1. Introduction
Over recent decades, there has been an increase in the amount of freight transport. This is explained by multiple factors, including population growth, improvements in infrastructure, and reduced trade barriers, among others [
1]. In terms of costs, transportation plays a relevant role in the supply chain, accounting for 50% of logistics costs [
2] and in the region of 10% of the total cost of a product, depending on the economic sector [
3]. In recent years, the amount of freight transported at the last mile has seen a sharp increase due to technological advances and the use of e-commerce [
4,
5]. This growth has been accelerated as a result of the COVID-19 pandemic. According to the Chilean National Chamber of Commerce, the first quarter of 2021 saw a 61% increase in the number of people that make purchases in Chile using online sales channels.
This increase in urban freight transportation has brought a host of problems in economic but also in social and environmental dimensions [
6]. These problems include congestion [
7], wear and tear on road infrastructure [
8], increased greenhouse gas emissions [
9], and noise pollution [
10]. In this regard, the literature has put forward several alternatives to mitigate these effects, including the incorporation of new infrastructure in the road network [
11] and sustainability investments [
12]. However, the implementation of these and other transport-mitigating policies requires an accurate characterization of freight transport. In the case of freight transport within urban areas, the key features are truck trip purpose, time of day, and trip origin and destination characteristics [
13].
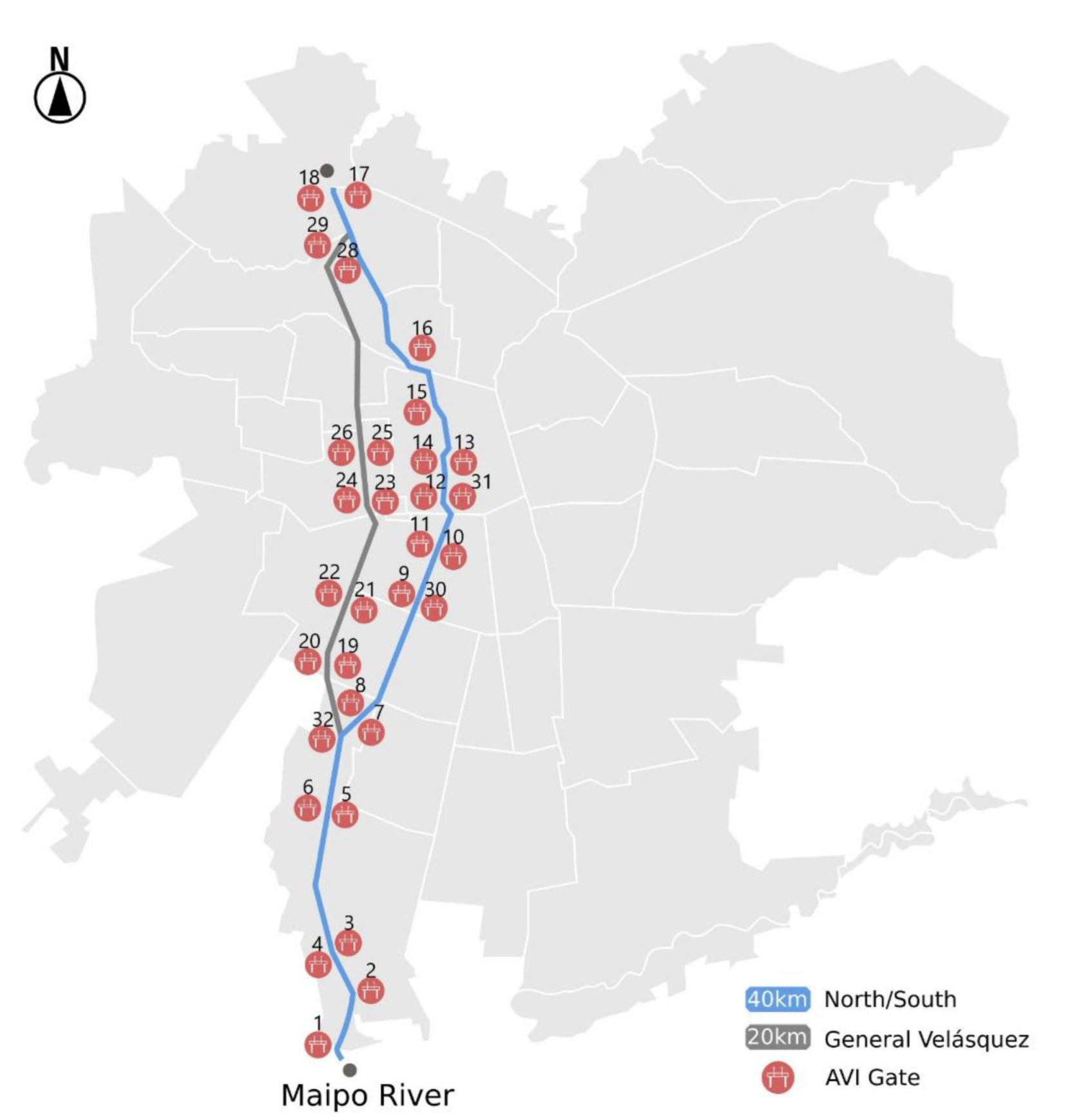
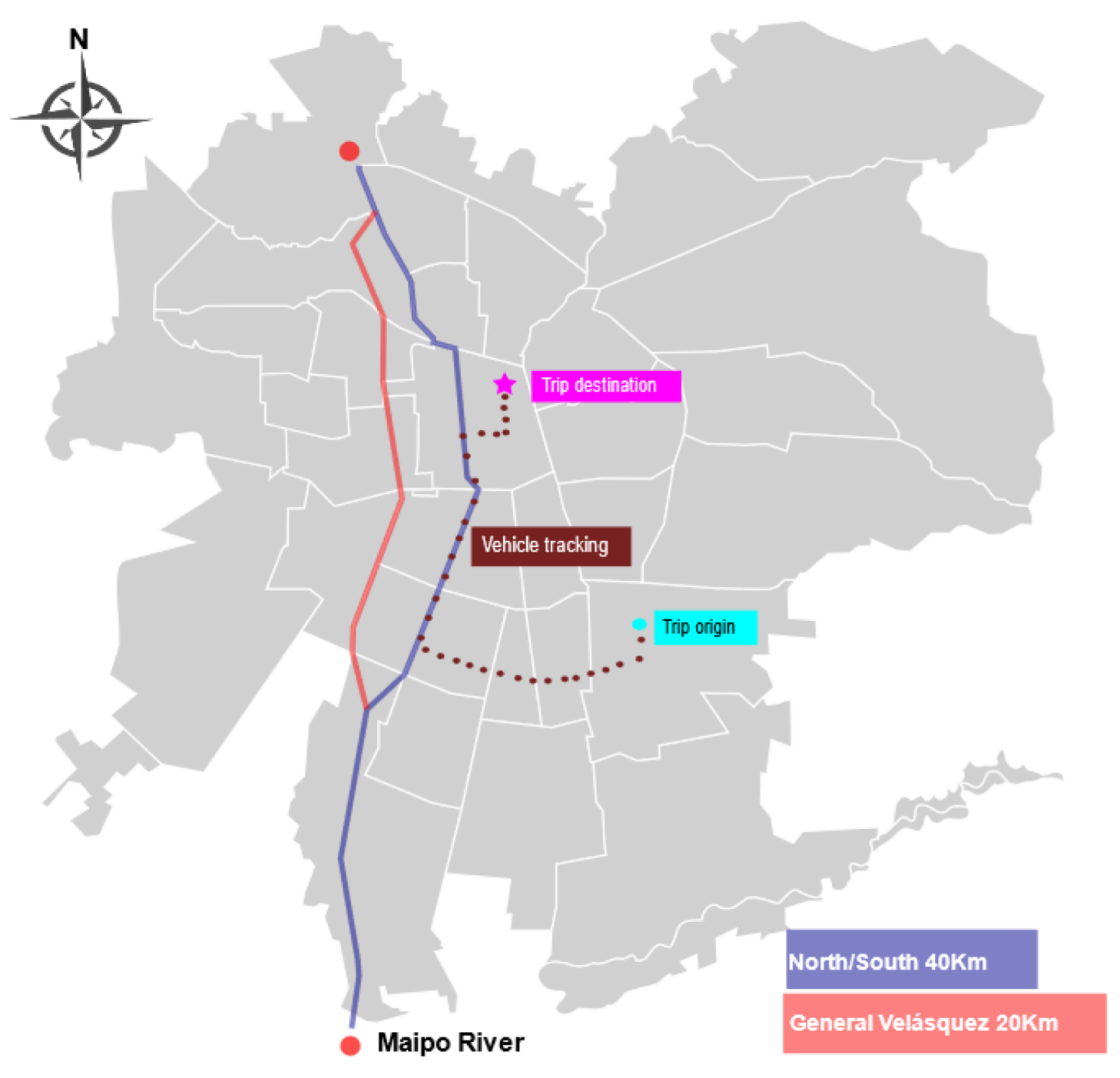
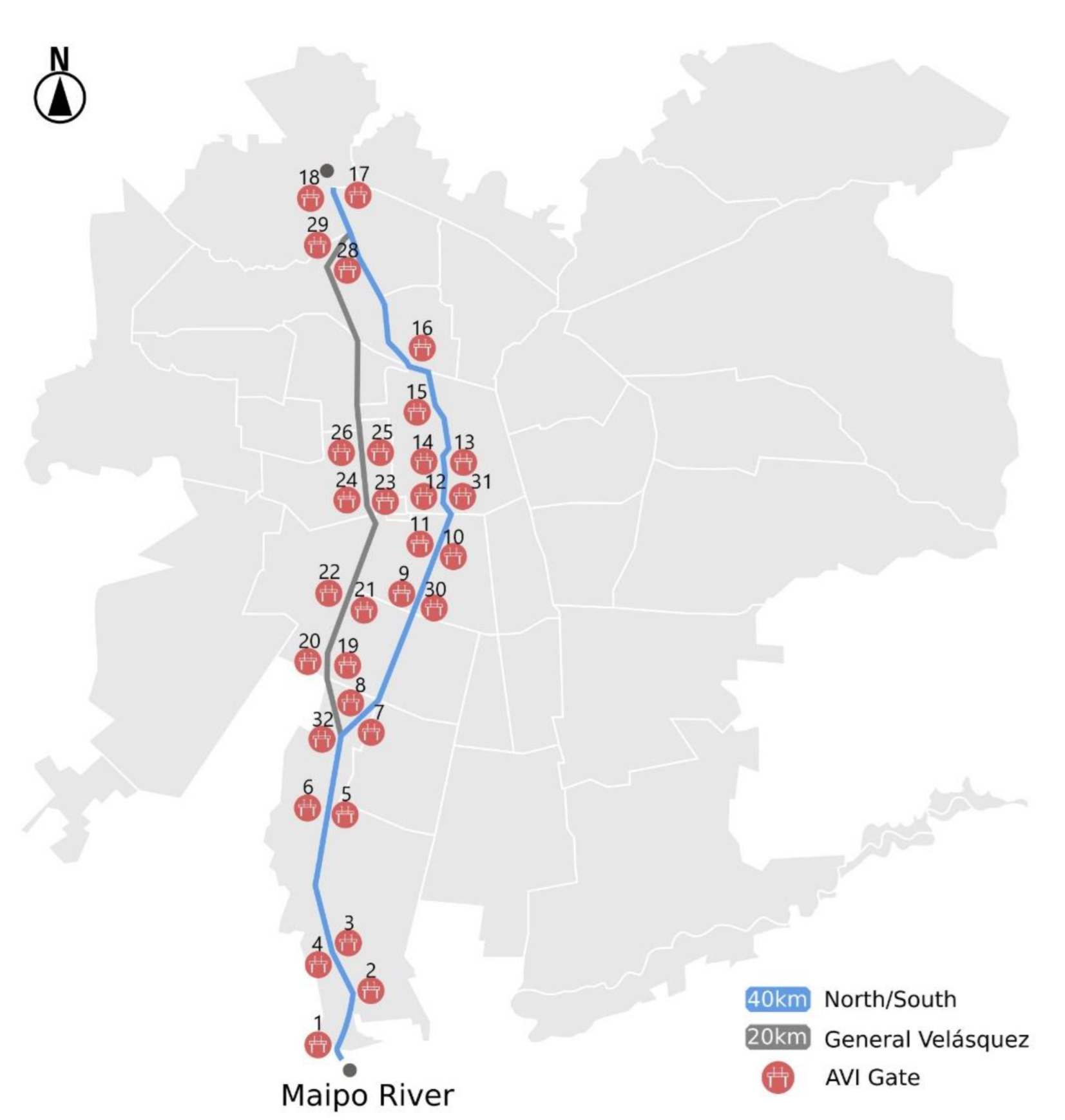
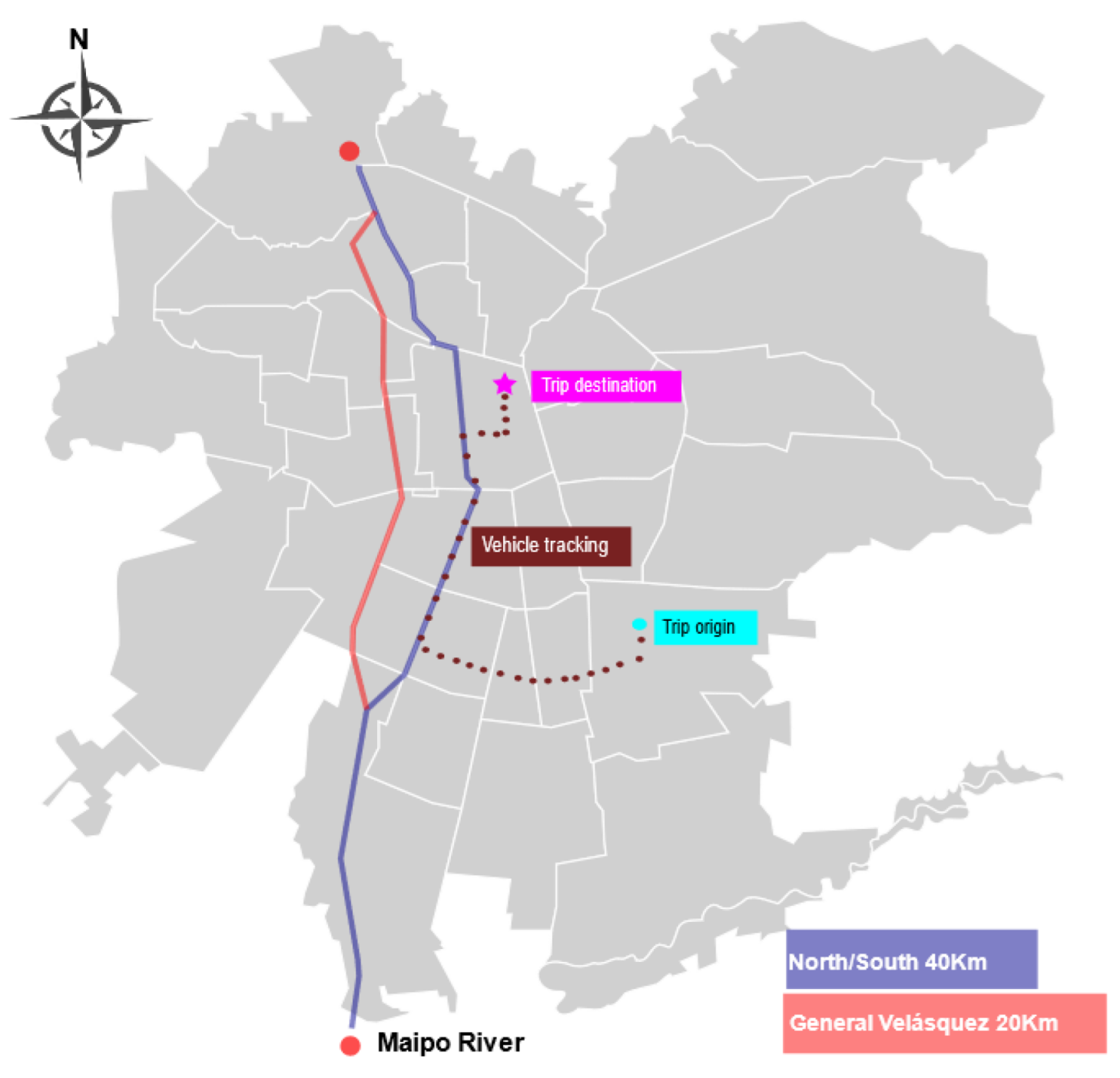
This paper uses a secondary data analysis research method to estimate an origin-destination (OD) matrix for all the trucks traveling on Autopista Central (AC), one of Santiago de Chile’s most important urban highways. For this purpose, we used complete information on the movement of freight vehicles along the highway, collected at discrete points through toll collection gates with free-flow technology. However, this information did not include vehicle movement before or after use of the highway. Therefore, in order to estimate the origins and destinations of trips that used the highway, we proposed a methodology that used two additional sources of information. The first came from a routing company called SimpliRoute (SR), which continuously tracks the operation of a subset of vehicles in the region (some 2200 vehicles) via GPS. The second corresponded to the economic sectors of the companies that own the trucks present in SR or AC data.
