1. Introduction
In recent years, China’s aging process has been accelerating. By October 2020, China’s population aged 60 or above reached 264 million, accounting for 18.7% of the total population, of which 191 million will be aged 65 or above, accounting for 13.5% of the total population [
1]. The research shows that China will enter a moderately aging society by 2024, with 14% of the population over 65 years old. According to research, China will enter into the serious aging society by 2035 and the proportion of the elderly population over 65 will be increased by more than 20%. In the past few decades, China has moved from the demographic dividend period to the population burden period [
2]. The cruel reality of getting old before getting rich will bring a great burden to young people, and will also pose the most severe challenge to the current endowment insurance system. Evaluation of the operation process and effects of the current endowment insurance system objectively and scientifically has become an urgent problem for the further improvement and development of the endowment insurance system. It creates a great significance to grasping the operation status of the endowment insurance system and promoting its sustainable development.
Research on the efficiency of insurance system began as early as the 1950s. Samuelson proposed the Overlapping Generation Model (OLG) to study the performance of endowment insurance [
3]. Later, Diamond improved the OLG model, he used the model to study the dynamic impact of two existing financing modes of endowment insurance system on capital [
4]. In the 1970s, Aaron proposed the ‘Aaron condition’, which became a reference standard for the choice of a pension insurance system. He found that the main factors restricting the efficiency of endowment insurance are the growth rate of population and the growth rate of labor production [
5]. In recent years, some scholars have studied China’s maternity insurance system and basic pension insurance system [
6,
7]. However, there is little research on endowment insurance systems in China. Charnes et al. proposed that DEA is the most popular non-parametric method to measure the relative efficiency of decision-maker units, and it was developed later on by Banker et al. [
8,
9]. The DEA method is widely used among various fields: Bank [
10,
11,
12], energy [
13,
14,
15,
16], educational system [
17,
18], entrepreneurship and innovation [
19,
20], software engineering [
21,
22]. Andreu proposed four variants of the slacks-based measure of efficiency (SBM) to evaluate the efficiency of the strategic style of pension funds [
23]. Further, Hu improved the three-stage DEA model to calculate the operation efficiency of urban and rural residential insurance system in 31 provinces of China from 2012 to 2016, he proposed that different regions should implement different efficiency promotion strategies according to their own problems and situation [
24].
With the deepening of population aging, the gap in endowment insurance system is becoming increasingly serious, which means that the consumption of accumulated pension balance will be increased. The change of population structure promotes the change of relevant national policies, it also has an impact on the pension payment rate. Moreover, the stable operation of the economy is very important for the sustainable operations of the endowment insurance system. In case of economic crisis, the accumulated pension balance will be affected. Hence, there are sufficient reasons to believe that the accumulated pension balance and pension expenditures are in an uncertain environment, and this uncertainty is caused by a variety of factors such as economic shock and adjustment of the policy. In previous studies, few scholars consider this uncertainty, likely to lead to wrong ranking results.
Robust Optimization is introduced in this study to resolve the problems mentioned above. It was first proposed by Soyster [
25]. El-Ghaoui and Lebret [
26] and Ben-Tal and Nemirovski [
27,
28,
29] extended the RO theory and proposed a new robust model based on ellipsoidal uncertainty sets. Subsequently, Bertsimas and Sim [
30,
31,
32] and Bertsimas et al. [
33] developed a robust optimization approach based on polyhedral uncertainty sets. Sadjadi and Omrani were the first scholars to apply robust optimization for DEA [
34]. Kazemia and Haji proposed robust DEA model based on Ben-Tal and Bertsimas approaches to measure the efficiency of high schools [
35]. Until now, no scholar has used the robust DEA method to resolve the problems in the field of endowment insurance systems.
However, it is highly subjective that the classical RO methods are mostly based on experience to obtain uncertainty sets. In previous studies, the advantages of big data are ignored, and the results are also too conservative. The data-driven RO method [
36,
37] uses historical data to construct uncertainty sets, which improves the rationality and economy of the uncertainty sets of the traditional RO method. However, few types of research were conducted previously on introducing data-driven RO to DEA models.
