
Uncovering Equity and Travelers’ Behavior on the Expressway: A Case Study of Shandong, China


Abstract
1. Introduction
2. Methods
2.1. Expressway Equity
- (1)
- Lorenz curve and Gini coefficient
- (2)
- Flow disequilibrium factor (FDF)
2.2. Features of Expressway Users
- (1)
- Number of trips (NT)
- (2)
- Unique number of trips (UNT)
- (3)
- Car type (CT)
- (4)
- Mean distance (MD)
- (5)
- Total pay fee (TPF)
- (6)
- Total discount pay fee (TDPF)
- (7)
- Travel time (TT)
- (8)
- Travel ratio (TR)
- (9)
- Maximum number of trips (MNT)
- (10)
- Maximum distance of maximum trips (MDMT)
- (11)
- Enter hour of maximum trips (EMT)
- (12)
- Number of maximum enter hour trips (NMET)
2.3. Kmeans Clustering Algorithm
2.4. Network-Based Measures
- (1)
- Node degree
- (2)
- Node strength
- (3)
- Betweenness
- (4)
- Clustering coefficient (CC)
- (5)
- Degree correlation
- (6)
- Community structure
3. Data Description
4. Results
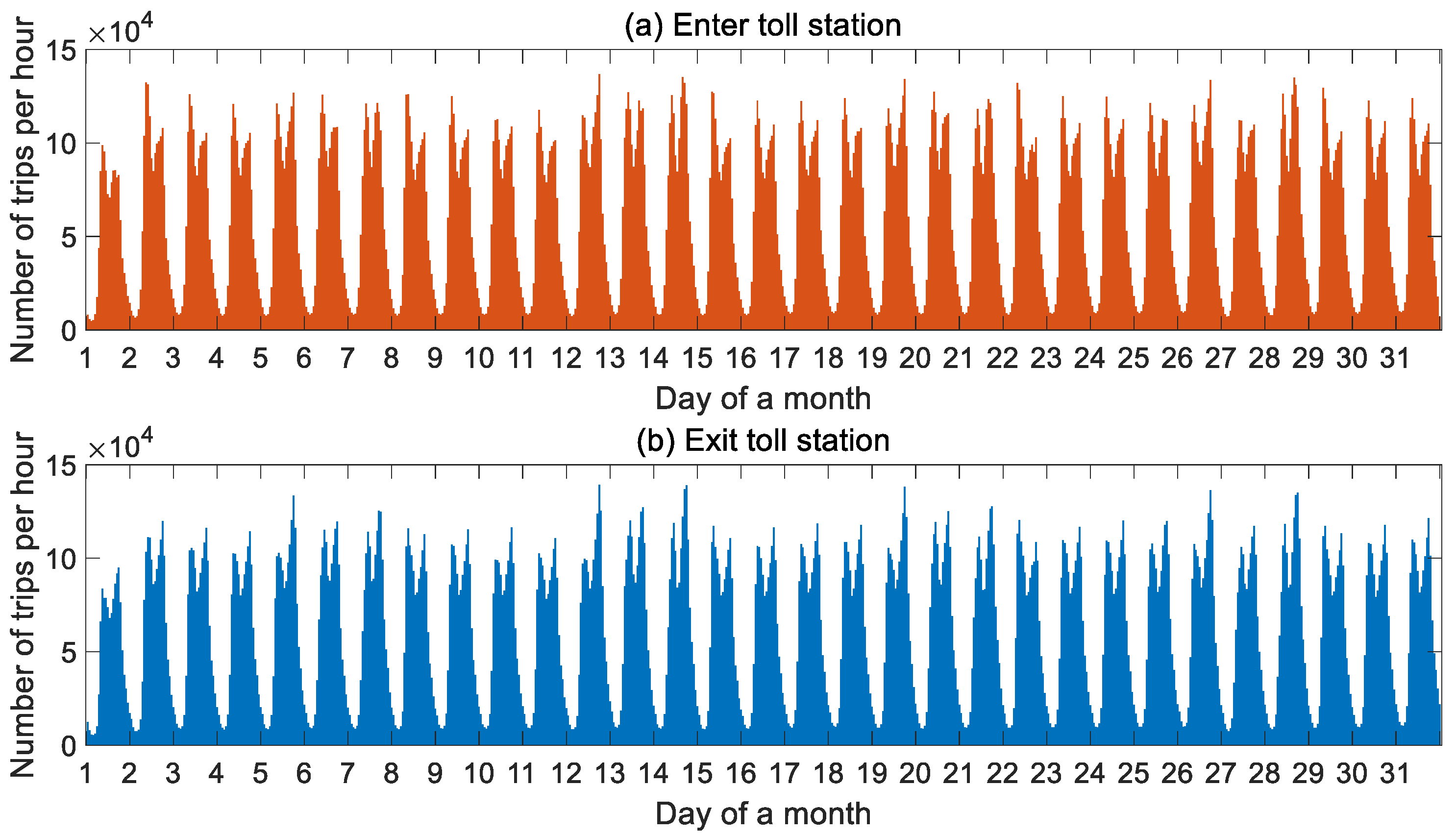
4.1. Temporal Characteristics of Expressway Users
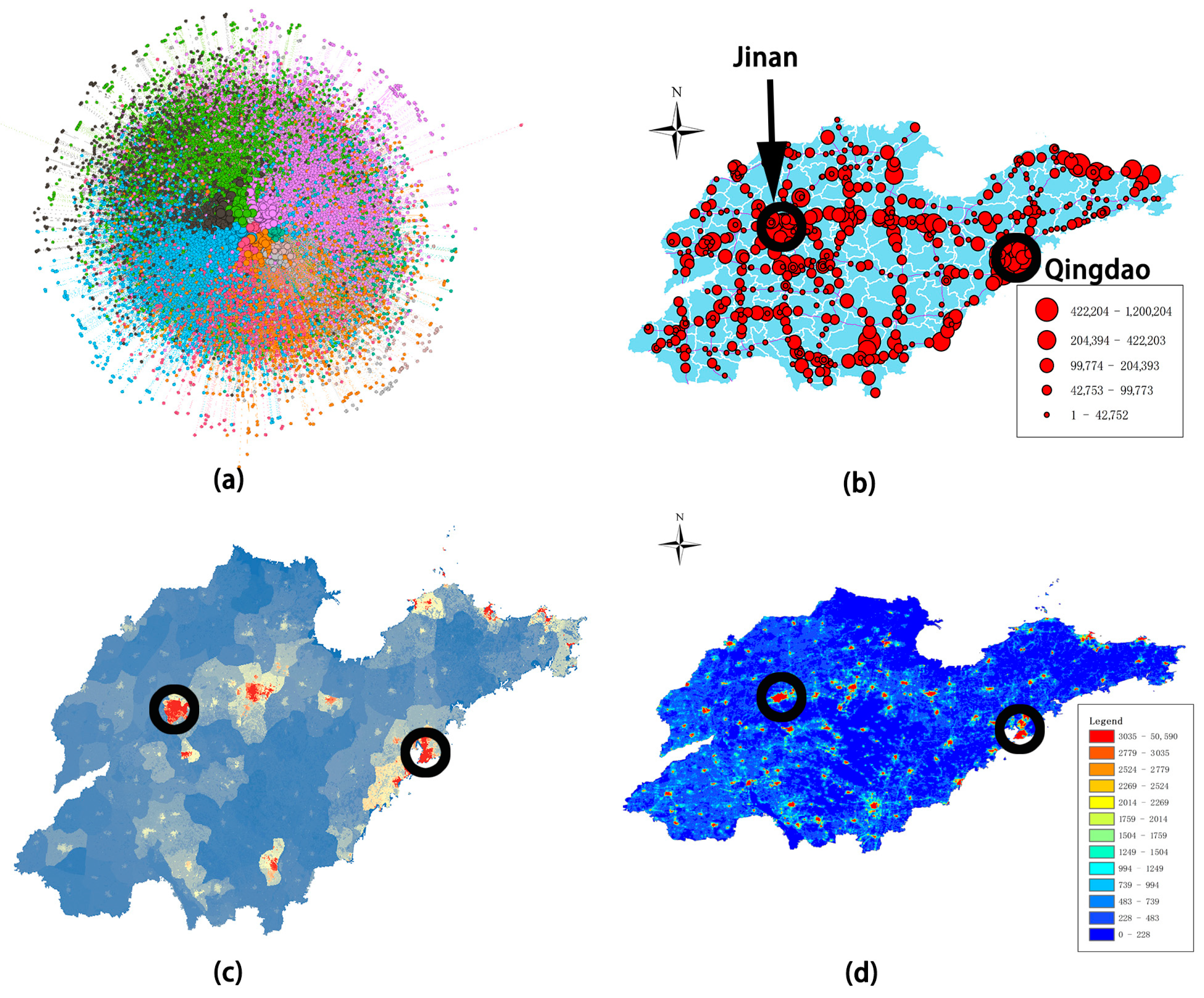
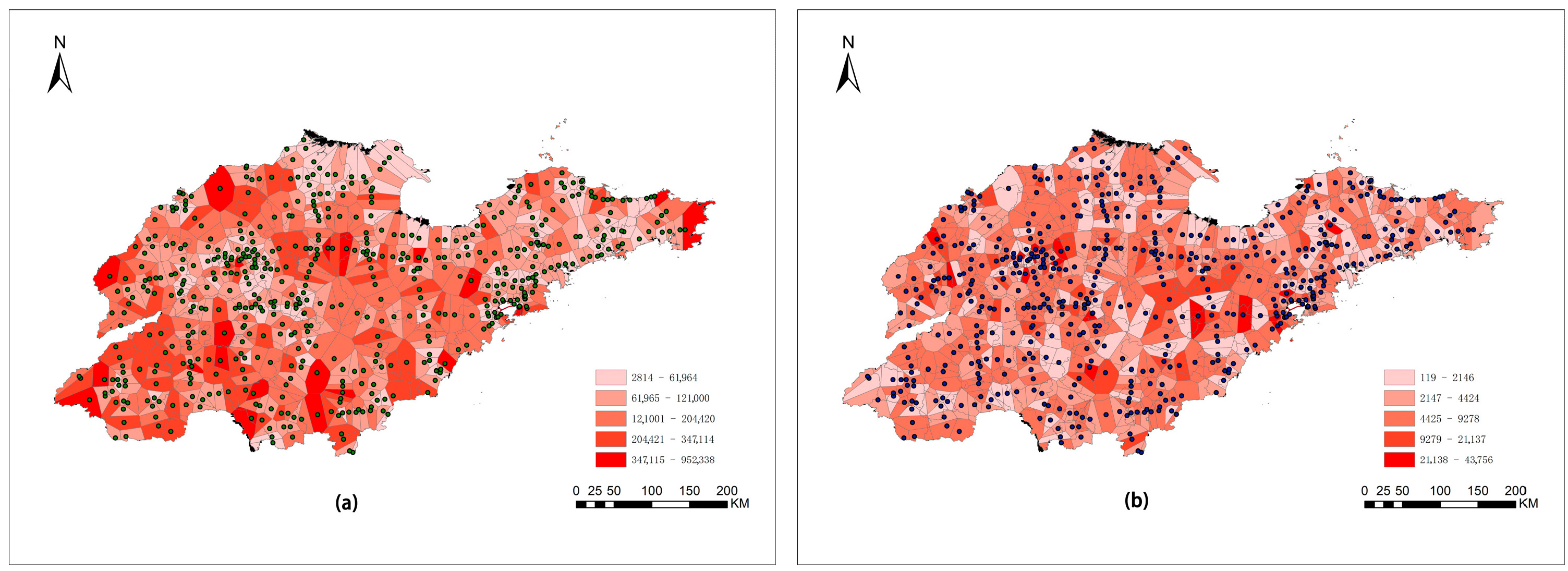
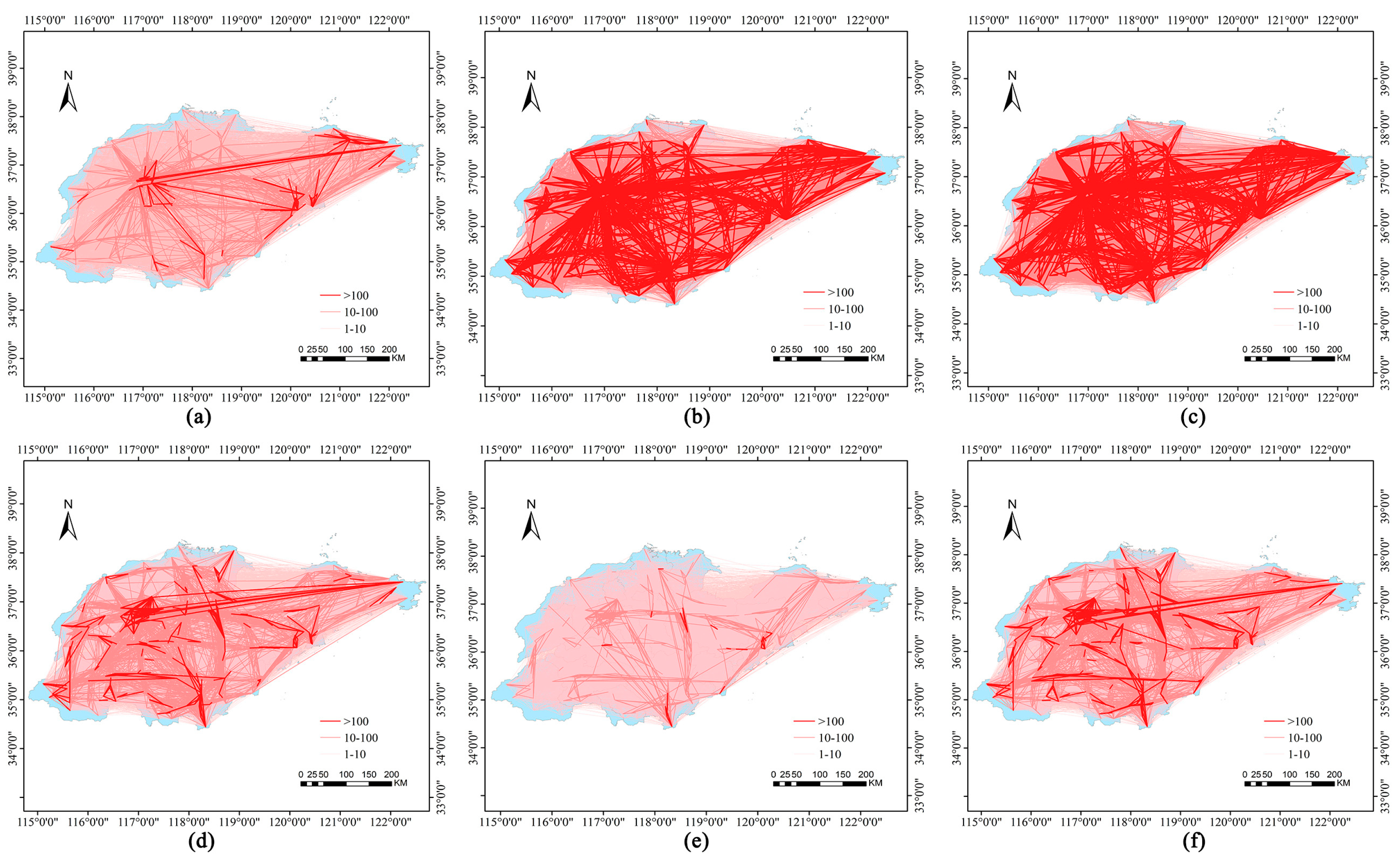
