



Development of Artificial Intelligence Based Safety Performance Measures for Urban Roundabouts

 , ,
, ,
Abstract
1. Introduction
- Identifying the roundabout parameters that are most responsible for improved safety at the roundabouts.
- Developing an optimized particle swarm optimized-ANN (PSO-ANN) model for the prediction of crash frequency at roundabouts.
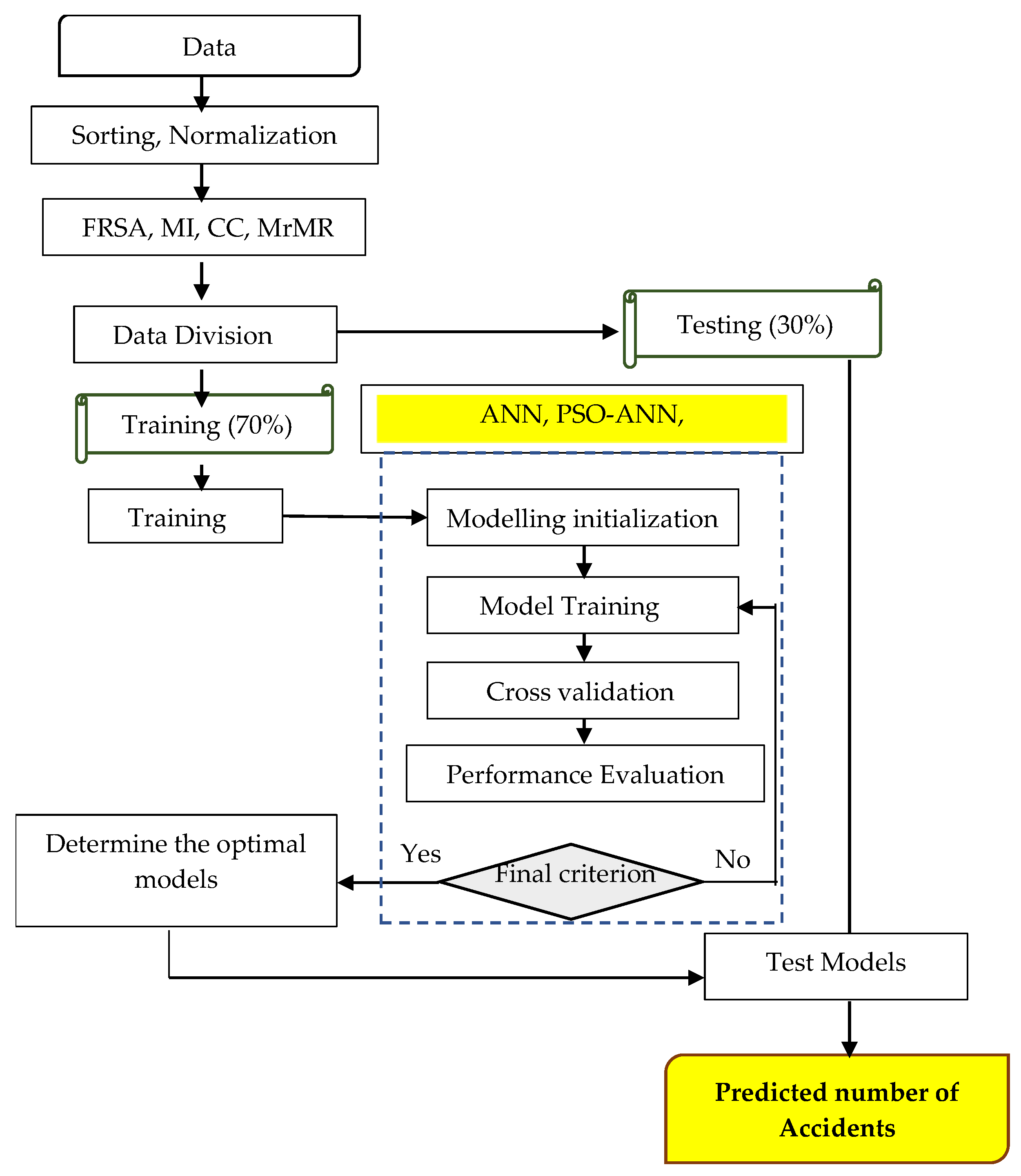
2. Materials and Methods
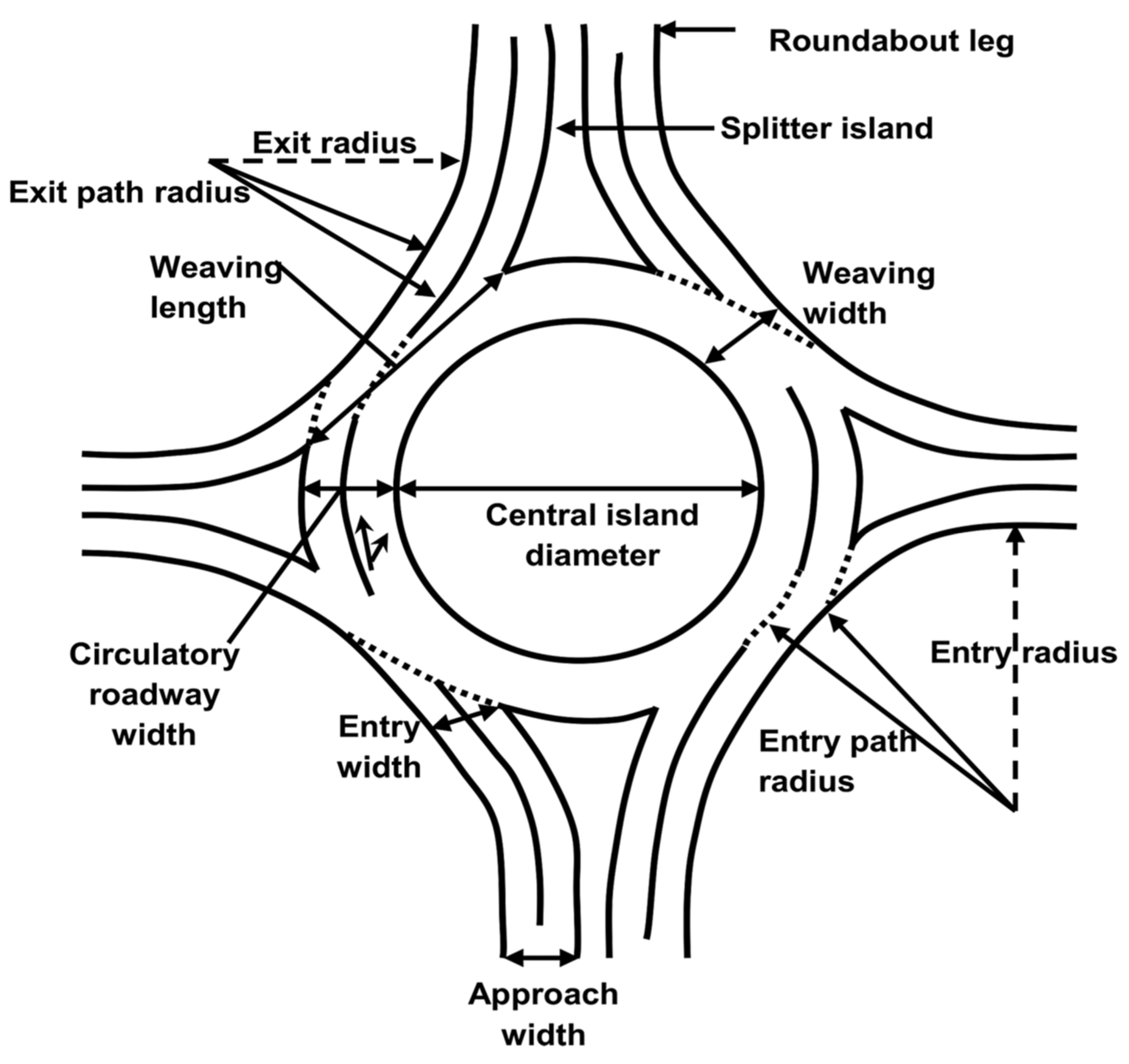
2.1. Dataset
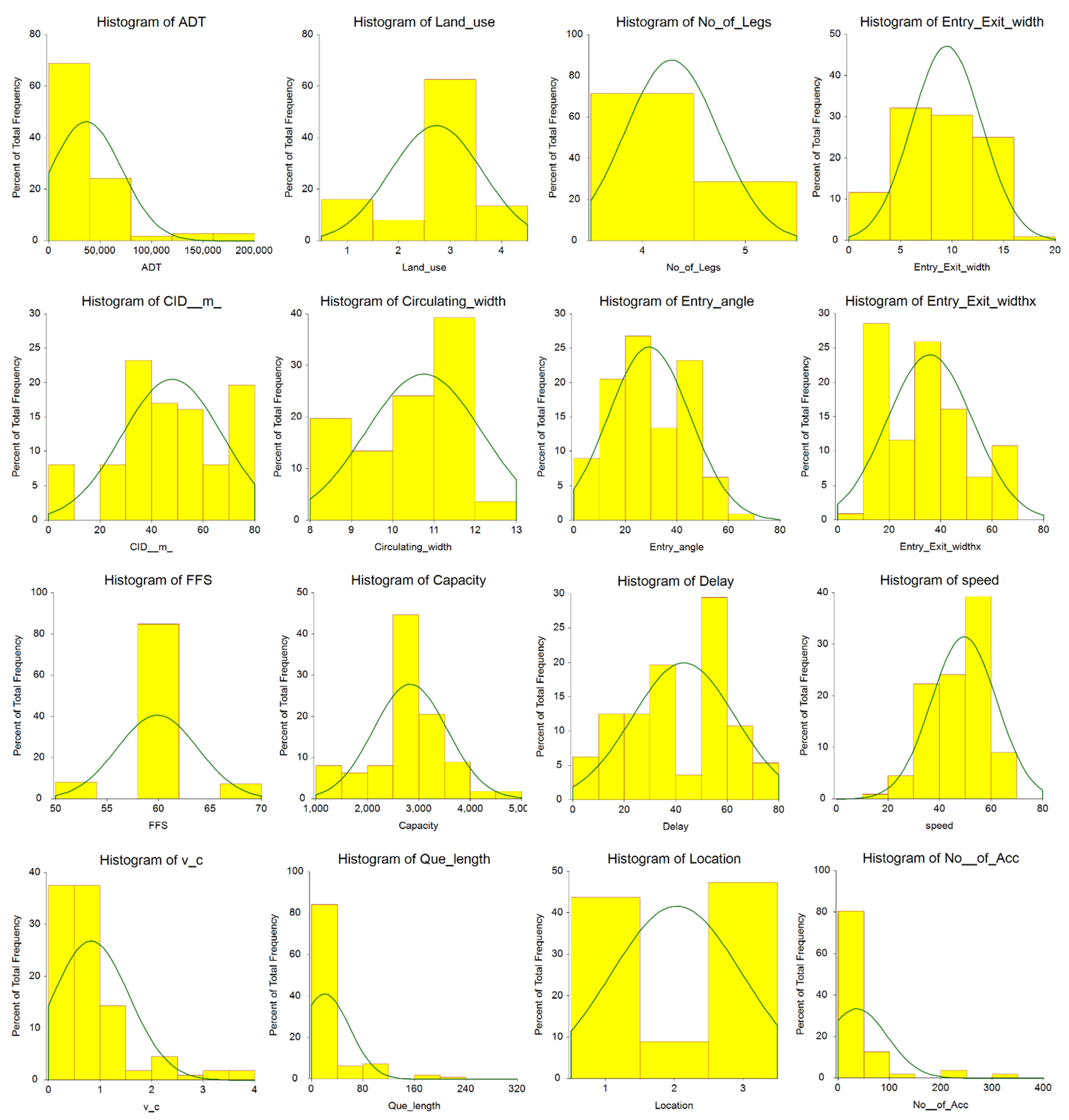
2.2. Descriptive Statistics of Data