In this paper, a new method is proposed to measure the efficiency of endowment insurance system of 31 provinces in China under uncertainty environment. It is proposed to use a data-driven robust data envelopment analysis (DRDEA) model. It is based on three uncertainty sets: Interval uncertainty set, Ellipsoid uncertainty set, Polyhedron uncertainty set. The determination of the government is to ensure that the operation of the endowment insurance system should be absolutely stable, so the purpose was to resort robust optimization to ensure robustness in the case of data disturbance. The main contributions of this research are as follows: (1) It is proposed that robust DEA models deal with the efficiency measurement in endowment insurance effectively. (2) We deduce the robust counterparts in different deterministic cases. (3) It is proposed that data-driven robust DEA models deal with the inherent defects of robust optimization. (4) This paper uses real numbers to verify the effectiveness of the model.
The structure of this paper is as follows.
Section 2 introduces some preliminary concepts. Three robust DEA models are explained in
Section 3.
Section 4 highlights applicability of models mentioned earlier with endowment insurance system in China along with suggestions and recommendations.
Section 5 elaborates the data-driven robust DEA models and its application in endowment insurance system. At the end,
Section 6 reflects the conclusion of this paper.
3. Robust DEA Model
In this model (2), decision variables and parameters are all deterministic. However, in a real-world scenario, this is likely to lead to errors when uncertain factors exist. In our research, the operational efficiency of the endowment insurance system will be affected by policy adjustments and economic shocks. Therefore, the DEA model under certain circumstances is not suitable for real situations. We must consider the impact of these two uncertainties on output.
Robust optimization is an approach which is seeking the optimal solution in the worst case. In this paper, three uncertainty sets to describe the uncertainty were considered to describe different kinds of uncertainties which may influence the results.
For the output, it consists of two parts. The first part is determinate value, the other part is uncertainty value. We express the uncertainty as follows:
Thus, model (2) takes the following form
and denote the outputs in the deterministic situation, and are output fluctuation caused by different uncertainty factor. Then, represents the uncertainty factor.
Finally, the following Programming can be obtained:
3.1. Robust Model Based on Box Uncertainty Set
For the RDEA model, we consider the most simple uncertainty set-box uncertainty set first.
Proposition 1. The robust data envelopment analysis model based on box uncertainty set can be constructed as:
where the uncertainty set can be defined as
,
.
represents the uncertainty parameter, which measures the degree of uncertainty in the case of box uncertainty set.
represents the disturbance of output data, and measures the disturbance of
uncertain factors to output.
3.2. Robust Model Based on Ellipsoid Uncertainty Set
Now, we consider the model based on the ellipsoid uncertainty set.
Proposition 2. The robust data envelopment analysis model based on ellipsoid uncertainty set can be constructed as:
where the uncertainty set can be defined as
,
.
represents the uncertainty parameter, which measures the degree of uncertainty in the case of the ellipsoid uncertainty set.
represents the disturbance of output data, and measures the disturbance of
uncertain factors to output.
3.3. Robust Model Based on Polyhedron Uncertainty Set
Finally, we consider the polyhedron uncertainty set.
Proposition 3. The robust data envelopment analysis model based on polyhedron uncertainty set can be constructed as:
where the uncertainty set can be defined as
,
.
represents the uncertainty parameter, which measures the degree of uncertainty in the case of polyhedron uncertainty set.
represents the disturbance of output data, and measures the disturbance of
uncertain factors to output.
We present proof of Proposition 1, Proposition 2 and Proposition 3 in
Appendix A.
4. Simulation Results
4.1. Data and Variable Selections
Although the endowment insurance system was implemented in 2014, the statistical caliber of the data can be traced back to 2012. To ensure the consistency of the data, this paper studies the operation efficiency of the endowment insurance system of 31 provinces in China from 2017 to 2019 (latest available data). The data of input and output indicators are all from China Statistical Yearbook and provincial statistical yearbooks [
39]. The data are shown in
Table 1.
Inputs of endowment insurance mainly include fund income, number of insured and the number of retirees. The first index is fund income. According to the relevant provisions in China, the income of the endowment insurance fund is paid by the payment units. The individuals are included in the scope of the endowment insurance according to the payment base and payment proportion stipulated by the government, as well as the income obtained through other ways to form the source of the fund. It includes the endowment insurance premium paid by the unit and individual employees, the interest income of the endowment insurance fund, the subsidy income of the higher level, the income of the lower level, the transfer income, the financial subsidy, and other income.