4.2. Spatial and Temporal Characteristics of Expressway Flow
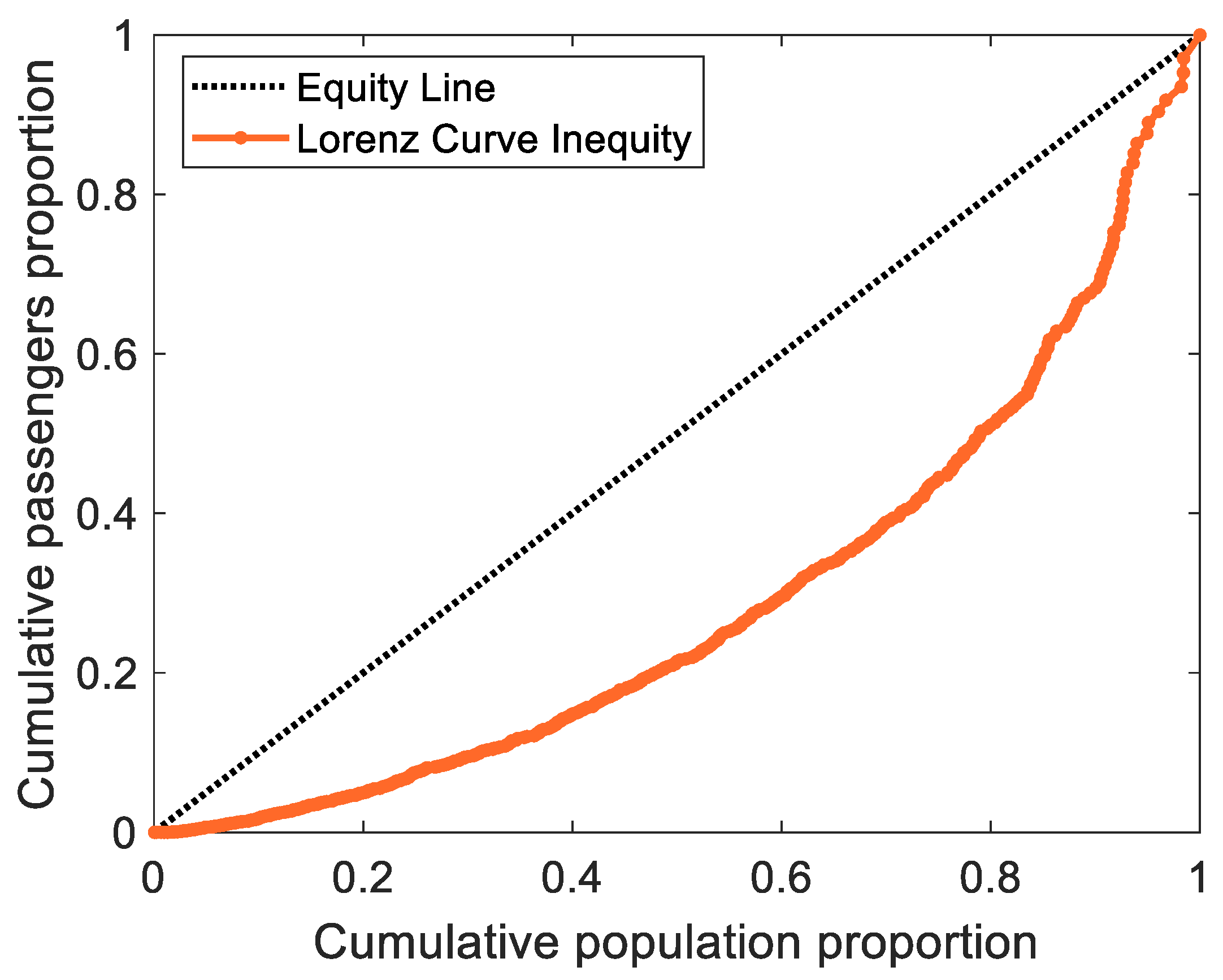
4.3. Lorenz Curve of Expressway
4.4. Characteristics of Traveler Behaviors
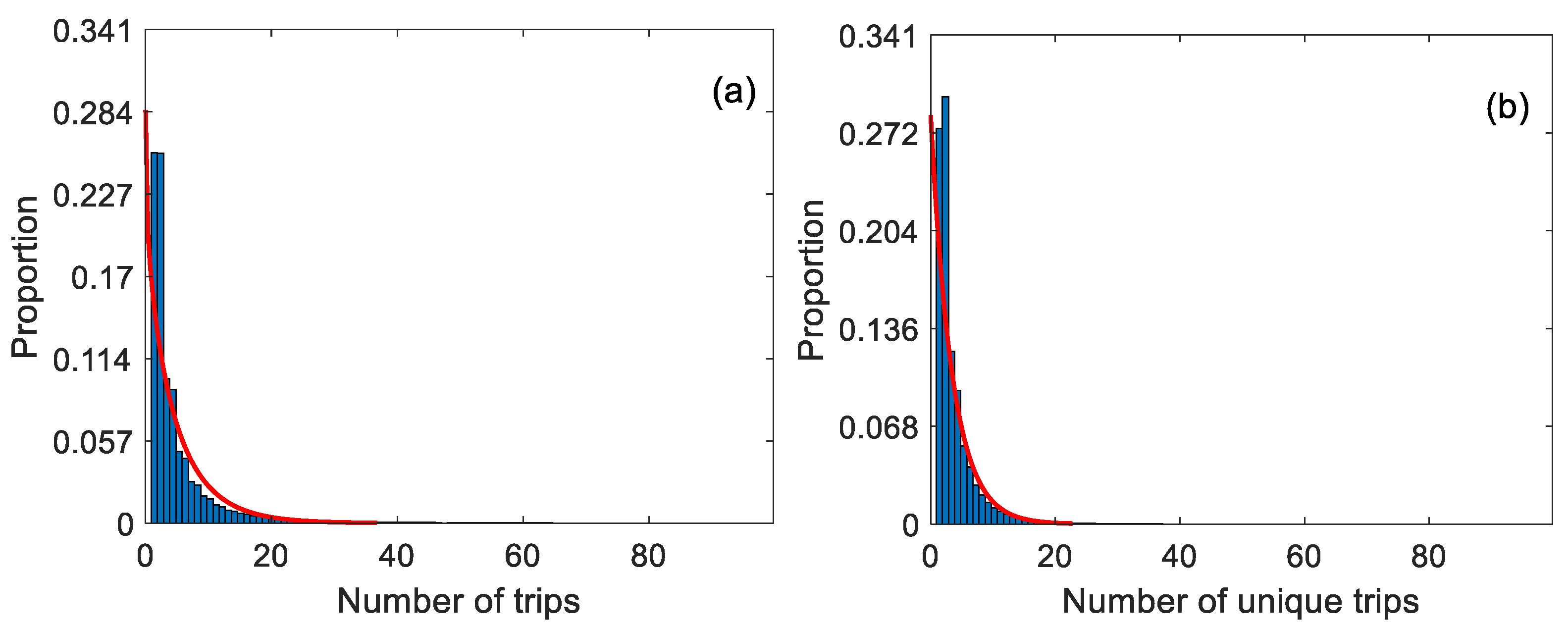
4.4.1. Number of Trips and Unique Trips
4.4.2. Basic Statistical Characteristics
4.4.3. Indicators for Maximum Repeating Trips
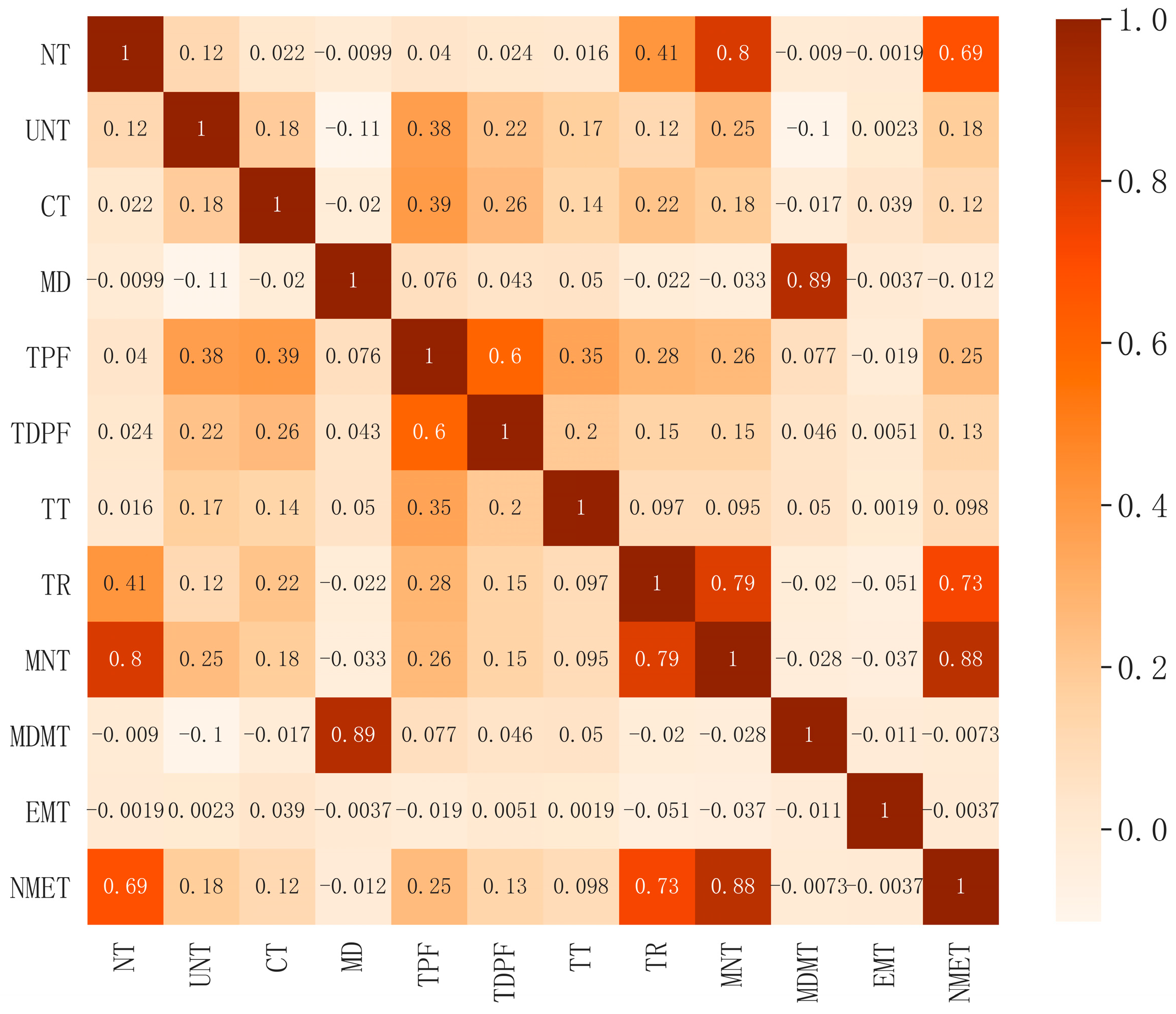
