
An Intelligent Algorithm for Solving Unit Commitments Based on Deep Reinforcement Learning


Abstract
1. Introduction
2. DRL-Based Algorithm Architecture for Unit Commitment
3. Solution of Unit Startup and Shutdown Scheme Based on DRL
3.1. Mathematical Model of Unit Commitment
- (1)
- Objective function
- (2)
- Constraints
- (a)
- Power balance constraint
- (b)
- Unit operation constraints
- (c)
- Unit climbing constraint
- (d)
- Minimum start–stop time constraint
- (e)
- Maximum start–stop time constraint
- (f)
- Maximum start–stop time constraint
3.2. MDP Modeling for Unit Commitment
- (1)
- State space
- (2)
- Action space
- (3)
- Transfer function
- (4)
- Reward function
- (5)
- Policy gradient algorithm
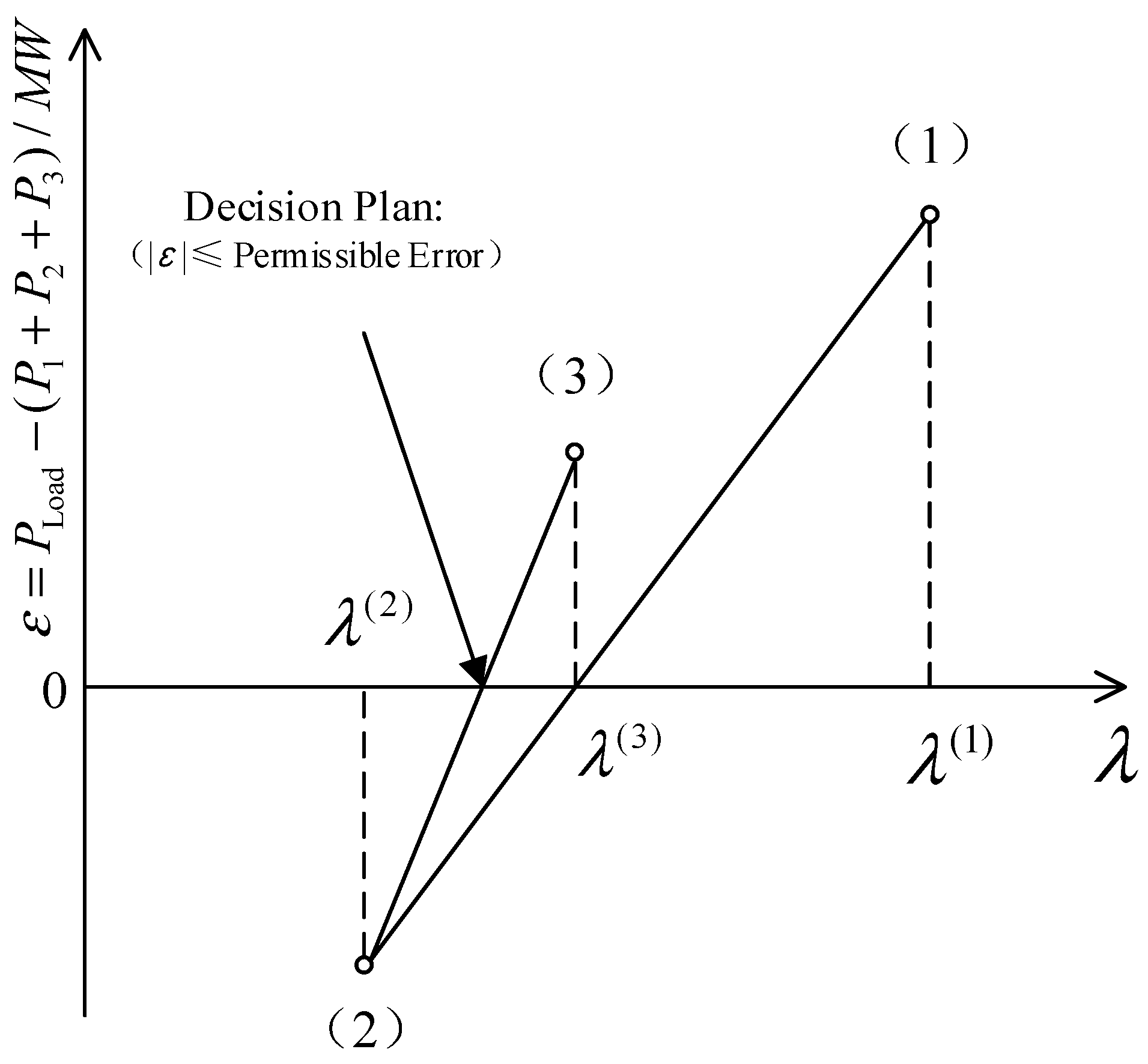
4. Solution of Unit Output Scheme Based on Lambda Iteration
5. Example Simulation and Analysis
5.1. Explanation of Calculation Examples
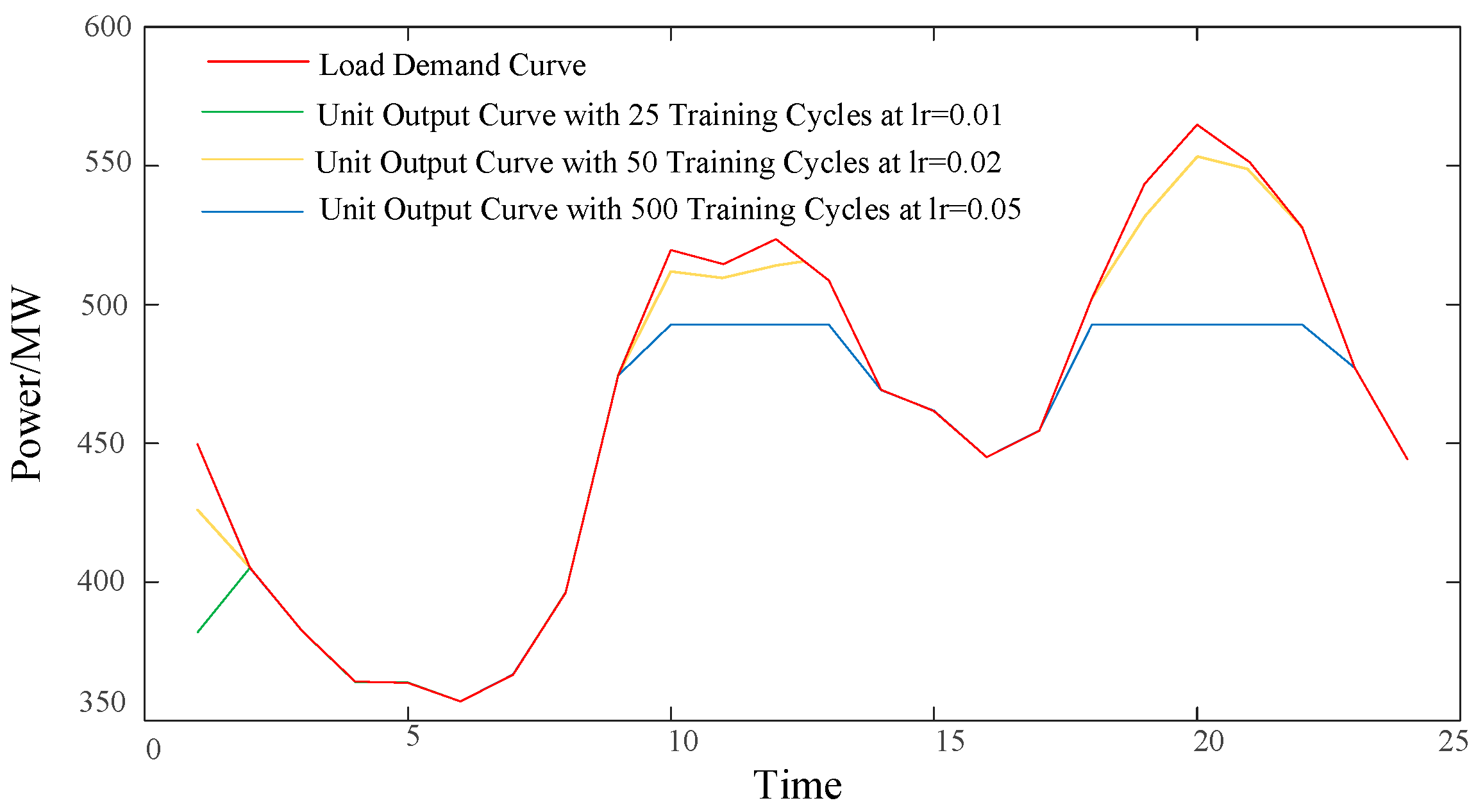
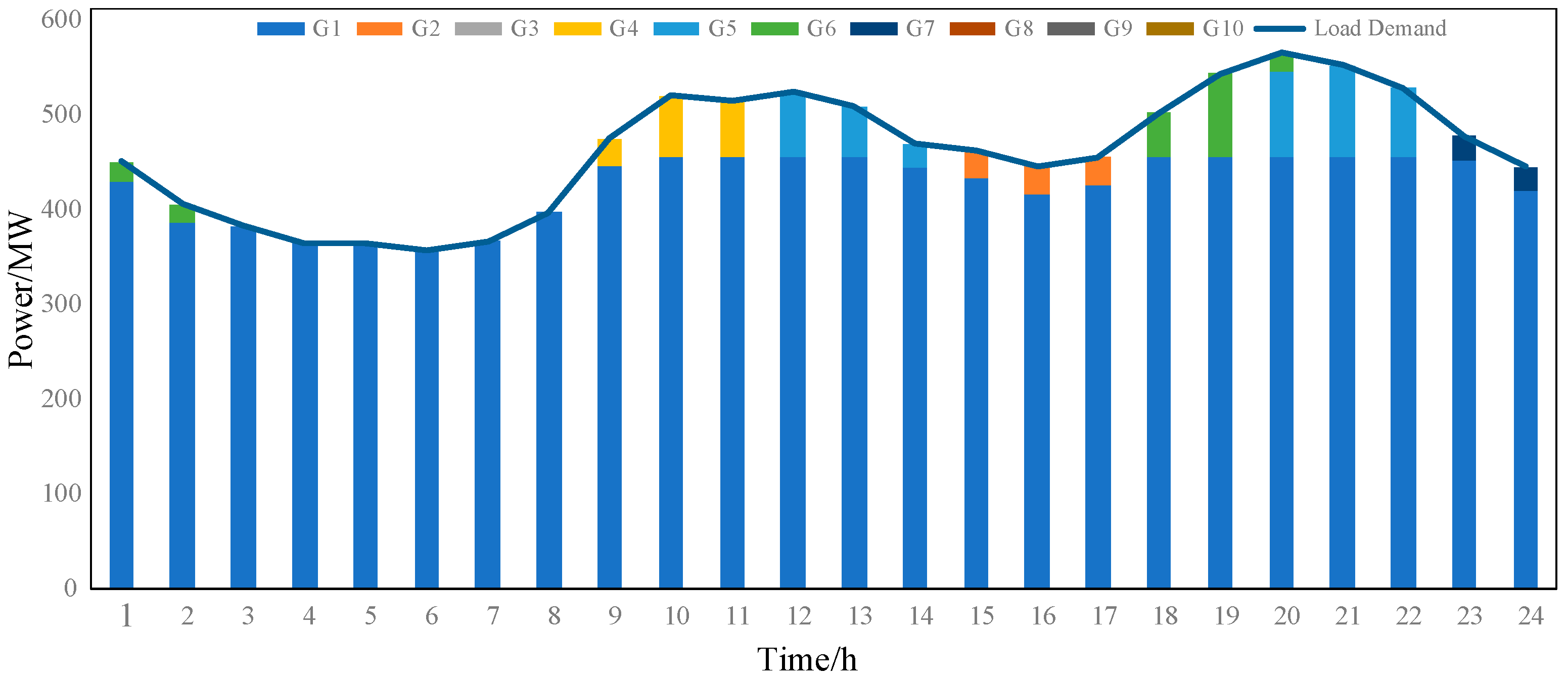
5.2. Procedural Simulation
5.3. Comparative Analysis
6. Conclusions
- (1)
- The intelligent solving algorithm of UC based on DRL proposed in this paper can effectively decide complex small-scale UC problems, and has high applicability.
- (2)
- Compared to supervised learning, the method does not require the construction of a large number of labeled sample data in advance, avoids the dependence on sample data, and has higher generalization performance.
- (3)
- Compared to the traditional method, this method can directly give the action decision through the strategy model of the model, and the solving efficiency is higher.
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
Appendix A

{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Unit Number | Maximum Unit Output (MW) | Minimum Unit Output (MW) | a (USD/h) | b (USD/MWh) | c ($/MWh2) | Minimum Startup Time (h) | Maximum Downtime (h) | Hot Start Cost (USD) | Cold Start Cost (USD) | Cold Start Time (h) | Initial State (h) |
|---|---|---|---|---|---|---|---|---|---|---|---|
| 1 | 455 | 30 | 800 | 16.19 | 0.00048 | 3 | 3 | 4500 | 9000 | 3 | 1 |
| 2 | 455 | 30 | 750 | 17.26 | 0.00031 | 2 | 2 | 5000 | 10,000 | 2 | 1 |
| 3 | 130 | 20 | 700 | 16.60 | 0.002 | 3 | 3 | 550 | 1100 | 3 | −1 |
| 4 | 130 | 20 | 680 | 16.50 | 0.00211 | 3 | 3 | 560 | 1120 | 3 | −1 |
| 5 | 162 | 25 | 450 | 19.70 | 0.00398 | 3 | 3 | 900 | 1800 | 3 | −1 |
