1. Introduction
Predictive modelling can help engineering educators to design an optimal learning and teaching practices considering the feedback generated through student performance data. In terms of monitoring student learning through problem solving, such models can convey important information on continuous progress and advancement in students’ knowledge [
1]. Predictive methods [
2,
3] are therefore a key component of learning analytics methods for dynamic learning environments to encourage students to participate continuously in learning and teaching platforms (both in-classrooms and online) while enabling the educators to evaluate their practice [
4]. Based on such models, teaching and learning have progressed dramatically, making them flexible and adaptable [
5]. This can help educators to present useful feedback and associated comments on continuous assessments with a description of areas where students are excelling and specific areas that require improvement. Most datasets comprising marks in short tests, online quizzes, or assignments are mathematically and statistically expressible and therefore can be utilised as inputs into learning analytics models with adaptive methods to forecast student progress in a course and thus continuously improve teaching and learning practice.
The literature has not fully established the adoption of statistical and machine learning predictive models, e.g., [
2,
3], to inform student’s short-term future progress through a teaching semester. The present study aims to develop a student progress-monitoring model that can be used as a vital part of the e-teaching and e-learning systems that guide educators in making better decisions to improve their practice for optimal outcomes. Based on the predicted performance using any current assessment, the educators can further implement comprehensive changes in their subsequent assignment or other tasks to capture the potential impact on the weighted course performances and final grades. If predictions are possible, the model can help facilitate a greater understanding of how the performance in continuous assessments improves a final grade and further identify factors that influence the knowledge domain and course progress using different kinds of learning attributes (e.g., online quizzes and written assignments).
In general, continuous assessment variables are based on formative assessments that can determine a student’s level of achievement in terms of their evolving capabilities [
6,
7]. They may also comprise both summative and formative evaluations that form the two kinds of student assessment procedures [
8] for generating information regarding student progression before, during, or after any particular set of sequenced learning activities [
9]. This information can enable educators to improve learning outcomes [
10] and predict student performance as an essential component of a robust education system [
11,
12]. Considering these benefits, teachers can evaluate and improve their teaching and students’ learning processes [
13] with subject-specific and general qualities when modelling students’ overall performances in a stage-by-stage approach. Subject-specific attributes, for example, can be used to determine how far students may develop in their mastery of various learning materials.
In terms of the published literature, the maximum likelihood estimation method has been used to measure student knowledge levels regarding the difficulty in understanding course learning materials. In another study, students’ self-assessment skills were investigated by determining the reasons for a student’s failure to solve a problem [
14]. This system gathered data on student development primarily based on the difficulty levels and the problem categories. The study of [
15] used self-assessment tests to improve students’ examination performance, where exam questions were adaptively created based on students’ responses to each previously answered question. It was therefore shown that the student’s likelihood to answer the questions correctly could be predicted based on their knowledge levels using the item response theory and that the accuracy of the responses and their probability distributions, i.e., the probability of the appropriate knowledge level, in terms of concepts, were also used to grade the students.
Current studies have used classification, and regression approaches such as, but not limited to, support vector machines, decision trees, artificial neural networks, and adaptive neuro-fuzzy inference systems to predict student course performance [
16,
17,
18,
19,
20]. For example, [
21] determined optimal variables to represent student attributes by developing an efficient model to aid in clustering students into distinct groups considering performance levels, behaviour, and engagement. The study of [
22] proposed a SPRAR (students’ performance prediction using relational association rules) classification model to predict the final result of a student at a certain academic discipline using relational association rules (RARs), conducting experiments performed on three real academic datasets to show its superiority. A study by Goga et al. [
23] designed an intelligent recommender system using background factors to predict students’ first-year academic performance while recommending actions for improvement, whereas Fariba [
24] studied the academic performance of online students using personality traits, learning styles, and psychological wellbeing data, showing a correlation between personality traits and learning styles. It was noted that this could lead learners to a higher level of learning and a sense of self-satisfaction and enjoyment of the learning process. Taylan and Karagözoglu [
25] introduced a fuzzy inference system model to assess students’ academic performance, showing that their method could produce crisp numerical outcomes to predict student’s academic performance and an alternative solution to address imprecise data issues. The study of Ashraf et al. [
26] developed base classifiers such as random tree, kernel ridge regression, and Naïve Bayes methods evaluated on a 10-fold validation with filtering such as oversampling (SMOTE) and undersampling (spread subsampling) to inspect any significant change in results among meta and base classifiers. Their study showed that both ensemble and filtering approaches met substantial improvement margins in predicting students’ performance compared with conventional classifiers.
Applying classification and prediction methods, Pallathadka et al. [
27] developed Naive Bayesian ID3, C4.5, and SVM models on student performance data to forecast student performance, classify individuals based on talents, and enhance future test performance. Other studies, e.g., [
28,
29], used predicted students’ performance in massive open online courses (MOOCs) to study students’ retention and make timely interventions and an early prediction of an university undergraduate student’s academic performance in completely online learning. The former proposed a hyper-model using convolutional neural network and a long short-term memory model to automatically extract features from MOOCs raw data and to determine course dropout rates, whereas the latter considered a cost-sensitive loss function to study various mis-classification costs for false negatives and false positives.
The study of Deo et al. [
3] has developed extreme learning machine models to analyse patterns embedded in continuous assessment to model the weighted course result and examination score for both mid-level (engineering mathematics) and advanced engineering mathematics performance in on-campus and online study modes compared with random forest and Volterra models. Using a statistical approach, Nguyen-Huy et al. [
2] developed a probabilistic model to predict weighted scores for on-campus and online students in advanced engineering mathematics. This study fitted parametric and non-parametric D-vine copula models utilising online quizzes, assignments, and examination results to model the predicted course weighted score. This was interpreted as the probability of whether a student’s continuous performance, individually or jointly with other assessments, leads to passing course grade conditional upon joint performance in online quizzes and written assignments. Other researchers, such as [
20,
30,
31,
32,
33,
34,
35,
36,
37,
38,
39,
40,
41,
41], have attempted to develop several types of classification and regression models and statistical methods for student performance predictions using a diverse set of predictor variables. Despite their success, no single machine learning or statistical model appears to generate universally accurate performance for the diverse datasets representing student performance; therefore, individual differences among these predictive models and the associated contextual factors could be considered when predicting student course performance.