4.4.4. Correlations between Indicators
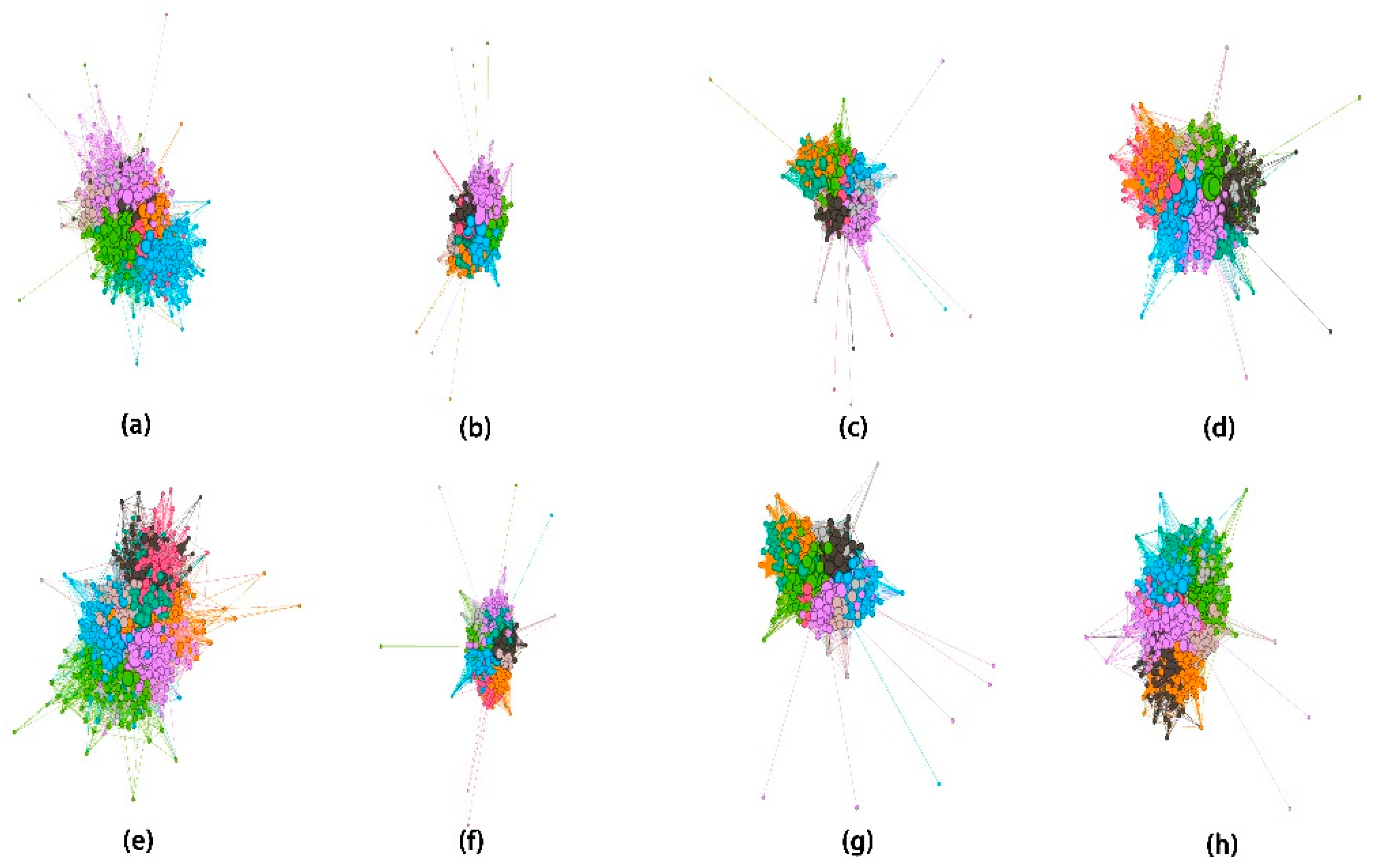
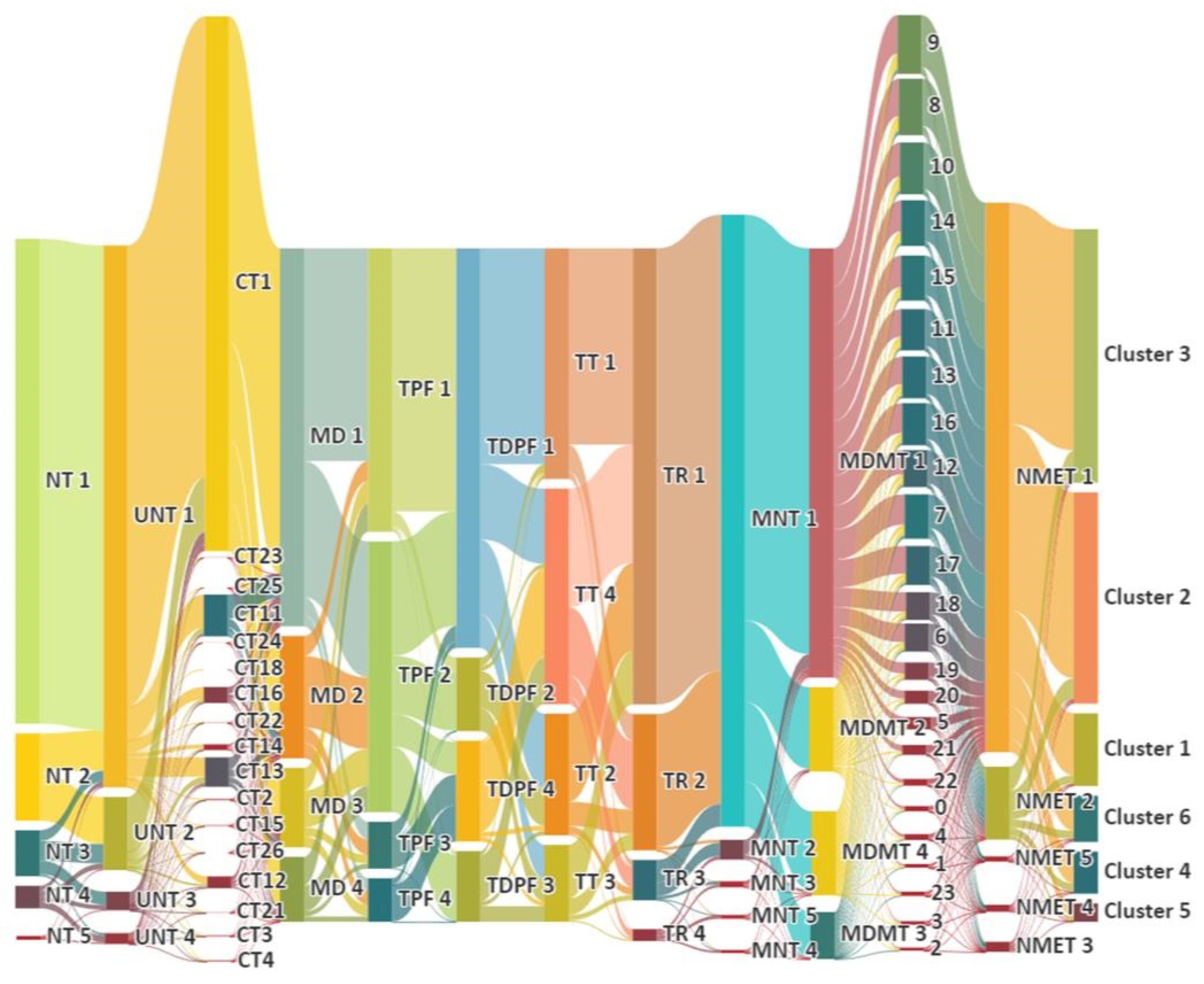
4.5. Clusters Based on Kmeans Algorithm
- (1)
- Cluster 1: As can be seen, this cluster mainly contains private vehicles. The average travel distance is very large. They prefer to travel after noon. Moreover, there are rare repeating trips.
