
Detecting Nontechnical Losses in Smart Meters Using a MLP-GRU Deep Model and Augmenting Data via Theft Attacks

 , , and
, , and
Abstract
1. Background
Contribution List
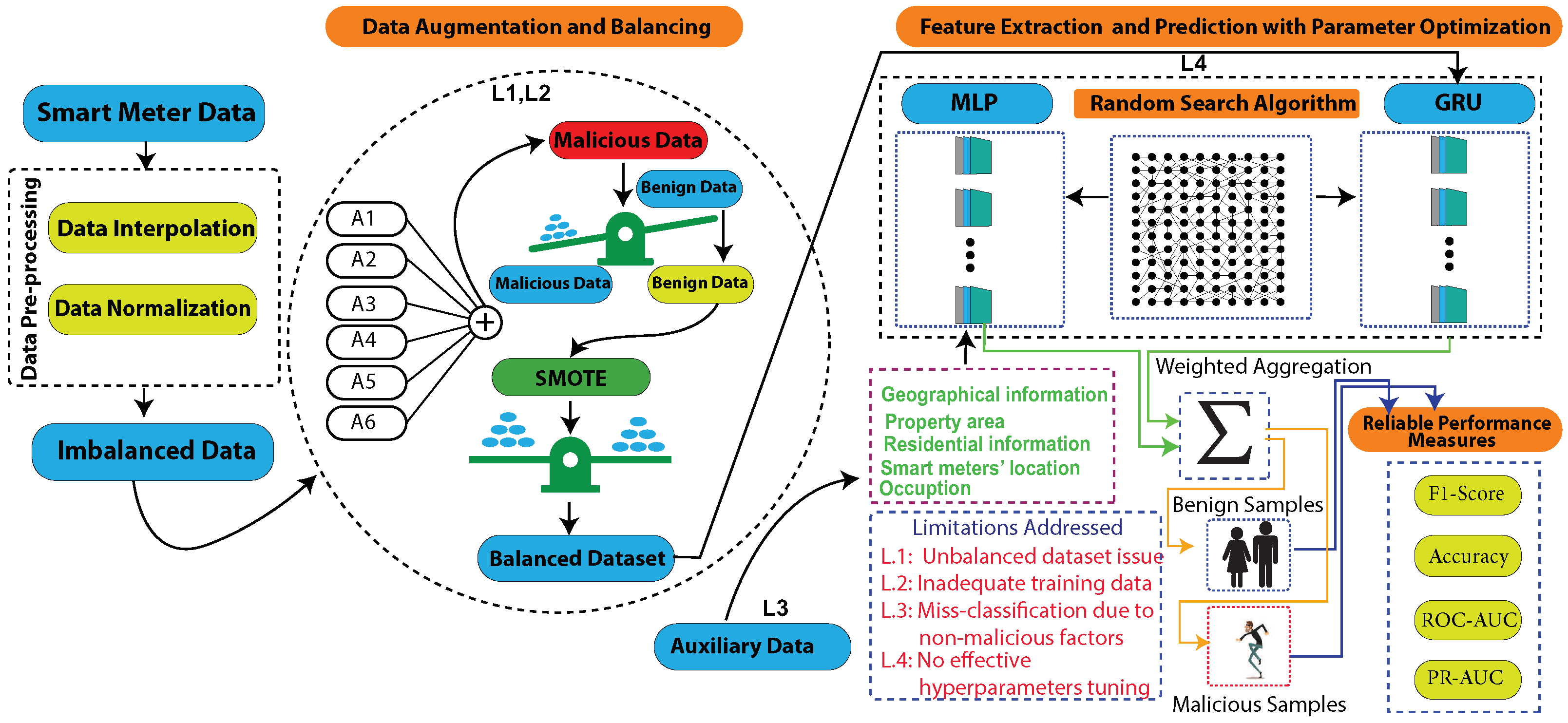
- A hybrid model, referred as MLP-GRU, that identifies NTLs using both metering data and auxiliary data is proposed.
- A data augmentation technique is used due to the scarcity of theft samples. This study uses six theft scenarios to create synthetic instances of EC by modifying the honest samples.
- Meanwhile, a Synthetic Minority Oversampling Technique (SMOTE) is employed to maintain a balance between synthetic and benign samples.
- An optimization algorithm, known as the Random Search Algorithm (RSA), is used to effectively tune the MLP-GRU model’s hyperparameters.
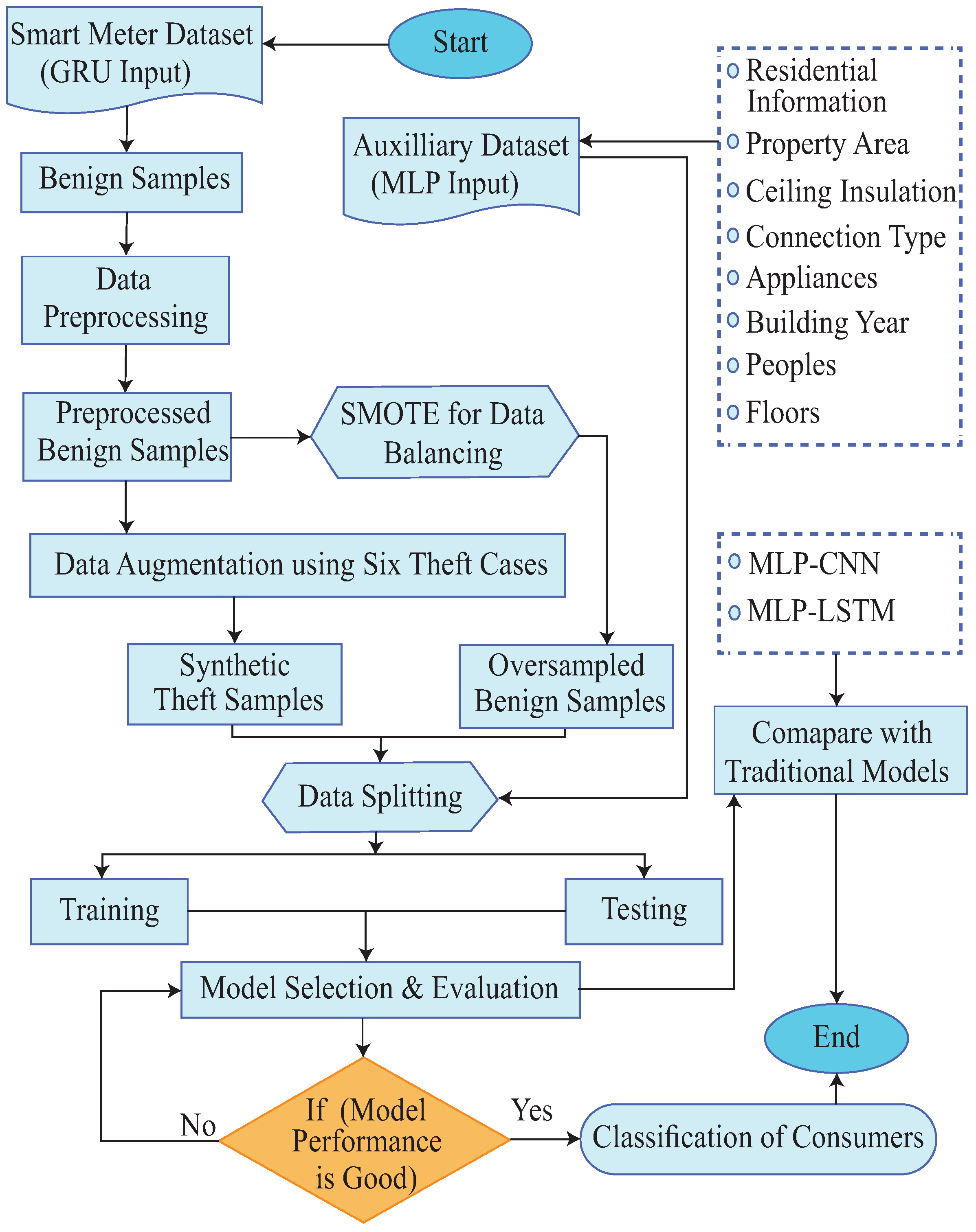
2. Proposed System Model
- (1)
- The data preprocessing take place before the training step in the first stage. The data interpolation method is employed to fill in the dataset’s missing values. Following that, a standard-scalar technique is used to normalize the data, which is a min-max procedure.
- (2)
- Data augmentation is performed after the data have been standardized and cleaned. Different theft patterns are created by modifying the honest users’ samples using six theft scenarios [18].
