



Intelligent Identification and Prediction Mineral Resources Deposit Based on Deep Learning
Abstract
1. Introduction
2. Literature Review
2.1. Deep Learning for Metallogenic Prediction
2.2. Multi-Scale Feature Fusion Technology for Mineral Prospecting
2.3. The Mechanism of Attention Used in Geodata Analysis
3. Materials and Methods
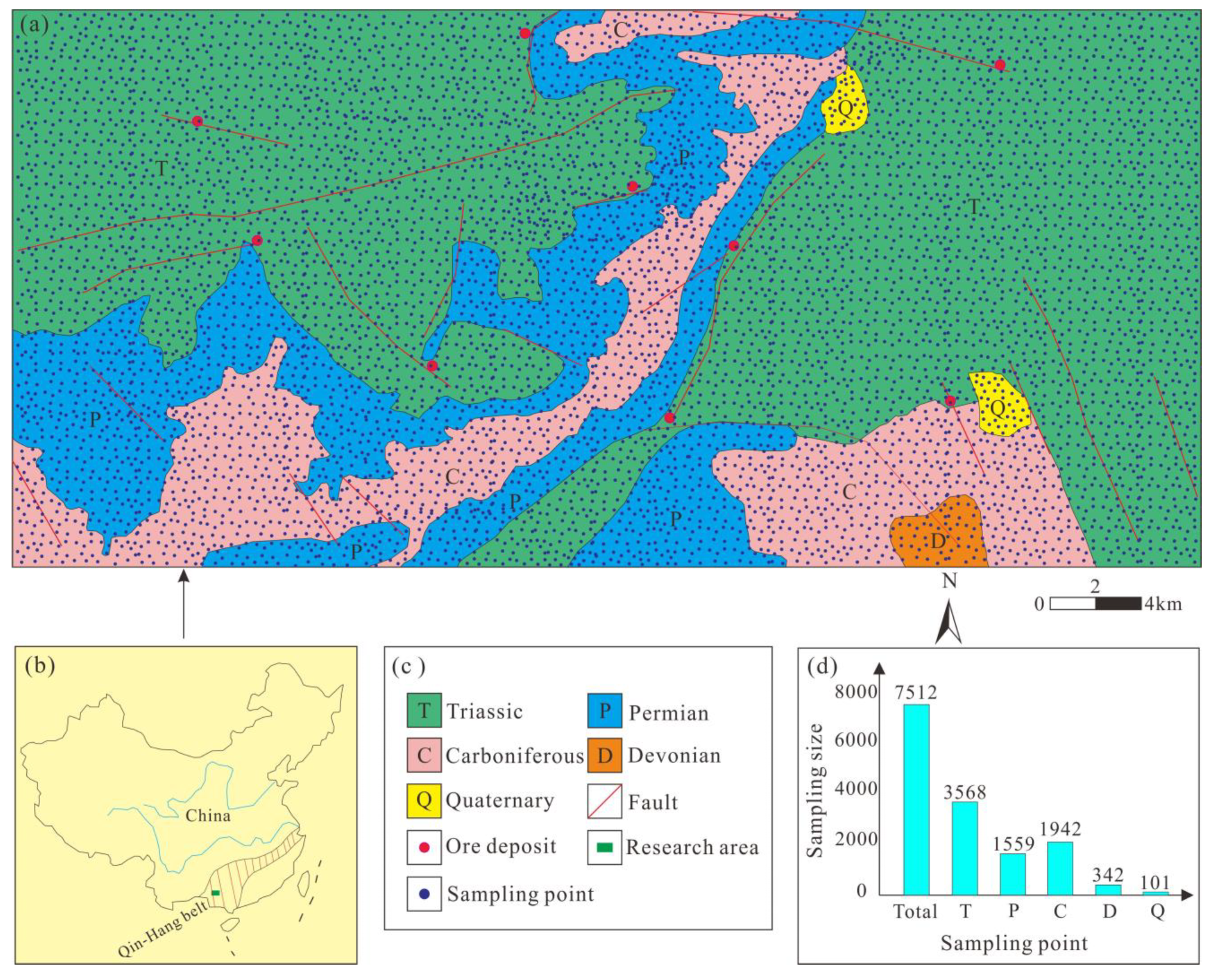
3.1. Materials
3.2. Methods
3.2.1. Data Pre-Processing
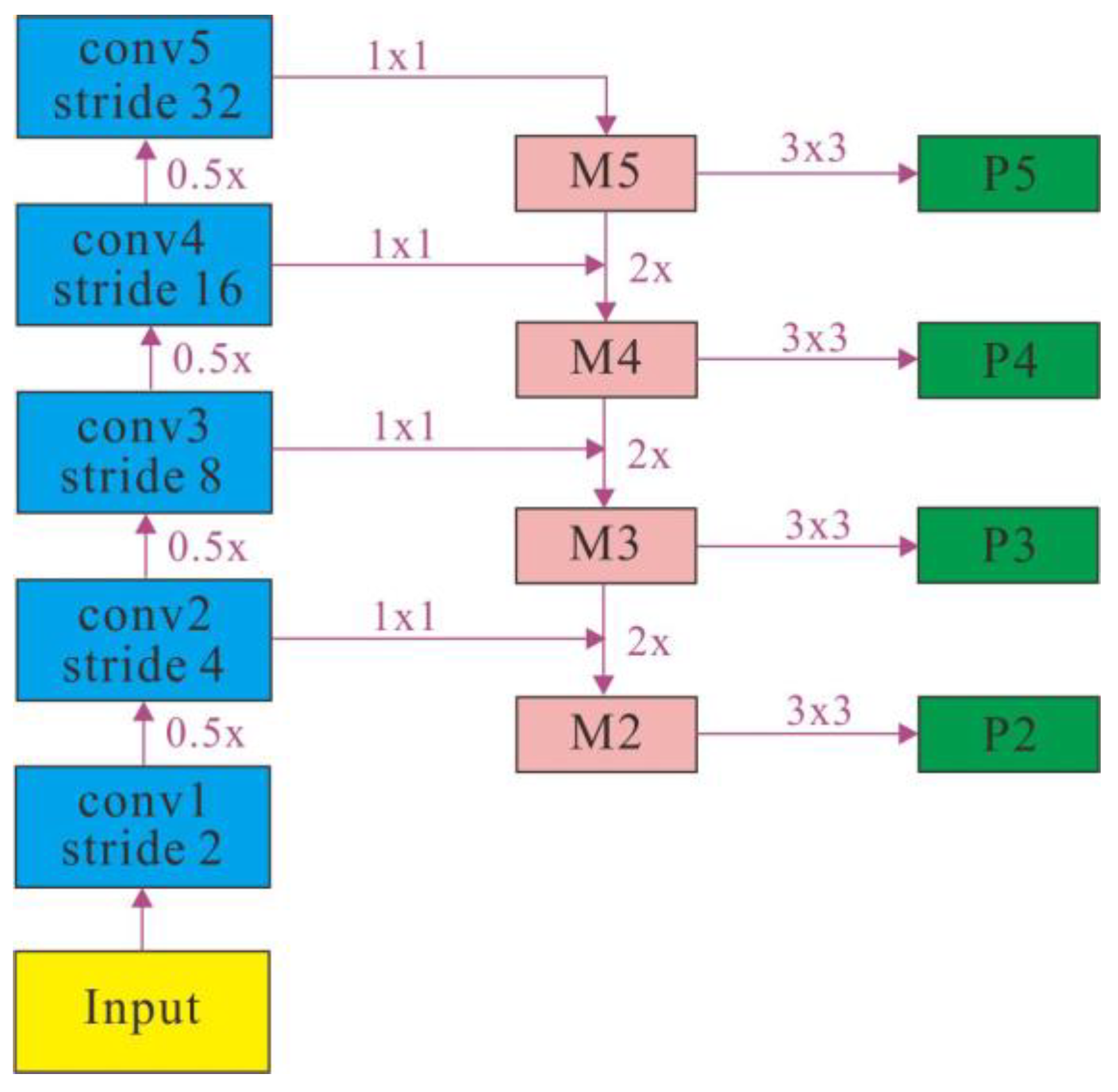
3.2.2. Multiscale Feature Attention Framework (MFAF)
3.2.3. Multi-Scale Feature Fusion
3.2.4. Channel Attention
3.2.5. Spatial Attention
3.2.6. Fully Connected Layer, Softmax, and Voting
4. Results and Discussion
4.1. Experiment Settings
4.2. Experiment Results and Analysis
4.3. Correlation Analysis Experiment
4.3.1. Ablation Experiments
- Different geological prospecting factors have different degrees of influence on ore deposits. This study adopted channel attention module in the process of training data can reduce the influence of human factors. According to the value of loss in the experiment, the weight values on different channels are adjusted reversely and dynamically, the weight values of important features are increased, the importance of features with little influence is suppressed. the accuracy of the deposit prospecting prediction is improved.