There have been multiple efforts in the literature to estimate freight OD matrices using different data sources. The first contributions on this topic use active data gathered from surveys of drivers and companies in charge of freight movement [
11,
12,
14,
15,
16]. However, this type of information has a high acquisition cost and a long update period, which, depending on the type of survey, might be one year or more [
17]. More recent contributions use passive data, mainly gathered from GPS devices, to estimate freight OD matrices [
18,
19,
20,
21,
22]. The disadvantage of this information source is that it is usually biased. This is due to the fact that the freight industry is highly fragmented [
23], and any effort to obtain complete data entails aligning the interests of numerous companies. Therefore, a gap persists in the literature to mitigate the bias generated in the estimation of freight OD matrices when using passive data from a sample of total trips. Moreover, to the best of our knowledge, there are no previous papers that estimate the origins and destinations of all the heavy vehicles that use an urban highway.
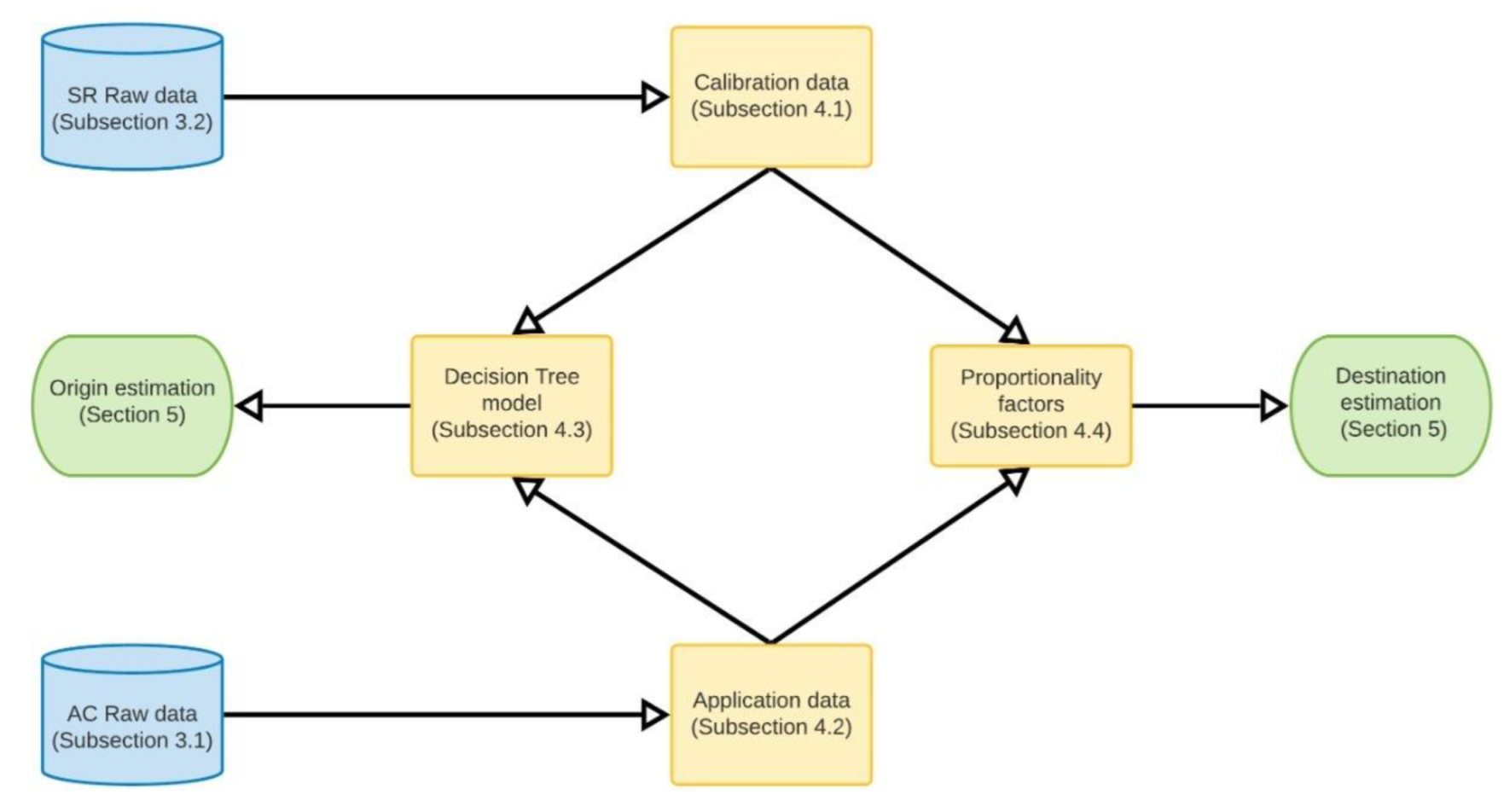
The contribution of this article is twofold. First, we proposed a methodology to estimate the origin of all the trucks traveling on an urban highway. The methodology involved the calibration of a decision tree model using biased GPS data from the routing company we worked with, which was complemented with freight companies’ data from Chile’s Internal Revenue Service. Then, this model was applied to data gathered from free-flow toll gates equipped with Automatic Vehicle Identification (AVI) technology in order to determine the origin of those trips. Second, we estimated the destinations of all the trucks traveling on the highway. To do so, we computed proportionality factors using the trips built from the GPS data, based on the origin municipality. The