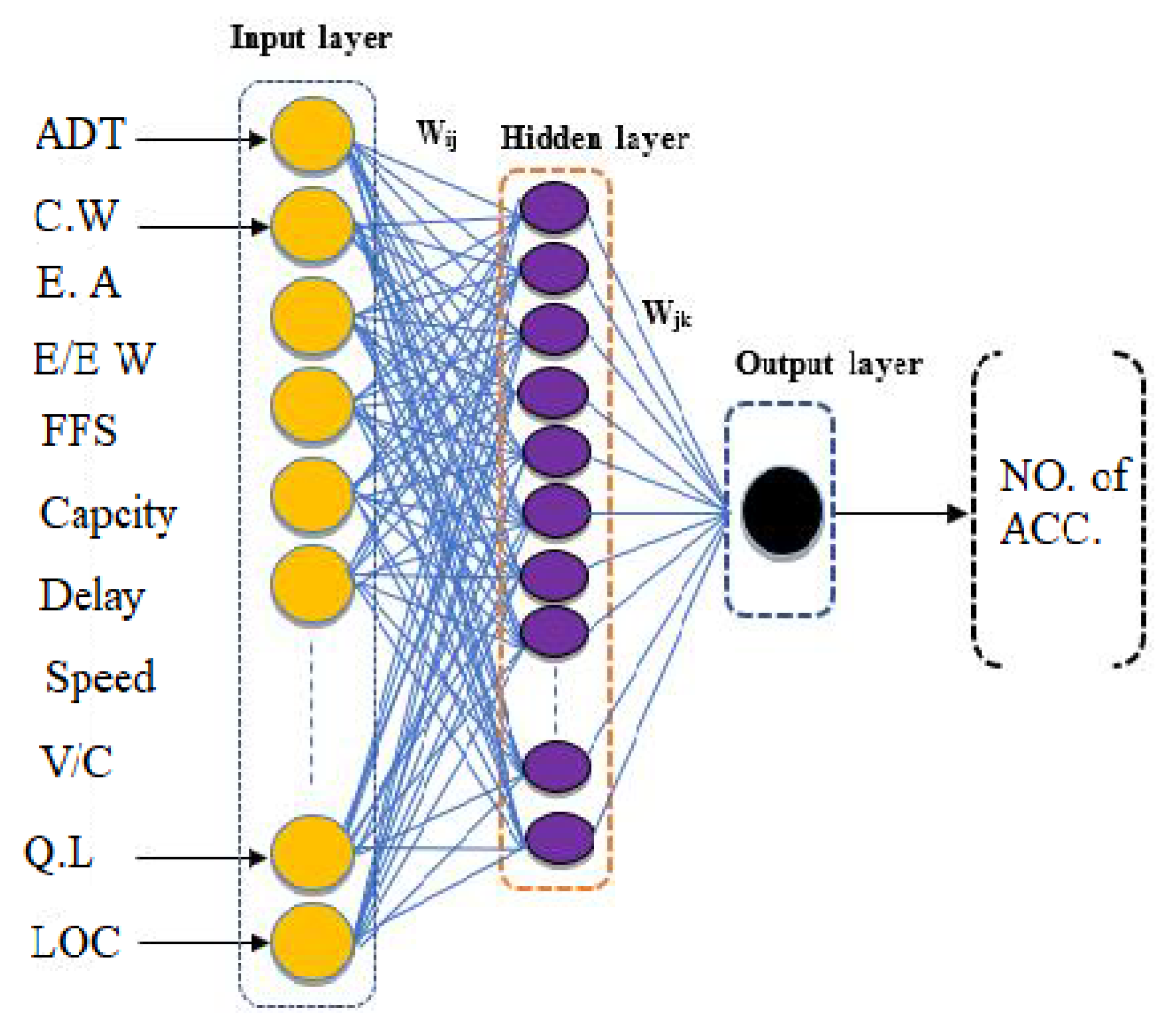
2.3. Artificial Neural Network
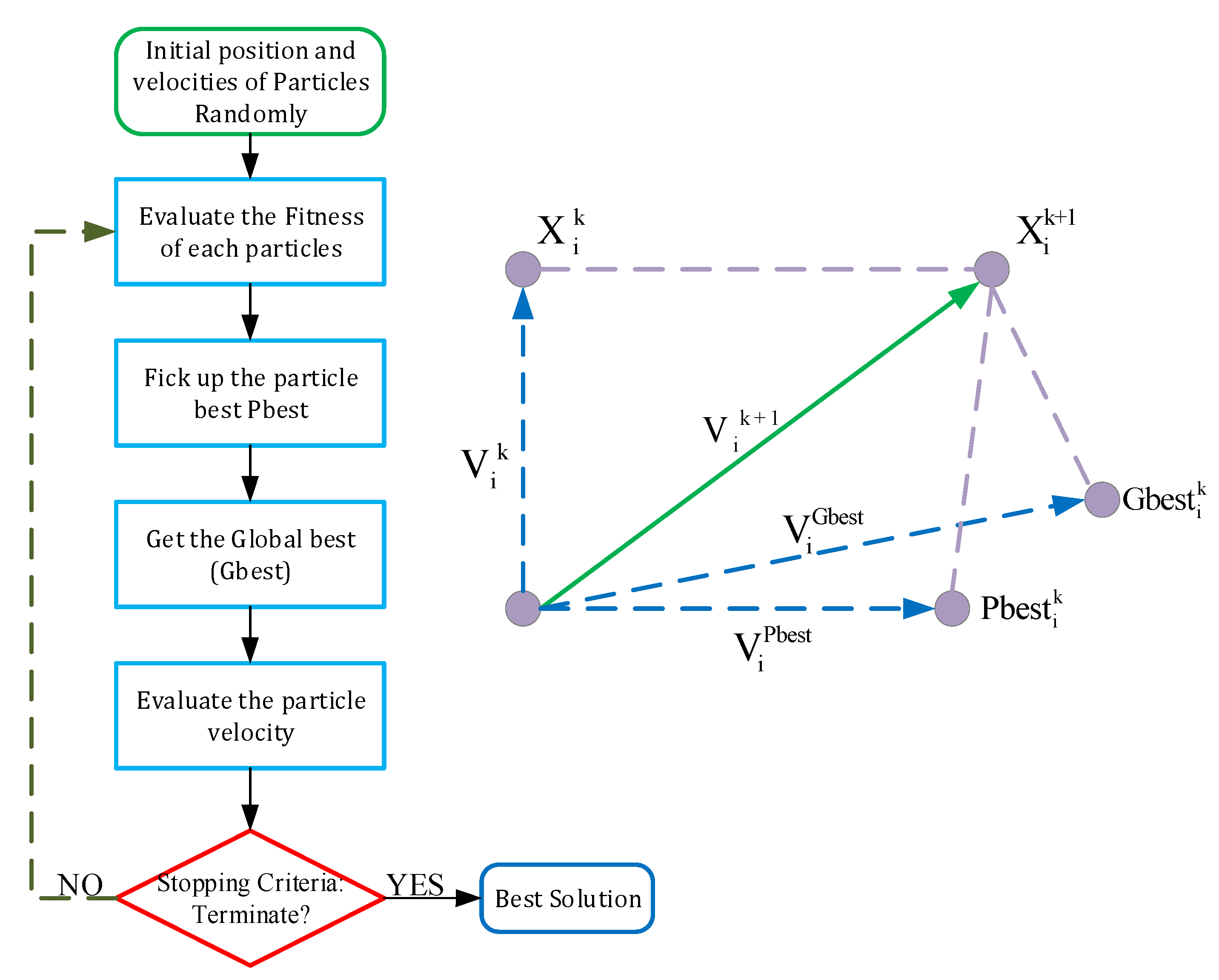
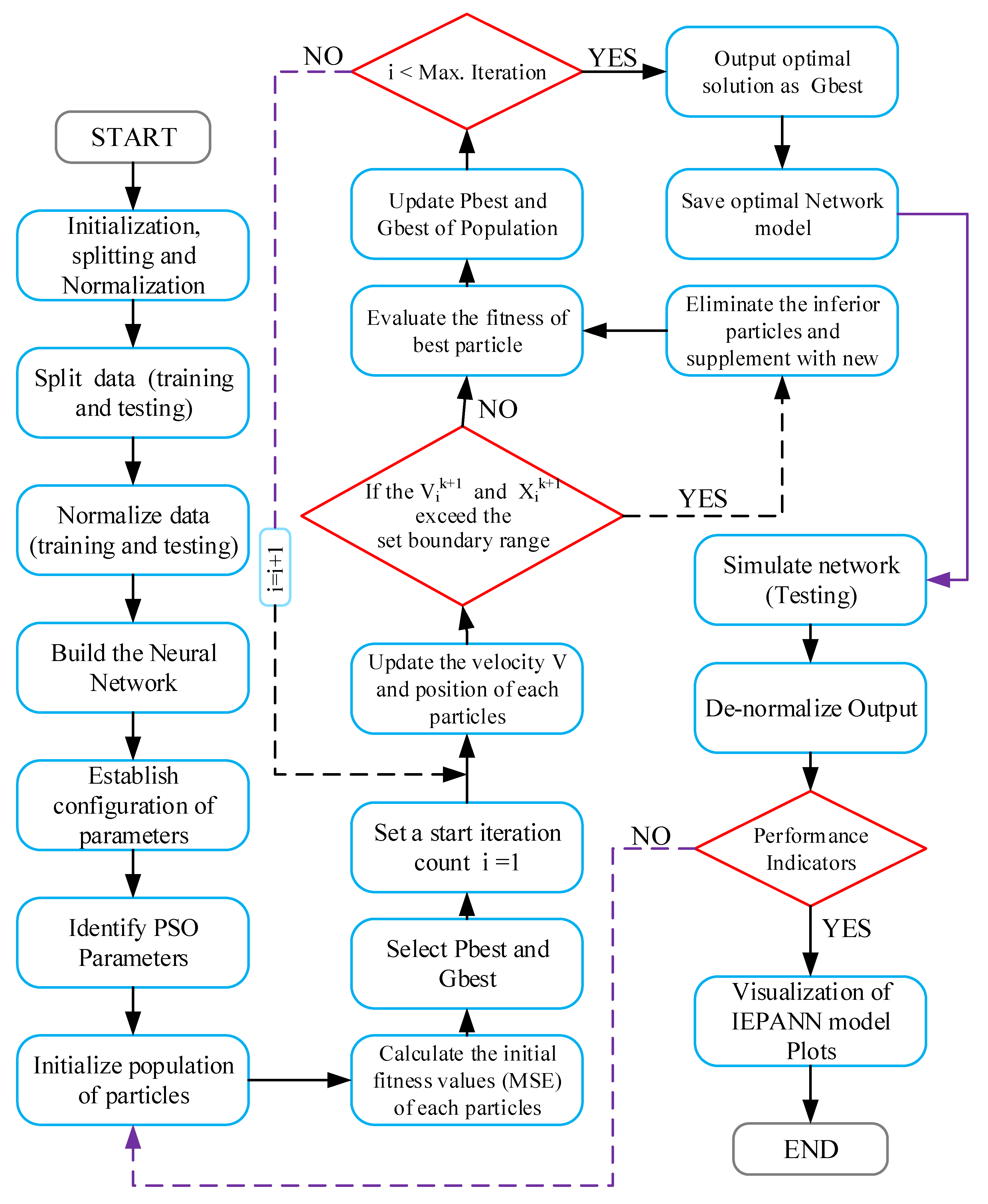
2.4. Particle Swarm Optimization (PSO)
2.5. Minimum Redundancy Maximum Relevance (mrMR)
2.6. Evaluation Criteria
3. Results and Discussion
