
A New Trend Pattern-Matching Method of Interactive Case-Based Reasoning for Stock Price Predictions


Abstract
:1. Introduction
2. Case-Based Reasoning and a New Trend Pattern-Matching Method
2.1. Case-Based Reasoning in the Financial Area
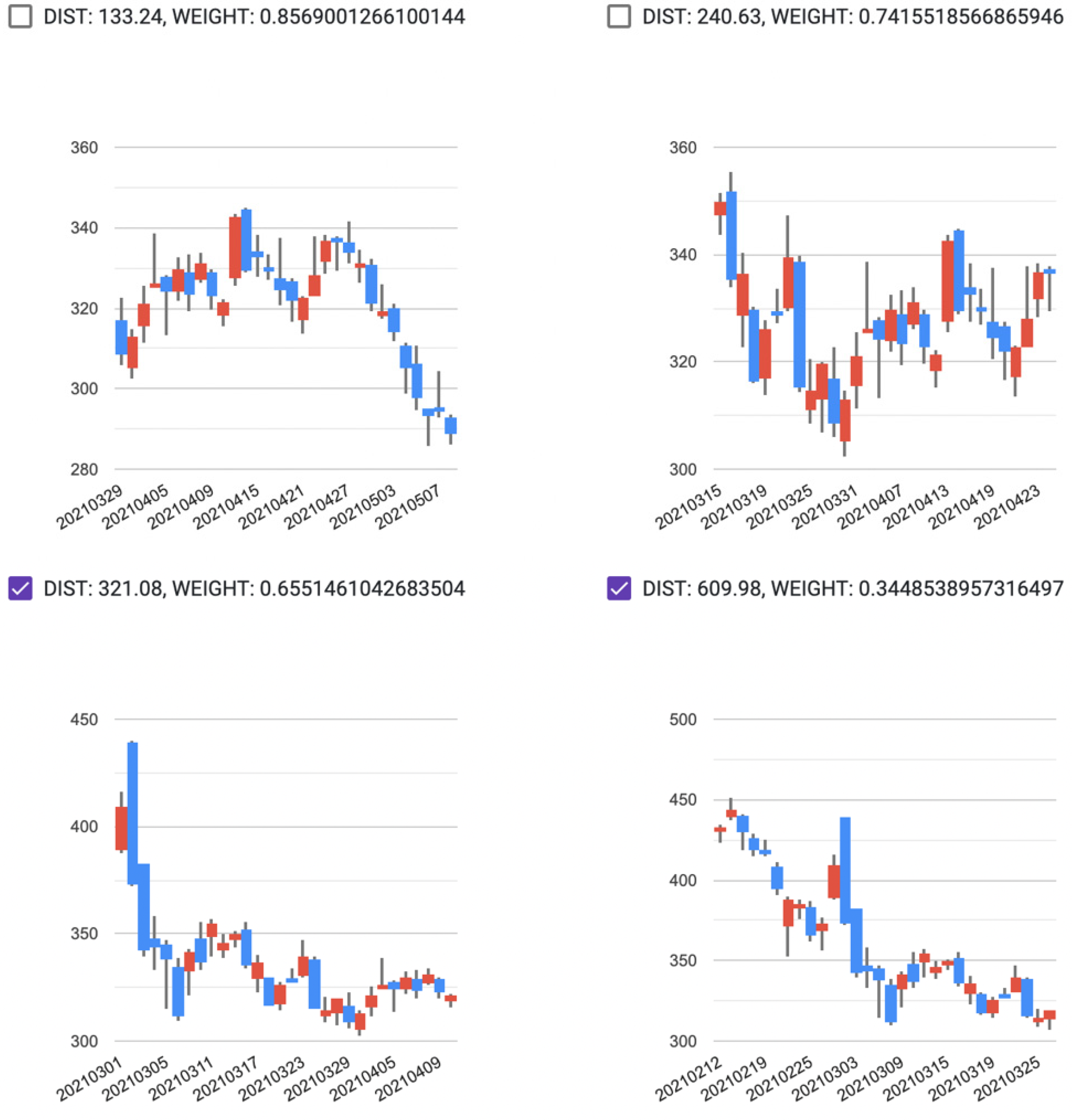