| 6 | 150 | 20 | 370 | 22.26 | 0.00712 | 2 | 2 | 170 | 340 | 2 | −1 |
| 7 | 85 | 25 | 480 | 27.24 | 0.0079 | 3 | 3 | 260 | 520 | 3 | −1 |
| 8 | 70 | 10 | 660 | 25.92 | 0.00413 | 1 | 1 | 30 | 60 | 0 | −1 |
| 9 | 70 | 10 | 665 | 27.27 | 0.00222 | 1 | 1 | 30 | 60 | 0 | −1 |
| 10 | 70 | 10 | 670 | 27.79 | 0.00173 | 1 | 1 | 30 | 60 | 0 | −1 |
Appendix B
| Algorithm A1 DRL for UC Problems |
|
Initialize parameters of UC problems Input historical load data set of Nd days Initialize day d = 1 Initialize learning counter m = 0 Initialize random parameters Initialize target network parameters Initialize n-step buffer D as a queue with a maximum length of n
|
References
- Zhao, H.; Wang, Y.; Guo, S.; Zhao, M.; Zhang, C. Application of a Gradient Descent Continuous Actor-Critic Algorithm for Double-Side Day-Ahead Electricity Market Modeling. Energies 2016, 9, 725. [Google Scholar] [CrossRef]
- Wang, C.; Chu, S.; Ying, Y.; Wang, A.; Chen, R.; Xu, H.; Zhu, B. Underfrequency Load Shedding Scheme for Islanded Microgrids Considering Objective and Subjective Weight of Loads. IEEE Trans. Smart Grid 2023, 14, 899–913. [Google Scholar] [CrossRef]
- Zhu, B.; Liu, Y.; Zhi, S.; Wang, K.; Liu, J. A Family of Bipolar High Step-Up Zeta–Buck–Boost Converter Based on “Coat Circuit. IEEE Trans. Power Electron. 2023, 38, 3328–3339. [Google Scholar] [CrossRef]
- Bertsimas, D.; Litvinov, E.; Sun, X.; Zhao, J.; Zheng, T. Adaptive Robust Optimization for the Security Constrained Unit Commitment Problem. IEEE Trans. Power Syst. A Publ. Power Eng. Soc. 2013, 28, 52–63. [Google Scholar] [CrossRef]
- Li, Z.; Jiang, W.; Abu-Siada, A.; Li, Z.; Xu, Y.; Liu, S. Research on a Composite Voltage and Current Measurement Device for HVDC Networks. IEEE Trans. Ind. Electron. 2021, 68, 8930–8941. [Google Scholar] [CrossRef]
- Chen, J.J.; Qi, B.X.; Rong, Z.K.; Peng, K.; Zhao, Y.L.; Zhang, X.H. Multi-energy coordinated microgrid scheduling with integrated demand response for flexibility improvement. Energy 2021, 217, 119387. [Google Scholar] [CrossRef]
- Liao, S.; Xu, J.; Sun, Y.; Bao, Y.; Tang, B. Control of Energy-intensive Load for Power Smoothing in Wind Power Plants. IEEE Trans. Power Syst. 2018, 33, 6142–6154. [Google Scholar] [CrossRef]
- Zhou, Y.; Zhai, Q.; Wu, L. Optimal operation of regional microgrids with renewable and energy storage: Solution robustness and nonanticipativity against uncertainties. IEEE Trans. Smart Grid 2022, 13, 4218–4230. [Google Scholar] [CrossRef]
