1. Introduction
Malaysia is an increasingly developed country. In line with this progress, there are plenty of advances in technology that indirectly contribute to air pollution. Moreover, open burning, power plants, motor vehicle emissions and industrial process emissions are the major sources of particulate matter less than or equal to 10 micrometers (PM
10) in Malaysia [
1].
In observing air quality, Malaysia has been following the Malaysian Ambient Air Quality Standard for allowable air pollutant levels. According to the Malaysian Ambient Air Quality Standard, the acceptable threshold levels of PM
10 are 50 µg/m
3 per year and 100 µg/m
3 per 24 h, which are considered to be safe [
2]. These particulate matters can become dissolved and absorbed into the bloodstream, which can later trigger serious biological effects. In addition, it is also one of the factors that cause lung cancer and cardiopulmonary deaths. Thus, in facing this hazardous situation, building optimized forecasting models of PM
10 is the best solution in controlling these particle concentrations, and this also helps to prepare for the worst circumstances.
Feature selection is considered as one of the data pre-processing essential steps and is important in solving problems of high dimensionality dataset. This method is significant in discovering correlated features and in removing uncorrelated or redundant features from the original data set. By implementing the feature selection method, the performance of the model will be improved as this method will reduce the error by removing irrelevant and redundant features. However, all of the previous studies in Malaysia were only limited to statistical methods, such as backward, forward and stepwise analysis, and none of these studies uses machine-learning approaches, such as brute-force, weight-guided and GA evolution. Therefore, this study will investigate which approaches are better at selecting features in predicting the PM10 concentration.
Various methods have been used by previous researchers in predicting PM
10 concentrations in Malaysia. For instance, a study by [
3] determined the best loss function in boosted regression trees (BRT) for the prediction of the PM
10 concentration in Alor Setar, Klang and Kota Bharu, Malaysia. A study conducted by [
4] suggested that the prediction of PM
10 concentrations can be made by considering the conditions of the previous day event. In China, [
5,
6] applied deep-learning-network models to predict air pollution. Most studies do not focus on optimizing the number of inputs in predicting the PM
10 concentration. Therefore, this study investigates the optimal number of inputs and identifies the influence factors for which predictive analytics are suitable for predicting PM
10 to compare the performances.
In summary, this study investigates which variables influence the PM10 concentration and which approaches are better in selecting features for predicting the PM10 concentration. Next, this study will investigate which predictive analytics for statistical and machine-learning methods are commonly used in predicting the PM10 and compare which method is best in predicting PM10.
According to [
7], the goal of feature selection is to discover features that can precisely and concisely describe the original dataset and later generate new features based on the original dataset. Feature selection is a method using an algorithm or procedure to retain the most vital features and their application domain. Feature selection is beneficial in performance accuracy and complexity reduction as this method removes irrelevant features from the model. It also reduces the integration time and produces a simpler model, which is much easier to debug [
8,
9,
10].
In machine learning, feature-selection techniques are mainly divided into supervised techniques and unsupervised techniques. The difference between these two techniques is whether to select features based on the target variable. The supervised techniques use the target variable in choosing its features. On the other hand, the unsupervised techniques ignore the target variable in selecting its features [
11]. Filter methods, wrapper methods and embedded methods are among the feature-selection techniques.
A study conducted by Ibrahim et al. [
12] aimed to compare the wrapper and filter methods to maximize the classifier accuracy. Correlation-based and information gain are the filter methods used in this study. The wrapper methods are sequential forward and sequential backward elimination. The study [
12] applied the selected feature selection methods obtained from the UCI Machine Learning Repository to measure its performance and the datasets are Pima Indians Diabetes, Breast Cancer Wisconsin and Spam base.
As a result, all of the datasets showed that the wrapper method had higher significant features compared with the filter method. The results also indicated that the logistic regression performed the best with the highest accuracy, specificity and sensitivity using the wrapper methods features. Thus, based on the evidence provided by the previous study, the wrapper method performs better in selecting the features compared to the filter method.
Lastly, a gap in the study was regarding predicting PM10 concentrations using different types of features. The common method is still limited to statistical model approaches in feature selection, such as forward, backward and stepwise selection. When compared to overseas, none of the studies in Malaysia used machine-learning approaches, such as brute-force, weight-guided, or GA evolution for feature selection in predicting the air pollutant concentration. On the other hand, MLR is the most commonly used statistical method for predicting PM10 concentrations, whereas ANN is the most commonly used machine-learning method. Therefore, this study implements both common statistical and machine-learning approaches in selecting its features and uses MLR and ANN in predicting PM10 concentrations.
2. Materials and Methods
As shown in
Figure 1, data acquisition, exploration, cleaning, transform and partitioning the data set are part of the data preparation. As for the feature selection, the partition data will be implemented in six wrapper methods, which are forward selection, backward elimination, stepwise, brute-force, weight-guided and genetic algorithm evolution. The significant variables obtained according to each method later will be used to develop predictive models, and MLR and ANN and will be evaluated using performance indicators. The performance of each model in MLR and ANN later will be compared and ranked according to its performance. The best model for each day of MLR and ANN will be compared again between the predictive analytics model. The best model obtained will be used to predict the concentration of PM
10 for the next day.
This section consists of data acquisition, data exploration, data cleaning, data transform and partitioning the dataset. The data acquisition will explain the information of data and parameters included in this study. Second, this study will conduct descriptive analysis in data exploration. Third, data cleaning will explain the technique involved in imputing the data. Next, data transform will explain the transformation on the data before being analyzed. Lastly, data partitioning will explain the partition of the dataset.