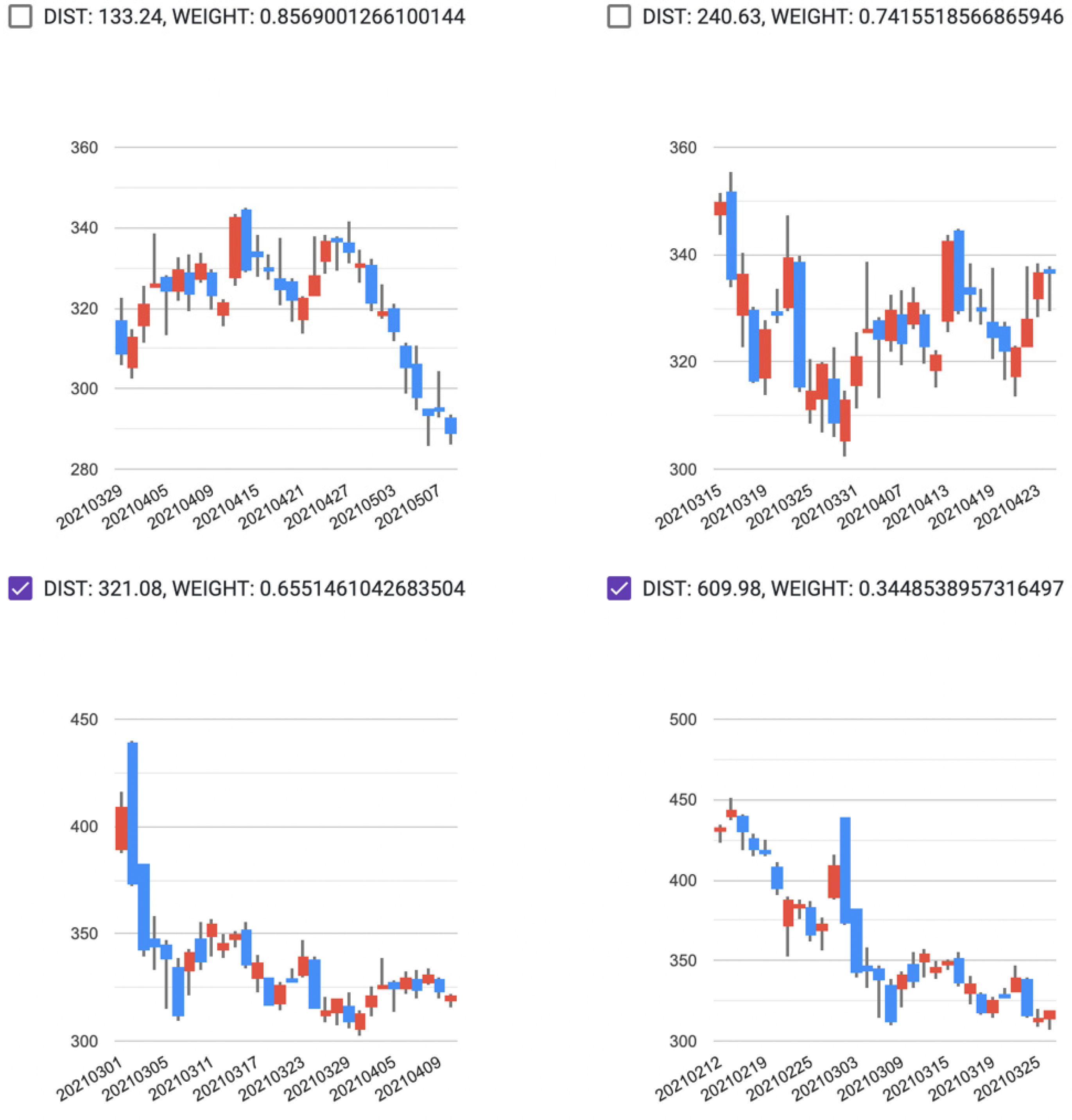
2.2. Interactive Case-Based Reasoning and the Time Series Pattern-Matching Method
3. Application to Stock Price Prediction
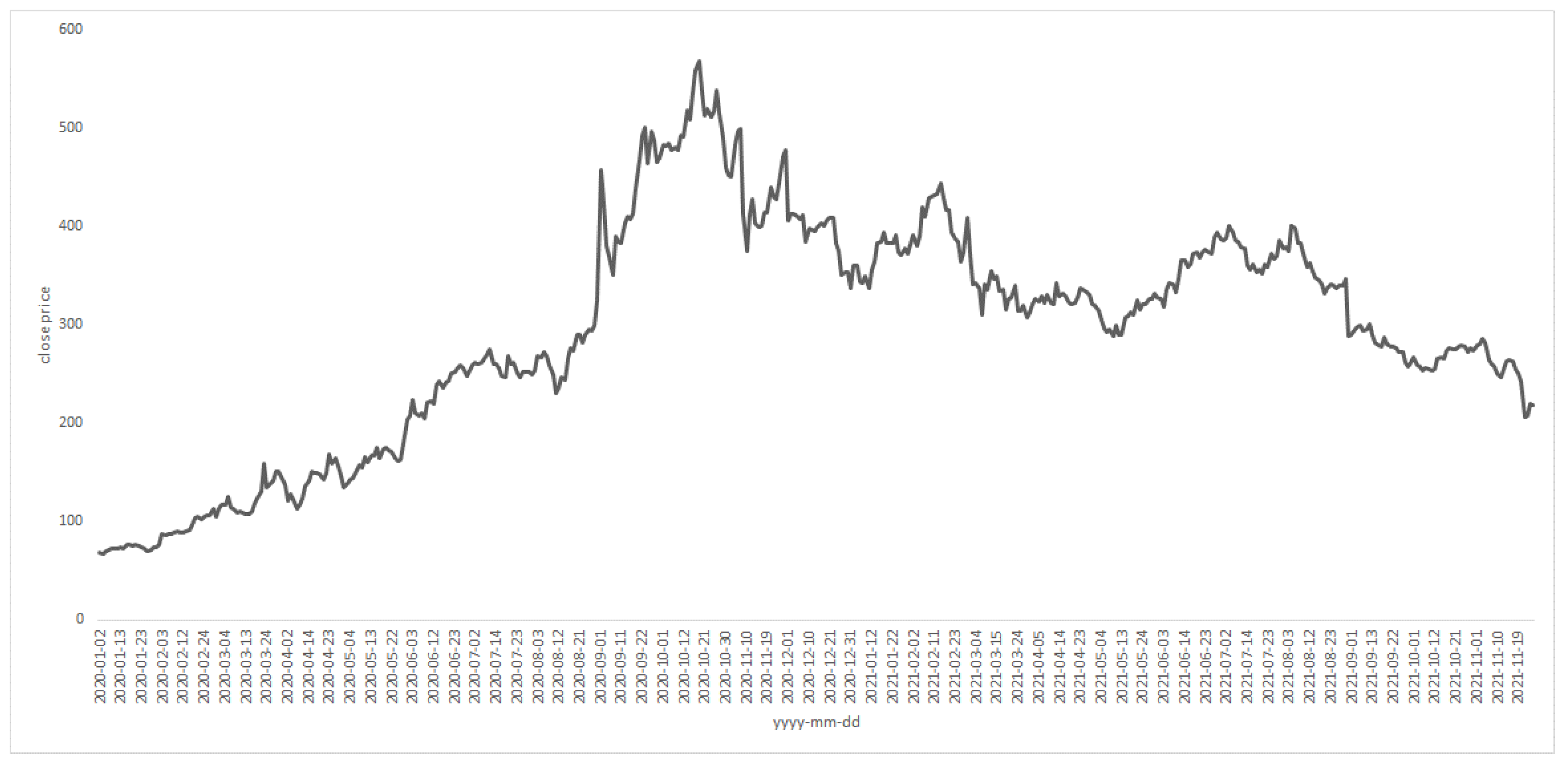
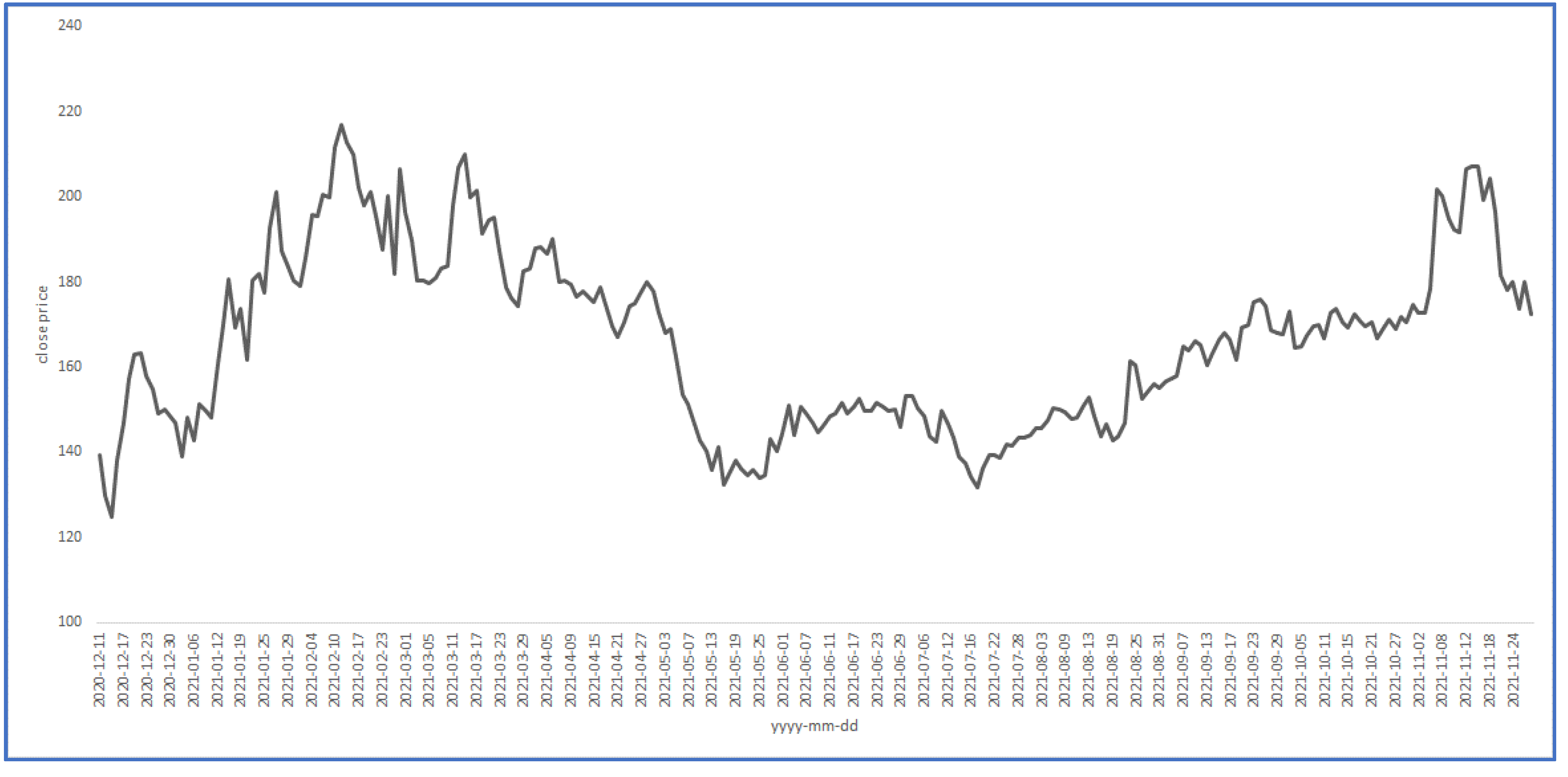
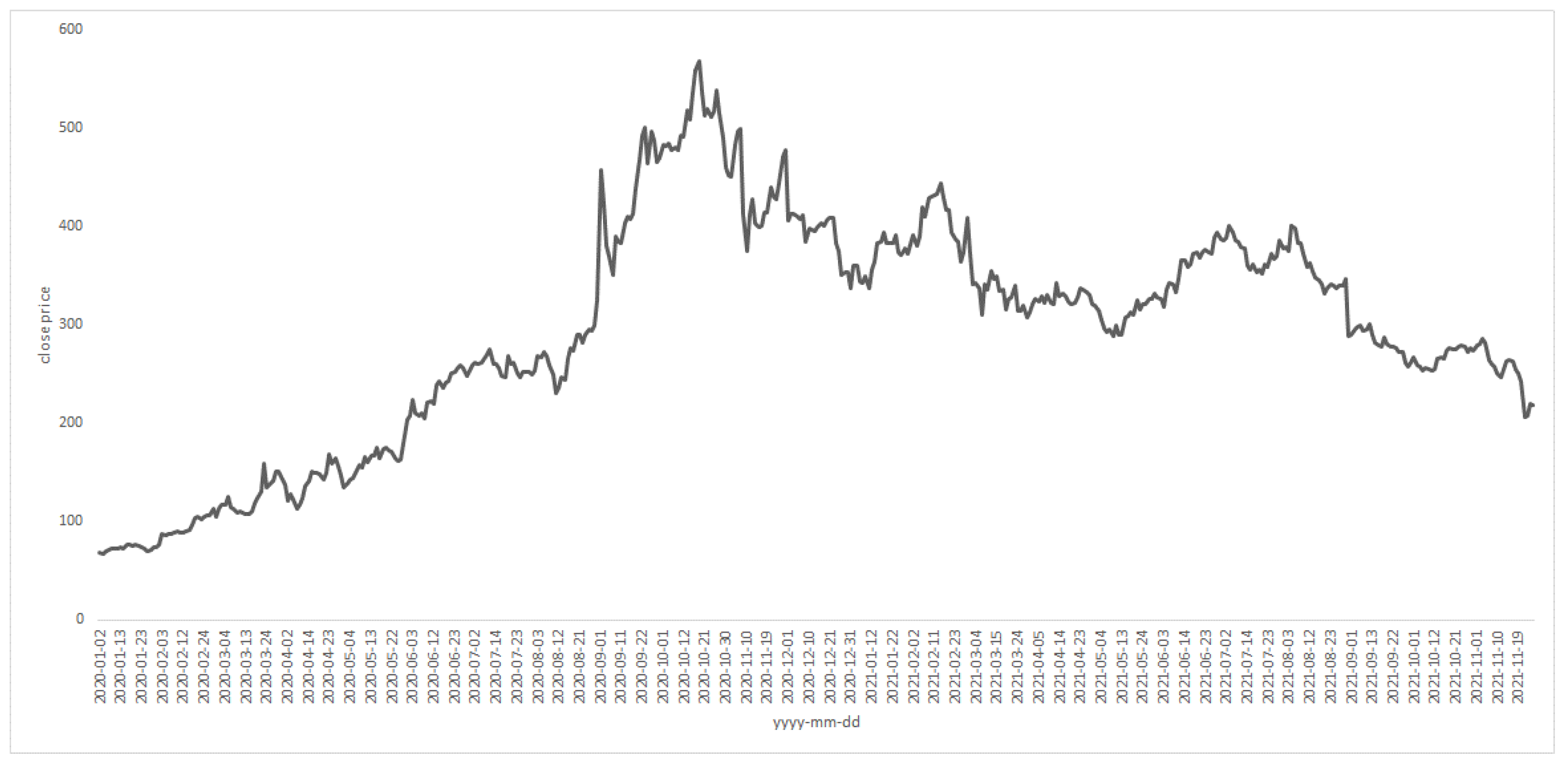
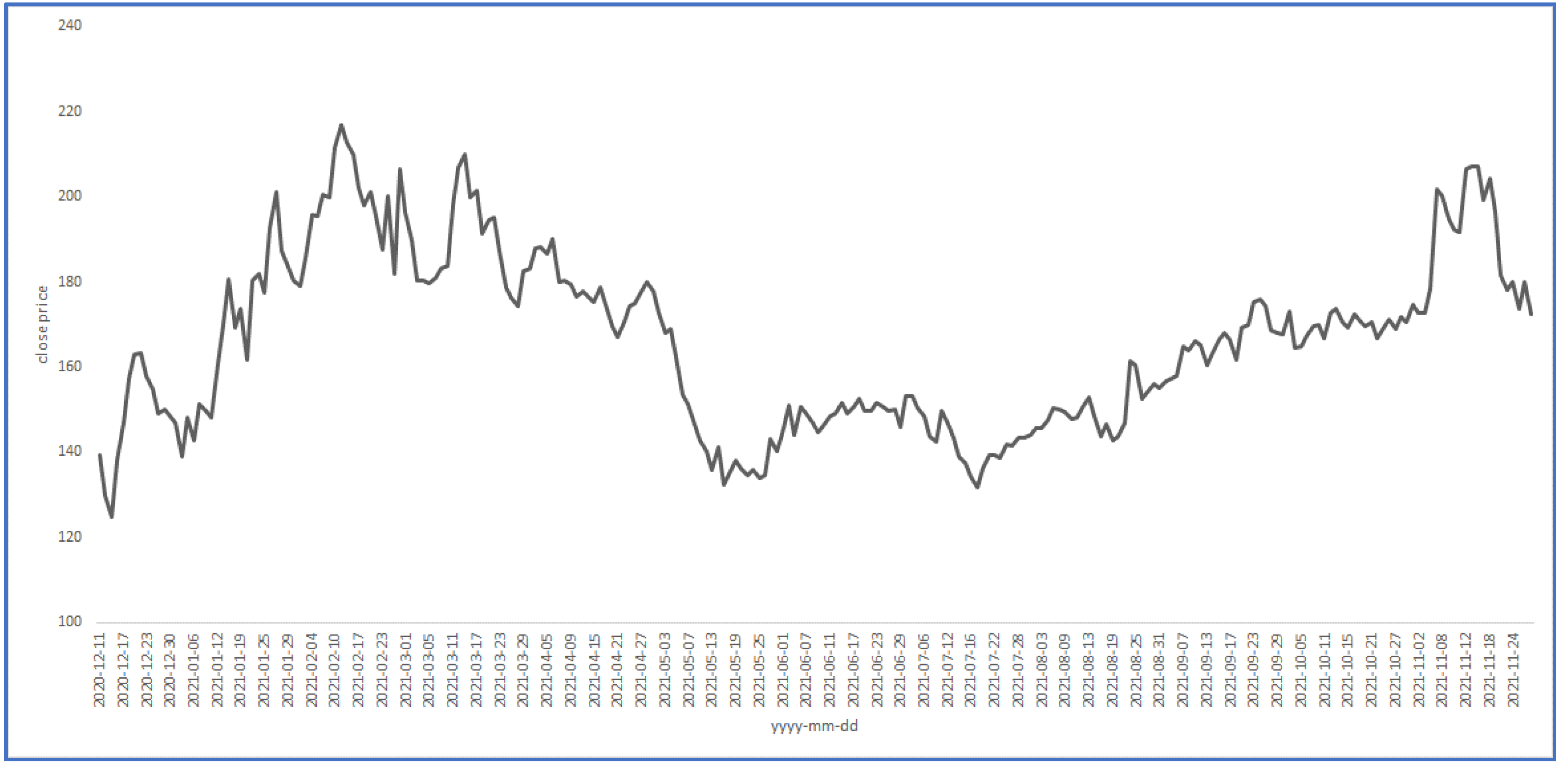