- Yu, G.; Liu, C.; Tang, B.; Chen, R.; Lu, L.; Cui, C.; Hu, Y.; Shen, L.; Muyeen, S.M. Short term wind power prediction for regional wind farms based on spatial-temporal characteristic distribution. Renew. Energy 2022, 199, 599–612. [Google Scholar] [CrossRef]
- Yang, N.; Jia, J.; Xing, C.; Liu, S.; Chen, D.; Ye, D.; Deng, Y. Data-driven intelligent decision-making method for unit commitment based on E-Seq2Seq technology. Proc. CSEE 2020, 40, 7587–7600. [Google Scholar]
- Shi, L.; Zhai, F. Data-driven unit commitment model considering wind-light-load uncertainty. Integr. Smart Energy 2022, 44, 18–25. [Google Scholar]
- Zhang, Y.; Ai, X.; Fang, J.; Wu, M.; Yao, W.; Wen, J. Data-driven robust unit commitment based on generalized convex hull uncertainty set. Proc. CSEE 2020, 40, 477–487. [Google Scholar]
- Yang, N.; Ye, D.; Lin, J.; Huang, Y.; Dong, B.; Hu, W.; Liu, S. Research on intelligent decision-making method of unit commitment based on data-driven and self-learning ability. Proc. CSEE 2019, 39, 2934–2946. [Google Scholar]
- Zhang, L.; Luo, Y. Combined Heat and Power Scheduling: Utilizing Building-level Thermal Inertia for Short-term Thermal Energy Storage in District Heat System. IEEJ Trans. Electr. Electron. Eng. 2018, 13, 804–814. [Google Scholar] [CrossRef]
- Jaderberg, M.; Czarnecki, W.M.; Dunning, I.; Marris, L.; Lever, G.; Castañeda, A.G.; Beattie, C.; Rabinowitz, N.C.; Morcos, A.S.; Ruderman, A.; et al. Human-level performance in 3D multiplayer games with population-based reinforcement learning. Science 2019, 364, 859–865. [Google Scholar] [CrossRef]
- Marot, A.; Donnot, B.; Romero, C.; Donon, B.; Lerousseau, M.; Veyrin-Forrer, L.; Guyon, I. Learning to run a power network challenge for training topology controllers. Electr. Power Syst. Res. 2020, 189, 106635. [Google Scholar] [CrossRef]
- Ahamed, T.P.; Imthias, P.S.; Nagendra Rao, P.; Sastry, S. A reinforcement learning approach to automatic generation control. Electr. Power Syst. Res. 2002, 63, 9–26. [Google Scholar] [CrossRef]
- Mevludin, G.; Ernst, D.; Wehenkel, L. A reinforcement learning based discrete supplementary control for power system transient stability enhancement. Int. J. Eng. Intell. Syst. Electr. Eng. Commun. 2005, 13, 81–88. [Google Scholar]