- (3)
- Since the proportion of the theft class exceeds the benign class, SMOTE is applied on the benign class to balance the dataset.
- (4)
- Afterwards, the preprocessed data are used to train the model. The datasets from the smart meters and relative auxiliary information are sent to the GRU and MLP networks, respectively. The RSA is used to effectively tune the parameters of the classifiers.
- (5)
- In the last step, efficient performance metrics, such as the accuracy, F1-score, Area Under the Receiver Operating Characteristics Curve (AUC-ROC)m and Area Under the Precision–Recall Curve (PR-AUC) are used for evaluating the proposed model’s performance.
2.1. Data Preprocessing
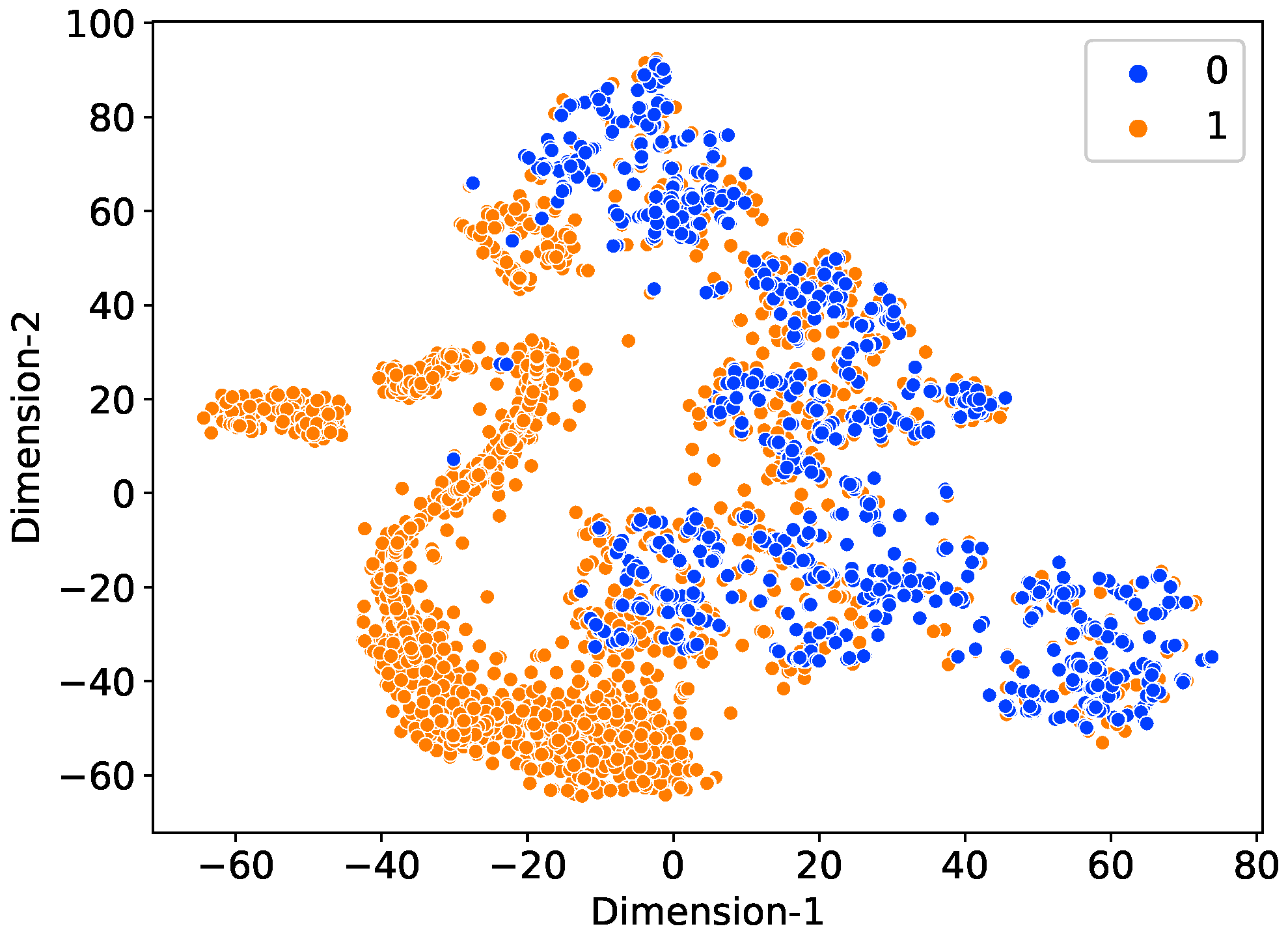
2.2. Data Balancing and Data Augmentation
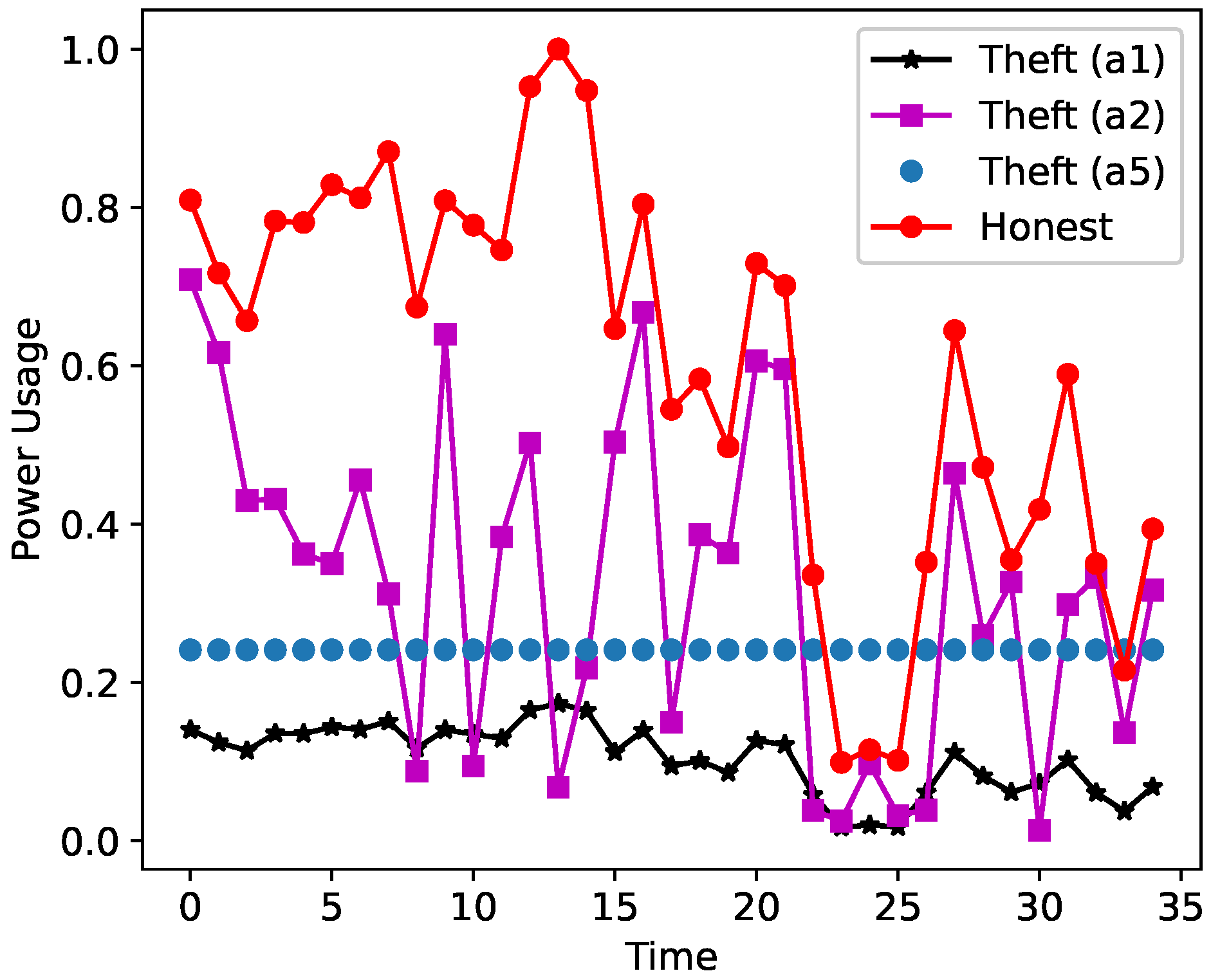
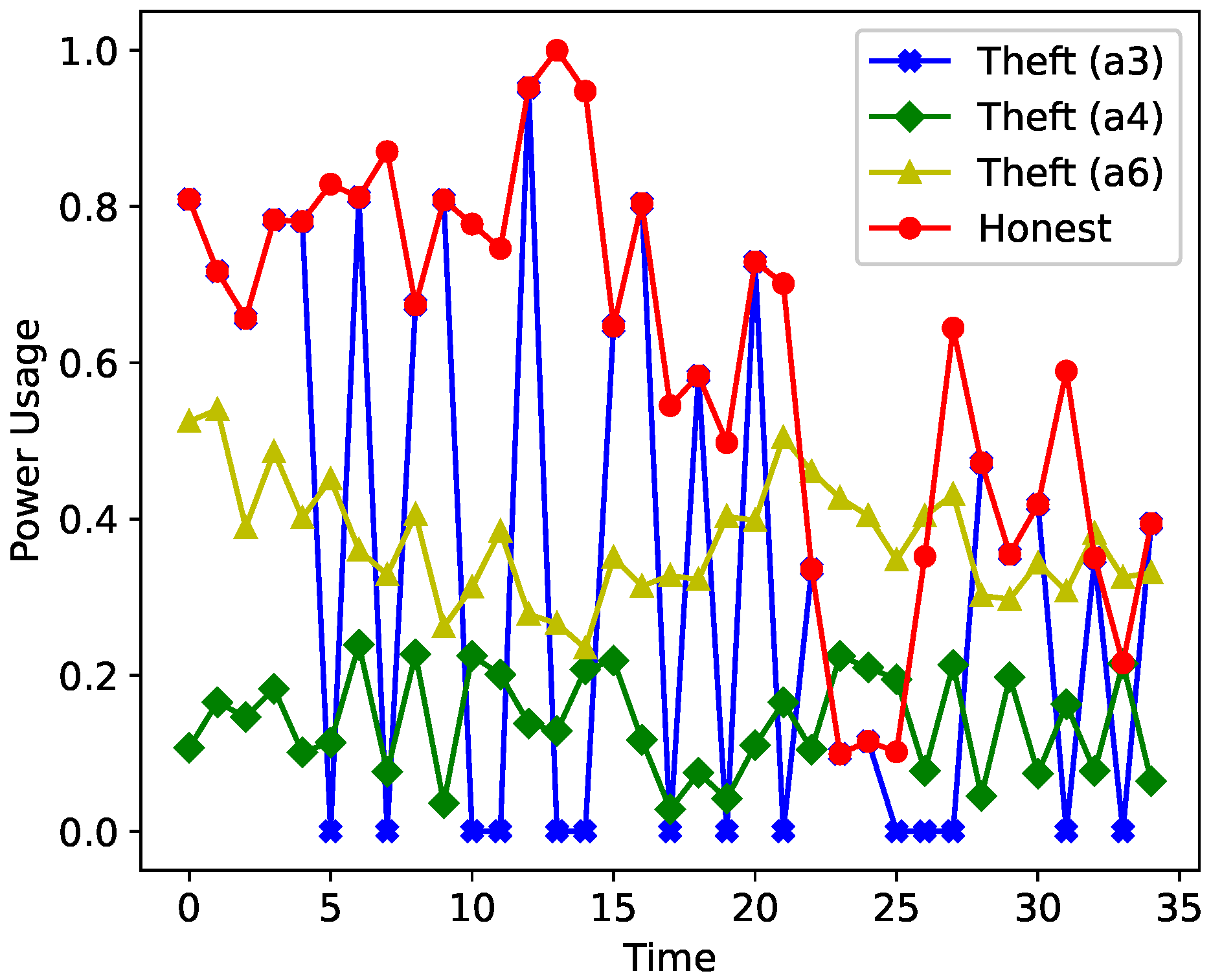
2.2.1. Six Theft Cases
- (A1).
- = * a, where a = rand (0.1, 0.9),
- (A2).
- = * , where = rand (0.1, 1.0),
- (A3).
- = * , where = rand [0, 1],
- (A4).
- = mean (H) * , where = rand (0.1, 1.0),
- (A5).
- = mean (H),
- (A6).
- = .
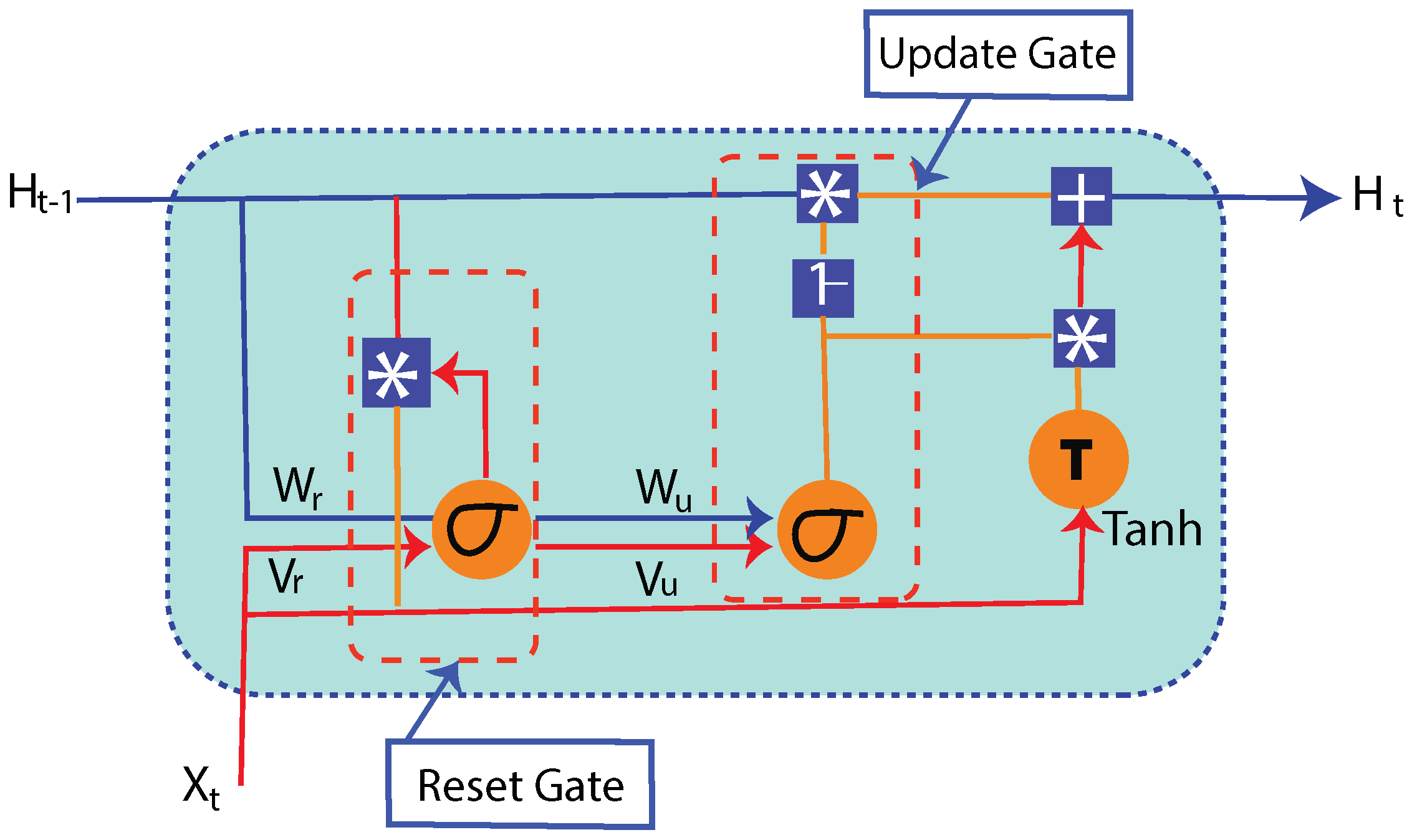
2.2.2. Hybrid MLP-GRU Network
2.2.3. Gated Recurrent Unit Network for Smart Meter Data
2.2.4. Multi-Layered Perceptron Network with Auxiliary Data
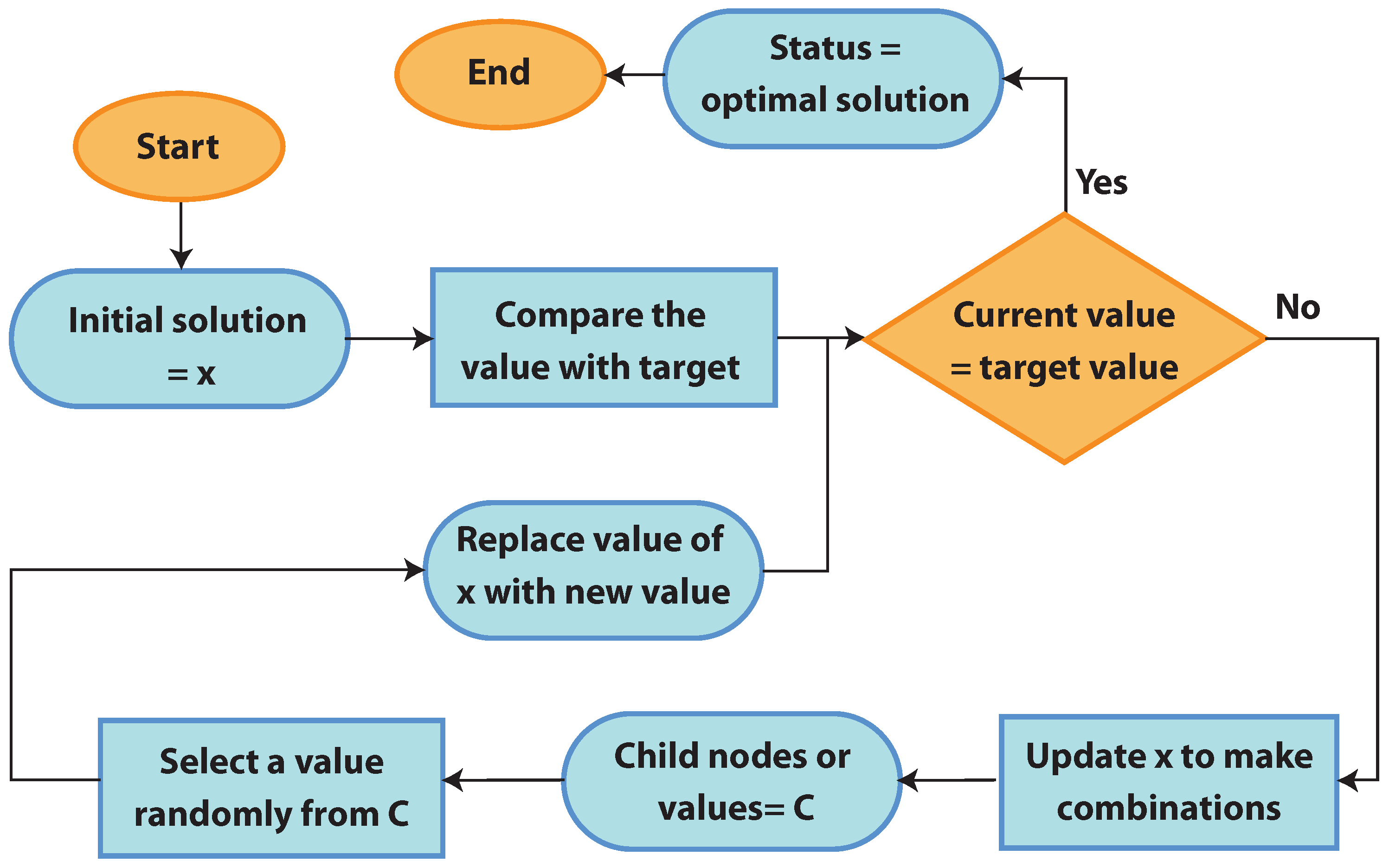
2.2.5. Random-Search-Based Parameters’ Optimization Algorithm
- The initial value is stored in a variable, denoted by x.
- If the values stored in x are target node values, the algorithm immediately stops with the success. Otherwise, it moves to the next step.
- The values of x are updated to get the optimal possible combination of x. We obtain the number of child nodes (values of x) and store them in another variable C.
- A value from all possible combinations of child node values is randomly selected.
- The values of x are replaced with the new values, and then the process returns to step 2 for validation, where the existing values are compared with the target values. The process continues until the final optimal solution is reached. Figure 9 shows the process of tuning hyperparameters with the RSA.
3. Performance Measurement Indicators