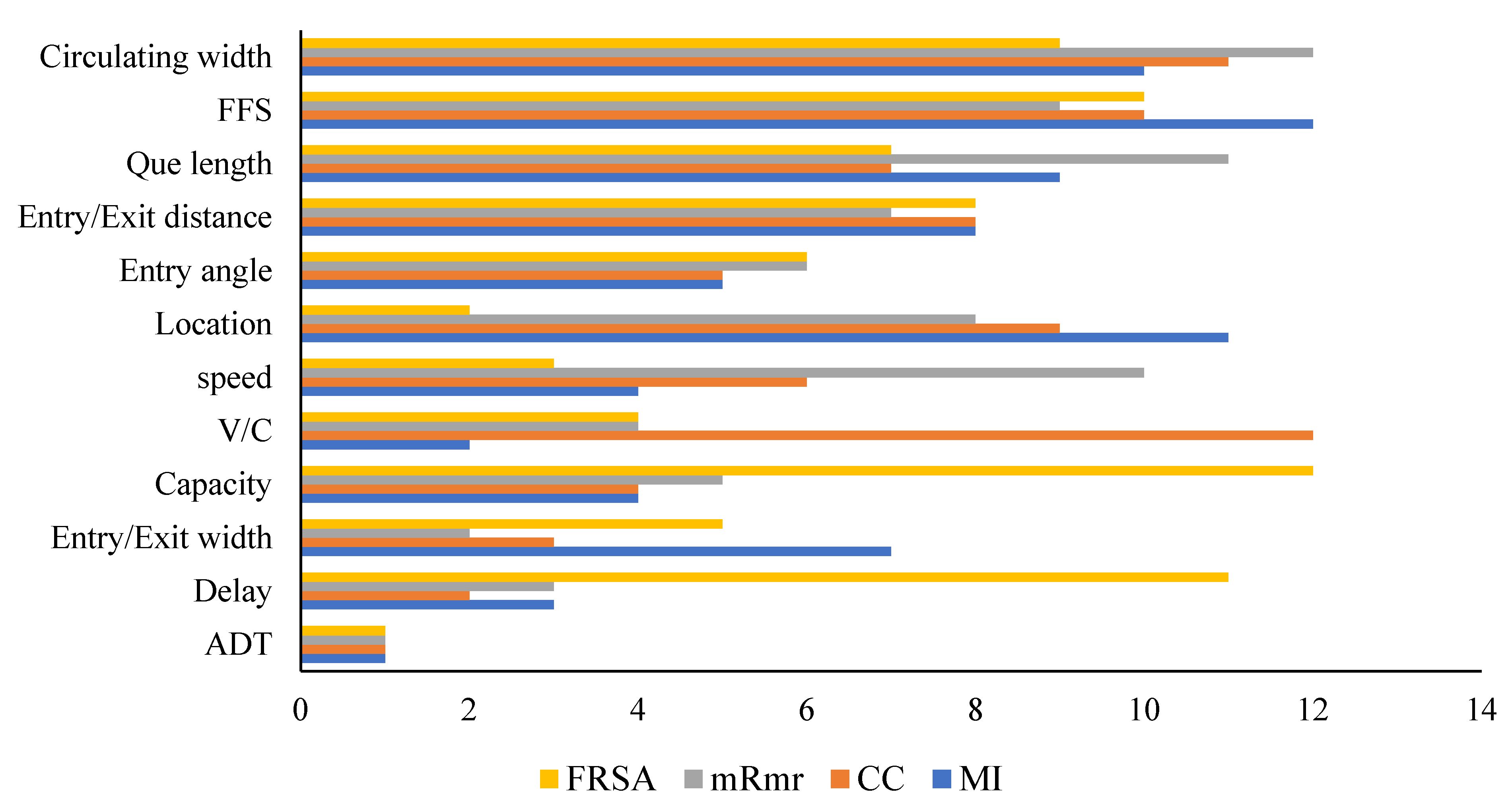
Dominant Input Selection
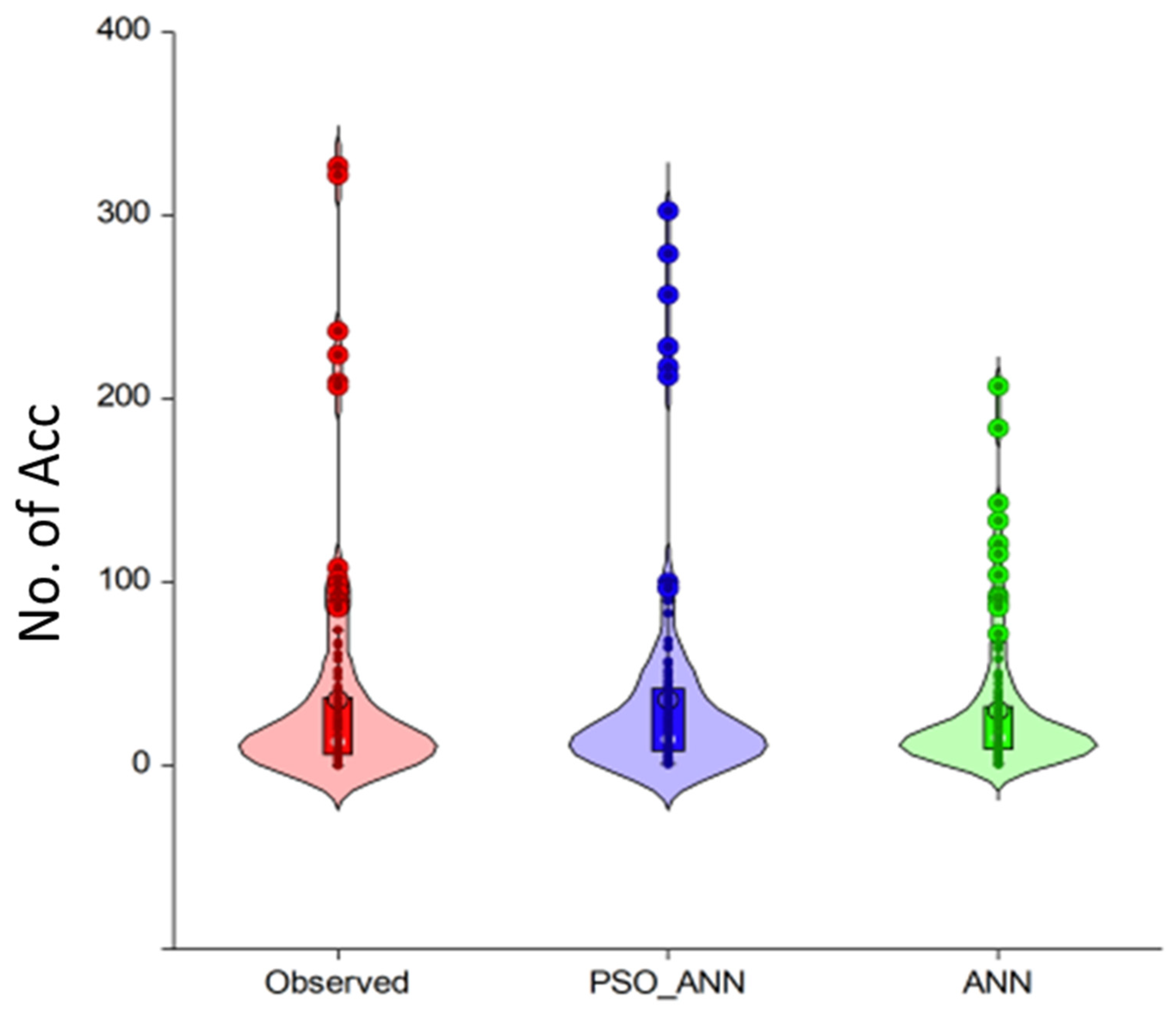
4. Modelling Result
5. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- Al-Omari, B.; Ghuzlan, K.; Hasan, H. Traffic accidents trends and characteristics in Jordan. Int. J. Civ. Environ. Eng. IJCEE-IJENS 2013, 13, 9–16. [Google Scholar]
- Badgley, J.M.; Condon, J.; Rainville, L.; Li, D. FHWA Research and Technology Evaluation: Roundabout Research Final Report (No. FHWA-HRT-17-040). 2018. Available online: http://www.ntis.gov (accessed on 15 March 2023).