- Gajjar, G.R.; Khaparde, S.A.; Nagaraju, P. Application of actor-critic learning algorithm for optimal bidding problem of a Genco. IEEE Trans. Power Syst. A Publ. Power Eng. Soc. 2003, 18, 11–18. [Google Scholar] [CrossRef]
- Fang, P.; Fu, W.; Wang, K.; Xiong, D.; Zhang, K. A compositive architecture coupling outlier correction, EWT, nonlinear Volterra multi-model fusion with multi-objective optimization for short-term wind speed forecasting. Appl. Energy 2022, 307, 118191. [Google Scholar] [CrossRef]
- Nan, Y.; Cong, Y.; Chao, X.; Di, Y.; Junjie, J.; Daojun, C.; Xun, S.; Yuehua, H.; Lei, Z.; Binxin, Z. Deep learning-based SCUC decision-making: An intelligent data-driven approach with self-learning capabilities. IET Gener. Transm. Distrib. 2022, 16, 629–640. [Google Scholar]
- Yang, N.; Dong, Z.; Wu, L.; Zhang, L.; Shen, X.; Chen, D.; Zhu, B.; Liu, Y. A Comprehensive Review of Security-constrained Unit Commitment. J. Mod. Power Syst. Clean Energy 2022, 10, 562–576. [Google Scholar] [CrossRef]
- Zhang, Y.; Xie, X.; Fu, W.; Chen, X.; Hu, S.; Zhang, L.; Xia, Y. An Optimal Combining Attack Strategy Against Economic Dispatch of Integrated Energy System. IEEE Trans. Circuits Syst. II Express Briefs 2023, 70, 246–250. [Google Scholar] [CrossRef]
- Yang, N.; Yang, C.; Wu, L.; Shen, X.; Jia, J.; Li, Z.; Chen, D.; Zhu, B.; Liu, S. Intelligent Data-Driven Decision-Making Method for Dynamic Multisequence: An E-Seq2Seq-Based SCUC Expert System. IEEE Trans. Ind. Inform. 2022, 18, 3126–3137. [Google Scholar] [CrossRef]
- Ma, H.; Zheng, K.; Jiang, H.; Yin, H. A family of dual-boost bridgeless five-level rectifiers with common-core inductors. IEEE Trans. Power Electron. 2021, 36, 12565–12578. [Google Scholar] [CrossRef]
- Fu, W.; Jiang, X.; Li, B.; Tan, C.; Chen, B.; Chen, X. Rolling Bearing Fault Diagnosis based on 2D Time-Frequency Images and Data Augmentation Technique. Meas. Sci. Technol. 2023, 34, 045005. [Google Scholar] [CrossRef]
- Zhang, Y.; Wei, L.; Fu, W.; Chen, X.; Hu, S. Secondary frequency control strategy considering DoS attacks for MTDC system. Electr. Power Syst. Res. 2023, 214, 108888. [Google Scholar] [CrossRef]
- Yang, N.; Qin, T.; Wu, L.; Huang, Y.; Huang, Y.; Xing, C.; Zhang, L.; Zhu, B. A multi-agent game based joint planning approach for electricity-gas integrated energy systems considering wind power uncertainty. Electr. Power Syst. Res. 2021, 204, 107673. [Google Scholar] [CrossRef]
