1. Introduction
With the increasing shortage of nonrenewable energy, environmental pollution is becoming more and more serious, and the development of renewable energy is becoming a common goal. As one of the countries with the highest carbon emissions in the world, China aims to peak its carbon emissions by 2030, and to become carbon neutral by 2060. China will continue to further optimize its energy structure and gradually improve the safe, efficient, clean, and low-carbon modern-energy-source system, and it will achieve carbon peak and carbon neutrality according to the established goals. As the main substitute for fossil energy, solar energy plays a very important strategic role in carbon-emission reduction. With the gradually increasing attention to solar energy resources, photovoltaic power generation (PV generation) has been vigorously promoted, and its scale has been expanding. Photovoltaic energy is becoming an important basic energy in social production and in life. According to the United Nations Madrid Climate Change Conference on China’s 2050 photovoltaic development outlook, China will soon enter the period of the large-scale and accelerated deployment of photovoltaic energy; by 2050, photovoltaic energy will become the largest power source in China, and it will account for about 40 percent of the country’s electricity consumption that year [
1]. However, meteorological factors, such as temperature and humidity, fluctuate greatly with time and show intermittent and random characteristics, which lead to constant fluctuations in the photovoltaic power generation and bring challenges to the operation of the power-supply system. Therefore, the prediction of photovoltaic power generation remains an important and challenging research field.
According to the time range, photovoltaic predictions can be divided into four types: very-short-term predictions, short-term predictions, medium-term predictions, and long-term predictions [
2]. Dimd et al. (2022) defined the prediction range of the min–hour as very-short-term prediction, the hour–week as short-term prediction, the day–month as medium-term prediction, and the month–year as long-term prediction [
2]. In order to develop an energy policy according to future photovoltaic energy generation, the government mainly pays attention to the long-term prediction. In order to prepare a power-production plan, to control power reserves, and to evaluate purchase and sales contracts, electric power enterprises mainly carry out short-term or very-short-term predictions. In this research, we propose a short-term forecasting model from the perspective of enterprises.
There are two types of prediction methods: traditional forecasting methods and machine-learning methods. The traditional prediction methods mainly include linear regression (LR) [
3], auto-regression (AR) [
4], regression moving average with exogenous variables (ARMAX) [
5,
6], and others. These traditional methods are mostly based on linear relationships and they have limited abilities to reflect nonlinear relationships. The relationship between the power generation and the influencing factors is mostly nonlinear. Machine learning is different from traditional statistical methods in that it does not have strict requirements on data distribution, it can deal with high-dimensional data, and dimension reduction is easy. Thanks to the development of machine-learning methods and the availability of photovoltaic-power-generation data and meteorological data, data-based machine-learning methods have become more and more popular in the field of photovoltaic forecasting [
7,
8,
9,
10,
11,
12,
13,
14,
15]. However, most studies use a single machine-learning model, and the generalization and the robustness of this research are not sufficient. In recent years, researchers have developed different ensemble-learning algorithms, including bagging, boosting, and stacking. On the basis of the above three algorithms, scholars developed three models: the bagging model, the boosting model, and the stacking model [
16,
17,
18]. The stacking model differs from the bagging and boosting models in two main ways. Firstly, the stacking model usually considers heterogeneous weak learners (different learning algorithms are combined together), while bagging and boosting mainly consider homogeneous weak learners. Secondly, the stacking model combines base models with the meta-model, while bagging and boosting combine weak learners according to deterministic algorithms. In this study, we attempt to develop four stacking models. More than three years of data from Australia, as well as data from a Chinese photovoltaic power station, were used in this study. Although there have been studies that use ensemble-learning-based models to predict the photovoltaic power generation, our study is quite different from theirs. Lee et al. (2020) compared the prediction performances of different ensemble-learning-based models, while we constructed stacking models on the basis of different ensemble-learning-based models and compared the prediction performances of different stacking models [
14]. Some scholars have also used stacking models to predict the photovoltaic power generation [
19,
20], in which only the results of the first layer were taken as the input of the second layer. We not only take the results of the first layer as the input of the second layer, but we also consider the input data of the first layer comprehensively. In addition, the previous authors built only one stacking model, while we built different stacking models and compared their predictive performances, which is one of the main contributions of this paper.
