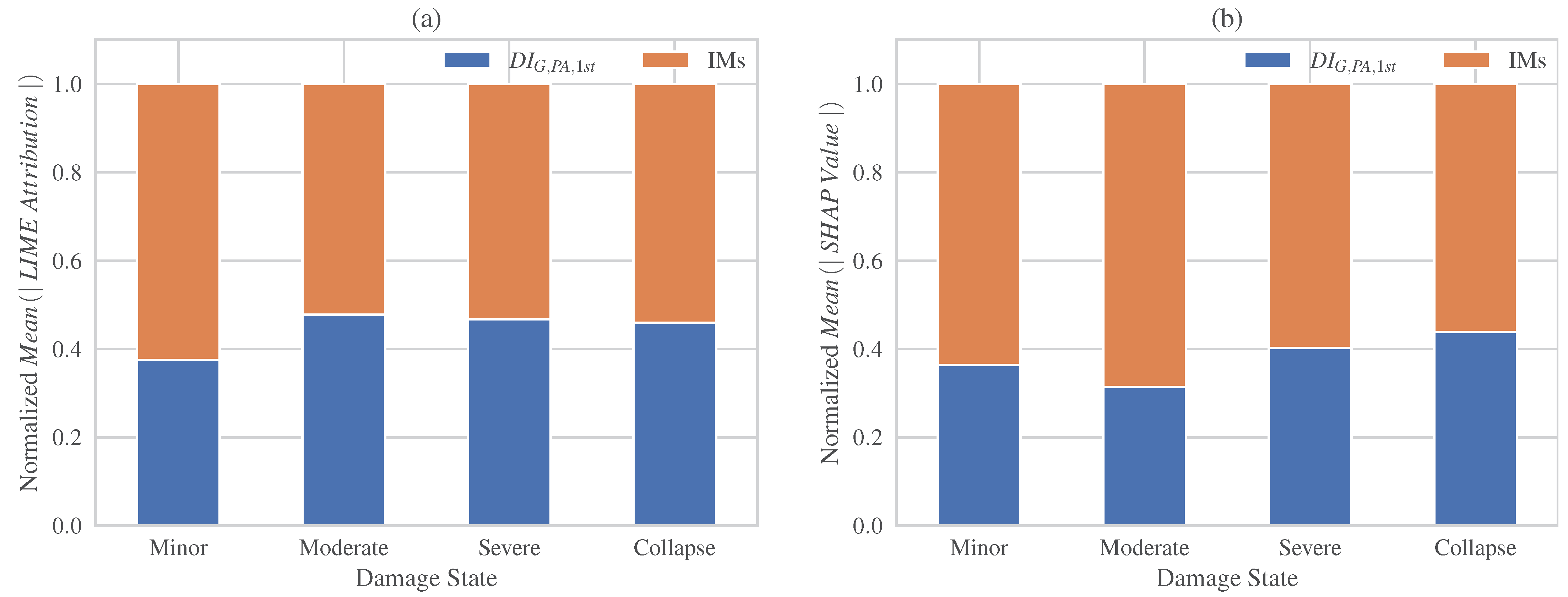
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Lazaridis, P.C.; Kavvadias, I.E.; Demertzis, K.; Iliadis, L.; Vasiliadis, L.K. Interpretable Machine Learning for Assessing the Cumulative Damage of a Reinforced Concrete Frame Induced by Seismic Sequences. Sustainability 2023, 15, 12768. https://doi.org/10.3390/su151712768
Lazaridis PC, Kavvadias IE, Demertzis K, Iliadis L, Vasiliadis LK. Interpretable Machine Learning for Assessing the Cumulative Damage of a Reinforced Concrete Frame Induced by Seismic Sequences. Sustainability. 2023; 15(17):12768. https://doi.org/10.3390/su151712768
Chicago/Turabian StyleLazaridis, Petros C., Ioannis E. Kavvadias, Konstantinos Demertzis, Lazaros Iliadis, and Lazaros K. Vasiliadis. 2023. "Interpretable Machine Learning for Assessing the Cumulative Damage of a Reinforced Concrete Frame Induced by Seismic Sequences" Sustainability 15, no. 17: 12768. https://doi.org/10.3390/su151712768
APA StyleLazaridis, P. C., Kavvadias, I. E., Demertzis, K., Iliadis, L., & Vasiliadis, L. K. (2023). Interpretable Machine Learning for Assessing the Cumulative Damage of a Reinforced Concrete Frame Induced by Seismic Sequences. Sustainability, 15(17), 12768. https://doi.org/10.3390/su151712768