


An Efficient Approach to Monocular Depth Estimation for Autonomous Vehicle Perception Systems

 ,
,
Abstract
1. Introduction
2. Materials and Methods
2.1. Deep-Learning-Based Object Detection Approaches
2.2. YOLOv7
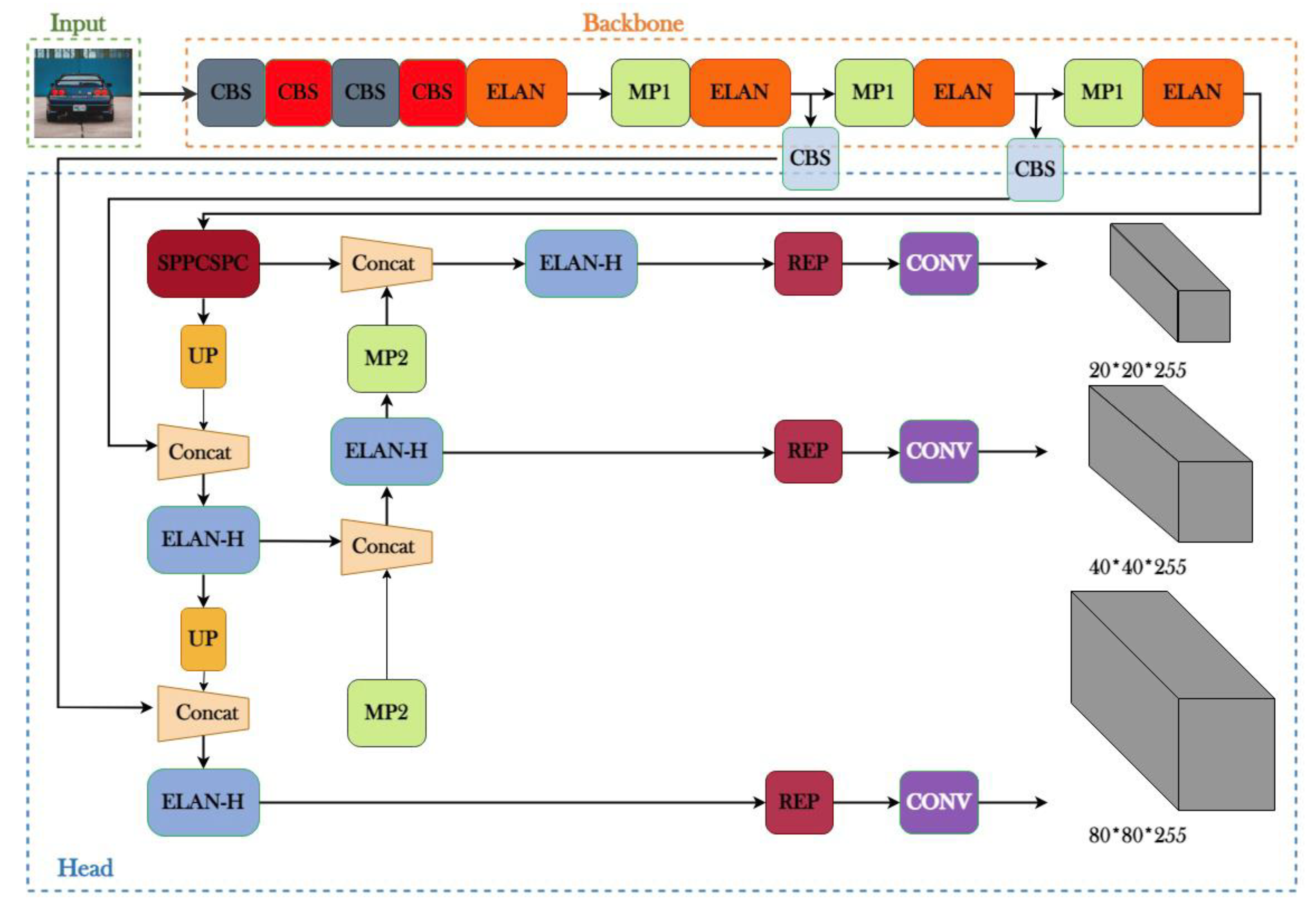
2.2.1. The YOLOv7 Architecture
2.2.2. Scaling of the YOLOv7 Compound Model
2.2.3. Re-Parametrized Convolution