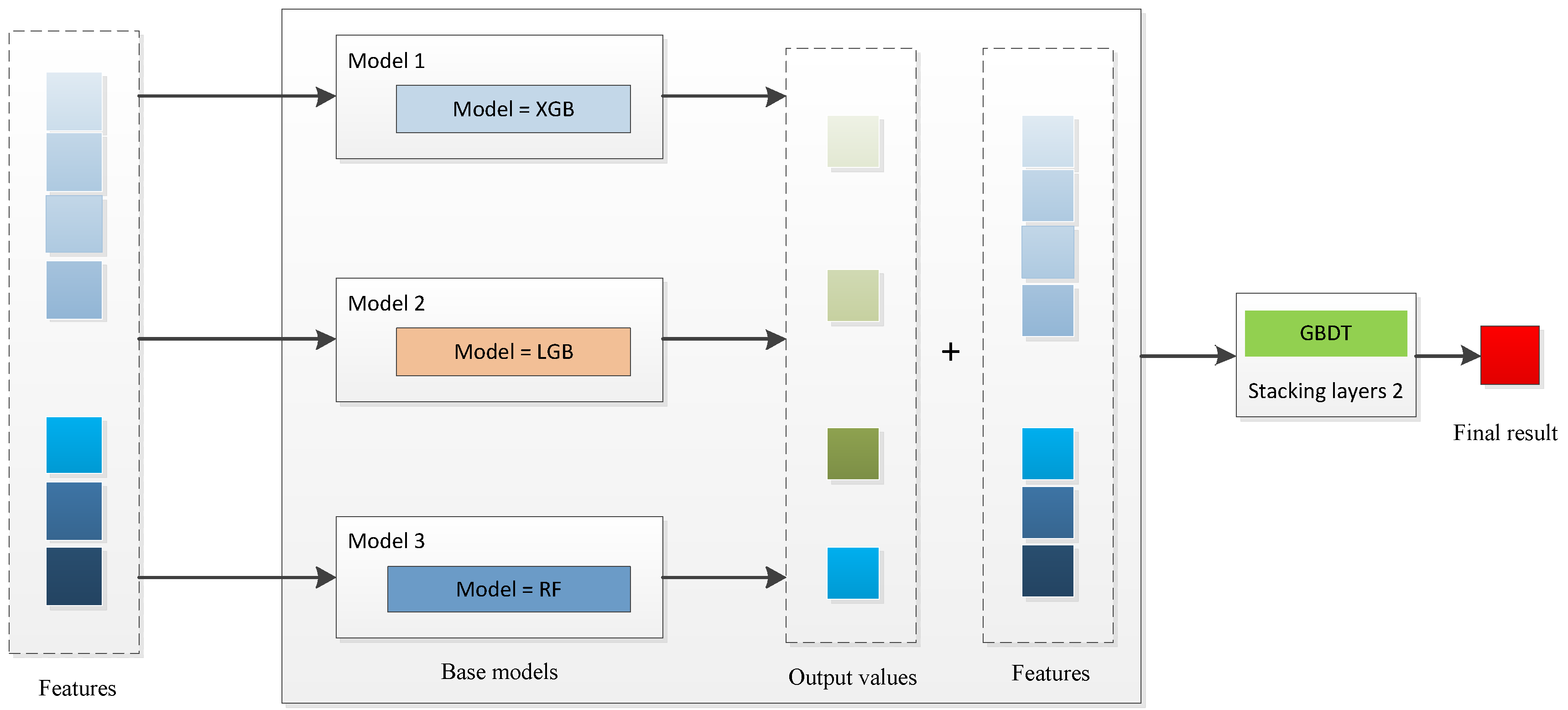
The contributions of this paper are as follows. (1) The first innovation was to propose a stacking model that is based on different ensemble algorithms (XGB, RF, GBDT, and LGB). We not only take the results of the first layer as the input of the second layer, but we also consider the input data of the first layer comprehensively. This is the first stacking model to predict photovoltaic power generation by using different ensemble algorithms, and by considering the input data and the output results of the first layer comprehensively. (2) The second innovative idea of this paper was to determine which stack model has the best predictive performance. As far as we know, this research is the first to systematically develop and compare the application of four different stacking models to the prediction of photovoltaic power generation. (3) Previous studies mainly used a single data source; however, this study used Australian panel and Chinese cross-sectional data. A comparative analysis of the various data not only verifies the robustness of the model, but also demonstrates its universality.
The rest of the study is arranged as follows.
Section 2 presents a literature review of the photovoltaic-power-generation-prediction models.