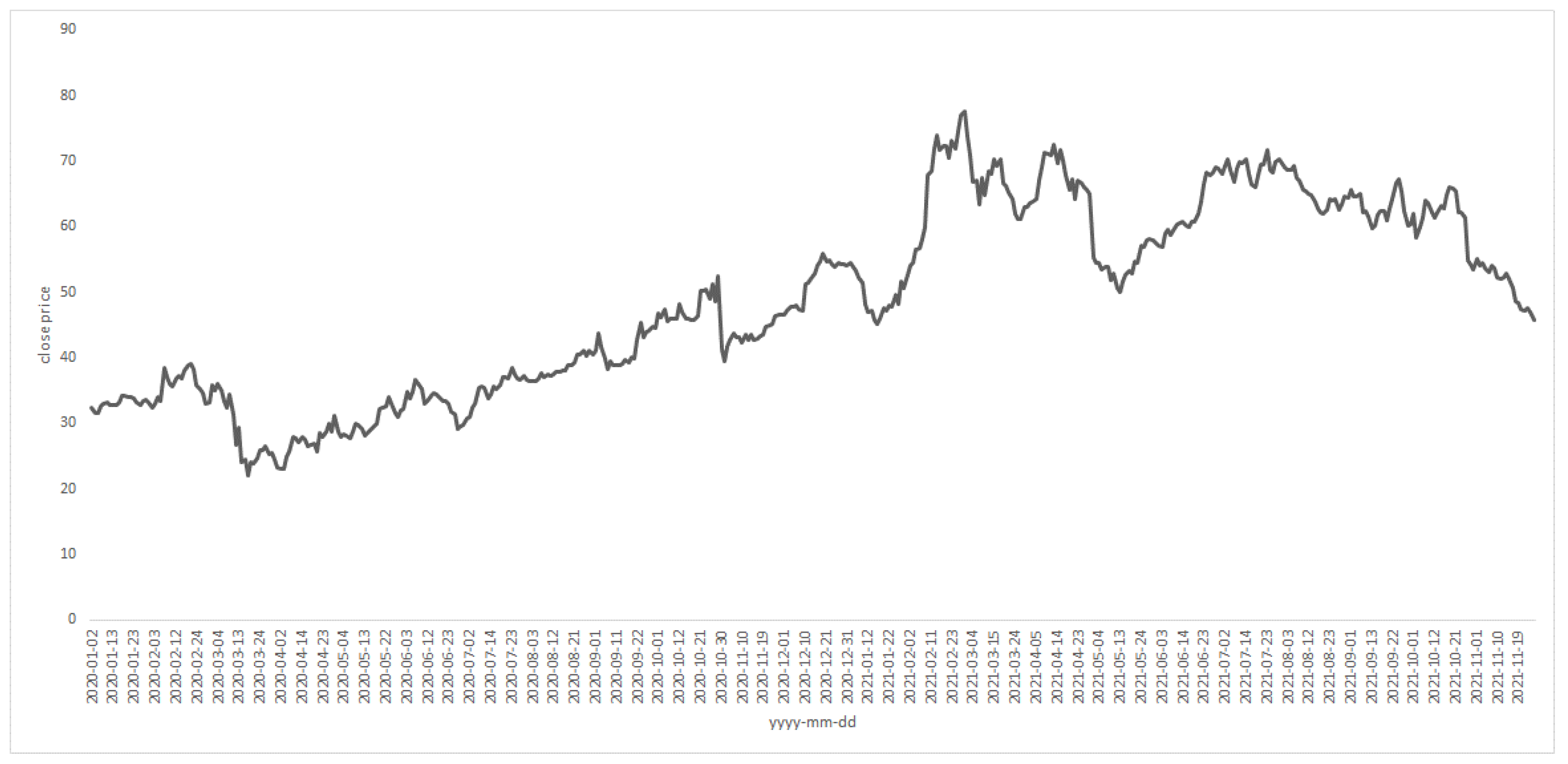
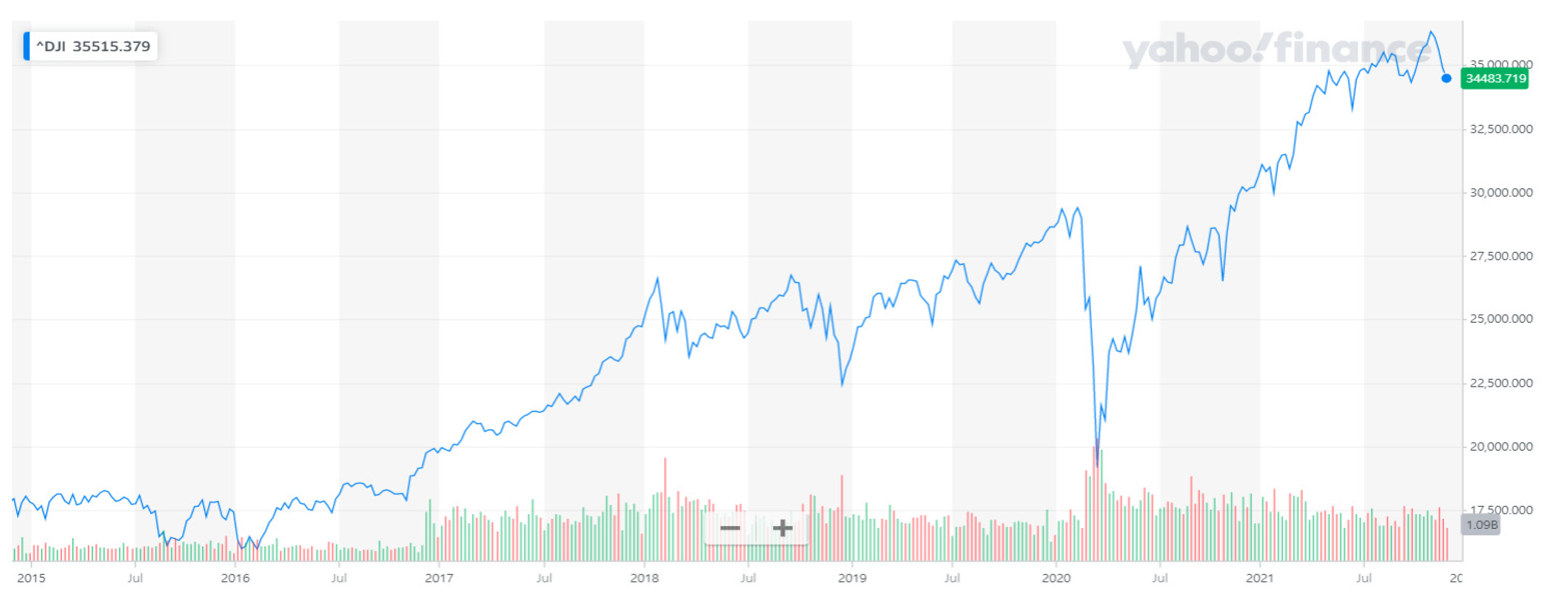
3.1. The Data
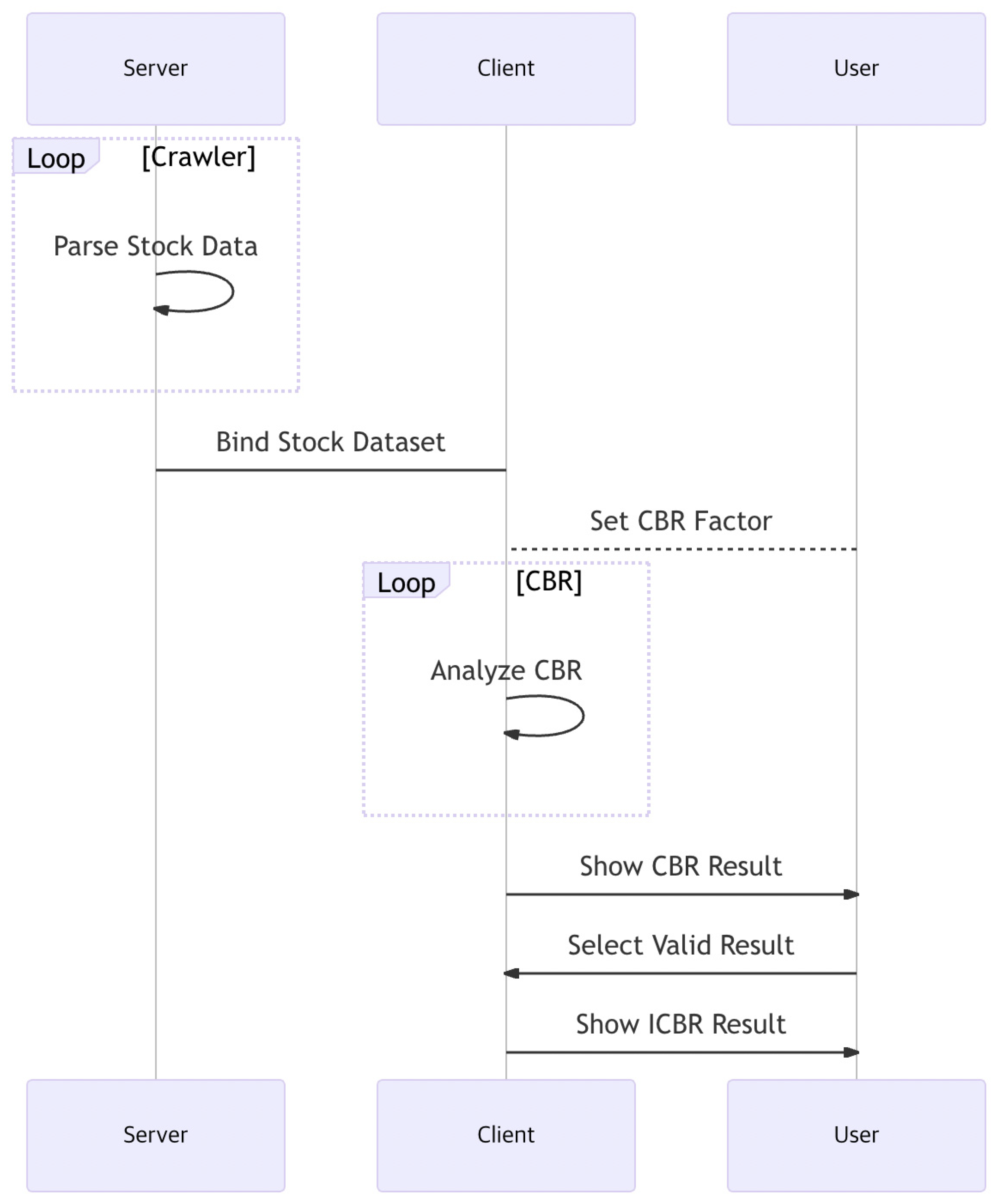
3.2. Model Construction
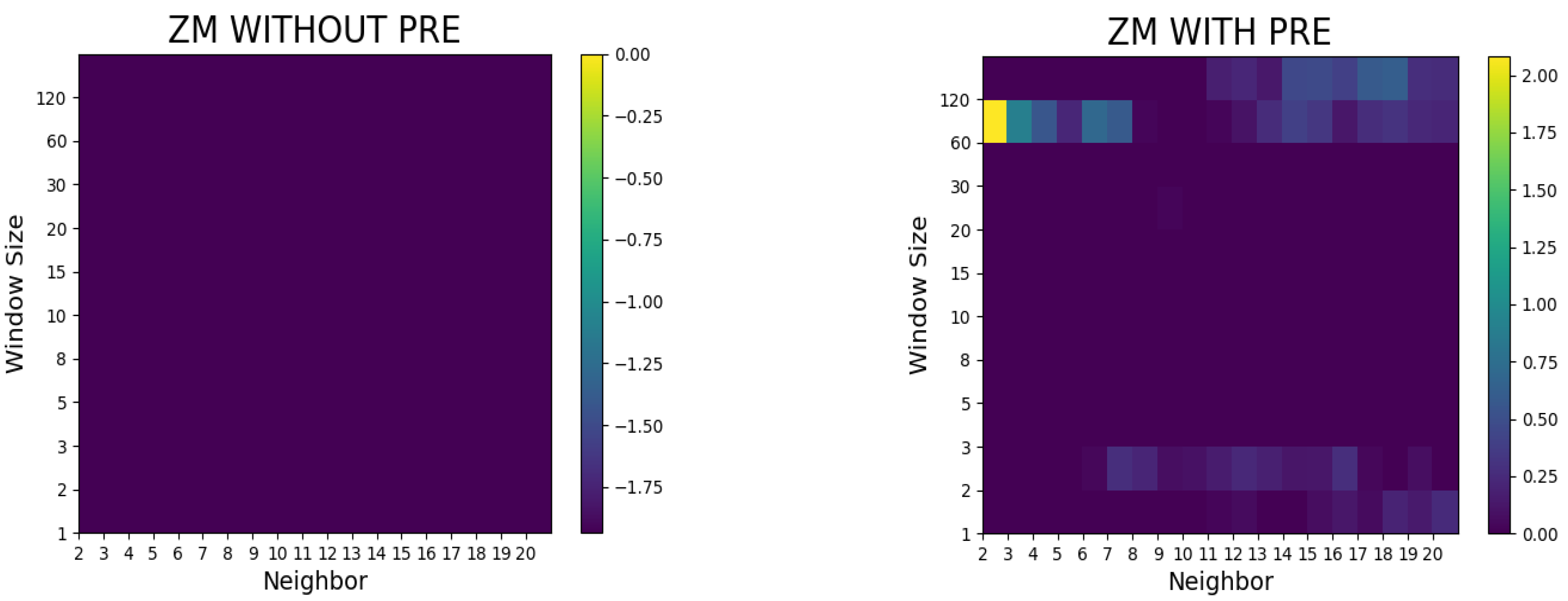
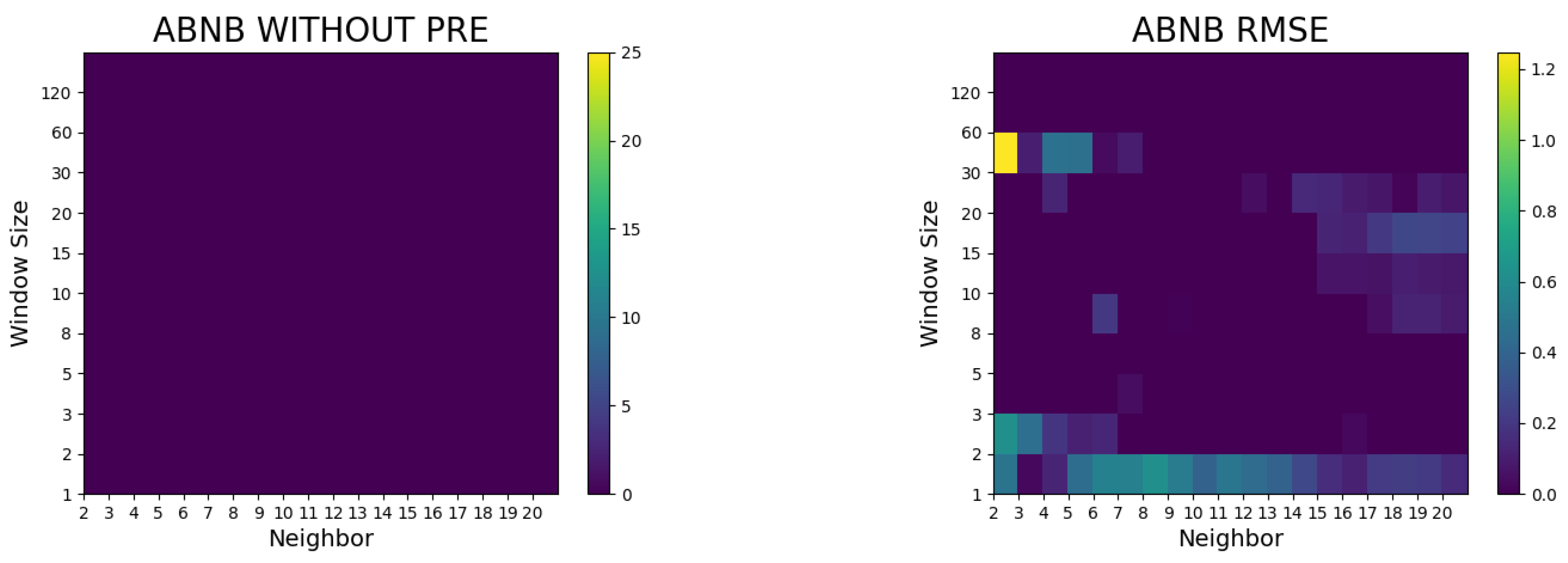
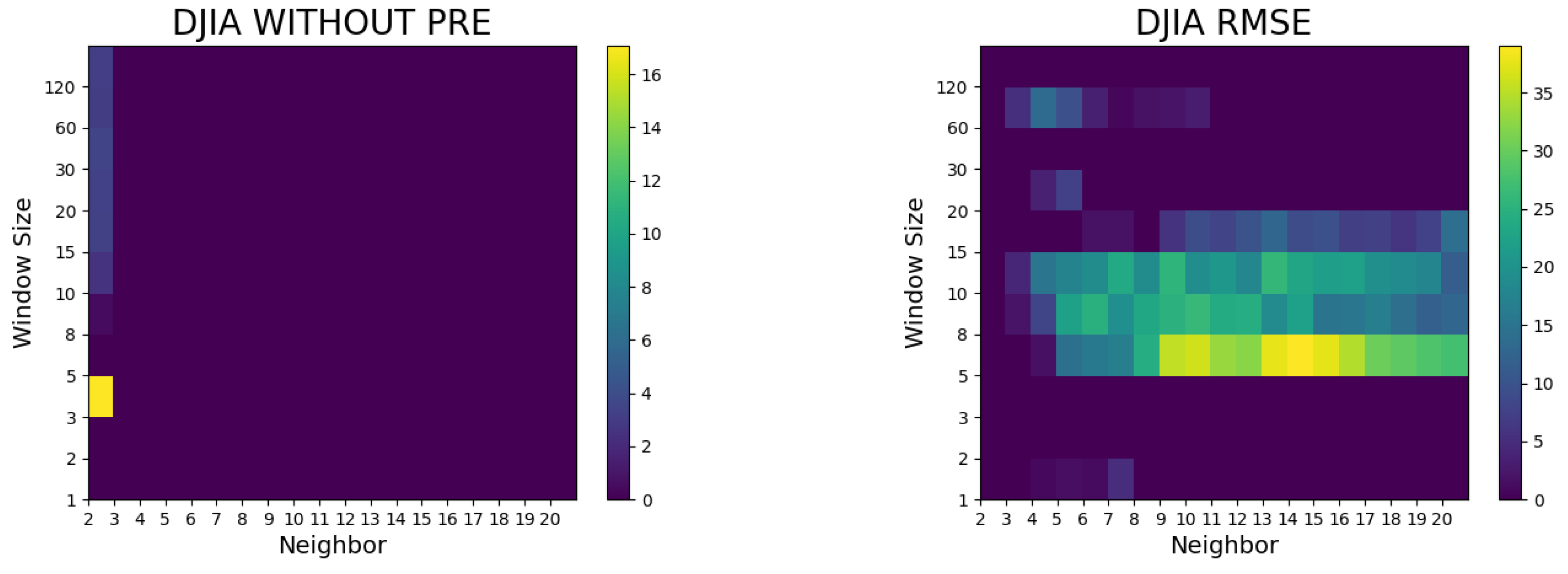