- Xie, K.; Hui, H.; Ding, Y. Review of modeling and control strategy of thermostatically controlled loads for virtual energy storage system. Prot. Control Mod. Power Syst. 2019, 4, 23. [Google Scholar] [CrossRef]
- Badal, F.R.; Das, P.; Sarker, S.K.; Das, S.K. A survey on control issues in renewable energy integration and microgrid. Prot. Control Mod. Power Syst. 2019, 4, 8. [Google Scholar] [CrossRef]
- Shen, X.; Raksincharoensak, P. Pedestrian-Aware Statistical Risk Assessment. IEEE Trans. Intell. Transp. Syst. 2022, 23, 7910–7918. [Google Scholar] [CrossRef]
- Li, Z.; Yub, C.; Abu-Siadac, A.; Lid, H.; Lia, Z.; Zhangb, T.; Xub, Y. An online correction system for electronic voltage transformers. Int. J. Electr. Power Energy Syst. 2021, 126, 106611. [Google Scholar] [CrossRef]
- Zhengmao, L.; Lei, W.; Yan, X. Risk-Averse Coordinated Operation of a Multi-Energy Microgrid Considering Voltage/Var Control and Thermal Flow: An Adaptive Stochastic Approach. IEEE Trans. Smart Grid 2021, 12, 3914–3927. [Google Scholar]
- Yang, N.; Liang, J.; Ding, L.; Zhao, J.; Xin, P.; Jiang, J.; Li, Z. Integrated Optical Storage Charging Considering Reconstruction Expansion and Safety Efficiency Cost. Grid Technol. 2023, 1–13. [Google Scholar] [CrossRef]
- Xu, P.; Fu, W.; Lu, Q.; Zhang, S.; Wang, R.; Meng, J. Stability analysis of hydro-turbine governing system with sloping ceiling tailrace tunnel and upstream surge tank considering nonlinear hydro-turbine characteristics. Renew. Energy 2023, 210, 556–574. [Google Scholar] [CrossRef]












| Time | Load Demand/MW | Time | Load Demand/MW |
|---|---|---|---|
| 1 | 449.717 | 13 | 508.613 |
| 2 | 405.164 | 14 | 469.191 |
| 3 | 382.190 | 15 | 461.64 |
| 4 | 364.110 | 16 | 444.960 |
| 5 | 363.736 | 17 | 454.509 |
| 6 | 357.007 | 18 | 502.122 |
| 7 | 366.625 | 19 | 543.379 |
| 8 | 396.158 | 20 | 564.789 |
| 9 | 474.458 | 21 | 551.297 |
| 10 | 519.556 | 22 | 527.678 |
| 11 | 514.560 | 23 | 477.109 |
| 12 | 523.566 | 24 | 444.144 |
| G1 | G2 | G3 | G4 | G5 | G6 | G7 | G8 | G9 | G10 | |
|---|---|---|---|---|---|---|---|---|---|---|
| 1 | 0 | 54.406 | 58.293 | 0 | 0 | 0 | 85 | 61.819 | 61.353 | 60.895 |
| 2 | 0 | 47.971 | 51.398 | 0 | 79.949 | 97.232 | 74.944 | 0 | 0 | 53.691 |
| 3 | 34.061 | 36.331 | 38.927 | 0 | 60.550 | 73.639 | 56.758 | 41.279 | 0 | 40.662 |