use of complementary information (AVI and GPS) and decision trees allowed us to mitigate the bias of OD estimation. We believe that the methodology proposed in this research is replicable in other contexts outside Chile, since license plate tracking technology is standard on highways in several countries worldwide, mainly to collect tolls or detect stolen vehicles. Additionally, the methodology requires GPS tracking information from only a subset of the total number of freight vehicles and readily available freight company-related information.
The rest of this article is organized as follows.
Section 2 reviews the literature.
Section 3 describes the data used in this article. In
Section 4, the methodology used to obtain the OD matrix is presented, while
Section 5 applies this methodology to the case of Autopista Central. Finally, in
Section 6, we provide some final remarks, and we conclude by highlighting lines for future research.
5. Results
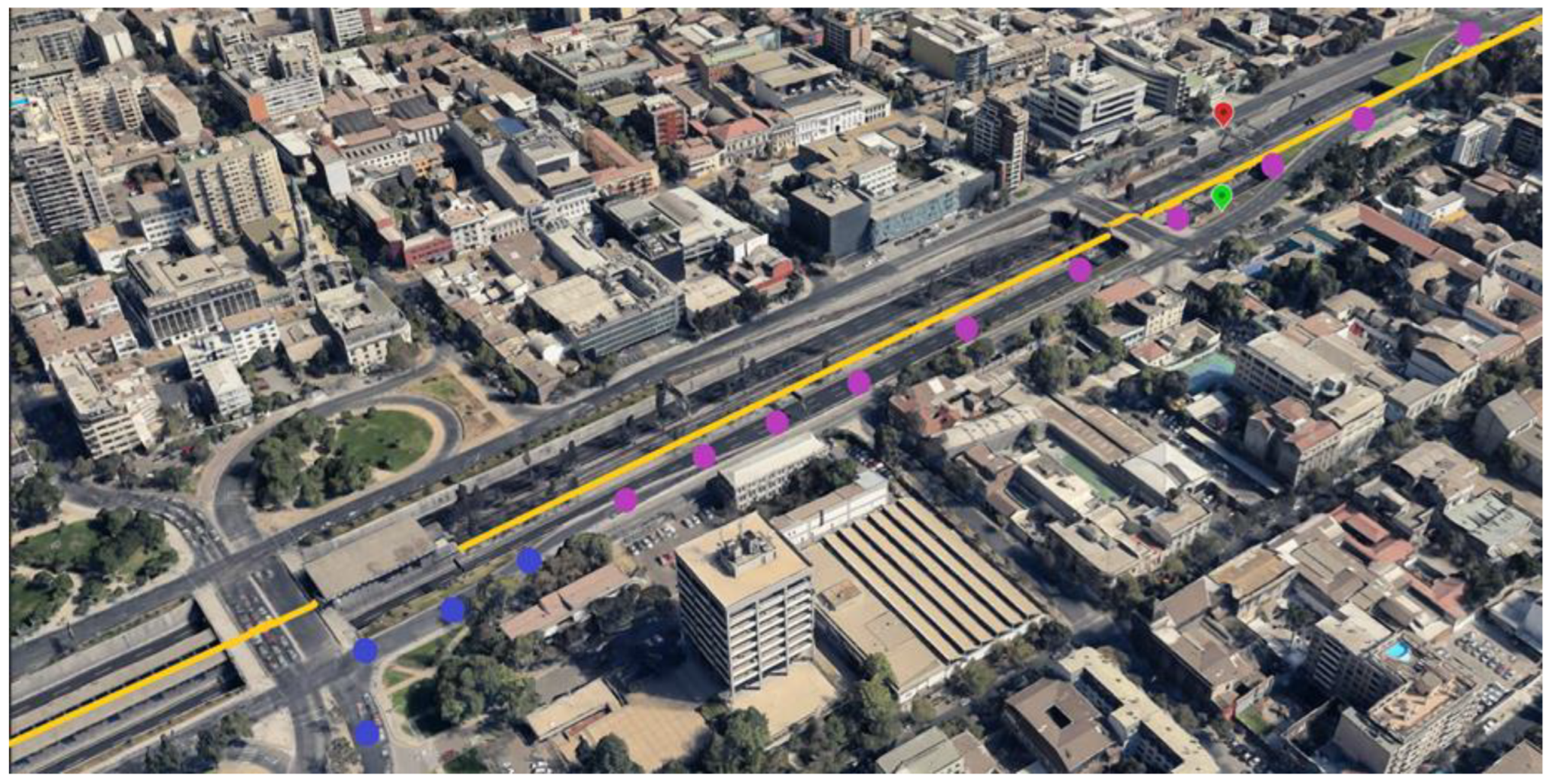
We considered initially the 19,501,223 GPS pings corresponding to the movement of SR vehicles during July 2019. Following the methodology described in
Section 4.1, we identified 570,696 GPS pings on the highway, which led to 12,097 trips that used the highway. Subsequently, by considering only the first segment of the day for each vehicle, this dataset was reduced to 5190 trips that used the highway. For each of these trips, we generated the variables shown in
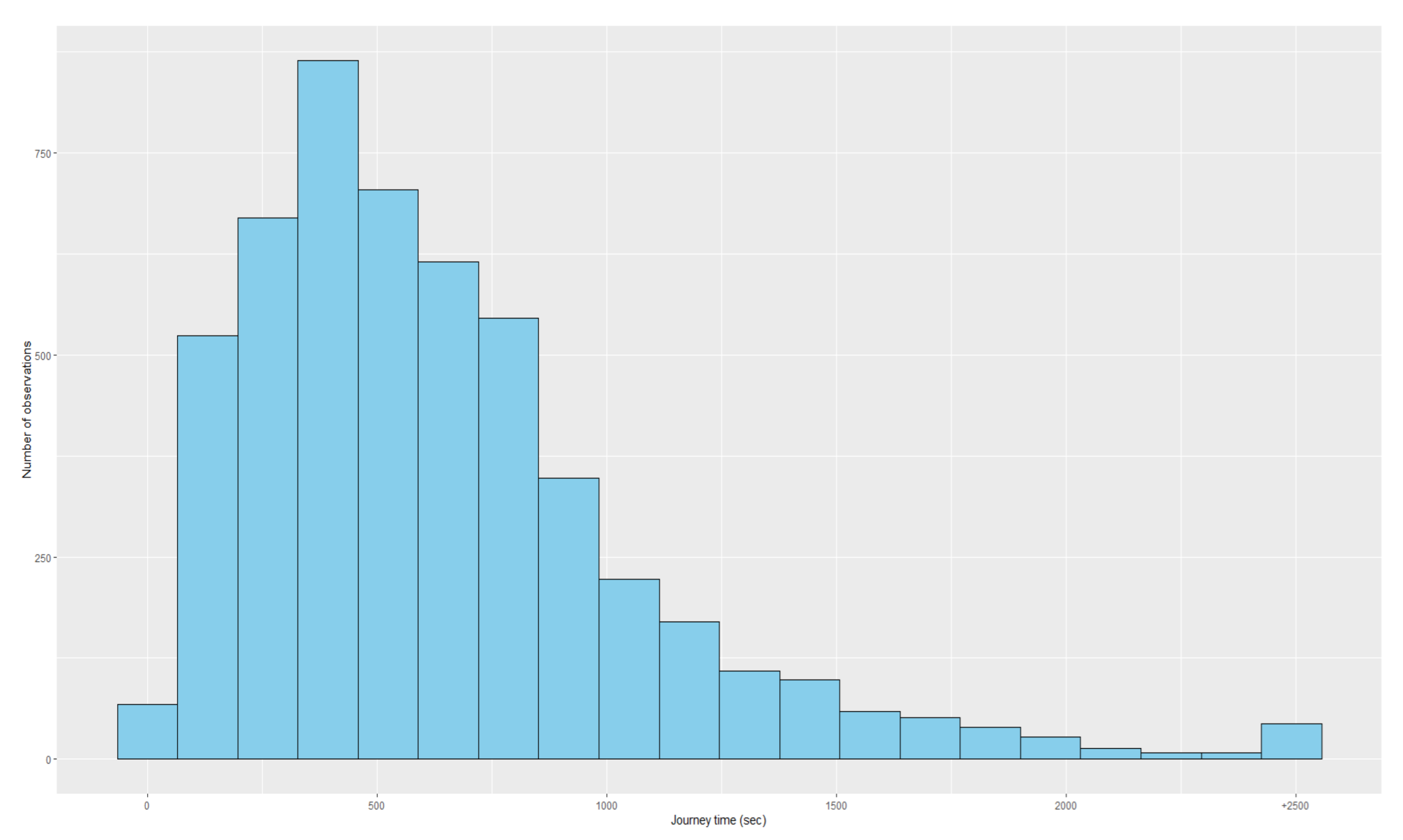
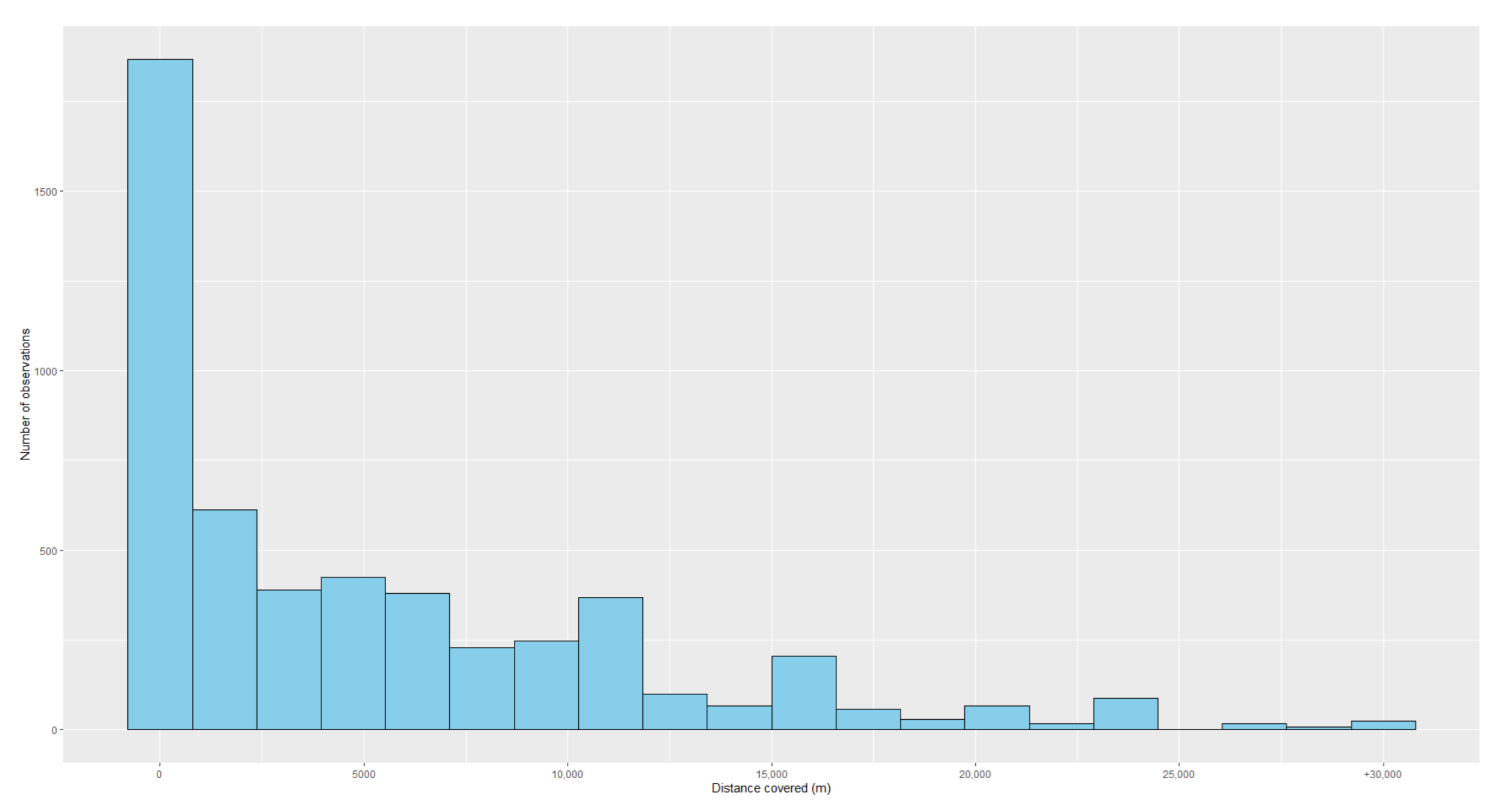
Table 7. A descriptive analysis of these variables is presented in
Table 8, while histograms of the numeric variables can be found in
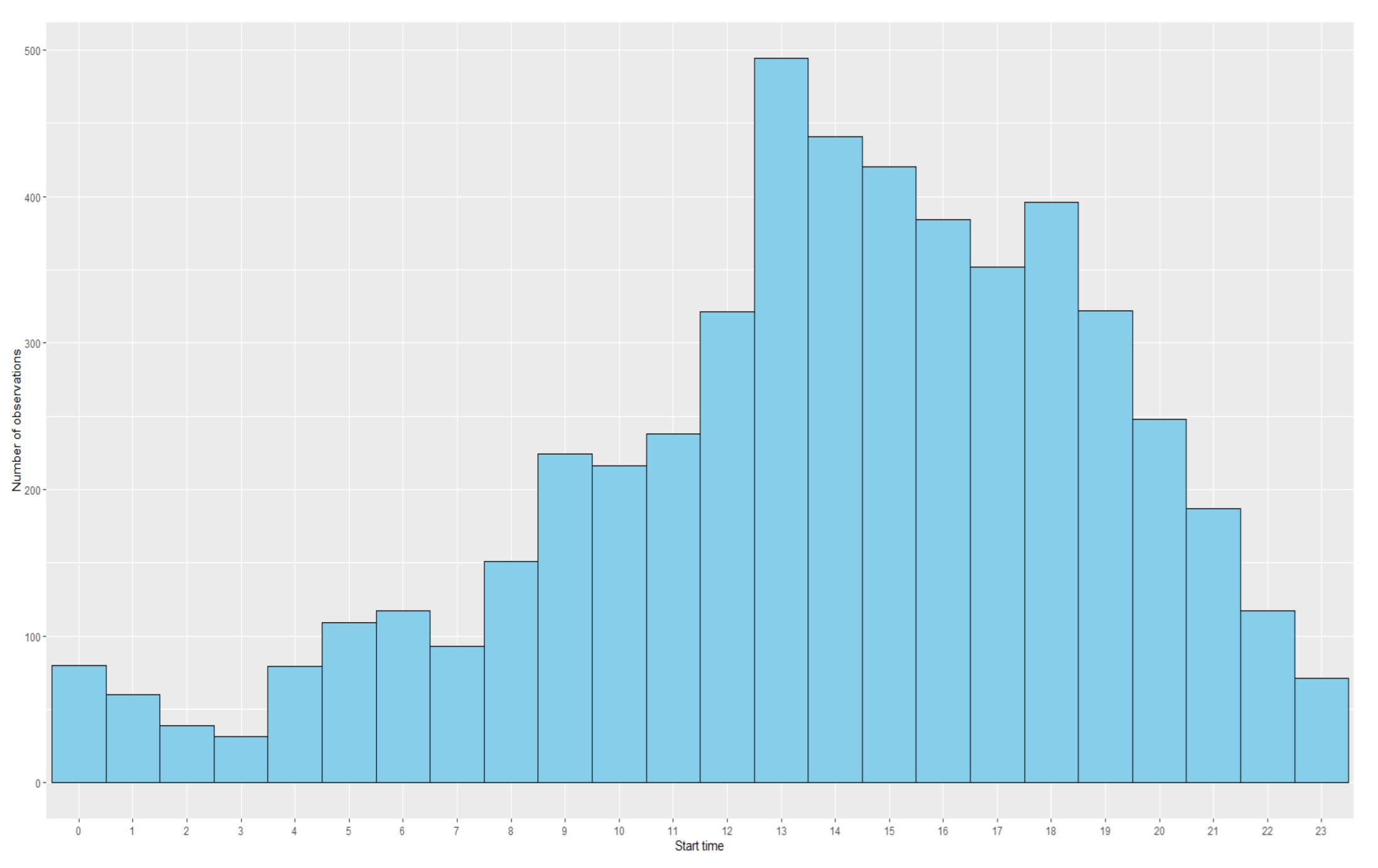
Figure A1,
Figure A2 and
Figure A3 in the
Appendix A.
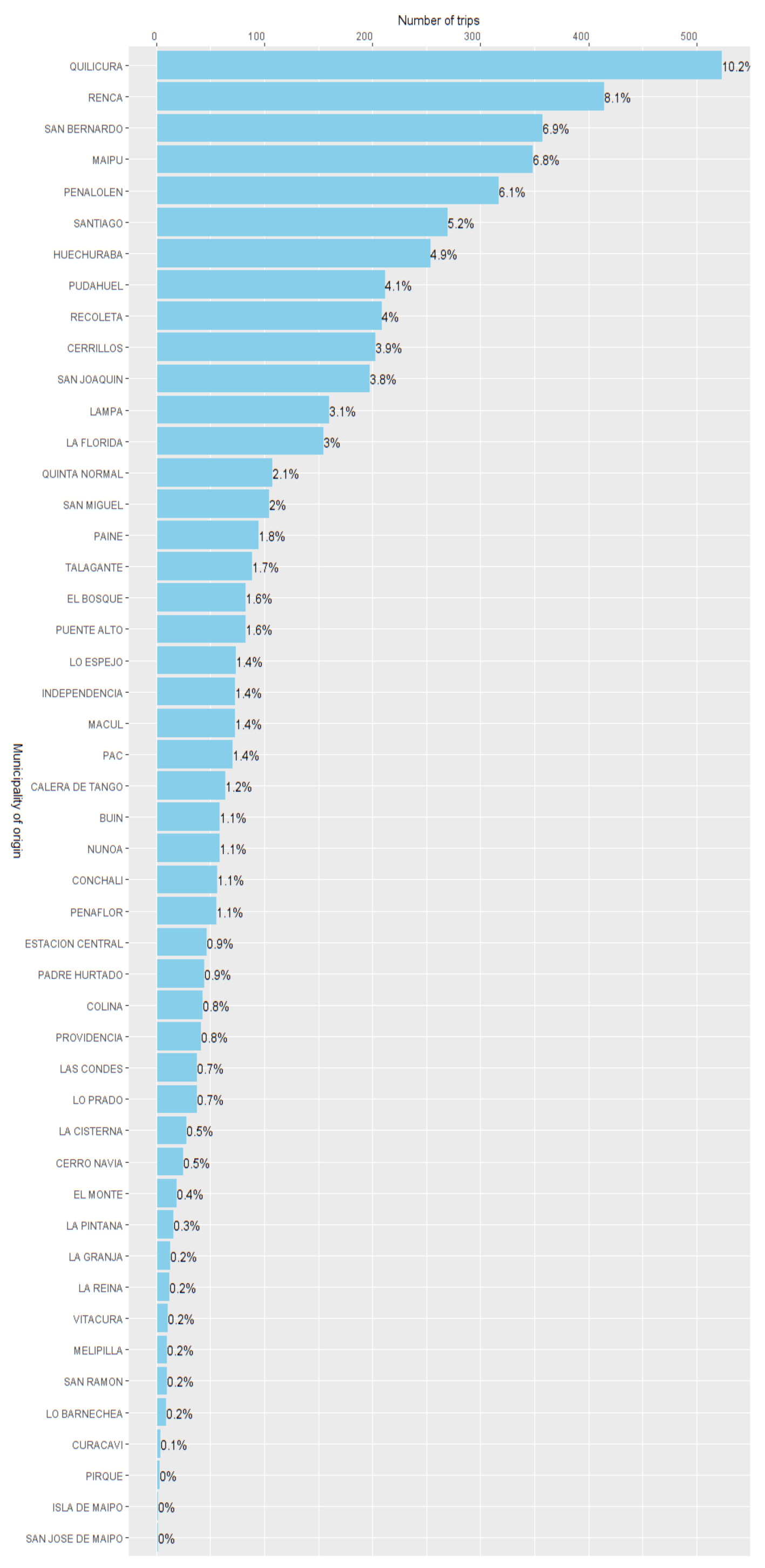
Figure 6 shows the distribution of trip origins, which provides the first insights into the AC’s freight trips.