This research builds upon earlier research involving undergraduate university mathematics courses [
2,
3]. The primary contributions are to develop a novel multivariate adaptive regression spline (MARS) model that has feature identification and regression capabilities to explore relationships between assessment-based predictors and the target course grade outcome. The performance of the proposed MARS model is also benchmarked with
k-nearest neighbour algorithm (KNN), kernel ridge regression (KRR), and decision tree regression (DTR) using five consecutive years of undergraduate student performance datasets (2015–2019) for both online and on-campus modes of course offers. The novelty of this research work is to develop a MARS for the first time to predict the first-year engineering mathematics student performance at the University of Southern Queensland, Australia, by employing several continuous assessment marks and the weighted scores that are used to assign a passing or a failing grade. The remainder of the research is dedicated to describing the novel properties of MARS with respect to related benchmark models. Several challenges after the presentation of results are then discussed, and a final section summarizes the conclusions.
3. Research Context, Project Design, and Model Performance Criteria
3.1. Engineering Mathematics Student Performance Data
The proposed MARS (and the comparative KRR, KNN, and DT) models developed to predict student performance in the first-year undergraduate engineering mathematics course consider the case of ENM1500 Introductory Engineering Mathematics that is taught at the University of Southern Queensland in Australia. The course welcomes students entering tertiary studies who are undertaking engineering and surveying programs but they require further skills in problem solving and basic mathematical competencies. The course aims to integrate mathematical concepts by introducing topics such as algebra, functions, graphing, exponential, logarithmic and trigonometric functions, geometry, vectors in two-dimensional spaces, matrices, differentiation, or integration. It develops mathematical thinking, interpreting, and solving authentic engineering problems using mathematical concepts. The course also aims to enable students to communicate mathematical concepts more effectively and express solutions to the engineering problems in a variety of written forms.
Therefore, continuous assessments in ENM1500 comprise two online quizzes, Quiz 1 (, 5%) and Quiz 2 (, 5%) (marked out of 50, administered in Week 3 and Week 11, respectively); Assignment 1 (, 15%) and Assignment 2 (, 15%), marked out of 150 (administered in Week 6 and Week 13, respectively); and an examination (, marked out of 600, 60%) in Week 15 in a regular teaching semester. Based on continuous assessments spread throughout the semester, students are awarded a grade for their weighted course score (, 100%). The course was developed as part of a major program update and revision of the previous mathematics syllabus to meet the program accreditation requirements under the Institute of Engineers, Australia (IEAust).
The School of Mathematics, Physics, and Computing in the Faculty of Health, Engineering, and Sciences at the University of Southern Queensland administers ENM1500 as a compulsory part of an Associate Degree of Engineering (ADNG) for Agricultural, Civil, Computer Systems, Electrical and Electronic, Environmental, Mechanical, and Mining Engineering specializations. In addition, it is a core part of the Bachelor of Construction Management (B. CON) for Civil and Management and Associate Degree in Construction Management.This course is also offered to the Graduate Certificate in Science under the High School and Middle/Primary Teaching Specialization to prepare teachers in engineering or technical subjects. To enter the course, students must have completed Queensland Senior Secondary School Studies Mathematics A (General Mathematics) or have equivalent assumed knowledge, and are advised to undertake an online pre-test on tacit knowledge before commencement. This pre-test informs prospective students on areas that need to be revised to ensure satisfactory progression, including recommendations for further work or an alternative study plan, such as the Tertiary Preparation Program. Therefore, the diversity of any given cohort enrolled in this course provides a rich combination of student learning abilities and learning profiles to build and test the prescribed models to predict .
Our study considers five consecutive years of student performance data (2015 to 2019, i.e., a pre-COVID period) generated by merging online and on-campus course results held three semesters per year and made available from examiner return sheets that are official results provided to the faculty after a rigorous moderation process prior to grade releases. The modelling data had marks for continuous internal assessments (i.e., two online quizzes, & , worth 5% each, and two major written assignments, & , worth 15% each), including a final examination score (, worth 60%) and a weighted score () (i.e., overall mark out of 100%) used to allocate a passing course grade. The content of Q1 and Q2 had four choices per question that students could possibly select for any given question. For both of the quizzes, there were 15 questions (1 mark each), converted to 50 marks total per Quiz. For the assignments, both A1 and A2 (marked out of 150) were written assignments with a set of problem-solving tasks for entry-level engineering mathematics applications, as well as basic skill builder tasks. For the examination, there were six long-answer-type application questions (600 marks total) completed over two hour examination period.
An ethics application (#H18REA236) was implemented in accordance with the Australian Code for Responsible Conduct of Research (2018) and the National Statement on Ethical Conduct in Human Research (2007). The research work was purely quantitative with artificial intelligence models that were not aimed at predicting any particular student’s performance. It did not draw upon personal information, nor did it disclose any student records such as their name, student identification number, gender, and socioeconomic status. Therefore, based on low risk, an expedited ethical approval was provided with pre-conditions that any form of identification attributes, such as the student names, gender, and personal identifiers, must be removed before processing the student performance data.
While pre-processing the data, incomplete records were deleted entirely (e.g., students who had not submitted assessments for particular items or did not take the exam) to prevent bias in the proposed model. While this led to some loss of student performance data from the original five-year record, the naturally lengthy records enabled us to use a total of 739 complete records of quizzes (, ), assignments (, ), examination scores (), and weighted score () to ensure negligible effects on the capability of the models to predict a passing or a failing grade. As missing data are a major problem for any machine learning model, this pre-processing data procedure has ensured that any potential bias due to a missing predictor value, for example, a missed assignment or a missed quiz mark for a student, does not cause a loss of predictive features in the overall trained model. This problem could arise from an incomplete record used in the MARS model training phase and, such, it was eliminated by using data records where every assessment data point per student had a corresponding value. As this research has used real student performance dataset, there was no suitable method for the recovery of any missing point,; therefore, the row with any missing predictor value was deleted prior to the training of the proposed MARS model.
3.2. Model Development Stages
Table 1 and
Table 2 show the first-year undergraduate engineering mathematics student performance statistics for a five-year period between 2015 and 2019. Each years of data, in their own, were considerably insufficient for model convergence. Therefore, individual years of data were pooled into a global set in order to increase the size of the overall dataset required to fully train, validate, and test the MARS model.
Figure 2 investigates the extent of association between the continuous assessments (
,
,
,
, and
) and weighted scores (
) using scatter plots and linear regression functions.
Notably, the extent of the associations between online quizzes, assignments, examination scores, and the final grade differs significantly. A positive correlation between all continuous assessment marks and is evident although the strength of correlation with is considerably higher (with = 0.9356) followed by ( = 0.409), ( = 0.367), and ( = 0.164). For example, the lowest magnitude of a correlation is recorded between and , whereas the highest correlation is evident for and , whereas marginal differences exist between the correlation coefficient of and analysed against .