| 4 | 32.441 | 34.603 | 37.075 | 0 | 57.669 | 70.135 | 54.057 | 39.315 | 0 | 38.727 |
| 5 | 32.420 | 34.581 | 37.051 | 0 | 57.632 | 70.090 | 54.023 | 39.290 | 0 | 38.702 |
| 6 | 31.815 | 33.935 | 36.360 | 0 | 56.557 | 68.782 | 53.014 | 38.556 | 0 | 37.980 |
| 7 | 32.666 | 34.843 | 37.333 | 0 | 58.070 | 70.622 | 54.433 | 39.588 | 0 | 38.996 |
| 8 | 35.313 | 37.666 | 40.357 | 0 | 62.775 | 76.344 | 58.843 | 42.796 | 0 | 42.156 |
| 9 | 42.288 | 45.106 | 48.329 | 0 | 75.175 | 91.425 | 70.468 | 51.251 | 0 | 50.484 |
| 10 | 46.309 | 49.395 | 52.924 | 0 | 82.323 | 100.11 | 77.170 | 56.124 | 0 | 55.285 |
| 11 | 45.857 | 48.914 | 52.408 | 0 | 81.520 | 99.143 | 76.418 | 55.577 | 0 | 54.746 |
| 12 | 46.657 | 49.767 | 53.322 | 0 | 82.943 | 100.87 | 77.751 | 56.547 | 0 | 55.702 |
| 13 | 45.324 | 48.345 | 51.798 | 0 | 80.572 | 97.990 | 75.529 | 54.931 | 0 | 54.109 |
| 14 | 41.816 | 44.603 | 47.789 | 0 | 74.336 | 90.405 | 69.682 | 50.679 | 0 | 49.921 |
| 15 | 41.139 | 43.881 | 47.016 | 0 | 73.132 | 88.941 | 68.554 | 49.858 | 0 | 49.113 |
| 16 | 39.652 | 42.294 | 45.316 | 0 | 70.488 | 85.726 | 66.075 | 48.055 | 0 | 47.337 |
| 17 | 40.503 | 43.202 | 46.289 | 0 | 72.002 | 87.566 | 67.494 | 49.087 | 0 | 48.353 |
| 18 | 44.749 | 47.732 | 51.142 | 0 | 79.551 | 96.748 | 74.571 | 54.235 | 0 | 53.424 |
| 19 | 48.422 | 51.649 | 55.339 | 0 | 86.079 | 104.68 | 80.691 | 58.686 | 0 | 57.808 |
| 20 | 50.329 | 53.684 | 57.519 | 0 | 89.471 | 108.81 | 83.871 | 60.998 | 0 | 60.086 |
| 21 | 49.129 | 52.404 | 56.148 | 0 | 87.338 | 106.21 | 81.871 | 59.543 | 0 | 58.653 |
| 22 | 47.027 | 50.161 | 53.744 | 0 | 83.599 | 101.67 | 78.366 | 56.995 | 0 | 56.143 |
| 23 | 42.513 | 45.347 | 48.586 | 0 | 75.576 | 91.913 | 70.844 | 51.524 | 0 | 50.754 |
| 24 | 39.580 | 42.218 | 45.234 | 0 | 70.361 | 85.570 | 65.955 | 47.968 | 0 | 47.251 |
| G1 | G2 | G3 | G4 | G5 | G6 | G7 | G8 | G9 | G10 | |
|---|---|---|---|---|---|---|---|---|---|---|
| 1 | 64.835 | 0 | 45.853 | 0 | 54.227 | 71.032 | 75.693 | 58.345 | 0 | 47.322 |
| 2 | 42.692 | 0 | 50.518 | 0 | 57.841 | 76.693 | 63.357 | 51.071 | 0 | 43.625 |
| 3 | 39.085 | 0 | 34.517 | 0 | 53.654 | 52.954 | 67.542 | 66.882 | 0 | 57.365 |
| 4 | 31.196 | 0 | 46.358 | 0 | 46.743 | 51.771 | 64.286 | 63.614 | 0 | 42.573 |
| 5 | 48.391 | 0 | 42.148 | 0 | 47.714 | 61.981 | 72.514 | 45.564 | 0 | 45.986 |