As for the data acquisition, this research used ten years of daily data on pollutant concentrations from two stations obtained from the Department of Environment Malaysia (DOE) from 2009 until 2018. The stations included in this study are Klang station located at Sekolah Menengah Perempuan Raja Zarina, Klang and Shah Alam station located at Sekolah Kebangsaan TTDI Jaya, Shah Alam. These two stations were selected because they are surrounded by major roads that experience heavy traffic, particularly during the morning rush hour.
Based on the Exploratory Data Analysis (EDA), this analysis measured the central tendency, dispersion, skewness and graphical representation. This study measured the central tendency of the data by estimating the mean, mode and median. This study also computed the variance, standard deviation and range in measuring the dispersion. Moreover, this research evaluated the skewness to check for the probability distribution of the data.
In this study, linear interpolation and the series mean are used to impute the missing values in the data as suggested by others [
13]. Linear interpolation is an interpolation method for single-dimensional data. This method estimates the data point value needed to be interpolated based on the two data points adjacent to that point in the single-dimensional data sequence. Equation (1) shows the formula and graph of linear interpolation. While the series means method was used to impute all missing values with the mean value of the data. Therefore, the data was imputed using linear interpolation first, and the rest was imputed using the series mean.
Based on the data retrieved, the readings of each parameter were recorded hourly. As this study predicts the PM
10 concentration by day, the data is transformed into a daily format. This study used the average PM
10 concentration of hourly data as the daily data. Next, the wind direction parameters in this study were split into two variables following [
14]. The variables were the sinusoidal (sinWD) and the cosinusoidal (cosWD).
Before developing the model, the original dataset was divided into three datasets for training, validation and verification so that there would be new data to assess the model. The dataset collected for this study was divided chronologically into 80% for training data (2009–2016) and 20% for validation data (2016–2017). The training data was for estimating the predictive method parameters, while the validation data is for analyzing the accuracy. The proposed model was verified using the new dataset for 2018.
2.1. Feature Selection
Feature selection is the process of minimizing the number of input variables when building a predictive model [
15]. In this research, the wrapper method was used to develop air pollution prediction modelling consisting forward selection, backward selection, stepwise selection, brute-force feature selection, Genetic Algorithm (GA) evolutionary and weight-guided.
Forward selection is a type of stepwise regression that begins with a null model. The approach initiates with no variables in the model and step by step adds variables to the model until no variable not included in the model can make a significant contribution to the model’s conclusion. The variable with the highest test statistic that is more than the cut-off value or the lowest p-value with less than the cut-off value is chosen and added to the model.
Backward elimination is the most basic approach to variable selection. This technique begins with a complete model that includes all of the variables in the model. Variables are subsequently removed from the whole model one by one until all remaining variables are sure to have a meaningful impact on the result. The variable with the lowest test statistic or the highest p-value more than the cut-off value is removed from the model. This procedure is repeated until every remaining variable is statistically significant at the cut-off value.
The stepwise selection method is the mixture of forward selection and backward elimination procedures that allow one to go in both directions while adding and eliminating variables at various stages. Forward selection and backward elimination can be applied to begin the process. If stepwise selection begins with forward selection, variables are added to the model one at a time according to the statistical significance. After each step, the model is analyzed. Any variable that is not significant will be removed from the model. The process repeats until every variable in the model is statistically significant.
If stepwise selection begins with backward elimination, the variables are removed from the full model based on statistical significance and then re-added if they show statistical significance afterward. Brute-force is a straightforward approach to solving a problem. It involves iterating through all possible features until the best feature selection is found. Brute-force feature selection tries every potential combination of the variables and provides the highest performing subset. The best subset is chosen by maximizing a defined performance metric in the presence of an arbitrary regressor or classifier. The algorithm will choose each combination and compute its score before selecting the optimal combination based on its score.
For this study, the number of possible subsets is calculated using the best subset regression formula, 2
p, where
p equals 11 (the number of predictors). As a result, this method will generate 2048 subsets. Essentially, this method starts with the generation of possible subsets, beginning with one variable, two variables, three variables and so on until eleven predictors are generated. Each subset will have its own regression equation, which will be evaluated using the adjusted
R square (
). The reason for using
rather than
R2 to compare the performance of subsets is that
values are often artificially inflated as more variables are chosen. The formula for
is stated below:
where
p is the number of predictors and
n is the number of samples. The best subset, which contains the most significant factors to predict PM
10 concentration, will be the subset with the highest
value.
Next, GA evolution is a type of optimization technique that mimics the concepts of natural evolution. There are three basic concepts in this process, which are selection, crossover and mutation. The first step of an evolutionary algorithm is an initialization phase where it creates a population of air pollution models, each with their unique set of chromosomes. The chromosomes are binary strings; 1 means the feature is included, and 0 means the feature is excluded. The models for the starting population are randomly generated.
A good rule of thumb is to use between 5% and 30% of the total number of features as the population size [
16]. For the second step, each model in the population will have their fitness calculated. Models with better fitness have a higher chance of being chosen for recombination. After calculating the fitness value, the third step is that the models will be selected randomly using the roulette wheel method and selected according to their fitness level. The number of selected models is half of the population size.
After selecting the models, the fourth step is the crossover, in which the selected models are recombined to create a new population. In this step, two models will be chosen at random and their features will be combined to produce offspring for the new population until the new population is the same size as the old one. In the crossover, offspring that are genetically identical to their parents may be produced, resulting in a low-diversity new generation. Therefore, in step five, the mutation is done by changing the value of some features in the offspring at random. Lastly, the process is looped to step two until a stopping criterion is met and the best feature selection is obtained.