The impact of Quiz 2 on the final grade, as evidenced by the weakest correlation of
with
, appears to be the lowest with
= 0.0685. Each of the assessment pieces are administered at different times of a 15-week teaching semester; thus, using a diverse set of information to examine the extent of association of each assessment on the weighted score and the estimation of weighted scores resulting from the MARS model can be a useful way to implement effective teaching practices prior to the examination period at the end of the semester. Based on the rank noted in
Table 2, the input sequence for the proposed models is designed following the order of increasing the importance of predictors and further testing their importance according to the individual inputs used to predict the weighted scores.
In this paper, two categories of predictive modelling systems are developed. The first is a single-input-based matrix that utilises
,
,
,
, and
. These individual models are designated as Models M1–M5. The second category of the modelling system (designated as Models M6–M8) is a multiple-input matrix-based system where the order of the multivariate input combination has been determined statistically. This variable order is selected based on the magnitude of the
, considering the lowest to the highest level of associations with the target variable (
), as shown in
Table 2. This research has built further models by using a combination of the highest correlated input variables. For example, we note that
and
have acquired
= 0.606 and 0.640 (i.e., M10), respectively, while adding the relatively low-correlated input
and the lowest correlated input
to further check if the less correlated input variables provide any improvements in the predicted value of
.
Table 3 shows the proposed MARS model along with the KNN, KRR, and DT models developed as benchmark methods to comprehensively evaluate the efficacy of the MARS model.
Following this specific modelling strategy, twelve distinct models are built to investigate how the different student assessment datasets impacted the student’s overall learning or success in this first-year undergraduate engineering mathematics course taught from Week 1 to 15. To build the proposed MARS (and the benchmark models), all the original data are randomized in the model training phase to ensure greater model credibility for predicting the weighted score. Subsequently, 60% (or 444 rows) of the datasets are allocated to a training set from which 33% (or 145 rows) are selected for model validation purposes. The remainder, 40% (or 295 rows), is used as an independent test set to cross-validate the performance of the proposed MARS and all the other deep learning models.
Table 4 shows the parameter for the MARS, including the KRR, DTR, and KNN models, whereas
Table 5 shows the parameters of the most optimal MARS model trained to predict the
using a combination of input variables based on continuous assessments for ENM1500. In accordance with
Table 5, we note that the most accurate training performance of the MARS model utilizes 11 basis functions whereby a linear regression model is learned from the outputs of each basis function regressed with the target variable (i.e.,
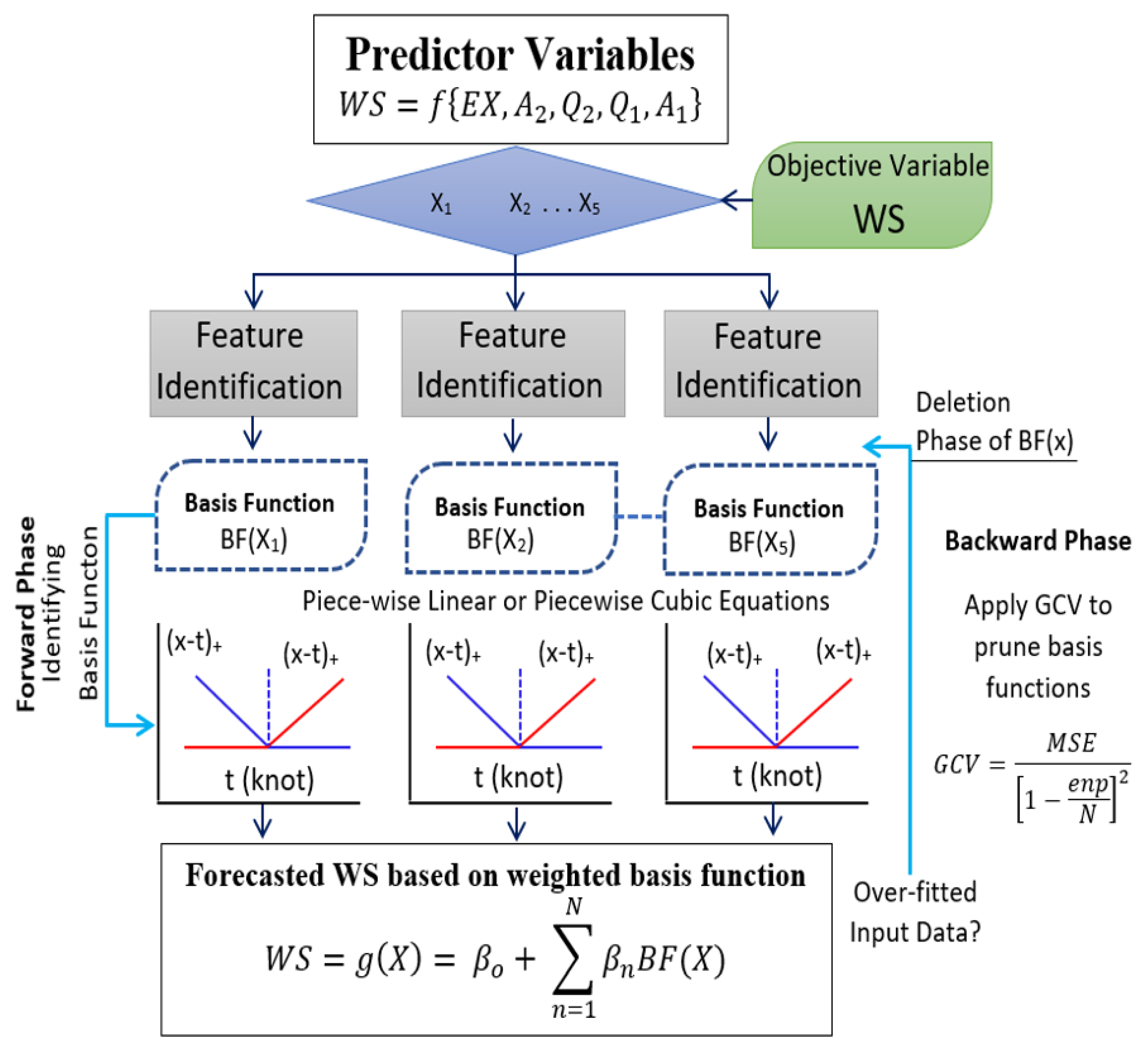
). The basis functions include the intercept term (i.e., 41.719), followed by a product of two or more hinge functions). Consequently, the final prediction is made by summing weighted outputs of all of the basis functions. This step also includes the growing and the generation phase (i.e., the forward-stage) and the pruning or the refining stage (i.e., the backward-stage), as illustrated in
Figure 1. This step somewhat resembles the operations of the decision tree (e.g., the DTR) model with each value of each input variable in the training dataset considered as a potential candidate for the basis functions.
