



Temporal and Spatial Characteristics of Meteorological Elements in the Vertical Direction at Airports and Hourly Airport Visibility Prediction by Artificial Intelligence Methods

 , and
, and
Abstract
1. Introduction
2. Methodology
2.1. Data
2.2. Methods
2.2.1. Trend Test
2.2.2. Artificial Intelligence Algorithms
Isotonic Regression (IST)
Bayesian Ridge Regression (BRR)
Least Absolute Shrinkage and Selection Operator (LASSO)
Passive Aggressive Regression (PAR)
Random Sample Consensus Regression (RANSAC)
Huber Regression (HBR)
Elastic-Net Regression (ENR)
Automatic Relevance Determination Regression (ARD)
Tweedie Regression (TWD)
2.2.3. The Kurtosis and Skewness Coefficient
3. Results
3.1. Vertical Distribution and Variation of Meteorological Elements at Airports
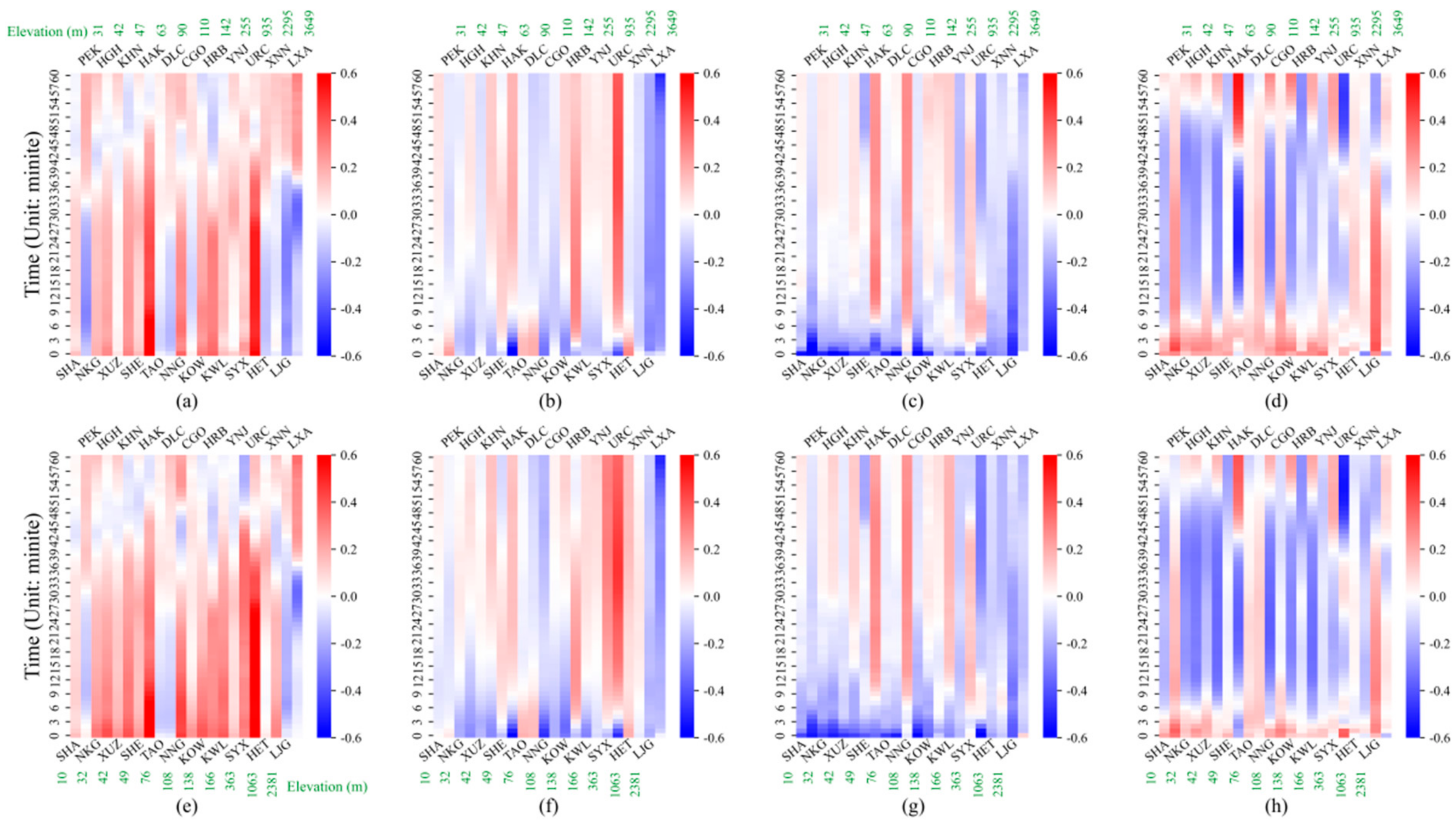
3.2. Relationship between Meteorological Elements and Visibility at Different Geopotential Heights
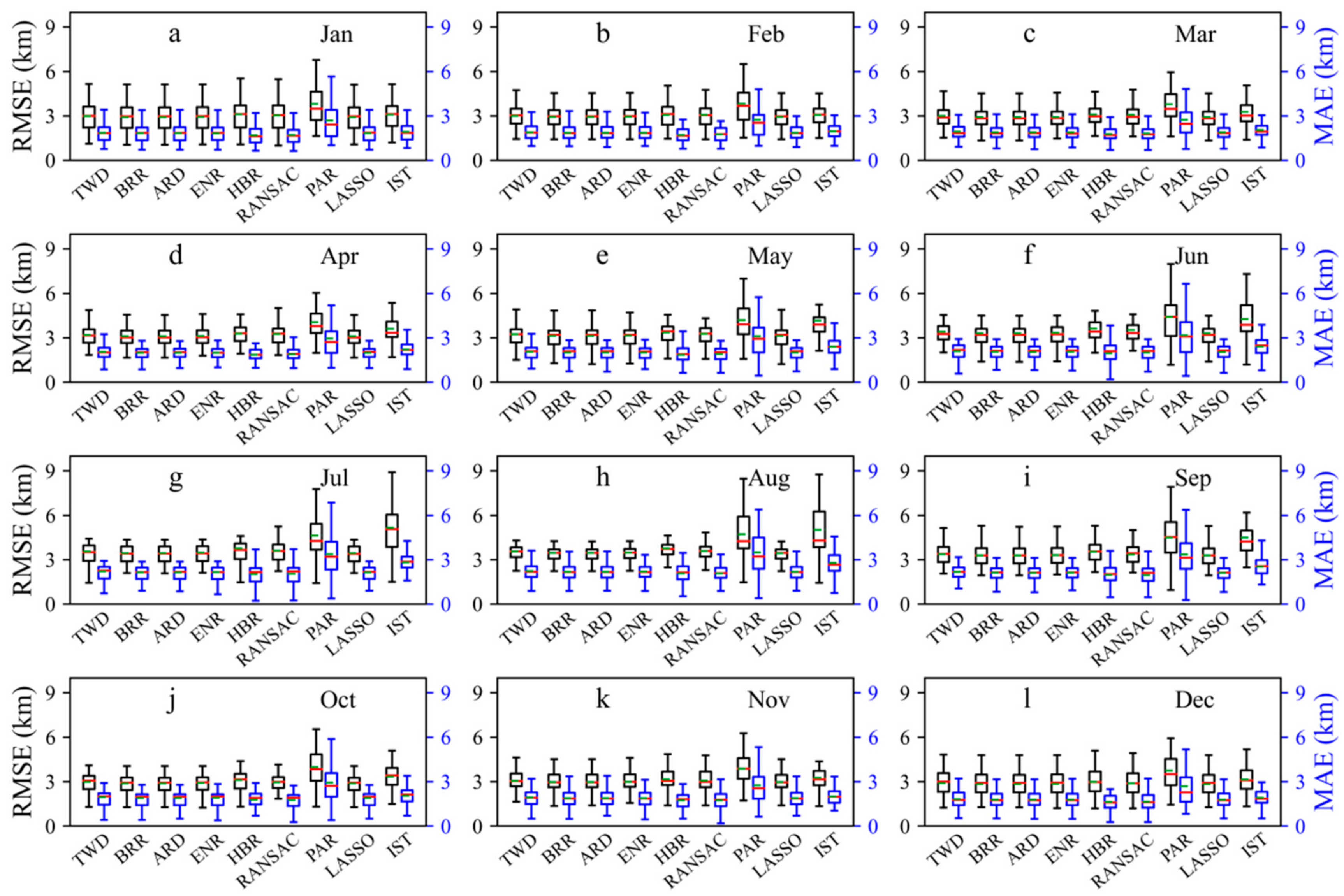
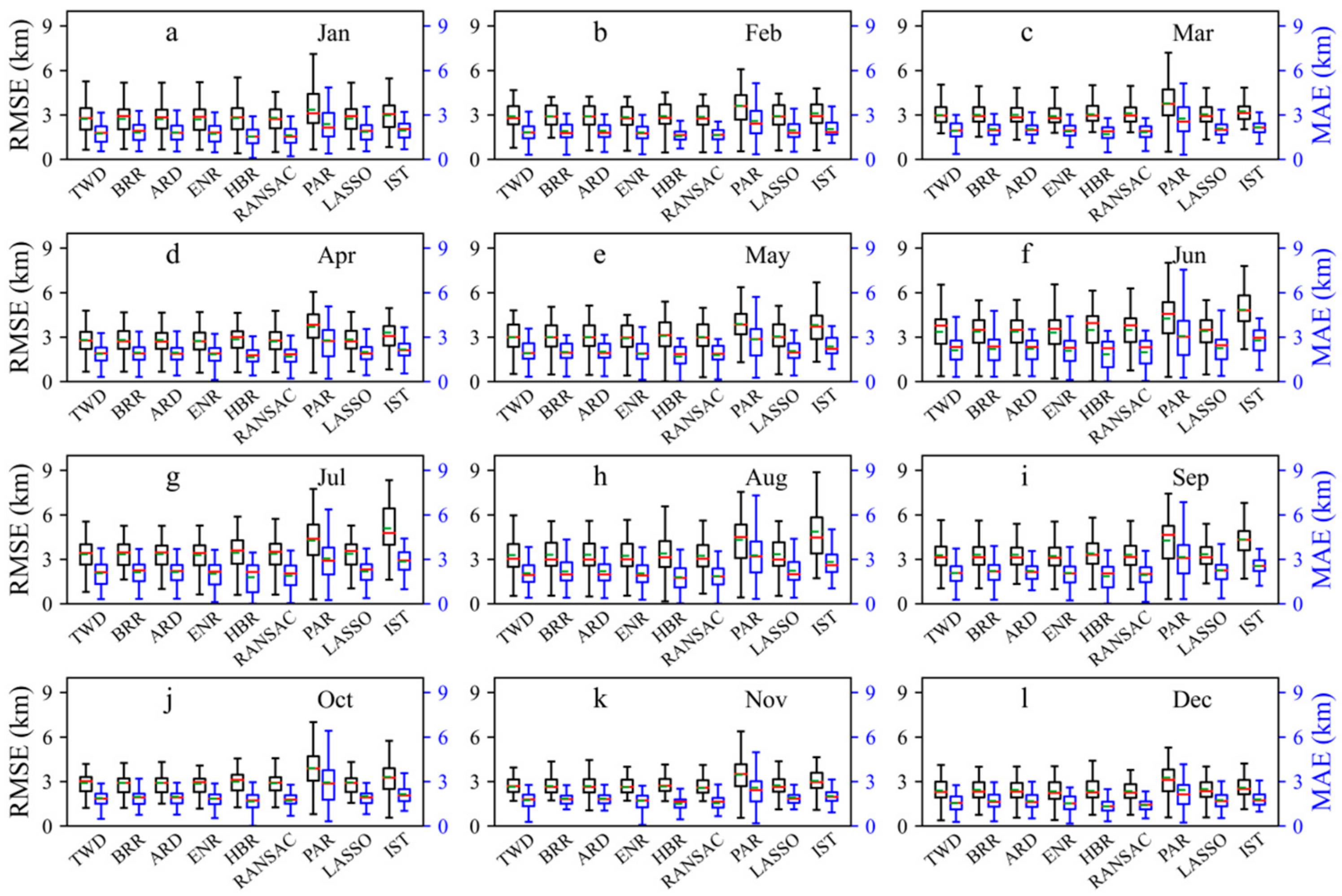
3.3. Hourly Airport Visibility Prediction by Artificial Intelligence Methods
3.3.1. Model Training
3.3.2. Model Testing
4. Discussions
4.1. Airports with Typical Relationship between Visibility and Sounding Data
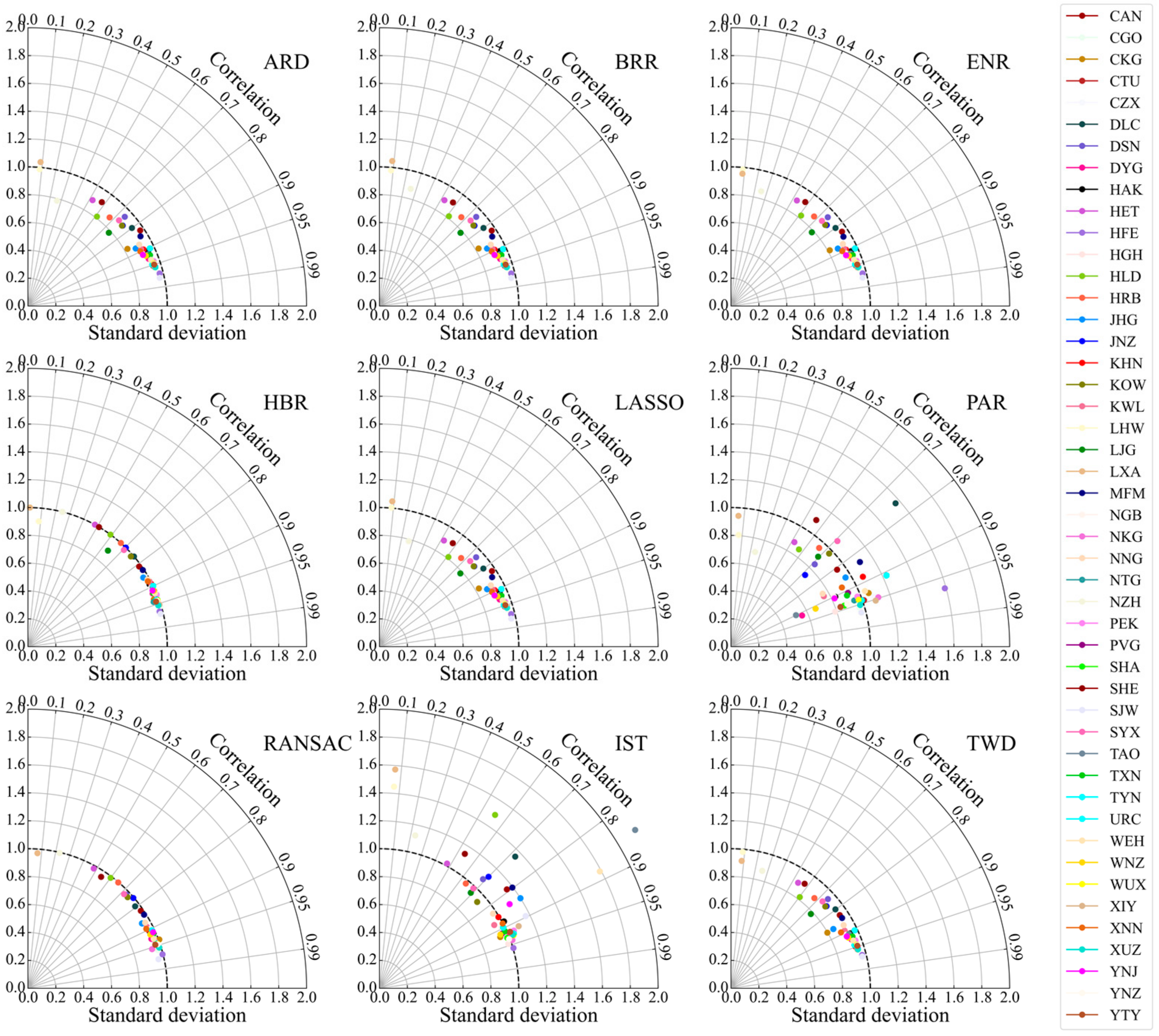
4.2. Comparison of Airport Visibility Prediction Models
5. Conclusions
- (1)
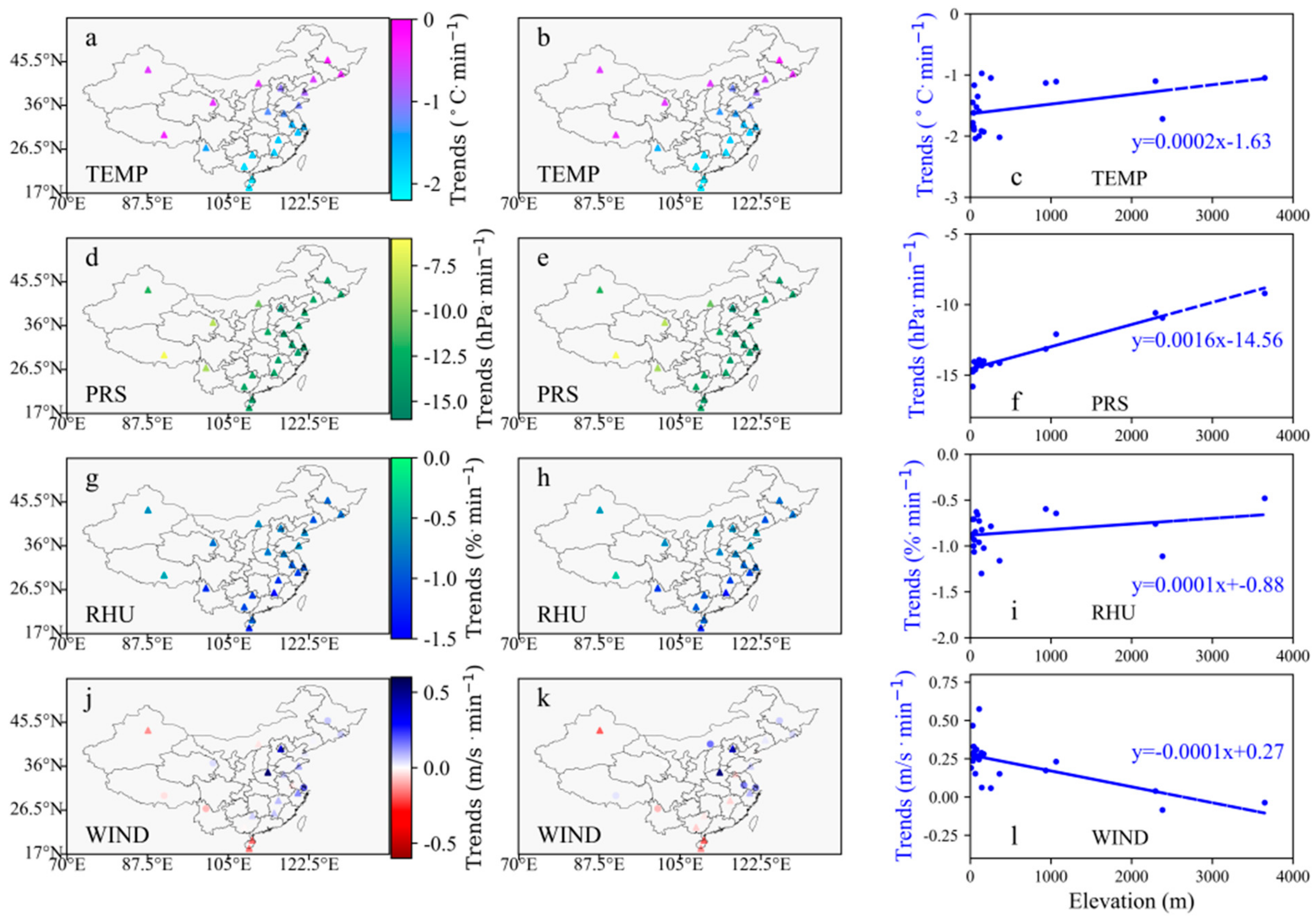
- For the vertical change in airport meteorological elements, the negative vertical trends of temperature and relative humidity have an obvious pattern of getting greater from northwestern to southeastern China. In eastern and western China, the vertical trend ranges of air pressure are different, although both are significantly decreased, and the negative trend in the eastern is greater.
- (2)
- Within about 2000 gpm from the ground, the visibility has a strong correlation with the air pressure and most of them are negative. The visibility is negatively correlated with the relative humidity within 400 gpm from the ground. At 8:00 a.m., the visibility is positively correlated with the wind speed within 2000 gpm from the ground at most airports, while at 20:00 p.m., the positive correlation mainly appear within 400 gpm from the ground.
- (3)
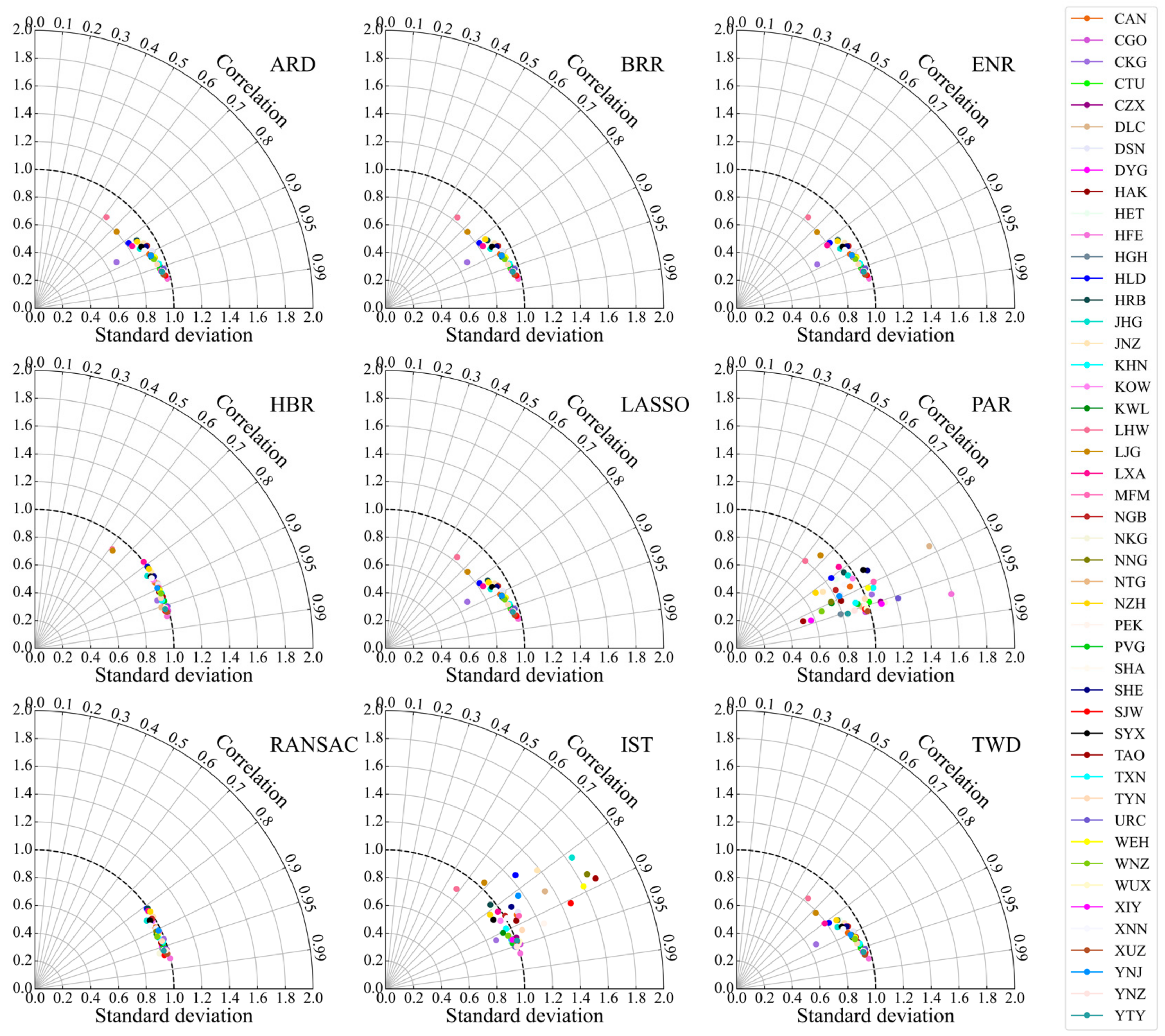