2.2.4. Auxiliary Coarse, Lead Loss Fine
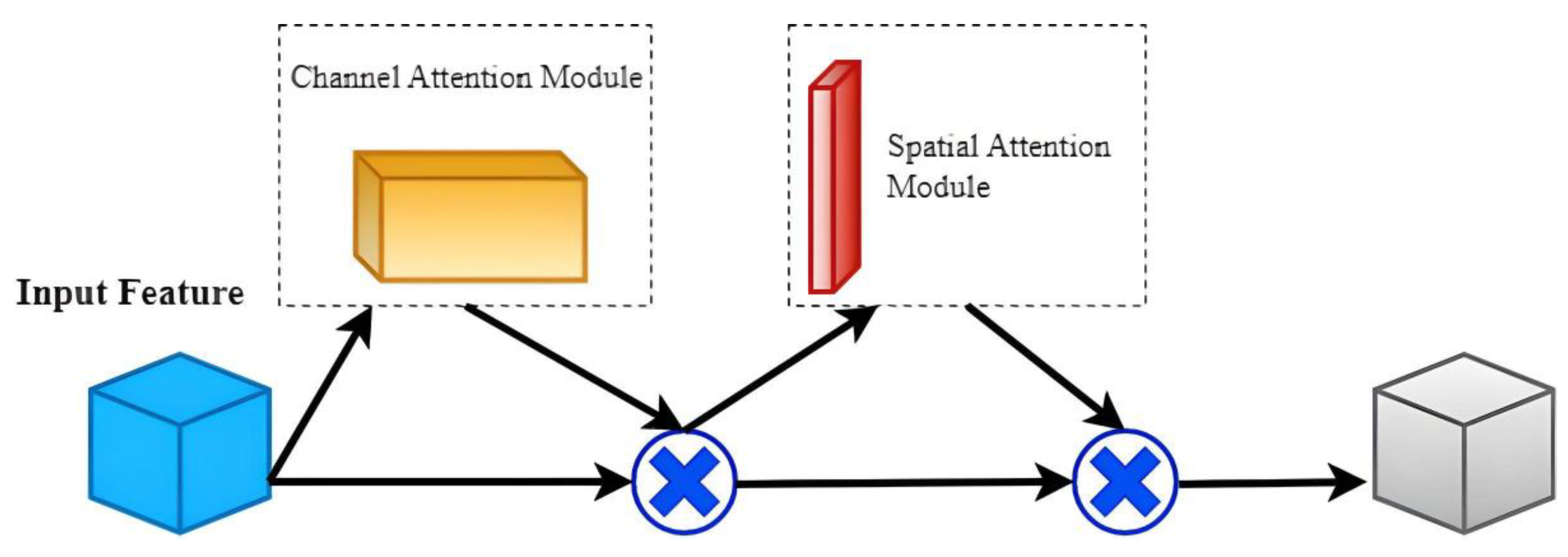
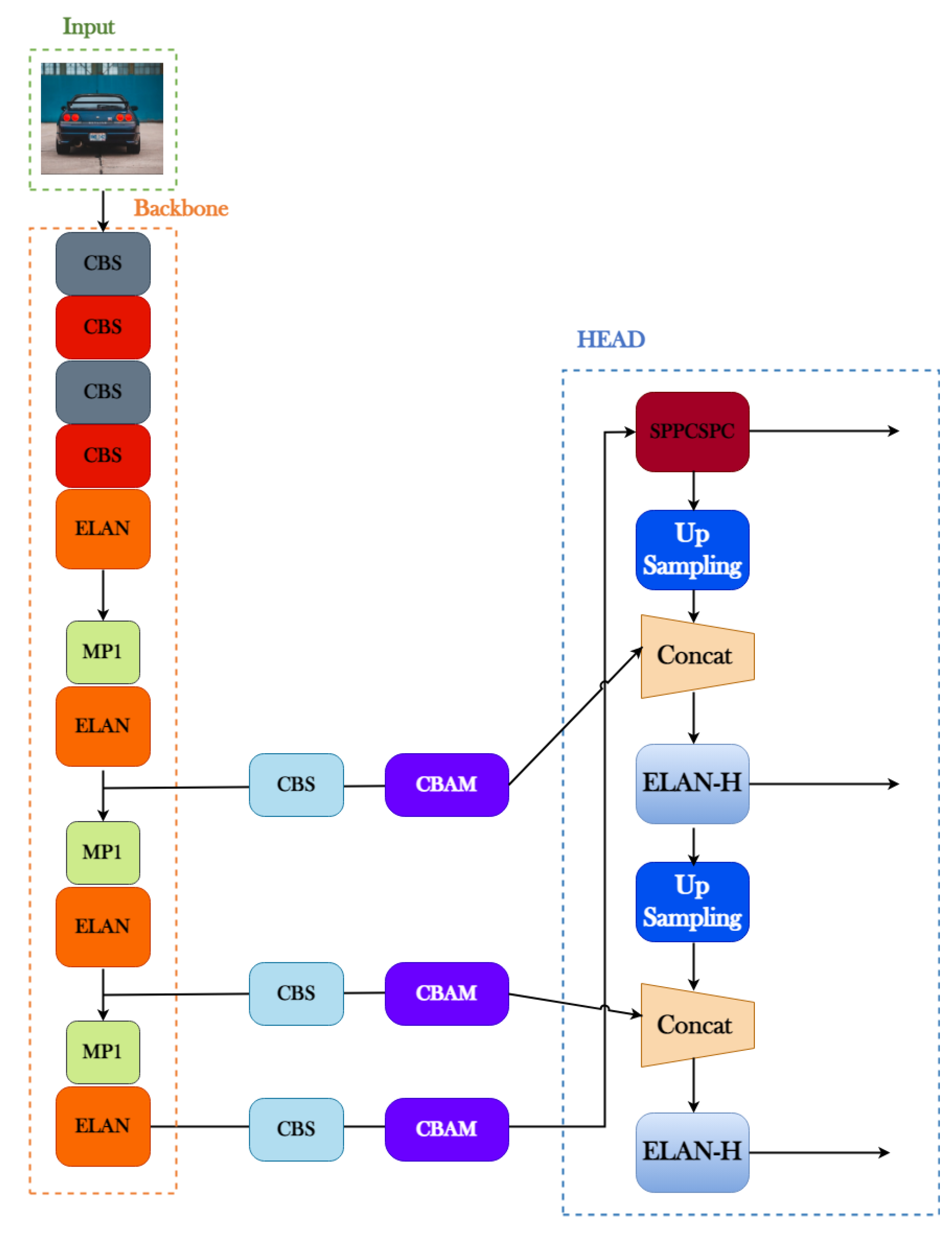
2.3. Integrating Attention Mechanism for Enhanced YOLOv7 Object Detection
2.4. CARLA
2.5. Preparation of Dataset
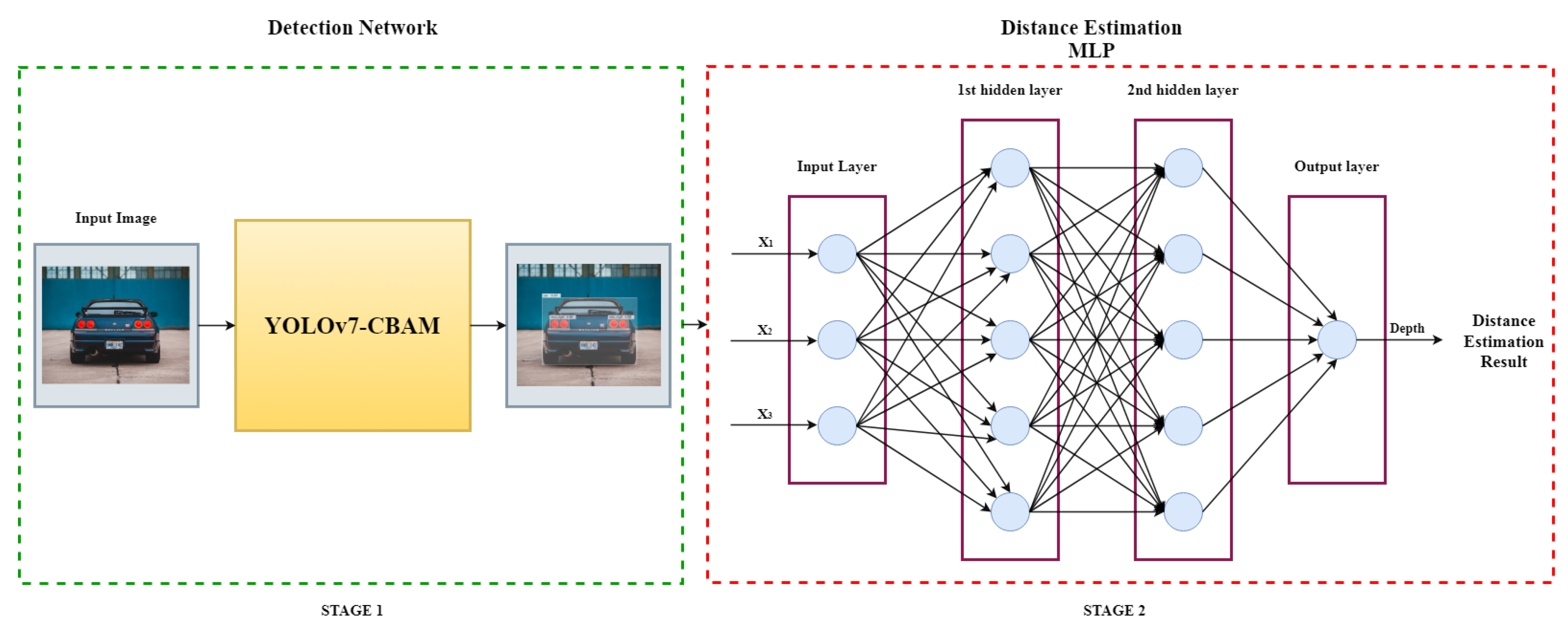
2.6. Intended Model
- Stage1: Detecting and recognizing the vehicle and its lights in the image.