The change in the MARS model performance in the backward stage is evaluated using cross-validation of the training dataset (i.e., generalized cross-validation,
;
Table 4). Notably, the optimal model (M12) attained the highest coefficient of determination (
), the lowest mean square error, and the lowest
. Moreover, the number of functions is determined automatically, as the pruning process halted when no further improvements were made. Therefore, one benefit of the MARS model was that it only used input variables that improved the performance of the final model, to the extent that the bagging and random forest ensemble algorithms, and the proposed MARS achieved an automatic type of feature selection to generate the most accurate
values in the testing phase.
3.3. Performance Evaluation Criteria
This research adopts visual and descriptive statistics of the observed (
) and the predicted weighted scores (
) to cross-check the discrepancy of the proposed MARS model using an independent testing dataset not used in the model construction phase. The testing dataset evaluations consider standardised performance metrics to comprehensively evaluate the credibility of the predicted
in ENM1500 Introductory Engineering Mathematics. The metrics for model evaluation recommended by the American Society for Civil Engineers are root mean square error (
), correlation coefficient (
r), Legate and McCabe’s index (
), Nash and Sutcliffe’s coefficient (
), and expanded uncertainty (
) with mathematical representations [
57,
58].
where
Note that and are the observed and predicted values of the WS; and are the observed and predicted in the testing phase; and N = the number of data points.
4. Results and Discussion
The results generated by the newly proposed MARS (and the comparative models) are presented with respect to their predictive skills in emulating the weighted course score used to allocate a final grade in ENM1500 Introductory Engineering Mathematics.
Table 6 compares the observed and the predicted
, presented in terms of the correlation (
r) and root mean square error (
) for diverse input combinations (i.e., M1 to M12). It becomes immediately apparent that the MARS model, designated as M5 with
=
and M12 (
=
), is the most accurate model compared with M1 to M12. However, the performance of the MARS model designated as M5 and M12 input combination appears to far exceed the performance of DTR, KNN, and KRR models in terms of the tested error and the correlation between the observed and the predicted weighted score.
Among the input combinations for models designated as M5 and M12, we also noticed that the model M12 used in the MARS model yields ≈ a 42% lower error, whereas that for the DTR model is 32.9% lower, KNN is 22.7% lower, and KRR is 33.9% lower than M5. This shows that the input combinations used in case of M12 with the variable , , , , and can improve the prediction of compared with the as a single input.
In a physical sense, this means that the influence of online quizzes and written assignments on ENM1500 student outcomes is significant. However, it is imperative to note that for the optimal input combination, the proposed MARS model far exceeds the performance of the DTR, KRR, and KNN models, as measured by the errors attained in their testing phase. This result concurs with the initial correlation coefficients stated in
Table 6, where the highest degree of agreement between the observed and tested
is evident by the largest
r value for the case of the MARS model relative to the counterpart models.
Interestingly, we note that among the combination of single predictors, the proposed MARS model (M5) with as input registers the best performance (r = 0.963; = 5.76), which is followed by the model with (M4) and (M1). Notwithstanding this, the worst performance is registered for the case of M3 (with as input). This indicates that Quiz 2 has the weakest influence on the weighted score while the examination score has the strongest influence on the weighted score (or final grade for ENM1500 students).