Finally, the wrapper method used weight-guided via correlation. Equation (3) is the formula of the correlation. A weight is given to the variables, and the highest weight of the variable is considered.
2.2. Model Development and Model Evaluation
In this model development, the process of developing MLR and ANN models is explained to conduct predictive modelling.
Figure 2 shows the process of the wrapper method in developing a predictive model.
There are four steps in developing a multiple linear regression (MLR) model. First, the development of the MLR model will be based on 80% of the data. Second, the assumption of the MLR models is checked using certain methods and tests, such as histograms and scatter plots. Next, the model is validated based on the performance indicator value using 20% of the data. Finally, the best model of MLR is obtained. The expected MLR models are as shown in Equation (4). The past PM
10 daily average concentration was used to predict the next day’s PM
10 concentration.
where
PM10,D+1 = Next day prediction of PM10 concentration.
PM10,D = Particulate matter (µg/m3).
COD = Carbon monoxides (ppm).
NO2,D = Nitrogen dioxide (ppm).
NOx,D = Nitrogen oxide (ppm).
NOD = Nitric oxide (ppm).
SO2,D = Sulfur dioxide (ppm).
RHD = Relative humidity (%).
TD = Temperature (°C).
WSD = Wind speed (km/h).
cosWDD = Cosine Wind direction (units).
sinWDD = Sine Wind direction (units).
β0 = regression constant.
β1, …, β11 = regression coefficient for each predictors used.
A feed forward backpropagation neural network (FFBP) was used in this study. The structure of FFBP was composed of three layers of neurons called the input, hidden and output layers. The first layer of neurons consisted of an input layer, representing independent variables. The input layer contained 12 independent variables—namely, O3, CO, NO2, SO2, NO, sinWD, cosWD, NOx, PM10, T, WS and RH. The second layer was the hidden layer, which is responsible for processing the input weight from the input layer and transferring it to the output layer. The third layer was the output layer, which represents the PM10,D+1 concentrations.
The maximum error used as a criterion for stopping was set at 0.05. In this study, the training process was set to 10,000 iterations or until the maximum error was reached, as suggested by [
17]. As a network training function, Levenberg–Marquardt optimization was used to update weight and bias values. As sigmoid units are easier to train than other activation functions, [
18] proposed using them. In this case, the layer size was 2 number of attributes + number of classes)/2 + 1 = 8 hidden nodes, as recommended by [
19]. This study fitted models with varying learning rate lr (0.01) values, which [
20] proposed for the study of air pollution datasets.
Furthermore, [
21] stated that changing the momentum rate and learning rate from 0.05 to 1 had no effect on the training and prediction networks’ errors. Performance indicators in this research are used to identify the best method to predict the concentration of PM
10,D+1. The Root Mean Square Error (RMSE), Normalized Absolute Error (NAE), Absolute Error (AE) and Relative Error (RE) are the error measures used to determine the error of the model, while the Coefficient of Determination (R
2) is the accuracy measure used to determine the accuracy of the model outcome.
Regarding the model deployment, the dataset from 2009 until 2017 was used to produce prediction models. The prediction models were later deployed on the 2018 dataset. However, there were extreme outliers in ozone concentration for the 2018 dataset for the Klang station. Based on the 2009 until 2017 dataset, the maximum ozone concentration value was 0.056 ppb. Some of the ozone concentration in the 2018 dataset exceeded 0.7 ppb. This situation may happen due to technical errors. Therefore, a total of 29 data were removed before deployment.
3. Results and Discussion
3.1. Descriptive Analysis
Table 1 is the descriptive statistics of each parameter in Klang and Shah Alam, Selangor. Based on the table, the maximum concentration of PM
10 was 551.542 µg/m
3 (Klang) and 1332.814 µg/m
3 (Shah Alam). The high concentration was taken on 25 of June 2013 for Klang, while Shah Alam happened during April 2017. Next, the skewness value of PM
10 is 4.62 (Klang) and 17.11 (Shah Alam). Since the value is more than 1, the data of PM
10 are highly skewed to the right. This may be due to the presence of extreme outliers in this data.