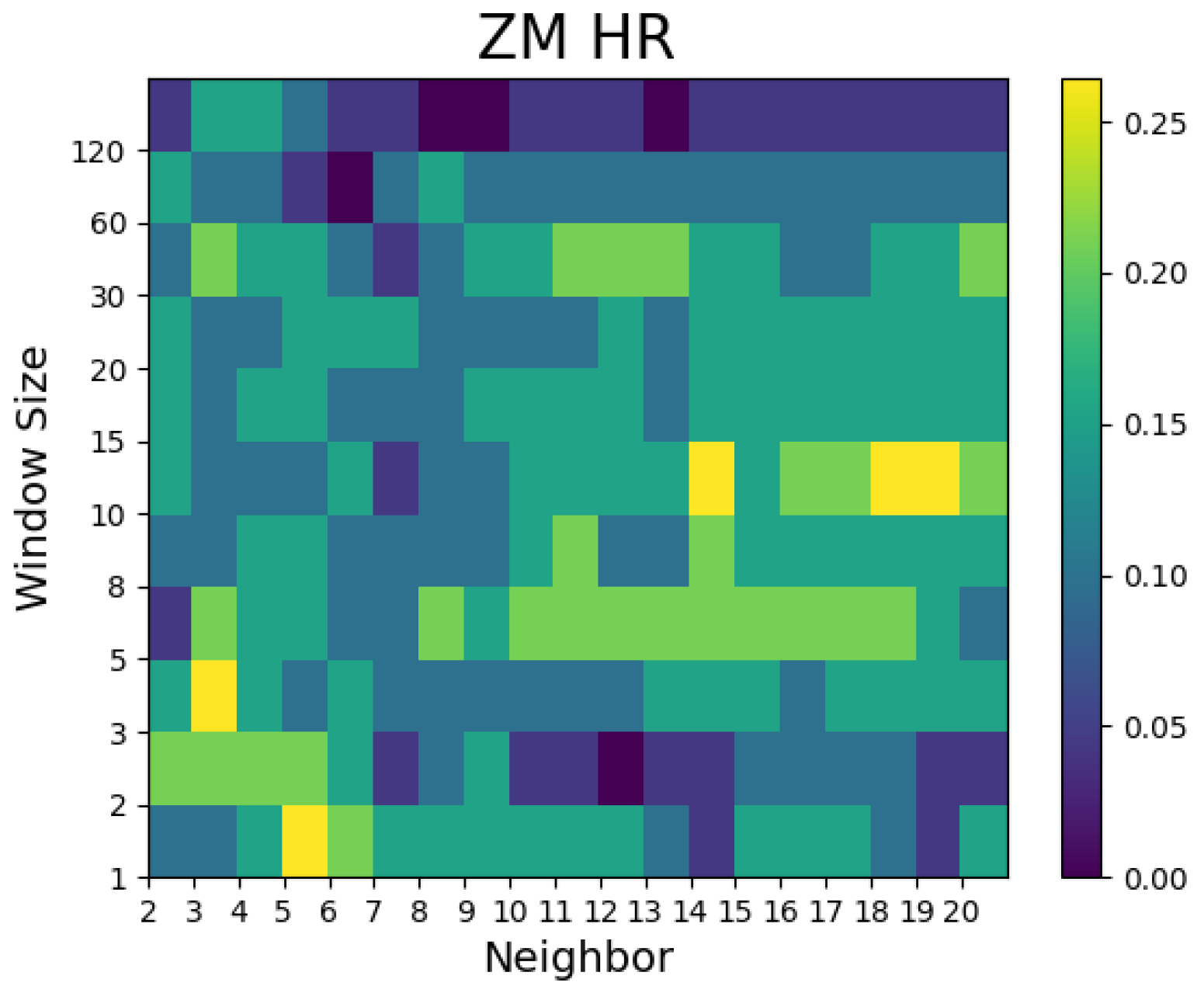
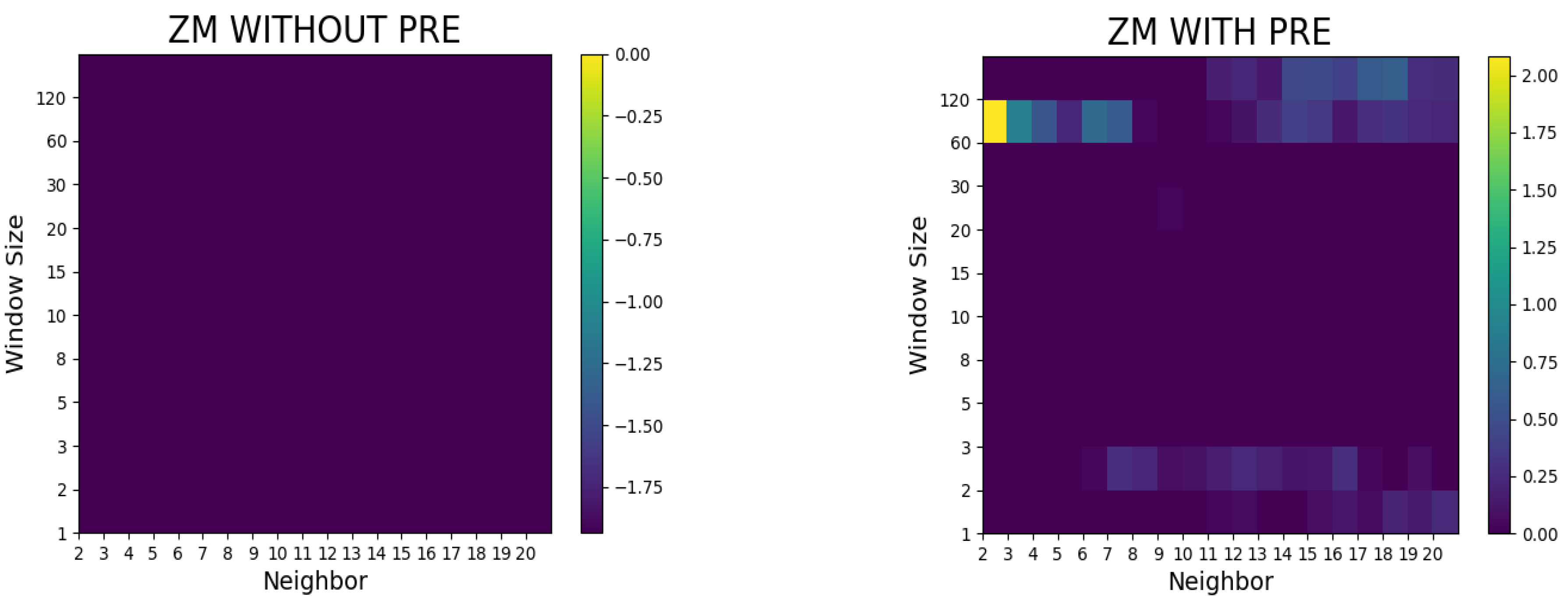
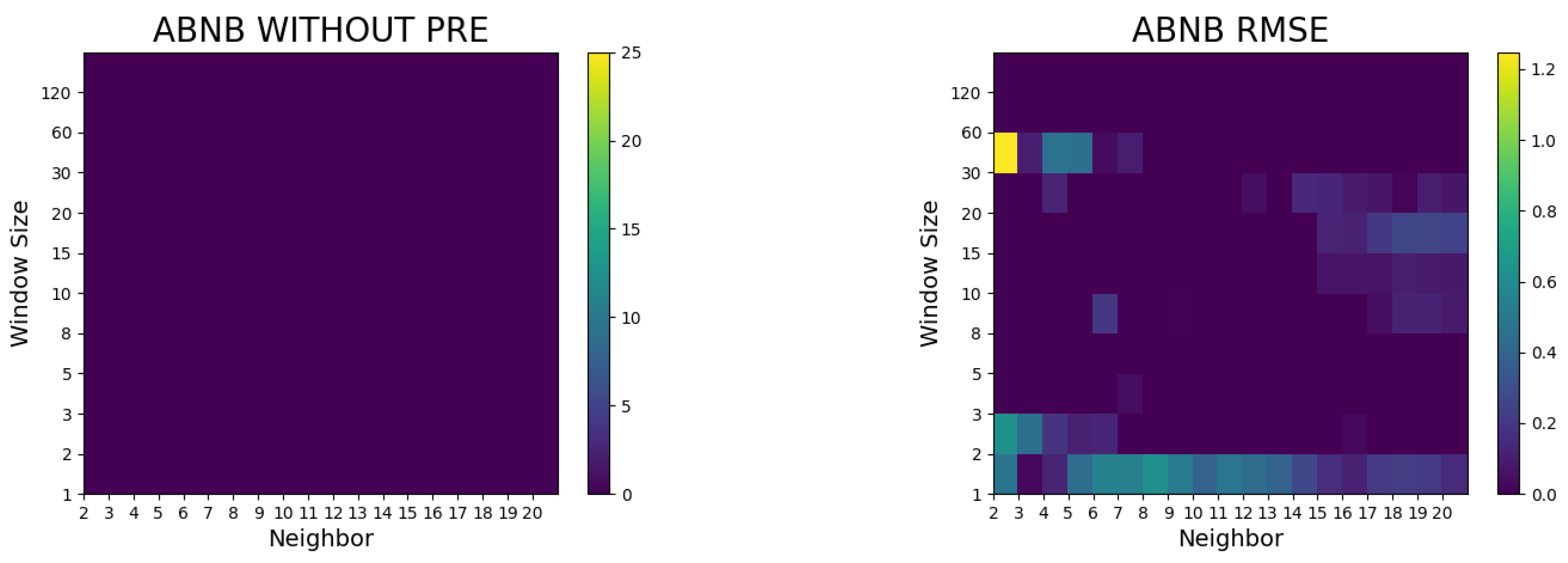
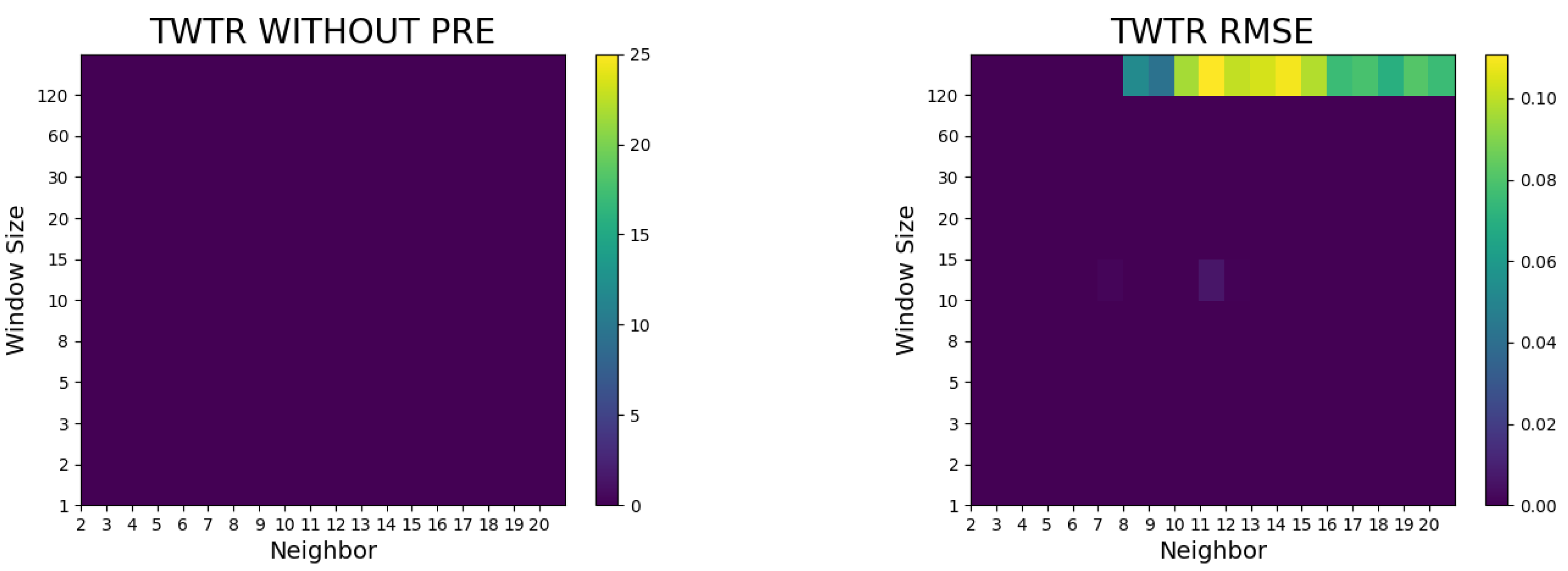
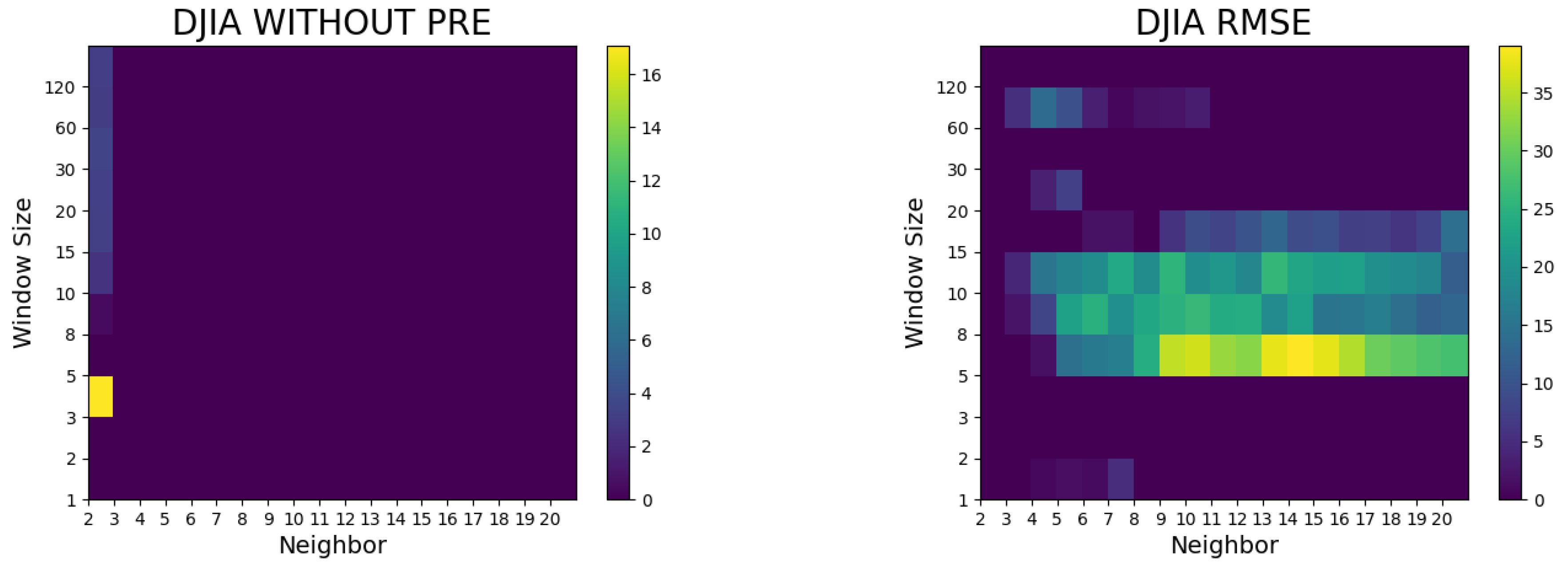
4. Results of the Study and Discussion
5. Concluding Remarks and Future Work
- The best model of the proposed technique was more effective than the random walk model.
- The proposed method did not surpass the random walk model without preprocessing, whereas it outperformed the random walk model in terms of the RMSE and Hit ratio after preprocessing (such as logarithms and differencing).
