
Research on Learning Concentration Recognition with Multi-Modal Features in Virtual Reality Environments


Abstract
:1. Introduction
- Does the accuracy of concentration recognition improve in VR environments when integrating interaction and vision data compared to using a single type of data?
- Does the accuracy of concentration recognition improve in VR environments when combining cognitive, emotional, and behavioral dimensions compared to using only a single dimension?
- Do learners with a high perceived sense of immersion in VR environments exhibit better learning concentration? Do learners with higher learning concentrations achieve better learning outcomes?
2. Literature Review
2.1. Concentration Recognition Based on Interaction and Vision Data
2.2. Concentration Recognition Based on Emotion, Behavior, and Cognition
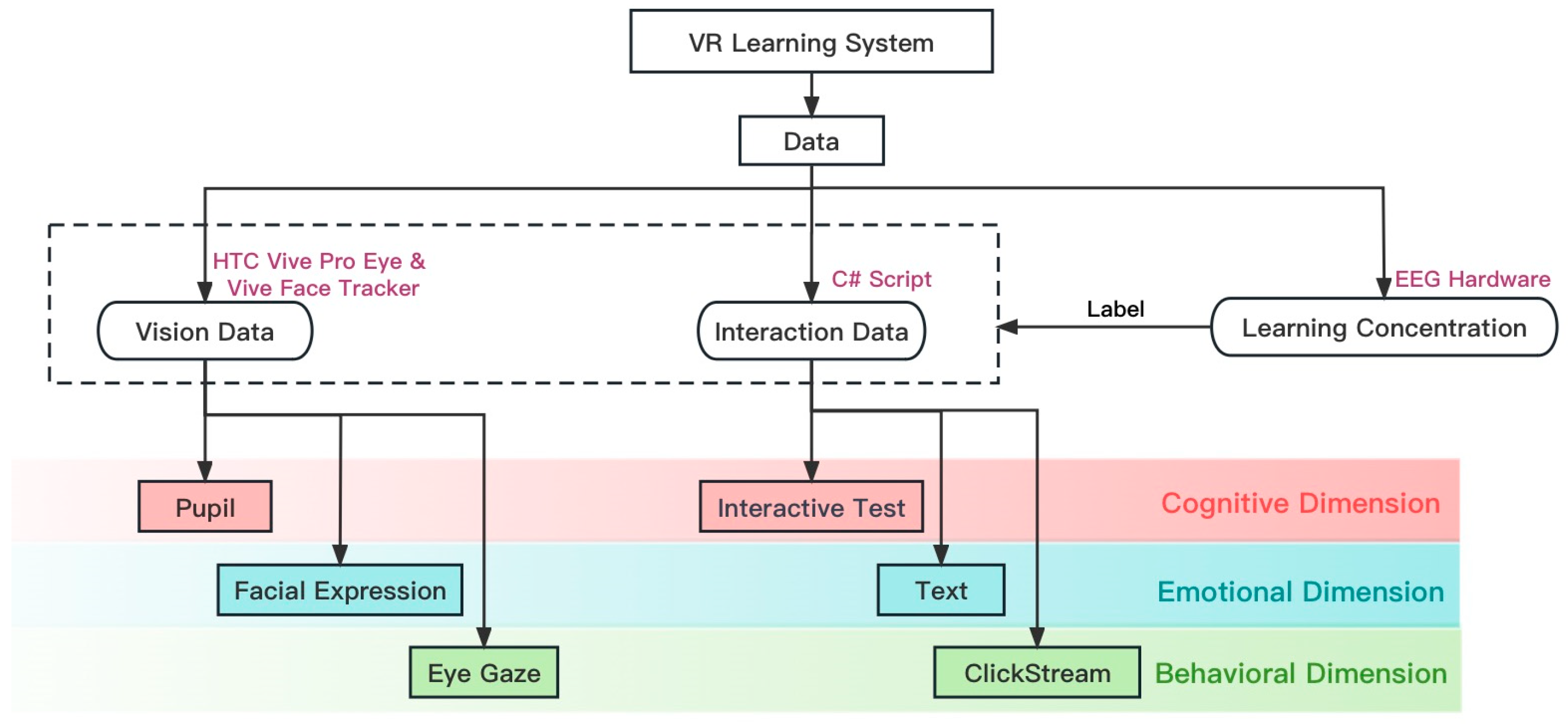
3. A Learning Concentration Recognition Approach by Three Dimensions and Two Types
4. Experiments Design
4.1. Participants
4.2. Experimental Materials and Environment
4.3. Experimental Procedure
5. Data Processing and Results
5.1. Features Extracted
5.2. Machine Learning Approach
5.2.1. Data Preprocessing
5.2.2. Data Partitioning
5.2.3. Model Setting
5.2.4. Performance Parameters
5.3. Results
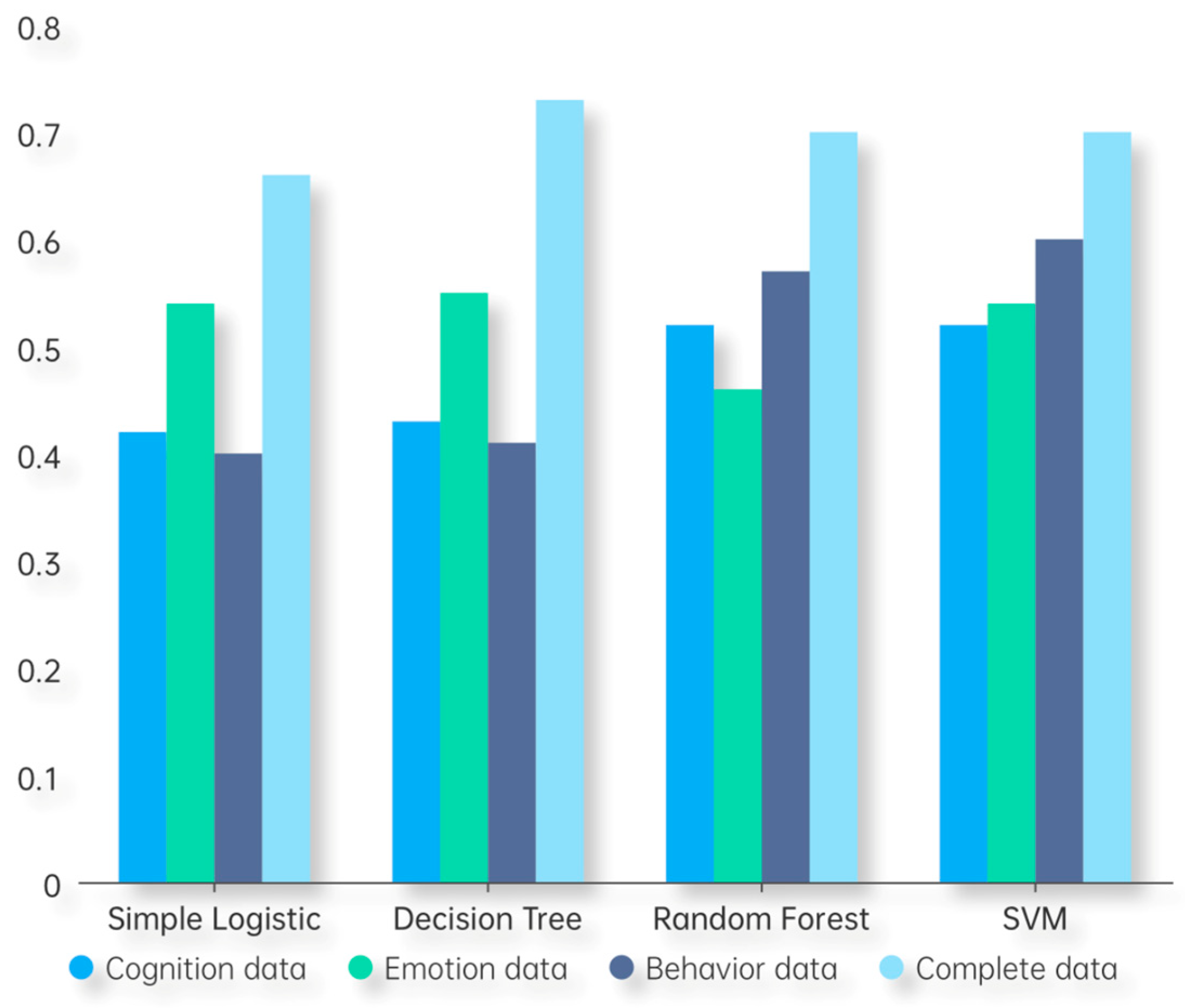
5.3.1. Recognition with Single-Dimensional Data
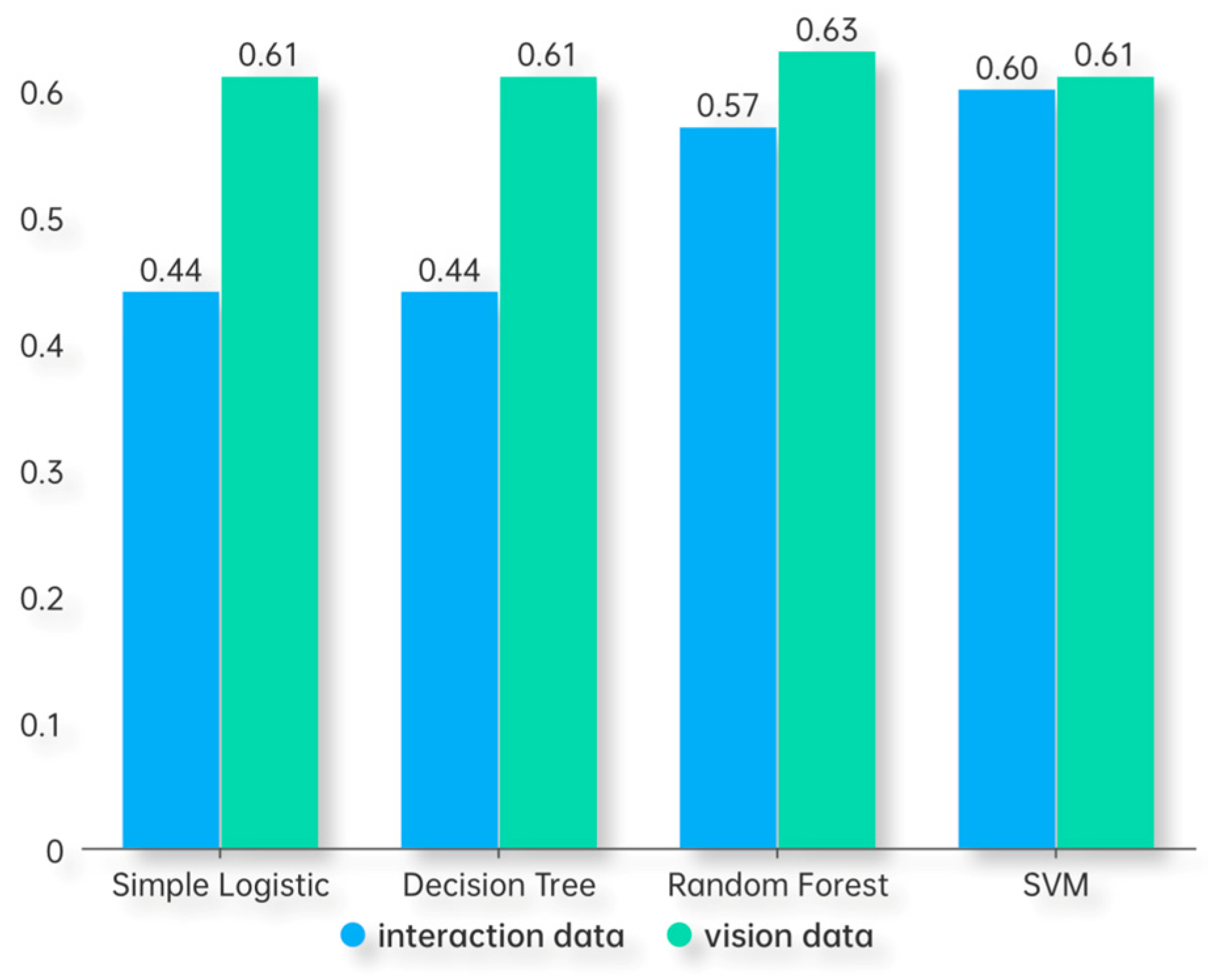
5.3.2. Recognition with Single-Type Data
5.3.3. Recognition with Complete Data
5.3.4. Model Validity
5.3.5. Learning Effect
6. Discussions and Conclusions
6.1. Better Recognition Capability of Vision Data in VR Environments
6.2. Interaction Data as an Effective Supplement for Recognizing Learning Concentration
6.3. Integration of Cognitive, Emotional, and Behavioral Dimensions Is Essential for Recognizing Learning Concentration Levels
6.4. Limitations and Future Directions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- Castelló, A.; Chavez, D.; Cladellas, R. Association between slides-format and major’s contents: Effects on perceived attention and significant learning. Multimed. Tools Appl. 2020, 79, 24969–24992. [Google Scholar] [CrossRef]