- Stage2: The second part of the proposed approach to estimating vehicle depth, as shown in Figure 4, used MLP to map the information from the detection and recognition network to the estimated depth value.
- We captured and stored simulator scenes’ images. For each scene, we also extracted a text file that contains the car name, longitudinal and lateral distance to the car, and the longitudinal and lateral speed of the car relative to the camera.
- To generate a video of a car’s motion and the corresponding target data for the distance to the preceding car in each scene, the simulator scenes were first connected, and then the text files were merged.
- To measure the width of a car, the distance between the centers of its lights is used. As the distance increases, the width of the car appears smaller.
- The car’s angle relative to the center line of the image is indicated by the distance between the line connecting the lights and the center of the detection bounding box. This parameter was previously discussed in [28] as a crucial factor in determining the car’s distance from the center of the image in both width and length dimensions.
- The height of the car’s detection bonding box is a parameter that indicates the car’s height. It is important to note that the height, like the width, appears greater at closer distances and smaller at greater distances.
| Algorithm 1: Define Pre-Requirements |
: Residual function : Cost function (Least square) : Gradient function Initializer: Training while ( if ( Update parameters else go to next step |
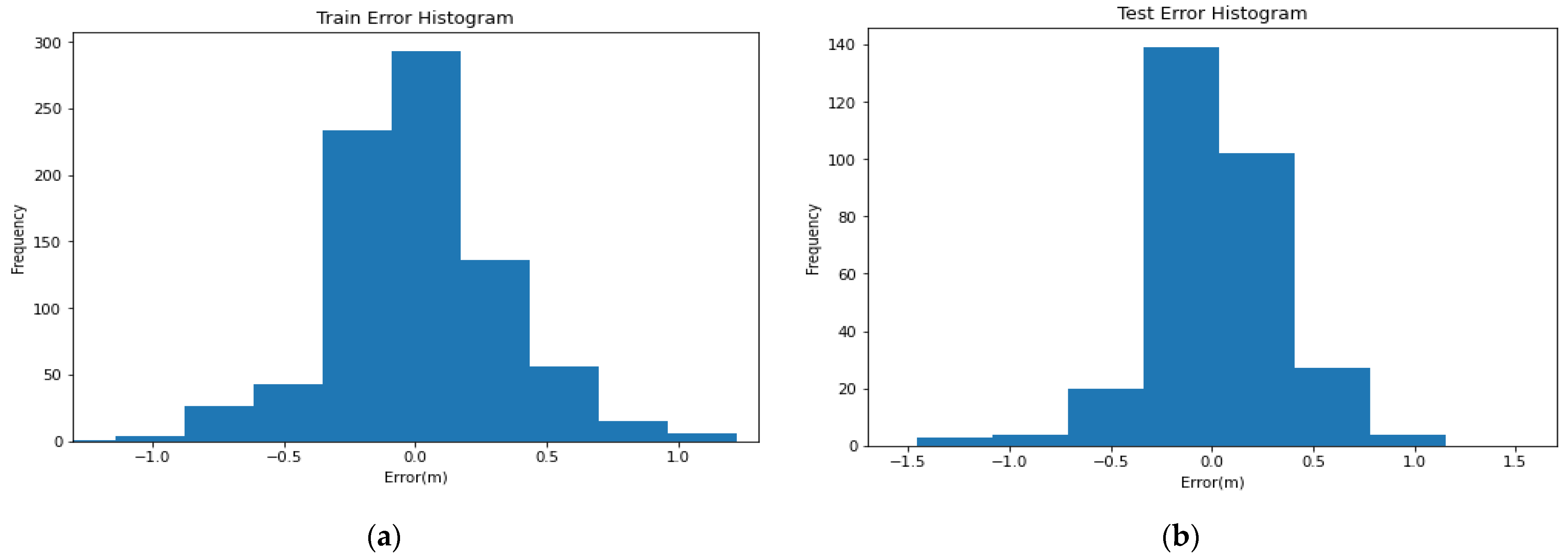
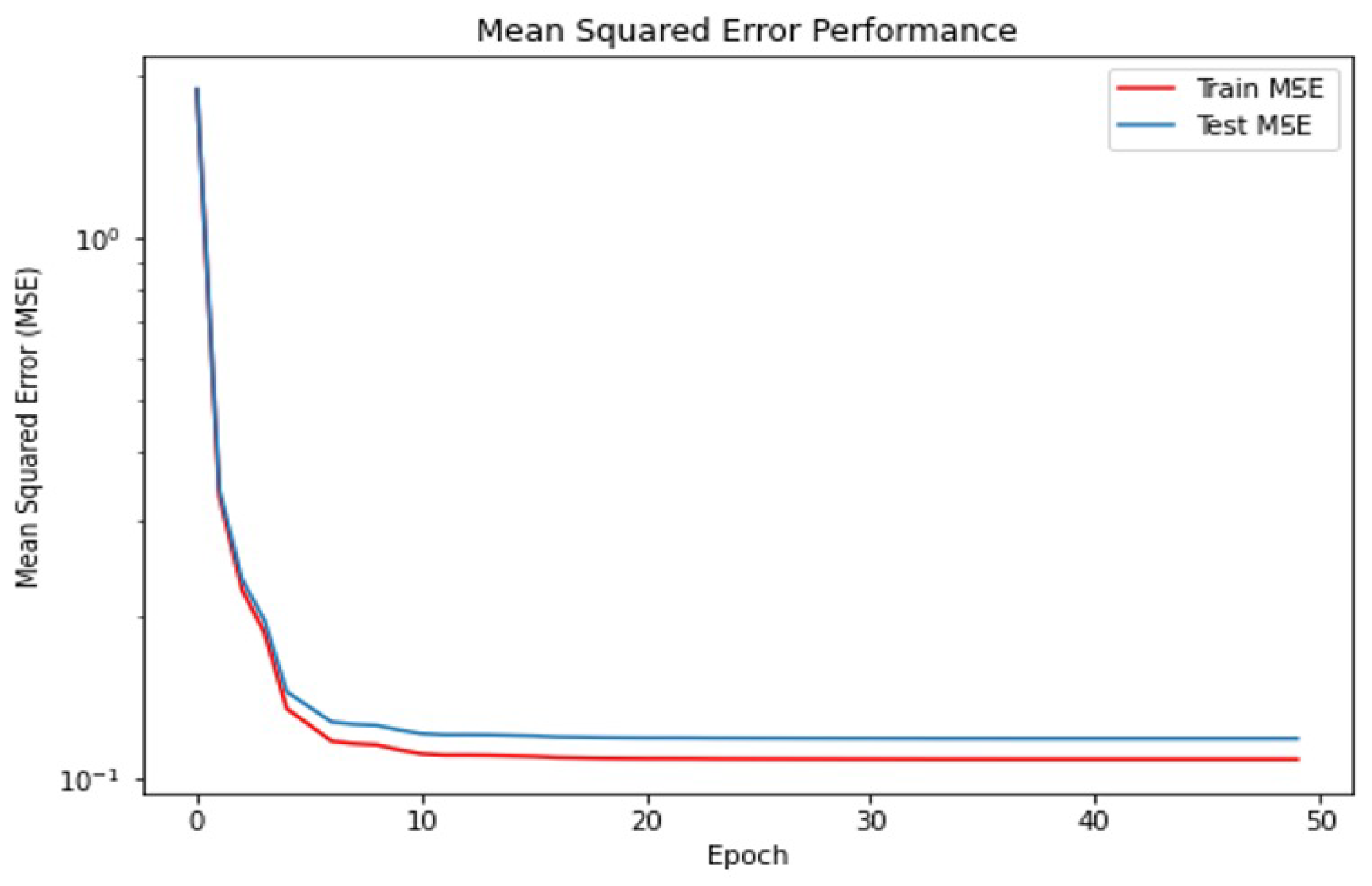
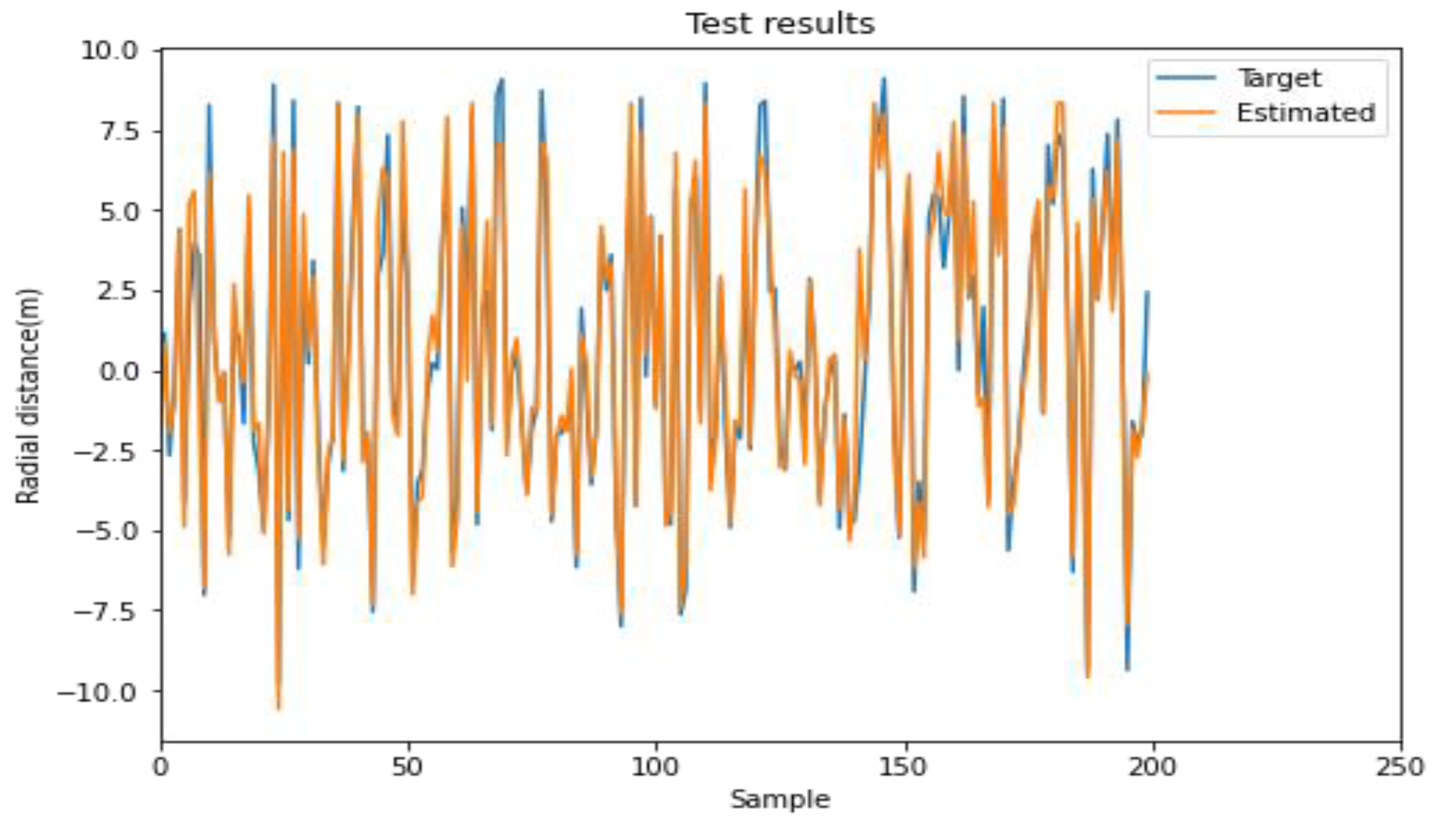
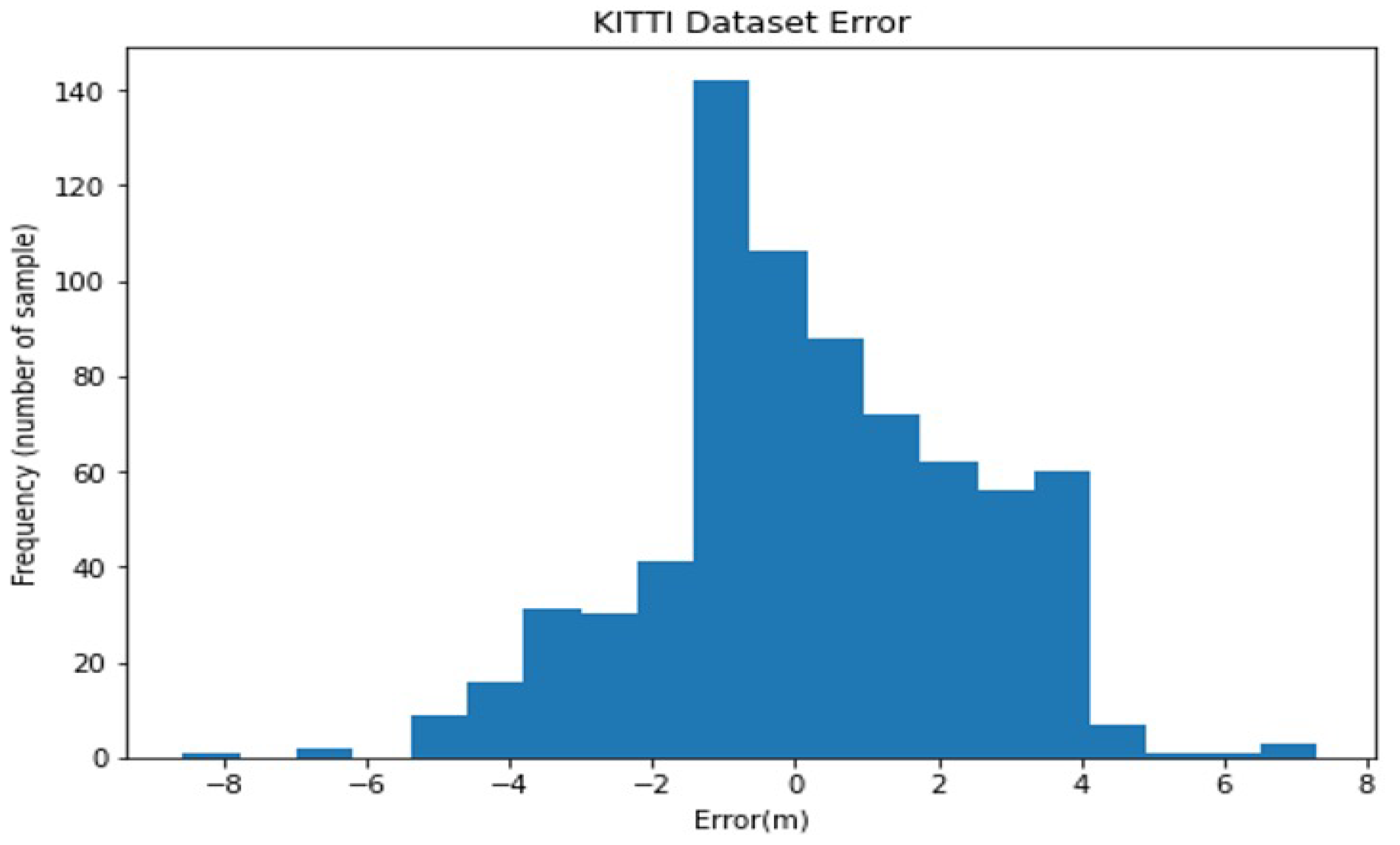
3. Results and Discussion
Evaluation Criteria
4. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- Sreenivas, K.; Kamakshiprasad, V. Improved image tamper localisation using chaotic maps and self-recovery. J. Vis. Commun. Image Represent. 2017, 49, 164–176. [Google Scholar] [CrossRef]
- Singh, S. Critical Reasons for Crashes Investigated in the National Motor Vehicle Crash Causation Survey; National Highway Traffic Safety Administration: Washington, DC, USA, 2015.