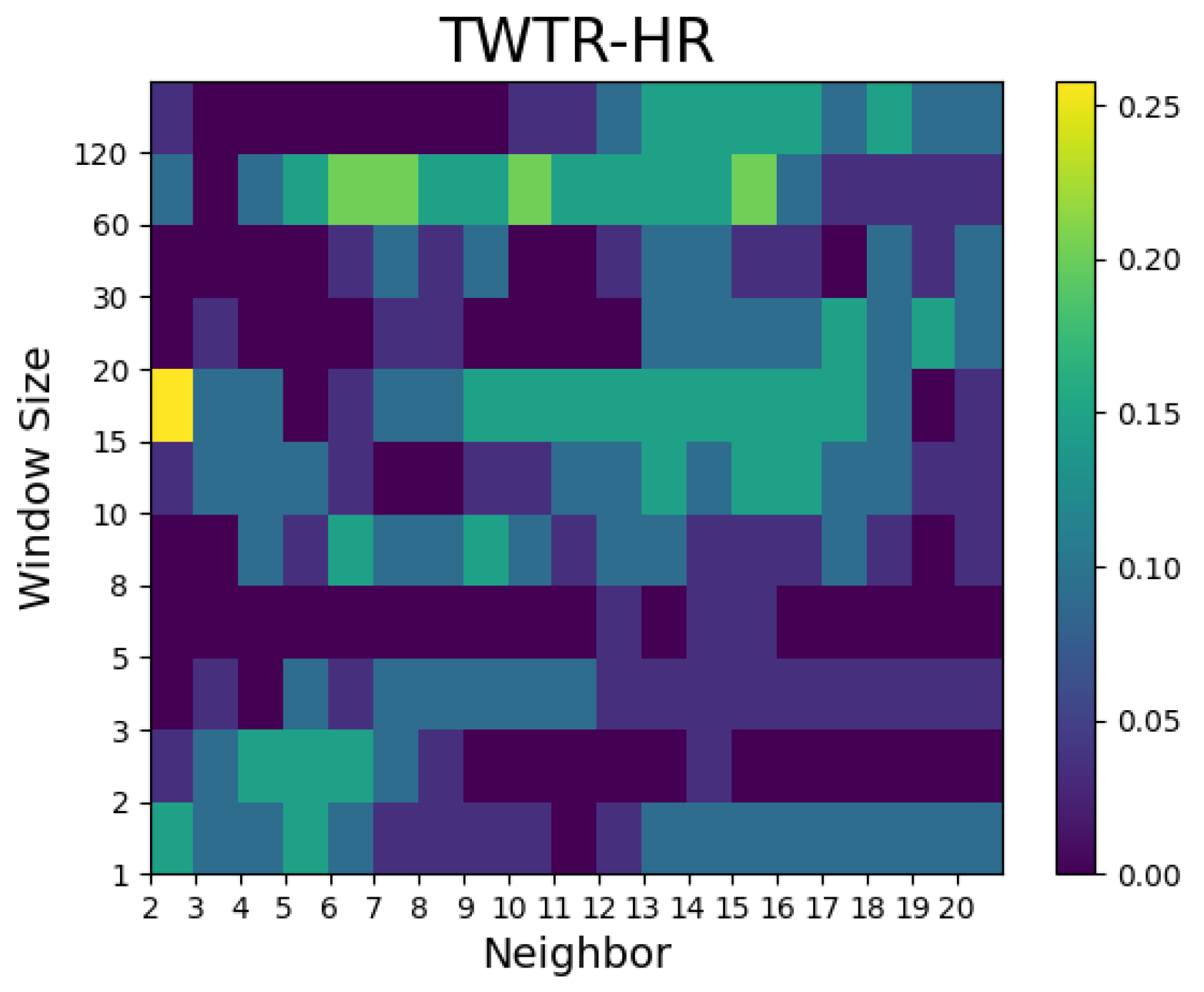
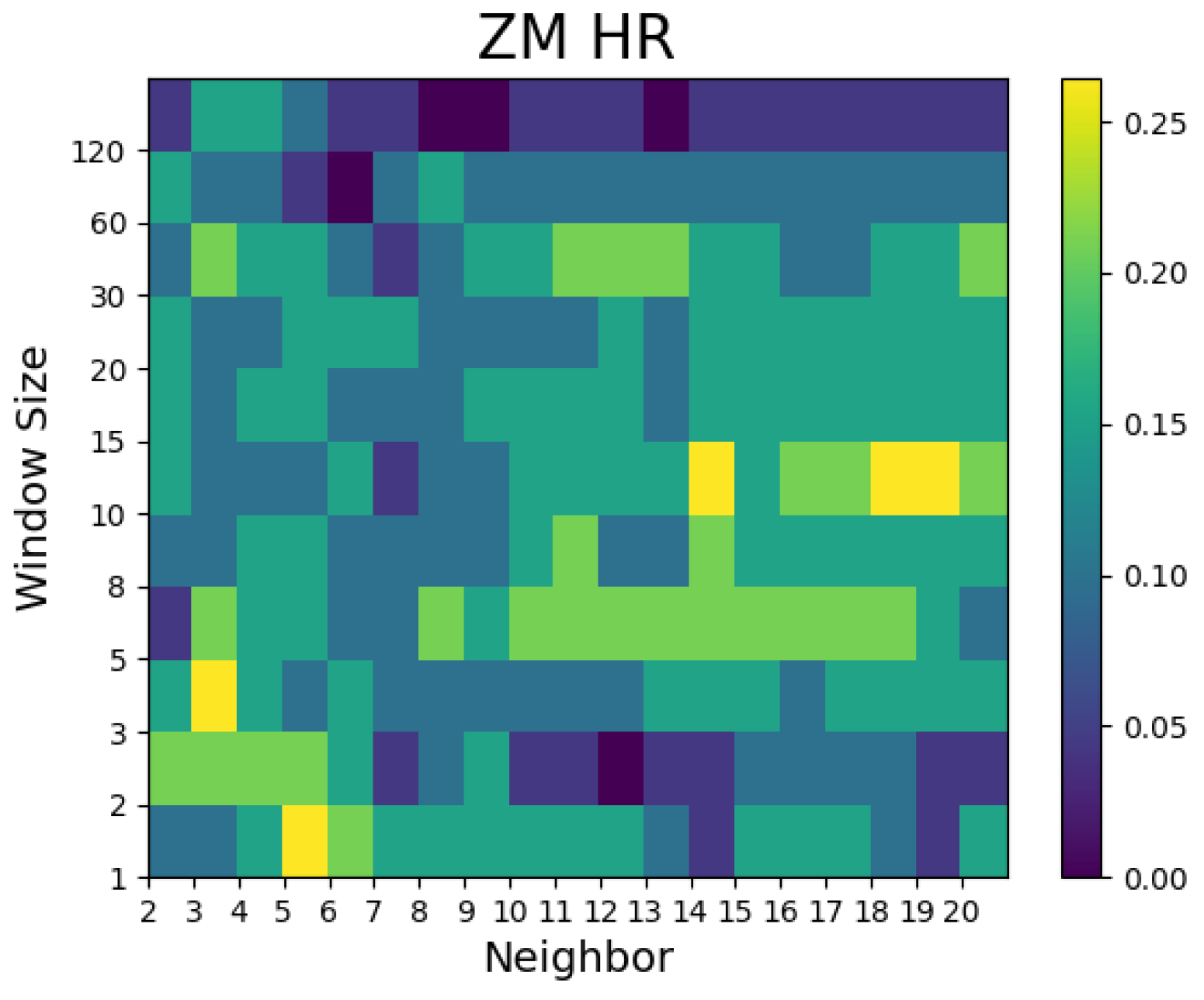
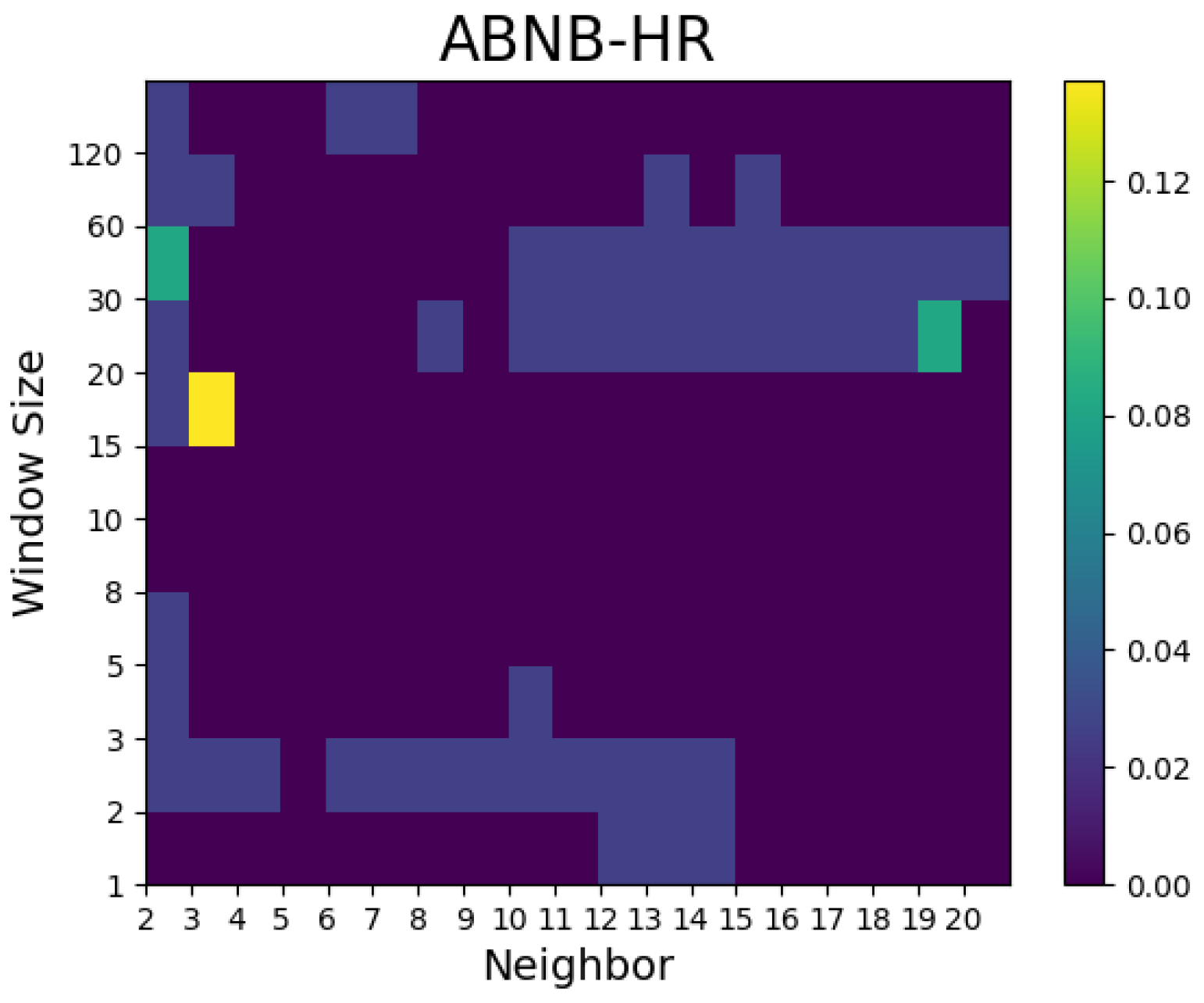
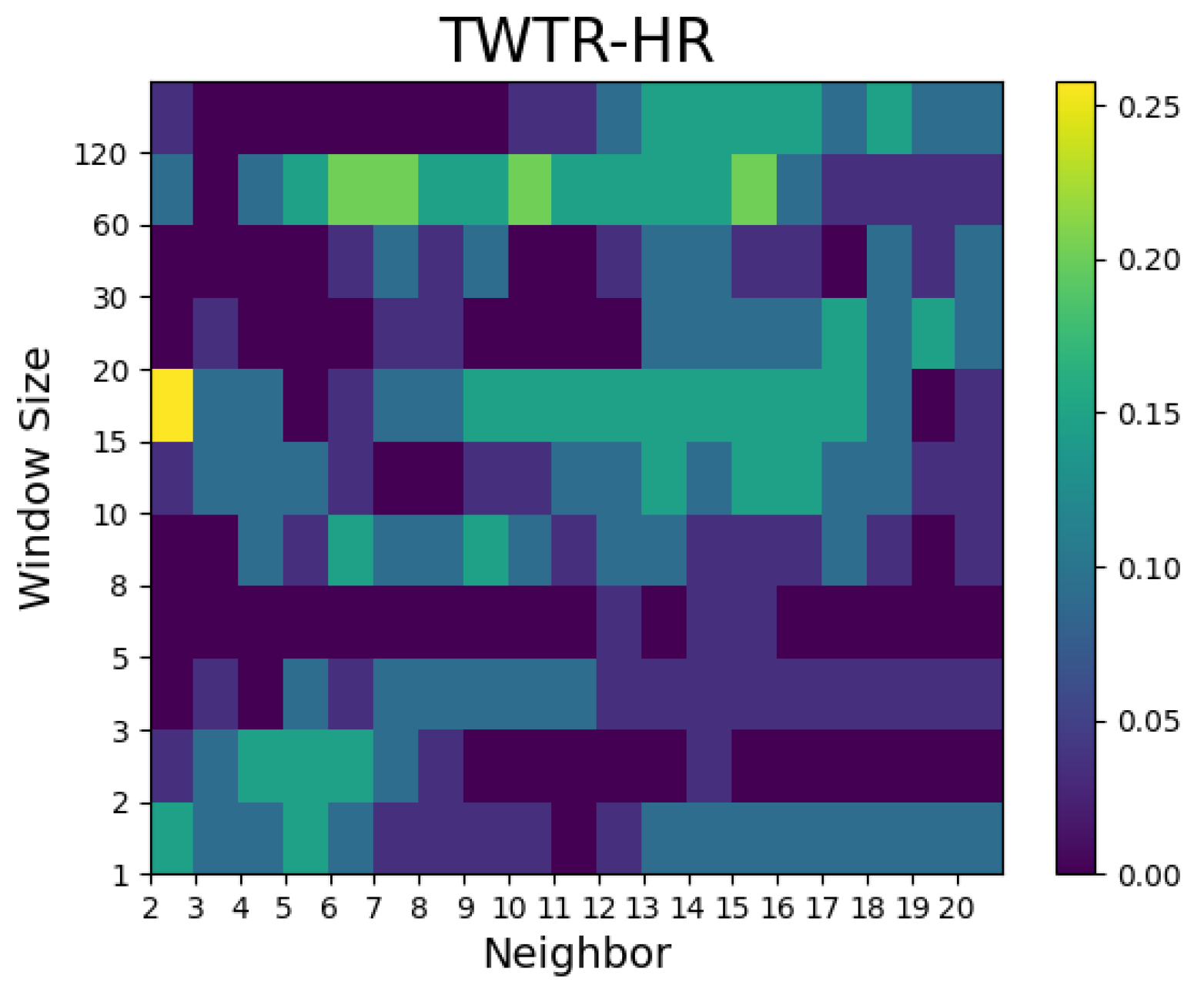
- In the case of Airbnb and Zoom, the predictive performances were superior to the random walk model with a small number of neighbors, whereas in the case of Twitter, the predictive power was notable when the number of neighbors was large.