It is noteworthy that a diverse range of model combinations prepared by adding the predictor variables in an ascending order (i.e., M9, M10, M11, M12) reveals a significant improvement in the accuracy of the tested dataset by a margin of ≈ 20% to a 43% reduction in the predicted RMSE values. Similarly, in terms of the r values, the improvement for the case of the MARS model is ≈ 2% to 4%, as we analyzed models M9 to M12, respectively. If we only compared the results for the input combination case M12 where all of the predictor variables (i.e., , , , , and ) are used, the proposed MARS model generates the best performance (i.e., r = 0.998; = 3.29 followed by KRR with r = 0.994; = 3.89, DTR with r = 0.987; = 4.39 and KNN with r = 0.990; = 4.60). By contrast, the model for the input combinations prepared in a descending order, namely M6, M7, and M8, yielded a comparatively poor performance.
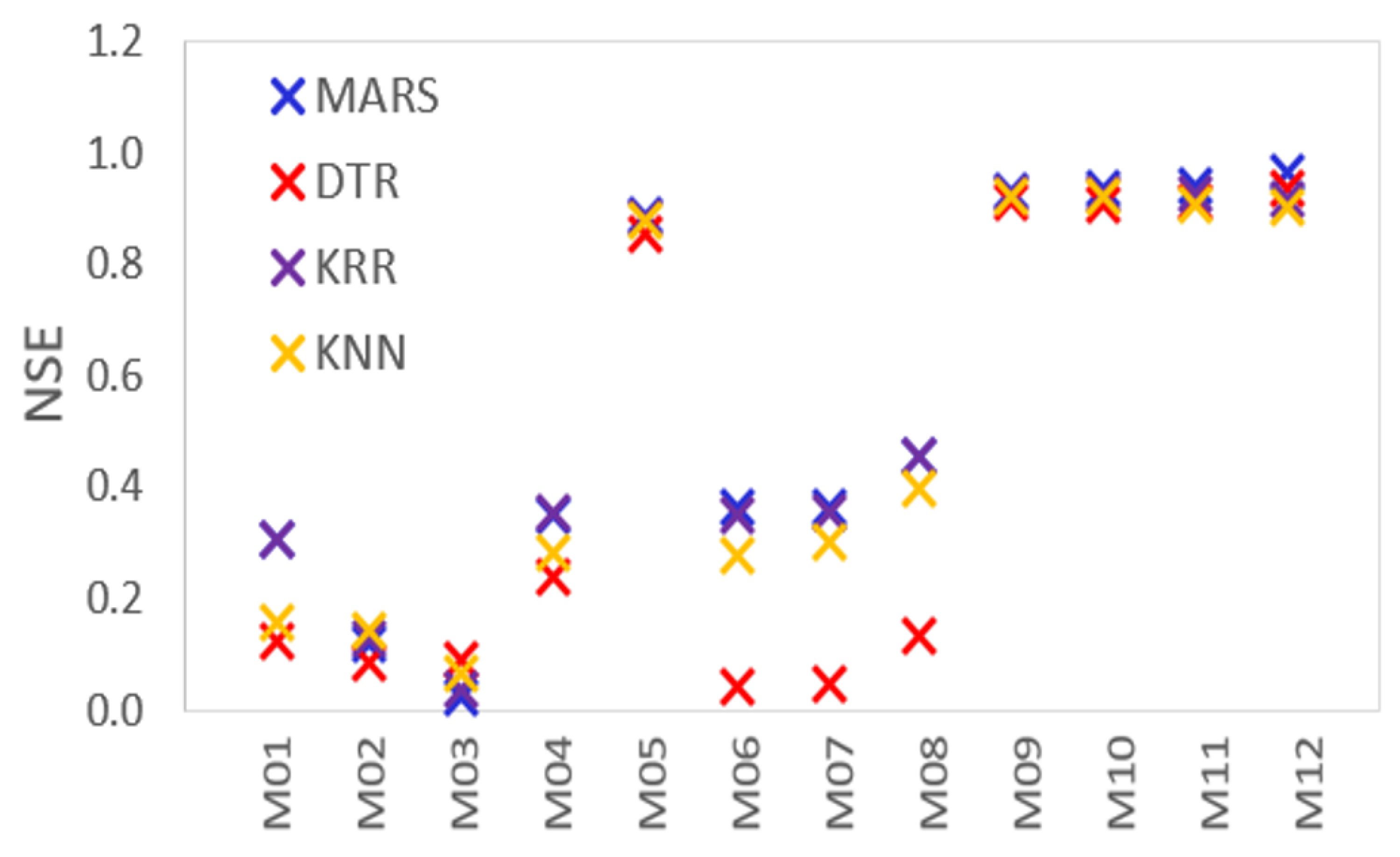
To appraise the proposed MARS model, we now show in
Figure 3 the Nash–Sutcliffe’s coefficients (Equation (
17)) employed to assess the predictive skills of all models. As the
is calculated as one minus the ratio of the error variance of the modelled data divided by the variance of the observed data, a perfect model with an estimation error variance equal to zero is expected to record the Nash–Sutcliffe efficiency of unity, whereas the model that produces an estimation error variance equal to the variance of the observed data will produce a trivial value of
. Therefore, for a model with NSE close to zero, it would have the same predictive skill as the mean of the data in terms of the sum of the squared error.
Figure 3 shows that MARS model designated as M9 to M12 yielded
value close to unity, although M12 (with
) appears to be a better fit compared with M9, M10, and M11 where
,
, and
have been excluded from the predictor variable list. It is also of note that DTR, KRR, and KNN are relatively less accurate than MARS to ascertain its superior skill in predicting the weighted scores for ENM1500 students. Interestingly, all the four algorithms with input combinations designated as M5 produce quite an accurate simulation of
, which concurs with
Table 6, where the same model yielded a significantly high correlation (
r = 0.950–0.963) and a relatively low
(5.76–5.89). Taken together with
and
r values, the high
for M5 shows that the examination score remains the most significant predictor of weighted scores. However, the importance of online quizzes and written assignments remain non-negligible (see designated inputs and results for M9–M11).
Figure 4 compares the percentage change in the root mean square error generated by the proposed MARS model (vs. DTR, KNN & KRR) for input combinations M1–M12. The purpose is to evaluate the exact level of improvement attained by the MARS model against that of the comparative counterpart models. Interestingly, the most significant improvement in the proposed MARS model performance is attained for the input combination M12, where it records a significant performance edge over KNN (30% improvement), followed by DTR (≈26% improvement) and KRR (15% improvement). It is quite interesting to note that model M5 (which attains a relatively high
and a relatively low
:
Figure 3;
Table 6) did not reveal a large improvement in terms of percentage change in
values. This seems to suggest that although
is highly correlated with
(
Figure 2 and
Figure 3), the inclusion of other assessment marks, such as online quizzes and written assignments, leads to a dramatic improvement in the MARS model’s ability to predict the weighted scores accurately. This suggests that the influence of continuous assessment remains quite significant on the final grade of a majority of the ENM1500 students.
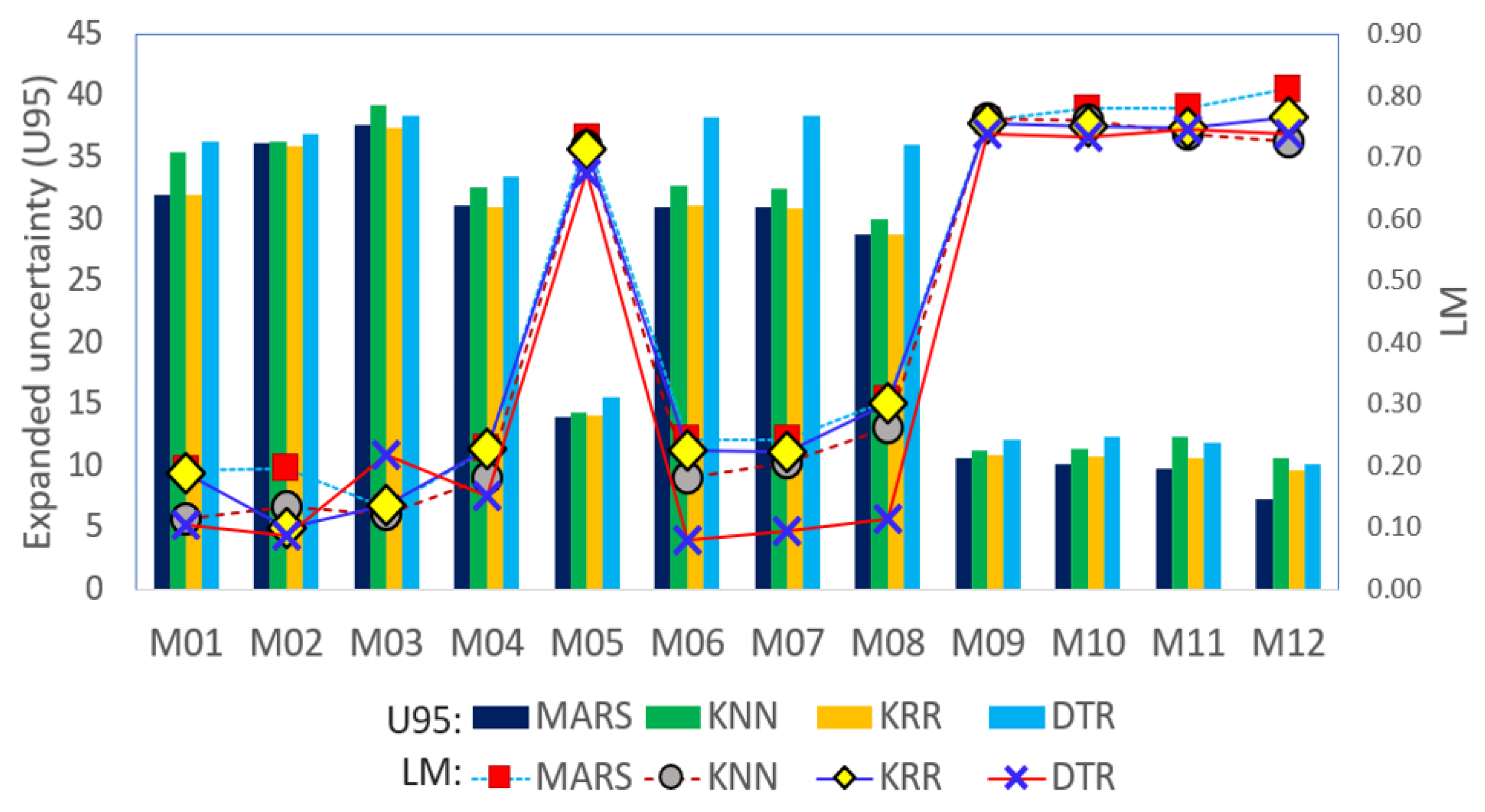
We now compare the capability of the proposed MARS model used to predict the weighted score using an expanded uncertainty (
) metric calculated by multiplying the combined uncertainty with a coverage factor (
k = 1.96 that is used for an infinite degree of freedom) to represent the errors at the 95% confidence level. In addition, the Legate and McCabe index (
), to more stringent metric than the
, is also used to benchmark the proposed MARS model against the comparative models for a range of input combinations (i.e., M1–M12). As shown in
Figure 5 for the testing phase, the magnitude of
and
are in tandem with each other, whereby the lowest value of
and the highest value of
are attained by the proposed MARS model, particularly for the case of Model M12.