The last indicator as an input is the number of retirees. For the service object of endowment insurance, the number of retirees is directly related to the number of services provided by endowment insurance. The more the number of retirees, the higher the expenditure of the endowment insurance fund and the greater the expenditure pressure of the corresponding endowment insurance fund will occur.
In the selection of output indicators, the following two indicators are determined: fund expenditure and accumulated fund balance. The first index is used to measure the number of public services in the operation of endowment insurance system, which is the direct performance of the operations of endowment insurance system. The scope of expenditure mainly includes the pension of retirees, who participate in endowment insurance. The pension of retirees, and the payment of various kinds of stickers, medical expenses, death and funeral subsidies, etc., are also included. Therefore, it can be used as an output indicator. This index refers to the accumulated balance of the endowment insurance fund in a certain period time for the accumulated balance of the fund. It measures the endurance of the endowment insurance system in China, that is, the sustainability of its development. Therefore, it is also an output index that can reflect the operation of the endowment insurance system.
4.2. Interval DEA Results
First of all, this paper uses the average data of input and output as the input and output of DEA model, and obtains the efficiency value and the rank of the comprehensive performance of the operation of endowment insurance in 31 provinces from 2017 to 2019. It should be mentioned that the efficiency value of DEA model does not consider the disturbance of data.
Table 2 shows the efficiency values calculated by DEA model. The operation of endowment insurance system in nine provinces is effective: Beijing, Shanxi, Liaoning, Heilongjiang, Shanghai, Zhejiang, Guangdong, Xizang, Qinghai. The efficiency of inefficient securities firms ranged from 0.651 to 0.994.
Table 3 show the results of interval DEA model. The difference between the upper bound and the lower bound is quite different among the 31 DMUs. Among them, the largest value is 0.726, while the smallest is 0.364. It is worth mentioning that all the DMUs have the same upper bound of 1.000, and this does not mean that so many DMUs are efficient. This is because it is hard to find a realistic scenario in which all DMUs are in the most favorable situation at the same time.
In the DEA model, we just need to rank them according to their efficiency value. As mentioned before, the data disturbance is not considered in DEA model. Therefore, the accuracy of the results is too difficult to be assured. In the interval DEA model, the data disturbance is considered. However, it is difficult to rank them accordingly. For DMUs with the same upper bound, ranking them according to their lower bounds is likely to lead to mistakes because we have to know their distribution. In a real-world scenario, these distributions are difficult to describe.
4.3. Robust DEA Results
In the robust DEA model, we consider not only the uncertainty of the output, but also the influence of different uncertain factors on the outputs. In our model, we mainly consider the impact of government policy adjustment and economic shocks on output, thus, we set , which means we consider two uncertain factors that affect the outputs. Here, we suppose , and the uncertainty parameter range from 0 to 5, which represents different degrees of uncertainty. From the previous parameter setting results, we can know the output disturbance value range from 0 to 0.1.
4.3.1. Robust DEA Results Based on Box Set
When the uncertainty set is a box set, the RDEA efficiency values of 31 DMUs are shown in
Table 3. As parameter
changes, RDEA efficiency changes accordingly. At the beginning, the parameter
, box-robust data envelopment analysis model is equivalent to the data envelopment analysis model. In this case, the robust problem here is equal to a nominal problem, which has no disturbance. When parameter
increases to 1, the box uncertainty set is equivalent to the interval uncertainty set. The maximum value of the efficiency of endowment insurance system in 31 provinces is 0.923, the minimum value is 0.791, and the average value is 0.874. With the increase of uncertainty parameter
, the average efficiency value of the RDEA model decreases from 0.947 to 0.631.