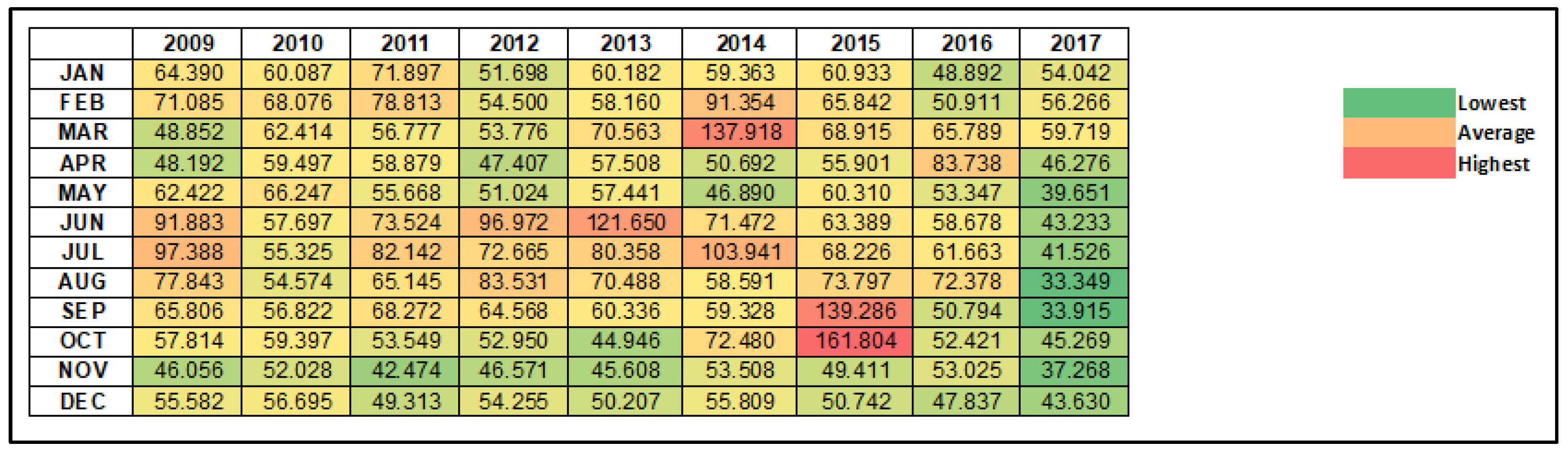
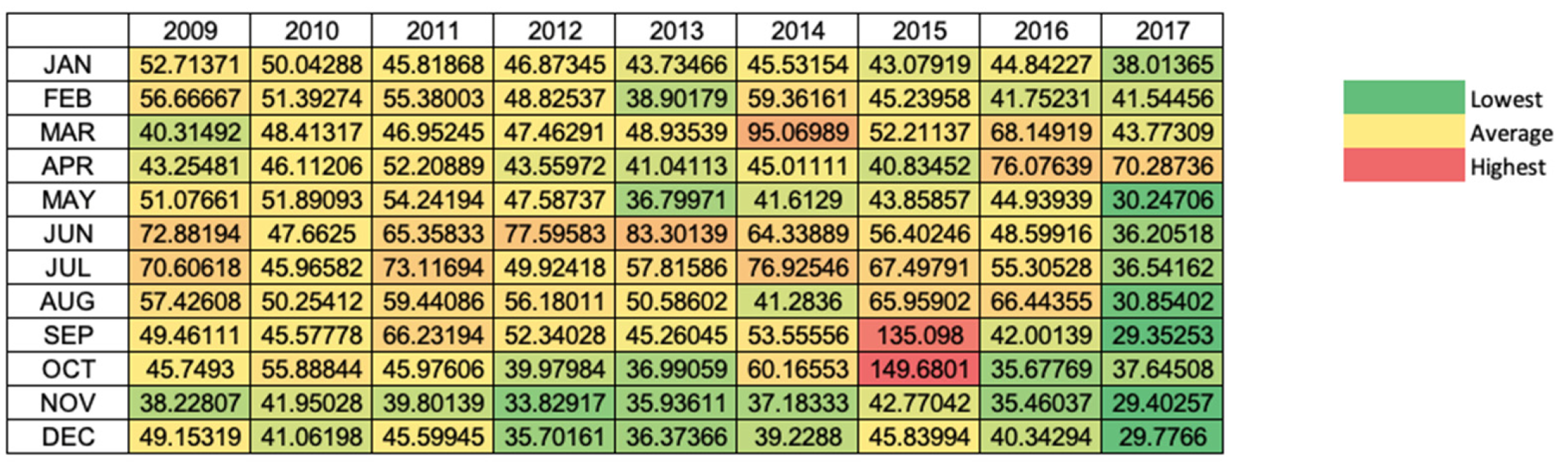
Figure 3 and
Figure 4 below are heatmaps of the average PM
10 concentrations according to the month and year for Klang and Shah Alam. The greenish parts have the lowest average concentration, and the reddish parts have the highest average concentration. Based on both Figures, it is indicated that October 2015 had the highest average concentration compared to the others. Moreover, the concentration of PM
10 in September 2015 was the second-highest concentration. Referring to haze incidents in Malaysia, this supports the outline of the heatmap as there was a hazing incident in 2015 in August and September due to massive land and forest fires in Indonesia [
22]. The high PM
10 concentration in October 2015 may be due to the backlash of this incident.
In March 2014, there was a high concentration of PM
10 in both locations where Klang was slightly higher than Shah Alam. It is also proved by the chronology of haze incidents in Malaysia as haze incidents happened between February and March 2014. This incident occurred due to forest and peatland fires. High PM
10 concentration incidents were also detected in June 2013 from both locations. However, Klang had a higher concentration value compared to Shah Alam. This incident may be due to haze incidents that happened from 15 to 27 June 2013 [
22]. In addition, both Figures show a low average of PM
10 concentration starting from May until December 2017. This situation may be due to zero cases of haze incidents happening in 2017.
In conclusion, the heatmaps of both locations align with the haze chronology in Malaysia. The heatmaps also makes it easier to observe the condition of air pollution in Malaysia.