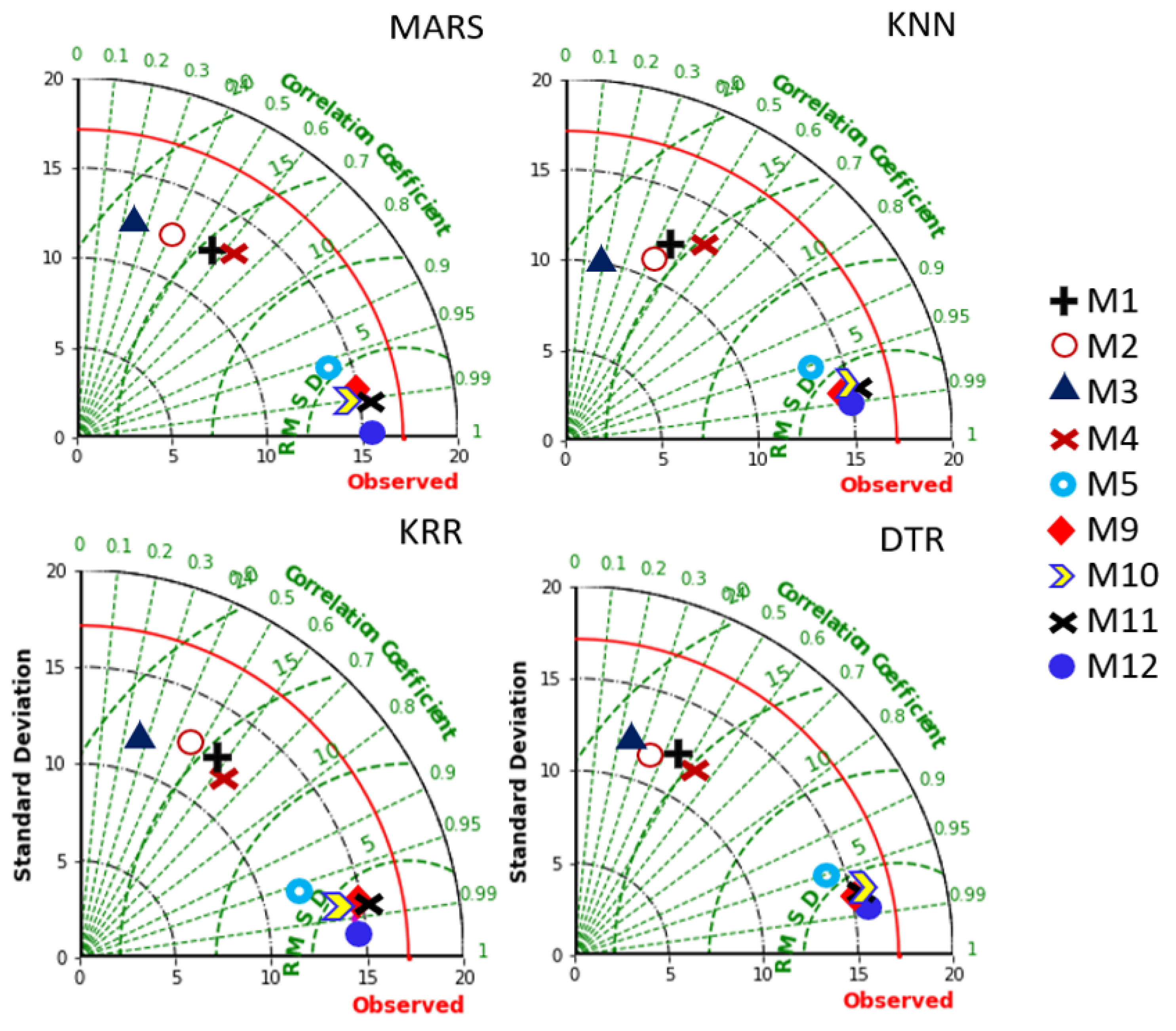
Figure 6 plots a Taylor diagram where the root-mean-square-centred difference (
) and the standard deviation are considered against the correlation coefficient of observed and predicted weighted score of the ENM1500 students. In this case, we plotted the objective model (i.e., MARS) in a separate panel compared with KNN, KRR, and DTR models for the complete set of input combinations M1–M12. There appears to be a clear separation of the results for M9-M12 from that of the other designated inputs for all four types of models. However, the MARS model (for M12) outperforms all counterpart models for this input combination to ascertain its outstanding ability to predict weighted scores.
Figure 7a,b and
Figure 8a,b represent a scatterplot of the predicted and the observed
for the proposed MARS model and the other comparative models. According to the scatterplot, the coefficient of determination (
) is associated with the goodness-of-fit between predicted and observed
as well as a line of least-square fit with appropriate equation
y =
, where “
m” = the gradient and “
c” = the regression line y-intercept. The proposed model with all predictors (i.e., M12) significantly outperformed the baseline models and all other input combinations in terms of the highest
value.