- There is a certain gap between the dispersion of the airport visibility prediction results obtained with the PAR- and IST-based models and the observations. Comparing the dispersion degree of the prediction and the observation, the dispersion degree of the visibility simulation results obtained by HBR- and RANSAC-based models is relatively consistent with the observations. For the airports located in Shijiazhuang (SJW), Hefei (HFE), Zhengzhou (CGO), Xuzhou (XUZ), Xianyang (XIY), Nanjing (NKG), and Hangzhou (HGH), the visibility can be accurately predicted by the algorithm models, while for the airport located in Lhasa (LXA), Lanzhou (LHW), Manzhouli (NZH), Hohhot (HET), and Shenyang (SHE), the visibility prediction performance are poor.
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Acknowledgments
Conflicts of Interest
References
- Qing, Q.; Luo, H.; Chen, G. Forecasting model of torrential rain in Sichuan basin based on v-3θ structural graphs of l-band second level sounding data. J. Chengdu Univ. Inf. Technol. 2019, 34, 186–193. (In Chinese) [Google Scholar] [CrossRef]
- Huang, Y.; Lu, T.; Deng, R. Application Analysis of L-band Detection Data. Agric. Mach. Agron. 2021, 52, 54–56. (In Chinese) [Google Scholar] [CrossRef]
- Hao, M.; Gong, J.; Tian, W.; Wan, X. Deviation correction and assimilation experiment on l-band radiosonde humidity data. J. Appl. Meteorol. Sci. 2018, 29, 559–570. (In Chinese) [Google Scholar] [CrossRef]
- Tian, G.; Zhang, P. Shallow discussion about the application of l-band sounding seconds data in the artificial precipitation. Meteorol. Environ. Res. 2011, 2, 57–59. [Google Scholar]
- Dutta, D.; Chaudhuri, S. Nowcasting visibility during wintertime fog over the airport of a metropolis of India: Decision tree algorithm and artificial neural network approach. Nat. Hazards 2014, 75, 1349–1368. [Google Scholar] [CrossRef]
- Bartoková, I.; Bott, A.; Bartok, J.; Gera, M. Fog Prediction for Road Traffic Safety in a Coastal Desert Region: Improvement of Nowcasting Skills by the Machine-Learning Approach. Bound.-Layer Meteorol. 2015, 157, 501–516. [Google Scholar] [CrossRef]
- Zhu, L.; Zhu, G.; Han, L.; Wang, N. The Application of Deep Learning in Airport Visibility Forecast. Atmospheric Clim. Sci. 2017, 07, 314–322. [Google Scholar] [CrossRef]
- Kneringer, P.; Dietz, S.J.; Mayr, G.J.; Zeileis, A. Probabilistic Nowcasting of Low-Visibility Procedure States at Vienna International Airport During Cold Season. Pure Appl. Geophys. 2018, 176, 2165–2177. [Google Scholar] [CrossRef]
- Deng, T.; Cheng, A.; Han, W.; Lin, H.-X. Visibility Forecast for Airport Operations by LSTM Neural Network. In Proceedings of the 11th International Conference on Agents and Artificial Intelligence (ICAART), Prague, Czech Republic, 19–21 February 2019; Volume 2, pp. 466–473. [Google Scholar] [CrossRef]
- Won, W.-S.; Oh, R.; Lee, W.; Kim, K.-Y.; Ku, S.; Su, P.-C.; Yoon, Y.-J. Impact of Fine Particulate Matter on Visibility at Incheon International Airport, South Korea. Aerosol Air Qual. Res. 2020, 20, 1048–1061. [Google Scholar] [CrossRef]