4. Simulations and Findings
4.1. Data Acquisition
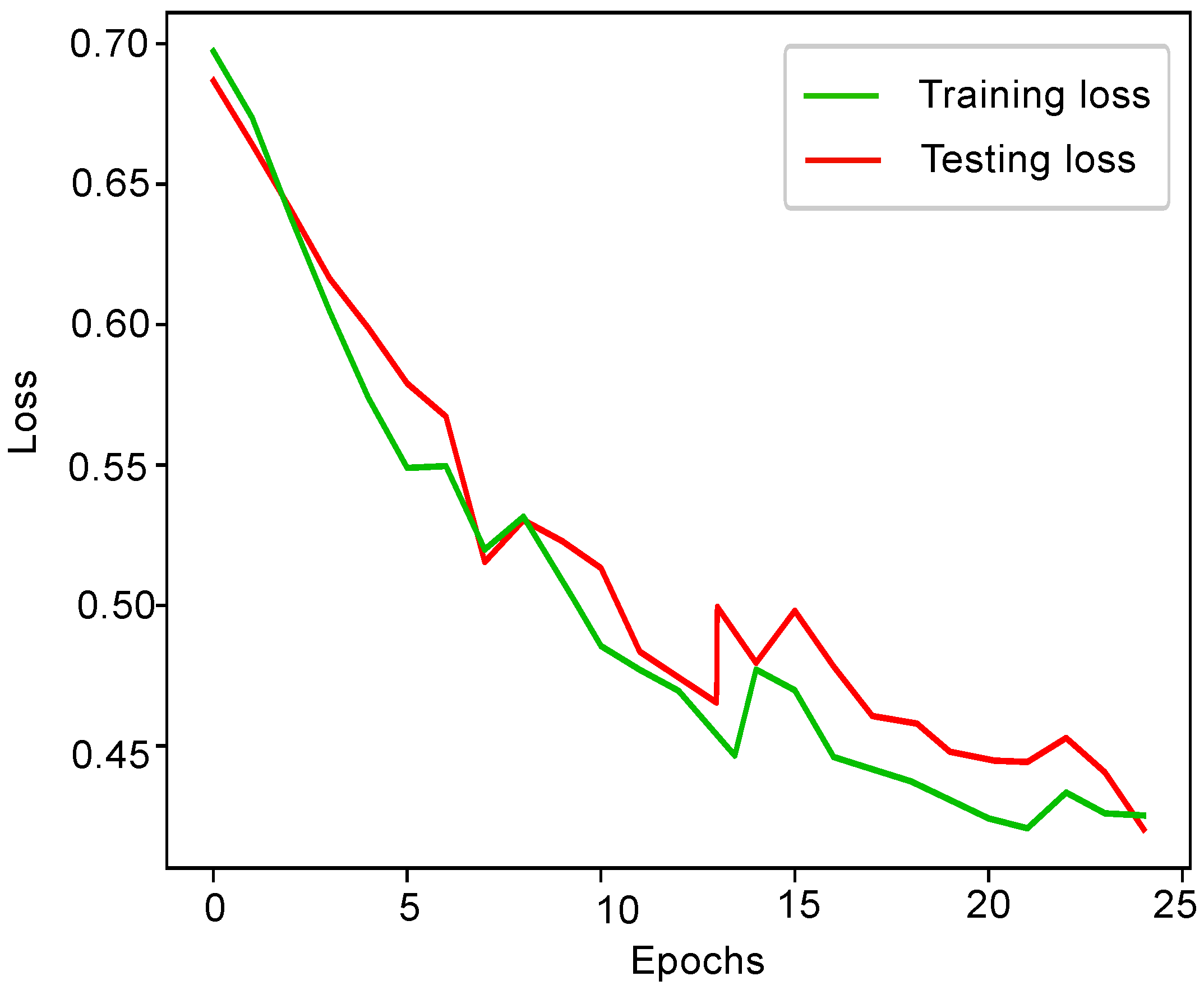
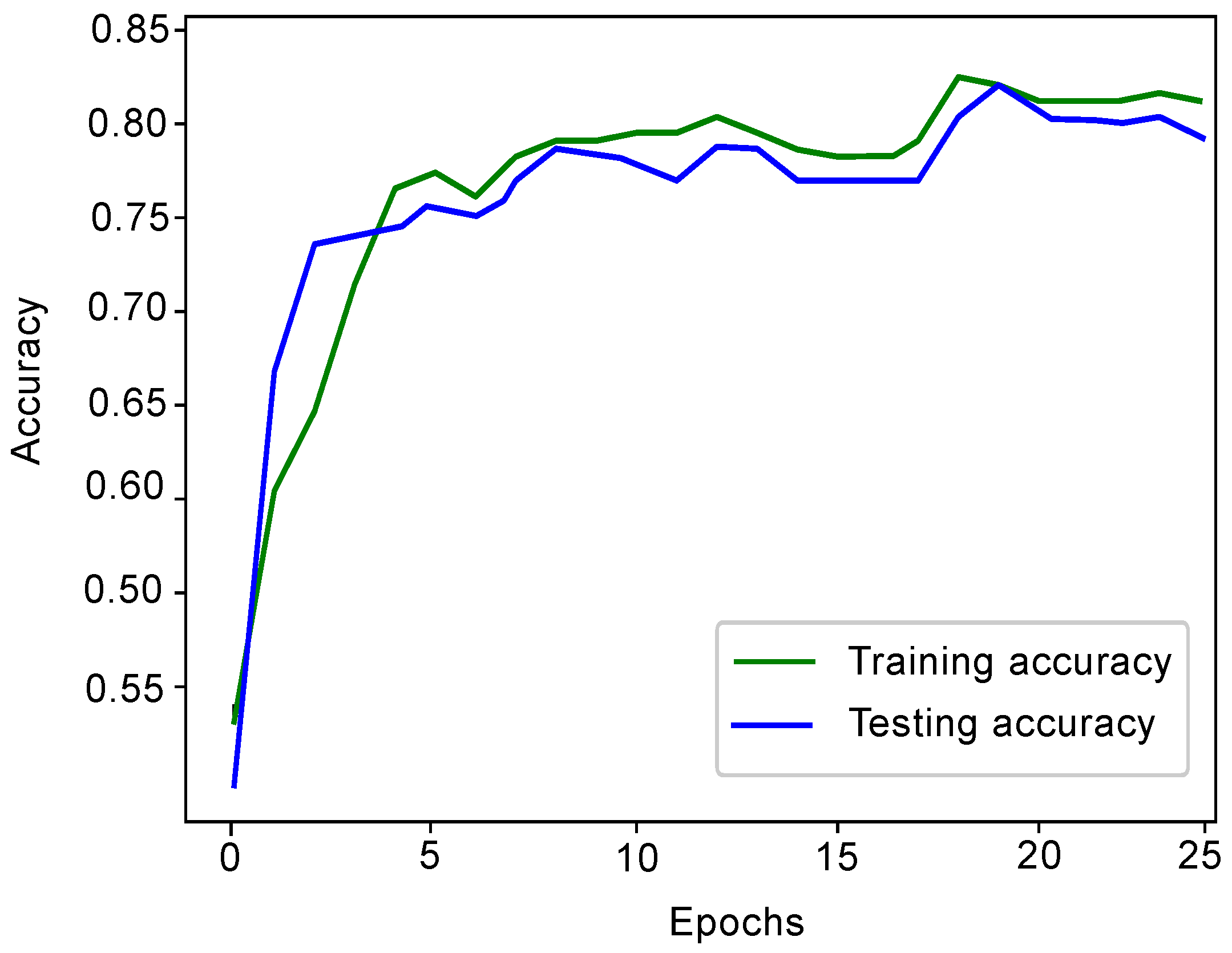
4.2. Evaluation Results
5. Conclusions
Author Contributions
Funding
Data Availability Statement
Acknowledgments
Conflicts of Interest
Abbreviations
| Abbreviation | Full Form |
| AMI | Advanced Metering Infrastructure |
| CNN | Convolutional Neural Network |
| CPBETD | Consumption Pattern Based Electricity Theft Detector |
| CVAE | Conditional Variational Auto Encoder |
| DNN | Deep Neural Network |
| DR | Detection Rate |
| EC | Electricity Consumption |
| ETD | Electricity Theft Detection |
| ETs | Extra Trees |
| FPR | False Positive Rate |
| GBTD | Gradient Boosting Theft Detector |
| GRU | Gated Recurrent Unit |
| GMM | Gaussian Mixture Model |
| GSA | Grid Search Algorithm |
| KNNs | K-Nearest Neighbors |
| LR | Logistic Regression |
| LSTM | Long-Short Term Memory |
| ML | Machine Learning |
| MLP | Multi-Layer Perceptron |
| NTL | Nontechnical Loss |
| PRECON | Pakistan Residential Electricity Consumption |
| RF | Random Forest |
| RSA | Random Search Algorithm |
| SVM | Support Vector Machine |
| SMOTE | Synthetic Minority Oversampling Technique |
| SSDAE | Stacked Sparse Denoising Auto-Encoder |
| SETS | Smart Energy Theft System |
| TL | Technical Loss |
| TPR | True Positive Rate |
| WGAN | Wasserstein Generative Adversarial Network |
| XGBoost | Extreme Gradient Boosting |
| Previous Layer Input | |
| r | Reset Gate |
| t | Time Period |
| u | Update Gate |
| Current Input State |
References
- Praju, T.K.S.; Samal, S.; Saravanakumar, R.; Yaseen, S.M.; Nandal, R.; Dhabliya, D. Advanced metering infrastructure for low voltage distribution system in smart grid based monitoring applications. Sustain. Comput. Inform. Syst. 2022, 35, 100691. [Google Scholar]
- Otuoze, A.O.; Mustafa, M.W.; Abioye, A.E.; Sultana, U.; Usman, A.M.; Ibrahim, O.; Abu-Saeed, A. A rule-based model for electricity theft prevention in advanced metering infrastructure. J. Electr. Syst. Inf. Technol. 2022, 9, 2. [Google Scholar] [CrossRef]