- Spatial attention module is adopted in the MFAF model can consider the difference of geological prospecting factors in different spatial locations on mineralization of ore deposits. The spatial attention module can use spatial attention as a supplement to the convolution operation, which enhances image features at different spatial locations.
- The contributions of these methods to MFAF are different. According to the contribution from large to small, they are ranked as follows: channel attention, spatial attention.
4.3.2. Parameter Analysis Experiments
4.4. Visualization
4.5. Significant Criticism and Research Limitations
5. Conclusions
- The deep learning model of MFAF can effectively solve the problems of fine features of geological images and few mineral points in the region. In this model, the expansion coefficient and multi-scale features are used to extract more and more detailed geological image feature information, and expansion convolution with different convolution kernel sizes is used to generate more labeled sample data.
- The network architecture of channel attention and spatial attention mechanism was used to assign different weight coefficients to the geological image feature data of different channels and different spatial locations. It can avoid the influence of human subjective factors and improve the accuracy of intelligent identification and prediction of ore deposits based on geoimage data.
- The smote method was used to enhance the labeled geological image samples. This can effectively expand the number of samples in geoscience image data set, ensure the data sent to the neural network to achieve balance, and complete the effective training of deep learning network model.
- In this study, MFAF was adopted to identify and predict the deposit in Jinshan research area. Experimental results showed that the predicted prospecting target area covered 100% of the known deposits in the study area. The other prediction areas have good metallogenic conditions and can be used as ore deposit prediction areas for further study. The research of this paper can provide resource guarantee and technical support for the sustainable exploitation of mineral resources and the sustainable growth of society and economy.
- Based on the limitations of our research conditions, the accuracy, AUC, recall, and F1-Score are all relatively low. The geological conditions are uncertain and data are difficult to obtain. We can try to adopt transfer learning in the geographic image research and enrich our geoscience and artificial intelligence knowledge in future work.