4.3.2. Robust DEA Results Based on Ellipsoid Set
When the uncertainty set is an ellipsoid set, the RDEA efficiency values of endowment insurance system in 31 provinces is shown in
Table 4. Similarly, the problem is equivalent to a nominal problem with the uncertainty parameter
. When the parameter increases from 0 to 1,
is the largest ellipsoid contained in the
. In this case, the maximum value of the efficiency of endowment insurance system in 31 provinces is 0.945, the minimum value is 0.616 and the average efficiency is 0.810. As the uncertainty parameter increases, the RDEA efficiency decreases gradually. It is worth noting that the speed of efficiency reduction here is lower than that of the former uncertainty set. When the uncertainty parameter
increases to 5, which represents the most conservative situation, the average efficiency drops to 0.712. From the mean results, we can infer that the ellipsoid set has stronger robustness than interval sets.
4.3.3. Robust DEA Results Based on Polyhedron Set
Here, we consider the case that the uncertainty set is a polyhedron uncertainty set. The results of endowment insurance system in 31 provinces are displayed in
Table 5. When the uncertainty parameter
, the problem is equivalent to a nominal problem. With the increase of the uncertainty parameter, the RDEA efficiency decrease from 0.947 to 0.686. Different from the previous table, with the change of uncertain parameters, the ranking of DMUs efficiency value is also changing. However, the range of change is small, and it is still relatively stable.
4.4. Comparison between Models Based on a Different Uncertainty Set
and
in the robust DEA model are adjustable parameters to control the size level of an uncertain set, which represents the conservative degree of constraints. They not only describe the fluctuation of the value of the uncertain parameters in the geometry of a certain shape, but also reflect the uncertainty of the outputs.
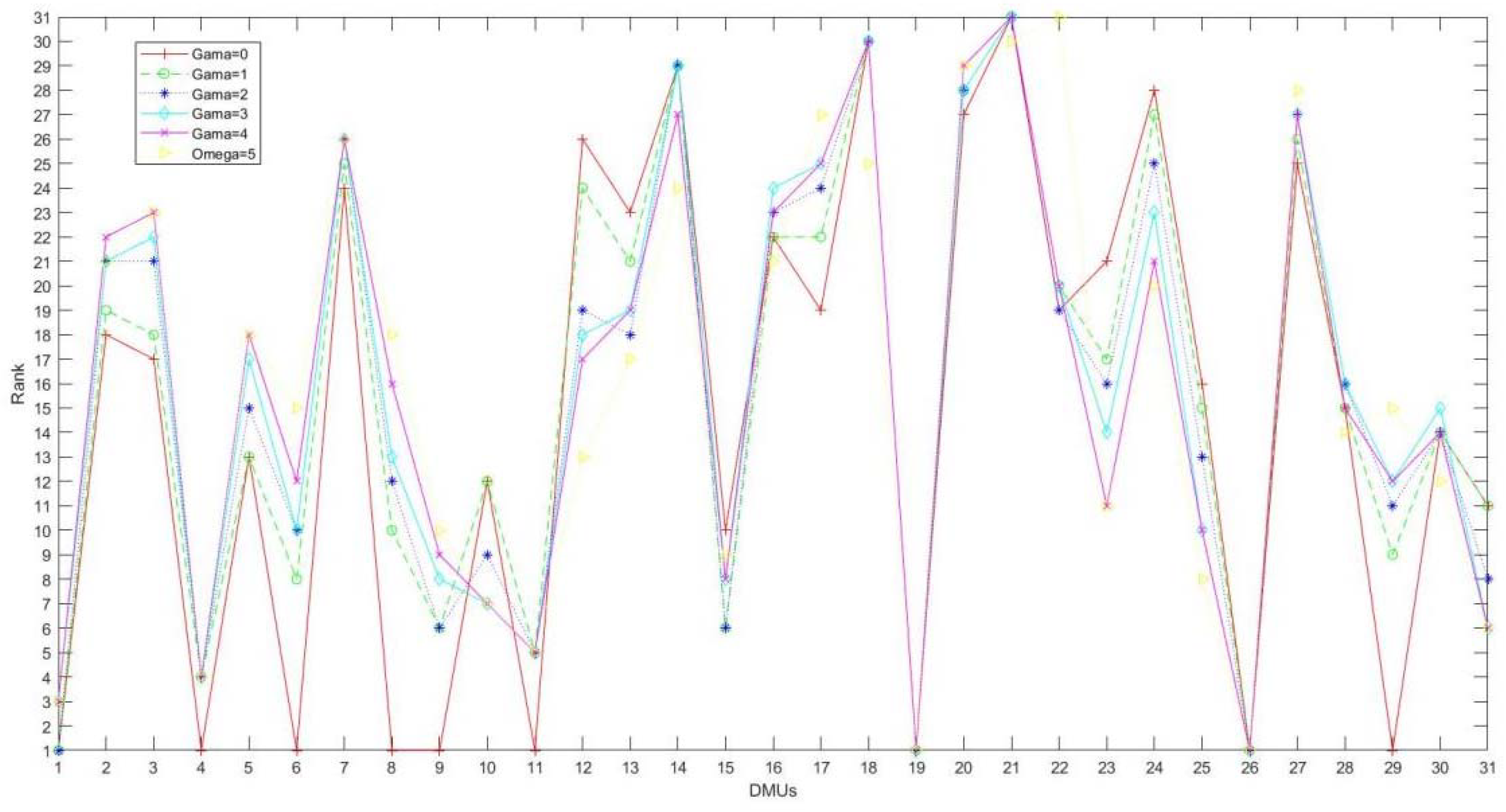
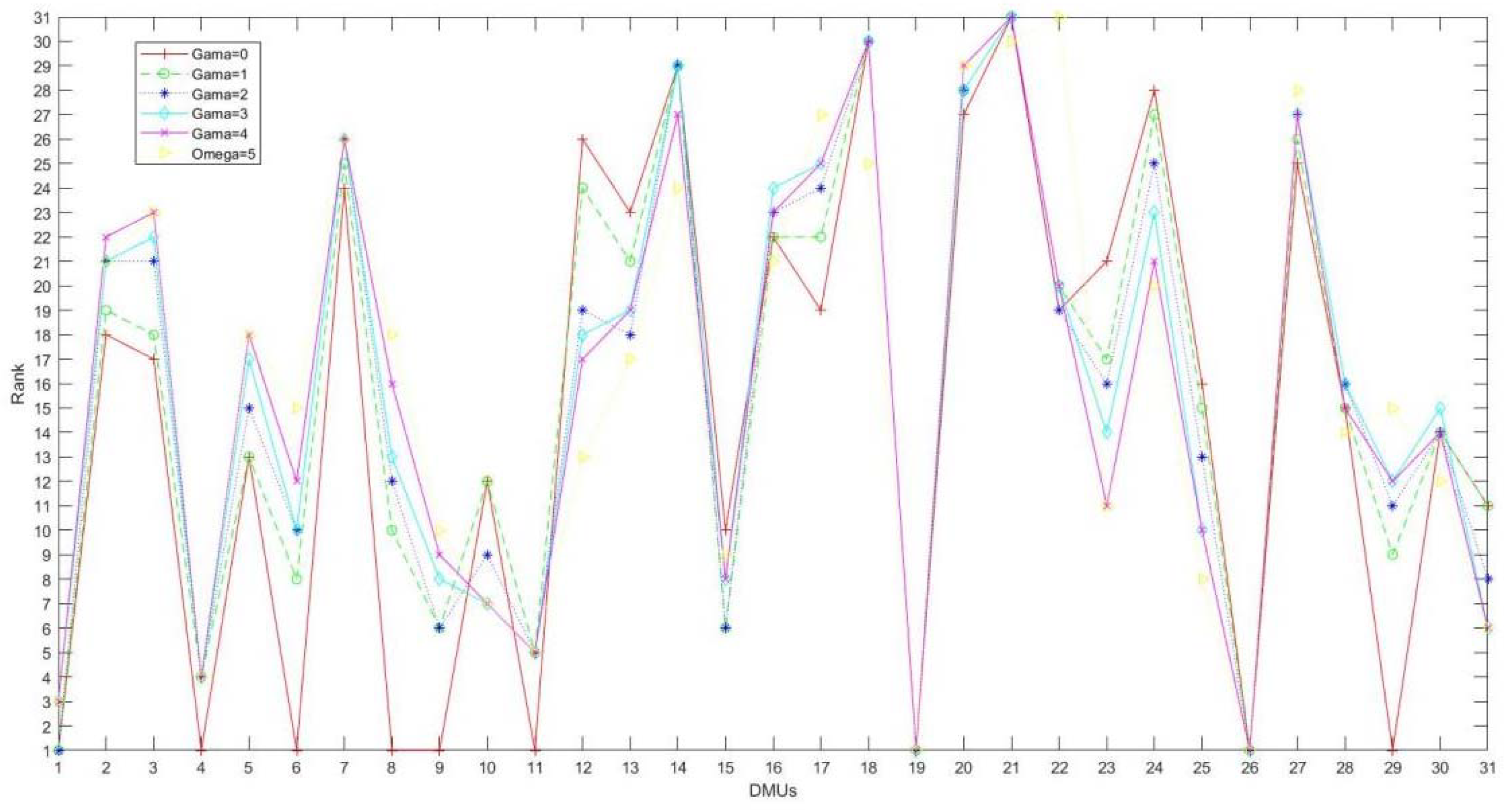