- Arana-Llanes, J.Y.; González-Serna, G.; Pineda-Tapia, R.; Olivares-Peregrino, V.; Ricarte-Trives, J.J.; Latorre-Postigo, J.M. EEG lecture on recommended activities for the induction of attention and concentration mental states on e-learning students. J. Intell. Fuzzy Syst. 2018, 34, 3359–3371. [Google Scholar] [CrossRef]
- Smallwood, J.; McSpadden, M.; Schooler, J.W. When attention matters: The curious incident of the wandering mind. Mem. Cogn. 2008, 36, 1144–1150. [Google Scholar] [CrossRef] [PubMed]
- Smithson, E.F.; Phillips, R.; Harvey, D.W.; Morrall, M.C.H.J. The use of stimulant medication to improve neurocognitive and learning outcomes in children diagnosed with brain tumours: A systematic review. Eur. J. Cancer 2013, 49, 3029–3040. [Google Scholar] [CrossRef] [PubMed]
- Skinner, E.A.; Belmont, M.J. Motivation in the classroom: Reciprocal effects of teacher behavior and student engagement. J. Educ. Psychol. 1993, 85, 571. [Google Scholar] [CrossRef]
- Chapman, E.; Assessing Student Engagement Rates. ERIC Digest. 2003. Available online: https://search.ebscohost.com/login.aspx?direct=true&db=eric&AN=ED482269&lang=zh-cn&site=ehost-live (accessed on 3 July 2023).
- Belle, A.; Hargraves, R.H.; Najarian, K. An Automated optimal engagement and attention detection system using electrocardiogram. Comput. Math. Methods Med. 2012, 2012, 528781. [Google Scholar] [CrossRef] [PubMed]
- Lee, H.; Kim, Y.; Park, C. Classification of Human Attention to Multimedia Lecture. In Proceedings of the 2018 International Conference on Information Networking (ICOIN), Chiang Mai, Thailand, 10–12 January 2018. [Google Scholar]
- Benitez, V.L.; Robison, M.K. Pupillometry as a window into young children’s sustained attention. J. Intell. 2022, 10, 107. [Google Scholar] [CrossRef]
- Gołębiowska, I.; Opach, T.; Çöltekin, A.; Korycka-Skorupa, J.; Ketil, J.R. Legends of the dashboard: An empirical evaluation of split and joint layout designs for geovisual analytics interfaces. Int. J. Digit. Earth 2023, 16, 1395–1417. [Google Scholar] [CrossRef]