- Mrovlje, J.; Vrancic, D. Distance measuring based on stereoscopic pictures. In Proceedings of the 9th International PhD Workshop on Systems and Control: Young Generation Viewpoint, Izola, Slovenia, 1–3 October 2008; pp. 1–6. [Google Scholar]
- Oberhammer, J.; Somjit, N.; Shah, U.; Baghchehsaraei, Z. RF MEMS for automotive radar. In Handbook of MEMS for Wireless and Mobile Applications; Elsevier: Amsterdam, The Netherlands, 2013; pp. 518–549. [Google Scholar]
- Ali, A.; Hassan, A.; Ali, A.R.; Khan, H.U.; Kazmi, W.; Zaheer, A. Real-time vehicle distance estimation using single view geometry. In Proceedings of the IEEE/CVF Winter Conference on Applications of Computer Vision, Snowmass, CO, USA, 1–5 March 2020; pp. 1111–1120. [Google Scholar]
- Khader, M.; Cherian, S. An Introduction to Automotive LIDAR; Texas Instruments: Dallas, TX, USA, 2020. [Google Scholar]
- Ding, M.; Zhang, Z.; Jiang, X.; Cao, Y. Vision-based distance measurement in advanced driving assistance systems. Appl. Sci. 2020, 10, 7276. [Google Scholar] [CrossRef]
- Raj, T.; Hanim Hashim, F.; Baseri Huddin, A.; Ibrahim, M.F.; Hussain, A. A survey on LiDAR scanning mechanisms. Electronics 2020, 9, 741. [Google Scholar] [CrossRef]
- Lim, Y.-C.; Lee, C.-H.; Kwon, S.; Jung, W.-Y. Distance estimation algorithm for both long and short ranges based on stereo vision system. In Proceedings of the 2008 IEEE Intelligent Vehicles Symposium, Eindhoven, The Netherlands, 4–6 June 2008; pp. 841–846. [Google Scholar]
- Liu, L.-C.; Fang, C.-Y.; Chen, S.-W. A novel distance estimation method leading a forward collision avoidance assist system for vehicles on highways. IEEE Trans. Intell. Transp. Syst. 2016, 18, 937–949. [Google Scholar] [CrossRef]
- Häne, C.; Sattler, T.; Pollefeys, M. Obstacle detection for self-driving cars using only monocular cameras and wheel odometry. In Proceedings of the 2015 IEEE/RSJ International Conference on Intelligent Robots and Systems (IROS), Hamburg, Germany, 28 September–2 October 2015; pp. 5101–5108. [Google Scholar]
- Zhang, K.; Xie, J.; Snavely, N.; Chen, Q. Depth sensing beyond LIDAR range. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Seattle, WA, USA, 13–19 June 2020; pp. 1692–1700. [Google Scholar]
- Schastein, D.; Szeliski, R. A taxonomy and evaluation of dense two-frame stereo correspondence algorithm. Int. J. Comput. Vis. 2002, 47, 7–42. [Google Scholar] [CrossRef]
- Liang, H.; Ma, Z.; Zhang, Q. Self-supervised object distance estimation using a monocular camera. Sensors 2022, 22, 2936. [Google Scholar] [CrossRef]
- Tram, V.T.B.; Yoo, M. Vehicle-to-vehicle distance estimation using a low-resolution camera based on visible light communications. IEEE Access 2018, 6, 4521–4527. [Google Scholar] [CrossRef]
- Kim, G.; Cho, J.-S. Vision-based vehicle detection and inter-vehicle distance estimation. In Proceedings of the 2012 12th International Conference on Control, Automation and Systems, Jeju, Republic of Korea, 17–21 October 2012; pp. 625–629. [Google Scholar]
- Alhashim, I.; Wonka, P. High quality monocular depth estimation via transfer learning. arXiv 2018, arXiv:1812.11941. [Google Scholar]
- Hu, H.-N.; Cai, Q.-Z.; Wang, D.; Lin, J.; Sun, M.; Krahenbuhl, P.; Darrell, T.; Yu, F. Joint monocular 3D vehicle detection and tracking. In Proceedings of the IEEE/CVF International Conference on Computer Vision, Seoul, Republic of Korea, 27 October–2 November 2019; pp. 5390–5399. [Google Scholar]
- Weng, X.; Wang, J.; Held, D.; Kitani, K. 3d multi-object tracking: A baseline and new evaluation metrics. In Proceedings of the 2020 IEEE/RSJ International Conference on Intelligent Robots and Systems (IROS), Las Vegas, NV, USA, 24 October 2020–24 January 2021; pp. 10359–10366. [Google Scholar]
- Wei, X.; Xiao, C. MVAD: Monocular vision-based autonomous driving distance perception system. In Proceedings of the Third International Conference on Computer Vision and Data Mining (ICCVDM 2022), Hulun Buir, China, 19–21 August 2022; pp. 258–263. [Google Scholar]