- Fei, K.; Li, Q.; Zhu, C. Non-technical losses detection using missing values’ pattern and neural architecture search. Int. J. Electr. Power Energy Syst. 2022, 134, 107410. [Google Scholar] [CrossRef]
- Buzau, M.M.; Tejedor-Aguilera, J.; Cruz-Romero, P.; Gómez-Expósito, A. Hybrid deep neural networks for detection of non-technical losses in electricity smart meters. IEEE Trans. Power Syst. 2019, 35, 1254–1263. [Google Scholar] [CrossRef]
- Kocaman, B.; Tümen, V. Detection of electricity theft using data processing and LSTM method in distribution systems. Sādhanā 2020, 45, 286. [Google Scholar] [CrossRef]
- Aslam, Z.; Javaid, N.; Ahmad, A.; Ahmed, A.; Gulfam, S.M. A combined deep learning and ensemble learning methodology to avoid electricity theft in smart grids. Energies 2020, 13, 5599. [Google Scholar]
- Ghori, K.M.; Abbasi, R.A.; Awais, M.; Imran, M.; Ullah, A.; Szathmary, L. Performance analysis of different types of machine learning classifiers for non-technical loss detection. IEEE Access 2019, 8, 16033–16048. [Google Scholar] [CrossRef]
- Shehzad, F.; Javaid, N.; Aslam, S.; Javaid, M.U. Electricity theft detection using big data and genetic algorithm in electric power systems. Electr. Power Syst. Res. 2022, 209, 107975. [Google Scholar] [CrossRef]
- Pamir Javaid, N.; Javaid, S.; Asif, M.; Javed, M.U.; Yahaya, A.S.; Aslam, S. Synthetic Theft Attacks and Long Short Term Memory-Based Preprocessing for Electricity Theft Detection Using Gated Recurrent Unit. Energies 2022, 15, 2778. [Google Scholar] [CrossRef]
- Li, S.; Han, Y.; Yao, X.; Yingchen, S.; Wang, J.; Zhao, Q. Electricity theft detection in power grids with deep learning and random forests. J. Electr. Comput. Eng. 2019, 2019, 4136874. [Google Scholar] [CrossRef]
- Saeed, M.S.; Mustafa, M.W.; Sheikh, U.U.; Jumani, T.A.; Mirjat, N.H. Ensemble bagged tree based classification for reducing non-technical losses in multan electric power company of Pakistan. Electronics 2019, 8, 860. [Google Scholar] [CrossRef]
- Gunturi, S.K.; Sarkar, D. Ensemble machine learning models for the detection of energy theft. Electr. Power Syst. Res. 2020, 192, 106904. [Google Scholar] [CrossRef]
- Fenza, G.; Gallo, M.; Loia, V. Drift-aware methodology for anomaly detection in smart grid. IEEE Access 2019, 7, 9645–9657. [Google Scholar] [CrossRef]