- Cornejo-Bueno, S.; Casillas-Pérez, D.; Cornejo-Bueno, L.; Chidean, M.I.; Caamaño, A.J.; Sanz-Justo, J.; Casanova-Mateo, C.; Salcedo-Sanz, S. Persistence Analysis and Prediction of Low-Visibility Events at Valladolid Airport, Spain. Symmetry 2020, 12, 1045. [Google Scholar] [CrossRef]
- Wu, Z.; Ye, Q.; Yi, Z.; Wang, Y.; Feng, Z. Visibility prediction of plateau airport based on lstm. In Proceedings of the 2021 IEEE 5th Advanced Information Technology, Electronic and Automation Control Conference (IAEAC), Chongqing, China, 12–14 March 2021; Volume 5, pp. 1886–1891. [Google Scholar]
- Liu, Z.; Chen, Y.; Gu, X.; Yeoh, J.K.; Zhang, Q. Visibility classification and influencing-factors analysis of airport: A deep learning approach. Atmospheric Environ. 2022, 278, 119085. [Google Scholar] [CrossRef]
- Mann, H.B. Nonparametric tests against trend. Econometrica 1945, 13, 245–259. [Google Scholar] [CrossRef]
- Kendall, M.G. Rank Correlation Methods; Griffin: London, UK, 1975. [Google Scholar]
- Sen, P.K. Estimates of the regression coefficient based on Kendall’s Tau. J. Am. Stat. Assoc. 1968, 63, 1379–1389. [Google Scholar] [CrossRef]
- Ding, J.; Zhang, G.; Wang, S.; Xue, B.; Yang, J.; Gao, J.; Wang, K.; Jiang, R.; Zhu, X. Forecast of Hourly Airport Visibility Based on Artificial Intelligence Methods. Atmosphere 2022, 13, 75. [Google Scholar] [CrossRef]
- Vincze, I.; Barlow, R.E.; Bartholomew, D.J.; Bremner, J.M.; Brunk, H.D. Statistical Inference under Order Restrictions (The Theory and Application of Isotonic Regression). Int. Stat. Rev. 1973, 41, 395. [Google Scholar] [CrossRef]
- Mackay, D.J.C. Bayesian Interpolation. Neural Comput. 1992, 4, 415–447. [Google Scholar] [CrossRef]
- Tipping, M.E. Sparse bayesian learning and the relevance vector machine. J. Mach. Learn. Res. 2001, 1, 211–244. [Google Scholar] [CrossRef]
- Tibshirani, R. Regression shrinkage and selection via the lasso. J. R. Stat. Society. Ser. B 1996, 58, 267–288. [Google Scholar] [CrossRef]
- Crammer, K.; Dekel, O.; Keshet, J.; Shalev-Shwartz, S.; Singer, Y.; Warmuth, M.K. Online passive-aggressive algorithms. J. Mach. Learn. Res. 2006, 7, 551–585. [Google Scholar] [CrossRef]
- Fischler, M.A.; Bolles, R.C. Random Sample Consensus: A Paradigm for Model Fitting with Applications to Image Analysis and Automated Cartography. Commun. ACM 1981, 24, 381–395. [Google Scholar] [CrossRef]
- Huber, P.J. Robust Regression: Asymptotics, Conjectures and Monte Carlo. Ann. Stat. 1973, 1, 799–821. [Google Scholar] [CrossRef]