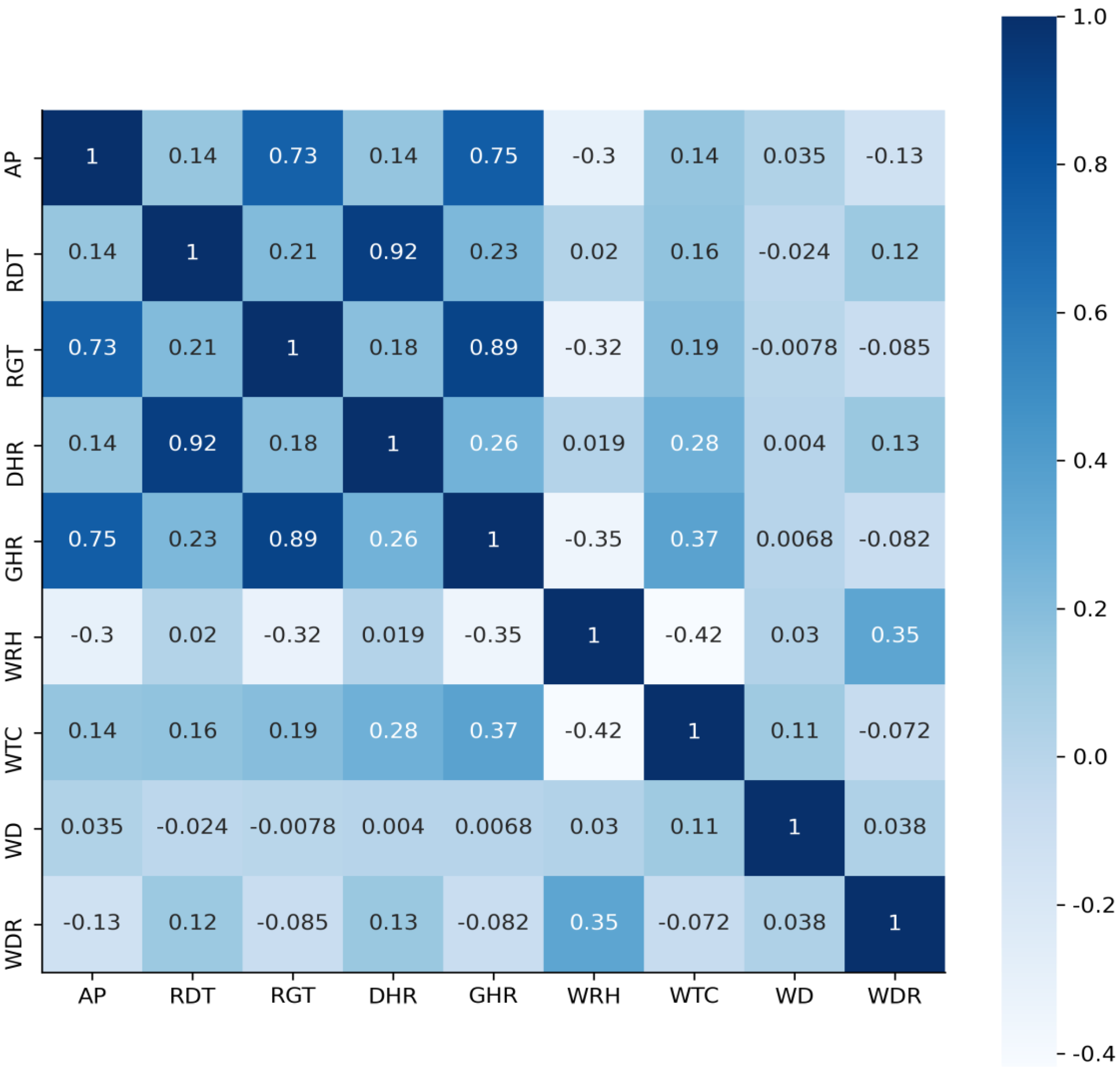
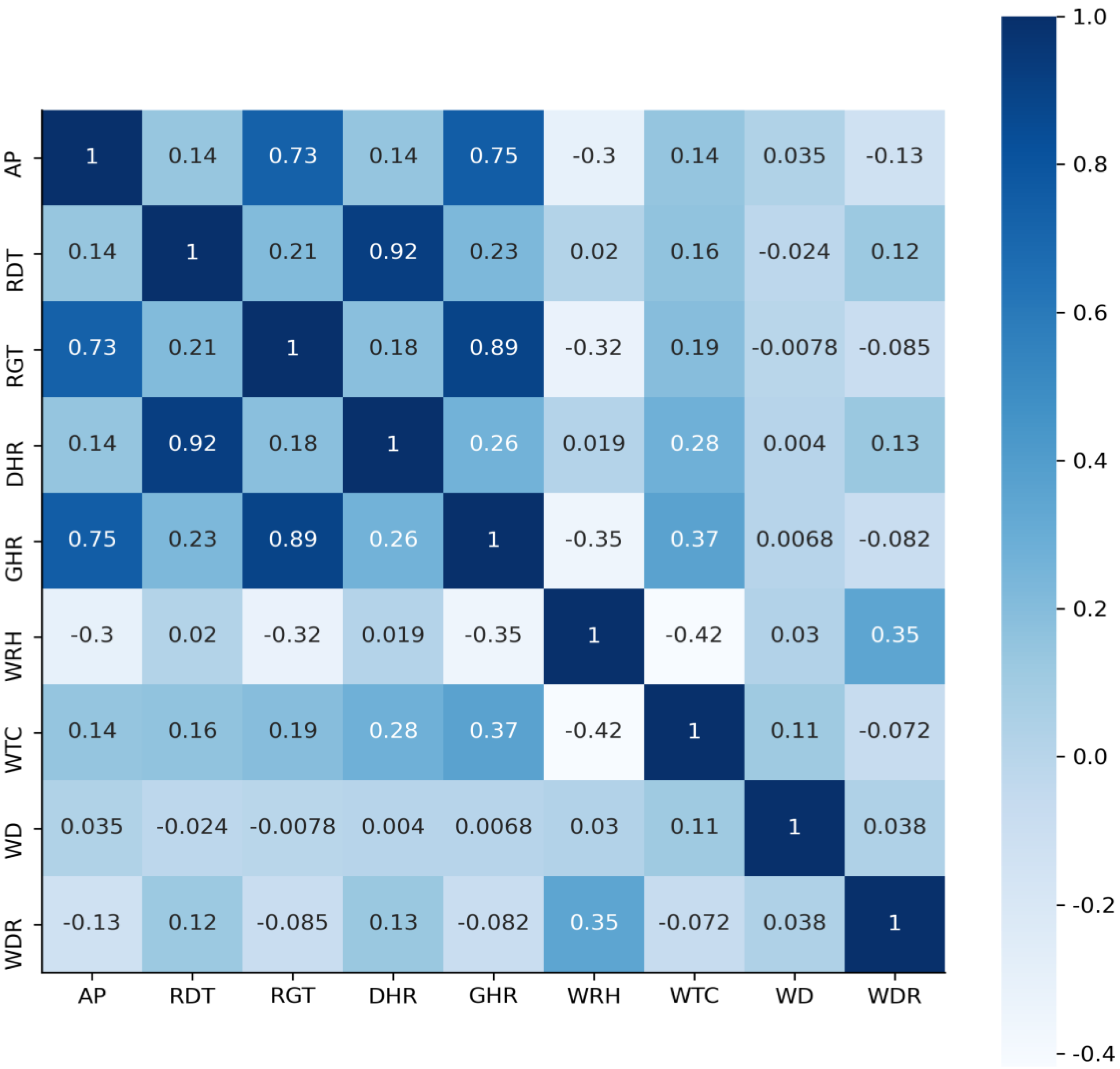
Section 3 introduces the sources and the processing of the data. In this section, the pre-processing of relevant