| 6 | 41.1 | 0 | 45.768 | 0 | 64.641 | 57.438 | 64.641 | 50.511 | 0 | 42.839 |
| 7 | 40.787 | 0 | 45.069 | 0 | 75.902 | 67.915 | 52.215 | 54.754 | 0 | 52.082 |
| 8 | 48.221 | 0 | 50.902 | 0 | 90.719 | 96.389 | 74.406 | 66.875 | 0 | 52.357 |
| 9 | 42.81 | 0 | 53.225 | 0 | 101.508 | 104.799 | 81.017 | 58.484 | 0 | 63.049 |
| 10 | 47.474 | 0 | 53.835 | 0 | 92.223 | 101.207 | 86.755 | 61.527 | 0 | 61.649 |
| 11 | 47.364 | 0 | 49.314 | 0 | 89.872 | 106.609 | 84.292 | 81.093 | 0 | 57.136 |
| 12 | 45.25 | 0 | 51.557 | 0 | 103.204 | 96.833 | 81.943 | 69.071 | 0 | 53.19 |
| 13 | 42.815 | 0 | 51.177 | 0 | 77.725 | 93.537 | 82.636 | 63.424 | 0 | 65.853 |
| 14 | 34.839 | 0 | 53.855 | 0 | 87.608 | 96.152 | 74.673 | 61.549 | 0 | 55.05 |
| 15 | 32.753 | 0 | 53.448 | 0 | 71.425 | 65.296 | 83.925 | 53.673 | 0 | 65.923 |
| 16 | 51.27 | 0 | 47.406 | 0 | 78.962 | 91.947 | 81.646 | 56.649 | 0 | 55.872 |
| 17 | 42.027 | 0 | 53.847 | 0 | 93.99 | 109.708 | 79.341 | 60.361 | 0 | 58.848 |
| 18 | 46.027 | 0 | 60.52 | 0 | 114.113 | 108.032 | 81.157 | 61.128 | 0 | 69.489 |
| 19 | 38.94 | 0 | 44.508 | 0 | 121.932 | 125.142 | 92.183 | 62.03 | 0 | 55.255 |
| 20 | 53.739 | 0 | 45.254 | 0 | 111.1 | 114.682 | 76.534 | 65.985 | 0 | 58.789 |
| 21 | 58.953 | 0 | 45.042 | 0 | 117.249 | 94.742 | 71.256 | 62.847 | 0 | 67.111 |
| 22 | 49.431 | 0 | 46.164 | 0 | 92.059 | 95.437 | 75.931 | 60.239 | 0 | 62.417 |
| 23 | 44.862 | 0 | 45.104 | 0 | 82.05 | 87.89 | 71.197 | 60.111 | 0 | 61.65 |
| 24 | 36.142 | 0 | 45.853 | 0 | 54.227 | 81.032 | 75.693 | 58.345 | 0 | 47.322 |
| G1 | G2 | G3 | G4 | G5 | G6 | G7 | G8 | G9 | G10 | |
|---|---|---|---|---|---|---|---|---|---|---|
| 1 | 52.714 | 0 | 0 | 62.016 | 93.710 | 113.96 | 0 | 63.888 | 63.407 | 0 |
| 2 | 47.483 | 0 | 0 | 55.862 | 84.410 | 102.65 | 0 | 57.547 | 57.114 | 0 |
| 3 | 44.799 | 0 | 0 | 52.705 | 79.639 | 96.855 | 0 | 54.295 | 53.885 | 0 |
| 4 | 42.685 | 0 | 0 | 50.217 | 75.881 | 92.284 | 0 | 51.732 | 51.342 | 0 |
| 5 | 42.631 | 0 | 0 | 50.154 | 75.784 | 92.167 | 0 | 51.666 | 51.277 | 0 |
| 6 | 41.845 | 0 | 0 | 49.229 | 74.387 | 90.467 | 0 | 50.713 | 50.331 | 0 |
| 7 | 42.983 | 0 | 0 | 50.568 | 76.411 | 92.929 | 0 | 52.093 | 51.701 | 0 |
| 8 | 46.439 | 0 | 0 | 54.634 | 82.555 | 100.40 | 0 | 56.282 | 55.858 | 0 |
| 9 | 55.614 | 0 | 0 | 65.428 | 98.866 | 120.23 | 0 | 67.404 | 66.896 | 0 |
| 10 | 57.756 | 0 | 0 | 67.948 | 102.67 | 124.86 | 0 | 70 | 69.472 | 0 |