Figure 1 shows three curves of efficiency values varying with uncertainty parameters. With the increase of uncertainty parameters, the efficiency values based on different uncertain sets decrease at different speeds. Intuitively, the results of polyhedron uncertainty model and ellipsoid uncertainty model are better, the efficiency based on box uncertainty model performs the worst, and the results are far from those of the former two models. From the perspective of ranking, the results of the box uncertainty set and the ellipsoid uncertainty set show extremely strong stability. The results of the polyhedron uncertainty set show some fluctuation, but the fluctuation is acceptable. The results of rank are shown in
Figure 2,
Figure 3 and
Figure 4, respectively. In general, the robust model with ellipsoidal uncertainty shows the highest efficiency and the strongest robustness.
4.5. Comparison between Interval DEA Model and Robust DEA Models
According to the previous subsection, we know that the robust DEA model based on ellipsoid uncertainty set performs the best. In this subsection, we compare the ellipsoid RDEA model with the interval DEA model, and the result are shown in
Figure 5.
We compare the two models from two perspectives:
- (1)
Is the result convenient to compare the efficiency of DMUs?
- (2)
Is the result close to the real scenario?
According to the results shown in
Figure 5, all the upper bounds of the IDEA model are 1. That is to say, all the DMUs can be judged to be effective under extremely favorable conditions. However, in the real world, the probability of this kind of situation is very low because it is difficult to make all units reach their best state. The lower bound of IDEA model ranges from 0.364 to 0.726, which seems to tell us that we can judge the efficiency ranking of DMUs with the same upper bound by comparing the lower bounds of DMUs. Yet this intuition is wrong, we have to know the distribution of efficiency value of each DMU, and this kind of information is often difficult to get in the real world. However, in the robust model, the final result is a certain number, and it is not necessary to determine the distribution of the value. The efficiency value of each DMU can be easily compared. From this point of view, the robust model performs better.