features, such as filling in missing values, is conducive to improving the performance of the prediction model.
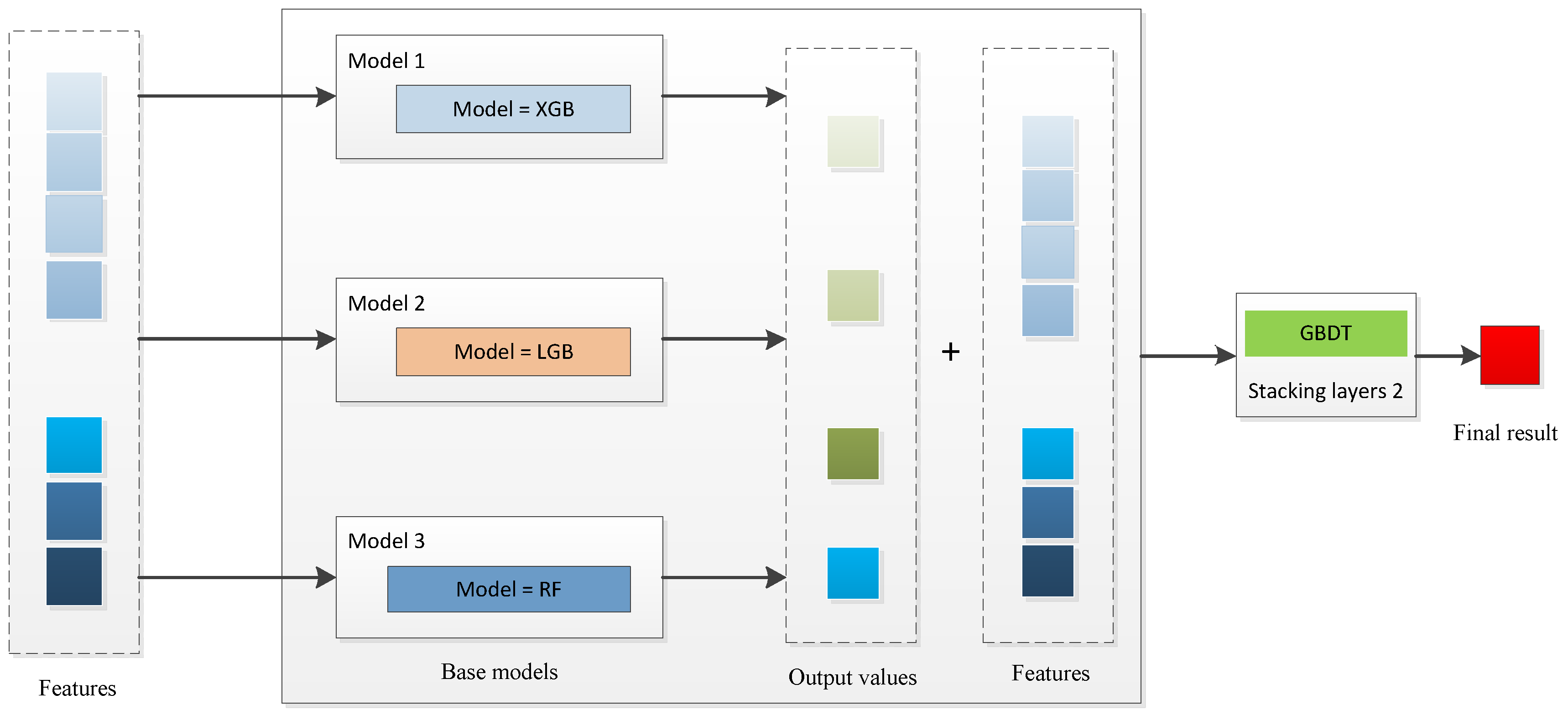
Section 4 describes the four stacking models.