- Bouazizi, M.; Ohtsuki, T. Multi-class sentiment analysis on twitter: Classification performance and challenges. Big Data Min. Anal. 2019, 2, 181–194. [Google Scholar] [CrossRef]
- Liu, S.; Liu, S.; Liu, Z.; Peng, X.; Yang, Z. Automated detection of emotional and cognitive engagement in MOOC discussions to predict learning achievement. Comput. Educ. 2022, 181, 104461. [Google Scholar] [CrossRef]
- Zaletelj, J.; Košir, A. Predicting students’ attention in the classroom from Kinect facial and body features. EURASIP J. Image Video Process. 2017, 2017, 80. [Google Scholar] [CrossRef] [Green Version]
- Yue, J.; Tian, F.; Chao, K.M.; Shah, N.; Li, L.Z.; Chen, Y.; Zheng, Q. Recognizing multidimensional engagement of e-learners based on multi-channel data in e-learning environment. IEEE Access 2019, 7, 149554–149567. [Google Scholar] [CrossRef]
- Veliyath, N.; De, P.; Allen, A.A.; Hodges, C.B.; Mitra, A. Modeling Students’ Attention in the Classroom Using Eyetrackers. In Proceedings of the 2019 ACM Southeast Conference (ACMSE 2019), New York, NY, USA, 18–20 April 2019. [Google Scholar]
- Dewan, M.A.A.; Murshed, M.; Lin, F. Engagement detection in online learning: A review. Smart Learn. Environ. 2019, 6, 1. [Google Scholar] [CrossRef]
- Lin, Y.; Lan, Y.; Wang, S. A method for evaluating the learning concentration in head-mounted virtual reality interaction. Virtual Real. 2023, 27, 863–885. [Google Scholar] [CrossRef]
- Parmar, D.; Lin, L.; Dsouza, N.; Sophie, J.; Alison, E.L.; Daily, S.B.; Babu, S. How immersion and self-avatars in VR affect learning programming and computational thinking in middle school education. IEEE Trans. Vis. Comput. Graph. 2023, 29, 3698–3713. [Google Scholar] [CrossRef] [PubMed]
- Chen, X.X.; Ju, K.S. An analysis of VR language learning applications: Focusing on the apps of speaking and vocabulary learning. J. Dong-Ak Lang. Lit. 2019, 78, 119–150. [Google Scholar] [CrossRef]
- Li, F.; Jiang, J.F.; Qin, Q.G.; Wang, X.B.; Zeng, G.Q.; Gu, Y.; Guo, W.T. Application of sustainable development of teaching in engineering education: A case study of undergraduate course design of raman spectroscopy based on virtual reality (VR) technology. Sustainability 2023, 15, 1782. [Google Scholar] [CrossRef]