When the magnitudes of these parameters are stated in pairs (), the proposed MARS model with M12 reports the values closest to unity at 0.998|0.907 (), followed by KRR for M12 (0.993|0.845). Additionally, the MARS model also showed a subsequent improvement measured by the single predictor variable-based model to all the predictor-based models (i.e., M12), signifying the contributions of all student evaluation components in assessing the student-graded performance. Therefore, the proposed MARS model with M12 input combination can be said to be well suited for predicting the weighted scores of ENM1500 students.
We now show the discrepancy ratio (
) as a metric to examine the robustness of all the developed models in
Figure 9. Note that the
metric indicates whether a model over- or under-estimates the value of a weighted score so that a DR value close to unity is expected to indicate a predicted value closely resembling the observed value. Notably, across the tested data points, the proposed MARS model (with M12 as the input combination) attained 90% and 98% of the observations distributed within the ±10% and ±30% band error, respectively. For the other input combinations, the outliers are somewhat higher, which indicated a poor prediction by the MARS model.
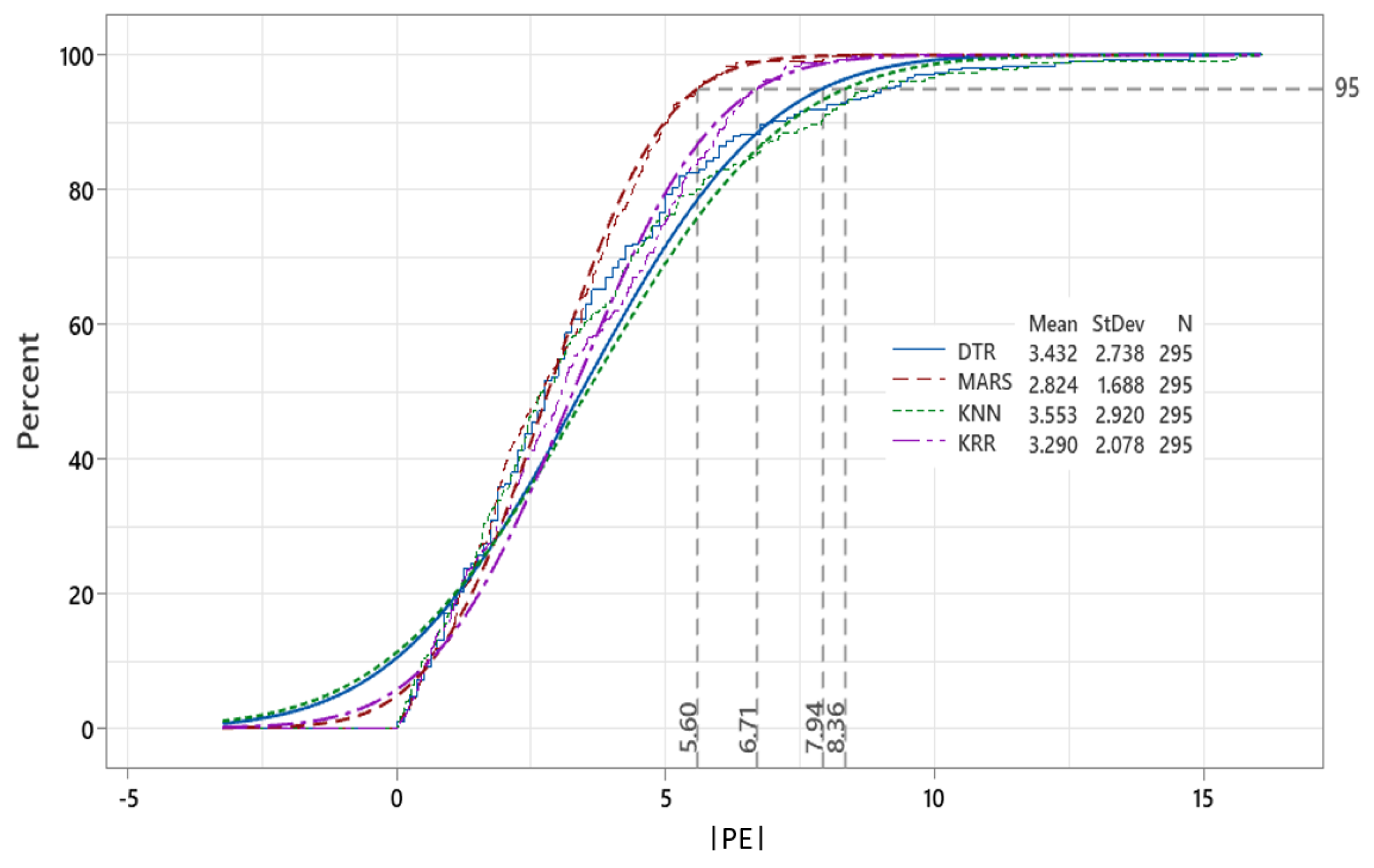
Further evaluation of the proposed MARS model is accomplished by investigating the empirical cumulative distribution function (
). Here, we show the absolute predicted error (|
|) for the case of Model M12 in
Figure 10. The figure demonstrates that about 95 percent of all |
| values generated by the MARS model fall within the ±5.60 error bracket, followed by ±6.71 for the KRR, ±7.94 for the DTR, and ±8.30 for the KNN model, respectively. The mean value of the predicted error for the proposed MARS is ≈2.824 (vs. 3.290–3.553 for KRR, DTR, and KNN models), whereas the standard deviation is ≈1.688 for MARS (vs. 2.078–2.920) for a total of 295 tested values of the weighted score in an independent testing phase. Taken together,
Figure 9 and
Figure 10 demonstrate the efficacy of the proposed MARS model to generate relatively accurate weighted scores for ENM1500 students.
5. Further Discussion, Limitations of This Work, and Future Research Direction
In this research, the performance of a novel MARS model was shown to far exceed three machine learning models for the specific case of Introductory Engineering Mathematics (ENM1500) taught at the University of Southern Queensland, Australia. A statistical and visual comparison of observed and predicted weighted scores used to determine final grades showed different levels of association of continuous assessments—evaluated both as single predictors and a combination of predictors based on the correlation coefficient of each assessment item (see
Table 3,
Table 6). Although the examination score was the most significant indicator of success in the course in terms of statistical evaluations (
Figure 2) and results (
Figure 3,
Figure 4,
Figure 5,
Figure 6,
Figure 7,
Figure 8,
Figure 9 and
Figure 10, the inclusion of online quizzes and written assignments led to a dramatic improvement in the predicted accuracy of the final course grade. This outcome highlights the critical role of every assessment in producing a successful grade. The effect of each input combination (and its contributory role in leading to a successful grade) was also notable, suggesting that the MARS model could be a useful stratagem for engineering mathematics educators in developing early intervention programs to redefine their teaching strategies as a semester progresses. As each assessment was spread throughout the 15-week teaching semester, the application of the MARS model fed with each assessment mark early into the semester could be a useful tool to develop scenarios of student success or failure.