- Tighkhorshid, A.; Tousi, S.M.A.; Nikoofard, A. Car depth estimation within a monocular image using a light CNN. J. Supercomput. 2023, 1–18. [Google Scholar] [CrossRef]
- Natanael, G.; Zet, C.; Foşalău, C. Estimating the distance to an object based on image processing. In Proceedings of the 2018 International Conference and Exposition on Electrical And Power Engineering (EPE), Iasi, Romania, 18–19 October 2018; pp. 211–216. [Google Scholar]
- Haseeb, M.A.; Ristić-Durrant, D.; Gräser, A. Long-range obstacle detection from a monocular camera. In Proceedings of the ACM Computer Science in Cars Symposium (CSCS), Munich, Germany, 13–14 September 2018; p. 3. [Google Scholar]
- Chen, Z.; Khemmar, R.; Decoux, B.; Atahouet, A.; Ertaud, J.-Y. Real time object detection, tracking, and distance and motion estimation based on deep learning: Application to smart mobility. In Proceedings of the 2019 Eighth International Conference on Emerging Security Technologies (EST), Colchester, UK, 22–24 July 2019; pp. 1–6. [Google Scholar]
- Godard, C.; Mac Aodha, O.; Brostow, G.J. Unsupervised monocular depth estimation with left-right consistency. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Honolulu, HI, USA, 21–26 July 2017; pp. 270–279. [Google Scholar]
- Strbac, B.; Gostovic, M.; Lukac, Z.; Samardzija, D. YOLO multi-camera object detection and distance estimation. In Proceedings of the 2020 Zooming Innovation in Consumer Technologies Conference (ZINC), Novi Sad, Serbia, 26–27 May 2020; pp. 26–30. [Google Scholar]
- Zhe, T.; Huang, L.; Wu, Q.; Zhang, J.; Pei, C.; Li, L. Inter-vehicle distance estimation method based on monocular vision using 3D detection. IEEE Trans. Veh. Technol. 2020, 69, 4907–4919. [Google Scholar] [CrossRef]
- Tousi, S.M.A.; Khorramdel, J.; Lotfi, F.; Nikoofard, A.H.; Ardekani, A.N.; Taghirad, H.D. A New Approach To Estimate Depth of Cars Using a Monocular Image. In Proceedings of the 2020 8th Iranian Joint Congress on Fuzzy and Intelligent Systems (CFIS), Mashhad, Iran, 2–4 September 2020; pp. 045–050. [Google Scholar]
- Redmon, J.; Divvala, S.; Girshick, R.; Farhadi, A. You only look once: Unified, real-time object detection. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 27–30 June 2016; pp. 779–788. [Google Scholar]
- Wang, C.-Y.; Bochkovskiy, A.; Liao, H.-Y.M. YOLOv7: Trainable bag-of-freebies sets new state-of-the-art for real-time object detectors. arXiv 2022, arXiv:2207.02696. [Google Scholar]
- Müller, J.; Dietmayer, K. Detecting traffic lights by single shot detection. In Proceedings of the 2018 21st International Conference on Intelligent Transportation Systems (ITSC), Maui, HI, USA, 4–7 November 2018; pp. 266–273. [Google Scholar]
- Weber, M.; Wolf, P.; Zöllner, J.M. DeepTLR: A single deep convolutional network for detection and classification of traffic lights. In Proceedings of the 2016 IEEE Intelligent Vehicles Symposium (IV), Gothenburg, Sweden, 19–22 June 2016; pp. 342–348. [Google Scholar]
- Behrendt, K.; Novak, L.; Botros, R. A deep learning approach to traffic lights: Detection, tracking, and classification. In Proceedings of the 2017 IEEE International Conference on Robotics and Automation (ICRA), Singapore, 29 May–3 June 2017; pp. 1370–1377. [Google Scholar]
- Lee, H.S.; Kim, K. Simultaneous traffic sign detection and boundary estimation using convolutional neural network. IEEE Trans. Intell. Transp. Syst. 2018, 19, 1652–1663. [Google Scholar] [CrossRef]
- Luo, H.; Yang, Y.; Tong, B.; Wu, F.; Fan, B. Traffic sign recognition using a multi-task convolutional neural network. IEEE Trans. Intell. Transp. Syst. 2017, 19, 1100–1111. [Google Scholar] [CrossRef]
- Zhang, S.; Benenson, R.; Omran, M.; Hosang, J.; Schiele, B. Towards reaching human performance in pedestrian detection. IEEE Trans. Pattern Anal. Mach. Intell. 2017, 40, 973–986. [Google Scholar] [CrossRef]