The result of the IDEA model is an interval. Its lower bound shows the lowest value that the DMU may take under the most unfavorable situation, while the upper bound shows the lowest value that the DMU may take under the most unfavorable situation. The IDEA model deals with uncertainty in the form of interval. However, once the interval is calculated, it is a value that cannot be adjusted. In the robust model, the uncertainty parameters describe the size of the uncertainty, we can adjust the size of the parameters according to the actual needs. The results are not only convenient to compare the efficiency of decision-making units, but also fit the real scenario, are more accurate, and provide important information for decision-makers. From the above analysis, a robust model is more suitable to solve our problem.
5. Data-Driven Robust DEA Models
In the
Section 3, we assume that the output unit is uncertain because of the needs of the real situation. In the robust optimization method, there is not enough information and we also want to ensure the absolute robustness of the result, which leads to the result being too conservative. In the real situation, the tendency of macro policy of government can be expected approximately. At the same time, we can obtain some useful information from some historical data, rather than having no information available.
In the
Section 5, contrary to the above, we assume that the observation sets of the output unit
can be obtained, where
and
. In other words,
is the raw data that we can obtain. At the same time, let
represent the average values of
, i.e.,
, where
. Therefore, we need to find a decision variable that maximize the worst-case efficiency over all the costs in uncertainty set
. This is the robust DEA problem:
In the next subsection, several methods for generating
will be introduced [
35], where each set has a scaling parameter to control its size.