- Gupta, S.; Wilcocks, K.; Matava, C.; Wiegelmann, J.; Kaustov, L.; Alam, F. Creating a successful virtual reality-based medical simulation environment: Tutorial. JMIR Med. Educ. 2023, 9, e41090. [Google Scholar] [CrossRef]
- Cheng, D.; Duan, J.; Chen, H.; Wang, H. Freeform OST-HMD system with large exit pupil diameter and vision correction capability. Photonics Res. 2022, 10, 21–32. [Google Scholar] [CrossRef]
- Ma, Y.C.; Gao, Y.H.; Wu, J.C.; Cao, L.C. Toward a see-through camera via AR lightguide. Opt. Lett. 2023, 48, 2809–2812. [Google Scholar] [CrossRef]
- Daniel, K.N.; Kamioka, E. Detection of learner’s concentration in distance learning system with multiple biological information. J. Comput. Commun. 2017, 5, 1–15. [Google Scholar] [CrossRef] [Green Version]
- Useche, O.; El-Sheikh, E. An Intelligent Web-Based System for Measuring Students’attention Levels. In Proceedings of the 2016 International Conference on Artificial Intelligence, Bangkok, Thailand, 24–25 January 2016. [Google Scholar]
- Xu, X.; Teng, X. Classroom Attention Analysis Based on Multiple Euler Angles Constraint and Head Pose Estimation. In Proceedings of the 26th International Conference on MultiMedia Modeling, Daejeon, Republic of Korea, 5–8 January 2020. [Google Scholar]
- Sharma, P.; Esengönül, M.; Khanal, S.R.; Khanal, T.T.; Filipe, V.; Manuel, J.C.S.R. Student Concentration Evaluation Index in an E-Learning Context Using Facial Emotion Analysis. In Proceedings of the International Conference on Technology and Innovation in Learning, Teaching and Education, Thessaloniki, Greece, 20–22 June 2018. [Google Scholar]
- Gerard, N.; Yousuf, T.; Johar, A.H.; Asgher, U.; Malik, I.; Hasan, A.U.; Shafait, F. Detection of Subject Attention in an Active Environment through Facial Expressions Using Deep Learning Techniques and Computer Vision. In Advances in Neuroergonomics and Cognitive Engineering, Proceedings of the AHFE 2020 Virtual Conferences on Neuroergonomics and Cognitive Engineering, and Industrial Cognitive Ergonomics and Engineering Psychology, July 16–20 2020, USA; Springer: Berlin/Heidelberg, Germany, 2021. [Google Scholar]