Section 5 presents the empirical results of this study, which show that the stacking model has a better prediction accuracy than the single machine-learning model. The Stacking-GBDT model has the highest predictive accuracy among the stacking models that are presented in this study. In
Section 6, we draw a conclusion and suggest future directions for research.
2. Related Work
PV-generation prediction is very important in power-grid dispatching and for power-market transactions. The accurate prediction of the PV generation is not only beneficial to power-enterprise decisionmakers for improvement in the operation planning of power systems, but it can also provide valuable guidance for power enterprises in the formulation of power production plans and control power reserves, and in the evaluation of purchase and sales contracts. The research on photovoltaic-power-generation prediction has obtained a significant number of research results. According to the different research methods, the research can be divided into traditional models and machine-learning models.
Among the traditional models, the auto-regression comprehensive moving average is the most widely used. For example, Chu et al. (2015) predicted the photovoltaic power generation of an American power station by constructing an ARMA model [
5]. Li et al. (2014) improved the ARMA model and proposed the auto-regressive moving average with exogenous variables, and they tested the model by using Chinese data [
6]. Some scholars have also used the spatial auto-regression ARMA model to predict the photovoltaic power generation of Portugal. Compared to the ARMA model, the ARMAX model has higher accuracy [
4]. In addition, bottom-up and up-scaling approaches are also used to forecast PV generation. For example, Koster et al. (2019) used a bottom-up approach to predict the PV generation of a power station in Germany [
21]. Iea et al. (2020) used an up-scaling approach to forecast the PV generation of power stations in Italy and The Netherlands [
22]. Although the traditional method can forecast photovoltaic power, it has a limited ability to deal with the nonlinear relationship between multidimensional data and variables. However, the factors that affect the photovoltaic power generation are multidimensional, and their relationship with the power generation is nonlinear, which leads to the poor prediction performance of traditional statistical methods.
Machine learning is a multidisciplinary specialty that covers probability theory, statistical approximation theory, and complex algorithms. It uses algorithms to extract valuable information and knowledge from existing data [
23]. Machine learning is common in many fields of research because of its advantages in processing multidimensional and nonlinear data [
23]. Over the years, researchers have adopted classical machine-learning models, such as SVR, SVM, and neural networks, to forecast photovoltaic power generation. Rana et al. (2016) constructed an SVR model to forecast the PV power generation of power stations located in Australia [
24]. Gigoni et al. (2018) constructed an SVR model to forecast the PV power generation of power stations located in Italy [
25]. Dewangan et al. (2020) constructed an SVR model to forecast the PV power generation of power stations located in Australia [
26]. Some scholars also use SVM models to predict the photovoltaic power generation, such as Shi et al. (2012), who constructed an SVM model to forecast the PV power generation of power stations located in China [
27]. Liu et al. (2019) constructed an SVM model to forecast the PV power generation of power stations located in Australia [
28]. Neural networks are computing systems that are inspired by, but are not identical to, the biological neural networks that make up the brains of animals, and they include ANN, DNN, RNN, and others. Neural networks are nonlinear statistical-data-modeling tools that are used to model the complex relationship between input and output. A number of scholars have used ANN models to predict photovoltaic power generation with different datasets [
25,
27,
29,
30,
31,
32,
33,
34]. Ramsami and Oree (2015) predicted Britain’s photovoltaic power generation by using an RNN model [
35]. Sharadga et al. (2020) constructed an RNN model to forecast the photovoltaic power generation in Mauritius [
36]. When RNN cells face long sequences of data, it is easy to encounter gradient discretization, which endows the RNN with only a short-term memory. In other words, when faced with long sequences of data, an RNN can only obtain the information of the relatively recent sequence; however, it does not have the memory function of the earlier sequence, and it thus loses the information. Therefore, researchers have proposed the LSTM method to solve such problems [
37]. Many scholars use the LSTM model to forecast photovoltaic power generation [
38,
39,
40]. For example, Dewangan et al. (2020) constructed an LSTM model to forecast photovoltaic power generation in Australia [
26]. Li et al. (2020 compared the prediction accuracies of the LSTM model and the RNN model, and the research results show that the LSTM model has a high prediction accuracy [
41].