- Alshannaq, M.; Imam, R. Evaluating the safety performance of roundabouts. Transp. Probl. 2020, 15, 141–152. [Google Scholar] [CrossRef]
- Anjana, S.; Anjaneyulu, M.V.L.R. Development of Safety Performance Measures for Urban Roundabouts in India. J. Transp. Eng. 2014, 141, 04014066. [Google Scholar] [CrossRef]
- Dabbour, E.; Al Awadhi, M.; Aljarah, M.; Mansoura, M.; Haider, M. Evaluating safety effectiveness of roundabouts in Abu Dhabi. IATSS Res. 2018, 42, 274–283. [Google Scholar] [CrossRef]
- Zubaidi, H.A.; Anderson, J.C.; Hernandez, S. Understanding roundabout safety through the application of advanced econometric techniques. Int. J. Transp. Sci. Technol. 2020, 9, 309–321. [Google Scholar] [CrossRef]
- Sameen, M.I.; Pradhan, B. Severity prediction of traffic accidents with recurrent neural networks. Appl. Sci. 2017, 7, 476. [Google Scholar] [CrossRef]
- García de Soto, B.; Bumbacher, A.; Deublein, M.; Adey, B.T. Predicting road traffic accidents using artificial neural network models. Infrastruct. Asset Manag. 2018, 5, 132–144. [Google Scholar] [CrossRef]
- Jadaan, K.S.; Al-Fayyad, M.; Gammoh, H.F. Prediction of Road Traffic Accidents in Jordan using Artificial Neural Network (ANN). J. Traffic Logist. Eng. 2014, 2, 92–94. [Google Scholar] [CrossRef]
- Alqatawna, A.; Rivas Alvarez, A.M.; Garcia-Moreno, S.S.C. Comparison of Multivariate Regression models and artificial neural networks for prediction highway traffic accidents in spain: A case study. Transp. Res. Procedia 2021, 58, 277–284. [Google Scholar] [CrossRef]
- Umar, I.K.; Gokcekus, H. Modeling severity of road traffic accident in Nigeria using artificial neural network. J. Kejuruter. 2019, 32, 221–227. [Google Scholar] [CrossRef]
- Rahmani, S.; Mousavi, S.M.; Kamali, M.J. Modeling of road-traffic noise with the use of genetic algorithm. Appl. Soft Comput. 2011, 11, 1008–1013. [Google Scholar] [CrossRef]
- Ibrahim Bibi Farouk, A.; Zhu, J.; Ding, J.; Haruna, S.I. Prediction and uncertainty quantification of ultimate bond strength between UHPC and reinforcing steel bar using a hybrid machine learning approach. Constr. Build. Mater. 2022, 345, 128360. [Google Scholar] [CrossRef]
- Sacchi, E.; Bassani, M.; Persaud, B. Comparison of safety performance models for Urban roundabouts in Italy and other countries. Transp. Res. Rec. 2011, 2265, 253–259. [Google Scholar] [CrossRef]
- Kumar, P.; Nigam, S.P.; Kumar, N. Vehicular traffic noise modeling using artificial neural network approach. Transp. Res. Part C Emerg. Technol. 2014, 40, 111–122. [Google Scholar] [CrossRef]
- Rumelhart, D.E.; Hinton, G.E.; Williams, R.J. Learning representations by back-propagating errors. Nature 1986, 323, 533–536. [Google Scholar] [CrossRef]
- Genaro, N.; Torija, A.J.; Requena, I.; Ruiz, D.P. A neural network based model for urban noise prediction. J. Acoust. Soc. Am. 2010, 128, 1738–1746. [Google Scholar] [CrossRef]
- Liao, T.; Stützle, T.; Montes De Oca, M.A.; Dorigo, M. A unified ant colony optimization algorithm for continuous optimization. Eur. J. Oper. Res. 2014, 234, 597–609. [Google Scholar] [CrossRef]
- Ji, J.; Weng, Y.; Yang, C.; Wu, T. A multi-resolution grid-based bacterial foraging optimization algorithm for multi-objective optimization problems. Swarm Evol. Comput. 2022, 72, 101098. [Google Scholar] [CrossRef]
- Moghaddas, S.A.; Nekoei, M.; Golafshani, E.M.; Behnood, A.; Arashpour, M. Application of artificial bee colony programming techniques for predicting the compressive strength of recycled aggregate concrete. Appl. Soft Comput. 2022, 130, 109641. [Google Scholar] [CrossRef]
- Kennedy, J.; Eberhart, R. New optimizers using particle swarm theory. In Proceedings of the 6th International Symposium on Micro Machine and Human Science, Nagoya, Japan, 4–6 October 1995; pp. 39–43. [Google Scholar] [CrossRef]