- Qu, Z.; Li, H.; Wang, Y.; Zhang, J.; Abu-Siada, A.; Yao, Y. Detection of electricity theft behavior based on improved synthetic minority oversampling technique and random forest classifier. Energies 2020, 13, 2039. [Google Scholar] [CrossRef]
- Li, W.; Logenthiran, T.; Phan, V.T.; Woo, W.L. A novel smart energy theft system (SETS) for IoT-based smart home. IEEE Internet Things J. 2019, 6, 5531–5539. [Google Scholar] [CrossRef]
- Yang, R.; Qin, X.; Liu, W.; Huang, Z.; Shi, Y.; Pang, Z.; Zhang, Y.; Li, J.; Wang, T. A Physics-Constrained Data-Driven Workflow for Predicting Coalbed Methane Well Production Using Artificial Neural Network. SPE J. 2022, 27, 1531–1552. [Google Scholar] [CrossRef]
- Yan, Z.; Wen, H. Electricity theft detection base on extreme gradient boosting in AMI. IEEE Trans. Instrum. Meas. 2021, 70, 2504909. [Google Scholar] [CrossRef]
- Punmiya, R.; Choe, S. Energy theft detection using gradient boosting theft detector with feature engineering-based preprocessing. IEEE Trans. Smart Grid 2019, 10, 2326–2329. [Google Scholar] [CrossRef]
- Huang, Y.; Xu, Q. Electricity theft detection based on stacked sparse denoising autoencoder. Int. J. Electr. Power Energy Syst. 2021, 125, 106448. [Google Scholar] [CrossRef]
- Gong, X.; Tang, B.; Zhu, R.; Liao, W.; Song, L. Data Augmentation for Electricity Theft Detection Using Conditional Variational Auto-Encoder. Energies 2020, 13, 4291. [Google Scholar] [CrossRef]
- Park, C.H.; Kim, T. Energy Theft Detection in Advanced Metering Infrastructure Based on Anomaly Pattern Detection. Energies 2020, 13, 3832. [Google Scholar] [CrossRef]
- Jokar, P.; Arianpoo, N.; Leung, V.C. Electricity theft detection in AMI using customers’ consumption patterns. IEEE Trans. Smart Grid 2015, 7, 216–226. [Google Scholar] [CrossRef]
- Maamar, A.; Benahmed, K. A hybrid model for anomalies detection in AMI system combining K-means clustering and deep neural network. Comput. Mater. Continua 2019, 60, 15–39. [Google Scholar] [CrossRef]
- Ding, N.; Ma, H.; Gao, H.; Ma, Y.; Tan, G. Real-time anomaly detection based on long short-Term memory and Gaussian Mixture Model. Comput. Electr. Eng. 2019, 79, 106458. [Google Scholar] [CrossRef]