After the SR final dataset was constructed, we trained the decision tree described in
Section 4.3. First, to assess the model’s performance, we adopted a training validation approach. In particular, we trained the model on a random subset of 4512 observations (80%), pruning the tree at the level that reached the minimum error on this training base. Then, we used this model to predict the remaining 1038 observations (20%). Using 80% of the sample to train statistical learning models and using the remaining 20% to validate it is a common practice (e.g., [
30,
31,
32]). Using more balanced training and validation datasets sizes (e.g., 50%–50%) has the disadvantage of reducing the training set size, and consequently, increasing the trained model variance [
33]. This, coupled with decision trees being high-variance methods [
34], can lead to unreliable estimates.
With this approach, we obtained a validation mean absolute percentage validation error (MAPE) of 14.5%. This error was in line with results reported in the literature for similar contexts, for example, passenger origin–destination estimates using statistical learning methods. For instance, using a probabilistic model, Dai et al. [
35] reports an average MAPE of 13.26% for subway short-term passenger inflow in Zhengzhou City, China. Similarly, using convolutional neural networks, Yao et al. [
36] shows that its best-performing model presents a MAPE of 24.3% for taxi flows in Beijing, China.
We then adjusted the decision tree model using the complete SR final database. After pruning the tree at the lowest training error level, we obtained a tree of 44 levels.
Table 9 shows the variable importance in the tree, as described in
Section 4.3. The gate of entry was the variable with the highest importance since, intuitively, it tended to be the one most correlated with the start of the trip. Likewise, note that the start time was also a high-importance variable. From this, we could imply that, depending on the municipality, trips started at significantly different times. Conversely, the economic sector was the least important variable for the decision tree. Therefore, the trip start municipality was not significantly influenced by the economic sector of the vehicle owner company.
Afterward, the AC database was generated following
Section 4.2. To do so, we considered the 3,751,553 AVI gate observations during July 2019. From this, we constructed 759,576 AC trips. This dataset was reduced to 355,400 trips by considering the day’s first trip for each license plate only.
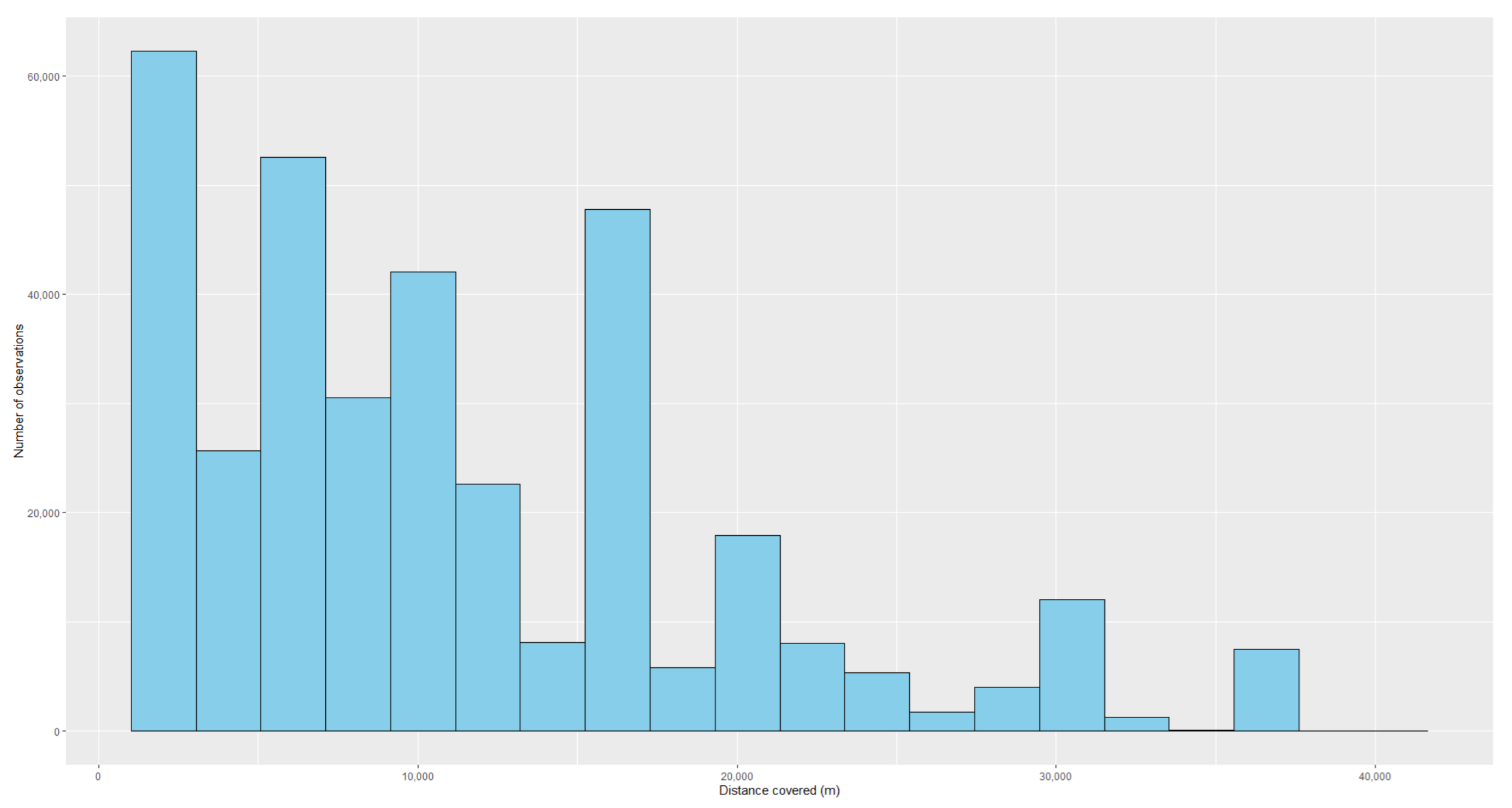
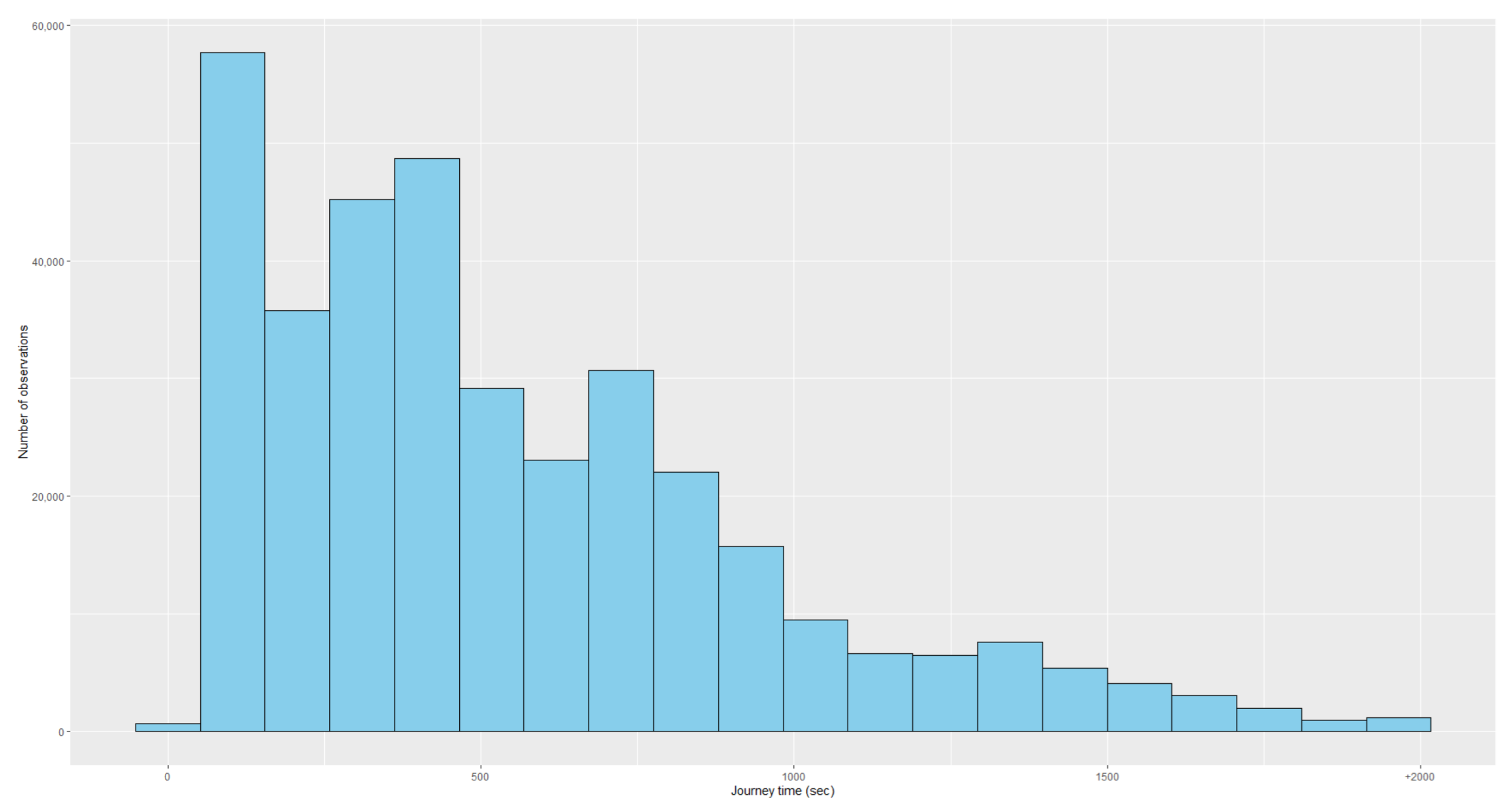
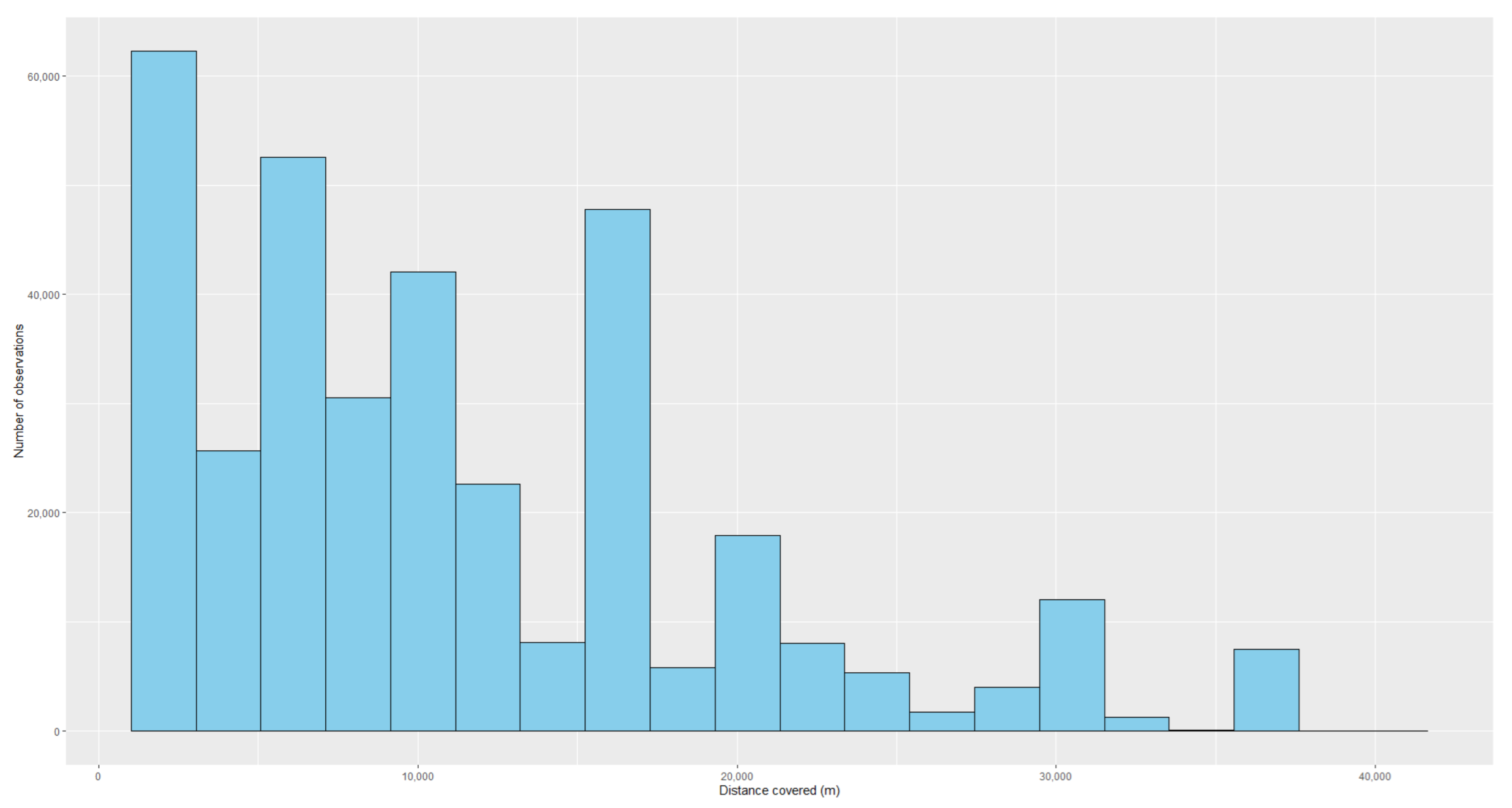
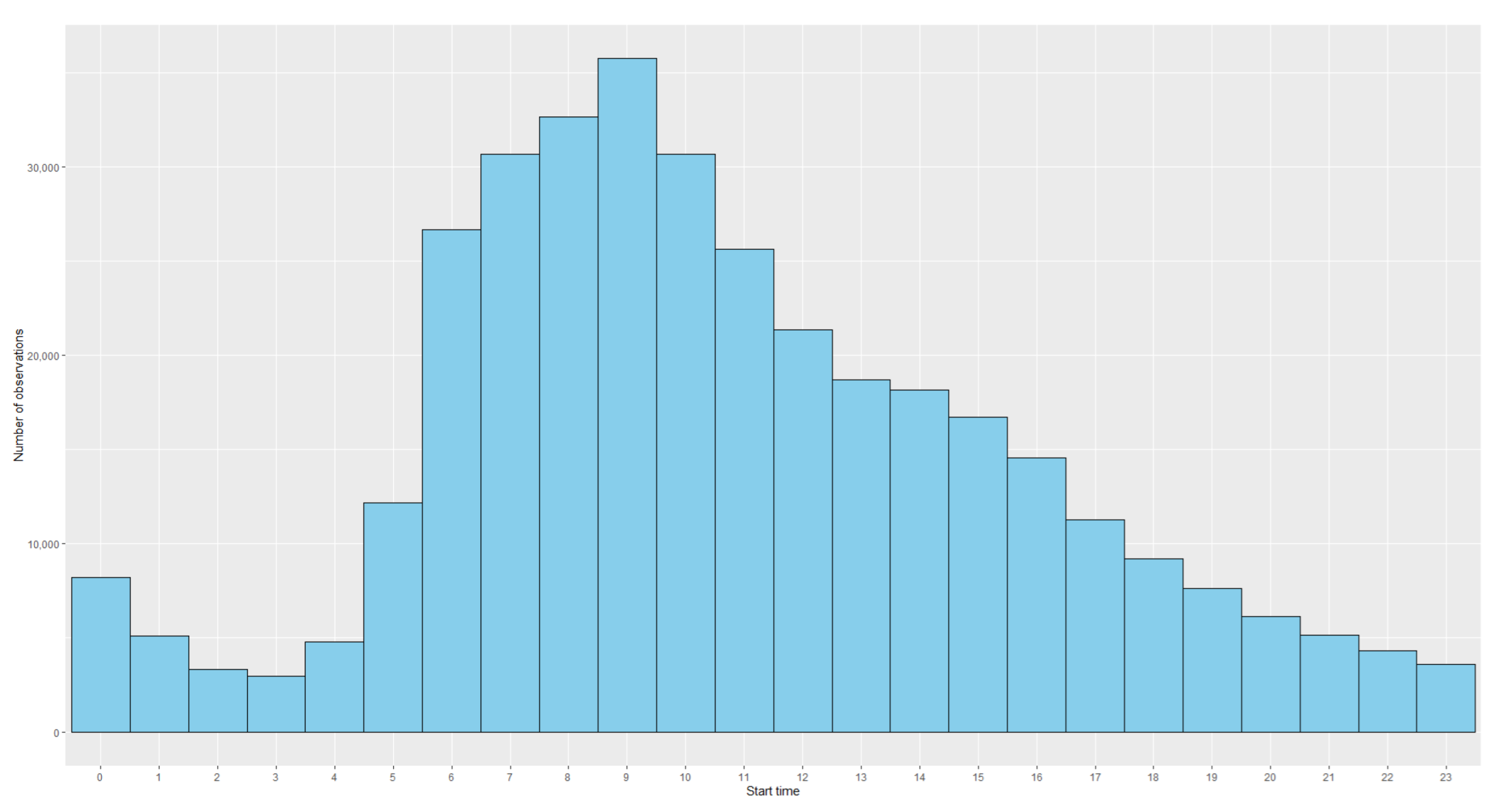
Table 10 shows a descriptive analysis of the variables associated with these trips, while histograms of the numeric variables can be found in
Figure A4,
Figure A5 and
Figure A6 in the
Appendix A.