| 11 | 57.756 | 0 | 0 | 67.948 | 102.67 | 124.86 | 0 | 70 | 69.472 | 0 |
| 12 | 57.756 | 0 | 0 | 67.948 | 102.67 | 124.86 | 0 | 70 | 69.472 | 0 |
| 13 | 57.756 | 0 | 0 | 67.948 | 102.67 | 124.86 | 0 | 70 | 69.472 | 0 |
| 14 | 54.991 | 0 | 0 | 64.695 | 97.758 | 118.89 | 0 | 66.648 | 66.146 | 0 |
| 15 | 54.123 | 0 | 0 | 63.674 | 96.216 | 117.01 | 0 | 65.597 | 65.103 | 0 |
| 16 | 52.158 | 0 | 0 | 61.363 | 92.722 | 112.76 | 0 | 63.215 | 62.739 | 0 |
| 17 | 53.283 | 0 | 0 | 62.686 | 94.722 | 115.19 | 0 | 64.578 | 64.092 | 0 |
| 18 | 57.756 | 0 | 0 | 67.948 | 102.67 | 124.86 | 0 | 70 | 69.472 | 0 |
| 19 | 57.756 | 0 | 0 | 67.948 | 102.67 | 124.86 | 0 | 70 | 69.472 | 0 |
| 20 | 57.756 | 0 | 0 | 67.948 | 102.67 | 124.86 | 0 | 70 | 69.472 | 0 |
| 21 | 57.756 | 0 | 0 | 67.948 | 102.67 | 124.86 | 0 | 70 | 69.472 | 0 |
| 22 | 57.756 | 0 | 0 | 67.948 | 102.67 | 124.86 | 0 | 70 | 69.472 | 0 |
| 23 | 55.926 | 0 | 0 | 65.795 | 99.420 | 120.91 | 0 | 67.782 | 67.271 | 0 |
| 24 | 52.063 | 0 | 0 | 61.251 | 92.554 | 112.56 | 0 | 63.085 | 62.624 | 0 |
| Learning Rate | 0.01 |
| Reward Decay Rate | 0.95 |
| Memory size | 500 |
| Batch size | 24 |
| Epochs | 30 |
| Optimization Solution Method | Adam |
| Method | Training Time/s | Decision Time/s | Cost Or Reward Value/CNY |
|---|---|---|---|
| Method 1 | - | 3938.16 | 228,200 |
| Method 2 | 97.54 | 0.31 | 236,910 |
| Method 3 | 2.13 | 0.43 | 304,339 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Huang, G.; Mao, T.; Zhang, B.; Cheng, R.; Ou, M. An Intelligent Algorithm for Solving Unit Commitments Based on Deep Reinforcement Learning. Sustainability 2023, 15, 11084. https://doi.org/10.3390/su151411084
Huang G, Mao T, Zhang B, Cheng R, Ou M. An Intelligent Algorithm for Solving Unit Commitments Based on Deep Reinforcement Learning. Sustainability. 2023; 15(14):11084. https://doi.org/10.3390/su151411084
Chicago/Turabian StyleHuang, Guanglei, Tian Mao, Bin Zhang, Renli Cheng, and Mingyu Ou. 2023. "An Intelligent Algorithm for Solving Unit Commitments Based on Deep Reinforcement Learning" Sustainability 15, no. 14: 11084. https://doi.org/10.3390/su151411084
APA StyleHuang, G., Mao, T., Zhang, B., Cheng, R., & Ou, M. (2023). An Intelligent Algorithm for Solving Unit Commitments Based on Deep Reinforcement Learning. Sustainability, 15(14), 11084. https://doi.org/10.3390/su151411084