- Huber, P.J. A Robust Version of the Probability Ratio Test. Ann. Math. Stat. 1965, 36, 1753–1758. [Google Scholar] [CrossRef]
- Farebrother, R.W. Further Results on the Mean Square Error of Ridge Regression. J. R. Stat. Soc. Ser. B 1976, 38, 248–250. [Google Scholar] [CrossRef]
- Durbin, R.; Willshaw, D. An analogue approach to the travelling salesman problem using an elastic net method. Nature 1987, 326, 689–691. [Google Scholar] [CrossRef]
- Mackay, D.J.C. Bayesian non-linear modeling for the energy prediction competition. ASHRAE Trans. 1994, 100, 1053–1062. [Google Scholar]
- Tweedie, M.C.K. An index which distinguishes between some important exponential families. In Statistics: Applications and New Directions. Proceedings of the Indian Statistical Institute Golden Jubilee International Conference; Indian Statistical Institute: Calcutta, India, 1984; pp. 579–604. [Google Scholar]
- Uyanık, T.; Karatuğ, Ç.; Arslanoğlu, Y. Machine learning based visibility estimation to ensure safer navigation in strait of Istanbul. Appl. Ocean Res. 2021, 112, 102693. [Google Scholar] [CrossRef]
- Liu, Z.; Zhang, G.; Ding, J.; Xiao, X. Biases of the mean and shape properties in CMIP6 extreme precipitation over Central Asia. Front. Earth Sci. 2022, 912. [Google Scholar] [CrossRef]
- Wang, G.; Zhou, R.; Zhaxi, S.; Liu, L. Comprehensive observations and preliminary statistical analysis of clouds and precipitation characteristics in Motuo of Tibet Plateau. Acta Meteorol. Sin. 2021, 79, 841–852. (In Chinese) [Google Scholar] [CrossRef]
- Yan, Y.; Miao, Y.; Jian, L.I.; Guo, J. Meteorological characteristics of prolong low-visibility events in Haikou during February 2018. Acta Entiarum Nat. Univ. Pekin. 2019, 55, 899–906. (In Chinese) [Google Scholar] [CrossRef]
- Yang, J.; Li, Z.; Huang, S. Influence of relative humidity on shortwave radiative properties of atmosphere aerosol particles. Chin. J. Atmos. Sci. 1993, 23, 239–247. (In Chinese) [Google Scholar]
- Boudala, F.S.; Isaac, G.A.; Crawford, R.W.; Reid, J. Parameterization of Runway Visual Range as a Function of Visibility: Implications for Numerical Weather Prediction Models. J. Atmos. Ocean. Technol. 2012, 29, 177–191. [Google Scholar] [CrossRef]
- Cui, Y.Y.; Liu, S.; Bai, Z.; Bian, J.; Li, D.; Fan, K.; McKeen, S.A.; Watts, L.A.; Ciciora, S.J.; Gao, R.-S. Religious burning as a potential major source of atmospheric fine aerosols in summertime Lhasa on the Tibetan Plateau. Atmos. Environ. 2018, 181, 186–191. [Google Scholar] [CrossRef]
- Wang, J.; Wan, L.; Miao, Y. Distribution Characteristics and Its Influence Factors of Fog in Winter in Urumqi City. Desert Oasis Meteorol. 2022, 16, 10–15. (In Chinese) [Google Scholar] [CrossRef]