Despite the superior performance of the MARS model, there are still some limitations that warrant further investigation. In this study, the dataset used to train the model was not partitioned into factors that could further limit the model’s generality. For example, student performance data divided into gender-based, socio-economic status, pre-requisite knowledge of mathematics, student marks based on personality traits, learning styles, and psychological well-being could also be considered to develop separate models for each type of student cohort. For example, Fariba [
24] found correlations between such factors that lead learners to a higher level of learning and redefine their self-satisfaction and enjoyment during their learning journeys. To investigate such factors, a much larger dataset from more than one academic institution with comparative specifications of their engineering mathematics courses could provide support for developing a more robust generic model for customised predictions of undergraduate student success at different institutions. Furthermore, in this study, we build the MARS model by pooling all years of data together to create a universally diverse dataset with a relatively lengthy record (see
Table 1). While this approach ensured the MARS model has enough data for the training, validating, and testing stages, and that each years of data, in their own, were considerably insufficient for model convergence, our study does have limitations in terms of not considering individual years of data to train each year-by-year model. A further study utilizing each years of data, or groups of years of data to further train the MARS model, is warranted to check for any model discrepancies.
In a future study, one could categorize datasets into different performance thresholds (or grades) to develop classification models that investigate the relatively poor-performing students to be identified early, thereby allowing the educational institution’s management to intervene and improve their performance [
59]. Unfortunately, it is difficult to scale the existing single classifier-based predictive models from one context to another or to attain a general model across a diverse range of learners. Therefore, a classification model studying the categorized dataset of low to moderate performers could be developed. In this study, datasets from only one university were used, so a predictive model constructed for one course at one institution may not apply more generally to another method or another institution. Therefore, the concept of integrated multiple classifiers for datasets from various universities and courses may lead to more robust and tailored strategies to predict students’ academic success. The idea behind combining such datasets through various classifiers is that the different classifiers, each of which are expected to use a distinct data representation, concept, and modelling technique, are more likely to produce classification performances with varying generalization patterns [
60] that can lead to a more universal model. Some scholars have demonstrated that the approach using multiple classifier models that aim to minimize the classification error while maximizing the generalization skills of the model [
61]. Therefore, in future applications, the MARS model could be made flexible, generalizable, and scalable through predictive modelling datasets using multiple classifier systems.
Different factors influence students’ academic performance, such as socioeconomic status, family atmosphere, schooling history and available training facilities, relational networks of the persons, and student–teacher interactions. These factors are parts of the academic problems that cannot be resolved without addressing the essential aspect. However, these factors may sometimes contribute less to some of the poor performance and academic problems observed among students but can be attributed to the poor performance at the psychological organization level, i.e., motivational and personality factors. In the face of severe external resources limitation, such as socioeconomic constraints, as seen in many rural areas, schools must rely on other resources to ensure they achieve their goals. Although some students in rural schools may have resources to support positive academic outcomes at home, most of them may be facing problems of resource availability and other family-related issues such as single parenting, low socioeconomic status, low parental education, etc., which may lead to low performance and risk of dropout. These issues could be the subject of further investigation to extend the use of MARS or other approaches to a more diverse set of targeted outcomes.
6. Conclusions
Predicting student performance is a crucial skill for educators, not only for those striving to provide their students with the opportunity to be productive in their fields of study but also for those educators who need to manage the teaching and learning resources required to deliver a quality education experience. In this study, the undergraduate Introductory Engineering Mathematics student weighted scores were predicted successfully using continuous assessment marks by developing a new multivariate adaptive regression splines (MARS) model using specific datasets from the University of Southern Queensland, Australia.
The model was constructed using ENM1500 (Introductory Engineering Mathematics) data over five years from the University of Southern Queensland, Australia, to simulate the overall student marks leading to a grade using online quizzes ( & ), written assignments ( & ), and the final examination score (). The model simulations showed that the examination, assignments, and quizzes together could be used to model the weighted score, although there was a significant influence of each assessment on the weighted score. Based on statistical and visual analysis of predicted and real weighted scores, a MARS model captured the dependence structure between the predictor and the target variable. Compared with a decision tree regression (DTR), kernel ridge regression (KRR), and k-nearest neighbour (KNN) model, the MARS model was able to capture the interaction between variables perfectly as an efficient and fast algorithm during computation and was very robust to the outliers in the weighted score. The MARS model registered the lowest predicted root mean square error () 5.76% vs. 5.89–6.54% for the three benchmark models, attaining the highest correlation of ≈ 0.963 vs. 0.950–0.961. With assignments and quiz marks added to the input list, the MARS model accuracy improved significantly, yielding a lower (3.29%) and a larger correlation of 0.998 for predicted vs. observed . This demonstrated the usefulness of the model to educators. In particular, the models developed can assist the educators in demonstrating how future students learning needs in terms of, or evidenced by, continuous assessments such as assignments may impact their examination performance. The predicted student marks in these assessments can help educators to reflect on their teaching strategies, or to identify deficits in teaching methods, their effectiveness, and student’s unique learning styles for a more productive planning and early intervention to prevent failures. The results confirmed that the proposed MARS model was superior to four other benchmark models, as demonstrated by the lowest expanded uncertainty and the highest Legates–McCabe index, with a Taylor diagram and empirical error plots for comparing predicted and observed weighted score. Therefore, such models can be used as an early intervention tool by using early assessments (e.g., quizzes or assignments) to predict either examination outcomes or final grades.
We conclude that this study used only students’ quizzes, examination, and assignment results to construct machine learning regression models, and therefore has ignored some of the other personal variables that may influence student outcomes. These variables are socioeconomic status, family atmosphere, schooling history and available training facilities, relational networks, student–teacher interactions, and many others. While the study has aimed to develop a flexible, generalizable, and scalable predictive modelling approach for predicting student course performance from ongoing assessment, the inclusion of factors that may impact personal performance in a future learning analytics model could possibly enhance the capability of the machine learning algorithm to extract patterns relating to grades from such data. This can therefore assist institutions in effective course health checks and early intervention strategies, and also modify teaching and learning practices to promote quality education and desirable graduate attributes.




 ,
, 















{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}