- Zenouzagh, Z.M.; Admiraal, W.; Saab, N. Learner autonomy, learner engagement and learner satisfaction in text-based and multimodal computer mediated writing environments. Educ. Inf. Technol. 2023, 1–41. [Google Scholar] [CrossRef]
- Cocea, M.; Weibelzahl, S. Cross-system validation of engagement prediction from log files. N. Learn. Exp. A Glob. Scale 2007, 4753, 14–25. [Google Scholar] [CrossRef]
- Arwa, A.; Khawlah, A.; Salma, K.J.; Nihal, A.; Samar, A. CNN-Based Face Emotion Detection and Mouse Movement Analysis to Detect Student’s Engagement Level. In Proceedings of the International Conference on Advanced Intelligent Systems for Sustainable Development, Rabat, Morocco, 22–27 May 2022. [Google Scholar]
- Altuwairqi, K.; Jarraya, S.K.; Allinjawi, A.; Hammami, M. Student behavior analysis to measure engagement levels in online learning environments. Signal Image Video Process. 2021, 15, 1387–1395. [Google Scholar] [CrossRef] [PubMed]
- Fredricks, J.A.; Mccolskey, W. The measurement of student engagement: A comparative analysis of various methods and student self-report instruments. In Handbook of Research on Student Engagement; Christenson, S., Reschly, A., Wylie, C., Eds.; Springer: Boston, MA, USA, 2012; pp. 763–782. [Google Scholar] [CrossRef]
- Ekman, P. Basic Emotions. In Encyclopedia of Personality and Individual Differences; Springer: Cham, Switzerland, 1999; pp. 1–6. [Google Scholar] [CrossRef]
- Krithika, L.B.; Lakshmi, P.G.G. Student emotion recognition system (SERS) for e-learning improvement based on learner concentration Metric. Procedia Comput. Sci. 2016, 85, 767–776. [Google Scholar] [CrossRef] [Green Version]
- Khawlah, A.; Salma, K.J.; Arwa, A.; Mohamed, H. A New Emotion–Based Affective Model to Detect Student’s Engagement. J. King Saud Univ. Comput. Inf. Sci. 2018, 33, 99–109. [Google Scholar] [CrossRef]
- Alemdag, E.; Cagiltay, K. A systematic review of eye tracking research on multimedia learning. Comput. Educ. 2018, 125, 413–428. [Google Scholar] [CrossRef]
- Rayner, K. Eye movements and attention in reading, scene perception, and visual search. Q. J. Exp. Psychol. 2009, 62, 1457–1506. [Google Scholar] [CrossRef]