3.2. Correlation of PM10 Concentration with Other Parameters
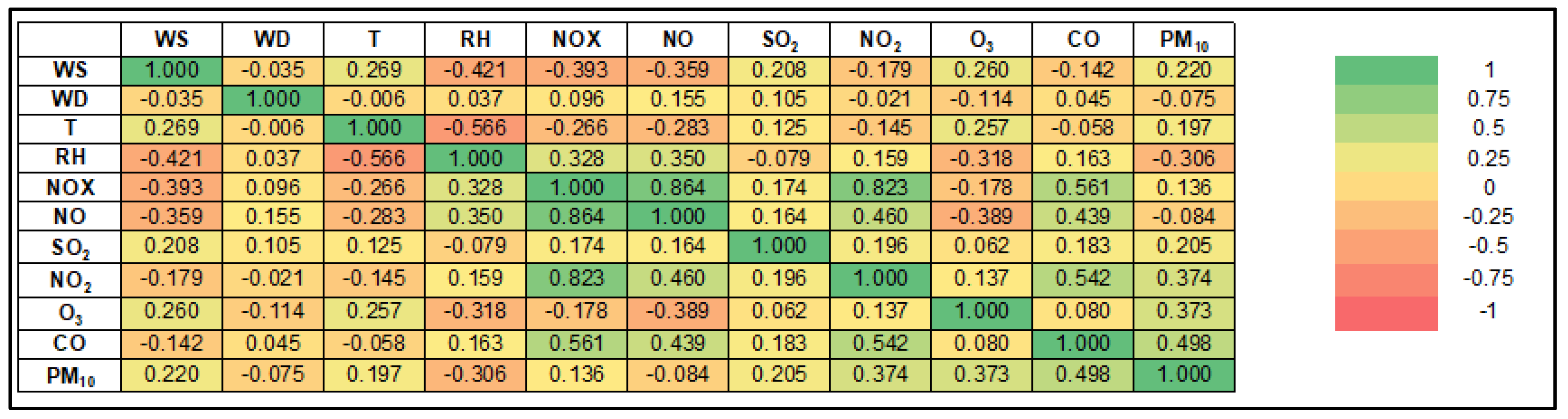
Figure 5 and
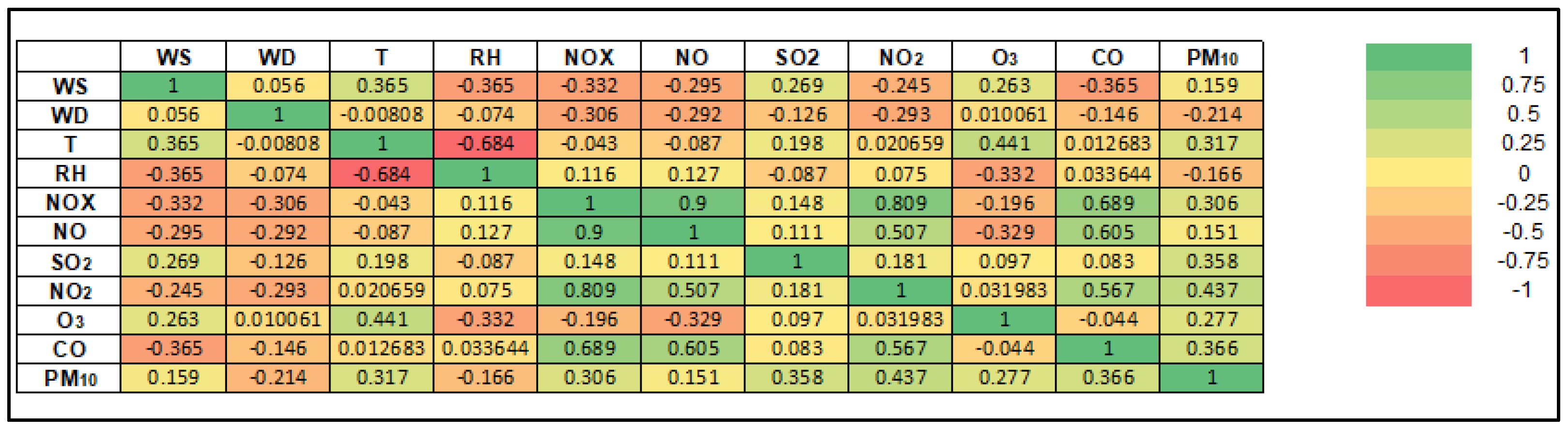
Figure 6 show the heatmap of the Spearman’s rank correlation coefficient (r) of the PM
10 concentration with other parameters in Klang and Shah Alam, respectively.
Figure 5 shows that all of the parameters have positive correlation with PM
10 except for WD, RH and NO in Klang. It also indicates all of the parameters have moderate-to-very-weak correlations with the PM
10 for Klang. CO has the highest correlation PM
10 concentration with a positive moderate correlation (r = 0.498), while WD has the lowest correlation with a negative very weak correlation (r = −0.075).
Figure 6 shows that all of the parameters have a positive correlation with PM
10 except for WD and RH in Shah Alam. All of the parameters have moderate, weak and very weak correlations with the PM
10 concentration. It also indicates that NO
2 has the highest correlation with PM
10 concentration with a positive moderate correlation (r = 0.437), while WD has the lowest correlation with PM
10 concentration with a positive very weak correlation (r = 0.151).
3.3. Performance Model and Feature Selection
Performance measures for this section used the validation dataset (20%).
Table 2 shows that the performance of all MLR model was compared to find the best model for next day prediction. Based on
Table 3, for Klang, brute-force has the lowest value of RMSE, AE, RE and NAE. The backward method has the highest R
2 value compared to others.
Therefore, it is shown that brute-force is the best model for Klang as it had the lowest value of error and the lowest total rank with WS, RH, SO2, O3 and PM10 as the parameters selected to predict the next day’s PM10 concentration. Furthermore, the performance for all models in predicting PM10 in Shah Alam also shows that brute-force had the lowest error measures for RMSE, AE, RE and NAE and the highest accuracy for R2. Therefore, brute-force is the best model with T, RH, SO2, NO2, sinWD, NO and PM10 as the parameters selected to predict the PM10,D+1.