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- Cheng, Q. What are Mathematical Geosciences and its frontiers? Earth Sci. Front. 2021, 28, 6–25. [Google Scholar] [CrossRef]
- Zhou, Y.; Zuo, R.; Liu, G.; Yuan, F.; Mao, X.; Guo, Y.; Xiao, F.; Liao, J.; Liu, Y. The Great-leap-forward Development of Mathematical Geoscience During 2010–2019: Big Data and Artificial Intelligence Algorithm Are Changing Mathematical Geoscience. Bull. Mineral. Petrol. Geochem. 2021, 40, 556–574. [Google Scholar] [CrossRef]
- Zuo, R. Data science-based theory and method of quantitative prediction of mineral resources. Earth Sci. Front. 2021, 28, 49–55. [Google Scholar] [CrossRef]
- Kost, S.; Rheinbach, O.; Schaeben, H. Using logistic regression model selection towards interpretable machine learning in mineral prospectivity modeling. Geochemistry 2021, 81, 125826. [Google Scholar] [CrossRef]
- Santos, J.S.; Ferreira, R.S.; Silva, V.T. Evaluating the classification of images from geoscience papers using small data. Appl. Comput. Geosci. 2020, 5, 100018. [Google Scholar] [CrossRef]
- Ghezelbash, R.; Maghsoudi, A.; Carranza, E.J.M. Optimization of geochemical anomaly detection using a novel genetic K-means clustering (GKMC) algorithm. Comput. Geosci. 2020, 134, 104335. [Google Scholar] [CrossRef]
- Martins, T.; Seoane, J.; Tavares, F. Cu-Au exploration target generation in the eastern carajas mineral province using random forest and multi-class index overlay mapping. J. S. Am. Earth Sci. 2022, 116, 103790. [Google Scholar] [CrossRef]
- Li, T.; Zuo, R.; Zhao, X.; Zhao, K. Mapping prospectivity for regolith-hosted REE deposits via convolutional neural network with generative adversarial network augmented data. Ore Geol. Rev. 2022, 142, 104693. [Google Scholar] [CrossRef]
- Zhang, C.; Zuo, R.; Xiong, Y.; Zhao, X.; Zhao, K. A geologically- constrained deep learning algorithm for recognizing geochemical anomalies. Comput. Geosci. 2022, 162, 105100. [Google Scholar] [CrossRef]
- Houshmand, N.; GoodFellow, S.; Esmaeili, K.; Calderon, J. Rock type classification based on petrophysical, geochemical, and core imaging data using machine and deep learning techniques. Appl. Comput. Geosci. 2022, 16, 100104. [Google Scholar] [CrossRef]
- Huang, Y.; Feng, Q.; Zhang, W.; Zhang, L.; Gao, L. Prediction of prospecting target based on selective transfer network. Minerals 2022, 12, 1112. [Google Scholar] [CrossRef]
- Xiong, Y.; Zuo, R. Recognizing multivariate geochemical anomalies for mineral exploration by combining deep learning and one- class support vector machine. Comput. Geosci. 2020, 140, 104484. [Google Scholar] [CrossRef]
- Gao, L.; Huang, Y.; Zhang, X.; Liu, Q.; Chen, Z. Prediction of prospecting target based on ResNet convolutional neural network. Appl. Sci. 2022, 12, 11433. [Google Scholar] [CrossRef]
- Zhang, W.; Gu, X.; Tang, L.; Yin, Y.; Liu, D.; Zhang, Y. Application of machine learning, deep learning and optimization algorithms in geoengineering and geoscience: Comprehensive review and future challenge. Gondwana Res. 2022, 109, 1–17. [Google Scholar] [CrossRef]