- Eberhart, R.; Shi, Y. Particle swarm optimization: Developments, applications and resources. In Proceedings of the 2001 Congress on Evolutionary Computation (IEEE Cat. No.01TH8546), Seoul, Republic of Korea, 27–30 May 2001; Volume 1, pp. 81–86. [Google Scholar] [CrossRef]
- Poli, R.; Kennedy, J.; Blackwell, T. Particle swarm optimization. Swarm Intell. 2007, 1, 33–57. [Google Scholar] [CrossRef]
- Umar, I.K.; Nourani, V.; Gökçekuş, H.; Abba, S.I. An intelligent hybridized computing technique for the prediction of roadway traffic noise in urban environment. Soft. Comput. 2023, 27, 10807–10825. [Google Scholar] [CrossRef]
- Peng, H.; Long, F.; Ding, C. Feature Selection Based on Mutual Information: Criteria of Max-Dependency, Max-Relevance, and Min-Redundancy. IEEE Trans. Pattern Anal. Mach. Intell. 2005, 27, 1226–1238. [Google Scholar] [CrossRef]
- Umar, I.K.; Nourani, V.; Gokcekus, H. A novel multi-model data-driven ensemble approach for the prediction of particulate matter concentration. Environ. Sci. Pollut. Res. 2021, 28, 49663–49677. [Google Scholar] [CrossRef] [PubMed]
- Moriasi, D.N.; Arnold, J.G.; Liew, M.W.; Van Bingner, R.L.; Harmel, R.D.; Veith, T.L. Model evaluation guidelines for systematic quantification of accuracy in watershed simulations. Trans. ASABE 2007, 50, 885–900. [Google Scholar] [CrossRef]
- Umar, I.K.; Gökçekuş, H.; Nourani, V. An intelligent soft computing technique for prediction of vehicular traffic noise. Arab. J. Geosci. 2022, 15, 1571. [Google Scholar] [CrossRef]
- Yang, Q.; Koutsopoulos, H.N.; Ben-Akiva, M.E. Simulation laboratory for evaluating dynamic traffic management systems. Transp. Res. Rec. 2000, 1710, 122–130. [Google Scholar] [CrossRef]
- Nourani, V.; Khanghah, T.R.; Baghanam, A.H. Application of entropy concept for input selection of wavelet-ANN based rainfall-runoff modeling. J. Environ. Inform. 2015, 26, 52–70. [Google Scholar] [CrossRef]
- Nourani, V.; Gökçekuş, H.; Umar, I.K. Artificial intelligence based ensemble model for prediction of vehicular traffic noise. Environ. Res. 2020, 180, 108852. [Google Scholar] [CrossRef]
- Nguyen, M.S.T.; Kim, S.E. A hybrid machine learning approach in prediction and uncertainty quantification of ultimate compressive strength of RCFST columns. Constr. Build. Mater. 2021, 302, 124208. [Google Scholar] [CrossRef]
- Osman, A.I.A.; Ahmed, A.N.; Huang, Y.F.; Kumar, P.; Birima, A.H.; Sherif, M.; Sefelnasr, A.; Ebraheemand, A.A.; El-Shafie, A. Past, Present and Perspective Methodology for Groundwater Modeling-Based Machine Learning Approaches. Arch. Comput. Methods Eng. 2022, 29, 3843–3859. [Google Scholar] [CrossRef]
- Ibrahim, K.S.M.H.; Huang, Y.F.; Ahmed, A.N.; Koo, C.H.; El-Shafie, A. A review of the hybrid artificial intelligence and optimization modelling of hydrological streamflow forecasting. Alex. Eng. J. 2022, 61, 279–303. [Google Scholar] [CrossRef]










{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Variables | Mean | Std. Dev. | Kurtosis | Skewness | Range | Minimum | Maximum |
|---|---|---|---|---|---|---|---|
| ADT | 36,490 | 34,418.76 | 6.45 | 2.41 | 18,7176.0 | 681.00 | 187,857.0 |
| No of Legs | 4.29 | 0.45 | −1.10 | 0.96 | 1.00 | 4.00 | 5.00 |
| CID (m) | 48.01 | 19.41 | −0.54 | −0.25 | 68.40 | 8.20 | 76.60 |
| Circulating width | 10.76 | 1.41 | −0.77 | −0.70 | 4.80 | 8.20 | 13.00 |
| Entry angle | 29.29 | 15.81 | −0.74 | 0.03 | 64.00 | 0.00 | 64.00 |
| Entry/Exit width | 9.50 | 3.38 | −0.27 | −0.16 | 17.50 | 0.00 | 17.50 |
| Entry/Exit width | 35.82 | 16.58 | −0.54 | 0.60 | 60.00 | 10.00 | 70.00 |
| FFS | 59.91 | 3.91 | 3.81 | −0.08 | 20.00 | 50.00 | 70.00 |
| Capacity | 2835.44 | 714.99 | 0.47 | −0.27 | 3672.00 | 1096.00 | 4768.00 |
| Delay | 43.17 | 19.96 | −0.99 | −0.11 | 73.00 | 7.00 | 80.00 |