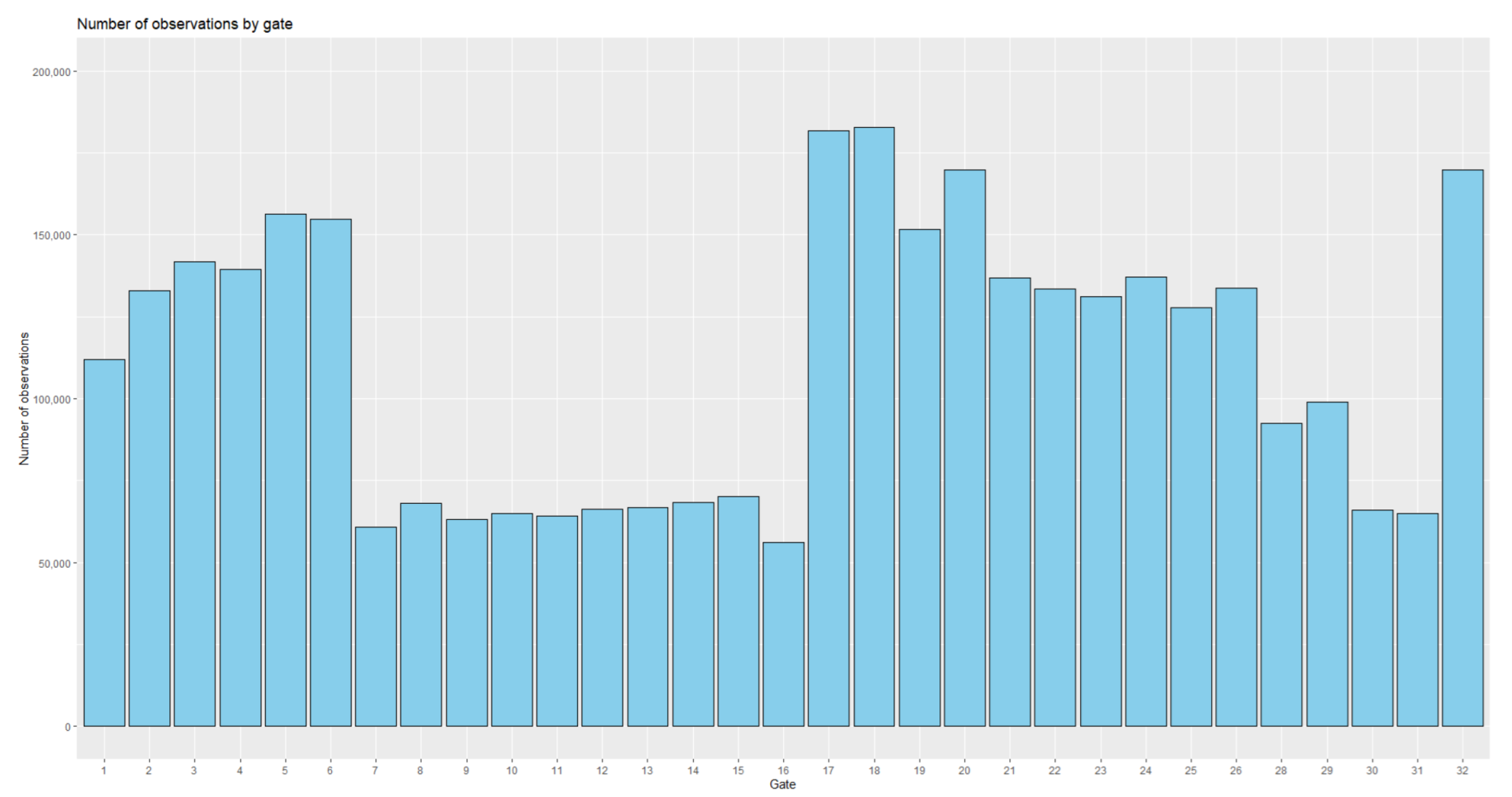
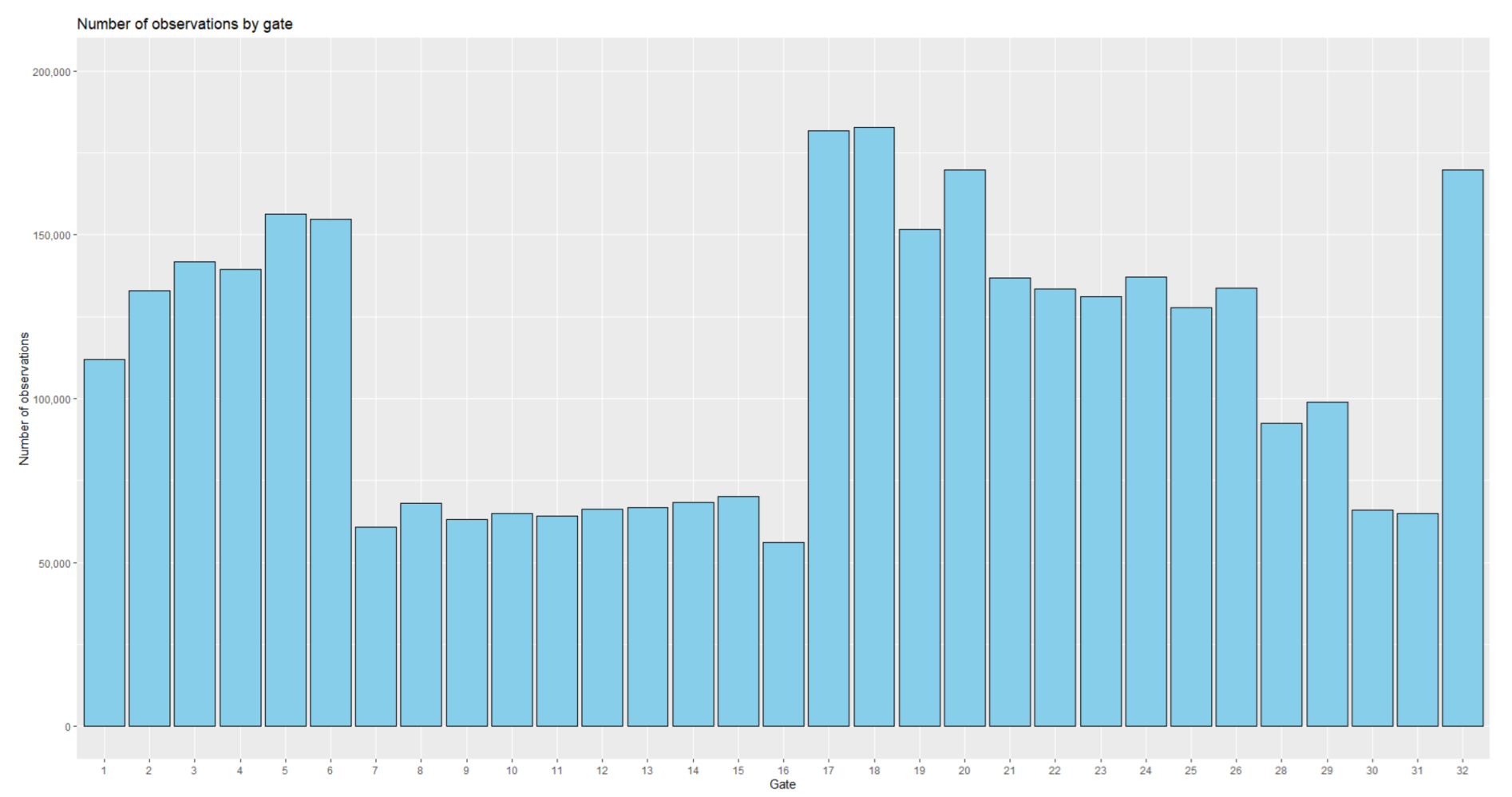
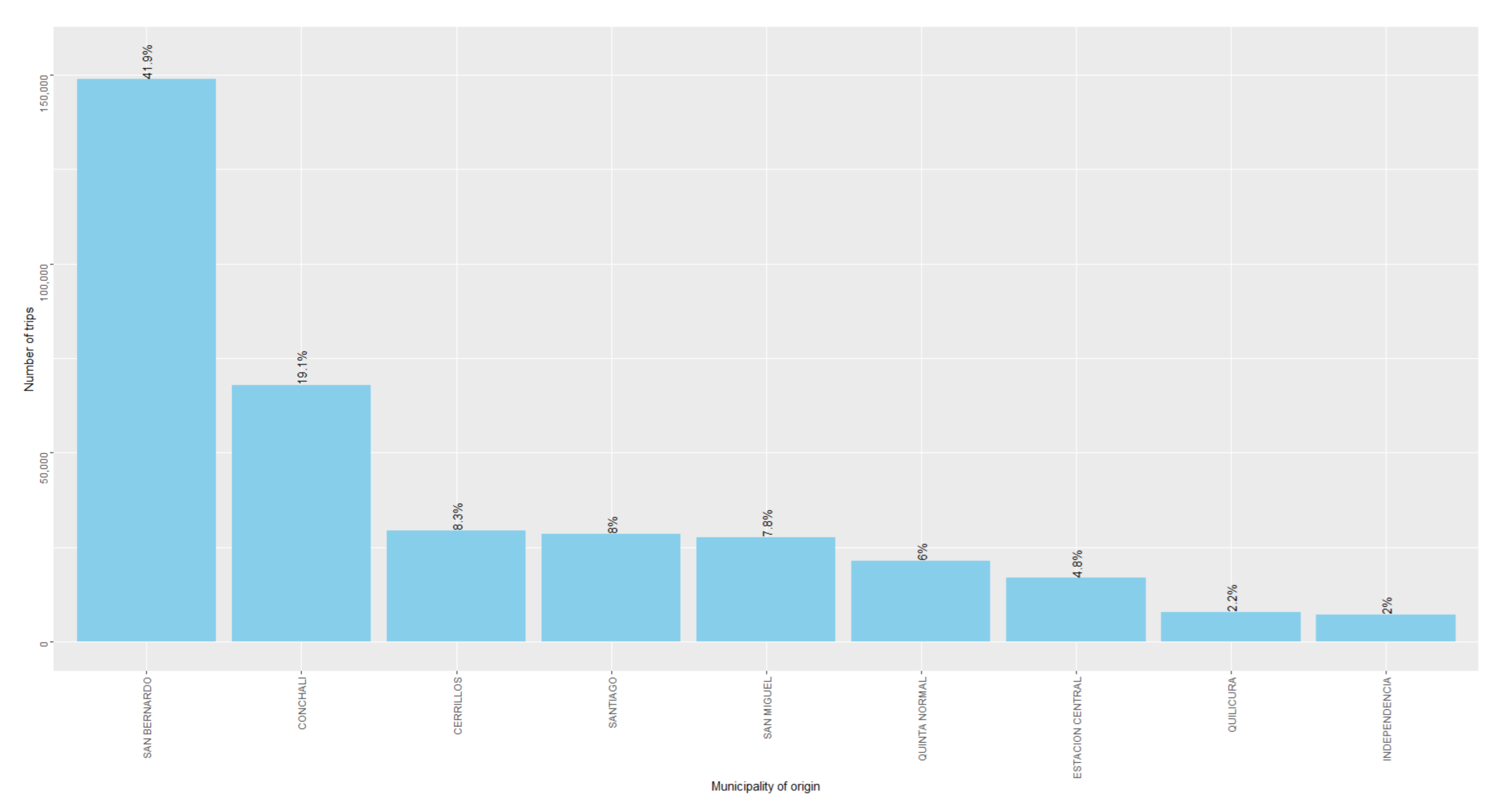
Figure 7 shows the distribution of the number of trips depending on the entry gate’s municipality. This distribution provided further insights into the AC’s freight trip origins.