With the development of technology, scholars continue to develop ensemble-learning algorithms, and they have found that ensemble-learning algorithms can improve the prediction accuracies of models [
42]. Ensemble learning is a machine-learning method that uses a series of models to learn, and it uses certain rules to integrate the learning results of each model so as to achieve better prediction results than a single model. Ensemble learning is a very popular machine-learning algorithm. It is not a single machine-learning algorithm; instead, it builds multiple models on the data and integrates the modeling results of all of the models. So far, scholars have developed a variety of ensemble-learning algorithms, which can be divided into bagging, boosting, and stacking, according to different integration strategies. (1) The bagging algorithm uses all of the features to train the basic learning-machine model, it samples a large amount of data in parallel at one time, and it outputs the predicted results of each basic learner through a combination strategy. RF is a machine-learning model that is based on bagging ideas. Random forest is an algorithm that integrates multiple trees through the idea of ensemble learning, and its basic units are decision trees [
43]. Sun et al. (2016) constructed an RF model to forecast the solar radiation of different photovoltaic power stations in China [
44]. (2) The boosting algorithm was first proposed by Kearns (1988) [
17]. On the basis of this algorithm, scholars have proposed the gradient boosting decision tree (GBDT), extreme gradient boosting (XGB), and light gradient boosting (LGB) [
45]. Hassan et al. (2017) compared the GBDT model to the corresponding MLP, SVR, and DT [
8]. They found that the GBDT model is relatively simple, but that it has high reliability and accuracy in photovoltaic power prediction. Pedro et al. (2018) found that the GBDT has a higher accuracy than the KNN model [
10]. Kumari and Toshniwal (2021) combined XGB with DNN and proposed the XGB-DNN model [
46]. (3) Stacking is an ensemble framework of the layered model that was proposed by Wolpert (1992) [
47]. In simple terms, stacking is learning a new learner through the use of the prediction results of several base learners as a new training set after learning several base learners from the initial training data. Stacking models can prevent over-fitting and can improve the accuracy of prediction. Ting and Witten (1999) confirm that the stacking model has a higher accuracy than the basic model [
48]. Ke et al. (2021) constructed an XGB model, an LR model, an LGB model, and a stacking model to predict the subjective wellbeing of residents, and they found that the stacking model had a significant advantage in terms of accuracy [
49]. Cao et al. (2019) used a stacking model to forecast individual credit. The results show that the stacking model has high prediction accuracy [
50].
Although the models that have been developed and that are based on ensemble algorithms have been widely used in photovoltaic power prediction, there are still some limitations in the related research. Most studies use one of the ensemble algorithms to construct a model. In this article, we focus on a stacking model that is based on an ensemble-algorithm model. It consists of multiple base models (XGB, RF, GBDT, and LGB).
6. Discussion and Conclusions
The most effective way to achieve peak carbon and carbon neutrality is to reduce carbon emissions by using renewable energy. Solar energy is a renewable energy that can reduce carbon emissions and achieve carbon neutrality. However, the unique random intermittency and the fluctuation of solar energy present many challenges to the safety of power grids with the increasing demand for photovoltaic installed capacities. The accurate forecasting of PV power generation is helpful for grid-planning improvement, scheduling optimization, and management development. Machine-learning models have high predictive accuracies, and they are widely used in various fields, including in photovoltaic power generation.
Although machine learning has been used by scholars to predict photovoltaic power generation, most studies use the single machine-learning model. In recent years, scholars have developed ensemble-learning algorithms that can significantly improve the performance of the model. The stacking model is one of the most popular ensemble-learning algorithms that is currently being applied to different prediction models.
In this work, four ensemble-learning algorithms (XGB, RF, LGB, and GBDT) were selected to build four stacking models to predict photovoltaic power generation. The four stacking models are: Stacking-GBDT, Stacking-XGB, Stacking-RF, and Stacking-LGB. We used two datasets to test the predictive performances of the different models. Data points from the Australian dataset (Dataset A) were taken every five minutes, and the time span was from 1 January 2018 to 10 September 2021. The results show that the stacking model has high prediction performance. Our results lead us to the following conclusions:
The prediction performance of the four stacked models is better than that of the single machine-learning model. First, by using Australian panel data, the prediction performance of the stacked model is better than that of the single machine-learning model. Second, by using Chinese cross-sectional data, the robustness of the conclusion is verified again;
The Stacking-GBDT model has a higher prediction accuracy than the Stacking-XGB model, the Stacking-RF model, and the Stacking-LGB model. By comparing the prediction accuracies of the above models by using the Australian dataset, it was found that the Stacking-GBDT model had the highest prediction accuracy, which was also verified by the Chinese dataset;
Machine-learning models have better prediction accuracies than traditional LR models, on the whole. In the research, we compared the prediction accuracy of a single machine-learning model with that of a traditional linear regression model. We found that the prediction accuracy of the single machine-learning model is higher than the traditional linear regression model. This conclusion is consistent with previous studies.