- Jindal, A.; Dua, A.; Kaur, K.; Singh, M.; Kumar, N.; Mishra, S. Decision tree and SVM-based data analytics for theft detection in smart grid. IEEE Trans. Ind. Inform. 2016, 12, 1005–1016. [Google Scholar] [CrossRef]
- Kabir, B.; Ullah, A.; Munawar, S.; Asif, M.; Javaid, N. Detection of non-technical losses using MLPGRU based neural network to secure smart grids. In Proceedings of the 15th International Conference on Complex, Intelligent and Software Intensive System (CISIS), Asan, Republic of Korea, 1–3 July 2021; ISBN 978-3-030-50454-0. [Google Scholar]
- Kong, X.; Zhao, X.; Liu, C.; Li, Q.; Dong, D.; Li, Y. Electricity theft detection in low-voltage stations based on similarity measure and DT-KSVM. Int. J. Electr. Power Energy Syst. 2021, 125, 106544. [Google Scholar]
- Gul, H.; Javaid, N.; Ullah, I.; Qamar, A.M.; Afzal, M.K.; Joshi, G.P. Detection of non-technical losses using SOSTLink and bidirectional gated recurrent unit to secure smart meters. Appl. Sci. 2020, 10, 3151. [Google Scholar]
- Kuo, P.H.; Huang, C.J. An electricity price forecasting model by hybrid structured deep neural networks. Sustainability 2018, 10, 1280. [Google Scholar] [CrossRef]
- George, S.; Sumathi, B. Grid search tuning of hyperparameters in random forest classifier for customer feedback sentiment prediction. Int. J. Adv. Comput. Sci. Appl. 2020, 11, 173–178. [Google Scholar]
- Ghori, K.M.; Imran, M.; Nawaz, A.; Abbasi, R.A.; Ullah, A.; Szathmary, L. Performance analysis of machine learning classifiers for non-technical loss detection. J. Ambient. Intell. Humaniz. Comput. 2020, 18, 1–16. [Google Scholar] [CrossRef]
- Razavi, R.; Gharipour, A.; Fleury, M.; Akpan, I.J. A practical feature-engineering framework for electricity theft detection in smart grids. Appl. Energy 2019, 238, 481–494. [Google Scholar] [CrossRef]
- Aslam, Z.; Ahmed, F.; Almogren, A.; Shafiq, M.; Zuair, M.; Javaid, N. An attention guided semi-supervised learning mechanism to detect electricity frauds in the distribution systems. IEEE Access 2020, 8, 221767–221782. [Google Scholar] [CrossRef]