- Doherty, K.; Doherty, G. Engagement in HCI: Conception, theory and measurement. ACM Comput. Surv. 2019, 51, 1–39. [Google Scholar] [CrossRef] [Green Version]
- Montgomery, A.L.; Li, S.; Srinivasan, K. Modeling online browsing and path analysis using clickstream datal. Mark. Sci. 2004, 23, 579–595. [Google Scholar] [CrossRef]
- Guo, P.J.; Kim, J.; Rubin, R. How Video Production Affects Student Engagement: An Empirical Study of MOOC Video. In Proceedings of the First ACM Conference on Learning @ Scale Conference, Atlanta, GA, USA, 4–5 March 2014. [Google Scholar]
- Hershman, R.; Milshtein, D.; Henik, A. The contribution of temporal analysis of pupillometry measurements to cognitive research. Psychol. Res. 2023, 87, 28–42. [Google Scholar] [CrossRef] [PubMed]
- McLaughlin, D.J.; Zink, M.; Gaunt, L.; Reilly, J.; Sommers, M.S.; Engen, K.V.; Peelle, J.E. Give me a break! Unavoidable fatigue effects in cognitive pupillometry. Psychophysiology 2022, 60, e14256. [Google Scholar] [CrossRef] [PubMed]
- Rebolledo-Mendez, G.; Dunwell, I.; Martínez-Mirón, E.; Vargas-Cerdán, M.D.; Freitas, S.; Liarokapis, F.; García-Gaona, A. Assessing neuroSky’s Usasessment Exercise. In Proceedings of the International Conference on Human-Computer Interaction, San Diego, CA, USA, 19–24 July 2009. [Google Scholar]
- Alfadil, M. Effectiveness of virtual reality game in foreign language vocabulary acquisition. Comput. Educ. 2020, 153, 103893. [Google Scholar] [CrossRef]
- Radianti, J.; Majchrzak, T.A.; Fromm, J.; Wohlgenannt, I. A systematic review of immersive virtual reality applications for higher education: Design elements, lessons learned, and a research agenda. Comput. Educ. 2020, 147, 103778. [Google Scholar] [CrossRef]
- Brockmyer, J.H.; Fox, C.M.; Curtiss, K.A.; McBroom, E.; Burkhart, K.M.; Pidruzny, J.N. The development of the Game Engagement Questionnaire: A measure of engagement in video game-playing. J. Exp. Soc. Psychol. 2009, 45, 624–634. [Google Scholar] [CrossRef]
- MindSet Communications Protocol. Available online: http://wearcam.org/ece516/mindset_communications_protocol (accessed on 26 May 2023).