- Zuo, R.; Carranza, E.J.M. Support vector machine: A tool for mapping mineral prospectivity. Comput. Geosci. 2011, 37, 1967–1975. [Google Scholar] [CrossRef]
- Daviran, M.; Maghsoudi, A.; Ghezelbash, R.; Pradhan, B. A new strategy for spatial predictive mapping of mineral prospectivity: Automated hyperparameter tuning of random forest approach. Comput. Geosci. 2021, 148, 104688. [Google Scholar] [CrossRef]
- Chen, G.; Huang, N.; Wu, G.; Luo, L.; Wang, D.; Cheng, Q. Mineral prospectivity mapping based on wavelet neural network and Monte Carlo simulations in the Nanling W-Sn metallogenic province. Ore Geol. Rev. 2022, 143, 104765. [Google Scholar] [CrossRef]
- Marjanovic, M.; Kovacevic, M.; Bajat, B.; Vozenilek, V. Landslide susceptibility assessment using SVM machine learning algorithm. Eng. Geol. 2011, 3, 225–234. [Google Scholar] [CrossRef]
- Yang, F.; Li, N.; Xu, W.; Liu, X.; Cui, Z.; Jia, L.; Liu, Y.; Xu, J.; Chen, Y.; Xu, X.; et al. Laser- induced breakdown spectroscopy combined with a convolutional neural network: A promising methodology for geochemical sample identification in Tianwen- 1 Mars mission. Spectrochim. Acta Part B At. Spectrosc. 2022, 192, 106417. [Google Scholar] [CrossRef]
- Li, Y.; Peng, C.; Ran, X.; Xue, L.; Chai, S. Soil geochemical prospecting prediction method based on deep convolutional neural networks- taking daqiao gold deposit in gansu province, China as an example. China Geol. 2022, 5, 71–83. [Google Scholar]
- Wang, Z.; Zuo, R. Mineral prospectivity mapping using a joint singularity- based weighting method and long short- term memory network. Comput. Geosci. 2022, 158, 104974. [Google Scholar] [CrossRef]
- Zhang, C.; Zuo, R. Recognition of multivariate geochemical anomalies associated with mineralization using an improved generative adversarial network. Ore Geol. Rev. 2021, 136, 104264. [Google Scholar] [CrossRef]
- Li, H.; Li, X.; Yuan, F.; Jowitt, S.; Zhang, M.; Zhou, J.; Zhou, T.; Li, X.; Ge, C.; Wu, B. Convolutional neural network and transfer learning based mineral prospectivity modeling for geochemical exploration of Au mineralization within the Guandian- Zhangbaling area, anhui province, China. Appl. Geochem. 2020, 122, 104747. [Google Scholar] [CrossRef]
- Chen, Y.; Shayilan, A. Dictionary learning for multivariate geochemical anomaly detection for mineral exploration targeting. J. Geochem. Explor. 2022, 235, 106958. [Google Scholar] [CrossRef]
- He, Y.; Zhou, Y.; Wen, T.; Zhang, S.; Huang, F.; Zou, X.; Ma, X.; Zhu, Y. A review of machine learning in geochemistry and cosmochemistry: Method improvements and applications. Appl. Geochem. 2022, 140, 105273. [Google Scholar] [CrossRef]
- Huang, Y.; Gao, L.; Yang, T.; Zhang, X. Experimental research on intelligent prospecting based on multi- scale feature and meta- learning. Appl. Res. Comput. 2022, 39, 1772–1778. [Google Scholar] [CrossRef]
- Guan, Q.; Ren, S.; Chen, L.; Feng, B.; Yao, Y. A spatial- compositional feature fusion convolutional autoencoder for multivariate geochemical anomaly recognition. Comput. Geosci. 2021, 156, 104890. [Google Scholar] [CrossRef]
- Zhou, W.; Yan, J.; Chen, C. Multiscale geophysics and mineral system detection: Status and progress. Prog. Geophys. 2021, 36, 1208–1225. [Google Scholar] [CrossRef]