- (2)
- Cluster 2: This cluster mainly contain private vehicles. The average travel distance of most vehicles is short. There is less discount pay fee and they prefer to travel after noon.
- (3)
- Cluster 3: The components of this cluster are similar to those of cluster 2. The average travel distance is larger than that of cluster 2. They prefer to travel before noon.
- (4)
- Cluster 4: This cluster consists of private vehicles and several kinds of vehicle that transport people. They prefer to travel between 14:00–22:00.
- (5)
- Cluster 5: This group contains most car types making long distance trips. The range of trip start time is wide.
- (6)
- Cluster 6: This group is similar to cluster 5, which contains most car types. The travel distance is shorter than that of cluster 5. They prefer to travel between 5:00–12:00.
4.6. Expressway Flow Characteristics of Different Clusters
5. Discussion
6. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- Fei, W.P.G.; Song, H.; Zang, J.R.; Gao, Y.; Sun, J.P.; Yu, L. Framework Model for Time-variant Propagation Speed and Congestion Boundary by Incident on Expressways. IET Intell. Transp. Syst. 2017, 11, 10–17. [Google Scholar] [CrossRef]
- Zhang, C.; Qin, J.H.; Zhang, M.; Zhang, H.; Hou, Y.D. Practical Road-resistance Functions for Expressway Work Zones in Occupied Lane Conditions. Sustainability 2019, 11, 382. [Google Scholar] [CrossRef]
- Zou, Y.J.; Zhu, T.; Xie, Y.F.; Li, L.B.; Chen, Y. Examining the Impact of Adverse Weather on Travel Time Reliability of Urban Corridors in Shanghai. J. Adv. Transp. 2020, 2020, 8860277. [Google Scholar] [CrossRef]
- Shukla, A.; Bhattacharya, P.; Tanwar, S.; Kumar, N.; Guizani, M. DwaRa: A Deep Learning-based Dynamic Toll Pricing Scheme for Intelligent Transportation Systems. IEEE Trans. Veh. Technol. 2020, 69, 12510–12520. [Google Scholar] [CrossRef]
- Liang, Z.J.; Xiao, Y. Analysis of factors influencing expressway speeding behavior in China. PLoS ONE 2020, 15, e0238359. [Google Scholar] [CrossRef]
- Shirke, C.; Sunanth, N.; Arkatkar, S.; Bhaskar, A.; Joshi, G. Modeling expressway lane utilization and lane choice behaviour: A case study on Delhi-Gurgaon expressway. Transp. Lett. 2019, 11, 250–263. [Google Scholar] [CrossRef]
- Gan, H.C.; Bai, Y.; Wei, J. Why do people change routes? Impact of information services. Ind. Manag. Data Syst. 2013, 113, 403–422. [Google Scholar] [CrossRef]
- Wang, Y.Q.; Li, L.; Wang, L.; Moore, A.; Staley, S.; Li, Z.Z. Modeling traveler mode choice behavior of a new high-speed rail corridor in China. Transp. Plan. Technol. 2014, 37, 466–483. [Google Scholar] [CrossRef]
- Lin, X.M.; Susilo, Y.O.; Shao, C.F.; Liu, C.X. The implication of road toll discount for mode choice: Intercity travel during the Chinese Spring Festival holiday. Sustainability 2018, 10, 2700. [Google Scholar] [CrossRef]
- Li, X.W.; Ma, R.Y.; Guo, Y.Y.; Wang, W.; Yan, B.; Chen, J. Investigation of factors and their dynamic effects on intercity travel modes competition. Travel Behav. Soc. 2021, 23, 166–176. [Google Scholar] [CrossRef]
- Choi, J.; Lee, K.; Kim, H.; An, S.; Nam, D. Classification of Inter-urban Highway Drivers’ Resting Behavior for Advanced Driver-Assistance System Technologies Using Vehicle Trajectory Data from Car Navigation Systems. Sustainability 2020, 12, 5936. [Google Scholar] [CrossRef]
- Ding, W.L.; Wang, Z.; Chen, J.; Xia, Y.Q.; Wang, J.W.; Zhao, Z.F. Potential Trend Discovery for Highway Drivers on Spatio-temporal Data. Wirel. Netw. 2021, 27, 3407–3422. [Google Scholar] [CrossRef]
- Liu, J.Y.; Wang, X.J.; Li, Y.T.; Kang, X.J.; Gao, L. Method of Evaluating and Predicting Traffic State of Highway Network Based on Deep Learning. J. Adv. Transp. 2021, 2021, 8878494. [Google Scholar] [CrossRef]
- Ki, Y.; Na, B.; Kim, B.I. Travel Time Prediction-based Routing Algorithms for Automated Highway Systems. IEEE Access 2019, 7, 121709–121718. [Google Scholar] [CrossRef]
- Lin, X.M.; Shao, C.F.; Qian, J.P.; Zhang, Y.D. Evolution Dynamic of the Expressway Toll-free Policy Impact on the Mode Choice in a Bimodal Transportation Network during Holidays. Adv. Mech. Eng. 2017, 9, 1687814017711080. [Google Scholar] [CrossRef]
- Yang, X.B.; Yue, X.F.; Sun, H.J.; Gao, Z.Y.; Wang, W.C. Impact of Weather on Freeway Origin-destination Volume in China. Transp. Res. A-POL 2021, 143, 30–47. [Google Scholar] [CrossRef]
- Simini, F.; Gonzalez, M.C.; Maritan, A.; Barabasi, A.L. A Universal Model for Mobility and Migration Patterns. Nature 2012, 484, 96–100. [Google Scholar] [CrossRef]
- Liu, W.C.; Cao, Y.H.; Wu, W.; Guo, J.Y. Spatial Impact Analysis of Trans-Yantze Highway Fixed Links: A Case Study of the Yangtze River Delta, China. J. Transp. Geogr. 2020, 88, 102822. [Google Scholar] [CrossRef]
- Abareshi, M.; Zaferanieh, M.; Safi, M.R. Origin-destination Matrix Estimation Problem in a Markov Chain Approach. Netw. Spat. Econ. 2019, 19, 1069–1096. [Google Scholar] [CrossRef]
- Zhou, W.X.; Wang, L.; Xie, W.J.; Yan, W.F. Predicting Highway Freight Transportation Networks Using Radiation Models. Phys. Rev. E 2020, 102, 052314. [Google Scholar] [CrossRef]