| speed | 49.52 | 12.65 | −1.14 | −0.31 | 51.00 | 19.00 | 70.00 |
| v/c | 0.83 | 0.74 | 5.66 | 2.22 | 3.96 | 0.02 | 3.97 |
| Que length | 20.57 | 38.69 | 15.04 | 3.60 | 240.00 | 0.00 | 240.00 |
| No. of Acc. | 36.48 | 59.41 | 11.05 | 3.18 | 327.00 | 0.00 | 327.00 |
| Variables | ADT | Land Use | No of Legs | CID (m) | Circulating Width | Entry Angle | Entry/Exit Width | Entry/Exit Width | FFS | Capacity | Delay | Speed | v/c | Que Length | Location | No. Acc |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| ADT | 1.00 | |||||||||||||||
| Land use | −0.01 | 1.00 | ||||||||||||||
| No of Legs | −0.03 | 0.44 | 1.00 | |||||||||||||
| CID (m) | 0.18 | 0.49 | 0.62 | 1.00 | ||||||||||||
| Circulating width | −0.07 | 0.02 | −0.01 | 0.04 | 1.00 | |||||||||||
| Entry angle | −0.28 | 0.23 | 0.43 | 0.07 | 0.38 | 1.00 | ||||||||||
| Entry/Exit width | 0.24 | 0.17 | −0.19 | 0.33 | −0.15 | −0.37 | 1.00 | |||||||||
| Entry/Exit width | −0.07 | 0.26 | 0.29 | 0.29 | 0.22 | 0.32 | −0.29 | 1.00 | ||||||||
| FFS | 0.06 | −0.21 | 0.01 | 0.42 | −0.12 | −0.15 | 0.21 | 0.13 | 1.00 | |||||||
| Capacity | 0.21 | 0.30 | 0.20 | 0.65 | −0.08 | −0.09 | 0.65 | 0.05 | 0.44 | 1.00 | ||||||
| Delay | 0.43 | −0.09 | 0.01 | 0.41 | −0.41 | −0.56 | 0.58 | −0.39 | 0.24 | 0.45 | 1.00 | |||||
| speed | −0.17 | −0.13 | −0.08 | 0.02 | −0.26 | −0.20 | 0.13 | 0.11 | 0.24 | 0.11 | 0.28 | 1.00 | ||||
| v/c | 0.01 | −0.22 | −0.18 | −0.08 | −0.14 | −0.21 | 0.08 | −0.15 | 0.01 | −0.04 | 0.18 | −0.08 | 1.00 | |||
| Que length | 0.09 | −0.42 | −0.28 | −0.37 | −0.20 | −0.32 | −0.10 | −0.36 | −0.14 | −0.31 | 0.21 | 0.07 | 0.17 | 1.00 | ||
| Location | 0.01 | 0.04 | 0.00 | −0.01 | 0.00 | 0.01 | −0.03 | 0.29 | 0.05 | −0.02 | 0.13 | 0.67 | −0.16 | −0.13 | 1.00 | |
| No. Acc | 0.83 | 0.10 | 0.03 | 0.24 | 0.02 | −0.17 | 0.23 | 0.08 | 0.05 | 0.21 | 0.29 | −0.16 | 0.02 | −0.11 | 0.07 | 1.00 |
| Parameter | MI | CC | mrMR | FRSA (RMSE) |
|---|---|---|---|---|
| ADT | 2.1112 | 0.8273 | 0.1396 | 0.2056 |
| Circulating width | 0.4513 | 0.0178 | 0 | 0.1462 |
| Entry angle | 0.8755 | −0.1725 | 0 | 0.1479 |
| Entry/Exit width | 0.7582 | 0.2278 | 0.047 | 0.1481 |
| Entry/Exit width | 0.8675 | 0.0847 | 0 | 0.1444 |
| FFS | 0.0978 | 0.0455 | 0 | 0.1462 |
| Capacity | 0.8811 | 0.2055 | 0 | 0.1400 |
| Delay | 0.8834 | 0.2925 | 0.0225 | 0.1421 |
| speed | 0.6932 | −0.1556 | 0 | 0.1606 |
| v/c | 1.1242 | 0.0151 | 2.82 × 10−15 | 0.1490 |
| Que length | 0.6168 | −0.1078 | 0 | 0.1476 |
| Location | 0.2012 | 0.0650 | 0 | 0.1843 |
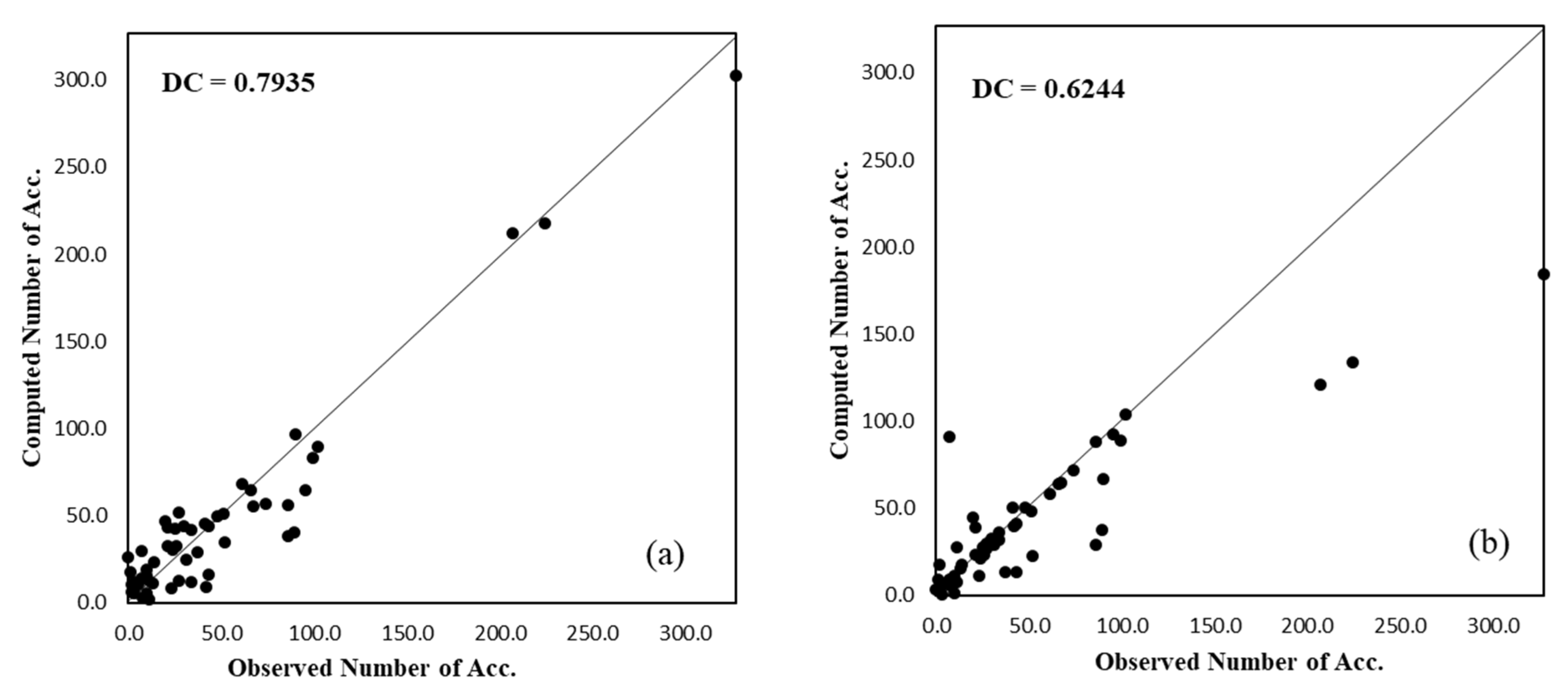
| Models | Training | Testing | ||||
|---|---|---|---|---|---|---|
| DC | RMSE | MAE | DC | RMSE | MAE | |
| PSO-ANN | 0.9459 | 0.0468 | 0.0332 | 0.7935 | 0.0403 | 0.0322 |
| ANN | 0.7227 | 0.1060 | 0.0463 | 0.6244 | 0.0543 | 0.0243 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Alanazi, F.; Umar, I.K.; Haruna, S.I.; El-Kady, M.; Azam, A. Development of Artificial Intelligence Based Safety Performance Measures for Urban Roundabouts. Sustainability 2023, 15, 11429. https://doi.org/10.3390/su151411429
Alanazi F, Umar IK, Haruna SI, El-Kady M, Azam A. Development of Artificial Intelligence Based Safety Performance Measures for Urban Roundabouts. Sustainability. 2023; 15(14):11429. https://doi.org/10.3390/su151411429
Chicago/Turabian StyleAlanazi, Fayez, Ibrahim Khalil Umar, Sadi Ibrahim Haruna, Mahmoud El-Kady, and Abdelhalim Azam. 2023. "Development of Artificial Intelligence Based Safety Performance Measures for Urban Roundabouts" Sustainability 15, no. 14: 11429. https://doi.org/10.3390/su151411429
APA StyleAlanazi, F., Umar, I. K., Haruna, S. I., El-Kady, M., & Azam, A. (2023). Development of Artificial Intelligence Based Safety Performance Measures for Urban Roundabouts. Sustainability, 15(14), 11429. https://doi.org/10.3390/su151411429