- Li, K.; Zou, C.; Bu, S.; Liang, Y.; Zhang, J.; Gong, M. Multi-modal feature fusion for geographic image annotation. Pattern Recognit. 2018, 73, 1–14. [Google Scholar] [CrossRef]
- Li, F.; Zhu, A.; Li, J.; Xu, Y.; Zhang, Y.; Yin, H.; Hua, G. Frequency-driven channel attention- augmented full-scale temporal modeling network for skeleton-based action recognition. Knowl.-Based Syst. 2022, 256, 109854. [Google Scholar] [CrossRef]
- Wang, J.; Wu, X. A deep learning refinement strategy based on efficient channel attention for atrial fibrillation and atrial flutter signals identification. Appl. Soft Comput. 2022, 130, 109552. [Google Scholar] [CrossRef]
- Yu, G.; Luo, Y.; Deng, R. Automatic segmentation of golden pomfret based on fusion of multi- head self- attention and channel- attention mechanism. Comput. Electron. Agric. 2022, 202, 107369. [Google Scholar] [CrossRef]
- Zhu, Y.; Gei, C.; So, E. Image super-resolution with dense-sampling residual channel-spatial attention networks for multi-temporal remote sensing image. Int. J. Appl. Earth Obs. Geoinf. 2021, 104, 102543. [Google Scholar] [CrossRef]
- Gajbhiye, G.; Nandedkar, A. Generating the captions for remote sensing images: A spatial- channel attention based memory- guided transformer approach. Eng. Appl. Artif. Intell. 2022, 114, 105076. [Google Scholar] [CrossRef]
- Gendy, G.; Sabor, N.; Hou, J.; He, G. Balanced spatial feature distillation and pyramid attention network for lightweight image super-resolution. Neurocomputing 2022, 509, 157–166. [Google Scholar] [CrossRef]
- Kurki, I.; Hyvarinen, A.; Henriksson, L. Dynamics of retinotopic spatial attention revealed by multifocal MEG. Neuroimage 2022, 263, 119643. [Google Scholar] [CrossRef]
- Heo, J.; Wang, Y.; Park, J. Occlusion-aware spatial attention transformer for occluded object recognition. Pattern Recognit. Lett. 2022, 159, 70–76. [Google Scholar] [CrossRef]
- Pan, D.; Xu, Z.; Lu, X.; Zhou, L.; Li, H. 3D scene and geological modeling using integrated multi-source spatial data: Methodology, challenges, and suggestions. Tunn. Undergr. Space Technol. 2020, 100, 103393. [Google Scholar] [CrossRef]
- Zhao, D.; Wang, X. Investigating the spatial distribution of antimony geochemical anomalies located in the Yunnan-Guizhou-Guangxi region, China. Geochemistry 2021, 81, 125829. [Google Scholar] [CrossRef]
- Zheng, Z.; Zhao, Q.; Li, S.; Qiu, S. Comparison of two machine learning algorithms for geochemical anomaly detection. Glob. Geol. 2018, 37, 1288–1294. [Google Scholar] [CrossRef]
- Ozdemir, A.; Polat, K.; Alhudhaif, A. Classification of imbalanced hyperspectral images using SMOTE-based deep learning methods. Expert Syst. Appl. 2021, 178, 114986. [Google Scholar] [CrossRef]
- Xie, Z.; Wang, Y.; Yu, M.; Yu, D.; Lv, J.; Yin, J.; Liu, J.; Wu, R. Triboelectric sensor for planetary gear fault diagnosis using data enhancement and CNN. Nano Energy 2022, 103, 107804. [Google Scholar] [CrossRef]
- Dai, L.; Luo, M.; Zhang, T.; Huang, J.; Tang, Y.; Li, X.; Wu, F.; Nie, X. Method and practiceof rapid evaluation of soil thickness in low mountain and hilly area based on principal component analysis- taking luoshan county, henan province as an example. South China Geol. 2021, 37, 377–386. [Google Scholar] [CrossRef]