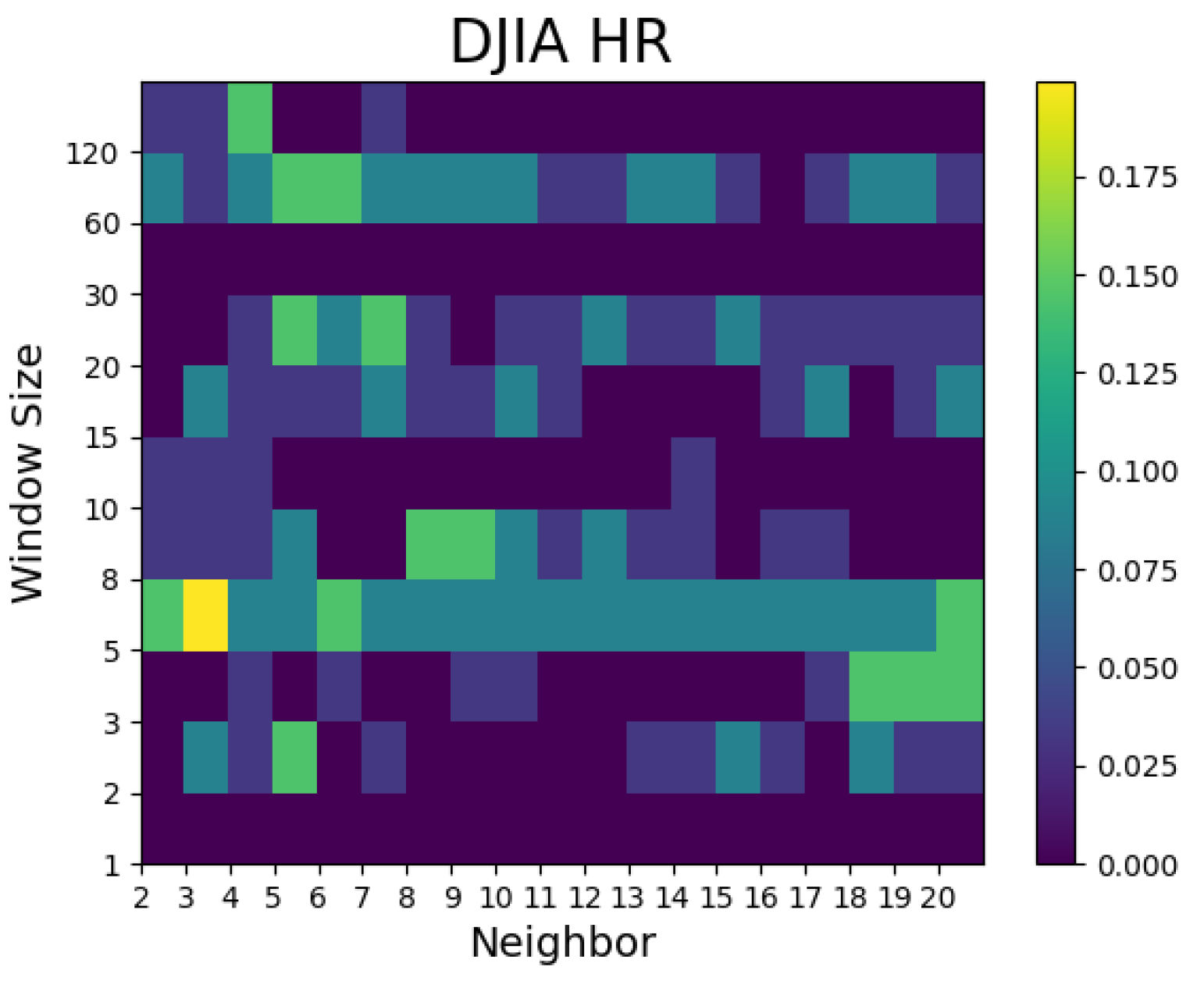
- In general, superior models with lower RMSEs were seen when the window sizes were 5, 10, 30, 60, and 120. The window size was a factor with a greater importance than the number of neighbors in the Dow Jones Industrial Average prediction.
- For the Hit ratio prediction, many models showed superior results to the random walk model regardless of the window size and number of neighbors. Compared with the Airbnb models, the predictive performances of the models for Zoom and Twitter as well as the Dow Jones Industrial Average prediction outperformed the random walk model in many combinations of window size and number of neighbors.
- The proposed method was not seen to statistically surpass the random walk model in terms of the RMSE and Hit ratio. The reason seemed to be that the statistically verifiable data size was small due to one of the companies we tested only recently being listed on the stock market exchange.
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- Ince, H. Short term stock selection with case-based reasoning technique. Appl. Soft Comput. 2014, 22, 205–212. [Google Scholar] [CrossRef]
- Chun, S.-H.; Ko, Y.-W. Geometric Case Based Reasoning for Stock Market Prediction. Sustainability 2020, 12, 7124. [Google Scholar] [CrossRef]
- Yoo, S.; Jeon, S.; Jeong, S.; Lee, H.; Ryou, H.; Park, T.; Choi, Y.; Oh, K. Prediction of the Change Points in Stock Markets Using DAE-LSTM. Sustainability 2021, 13, 11822. [Google Scholar] [CrossRef]
- Chung, H.; Shin, K.-S. Genetic Algorithm-Optimized Long Short-Term Memory Network for Stock Market Prediction. Sustainability 2018, 10, 3765. [Google Scholar] [CrossRef] [Green Version]
- Aamodt, A.; Plaza, E. Case-based reasoning: Foundational issues, methodological variations, and system approaches. AI Commun. Eur. J. Artif. Intell. 1994, 7, 39–59. [Google Scholar] [CrossRef]
- Kim, S.H.; Chun, S.H. Graded forecasting using an array of bipolar predictions: Application of probabilistic neural networks to a stock market index. Int. J. Forecast. 1998, 14, 323–337. [Google Scholar] [CrossRef]
- Chun, S.-H.; Kim, K.; Kim, S.H. Chaotic analysis of predictability versus knowledge discovery techniques: Case study of the Polish stock market. Expert Syst. 2002, 19, 264–272. [Google Scholar] [CrossRef]
- Chun, S.-H.; Kim, K.; Kim, S.H. Impact of momentum bias on forecasting through knowledge discovery techniques in the foreign exchange market. Expert Syst. Appl. 2003, 24, 115–122. [Google Scholar] [CrossRef]
- Chun, S.-H.; Kim, K.; Kim, S.H. Data mining for financial prediction and trading: Application to single and multiple markets. Expert Syst. Appl. 2004, 26, 131–139. [Google Scholar] [CrossRef]
- Chun, S.-H.; Kim, K.; Kim, S.H. Automated generation of new knowledge to support managerial decision making: Case study in forecasting a stock market. Expert Syst. 2004, 21, 192–207. [Google Scholar] [CrossRef]
- Chun, S.-H.; Park, Y.-J. Dynamic adaptive ensemble case-based reasoning: Application to stock market prediction. Expert Syst. Appl. 2005, 28, 435–443. [Google Scholar] [CrossRef]
- Chun, S.-H.; Park, Y.-J. A new hybrid data mining technique using a regression case based reasoning: Application to financial forecasting. Expert Syst. Appl. 2006, 31, 329–336. [Google Scholar] [CrossRef]
- Dutta, S.; Shekkar, S. Bond rating: A non-conservative application of neural networks. Int. Jt. Conf. Neural Netw. 1988, 2, 443–450. [Google Scholar]
- Shin, K.S.; Han, I. A case-based approach using inductive indexing for corporate bond rating. Decis. Support Syst. 2001, 32, 41–52. [Google Scholar] [CrossRef]
- Kim, K.-J.; Han, I. Maintaining case-based reasoning systems using a genetic algorithms approach. Expert Syst. Appl. 2001, 21, 139–145. [Google Scholar] [CrossRef]
- Li, H.; Sun, J. Gaussian case-based reasoning for business failure prediction with empirical data in China. Inf. Sci. 2009, 179, 89–108. [Google Scholar] [CrossRef]
- Li, H.; Huang, H.-B.; Sun, J.; Lin, C. On sensitivity of case-based reasoning to optimal feature subsets in business failure prediction. Expert Syst. Appl. 2010, 37, 4811–4821. [Google Scholar] [CrossRef]
- Li, H.; Sun, J. Predicting Business Failure Using an RSF-based Case-Based Reasoning Ensemble Forecasting Method. J. Forecast. 2013, 32, 180–192. [Google Scholar] [CrossRef]
- Yip, A.Y.N. Business Failure Prediction: A Case-Based Reasoning Approach. Rev. Pac. Basin Financ. Mark. Policies 2006, 9, 491–508. [Google Scholar] [CrossRef]
- Li, H.; Sun, J. On performance of case-based reasoning in Chinese business failure prediction from sensitivity, specificity, positive and negative values. Appl. Soft Comput. 2011, 11, 460–467. [Google Scholar] [CrossRef]
- Yip, A.Y.N. Predicting business failure with a case-based reasoning approach. In Proceedings of the Knowledge-Based Intelligent Information and Engineering Systems: 8th International Conference, KES 2004, Wellington, New Zealand, 20–25 September 2004; Proceedings Part III. pp. 20–25. [Google Scholar]
- Li, H.; Sun, J. Ranking-order case-based reasoning for financial distress prediction. Knowl.-Based Syst. 2008, 21, 868–878. [Google Scholar] [CrossRef]
- Li, H.; Sun, J.; Sun, B.-L. Financial distress prediction based on OR-CBR in the principle of k-nearest neighbors. Expert Syst. Appl. 2009, 36, 643–659. [Google Scholar] [CrossRef]
- Bryant, S.M. A case-based reasoning approach to bankruptcy prediction modeling. Intell. Syst. Account. Financ. Manag. 1997, 6, 195–214. [Google Scholar] [CrossRef]
- Elhadi, M.T. Bankruptcy support system: Taking advantage of information retrieval and case-based reasoning. Expert Syst. Appl. 2000, 18, 215–219. [Google Scholar] [CrossRef]
- Park, C.S.; Han, I. A case-based reasoning with the feature weights derived by analytic hierarchy process for bankruptcy prediction. Expert Syst. Appl. 2002, 23, 255–264. [Google Scholar] [CrossRef]
- Ahn, H.; Kim, K.J. Bankruptcy prediction modeling with hybrid case-based reasoning and genetic algorithms approach. Appl. Soft Comput. 2009, 9, 599–607. [Google Scholar] [CrossRef]
- Park, Y.-J.; Kim, B.-C.; Chun, S.-H. New knowledge extraction technique using probability for case-based reasoning: Application to medical diagnosis. Expert Syst. 2006, 23, 2–20. [Google Scholar] [CrossRef]
- Chun, S.-C.; Kim, J.; Hahm, K.-B.; Park, Y.-J. Data mining technique for medical informatics: Detecting gastric cancer using case-based reasoning and single nucleotide polymorphisms. Expert Syst. 2008, 25, 163–172. [Google Scholar] [CrossRef]
- Lei, Z.; Yin, D. Intelligent Generation Technology of Sub-health Diagnosis Case Based on Case Reasoning. In Proceedings of the 2019 IEEE 3rd Advanced Information Management, Communicates, Electronic and Automation Control Conference (IMCEC), Chongqing, China, 11–13 October 2019; pp. 1311–1318. [Google Scholar]
- Elisabet, D.; Sensuse, D.I.; Al Hakim, S. Implementation of Case-Method Cycle for Case-Based Reasoning in Human Medical Health: A Systematic Review. In Proceedings of the 2019 3rd International Conference on Informatics and Computational Sciences (ICICoS), Mathura, India, 21–22 November 2019. [Google Scholar]