Referring to
Table 4, the ticked table means that the parameter is selected in that model. For the best model PM
10,D+1 for Klang (MLR-Brute-Force), RH, SO
2, NO
2, O
3 and PM
10 were analyzed to predict the next day for Klang. For the best model PM
10,D+1 for Shah Alam (MLR-Brute -Force), T, RH, SO
2, NO
2, sinWD, NO and PM
10 are the parameters selected to predict the next day for Shah Alam.
Based on
Table 5, the performances of all ANN models for next-day prediction in Klang and Shah Alam were compared to determine the best model. For Klang, brute-force had the lowest value of RMSE and RE, and backward had the lowest value AE and highest R
2 value compared to the others. Evolution had the lowest value of NAE. However, backward is the best model for Klang station as it had the lowest total rank compared to the others with T, RH, SO
2, NO
2, O
3, sinWD, cosWD, NO
x, NO and PM
10 as the parameters selected to predict the PM
10,D+1.
Next, the performance for all ANN models in predicting PM
10,D+1 in Shah Alam shows that brute-force had the lowest value for RMSE, weight-guided had the lowest value for AE and RE, and forward had the lowest value for NAE and the highest value for R
2. However, forward is the best model in predicting PM
10,D+1 since it hd the lowest total rank with WS, NO
X and PM
10 as the parameters selected to predict the PM
10,D+1 as shown in
Table 6.
Referring to
Table 7, the ticked (/) table means that the parameter is selected in that model. For the best model PM
10,D+1 for Klang (ANN-Backward), RH, SO
2, NO
2, O
3, PM
10, sinWD, cosWD, NO
X and NO were analyzed to predict the next day. For the best model PM
10,D+1 for Shah Alam (ANN-Forward), WS, NO
X and PM
10 are the parameters selected to predict the next day for Shah Alam using ANN.
As a conclusion, brute-force is the best feature selection to predict the next day’s PM10 concentration in Klang and Shah Alam by using MLR, and the models fulfil the assumptions of MLR. The backward for Klang and forward for Shah Alam are the best feature selections for predicting the next day’s PM10 concentration using the ANN model.
3.4. The Best Model
The best model to predict the PM
10,D+1 for each station was obtained by comparing the performance of models between MLR and ANN. For the overall performance, each predicted day shows that the ANN model had the best performance compared to the MLR model for both Klang and Shah Alam station. This result is supported with
Table 8 as the ANN model for each predicted day for both stations shows the lowest total score. In Klang, ANN with backward elimination is the best model selected, while for Shah Alam, ANN with forward selection is the best model.
Furthermore,
Table 9 summarizes the comparison results with other research. This indicates that the results in this study are similar to those in other studies. Regression is involved with linear dependencies, whereas neural networks are involved with nonlinearities. As a result, if the data contains nonlinear dependencies, neural networks should outperform regression.
According to studies [
23,
24,
25], the ANN method predicts the dependent variable more accurately than MLR. Although ANN is regarded as a powerful technique for non-linear models [
26], some researchers have used and reported on this linear model better than the regression model [
27,
28,
29]. This showed that our ANN model can be used to predict PM
10 concentrations since it improved the performance of the model.
Table 9.
Performance indicators results gained from other research.
Table 9.
Performance indicators results gained from other research.
| Authors | Method | Result |
|---|
| [30] | MLR | = 0.347–0.614 |
| [31] | MLR | RMSE = 126.728–164.978
NAE = 0.325–0.429
PA = 0.359–0.668 |
| [32] | MLR | = 0.3239 |
| [33] | MLR | = 0.586–0.715 |
| This Study | ANN-Forward
ANN-Backward
MLR-Brute-Force | R2 = 0.63–0.74
RMSE = 12.33–15.08 |
3.5. Model Verification
For the model verification, the dataset from 2009 until 2017 was used to develop prediction models. The proposed prediction models were used to predict the PM
10 concentration using the 2018 dataset [
30,
31,
32,
33,
34,
35].