- Peng, C.; Wang, L.; Jiang, D.; Yang, N.; Chen, R.; Dong, C. Establishing and validating a spotted tongue recognition and extraction model based on multiscale convolutional neural network. Digit. Chin. Med. 2022, 5, 49–58. [Google Scholar] [CrossRef]
- Zhang, S.; Deng, X.; Lu, Y.; Hong, S.; Kong, Z.; Peng, Y.; Luo, Y. A channel attention based deep neural network for automatic metallic corrosion detection. J. Build. Eng. 2021, 42, 103046. [Google Scholar] [CrossRef]
- Qiu, Z.; Becker, S.I.; Pegna, A.J. Spatial attention shifting to fearful faces depends on visual awareness in attentional blink: An ERP study. Neuropsychologia 2022, 172, 108283. [Google Scholar] [CrossRef]
- Parisi, L.; Neagu, D.; Ma, R.; Campea, F. Quantum ReLu activation for convolutional neural networks to improve diagnosis of parkinson’s disease and COVID-19. Expert Syst. Appl. 2022, 187, 115892. [Google Scholar] [CrossRef]
- He, K.; Zhang, X.; Ren, S.; Sun, J. Deep Residual Learning for Image Recognition. In Proceedings of the 2016 IEEE Conference on Computer Vision and Pattern Recogintion, Las Vegas, NV, USA, 27–30 June 2016. [Google Scholar] [CrossRef]
- Ma, N.; Zhang, X.; Zheng, H.; Sun, J. ShuffleNet V2: Practical Guidelines for Efficient CNN Architecture Design. Lect. Notes Comput. Sci. 2018, 122–138. [Google Scholar] [CrossRef]
- Hua, C.; Chen, S.; Xu, G.; Lu, Y.; Du, B. Defect identification method of carbon fiber sucker rod based on GoogLeNet-based deep learning model and transfer learning. Mater. Commun. 2022, 33, 104228. [Google Scholar] [CrossRef]
- Shafi, I.; Mazahir, A.; Fatima, A.; Ashraf, I. Internal defects detection and classification in hollow cylindrical surfaces using single shot detection and MobileNet. Measurement 2022, 202, 111836. [Google Scholar] [CrossRef]
- Tan, M.; Chen, B.; Pang, R.; Vasudevan, V.; Sandler, M.; Howard, A.; Le, Q. MnasNet: Platform-aware neural architecture search for mobile. In Proceedings of the Computer Vision and Pattern Recognition 2019, Long Beach, CA, USA, 16–20 June 2019. [Google Scholar] [CrossRef]
- Tanveer, M.; Sharma, A.; Sugathan, P.N. General twin support vector machine with pinball loss function. Inf. Sci. 2019, 494, 311–327. [Google Scholar] [CrossRef]
- Chu, C.; Ge, Y.; Qian, Q.; Hua, B.; Guo, J. A novel multi-scale convolution model based on multi-dilation rates and multi-attention mechanism for mechanical fault diagnosis. Digit. Signal Process. 2022, 122, 103355. [Google Scholar] [CrossRef]









{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| X | Y | Ag | Au | B | Sn | Cu | Ba | Mn | Pb | Zn | As | Sb | Hg | Mo | W | Bi | F |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 421.63 | 2416.85 | 0.078 | 0.54 | 4 | 2.56 | 7 | 88 | 209 | 12 | 23 | 0.9 | 0.29 | 0.04 | 0.82 | 1.16 | 0.42 | 204 |
| 420.93 | 2416.80 | 0.06 | 0.81 | 3 | 3.74 | 5 | 885 | 305 | 33 | 22 | 0.58 | 0.36 | 0.04 | 0.82 | 1.11 | 1.41 | 222 |
| 420.95 | 2416.35 | 0.086 | 0.94 | 4 | 2.41 | 5 | 797 | 267 | 53 | 35 | 1.15 | 0.34 | 0.09 | 0.51 | 1.16 | 0.42 | 212 |