Once the AC database was obtained, the decision tree previously trained in the complete SR base was applied to the observations obtained from AC, calculating the values of
for all the municipalities
j ∈ J and economic sectors
s ∈ S following Equation (3). Using Equation (4), summing over the economic sectors
s ∈ S, we obtained the number of trips
starting at each municipality
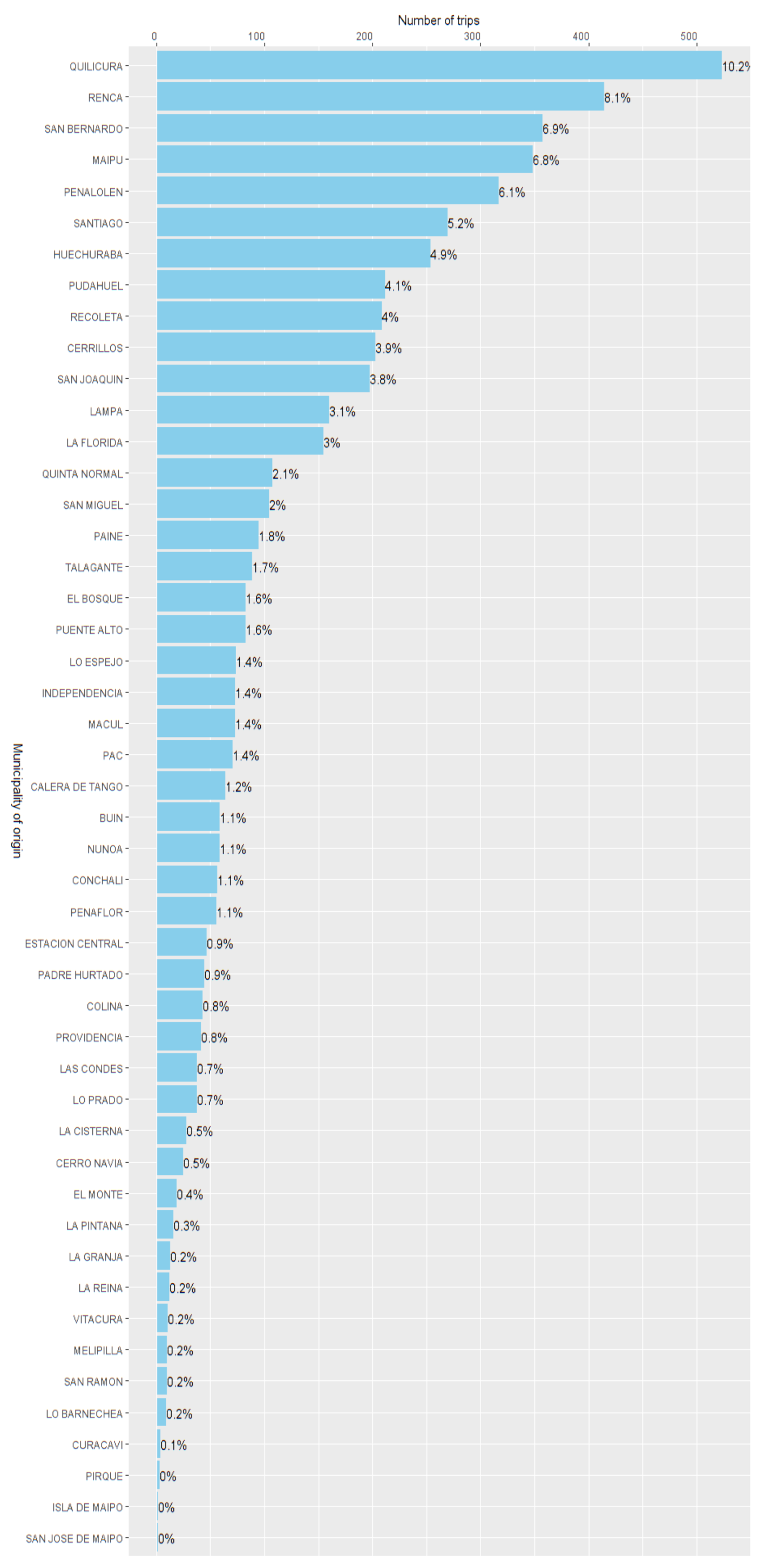
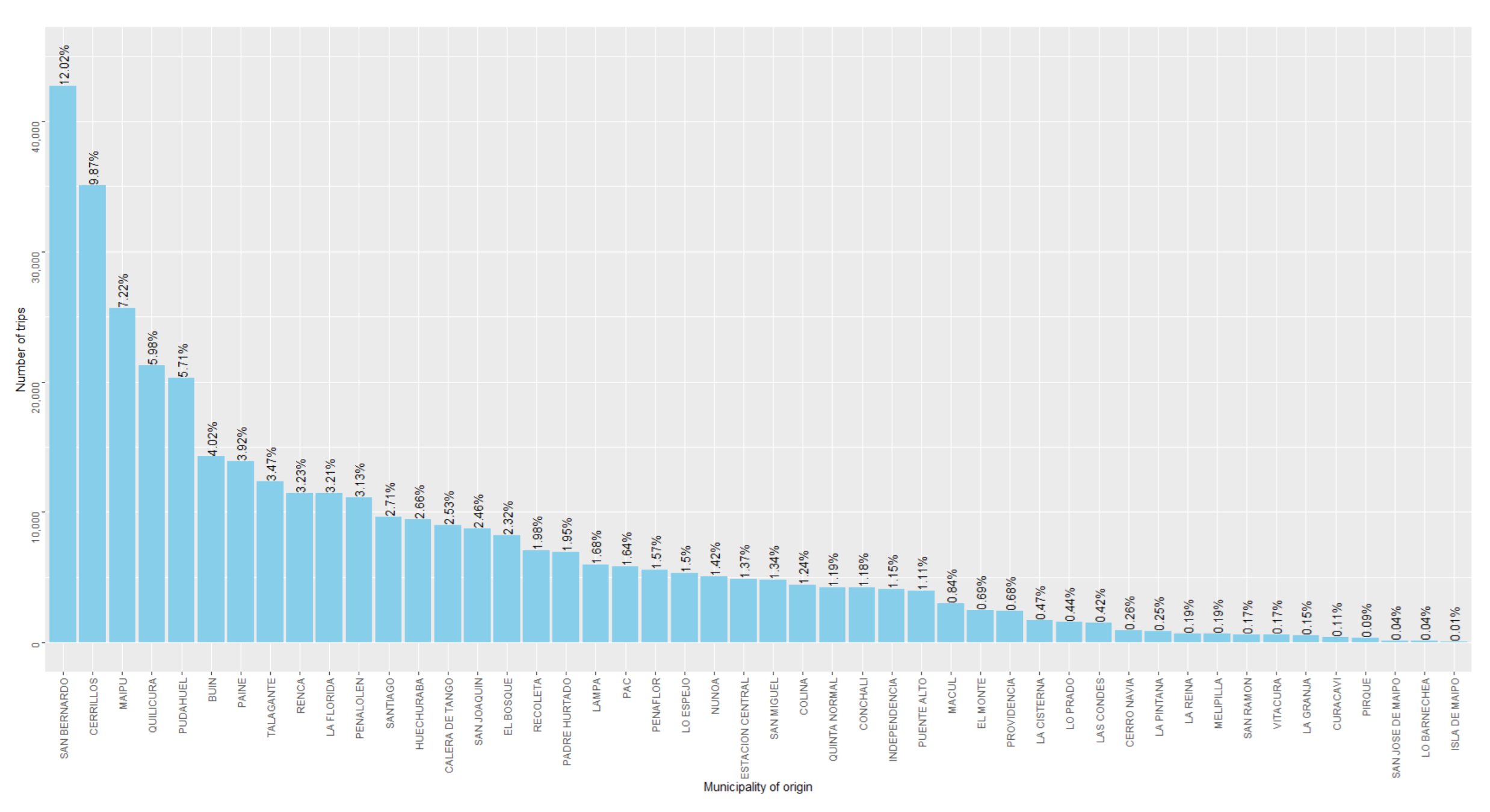
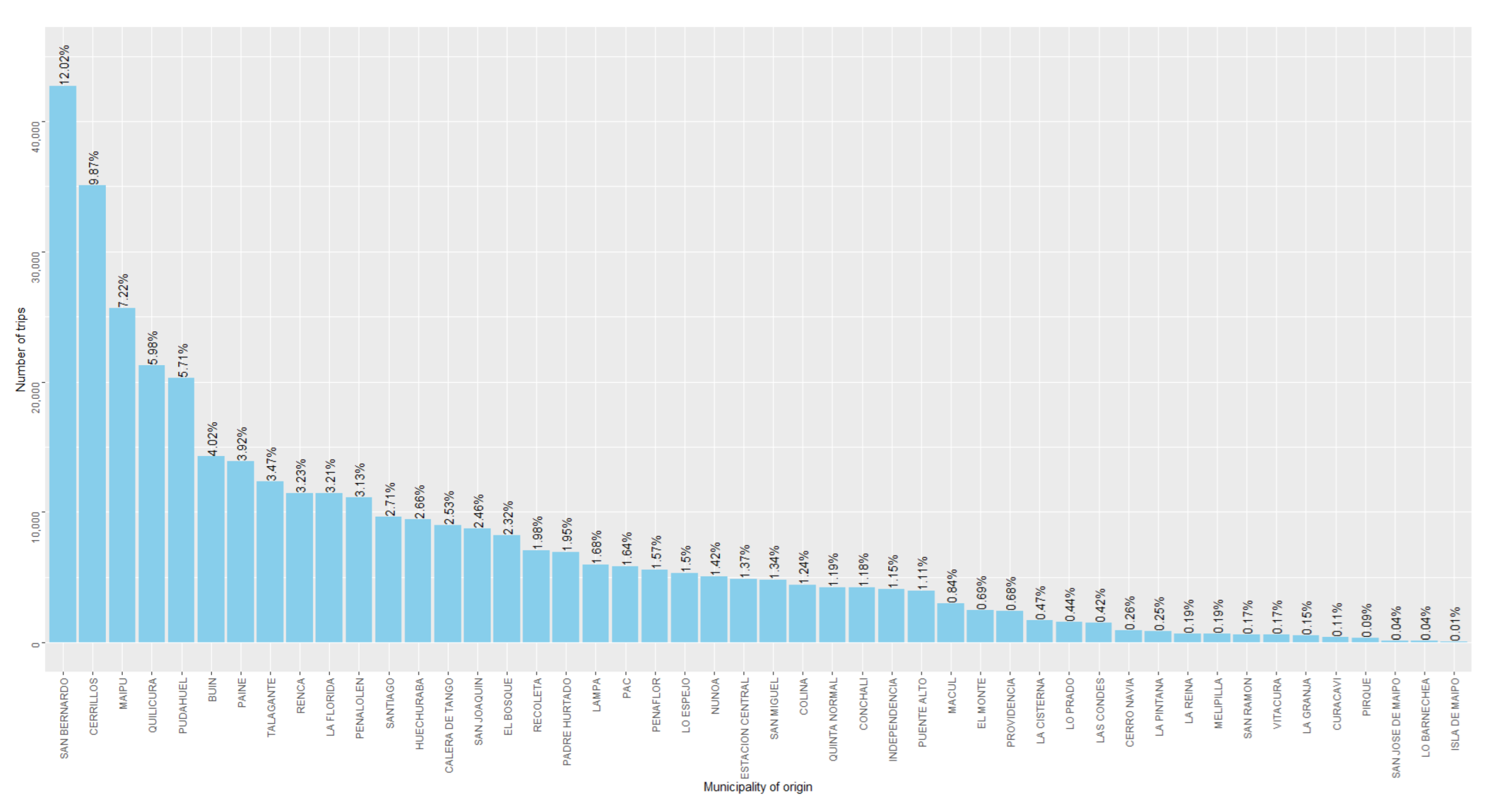
j ∈ J. The distribution of the estimated trips per origin is depicted in
Figure 8.