- Liang, X. Research on Causes of Low Visibility Weather and Flight Safety Countermeasures—Taking the freezing fog weather in winter at Urumqi Airport as an example. J. Chang. Aeronaut. Vocat. Tuchnical Coll. 2021, 21, 27–32. (In Chinese) [Google Scholar] [CrossRef]
- Bacchetti, P. Additive Isotonic Models. J. Am. Stat. Assoc. 1989, 84, 289–294. [Google Scholar] [CrossRef]
- Schell, M.J.; Singh, B. The Reduced Monotonic Regression Method. J. Am. Stat. Assoc. 1997, 92, 128–135. [Google Scholar] [CrossRef]
- Luss, R.; Rosset, S.; Shahar, M. Efficient regularized isotonic regression with application to gene–gene interaction search. Ann. Appl. Stat. 2012, 6, 253–283. [Google Scholar] [CrossRef]
- Zhou, X.; Xiao, D.; Fu, Y. Study on Online Algorithm of Huber-support Vector Regression Machine. Stat. Decis. Mak. 2021, 20, 10–14. (In Chinese) [Google Scholar] [CrossRef]
- Wang, K.; Wang, W.; Li, L.; Li, J.; Wei, L.; Chi, W.; Hong, L.; Zhao, Q.; Jiang, J. Seasonal concentration distribution of PM1.0 and PM2.5 and a risk assessment of bound trace metals in Harbin, China: Effect of the species distribution of heavy metals and heat supply. Sci. Rep. 2020, 10, 8160. [Google Scholar] [CrossRef]
- Chen, X.; Li, X.; Yuan, X.; Zeng, G.; Liang, J.; Li, X.; Xu, W.; Luo, Y.; Chen, G. Effects of human activities and climate change on the reduction of visibility in Beijing over the past 36 years. Environ. Int. 2018, 116, 92–100. [Google Scholar] [CrossRef]
- Wiston, M. Status of Air Pollution in Botswana and Significance to Air Quality and Human Health. J. Health Pollut. 2017, 8, 15–24. [Google Scholar] [CrossRef]
- Irani, T.; Amiri, H.; Deyhim, H. Evaluating Visibility Range on Air Pollution using NARX Neural Network. J. Environ. Treat. Technol. 2020, 9, 540–547. [Google Scholar] [CrossRef]
- Lee, H.-H.; Iraqui, O.; Gu, Y.; Yim, S.H.-L.; Chulakadabba, A.; Tonks, A.Y.-M.; Yang, Z.; Wang, C. Impacts of air pollutants from fire and non-fire emissions on the regional air quality in Southeast Asia. Atmos. Chem. Phys. 2018, 18, 6141–6156. [Google Scholar] [CrossRef]











{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Airports with L-Band Sounding Data | Airports without L-Band Sounding Data | ||||||
|---|---|---|---|---|---|---|---|
| ID | Code | Name | City | ID | Code | Name | City |
| 1 | CGO | Xinzheng | Zhengzhou | 1 | CAN | Baiyun | Guangzhou |
| 2 | DLC | Zhoushuizi | Dalian | 2 | CKG | Jiangbei | Chongqing |
| 3 | HAK | Meilan | Haikou | 3 | CTU | Shuangliu | Chengdu |
| 4 | HET | Baita | Hohhot | 4 | CZX | Benniu | Changzhou |