- Zhang, L.; Lin, L.; Liang, X.; He, K. Is faster R-CNN doing well for pedestrian detection? In Proceedings of the Computer Vision–ECCV 2016: 14th European Conference, Amsterdam, The Netherlands, 11–14 October 2016; Part II 14. pp. 443–457. [Google Scholar]
- Li, B. 3d fully convolutional network for vehicle detection in point cloud. In Proceedings of the 2017 IEEE/RSJ International Conference on Intelligent Robots and Systems (IROS), Vancouver, BC, Canada, 24–28 September 2017; pp. 1513–1518. [Google Scholar]
- Li, B.; Zhang, T.; Xia, T. Vehicle detection from 3d lidar using fully convolutional network. arXiv 2016, arXiv:1608.07916. [Google Scholar]
- Fang, J.; Zhou, Y.; Yu, Y.; Du, S. Fine-grained vehicle model recognition using a coarse-to-fine convolutional neural network architecture. IEEE Trans. Intell. Transp. Syst. 2016, 18, 1782–1792. [Google Scholar] [CrossRef]
- Sermanet, P.; Eigen, D.; Zhang, X.; Mathieu, M.; Fergus, R.; LeCun, Y. Overfeat: Integrated recognition, localization and detection using convolutional networks. arXiv 2013, arXiv:1312.6229. [Google Scholar]
- Girshick, R.; Donahue, J.; Darrell, T.; Malik, J. Rich feature hierarchies for accurate object detection and semantic segmentation. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Columbus, OH, USA, 23–28 June 2014; pp. 580–587. [Google Scholar]
- He, K.; Zhang, X.; Ren, S.; Sun, J. Spatial pyramid pooling in deep convolutional networks for visual recognition. IEEE Trans. Pattern Anal. Mach. Intell. 2015, 37, 1904–1916. [Google Scholar] [CrossRef]
- Girshick, R. Fast r-cnn. In Proceedings of the IEEE International Conference on Computer Vision, Santiago, Chile, 7–13 December 2015; pp. 1440–1448. [Google Scholar]
- Simonyan, K.; Zisserman, A. Very deep convolutional networks for large-scale image recognition. arXiv 2014, arXiv:1409.1556. [Google Scholar]
- He, K.; Zhang, X.; Ren, S.; Sun, J. Deep residual learning for image recognition. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 27–30 June 2016; pp. 770–778. [Google Scholar]
- Szegedy, C.; Liu, W.; Jia, Y.; Sermanet, P.; Reed, S.; Anguelov, D.; Erhan, D.; Vanhoucke, V.; Rabinovich, A. Going deeper with convolutions. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Boston, MA, USA, 7–12 June 2015; pp. 1–9. [Google Scholar]
- Ren, S.; He, K.; Girshick, R.; Sun, J. Faster r-cnn: Towards real-time object detection with region proposal networks. Adv. Neural Inf. Process. Syst. 2015, 28. Available online: https://proceedings.neurips.cc/paper/2015/hash/14bfa6bb14875e45bba028a21ed38046-Abstract.html (accessed on 20 October 2022). [CrossRef]
- Bochkovskiy, A.; Wang, C.-Y.; Liao, H.-Y.M. Yolov4: Optimal speed and accuracy of object detection. arXiv 2020, arXiv:2004.10934. [Google Scholar]
- Zhu, X.; Lyu, S.; Wang, X.; Zhao, Q. TPH-YOLOv5: Improved YOLOv5 based on transformer prediction head for object detection on drone-captured scenarios. In Proceedings of the IEEE/CVF International Conference on Computer Vision, Montreal, BC, Canada, 11–17 October 2021; pp. 2778–2788. [Google Scholar]
- Wang, C.-Y.; Yeh, I.-H.; Liao, H.-Y.M. You only learn one representation: Unified network for multiple tasks. arXiv 2021, arXiv:2105.04206. [Google Scholar]
- Niu, Z.; Zhong, G.; Yu, H. A review on the attention mechanism of deep learning. Neurocomputing 2021, 452, 48–62. [Google Scholar] [CrossRef]
- Woo, S.; Park, J.; Lee, J.-Y.; Kweon, I.S. Cbam: Convolutional block attention module. In Proceedings of the European Conference on Computer Vision (ECCV), Munich, Germany, 8–14 September 2018; pp. 3–19. [Google Scholar]
- Muhammad, M.B.; Yeasin, M. Eigen-cam: Class activation map using principal components. In Proceedings of the 2020 International Joint Conference on Neural Networks (IJCNN), Glasgow, UK, 19–24 July 2020; pp. 1–7. [Google Scholar]
- Ying, X.; Wang, Y.; Wang, L.; Sheng, W.; An, W.; Guo, Y. A stereo attention module for stereo image super-resolution. IEEE Signal Process. Lett. 2020, 27, 496–500. [Google Scholar] [CrossRef]