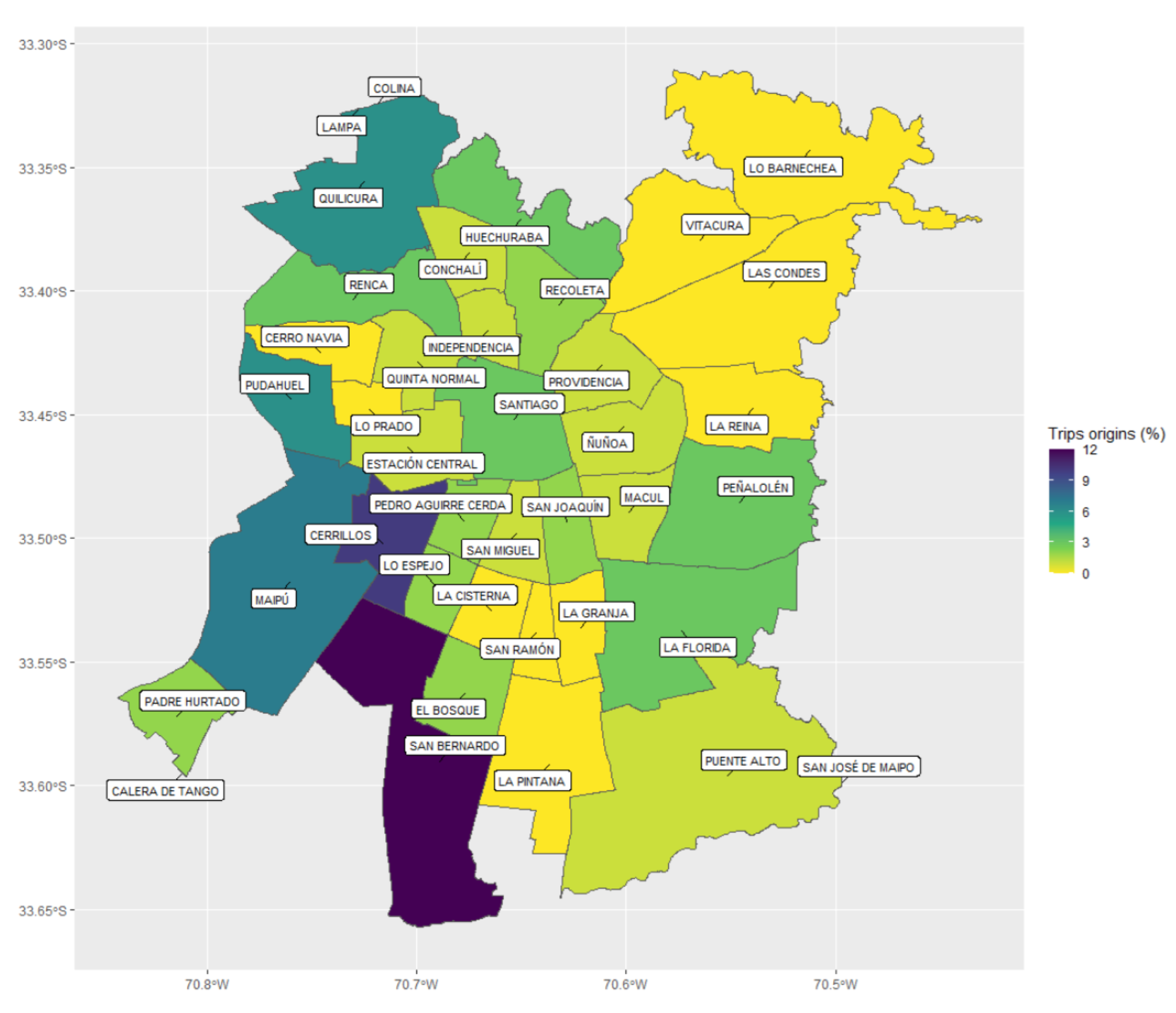
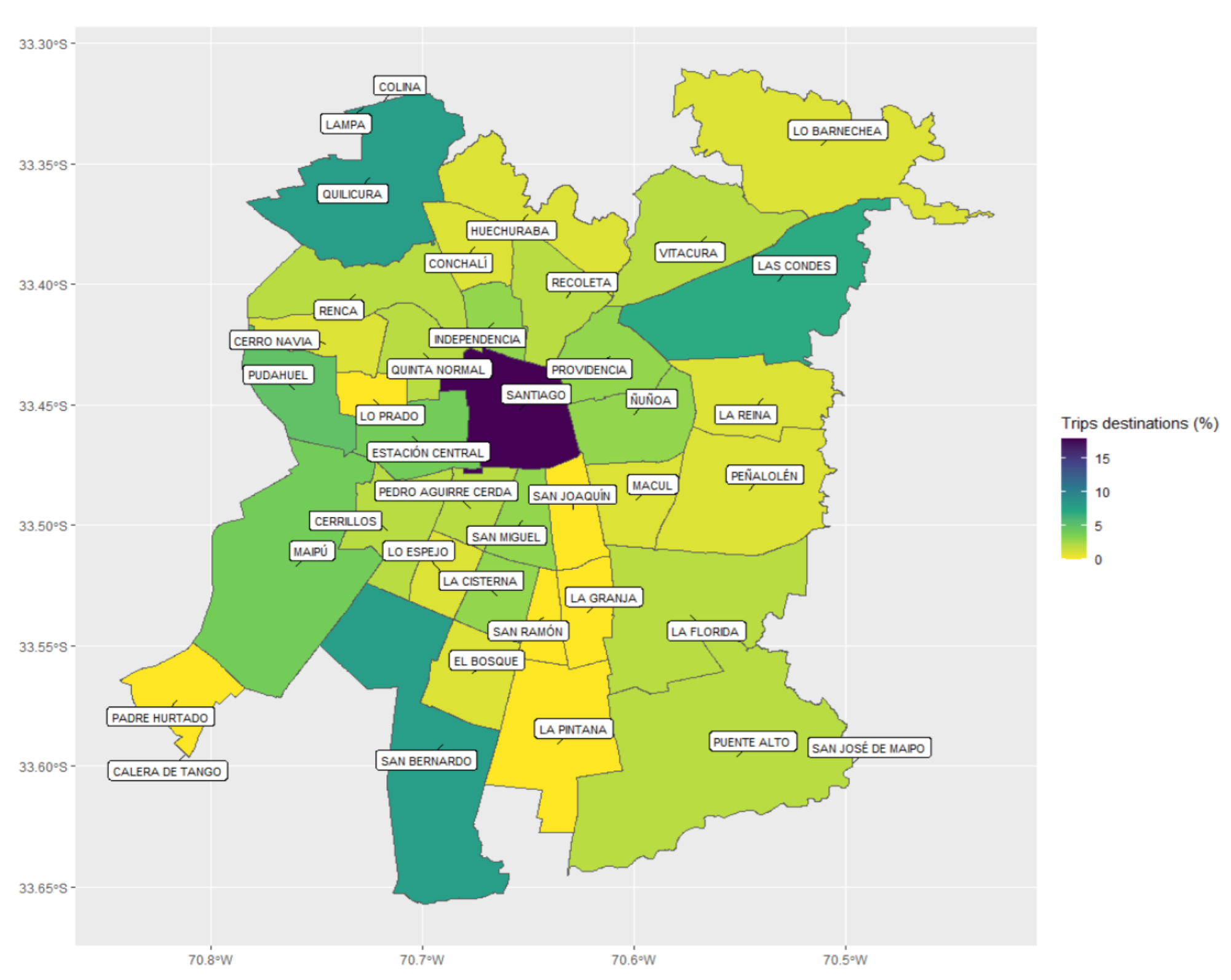
Figure 9 and
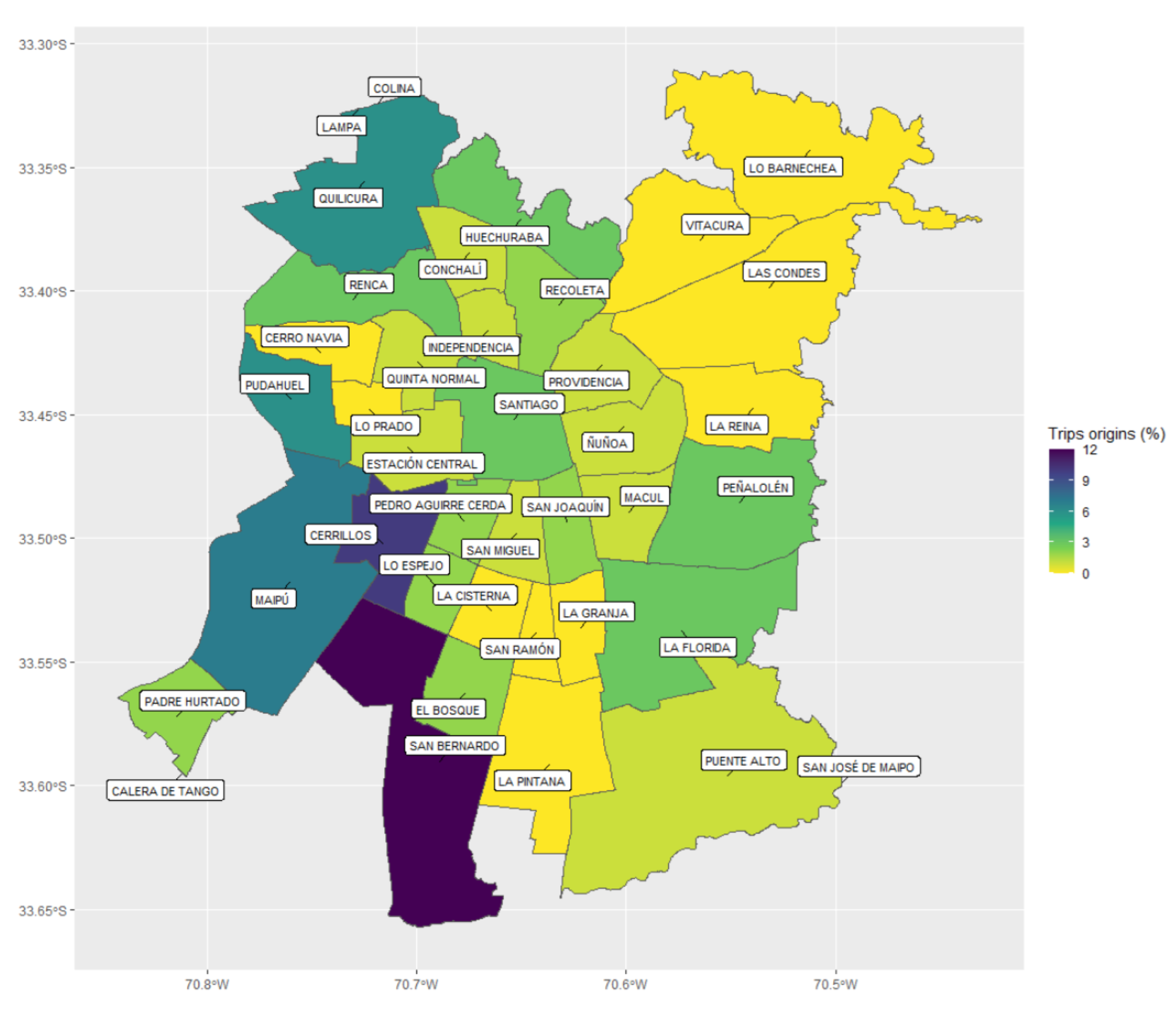
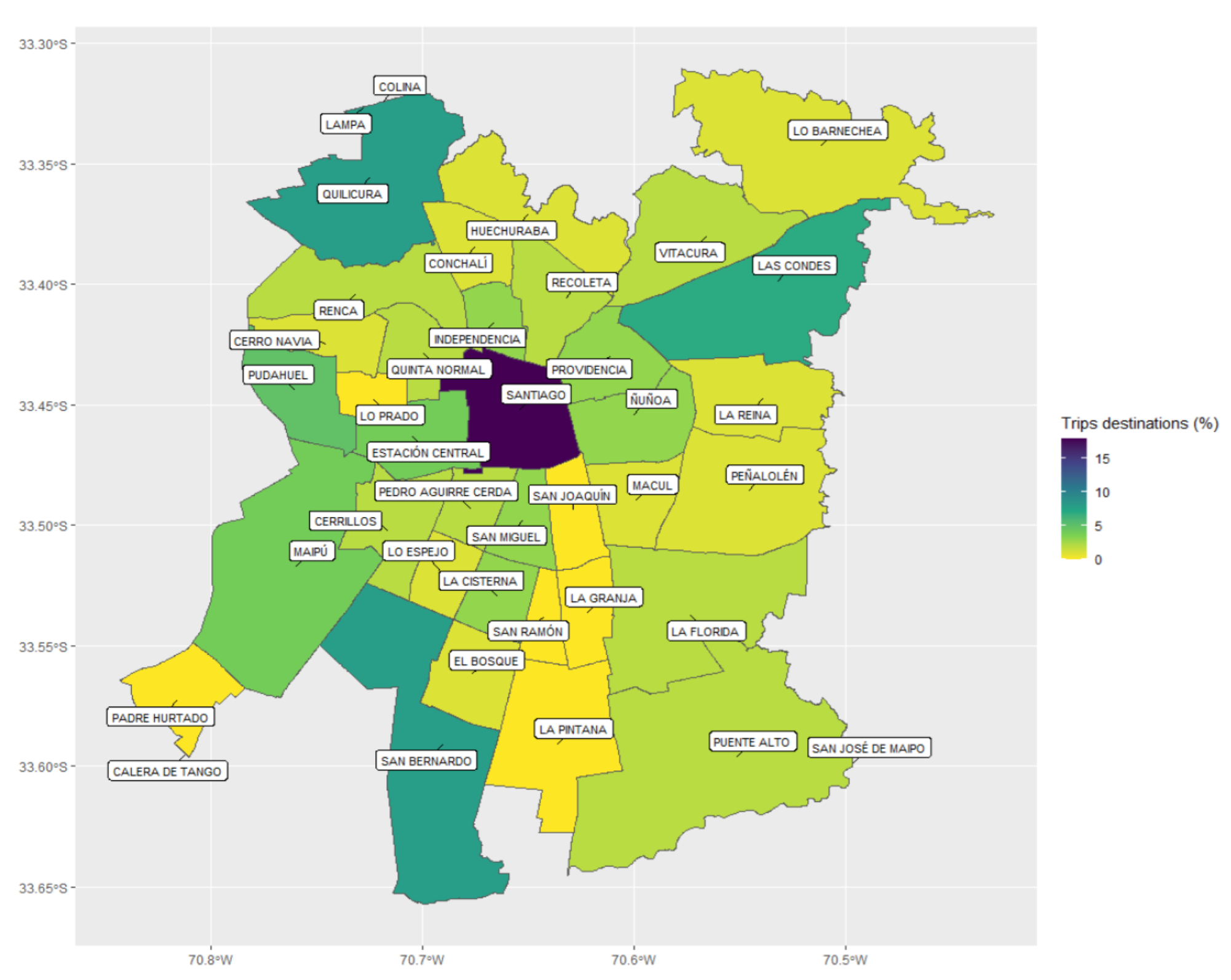
Figure 10 present the distribution maps of trip origins and destinations per municipality, respectively. From
Figure 9, we could see that most of the trips started on the westernmost outskirts. The suburbanization of warehousing is an increasingly common phenomenon in cities [
37], and it has been termed as “Logistics Sprawl” [
38]. Indeed, for example, in most US cities, freight distribution activity has moved from its traditional central city locations to suburban in the last decades [
39]. The main reason for this shift is the increase in land prices in central areas, combined with both the availability of affordable land and connections to transport infrastructure in suburban locations [
40]. This last is indeed the case of Santiago, where the westernmost municipalities provide at the same time some of the lowest land prices and connections to the largest urban highways and the two most important ports in the country, Valparaíso and San Antonio.