- Krejtz, K.; Duchowski, A.; Niedzielska, A.; Biele, C.; Krejtz, I. Eye tracking cognitive load using pupil diameter and microsaccades with fixed gaze. PLoS ONE 2018, 13, e0203629. [Google Scholar] [CrossRef]
- Kiefer, P.; Giannopoulos, I.; Duchowski, A.; Martin, R. Measuring cognitive load for map tasks through pupil diameter. Geogr. Inf. Sci. 2016, 9927, 323–337. [Google Scholar] [CrossRef]
- Karumbaiah, S.; Ocumpaugh, J.; Baker, R. Predicting math identity through language and clickstream patterns in a blended learning mathematics program for elementary students. J. Learn. Anal. 2020, 7, 19–37. [Google Scholar] [CrossRef] [Green Version]
- Crossley, S.A.; Karumbaiah, S.; Ocumpaugh, J.L.; Labrum, M.J.; Baker, R. Predicting Math Success in an Online Tutoring System Using Language Data and Clickstream Variables: A Longitudinal Analysis. In Proceedings of the International Conference on Language, Data, and Knowledge, Leipzig, Germany, 20–23 May 2019. [Google Scholar]
- Bota, P.J.; Wang, C.; Fred, A.L.N.; Placido, D.S.H. A Review, current challenges, and future possibilities on emotion recognition using machine learning and physiological signals. IEEE Access 2019, 7, 140990–141020. [Google Scholar] [CrossRef]
- Olson, D.L.; Delen, D. Advanced Data Mining Techniques; Springer: Berlin/Heidelberg, Germany, 2008; pp. 39–147. [Google Scholar]
- Gupta, S.; Kumar, P.; Tekchandani, R. A multimodal facial cues based engagement detection system in e-learning context using deep learning approach. Multimed. Tools Appl. 2023, 82, 1–27. [Google Scholar] [CrossRef]
- Whitehill, J.; Serpell, Z.; Lin, Y.; Fotser, A.; Movellan, J.R. The faces of engagement: Automatic recognition of student engagementfrom facial expressions. IEEE Trans. Affect. Comput. 2014, 5, 86–98. [Google Scholar] [CrossRef]
- Alkabbany, I.; Ali, A.M.; Foreman, C.; Tretter, T.; Hindy, N.; Farag, A. An Experimental Platform for Real-Time Students Engagement Measurements from Video in STEM Classrooms. Sensors 2023, 23, 1614. [Google Scholar] [CrossRef] [PubMed]
- Sukumaran, A.; Manoharan, A. A survey on automatic engagement recognition methods: Online and traditional classroom. Indones. J. Electr. Eng. Comput. Sci. 2023, 30, 1178–1191. [Google Scholar] [CrossRef]
- Li, J.; Ngai, G.; Leong, H.V.; Stephen, C.F. Multimodal human attention detection for reading from facial expression, eye gaze, and mouse dynamics. ACM SIGAPP Appl. Comput. Rev. 2016, 16, 37–49. [Google Scholar] [CrossRef]
- Oviatt, S.L. Multimodal Interfaces. In Human-Computer Interaction Handbook: Fundamentals, Evolving Technologies, and Emerging Applications; L. Erlbaum Associates Inc.: Hillsdale, MI, USA, 2007; pp. 286–304. [Google Scholar]
- Yamauchi, T. Mouse Trajectories and State Anxiety: Feature Selection with Random Forest. In Proceedings of the 2013 Humaine Association Conference on Affective Computing and Intelligent Interaction, Geneva, Switzerland, 2–5 September 2013. [Google Scholar]




{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Modules | Data | Dimension | Features |
|---|---|---|---|
| C# Script | Interactive test | Cognition | The number of attempts and correct rate |
| Text | Emotion | Emotion process words, positive emotion words, negative emotion words, anxious words, angry words, and sad words | |