Although this study contributes to the literature on photovoltaic-power-generation prediction, it has several limitations. In this work, LGB, XGB, and random forest were only used as the base models of the stacking model to predict the photovoltaic power generation. In the future, more machine-learning models could be used as the first layer of the stacking model in order to conduct a more detailed division and analysis of the model architecture. Data from Australia and China were used in this study. Data from other countries can be considered in future studies to overcome the limitations in the two countries, and to expand the universal applicability of the model.





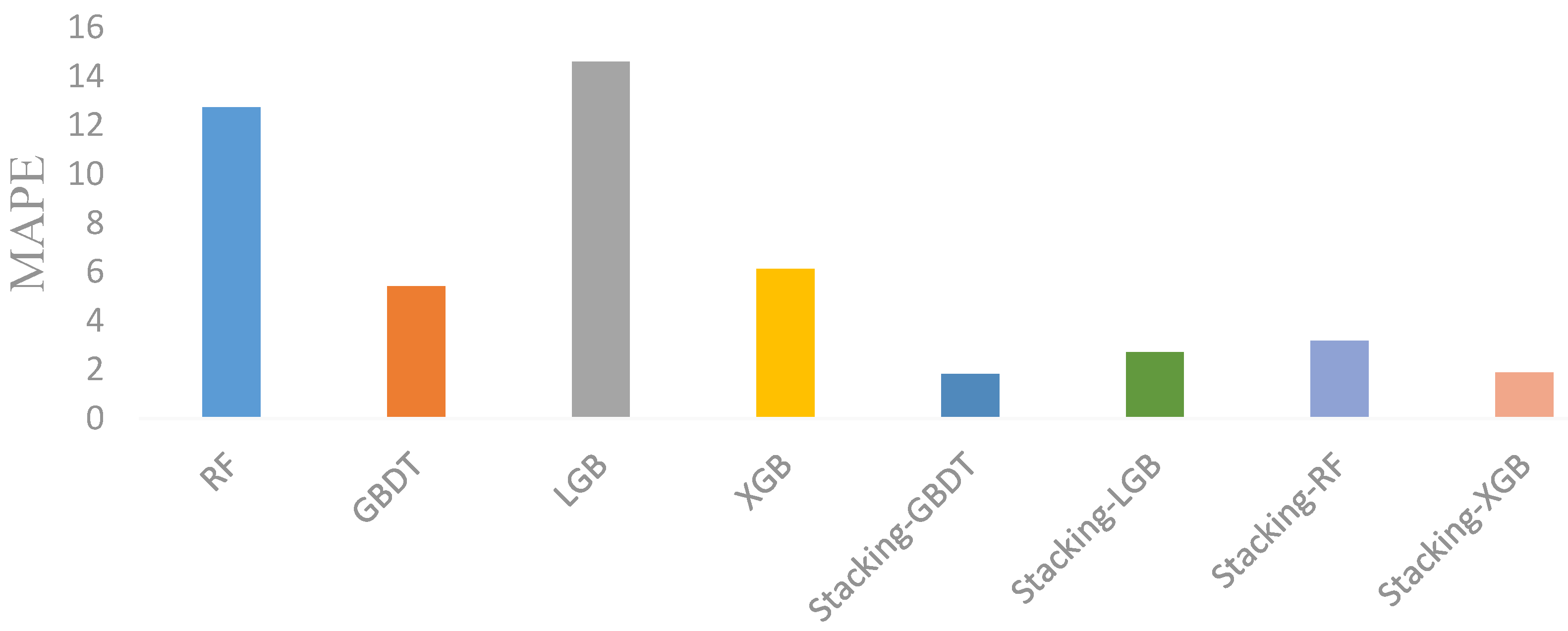
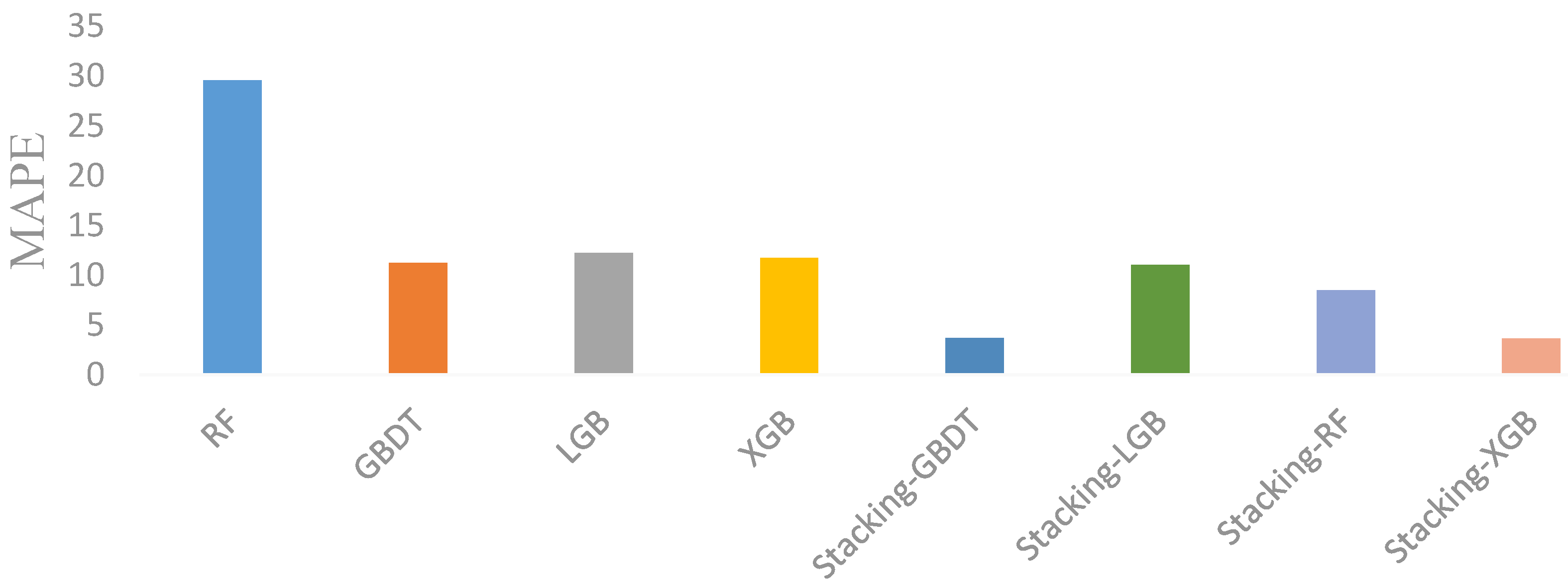

{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
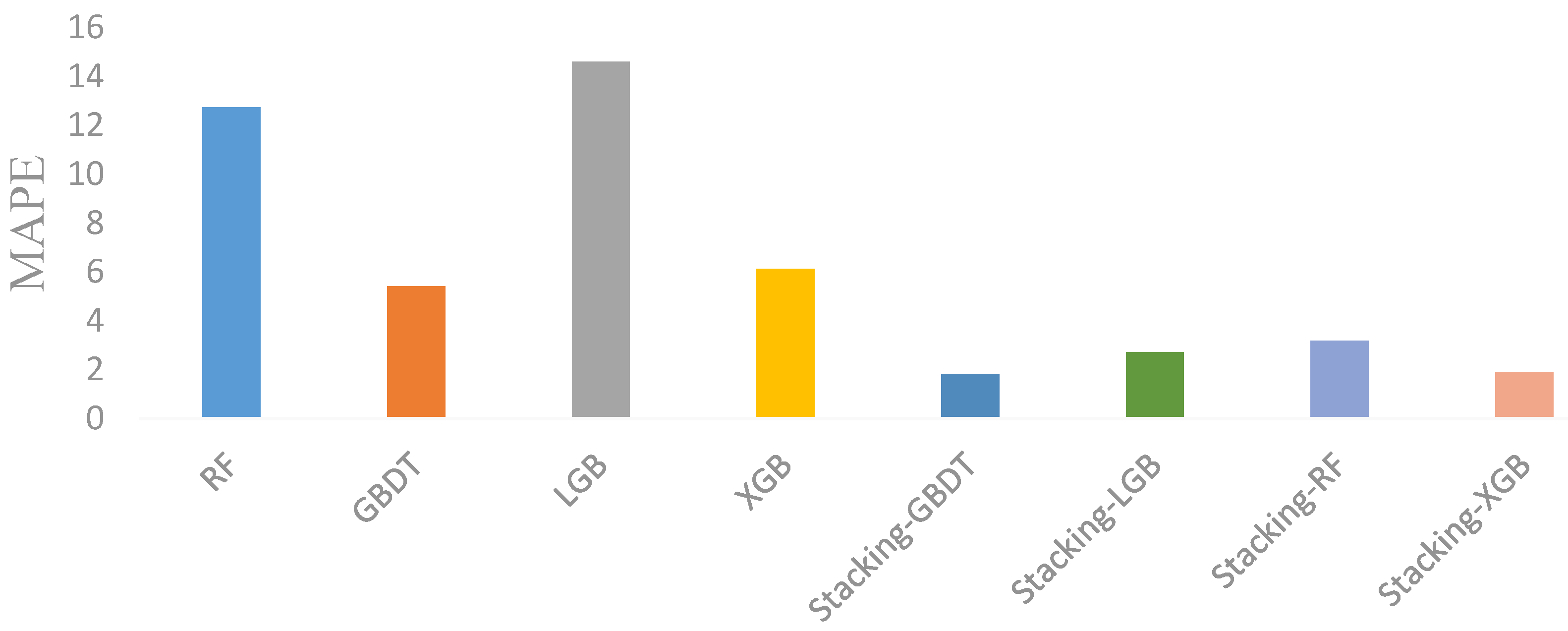{kind=link}
{kind=link}