| 5 | HGH | Xiaoshan | Hangzhou | 5 | DSN | Yijinhuoluo | Erdos |
| 6 | HRB | Taiping | Harbin | 6 | DYG | Hehua | Zhangjiajie |
| 7 | KHH | Gaoxiong | Gaoxiong | 7 | HFE | Xinqiao | Hefei |
| 8 | KOW | Huangjin | Ganzhou | 8 | HLD | Dongshan | Hailar |
| 9 | KWL | Liangjiang | Guilin | 9 | JHG | Gasa | Xishuangbanna |
| 10 | LJG | Sanyi | Lijiang | 10 | JNZ | Jinzhou | Jinzhou |
| 11 | LXA | Gongga | Lhasa | 11 | LHW | Zhongchuan | Lanzhou |
| 12 | NKG | Lukou | Nanjing | 12 | MFM | Aomen | Macao |
| 13 | NNG | Wuwei | Nanning | 13 | NGB | Lishe | Ningbo |
| 14 | PEK | Shoudu | Beijing | 14 | NTG | Xingdong | Nantong |
| 15 | SHA | Honqiao | Shanghai | 15 | NZH | Xijiao | Manzhouli |
| 16 | SHE | Taoxian | Shenyang | 16 | PVG | Pudong | Shanghai |
| 17 | SYX | Fenghuang | Sanya | 17 | SJW | Zhengding | Shijiazhuang |
| 18 | TAO | Liuting | Qingdao | 18 | TXN | Tunxi | Huangshan |
| 19 | URC | Diwobu | Urumqi | 19 | TYN | Wusu | Taiyuan |
| 20 | XMN | Gaoqi | Xiamen | 20 | WEH | Dashuipo | Weihai |
| 21 | XUZ | Guanyin | Xuzhou | 21 | WNZ | Longwan | Wenzhou |
| 22 | YNJ | Chaoyangchuan | Yanji | 22 | WUH | Tianhe | Wuhan |
| 23 | XIY | Xianyang | Xian | ||||
| 24 | YNZ | Nanyang | Yancheng | ||||
| 25 | YTY | Taizhou | Yangzhou | ||||
| Elements of the Hourly Meteorological Data | Elements of the Minute Sounding Data | |
|---|---|---|
| Air temperature (°C) | Pressure (hPa) | Air temperature (℃) |
| Minimum temperature (°C) | Sea level pressure (hPa) | Pressure (hPa) |
| Maximum temperature (°C) | Vapor pressure (hPa) | Relative humidity (%) |
| Dew point temperature (°C) | 2-min average wind speed (m/s) | Wind speed (m/s) |
| Relative humidity (%) | 10-min average wind speed (m/s) | Wind direction (degree) |
| Precipitation in the past hour (mm) | Maximum wind speed (m/s) | Geopotential hight (gpm) |
| Precipitation in the past 6 h (mm) | Wind direction of maximum wind speed (degree) | |
| Precipitation in the past 12 h (mm) | Extreme instantaneous wind speed (m/s) | |
| Ground surface temperature (°C) | Direction with extreme wind speed (degree) | |
| Ground temperature at 5 cm depth (°C) | Maximum instantaneous wind speed in the past 6 h (m/s) | |
| Ground temperature at 10 cm depth (°C) | Direction of Maximum instantaneous wind speed in the past 6 h (degree) | |
| Ground temperature at 15 cm depth (°C) | Maximum instantaneous wind speed in the past 12 h (m/s) | |
| Ground temperature at 20 cm depth (°C) | Direction of Maximum instantaneous wind speed in the past 12 h (degree) | |
| Model Names | Applicability | |
|---|---|---|