5.1. Box Uncertainty
We set
, for any
, there is
where
is the Cartesian product and
. It should be noticed that
.
Therefore, the robust problem obtained is
Proof. For the objective function of (2), we just obtain its maximum value:
Then, it can be transformed to the equivalent form:
Similarly, the third inequality of (2) can be transformed to the following form:
Here, the size of box uncertainty set in decided by both uncertainty parameter and the observation sets, which is different from the box uncertainty set of
Section 3.1. The proof of
Section 5.2 and
Section 5.3 is just similar to the proof above.□
5.2. Ellipsoidal Uncertainty
Ellipsoid uncertainty sets were derived from the observation that the iso-density locus of the multivariate normal distribution is an ellipse. Therefore, the maximum likelihood fit of a normal distribution
of data point
is given by
. We set an ellipsoid of the form
with the scaling parameter
and it is centered on
. Following the similar proof of
Section 5.1, the robust problem obtained is
5.3. Polyhedron Uncertainty
A polyhedron defined using linear equations and inequalities is equivalent to a convex hull. We set
where the scaling parameter
controls the size of the set. Through the duality of the internal maximization problem, we arrive at the robust problem:
5.4. Numerical Analysis
It is obvious that the scaling parameters will affect the size of each uncertainty set. Here, we just follow the analysis of
Section 4, comparing the trends of three proposed uncertainty sets under the same scaling parameters. Scaling parameters here are set from 1 to 5 with a step of 1. In this way, we can clearly see the gradual change of efficiency value.
When the uncertainty set is an interval set, the RDEA efficiency values of 31 DMUs are shown in
Table 6. When the uncertainty parameter
equals 1, the maximum value of the efficiency of endowment insurance system in 31 provinces is 0.942, the minimum value is 0.744. Compared with the Robust DEA model, the result has a larger range. The efficiency rank of some provinces has changed greatly under uncertain circumstances. For example, in the robust DEA model, the rank of Hainan is the last one, but it soars up to 21st in a data-driven robust DEA model. When the uncertainty set is an ellipsoidal set, the RDEA efficiency values of 31 DMUs are shown in
Table 7. Similar to the interval uncertainty sets of data-driven DEA model, the result shows a larger range and a more stable decreasing with the increasing of the uncertainty level.
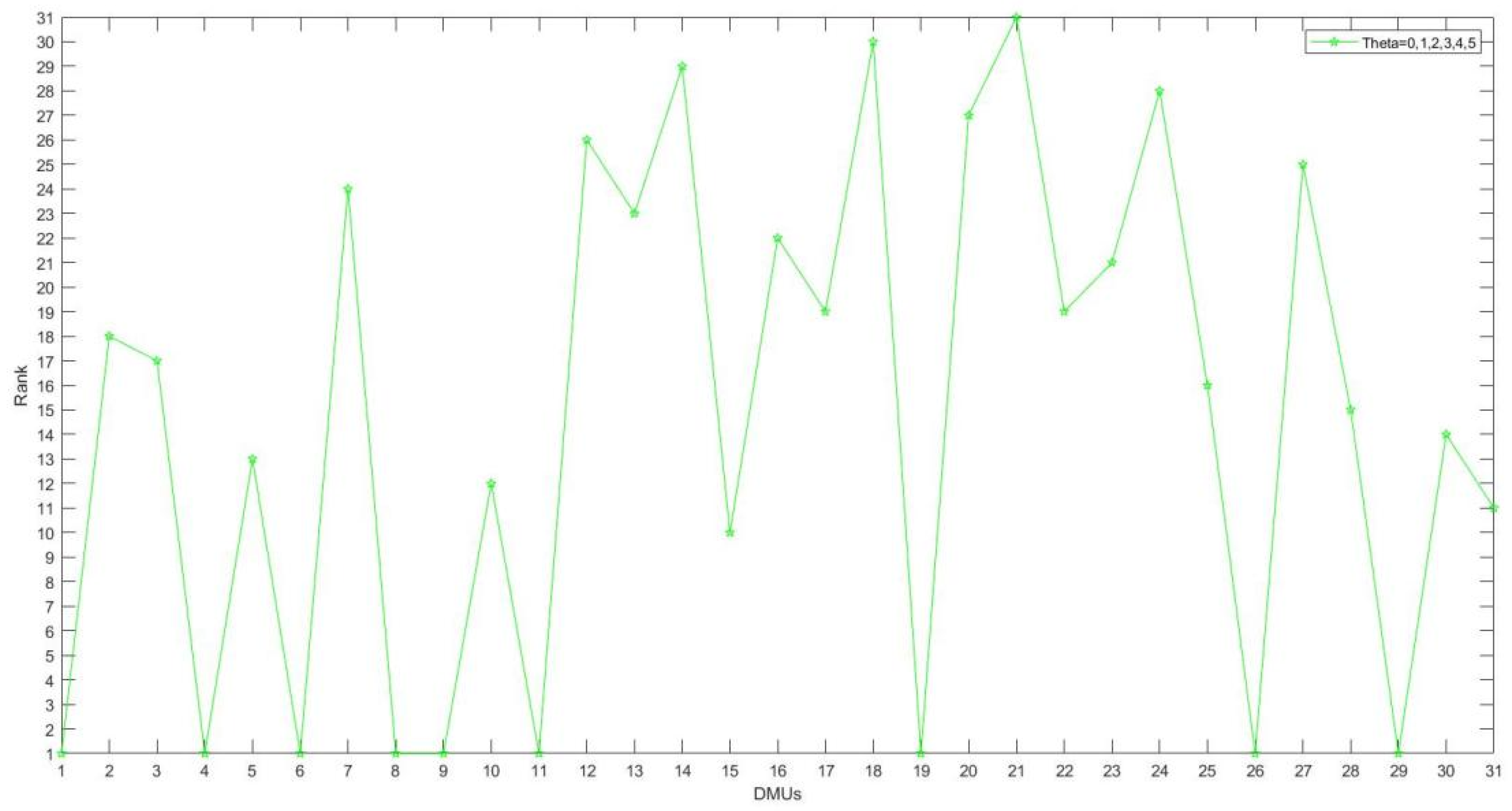
While the uncertainty set turns out to be a polyhedron set, the rank is quite different with that in robust DEA model. From the