- Nadeem, A.; Arshad, N. PRECON: Pakistan residential electricity consumption dataset. In Proceedings of the Tenth ACM International Conference on Future Energy Systems, Phoenix, AZ, USA, 25–28 June 2019; pp. 52–57. Available online: http://web.lums.edu.pk/~eig/CXyzsMgyXGpW1sBo (accessed on 15 September 2022).
- Zheng, Z.; Yang, Y.; Niu, X.; Dai, H.N.; Zhou, Y. Wide and deep convolutional neural networks for electricity-theft detection to secure smart grids. IEEE Trans. Ind. Inform. 2017, 14, 1606–1615. [Google Scholar] [CrossRef]
- Arif, A.; Javaid, N.; Aldegheishem, A.; Alrajeh, N. Big data analytics for identifying electricity theft using machine learning approaches in micro grids for smart communities. Concurr. Comput. Pract. Exp. 2021, 33, e6316. [Google Scholar] [CrossRef]
















{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Shortcomings | Proposed Solutions | Evaluation |
|---|---|---|
| L1 and L2: imbalanced dataset issue and inadequate training data | S1: Employ six theft attacks on normal samples, then apply SMOTE to balance the dataset | V1: Comparison with oversampling techniques |
| L3: Misclassification as a result of non-malicious circumstances | S2: Integrate auxiliary data | V2: Performance comparison with traditional models |
| L4: Inappropriate tuning of model’s hyperparameters | S3: RSA | V3: Compare the RSA with the existing GRA approach |
| Data Type | Description (MLP Input Data) | Size of Data |
|---|---|---|
| Residents’ Information | Temporary residents and permanent residents | 2 |
| People | Total number of people including adults, children | 3 |
| Appliances | Number of appliances in a home including washing machine, fridge, iron, electronic devices, fans, AC, water-pump, UPS, water-dispenser, refrigerator and lightening devices | 11 |
| Connection Type | Single-phase and multi-phase | 2 |
| Rooms’ Information | Number of rooms including bed room, living room, kitchen, washroom, dining room | 6 |
| Roof or Ceiling | The total height of ceiling, ceiling insulation used, ceiling insulation not used | 2 |
| Building Year | The year of building construction | 1 |
| Property Area | The area or location of house | 1 |