| 1 | Isotonic regression (IST)-based model | IST can find a non decreasing approximation function on the training data while minimizing the mean square error. The advantage of this model is that it does not assume any form of objective function. Isotonic expression has no requirements on the output characteristics of the model and is applicable to the case of large sample size. However, it is easy to over fit when the sample size is small. IST is usually used as an auxiliary method to repair the uneven correction results caused by data sparsity. |
| 2 | Bayesian Ridge Regression (BRR)-based model | BRR is a special case of Bayesian linear regression and belongs to Ridge regression. It has all the characteristics of ridge regression and Bayesian linear regression. |
| 3 | Least absolute shrinkage and selection operator (LASSO)-based model | LASSO is a method that can establish a generalized linear model and filter variables, which is powerful and effective. At the beginning, this statistical model was applied in the field of geophysics, and later it was applied to model building in the medical field. As LASSO has the function of “variable selection”, it is often used in traditional low dimensional data in economics. |
| 4 | Passive Aggressive Regression (PAR)-based model | PAR embodies an idea of online learning, which can continuously integrate new samples to adjust the classification model and enhance the classification ability of the model. |
| 5 | Random sample consensus Regression (RANSAC)-based model | RANSAC can estimate the parameters of the mathematical model through iteration from a set of observation data containing outliers. It is an uncertain algorithm—it has a certain probability to get a reasonable result; In order to improve the probability, the number of iterations must be increased. Its advantage is that it can estimate model parameters robustly, but its disadvantage is that only a certain probability can get a credible model, and the probability is proportional to the number of iterations.RANSAC is commonly used in computer vision. |
| 6 | Huber Regression (HBR)-based model | HBR model depends on M-estimate. Compared with the mean, the measurement is less sensitive to outliers. HBR does not ignore outlier, and the linear loss of outlier is adopted, which relatively reduces the weight of outlier and ultimately reduced the impact of outlier on the regression results. And HBR should be faster than RANSAC. |