- Wang, L.; Ma, J.C.; Jiang, Z.Q.; Yan, W.F.; Zhou, W.X. Highway Freight Transportation Diversity of Cities Based on Radiation Models. Entropy 2021, 23, 637. [Google Scholar] [CrossRef] [PubMed]
- Yu, H.; Zhu, S.L.; Yang, J.; Guo, Y.T.; Tang, T.P. A Bayesian Method for Dynamic Origin-destination Demand Estimation Synthesizing Multiple Sources of Data. Sensors 2021, 21, 4971. [Google Scholar] [CrossRef] [PubMed]
- Kuusela, P.; Norros, I.; Kilpi, J.; Raty, T. Origin-destination Matrix Estimation with a Conditionally Binomial Model. Eur. Transp. Res. Rev. 2020, 12, 43. [Google Scholar] [CrossRef]
- Lee, M.; Holme, P. Relating Land Use and Human Intra-city Mobility. PLoS ONE 2015, 10, e0140152. [Google Scholar] [CrossRef] [PubMed]
- He, B.Y.; Chow, J.Y.J. Gravity Model of Passenger and Mobility Fleet Origin-destination Patterns with Partially Observed Service Data. Transp. Res. Rec. 2021, 2675, 235–253. [Google Scholar] [CrossRef]
- Li, R.Q.; Gao, S.; Luo, A.K.; Yao, Q.; Chen, B.S.; Shang, F.; Jiang, R.; Stanley, H.E. Gravity Model in Dockless Bike-sharing Systems within Cities. Phys. Rev. E 2021, 103, 012312. [Google Scholar] [CrossRef]
- Guo, X.G.; Xu, Z.J.; Zhang, J.Q.; Lu, J.; Zhang, H. An OD Flow Clustering Method Based on Vector Constraints: A Case Study for Beijing Taxi Origin-destination Data. ISPRS Int. J. Geo-Inf. 2020, 9, 128. [Google Scholar] [CrossRef]
- Luo, L.K.; He, Z.C.; Lu, Y.H.; Chen, J.Y. Clarifying Origin-destination Flows Using Force-directed Edge Bundling Layout. IEEE Access 2020, 8, 62572–62583. [Google Scholar] [CrossRef]
- Qi, G.Q.; Ceder, A.; Huang, A.L.; Guan, W. A Methodology to Attain Public Transit Origin-destination Mobility Patterns Using Multi-layered Mesoscopic Analysis. IEEE Trans. Intell. Transp. 2021, 22, 6256–6274. [Google Scholar] [CrossRef]
- Song, C.; Pei, T.; Ma, T.; Du, Y.Y.; Shu, H.; Guo, S.H.; Fan, Z.D. Detecting Arbitrarily Shaped Clusters in Origin-destination Flows Using Ant Colony Optimization. Int. J. Geogr. Inf. Sci. 2019, 33, 134–154. [Google Scholar] [CrossRef]
- Tak, S.; Kim, S.; Byon, Y.J.; Lee, D.; Yeo, H. Measuring Health of Highway Network Configuration Against Dynamic Origin-destination Demand Network Using Weighted Complex Network Analysis. PLoS ONE 2018, 13, e0206538. [Google Scholar] [CrossRef] [PubMed]
- Lombardi, A.; Amoroso, N.; Monaco, A.; Tangaro, S.; Bellotti, R. Complex Network Modelling of Origin-destination Commuting Flows for the COVID-19 Epidemic Spread Analysis in Italian Lombardy Region. Appl. Sci. 2021, 11, 4381. [Google Scholar] [CrossRef]
- Ou, J.S.; Lu, J.W.; Xia, J.X.; An, C.C.; Lu, Z.B. Learn, Assign, and Search: Real-time Estimation of Dynamic Origin-destination Flows Using Machine Learning Algorithms. IEEE Access 2019, 7, 26967–26983. [Google Scholar] [CrossRef]
- Rodriguez-Rueda, P.J.; Ruiz-Aguilar, J.J.; Gonzalez-Enrique, J.; Turias, I. Origin-destination Matrix Estimation and Prediction from Socioeconomic Variables Using Automatic Feature Selection Procedure-based Machine Learning Model. J. Urban Plan. Dev. 2021, 147, 04021056. [Google Scholar] [CrossRef]
- Liu, Y.; Tong, D.Q.; Liu, X. Measuring Spatial Autocorrelation of Vectors. Geogr. Anal. 2015, 47, 300–319. [Google Scholar] [CrossRef]
- Behara, K.N.S.; Bhaskar, A.; Chung, E. A DBSCAN-based Framework to Mine Travel Patterns from Origin-destination Matrices: Proof-of-concept on Proxy Static OD from Brisbane. Transp. Res. C-EMER 2021, 131, 103370. [Google Scholar] [CrossRef]
- Cui, Y.; He, Q.; Khani, A. Travel Behavior Classification: An Approach with Social Network and Deep Learning. Transp. Res. Rec. 2018, 2672, 68–80. [Google Scholar] [CrossRef]
- Yang, J.; Ma, J. Compressive Sensing-enhanced Feature Selection and Its Application in Travel Mode Choice Prediction. Appl. Soft Comput. 2019, 75, 537–547. [Google Scholar] [CrossRef]
- Magdolen, M.; von Behren, S.; Chlond, B.; Vortisch, P. Long-distance Travel in Tension with Everyday Mobility of Urbanites-A Classification of Leisure Travelers. Travel Behav. Soc. 2022, 26, 290–300. [Google Scholar] [CrossRef]
- Zaki, M.H.; Sayed, T. A Framework for Automated Road-users Classification Using Movement Trajectories. Transpt. Res. C 2013, 33, 50–73. [Google Scholar] [CrossRef]
- Yan, M.; Li, S.J.; Chan, C.A.; Shen, Y.H.; Yu, Y. Mobility Prediction Using a Weighted Markov Model Based on Mobile User Classification. Sensors 2021, 21, 1740. [Google Scholar] [CrossRef] [PubMed]
- Delbosc, A.; Currie, G. Using Lorenz curves to assess public transport equity. J. Transp. Geogr. 2011, 19, 1252–1259. [Google Scholar] [CrossRef]
- Zahra, S.; Ghazanfar, M.A.; Khalid, A.; Azam, M.A.; Naeem, U.; Prugel-Bennett, A. Novel Centroid Selection Approaches for Kmeans-clustering Based Recommender Systems. Inform. Sci. 2015, 320, 156–189. [Google Scholar] [CrossRef]
- Wu, S.T.; Liu, Y.L.; Wang, J.W.; Li, Q. Sentiment Analysis Method Based on Kmeans and Online Transfer Learning. CMC-Comput. Mater. Contin. 2019, 60, 1207–1222. [Google Scholar] [CrossRef]
- Adnan, R.M.; Parmar, K.S.; Heddam, S.; Shahid, S.; Kisi, O. Suspended Sediment Modeling Using a Heuristic Regression Method Hybridized with Kmeans Clustering. Sustainability 2021, 13, 4648. [Google Scholar] [CrossRef]