| Floors | The total number of floors in a building | 1 |
| Hyperparameter | Optimal Value | Values Range |
|---|---|---|
| Units | 100 | 100, 10, 15, 50, 20, 35, 400, 25 |
| Optimizer | Adam | Adam, Adamax and SGD |
| Dropout | 0.01 | 0.3, 0.2, 0.5, 0.01, 0.1 |
| Batch-size | 32 | 10, 32, 25, 15 |
| Activation function | relu | relu, elu, sigmoid, softmax, tanh and linear |
| Epochs | 10 | 15, 25, 10, 20 |
| Hyperparameter | Optimal Value | Values Range |
|---|---|---|
| Dropout | 0.2 | 0.2, 0.5 |
| Units | 10 | 100, 10, 50 |
| Optimizer | Adam | Adam and SGD |
| Activation function | sigmoid | relu and sigmoid |
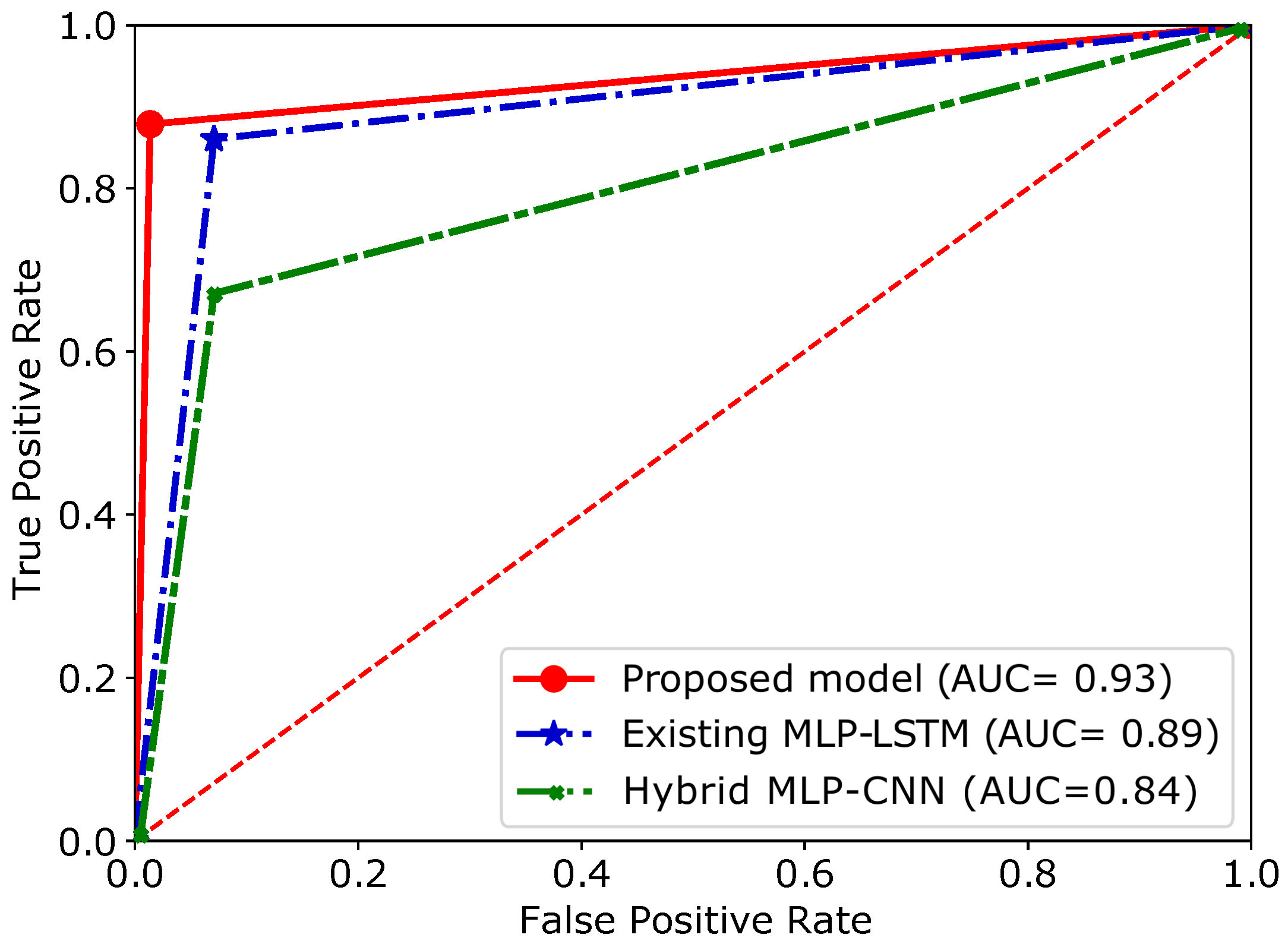
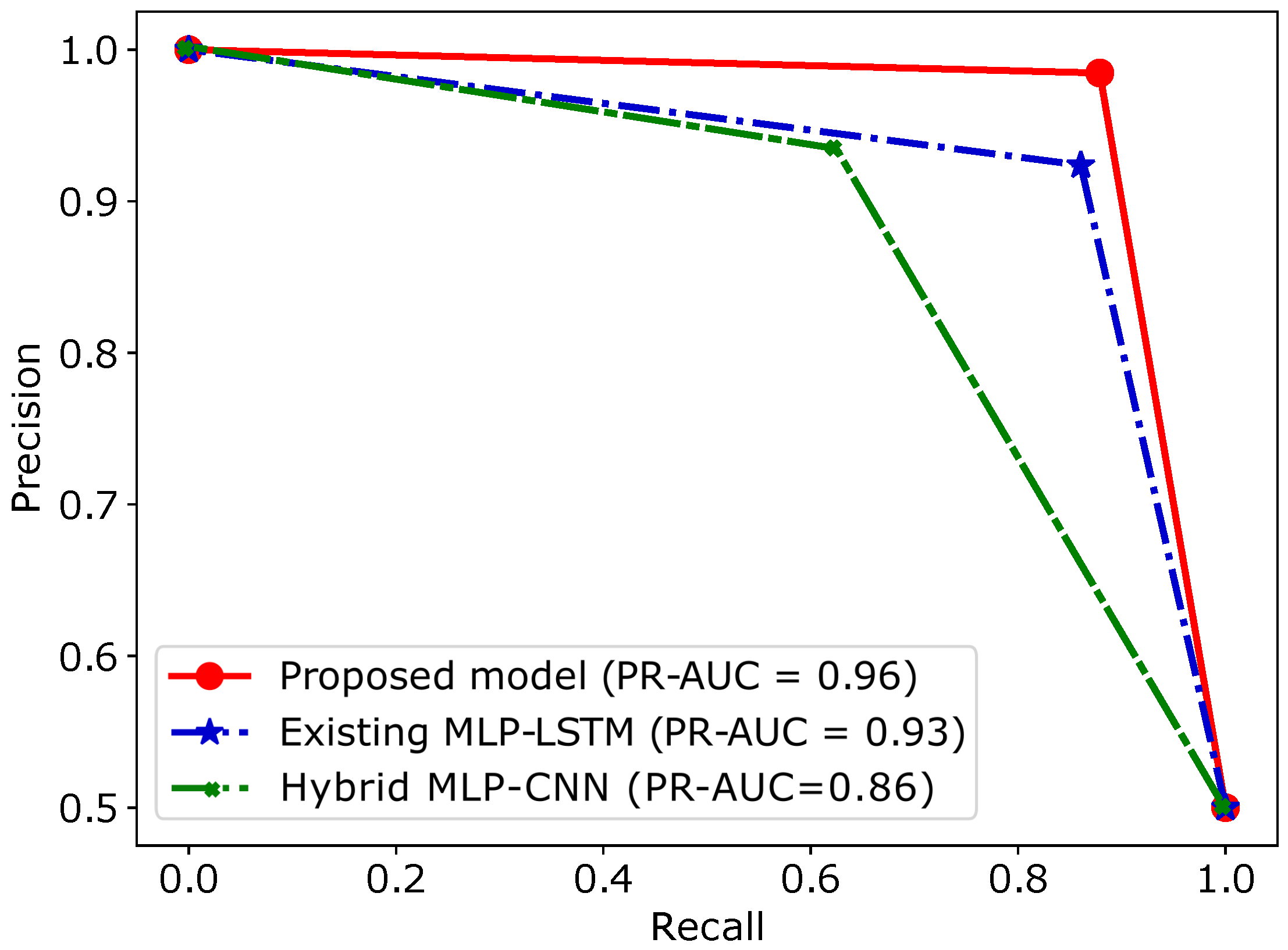
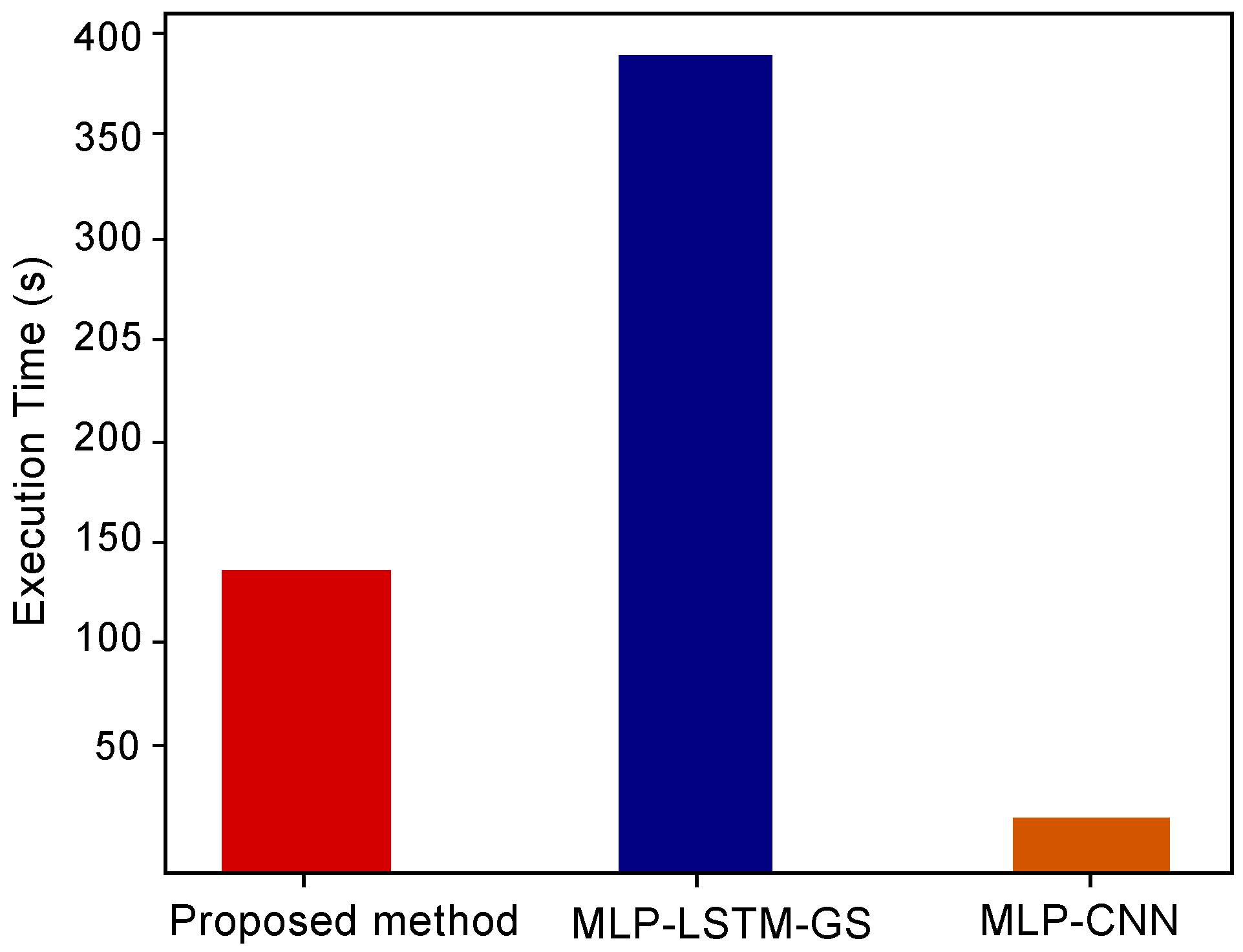
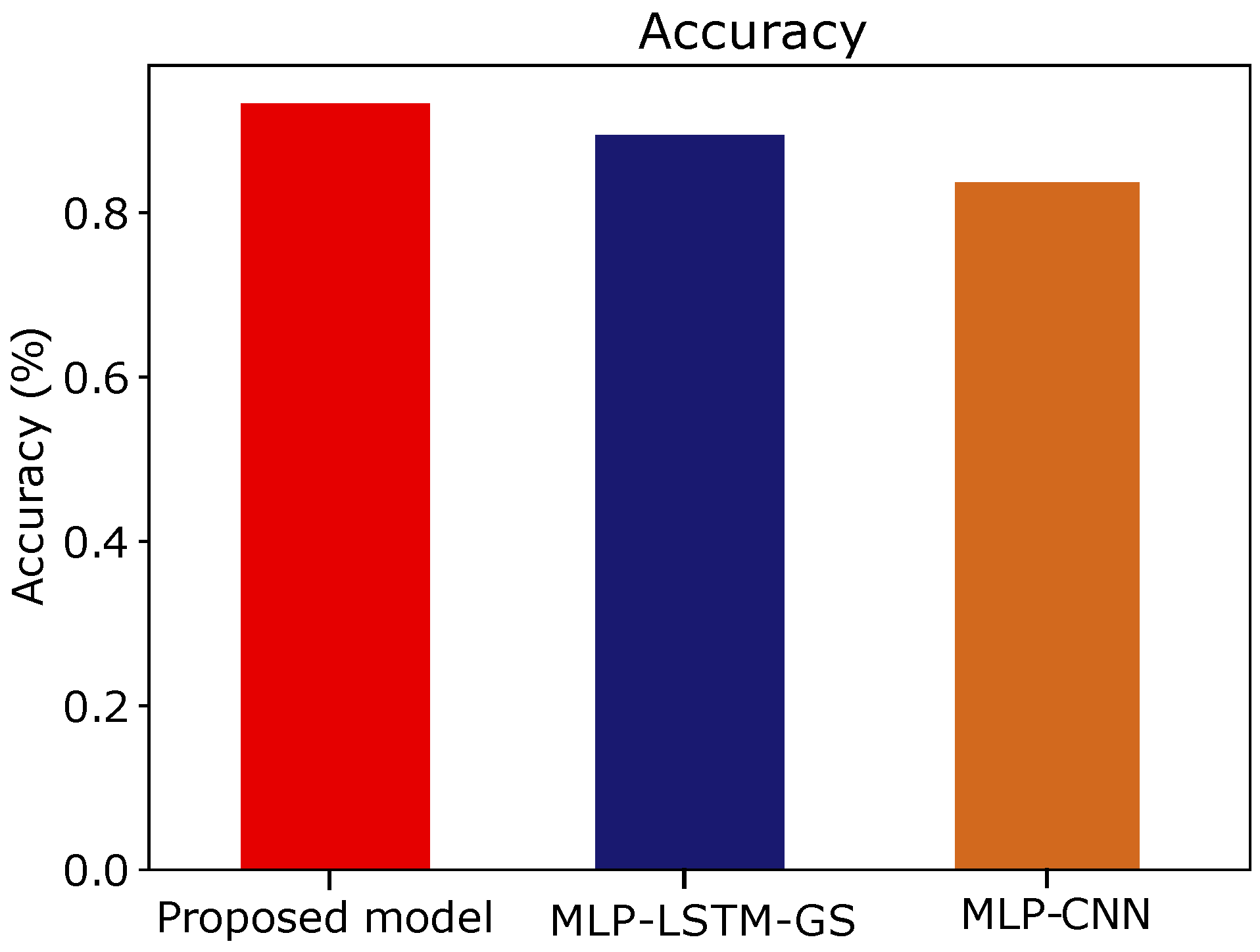
| Models | Accuracy | AUC | F1-Score | Time Required (s) |
|---|---|---|---|---|
| Proposed model | 0.93 | 0.93 | 0.92 | 144 |
| MLP-LSTM-GS | 0.89 | 0.89 | 0.89 | 391 |
| MLP-CNN | 0.67 | 0.84 | 0.71 | 26 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Kabir, B.; Qasim, U.; Javaid, N.; Aldegheishem, A.; Alrajeh, N.; Mohammed, E.A. Detecting Nontechnical Losses in Smart Meters Using a MLP-GRU Deep Model and Augmenting Data via Theft Attacks. Sustainability 2022, 14, 15001. https://doi.org/10.3390/su142215001
Kabir B, Qasim U, Javaid N, Aldegheishem A, Alrajeh N, Mohammed EA. Detecting Nontechnical Losses in Smart Meters Using a MLP-GRU Deep Model and Augmenting Data via Theft Attacks. Sustainability. 2022; 14(22):15001. https://doi.org/10.3390/su142215001
Chicago/Turabian StyleKabir, Benish, Umar Qasim, Nadeem Javaid, Abdulaziz Aldegheishem, Nabil Alrajeh, and Emad A. Mohammed. 2022. "Detecting Nontechnical Losses in Smart Meters Using a MLP-GRU Deep Model and Augmenting Data via Theft Attacks" Sustainability 14, no. 22: 15001. https://doi.org/10.3390/su142215001
APA StyleKabir, B., Qasim, U., Javaid, N., Aldegheishem, A., Alrajeh, N., & Mohammed, E. A. (2022). Detecting Nontechnical Losses in Smart Meters Using a MLP-GRU Deep Model and Augmenting Data via Theft Attacks. Sustainability, 14(22), 15001. https://doi.org/10.3390/su142215001