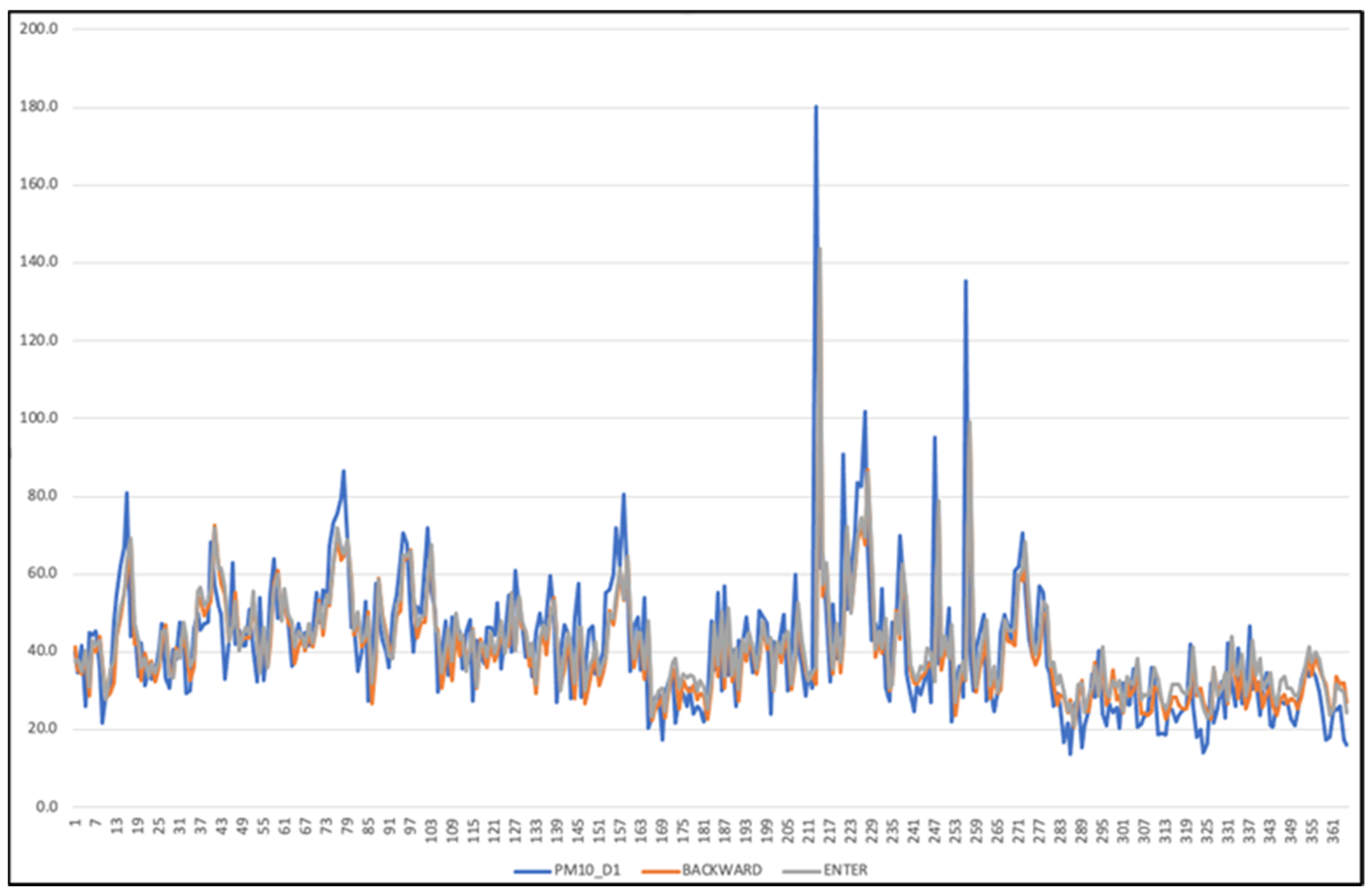
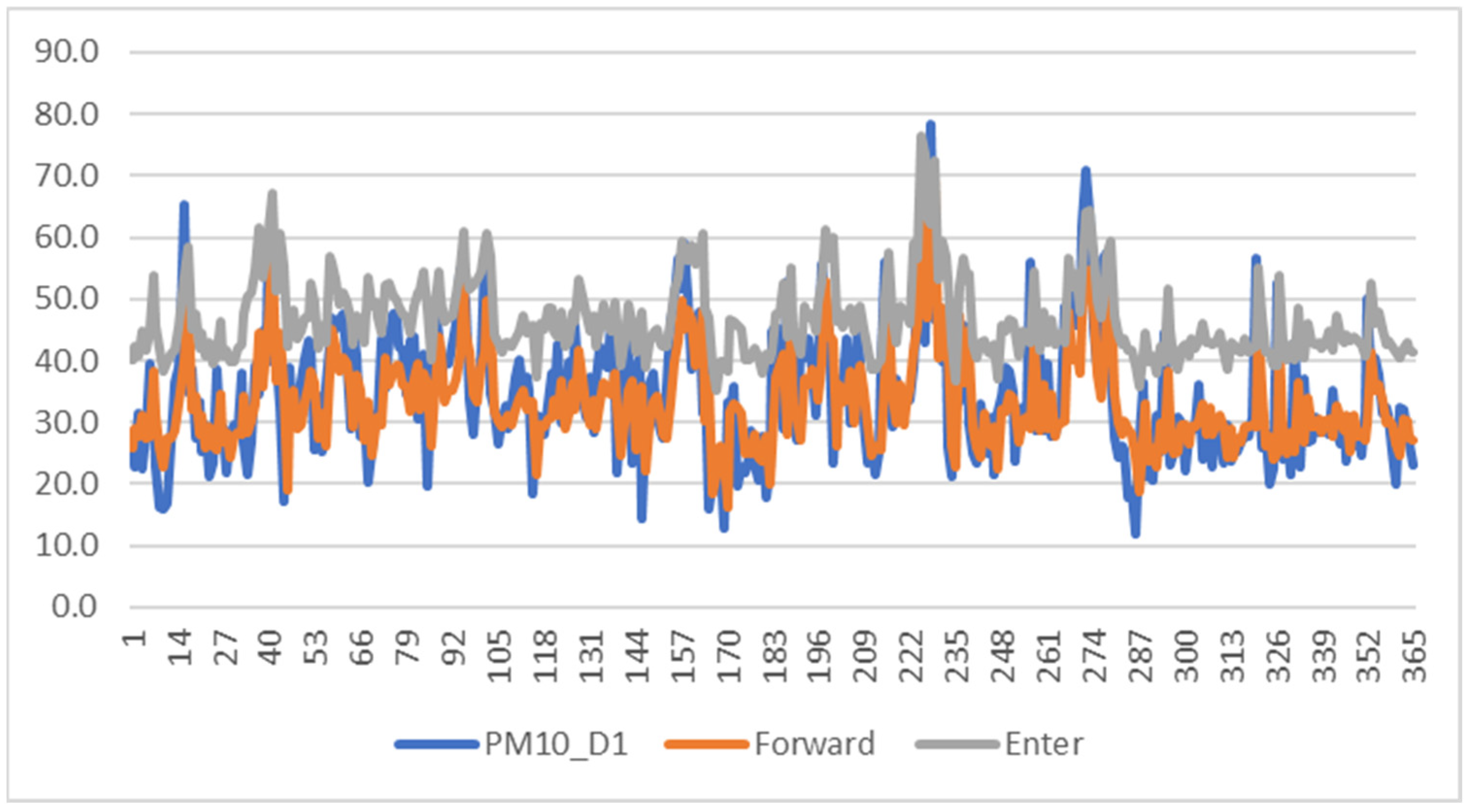
Figure 7 and
Figure 8 below show line charts of the observed and predicted values of the PM
10 concentration in Shah Alam and Klang.