- Han, P.; Wang, W.Q.; Shi, Q.Y.; Yue, J.C. A Combined Online-learning Model with K-means Clustering and GRU Neural Networks for Trajectory Prediction. Ad Hoc Netw. 2021, 117, 102476. [Google Scholar] [CrossRef]
- Yan, A.; Wang, W.; Ren, Y.; Geng, H.W. A Clustering Algorithm for Multi-modal Heterogeneous Big Data with Abnormal Data. Front. Neurorobot. 2021, 15, 680613. [Google Scholar] [CrossRef]
- He, H.; Zhao, Z.H.; Luo, W.W.; Zhang, J.H. Community Detection in Aviation Network Based on K-means and Complex Network. Comput. Syst. Sci. Eng. 2021, 39, 251–264. [Google Scholar]
- Zhang, H.; Zhuge, C.X.; Jia, J.M.; Shi, B.Y.; Wang, W. Green travel mobility of dockless bike-sharing based on trip data in big cities: A spatial network analysis. J. Clean Prod. 2021, 313, 127930. [Google Scholar] [CrossRef]
- Xiao, G.N.; Lu, Q.W.; Ni, A.N.; Zhang, C.Q.; Zong, F. Which factors affect user satisfaction with ETC? Evidence from Shanghai and Beijing. J. Adv. Transp. 2022, 2022, 3102249. [Google Scholar] [CrossRef]
- Hughes, A. Strategic Database Marketing; McGraw-Hill Education: New York, NY, USA, 1994. [Google Scholar]
- Stone, B.; Jacobs, R. Successful Direct Marketing Methods, 8th ed.; McGraw-Hill Education: New York, NY, USA, 2007. [Google Scholar]
- Qian, C.; Meng, Y.; Li, P.Q.; Li, S.G. Application of customer segmentation for electronic toll collection: A case study. J. Adv. Transp. 2018, 2018, 3635107. [Google Scholar] [CrossRef]
- Chen, S.H.; Xi, J.C.; Liu, M.H.; Li, T. Analysis of complex transportation network and its tourism utilization potential: A case study of Guizhou expressways. Complexity 2020, 2020, 1042506. [Google Scholar] [CrossRef]













{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Kinds of Car | Type | Explanation |
|---|---|---|
| Passenger cars | CT 1 | The number of seats is smaller than 9 |
| CT 2 | The number of seats is between 10 and 19 | |
| CT 3 | The number of seats is between 20 and 39 | |
| CT 4 | The number of seats is larger than 40 | |
| Trucks | CT 11 | Two-axle with length smaller than 6 m and weight smaller than 4500 kg |
| CT 12 | Two-axle with length larger than 6 m and weight larger than CT11 | |
| CT 13 | Three-axle | |
| CT 14 | Four-axle | |
| CT 15 | Five-axle | |
| CT 16 | Six-axle | |
| Special motor vehicle | CT 21 | - |
| CT 22 | - | |
| CT 23 | - | |
| CT 24 | - | |
| CT 25 | - | |
| CT 26 | - |
| Field | Example | Description |
|---|---|---|
| Vehicle ID | *** T3Y3 | Vehicle plate number, unique |
| Entry station | Caoxian | Station name when a vehicle enters the expressway |
| Entry time | 1 March 2021 10:09:39 | Datetime when a vehicle enters the expressway |
| Exit station | Jinannan | Station name when a vehicle exits the expressway |
| Exit time | 1 March 2021 14:01:40 | Datetime when a vehicle exits the expressway |
| Car type | 1 | Kinds of vehicles |
| Fee | 154 | Fee paid for using the expressway |
| Discount fee | 0 | Discount fee for the trip |
| Other fields | … | … |
| P1 | P2 | P3 | P4 | P5 | P6 | P7 | P8 | |
|---|---|---|---|---|---|---|---|---|
| Degree | 34.53 | 107.21 | 113.82 | 61.69 | 37.36 | 110.26 | 116.33 | 62.92 |
| Strength | 114.55 | 983.70 | 1130.42 | 384.36 | 127.93 | 1090.31 | 1280.12 | 436.33 |
| CC | 0.237 | 0.404 | 0.42 | 0.318 | 0.244 | 0.415 | 0.427 | 0.328 |
| Betweenness | 0.0024 | 0.0016 | 0.0015 | 0.0019 | 0.0024 | 0.0015 | 0.0015 | 0.0019 |
| r | 0.0159 | 0.0018 | 0.0050 | 0.0518 | 0.0316 | 0.0017 | 0.0097 | 0.0326 |
| Modularity | 0.522 | 0.591 | 0.609 | 0.598 | 0.518 | 0.602 | 0.617 | 0.62 |
| FDF | 0.8948 | 0.8348 | 0.8218 | 0.8557 | 0.8907 | 0.8269 | 0.8188 | 0.8501 |
| Clusters | 4 | 5 | 6 | 7 | 8 | 9 | 10 |
|---|---|---|---|---|---|---|---|
| Values | 0.3852 | 0.4189 | 0.4383 | 0.4243 | 0.3624 | 0.3605 | 0.3521 |
| Cluster 1 | Cluster 2 | Cluster 3 | Cluster 4 | Cluster 5 | Cluster 6 | |
|---|---|---|---|---|---|---|
| N | 516 | 538 | 545 | 521 | 515 | 520 |
| Degree | 50.73 | 105.19 | 230.96 | 64.84 | 32.52 | 65.31 |
| Strength | 713.79 | 2443.64 | 5632.87 | 465.71 | 158.53 | 529.03 |
| CC | 0.220 | 0.292 | 0.606 | 0.211 | 0.162 | 0.214 |
| Betweenness | 0.0014 | 0.0010 | 0.0009 | 0.0013 | 0.0016 | 0.0013 |
| r | −0.1609 | −0.0044 | −0.0580 | 0.0111 | −0.0416 | 0.0235 |
| Modularity | 0.593 | 0.591 | 0.577 | 0.554 | 0.527 | 0.578 |
| FDF | 0.8437 | 0.7752 | 0.7712 | 0.8326 | 0.8720 | 0.8296 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Cao, R.; Chen, X.; Jia, J.; Zhang, H. Uncovering Equity and Travelers’ Behavior on the Expressway: A Case Study of Shandong, China. Sustainability 2023, 15, 8688. https://doi.org/10.3390/su15118688
Cao R, Chen X, Jia J, Zhang H. Uncovering Equity and Travelers’ Behavior on the Expressway: A Case Study of Shandong, China. Sustainability. 2023; 15(11):8688. https://doi.org/10.3390/su15118688
Chicago/Turabian StyleCao, Rong, Xuehui Chen, Jianmin Jia, and Hui Zhang. 2023. "Uncovering Equity and Travelers’ Behavior on the Expressway: A Case Study of Shandong, China" Sustainability 15, no. 11: 8688. https://doi.org/10.3390/su15118688
APA StyleCao, R., Chen, X., Jia, J., & Zhang, H. (2023). Uncovering Equity and Travelers’ Behavior on the Expressway: A Case Study of Shandong, China. Sustainability, 15(11), 8688. https://doi.org/10.3390/su15118688