This pattern of freight trips brings multiple challenges to cities. For example, more distant terminals increase the freight transport total mileage since central locations—the main destinations of the trips—lack affordable and available land to locate logistics facilities [
38]. This, in turn, increases both congestion and total emissions generated by logistics activities [
41]. In this regard, different measures and policies have been proposed to make urban logistics more sustainable. For instance, some authors argue that local authorities should evaluate the benefits of easing the presence of logistics facilities in the inner city to reduce travel distances (e.g., [
42]), while other authors have shown that freight time restrictions can help alleviate the negative effects of logistics sprawl [
43].
As in most countries, there is no public data in Chile to validate these results. For this reason, we proposed a validation based on land use information provided by Chile’s Internal Revenue Service. This method establishes the total square meters destined for commercial land use for each municipality. Subsequently, we computed the Pearson correlation between such land use and the proportion of trips by origin obtained according to (i) original distribution of SR data (
Figure 6), (ii) distribution according to the municipality of the gate of entry of the trip (
Figure 7), and (iii) the distribution predicted by our approach (
Figure 8). These correlations were 0.504, −0.501, and 0.548, respectively. Thus, our approach maximized the mentioned correlation. This suggests that our OD matrix could better represent the distribution of commercial activities in the city, compared to the other two simpler approaches, by mitigating the bias of the GPS data.
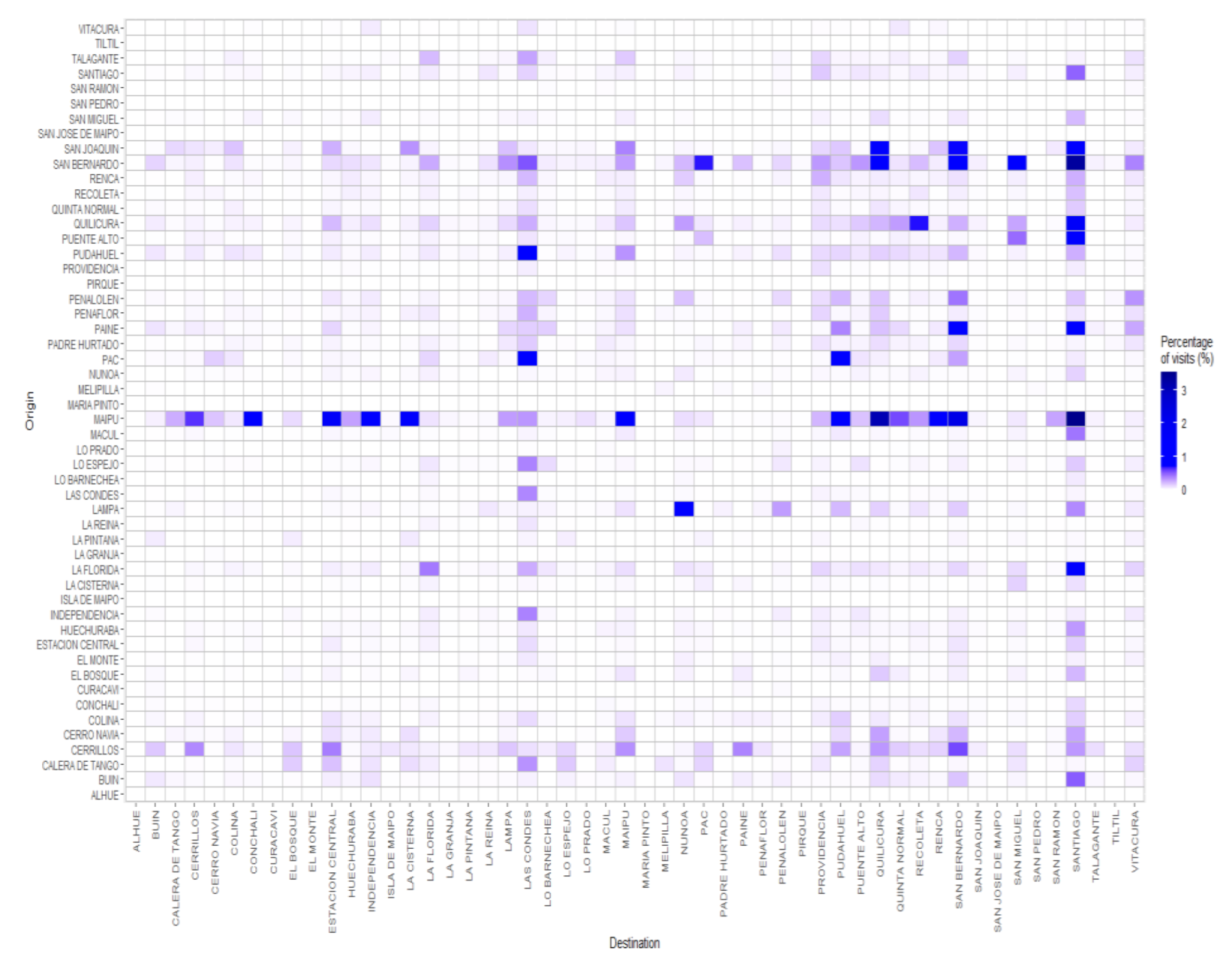
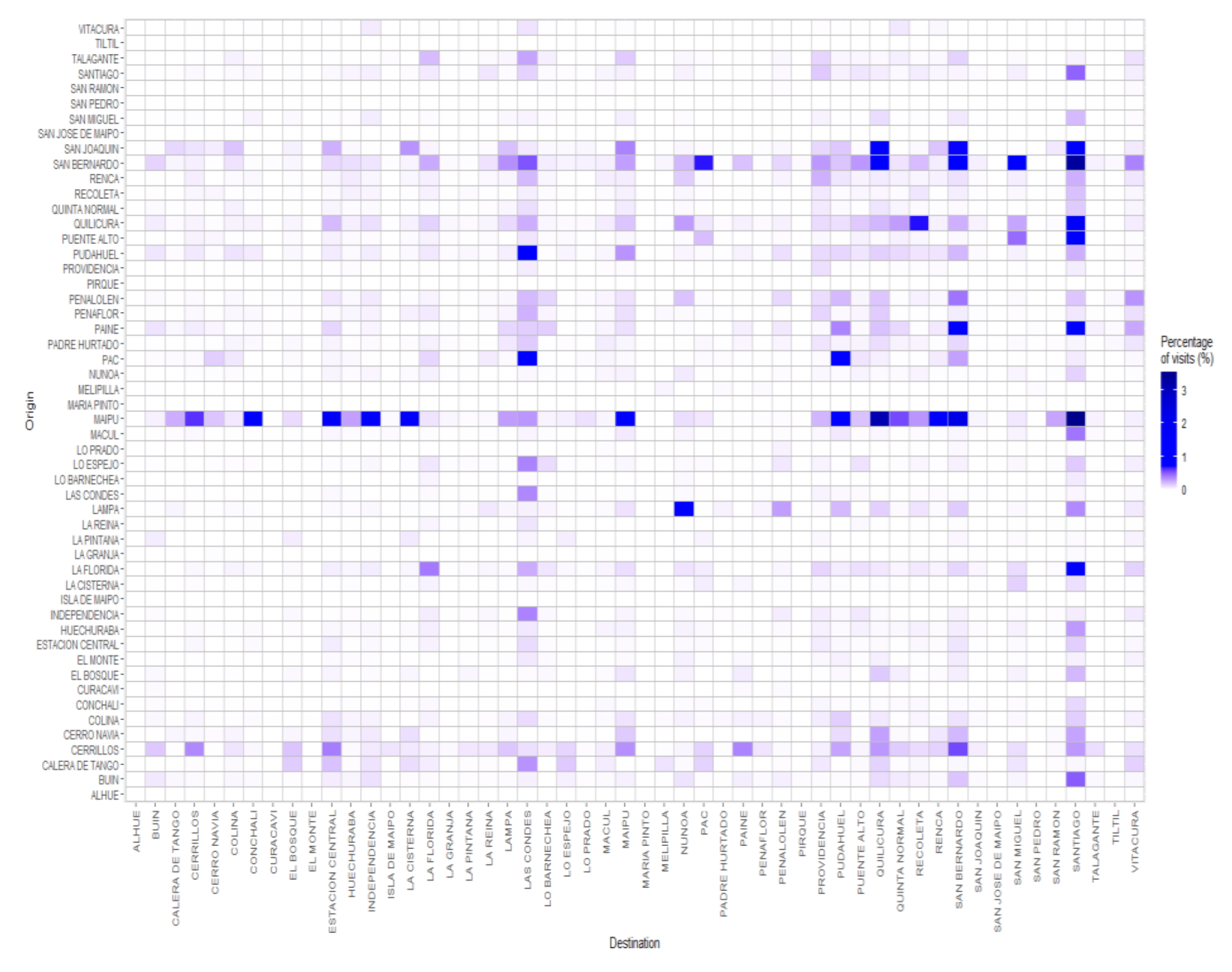
Finally, using Equations (5) and (6), we estimated the entries
of the estimated OD matrix.
Figure 11 shows these results as percentages of the overall estimated visits.
6. Discussion and Conclusions
Freight transportation can generate several negative externalities such as pollution, congestion, and wear and tear on infrastructure. These externalities negatively impact the urban environment [
44]. Thus, it becomes relevant to characterize freight transportation to facilitate the implementation of public policies designed to mitigate these problems. This assessment is particularly important in cities, since pollution and congestion impact people’s health and life quality. This endeavor usually begins with understanding where the freight comes from and where it goes. This information might be stored using a freight OD matrix. However, the study of freight OD lags behind OD matrices involving passengers due to the difficulty of obtaining complete data. This drawback is caused mainly by the large number of logistics companies that usually coexist in the freight transportation market. For the same reason, most articles that estimate OD matrices are not generalizable to a broader environment beyond the company, including all the vehicles using a highway, as we do. This is explained due to the inherent bias of using small data sizes obtained without sampling.
To bridge this gap, this research developed a multi-data source methodology to estimate an OD matrix for all the trucks using Autopista Central in Santiago, Chile. We used information gathered from SR, a Chilean routing company. This allowed us to identify the origin and destination of the trips of SR’s customers using Autopista Central. However, SR information was not necessarily representative of all the trips on the highway. To cope with this issue, we developed a framework to mitigate the bias, which involved building a decision tree model for estimating the trips’ origin, whose input data was complemented with other public databases. On the other hand, the trips’ destinations were calculated using proportionality factors obtained from the SR data. Then, the model was applied to estimate the OD matrix, using data gathered from AVI free-flow gates, which have an exceptionally low failure rate.
The results show that most trips originated in the outskirt municipalities of San Bernando, Cerrillos, Maipú, Quilicura, and Pudahuel, while the destinations were mainly located in the downtown area. Additionally, the estimated trip distribution differed greatly from the empirical distribution obtained from the (biased) SR base, as well as from that determined through the use of the entry gate municipality. By way of validation, we calculated the Pearson correlation of these three origin distributions with the total square meters destined for commercial land use. This analysis showed that our approach maximized the mentioned correlation, supporting the validity of estimations.
We think that the methodology proposed in this paper could be easily employed in other cities and countries due to, on the one hand, the rapid increase in the available transportation massive data, and on the other, the advancements of big data technologies [
45]. Nowadays, most highways in developed countries, as well as in some developing countries, such as Chile, are equipped with technologies capable of tracking individual freight vehicles, such as device recognition for toll payment [
46] and license plate recognition [
47]. In addition, GPS devices are quite common in trucks of many logistics providers worldwide, increasing the monitoring of logistics performance indicators [
48].
Our findings might help improve freight transport understanding in the city, enabling the implementation of focused transport policies and investments to help mitigate negative externalities, such as congestion and pollution. Moreover, our results can be used as an input for developing Intelligent Visualizations tools [
49] or to better support the development of freight-efficient land-use (FELU) planning [
50].
The methodology proposed in this research can be regarded as a building block for estimating logistics indicators in a highly atomized industry, such as the freight transportation industry. Even though our methodology aims to compute a less-biased estimation of the OD matrix for an urban highway, the expansion of our estimates to the whole city remains an open challenge. To achieve this goal, a step forward requires incorporating additional data sources, such as traffic control information from cameras. This is a promising research stream due to recent video analytics tools and vehicle classification developments (e.g., [
51]).
Finally, it is important to point out that this effort belongs to a broader research project which aims to understand the urban freight transportation in Santiago, Chile, using multiple data sources. The project is funded by the public agency Production Development Corporation (CORFO by its acronym in Spanish) and seeks to generate public information to improve public policies and decision making. Additionally, CORFO has the objective of promoting new business and technologies. Hence, as a side-product of this research project, we expect to start a technology company that helps both private and public sectors access customized logistics performance indicators in order to improve productivity. This could be done by using an open innovation model, in which companies and selected partners develop and sell ideas in the form of a valuable product for some customers [
52].








{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}