- Chowdhury, A.R.; Banerjee, S. Case Based Reasoning in Retina Abnormalities Detection. In Proceedings of the 2019 4th International Conference on Information Systems and Computer Networks (ISCON), Mathura, India, 21–22 November 2019; pp. 273–278. [Google Scholar]
- Lamy, J.-B.; Sekar, B.; Guezennec, G.; Bouaud, J.; Seroussi, B. Hierarchical visual case-based reasoning for supporting breast cancer therapy. In Proceedings of the 2019 Fifth International Conference on Advances in Biomedical Engineering (ICABME), Tripoli, Lebanon, 7–19 October 2019. [Google Scholar]
- Bentaiba-Lagrid, M.B.; Bouzar-Benlabiod, L.; Rubin, S.H.; Bouabana-Tebibel, T.; Hanini, M.R. A Case-Based Reasoning System for Supervised Classification Problems in the Medical Field. Expert Syst. Appl. 2020, 150, 113335. [Google Scholar] [CrossRef]
- Lamy, J.-B.; Sekar, B.; Guezennec, G.; Bouaud, J.; Séroussi, B. Explainable artificial intelligence for breast cancer: A visual case-based reasoning approach. Artif. Intell. Med. 2019, 94, 42–53. [Google Scholar] [CrossRef]
- Silva, G.C.; Carvalho, E.E.; Caminhas, W.M. An artificial immune systems approach to Case-based Reasoning applied to fault detection and diagnosis. Expert Syst. Appl. 2020, 140, 112906. [Google Scholar] [CrossRef]
- Sun, J.; Zhai, Y.; Zhao, Y.; Li, J.; Yan, N. Information Acquisition and Analysis Technology of Personalized Recommendation System Based on Case-Based Reasoning for Internet of Things. In Proceedings of the 2018 International Conference on Cyber-Enabled Distributed Computing and Knowledge Discovery (CyberC), Zhengzhou, China, 18–20 October 2018; pp. 107–1073. [Google Scholar]
- Supic, H. Case-Based Reasoning Model for Personalized Learning Path Recommendation in Example-Based Learning Activities. In Proceedings of the 2018 IEEE 27th International Conference on Enabling Technologies: Infrastructure for Collaborative Enterprises (WETICE) WETICE Enabling Technologies: Infrastructure for Collaborative Enterprises (WETICE), Paris, France, 27–29 June 2018; pp. 175–178. [Google Scholar]
- CamiloCorralesab, D.; Ledezmaa, A.; Corrales, J.C. A case-based reasoning system for recommendation of data cleaning algorithms in classification and regression tasks. Appl. Soft Comput. 2020, 90, 106180. [Google Scholar]
- Nunes, R.C.; Colomé, M.; Barcelos, F.A.; Garbin, M.; Paulus, G.B.; Silva, L.A.D.L. A Case-Based Reasoning Approach for the Cybersecurity Incident Recording and Resolution. Int. J. Softw. Eng. Knowl. Eng. 2019, 29, 1607–1627. [Google Scholar] [CrossRef]
- Abutair, H.; Belghith, A.; Alahmadi, S. CBR-PDS: A case-based reasoning phishing detection system. J. Ambient. Intell. Humaniz. Comput. 2019, 10, 2593–2606. [Google Scholar] [CrossRef]








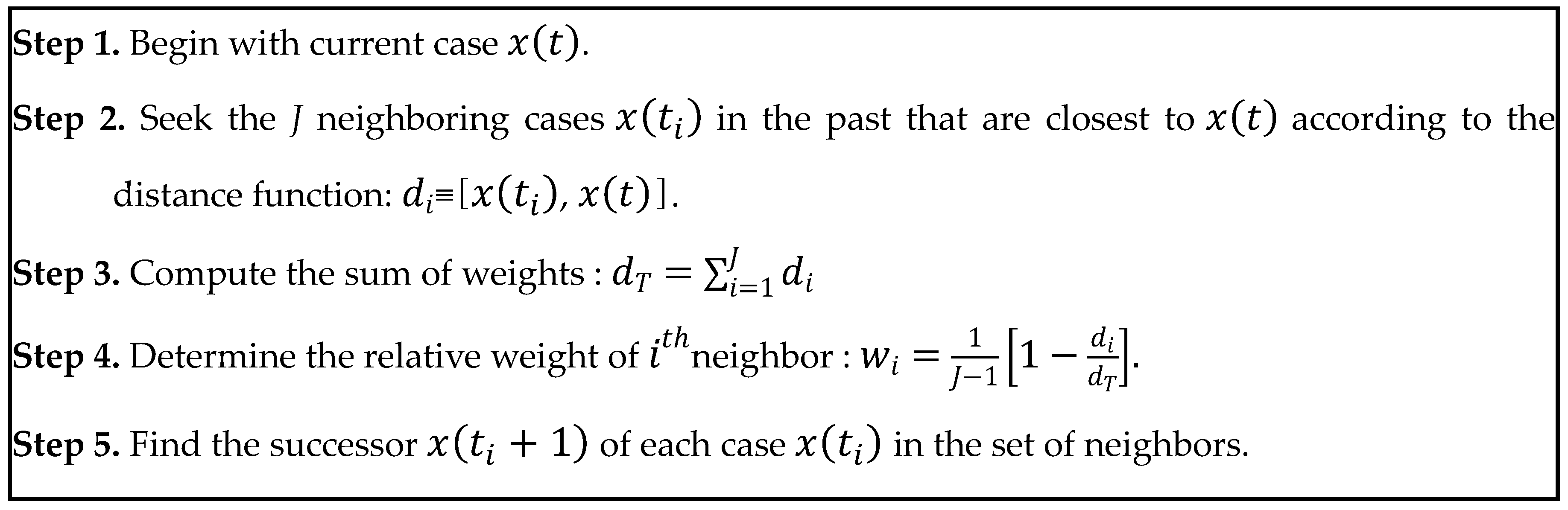{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| N W | 2 | 3 | 5 | 8 | 10 | 20 |
|---|---|---|---|---|---|---|
| 1 | 13.966 | 14.493 | 13.912 | 13.705 | 13.010 | 14.038 |
| 2 | 15.256 | 14.840 | 13.603 | 13.405 | 13.892 | 15.214 |
| 5 | 16.673 | 16.164 | 17.026 | 17.975 | 18.432 | 20.264 |
| 10 | 16.685 | 18.033 | 18.130 | 19.634 | 20.620 | 22.771 |
| 20 | 15.624 | 17.047 | 20.201 | 22.008 | 23.150 | 24.196 |
| 30 | 12.738 | 14.386 | 17.516 | 19.498 | 20.867 | 22.968 |
| 60 | 12.650 | 14.395 | 17.508 | 20.121 | 21.052 | 34.465 |
| 90 | 12.732 | 14.413 | 17.535 | 20.137 | 21.062 | 27.270 |
| 120 | 12.712 | 14.411 | 17.535 | 20.127 | 20.053 | 27.433 |
| N W | 2 | 3 | 5 | 8 | 10 | 20 |
|---|---|---|---|---|---|---|
| 1 | 13.120 | 12.725 | 12.075 | 10.979 | 10.943 | 10.532 |
| 2 | 11.831 | 12.061 | 11.182 | 10.557 | 10.684 | 10.817 |
| 5 | 11.835 | 11.431 | 11.858 | 11.800 | 11.942 | 11.654 |
| 10 | 11.580 | 11.060 | 10.776 | 11.254 | 11.270 | 11.558 |
| 20 | 11.928 | 11.678 | 11.387 | 10.850 | 10.973 | 11.198 |
| 30 | 15.879 | 15.682 | 13.188 | 12.437 | 12.283 | 11.052 |
| 60 | 8.693 | 9.887 | 10.554 | 10.747 | 11.014 | 10.563 |
| 90 | 13.627 | 13.531 | 11.819 | 11.309 | 10.946 | 10.281 |
| 120 | 13.786 | 12.604 | 11.496 | 11.179 | 10.989 | 10.522 |
| N W | 2 | 3 | 5 | 8 | 10 | 20 |
|---|---|---|---|---|---|---|
| 1 | 7.939 | 8.393 | 7.979 | 7.797 | 8.025 | 8.271 |
| 2 | 7.795 | 7.971 | 8.303 | 8.777 | 8.606 | 8.624 |
| 5 | 8.491 | 8.989 | 8.440 | 8.673 | 8.854 | 8.784 |
| 10 | 8.419 | 8.775 | 9.225 | 8.642 | 8.686 | 8.336 |
| 20 | 9.912 | 8.688 | 8.492 | 8.637 | 8.435 | 8.348 |
| 30 | 7.169 | 8.311 | 7.962 | 8.549 | 8.643 | 8.741 |
| 60 | 9.169 | 9.344 | 8.418 | 8.527 | 8.722 | 8.514 |
| 90 | 9.038 | 9.160 | 8.618 | 8.649 | 8.842 | 8.915 |
| 120 | 9.379 | 9.463 | 10.141 | 9.291 | 9.358 | 8.782 |
| N W | 2 | 3 | 5 | 8 | 10 | 20 |
|---|---|---|---|---|---|---|
| 1 | 1.365 | 1.283 | 1.335 | 1.151 | 1.205 | 1.104 |
| 2 | 1.553 | 1.391 | 1.318 | 1.250 | 1.175 | 1.031 |
| 5 | 1.250 | 1.189 | 1.089 | 1.042 | 1.054 | 1.059 |
| 10 | 1.247 | 1.143 | 1.001 | 1.000 | 1.011 | 0.994 |
| 20 | 1.318 | 1.334 | 1.231 | 1.124 | 1.090 | 1.117 |
| 30 | 1.808 | 1.658 | 1.200 | 1.062 | 0.998 | 1.072 |
| 60 | 1.375 | 1.327 | 1.080 | 1.093 | 1.059 | 0.907 |
| 90 | 1.631 | 1.377 | 1.271 | 1.094 | 1.057 | 0.977 |
| 120 | 1.724 | 1.286 | 1.254 | 0.992 | 0.949 | 0.878 |
| N W | 2 | 3 | 5 | 8 | 10 | 20 |
|---|---|---|---|---|---|---|
| 1 | 297.89 | 301.82 | 293.62 | 299.39 | 303.13 | 314.98 |
| 2 | 324.27 | 324.40 | 312.63 | 299.96 | 312.45 | 304.34 |
| 5 | 348.96 | 309.02 | 280.81 | 270.93 | 258.90 | 267.69 |
| 10 | 350.70 | 290.81 | 277.56 | 276.16 | 275.89 | 283.55 |
| 20 | 331.45 | 320.51 | 287.70 | 320.23 | 312.07 | 301.83 |
| 30 | 348.98 | 344.01 | 331.66 | 316.19 | 305.89 | 295.60 |
| 60 | 330.73 | 339.59 | 327.74 | 313.10 | 313.20 | 312.10 |
| 120 | 337.48 | 324.87 | 309.41 | 326.41 | 321.95 | 325.69 |
| Models Cases | Best Models ** | RW vs. CBR | t-Value * (p-Value) | Decision |
|---|---|---|---|---|
| Zoom | W (60) N (2) | 10.777 vs. 8.693 | 0.5867 (0.2806) | Accept HO |
| Airbnb | W (30) N (2) | 8.418 vs. 7.169 | 0.5801 (0.2828) | Accept HO |
| W (120) N (20) | 0.987 vs. 0.876 | 0.7719 (0.2227) | Accept HO | |
| DJI | W (5) N (10) | 295 vs. 256 | 0.3820 (0.3524) | Accept HO |
| Models Cases | CBR Model | RW vs. CBR | z-Value * (p-Value) | Decision |
|---|---|---|---|---|
| Zoom | W (60) N (2) | 76.5 vs. 77.8% | 0.0888 | Accept HO |
| Airbnb | W (30) N (2) | 47.1 vs. 61.1% | 0.8662 | Accept HO |
| W (120) N (20) | 64.7 vs. 83.3% | 1.2351 | Accept HO | |
| DJI | W (5) N (10) | 47.1 vs. 50.0% | 0.5508 | Accept HO |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Chun, S.-H.; Jang, J.-W. A New Trend Pattern-Matching Method of Interactive Case-Based Reasoning for Stock Price Predictions. Sustainability 2022, 14, 1366. https://doi.org/10.3390/su14031366
Chun S-H, Jang J-W. A New Trend Pattern-Matching Method of Interactive Case-Based Reasoning for Stock Price Predictions. Sustainability. 2022; 14(3):1366. https://doi.org/10.3390/su14031366
Chicago/Turabian StyleChun, Se-Hak, and Jae-Won Jang. 2022. "A New Trend Pattern-Matching Method of Interactive Case-Based Reasoning for Stock Price Predictions" Sustainability 14, no. 3: 1366. https://doi.org/10.3390/su14031366
APA StyleChun, S.-H., & Jang, J.-W. (2022). A New Trend Pattern-Matching Method of Interactive Case-Based Reasoning for Stock Price Predictions. Sustainability, 14(3), 1366. https://doi.org/10.3390/su14031366