| 7 | Elastic-Net Regression (ENR)-based model | When multiple features are related, LASSO can only randomly select one of them, while Ridge regression will select all features. ENR can combine the advantages of the two regularization methods, making this method very useful when many features are interrelated. The best thing about ENR is that they can always produce efficient solutions. Since it does not generate cross paths, the resulting solutions are quite good. |
| 8 | Automatic Relevance Determination Regression (ARD)-based model | The maximum likelihood method is used to optimize the parameters, which can infer the relative importance of different inputs from the data. This is an example of ARD. The model is suitable for real-time operation and has been applied to earthquake early warning, earthquake ground motion attenuation estimation and structural health monitoring |
| 9 | Tweedie Regression (TWD)-based model | TWD distribution is a compound distribution of Poisson distribution and gamma distribution. One of the most obvious characteristics of TWD distribution is to generate samples with a value of 0 with a certain probability. This method is often used to analyze semi-continuous data composed of zero and positive continuous data, which widely exists in actuarial science, geosciences and other fields. |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Ding, J.; Zhang, G.; Yang, J.; Wang, S.; Xue, B.; Du, X.; Tian, Y.; Wang, K.; Jiang, R.; Gao, J. Temporal and Spatial Characteristics of Meteorological Elements in the Vertical Direction at Airports and Hourly Airport Visibility Prediction by Artificial Intelligence Methods. Sustainability 2022, 14, 12213. https://doi.org/10.3390/su141912213
Ding J, Zhang G, Yang J, Wang S, Xue B, Du X, Tian Y, Wang K, Jiang R, Gao J. Temporal and Spatial Characteristics of Meteorological Elements in the Vertical Direction at Airports and Hourly Airport Visibility Prediction by Artificial Intelligence Methods. Sustainability. 2022; 14(19):12213. https://doi.org/10.3390/su141912213
Chicago/Turabian StyleDing, Jin, Guoping Zhang, Jing Yang, Shudong Wang, Bing Xue, Xiangyu Du, Ye Tian, Kuoyin Wang, Ruijiao Jiang, and Jinbing Gao. 2022. "Temporal and Spatial Characteristics of Meteorological Elements in the Vertical Direction at Airports and Hourly Airport Visibility Prediction by Artificial Intelligence Methods" Sustainability 14, no. 19: 12213. https://doi.org/10.3390/su141912213
APA StyleDing, J., Zhang, G., Yang, J., Wang, S., Xue, B., Du, X., Tian, Y., Wang, K., Jiang, R., & Gao, J. (2022). Temporal and Spatial Characteristics of Meteorological Elements in the Vertical Direction at Airports and Hourly Airport Visibility Prediction by Artificial Intelligence Methods. Sustainability, 14(19), 12213. https://doi.org/10.3390/su141912213