| Clickstream | Behavior | The number of clickstreams, the proportion of click behaviors of each part, and the proportion of click behavior conversion of each part | |
| HTC Vive Pro eye & HTC Vive Face Tracker | Pupil | Cognition | The mean value of the pupil diameters, the standard deviation of the pupil diameters, the maximum value of the pupil diameters, and the minimum value of the pupil diameters |
| Facial expression | Emotion | The mean frequency of emotion, the mean intensity of emotion, the standard deviation of emotion, and the maximum value of emotion | |
| Eye gaze | Behavior | The number of eye gaze point number in each part, the average time of eye gaze in each part, the proportion of eye gaze in each part, and the proportion of saccades in each part |
| Methods | Dimension | Precision | Recall | F1 Score |
|---|---|---|---|---|
| Simple Logistic | Cognition | 0.43 | 0.43 | 0.42 |
| Emotion | 0.55 | 0.55 | 0.54 | |
| Behavior | 0.41 | 0.40 | 0.40 | |
| Decision Tree | Cognition | 0.44 | 0.45 | 0.43 |
| Emotion | 0.56 | 0.55 | 0.55 | |
| Behavior | 0.43 | 0.41 | 0.41 | |
| Random Forest | Cognition | 0.60 | 0.58 | 0.52 |
| Emotion | 0.50 | 0.50 | 0.46 | |
| Behavior | 0.58 | 0.58 | 0.57 | |
| SVM | Cognition | 0.57 | 0.55 | 0.52 |
| Emotion | 0.56 | 0.55 | 0.54 | |
| Behavior | 0.60 | 0.60 | 0.60 |
| Methods | Dimension | Precision | Recall | F1 Score |
|---|---|---|---|---|
| Simple Logistic | Vision data | 0.61 | 0.62 | 0.61 |
| Interaction data | 0.44 | 0.43 | 0.44 | |
| Decision Tree | Vision data | 0.62 | 0.61 | 0.61 |
| Interaction data | 0.45 | 0.43 | 0.44 | |
| Random Forest | Vision data | 0.67 | 0.67 | 0.63 |
| Interaction data | 0.58 | 0.58 | 0.57 | |
| SVM | Vision data | 0.61 | 0.61 | 0.60 |
| Interaction data | 0.60 | 0.60 | 0.60 |
| Methods | Precision | Recall | F1 Score |
|---|---|---|---|
| Simple Logistic | 0.68 | 0.70 | 0.66 |
| Decision Tree | 0.73 | 0.73 | 0.73 |
| Random Forest | 0.74 | 0.74 | 0.70 |
| SVM | 0.70 | 0.70 | 0.70 |
| Simple Logistic | Decision Tree | Random Forest | SVM | |
|---|---|---|---|---|
| Cognition | 3.418 ** | 9.631 *** | 6.408 ** | 7.389 ** |
| Emotion | 0.553 | 5.465 ** | 4.472 ** | 6.680 ** |
| Behavior | 2.597 * | −1.550 | −2.236 * | 8.093 *** |
| Vision data | −1.183 | 2.311 * | 2.713 * | 5.659 ** |
| Interaction data | 2.538 * | 3.597 ** | 6.465 ** | 4.041 ** |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Hu, R.; Hui, Z.; Li, Y.; Guan, J. Research on Learning Concentration Recognition with Multi-Modal Features in Virtual Reality Environments. Sustainability 2023, 15, 11606. https://doi.org/10.3390/su151511606
Hu R, Hui Z, Li Y, Guan J. Research on Learning Concentration Recognition with Multi-Modal Features in Virtual Reality Environments. Sustainability. 2023; 15(15):11606. https://doi.org/10.3390/su151511606
Chicago/Turabian StyleHu, Renhe, Zihan Hui, Yifan Li, and Jueqi Guan. 2023. "Research on Learning Concentration Recognition with Multi-Modal Features in Virtual Reality Environments" Sustainability 15, no. 15: 11606. https://doi.org/10.3390/su151511606
APA StyleHu, R., Hui, Z., Li, Y., & Guan, J. (2023). Research on Learning Concentration Recognition with Multi-Modal Features in Virtual Reality Environments. Sustainability, 15(15), 11606. https://doi.org/10.3390/su151511606