- Jiang, K.; Xie, T.; Yan, R.; Wen, X.; Li, D.; Jiang, H.; Jiang, N.; Feng, L.; Duan, X.; Wang, J. An Attention Mechanism-Improved YOLOv7 Object Detection Algorithm for Hemp Duck Count Estimation. Agriculture 2022, 12, 1659. [Google Scholar] [CrossRef]
- Dosovitskiy, A.; Ros, G.; Codevilla, F.; Lopez, A.; Koltun, V. CARLA: An open urban driving simulator. In Proceedings of the Conference on Robot Learning, Mountain View, CA, USA, 13–15 November 2017; pp. 1–16. [Google Scholar]
- Lin, T.-Y.; Maire, M.; Belongie, S.; Hays, J.; Perona, P.; Ramanan, D.; Dollár, P.; Zitnick, C.L. Microsoft coco: Common objects in context. In Proceedings of the Computer Vision—ECCV 2014: 13th European Conference, Zurich, Switzerland, 6–12 September 2014; Part V 13. pp. 740–755. [Google Scholar]
- Domini, F.; Caudek, C. 3-D structure perceived from dynamic information: A new theory. Trends Cogn. Sci. 2003, 7, 444–449. [Google Scholar] [CrossRef]
- Reddy, N.D.; Vo, M.; Narasimhan, S.G. Carfusion: Combining point tracking and part detection for dynamic 3d reconstruction of vehicles. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–23 June 2018; pp. 1906–1915. [Google Scholar]
- Vajgl, M.; Hurtik, P.; Nejezchleba, T. Dist-YOLO: Fast Object Detection with Distance Estimation. Appl. Sci. 2022, 12, 1354. [Google Scholar] [CrossRef]
- Geiger, A.; Lenz, P.; Urtasun, R. Are we ready for autonomous driving? The KITTI vision benchmark suite. In Proceedings of the 2012 IEEE Conference on Computer Vision and Pattern Recognition, Providence, RI, USA, 16–21 June 2012; pp. 3354–3361. [Google Scholar]
- Zhu, J.; Fang, Y. Learning object-specific distance from a monocular image. In Proceedings of the IEEE/CVF International Conference on Computer Vision, Seoul, Republic of Korea, 27 October–2 November 2019; pp. 3839–3848. [Google Scholar]
- Fu, H.; Gong, M.; Wang, C.; Batmanghelich, K.; Tao, D. Deep ordinal regression network for monocular depth estimation. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–23 June 2018; pp. 2002–2011. [Google Scholar]
- Mauri, A.; Khemmar, R.; Decoux, B.; Haddad, M.; Boutteau, R. Real-time 3D multi-object detection and localization based on deep learning for road and railway smart mobility. J. Imaging 2021, 7, 145. [Google Scholar] [CrossRef]
















{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Method | Training Loss | Precision (P) | Recall (R) | mAP@0.5:0.95 | mAP@0.5 | F1 | FPS |
|---|---|---|---|---|---|---|---|
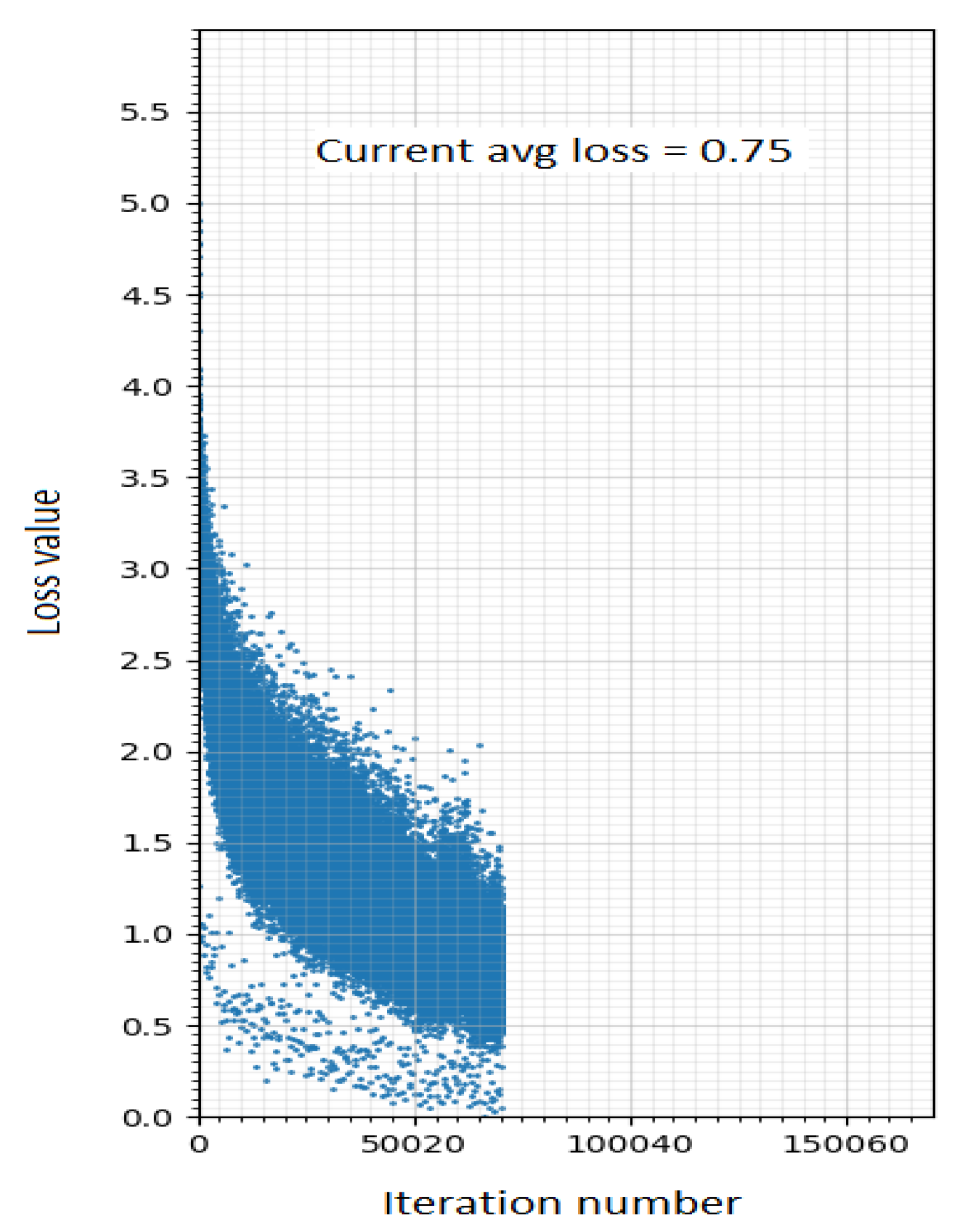
| YOLOv7 | 0.75 | 0.7674 | 0.667 | 0.375 | 0.681 | 0.71 | 65 |
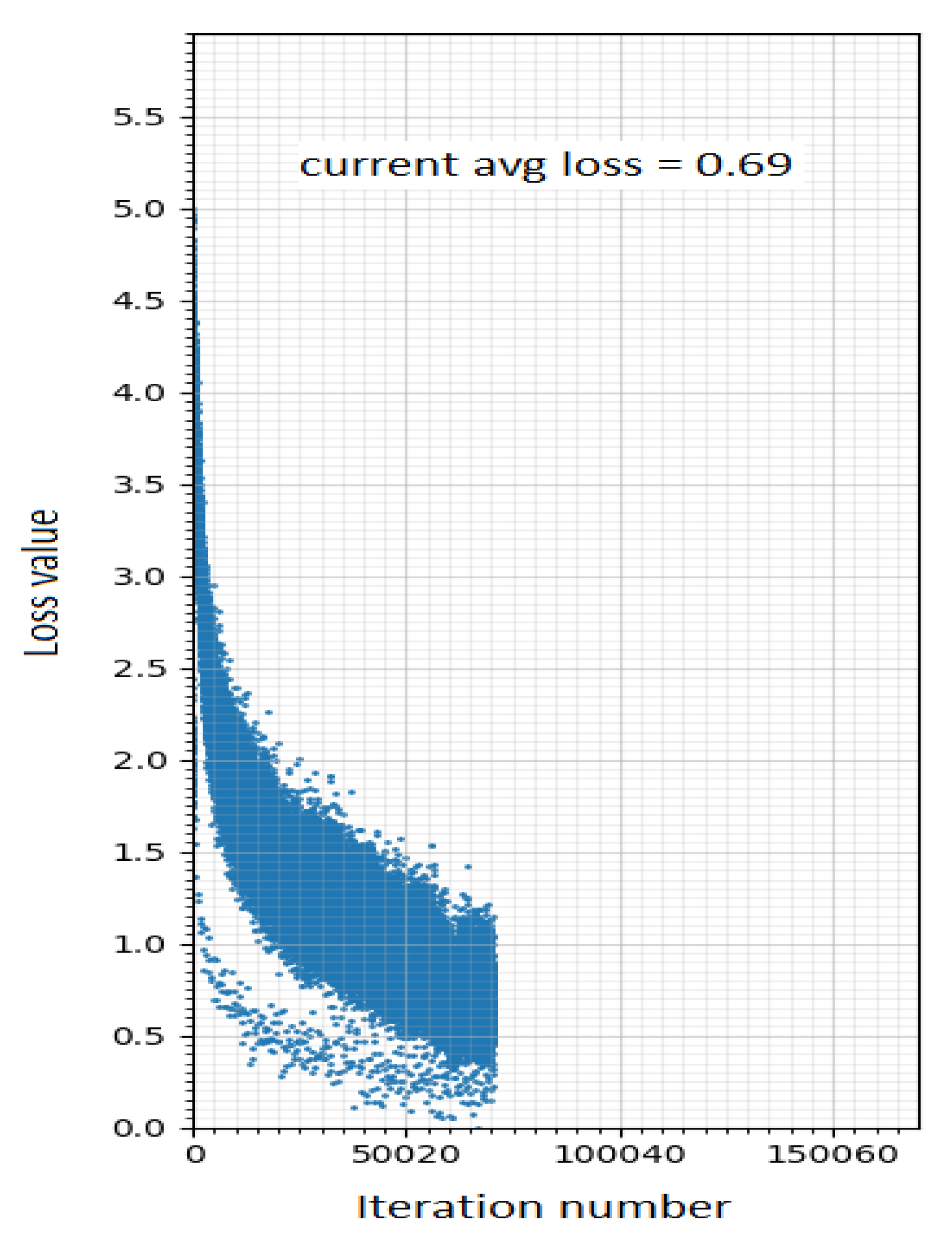
| YOLOv7-CBAM | 0.69 | 0.8056 | 0.6704 | 0.3824 | 0.7096 | 0.73 | 61 |
| Method | Min | Mean | Max | εA | εR |
|---|---|---|---|---|---|
| Dist-YOLO [61] | −24.87 | −0.81 | 14.47 | 2.49 | 0.11 |
| Our method | −8.5 | 0.22 | 7.3 | 1.7 | 0.17 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Afshar, M.F.; Shirmohammadi, Z.; Ghahramani, S.A.A.G.; Noorparvar, A.; Hemmatyar, A.M.A. An Efficient Approach to Monocular Depth Estimation for Autonomous Vehicle Perception Systems. Sustainability 2023, 15, 8897. https://doi.org/10.3390/su15118897
Afshar MF, Shirmohammadi Z, Ghahramani SAAG, Noorparvar A, Hemmatyar AMA. An Efficient Approach to Monocular Depth Estimation for Autonomous Vehicle Perception Systems. Sustainability. 2023; 15(11):8897. https://doi.org/10.3390/su15118897
Chicago/Turabian StyleAfshar, Mehrnaz Farokhnejad, Zahra Shirmohammadi, Seyyed Amir Ali Ghafourian Ghahramani, Azadeh Noorparvar, and Ali Mohammad Afshin Hemmatyar. 2023. "An Efficient Approach to Monocular Depth Estimation for Autonomous Vehicle Perception Systems" Sustainability 15, no. 11: 8897. https://doi.org/10.3390/su15118897
APA StyleAfshar, M. F., Shirmohammadi, Z., Ghahramani, S. A. A. G., Noorparvar, A., & Hemmatyar, A. M. A. (2023). An Efficient Approach to Monocular Depth Estimation for Autonomous Vehicle Perception Systems. Sustainability, 15(11), 8897. https://doi.org/10.3390/su15118897