Table 8, we can explicitly see that the rank is gradually in a fairly stable state when the uncertainty parameter is greater than 2.
From the analysis above, we can obtain the following conclusion:
- (1)
In a data-driven robust DEA model, among three uncertainty sets, the ellipsoidal set shows the strongest robustness which is similar to the robust DEA model.
- (2)
Compared with robust DEA model, the data-driven robust DEA model shows better performance. All three uncertainty sets have greater efficiency than the former. It is worth mentioning that the rank is gradually in a fairly stable state when the uncertainty parameter greater than 2. The reason for these two phenomena is also easy to find. In data-driven methods, more information is provided, so we can describe the uncertainty more accurately, which leads to the more satisfactory result.
5.5. Managerial Insights
The only drawback of the robust model is that it may lead to over conservative results. For this reason, we use data-driven method to solve it. According to the results shown in
Table 2, the lowest efficiency of endowment insurance system among 31 provinces is 0.857 (Hainan Province). The endowment insurance system efficiency value of 28 provinces is higher than 0.9, which means that China’s endowment insurance system is generally in good condition. On the other hand, as shown in
Figure 5, there is little difference in the efficiency of endowment insurance among 31 provinces, which means that the difference between regions is not significant. From the results shown in
Figure 1, with the increase of uncertainty, the efficiency of endowment insurance system in China’s provinces shows a downward trend.
At the same time, the increase of population aging and the improvement of life expectancy are a fixed trend in the next 30 years, which leads to the increase of endowment insurance expenditure. The Chinese government must increase the financial expenditure on endowment insurance to resolve this grim situation. For some provinces with low efficiency, such as Shanxi, Hunan, Hainan, the government should give priority to providing subsidies to promote fair distribution. What is more, local governments should pay more attention to the development of the endowment insurance system, and pay attention to the differences in the operation of the endowment insurance system in different regions. To improve the operation efficiency of endowment insurance, the government of underdeveloped regions can consider learning from the advanced systems and experience of other areas and reasonably guide the input and output of resources.









{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}