| 421.21 | 2415.85 | 0.043 | 0.81 | 3 | 1.52 | 5 | 1111 | 423 | 42 | 14 | 0.51 | 0.35 | 0.07 | 0.59 | 0.38 | 0.23 | 222 |
| 420.30 | 2416.35 | 0.046 | 0.37 | 2 | 1.65 | 6 | 941 | 498 | 38 | 17 | 0.53 | 0.31 | 0.02 | 0.57 | 0.33 | 0.61 | 222 |
| 419.86 | 2416.15 | 0.033 | 1.09 | 4 | 1.53 | 8 | 427 | 338 | 37 | 29 | 0.74 | 0.28 | 0.07 | 1.68 | 0.73 | 0.47 | 204 |
| Element | AUC | ZAUC | Element | AUC | ZAUC |
|---|---|---|---|---|---|
| Au | 0.6024 | 2.8395 | B | 0.5901 | 2.4839 |
| Sn | 0.6065 | 2.9595 | Cu | 0.6311 | 3.6977 |
| Ag | 0.6762 | 5.1563 | Ba | 0.6147 | 3.2020 |
| Mn | 0.5573 | 1.5617 | Pb | 0.5778 | 2.1341 |
| Zn | 0.5450 | 1.2232 | As | 0.5655 | 1.7893 |
| Sb | 0.5942 | 2.6017 | Bi | 0.5901 | 2.4839 |
| Hg | 0.6393 | 3.9516 | Mo | 0.5983 | 2.7203 |
| W | 0.5778 | 2.1341 | F | 0.5696 | 1.9037 |
| Methods | Accuracy | AUC | Recall | F1-Score |
|---|---|---|---|---|
| ResNet18 [48] | 64.84 | 63.13 | 32.05 | 59.41 |
| ResNet18* | 72.66 | 73.46 | 42.66 | 63.76 |
| ShuffleNetV2 [49] | 62.37 | 61.43 | 18.43 | 53.98 |
| ShuffleNetV2* | 67.23 | 65.42 | 37.32 | 63.72 |
| GoogLeNet [50] | 62.38 | 61.45 | 20.14 | 56.33 |
| MobileNetV2 [51] | 64.23 | 64.13 | 16.23 | 58.36 |
| MnasNet [52] | 68.79 | 67.23 | 17.69 | 60.86 |
| Methods | Accuracy | AUC | Recall | F1-Score |
|---|---|---|---|---|
| ResNet18* | 72.66 | 73.46 | 42.66 | 63.71 |
| R-CA-ResNet18* | 69.54 | 64.89 | 33.98 | 58.64 |
| ShuffleNetV2* | 67.23 | 65.42 | 37.32 | 63.72 |
| R-CA-ShuffleNetV2* | 63.42 | 63.24 | 35.51 | 60.99 |
| ResNet18* | 72.66 | 73.46 | 42.66 | 63.71 |
| R-SA-ResNet18* | 71.13 | 71.68 | 39.46 | 61.34 |
| ShuffleNetV2* | 67.23 | 65.42 | 37.32 | 63.72 |
| R-SA-ShuffleNetV2* | 64.48 | 63.96 | 35.12 | 62.04 |
| Loss Function | Accuracy | AUC | Recall | F1-Score |
|---|---|---|---|---|
| 0 | 64.84 | 63.13 | 32.05 | 59.41 |
| 0.1 | 71.21 | 70.22 | 39.12 | 60.34 |
| 0.4 | 72.66 | 73.46 | 42.66 | 63.71 |
| 0.6 | 71.45 | 70.32 | 38.49 | 60.19 |
| 0.7 | 68.44 | 65.54 | 37.55 | 58.84 |
| 0.8 | 64.96 | 63.27 | 32.64 | 60.34 |
| Dilation Rate | Accuracy | AUC | Recall | F1-Score |
|---|---|---|---|---|
| rate 1 | 63.45 | 62.02 | 32.79 | 50.43 |
| rate 2 | 67.34 | 66.22 | 38.28 | 61.14 |
| rate 3 | 72.66 | 73.46 | 42.66 | 63.71 |
| rate 4 | 70.22 | 68.86 | 31.46 | 55.65 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Gao, L.; Wang, K.; Zhang, X.; Wang, C. Intelligent Identification and Prediction Mineral Resources Deposit Based on Deep Learning. Sustainability 2023, 15, 10269. https://doi.org/10.3390/su151310269
Gao L, Wang K, Zhang X, Wang C. Intelligent Identification and Prediction Mineral Resources Deposit Based on Deep Learning. Sustainability. 2023; 15(13):10269. https://doi.org/10.3390/su151310269
Chicago/Turabian StyleGao, Le, Kun Wang, Xin Zhang, and Chen Wang. 2023. "Intelligent Identification and Prediction Mineral Resources Deposit Based on Deep Learning" Sustainability 15, no. 13: 10269. https://doi.org/10.3390/su151310269
APA StyleGao, L., Wang, K., Zhang, X., & Wang, C. (2023). Intelligent Identification and Prediction Mineral Resources Deposit Based on Deep Learning. Sustainability, 15(13), 10269. https://doi.org/10.3390/su151310269