This predictive model used ANN with backward elimination using RH, SO2, NO2, O3, PM10, sinWD, cosWD, NOX and NO as a parameters in Klang. For the best model PM10,D+1 for Shah Alam (ANN-Forward), WS, NOX and PM10 are the parameters selected to predict the next day for Shah Alam using ANN.
Figure 7 shows the comparison of the line chart between the observed and predicted value for PM
10,D+1 for model ANN-forward selection and predicted ANN using all variables. Referring to the line chart, it shows that, on average, the observed and predicted values have a slight gap. Most of the prediction values exceed the observed value; however, in some cases, the observed value exceeds the prediction value. Furthermore, the enter method has a large gap since, in 2018, there was a slight increase in the value of ozone, causing the prediction using all parameters to be higher than the observed value. Therefore, it shows that the predicted values of the PM
10 concentration were not notably affected by the ozone concentration.
Overall, the values of RMSE and AE of this model are 20.728 and 15.69, respectively. Hence, this model can be used for unseen data since there is no huge difference between the observed and predicted values.
Figure 8 shows the comparison of the line chart between the observed and predicted values for PM
10,D+1 for the model ANN-forward selection and predicted ANN using all variables. Referring to the line chart, it shows that, on average, the observed and predicted values have a minimum gap between each other with the value of RMSE at 10.004 and value of AE at 7.982. Most of the prediction values exceed the observed value, and in only a few cases does the observed value exceed the prediction value. Hence, this model can be used for unseen data since there is no great difference between the observed and predicted values.s
The prediction error in Klang is higher than in Shah Alam because the industrial area of Klang suffers from severe haze, while Shah Alam is only a residential area. Furthermore, if all variables based on previous studies are selected to predict PM10 concentrations for the next day, it will take more time to determine the best model and reduce the maintenance data cost for the future.
4. Conclusions
In this study, the wrapper methods of six different feature selections were analyzed and compared to determine the best feature selection method. The methods included were forward, backward, stepwise, brute-force, weight-guided and GA evolution. These methods were analyzed together with the predictive analytics methods MLR and ANN. The performance of the models determined the best model to predict the next day. This study found that the best feature selections were backward elimination, forward selection and brute-force in predicting the PM10 concentration in Malaysia.
Based on the results, the best feature selection method to predict the PM10,D+1 in Klang was the backward method with the parameters T, RH, SO2, NO2, O3, PM10, sinWD, cosWD, NOX and NO. For Shah Alam, the best feature selection method to predict PM10,D+1 was the forward method with the parameters WS, NOX and PM10.
The prediction of the ANN model for PM
10,D+1 was deployed in the 2018 dataset. Based on the line chart in
Figure 7 and
Figure 8, the gaps between the observed and predicted lines show a minimum difference. The RMSE value in Klang for PM
10,D+1 was 20.728, while the AE value was 15.69. In addition, the line chart of observed and predicted of each predicted day in Shah Alam also shows a minimum gap between each line with the RMSE value for PM
10,D+1 of 10.004, while the AE value was 7.982. In conclusion, all of the predicted models in Klang and Shah Alam can be used for unseen data.
There are a few recommendations for improving the performance of air pollution modelling that can be suggested to other researchers. This study used the cross-sectional method, and for future research, we suggest using time series, since the time-series forecasting method is better at predicting extreme events compared to the cross-sectional method. Apart from the MLR and ANN models, a new approach can be implemented to the predicted modelling to forecast the concentration of PM
10 using machine-learning methods, such as long short-term memory (LSTM), gated recurrent units (GRU) and deep learning [
36].
Other methods, aside from wrapper methods, can be applied to conduct feature selection for air pollution modelling, such as the filter method, embedded method and hybrid method. Hence, various approaches to predicted modelling and feature selection methods for air pollution modelling will be beneficial as they will produce better results. In addition, predictions for other particulate matter, such as PM2.5, should be made since the DOE began to include PM2.5 in calculating the API from 2018. In addition, PM2.5 is more dangerous since the size of the particles is smaller compared to PM10. Therefore, predicting PM2.5 may help to improve the performance of air pollution modelling. Lastly, this output can be used by the authorities as it will be helpful to reduce the impact of air pollutants.
For example, the DOE’s prediction of air pollutants can be used for early alertness to help in performing the relevant procedures. Hopefully, this recommendation will help improve air pollution modelling and help the authorities to pay early attention to the air pollutants in Malaysia. The limitation of this research is that the model can only be used when the sources and conditions of the characteristics of PM10 remain the same. Therefore, it may not be suitable for the other locations. For instance, if there is a sudden forest fire or storm in a selected area, this would affect the PM10 concentration.



 ,
, 




{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}